A. SAMPEL ACAK
Teknik sampling ini diberi nama demikian karena dalam pengambilan sampelnya, peneliti ”mencampur” subjek-subjek di dalam populasi sehingga semua subjek dianggap sama. dengan demikian maka peneliti memberi hak yang sama kepada setiap subjek untuk memperoleh kesempatan (change) dipilih menjadi sampel. Oleh karena hak setiap subjek sama, maka peneliti terlepas dari perasaan ingin mengistimewakan satu atau beberapa subjek untuk dijadikan sampel.
Setiap subjek yang terdaftar sebagai populasi, diberi nomor urut mulai dari 1 sampai dengan banyaknya subjek. Di dalam pengambilan sampel biasanya peneliti sudah menentukan terlebih dahulu besarnya jumlah sampel yang paling baik. Jawaban terhadap pertanyaan ini tidaklah begitu sederhana. Di dalam statistik kadang-kadang terdapat rumus untuk menentukan perkiraan besarnya sampel.
Untuk menentukan besarnya sampel, peneliti harus melakukannya dengan berbagai pertimbangan, antara lain keberagaman karakteristik, misalnya jenis kelamin, tingkat pendidikan, asal daerah, suku, agama atau kepercayaan, usia, dan lain-lain yang sekiranya terkait dengan variabel yang diteliti. Sebagai contoh, kalau peneliti ingin mengetahui perbedaan kemampuan siswa dalam sebuah sekolah di suatu daerah, maka perbedaan suku tidak harus dipertimbangkan. Tetapi jika peneliti ingin mengetahui kemampuan berbahasa tertentu, dalam hal ini suku berpengaruh terhadap kemampuan berbahasa tertentu tersebut, maka perbedaan suku merupakan hal yang perlu dipertimbangkan.
Mengenai berapa banyaknya subjek yang diambil, atau dengan kata lain berapa besar sampel, maka peneliti perlu mempertimbangkan hal-hal berikut.
a. Kemampuan peneliti dilihat dari waktu, tenaga, dan dana.
b. Sempit luasnya wilayah pengamatan dari setiap subjek, karena hal ini menyangkut banyak sedikitnya data.
c. Besar kecilnya resiko yang ditanggung oleh peneliti. Untuk penelitian yang resikonya besar, tentu saja jika sampel besar, hasilnya akan lebih baik.
Kebanyakan peneliti berangggapan bahwa semakin banyak sampel, atau semakin besar persentase sampel dari populasi, hasil penelitian akan semakin baik. Anggapan ini benar, tetapi tidak selalu demikian. Hal ini tergantung dari sifat-sifat atau ciri-ciri yang dikandung oleh subjek penelitian dalam populasi. Selanjutnya sifat-sifat atau ciri-ciri tersebut bertalian erat dengan homogenitas subjek dalam populasi.
Untuk memperjelas uraian ini, kita contohnya pada air the. Air teh dalam poci dapat dikatakan homogen karena apabila sudah diaduk, tetes air teh di semua sudut poci akan sama keadaannya. Air teh tersebut andai kata manis hanya mengandung dua ciri, yakni ciri yang berhubungan dengan kekentalan teh dan kemanisannya. Dalam keadaan yang demikian, sampel yang diperlukan tidak usah terlalu banyak. Boleh mengambil satu ujung sendok teh menjadi satu sendok penuh maupun satu gelas, tidak akan memperjelas kesimpulan penelitian.
pendidikan orang tua dan hubungan antara anggota keluarga sebagai pendukung kedisplinan, maka sekurang-kurangnya kita harus mengambil waktu dari berbagai unsur ini. Misalnya, tingkat kelas ada 3 (kelas I, II, dan III) jenis kelamin ada 2 (pria dan wanita), pekerjaan ayah dikelompokan menjadi 4 (pegawai negeri, pegawai swasta, petani, dan anggota ABRI), pendidikan orang tua dibedakan menjadi 4 (SD ke bawah, SMP, SMA, dan perguruan tinggi), hubungan antar anggota keluarga yang dikelompokan atas 3 (ketat, cukup, dan longgar), maka akan diperlukan wakil dari setiap jenis gabungan sifat-sifat ini. Secara teliti akan terdapat kemungkinan gabungan sebanyak perkalian unsur yang ada yakni 3 x 2 x 4 x 4 x 3 = 288! Dengan demikian jika diinginkan sampel yang betul mewakili populasi atas dasar pertimbangan ini dan masing-masing kategori diambil satu orang saja sudah diperlukan sebanyak 288 orang. Pengambilan sampel kurang dari banyak jumlah tersebut tentu kurang refresentatif.
Penentuan besarnya sampel dengan persentase seperti yang dahulu banyak digunkan tampaknya kini sudah harus ditinggalkan. Agar diperoleh hasil yang lebih baik, diperlukan sampel yang baik pula, yakni betul-betul mencerminkan populasi. Supaya perolehan sampel lebih akurat, diperlukan rumus-rumus penentuan besarnya sampel.
a. Dengan rumus Jacob Cohen:
N = + u + 1
Dengan keterangan: N = Ukuran Sampel f2 = Effect size
u = Banyaknya ubahan yang terkait dalam penelitian L = Fungsi power dari u, diperoleh dari tabel, t.s 1%. Power (p) = 0,95 dan effect size (f2) = 0,1
Harga L tabel dengan t.s 1% power 0,95 dan u = 5 adalah 19,76. Maka dengan rumus tersebut didapat:
N = + 5 + 1 = 203,6 dibulatkan 204.
