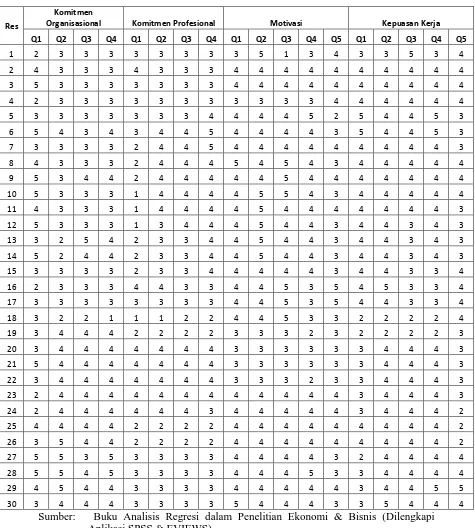
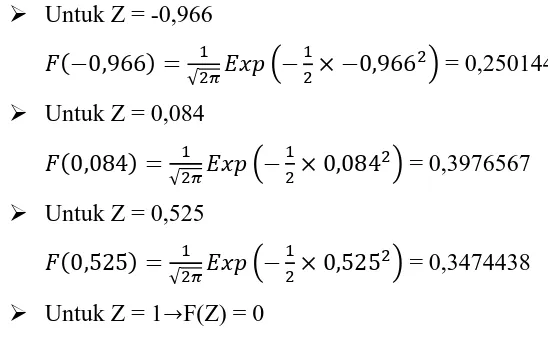Lampiran 1. Data pengaruh komitmen organisasional, komitmen profesional, dan motivasi terhadap kepuasan kerja
.
Res
Komitmen
Organisasional Komitmen Profesional Motivasi Kepuasan Kerja
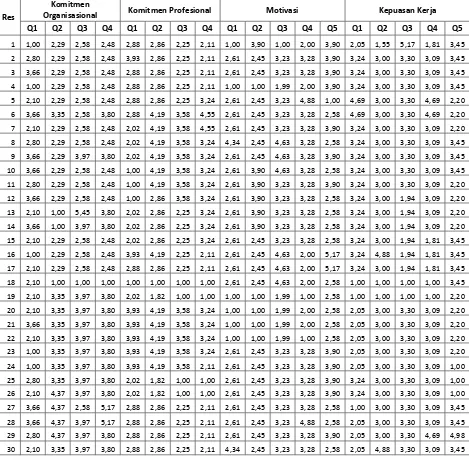
Lampiran 2. Hasil transformasi data interval.
Res
Komitmen
Organisasional Komitmen Profesional Motivasi Kepuasan Kerja
Lampiran 3. Output SPSS untuk deskriptif data ordinal dan data interval
Median 14.0000 12.0000 20.0000 18.0000
Mode 14.00 12.00 20.00 18.00
Std. Deviation 2.36254 2.54070 2.17324 2.19220
Variance 5.582 6.455 4.723 4.806
Median 12,1230 10,5220 15,4660 13,9355
Mode 9,45a 10,10 15,47 16,08
Std. Deviation 2,63720 2,92408 2,90589 2,55379
Variance 6.955 8.550 8.444 6.522
Lampiran 4. Output minitab untuk scatterplot data ordinal dan data interval.
Output minitab untuk scatterplot data ordinal
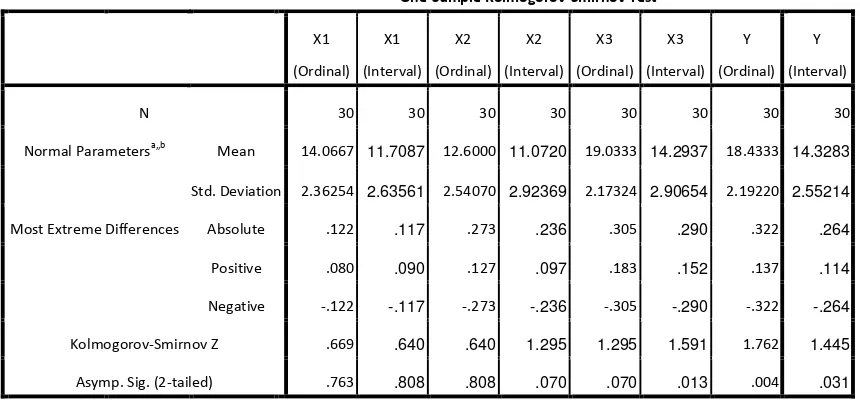
Lampiran 5. Output SPSS untuk pengujian distribusi normal data ordinal dan interval.
Output SPSS pengujian distribusi normal untuk data ordinal
One-Sample Kolmogorov-Smirnov Test
X1 X2 X3 Y
N 30 30 30 30
Normal Parametersa,,b Mean 14.0667 12.6000 19.0333 18.4333
Std. Deviation 2.36254 2.54070 2.17324 2.19220
Most Extreme Differences
Absolute .122 .273 .305 .322
Positive .080 .127 .183 .137
Negative -.122 -.273 -.305 -.322
Kolmogorov-Smirnov Z .669 1.497 1.671 1.762
Asymp. Sig. (2-tailed) .763 .023 .008 .004
a. Test distribution is Normal.
b. Calculated from data.
Output SPSS pengujian distribusi normal untuk data interval
One-Sample Kolmogorov-Smirnov Test
X1 X2 X3 Y
N 30 30 30 30
Normal Parametersa,,b Mean 11.7087 11.0720 14.2937 14.3283
Std. Deviation 2.63561 2.92369 2.90654 2.55214
Most Extreme Differences
Absolute .117 .236 .290 .264
Positive .090 .097 .152 .114
Negative -.117 -.236 -.290 -.264
Kolmogorov-Smirnov Z .640 1.295 1.591 1.445
Asymp. Sig. (2-tailed) .808 .070 .013 .031
a. Test distribution is Normal.
Lampiran 6. Output SPSS Uji t untuk Data Berskala Ordinal dan Data Berskala Interval
Output SPSS Uji t untuk data ordinal
Coefficientsa
Output SPSS Uji t untuk data interval
Lampiran 7. Output SPSS Uji Multikolinieritas untuk Data Berskala Ordinal dan Data Berskala Interval
Coefficients
Model
Collinearity Statistics (Ordinal) Collinearity Statistics (Interval)
Tolerance VIF Tolerance VIF
1 (Constant)
X1 .972 1.029 .970 1.031
X2 .967 1.034 .978 1.022
X3 .992 1.008 .981 1.019
a. Dependent Variable: Y
DAFTAR PUSTAKA
Alder, Hendry L. 1977. Introduction To Probability And Statistics. New York: W. H Freeman And Company
Basuki, Agus Tri. Prawoto, Nano. 2016. Analisis Regresi Dalam Penelitian
Ekonomi & Bisnis (Dilengkapi Aplikasi SPSS & EVIEWS). Edisi
Pertama. PT. RajaGrafindo Persada. Jakarta
Draper, N. R. Dan Smith, H. 1992. Analisis Regresi Terapan. Edisi Kedua. Bambang Sumantri. Jakarta: PT Gramedia Pustaka Utama.
Gio, Prana Ugiana dan Elly. 2015. Belajar Olah Data dengan SPSS, MINITAB, R,
Microsoft Excel. EVIEWS, LISREL, AMOS, dan, SMARTPLS. Medan:
USU Press
Gudono.2015. Analisis Data Multivariat. Edisi Keempat. BPFE Yogyakarta. Yogyakarta.
