DALAM MENGKLASIFIKASI
GENRE
MUSIK
SYAHZAM
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
2
PERNYATAAN MENGENAI TESIS DAN SUMBER
INFORMASI
Dengan ini saya menyatakan bahwa tesis : Perbandingan Metode Voting Feature Intervals Dengan Jaringan Saraf Tiruan Dalam Mengklasifikasi Genre Musik adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Juni 2011
ABSTRACT
SYAHZAM. Comparison of Voting Feature Intervals with Neural Network Methode in Classifying Music Genre. Under direction of AGUS BUONO and AZIZ KUSTIYO.
Music genre is one of the important descriptions that have been used to classify digital music. The aim of this research is to compare Voting Feature Intervals (VFI) methode with the Neural Network (NN) methode in classifying music genre.
There are 12 scenarios of feature extractions in this research. Three variations of MFCC coefficient number (7, 13 and 20 coefficients) and four variations of music length (1, 5, 10, and 30 seconds). From each of the feature vector, mean was calculated. For the NN methode after the feature vectors were extracted, normalization was applied using the cumulative normal distribution methode.
This research shown that the optimal number of MFCC coefficients was 13 coefficients. NN predictions were better than VFI predictions. NN has an accuracy up to 95% which was obtained by using 30 neurons of hidden layer, 10 seconds length of music and 13 MFCC coefficients. While the VFI has an accuracy up to 85% which was obtained by using 30 seconds length of music and 7 MFCC coefficients. Both experiments that used 13 and 20 coefficients of MFCC feature obtained same accuracy using the NN method. Classic genre has an accuracy of 100% in VFI. The reliability of the system was 57,14% for disco up to 94,44% for classic.
4
RINGKASAN
SYAHZAM. Perbandingan Metode Voting Feature Intervals Dengan Jaringan Saraf Tiruan Dalam Mengklasifikasi Genre Musik. Dibimbing oleh AGUSU BUONO dan AZIZ KUSTIYO.
Perkembangan teknologi media penyimpanan (storage) digital dan pertambahan kapasitas lebar pita jaringan di dunia telah mengakibatkan terciptanya koleksi musik digital yang sangat banyak yang dapat dinikmati oleh beragam pengguna komputer. Oleh karena itu, dibutuhkan sebuah sistem yang memiliki kemampuan untuk manajemen dan mengambil (retrieve) secara otomatis koleksi berkas musik yang sangat banyak dari dalam media penyimpanan
Genre musik adalah salah satu deskripsi penting yang digunakan untuk mengklasifikasi musik. Tujuan utama penelitian ini adalah untuk mengembangkan suatu prototipe sistem yang dapat digunakan untuk mengklasifikasi musik digital berdasarkan genrenya dengan menggunakan metode Voting Feature Intervals (VFI) dan membandingkan akurasi prototipe sistem ini dalam mengenali genre musik dengan metode Jaringan Saraf Tiruan (JST).
Jumlah dataset yang digunakan pada penelitian ini adalah 80 berkas musik berformat au mono 16-bit yang memiliki frekuensi sampling sebesar 22,05 kHz dengan durasi 30 detik setiap berkasnya. Setiap genre akan memiliki 20 berkas musik yang dapat dijadikan sebagai data pelatihan dan pengujian. Genre musik yang akan dipakai untuk penelitian ini adalah genre musik klasik, disko, metal dan reggae.
Terdapat 12 skenario ekstraksi ciri pada penelitian ini yaitu tiga variasi jumlah koefisien MFCC (7, 13 dan 20 koefisien) dan empat variasi penggunaan waktu berkas musik (1, 5, 10 dan 30 detik). Ciri yang diekstrak diperlakukan window Hamming dengan time frame 30 ms (mili detik) serta overlap sebesar 75%.Dari setiap ciri tersebut, mean (rataan) dihitung untuk membentuk vektor ciri. Untuk metode JST, setelah ciri diekstrak maka dilakukan normalisasi menggunakan metode distribusi normal kumulatif.
Penelitian ini masih dapat dikembangkan sebagai upaya untuk meningkatkan akurasi model VFI ataupun JST dalam melakukan prakiraan atau prediksi genre musik, antara lain dengan menambah data training dan testing. Pada penelitian ini, data set yang digunakan sebanyak 80 data. Oleh karena itu, diperlukan penelitian lebih lanjut dengan menggunakan data set yang lebih banyak sehingga memperoleh akurasi yang lebih baik. Perlu dilakukan pengujian dengan menambahkan ciri selain dari MFCC dan melihat kinerja akurasi kedua metode dalam mengklasifikasi genre musik.
6
©Hak Cipta milik IPB, tahun 2011 Hak Cipta dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan
laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan yang wajar IPB. Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis dalam
PERBANDINGAN METODE
VOTING FEATURE
INTERVALS
DENGAN JARINGAN SARAF TIRUAN
DALAM MENGKLASIFIKASI
GENRE
MUSIK
SYAHZAM
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
8
Judul : Perbandingan Metode Voting Feature Intervals Dengan Jaringan Saraf Tiruan Dalam Mengklasifikasi Genre Musik
Nama : Syahzam
NRP : G651050144
Disetujui
Komisi Pembimbing
Dr. Ir. Agus Buono, M.Si, M.Kom Aziz Kustiyo, S.Si, M.Kom
Ketua Anggota
Diketahui
Ketua Program Studi Ilmu Komputer
Dekan Sekolah Pascasarjana IPB
Dr. Ir. Agus Buono, M.Si, M.Kom Dr. Ir. Dahrul Syah, M.Sc. Agr
10
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Judul yang dipilih dalam penelitian ini adalah Perbandingan Metode Voting Feature Intervals Dengan Jaringan Saraf Tiruan Dalam Mengklasifikasi Genre Musik.
Terima kasih penulis ucapkan kepada Bapak Dr. Ir. Agus Buono, M.Si, M.Kom dan Bapak Aziz Kustiyo, S.Si, M.Kom selaku pembimbing atas arahan dan masukannya. Ucapan terima kasih juga penulis sampaikan kepada Bapak Toto Haryanto, S.Kom, M.Si selaku penguji pada sidang tesis. Ungkapan terima kasih juga disampaikan kepada ayah ,ibu, serta seluruh keluarga dan teman, atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juni 2011
RIWAYAT HIDUP
Penulis dilahirkan di Medan pada tanggal 12 Mei 1981 sebagai anak dari pasangan Burhani Syah dan Fazariah Mahroezar. Penulis merupakan anak keempat dari empat bersaudara.
Tahun 1999 penulis lulus dari SMU Negeri 1 Bogor dan pada tahun yang sama melanjutkan program diploma ke Politeknik Negeri Jakarta. Penulis memilih Program Studi Mesin Spesialisasi Konstruksi dan Perancangan Jurusan Teknik Mesin dan lulus pada tahun 2002. Pendidikan sarjana penulis ditempuh di Fakultas Teknologi Industri Teknik Mesin Konsentrasi Mesin Industri, Universitas Jayabaya dan lulus pada tahun 2004.