b. Dengan rumus berdasarkan proporsi, ada dua rumus. 1. Dikemukakan oleh Issac & Michael
Dimana:
S = ukuran sampel N = ukuran populasi
P = proporsi dalam populasi d = ketelitian (error)
x2 = harga tabel chi-kuadrat untuk o tertentu
N = ( )2 (P) (1-P)
Dimana:
N = ukuran sampel
Z = standard score untuk o yang dipilih e = sampling error
p = proporsi harus dalam populasi
Pembicaraan mengenai sampel ini akan lebih terpahami setelah pembaca mempelajari berjenis-jenis sampel dari populasi yang tidak homogen. Untuk mempermudah dalam mengikuti uraian, maka akan diambil missal, kita populasi sebanyak 1000 orang dan sampelnya kita tentukan 200 orang. Setelah seluruh subjek diberi nomor, yaitu nomor 1 sampai dengan 1000, maka sampel random kita lakukan dengan salah satu cara demikian:
a. Undian (untung-untungan)
Pada kertas kecil-kecil kita tuliskannomor subjek, satu nomor untuk setiap kertas, kemudian kertas itu kita gulung. Dengan tanpa prasangka kita mengambil 200 gulungan kertas, sehingga nomor-nomor yang tertera pada gulungan kertas yang terambil itulah yang merupakan nomor subjek sampel penelitian kita.
b. Ordinal (tingkatan sama)
Setelah 1000 orang subjek kita beri nomor, kita membuat 5 gulungan kertas dengan nomor 1, 2, 3, 4, 5. Kita ambil satu, misalnya setelah dibuka tertera angka 3. Oleh karena sampel kita 200 padahal populasinya 1000 maka besarnya sampel seperlima dari populasi. Demikianlah maka kita ambil nomor dengan melompat setiap subjek, mulai dari nomor 3, lalu 8, 13, 18, 23, dan seterusnya, dan kalau sudah sampai pada nomor terbawah padahal belum diperoleh 200 subjek, kita kembali ke atas lagi. c. Menggunakan tabel bilangan random
Di bagian buku-buku statistik bagian belakang, biasanya terdapat halaman yang memuat angka-angka yang disusun secara acak. Angka-angka tersebut dapat dicari letaknya menurut baris dan kolom. Agar pengambilan sampel terlepas dari perasaan subjektif, maka sebaiknya peneliti menuliskan langkah-langkah yang diambil, misalnya:
1. Menjatuhkan ujung pensil, menemukan nomor baris;
2. Menjatuhkan ujung pensil kedua, menemukan nomor kolom. Pertemuan antara baris dan kolom inilah nomor subjek ke-1;
3. Bergerak dari nomor tersebut 2 langkah ke kanan, menemukan nomor subjek ke-2;
4. Bergerak ke bawah 5 langkah menemukan nomor subjek, ke-3; 5. Bergerak ke kiri 2 langkah menemukan nomor subjek ke-4.
Dan seterusnya sampai diperoleh jumlah subjek yang dikehendaki.
Perlu ditambahkan disini bahwa apabila jumlah subjeknya tidak terlalu banyak, maka semua langkah dapat ditulis. Tetapi jika jumlah subjeknya banyak, kita dapat mengulang langkah yang sudah kita lalui.
b. Pengambilan nomor tentu saja tidak selalu harus satu angka.
Untuk memperoleh subjek dengan nomor lebih besar dari 9, kita gunakan 2 atau 3 angka, ke kanan, ke kiri, ke bawah, ke atas. Pengambilan sampel dengan cara random ini hanya dapat dilakukan jika keadaan populasi memang homogen. Bagi populasi yang tidak homogen, peneliti perlu mempertimbangkan ciri-ciri yang ada, dan cara pengambilan sampelnya diterangkan pada nomor-nomor berikut ini.
Stratified random sampling
Stratified random sampling adalah pengambilan sampel yang dilakukan dengan membagi populasi menjadi beberapa strata dimana setiap strata adalah homogen. Sistem pengambilan sampel yang dibagi menurut lapisan-lapisan tertentu dan masing-masing lapisan memiliki jumlah sampel yang sama. Kelebihan dari pengambilan acak berdasar lapisan ini adalah lebih tepat dalam menduga populasi karena variasi pada populasi dapat terwakili oleh sampel. Sedangkan, kekurangannya adalah harus memiliki informasi dandata yang cukup tentang variasi populasi penelitian. Selain itu, kadang-kadang ada perbedaan jumlah yang besar antar masing-masing strata.
Contoh: Seorang direktur rumah sakit ingin mengetahui prestasi kerja tenaga kesehatan dan diukur berdasarkan kepatuhan dalam menggunakan prosedur tetap dalam memberikan pelayanan kepada penderita. Untuk itu, 36 orang tenaga kesehatan sebagai populasi dibagi menjadi 4 kelompok berdasrakan prestasi kerja tahun yang lalu. Masing-masing kelompok terdiri dari 9 orang dengan prestasi kerja yang hampir sama dan terdapat perbedaan antar kelompok kemudian pada setiap kelompok diambil 8 orang sebagai sampel hingga diperoleh sampel sebanyak 32 orang.
Multstage random sampling
Pengambilan sampel yang membagi populasi menjadi beberapa fraksi kemudian diambil sampelnya. Cara ini merupakan salah satu model pengambilan sampel secara acak yang pelaksanaannya dilakukan dengan membagi populasi menjadi beberapa fraksi kemudian sampelnya Contoh: Akan diadakan penelitian tentang pola pemanfaatan sarana pelayanan kesehatan oleh penduduk sebuah kota. Kota tersebut merupakan populasi studi dengan RT sebagai unit sampel dan kelurahan sebagai PSU. Dari jumlah PSU tersebut diambil sampel dengan cara acak sederhana kemudian sam[pel kelurahan dibagi menjadi RW dan diambil sampelnya. Selanjutnya, dari sampel RW diambil sambil RT dan semua penduduk dewasa dalam RT tersebut merupakan sasaran penelitian.