Hasan, M. Iqbal. 2008. Pokok-pokok Materi Statistik I (Statistik Deskriptif). Jakarta. Bumi Aksara.
Hyndman, Rob J. The Problem with Sturges’s Rule for Constructing Histograms.
A shorts notes (2). Unpublished Article.
Santoso, Singgih. 2003. Statistik Diskriptif: Konsep dan Aplikasi dengan
Microsoft Excel dan SPSS. Yogyakarta: Andi.
Sarwono, Jonathan. 2013. Statistika Multivariat Aplikasi Untuk Riset Dan Skripsi. Edisi Pertama. C.V Andi Offset (Penerbit Andi). Yogyakarta.
Spiegel, R. Murray. 2000. Probabilitas dan Statistik Edisi Kedua. Jakarta: Erlangga
Sturges, H. 1926. The Choice of A Class Interval. Journal American Statistical
Sudjana. 2005. Metoda Statistika. Edisi Keenam. Tarsito. Bandung.
Usman, Husaini dan Akbar, R. Purnomo Setiady. 2006. Pengantar Statistika. Jakarta: PT Bumi Aksara
BAB 3
HASIL DAN PEMBAHASAN
3.1 Metode Suksesif Interval
Metode suksesif interval merupakan proses mengubah data ordinal menjadi data interval. Data ordinal diubah menjadi data interval dikarenakan data ordinal sebenarnya adalah data kualitatif atau bukan angka sebenarnya. Data ordinal menggunakan angka sebagai simbol data kualitatif.
Pada bab ini dibahas proses perhitungan manual metode suksesif interval dan juga hasil transformasi dengan menggunakan microsoft excel.
3.2 Statistika Deskriptif
Statistika deskriptif merupakan suatu proses statistika dimana hanya berusaha melukiskan atau mengalisa kelompok yang diberikan tanpa membuat atau menarik kesimpulan tentang populasi atau kelompok yang lebih besar. Dengan kata lain, statistika deskriptif hanya digunakan untuk menunjukkan kondisi suatu data dan tidak dapat digunakan untuk menunjukkan kondisi data lain ataupun kondisi data yang lebih besar.
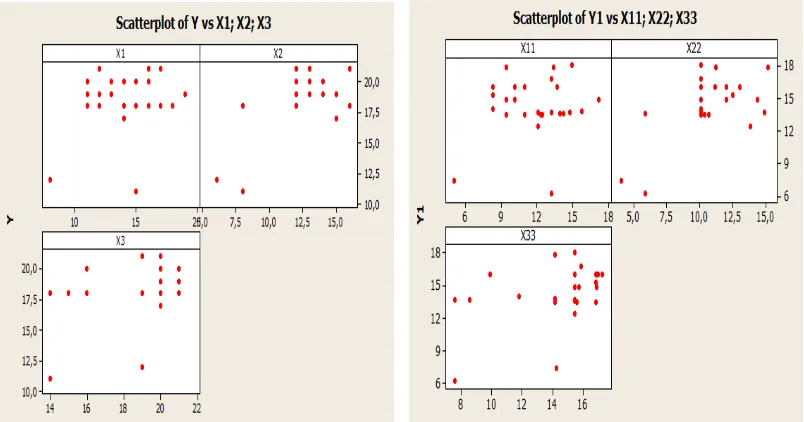
3.3 Scatterplot
Scatterplot digunakan untuk melihat pola penyebaran data apakah membentuk
suatu pola tertentu atau tidak. Pola data yang menyebar tidak beraturan menandakan bahwa tidak ada hubungan yang kuat antara variabel bebas.
3.4 Contoh Ilustrasi
pertanyaan yang terdiri dari “Sangat Setuju” = 5, “Setuju” = 4, “Netral” = 3, “Tidak Setuju” = 2, “Sangat Tidak Setuju” = 1. Data ini untuk menilai pengaruh
komitmen organisasional, komitmen profesional, dan motivasi terhadap kepuasan kerja.
Tabel 3.1 Data pengaruh komitmen organisasional, komitmen profesional, dan motivasi terhadap kepuasan kerja
Res
Komitmen
Organisasional Komitmen Profesional Motivasi Kepuasan Kerja
Berikut perhitungan manual metode suksesif interval untuk data Q1 pada X1:
Langkah 1 : Menghitung Frekuensi
Skor jawaban pada Q1, untuk skor 2, frekuensinya adalah sebanyak 5 data, untuk skor 3, frekuensinya adalah sebanyak 11 data, untuk skor 4, frekuensinya adalah sebanyak 5 data, untuk skor 5, frekuensinya adalah sebanyak 9 data.
Langkah 2 : Menghitung Proporsi (P)
dengan = Proporsi pada skor-s
= Skor pada data dalam satu pertanyaan (s: 1,2,3,4,5)
= Frekuensi skor-s
= Banyak data
Karena pada Q1 tidak terdapat skor 1, dan skornya adalah 2, 3, 4, dan 5, maka proporsi yang dihitung juga proporsi untuk skor 2, 3, 4, dan 5.
Langkah 3 : Menghitung Proporsi Kumulatif (PK)
dengan = Proporsi kumulatif untuk skor-s
= Proporsi kumulatif untuk skor-(s-1)
Cara mencari nilai Z sebagai berikut:
Tentukan nilai proporsi pada tabel Z yang akan dihitung, jika nilai proporsi kumulatif lebih besar dari 0,5, maka nilai proporsi pada tabel Z ditentukan dengan mengurangkan nilai proporsi kumulatif dengan 0,5. Jika nilai proporsi kumulatif lebih kecil dari 0,5, maka nilai proporsi pada tabel Z ditentukan dengan mengurangkan 0,5 dengan proporsi kumulatif.
Temukan nilai Z pada tabel Z yang memiliki nilai proporsi sesuai dengan
nilai proporsi yang telah dihitung. Jika tidak ada, maka diambil 2 nilai Z yang mendekati nilai Z yang sebenarnya, kemudian nilai Z dicari dengan cara interpolasi.
Nilai Z hasil interpolasi dicari dengan cara sebagai berikut:
nilai proporsi pada tabel Z yang akan dihitung adalah . Nilai proporsi pada tabel Z yang mendekati 0,0334 adalah pada Z = 0,08 dan Z = 0,09 yang masing-masing memiliki nilai proporsi sebesar 0,0319 dan 0,0359. Maka nilai Z dicari dengan cara interpolasi.
nilai proporsi sebesar 0,1985 dan 0,2019. Maka nilai Z dicari dengan cara interpolasi.
Langkah 5 : Menghitung densitas F(Z)
Cara untuk menghitung nilai densitas F(Z) adalah sebagai berikut:
√ ( )
dengan = nilai densitas-Z
= 3,14
Untuk Z = -0,966
√ = 0,250144
Untuk Z = 0,084
√ = 0,3976567
Untuk Z = 0,525
√ = 0,3474438
Untuk Z = 1 F(Z) = 0
Langkah 6 : Menghitung Scale Value
Cara untuk menghitung Scale Value adalah sebagai berikut:
dengan = Scale Value pada skor-s
untuk lebih memudahkan dalam perhitungan, maka dibuat tabel penolong untuk nilai proporsi kumulatif dan nilai densitas F(Z).
