BAB 2
TINJAUAN PUSTAKA
2.1 Data
Data adalah bentuk jamak dari datum, yang dapat diartikan sebagai informasi
yang diterima yang bentuknya dapat berupa angka, kata-kata, atau dalam bentuk
lisan dan tulisan lainnya. Ada beberapa cara yang dapat dilakukan dalam
memperoleh data, diantaranya data yang diperoleh secara langsung (primer), dan
data yang diperoleh secara tidak langsung (sekunder). Koleksi data merupakan
tahapan yang paling penting dalam pelaksanaan penelitian, karena hanya dengan
mendapatkan data yang tepat maka proses penelitian akan berlangsung dengan
baik.
2.2 Data Acak Atau Data Tunggal
Data acak atau tunggal adalah data yang belum tersusun atau dikelompokkan ke
dalam kelas-kelas interval.
2.3 Data Berkelompok
Data berkelompok adalah data yang sudah tersusun atau dikelompokkan dalam
kelas-kelas interval. Data kelompok disusun dalam bentuk distribusi frekuensi
2.4 Data Diskrit
Data diskrit, data kategorik, atau data nominal. Data ini merupakan hasil
perhitungan, sehingga tidak dijumpai bilangan pecahan. Data diskrit adalah data
yang paling sederhana yang disusun menurut jenisnya atau kategorinya.
2.5 Data Kontinu
Data kontinu terdiri atas tiga macam data yaitu: data ordinal, data interval, dan
data rasio. Data ordinal adalah data yang sudah diurutkan dari jenjang yang paling
rendah sampai ke jenjang yang paling tinggi, atau sebaliknya tergantung
peringkat. Data interval mempunyai sifat-sifat nominal dari data ordinal, dan sifat
tambahan lainnya yaitu mempunyai nol mutlak, akibatnya terdapat skala interval
yang sama jaraknya. Data rasio mengandung sifat-sifat interval, dan selain itu
sudah mempunyai nilai nol mutlak.
2.6 Skala Pengukuran Data
Skala pengukuran data merupakan prosedur pemberian angka pada suatu objek
agar dapat menyatakan karakteristik dari objek tersebut. Ada empat tipe skala
pengukuran data dalam penelitian, yaitu nominal, ordinal, interval, dan rasio.
2.7 Skala Nominal
Skala nominal adalah suatu skala yang diberikan pada suatu objek atau kategori
yang tidak menggambarkan kedudukan objek atau kategori tersebut terhadap
objek atau kategori lainnya, tetapi hanya sekedar label atau kode saja. Skala ini
hanya mengelompokkan objek atau kategori ke dalam kelompok tertentu.
Sebagai contoh, mengklasifikasi jenis kelamin, agama, pekerjaan, dan area
sebagai simbol. Skala pengukuran data nominal digunakan dalam statistika
nonparametrik. Hasil analisis dipresentasikan dalam bentuk persentase. Sebagai
contoh, dalam mengklasifikasikan variabel jenis kelamin menjadi seperti berikut:
laki-laki diberikan simbol angka 1 dan wanita diberikan simbol angka 2. Operasi
aritmetika tidak dapat dilakukan dengan angka tersebut karena
angka-angka tersebut hanya menunjukkan keberadaan atau ketiadaan karakteristik
tertentu.
2.8 Skala Ordinal
Skala pengukuran ordinal merupakan skala pengukuran yang memberikan
informasi tentang jumlah relatif karakteristik yang berbeda yang dimiliki oleh
objek atau individu tertentu. Tingkat pengukuran ini mempunyai informasi skala
nominal yang ditambah dengan sarana peringkat relatif tertentu yang memberikan
informasi apakah suatu objek memiliki karakteristik yang lebih atau kurang, tetapi
bukan berapa banyak kekurangan dan kelebihannya. Dalam skala ordinal tidak
dapat dilakukan operasi aritmetika, seperti menjumlah, mengurangi, mengalikan,
membagi, dan merata-ratakan angka-angka tersebut, karena angka-angka tersebut
hanya menunjukkan keberadaan atau ketiadaan karakteristik tertentu.