Sistematik random sampling
Cluster Random sampling
Pengambilan sampel acak kelompok dilakukan bila kita akan mengadakan suatu penelitian dengan mengambil kelompok unit dasar sebagai sampel. Sistem pengambilan sampel yang dibagi berdasarkan areanya. Setiap area memiliki jatah terambil yang sama. Kelebihan dari pengambilan acak berdasar area ini adalah lebih tepat menduga populasi karena variasi dalam populasi dapat terwakili dalam sampel. Sedangkan, kekurangannya adalah memerlukan waktu yang lama karena harus membaginya dalam area-area tertentu.
Pada penggunaan teknik sampling kluster, biasanya digunakan dua tahapan, yaitu tahap pertama menentukan sampel daerah, dan tahap kedua menentukan orang/orang atau objek yang dijadikan penelitian pada daerah yang terpilih yang dilakukan secara random.
Keuntungan menggunakan teknik ini ialah: (1) dapat mengambil populasi besar yang tersebar diberbagai daerah, dan (2) pelaksanaannya lebih mudah dan murah dibandingkan teknik lainnya. Sedangkan kelemahannya ialah (1) jumlah individu dalam setiap pilihan tidak sama, karena itu teknik ini tidaklah sebaik teknik lainnya; (2) ada kemungkinan penduduk satu daerah berpindah kedaerah lain tanpa sepengetahuan peneliti, sehingga penduduk tersebut mungkin menjadi anggota rangkap sampel penelitian.
Probability Proporsionate to Size
Pengambilan sampel dengan cara PPS ini merupakan variasi dari pengambilan sampel bertingkat dengan PSU besar yang dilakukan secara proporsional. Berdasarkan pembahasan diatas penulis menyimpulkan Pengambilan (Simple Random Sampling) sampel acak sederhana adl suatu cara pengambilan sampel dimana tiap unsur yg membentuk populasi diberi kesempatan yg sama utk terpilih menjadi sampel. Cara ini sangat mudah apabila telah terdapat daptar lengkap unsur-unsur populasi.
Penarikan sampel secara random berdasarkan banyaknya langkah yang harus ditempuh dapat dibagi atas 2 kategori, yaitu : simple random sampling dan multistage random sampling. Simple random sampling adalah teknik sampling yang hanya memerlukan cukup 1 tahapan dalam penarikan sampel. Sedangkan multistage random sampling adalah teknik sampling yang memerlukan minimal 2 tahapan penarikan sampel. Teknik sampling yang termasuk kategori simple random adalah simple random dan systematic random sampling. Sedangkan yang termasuk kategori multistage random adalah stratified random sampling, cluster random sampling dan kombinasi antara keduanya.
B. VARIABEL ACAK
Lebih jauh variabel kuantitatif diklasifikasikan menjadi 2 kelompok yaitu variabel diskrit dan variabel kontinu (discrete and continuous).
1. Variabel dikrit disebut juga variabel nominal atau variabel kategorik karena hanya dapat dikategorikan atas 2 kutub yang berlawanan yakni ”ya” dan ”tidak”. Misalnya ya wanita, atau dengan kata lain ”wanita – pria”, ”hadir – tidak hadir”, ”atas – bawah”. Angka-angka digunakan dalam variabel diskrit ini untuk menghitung, yaitu banyaknya pria, banyaknya yang hadir dan sebagainya. Maka angka dinyatakan sebagai frekuensi.
2. Variabel kontinu dipisahkan menjadi 3 variabel kecil yaitu:
a. Variabel ordinal, yaitu variabel yang menunjukan tingkatan-tingkatan misalnya panjang, kurang panjang, dan pendek. Untuk sebutan lain adalah variabel ”lebih kurang” karena yang satu mempunyai kelebihan dibandingkan yang lain. Contoh: Ani terpandai, Siti pandai, Nono tidak pandai.
b. Variabel interval, yaitu variabel yang mempunyai jarak, jika dibandingkan dengan variabel lain, sedang jarak itu sendiri dapat diketahui dengan pasti. Misalnya: suhu udara di luar rumah 31o C. Suhu tubuh kita 37o C. Maka selisih suhu adalah 6oC. Contoh lain: Jarak Semarang – Magelang 70km, sedangkan Magelang – Yogyakarta 101km. Maka selisih jarak Magelang – Yogyakarta, yaitu 31km.
Dibandingkan dengan variabel ordinal, jarak dalam variabel ordinal tidak jelas. Jarak kepandaian antara Ani dan Siti tidak dapat diukur.
c. Variabel ratio, yaitu variabel perbandingan. Variabel ini dalam hubungan antar anta – sesamanya merupakan ”sekian kali”. Contoh: Berat Pak Karto 70kg, sedangkan anaknya 35kg. Maka Pak Karto beratnya dua kali berat anaknya.
Kembali kepada variabel diskrit, variabel diskrit bukan hanya hasil hitungan, tetapi juga penomoran. Nomor telepon misalnya, dapat digolongkan dalam variabel diskrit. Tinjauannya adalah karena nomor telepon tidak menunjukan ”lebih kurang”, ”jarak”, atau ”sekian kali”. Jika nomor telepon Pak Sosro 8000 dan nomor telepon Pak Noto 400, tidak dapat diartikan.
1. Nomor telepon Pak Sosro lebih banyak daripada nomor telepon Pak Noto. 2. Nomor telepon Pak Sosro berjarak 4000 dari nomor telepon Pak Noto. 3. Nomor telepon Pak Sosro dua kali nomor telepon Pak Noto.