Tabel 3.2 nilai proporsi kumulatif dan nilai densitas F(Z)
Proporsi Kumulatif Densitas F(Z)
0,1667 0,250144
0,5334 0,3976567
0,7001 0,3474438
1 0
Langkah 7 :Menghitung nilai hasil skala interval
Untuk menghitung nilai hasil skala interval dilakukan langkah-langkah berikut ini:
Cari nilai SV minimum dengan rumus:
Kemudian transformasi nilai skala ordinal menjadi interval dengan rumus:
dengan = nilai skala interval hasil transformasi
Dari hasil perhitungan manual diperoleh nilai skala interval untuk skor 2 adalah 1, nilai skala interval untuk skor 3 adalah 2,098, nilai skala interval untuk skor 4 adalah 2,802, dan nilai skala interval untuk skor 5 adalah 3,6591.
Tabel 3.3 Hasil transformasi data interval
Res
Komitmen
Organisasional Komitmen Profesional Motivasi Kepuasan Kerja Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q5 Q1 Q2 Q3 Q4 Q5
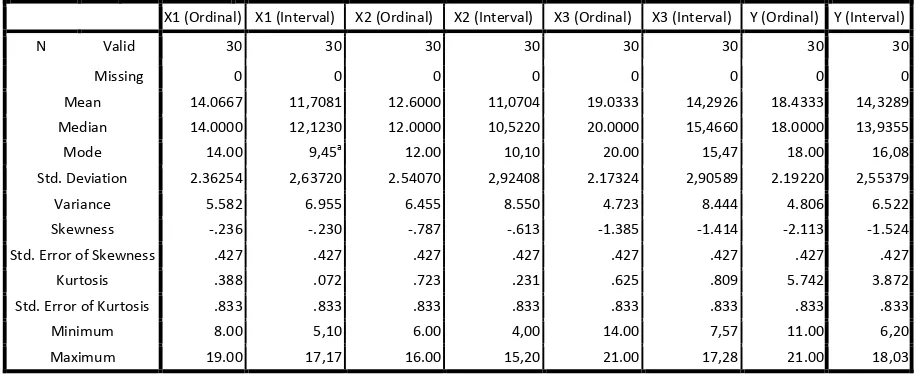
Tabel 3.4 Hasil statistika deskriptif untuk data ordinal dan data interval dengan menggunakan SPSS
Statistics
X1 (Ordinal) X1 (Interval) X2 (Ordinal) X2 (Interval) X3 (Ordinal) X3 (Interval) Y (Ordinal) Y (Interval)
N Valid 30 30 30 30 30 30 30 30
Missing 0 0 0 0 0 0 0 0
Mean 14.0667 11,7081 12.6000 11,0704 19.0333 14,2926 18.4333 14,3289
Median 14.0000 12,1230 12.0000 10,5220 20.0000 15,4660 18.0000 13,9355
Mode 14.00 9,45a 12.00 10,10 20.00 15,47 18.00 16,08
Std. Deviation 2.36254 2,63720 2.54070 2,92408 2.17324 2,90589 2.19220 2,55379
Variance 5.582 6.955 6.455 8.550 4.723 8.444 4.806 6.522
Berdasarkan tabel 3.4 dapat dilihat bahwa nilai Mean, Median, dan Modus hampir sama, yang berarti, distribusi data untuk variabel komitmen organisasional, komitmen profesional, motivasi, dan kepuasan kerja mendekati distribusi normal. Standar deviasi dari variabel komitmen organisasional adalah 2,36254, standar deviasi dari variabel komitmen profesional adalah 2,54070, standar deviasi dari variabel motivasi adalah 2,17324, standar deviasi dari variabel kepuasan kerja adalah 2,19220. Varians dari variabel komitmen organisasional adalah 5,582, varians dari variabel komitmen profesional adalah 6,455, varians dari variabel motivasi adalah 4,723, varians dari variabel kepuasan kerja adalah 4,806. Nilai-nilai ini lebih kecil daripada nilai standar deviasi dan nilai varians pada tabel 3.5 yang berarti data nilai standar deviasi dan nilai varians pada tabel 3.4 lebih baik daripada pada tabel 3.5.
profesional adalah 0,723, kurtosis dari variabel motivasi adalah 0,625, kurtosis dari variabel kepuasan kerja adalah 5,742. Nilai- nilai kurtosis pada tabel 3.4 lebih mendekati 0,263 ( kriteria pengujian distribusi normal berdasarkan nilai kurtosis) dibandingkan dengan nilai-nilai kurtosis pada tabel 3.5, yang berarti, data ordinal lebih mendekati distribusi normal dibandingkan data interval.
Berdasarkan tabel 3.4 juga dapat dilihat bahwa nilai Mean, Median, dan Modus dari data interval cukup jauh berbeda, yang berarti data interval hasil penerapan MSI tidak mendekati distribusi normal. Pada variabel komitmen organisasional juga terdapat lebih dari 1 modus, hal ini menyalahi kriteria distribusi normal yang menganjurkan data hanya memiliki satu buah modus. Standar deviasi dari variabel komitmen organisasional adalah 2,63720, standar deviasi dari variabel komitmen profesional adalah 2,92408, standar deviasi dari variabel motivasi adalah 2,90589, standar deviasi dari variabel kepuasan kerja adalah 2,55379. Varians dari variabel komitmen organisasional adalah 6,955, varians dari variabel komitmen profesional adalah 8,550 , varians dari variabel motivasi adalah 8,444, varians dari variabel kepuasan kerja adalah 6,522. Nilai-nilai tersebut lebih besar daripada Nilai-nilai-Nilai-nilai pada tabel 3.4 yang berarti data ordinal lebih baik daripada data interval hasil penerapan MSI.
Gambar 3.1 Perbandingan scatterplot antara data berskala ordinal dengan data berskala interval menggunakan software minitab
Tabel 3.5 Pengujian Distribusi Normal data ordinal dan data interval
Normal Parametersa,,b Mean 14.0667 11.7087 12.6000 11.0720 19.0333 14.2937 18.4333 14.3283
Std. Deviation 2.36254 2.63561 2.54070 2.92369 2.17324 2.90654 2.19220 2.55214
Most Extreme Differences Absolute .122 .117 .273 .236 .305 .290 .322 .264
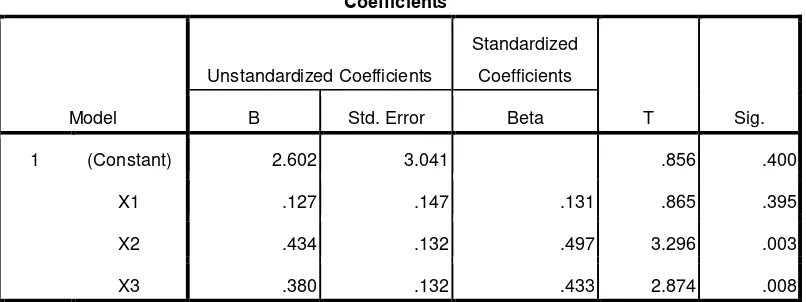
Tabel 3.6 Output SPSS Uji t untuk data ordinal
Persamaan regresi untuk data ordinal adalah sebagai berikut:
Berdasarkan output uji t untuk data ordinal diketahui bahwa terdapat dua variabel bebas yang berpengaruh signifikan terhadap variabel terikat, yaitu variabel X2 dan X3 yang masing-masing merupakan Komitmen Profesional dan Motivasi.
Tabel 3.7 Output SPSS Uji t untuk data interval
Coefficientsa
Berdasarkan output uji t untuk data interval dapat diketahui bahwa hanya terdapat satu variabel bebas yang berpengaruh signifikan terhadap variabel terikat yaitu variabel X2 sebagai Komitmen Profesional.
