1
BAB I
PENDAHULUAN
1.1. Jaringan Syaraf Tiruan
Jaringan syaraf tiruan (JST) adalah sistem pemroses informasi yang memiliki karakteristik mirip dengan jaringan syaraf biologi yang digambarkan sebagai berikut :
a. Menerima input atau masukan (baik dari data yang dimasukkan atau dari output sel syaraf pada jaringan syaraf. Setiap input datang melalui suatu koneksi atau hubungan yang mempunyai sebuah bobot (weight).
b. Setiap sel syaraf mempunyai sebuah nilai ambang. Jumlah bobot dari input dan dikurangi dengan nilai ambang kemudian akan mendapatkan suatu aktivasi dari sel syaraf (post
synaptic potential, PSP, dari sel syaraf). Signal aktivasi kemudian menjadi fungsi
aktivasi / fungsi transfer untuk menghasilkan output dari sel syaraf.
JST dibentuk sebagai generalisasi model matematika dari jaringan syaraf biologi, dengan asumsi bahwa :
a. Pemrosesan informasi terjadi pada banyak elemen sederhana (neuron). b. Sinyal dikirimkan diantara neuron-neuron melalui penghubung-penghubung.
c. Penghubung antar neuron memiliki bobot yang akan memperkuat atau memperlemah sinyal.
d. Untuk menentukan output, setiap neuron menggunakan fungsi aktivasi (biasanya bukan fungsi linier) yang dikenakan pada jumlahan input yang diterima. Besarnya output ini selanjutnya dibandingkan dengan suatu batas ambang.
JST ditentukan oleh 3 hal :
a) Pola hubungan antar neuron (disebut arsitektur jaringan)
b) Metode untuk menentukan bobot penghubung (metode training/ learning / algoritma) c) Fungsi aktivasi
2 Gambar 1.1 Neuron Y
Y menerima input dari nuron x1, x2, dan x3 dengan bobot hubungan masing-masing adalah w1, w2, dan w3. Ketiga impuls neuron yang ada dijumlahkan.
Besarnya impuls yang diterima oleh Y mengikuti fungsi aktivasi y = f(net). Apabila nilai fungsi aktivasi cukup kuat, maka sinyal akan diteruskan. Nilai fungsi aktivasi (keluaran model jaringan) juga dapat dipakai sebagai dasar untuk merubah bobot.
1.1.1. Model Neuron
Neuron adalah unit pemroses informasi yang menjadi dasar dalam pengoperasian JST. Neuron terdiri dari 3 elemen:
1) Himpunan unit-unit yang dihubungkan dengan jalus koneksi. Jalur tersebut memiliki bobot yang berbeda-beda. Bobot yang benilai positif akan memperkuat sinyal dan yang bernilai negatif akan memperlemah sinyal yang dibawanya. Jumlah, struktur dan pola hubungan antar unit-unit tersebut akan menentukan ”ARSISTEKTUR JARINGAN” (dan juga model jaringan yang terbentuk).
2) Suatu unit penjumlah yang akan menjumlahkan input-input sinyal yang sudah dikalikan dengan bobot. Misalkan x1, x2, ....xm adalah unit2 input dan wji, wj2, ... wjm adalah bobot penghubung dari unit2 tsb ke unit keluaran Yj , maka unit penjumlah akan memberikan keluaran sebesar uj = x1wj1+ x2wj2+...+xmwjm
3) Fungsi aktivasi yang akan menentukan apakah sinyal dari input neuron akan diteruskan ke neuron lain ataukah tidak.
a. Jika tahapan fungsi aktivasi digunakan (output sel syaraf = 0 jika input <0 dan 1 jika input >= 0) maka tindakan sel syaraf sama dengan sel syaraf biologi yang dijelaskan diatas (pengurangan nilai ambang dari jumlah bobot dan membandingkan dengan 0 adalah sama dengan membandingkan jumlah bobot dengan nilai ambang).
3 b. Biasanya tahapan fungsi jarang digunakan dalan Jaringan Syaraf Tiruan. Fungsi
aktivasi (f(.)) dapat dilihat pada Gambar berikut.
Gambar 1.2 Fungsi Aktivasi
1.1.2. Arsitektur Jaringan Syaraf Tiruan
Beberapa arsitektur jaringan yang sering dipakai dalam jaringan syaraf tiruan antara lain :
a. Jaringan Layar Tunggal (single layer network)
Dalam jaringan ini, sekumpulan input neuron dihubungkan langsung dengan sekumpulan outputnya. Beberapa model (misal perceptron), hanya ada sebuah unit neuron output.
Gambar 1.3 Single Layer Network
Gambar 1.3 menunjukkan arsitektur jaringan dengan n buah unit input (x1, x2,...,xn) dan m buah unit output (Y1,Y2,...,Ym).
Perhatikan bahwa jaringan ini, semua unit input dihubungkan dengan semua unit output, meskipun dengan bobot yang berbeda-beda. Tidak ada unit input yang dihubungkan dengan unit input lain. Demikian pula dengan unit ouput.
Besaran wji menyatakan bobot hubungan antara unit ke-i dalam input dengan unit ke-j dalam output. Bobot-bobot ini saling independen. Selama proses pelatihan, bobot-bobot tersebut akan dimodifikasi untuk meningkatkan keakuratan hasil. Model semacam ini tepat digunakan untuk pengenalan pola karena kesederhanaannya. Model yang masuk kategori ini antara lain : Adaline, Hopfield, Perceptron, LVQ, dll.
4 Jaringan layar jamak merupakan perluasan dari layar tunggal. Dalam jaringan ini, selain unit input dan output, ada unit-unit lain yang disebut dengan layar tersembunyi (hidden layer). Dimungkinkan pula ada beberapa layar tersembunyi. Sama seperti pada unit input dan output, unit-unit dalam satu layar tidak saling berhubungan.
Gambar 1.4 Multi Layer Network
Gambar 1.4 adalah jaringan dengan n buah unit input (x1, x2,...,xn), sebuah layar tersembunyi yang terdiri dari p buah unit (z1, z2,...,zn) dan m buah unit output (Y1, Y2,..., Yn).
Jaringan layar jamak dapat menyelesaikan masalah yang lebih kompleks dibandingkan dengan layar tunggal, meskipun kadangkala proses pelatihan lebih kompleks dan lama. Model yang masuk kategori ini antara lain : Madaline, Backpropagation, Neocognitron, dll.
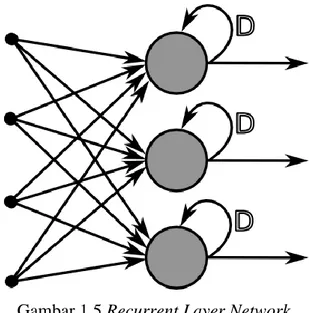
c. Jaringan Recurrent
Model jaringan recurrent mirip dengan jaringan layar tunggal ataupun jamak. Hanya saja, ada neuron output yang memberikan sinyal pada unit input (feedback loop). Model yang masuk kategori ini antara lain : BAM (Bidirectional Associative Memory), Boltzman Machine, Hopfield, dll.
5 Gambar 1.5 Recurrent Layer Network
1.1.3. Fungsi Aktivasi
Dalam jaringan syaraf tiruan, fungsi aktivasi dipakai untuk menentukan keluaran suatu neuron. Argumen fungsi aktivasi adalah net masukan (kombinasi linier masukan dan bobotnya). Jika net = ∑𝑥𝑖 𝑤𝑖 , maka fungsi aktivasinya adalah f(net) = 𝑓(∑ 𝑥𝑖 𝑤𝑖).
6 Kadang dalam jaringan ditambahkan sebuah unit masukan yang nilainya selalu = 1. Unit yang demikian disebut bias . Bias dapat dipandang sebagai sebuah input yang nilainya = 1. Bias berfungsi y g untuk mengubah nilai threshold menjadi = 0 (bukan =a).