Sebagai contoh, jawaban dari suatu pertanyaan berupa peringkat, misalnya
sangat tidak setuju, tidak setuju, netral, setuju, dan sangat setuju, dapat diberi
simbol angka 1, 2, 3, 4, dan 5. Angka-angka tersebut hanya merupakan simbol peringkat, tidak mengekspresikan jumlah. Misalnya dalam pertanyaan “Apakah saudara setuju dengan kenaikan tarif tiket pesawat terbang?”. Jawaban: a. sangat tidak setuju, b. tidak setuju, c. ragu-ragu, d. setuju, e. setuju sekali. Jika
2.9 Skala Interval
Skala interval memiliki karakteristik yang sama seperti yang dimiliki oleh skala
nominal dan ordinal dengan ditambah karakteristik lain, yaitu interval yang tetap.
Dengan demikian, seorang peneliti dapat melihat besarnya perbedaan karakteristik
antara satu individu atau objek dengan yang lainnya. Skala pengukuran interval
benar-benar merupakan angka sehingga operasi aritmetika, misalnya penjumlahan
atau perkalian dapat dilakukan. Untuk melakukan analisis, skala pengukuran
interval menggunakan statistika parametrik.
Sebagai contoh, jawaban tentang frekuensi dalam pertanyaan “Berapa kali Anda berbelanja di Supermarket X dalam satu bulan?” adalah 1 kali, 3 kali, dan 5 kali. Angka-angka 1, 3, dan 5 merupakan angka sebenarnya yang menggunakan
interval 2. Jika menggunakan interval 1, jawabannya menjadi 1 kali, 2 kali, 3 kali,
atau 4 kali.
2.10 Skala Rasio
Skala pengukuran rasio memiliki semua karakteristik yang dimiliki oleh skala
nominal, ordinal, dan interval dengan kelebihan bahwa skala ini memiliki nilai 0
(nol) empiris absolut. Nilai absolut nol tersebut terjadi ketika suatu karakteristik
yang sedang diukur tidak ada. Pengukuran rasio biasanya berbentuk perbandingan
antara satu individu atau objek tertentu dengan yang lainnya.
Sebagai contoh berat Rinso 3 gram, sedangkan berat Soklin 6 gram. Maka,
berat Rinso dibanding dengan berat Soklin sama dengan 1 dibanding 2. Dalam pertanyaan “Berapa berat badan Anda sebelum dan sesudah makan obat diet?”, jawabannya berupa angka sebenarnya, yaitu berat sebelum minum obat 70 kg dan
berat sesudah minum obat 60 kg.
Dalam penelitian ini, skala pengukuran yang dibahas adalah skala
2.11 Statistika Deskriptif
Statistika deskriptif merupakan suatu proses statistika dimana hanya berusaha
melukiskan atau mengalisa kelompok yang diberikan tanpa membuat atau
menarik kesimpulan tentang populasi atau kelompok yang lebih besar. Dengan
kata lain, statistika deskriptif hanya digunakan untuk menunjukkan kondisi suatu
data dan tidak dapat digunakan untuk menunjukkan kondisi data lain ataupun
kondisi data yang lebih besar.
Di dalam statistika deskriptif, terdapat beberapa rposedur pengujian
statistika yang digunakan untuk menunjukkan kondisi suatu data, seperti rata-rata
atau mean, median, modus, standar deviasi, varians, kemiringan, kurtosis, nilai
minimum dan nilai maksimum.
2.12 Rata- Rata atau Rata-Rata Hitung
Rata-rata, atau lengkapnya rata-rata hitung, untuk data kuantitatif yang terdapat
dalam sebuah sampel dihitung dengan cara membagi jumlah nilai data oleh
banyak data. Simbol rata-rata untuk sampel adalah ̅, sedangkan rata-rata untuk
populasi dipakai simbol µ.