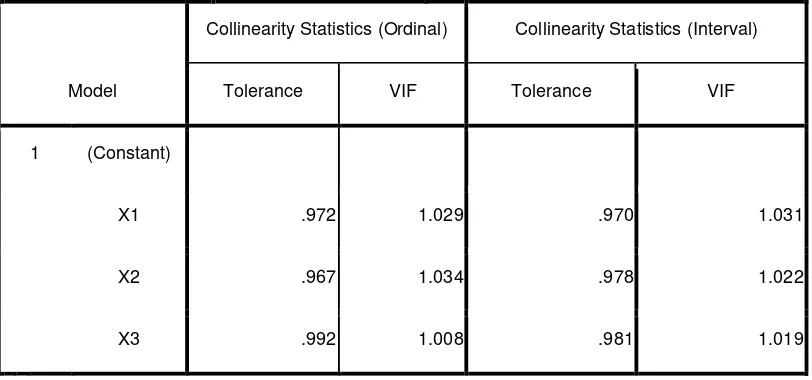
Tabel 3.8 Output SPSS untuk Uji Multikolinieritas pada data berskala ordinal dan skala interval
Coefficients
Model
Collinearity Statistics (Ordinal) Collinearity Statistics (Interval)
Tolerance VIF Tolerance VIF
1 (Constant)
X1 .972 1.029 .970 1.031
X2 .967 1.034 .978 1.022
X3 .992 1.008 .981 1.019
a. Dependent Variable: Y
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Metode Suksesif Interval digunakan untuk mengubah data ordinal menjadi data interval agar data tersebut dapat digunakan untuk pengujian statistika yang mengharuskan data berskala interval. Pengubahan data ordinal itu akan menghasilkan data baru yang memiliki tingkatan dan dapat digunakan dalam perhitungan matematis baik perkalian, pembagian, pengurangan, dan sebagainya.
Berdasarkan hasil penelitian, setelah dibandingkan menurut data, statistika deskriptif, dan scatterplot-nya, data ordinal dengan data interval setelah diterapkan MSI tidak begitu berbeda. Tetapi setelah dibandingkan menurut distribusinya, diketahui bahwa data dengan skala ordinal hanya memiliki satu variabel yang berdistribusi normal, tetapi setelah dilakukan transformasi ke bentuk skala interval dengan MSI, terdapat dua variabel yang berdistribusi normal. Secara keseluruhan, nilai hasil pengujian distribusi normal pada data berskala interval lebih tinggi dibandingkan data berskala ordinal.
Oleh karena itu, dapat disimpulkan bahwa dengan melakukan transformasi data dari skala ordinal menjadi skala interval dengan Metode Suksesif Interval (MSI) berpengaruh pada peningkatan nilai distribusi, sehingga dapat menjadikan data yang awalnya tidak berdistribusi normal menjadi berdistribusi normal dikarenakan di dalam proses transformasi dengan Metode Suksesif Interval dilakukan perhitungan nilai Z dan nilai kepadatan F(Z).
4.2 Saran
BAB 2
TINJAUAN PUSTAKA
2.1 Data
Data adalah bentuk jamak dari datum, yang dapat diartikan sebagai informasi yang diterima yang bentuknya dapat berupa angka, kata-kata, atau dalam bentuk lisan dan tulisan lainnya. Ada beberapa cara yang dapat dilakukan dalam memperoleh data, diantaranya data yang diperoleh secara langsung (primer), dan data yang diperoleh secara tidak langsung (sekunder). Koleksi data merupakan tahapan yang paling penting dalam pelaksanaan penelitian, karena hanya dengan mendapatkan data yang tepat maka proses penelitian akan berlangsung dengan baik.
2.2 Data Acak Atau Data Tunggal
Data acak atau tunggal adalah data yang belum tersusun atau dikelompokkan ke dalam kelas-kelas interval.
2.3 Data Berkelompok
2.4 Data Diskrit
Data diskrit, data kategorik, atau data nominal. Data ini merupakan hasil perhitungan, sehingga tidak dijumpai bilangan pecahan. Data diskrit adalah data yang paling sederhana yang disusun menurut jenisnya atau kategorinya.
2.5 Data Kontinu
Data kontinu terdiri atas tiga macam data yaitu: data ordinal, data interval, dan data rasio. Data ordinal adalah data yang sudah diurutkan dari jenjang yang paling rendah sampai ke jenjang yang paling tinggi, atau sebaliknya tergantung peringkat. Data interval mempunyai sifat-sifat nominal dari data ordinal, dan sifat tambahan lainnya yaitu mempunyai nol mutlak, akibatnya terdapat skala interval yang sama jaraknya. Data rasio mengandung sifat-sifat interval, dan selain itu sudah mempunyai nilai nol mutlak.
2.6 Skala Pengukuran Data
Skala pengukuran data merupakan prosedur pemberian angka pada suatu objek agar dapat menyatakan karakteristik dari objek tersebut. Ada empat tipe skala pengukuran data dalam penelitian, yaitu nominal, ordinal, interval, dan rasio.
2.7 Skala Nominal
Skala nominal adalah suatu skala yang diberikan pada suatu objek atau kategori yang tidak menggambarkan kedudukan objek atau kategori tersebut terhadap objek atau kategori lainnya, tetapi hanya sekedar label atau kode saja. Skala ini hanya mengelompokkan objek atau kategori ke dalam kelompok tertentu.
sebagai simbol. Skala pengukuran data nominal digunakan dalam statistika nonparametrik. Hasil analisis dipresentasikan dalam bentuk persentase. Sebagai contoh, dalam mengklasifikasikan variabel jenis kelamin menjadi seperti berikut: laki-laki diberikan simbol angka 1 dan wanita diberikan simbol angka 2. Operasi aritmetika tidak dapat dilakukan dengan angka tersebut karena angka-angka tersebut hanya menunjukkan keberadaan atau ketiadaan karakteristik tertentu.
2.8 Skala Ordinal
Skala pengukuran ordinal merupakan skala pengukuran yang memberikan informasi tentang jumlah relatif karakteristik yang berbeda yang dimiliki oleh objek atau individu tertentu. Tingkat pengukuran ini mempunyai informasi skala nominal yang ditambah dengan sarana peringkat relatif tertentu yang memberikan informasi apakah suatu objek memiliki karakteristik yang lebih atau kurang, tetapi bukan berapa banyak kekurangan dan kelebihannya. Dalam skala ordinal tidak dapat dilakukan operasi aritmetika, seperti menjumlah, mengurangi, mengalikan, membagi, dan merata-ratakan angka-angka tersebut, karena angka-angka tersebut hanya menunjukkan keberadaan atau ketiadaan karakteristik tertentu.
Sebagai contoh, jawaban dari suatu pertanyaan berupa peringkat, misalnya sangat tidak setuju, tidak setuju, netral, setuju, dan sangat setuju, dapat diberi simbol angka 1, 2, 3, 4, dan 5. Angka-angka tersebut hanya merupakan simbol
peringkat, tidak mengekspresikan jumlah. Misalnya dalam pertanyaan “Apakah saudara setuju dengan kenaikan tarif tiket pesawat terbang?”. Jawaban: a. sangat
tidak setuju, b. tidak setuju, c. ragu-ragu, d. setuju, e. setuju sekali. Jika menggunakan skala ordinal, “sangat tidak setuju” diberi nilai 1, “tidak setuju”
2.9 Skala Interval
Skala interval memiliki karakteristik yang sama seperti yang dimiliki oleh skala nominal dan ordinal dengan ditambah karakteristik lain, yaitu interval yang tetap. Dengan demikian, seorang peneliti dapat melihat besarnya perbedaan karakteristik antara satu individu atau objek dengan yang lainnya. Skala pengukuran interval benar-benar merupakan angka sehingga operasi aritmetika, misalnya penjumlahan atau perkalian dapat dilakukan. Untuk melakukan analisis, skala pengukuran interval menggunakan statistika parametrik.