Jika melibatkan bias, maka keluaran unit penjumlah adalah 𝑛𝑒𝑡 = ∑ 𝑥𝑖 𝑖𝑤𝑖 Fungsi aktivasi threshold menjadi:
𝑓(𝑛𝑒𝑡) = {1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 ≥ 0 −1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 < 0
Contoh:
Suatu jaringan layar tunggal seperti gambar di atas terdiri dari 2 input x1 = 0,7 dan x2 = 2,1 dan memiliki bias. Bobot w1 = 0,5 dan w2 = -0,3 dan bobot bias b = 1,2. Tentukan keluaran neuron Y jika fungsi aktivasi adalah threshold bipolar.
Penyelesaian:
𝑛𝑒𝑡 = 𝑏 + ∑ 𝑥𝑖 𝑤𝑖 = 1,2 + (0,7 ∗ 0,5) + (2,1 ∗ (−0,3)) = 0,92 𝑖
Karena net > 0 maka keluaran dari jaringan y =f(net) = 1
1.2. Klasifikasi JST Berdasarkan Pelatihan Umum
7 1. Supervised-Feedforward: JST dibimbing dalam hal penyimpanan
pengetahuannnya serta sinyal masuk akan diteruskan tanpa umpan balik
2. Unsupervised-Feedforward: JST tidak dibimbing dalam hal penyimpanan pengetahuannnya serta sinyal masuk akan diteruskan tanpa umpan balik
3. Unsupervised-Feedback: JST tidak dibimbing dalam hal penyimpanan pengetahuannnya serta sinyal masuk akan diteruskan dan memberikan umpan balik
4. Supervised-Feedback: JST dibimbing dalam hal penyimpanan pengetahuannnya serta sinyal masuk akan diteruskan dan memberikan umpan balik
Konsep JST yang dibimbing (supervised): JST diberi masukan tertentu dan keluarannya ditentukan oleh pengajarnya. Dalam proses tsb, JST akan menyesuaikan bobot sinapsisnya.
Konsep JST tanpa dibimbing (unsupervised): kebalikan dari supervised, JST secara mandiri akan mengatur keluarannya sesuai aturan yang dimiliki. Konsep JST feedforward: hasil outputnya sudah dapat diketahui sebelumnya. Konsep JST feedback: lebih bersifat dinamis, dalam hal ini kondisi jaringan akan selalu berubah sampai diperoleh keseimbangan tertentu.
Hingga saat ini terdapat lebih dari 20 model JST. Masing2 model menggunakan arsitektur, fungsi aktivasi dan algoritma yang berbeda-beda dalam prosesnya. Taksonomi JST didasarkan pada metode pembelajaran, aplikasi dan jenis arsitekturnya
Berdasarkan stategi pembelajaran, model JST dibagi menjadi:
a. Pelatihan dengan supervisi. Contoh: model Hebbian, Perceptron, Delta, ADALINE, Backpropagation, Heteroassociative Memory, Biderectional Associative Memory (BAM).
b. Pelatihan tanpa supervisi. Contoh: model Hebian, competitive, Kohonen, Learning Vector Quantization (LVQ), Hopfield.
1.3. Contoh-contoh Aplikasi Jaringan Syaraf Tiruan
Aplikasi yang sudah ditemukan
a. Klasifikasi. Model yang digunakan: ADALINE, LVQ, Backpropagation
b. Pengenalaan Pola. Model yang digunakan: Adaptive Resononance Theory (ART), LVQ, Backpropagation
c. Peramalan. Model yang digunakan: ADALINE, MADALINE, Backpropagation d. Optimisasi. Model yang digunakan: ADALINE, Hopfield, Backpropagation
8
1.4. Neuron McCulloch-Pitts
Model JST yang digunakan oleh McP merupakan model yang pertama ditemukan. Model neuron McP memiliki karakteristik sbb:
a. Fungsi aktivasinya biner.
b. Semua garis yang memperkuat sinyal (bobot positif) ke arah suatu neuron memiliki kekuatan (besar bobot) yang sama. Hal yang sama untuk garis yang memperlemah sinyal (bobot negatif) ke arah neuron tertentu.
c. Setiap neuron memiliki batas ambang (threshold) yang sama. Apabila total input ke neuron tersebut melebihi threshold, maka neuron akan meneruskan sinyal.
Gambar 1.7 Model Neuron McP
Neuron Y menerima sinyal dari (n+m) buah neuron x1 x2, …..xn, xn+1, ….xn+m. n buah penghubung dengan dari x1, x2, …..xn ke Y merupakan garis yang memperkuat sinyal (bobot positif), sedangkan m buah penghubung dari xn+1, ….xn+m ke Y merupakan garis yang memperlemah sinyal (bobot negatif). Semua penghubung dari x1, x2, …..xn ke Y memiliki bobot yang sama. Hal yang sama dengan penghubung dari xn+1,….xn+m ke Y memiliki bobot yang sama. Namun jika ada neuron lain katakan Y2, maka bobot x1 ke Y1 boleh berbeda dengan bobot dari x2 ke Y2.
Fungsi aktivasi neuron Y adalah
𝑓(𝑛𝑒𝑡) = {1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 ≥ 𝑎 0 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 < 𝑎
Bobot tiap garis tidak ditentukan dengan proses pelatihan, tetapi dengan metode analitik. Beberapa contoh berikut memaparkan bagaiman neuron McP digunakan untuk memodelkan fungsi logika sederhana.
Contoh:
Fungsi logika ”AND” dengan 2 masukan x1 dan x2 akan memiliki keluaran Y =1 jika dan hanya jika kedua masukan bernilai 1.
9 Buatlah model neuron McP untuk menyatakan fungsi logika AND
Penyelesaian :
Model neuron fungsi AND tampak pada gambar di bawah ini. Bobot tiap garis adalah = 1 dan fungsi aktivasi memiliki nilai threshold = 2.
Untuk semua kemungkinan masukan, nilai aktivasi tampak pada tabel berikut:
Tampak bahwa keluaran jaringan tepat sama dengan tabel logika AND. Berarti jaringan dapat dengan tepat merepresentasika fungsi AND. Besarnya nilai threshold dapat diganti menjadi suatu bias dengan nilai yang sama. Dengan menggunakan nilai bias, batas garis pemisah ditentukan dari persamaan
10 b + x1w1 + x2w2 = 0 atau x2 = -w1x1/w2 – b/w2
Apabila garis pemisalnya diambil dengan persamaan x1 + x2 = 2, maka berarti –w1/w2 =-1 dan –b/w2 = 2.
Ada banyak w1, w2 dan b yang memenuhi persamaan tersebut, salah satunya adalah w1=w2=1 dan b=-2, seperti penyelesaian contoh diatas.
Latihan
1) Buatlah model neuron McP untuk menyatakan fungsi logika OR 2) Buatlah model neuron McP untuk menyatakan fungsi logika XOR
11
BAB II
ALGORITMA HEBB
2.1. Jaringan Hebb
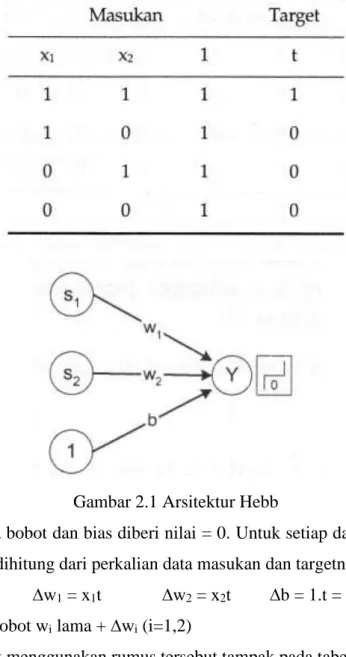
Pada tahun 1949, D.O. Hebb memperkenalkan cara menghitung bobot dan bias secara iteratif. Model Hebb adalah model tertua yang menggunakan aturan supervisi.