̅ ̅ ∑
Atau lebih sederhana lagi ditulis:
̅ ∑
dengan = nilai pada data
= 1, 2, 3, ...,
n = banyak data
Untuk data yang telah dikelompokkan dalam tabel distribusi frekuensi, maka
rata-ratanya adalah:
̅ ∑
Dengan = frekuensi pada kelas ke-k
2.13 Modus
Untuk menyatakan fenomena yang paling banyak terjadi atau paling banyak
terdapat digunakan ukuran modus atau disingkat Mo. Ukuran ini juga dalam keadaan tidak disadari sering dipakai untuk menentukan “rata-rata” data kualitatif. Sebagai contoh, jika terdapat suatu pernyataan “kebanyakan kematian di Indonesia disebabkan oleh penyakit malaria”, “pada umumnya kecelakaan lalu lintas karena kecerobohan pengemudi”, maka pernyataan-pernyataan tersebut merupakan modus penyebab kematian di Indonesia dan modus kecelakaan lalu
lintas.
Modus untuk data kuantitatif ditentukan dengan cara menentukan
frekuensi terbanyak di dalam data kuantitatif tersebut. Jika data kuantitatif telah
disusun di dalam daftar distribusi frekuensi, maka modusnya dapat ditentukan
dengan rumus:
( )
dengan = batas bawah kelas modal, ialah kelas interval dengan frekuensi
terbanyak,
= panjang kelas,
= frekuensi kelas modal dikurangi frekuensi kelas interval dengan
tanda kelas yang lebih kecil sebelum tanda kelas modal,
= frekuensi kelas modal dikurangi frekuensi kelas interval dengan
tanda kelas yang lebih besar sesudah tanda kelas modal.
2.14 Median
Median merupakan suatu nilai yang membagi data menjadi dua bagian yang sama.
Sebelum menghitung nilai median, terlebih dahulu data diurutkan dari yang
terkecil hingga yang terbesar. Median biasa disingkat dengan Me. Jika banyak
data paling tengah. Untuk sampel berukuran genap, setelah data disusun menurut
urutan nilainya, maka mediannya sama dengan rata-rata hitung dua data tengah.
Untuk data yang telah disusun dalam daftar distribusi frekuensi,
mediannya dihitung dengan rumus:
dengan = batas bawah kelas median, ialah kelas di mana median akan
terletak,
= panjang kelas,
= Banyak data,
= Jumlah semua frekuensi dengan tanda kelas lebih kecil dari
tanda kelas median,
= Frekuensi kelas median.
2.15 Deviasi Standar (Simpangan Baku)
Deviasi standar adalah ukuran penyimpangan terhadap nilai rata-ratanya, nilai
simpangan baku merupakan harga akar positif dari selisih item data dengan nilai
rata-rata yang dibagi oleh jumlah data.
Untuk sebuah himpunan dari jumlah n data, di mana
rata-ratanya adalah adalah ̅, standar deviasi sampel yang dinotasikan didefinisikan
sebagai berikut:
√∑ ̅
2.4
dengan:
= standar deviasi
= banyak data
̅ = rata-rata sampel
Untuk data yang sudah dikelompokkan, formula deviasi standar atau simpangan
baku sampel adalah sebagai berikut:
√∑ ̅ 2.5
dengan:
= simpangan baku
= banyak data
̅ = rata-rata sampel
= frekuensi kelas ke-i
= nilai tengah dari kelas ke-i , i = 1, 2, …, k
2.16 Varians
Varians adalah rata-rata hitung dari kuadrat simpangan setiap pengamatan
terhadap rata-rata hitungnya. Untuk data yang tidak dikelompokkan, varians
sampel adalah sebagai berikut:
∑ ̅
2.6
dengan:
= varians
= banyak data
̅ = rata-rata sampel
Untuk data yang sudah dikelompokkan, varians populasi adalah sebagai berikut:
∑ ̅
2.7
dengan:
= varians
= banyak data
̅ = rata-rata sampel
= frekuensi kelas ke-i
= nilai tengah dari kelas ke-i , i = 1, 2, …, k
2.17 Distribusi Normal
Distribusi normal termasuk ke dalam salah satu distribusi probabilitas nondiskrit
atau kontinu. Dalam distribusi normal, variabel acak dinyatakan dalam interval
dan bersifat tidak dapat dihitung (uncountable). Sebagai contoh variabel acak X
dinyatakan dalam interval dengan . Beberapa fenomena dalam
kehidupan mendekati kurva dari distribusi normal, contohnya adalah fenomena
mengenai nilai IQ manusia, tinggi badan, berat badan, dan sebagainya.