Berdasarkan uraian tersebut, maka untuk mudahnya mengingat-ingat: a. Variabel diskrit diberi simbil laki-laki perempuan dan gambar telepon. b. Variabel ordinal diberi symbol gambar 3 orang yang berbeda tingginya. c. Variabel interval diberi gambar thermometer.
d. Variabel ration diberi simbol kayu penggaris.
Jika kita menghendaki, variabel kontinum dapat diubah menjadi variabel diskrit dengan cara mengklasifikasikannya menjadi ”ya” dan ”tidak”.
Caranya:
A. Menentukan batas misalnya nilai rata-rata, maka angka di atas rata-rata diberi ”ya”, rata-rata ke bawah diberi ”tidak”.
Contoh: nilai Bahasa Indonesia berjarak antara 3 dan 9 (variabel interval), variabel ini dapat dibuat diskrit dengan mengambil misalnya nilai 7 sebagai ”ya”, dan selain nilai itu (di atas atau bawahnya) diberi ”tidak”.
C. DATA STATISTIKA 1. Pengertian Data Statistika
Para ahli matematika mengembangkan statistika, di atas teori peluang, sebagai alat untuk membantu manusia, secara matematis, memecahkan berbagai persoalan yang dihadapi. Oleh karena itu, statistika tidak dapat dipisahkan oleh teori peluang dan merupakan bagian dari matematika.
Statistika yang telah dikembangkan secara matematis kemudian digunakan di berbagai persoalan yang ditemukan pada masing-masing bidang. Keragaman permasalahan yang ditemukan pada berbagai bidang juga telah mendorong para ahli matematika (statistika matematik) untuk mengembangkan berbagai teknik statistika yang sesuai dengan kondisi permasalahannya. Sungguh, suatu konsep statistika dapat muncul ke dalam sejumlah teknik statistika karena perbedaan asumsi mengenai kondisi permasalahnnya yang hendak dipecahkan.
Dalam memecahkan suatu masalah, karena alasan tertentu kita seringkali tidak memiliki data dari seluruh anggota populasi yang hendak dipahami. Alih-alih, kita biasanya hanya memiliki data dari sebagian anggota populasi yang disebut sampel. Oleh karena itu, para ahli matematika juga mengembangkan rumusan-rumusan yang dapat membantu kita dalam menarik sampel sehingga data yang ada di tangan dapat mewakili keadaan populasinya. Dengan kata lain statistika juga membicarakan cara-cara pengumpulan data, terutama mengenai penarikan sampel.
Data dari sampel yang diperoleh kemudian dianalisi dengan menggunkan teknik tertentu sesuai dengan permasalahan dan jenis datanya. Ukuran-ukuran statistik hasil analisis tersebut lalu digunakan untuk melakukan inferensi tentang persoalan yang akan dikaji pada populasi darimana sampel itu diambil. Berdasarkan uraian di atas, kita dapat memahami bahwa statistika adalah bagian dari matematika yang secara khusus membicarakan cara-cara pengumpulan, pengolahan, penyajian, analisis, dan penafsiran data. Dengan kata lain, istilah statistika di sini digunakan untuk menunjukan tubuh pengetahuan (body of knowledge) tentang cara-cara penarikan sampel (pengumpulan data), serta analisis dan penafsiran data.
2. Jenis Data dan Skala Pengukuran
Data dapat digolongkan menjadi data diskrit dan data kontinu. Banyaknya anak di suatu keluarga, jumlah rumah di suatu desa, banyaknya penduduk di suatu daerah, dan jumlah mobil di kantor tertentu merupakan contoh data diskrit. Sedangkan tingkat kecerdasan, prestasi belajar, berat badan, dan daya tahan mobil merupakan contoh data kontinu.
Berbeda dengan data deskrit, di antara dua data continue dikonsepsikan adanya sejumlah nilai dengan jumlah yang tidak terhingga. Jika bilangan 2 dan 3 di atas menunjukan berat suatu benda, maka di antara keduanya terdapat kemungkinan adanya sejumlah bilangan lain yang tidak terhingga, seperti 2,0001, 2,0002, 2,0010, 2,0021, dan sebagainya. Dikatakan tidak terhingga jumlahnya, karena kemungkinan nilai yang terjadi memang terlalu banyak dan tidak dapat ditentukan. Jika kita mencatat data dalam 2 desimal di belakang koma, maka di antara angka 2 dan 3 akan terdapat 99 nilai.
Dilihat dari skala pengukuran yang digunakan, data dibagi menjadi 4 jenis yang bersifat hierarkis, yaitu data yang berskala nominal (data nomilal), data yang berskala ordinal (data ordinal), data yang berskala interval (data interval), dan data yang berskala rasio(data rasio). Skala nominal merupakan jenis skala yang paling rendah, diikuti oleh skala ordinal, skala interval, dan kemudian skala rasio.
Data nominal memiliki skala yang bersifat kategorikal atau pengemlompokan. Jenis kelamin, warna kulit, dan agama merupakan contoh data nominal yang sering dijumpai pada buku-buku statistika. Pada contoh tersebut, kita memahami bahwa dengan data nominal kita hanya dapat mengetahui bahwa subjek termasuk ke dalam kategori tertentu (pria atau wanita, hitam atau putih ,sawong matang, Islam atau Kristen atau Hindu atau lainnya); sekali-kali kita tidak mengatakan bahwa pria lebih rendah atau lebih tinggi dari wanita, kulit hitam memiliki nilai lebih rendah daripada warna putih, dan sebagainya. Nama kelompok atau kategori digunakan di sini hanya untuk mengenali indentitas subjek dilihat dari variabel tertentu. Perbedaan subjek dalam data nominal bersifat kualitatif dan tidak mempunyai makna kuantitaif.
Data ordinal memiliki skala yang menunjukan perbedaan tingkatan subjek secara kuantitatif. Contoh yang paling gambling dari data ordinal adalah data yang dinyatakan dalam bentuk peringkat atau rangking. Selain kita dapat menyatakan bahwa seorang subjek termasuk kelompok tertentu (sifat data nominal), pada data ordinal, kita juga dapat menyatakan bahwa subjek atau kelompok yang menduduki peringkat tertentu memiliki nilai yang lebih tinggi dari subjek atau kelompok yang menduduki peringkat lain (di bawahnya). Kita dapat mengatakan bahwa siswa yang menduduki peringkat kedua pada suatu variabel memiliki kemampuan atau skor yang lebih tinggi pada variabel itu daripada siswa yang menduduki peringkat ketiga. Secara singkat, dapat dikatakan bahwa data ordinal, di samping memiliki sifat yang dimiliki data nominal juga menunjukan kedudukan (tingkatan) subjek dalam suatu kelompok pada suatu variabel.
Data yang berskala rasio (data rasio) hampir sama dengan data interval, yakni keduanya memiliki ketiga sifat di atas (menunjukan klasifikasi dan kedudukan subjek dalam suatu kelompok, serta sifat persamaan jarak). Data rasio berbeda dari data interval karena yang pertama (data rasio) memiliki nilai mutlak nol. Sebagai konsekuensi dari asumsi tentang adanya nilai mutlak nol, kita dapat membuat perbandingan (rasio) antara skor-skor yang berskala rasio. Sebagai contoh, 20kg adalah 2 kali 10kg, 15m = 3 x 5, dan sebagainya. Kita dapat secara bermakna menyatakan bahwa orang yang berat badannya 80 kg adalah dua kali berat orang yang berat badannya 40kg. Pernyataan semacam ini tidak dapat dibuat dengan menggunkan data interval. Kita tidak dapat mengatakan bahwa tingkat kecerdasan orang yang memiliki I.Q. sebesar 150 adalah satu setengah kali tingkat kecerdasan orang yang memiliki I.Q. sebesar 100.
Data populasi atau data sampel yang sudah terkumpul, jika digunakan untuk keperluan informasi, baik berupa laporan atau analisis lanjutan dalam penelitian hendaknya diatur. Disusun, disajikan dalam bentuk yang jelas dan komunikatif dengan penyajian data yang lebih menarik publik. Secara umum ada beberapa cara penyajian data statistik yang sering digunakan, yaitu: tabel, grafis, diagram, pengukuran tendensi sentral (gejala pusat) dan ukuran penempatan (gejala letak), pengukuran penyimpangan. Penyajian data dapat digambarkan.
2. TABEL
a. Tabel Biasa
Tabel biasa sering digunakan untuk berbagai macam keperluan baik bidang ekonomi, sosial, budaya, dan lain-lain untuk menginformasikan data dari hasil penelitian atau hasil penyelidikan. Contoh:
Judul Tabel
Judul Kolom
1. Biasa 2. Kontigensi
3. Distribusi Frekuensi a. Relatif
b. Kumulatif c. Kumulatif Relatif
1. Histogram 2. Poligon frekuensi 3. Ogive
1. Batang 2. Garis 3. Lambang
4. Lingkaran dan Pastel 5. Peta
6. Pencar 7. Campuran Tabel
Grafik
Diagram Penyajian
Judul
1. Judul tabel ditulis simetris di atas sumbu Y dengan huruf kapital tanpa penggalan kata secara singkat dan jelas tentang apa, macam atau klarifikasi, dimana, kapan, dan apabila ada cantumkan satuan atau unit data yang digunakan.
2. Judul kolom ditulis singkat, jelas, dan diupayakan jangan memutus (memenggal kata). 3. Sel-sel tempat penulisan angka-angka atau data.
4. Catatan ditulis dibagian kiri bawah berguna untuk mencatat hal-hal penting dan perlu diberikan. Pada bagian tersebut juga terdapat kata sumber untuk menjelaskan
darimana data tersebut dikutip, kalau tidak ada berarti pelopor ikut di dalamnya. 5. Selain nomor 1-4 di atas, perlu diperhatikan yaitu nama sebaiknya disusun menurut
abjad; waktu secara berurutan (kronologis) urutan kepangkatan, urutan golongan pegawai, dan sebagainya. Contohnya 2001, 2002, 2003; Jendral, Letjen, Mayjen, Brigjen, Golongan I, II, III, IV, dan seterusnya; menempatkan data kategori disusun secara sistematis contohnya mulai dari data terbesar sampai data terkecil, data keuntungan dilanjutkan data kerugian dan sejenisnya.
b. Tabel Kontigensi
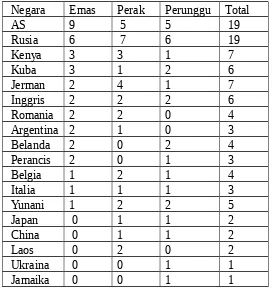
Tabel kontigensi digunakan khusus data yang terletak antara baris dan kolom berjenis variabel kategori. Contoh:
Tabel Distribusi Mendali Kejuaraan Dunia Atletik 2001
c. Tabel Distribusi Frekuensi
1. Pengertian Distribusi Frekuensi
Distribusi frekuensi adalah penyusunan suatu data mulai dari terkecil sampai terbesar yang membagi banyaknya data kedalam beberapa kelas. Kegunaan data yang masuk dalam distribusi frekuensi adalah untuk memudahkan data dalam penyajian, mudah dipahami, dan mudah dibaca sebagai bahan informasi, pada gilirannya digunakan untuk perhitungan membuat gambar statistik dalam berbagai bentuk penyajian data.
Distribusi frekuensi terdiri dari dua yaitu distribusi frekuensi kategori dan distribusi frekuensi numerik.
Distribusi frekuensi kategori adalah distribusi frekuensi yang pengelompokan datanya disusun berbentuk kata-kata atau distribusi frekuensi yang penyatuan kelas-kelasnya didasarkan pada data kategori (kualitatif). Sedangkan distibusi numerik adalah distribusi frekuensi yang penyatuan kelas-kelasnya (disusun secara interval) didasarkan pada angka-angka (kuantitatif).
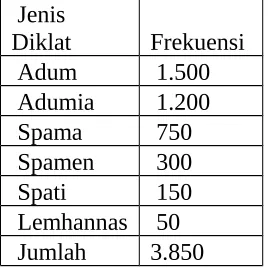
1.1 Contoh Distribusi Frekuensi Kategorik
Distribusi frekuensi peserta diklat penjenjangan
Jenis
Diklat Frekuensi
Adum 1.500
Adumia 1.200
Spama 750
Spamen 300
Spati 150
Lemhannas 50 Jumlah 3.850
2.1 Contoh Distribusi Frekuensi Numerik
Distribusi Frekuensi Nilai Pelayanan Masyarakat
Nilai
Interval Frekuensi
60 – 65 4
66 – 71 5
72 – 77 16
78 – 83 12
90 – 95 3
jumlah 40
Sebelum membahas kepada pembahasan lanjutan, maka terlebih dahulu dikupas mengenai beberapa istilah yang berhubungan dengan distribusi frekuensi numerik (kelompok).
Interval kelas adalah sejumlah nilai variabel yang ada dalam batas kelas tertentu. Misalnya tabel di atas yang berisikan enam interval kelas (60 – 65 disebut interval kelas pertama dan 90 – 95 interval kelas keenam). Nilai interval kelas 60 – 65 yang bermakna bahwa di dalam interval kelas tersebut terdapat nilai antara 60 hingga 65 sebanyak 4 orang. Nilai interval kelas 66 – 71 artinya terdapat sejumlah nilai antara 66 hingga 71 sebanyak 5 orang, dan seterusnya sampai pada nilai interval kelas 90 – 95 terdapat 3 orang.
Batas kelas adalah suatu nilai yang membatasi kelas pihak satu dengan pihak kelas yang lain. Batas kelas ini kegunaanya waktu pembuatan histogram. Pada nilai interval kelas pertama yaitu angka 60 sampai 65. Nilai 65 adalah ujung atas interval kelas pertama yaitu angka 60 sampai 65. Nilai 65 adalah ujung atas interval kelas pertama, sedangkan nilai 66 adalah ujung bawah interval kelas kedua. Apabila ujung atas interval kelas pertama ditambah ujung bawah interval kedua dikalikan setengah, maka hasil tersebut dinamakan batas kelas, atau ujung bawah interval kelas dikurangi 0,5; 0,05 bahkan 0,005 tergantung ketelitian data yang dibuat oleh peneliti dan ujung kelas atas ditambah 0,5; 0,05, bahkan 0,005, maka nilai itu dinamakan batas kelas.
2. Teknik Pembuatan Distribusi Frekuensi
Langkah-langkah teknik pembuatan distribusi frekuensi dilakukan sebagai berikut.
a. Urutkan data dari yang terkecil sampai yang terbesar. b. Hitung jarak atau rentangan (R).
rumus: R = data tertinggi – data terendah c. Hitung jumlah kelas (K) dengan Struges: rumus: Jumlah Kelas (K) = 1 + 3,3 log n n = jumlah data
d. Hitung panjang kelas interval (P) Rumus =
e. Tentukan batas data terendah atau ujung data pertama, dilanjutkan menghitung kelas interval, caranya menjumlahkan ujung bawah kelas sampai pada data akhir.
f. Buat tabel sementara (tabulasi data) dengan cara dihitung satu demi satu yang sesuai dengan urutan interval kelas.
Contoh Tabulasi Data
Jumlah
g. Membuat tabel distribusi frekuensi dengan cara memindahkan semua angka frekuensi (f).
Contoh: Distribusi Frekuensi
Diketahui nilai ujian akhir kuliah Statistika di Universitas CJWD Tahun 2001 yang diikuti mahasiswa, diperoleh data:
70, 70, 71, 60, 63, 80, 81, 81, 74, 74, 66, 66, 67, 67, 67, 68, 67, 67, 77, 77, 77, 80, 80, 80, 80, 73, 73, 74, 74, 74, 71, 72, 72, 72, 72, 83, 84, 84, 84, 84, 75, 75, 75, 75, 75, 75, 75, 75, 78, 78, 78, 78, 78, 79, 79, 81, 82, 82, 83, 89, 85, 85, 87, 90, 93, 94, 94, 87, 87, 89.
a. Urutkan data dari terkecil sampai terbesar. 60, 63
66, 66, 67, 67, 67, 68
70, 70, 71, 71, 72, 72, 72, 72, 73, 73, 74, 74, 74, 74, 74
75, 75, 75, 75, 75, 75, 75, 75, 76, 76, 77, 77, 77, 78, 78, 78, 78, 78, 79, 79 80, 80, 80, 80, 80, 81, 81, 81, 82, 82, 83, 83, 84, 84, 84, 84
90, 93, 94, 94
b. Hitungalah jarak atau rentangan R = data tertinggi – data terendah R = 94 – 60 = 34
c. Hitung jumlah kelas (K) dengan Sturges: K = 1 + 3,3 log 70
K = 1 + 3,3 1,845
K = 1 + 6,0885 = 7,0887 = 7
d. Hitung panjang kelas interval (P)
= = 4,857 = 5
e. Tentukan batas kelas interval panjang kelas (P)
(60 + 5) = 65 – 1 = 64 (65 + 5) = 65 – 1 = 69 (70 + 5) = 65 – 1 = 74 (75 + 5) = 65 – 1 = 79 (80 + 5) = 65 – 1 = 84 (85 + 5) = 65 – 1 = 89 (90 + 5) = 65 – 1 = 94
f. Buat tabel sementara dengan cara dihitung satu demi satu yang sesuai dengan urutan interval kelas.
60 – 64
g. Membuat tabel distribusi frekuensi dengan cara memindahkan semua angka frekuensi Telah dijelaskan di atas tentang distribusi frekuensi, tetapi ada beberapa bentuk distibusi frekuensi, yaitu:
1. Distribusi frekuensi relatif 2. Distribusi frekuensi kumulatif
a. Distibusi frekuensi relatif (kurang dari), dan b. Distribusi frekuensi kumulatif (atau lebih) 3. Distribusi frekuensi kumulatif relatif
a. Distribusi frekuensi kumulatif relatif (kurang dari), dan
b. Distribusi frekuensi kumulatif relatif (atau lebih) agar lebih jelas diterangkan berikut.
1) Distribusi frekuensi relatif
Distribusi frekuensi relatif adalah distribusi frekuensi yang nilai frekuensinya tidak dinyatakan dalam bentuk angka mutlak atau nilai mutlak, akan tetapi setiap kelasnya dinyatakan dalam bentuk angka persentase (%) atau angka relatif. Teknik perhitungan distribusi frekuensi relatif yaitu dengan cara membagi angka distribusi frekuensi mutlak dengan jumlah keseluruhan distribusi frekuensi (n) dikalikan 100% atau dengan rumus:
Frelatifitas - i = = 100%
Dari hasil perhitungan di atas, dimasukan ke dalam tabel distribusi frekuensi relatif. Jika mau digabungkan tabel distribusi frekuensi dengan tabel distribusi frekuensi relatif maka hal ini dapat saja terjadi tergantung selera saja.
2) Distribusi frekuensi kumulatif
Distribusi frekuensi kumulatif (fkum) ialah distribusi frekuensi yang nilai frekuensinya (f) diperoleh dengan cara menjumlahkan frekuensi demi frekuensi. Tabel distribusi frekuensi kumulatif (fkum) bisa dibuat berdasarkan tabel distribusi frekuensi mutlak. Distribusi frekuensi kumulatif (fkum) dibagi menjadi dua yaitu: (1) distribusi frekuensi kumulatif (kurang dari) dan (2) distribusi kumulatif (atau lebih).
Distribusi frekuensi relatif kumulatif {fkum %} ialah distribusi frekuensi yang mana nilai frekuensi kumulatif diubah menjadi nilai frekuensi relatif atau dalam bentuk persentase (%) atau dengan rumus:
Fkum(%)kelas-i - i = = 100%
Tabel distribusi frekuensi kumulatif relatif dibagi menjadi dua yaitu: (1) distribusi frekuensi kumulatif relatif (kurang dari) dan (2) distribusi frekuensi kumulatif relative (atau lebih).
3. GRAFIK
Grafik adalah ilkisan pasang surutnya suatu keadaan dengan garis atau gambar (tentang turun naiknya hasil statistik). Apabila data yang disusun rapih berbentuk distribusi frekuensi dapat digambarkan dengan cara membuat grafik, yaitu: histogram, poligon, frekuensi, dan ogive.
a. Histogram
Histogram adalah grafik yang menggambarkan suatu distribusi frekuensi dengan bentuk beberapa segi empat. Langkah-langkah membuat histogram.
1. Buatlah absis dan ordinat
Absis ialah sumbu mendatar (X) menyatakan nilai. Ordinat ialah sumbu tegak (Y) menyatakan frekuensi.
2. Berilah nama pada masing-masing sumbu dengan cara, sumbu abisis diberi nama nilai dan ordinat diberi nama frekuensi.
3. Buatlah skala absis dan ordinat. 4. Buatlah batas kelas dengan cara.
a) Ujung bawah interval kelas dikurangi 0,5.
b) Ujung atas interval kelas pertama ditambah ujung bawah interval kelas kedua dan dikalikan setengah.
c) Ujung kelas atas ditambah 0,5. Perhitungan sebagai berikut. 60 – 0,5 = 59,5
(64 + 65) x ½ = 64,4 (69 + 70) x ½ = 69,5 (74 + 75) x ½ = 74,5 (79 + 80) x ½ = 79,5 (84 + 85) x ½ = 84,5 (89 + 90) x ½ = 89,5 (94 + 95) x ½ = 95,5
5. Membuat tabel distribusi frekuensi untuk membuat histogram sebagai berikut.
60 – 64
6. Membuat grafik histogram, contoh sebagai berikut.
b. Poligon Frekuensi
Poligon frekuensi ialah grafik garis yang menghubungkan nilai tengah tiap sisi atas yang berdekatan dengan nilai tengah jarak frekuensi mutlak masing-masing. Pada dasarnya pembuatan grafik poligon sama dengan histogram, hanya cara membuat batas-batasnya yang berbeda. Perbedaan antara histogram dan poligon adalah: (1) Histogram menggunakan batas kelas sedangkan poligon menggunakan titik tengah dan (2) Grafik histogram berwujud segi empat sedang grafik polygon berwujud garis-garis atau kurva yang saling berhubungan satu dengan yang lainnya.
Berdasarkan hal tersebut di atas, maka poligon frekuensi dapat dibuat dengan langkah-langkah sebagai berikut.
a. Buatlah titik tengah kelas dengan cara: Nilai yang terdapat ditengah interval kelas atau nilai ujung bawah kelas ditambah nilai ujung atau kelas dikaitkan setengah, sebagai berikut.
b. Buatlah tabel distribusi frekuensi untuk membuat histogram.
Nilai Titik Tengah Kelas Frekuensi (f)
60 - 64 62 2
65 - 69 67 6
70 - 74 72 15
80 - 84 82 16
85 - 89 87 7
90 - 94 92 4
Jumlah 70
c. Buatlah grafik poligon frekuensi dan keterangan lengkap. Contoh grafik poligon.
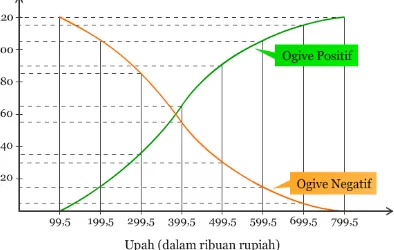
c. Ogive
Ogive adalah distribusi frekuensi kumulatif yang menggambarkan diagramnya dalam sumbu tegak dan mendatar atau eksponensial.
Pada dasarnya pembuatan grafik ogive tidak jauh berbeda dengan pembuatan grafik poligon. Perbedaannya (1) ogive menggunakan batas kelas (batas nyata) sedangkan poligon menggunakan titik tengah, (2) pada grafik ogive menggambarkan distribusi frekuensi kumulatif kurang dari dan distribusi frekuensi kumulatif atau lebih, serta distribusi frekuensi kumulatif secara meningkat dengan menggunakan batas kelas (batas nyata), sedangkan poligon mencantumkan nilai frekuensi tiap-tiap variabel. Persamaanya antara ogive dan polygon terletak pada gambar grafik berwujud garis-garis atau kurva yang saling menghubungkan satu titik dengan titik yang lainnya.
Grafik ogive ini jarang dijumpai dalam suatu penelitian, walaupun demikian grafik ogive berguna bagi: contoh sensus penduduk yang ingin mengetahui perkembangan kelahiran dan kematian bayi.
4. DIAGRAM
Diagram ialah gambaran untuk memperlihatkan atau menerangkan sesuatu data yang akan disajikan.
a. Diagram Batang
diagram batang adalah untuk menyajikan data yang bersifat kategori atau data distribusi. Cara menggambar diagram batang yaitu diperlukan sumbu tegak (vertikal) dan sumbu mendatar (horizontal) yang berpotongan tegak lurus. Sumbu tegak maupun sumbu mendatar dibagi beberapa bagian dengan skala nilai yang sama, walaupun demikian skala (ukuran) antara sumbu tegak dengan sumbu mendatar tidak perlu dibuat sama disesuaikan dengan penampilan diagramnya. Apabila diagram dibentuk berdiri (tegak lurus), maka sumbu mendatar digunakan untuk menyatakan atribut atau waktu, sedangkan nilai data (kuantum) dituliskan pada sumbu tegak. Adapun letak batang satu dengan lainnya harus terpisah dan serasi mengikuti tempat diagram yang ada.
Penyajian data berbentuk diagram batang ini banyak modelnya antara lain: diagram batang satu komponen atau lebih, diagram dua arah, diagram batang tiga dimensi, dan lain-lain sesuai dengan variasinya atau tergantung kepada keahlian pembuat diagram.
b. Diagram Garis
Diagram garis digunakan untuk menggambarkan keadaan yang erba terus menerus. Misalnya pergerakan indeks bursa saham, bursa komoditas dunia, grafik kurs valuta, dan lain-lain. Cara menggambarkan diagram garis ini pada intinya sama dengan menggambarkan diagram batang.
c. Diagram Lambang
d. Diagram Lingkaran dan Diagram Pastel
Diagram lingkaran digunakan untuk penyajian data berbentuk kategori dinyatakan dalam persentase. Langkah-langkah membuat diagram lingkaran:
1. Ubahlah setiap perubahan nilai data disesuaikan dengan nilai data tersebut ke dalam derajat.
2. Buatlah lingkaran (360o) lalu bagilah lingkarang tersebut menjadi beberapa bidang.
3. Setiap bidang menggambarkan kategori data.
Diagram pastel yaitu perubahan wujud dari model diagram lingkaran disajikan dalam bentuk tiga dimensi. Misalnya luas lahan Tanaman Pangan Tahun 2000, Tambang Emas di Indonesia, Jejak Pendapat Sidang Istimewa dan lain-lain.
e. Diagram Peta
Diagram peta (diagram kartogram) yaitu diagram yang melukiskan fenomena atau keadaan dihubungkan dengan tempat kejadian itu berada. Teknik pembuatannya digunakan peta geografis sebagai dasar untuk menerengkan data dan fakta yang terjadi. Misalnya China Berangus Pejuang Xianjiang, Negara-negara Nuklir, dan lain-lain.
f. Diagram Pencar
g. Diagram Campuran
Diagram campuran ialah diagram yang disajikan dalam bentuk gabungan dari beberapa dimensi dalam satu penyajian data, contoh:
1. diagram pastel dengan diagram lambang, 2. diagram pastel dengan diagram peta, 3. diagram pastel dengan diagram batang, 4. diagram batang dengan diagram garis, 5. diagram batang dengan diagram lambang, 6. diagram peta dengan tabel,
7. diagram lambang dengan tabel,
8. diagram batang dengan diagram simbol dan diagram pastel, dan sebagainya.
SUMBER:
Arikunto, S. 2010. Prosedur Penelitian Suatu Pendekatan Praktik. Jakarta. Rineka Cipta. Furqon. 2011. Statistika Terapan Untuk Penelitian. Bandung. Alfabeta.