Dasar algoritma Hebb adalah kenyataan bahwa apabila 2 neuron yang dihubungkan dengan sinapsis secara serentak menjadi aktif (sama-sama bernilai positif atau negatif), maka kekuatan sinapsisnya meningkat. Sebaliknya, apabila kedua neuron aktif secara tidak sinkron (salah satu bernilai positif dan yang lain bernilai negatif), maka kekuatan sinapsisnya akan melemah.
Karena itulah, dalam setiap iterasi bobot sinapsis dan bias diubah berdasarkan perkalian neuron-neuron di kedua sisinya. Untuk jaringan layar tunggal dengan 1 unit keluaran dimana semua unit masukan xi terhubung langsung dengan unit keluaran y, maka perubahan nilai bobot dilakukan berdasarkan persamaan :
wi (baru) = wi (lama) + xiy
2.2. Pelatihan Hebb
Algoritma pelatihan Hebb dengan vektor input s dan unit target t sebagai berikut : 1. Inisialisasi semua bobot = wi = 0 (i =1,...,n)
2. Untuk semua vektor input s dan unit target t, lakukan : a. Set aktivasi unit masukan xi = si (i =1,...,n)
b. Set aktivasi unit keluaran : y = t c. Perbaiki bobot menurut persamaan
wi (baru) = wi (lama) + ∆w (i=1,...,n) dengan ∆w = xiy d. Perbaiki bias menurut persamaan b (baru) = b (lama) + y
Masalah yang sering timbul dalam jaringan Hebb adalah dalam menentukan representasi data masukan/keluaran untuk fungsi aktivasi yang berupa threshold. Representasi yang sering dipakai adalah bipolar (nilai -1 atau 1). Kadangkala jaringan dapat menentukan pola secara benar jika dipakai reperesentasi bipolar saja, dan akan salah jika dipakai reperesentasi biner (nilai 0 atau 1).
12
Contoh :
Buatlah jaringan Hebb untuk menyatakan fungsi logika “dan: jika representasi masukan/keluaran yang dipakai adalah :
a. Biner
b. Masukan biner dan keluaran bipolar c. Masukan dan keluaran bipolar Penyelesaian :
a. Tabel masukan dan target adalah biner, baik masukan maupun keluaran semuanya bernilai 0 atau 1.
Tabel 2.1 AND dengan biner
Gambar 2.1 Arsitektur Hebb
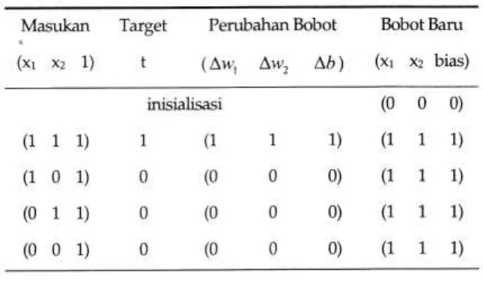
Mula-mula semua bobot dan bias diberi nilai = 0. Untuk setiap data masukan dan target, perubahan bobot dihitung dari perkalian data masukan dan targetnya.
∆w1 = x1t ∆w2 = x2t ∆b = 1.t = t Bobot wi baru = bobot wi lama + ∆wi (i=1,2)
13 Tabel 2.2 Iterasi Bobot Biner
Tampak bahwa bobot hanya berubah akibat pasangan data pertama saja. Pada data ke-2 hingga ke-4, tidak ada perubahan bobot karena target = 0 sehingga perubahan bobot (hasil kali masukan dan target) juga = 0.
Jadi menurut iterasi tabel 2.2, bobot jaringan akhir adalah w1 = 1, w2 = 1 dan b = 1. 𝑛𝑒𝑡 = ∑ 𝑤𝑖𝑥𝑖+ 𝑏 = 1. 𝑥1+ 1. 𝑥2+ 1 = 𝑥1+ 𝑥2+ 1
2
𝑖=1
Kalau diuji cobakan pada seluruh data masukan, maka akan diperoleh hasil seperti pada tabel 2.3. Tampak bahwa nilai f(net) tidak sama dengan target yang dimaksudkan dalam fungsi “dan”. Berarti jaringan tidak dapat “mengerti” pola yang dimaksudkan.
Tabel 2.3 Hasil Algoritma Dengan Biner
14 Tabel 2.4 AND Dengan Masukan Biner dan Keluaran Bipolar
Tabel 2.5 Hasil Iterasi Masukan Biner dan Keluaran Bipolar
Diperoleh w1 = 0, w2 = 0 dan b =-2.
Kalau ini diuji cobakan pada data masukan maka akan diperoleh hasil seperti pada tabel 2.6.
15 Tampak bahwa jaringan tidak memberi respon yang benar sesuai dengan fungsi logika “dan”
c. Tabel masukan dan target data bipolar tampak pada tabel 2.7
Tabel 2.7 AND Dengan Bipolar
16 Diperoleh w1 = 2, w2 = 2, dan b = -2.
𝑛𝑒𝑡 = ∑ 𝑤𝑖𝑥𝑖 + 𝑏 = 2𝑥1+ 2𝑥2 − 2 2
𝑖=1
Kalau diujicobakan maka akan diperoleh hasil seperti tabel di bawah ini. Tabel 2.9 Hasil Algoritma Dengan Bipolar
Respon jaringan terhadap semua vektor masukan pada tabel 2.9 sama seperti tabel fungsi logika “dan” dalam bentuk bipolar. Berarti jaringan mampu mengenali pola dengan tepat.
Berdasarkan ketiga kasus contoh diatas, tampak bahwa dalam jaringan Hebb bisa tidaknya suatu jaringan mengenali pola tidak hanya ditentukan oleh algoritma untuk merevisi bobot, tapi juga dari bagaimana bentuk representasi data yang dipakai. Adakalanya kelemahan jaringan Hebb tidak selalu dapat mengenali pola, baik menggunakan bentuk biner maupun bipolar.
2.3. Pengenalan Pola Karakter pada Hebb
Jaringan Hebb dapat pula dipakai untuk mengenali pola. Caranya dengan melatih jaringan untuk membedakan 2 macam pola. Untuk jelasnya perhatikan contoh berikut ini.
Contoh :
Diketahui 2 buah pola seperti X dan O pada gambar 2.2. gunakan jaringan Hebb untuk mengenali pola tersebut.
17 Gambar 2.2 Pola X dan Pola Y
Penyelesaian
Untuk merepresentasikan kasus tersebut dalam jaringan Hebb, tiap karakter pola dianggap sebagai sebuah unit masukan. Misalnya karakter “#” dalam pola diberi nilai = 1 dan karakter “.” Diberi nilai = -1. Karena setiap pola terdiri dari 5 baris dan 5 kolom (5x5), berarti jaringan Hebb terdiri dari 25 unit masukan x1...x25 (x1..x5 karakter baris-1, x6..x10 karakter baris-2, dst) dan sebuah bias yang bernilai 1.
Sebagai target diambil sebuah unit yang akan bernilai = 1 jika masukan berupa pola 1 dan bernilai = -1 jika masukan berupa pola 2. Unit masukan dan terget yang harus dipresentasikan ke jaringan adlah sebagai berikut :
Tabel 2.10 Unit Masukan Pola
Jika pola pertama dimasukkan, perubahan pola yang terjadi merupakan hasil kali antara target dengan masukan pertama. Karena target = 1, maka hasil kali ini akan sama dengan pola pertama. Jadi bobot jaringan setelah pola pertama dimasukkan sama dengan nilai pola pertama :
18 Bobot bias adalah = 1
Perkalian masukan kedua dengan targetnya menghasilkan ∆wi (i = 1...25) : 1 -1 -1 -1 1; -1 1 1 1 -1; -1 1 1 1 -1; -1 1 1 1 -1; 1 -1 -1 -1 1
Dan perubahan bobot bias = ∆b = (-1). 1 = -1
Jika ∆wi ditambahkan ke bobot jaringan hasil pola pertama maka diperoleh bobot final = w = 2 -2 -2 -2 2; -2 2 0 2 -2; -2 0 2 0 -2; -2 2 0 2 -2; 2 -2 -2 -2 2
Bobot bias = 1 + (-1) = 0
Sebagai uji apakah bobot ini sudah dapat memisahkan kedua pola, maka dilakukan perkalian antara nilai urut masukan tiap pola dengan bobot final.