Sebagai contoh, jawaban tentang frekuensi dalam pertanyaan “Berapa kali
Anda berbelanja di Supermarket X dalam satu bulan?” adalah 1 kali, 3 kali, dan 5
kali. Angka-angka 1, 3, dan 5 merupakan angka sebenarnya yang menggunakan interval 2. Jika menggunakan interval 1, jawabannya menjadi 1 kali, 2 kali, 3 kali, atau 4 kali.
2.10 Skala Rasio
Skala pengukuran rasio memiliki semua karakteristik yang dimiliki oleh skala nominal, ordinal, dan interval dengan kelebihan bahwa skala ini memiliki nilai 0 (nol) empiris absolut. Nilai absolut nol tersebut terjadi ketika suatu karakteristik yang sedang diukur tidak ada. Pengukuran rasio biasanya berbentuk perbandingan antara satu individu atau objek tertentu dengan yang lainnya.
Sebagai contoh berat Rinso 3 gram, sedangkan berat Soklin 6 gram. Maka, berat Rinso dibanding dengan berat Soklin sama dengan 1 dibanding 2. Dalam
pertanyaan “Berapa berat badan Anda sebelum dan sesudah makan obat diet?”,
jawabannya berupa angka sebenarnya, yaitu berat sebelum minum obat 70 kg dan berat sesudah minum obat 60 kg.
2.11 Statistika Deskriptif
Statistika deskriptif merupakan suatu proses statistika dimana hanya berusaha melukiskan atau mengalisa kelompok yang diberikan tanpa membuat atau menarik kesimpulan tentang populasi atau kelompok yang lebih besar. Dengan kata lain, statistika deskriptif hanya digunakan untuk menunjukkan kondisi suatu data dan tidak dapat digunakan untuk menunjukkan kondisi data lain ataupun kondisi data yang lebih besar.
Di dalam statistika deskriptif, terdapat beberapa rposedur pengujian statistika yang digunakan untuk menunjukkan kondisi suatu data, seperti rata-rata atau mean, median, modus, standar deviasi, varians, kemiringan, kurtosis, nilai minimum dan nilai maksimum.
2.12 Rata- Rata atau Rata-Rata Hitung
Rata-rata, atau lengkapnya rata-rata hitung, untuk data kuantitatif yang terdapat dalam sebuah sampel dihitung dengan cara membagi jumlah nilai data oleh
Untuk data yang telah dikelompokkan dalam tabel distribusi frekuensi, maka rata-ratanya adalah:
̅ ∑
Dengan = frekuensi pada kelas ke-k
2.13 Modus
Untuk menyatakan fenomena yang paling banyak terjadi atau paling banyak terdapat digunakan ukuran modus atau disingkat Mo. Ukuran ini juga dalam
keadaan tidak disadari sering dipakai untuk menentukan “rata-rata” data kualitatif.
Sebagai contoh, jika terdapat suatu pernyataan “kebanyakan kematian di Indonesia disebabkan oleh penyakit malaria”, “pada umumnya kecelakaan lalu
lintas karena kecerobohan pengemudi”, maka pernyataan-pernyataan tersebut merupakan modus penyebab kematian di Indonesia dan modus kecelakaan lalu lintas.
Modus untuk data kuantitatif ditentukan dengan cara menentukan frekuensi terbanyak di dalam data kuantitatif tersebut. Jika data kuantitatif telah disusun di dalam daftar distribusi frekuensi, maka modusnya dapat ditentukan dengan rumus:
( )
dengan = batas bawah kelas modal, ialah kelas interval dengan frekuensi terbanyak,
= panjang kelas,
= frekuensi kelas modal dikurangi frekuensi kelas interval dengan tanda kelas yang lebih kecil sebelum tanda kelas modal,
= frekuensi kelas modal dikurangi frekuensi kelas interval dengan tanda kelas yang lebih besar sesudah tanda kelas modal.
2.14 Median
data paling tengah. Untuk sampel berukuran genap, setelah data disusun menurut urutan nilainya, maka mediannya sama dengan rata-rata hitung dua data tengah.
Untuk data yang telah disusun dalam daftar distribusi frekuensi, mediannya dihitung dengan rumus:
Deviasi standar adalah ukuran penyimpangan terhadap nilai rata-ratanya, nilai simpangan baku merupakan harga akar positif dari selisih item data dengan nilai rata-rata yang dibagi oleh jumlah data.
rata-Untuk data yang sudah dikelompokkan, formula deviasi standar atau simpangan baku sampel adalah sebagai berikut:
√∑ ̅ 2.5
dengan:
= simpangan baku
= banyak data
̅ = rata-rata sampel
= frekuensi kelas ke-i
= nilai tengah dari kelas ke-i , i = 1, 2, …, k
2.16 Varians
Varians adalah rata-rata hitung dari kuadrat simpangan setiap pengamatan terhadap rata-rata hitungnya. Untuk data yang tidak dikelompokkan, varians sampel adalah sebagai berikut:
∑ ̅
2.6
dengan:
= varians
= banyak data
̅ = rata-rata sampel
Untuk data yang sudah dikelompokkan, varians populasi adalah sebagai berikut:
Distribusi normal termasuk ke dalam salah satu distribusi probabilitas nondiskrit atau kontinu. Dalam distribusi normal, variabel acak dinyatakan dalam interval dan bersifat tidak dapat dihitung (uncountable). Sebagai contoh variabel acak X dinyatakan dalam interval dengan . Beberapa fenomena dalam kehidupan mendekati kurva dari distribusi normal, contohnya adalah fenomena mengenai nilai IQ manusia, tinggi badan, berat badan, dan sebagainya.
Dengan menggunakan distribusi normal, penyajian data dapat lebih bermakna daripada hanya menggunakan penyajian berkelompok saja, karena dengan adanya persyaratan normalitas data, maka data dapat dilanjutkan penyajiannya dalam bentuk membedakan, mencari hubungan, dan meramalkan.
Distribusi normal atau kurva normal disebut juga dengan distribusi Gauss, karena persamaan matematisnya ditemukan oleh Gauss. Fungsi kepadatan untuk distribusi ini ditentukan oleh:
√
dengan:
= parameter yang merupakan rata-rata distribusi
= parameter yang merupakan simpangan baku distribusi
Jika Z adalah variabel terstandarisasi yang sesuai dengan X, yaitu jika
Maka nilai mean atau nilai ekspektasi dari Z adalah 0 dan variansnya adalah 1. Dalam kasus semacam ini fungsi kepadatan untuk Z dapat diperoleh dari
persamaan (2.9) dengan memasukkan dan , menghasilkan
√ 2.9
Fungsi ini sering dinyatakan sebagai fungsi kepadatan normal standar. Grafik dari fungsi kepadatan (2.9), disebut kurva normal standar, seperti tampak pada Gambar 2.1 f(x)
Gambar 2.1 Kurva Normal Standar
2.18 Kemiringan
Dikatakan suatu model merupakan model positif jika kemiringan bernilai positif, model negatif jika kemiringan bernilai negatif, dan simetrik jika kemiringan sama dengan nol.