Halaman
DAFTAR TABEL ... iii
DAFTAR GAMBAR ... iv
DAFTAR LAMPIRAN ... vi
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 2
Ruang Lingkup ... 2
Manfaat Penelitian ... 3
TINJAUAN PUSTAKA ... 4
Musik ... 4
Genre Musik ... 4
Sinyal Suara ... 5
Frame Blocking dan Windowing ... 7
Penyiapan Data untuk Klasifikasi ... 9
Ekstraksi Ciri ... 10
Voting Feature Intervals (VFI) ... 18
Jaringan Saraf Tiruan (JST) ... 22
Multi Layer Perceptron (MLP) ... 23
Propagasi Balik ... 24
Pengukuran Kinerja Sistem ... 27
Review Riset Terdahulu ………....…...…… 27
METODE PENELITIAN ... 29
Kerangka Pemikiran ……….…...……... 29
Identifikasi Masalah ………...…...….. 30
Studi Pustaka ………..………... 30
ii
Halaman
Ekstraksi Ciri ………...…....…… 31
Pengembangan Model VFI dan JST ... 31
Pembuat Keputusan ………...…………....……... 31
Alat dan Bahan ………...…..……... 31
Waktu dan Tempat Penelitian ……….………...…...……. 32
IMPLEMENTASI DAN PERANCANGAN SISTEM ... 33
Ekstraksi Ciri ... 33
Arsitektur Sistem ... 34
Implementasi Metode VFI ... 34
Model VFI ... 35
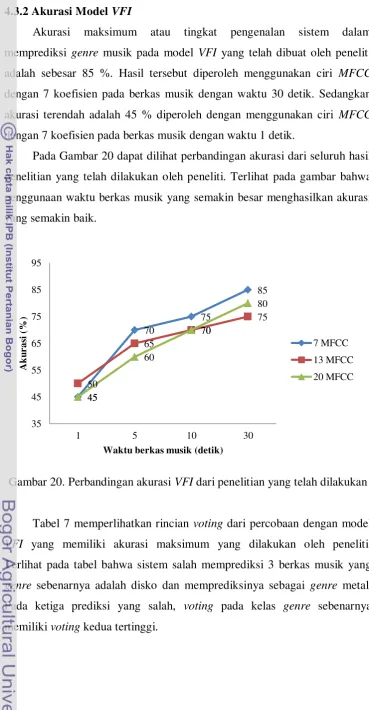
Akurasi Model VFI ... 37
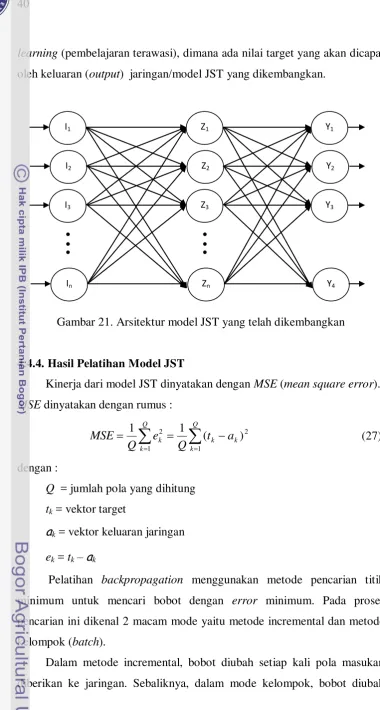
Implementasi Metode JST ... 38
Desain Arsitektur Model JST ... 38
Penentuan Pola Input dan Output ... 39
Algoritma Pembelajaran Jaringan ... 39
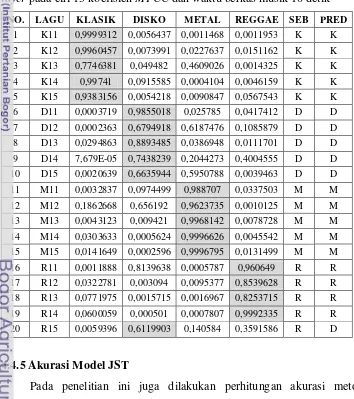
Hasil Pelatihan Model JST ... 40
Akurasi Model JST ... 42
Confusion Matrix ... 43
SIMPULAN DAN SARAN ... 47
Simpulan ... 47
Saran ... 47
DAFTAR PUSTAKA ………....……….. 49
DAFTAR TABEL
Halaman
1. Beberapa contoh genre dan sub-genrenya (Hayne et al. 2005) .... 5
2. Beberapa contoh penelitian klasifikasi genre musik ... 28
3. Dimensi vektor ciri untuk setiap variasi penelitian ... 33
4. Titik interval dan presentase frekuensi kemunculan pada ciri
MFCC koefisien ke-1 pada contoh sebuah 30 detik berkas
musik ... 35
5. Contoh voting sistem pada sebuah 30 detik berkas musik dengan
ciri MFCC koefisien ke-1 ... 36
6. Contoh prediksi sistem terhadap sebuah 30 detik berkas musik
dengan ciri MFCC 20 koefisien ... 36
7. Rincian voting sistem dengan menggunakan ciri MFCC 7
koefisien dan 30 detik berkas musik ... 38
8. Hasil akurasi percobaan model JST dengan beragam jumlah
neuron hidden layer pada ciri 13 koefisien MFCC dan waktu
berkas musik 10 detik ... 41
9. Hasil prediksi percobaan model JST dengan 30 neuron hidden
layer pada ciri 13 koefisien MFCC dan waktu berkas musik 10
detik ... 42
10. Confusion matrix dari prediksi sistem dengan metode VFI dengan
ciri 7 koefisien MFCC dan 30 detik berkas musik ... 44
11. Confusion matrix dari prediksi sistem dengan metode JST dengan
ciri 13 koefisien MFCC dan 10 detik berkas musik ... 44
iv
DAFTAR GAMBAR
Halaman
1. Spectrogram menggunakan metode Welch (Nilsson &
Ejnarsson 2002) ... 6
2. Pembentukan frame pada sinyal suara (Rabiner dan Juang 1993) ... 8
3. Sistem dasar klasifikasi (Andersson 2004) ... 10
4. Ilustrasi dari perhitungan MFCC ... 11
5. Ilustrasi transformasi DFT (Buono 2009) ... 12
6. Ilustrasi fase X[k] ... 14
7. Grafik hubungan frekuensi dengan skala mel ... 15
8. Filter yang diperkenalkan oleh Davis dan Mermelstein ... 16
9. Ekstraksi ciri teknik MFCC dengan panjang frame 256 ... 18
10. Tahap pembelajaran pada algoritma VFI5 (Demiroz 1997) ... 19
11. Sampel dataset pembelajaran dengan 2 feature dan 2 kelas (Demiroz 1997) ... 20
12. Interval yang diperoleh dari VFI5 dengan class counts untuk contoh dataset pembelajaran ... 20
13. Contoh pengklasifikasian pada algoritma VFI5 dengan contoh pengujian t=<5,6> ... 21
14. Sistem komputasi pemodelan neuron ... 23
15. Arsitektur jaringan propagasi balik (Kusumadewi 2004) ... 25
16. Sigmoid biner pada selang [0,1] ... 25
17. Sigmoid bipolar pada selang [-1,1] ... 26
18. Diagram alir penelitian pengembangan model sistem ... 29
19. Arsitektur sistem klasifikasi genre musik yang telah dikembangkan ... 34
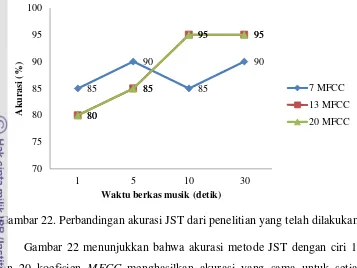
20. Perbandingan akurasi VFI dari penelitian yang telah dilakukan ... 37
Halaman
22. Perbandingan akurasi JST dari penelitian yang telah
dilakukan ... 43
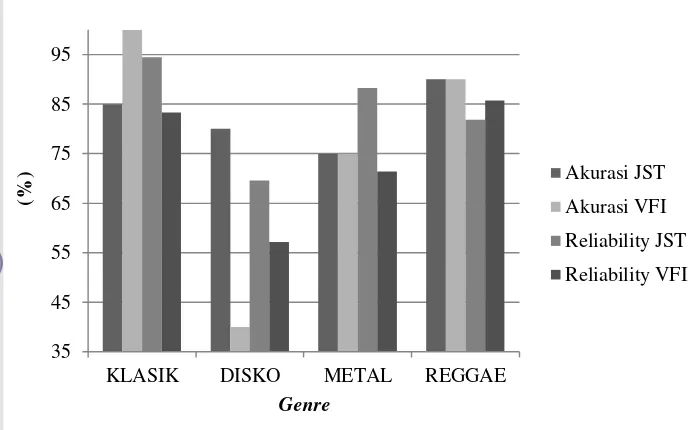
23. Diagram batang dari akurasi dan reliability sistem ... 45
24. Diagram batang perbandingan mean akurasi dan mean
vi
DAFTAR LAMPIRAN
Halaman
1. Prediksi sistem dengan Metode VFI dengan ciri 7 koefisien MFCC,
30 detik waktu berkas musik pada fold kedua ... 53
2. Prediksi sistem dengan Metode VFI dengan ciri 7 koefisien MFCC,
30 detik waktu berkas musik pada fold ketiga ... 53
3. Prediksi sistem dengan Metode VFI dengan ciri 7 koefisien MFCC,
30 detik waktu berkas musik pada fold keempat ... 54
4. Prediksi sistem dengan Metode JST dengan ciri 13 koefisien
MFCC, 10 detik waktu berkas musik pada fold kedua ... 54
5. Prediksi sistem dengan Metode JST dengan ciri 13 koefisien
MFCC, 10 detik waktu berkas musik pada fold ketiga ... 55
6. Prediksi sistem dengan Metode JST dengan ciri 13 koefisien
I PENDAHULUAN
1.1 Latar Belakang
Perkembangan teknologi media penyimpanan (storage) digital dan
pertambahan kapasitas lebar pita jaringan di dunia telah mengakibatkan
terciptanya koleksi musik digital yang sangat banyak yang dapat dinikmati
oleh beragam kelas pengguna komputer. Oleh karena itu, dibutuhkan sebuah
sistem yang memiliki kemampuan untuk manajemen dan mengambil
(retrieve) secara efisien koleksi berkas musik yang sangat banyak dari
dalam media penyimpanan.
Hingga saat ini, untuk manajemen dan retrieve berkas musik masih
berdasarkan pada metadata berkas musik seperti nama berkas, judul lagu,
album, genre, dan lain-lainnya. Metadata berkas musik tersebut masih
diinput secara manual oleh manusia sesuai dengan pengetahuan dan
penilaiannya. Ekstraksi informasi melalui proses yang otomatis dan
sistematis dapat mengatasi masalah tersebut.
Genre musik adalah salah satu deskripsi penting yang telah
digunakan untuk mengklasifikasi dan mengkarakterisasi musik digital serta
untuk manajemen koleksi besar berkas musik yang tersedia pada web
(Tzanetakis dan Cook 2002). Genre musik juga sangat berguna dalam
pengindeksan musik dan retrieval musik berbasis content. Akan tetapi,
genre musik adalah konsep yang subyektif dan bahkan industri musik
terkadang mengalami permasalahan dalam menentukan genre sebuah
musik.
Cara praktis yang umum digunakan untuk mengkategorikan sebuah
musik adalah menyesuaikannya dengan profil dari sang artis. Oleh karena
itu, klasifikasi genre musik otomatis dapat membantu atau mengganti peran
manusia dalam proses ini dan juga menyediakan komponen penting dalam
sistem retrieval informasi musik yang lengkap untuk sinyal audio.
Banyak penelitian mengenai otomasi klasifikasi genre musik yang
telah dilakukan dengan menggunakan beragam ciri (feature) dan metode.
2
digunakan untuk mengkarakterisasi dan mengklasifikasi musik. Akan tetapi
pada penelitian tersebut hanya digunakan 20 ciri. Sebagai
pengklasifikasinya digunakan Jaringan Saraf Tiruan (JST) feed-forward
pada penelitian tersebut.
Penelitian Costa et al. (2004) menggunakan ciri permukaan musik
(musical surface) dan ciri yang berhubungan dengan tempo serta
pendekatan kombinasi pengklasifikasi. Ekstraksi ciri diperoleh dari tiga
segmen pada sebuah musik klip berformat mp3. Ketiga segmen tersebut
diekstrak dari awal, tengah, dan akhir bagian musik klip. Penelitian tersebut
menggunakan JST sebagai pengklasifikasinya.
Oleh karena sudah banyak penelitian yang mengklasifikasi genre
musik barat, Norowi et al. (2005) mencoba untuk mengklasifikasi genre
musik tradisional negaranya (Malaysia). Penelitian tersebut menggunakan
ciri yang berhubungan dengan timbral, ritme, dan pitch serta pengklasifikasi
J48 dan OneR. J48 dan OneR adalah pengklasifikasi yang terdapat pada
sistem pembelajaran mesin WEKA (Waikato Environment for Knowledge
Analysis).
1.2 Tujuan Penelitian
Tujuan utama penelitian ini adalah untuk mengembangkan suatu
prototipe sistem yang dapat digunakan untuk mengklasifikasi musik digital
berdasarkan genrenya dengan menggunakan metode Voting Feature
Intervals (VFI) dan membandingkan akurasi prototipe sistem ini dalam
mengenali genre musik dengan metode Jaringan Saraf Tiruan (JST).
1.3 Ruang Lingkup
Ruang lingkup penelitian ini meliputi :
1. Genre yang akan diklasifikasi hanya terbatas pada genre klasik, disko,
metal dan reggae.
2. Klasifikasi menggunakan metode Voting Feature Intervals (VFI) dan
Jaringan Saraf Tiruan (JST).
1.4 Manfaat Penelitian
Prototipe sistem yang dihasilkan penelitian ini diharapkan dapat
dikembangkan lebih lanjut menjadi sebuah sistem yang memiliki
kemampuan dalam manajemen dan memanggil (retrieve) basisdata berkas
4
II TINJAUAN PUSTAKA
2.1 Musik
Definisi dari musik adalah pengaturan (aransemen) bunyi atau suara
yang memiliki nilai seni terhadap rentang waktu. Musik adalah bagian dari
setiap budaya di dunia, akan tetapi memiliki ragam yang luas antara
budaya-budaya dalam corak dan struktur (Butler 2005).
Pada awalnya musik dihasilkan baik dari vokal manusia maupun dari
sebuah alat instrumen musik atau lebih, yang dimainkan secara harmonis
atau gabungan dari kedua unsur tersebut. Dengan berkembangnya teknologi,
maka kini musik dapat dibuat dengan bantuan komputer atau alat elektronik
(sound synthesizer) yang menggunakan suara-suara buatan (artificial) yang
telah direkam sebelumnya.
Perkembangan musik juga dibantu dengan perkembangan industri
musik. Hal ini juga mengakibatkan munculnya budaya-budaya baru yang
berhubungan dengan gaya hidup manusia dan teknologi-teknologi baru yang
mendukung perkembangan musik itu sendiri.
Media penyimpanan musik pun berubah dari piringan hitam, pita
kaset, hingga cakram optik sesuai dengan teknologi perekaman yang ada.
Media yang terakhir diakibatkan oleh perubahan sinyal audio yang dulunya
berbentuk analog menjadi bentuk digital. Dengan adanya digitalisasi musik,
maka distribusi musik menjadi lebih mudah, murah, dan cepat ke seluruh
dunia terutama karena adanya web.
2.2 Genre Musik
Genre musik adalah jenis atau kategori dari hasil artistik musik yang
biasanya dipengaruhi oleh budaya masyarakat. Perkembangan dari genre
yang sudah ada menghasilkan genre-genre baru yang terdengar sangat
berbeda yang disebut sub-genre.
Pada akhir abad ke-20, terdapat genre-genre baru yang dihasilkan dari
perkawinan dua atau lebih genre yang ada. Percobaan-percobaan tersebut
memperkaya genre-genre dan budaya-budaya yang sudah ada. Pada Tabel 1
dapat dilihat beberapa contoh genre dan sub-genrenya.
Tabel 1. Beberapa contoh genre dan sub-genrenya (Hayne et al. 2005)
Genre Sub-genre
Modern Rock Alternative rock, experimental rock, indie rock, jam rock, new wave, post punk, power pop
Rock Classic rock (british invasion, glam rock, folk rock), hard rock, prog rock, southern rock Metal Funk metal, industrial metal, thrash
Punk ’77 style punk, hardcore punk, pop punk, ska punk, psychobilly
Folk 60s revival, anti-folk, contemporary folk, singer-songwriter, traditional folk
Electronica Acid Jazz, ambient, downbeat, intelligent dance music, techno, industrial, drum ’n’ bass
Jazz Be bop, big band, crossover jazz, lounge, vocal jazz, cool jazz, soul jazz
Blues Chicago blues, electric blues, country blues, female vocal blues
Country Alt country, bluegrass, contemporary country, country rock, traditional country
Oldies Doo wop, early rock & roll. Rockabilly, surf
Pop Dance pop, easy listening, euro pop, soft rock, teen pop, vocalists
Hip hop Abstract hip hop, bass, gangsta rap, pop rap R&B Funk, disco, gospel, soul
Reggae Roots reggae, ska
2.3 Sinyal Suara
Sinyal suara dan seluruh karakteristiknya dapat direpresentasikan
dalam dua domain nilai yang berbeda, yaitu waktu dan frekuensi (Nilsson
dan Ejnarsson 2002). Domain waktu (time-domain) yaitu domain yang
berhubungan dengan perubahan amplitudo dari waktu ke waktu. Sedangkan
domain frekuensi yaitu domain yang terdapat dalam interval waktu tertentu.
Representasi dalam bentuk spectral merupakan representasi sinyal
suara berdasarkan intensitasnya terhadap waktu. Salah satu bentuk
6
Pada Gambar 1 diperlihatkan adanya bagian yang berwarna biru gelap
yang merepresentasikan bagian dari sinyal suara di mana suara tidak
dihasilkan. Sedangkan, bagian yang bewarna merah merepresentasikan
intensitas yang menandakan suara dihasilkan.
Gambar 1. Spectrogram menggunakan metode Welch (Nilsson dan
Ejnarsson 2002)
Proses analisa sinyal dalam bentuk jumlah sinusoida telah banyak
digunakan seperti pada aplikasi analisa ucapan, sonar, hingga analisa musik
terkini dimana mereka berkaitan dengan keharmonisan sumber suara musik.
Metode yang paling tua dari analisa sinyal suara adalah berdasarkan
dari transformasi Fourier yang diformulasikan sebagai berikut :
x
te dt X jt
(1)
dan inversnya, yaitu :
X e d
t
x
j t 2 1 (2)
di mana x(t) adalah sinyal time-domain kontinu sementara X(ω) adalah
transformasinya, yang sama-sama kontinu dalam frekuensi dan t serta ω
tidak terikat. Sifat ini tidak cocok untuk sinyal audio digital karena diskret
terhadap proses sampling dan juga terikat dengan waktu (Hainsworth 2003).
Oleh karena itu, digunakan Discrete Fourier Transform (DFT):
Mdi mana X[k] dikalkulasikan untuk range –M/2 ≤ k < M/2 dan juga
tergantung pada panjang sinyal time-domain M.
Sinyal musik menunjukkan variasi amplitudo dan frekuensi dari waktu
ke waktu. Representasi sinyal musik yang lebih baik dari DFT adalah short
time Fourier Transform (STFT). Hal ini menerapkan window h[n], panjang
N << M pada data :
N j k NN
h k n h xn e
X 2 1 2 2 ,
(5)2.4Frame Blocking dan Windowing
Sinyal suara umumnya dipilah-pilah menjadi sejumlah segmen sinyal.
Segmen sinyal suara ini disebut frame. Tujuan sinyal suara dipilah-pilah ke
dalam sejumlah frame agar karakteristiknya dapat ditangkap, di mana
karakteristiknya tidak berubah dalam rentang waktu yang pendek.
Lebar setiap frame yang ditentukan di dalam suatu aplikasi
pengolahan suara adalah sama misalnya 30 milidetik, sehingga setiap
framenya akan memiliki jumlah sampel yang sama pula, misalnya N sampel
(Lai 2003). Frame kedua adalah frame yang juga memiliki N sampel yang
posisi awal framenya bergeser sebanyak M sampel dari posisi awal frame
pertama.
Begitu juga frame ketiga, dengan N sampel yang posisi awal framenya
bergeser sebanyak M sampel dari posisi awal frame kedua atau sebanyak
2M sampel dari posisi awal frame pertama. Demikian pula seterusnya
hingga frame terakhir.
M dapat diperoleh dari M(1/3)N atau M = (a/b)N di mana a dan b adalah bilangan asli, a ≤ b dan M ≤ N. Overlap antara suatu frame dengan
frame sebelahnya adalah N – M sampel (Rabiner dan Juang 1993). Adanya
overlap dimaksudkan agar pengambilan sampel-sampel dari frame
berikutnya dapat bergerak secara halus (smooth) sehingga karakteristik
sinyal suara dalam setiap framenya tidak banyak berkurang. Ilustrasi tentang
8
Gambar 2. Pembentukan frame pada sinyal suara (Rabiner dan Juang 1993)
Tahap selanjutnya dari pemrosesan sinyal adalah membuat window
terhadap tiap-tiap frame dengan tujuan untuk meminimalkan
ketidak-kontinuan pada awal dan akhir setiap frame. Umumnya, window yang
digunakan adalah window Hamming. Pembentukan window Hamming
menggunakan formula :
1 , , 0 ; 1 2 cos 46 , 0 54 ,
0
n N
N n
n
(6)
dengan N adalah banyaknya sampel.
Keuntungan menggunakan window Hamming adalah memiliki
kebocoran spektral yang lebih sedikit dari pada tanpa menggunakan window
Hamming (Ahrendt 2006).
Kebocoran spektral (spectral leakage) adalah efek pada analisis
frekuensi sinyal di mana munculnya sejumlah energi sinyal kecil yang
diamati pada komponen frekuensi yang tidak terdapat pada bentuk
gelombang aslinya. Istilah kebocoran di sini dimaksudkan bahwa
seolah-olah terdapat sebagian energi yang bocor keluar dari spektrum sinyal aslinya
ke frekuensi yang lain (http://en.wikipedia.org/wiki/Spectral_leakage).
Setelah sinyal suara dibagi-bagi ke dalam frame, setiap frame sinyal
suara tersebut dikenakan operasi window Hamming. Selanjutnya proses
ekstraksi ciri akan dilakukan terhadap setiap frame tersebut.
Sinyal suara N N N M M Frame3 Frame1 Frame2
2.5 Penyiapan Data untuk Klasifikasi
Menurut Han dan Kamber (2001) terdapat beberapa langkah praproses
terhadap data untuk meningkatkan akurasi, efisiensi, dan skalabilitas dari
klasifikasi atau prediksi, antara lain :
1) Pembersihan Data
Tujuan dari praproses ini adalah untuk menghilangkan atau
mengurangi noise (misalnya dengan melakukan proses smoothing) dan
mengadakan perlakuan khusus pada data yang hilang (misalnya
menggantinya dengan nilai modus data tersebut).
2) Analisa Relevansi atau Pemilihan Ciri
Sejumlah atribut di dalam data mungkin saja tidak relevan untuk
diklasifikasi atau diprediksi atau juga atribut yang lain mungkin redundant.
Praproses ini dilakukan untuk menghilangkan atribut yang redundant atau
tidak relevan.
3) Transformasi atau Normalisasi Data
Data dapat digeneralisasi ke konsep yang lebih tinggi. Konsep hirarki
dapat digunakan di sini. Misalnya nilai untuk atribut frekuensi dapat diganti
dengan rendah, sedang, atau tinggi. Beberapa metode yang umum
digunakan yaitu :
a. Min-Max
Min-Max merupakan metode normalisasi dengan melakukan
transformasi linier terhadap data asli. Salah satu metodenya adalah
distribusi normal kumulatif dengan rumus sebagai berikut :
√ (7)
Di mana x adalah nilai yang akan didistribusi dan erf adalah error
function. Error function didapatkan dengan rumus sebagai berikut :
√ ∫ (8)
Metode ini akan menormalisasi input dan target sedemikian rupa
sehingga hasil normalisasi akan berada pada interval 0 dan 1.
b. Unary Encoding
Unary Encoding merupakan metode transformasi data yaitu
10
(variabel bilangan biner). Metode ini digunakan untuk mentransformasi
data bersifat kategori. Sebagai contoh ‘10’ untuk data ‘musik’ dan ‘01’
untuk data ‘bukan musik’.
c. Data Numerik dan Kategorik
Menurur Kantardzic (2003) tipe data yang umum adalah numerik
dan kategorik. Nilai numerik termasuk nilai real maupun integer seperti
waktu dan frekuensi. Nilai numerik memiliki 2 properti yang penting
yaitu relasi urut (2 < 5 dan 5 < 7) dan jarak (jarak (2,1, 3,2) = 1, 1).
Sedangkan untuk kategorik data tidak memiliki keduanya tersebut. Nilai
dari 2 variabel ini bisa sama atau tidak sama yang artinya hanya
mempunyai relasi equality (rock = rock, rock <> klasik). Variabel
dengan tipe ini dapat dikonversi menjadi numeric binary variable atau
dalam statistik disebut dengan dummy variables.
Variabel kategorik dengan n nilai dapat dikonversi menjadi n
numerical binary variable. Jika terdapat 4 pilihan genre yaitu rock,
klasik, pop dan jazz. Maka 4 genre tersebut dapat dikonversi menjadi 4
bit numerical binary variable yaitu klasik bernilai 1000, disko bernilai
0100, metal bernilai 0010, dan reggae bernilai 0001.
2.6 Ekstraksi Ciri
Tahap pertama dalam sistem klasifikasi, seperti yang ditunjukkan
dalam Gambar 3, adalah penting bagi akurasi sistem klasifikasi. Vektor ciri
y, yang merupakan komposisi dari beberapa ciri harus sediskriminatif
mungkin dari kelas yang bersangkutan. Idealnya, vektor ciri harus dapat
memisahkan seluruh sampel dari kelas-kelas yang berbeda.
Gambar 3. Sistem dasar klasifikasi (Andersson 2004)
y
Pengklasifikasi Ekstraksi Ciri
Pengamatan Vektor Ciri
Bagaimana vektor ciri y dibentuk adalah penting bagi akurasi
klasifikasi. Vektor ciri yang dibentuk secara efektif memudahkan
pengklasifikasian dan juga memudahkan perancangan pengklasifikasi. Oleh
karena itu, ciri apa yang akan diekstrak tergantung dari konteks.
Adapun tujuan dari ekstraksi ciri (feature extraction) adalah untuk
mengurangi jumlah data yang sebenarnya dengan melakukan pengukuran
terhadap properti atau ciri tertentu yang membedakan pola masukan (input)
yang satu dengan yang lainnya (Duda et al. 2001).
Dalam sistem klasifikasi musik, ciri diekstrak oleh algoritma
pemproses sinyal untuk mendapatkan informasi diskriminatif sebanyak
mungkin dari tahap pengamatan. Ciri yang sering dipakai dalam penelitian
sitem klasifikasi musik seperti pada penelitian Costa et al. (2004),
Tzanetakis et al. (2002), dan Norowi et al. (2005) adalah Mel-Frequency
Cepstral Coefficents (MFCC).
Ciri MFCC menghitung koefisien cepstral dengan
mempertimbangkan persepsi sistem pendengaran manusia terhadap
frekuensi suara.
Gambar 4. Ilustrasi dari perhitungan MFCC
Diagram alir yang terlihat pada Gambar 4 mengilustrasikan
langkah-langkah dalam menghitung MFCC dari sinyal audio mentah menjadi ciri
MFCC. Sinyal audio dibaca frame demi frame, dan dilakukan windowing
untuk setiap frame untuk berikutnya dilakukan transformasi Fourier. Dari
nilai hasil transformasi Foruier ini selanjutnya dihitung spektrum mel
menggunakan sejumlah filter yang dibentuk sedemikian sehingga jarak
antar pusat filter adalah konstan pada ruang frekuensi mel. Dari literatur
yang ada, skala mel ini dibentuk untuk mengikuti persepsi sistem
Hamming Window
Dicsrete Fourier Transform
Mel-Frequency
Wrapping
Dicsrete Cosine Transform
12
pendengaran manusia yang bersifat linear untuk frekuensi rendah dan
logaritmik untuk frekuensi tinggi, dengan batas pada nilai frekuensi akustik
sebesar 1000 Hz. Proses ini dikenal dengan nama Mel-Frequency Wrapping.
Koefisien MFCC merupakan hasil transformasi kosinus dari spektrum mel
tersebut, dan dipilih K koefisien. Transformasi kosinus berfungsi untuk
mengembalikan domain, dari frekuensi ke domain waktu (Buono 2009).
Setelah menerapkan window Hamming pada frame, maka langkah
berikutnya untuk menghitung MFCC adalah sebagai berikut :
a. Discrete Fourier Transform (DFT)
DFT merupakan analisis sinyal suara yang berkaitan dengan sinyal
periodik-diskret, yaitu sinyal diskret yang dapat diperlebar tanpa batas ke
kiri dan ke kanan, dengan pola yang berulang.
Pada analisis sinyal digital, dilakukan sampling sinyal sebanyak N.
Anggap bahwa sampel ini sebagai satu periode dan dapat diduplikasi
terus-menerus ke kiri dan ke kanan, sehingga dapat dianalisis dengan
menggunakan DFT. DFT mentransformasikan N titik sinyal sebagai input
menjadi N/2+1 titik sinyal output, seperti yang diilustrasikan pada Gambar
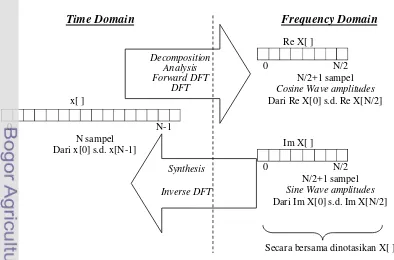
[image:30.595.107.501.454.714.2]5.