Dengan menggunakan distribusi normal, penyajian data dapat lebih
bermakna daripada hanya menggunakan penyajian berkelompok saja, karena
dengan adanya persyaratan normalitas data, maka data dapat dilanjutkan
penyajiannya dalam bentuk membedakan, mencari hubungan, dan meramalkan.
Distribusi normal atau kurva normal disebut juga dengan distribusi Gauss,
karena persamaan matematisnya ditemukan oleh Gauss. Fungsi kepadatan untuk
distribusi ini ditentukan oleh:
√
dengan:
= parameter yang merupakan rata-rata distribusi
= parameter yang merupakan simpangan baku distribusi
Jika Z adalah variabel terstandarisasi yang sesuai dengan X, yaitu jika
Maka nilai mean atau nilai ekspektasi dari Z adalah 0 dan variansnya adalah 1.
Dalam kasus semacam ini fungsi kepadatan untuk Z dapat diperoleh dari
persamaan (2.9) dengan memasukkan dan , menghasilkan
√ 2.9
Fungsi ini sering dinyatakan sebagai fungsi kepadatan normal standar. Grafik dari
fungsi kepadatan (2.9), disebut kurva normal standar, seperti tampak pada
Gambar 2.1 f(x)
Gambar 2.1 Kurva Normal Standar
2.18 Kemiringan
Kemiringan merupakan ukuran yang digunakan untuk mengetahui derajat
taksimetri dari sebuah model. Terdapat beberapa bentuk kurva atau model yang
bentuknya bisa positif, negatif, atau simetrik. Model positif terjadi bila suatu
kurva membentuk ekor yang memanjang ke sebelah kanan. Sebaliknya, jika
ekornya memanjang ke sebelah kiri maka didapatkan model negatif. Dalam kedua
Dikatakan suatu model merupakan model positif jika kemiringan bernilai
positif, model negatif jika kemiringan bernilai negatif, dan simetrik jika
kemiringan sama dengan nol.
2.19 Kuartil
Jika sekumpulan data dibagi menjadi empat bagian yang sama banyak, sesudah
disusun menurut urutan nilainya, maka bilangan pembaginya disebut kuartil.
Terdapat tiga macam kuartil, yaitu kuartil pertama, kuartil kedua, dan kuartil
ketiga yang masing-masing disingkat dengan dan . Pemberian nama ini
dimulai dari nilai kuartil paling kecil. Untuk menentukan nilai kuartil caranya
adalah:
1) Susun data menurut urutan nilainya dari yang terkecil sampai terbesar.
2) Tentukan letak kuartil.
3) Tentukan nilai kuartil
Letak kuartil ke-i, diberi lambang , ditentukan oleh rumus:
dengan = 1, 2, 3
= Banyak data
2.20 Persentil
Sekumpulan data yang dibagi menjadi 100 bagian yang sama akan menghasilkan
99 pembagi yang berturut-turut dinamakan persentil pertama, persentil kedua, . . .,
persentil ke-99. Simbol yang digunakan berturut-turut adalah . . ., .
Cara perhitungan persentil sama seperti perhitungan kuartil. Letak
dengan = 1, 2, . . ., 99.
= Banyak data.
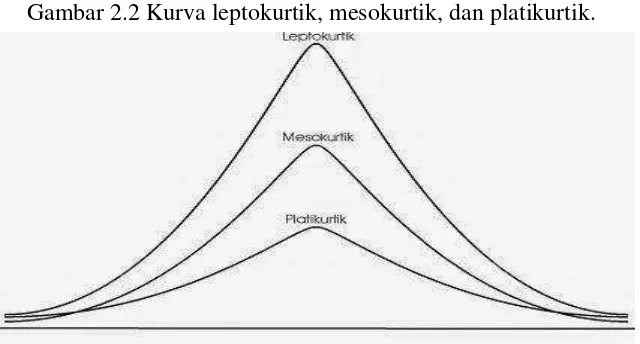
2.21 Kurtosis
Tinggi rendahnya atau runcing datarnya bentuk kurva disebut kurtosis. Kurva
distribusi normal, yang tidak terlalu runcing atau tidak terlalu datar, dinamakan
mesokurtik. Kurva yang runcing dinamakan leptokurtik, sedangkan kurva yang
datar disebut platikurtik.