2.19 Kuartil
Jika sekumpulan data dibagi menjadi empat bagian yang sama banyak, sesudah disusun menurut urutan nilainya, maka bilangan pembaginya disebut kuartil. Terdapat tiga macam kuartil, yaitu kuartil pertama, kuartil kedua, dan kuartil
ketiga yang masing-masing disingkat dengan dan . Pemberian nama ini
dimulai dari nilai kuartil paling kecil. Untuk menentukan nilai kuartil caranya adalah:
1) Susun data menurut urutan nilainya dari yang terkecil sampai terbesar. 2) Tentukan letak kuartil.
3) Tentukan nilai kuartil
Letak kuartil ke-i, diberi lambang , ditentukan oleh rumus:
dengan = 1, 2, 3
= Banyak data
2.20 Persentil
Sekumpulan data yang dibagi menjadi 100 bagian yang sama akan menghasilkan 99 pembagi yang berturut-turut dinamakan persentil pertama, persentil kedua, . . ., persentil ke-99. Simbol yang digunakan berturut-turut adalah . . ., .
dengan = 1, 2, . . ., 99.
= Banyak data. 2.21 Kurtosis
Tinggi rendahnya atau runcing datarnya bentuk kurva disebut kurtosis. Kurva distribusi normal, yang tidak terlalu runcing atau tidak terlalu datar, dinamakan mesokurtik. Kurva yang runcing dinamakan leptokurtik, sedangkan kurva yang datar disebut platikurtik.
Salah satu ukuran kurtosis adalah koefisien kurtosis yang diberi simbol , ditentukan oleh rumus:
⁄
dengan = Kuartil pertama
= Kuartil ketiga
= Persentil kesepuluh = Persentil kesembilanpuluh
Untuk distribusi normal, nilai = 0,263.
Berikut ini merupakan gambar kurva yang berbentuk leptokurtik, platikurtik, dan mesokurtik.
2.22 Rata-Rata Ukur
Jika perbandingan tiap data berurutan tetap atau hampir tetap, rata-rata ukur lebih baik digunakan daripada rata-rata hitung. Untuk bilangan-bilangan bernilai besar, rata-rata ukur dapat ditentukan dengan rumus:
n x
U
log ilog (2.14)
atau
Jika data tersusun dalam daftar distribusi frekuensi, maka rata-rata harmonik dinyatakan dengan:
Secara umum, untuk sekumpulan data berlaku H U X
2.24 Scatterplot
Scatterplot adalah sebuah grafik yang biasa digunakan untuk melihat suatu pola
2.25 Metode Suksesif Interval
Metode suksesif interval merupakan proses mengubah data ordinal menjadi data interval. Data ordinal diubah menjadi data interval dikarenakan data ordinal sebenarnya adalah data kualitatif atau bukan angka sebenarnya. Data ordinal menggunakan angka sebagai simbol data kualitatif.
Beberapa akibat yang dapat terjadi jika seorang peneliti memaksakan data berskala ordinal dianalisis tanpa ditransformasi menjadi data berskala interval adalah: Pelanggaran asumsi yang mendasari prosedur statistika yang digunakan, hasil analisis yang menjadi tidak signifikan, kesimpulan yang dibuat dalam penelitian dapat terbalik atau keliru.
Pengubahan data dengan skala pengukuran ordinal menjadi data dengan skala pengukuran interval tergantung pada besarnya frekuensi dari data tersebut. Karena frekuensi berpengaruh pada setiap perhitungan yang dilakukan di dalam proses transformasi skala pengukuran ordinal menjadi interval. Terdapat tujuh langkah dalam MSI, sebagai berikut:
Langkah 1 : Menghitung Frekuensi
Menghitung frekuensi dilakukan pada setiap poin-poin dalam variabel dengan memakai turus, sehingga mempermudah dalam menentukan banyaknya frekuensi dalam satu poin pertanyaan.
Langkah 2 : Menghitung Proporsi (P)
Proporsi merupakan perbandingan antara besarnya frekuensi dalam suatu poin variabel dengan banyaknya data. Proporsi bisa ditunjukkan dalam bentuk persen dan bisa juga tidak ditunjukkan dalam bentuk persen. Proporsi memberikan informasi mengenai perbedaan antara setiap skor dalam suatu variabel dibandingkan dengan banyak datanya. Perhitungan proporsi dapat dilakukan dengan rumus berikut:
dengan = Proporsi pada skor-s
= Skor pada data dalam satu pertanyaan ( s: 1, 2, 3, 4, 5)
= Frekuensi skor-s
= Banyak data
Langkah 3 : Menghitung Proporsi Kumulatif (PK)
Proporsi kumulatif merupakan jumlah dari perbandingan frekuensi setiap skor dalam suatu variabel dengan banyaknya data. Proporsi kumulatif juga bisa ditunjukkan dalam bentuk persen maupun tidak. Proporsi kumulatif dari skor data terendah sampai dengan skor data tertinggi, jika dijumlahkan haruslah bernilai 100% atau dapat juga bernilai 1. normal, kebanyakan dari fenomena yang terjadi dalam kehidupan sehari-hari menggunakan distribusi normal. Untuk mengubah data ordinal menjadi data interval perlu dilakukan standarisasi data untuk menemukan nilai pada data yang sesuai dengan nilai dalam tabel Z. Dengan menggunakan distribusi normal, penyajian data dapat lebih bermakna daripada hanya menggunakan penyajian berkelompok saja, karena dengan adanya persyaratan normalitas data, maka data dapat dilanjutkan penyajiannya dalam bentuk membedakan, mencari hubungan, dan meramalkan.
Cara mencari nilai Z sebagai berikut:
ditentukan dengan mengurangkan nilai proporsi kumulatif dengan 0,5. Jika nilai proporsi kumulatif lebih kecil dari 0,5, maka nilai proporsi pada tabel Z ditentukan dengan mengurangkan 0,5 dengan proporsi kumulatif.
Temukan nilai Z pada tabel Z yang memiliki nilai proporsi sesuai dengan
nilai proporsi yang telah dihitung. Jika tidak ada, maka diambil 2 nilai Z yang mendekati nilai Z yang sebenarnya, kemudian nilai Z dicari dengan cara interpolasi.
Nilai Z hasil interpolasi dicari dengan cara sebagai berikut:
Kemudian, jika nilai proporsi kumulatif lebih besar dari 0,5, maka Z bernilai positif, dan jika nilai proporsi kumulatif lebih kecil dari 0,5, maka Z bernilai negatif.
Langkah 5 : Menghitung densitas F(Z)
F(Z) merupakan fungsi kepadatan untuk nilai Z.Jika Z adalah variabel terstandarisasi yang sesuai dengan X, yaitu jika
Maka nilai mean atau nilai ekspektasi dari Z adalah 0 dan variansnya adalah 1. Dalam kasus semacam ini fungsi kepadatan untuk Z dapat diperoleh dari
persamaan (2.9) dengan memasukkan dan , menghasilkan cara untuk
menghitung nilai densitas F(Z) adalah sebagai berikut:
√ ( )
dengan = nilai densitas-Z
= 2,718
Langkah 6 : Menghitung Scale Value
Data interval memiliki jarak tertentu antara masing-masing skor pada data. Scale
value dihitung untuk mengetahui jarak terkecil di antara semua skor yang ada
pada data. Kemudian jarak terkecil itu akan digunakan untuk menentukan jarak yang akan ditambahkan dengan masing-masing scale value sebelumnya. Cara untuk menghitung Scale Value adalah sebagai berikut:
dengan = Scale Value pada skor-s
untuk lebih memudahkan dalam perhitungan, maka dibuat tabel penolong untuk nilai proporsi kumulatif dan nilai densitas F(Z).
Langkah 7 :Menghitung nilai hasil skala interval
Langkah terakhir dalam proses pengubahan data berskala ordinal menjadi data berskala interval adalah dengan menghitung nilai hasil penskalaan. Nilai inilah yang kemudian menjadi hasil transformasi data setelah penerapan MSI. Untuk menghitung nilai hasil skala interval dilakukan langkah-langkah berikut ini:
Cari nilai SV minimum dengan rumus:
Nilai inilah yang akan dijadikan jarak patokan untuk ditambahkan dengan nilai scale value masing-masing skor sehingga mendapatkan nilai skala interval.
Kemudian transformasi nilai skala ordinal menjadi interval dengan rumus:
BAB 1
PENDAHULUAN
1.1Latar Belakang
Statistika merupakan salah satu ilmu pengetahuan yang dapat membantu memberikan informasi berdasarkan data sehingga memudahkan seseorang dalam mengambil keputusan. Terdapat beberapa jenis skala pengukuran data yan digunakan dalam penelitian statistika seperti skala ordinal dan interval. Jenis data yang digunakan dalam penelitian dapat memengaruhi kesimpulan dari penelitian itu sendiri yang mengakibatkan peneliti harus mengubah jenis data sesuai dengan kebutuhan penelitian.
Dalam mengubah data ordinal menjadi data interval dapat digunakan sebuah metode yang disebut Metode Suksesif Interval (MSI). Dalam beberapa penelitian terdahulu, diketahui bahwa terdapat beberapa akibat yang terjadi jika data dengan skala pengukuran ordinal tidak diubah menjadi skala interval, yaitu pelanggaran asumsi dari prosedur statistika yang digunakan dalam penelitian, terjadi kekeliruan dalam pembuatan kesimpulan, atau terdapat hasil yang tidak signifikan. Tetapi, tidak jarang peneliti membiarkan saja data ordinal digunakan dalam penelitian yang menyaratkan data berbentuk interval karena menganggap bahwa tidak terdapat perbedaan yang terlalu besar di antara data berbentuk ordinal dengan data berbentuk interval. Karena itu, penulis merasa perlu untuk membuat penelitian mengenai dampak transformasi skala pengukuran data dari ordinal menjadi interval dilihat dari distribusinya, apakah dengan mengubah skala pengukuran data dari ordinal menjadi interval dengan MSI juga dapat mengubah distribusi data.
Berdasarkan penjelasan di atas, maka penulis melakukan penelitian
1.2Perumusan Masalah
Permasalahan yang dibahas dalam penelitian ini adalah bagaimana cara mengubah data ordinal menjadi data interval, dan untuk membandingkan data ordinal dengan data interval berdasarkan statistika deskriptif.
1.3Batasan Masalah
Untuk menghindari meluasnya materi pembahasan dalam penelitian ini, maka penulis membatasi permasalahan hanya mencakup pada hal-hal berikut:
a. Data ordinal dan data interval akan dibandingkan menggunakan statistika deskriptif.
b. Data yang digunakan dalam penelitian ini hanyalah sebagai contoh dan bukan
sebagai dasar pengambilan kesimpulan.
1.4Tujuan Penelitian
Tujuan penelitian ini adalah mengubah data ordinal menjadi data interval dan membandingkan hasil uji statistika deskriptif antara data ordinal dengan data interval.
1.5Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut:
1. Dapat menunjukkan cara mengubah data ordinal menjadi data interval dengan
MSI dan perbedaannya dari uji statistika deskriptif.
1.6Kerangka Pemikiran
Diagram konsep proses pengubahan data ordinal menjadi data interval menggunakan Metode Suksesif Interval:
Gambar 1.1 Diagram konsep proses pengubahan data ordinal menjadi interval dengan Metode Suksesif Interval
1.7Metodologi Penelitian
Penelitian ini disusun dengan langkah – langkah sebagai berikut:
1. Melakukan studi literature mengenai Metode Suksesif Interval yang
bersumber dari buku, jurnal, situs internet dan berbagai sumber lainnya.
2. Analisis terhadap studi literature untuk mengetahui dan mendapatkan
pemahaman mengenai Metode Suksesif Interval.
3. Menerapkan Metode Suksesif Interval pada data yang diambil dari buku.
Mengambil data ordinal dari buku
Proses MSI
Membandingkan uji Statistika Deskriptif
4. Hasil dan pembahasan dari Metode Suksesif Interval dilakukan dengan membandingkan hasil uji statistika deskriptif antara data ordinal dan data interval.
KAJIAN METODE SUKSESIF INTERVAL (MSI) DALAM MENGUBAH DATA ORDINAL MENJADI DATA
INTERVAL DAN DAMPAKNYA TERHADAP DISTRIBUSI
ABSTRAK
Metode Suksesif Interval merupakan suatu metode yang dapat mengubah data ordinal menjadi data interval. Dalam berbagai proses pengujian statistika, data yang digunakan haruslah berskala interval, oleh karenanya, jika data yang dimiliki oleh peneliti berskala ordinal maka haruslah terlebih dahulu diubah ke dalam bentuk skala interval. Statistika deskriptif digunakan untuk melihat perbedaan kondisi data antara data berskala ordinal dengan data berskala interval. Scatterplot digunakan untuk melihat pola penyebaran data dan membandingkan pola penyebaran data antara data berskala ordinal dengan data berskala interval. Perhitungan manual terhadap metode suksesif interval dilakukan untuk memperjelas proses transformasi dari data yang awalnya berskala ordinal menjadi data yang berskala interval
ASSESSMENT METHOD SUCCESSIVE INTERVAL ( MSI ) IN TURNING DATA INTO ORDINAL INTERVAL
AND IT’S EFFECT TO DISTRIBUTION
ABSTRACT
Interval successive method is a method that can change the ordinal data into interval data . In a variety of statistical testing process , the data used must be interval scale , therefore , if the data held by investigators ordinal scale it must first be converted into the form of a scale interval . Descriptive statistics are used to see the difference of condition data between the data ordinal scale with interval scale data . Scatterplot is used to see the pattern of dissemination of data and comparing the pattern of dissemination of data between the data ordinal scale with interval scale data . Manual calculations of the method of successive intervals carried out to clarify the process of transformation of the data originally ordinal scale into an interval scale data
KAJIAN METODE SUKSESIF INTERVAL (MSI) DALAM
MENGUBAH DATA ORDINAL MENJADI DATA
INTERVAL DAN DAMPAKNYA
TERHADAP DISTRIBUSI
SKRIPSI
MHD. FAHMI NASUTION
120803004
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
KAJIAN METODE SUKSESIF INTERVAL (MSI) DALAM MENGUBAH DATA ORDINAL MENJADI DATA
INTERVAL DAN DAMPAKNYA TERHADAP DISTRIBUSI
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
MHD. FAHMI NASUTION 120803004
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : KAJIAN METODE SUKSESIF INTERVAL
(MSI) DALAM MENGUBAH DATA ORDINAL MENJADI DATA INTERVAL DAN
DAMPAKNYA TERHADAP DISTRIBUSI
Kategori : SKRIPSI
Nama : MHD. FAHMI NASUTION
Nomor Induk Mahasiswa : 120803004
Program Studi : (S1) MATEMATIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (MIPA) UNIVERSITAS SUMATERA UTARA
Disetujui di Medan, Agustus 2016
Komisi Pembimbing :
Pembimbing 2, Pembimbing 1,
Drs. Gim Tarigan, M.Si Drs. Henry Rani Sitepu , M.Si
NIP. 19550202 198601 1 001 NIP. 19530303 198303 1 002
Disetujui Oleh
Departemen Matematika FMIPA USU Ketua,
PERNYATAAN
KAJIAN METODE SUKSESIF INTERVAL (MSI) DALAM MENGUBAH DATA ORDINAL MENJADI DATA
INTERVAL DAN DAMPAKNYA TERHADAP DISTRIBUSI
SKRIPSI
Menyatakan dengan sebenarnya bahwa skripsi yang saya serahkan ini benar-benar merupakan hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan , Agustus 2016
PENGHARGAAN
Puji dan syukur penulis panjatkan kehadirat Allah swt yang telah melimpahkan rahmat dan hidayah-Nya kepada penulis, sehingga penulis dapat menyelesaikan
skripsi ini tepat pada waktunya. Skripsi dengan judul “Kajian Metode Suksesif
Interval (MSI) dalam Mengubah Data Ordinal Menjadi Interval”. Salawat dan salam semoga selalu tercurahkan kepada Nabi Muhammad saw, yang telah memberikan contoh teladan sebagai pedoman hidup bagi seluruh umat manusia.
Dalam menyelesaikan skripsi ini, banyak pihak yang telah membantu penulis baik moral maupun spiritual sehingga skripsi ini dapat selesai tepat pada waktunya. Untuk itu, penulis menyampaikan ucapan terima kasih yang sebesar-besarnya dan penghargaan yang setinggi-tingginya kepada:
1. Bapak Drs. Henry Rani Sitepu, MSi dan Bapak Drs. Gim Tarigan, M.Si selaku dosen pembimbing yang senantiasa membantu dan mengarahkan saya dalam menyelesaikan skripsi ini.
2. Bapak Dr. Sutarman, M.Sc dan Bapak Dr. Open Darnius, M.Sc selaku dosen pembanding yang memberikan kritik dan saran yang membangun dalam menyelesaikan skripsi penulis.
3. Bapak Dr. Kerista Sebayang, M.S selaku Dekan FMIPA Universitas
Sumatera Utara.
4. Seluruh Bapak dan Ibu dosen yang telah mendidik penulis selama
menjalani pendidikan dan Staf pegawai di Fakultas Matematika Dan Ilmu Pengetahuan Alam USU Medan.
5. Yang paling teristimewa kepada kedua orangtua tercinta, ayahanda Drs. H.
6. Terimakasih penulis ucapkan kepada Nurhasanah Widyasari Pulungan yang selalu memberikan semangat dan dukungan moral kepada penulis sehingga penulis dapat menyelesaikan skripsi tepat pada waktunya.
7. Kepada sahabat-sahabat Muhammad Budiman Khanafi Manurung, S.Si,
Rahmat Hidayat, S.Si, Viki Trinanda, S.Si, Wanda Surianto, S.Si, Nurul Hanani Lubis, S.Si, Ade Affany, S.Si, Alfina Laily, S.Si, Novia Erika, S.Si, dan Via Annisa, S.Si, yang selalu menjadi tempat berbagi kebahagiaan dan kesedihan, penulis mengucapkan terimakasih.
Terima kasih penulis ucapkan kepada seluruh pihak yang telah membantu dalam proses pembuatan skripsi.
Medan, Agustus 2016
KAJIAN METODE SUKSESIF INTERVAL (MSI) DALAM MENGUBAH DATA ORDINAL MENJADI DATA
INTERVAL DAN DAMPAKNYA TERHADAP DISTRIBUSI
ABSTRAK
Metode Suksesif Interval merupakan suatu metode yang dapat mengubah data ordinal menjadi data interval. Dalam berbagai proses pengujian statistika, data yang digunakan haruslah berskala interval, oleh karenanya, jika data yang dimiliki oleh peneliti berskala ordinal maka haruslah terlebih dahulu diubah ke dalam bentuk skala interval. Statistika deskriptif digunakan untuk melihat perbedaan kondisi data antara data berskala ordinal dengan data berskala interval. Scatterplot digunakan untuk melihat pola penyebaran data dan membandingkan pola penyebaran data antara data berskala ordinal dengan data berskala interval. Perhitungan manual terhadap metode suksesif interval dilakukan untuk memperjelas proses transformasi dari data yang awalnya berskala ordinal menjadi data yang berskala interval
ASSESSMENT METHOD SUCCESSIVE INTERVAL ( MSI ) IN TURNING DATA INTO ORDINAL INTERVAL
AND IT’S EFFECT TO DISTRIBUTION
ABSTRACT
Interval successive method is a method that can change the ordinal data into interval data . In a variety of statistical testing process , the data used must be interval scale , therefore , if the data held by investigators ordinal scale it must first be converted into the form of a scale interval . Descriptive statistics are used to see the difference of condition data between the data ordinal scale with interval scale data . Scatterplot is used to see the pattern of dissemination of data and comparing the pattern of dissemination of data between the data ordinal scale with interval scale data . Manual calculations of the method of successive intervals carried out to clarify the process of transformation of the data originally ordinal scale into an interval scale data
3.2. Statistika Deskriptif 23
3.3. Scatterplot 23
3.4. Contoh Ilustrasi 23
Bab 4. KESIMPULAN DAN SARAN
1.1. Kesimpulan 38
1.2. Saran 38
DAFTAR TABEL
Nomor Judul Halaman
Tabel
Tabel 3.1 Data pengaruh komitmen organisasional, komitmen
profesional, dan motivasi terhadap kepuasan kerja
24
Tabel 3.2 Nilai proporsi kumulatif dan nilai densitas F(Z) 29
Tabel 3.3 Hasil transformasi data interval 31
Tabel 3.4 Hasil statistika deskriptif untuk data ordinal dan data interval dengan menggunakan SPSS
32
Tabel 3.5 Pengujian Distribusi Normal data ordinal dan data interval
dengan SPSS
35
Tabel 3.6
Output SPSS Uji t untuk data ordinal 36
Tabel 3.7
Output SPSS Uji t untuk data interval 36
Tabel 3.8
Output SPSS untuk Uji Multikolinieritas pada data berskala ordinal dan skala interval
DAFTAR GAMBAR
Nomor Judul Halaman
Gambar
Gambar 2.1 Kurva Normal Standar 14
Gambar 2.2 Kurva leptokurtik, mesokurtik, dan platikurtik 16
Gambar 3.1 Perbandingan scatterplot antara data berskala ordinal dengan data berskala interval menggunakan software minitab
DAFTAR LAMPIRAN
Nomor Judul Halaman
Lampiran
Lampiran 1 Data pengaruh komitmen organisasional, komitmen profesional, dan motivasi terhadap kepuasan kerja
41
Lampiran 2 Hasil transformasi data interval 42
Lampiran 3 Output SPSS untuk deskriptif data ordinal dan data interval 43
Lampiran 4 Output minitab untuk scatterplot data ordinal dan data interval.
44
Lampiran 5 Output SPSS untuk pengujian distribusi normal data ordinal dan interval.
45
Lampiran 6 Output SPSS Uji t untuk Data Berskala Ordinal dan Data Berskala Interval
46
Lampiran 7 Output SPSS Uji Multikolinieritas untuk Data Berskala Ordinal dan Data Berskala Interval
47