Gambar 5. Ilustrasi transformasi DFT (Buono 2009)
Time Domain Frequency Domain
0 N-1
N sampel Dari x[0] s.d. x[N-1]
Decomposition Analysis Forward DFT
DFT
Re X[ ] 0 N/2
N/2+1 sampel Cosine Wave amplitudes Dari Re X[0] s.d. Re X[N/2] x[ ]
Im X[ ] 0 N/2
N/2+1 sampel Sine Wave amplitudes Dari Im X[0] s.d. Im X[N/2]
Secara bersama dinotasikan X[ ] Synthesis
Notasi untuk domain frekuensi adalah Re X[k] dan Im X[k] untuk
k [0,N/2] atau Re X[f] dan Im X[f] untuk f=k/N atau f [0, 0,5]. Hal ini
dikarenakan sinyal diskret hanya mengandung frekuensi antara 0 dan 0,5
dari sampling rate. Atau bisa juga Re X[] dan Im X[] untuk
=2πk/N [0, π]. Oleh karena itu, gelombang kosinus pada domain
frekuensi tersebut bisa dituliskan sebagai berikut :
c[n] = cos(2πkn/N) = cos(2πfn) = cos(n) (9) Fungsi basis (basis function) dalam DFT adalah gelombang sinus dan
kosinus dengan amplitudo satu. Fungsi basis ini dituliskan dengan rumus
sebagai berikut :
ck[i] = cos(2πki/N) dan sk[i] = sin(2πki/N) (10)
untuk i = 0, 1, 2, ..., N-1, dan k = 0, 1, 2, ..., N/2 (dalam hal ini k adalah
banyaknya gelombnag pada N sampel). Sebagai contoh untuk 32 titik
sampel, DFT direpresentasikan dengan basis gelombang sinus dan kosinus
masing-masing sebanyak 17 buah, yaitu untuk k = 0, 1, 2, ..., 16. Dalam hal
ini sinyal dalam domain waktu dapat dirumuskan sebagai penjumlahan
terboboti dari fungsi basis dengan formula :
[ ] ∑ ⁄ ̅ [ ] ⁄ ∑ ⁄ ̅ [ ] ⁄ (11) dengan i = 0, 1, 2, ..., N-1 yang disebut persamaan sintesa. Sinyal sampel
sebanyak N titik dibentuk oleh N/2+1 gelombang kosinus dan N/2+1
gelombang sinus dengan amplitudo untuk kosinus dan sinus masing-masing
adalah array ̅[ ] dan ̅[ ], yang dalam hal ini :
̅[ ] [ ] ⁄ dan ̅ [ ] [ ]
⁄ (12)
Sedangkan untuk k = 0 dan k = N/2, bagian real adalah :
̅[ ] [ ] dan ̅[ ⁄ ] [ ⁄ ] (13)
Nilai-nilai DFT untuk k = 0, 1, 2, ..., N/2 dihitung dari sinyal input dengan
rumus sebagai berikut :
[ ] ∑ [ ] ⁄
(14)
[ ] ∑ [ ] ⁄
14
Yang disebut sebagai persamaan analisis. Ada kalanya array dalam
domain frekuensi direpresentasikan dengan koordinat polar. Dalam
koordinat polar, pasangan [ ] dan [ ] digantikan oleh pasangan
magnitudo, Mag [ ], dan fase X[k].
Gambar 6. Ilustrasi fase X[k]
Berdasarkan ilustrasi pada Gambar 6, maka domain frekuensi dapat
dirumuskan sebagai berikut :
Mag X[k] = (Re X[k]2 + Im X[k]2)1/2 dalam amplitudo
Fase X[k] = arctan [ ]
[ ] dalam radian
Juga sebaliknya :
Re X[k] = Mag X[k] cos(Fase X[k])
Im X[k] = Mag X[k] sin(Fase X[k])
Oleh karena itu, sinyal input dalam domain waktu dapat
ditransformasikan menjadi domain frekuensi melalui analisis DFT, baik
dalam bentuk komponen real dan imajiner, maupun dalam bentuk koordinat
polar (magnitudo dan fase) tanpa mengubah informasi yang terkandung
dalam sinyal. Secara umum ada tiga cara untuk menghitung DFT, yaitu
mealui persamaan simultan, korelasi dan algoritma FFT. Dengan algoritma
FFT, kompleksitas menjadi rendah dari n2 menjadi n*log2(n).
b. Mel-Frequency Wrapping dan Transformasi Kosinus
Untuk proses wrapping, diperlukan beberapa filter yang saling overlap
dalam domain frekuensi. Filter yang digunakan adalah berbentuk segitiga
dengan tinggi satu dan rentang filter segitiga tersebut ditentukan
berdasarkan hasil studi psikologi mengenai persepsi manusia dalam
menerima frekuensi bunyi.
B
A M
θ
A cos (x) + B sin (x) = M cox (x+θ)
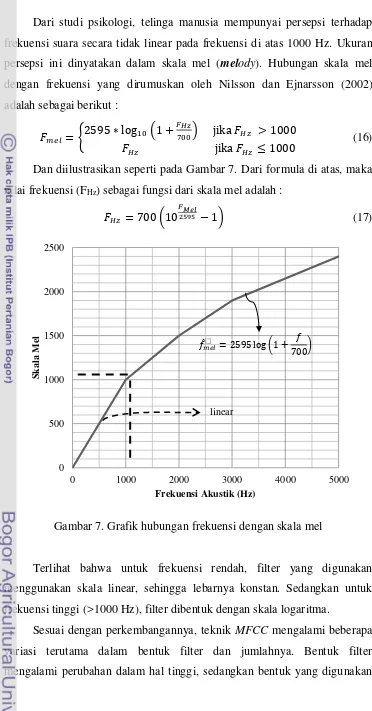
Dari studi psikologi, telinga manusia mempunyai persepsi terhadap
frekuensi suara secara tidak linear pada frekuensi di atas 1000 Hz. Ukuran
persepsi ini dinyatakan dalam skala mel (melody). Hubungan skala mel
dengan frekuensi yang dirumuskan oleh Nilsson dan Ejnarsson (2002)
adalah sebagai berikut :
{
(16)
Dan diilustrasikan seperti pada Gambar 7. Dari formula di atas, maka
nilai frekuensi (FHz) sebagai fungsi dari skala mel adalah :
(
[image:33.595.109.481.70.781.2]) (17)
Gambar 7. Grafik hubungan frekuensi dengan skala mel
Terlihat bahwa untuk frekuensi rendah, filter yang digunakan
menggunakan skala linear, sehingga lebarnya konstan. Sedangkan untuk
frekuensi tinggi (>1000 Hz), filter dibentuk dengan skala logaritma.
Sesuai dengan perkembangannya, teknik MFCC mengalami beberapa
variasi terutama dalam bentuk filter dan jumlahnya. Bentuk filter
mengalami perubahan dalam hal tinggi, sedangkan bentuk yang digunakan
0 500 1000 1500 2000 2500
0 1000 2000 3000 4000 5000
S
k
al
a
M
e
l
Frekuensi Akustik (Hz)
linear
16
tetap segitiga dengan jumlah 20, 24 atau 40. Gambar 8 menyajikan contoh
filter yang diperkenalkan oleh Davis dan Mermelstein pada tahun 1980.
Berikut akan diuraikan tahapan pembentukan filter yang pertama kali
diperkenalkan oleh Davis dan Mermelstein. Pada penjelasan ini dimisalkan
frekuensi suara yang akan dicakup adalah pada rentang 0 hingga 5000 Hz.
Secara umum ada tiga tahapan yaitu :
1) Gambarkan fungsi Fmel mulai frekuensi terendah hingga FHz = 5000 Hz
dengan menggunakan persamaan 16, dan tentukan nilai mel untuk
frekuensi akustik 5000 Hz (misal M2) dan nilai mel untuk frekuensi
akustik 1000 Hz (misal M1).
2) Sumbu mel dari 0 hingga M1 dan M1 ke M2 disekat masing-masing
menjadi M/2 sekatan yang sama lebarnya.
3) Dari setiap batas sekatan ditarik garis ke kurva fungsi dan diproyeksikan
ke sumbu FHz sehingga diperoleh titik tengah filter pada sumbu FHz.
Gambar 8. Filter yang diperkenalkan oleh Davis dan Mermelstein
Algoritma detail untuk membentuk M filter pada teknik MFCC yang
disarankan oleh Davis dan Mermelstein adalah sebagai berikut :
a) Pilih jumlah filter yang akan dibuat (M)
b) Pilih frekuensi terbesar (fhigh). Dari nilai ini, maka nilai tertinggi dari
adalah :
A
mp
li
tu
d
o
c) Pusat filter ke i adalah fi :
c.1.
untuk i = 1, 2, 3, ..., M/2
c.2. untuk i = M/2, M/2+1, ..., M, maka fi dihitung dengan prosedur
berikut :
1. skala mel disekat dengan lebar yang sama, yaitu sebesar ,
dengan :
Dari point (b), maka nilai dapat ditulis sebagai :
2. nilai mel untuk pusat filter ke i adalah :
3. pusat dari filter ke i adalah :
( ⁄ )
Dari M filter yang sudah dibentuk, maka dilakukan wrapping terhadap
sinyal dalam domain frekuensi dan menghasilkan satu komponen untuk
setiap filter dengan formula sebagai berikut :
∑ | | (18)
Dalam hal ini i = 1, 2, 3, ..., M (M adalah jumlah filter segitiga) dan
adalah nilai filter segitga ke i untuk frekuensi akustik sebesar k. Nilai
koefisien MFCC ke j akhirnya diperoleh menggunakan transformasi kosinus
dengan formula sebagai berikut :
∑ (19)
dengan j = 1, 2, 3, ..., K, K adalah jumlah koefisien MFCC yang diinginkan
dan M adalah jumlah filter. Gambar 9 memberikan ilustrasi ekstraksi ciri
dibangun pada setiap dimensi feature pada tahap pembelajaran dan
interval-interval berkoresponden pada setiap feature memberikan suara (vote) untuk
setiap kelas pada tahap klasifikasi algoritma VFI (Demiroz 1997).