Untuk pola 1, net = { 1(2) + 1)2) + 1)2) + 1)2) + (1) (2) } + {1)2) + 1(2) + (-1)(0) + 1(2) + (-1)(-2)} + {(-1)(-2) + (-(-1)(0) + 1 (2) + (-(-1)(0) + (-1)(-2)} + {(-1)(-2) + 1(2) + (-1)(0) + 1 (2) + (-1)(-2)} + {1(2) + (-1)(-2) + (-1)(-2) + (-1)(-2) + 1 (2)} = 42. Maka f(net) = 1
Untuk pola 2, net = {(-1)(2) + 1 (-2) + 1(-2) + 1(-2) + (-1)(2) } + { 1(-2) + (-1)(2) + (-1)(0) + (-1)(2) + 1(-2) } + {1(-2) + (-1)(0) + (-1)(2) + (-1)(0) + (1)(-2)} + {1(-2) + (-1)(2) + (-1)(0) + (-1)(2) + 1(-2)} + {(-1)(2) + 1(-2) + 1(-2) + 1(-2) + (-1)(2) } = -42. Maka f(net) = -1
Tampak bahwa untuk kedua pola, keluaran jaringan sama dengan target yang diinginkan. Berarti jaringan telah mengenali pola dengan baik.
Latihan :
1. Dalam jaringan Hebb, mengapa jaringan tidak akan dapat mengenali pola jika akan dapat mengenali pola jika menggunakan representasi biner yang satu elemennya = 0?
2. Buatlah jatingan Hebb untuk menyatakan fungsi “atau” dengan menggunakan : a. Pola masukan dan keluaran biner
b. Pola masukan biner dan pola target bipolar c. Baik pola masukan maupun target bipolar
19
BAB III
ALGORITMA PERCEPTRON
Model jaringan perceptron ditemukan Rosenblatt (1962) dan Minsky-Papert (1969). Model tersebut merupakan model yang memiliki aplikasi dan pelatihan yang paling baik pada era tersebut.
3.1. Arsitektur Jaringan
Arsitektur jaringan perceptron mirip dengan arsitektur jaringan Hebb.
Jaringan terdiri dari beberapa unit masukan (ditambah sebuah bias), memiliki sebuah unit keluaran. Hanya saja fungsi aktivasi bukan merupakan fungsi biner (atau bipolar), tetapi memiliki kemungkinan nilai -1, 0 atau 1.
Harga threshold 𝜃 yang ditentukan : f(net) = {
1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 > 𝜃 0 𝑗𝑖𝑘𝑎 − 𝜃 ≤ 𝑛𝑒𝑡 ≤ 𝜃 −1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 < −𝜃
Secara geometris, fungsi aktivasi membentuk 2 garis sekaligus, masing-masing dengan persamaan :
w1x1 + w2x2 + ... + wnxn + b = 𝜃 dan w1x1 + w2x2 + ... + wnxn + b = - 𝜃
20
3.2. Pelatihan Perceptron
Misalkan
s adalah vektor masukan dan t adalah target keluaran α adalah laju pemahaman (learning rate) yang ditentukan 𝜃 adalah threshold yang ditentukan
Algoritma pelatihan perceptron :
1. Inisialisasi semua bobot dan bias (umumnya wi = b = 0). Tentukan laju pemahaman (=α). Untuk penyederhana, biasanya α diberi nilai = 1
2. Selama ada elemen vektor masukan yang respon unit keluarnya tidak sama dengan target, lakukan :
a. Set aktivasi unit masukan xi = si (i = 1,...,n) b. Hitung respon unit keluaran : net = ∑𝑖𝑥𝑖𝑤𝑖 + 𝑏
y =f(net) = {
1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 > 𝜃 0 𝑗𝑖𝑘𝑎 − 𝜃 ≤ 𝑛𝑒𝑡 ≤ 𝜃 −1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 < −𝜃
c. Perbaiki bobot pola yang mengandung kesalahan (y ≠ t) menurut persamaan ; wi (baru) = wi (lama) + ∆w (i=1,...,n) dengan ∆w = α t xi
b (baru) = b (lama) + ∆b dengan ∆b = α t
Ada beberapa hal yang perlu diperhatikan dalam algoritma tersebut :
a. Iterasi dilakukan terus hingga semua pola memiliki keluaran jaringan yang sama dengan targetnya (jaringan sudah memahami pola). Iterasi tidak berhenti setelah semua pola dimasukkan seperti yang terjadi pada model Hebb.
b. Pada langkah 2(c), perubahan bobot hanya dilakukan pada pola yang mengandung kesalahan (keluaran jaringan ≠ target). Perubahan tersebut merupakan hasil kali unit masukan dengan target dan laju pemahaman. Perubahan bobot hanya akan terjadi kalau unit masukan ≠ 0.
c. Kecepatan iterasi ditentukan pula oleh laju pemahaman (=α dengan 0 ≤ α ≤ 1) . semakin besar harga α, semakin sedikit iterasi yang diperlukan. Akan tetapi jika α terlalu besar, maka akan merusak pola yang sudah benar sehingga pemahaman menjadi lambat.
Contoh :
Buatlah perceptron untuk mengenali fungsi logika “dan” dengan masukan dan keluaran bipolar. Untuk inisialisasi, gunakan bobot dan bias awal = 0, α = 1 dan threshold = 𝜃 = 0 Penyelesaian :
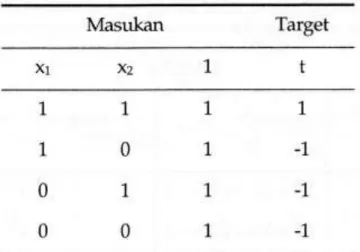
21 Tabel masukan dan target fungsi logika “dan” dengan masukan dan keluaran bipolar tampak dalam tabel 3.1
Tabel 3.1 Fungsi Logika “and” Dengan Bipolar
Untuk threshold = 0, maka fungsi aktivasi menjadi : 𝑦 = 𝑓(𝑛𝑒𝑡) = {
1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 > 0 0 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 = 0 −1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 < 0
Iterasi untuk seluruh pola yang ada disebut epoch Tabel 3.2 menunjukkan hasil pada epoch pertama.
22 Tabel 3.3 Perceptron Epoch Kedua
Pada tabel 3.3 sudah tidak ada perubahan bobot lagi, maka jaringan Perceptron tersebut sudah mengenali pola sehingga iterasi dihentikan.
3.3. Pengenalan Pola Karakter pada perceptron
Algoritma untuk mengenali apakah pola masukan yang diberikan menyerupai sebuah karakter tertentu (misal mirip huruf “A”) atau tidak, sebagai berikut :
1. Nyatakan tiap pola masukan sebagai vektor bipolar yang elemennya adalah tiap titik dalam pola tersebut.
2. Berikan nilai target = +1 jika pola masukan menyerupai huruf yang diinginkan. Jika sebaliknya, berikan nilai target = -1.
3. Berikan inisialisasi bobot, bias, laju pemahaman dan threshold. 4. Lakukan proses pelatihan perceptron.
Contoh :
Diketahui 6 buah pola masukan seperti gambar 3.1 :
23 Buatlah model perceptron untuk mengenali pola “A”.
Penyelesaian :
Untuk menentukan vektor masukan, tiap titik dalam pola diambil sebagai komponen vektor. Jadi tiap vektor masukan memiliki 9*7 = 63 komponen. Titik dalam pola yang bertanda “#” diberi nilai = +1 dan titik bertanda “.” Diberi nilai -1. Pembacaan pola dilakukan dari kiri ke kanan, dimulai dari baris paling atas.
Vektor masukan pola 1 adalah
(-1 -1 1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 1 1 1 1 1 -1 -1 1-1 -1 -1 1 -1 -1 1 -1 -1 -1 1 -1 1 1 1 -1 1 1 1) Vektor masukan pola 2 adalah
(1 1 1 1 1 1 -1 -1 1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 1 -1 1 1 1 1 1 -1 -1 1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 1 1 1 1 1 1 1 -1) Vektor masukan pola 3 adalah
(-1 -1 1 1 1 1 1 -1 1 -1 -1 -1 -1 1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 1 -1 -1 1 1 1 1 -1) Vektor masukan pola 4 adalah
(-1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 1 1 1 1 1 -1 -1 1 -1 -1 -1 1 -1 -1 1 -1 -1 -1 1 -1) Vektor masukan pola 5 adalah
(1 1 1 1 1 1 -1 1 -1 -1 -1 -1 -1 1 1 -1 -1 -1 -1 -1 1 1 -1 -1 -1 -1 -1 1 1 1 1 1 1 1 -1 1 -1 -1 -1 -1 -1 1 1 -1 -1 -1 -1 -1 1 1 -1 -1 -1 -1 -1 1 1 1 1 1 1 1 -1) Vektor masukan pola 6 adalah
(-1 -1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 1 -1 -1 -1 1 1 1 -1 -1)
Target bernilai = +1 bila pola masukan menyerupai huruf “A”. Jika tidak, maka target bernilai = -1. Pola yang menyerupai huruf “A” adalah pola 1 dan pola 4. Pasangan pola dan targetnya tampak pada tabel 3.4
24 Tabel 3.4 Pola Masukan Untuk Mengenali Pola “A”
Perceptron yang dipakai untuk mengenali pola huruf “A” (atau bukan “A”) memiliki 63 unit masukan, sebuah bias dan sebuah unit keluaran. Misalnya bobot awal diambil = 0 untuk semua bobot maupun bias, α = 1, 𝜃 = 0.5
Pelatihan dilakukan dengan cara memasukkan 63 unit masukan (sebuah pola huruf). Dihitung net = ∑63𝑖=1xiwi+ b. Berikutnya, fungsi aktivasi dihitung menggunakan persamaan
𝑦 = 𝑓(𝑛𝑒𝑡) = {
1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 > 0.5 0 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 − 0.5 ≤ 𝑛𝑒𝑡 ≤ 0.5 −1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 < −0.5 Apabila f(net) ≠ target, maka bobot dan bias diubah
Proses pelatihan dilakukan terus hingga semua keluaran jaringan sama dengan targetnya.
Latihan :
1. Buatlah perceptron untuk mengenali pola yang berbentuk pada fungsi logika XOR dengan α = 1 dan 𝜃 = 0.2
a. Tanpa menggunakan bias (jika mungkin) b. Menggunakan bias
c. Tunjukkan secara grafik bahwa tanpa bias, perceptron tidak akan mampu mengenali pola secara benar.
25
BAB IV
ALGORITMA ADALINE
Model ADALINE (Adaptive Linear Neuron) ditemukan oleh Widrow dan Hoff (1960). Arsitekturnya mirip dengan perceptron.
4.1. Pelatihan ADALINE
Beberapa masukan (dan sebuah bias) dihubungkan langsung dengan sebuah neuron keluaran. Perbedaan dengan perceptron adalah cara modifikasi bobot. Bobot dimodifikasi dengan aturan delta (least mean square). Selama pelatihan, fungsi aktivasi yang dipakai adalah fungsi identitas.
𝒏𝒆𝒕 = ∑ 𝒙𝒊𝒘𝒊+ 𝒃 𝒊
𝒚 = 𝒇(𝒏𝒆𝒕) = 𝒏𝒆𝒕 = ∑ 𝒙𝒊𝒘𝒊+ 𝒃 𝒊
Kuadrat selisih antara target (t) dan keluaran jaringan (f(net)) merupakan error yang terjadi. Dalam aturan delta, bobot dimodifikasi sedemikian hingga errornya minimum.
E = (t – f(net))2 = (𝑡 − (∑ 𝑥𝑖 𝑖𝑤𝑖 + 𝑏))2
E merupakan fungsi bobot wi. Penurunan E tercepat terjadi pada arah 𝛿𝐸
𝛿𝑤𝑖= −2 (𝑡 − (∑ 𝑥𝑖 𝑖𝑤𝑖 + 𝑏))𝑥𝑖 = −2(𝑡 − 𝑦)𝑥𝑖. Maka perubahan bobot adalah :
∆𝑤𝑖 = 𝛼(𝑡 − 𝑦)𝑥𝑖 Α merupakan bilangan positif kecil (umumnya diambil 0.1)
Algoritma pelatihan ADALINE :
1. Inisialisasi semua bobot dan bias (wi = b = 0). Tentukan α, biasanya α = 0.1, tentukan toleransi kesalahan yang diijinkan
2. Selama max ∆wi > batas toleransi, lakukan : a. Set aktivasi unit masukan xi = si (i = 1,...,n) b. Hitung respon unit keluaran : 𝑛𝑒𝑡 = ∑ 𝑥𝑖 𝑖𝑤𝑖 + 𝑏
Y = f(net) = net
c. Perbaiki bobot pola yang mengandung kesalahan (y ≠ t) menurut persamaan : wi (baru) = wi (lama) +α (t-y)xi
26 Setelah proses pelatihan selesai, ADALINE dapat dipakai untuk pengenalan pola. Umumnya dipakai fungsi 𝜃 bipolar. Caranya sebagai berikut :
1. Inisialisasi semua bobot dan bias dengan bobot dan bias hasilm pelatihan 2. Untuk semua input masukan bipolar x, lakukan :
a. Set aktivasi unit masukan xi = si (i = 1,..., n) b. Hitung net vektor keluaran :
𝒏𝒆𝒕 = ∑ 𝒙𝒊𝒘𝒊+ 𝒃 𝒊
c. Kenakan fungsi aktivasi :
𝑦 = {1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 ≥ 0 −1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 < 0
Contoh :
Gunakan model ADALINE untuk mengenali pola fungsi logika “dan” dengan masukan dan target bipolar :
Gunakan batas toleransi = 0.05 dan α = 0.1 Penyelesaian :
27 Maksimum ∆wi = 0.07 > toleransi, maka iterasi dilanjutkan untuk epoch kedua
Maksimum ∆wi = 0.002 < toleransi, maka iterasi dihentikan dan bobot terakhir yang diperoleh (w1 = 0.29, w2 = 0.26, dan b = -0.32) merupakan bobot yang digunakan dalam pengenalan pola.
Perhatikan bahwa fungsi aktivasi yang dipakai berbeda dengan fungsi aktivasi pada pelatihan. Dalam pengenalan pola, fungsi aktivasinya adalah :
𝑦 = {1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 ≥ 0 −1 𝑗𝑖𝑘𝑎 𝑛𝑒𝑡 < 0
28 Tampak bahwa keluaran jaringan tepat sama dengan targetnya. Disimpulkan bahwa pola dapat dikenali dengan sempurna menggunakan bobot hasil pelatihan.
4.2. Pengenalan Pola Karakter pada ADALINE
29
BAB V
ALGORITMA MADALINE
5.1. Arsitektur Jaringan
Beberapa ADALINE dapat digabungkan untuk membentuk suatu jaringan baru yang di sebuat MADALINE (many ADALINE). Dalam MADALINE terdapat sebuah layar tersembunyi.
Gambar 5.1 Arsitektur MADALINE
5.2. Pelatihan MADALINE
Algoritma pelatihan MADALINE mula-mula untuk pola masukan dan target bipolar : 1. Inisialisasi semua bobot dan bias dengan bilangan acak kecil. Inisialiasasi α dengan
bilangan kecil.
2. Selama perubahan bobot lebih besar dari toleransi (jumlah epoch belum melebihi batas yang ditentukan), lakukan langkah a s/d e
a. Set aktivasi unit masukan : xi = si untuk semua i
b. Hitung net input untuk setiap unit tersembunyi ADALINE (z1, z2,...) 𝑧𝑖𝑛_𝑗 = 𝑏𝑗 ∑ 𝑥𝑖𝑤𝑗𝑖
𝑖
c. Hitung keluaran setiap unit tersembunyi dengan menggunakan fungsi aktivasi bipolar :
𝑧𝑗 = 𝑓 (𝑧𝑖𝑛𝑗) = {1 𝑗𝑖𝑘𝑎 𝑧𝑖𝑛_𝑗 ≥ 0 −1 𝑗𝑖𝑘𝑎 𝑧𝑖𝑛_𝑗 < 0 d. Tentukan keluaran jaringan
30 𝑦𝑖𝑛 = 𝑏𝑘+ ∑ 𝑧𝑗𝑣𝑗 𝑗 𝑦 = 𝑓(𝑦𝑖𝑛) = { 1 𝑗𝑖𝑘𝑎 𝑦𝑖𝑛 ≥ 0 −1 𝑗𝑖𝑘𝑎 𝑦𝑖𝑛 < 0 e. Hitung error dan tentukan perubahan bobot
Jika y = target, maka tidak dilakukan perubahan bobot Jika y ≠ target :
Untuk t = 1, ubah bobot ke unit zj yang zin nya terdekat dengan 0 (misal ke unit zp) : 𝑏𝑝𝑏𝑎𝑟𝑢 = 𝑏𝑝𝑙𝑎𝑚𝑎 + 𝛼 (1 − 𝑧𝑖𝑛𝑝)
𝑤𝑝𝑖𝑏𝑎𝑟𝑢 = 𝑤𝑝𝑖𝑙𝑎𝑚𝑎 + 𝛼 (1 − 𝑧𝑖𝑛𝑝) 𝑥𝑖 Untuk t = -1, ubah semua bobot ke unit zk yang zin nya positif :
𝑏𝑘𝑏𝑎𝑟𝑢 = 𝑏𝑘𝑙𝑎𝑚𝑎 + 𝛼(−1 − 𝑧𝑖𝑛𝑘) 𝑤𝑘𝑖𝑏𝑎𝑟𝑢 = 𝑤𝑘𝑖𝑙𝑎𝑚𝑎 + 𝛼 (−1 − 𝑧𝑖𝑛𝑘)𝑥𝑖
Contoh :
Gunakan MADALINE mula-mula mengenali pola fungsi logika XOR dengan 2 masukan x1 dan x2. Gunakan α =0.5 dan toleransi = 0.1
Penyelesaian :
Inisialisasi dilakukan pada semua bobot ke unit tersembunyi dengan suatu bilangan acak kecil. Contoh :
31 Bobot ke unit keluaran Y adalah : v1 = v2 = b = ½
Disini dilakukan iterasi untuk pola pertama saja. Pelatihan pola-pola selanjutnya dilakukan secara analog dan diserahkan kepada saudara untuk latihan.
Pola-1 : Masukan : x1 = 1, x2 =1, t=-1
Hitung net untuk unit tersembunyi z1 dan z2 :
Zin_1 = b1 + x1w11 + x2w12 = 0.3 + 1 (0.05) + 1 (0.2) = 0.55 Zin_2 = b2 + x1w21 + x2w22 = 0.15 + 1 (0.1) + 1 (0.2) = 0.45
Hitung keluaran unit tersembunyi z1 dan z2 menggunakan fungsi aktivasi bipolar.
z1 = f (zin_1) = 1 dan z2 = f (zin_2) = 1
Tentukan keluaran jaringan Y :
Y_in = b3 + z1v1 + z2v2 = 0.5 + 1 (0.5) + 1 (0.5) = 1.5 Maka y = f (y_in) = 1
t-y = -1-1 = -2 ≠ 0 dan t = -1. Semua bobot yang menghasilkan z_in yang positif dimodifikasi. Karena zin_1 > 0 dan zin_2 > 0, maka semua bobotnya dimodifikasi sebagai berikut :
perubahan bobot ke unit tersembunyi z1 :
32 w11 baru = w11 lama + α (-1- zin_1) x1 = 0.05 + 0.5 (-1 – 0.55) = -0.725
w12 baru = w12 lama + α (-1- zin_1) x2 = 0.2 + 0.5 (-1 – 0.55) = -0.575 perubahan bobot ke unit tersembunyi z2 :
b2 baru = b2 lama + α (-1- zin_2) = 0.15 + 0.5 (-1 – 0.45) = -0.575 w21 baru = w21 lama + α (-1- zin_2) x1 = 0.1 + 0.5 (-1 – 0.45) = -0.625 w22 baru = w22 lama + α (-1- zin_2) x2 = 0.2 + 0.5 (-1 – 0.45) = -0.525
Karena masih ada (bahkan semua) perubahan bobot > toleransi yang ditetapkan, maka iterasi dilanjutkan untuk pola 2. Iterasi dilakukan untuk semua pola. Apabila ada perubahan bobot yang masih lebih besar dari batas toleransi, maka iterasi dilanjutkan untuk epoch-2 dan seterusnya.
5.3. Pengenalan Pola Karakter pada MADALINE
33
BAB VI
ALGORITMA HOPFIELD DISKRIT
Dikembangkan oleh John Hopfield (1982). Struktur jaringan terkoneksi secara penuh yaitu setiap unit terhubung dengan setiap unit yang lain. Jaringan memiliki bobot simetris tanpa ada koneksi pada diri sendiri sehingga wij = wji dan wii = 0
6.1. Arsitektur Jaringan
Gambar 6. 1 Arsitektur Hopfield Diskrit
Fungsi ambang : F(t) = 1 jika t >= ambang, 0 jika t < ambang Jaringan hopfield 6 neuron
Contoh 1 :
Ada 2 buah pola yg ingin dikenali: pola A (1,0,1,0,1,0)
34 Bobot-bobotnya sbb:
Algoritma :
1. Aktivasi node pertama pola A
2. Aktivasi node kedua pola A
3. Node 3-6 hasilnya 4,-6,4,-6
4. cara yg sama lakukan utk pola B yg hasilnya -6,4,-6,4,-6,4 pengujian :
1. Mengenali pola C (1,0,1,0,0,0) dianggap citra pola A yg mengalami distorsi 2. Aktivasi node 1-6 menghasilkan (2,-4,2,-4, 4,-4), maka output (1,0,1,0,1,0) 3. Mengenali pola D (0,0,0,1,0,1) dianggap citra pola B yg mengalami distorsi 4. Bagaimana dg pola D?
Algoritma dg Asynchronous update 1. Mengenali pola E (1,0,1,1,0,1)
2. Aktivasi node 1-6 diperoleh (-2,0,-2,-2,0,-2) dg output (0,1,0,0,1,0) -> bukan A atau
B
3. solusi dg Asynchronous update
6.2. Algoritma Hopfield
35 2. Masukan vector input (invec), lalu inisialisasi vector output (outvec) yaitu outvec =
invec
3. Mulai dg counter i=1
Selama invec ≠ outvec lakukan langakh 4-7,jika I sampai maks maka reset mjd 1 4. Hitung nilai ke-i = dotproduct(invec, kolom ke-I dari W)
5. Hitung outvec ke-i = f(nilai ke-i), f adalah fungsi ambang 6. Update invec dg outvec
7. i=i+1
Aplikasi pada vektor E
6.3. Pengenalan Pola Karakter pada Hopfield Diskrit
Contoh :
1. Pengenalan pola “=“ dan “x” 2. Pola “=“ (1,1,1,-1,-1,-1,1,1,1) 3. Pola “x” (1,-1,1,-1,1,-1,1,-1,1) 4. Bobot diset matrik (-3,3)
5. Pola input “=“ nilai aktivasinya (3,3,3,-9,-6,-9,12,6,15), dg output (1,1,1,-1,-1,-1,1,1,1) 6. Pola “x” nilai aktivasinya (9,-9,9,-9,6,-9,6,-6,9), dg output (1,-1,1,-1,1,-1,1,-1,1) 7. Berarti jaringan telah sukses memanggil kembali pola-pola tsb
36
Vektor Bobot (-3,3)
Spurious stable state
37
BAB VII
ALGORITMA PROPAGASI BALIK
(BACK PROPAGATION)
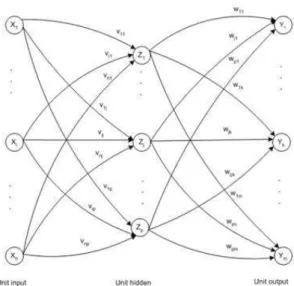
7.1. Arsitektur Jaringan
Salah satu metode pelatihan terawasi pada jaringan syaraf adalah metode
Backpropagation, di mana ciri dari metode ini adalah meminimalkan error pada output yang
dihasilkan oleh jaringan. Dalam metode Backpropagation, biasanya digunakan jaringan multilayer.
Pada gambar, unit input dilambangkan dengan X, hidden unit dilambangkan dengan Z, dan unit output dilambangkan dengan Y. Bobot antara X dan Z dilambangkan dengan v sedangkan bobot antara Z dan Y dilambangkan dengan w.
7.2. Pelatihan Back Propagation 7.2.1. Proses belajar & Pengujian
Penggunaan Back Propagation terdiri dari 2 tahap:
a. Tahap belajar atau pelatihan, di mana pada tahap ini diberikan sejumlah data pelatihan dan target
38 b. Tahap pengujian atau penggunaan, pengujian dan penggunaan dilakukan setelah selesai
belajar
7.2.2. Tahap Belajar atau Pelatihan
Pada intinya, pelatihan dengan metode backpropagation terdiri dari tiga langkah, yaitu:
a. Data dimasukkan ke input jaringan (feedforward)
b. Perhitungan dan propagasi balik dari error yang bersangkutan c. Pembaharuan (adjustment) bobot dan bias.
Saat umpan maju (feedforward), setiap unit input (Xi) akan menerima sinyal input dan akan menyebarkan sinyal tersebut pada tiap hidden unit (Zj). Setiap hidden unit kemudian akan menghitung aktivasinya dan mengirim sinyal (zj) ke tiap unit output. Kemudian setiap unit output (Yk) juga akan menghitung aktivasinya (yk) untuk menghasilkan respons terhadap input yang diberikan jaringan.
Saat proses pelatihan (training), setiap unit output membandingkan aktivasinya (yk) dengan nilai target (tk) untuk menentukan besarnya error. Berdasarkan error ini, dihitung faktor k, di mana faktor ini digunakan untuk mendistribusikan error dari output ke layer sebelumnya. Dengan cara yang sama, faktor j juga dihitung pada hidden unit Zj, di mana faktor ini digunakan untuk memperbaharui bobot antara hidden layer dan input layer. Setelah semua faktor ditentukan, bobot untuk semua layer diperbaharui.
7.2.3. Proses belajar secara detail
Step 0 : Inisialisasi bobot dan bias
Baik bobot maupun bias dapat diset dengan sembarang angka (acak) dan biasanya angka di sekitar 0 dan 1 atau -1 (bias positif atau negatif)
Step 1 : Jika stopping condition masih belum terpenuhi, jalankan step 2-9. Step 2 : Untuk setiap data training, lakukan step 3-8.
Umpan maju (feedforward)
Step 3 : Setiap unit input (Xi,i=1,…,n) menerima sinyal input xi dan menyebarkan sinyal tersebut pada seluruh unit pada hidden layer. Perlu diketahui bahwa input xi yang dipakai di sini adalah input training data yang sudah diskalakan.
Step 4 : Setiap hidden unit (Zj,j=1,…,p) akan menjumlahkan sinyal-sinyal input yang sudah berbobot, termasuk biasnya
𝑧𝑖𝑛𝑗 = 𝑣𝑜𝑗 + ∑ x-ivij 𝑛
39 dan memakai fungsi aktivasi yang telah ditentukan untuk menghitung sinyal output dari hidden unit yang bersangkutan,
𝑧𝑗 = 𝑓(𝑧𝑖𝑛𝑗)
lalu mengirim sinyal output ini ke seluruh unit pada unit output
Step 5 : Setiap unit output (Yk,k=1,…,m) akan menjumlahkan sinyal-sinyal input yang sudah berbobot, termasuk biasnya,
𝑦𝑖𝑛𝑘 = 𝑤𝑜𝑘+ ∑ 𝑧𝑗𝑤𝑗𝑘 𝑝
𝑗=1
dan memakai fungsi aktivasi yang telah ditentukan untuk menghitung sinyal output dari unit output yang bersangkutan:
𝑦𝑘= 𝑓(𝑦𝑖𝑛𝑘) Propagasi balik error (backpropagation of error)
Step 6 : Setiap unit output (Yk,k=1,…,m) menerima suatu target (output yang diharapkan) yang akan dibandingkan dengan output yang dihasilkan.
𝛿𝑘 = (𝑡𝑘− 𝑦𝑘)𝑓′(𝑦 𝑖𝑛𝑘)
Faktor k ini digunakan untuk menghitung koreksi error ( wjk) yang nantinya akan dipakai untuk memperbaharui wjk, di mana:
wjk= kzj
Selain itu juga dihitung koreksi bias w0k yang nantinya akan dipakai untuk memperbaharui w0k, di mana:
w0k= k
Faktor k ini kemudian dikirimkan ke layer di depannya.
Step 7 : Setiap hidden unit (Zj,j=1,…,p) menjumlah input delta (yang dikirim dari layer pada step 6) yang sudah berbobot.
𝛿𝑖𝑛𝑗 = ∑ 𝛿𝑘𝑤𝑗𝑘 𝑚
𝑘=1
Kemudian hasilnya dikalikan dengan turunan dari fungsi aktivasi yang digunakan jaringan untuk menghasilkan faktor koreksi error j, di mana:
40 Faktor j ini digunakan untuk menghitung koreksi error (vij) yang nantinya akan dipakai untuk memperbaharui vij, di mana:
vij=jxi
Selain itu juga dihitung koreksi bias v0j yang nantinya akan dipakai untuk memperbaharui v0j, di mana:
v0j=j Pembaharuan bobot dan bias:
Step 8 :
a. Setiap unit output (Yk,k=1,…,m) akan memperbaharui bias dan bobotnya dengan setiap hidden unit.
wjk(baru)=wjk(lama) + wjk
b. Demikian pula untuk setiap hidden unit akan memperbaharui bias dan bobotnya dengan setiap unit input.
vij(baru)=vij(lama) + vij
Step 9 : Memeriksa stopping condition
Jika stop condition telah terpenuhi, maka pelatihan jaringan dapat dihentikan.
7.2.4. Stopping Condition
Untuk menentukan stopping condition terdapat dua cara yang biasa dipakai, yaitu: a. Membatasi iterasi yang ingin dilakukan.
i. Misalnya jaringan akan dilatih sampai iterasi yang ke-500.
ii. Yang dimaksud dengan satu iterasi adalah perulangan step 3 sampai step 8 untuk semua training data yang ada.
b. Membatasi error.
i. Misalnya menentukan besar Mean Square Error antara output yang dikehendaki dan output yang dihasilkan oleh jaringan.
7.2.5. Mean Square Error
Jika terdapat sebanyak m training data, maka untuk menghitung Mean Square Error digunakan persamaan berikut:
41
7.2.6. Tahap pengujian & Penggunaan
Setelah pelatihan selesai, Back Propagation dianggap telah pintar sehingga apabila jaringan diberi input tertentu, jaringan akan menghasilkan output seperti yang diharapkan.
Cara mendapatkan output tersebut adalah dengan mengimplementasikan metode backpropagation yang sama seperti proses belajar, tetapi hanya pada bagian umpan majunya saja, yaitu dengan langkah-langkah sebagai berikut:
Step 0 : Inisialisasi bobot sesuai dengan bobot yang telah dihasilkan pada proses pelatihan di atas.
Step 1 : Untuk setiap input, lakukan step 2-4.
Step 2 : Untuk setiap input i=1,…,n skalakan bilangan dalam range fungsi aktivasi seperti yang dilakukan pada proses pelatihan di atas.
Step 3 : Untuk j=1,…,p: 𝑧𝑖𝑛𝑗 = 𝑣𝑜𝑗+ ∑ 𝑥𝑖𝑣𝑖𝑗 𝑛 𝑖=1 𝑧𝑗 = 𝑓(𝑧𝑖𝑛𝑗) Step 4 : Untuk k=1,…,m: 𝑦𝑖𝑛𝑘 = 𝑤𝑜𝑘 + ∑ 𝑧𝑗𝑤𝑗𝑘 𝑝 𝑗=1 𝑦𝑘= 𝑓(𝑦𝑖𝑛𝑘)
Variabel yk adalah output yang masih dalam skala menurut range fungsi aktivasi. Untuk mendapatkan nilai output yang sesungguhnya, yk harus dikembalikan seperti semula.
Contoh :
Misalkan, jaringan terdiri dari 2 unit input, 1 hidden unit (dengan 1 hidden layer), dan 1 unit output.
Jaringan akan dilatih untuk memecahkan fungsi XOR.
Fungsi aktivasi yang digunakan adalah sigmoid biner dengan nilai learning rate () = 0,01 dan nilai =1.
42 Training data yang digunakan terdiri dari 4 pasang input-output, yaitu:
Sebelum pelatihan, harus ditentukan terlebih dahulu stopping conditionnya. Misalnya dihentikan jika error telah mencapai 0,41.
Langkah-langkah pelatihan
Step 0: Misalnya inisialisasi bobot dan bias adalah: v01=1,718946
v11=-1,263178 v21=-1,083092 w01=-0,541180 w11=0,543960
Step 1: Dengan bobot di atas, tentukan error untuk training data secara keseluruhan dengan Mean Square Error:
• z_in11=1,718946+{(0 x -1,263178)+(0 x-1,083092)}=1,718946 • z11=f(z_in11)=0,847993
• z_in12=1,718946+{(0 x-1,263178)+(1 x -1,083092)}=0,635854 • z12=f(z_in12)=0,653816
43 • z13=f(z_in13)=0,612009
• z_in14=1,718946+{(1 x -1,263178)+(1 x -1,083092)=-0,627324 • z14=f(z_in14)=0,348118
di mana indeks zjn berarti hidden unit ke-j dan training data ke-n. • y_in11=-0,541180+(0,847993 x 0,543960)=0,079906 • y11=f(y_in11)=0,480034 • y_in12=-0,541180+(0,653816 x 0,543960)=-0,185530 • y12=f(y_in12)=0,453750 • y_in13=-0,541180+(0,612009 x 0,543960)=0,208271 • y13=f(y_in13)=0,448119 • y_in14=-0,541180+(0,348118 x 0,543960)=-0,351818 • y14=f(y_in14)=0,412941 • Maka E=0,5 x {(0-0,480034)2 + (1-0,453750)2) + (1-0,448119)2 + (0-0,412941)2}=0,501957
Step2 : Karena error masih lebih besar dari 0,41 maka step 3-8 dijalankan. Step 3 : x1=0; x2=0 (iterasi pertama, training data pertama)
Step 4 : • z_in1=1,718946+{(0x-1,263126)+(0x-1,083049)}=1,718946. • z1=f(z_in1)=0,847993 Step 5 : • y_in11=-0,541180+(0,847993x0,543960)=0,079906 • y11=f(y_in11)=0,480034 Step 6 : • 1=(0-0,480034)f ’(0,079906)=-0,119817 • w11=0,01x-0,119817x0,847993=-0,001016 • w01=0,01x-0,119817=-0,00119817 Step 7. • _in1=-0,00119817x0,543960=-0,00065176 • 1=-0,00065176xf’(1,718946)=-0,00008401 • v11=0,01x-0,00008401x0=0 • v21=0,01x-0,00008401x0=0 • v01=0,01x-0,00008401=-0,0000008401 Step 8.
44 • w01(baru)=-0,541180+(-0,00119817)=-0,542378 • w11(baru)=0,543960+(-0,001016)=0,542944 • v01(baru)=1,718946+(-0,0000008401)=1,718862 • v11(baru)=-1,263178+0=-1,263178 • v21(baru)=-1,083092+0=-1,083092
• Saat ini v11 dan v12 masih belum berubah karena kedua inputnya =0. Nilai v01 dan v02 baru berubah pada iterasi pertama untuk training data yang kedua Setelah step 3-8 untuk training data pertama dijalankan, selanjutnya kembali lagi ke
step 3 untuk training data yang kedua (x1=0 dan x2=1).
Langkah yang sama dilakukan sampai pada training data yang keempat. Bobot yang dihasilkan pada iterasi pertama, training data ke-2,3, dan 4 adalah:
• Training data ke-2: w01=-0,541023 w11=0,543830 v01=1,718862 v11=-1,263178 v21=-1,083092 • Training data ke-3:
w01=-0,539659 w11=0,544665 v01=1,719205 v11=-1,263002 v21=-1,082925 • Training data ke-4:
w01=-0,540661 w11=0,544316 v01=1,719081 v11=-1,263126 v21=-1,083049
Setelah sampai pada training data ke-4, maka iterasi pertama selesai.
Berikutnya, pelatihan sampai pada step9, yaitu memeriksa stopping condition dan kembali pada step 2.
Demikian seterusnya sampai stopping condition yang ditentukan terpenuhi. Setelah pelatihan selesai, bobot yang didapatkan adalah:
45 • v01=12,719601 • v11=-6,779127 • v21=-6,779127 • w01=-5,018457 • w11=5,719889
Jika ada input baru, misalnya x1=0,2 dan x2=0,9 maka outputnya dapat dicari dengan langkah umpan maju sebagai berikut:
Step 0. Bobot yang dipakai adalah bobot hasil pelatihan di atas. Step 1. Perhitungan dilakukan pada step 2-4
Step 2. Dalam contoh ini, bilangan telah berada dalam interval 0 sampai dengan 1, jadi tidak perlu diskalakan lagi.
Step 3. • z_in1=12,719601+{(0,2x-6,779127)+(0,9x-6,779127)}=5,262561 • z1=f(5,262561)=0,994845 Step 4. • y_in1=-5,018457+(0,994845x5,719889)=0,671944 • y1=f(0,671944)=0,661938
Jadi jika input x1=0,2 dan x2=0,9; output yang dihasilkan jaringan adalah 0,661938
7.3. Pengenalan Pola Karakter pada Back Propagation
46
DAFTAR PUSTAKA
Fausett, L., Fundamental of Neural Network. Architecture, Algorithms, dan Applications, Prentice Hall, 1994.
Jong Jek Siang, Jaringan Syaraf Tiruan & Pemrogramannya menggunakan MATLAB, Penerbit ANDI, 2006.
Puspitaningrum, D., Pengantar Jaringan Syaraf Tiruan, Penerbit ANDI, 2006. Haykin, S., Neural Networks, a Comprehensive Fundation, Prentice Hall, 1994.