1.
IDENTITAS PRIBADI
2. RIWAYAT PENDIDIKAN
Nama Dimas Ricky Firmansyah Tempat, tanggal lahir Bandung, 27 Juni 1990 Jenis kelamin Pria
Status Belum kawin
Agama Islam
Kewarganegaraan Indonesia Golongan darah B
Alamat Jl.Kopo Gg.Babakan Rahayu no.30 Bandung 40233 No. Telepon 083822900418
Email [email protected]
2008 â 2013 FTIK Unikom Bandung 2005 â 2008 SMA Negeri 17, Bandung 2002 â 2005 SMP Negeri 10, Bandung
1996 â 2002 SD Negeri Babakan Tarogong 1 Bandung
Demikian riwayat hidup ini saya buat dengan sebenar-benarnya dalam keadaan sadar dan tanpa paksaan.
Bandung,
SKRIPSI
Diajukan untuk memenuhi Ujian Akhir Sarjana Program Strata Satu Jurusan Teknik Informatika
Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia
OLEH :
DIMAS RICKY FIRMANSYAH
10108401
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii Assalaamuâalaikum wr. wb,
Alhamdulillahi Rabbil alamiin, segala puji dan syukur penulis panjatkan kepada Allah SWT atas rahmat dan karunia-Nya yang telah dilimpahkan, shalawat dan salam tidak lupa dicurahkan kepada Nabi Muhammad SAW, penulis dapat menyelesaikan laporan tugas akhir ini dengan judul â IMPLEMENTASI TEXT
MINING KLASIFIKASI OBJEK WISATA DENGAN METODE NAÃVE
BAYES CLASSIFIER DI DINAS PARIWISATA JAWA BARAT â.
Adapun tujuan dari penyusunan skripsi ini adalah untuk memenuhi salah satu syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika Universitas Komputer Indonesia.
Dalam penyusunan skripsi ini banyak sekali bantuan yang penulis terima. Karena itu, penulis ingin menyampaikan rasa hormat dan terima kasih sebesar-besarnya kepada :
1. Ibu tercinta serta kakak-kakakku tersayang, yang senantiasa memberikan kasih sayang, doa dan dukungan yang tiada hentinya.
2. Bapak Dr. Ir. Eddi Soeryanto Soegoto, M.Sc. selaku Rektor Universitas Komputer Indonesia.
3. Bapak Prof. Dr. H. Denny Kurniadie, Ir., M.Sc. selaku Dekan Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia.
4. Bapak Irawan Afrianto,S.T., M.T. selaku Ketua Jurusan Teknik Informatika FTIK Universitas Komputer Indonesia.
iv
Komputer Indonesia Bandung.
8. Dra. Siti Tohariyah selaku Ibu Kepala Bidang Pemasaran Dinas Pariwisata dan Kebudayaan Jawa Barat.
9. Ibu Hetty Susilawati S.E.,M.Si. yang telah menerima penulis untuk melakukan penelitian tugas akhir di Dinas Pariwisata dan Kebudayaan Jawa Barat.
10.Bapak Dante Syailendra yang telah memberikan informasi-informasi mengenai data yang dibutuhkan penulis dalam penyusunan skripsi.
11.Kepada Teman-teman seperjuangan khususnya anak kelas IF-8 angkatan 08.
Keterbatasan kemampuan, pengetahuan dan pengalaman penulis dalam pembuatan Skripsi ini masih jauh dari kesempurnaan. Untuk itu penulis akan selalu menerima segala masukkan yang ditujukan untuk menyempurnakan skripsi ini. Akhir kata penulis mengharapkan semoga tugas akhir ini dapat bermanfaat serta menambah wawasan pengetahuan baik bagi penulis sendiri maupun bagi pembaca pada umumnya.
Wassalam
Bandung, februari 2013
v
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... xii
DAFTAR SIMBOL ... xv
DAFTAR LAMPIRAN ... xxi
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 2
1.3 Maksud Dan Tujuan ... 2
1.4 Batasan Masalah ... 2
1.5 Metodologi Penelitian ... 3
1.6 Sistematika Penulisan ... 6
BAB 2 LANDASAN TEORI ... 7
2.1 Tinjauan Instansi ... 7
2.1.1 Sejarah Dinas Pariwisata dan Kebudayaan Provinsi Jawa Barat dan Badan Hukum Instansi ... 7
2.1.2 Logo Instansi ... 8
2.1.3 Visi dan Misi ... 9
2.1.4 Struktur Organisasi ... 9
2.1.5 Tugas Pokok dan Fungi(Tupoksi) Disparbud Prov. Jabar ... 10
2.1.6 Deskripsi Pekerjaan ... 11
2.2 Pariwisata ... 12
2.2.1 Objek Wisata ... 12
2.3 Text Mining ... 13
2.3.1 Pengertian Text Mining ... 13
vi
2.4 Naïve Bayes Classifier ... 20
2.5 Konsep Dasar Pemrograman Objek ... 24
2.5.1 Pemrograman Berorientasi Objek (PBO) ... 24
2.6 Pengertian UML (Unified Modelling Language) ... 24
2.6.1 Diagram-Diagram UML ... 25
2.7 MYSQL ... 29
2.8 Macromedia Dreamweaver Adobe Cs 5 ... 30
2.9 PHP ... 30
2.10 Wamp (Windows Apache Mysql PHP) ... 30
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 31
3.1 Analisis Sistem ... 31
3.1.1 Analisis Masalah ... 31
3.1.2 Analisis Sumber Data ... 31
3.1.3 Analisis Text Mining Klasifikasi Objek Wisata ... 33
3.1.3.1 Analisis Preprocessing Data Latih ... 33
3.1.3.2 Analisis Pembuatan Indeks Keyword ... 44
3.1.3.3 Analisis Metode Naïve Bayes Classifier ... 45
3.1.3.3.1 Klasifikasi Naïve Bayes Classifier (Learning) Data Latih ... 45
3.1.3.3.2 Klasifikasi Naïve Bayes Classifier (Classify) Data Uji ... 57
3.1.4 Spesifikasi Kebutuhan Perangkat Lunak ... 59
3.1.5 Analisis Kebutuhan Non Fungsional ... 59
3.1.5.1 Analisis Kebutuhan Perangkat Lunak ... 60
3.1.5.2 Analisis Kebutuhan Perangkat Keras ... 61
3.1.5.3 Analisis Kebutuhan Pengguna ... 62
3.1.6 Analisis Kebutuhan Fungsional ... 63
3.1.6.1 Identifikasi Aktor ... 63
3.1.6.2 Use Case Diagram ... 63
vii
3.1.6.7 Class Diagram Admin ... 93
3.2 Perancangan Sistem ... 94
3.2.1 Perancangan Struktur Menu Admin ... 94
3.2.2 Perancangan Antarmuka Admin ... 94
3.2.3 Perancangan Pesan ... 99
3.2.4 Jaringan Semantik Admin ... 100
3.2.5 Perancangan Prosedural ... 100
3.2.5.1 Login Administrator ... 100
3.2.5.2 Pembelajaran Naïve Bayes Tambah Data Latih ... 101
3.2.5.3 Pembelajaran Naïve Bayes Ubah Data Latih ... 102
3.2.5.4 Klasifikasi Naïve Bayes Tambah Data Uji ... 103
3.2.5.5 Klasifikasi Naïve Bayes Ubah Data Uji ... 104
3.2.5.6 Hapus Data Uji ... 105
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... 107
4.1 Implementasi Sistem ... 107
4.1.1 Implementasi Perangkat Keras ... 107
4.1.2 Implementasi Perangkat Lunak ... 107
4.1.3 Implementasi Basis Data... 107
4.1.4 Implementasi Kelas ... 109
4.1.5 Implementasi Antarmuka Admin ... 110
4.2 Pengujian Sistem ... 112
4.2.1 Pengujian Alpha ... 113
4.2.1.1 Skenario Pengujian Aplikasi ... 113
4.2.1.2 Kasus dan Hasil Pengujian Black Box ... 115
4.2.1.3 Kesimpulan Hasil Pengujian Black Box ... 124
4.2.2 Pengujian Beta ... 124
4.2.2.1 Wawancara Admin... 124
viii
5.2 Saran ... 127
129
[2] RPJMB, Dinas Pariwisata dan Kebudayaan Jawa Barat. 2008-2013.
[3] Departemen Kebudayaan dan Pariwisata Republik Indonesia, Tentang
Kepariwisataan. Nomor 10 Tahun 2009.
[4] Feldman, Ronen and Sanger, James. The Text Mining HandBook. Cambridge
University Pres.2007.
[5} Tan, Ah-Hwee, 1999, Text Mining: The state of the art and the challenges,
Kent Ridge Digital Labs 21 Heng Mui Keng Terrace Singapore 119613,
online pada (
http://www3.ntu.edu.sg/sce/labs/erlab/publications/papers/asahtan/tm_pakdd9 9.pdf diakses pada tgl 19/11/2012)
[6] Even, Yair and Zohar. Introduction to Text Mining.National Center for
Supercomputing Applications University of Illinois.2002. (online)
http://www.docstoc.com/docs/25443990/Introduction-to-Text-Mining diakses
pada tanggal 17 Juni 2012.
[7] Agusta, Ledy. Perbandingan Algoritma Stemming Porter Dengan Algoritma
Nazief & Adriani Untuk Stemming Dokumen Teks Bahasa Indonesia. 2009.
Fakultas Teknologi Informasi dari Universitas Kristen Satya Wacana
[8] M. Weiss, Sholom, Indurkhya, Nitin and zhang,Tong. Fundamental of
Predictive Text Mining. Springer.2010.