Algoritma VFI telah dikembangkan menjadi lima versi, yaitu VFI1, VFI2,
VFI3, VFI4, dan VFI5. Pada penelitian ini akan digunakan algoritma yang
terakhir yaitu VFI5.
Algoritma VFI5 adalah versi terakhir dari algoritma VFI yang
menggeneralisasi pembentukan point intervals pada seluruh end points.
Algoritma VFI5 membentuk point interval dari setiap end point yang
berbeda dan range interval antara sepasang end point yang berbeda
mengecualikan end points. Algoritma pembelajaran dari VFI5 dapat dilihat
pada Gambar 10.
Gambar 10. Tahap pembelajaran pada algoritma VFI5 (Demiroz 1997)
Interval-interval beserta kelas yang diperoleh dari contoh dataset
pembelajaran pada Gambar 11 dapat dilihat pada Gambar 12. Batas bawah
dari semua interval adalah point intervals dan terdapat range intervals
antara batas bawah tersebut meniadakan batas bawah.
train(TrainingSet): begin
for each feature f for each class c
EndPoints[f] = EndPoints[f] find_end_points(TrainingSet,f,c); sort(EndPoints[f]);
if f is linear
for each end point p in EndPoints[f] form a point interval from end point p
form a range interval between pand the next endpoint ≠ p else /* f is nominal */
each distinct point in EndPoints[f] forms a point interval
for each interval i on feature dimension f for each class c
interval_class_count[f,i,c] = 0 count_instances(f, TrainingSet); for each interval i on feature dimension f for each class c
interval_class_vote[f,i,c] = _� _� [ �]
� _� [�]
normalize interval_class_vote[f, i, c];
interval i26 dengan batas bawah 6 dan dimensi feature f2. Hal ini dapat
dilihat pada Gambar 13. Karena terdapat point intervals dimana t1 = 5 dan t2
= 6 keduanya terletak, vote feature individu diambil dari point intervals
yang berkoresponden.
Gambar 13. Contoh pengklsifikasian pada algoritma VFI5 dengan contoh
pengujian t=<5,6>
Vote point interval i16 dari feature f1 dimana t1 = 5 terletak sama
dengan interval_class_vote[f1, i16, A] = 0 dan interval_class_vote[f1, i16, B]
= 1 untuk kelas A dan juga kelas B. Sehingga, vektor vote individu f1 adalah
v1 = <0;1>. Jika f1 diberikan kesempatan untuk memprediksi sendirian,
maka ia akan memprediksi kelas B dengan pasti karena B menerima seluruh
vote feature f1 dan kelas A tidak mendapatkan vote. Pada dimensi feature f2,
point interval i26 dimana t2 = 6 terletak memiliki vote yang sama dengan
interval_class_vote[f1, i26, A] = 0,57 untuk kelas A dan vote yang sama
dengan interval_class_vote[f1, i26, B] = 0,43 untuk kelas B. Sehingga vektor
vote individu f2 adalah v2 = <0,57;0,43>. Jika f2 diberikan kesempatan untuk
memprediksi, maka ia akan memprediksi kelas A.
Pada tahap akhir, vote individu dari kedia feature dijumlahkan dan
jumlah vektor vote v = <0,57;1,43>. Algoritma VFI5 memberikan vote 0,57
untuk kelas A dan 1,43 untuk kelas B, sehingga kelas B dengan nilai vote
22
2.8 Jaringan Saraf Tiruan (JST)
Dalam sistem pengenalan musik (music recognition), pembentukan
model referensi musik dan pencocokan pola adalah dua tahapan yang sangat
berkaitan. Pembentukan model referensi musik akan membentuk suatu
model referensi yang akan digunakan untuk pencocokan pola (pattern
recognition).
Salah satu teknik yang dapat digunakan dalam pencocokan pola
adalah JST. JST atau Neural Network adalah metode soft computing yang
merupakan salah satu representasi buatan dari otak manusia yang selalu
mencoba untuk mensimulasikan proses pembelajaran pada otak manusia
tersebut. Istilah buatan (artificial) digunakan karena jaringan saraf ini
diimplementasikan dengan menggunakan program komputer yang mampu
menyelesaikan sejumlah proses perhitungan selama proses pembelajaran.
JST akan melakukan pembelajaran untuk membentuk suatu model
referensi, kemudian JST yang telah melakukan pembelajaran tersebut dapat
digunakan untuk pencocokan atau pengenalan pola. (Kusumadewi 2004).
JST merupakan kumpulan-kumpulan neuron yang telah dimodelkan
yang bereaksi terhadap input dan menghasilkan output. Biasanya terdiri dari
sebuah kumpulan neuron-neuron lapisan (layer) input yang menerima
vektor parameter yang datang, satu atau lebih lapisan tersembunyi (hidden
layer) yang melakukan pemprosesan, dan sebuah lapisan (layer) output
yang menghasilkan klasifikasi (Gerhard 2000).
Karakteristik dari JST menurut Fausett (1994) adalah :
1) Pemprosesan informasi terjadi pada banyak elemen sederhana yang
disebut neuron,
2) Sinyal dilewatkan antar neuron melalui jalur koneksi,
3) Setiap koneksi mempunyai bobot, dan
4) Setiap neuron mempunyai fungsi aktivasi dan biasanya non-linier.
Pernyataan matematis dari neuron adalah sebagai berikut :
n i i ix
w
f
y
1dimana xi = sinyal input, i = 1,2,..,n
n = banyaknya simpul input
wi = bobot hubungan atau synapsis
θ = threshold atau bias
(*) = fungsi aktivasi
y = sinyal output dari neuron
Model neuron sederhana dapat dilihat pada Gambar 14.
………..
………..
f(*)
y
1 x
2 x
n
x
1 w
2 w
n
w
Gambar 14. Sistem komputasi pemodelan neuron
Keunggulan dari JST adalah kemampuan pengklasifikasi terhadap
data yang belum diberikan pada saat pembelajaran sebelumnya (Han dan
Kamber 2001). Untuk menyelesaikan permasalahan, JST memerlukan
algoritma untuk belajar, yaitu bagaimana konfigurasi JST dapat dilatih
untuk mempelajari data histories yang ada. Dengan pelatihan ini,
pengetahuan yang terdapat pada data bisa diketahui dan direpresentasikan
dalam bobot sambungannya.
Jenis algoritma pembelajaran yang ada di antaranya adalah
Supervised Learning (pembelajaran terawasi). Algoritma ini diberikan target
yang akan dicapai. Contohnya adalah back propagation algorithm
(algoritma propagasi balik) dan Radial basis function (Jang et al. 1997).
2.9 Multi Layer Perceptron (MLP)
Dalam klasifikasi atau pengenalan pola, JST merupakan salah satu
teknik yang paling handal. Multi-layer Perceptron propagasi balik dengan
pembelajaran terawasi (supervised) merupakan salah satu jenis JST yang
24
Menurut Kantardzic (2003) MLP mempunyai tiga karakteristik, yaitu :
1) Model dari setiap neuron biasanya mengandung fungsi aktivasi
non-linier, misalnya sigmoid atau hiperbolik,
2) Jaringan mengandung satu atau lebih lapisan tersembunyi (hidden layer)
yang bukan merupakan bagian dari lapisan input ataupun lapisan output,
dan
3) Jaringan mempunyai koneksi dari satu lapisan ke lapisan lainnya.
2.10 Propagasi Balik
Propagasi balik merupakan algoritma pembelajaran terawasi dan
biasanya digunakan oleh perceptron dengan banyak lapisan untuk
mengubah bobot yang terhubung dengan neuron-neuron yang ada pada
lapisan tersembunyinya (Duda et al. 2000).
Walaupun JST propagasi balik membutuhkan waktu yang lama untuk
pembelajaran tetapi bila pembelajaran telah selesai dilakukan, JST akan
dapat mengenali suatu pola dengan cepat. Algoritma propagasi balik
menggunakan output error untuk mengubah nilai bobot-bobotnya dalam
perambatan mundur (backward). Untuk mendapatkan error ini, tahap
perambatan maju (forward) harus dikerjakan terlebih dahulu.
Karakteristik dari JST propagasi balik adalah sebagai berikut :
a. Multi-layer-network
JST propagasi balik (Gambar 15) mempunyai lapisan input, lapisan
tersembunyi dan lapisan output dan setiap neuron pada satu lapisan
menerima input dari semua neuron pada lapisan sebelumnya.
b. Fungsi aktivasi
Fungsi aktivasi (activation-function) akan menghitung input yang
diterima oleh suatu neuron, kemudian neuron tersebut meneruskan hasil
dari fungsi pengaktifan ke neuron berikutnya. Sehingga fungsi aktivasi
berfungsi sebagai penentu kuat lemahnya sinyal yang dikeluarkan oleh suatu
Gambar 15. Arsitektur jaringan propagasi balik (Kusumadewi 2004)
Beberapa fungsi pengaktifan yang sering digunakan dalam JST
propagasi balik adalah sebagai berikut :
1) Fungsi sigmoid biner (Gambar 16), yaitu fungsi biner yang
memiliki rentang 0 s/d 1 dengan fungsi sebagai berikut :
) exp( 1
1 )
(
x x
f
(21)
f(x)
x
1
0
Gambar 16. Sigmoid biner pada selang [ 0,1]
2) Fungsi sigmoid bipolar (Gambar 17), yaitu fungsi yang memiliki
rentang -1 s/d 1 dengan fungsi sebagai berikut :
1 ) exp( 1
2 )
(
x x
26
f(x)
x
1
-1
Gambar 17. Sigmoid bipolar pada selang [-1,1]
3) Fungsi linier, yaitu fungsi yang memiliki output yang sama
dengan nilai inputnya, dengan fungsi sebagai berikut :
y = f (x) = x (23)
dan turunan dari fungsinya adalah :
f’ (x) = 1 (24) Pada JST propagasi balik proses pembelajaran bersifat iterative
(berulang) dan dirancang untuk meminimalkan mean square error (MSE)
antara output yang dihasilkan dengan output yang diinginkan (target).
Langkah-langkah algoritma pembelajaran JST propagasi balik yang
diformulasikan oleh Rumelhart et al. (1986) secara singkat adalah sebagai
berikut :
a. Inisialisasi bobot, dapat dilakukan secara acak atau melalui metode
Nguyen Widrow
b. Perhitungan nilai aktivasi, tiap neuron menghitung nilai aktivasi dari
input yang diterimanya. Pada lapisan input nilai aktivasi adalah fungsi
identitas. Pada lapisan tersembunyi dan output nilai aktivasi dihitung
melalui fungsi aktivasi
c. Penyesuaian bobot, penyesuaian bobot dipengaruhi oleh besarnya nilai
kesalahan (error) antara target output dan nilai output jaringan saat ini.
d. Iterasi akan terus dilakukan sampai kriteria error tertentu dipenuhi.
Untuk mengimplementasikan algoritma di atas (pembelajaran), JST
harus memiliki suatu set data pembelajaran. Data pembelajaran harus
mencakup seluruh jenis pola yang ingin dikenal agar nantinya dapat
2.11 Pengukuran Kinerja Sistem
Kinerja sistem diukur dengan menggunakan parameter akurasi yaitu
presentase pengenalan sistem dalam memprediksi dataset pengujian yang
diberikan.
(25)
2.12 Review Riset Terdahulu
Penelitian pada bidang klasifikasi musik yang paling sering
direferensikan adalah Tzanetakis dan Cook (2000, 2002). Penelitian mereka
menghasilkan sebuah framework analisa audio MARSYAS, yang juga
sering dipakai oleh peneliti-peneliti lainnya sebagai aplikasi bantu untuk
pengekstraksi ciri.
Lampropoulos et al. (2005) pada penelitiannya melakukan pemisahan
(separasi) ciri sinyal dari sumber instrumen musik sebelum diklasifikasikan
menggunakan algoritma Convolutive Sparse Coding (CSC) dan
menggunakan JST sebagai pengklasifikasinya. Untuk ekstraksi ciri, mereka
menggunakan aplikasi bantu MARSYAS versi 0.1 dan menghasilkan vektor
ciri (feature vector) berdimensi 30.
Costa et al. (2004) menggunakan pendekatan kombinasi
pengklasifikasi. Ekstraksi ciri diperoleh dari tiga segmen pada musik klip
yaitu awal, tengah, dan akhir lagu. Dari setiap segmen tersebut, dihasilkan
vektor ciri (feature vector) berdimensi 15. Penelitian tersebut juga
menggunakan JST sebagai pengklasifikasinya. Adapun pengambilan
keputusan akhir dari klasifikasi menggunakan aturan majority voting.
Adapun pada penelitian Norowi et al. (2005) digunakan ciri yang
berhubungan dengan timbral, ritme, dan pitch dan pengklasifikasi J48 dan
OneR. J48 dan OneR adalah pengklasifikasi yang terdapat pada sistem
pembelajaran mesin WEKA (Waikato Environment for Knowledge
Analysis). Sedangkan klasifikasi genre musik pada penelitian mereka adalah
genre-genre musik barat dan musik tradisional Malaysia. Mereka juga
menggunakan MARSYAS versi 0.1 sebagai aplikasi bantu pengekstraksi
28
Pada Tabel 2 dapat dilihat beberapa contoh penelitian klasifikasi genre
musik dengan beragam ciri dan pengklasifikasinya.
Tabel 2. Beberapa contoh penelitian klasifikasi genre musik
Peneliti Ciri Pengklasifikasi
Lampropoulos et
al. (2005) Ritme, STFT, MFCC dan pitch
Nearest-Neighbor dan MLP
Costa et al. (2004)
Spectral centroid, spectral rolloff, spectral flux, time domain
zero-crossing, low energy dan beat
Nearest-Neighbor dan MLP
Norowi et al. (2005)
Spectral centroid, spectral rolloff, spectral flux, time domain zero-crossing, MFCC, beat dan pitch
OneR dan J48 (WEKA)
Ahrendt (2006) MFCC, LPC, DMFCC, DLPC, ZCR, STE, ASE, ASC, ASS dan SFM
Gaussian, GMM, Linear regression, dan GLM
Andersson (2004)
ZCR, STE, RMS, HFVR,LFVR, spectrum centroid, spectrum spread,
delta spectrum, spectral rolloff dan MPEG-7 audio descriptors
III METODE PENELITIAN
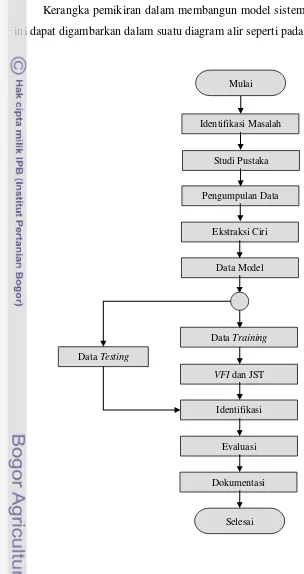
3.1 Kerangka Pemikiran
Kerangka pemikiran dalam membangun model sistem pada penelitian
[image:47.595.99.403.147.721.2]ini dapat digambarkan dalam suatu diagram alir seperti pada Gambar 18.
Gambar 18. Diagram alir penelitian pengembangan model sistem
Identifikasi Masalah Mulai
Studi Pustaka
Pengumpulan Data
Ekstraksi Ciri
Data Model
Dokumentasi VFI dan JST
Identifikasi
Evaluasi
Selesai Data Training
30
Dengan demikian diharapkan dapat diperoleh gambaran yang lengkap
dan menyeluruh tentang tahap-tahap penelitian yang akan dilaksanakan
serta keterkaitan antara satu tahap dengan tahap berikutnya. Berikut ini akan
dijelaskan beberapa tahap yang ada di dalam diagram alir tersebut.
3.1.1 Identifikasi Masalah
Identifikasi masalah merupakan tahap awal dari penyusunan
penelitian ini. Penelitian mengenai klasifikasi genre musik telah banyak
dilakukan menggunakan berbagai macam metode. Penggunaan metode VFI
merupakan metode yang belum pernah dilakukan dalam mengklasifikasi
genre musik. Oleh karena itu, penelitian ini dilakukan untuk melihat
bagaimana akurasi metode VFI dalam mengklasifikasi genre musik dan
membandingkannya dengan metode yang sudah banyak dipakai oleh
penelitian-penelitian sebelumnya yaitu Jaringan Saraf Tiruan (JST).
3.1.2 Studi Pustaka
Studi pustaka yang dilakukan meliputi pengetahuan musik dan
genrenya, praproses data, ekstraksi ciri (feature extraction), Voting Feature
Intervals (VFI), Jaringan Saraf Tiruan (JST), pemprograman dengan
perangkat lunak MATLAB serta metode pendukung lainnya.
3.1.3 Pengumpulan Data
Setiap data berkas musik yang digunakan pada penelitian ini diperoleh
dari data-set pada penelitian Tzanetakis dan Cook (2000) yang diunduh
melalui http://opihi.cs.uvic.ca/sound/genres.tar.gz. Jumlah data yang akan
digunakan pada penelitian ini adalah 80 berkas musik berformat au mono
16-bit yang memiliki frekuensi sampling sebesar 22,05 kHz dengan durasi
30 detik setiap berkasnya.
Setiap genre akan memiliki 20 berkas musik yang dapat dijadikan
sebagai data training (15 berkas) dan testing (5 berkas). Genre musik yang
dipakai untuk penelitian ini adalah genre musik klasik, disko, metal dan
3.1.4 Ekstraksi Ciri
Prototipe sistem yang telah dikembangkan menggunakan ciri yang
diajukan oleh Tzanetakis dan Cook (2000, 2002) dan yang telah digunakan
oleh peneliti lainnya (Lampropus et al. 2005, Foote 1999, M. Welsh et al.
1999). Ciri yang digunakan adalah MFCC hingga 20 koefisien.