Salah satu ukuran kurtosis adalah koefisien kurtosis yang diberi simbol ,
ditentukan oleh rumus:
⁄
dengan = Kuartil pertama
= Kuartil ketiga
= Persentil kesepuluh
= Persentil kesembilanpuluh Untuk distribusi normal, nilai = 0,263.
Berikut ini merupakan gambar kurva yang berbentuk leptokurtik,
platikurtik, dan mesokurtik.
2.22 Rata-Rata Ukur
Jika perbandingan tiap data berurutan tetap atau hampir tetap, rata-rata
ukur lebih baik digunakan daripada rata-rata hitung. Untuk bilangan-bilangan
bernilai besar, rata-rata ukur dapat ditentukan dengan rumus:
n x
U
log ilog (2.14)
Jika data disusun dalam daftar distribusi frekuensi rata-r ata ukurnya
atau
Jika data tersusun dalam daftar distribusi frekuensi, maka rata-rata harmonik
dinyatakan dengan:
Secara umum, untuk sekumpulan data berlaku H U X
2.24 Scatterplot
Scatterplot adalah sebuah grafik yang biasa digunakan untuk melihat suatu pola
hubungan antara 2 variabel. Jika Scatterplot membentuk pola yang menyerupai
garis lurus, maka mengindikasikan bahwa ada hubungan yang erat antara satu
variabel dengan variabel lain. Hubungan yang membentuk garis lurus biasa
disebut dengan hubungan linier. Hubungan linier dapat membentuk hubungan
yang positif dan negatif. Jika plotnya menyebar, maka bisa disimpulkan bahwa
hubungan antara satu variabel dengan variabel lain sangatlah kecil atau tidak ada
hubungan. Scatterplot juga bisa digunakan untuk melihat penyebaran data.
2.25 Metode Suksesif Interval
Metode suksesif interval merupakan proses mengubah data ordinal menjadi data
interval. Data ordinal diubah menjadi data interval dikarenakan data ordinal
sebenarnya adalah data kualitatif atau bukan angka sebenarnya. Data ordinal
menggunakan angka sebagai simbol data kualitatif.
Beberapa akibat yang dapat terjadi jika seorang peneliti memaksakan data
berskala ordinal dianalisis tanpa ditransformasi menjadi data berskala interval
adalah: Pelanggaran asumsi yang mendasari prosedur statistika yang digunakan,
hasil analisis yang menjadi tidak signifikan, kesimpulan yang dibuat dalam
penelitian dapat terbalik atau keliru.
Pengubahan data dengan skala pengukuran ordinal menjadi data dengan
skala pengukuran interval tergantung pada besarnya frekuensi dari data tersebut.
Karena frekuensi berpengaruh pada setiap perhitungan yang dilakukan di dalam
proses transformasi skala pengukuran ordinal menjadi interval. Terdapat tujuh
langkah dalam MSI, sebagai berikut:
Langkah 1 : Menghitung Frekuensi
Menghitung frekuensi dilakukan pada setiap poin-poin dalam variabel
dengan memakai turus, sehingga mempermudah dalam menentukan banyaknya
frekuensi dalam satu poin pertanyaan.
Langkah 2 : Menghitung Proporsi (P)
Proporsi merupakan perbandingan antara besarnya frekuensi dalam suatu
poin variabel dengan banyaknya data. Proporsi bisa ditunjukkan dalam bentuk
persen dan bisa juga tidak ditunjukkan dalam bentuk persen. Proporsi
memberikan informasi mengenai perbedaan antara setiap skor dalam suatu
variabel dibandingkan dengan banyak datanya. Perhitungan proporsi dapat
dilakukan dengan rumus berikut:
dengan = Proporsi pada skor-s
= Skor pada data dalam satu pertanyaan ( s: 1, 2, 3, 4, 5)
= Frekuensi skor-s
= Banyak data
Langkah 3 : Menghitung Proporsi Kumulatif (PK)
Proporsi kumulatif merupakan jumlah dari perbandingan frekuensi setiap
skor dalam suatu variabel dengan banyaknya data. Proporsi kumulatif juga bisa
ditunjukkan dalam bentuk persen maupun tidak. Proporsi kumulatif dari skor data
terendah sampai dengan skor data tertinggi, jika dijumlahkan haruslah bernilai
100% atau dapat juga bernilai 1.