[9] Grobelnik, Marko, Mladenic, Dunja, Stefan.J. Text-Mining Tutorial.Slovenia
http://eprints.pascal-network.org/archive/00000017/01/Tutorial_Marko.pdf
(diakses tgl 23 Maret 2012).
[10] Mitchell, Tom A. Machine Learning. McGraw-Hill.1997
[11] Harrington , Peter. Machine Learning In Action. Manning.2012
[12] Hamzah, Amir. Klasifikasi Teks dengan Naïve bayes Classifier (NBC) Untuk
Pengelompokkan Teks Berita Dan Abstract Akademis.2012. Fakultas
Teknologi Industri Jurusan Teknik Informatika. Institut Sains Dan Teknologi
AKPRIND. Indonesia (online)
http://ie.akprind.ac.id/sites/default/files/Amir%20Hamzah%20_Teknik%20Inf ormatika_.pdf ( diakses pada tgl 30/11/12).
[13] B.sakur, Stendy. PHP5 Pemrograman berorientasi objek Konsep &
Implementasi.Andi Yogyakarta.2010.
[14] Widodo,Pudjo.Prabowo, dan Heriawati. MenggunakanUML.Informatika.2011
[15] Khodra, Leylia, Masayu. Text Mining Kategorisasi Teks Naïve Bayes.IF-ITB
http://kur2003.if.itb.ac.id/file/TextMiningKlasifikasiNB.pdf (diakses tgl 23
Oktober 2012).
[16] Rosa A.S, M.Salahudin. 2011. Modul Pembelajaran Rekayasa Perangkat
1 1.1 Latar Belakang Masalah
Dinas Pariwisata dan Kebudayaan Jawa Barat yang beralamat di Jl. L.L.R.E. Martadinata No.239 Bandung, merupakan suatu lembaga negara yang mempunyai tugas salah satunya adalah mempromosikan pariwisata di Jawa Barat. Berdasarkan hasil wawancara terhadap pihak dinas pariwisata, sebagai salah satu strategi untuk mempromosikan objek wisata di Jawa barat, maka pihak disparbud mengelompokkan objek wisata di Jawa Barat berdasarkan kategori. Kategori tersebut terdiri dari 8 karakter, yaitu Karakter Hutan, Karakter Pantai, Karakter Religius, Karakter Tradisi dan Komunikasi Adat, Karakter Kepurbakalaan, Karakter Gelar Seni & Ragam Festival, Karakter Heritage, dan Karakter Wisata Belanja.
Proses pengklasifikasian saat ini dilakukan melalui analisa terhadap kemunculan kata-kata yang dianggap mewakili dari masing-masing karakter berdasarkan asumsi pribadi orang yang mengklasifikasikan. Hal yang menjadi kendala selain menghasilkan klasifikasi yang cenderung subjektif, proses klasifikasi ini membutuhkan waktu yang lama karena jumlah objek wisata yang semakin banyak. Klasifikasi yang ada tidak dapat memberikan solusi untuk permasalahan yang sudah dipaparkan sebelumnya.
Klasifikasi adalah salah satu metode dalam Text Mining. Menurut Ronen Feldman dan James Sanger[4] text mining, yaitu suatu proses penggalian informasi dimana seorang user berinteraksi dengan sekumpulan dokumen menggunakan tools analisis yang merupakan komponen-komponen dalam data
Atas dasar permasalahan tersebut perlu dibangun sistem pengklasifikasian objek wisata yang dapat menjadi solusi permasalahan diatas, maka penelitian yang akan dilakukan adalah âImplementasi Text Mining Klasifikasi Karakter Objek Wisata DenganMetode Naive Bayes Classifier Di Dinas Pariwisata dan Kebudayaan Jawa Baratâ.
1.2 Rumusan Masalah
Berdasarkan latar belakang masalah yang sudah dijabarkan sebelumnya, maka rumusan masalah dari penelitian ini adalah bagaimana cara membangun sistem pengklasifikasian objek wisata berdasarkan kategori ke dalam 8 karakter dengan metode naïve bayes classifier di Dinas Pariwisata Jawa Barat.
1.3 Maksud dan Tujuan
Maksud dari penelitian ini adalah untuk membangun implementasi text mining untuk pengklasifikasian objek wisata Jawa Barat berdasarkan kategori ke dalam 8 karakter menggunakan metode Naive Bayes Classifier. Adapun Tujuan yang akan dibangun adalah :
1. Menghasilkan aturan klasifikasi untuk setiap kategori objek wisata ke dalam 8 karakter.
2. Membantu dalam proses pengklasifikasian objek wisata berdasarkan kategori ke dalam 8 karakter objek wisata.
1.4 Batasan Masalah
Berdasarkan latar belakang yang telah diuraikan sebelumnya, maka dibuat batasan masalah agar ruang lingkup penelitian skripsi ini jelas batasannya. Adapun batasan masalah yang dibuat adalah sebagai berikut:
1. Sistem yang akan dibangun adalah sistem pengklasifikasian mengenai objek wisata di Dinas Pariwisata Jawa Barat.
3. Informasi yang diberikan sistem yaitu berupa identitas objek wisata (nama objek wisata, karakter, dan kota/kab) dan deskripsi objek wisata.
4. Data objek wisata yang digunakan yaitu data objek wisata yang ditulis dalam bahasa Indonesia, dan tidak dilakukan tahap tagging pada proses
text mining karena tidak menangani teks yang berbahasa inggris.
5. Pengklasifikasian objek wisata berdasarkan 8 karakter, yaitu proses pengelompokkan objek wisata yang ada di Jawa Barat berdasarkan kategori.
6. Data Latih yang digunakan adalah 40 objek wisata yang terdapat pada buku informasi pariwisata Jawa Barat.
7. Pada data latih kemunculan kata yang muncul hanya 1x dan tidak relevan dengan masing-masing karakter, maka tidak akan digunakan dalam proses pembelajaran naïve bayes classifier (learning).
8. Algoritma yang akan diimplementasikan pada bahasan mengenai proses pengklasifikasian objek wisata adalah Naïve Bayes Clasifier.
9. Perangkat lunak atau aplikasi ini akan berjalan pada sistem berbasis website.
10.Pendekatan analisis yang digunakan adalah Objek Oriented (OO).
1.5 Metodologi Penelitian
Metodologi penelitian yang akan digunakan dalam pembuatan skripsi ini menggunakan metodologi analisis deskriptif, yaitu metode penelitian menggunakan studi kasus. Metodologi ini terbagi menjadi dua metode yaitu : 1. Tahap pengumpulan data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah sebagai berikut :
a. Studi Literatur.
b. Observasi.
Teknik pengumpulan data dengan mengadakan penelitian langsung pada tempat Dinas Pariwisata Jawa Barat untuk mendapatkan informasi yang diperlukan terhadap permasalahan yang diambil.
c. Interview/Wawancara.
Teknik pengumpulan data dengan mengadakan tanya jawab secara langsung kepada pihak yang berwenang yaitu, Bapak Dante Syailendra dari bidang Analisa data dan informasi bagian Pemasaran di tempat Dinas Pariwisata Jawa Barat guna mendapatkan informasi terhadap topik yang diambil.
2. Tahap pembuatan perangkat lunak.
Metode pengembangan perangkat lunak yang digunakan untuk membangun sistem pengklasifikasian objek wisata berdasarkan kategori ke dalam 8 karakter menggunakan paradigm model waterfall, yang meliputi beberapa proses seperti yang digambarkan pada diagram dibawah ini:[1]
a. Requirements analysis and Definition
Tahap ini mengumpulkan kebutuhan secara lengkap kemudian kemudian dianalisis dan didefinisikan kebutuhan yang harus dipenuhi oleh program yang akan dibangun. Fase ini harus dikerjakan secara lengkap untuk bisa menghasilkan desain yang lengkap.
b. System and Software Design
Tahap ini merupakan kegiatan mengumpulkan kebutuhan secara lengkap kemudian dianalisis dan didefinisikan kebutuhan yang harus dipenuhi oleh aplikasi yang akan dibangun. Tahap ini harus dikerjakan secara lengkap untuk bisa menghasilkan desain yang lengkap, juga tahap ini juga dilakukan analisis algoritma yang akan dipakai pada sistem pengklasifikasian objek wisata ini.
c. Implementation and Unit Testing
Desain program diterjemahkan ke dalam kode-kode dengan menggunakan bahasa pemrograman yang sudah ditentukan. Program yang dibangun langsung diuji baik secara unit.
d. Integration and System Testing
Penyatuan unit-unit program kemudian diuji secara keseluruhan (system testing).
e. Operation and Maintenance
1.6 Sistematika Penulisan
Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB 1. PENDAHULUAN
Menguraikan tentang latar belakang permasalahan, mencoba merumuskan inti permasalahan yang dihadapi, menentukan maksud dan tujuan penelitian, yang kemudian diikuti dengan pembatasan masalah, metodologi penelitian, serta sistematika penulisan.
BAB 2. TINJAUAN PUSTAKA
Membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis permasalahan serta tinjauan terhadap penelitian-penelitian serupa yang telah pernah dilakukan sebelumnya.
BAB 3. ANALISIS DAN PERANCANGAN
Menganalisis masalah baik Analisis Prosedur yang berjalan, Analisis Kebutuhan Data, Analisis Kebutuhan Fungsional (Pengguna, Perangkat Lunak, Perangkat Keras) dan Analisis Kebutuhan Non-Fungsional dari sistem yang dibuat serta menggambarkan bagaimana perancangan dari sistem pengklasifikasian pada objek wisata, mulai dari tahapan perancangan Sistem yang mencakup Perancangan Antarmuka, perancangan struktur menu dan perancangan jaringan semantik.
BAB 4. IMPLEMENTASI DAN PENGUJIAN
Bab ini menguraikan implementasi dari rancang bangun sistem pengklasifikasian objek wisata sesuai dari hasil analisis dan perancangan. Selanjutnya tahap pengujiannya juga diuraikan pada bab ini.
BAB 5. KESIMPULAN DAN SARAN
7 2.1Tinjauan Instansi
2.1.1 Sejarah Dinas Pariwisata dan Kebudayaan Provinsi Jawa Barat dan Badan Hukum Instansi
Dinas Pariwisata dan Kebudayaan Provinsi Jawa Barat (DISPARBUD JABAR) merupakan salah satu lembaga pemerintahan yang bergerak dalam bidang pelestarian serta pemberdayaan pariwisata dan kebudayaan yang ada di Provinsi Jawa Barat berlokasi di Jl.L.L.R.E Martadinata No.209 Bandung. Berdasarkan Peraturan Pemerintah Nomor : 25 Tahun 2000 tentang Kewenangan Pemerintah dan Kewenangan Propinsi sebagai Daerah Otonom, sebagaimana diamanatkan Undang-undang Nomor : 22 Tahun 1999 tentang Pemerintah Daerah dan Peraturan Pemerintah Nomor : 84 Tahun 2000 tentang Pedoman Organisasi Perangkat Daerah, maka Gubernur Kepala Daerah Tingkat I Jawa Barat mengeluarkan Peraturan Daerah Nomor : 15 Tahun 2000 tentang Pembentukan Dinas Daerah Propinsi Jawa Barat.
Dengan dikeluarkannya Peraturan Daerah Nomor : 15 Tahun 2000 tersebut, maka terbentuklah Dinas Kebudayaan dan Pariwisata Propinsi Jawa Barat yang merupakan gabungan 4 (empat) Instansi yaitu dari Dinas Pariwisata Propinsi Jawa Barat, Dinas Pendidikan Propinsi Jawa Barat Bidang Kebudayaan, Kantor Wilayah Departemen Pariwisata, Pos dan Telekomunikasi Propinsi Jawa Barat dan Kantor Wilayah Departemen Pendidikan Bidang Kebudayaan.
Barat, nama Dinas Kebudayaan dan Pariwisata Propinsi Jawa Barat berubah nama menjadi Dinas Pariwisata dan Kebudayaan Provinsi Jawa Barat.
Menyimak hal tersebut diatas, Dinas Pariwisata dan Kebudayaan Provinsi Jawa Barat berupaya mengarahkan peningkatan sektor ekonomi melalui peningkatan sektor pariwisata yang dukung sektor kebudayaan menjadi salah satu faktor andalan yang mampu menggalakkan roda perekonomian sehingga mampu memberi kesempatan kepada masyarakat untuk membuka lapangan kerja dan berusaha secara mandiri yang pada gilirannya akan meningkatkan pendapatan daerah dan masyarakat juga pendapatan negara melalui devisa.
2.1.2 Logo Instansi
Gambar 2.1 Logo Disparbud
Logo Dinas Pariwisata dan Kebudayaan Jawa Barat ini mengacu pada Logo Provinsi Jawa Barat. Adapun arti dan makna dari logo ini yaitu:
1. Tulisan Gemah Ripah Repeh Rapih, melambangkan pepatah lama Sunda yang bermaksud menyatakan bahwa Jawa Barat adalah daerah yang kaya raya dan didiami oleh banyak penduduk yang rukun dan damai.
2. Gambar Bentuk Bulat Telur, pada lambang Jawa Barat ini berasal dari bentuk perisai sebagai penjagaan diri.
3. Kujang, melambangkan senjata suku bangsa Sunda yang merupakan penduduk asli Jawa Barat. Lima lubang pada kujang melambangkan lima sila dari Dasar Negara Indonesia yaitu Garuda Pancasila.
5. Kapas, melambangkan kesuburan sandang dan jumlah bunga kapas 8 buah melambangkan bulan Proklamasi Republik Indonesia.
6. Gunung yang terdapat dibawah padi dan kapas, melambangkan bahwa daerah Jawa Barat terdiri atas daerah pegunungan.
7. Sungai dan terusan yang terdapat dibawah gunung sebelah kiri, melambangkan di daerah Jawa Barat banyak terdapat sungai dan saluran air seperti persawahan dan perkebunan.
8. DAM yang terdapat ditengah-tengah bagian bawah antara gambar sungai dan petak, melambangkan kegiatan dibidang irigasi yang merupakan salah satu perhatian pokok mengingat Jawa Barat adalah daerah agraris. Hal ini juga melambangkan dam-dam yang berada Di Jawa Barat seperti Waduk Jatiluhur.
2.1.3 Visi dan Misi A. Visi
" Terwujudnya Jawa Barat sebagai daerah budaya dan tujuan wisata andalan ".
B. Misi
a) Pembinaan, pelestarian dan pengembangan asset budaya yang mendukung upaya pengembangan Pariwisata Jawa Barat.
b) Mengefektifkan kebudayaan sebagai asset daerah yang mendukung kepada pengembangan Usaha Jasa Pariwisata.
c) Mempromosikan Kepariwisataan Jawa Barat.
d) Meningkatkan sumber daya manusia Kebudayaan dan Kepariwisataan. Memuliakan nilai-nilai budaya yang terkandung dalam aspek jarahnitra dan tradisi Jawa Barat.
2.1.4 Struktur Organisasi
serta adanya kejelasan pembagian tugas, wewenang dan tanggung jawab dari orang-orang yang melaksanakan tugas tersebut. Berdasarkan Peraturan Daerah Jawa Barat No.21 Tahun 2008 Tentang Organisasi dan Tata Kerja Dinas Daerah Provinsi Jawa Barat, struktur organisasi Dinas Pariwisata dan Kebudayaan sebagai berikut:
Gambar 2.2 Struktur Organisasi Disparbud
2.1.5 Tugas Pokok dan Fungsi (Tupoksi) Disparbud Prov. Jabar
1. Deskripsi :
Daerah di bidang pariwisata dan kebudayaan berdasarkan asas otonomi, dekonsentrasi dan tugas pembantuan.
2. Fungsi :
a) Penyelenggaraan perumusan dan penetapan kebijakan teknis kepariwisataan, kebudayaan, kesenian dan perfilman serta pemasaran.
b) Penyelenggaraan pariwisata dan kebudayaan meliputi kepariwisataan, kebudayaan, kesenian dan perfilman serta pemasaran.
c) Penyelenggaraan pembinaan dan pelaksanaan tugas-tugas pariwisata dan kebudayaan meliputi kepariwisataan, kebudayaan, kesenian dan perfilman serta pemasaran.
d) Penyelenggaraan koordinasi dan pembinaan UPTD.
e) Penyelenggaraan tugas lain sesuai dengan tugas pokok dan fungsinya.
2.1.6 Deskripsi Pekerjaan
Pembagian tugas dalam suatu instansi lembaga sangat penting, supaya terjadi keharmonisan dalam mencapai suatu tujuan. Berikut ini terdapat deskripsi jabatan yang berlaku di Dinas Pariwisata Jawa Barat :
A. Tugas Kepala Dinas
Menyelenggarakan perumusan, penetapan, memimpin,mengkoordinasikan dan mengendalikan pelaksanaan kegiatan tugas pokok Dinas serta mengkoordinasikan dan membina UPTD.
B. Tugas Sekretaris
Menyelenggarakan koordinasi perencanaan dan program Dinas, pengkajian perencanaan dan program, pengelolaan keuangan, kepegawaian dan umum.
C. Tugas Bidang Kesenian dan Perfilman
Menyelenggarakan pengkajian bahan kebijakan teknis dan melestarikan, mengembangkan dan memanfaatkan kesenian meliputi seni tradisi, seni kontemporer dan perfilman, prasarana dan sarana kesenian.
D. Tugas Bidang Pemasaran :
produk pariwisata, usaha pariwisata, obyek dan daya tarik wisata serta pemberdayaan masyarakat pariwisata.
E. Tugas Bidang Kebudayaan :
Menyelenggarakan pengkajian bahan kebijakan teknis, fasilitasi dan penyelenggaraan pelestarian, pengembangan dan pemanfaatan kebudayaan meliputi permuseuman, peninggalan sejarah dan kepurbakalaan, kesejarahan, nilai tradisional dan kebahasaan daerah.
2.2Pariwisata
Kepariwisataan itu sendiri merupakan pengertian jamak yang diartikan sebagai hal-hal yang berhubungan dengan pariwisata, yang dalam bahasa Inggris disebutkan tourism. Dalam kegiatan kepariwisataan ada yang disebut subyek wisata yaitu orang-orang yang melakukan perjalanan wisata dan obyek wisata yang merupakan tujuan wisatawan. Sebagai dasar untuk mengkaji dan memahami berbagai istilah kepariwisataan, berpedoman pada Bab 1 pasal 1 Undang-Undang Republik Indonesia Nomor 10 Tahun 2009 tentang kepariwisataan yang menjelaskan sebagai berikut : [3]
1. Wisata adalah kegiatan perjalanan yang dilakukan oleh sebagian atau kelompok orang dengan mengunjungi tempat tertentu untuk tujuan rekreasi, pengembangan pribadi, atau mempelajari keunikan daya tarik wisata yang dikunjungi dalam jangka waktu sementara.
2. Wisatawan adalah orang yang melakukan wisata.
3. Pariwisata adalah berbagai macam kegiatan wisata dan didukung berbagai fasilitas serta layanan yang disediakan oleh masyarakat, pengusaha, Pemerintah dan Pemerintah Daerah.
2.2.1 Objek Wisata
daya tariknya bersumber pada keindahan sumber daya alam dan tata lingkungannya. Jenis Obyek wisata Penggolongan jenis objek wisata akan terlihat dari ciri-ciri khas yang ditonjolkan oleh tiap-tiap obyek wisata. Dalam UU No. 9 Tahun 1990 Tentang Kepariwisataan disebutkan bahwa obyek dan daya tarik wisata terdiri dari :
1. Objek dan daya tarik wisata ciptaan Tuhan Yang Maha Esa, yang berwujud keadaan alam, serta flora dan fauna.
2. Objek dan daya tarik wisata hasil karya manusia yang berwujud museum,peninggalan sejarah, wisata agro, wisata tirta, wisata buru, wisata petualangan alam, taman rekreasi dan tempat hiburan.
Namun kepariwisataan di jawa barat membagi objek wisata menjadi 8 karakter objek wisata, dimana karakter disini adalah proses pengelompokkan objek wisata sesuai kategorinya. dan 8 karakter adalah sebagai berikut :
a) Karakter Hutan b) Karakter Pantai c) Karakter Religius
d) Karakter Tradisi dan Komunikasi Adat.
e) Karakter Kepurbakalaan
f) Karakter Gelar Seni dan Ragam Festival
g) Karakter Wisata Belanja h) Karakter Heritage
Dinas Pariwisata dan Kebudayaan Jawa barat (Disparbud Jabar) mengklasifikasian objek wisata menjadi 8 karakter objek wisata didasarkan atas kawasan Wisata Unggulan (KWU) yang ada di Jawa Barat. [2]
2.3Text Mining
2.3.1 Pengertian Text Mining
dari permasalahan seperti pemrosesan, pengorganisasian / pengelompokkan dan menganalisa unstructured text dalam jumlah besar.
Dalam memberikan solusi, text mining mengadopsi dan mengembangkan banyak teknik dari bidang lain, seperti Data mining, Information Retrieval, Statistik dan Matematik, Machine Learning, Linguistic, Natural Languange Processing, dan Visualization. Kegiatan riset untuk text mining antara lain ekstraksi dan penyimpanan text, preprocessing akan konten text, pengumpulan data statistik dan indexing dan analisa konten.
2.3.2 Tujuan Text Mining
Tujuan dari Text Mining adalah untuk mendapatkan informasi yang berguna dari sekumpulan dokumen tetapi Tujuan utama text mining adalah mendukung proses knowledge discovery pada koleksi dokumen yang besar. Jadi, sumber data yang digunakan pada text mining adalah kumpulan teks yang memiliki format yang tidak terstruktur atau minimal semi terstruktur. Adapun tugas khusus dari text mining antara lain yaitu pengkategorisasian teks(text categorization) dan pengelompokkan teks (text clustering)[4].
2.3.3 Kinerja Text Mining
Tabel 2.3 Kinerja Text Mining[5]
knowledge distillation. Pada tahap ini jika bentuk intermediate berupa dokumen maka kegiatan distilasi pengetahuan dapat berupa kegiatan clustering dokumen, kategorisasi dokumen, visualisasi dan sebagainya. Untuk bentuk intermediate
berupa konsep kegiatan distilasi dapat berupa predictive modeling, assosiative discovery dan visualisasi. Salah satu kegiatan penting dalam distilasi pengetahuan adalah klasifikasi atau kategorisasi teks dengan pendekatan supervised learning. Kategorisasi teks sendiri saat ini memiliki berbagai cara pendekatan antara lain berbasis numeris, misalnya pendekatan probabilistic, support vector machine, dan artificial neural network, serta berbasis non numeris seperti decision tree classification.[5]
2.3.4 Proses Text Mining
Beberapa tahapan proses pokok dalam text mining, yaitu pemrosesan awal
text, (text preprocessing), transformasi teks (text transformation)/ (Feature Generation), pemilihan fitur (feature selection), dan penemuan pola text/data mining (pattern discovery).[6]
Gambar 2.4 Proses Text Mining menurut even,zohar [6]
a. Text
besar, dimensi yang tinggi, data dan struktur yang terus berubah, dan data noise. Perbedaan di antara keduanya adalah pada data yang digunakan. Pada data mining, data yang digunakan adalah structured data, sedangkan pada text mining, data yang digunakan text mining pada umumnya adalah unstructured data, atau minimal semistructured. Hal ini menyebabkan adanya tantangan tambahan pada
text mining yaitu struktur text yang complex dan tidak lengkap, arti yang tidak jelas dan tidak standar, dan bahasa yang berbeda ditambah translasi yang tidak akurat.
b. Text Preprocessing
Tahap ini melakukan analisis semantik (kebenaran arti) dan sintaktik (kebenaran susunan) terhadap teks. Tujuan dari pemrosesan awal adalah untuk mempersiapkan teks menjadi data yang akan mengalami pengolahan lebih lanjut. Operasi yang dapat dilakukan pada tahap ini meliputi :[4]
1. Text clean up.
Menghapus iklan dari halaman web, menormalkan teks dikonversi dari format biner.
2. Case Folding
adalah mengubah semua huruf dalam dokumen menjadi huruf kecil. Hanya
huruf âaâ sampai dengan âzâ yang diterima. Karakter selain huruf dihilangkan
dan dianggap delimiter.
3. Tokenization
Sebelum pengolahan yang lebih canggih, aliran karakter berkelanjutan harus dipecah menjadi konstituen bermakna. Hal ini dapat terjadi pada tingkat yang berbeda. Dokumen dapat dipecah menjadi bab-bab, bagian, paragraf, kalimat, kata, dan bahkan suku kata. Pendekatan yang paling sering ditemukan dalam sistem text mining melibatkan teks menjadi kalimat dan kata-kata, yang disebut tokenization.
4. part-of-speech (PoS) tagging,
c. Text Transformation (Feature Generation)
Transformasi teks atau pembentukan atribut mengacu pada proses untuk mendapatkan representasi dokumen yang diharapkan. Pendekatan representasi dokumen yang lazim bag of words. Transformasi teks sekaligus juga melakukan pengubahan kata-kata ke bentuk dasarnya dan pengurangan dimensi kata di dalam dokumen.
d. Feature Selection
Pemilihan fitur (kata) merupakan tahap lanjut dari pengurangan dimensi pada proses transformasi teks. Operasi feature selection ini meliputi :
1. Stop words removal
Walaupun tahap sebelumnya sudah melakukan penghapusan kata-kata yang tidak deskriptif (stopwords), namun tidak semua kata-kata di dalam dokumen memiliki arti penting. Oleh karena itu, untuk mengurangi dimensi, pemilihan hanya dilakukan terhadap kata-kata yang relevan yang benar-benar merepresentasikan isi dari suatu dokumen. Langkah preprocessing yang menghilangkan atau menghapus kata-kata yang tidak penting atau tidak relevan disebut fitur seleksi. Banyak sistem, bagaimanapun, melakukan penyaringan jauh lebih agresif, menghilangkan 90 hingga 99 persen dari semua fitur[4].
2. Stemming
Stemming merupakan suatu proses yang mentransformasi kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Algoritma Nazief & Adriani sebagai algoritma stemming untuk teks berbahasa Indonesia yang memiliki kemampuan presentase keakuratan (presisi) lebih baik dari algoritma lainnya. Sebagai contoh, kata bersama, kebersamaan, menyamai, akan distem ke root word-nya yaitu
âsamaâ. Proses stemming pada teks ber Bahasa Indonesia berbeda dengan
Gambar 2.5 Flow Chart Algoritma Nazief & Adriani [7] e. Pattern Discovery
Text/Data mining/Pattern discovery merupakan tahap penting untuk menemukan pola atau pengetahuan (knowledge) dari keseluruhan teks. Tindakan yang lazim dilakukan pada tahap ini adalah operasi text mining, dan biasanya menggunakan teknik-teknik data mining. Dalam penemuan pola ini, proses text mining dikombinasikan dengan proses-proses data mining. [6]
f. Interpretation/evaluation
2.3.5 Kategori Teks
Kategorisasi adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui. Pada kategorisasi teks, diberikan sekumpulan kategori (label) dan koleksi dokumen yang berfungsi sebagai data latih, yaitu data yang digunakan untuk membangun model, dan kemudian dilakukan proses untuk menemukan kategori yang tepat untuk dokumen test, yaitu dokumen yang digunakan untuk menentukan akurasi dari model. Misalkan ada sebuah dokumen x sebagai inputan, maka output yang dihasilkan oleh model tersebuat adalah kelas atau kategori y dari beberapa
kategori tertentu yang telah didefinisikan sebelumnya (y1,â¦,yk). Adapun contoh
dari pemanfaatan kategorisasi teks adalah pengkategorisasian berita ke dalam beberapa kategori seperti bisnis, teknologi, kesehatan dan lain sebagainya; pengkategorisasian email sebagai spam atau bukan; pengkategorisasian kilasan film sebagai film favorit, netral atau tidak favorit; pengkategorisasian paper yang menarik dan tidak menarik; dan penggunaan dari kategorisasi teks yang paling umum adalah kategorisasi otomatis dari web pages yang dimanfaatkan oleh portal Internet seperti Yahoo. Kategorisasi otomatis ini memudahkan proses browsing
artikel berdasarkan topik tertentu yang dilakukan oleh user. Salah satu algoritma kategorisasi yang sering digunakan adalah algoritma Naive bayes. Algoritma ini merupakan algoritma yang menerapkan metode probabilistic learning method.[4]
Kategorisasi teks adalah banyak digunakan, namun lamban, nama untuk klasifikasi dokumen. Ini adalah perwujudan paling murni dari model spreadsheet
dengan jawaban berlabel. Setelah data ditransformasikan ke format spreadsheet
Gambar 2.6 Kategori Teks[8]
2.4Naïve Bayes Classifier
Bayesian Classifier adalah pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Bayesian Classifier didasarkan pada teorema bayes yang memiliki kemampuan klasifikasi serupa dengan decision tree dan neural network. Bayesian Classifier terbukti memiliki akurasi dan kecepatan yang tinggi saat diaplikasikan ke dalam database dengan data yang besar.[10]
Naïve Bayes Classifier menggunakan teori probabilitas sebagai dasar teori, Metode ini adalah metode yang dipergunakan untuk proses klasifikasi teks. Terdapat 2 tahap pada proses klasifikasi teks. Tahap pertama adalah pelatihan terhadap himpunan artikel contoh (training example). Contoh dari asumsi bahwa kita memiliki dataset dengan dua kelas data di dalam. data ini ditunjukkan pada Gambar 27.
Sedangkan tahap kedua adalah proses klasifikasi dokumen yang belum dikategorikan. Gambar ini menunjukkan proses klasifikasi dokumen dengan naïve bayes classifier.
Gambar 2.8 klasifikasi naïve bayes classifier.[9]
selanjutnya yaitu melakukan klasifikasi dokumen dengan mencari nilai maksimum dari :[12]
) (2.1)
konsep dasar yang digunakan oleh naïve bayes adalah Teorema Bayes, dengan perhitungan nilai probabilitas bersyarat :
(2.2)
yaitu, Peluang kejadian A sebagai B ditentukan dari peluang B saat A, peluang A, peluang A, dan peluang B. pada saat pengaplikasiannya nanti rumus ini berubah menjadi :
(2.3)
dengan menerapkan teorema bayes persamaan (2.1) maka dapat ditulis :
karena nilai konstan, sehingga untuk semua vj
besarnya sama maka nilainya dapat diabaikan, menjadi persamaan :
= (2.5)
dengan mengasumsikan bahwa setiap kata dalam
sulit untuk dihitung, maka akan diasumsikan bahwa
setiap kata pada dokumen tidak mempunyai keterkaitan, dan ditulis persamaan menjadi :
= (2.6)
nilai ditentukan pada saat pelatihan, yang nilainya didekati dengan
persamaan :
= (2.7)
dimana :
: probabilitas setiap dokumen terhadap sekumpulan dokumen.
: banyaknya dokumen yang memiliki kategori j dalam pelatihan,
: banyaknya dokumen dalam contoh yang digunakan saat pelatihan.
untuk nilai ditentukan dengan persamaan :
= (2.8)
Dimana :
: Probabilitas kemunculan kata wk pada suatu dokumen dengan
kategori vj.
nk : frekuensi munculnya kata wk dalam dokumen yang berkategori vj.
Pada persamaan 2.8 terdapat suatu penambahan 1 pada pembilang, hal ini dilakukan untuk mengantisipasi jika terdapat suatu kata pada dokumen uji yang tidak ada pada setiap dokumen data pelatihan.
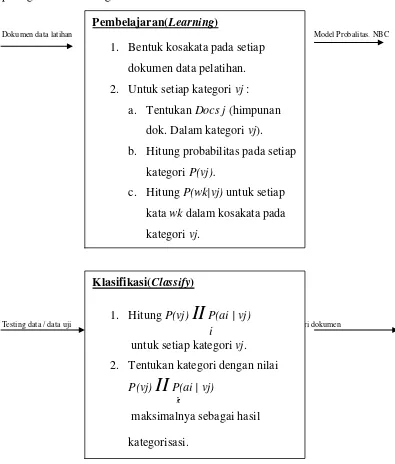
Selanjutnya, pembelajaran algoritma Naïve Bayes Classifier dapat dilihat pada gambar 2.9 sebagai berikut :
Dokumen data latihan Model Probalitas. NBC
[image:37.595.112.507.208.672.2]
Testing data / data uji kategori dokumen
Gambar 2.9 Tahapan Proses Klasifikasi Dokumen Dengan Algoritma Naïve Bayes Classifier [12]
Pembelajaran(Learning)
1. Bentuk kosakata pada setiap dokumen data pelatihan. 2. Untuk setiap kategori vj :
a. Tentukan Docs j (himpunan dok. Dalam kategori vj). b. Hitung probabilitas pada setiap
kategori P(vj).
c. Hitung P(wk|vj) untuk setiap kata wk dalam kosakata pada kategori vj.
Klasifikasi(Classify)
1. Hitung P(vj)
II
P(ai | vj) iuntuk setiap kategori vj. 2. Tentukan kategori dengan nilai
P(vj)
II
P(ai | vj) áµmaksimalnya sebagai hasil
2.5Konsep Dasar Pemrograman Objek
2.5.1 Pemrograman Berorientasi Objek (PBO)
Pemrograman berorientasi objek berarti sebuah teknik pemrograman yang dalam proses pengembangannya menggunakan terminologi objek, di mana setiap objek memiliki atribut beserta dengan fungsi yang dapat saling berinteraksi satu dengan yang lain. Contohnya objek makhluk hidup â baik manusia ataupun binatang maka kita akan mengenalinya dari bentuk, ukuran, beratnya kemudian dari perilakunya kita dapat melihat bahwa makhluk hidup dapat melihat, makan, berjalan, berlari dan selain itu terdapat fungsi lainnya seperti fungsi peredaran darah yang berhubungan dengan fungsi pernapasan atau fungsi pencernaan.
Ciri-ciri inilah yang menjadi ide dasar bagaimana mengembangkan sebuah perangkat lunak yang kompleks dengan menggunakan model objek tersebut. Dengan demikian, proses pengembangan perangkat lunak akan lebih mudah karena hanya akan menyesuaikan model pemrograman dengan objek yang kita buat. PBO memiliki tujuan untuk memberikan pemahaman sistem kepada user atau client. Hal ini karena user/client dapat lebih mudah memahami alur pemrograman dengan kasus yang dihadapi, hal ini berbeda dengan pemrograman terstruktur karena lebih berorientasi kepada programmer untuk menyelesaikan sebuah kasus.[13]
2.6Pengertian UML ( Unified Modeling Language)
UML singkatan dari Unified Modeling Language yang berarti bahasa pemodelan standar. (Chonoles, 2003 : Bab1) mengatakan sebagai bahasa, berarti UML memiliki sintaks dan semantik. Ketika akan membuat model menggunakan konsep UML ada aturan-aturan yang harus diikuti. Bagaimana elemen pada model-model yang dibuat berhubungan satu dengan lainnya dan harus mengikuti standar yang ada. UML bukan hanya sekedar diagram, tetapi juga menceritakan konteksnya.[14]
mendukung pengembangan sistem tersebut UML mulai diperkenalkan oleh Object Management Group, sebuah organisasi yang telah mengembangkan model, teknologi, dan standar OOP sejak tahun 1980-an. Sekarang UML sudah mulai banyak digunakan oleh para praktisi OOP. UML merupakan dasar bagi perangkat (tool) desain berorientasi objek dari IBM.
UML adalah suatu bahasa yang digunakan untuk menentukan, memvisualisasikan, membangun, dan mendokumentasikan suatu sistem informasi. UML dikembangkan sebagai suatu alat untuk analisis dan desain berorientasi objek oleh Grady Booch, Jim Rumbaugh, dan Ivar Jacobson.Namun demikian UML dapat digunakan untuk memahami dan mendokumentasikan setiap sistem informasi.Penggunaan UML dalam industri terus meningkat. Ini merupakan standar terbuka yang menjadikannya sebagai bahasa pemodelan yang umum dalam industri peranti lunak dan pengembangan sistem.
UML diaplikasikan untuk maksud tertentu, biasanya antara lain untuk : 1. Merancang perangkat Lunak
2. Sarana Komunikasi antara perangkat lunak dengan proses bisnis.
3. Menjabarkan sistem secara rinci untuk analisa dan mencari apa yang diperlukan sistem.
4. Mendokumentasi sistem yang ada, proses-proses dan organisasinya.
2.6.1 Diagram-Diagram UML
Beberapa literature menyebutkan bahwa UML menyediakan Sembilan jenis diagram, yang lain menyebutkan sepuluh karena ada beberapa diagram yang digabung, misalnya diagram komunikasi, diagram urutan dan diagram perwaktuan digabung menjadi diagram interaksi. Namun demikian model-model itu dapat dikelompokkan menjadi 10 macam diagram untuk memodelkan aplikasi berorientasi objek, yaitu :
UML menyediakan 10 macam diagram untuk memodelkan aplikasi berorientasi objek, yaitu:
2. Conceptual Diagram untuk memodelkan konsep-konsep yang ada di dalam aplikasi.
3. Sequence Diagram untuk memodelkan pengiriman pesan (message) antar objek.
4. Collaboration Diagram untuk memodelkan interaksi antar objek. 5. State Diagram untuk memodelkan perilaku objek di dalam sistem.
6. Activity Diagram untuk memodelkan perilaku userdan objek di dalam sistem. 7. Class Diagram untuk memodelkan struktur kelas.
8. Objek Diagram untuk memodelkan struktur objek.
9. Component Diagram untuk memodelkan komponen objek. 10.Deployment Diagram untuk memodelkan distribusi aplikasi.
Berikut akan dijelaskan 4 macam diagram yang paling sering digunakan dalam pembangunan aplikasi berorientasi objek, yaitu use case diagram, sequence diagram, collaboration diagram, dan class diagram.
a. Use Case Diagram
Use case diagram digunakan untuk memodelkan bisnis proses berdasarkan perspektif pengguna sistem. Use case diagram terdiri atas diagram untuk use case
dan actor. Actor merepresentasikan orang yang akan mengoperasikan atau orang yang berinteraksi dengan sistem aplikasi. Use case merepresentasikan operasi-operasi yang dilakukan oleh actor. Use case digambarkan berbentuk elips dengan nama operasi dituliskan didalamnya. Actor yang melakukan operasi dihubungkan dengan garis lurus ke use case.
Gambar 2.10 Diagram Use Case
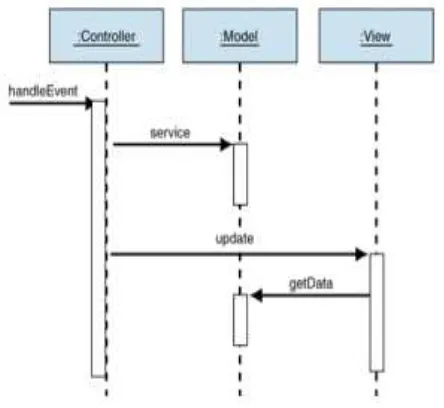
b. Sequence Diagram
Sequence diagram menjelaskan secara detil urutan proses yang dilakukan dalam sistem untuk mencapai tujuan dari use case. Interaksi yang terjadi antar
class, operasi apa saja yang terlibat, urutan antar operasi, dan informasi yang diperlukan oleh masing-masing operasi.
Gambar di bawah ini merupakan salah satu contoh bentuk diagram sequence
[image:41.595.200.422.490.694.2]diagram.
b. Activity Diagram
Activity diagram adalah representasi grafis dari alur kerja tahapan aktifitas. Diagram ini mendukung pilihan tindakan, iterasi dan concurrency. Pada pemodelan UML, activity diagram dapat digunakan untuk menjelaskan bisnis dan alur kerja operasional secara step-by-step dari komponen suatu sistem. Activity diagram menunjukkan keseluruhan dari aliran kontrol.
Gambar di bawah ini merupakan salah satu contoh bentuk diagram activity
diagram.
Gambar 2.12 Diagram Activity
c. Class Diagram
Class diagram merupakan diagram yang selalu ada di permodelan sistem berorientasi objek. Class diagram menunjukkan hubungan antar class dalam sistem yang sedang dibangun dan bagaimana mereka saling berkolaborasi untuk mencapai suatu tujuan.
Gambar 2.13 Class Diagram
Nama Kelas
Atribut
2.7MYSQL
MySQL adalah sebuah perangkat lunak sistem manajemen basis data SQL atau DBMS yang multithread, multi-user, dengan sekitar 6 juta instalasi di seluruh dunia. MySQL AB membuat MySQL tersedia sebagai perangkat lunak gratis dibawah lisensi GNU General Public License (GPL), tetapi mereka juga menjual dibawah lisensi komersial untuk kasus-kasus dimana penggunaannya tidak cocok dengan penggunaan GPL.
Tidak sama dengan proyek-proyek seperti Apache, dimana perangkat lunak dikembangkan oleh komunitas umum, dan hak cipta untuk kode sumber dimiliki oleh penulisnya masing-masing, MySQL dimiliki dan disponsori oleh sebuah perusahaan komersial Swedia MySQL AB, dimana memegang hak cipta hampir atas semua kode sumbernya. Kedua orang Swedia dan satu orang Finlandia yang mendirikan MySQL AB adalah David Axmark, Allan Larsson, dan Michael "Monty" Widenius.
Ada beberapa kelebihan yang dimiliki MySQL sehingga dapat menarik banyak pengguna. Kelebihan tersebut yaitu:
1. Fleksibilitas. Saat ini, MySQL telah dioptimasi untuk duabelas platform seperti HP-UX, Linux, Mac OS X, Novell Netware, OpenBSD, Solaris, Microsoft Windows dan lain-lain. MySQL juga menyediakan source code yang dapat diunduh secara gratis, sehingga pengguna dapat mengkompilasi sendiri sesuai platform yang digunakan. Selain itu, MySQL juga dapat dikustomisasi sesuai keinginan penggunanya, misalnya mengganti bahasa yang digunakan pada antarmukanya.
2. Performansi. Sejak rilis pertama, pengembang MySQL fokus kepada performa. Hal ini masih tetap dipertahankan hingga sekarang dengan terus meningkatkan fiturnya.
2.8Macromedia Dreamweaver Adobe Cs 5
Dreamweaver merupakan sebuah aplikasi untuk merancang pembuatan website. Dreamweaver dibuat oleh perusahaan Macromedia sehingga dinamakan Macromedia Dreamweaver. Sejak Macromedia diakuisisi Adobe Inc., namanya berubah menjadi Adobe Dreamweaver. Versi Pertama Dreamweaver dibawah adobe adalah Cs5, mengikuti versi rilisnya yang dipaketkan dalam Adobe Creative Suite 5.
Untuk pengguna tingkat lanjut, Dreamweaver menyediakan tampilan Code sehingga pengguna dapat merancang tampilan yang lebih lengkap menggunakan kode. Pengguna juga dimudahkan dengan berbagai fasilitas yang dimiliki Dreamweaver seperti tag auto-completion untuk penulisan kode HTML. Format yang didukung Dreamweaver juga cukup lengkap, mulai dari HTML, JavaScript, CSS, sampai XML.
2.9PHP
PHP adalah salah satu bahasa Sever-side yang didesain khusus untuk aplikasi web.PHP dapat disisipkan diantara bahasa HTML dan karena bahasa Server side, maka PHP akan dieksekusi di server,sehingga yang dikirimkan ke
browse adalah âhasil jadiâ dalam bentuk HTML, dan kode PHP anda tidak akan
terlihat.PHP dahulunya merupakan proyek pribadi dari Rasmus Lerdof (dengan dikeluarkannya PHP versi 1) yang digunakan untuk membuat home pribadinya.Versi pertama ini berupa kumpulan script PERL.Untuk versi keduanya, Rasmus menulis ulang script-script PERL tersebut menggunakan bahasa C.kemudian menambahkan fasilitas untuk Form HTML dan koneksi Mysql. Adapun PHP didapat dari singkatan Personal Home Pages.
2.10 WAMP (Windows Apache Mysql PHP)
31 3.1 Analisis Sistem
Analisis sistem bertujuan untuk mengidentifikasi masalah yang muncul pada pembangunan sistem, hal ini bertujuan untuk membantu ketika proses perancangan berlangsung. Dalam analisa sistem ini, meliputi beberapa bagian, yaitu: Analisis Masalah, Analisis Kebutuhan Data, Analisis Text Mining, Analisis Spesifikasi Kebutuhan Perangkat Lunak, Analisis Kebutuhan Non Fungsional, Analisis Kebutuhan Fungsional, Perancangan Antarmuka dan Jaringan Semantik.
3.1.1 Analisis Masalah
Permasalahan pada penelitian ini adalah sebagai berikut :
1. Dalam proses pengklasifikasian, kemunculan kata yang dianalisa hanya kemunculan kata-kata yang dianggap mewakili dari masing-masing karakter, berdasarkan asumsi pribadi orang yang mengklasifikasikan sehingga hasil klasifikasi itu cenderung subjektif.
2. Membutuhkan waktu yang lama dalam proses pengklasifikasiannya.
3.1.2 Analisis Sumber Data
Sistem yang akan dibangun merupakan sistem pengklasifikasian objek wisata di Jawa Barat. Sebagai salah strategi untuk mempromosikan objek wisata yang ada di Jawa Barat saat ini pihak disparbud mengklasifikasian objek wisata berdasarkan kategori ke dalam 8 karakter objek wisata. Kategori tersebut terdiri dari 8 karakter, yaitu
1. Karakter Hutan 2. Karakter Pantai. 3. Karakter Religius.
4. Karakter Tradisi dan Komunikasi Adat.
5. Karakter Kepurbakalaan.
6. Karakter Gelar Seni dan Ragam Festival.
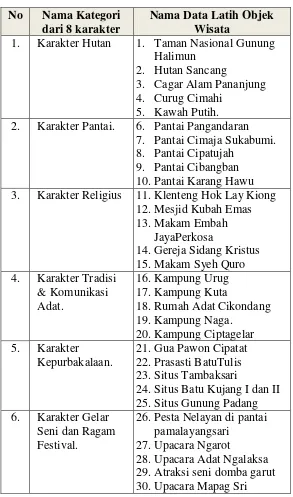
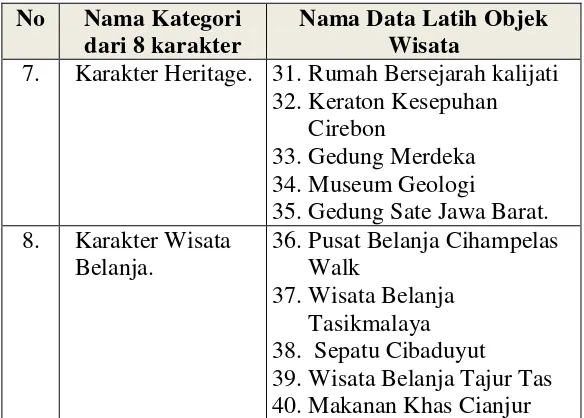
Sebuah sistem pengklasifikasian hanya dapat melakukan proses pengklasifikasian jika sebelumnya sudah ada data latih . Dalam penelitian ini terdapat 40 objek wisata yang sudah diklasifikasikan dari masing-masing objek wisata sesuai dari data yang ada di dinas pariwisata jawa barat yang sudah diklasifikasikan berdasarkan kategori 8 karakter yang kemudian akan dijadikan data latih dan disajikan pada tabel 3.1 sebagai berikut :
Tabel 3.1 Data Latih
No Nama Kategori dari 8 karakter
Nama Data Latih Objek Wisata
1. Karakter Hutan 1. Taman Nasional Gunung Halimun
2. Hutan Sancang
3. Cagar Alam Pananjung 4. Curug Cimahi
5. Kawah Putih. 2. Karakter Pantai. 6. Pantai Pangandaran
7. Pantai Cimaja Sukabumi. 8. Pantai Cipatujah
9. Pantai Cibangban 10.Pantai Karang Hawu 3. Karakter Religius 11.Klenteng Hok Lay Kiong
12.Mesjid Kubah Emas 13.Makam Embah
JayaPerkosa
14.Gereja Sidang Kristus 15.Makam Syeh Quro 4. Karakter Tradisi
& Komunikasi Adat.
16.Kampung Urug 17.Kampung Kuta
18.Rumah Adat Cikondang 19.Kampung Naga.
20.Kampung Ciptagelar 5. Karakter
Kepurbakalaan.
21.Gua Pawon Cipatat 22.Prasasti BatuTulis 23.Situs Tambaksari
24.Situs Batu Kujang I dan II 25.Situs Gunung Padang 6. Karakter Gelar
Seni dan Ragam Festival.
26.Pesta Nelayan di pantai pamalayangsari
27.Upacara Ngarot
No Nama Kategori dari 8 karakter
Nama Data Latih Objek Wisata
7. Karakter Heritage. 31.Rumah Bersejarah kalijati 32.Keraton Kesepuhan
Cirebon
33.Gedung Merdeka 34.Museum Geologi
35.Gedung Sate Jawa Barat. 8. Karakter Wisata
Belanja.
36.Pusat Belanja Cihampelas Walk
37.Wisata Belanja Tasikmalaya 38. Sepatu Cibaduyut 39.Wisata Belanja Tajur Tas 40.Makanan Khas Cianjur
3.1.3 Analisis Text Mining Klasifikasi Objek Wisata
Text mining mempunyai definisi sebagai menambang data berupa teks dimana sumber data biasanya didapat dari suatu dokumen dengan tujuan mencari kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisa keterhubungan antar dokumen. Secara umum sistem ini dibagi menjadi beberapa tahapan proses, pada gambar 3.1 dibawah ini merupakan blok diagram proses kerja pada text mining klasifikasi objek wisata sebagai berikut :
Preprocessing
Pembuatan Indeks
Keyword
Data Latih Objek Wisata
Perhitungan
Naïve
[image:47.595.166.458.112.321.2]Bayes Classifier (NVB)
Gambar 3.1 Alur kerja proses Text Mining Klasifikasi Objek Wisata
3.1.3.1Analisis Preprocessing Data Latih
Folding, Tokenizing , Filtering, dan Stemming. Pada gambar 3.2 dibawah ini merupakan Alur kerja pada tahapan preprocessing sebagai berikut.
Data Latih Teks Objek
Wisata
Tahap Preprocessing Case
Folding Tokenizing Filtering
Keyword Hasil Data Latih
[image:48.595.242.381.440.728.2]Stemming
Gambar 3.2 Alur kerja tahapan preprocessing
A. Case Folding
Case Folding adalah mengubah semua huruf dalam dokumen menjadi huruf kecil (lower case). Hanya huruf âaâ sampai dengan âzâ yang diterima. Karakter selain huruf dihilangkan dan dianggap delimiter. Berikut ini adalah alur proses tahapan dari case folding :
Mulai
Data Latih
Data latih hasil pengubahan teks menjadi huruf kecil
Data latih hasil penghapusan
karakter selain huruf
selesai Menghapus karakter
simbol selain huruf Mengubah semua teks
menjadi huruf kecil
(case folding)
Pada tahapan ini, ada beberapa aturan proses agar hasil case folding dapat sesuai dengan yang diharapkan. Adapun aturan-aturan tersebut sebagai berikut :
Tabel 3.2 Aturan tahapan case folding
Kondisi Aksi
Inputan data latih memiliki huruf
kapital [Aâ¦..Z]. Maka akan mengubah semua inputan tersebut menjadi huruf kecil [aâ¦â¦z] semua.
Inputan data latih memiliki karakter simbol
Maka akan menghapus karakter simbol tersebut dari inputan
Inputan data latih memiliki huruf kecil Tidak ada aksi Inputan data latih memiliki spasi Tidak ada aksi
Karakter-karakter simbol yang akan dihapus atau dianggap sebagai pemisah kata, dapat dilihat di tabel 3.3 dibawah ini
Tabel 3.3 Karakter Simbol
Karakter Simbol
^ , :
@ ( ;
% ) |
$ - ]
# < }
â > {
~ + \
& = /
. ! â
Berikut ini adalah contoh tahapan case folding yang akan di ilustrasikan pada tabel 3.4 dibawah ini.
Tabel 3.4 Ilustrasi tahapan case folding Contoh Data
Data Latih Tahapan Case Folding
Input
Kawasan hutan tropis di lereng Gunung Pangrango dan
Gunung Gede. Gunung Gede juga memiliki keanekaragaman ekosistem.
Output
kawasan hutan tropis di lereng gunung
pangrango dan gunung gede gunung gede juga memiliki
B. Tokenizing
Tokenizing merupakan proses pemotongan string input berdasarkan tiap kata yang menyusunya serta membedakan karakter-karakter tertentu yang dapat diperlakukan sebagai pemisah kata atau bukan. Tahapan ini dilakukan setelah inputan data latih melewati tahap Case Folding. Proses Tokenizing ini mempunyai alur yang digambarkan pada gambar 3.4 sebagai berikut :
Mulai
Data Latih hasil tahapan
case folding
Data latih hasil pemotongan string
menjadi kata-kata
selesai
Memecah dokumen data latih dengan memotong string berdasarkan kata
penyusunnya
Gambar 3.4 Flowchart Tahapan Tokenizing
[image:50.595.241.383.239.528.2]Pada tahapan ini dilakukan pemecahan deskripsi dari data latih menjadi bab-bab, paragrap, kalimat, dan menjadi kata-kata dengan memotong string dari penyusunnya. Ada beberapa aturan proses agar hasilnya sesuai dengan yang diinginkan. Adapun aturan-aturan tersebut sebagai berikut.
Tabel 3.5 Aturan tahapan Tokenizing
Kondisi Aksi
Jika inputan data latih bertemu spasi. Maka akan memecah dari deskripsi data latih menjadi bab-bab per bagian kata atau string.
Tabel 3.6 dibawah ini merupakan contoh tahapan tokenizing sebagai berikut.
Tabel 3.6 Ilustrasi tokenizing
Contoh Data
Data Latih hasil Case Folding Tahapan Tokenizing
Input
kawasan hutan tropis di lereng gunung pangrango dan gunung gede gunung gede juga memiliki keanekaragaman ekosistem Output kawasan hutan tropis di lereng gunung pangrango dan gunung gede gunung gede juga memiliki keanekaragaman ekosistem C. Filtering
Filtering merupakan proses mengambil kata-kata penting dari hasil token. Untuk bisa melakukan analisis filtering ini dapat digunakan algoritma stop-word
Mulai
Data latih objek wisata
hasil
tokenizing
Data latih hasil penghapusan
kata yang tidak penting
selesai Membuang kata
[image:52.595.252.371.109.384.2]yang tidak penting(Stopword)
Gambar 3.5 Flowchart tahapan Filtering
Pada tahapan ini, ada beberapa aturan proses agar hasil filtering sesuai apa yang diharapkan. Adapun aturan-aturan tersebut disajikan sebagai berikut.
Tabel 3.7 Aturan tahapan Filtering
Kondisi Aksi
Jika Inputan data latih mengandung kata pada database stopword
Maka akan menghapus kata atau string
dalam data latih. Jika Inputan data latih tidak
mengandung kata pada database stopword
Maka tidak akan dihapus kata atau
string data latih.
Adapun isi dari sebagian daftar kata stopword pada database yang disajikan sebagai berikut.
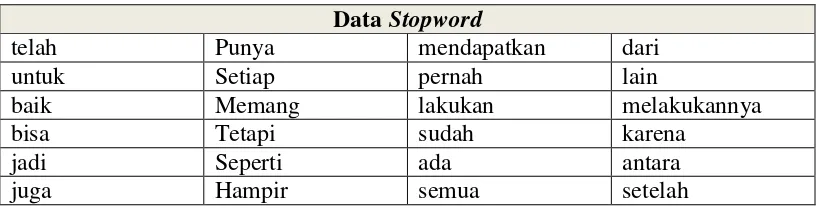
Tabel 3.8 Daftar sebagian Kata-kata Stopword Data Stopword
telah Punya mendapatkan dari untuk Setiap pernah lain
baik Memang lakukan melakukannya
bisa Tetapi sudah karena
jadi Seperti ada antara
[image:52.595.108.518.650.755.2]Data Stopword
di tentang mampu yang
memiliki dia maka bagaimana
bagaimanapun jika ke dalam
akan sekali suka jauh
belum disini kecil secara
anda terus banyak kembali
atas mari dekat masih
Tabel 3.9 dibawah ini merupakan contoh tahapan filtering sebagai berikut.
Tabel 3.9 Ilustrasi Filtering Contoh Data
Data Latih Hasil Tokenizing Tahapan Filtering
Input kawasan hutan tropis di lereng gunung pangrango dan gunung gede gunung gede juga memiliki keanekaragaman ekosistem Output kawasan hutan tropis lereng gunung pangrango gunung gede gunung gede memiliki keanekaragaman ekosistem D. Stemming
Stemming adalah tahap mencari root kata dari tiap kata hasil filtering. Pada tahap ini dilakukan proses pengembalian berbagai bentukan kata imbuhan ke dalam suatu representasi yang sama dengan menghilangkan imbuhan seperti
diantaranya âyangâ, âdiâ, âkeâ, âmeâ, âmengâ, âkanâ menjadi bentuk kata
dasarnya (stem). Pada penelitian ini penulis memakai algoritma Confix stripping (CS) stemmer adalah metode stemming pada bahasa Indonesia yang diperkenalkan oleh Jelita Asian [11] yang merupakan pengembangan dari metode stemming yang dibuat oleh Nazief dan Andriani 1996. Pada dasarnya algoritma ini mengelompokkan imbuhan ke dalam beberapa kategori sebagai berikut :
1. Inflection Suffixes yakni kelompok-kelompok akhiran yang tidak mengubah bentuk kata dasar. Kelompok ini dapat dibagi menjadi dua:
a. Particle (P)atau partikel, termasuk di dalamnya adalah partikel â-lahâ, â
b. Possessive Pronoun (PP) atau kata ganti kepunyaan, termasuk di
dalamnya adalah â-kuâ , â-muâ, dan â-nyaâ.
2. Derivation Suffixes (DS) yakni kumpulan akhiran yang secara langsung dapat
ditambahkan pada kata dasar. Termasuk di dalam tipe ini adalah akhiran â-iâ,
â-kanâ, dan â-anâ.
3. Derivation Prefixes (DP) yakni kumpulan awalan yang dapat langsung diberikan pada kata dasar murni, atau pada kata dasar yang sudah mendapatkan penambahan sampai dengan 2 awalan. Termasuk di dalamnya
adalah awalan yang dapat bermorfologi (âme-â, âbe-â, âpe-â, dan âte-â) dan awalan yang tidak bermorfologi (âdi-â, âke-â dan âse-â).
Dengan batasan-batasan sebagai berikut :
1. Tidak semua kombinasi imbuhan diperbolehkan. Kombinasi imbuhan yang dilarang dapat dilihat pada tabel 3.10.
2. Penggunaan imbuhan yang sama secara berulang tidak diperkenankan.
3. Jika suatu kata hanya terdiri dari satu atau dua huruf, maka proses stemming
tidak dilakukan.
4. Penambahan suatu awalan tertentu dapat mengubah bentuk asli kara dasar, ataupun awaln yang telah diberikan sebelumnya pada kata dasar yang bersangkutan (bermorfologi).
Tabel 3.10 Kombinasi Awalan Akhiran yang dilarang Awalan (prefix) Akhiran (suffix) yang dilarang
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
te- -an
Tabel 3.11 Aturan Pemenggalan Awalan
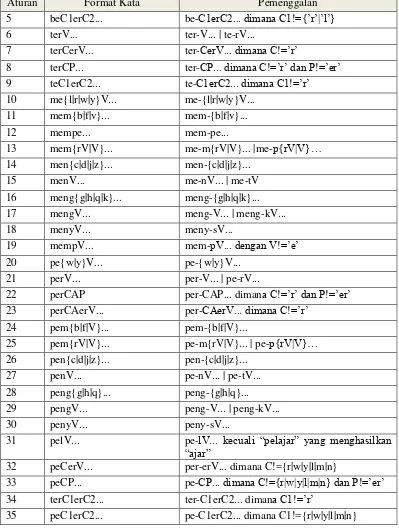
Aturan Format Kata Pemenggalan
1 berV⦠ber-V... | be-rV...
2 berCAP⦠ber-CAP... dimana C!=ârâ & P!=âerâ 3 berCAerV... ber-CaerV... dimana C!=ârâ
Aturan Format Kata Pemenggalan 5 beC1erC2... be-C1erC2... dimana C1!={ârâ|âlâ} 6 terV... ter-V... | te-rV...
7 terCerV... ter-CerV... dimana C!=ârâ
8 terCP... ter-CP... dimana C!=ârâ dan P!=âerâ 9 teC1erC2... te-C1erC2... dimana C1!=ârâ 10 me{l|r|w|y}V... me-{l|r|w|y}V...
11 mem{b|f|v}... mem-{b|f|v}...
12 mempe... mem-pe...
13 mem{rV|V}... me-m{rV|V}... |me-p{rV|V}⦠14 men{c|d|j|z}... men-{c|d|j|z}...
15 menV... me-nV... | me-tV 16 meng{g|h|q|k}... meng-{g|h|q|k}... 17 mengV... meng-V... | meng-kV... 18 menyV... meny-sV...
19 mempV... mem-pV... dengan V!=âeâ 20 pe{w|y}V... pe-{w|y}V...
21 perV... per-V... | pe-rV...
22 perCAP per-CAP... dimana C!=ârâ dan P!=âerâ 23 perCAerV... per-CAerV... dimana C!=ârâ
24 pem{b|f|V}... pem-{b|f|V}...
25 pem{rV|V}... pe-m{rV|V}... | pe-p{rV|V}⦠26 pen{c|d|j|z}... pen-{c|d|j|z}...
27 penV... pe-nV... | pe-tV... 28 peng{g|h|q}... peng-{g|h|q}... 29 pengV... peng-V... | peng-kV... 30 penyV... peny-sV...
31 pelV... pe-lV... kecuali âpelajarâ yang menghasilkan
âajarâ
32 peCerV... per-erV... dimana C!={r|w|y|l|m|n}
33 peCP... pe-CP... dimana C!={r|w|y|l|m|n} dan P!=âerâ 34 terC1erC2... ter-C1erC2... dimana C1!=ârâ
35 peC1erC2... pe-C1erC2... dimana C1!={r|w|y|l|m|n}
[image:55.595.113.512.118.648.2]Mulai Kata
âPeninggalanâ
dalam data latih Cek kata dalam
database kata dasar Cek kata âpeninggalanâ apakah memiliki inflection suffixes Tidak Kata Dasar Ya Hasil kata âpeninggalanâ tidak memiliki inflection suffixes Cek kata âpeninggalanâ apakah memiliki derivation suffixes (-an,-i,-kan) Hasil kata âpeninggalanâ menjadi kata âpeninggalâ
Cek kata dalam
database kata dasar
Ya Cek kata âpeninggalanâ apakah memiliki derivation prefixes (pe-) Tidak Hasil kata âpeninggalâ menjadi kata âninggalâ Melakukan recoding kata âninggalâ dengan aturan tabel 3.8 nomor 27 menjadi kata
âtinggalâ
Cek kata dalam
database kata dasar
Ya
tidak
Cek kata dalam
database kata dasar
Ya
Pencarian tidak ditemukan
tidak
[image:56.595.134.482.124.709.2]selesai
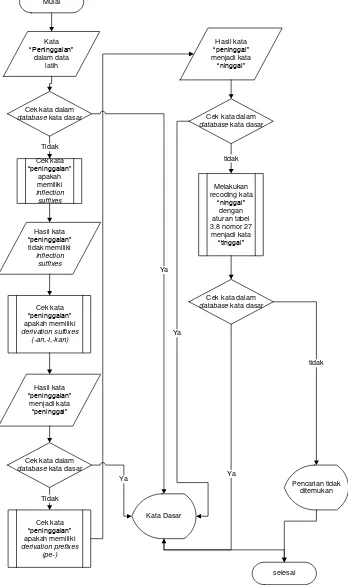
Pada contoh kasus hanya mengambil kata â Peninggalanâ. Tahapan yang
dilakukan untuk kata âPeninggalanâ, dikerjakan sebagai berikut :
1. Kata yang hendak di stemming dicari terlebih dahulu pada kamus. Jika ditemukan, berati kata tersebut adalah kata dasar, jika tidak maka langkah 2 yang dilakukan.
2. Pada kata âPeninggalanâ, akan dicek apakah memiliki inflection suffixes, yaitu akhiran(â-lahâ,â-kahâ,â-tahâ,â-punâ) dan kata ganti kepunyaan atau possessive pronoun PP (â-kuâ, â-muâ, â-nyaâ) ternyata pada kata âPeninggalanâ tidak terdapat inflectional particle maka proses selanjutnya.
3. Hilangkan Derivation Suffixes DS (â-iâ, â-kanâ, atau â-anâ). Ternyata kata
âpeninggalanâ terdapat Derivation Suffixes dimana terdapat akhiran â-anâ
maka hapus akhiran â-anâ, sehingga kata menjadi âpeninggalâ, kemudian sistem mengerjakan pencarian ke database jika kata âpeninggalâ ditemukan
maka proses berhenti jika tidak ditemukan akan dilakukan proses selanjutnya. 4. Kata âpeninggalâ akan dicek, apakah memiliki derivation prefiixes, ternyata
kata âpeninggalâ mengandung derivation prefiixesâpe, sehingga kata menjadi
âninggalâ, kemudian sistem mencari kata âninggalâ ke database jika
ditemukan maka kata âninggalâ adalah kata dasar dan proses berhenti, jika
tidak maka kata âninggalâ kembali menjadi kata âpeninggalâ dan melanjutkan proses berikutnya.
5. Setelah selesai menjalankan langkah 1 sampai 4, tetapi masih belum menemukan kata dasar maka tahapan selanjutnya adalah recoding
menggunakan aturan pada tabel 3.11 Kata âpeninggalâ merupakan kata yang memiliki imbuhan peng- dan diikuti huruf vokal, dengan kondisi tersebut maka aturan yang dipakai adalah aturan nomor 27. Pertama sistem akan memotong kata dengan pen- maka hasilnya menjadi kata âinggalâ selanjutnya
sistem akan mencari kata âinggalâ ke database jika ditemukan maka kata
âinggalâ adalah kata dasar jika tidak maka sistem akan memenggal kata
âpeninggalâ dengan pen- dan menambah huruf âtâ pada hasil pemenggalan
âtinggalâ ke database dan ternyata kata âtinggalâ terdapat dalam database, maka proses berhenti.
Berikut ini merupakan contoh tahapan stemming dibawah ini sebagai berikut :
Tabel 3. 12 Ilustrasi Stemming Contoh Data
Data Latih Hasil
![Gambar 2.5 Flow Chart Algoritma Nazief & Adriani [7]](https://thumb-ap.123doks.com/thumbv2/123dok/1219212.780210/32.595.113.510.109.416/gambar-flow-chart-algoritma-nazief-adriani.webp)