Dari setiap ciri tersebut, mean (rataan) dihitung untuk membentuk
vektor ciri. Hal ini adalah prinsip dasar dari pemprosesan window tekstur
yang diperkenalkan oleh Tzanetakis dan Cook (2002).
Mean dapat diformulasikan sebagai berikut :
n
i i x n x
1 1
(26)
di mana n adalah jumlah sampel. Untuk metode JST, setelah ciri diekstrak
maka dilakukan normalisasi menggunakan metode distribusi normal
kumulatif.
3.1.5 Pengembangan Model VFI dan JST
Dalam penelitian ini metode VFI yang digunakan adalah metode
VFI5. Pengembangan model JST menggunakan perangkat lunak MATLAB
versi 7.8.0.
3.1.6 Pembuatan Keputusan
Setelah setiap berkas musik sudah diekstrak dan diklasifikasi, maka
prototipe sistem akan melakukan prediksi. Prediksi diperoleh berdasarkan
proses pembelajaran algoritma VFI dan JST dalam mengenali sejumlah pola
yang diberikan. Nilai prediksi yang terbesar dari seluruh genre merupakan
prediksi genre pada sistem.
3.2 Alat dan Bahan
Alat-alat bantu yang digunakan dalam penelitian ini adalah sebagai
berikut :
1. Komputer desktop dengan spesifikasi dual processor 3,3 GHz, memori
32
2. Perangkat lunak MATLAB versi 7.8.0.
3. Perangkat lunak Microsoft Excel dan Word 2007.
3.3 Waktu dan Tempat Penelitian
Penelitian dilaksanakan mulai Desember 2010 hingga Mei 2011
bertempat di Laboratorium Pascasarjana Departemen Ilmu Komputer
IV IMPLEMENTASI DAN PERANCANGAN SISTEM
4.1 Ekstraksi Ciri
Ekstraksi ciri pada penelitian ini dilakukan menggunakan perangkat
lunak Matlab 7.8.0. Tahap pertama dari proses ini adalah mengubah sinyal
suara menjadi nilai-nilai variabel untuk dijadikan input sistem. Ciri yang
digunakan pada penelitian ini adalah MFCC. Koefisien MFCC yang
digunakan terdapat 3 variasi yaitu 7 koefisien, 13 koefisien dan 20
koefisien. Hal ini dilakukan untuk mengetahui jumlah koefisien yang
optimum pada sistem dalam mengklasifikasi genre musik.
Pada tahap awal MFCC, sinyal suara akan diperlakukan Hamming
Window sehingga menghasilkan sejumlah frame. Ukuran setiap frame
adalah sebesar 30 milidetik dengan sampling rate sebesar 22050 Hz dan
mengalami overlap sebesar 75%.
Penelitian ini juga menggunakan 4 variasi waktu berkas musik, yaitu 1
detik, 5 detik, 10 detik dan 30 detik. Hal ini juga dilakukan untuk
mengetahui waktu berkas musik yang optimum pada sistem dalam
mengklasifikasi genre musik.
Dari proses ekstraksi ciri tersebut, maka didapatkan vektor ciri dengan
dimensi yang beragam, tergantung dengan jumlah koefisien MFCC dan
waktu berkas musik yang digunakan. Tabel 3 memperlihatkan ragam
dimensi vektor ciri yang dihasilkan pada penelitian ini.
Tabel 3. Dimensi vektor ciri untuk setiap variasi penelitian
No. Jumlah Koefisien MFCC Waktu Berkas Musik Dimensi Vektor Ciri
1. 7 koefisien 1 detik 7 x 134
2. 7 koefisien 5 detik 7 x 668
3. 7 koefisien 10 detik 7 x 1336
4. 7 koefisien 30 detik 7 x 4008
5. 13 koefisien 1 detik 13 x 134
6. 13 koefisien 5 detik 13 x 668
7. 13 koefisien 10 detik 13 x 1336
8. 13 koefisien 30 detik 13 x 4008
9. 20 koefisien 1 detik 20 x 134
10. 20 koefisien 5 detik 20 x 668
11. 20 koefisien 10 detik 20 x 1336
34
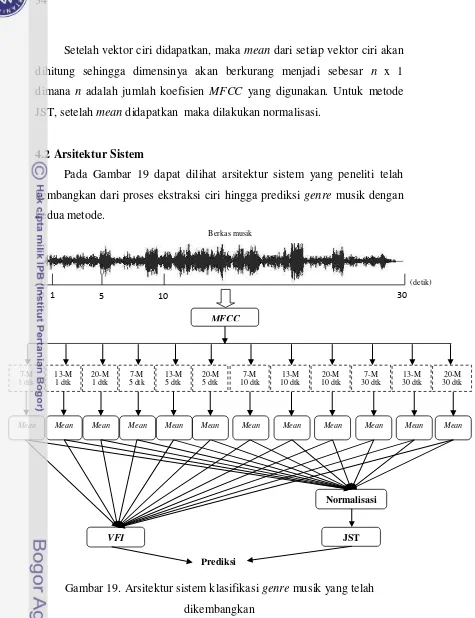
Setelah vektor ciri didapatkan, maka mean dari setiap vektor ciri akan
dihitung sehingga dimensinya akan berkurang menjadi sebesar n x 1
dimana n adalah jumlah koefisien MFCC yang digunakan. Untuk metode
JST, setelah mean didapatkan maka dilakukan normalisasi.
4.2 Arsitektur Sistem
Pada Gambar 19 dapat dilihat arsitektur sistem yang peneliti telah
kembangkan dari proses ekstraksi ciri hingga prediksi genre musik dengan
[image:52.595.78.553.42.660.2]kedua metode.
Gambar 19. Arsitektur sistem klasifikasi genre musik yang telah
dikembangkan
4.3 Implementasi Metode VFI
Setelah proses ekstraksi ciri, maka proses pembelajaran pada model
VFI dapat dilakukan. Proses pembelajaran dilakukan menggunakan data
1 5 10 30
0 MFCC 7-M 1 dtk 20-M 5 dtk 13-M 1 dtk 7-M 10 dtk 20-M 1 dtk 7-M 5 dtk 13-M 5 dtk 13-M 10 dtk 20-M 10 dtk 7-M 30 dtk 13-M 30 dtk 20-M 30 dtk Mean
VFI JST
Normalisasi
Mean Mean Mean Mean Mean Mean Mean Mean Mean Mean Mean
Prediksi
Berkas musik
training sebanyak 60 berkas musik yang terdiri dari 15 berkas musik pada
setiap genre. Sedangkan untuk pengujian, digunakan 5 berkas musik untuk
setiap genre.
4.3.1 Model VFI
Pada proses pembelajaran didapatkan 8 (2 x 4) titik interval yang
diperoleh dari titik minimum dan maksimum dari sebuah interval ciri setiap
kelas yang dapat dilihat pada Tabel 4.
Tabel 4. Titik interval dan presentase frekuensi kemunculan pada ciri MFCC
koefisien ke-1 pada contoh sebuah 30 detik berkas musik
TITIK KLASIK DISKO METAL REGGAE
0 0 0 0
-20,51534 0,0666667 0 0 0
0,8 0 0 0
-15,85193 0 0 0 0,0666667
0,0666667 0 0 0,4
-15,19517 0,0666667 0 0 0
0 0 0 0,3333333
-14,72691 0 0 0,0666667 0
0 0 0,1333333 0,1333333
-14,13456 0 0 0 0,0666667
0 0 0,2 0
-13,1284 0 0,0666667 0 0
0 0,8666667 0,4666667 0
-10,96637 0 0,0666667 0 0
0 0 0,0666667 0
-9,943883 0 0 0,0666667 0
0 0 0 0
Kemudian sistem memberikan voting pada setiap titik atau interval
sebuah berkas musik yang diberikan. Pada Tabel 5 dapat dilihat contoh
voting sistem pada sebuah ciri MFCC koefisien ke-1 dengan waktu berkas
musik 30 detik.
Pada Tabel 6 dapat dilihat contoh prediksi sistem terhadap sebuah
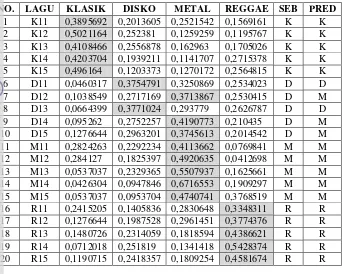
berkas musik. Presentase voting dari setiap ciri akan dijumlahkan sehingga
menghasilkan presentase voting total. Dari hasil prediksi pada Tabel 6,
terlihat bahwa prediksi presentase voting terbesar adalah genre klasik
(35,16%) sehingga sistem memprediksi bahwa berkas musik tersebut
36
Tabel 5. Contoh voting sistem pada sebuah 30 detik berkas musik dengan
ciri MFCC koefisien ke-1
TITIK KLASIK DISKO METAL REGGAE
0 0 0 0
-20,51534 1 0 0 0
1 0 0 0
-15,85193 0 0 0 1
0,1428571 0 0 0,8571429
-15,19517 1 0 0 0
0 0 0 1
-14,72691 0 0 1 0
0 0 0,5 0,5
-14,13456 0 0 0 1
0 0 1 0
-13,1284 0 1 0 0
0 0,65 0,35 0
-10,96637 0 1 0 0
0 0 1 0
-9,943883 0 0 1 0
0 0 0 0
Tabel 6. Contoh prediksi sistem terhadap sebuah 30 detik berkas musik
dengan ciri MFCC 20 koefisien
FITUR INPUT KLASIK DI