dengan = Proporsi kumulatif untuk skor-s
= Proporsi kumulatif untuk skor-(s-1)
Langkah 4 : Mencari nilai Z
Nilai Z dicari dengan asumsi bahwa data yang digunakan berdistribusi
normal, kebanyakan dari fenomena yang terjadi dalam kehidupan sehari-hari
menggunakan distribusi normal. Untuk mengubah data ordinal menjadi data
interval perlu dilakukan standarisasi data untuk menemukan nilai pada data yang
sesuai dengan nilai dalam tabel Z. Dengan menggunakan distribusi normal,
penyajian data dapat lebih bermakna daripada hanya menggunakan penyajian
berkelompok saja, karena dengan adanya persyaratan normalitas data, maka data
dapat dilanjutkan penyajiannya dalam bentuk membedakan, mencari hubungan,
dan meramalkan.
Cara mencari nilai Z sebagai berikut:
Tentukan nilai proporsi pada tabel Z yang akan dihitung, jika nilai
ditentukan dengan mengurangkan nilai proporsi kumulatif dengan 0,5. Jika
nilai proporsi kumulatif lebih kecil dari 0,5, maka nilai proporsi pada tabel
Z ditentukan dengan mengurangkan 0,5 dengan proporsi kumulatif.
Temukan nilai Z pada tabel Z yang memiliki nilai proporsi sesuai dengan
nilai proporsi yang telah dihitung. Jika tidak ada, maka diambil 2 nilai Z
yang mendekati nilai Z yang sebenarnya, kemudian nilai Z dicari dengan
cara interpolasi.
Nilai Z hasil interpolasi dicari dengan cara sebagai berikut:
Kemudian, jika nilai proporsi kumulatif lebih besar dari 0,5, maka Z
bernilai positif, dan jika nilai proporsi kumulatif lebih kecil dari 0,5, maka
Z bernilai negatif.
Langkah 5 : Menghitung densitas F(Z)
F(Z) merupakan fungsi kepadatan untuk nilai Z.Jika Z adalah variabel
terstandarisasi yang sesuai dengan X, yaitu jika
Maka nilai mean atau nilai ekspektasi dari Z adalah 0 dan variansnya adalah 1.
Dalam kasus semacam ini fungsi kepadatan untuk Z dapat diperoleh dari
persamaan (2.9) dengan memasukkan dan , menghasilkan cara untuk
menghitung nilai densitas F(Z) adalah sebagai berikut:
√ ( )
dengan = nilai densitas-Z
= 2,718
Langkah 6 : Menghitung Scale Value
Data interval memiliki jarak tertentu antara masing-masing skor pada data. Scale
value dihitung untuk mengetahui jarak terkecil di antara semua skor yang ada
pada data. Kemudian jarak terkecil itu akan digunakan untuk menentukan jarak
yang akan ditambahkan dengan masing-masing scale value sebelumnya. Cara
untuk menghitung Scale Value adalah sebagai berikut:
dengan = Scale Value pada skor-s
untuk lebih memudahkan dalam perhitungan, maka dibuat tabel penolong
untuk nilai proporsi kumulatif dan nilai densitas F(Z).
Langkah 7 :Menghitung nilai hasil skala interval
Langkah terakhir dalam proses pengubahan data berskala ordinal menjadi data
berskala interval adalah dengan menghitung nilai hasil penskalaan. Nilai inilah
yang kemudian menjadi hasil transformasi data setelah penerapan MSI. Untuk
menghitung nilai hasil skala interval dilakukan langkah-langkah berikut ini:
Cari nilai SV minimum dengan rumus:
Nilai inilah yang akan dijadikan jarak patokan untuk ditambahkan dengan
nilai scale value masing-masing skor sehingga mendapatkan nilai skala interval.
Kemudian transformasi nilai skala ordinal menjadi interval dengan rumus: