TINJAUAN PUSTAKA
Definisi Data Mining
Sistem Manajemen Basis Data tingkat lanjut dan teknologi data warehousing mampu untuk mengumpulkan “banjir” data dan untuk mentransformasikannya ke dalam basis data yang berukuran besar. Diperlukan teknik baru yang secara pintar dan otomatis mentransformasikan data-data yang diproses untuk menghasilkan informasi dan pengetahuan yang berguna. Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Kata mining berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar (Pramudiono, 2003). Data mining merupakan proses pencarian pola dan relasi-relasi yang tersembunyi dalam sejumlah data yang besar dengan tujuan untuk melakukan klasifikasi, estimasi, prediksi, association rule, clustering, deskripsi dan visualisasi (Han dan Kamber, 2001).
Secara garis besar data mining dapat dikelompokkan menjadi 2 kategori utama, yaitu (Tan et al, 2005) :
1. Descriptive mining, yaitu proses untuk menemukan karakteristik penting dari data dalam suatu basis data. Teknik data mining yang termasuk dalam descriptive mining adalah clustering, association, dan sequential mining.
2. Predictive, yaitu proses untuk menemukan pola dari data dengan menggunakan beberapa variabel lain di masa depan. Salah satu teknik yang terdapat dalam predictive mining adalah klasifikasi.
Secara sederhana data mining bisa dikatakan sebagai proses menyaring atau
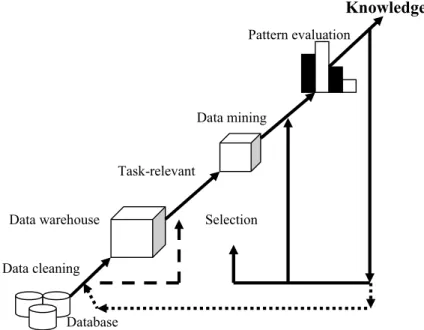
“menambang” pengetahuan dari sejumlah data yang besar. Istilah lain untuk data mining adalah Knowledge Discovery in Database atau KDD. Walaupun sebenarnya data mining sendiri adalah bagian dari tahapan proses dalam KDD, seperti yang terlihat pada Gambar 1 (Han dan Kamber, 2001).
Knowledge Pattern evaluation
Data mining
Task-relevant
Data warehouse Selection
Data cleaning
Database
Gambar 1. Data mining sebagai salah satu tahapan dalam proses Knowledge Discovery
Tujuan dari adanya data mining adalah (Thomas, 2004) :
1. explanatory, yaitu untuk menjelaskan beberapa kegiatan observasi atau suatu kondisi.
2. confirmatory, yaitu untuk mengkonfirmasi suatu hipotesis yang telah ada.
3. exploratory, yaitu untuk menganalisis data baru suatu relasi yang janggal.
Klasifikasi
Klasifikasi dan prediksi adalah dua bentuk analisis data yang bisa digunakan untuk mengekstrak model dari data yang berisi kelas-kelas atau untuk memprediksi trend data yang akan datang. Klasifikasi memprediksi data dalam bentuk kategori, sedangkan prediksi memodelkan fungsi-fungsi dari nilai yang kontinyu. Misalnya model klasifikasi bisa dibuat untuk mengelompokkan aplikasi peminjaman pada bank apakah berisiko atau aman, sedangkan model prediksi bisa dibuat untuk memprediksi pengeluaran untuk membeli peralatan komputer dari pelanggan potensial berdasarkan pendapatan dan lokasi tinggalnya.
Prediksi bisa dipandang sebagai pembentukan dan penggunaan model untuk menguji kelas dari sampel yang tidak berlabel, atau menguji nilai atau rentang
nilai dari suatu atribut. Dalam pendangan ini, klasifikasi dan regresi adalah dua jenis masalah prediksi, dimana klasifikasi digunakan untuk memprediksi nilai- nilai diskrit atau nominal, sedangkan regresi digunakan untuk memprediksi nilai- nilai yang kontinyu. Untuk selanjutnya penggunaan istilah prediction untuk memprediksi kelas yang berlabel disebut classification, dan penggunaan istilah prediksi untuk memprediksi nilai-nilai yang kontinyu sebagai prediction (Han &
Kamber, 2001).
Model Klasifikasi
Data input untuk klasifikasi adalah koleksi dari record. Setiap record dikenal sebagai instance atau contoh, yang ditentukan oleh sebuah tuple (x,y), dimana x adalah himpunan atribut dan y adalah atribut tertentu, yang dinyatakan sebagai label kelas (juga dikenal sebagai kategori atau atribut target).
Klasifikasi adalah tugas pembelajaran sebuah fungsi target f yang memetakan setiap himpunan atribut x ke salah satu label kelas y yang telah didefinisikan sebelumnya.
Fungsi target juga dikenal secara informal sebagai model klasifikasi.
Model klasifikasi berguna untuk keperluan berikut :
Pemodelan Deskriptif. Model klasifikasi dapat bertindak sebagai alat penjelas untuk membedakan objek-objek dari kelas-kelas yang berbeda. Sebagai contoh untuk para ahli Biologi, model deskriptif yang meringkas data.
Pemodelan Prediktif. Model klasifikasi juga dapat digunakan untuk memprediksi label kelas dari rekord yang tidak diketahui. Seperti pada Gambar 2 tampak sebuah model klasifikasi dapat dipandang sebagai kotak hitam yang secara otomatis memberikan sebuah label ketika dipresentasikan dengan himpunan atribut dari record yang tidak diketahui.
Input Output
Attribut set (x) Class label (y)
Gambar 2. Klasifikasi sebagai pemetaan sebuah himpunan atribut input x ke dalam label kelasnya
Classification model
Beberapa teknik klasifikasi yang digunakan adalah decision tree classifier, rule-based classifier, neural-network, support vector machine, dan naive Bayes classifier. Setiap teknik menggunakan algoritme pembelajaran untuk mengidentifikasi model yang memberikan hubungan yang paling sesuai antara himpunan atribut dan label kelas dari data input.
Pendekatan umum yang digunakan dalam masalah klasifikasi adalah, pertama, training set berisi record yang mempunyai label kelas yang diketahui haruslah tersedia. Training set digunakan untuk membangun model klasifikasi, yang kemudian diaplikasikan ke test set, yang berisi record-record dengan label kelas yang tidak diketahui.
Decision Tree (Pohon Keputusan)
”Apakah yang dimaksud dengan decision tree?” Decision tree (pohon keputusan) adalah sebuah diagram alir yang mirip dengan struktur pohon, di mana setiap internal node menotasikan atribut yang diuji, setiap cabangnya merepresentasikan hasil dari atribut tes tersebut, dan leaf node merepresentasikan kelas-kelas tertentu atau distribusi dari kelas-kelas (Han & Kamber, 2001).
Klasifier pohon keputusan merupakan teknik klasifikasi yang sederhana yang banyak digunakan. Bagian ini membahas bagaimana pohon keputusan bekerja dan bagaimana pohon keputusan dibangun.
Seringkali untuk mengklasifikasikan obyek, kita ajukan urutan pertanyaan sebelum bisa kita tentukan kelompoknya. Jawaban pertanyaan pertama akan mempengaruhi pertanyaan berikutnya dan seterusnya. Dalam decision tree, pertanyaan pertama akan kita tanyakan pada simpul akar pada level 0. Jawaban dari pertanyaan ini dikemukakan dalam cabang-cabang. Jawaban dalam cabang akan disusul dengan pertanyaan kedua lewat simpul yang berikutnya pada level 1.
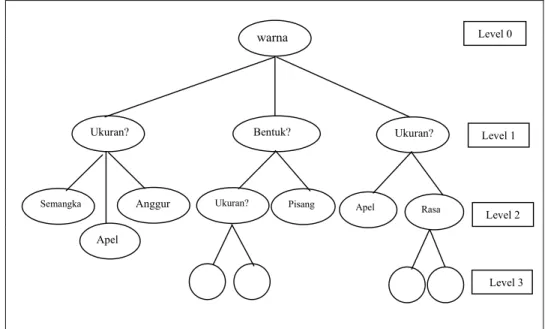
Dengan memperhatikan decision tree dalam Gambar 3 akan nampak ada 4 level pertanyaan. Dalam setiap level ditanyakan nilai atribut melalui sebuah simpul.
Jawaban dari pertanyaan itu dikemukakan lewat cabang-cabang. Langkah ini akan berakhir di suatu simpul jika pada simpul tersebut sudah ditemukan kelas atau jenis obyeknya. Kalau dalam satu tingkat suatu obyek sudah diketahui termasuk
warna
Ukuran? Bentuk? Ukuran?
Semangka Anggur
Apel
Ukuran? Pisang Apel Rasa
Level 0
Level 1
Level 2
Level 3
dalam kelas tertentu, maka kita berhenti di level tersebut. Jika tidak, maka dilanjutkan dengan pertanyaan di level berikutnya hingga jelas ciri-cirinya dan jenis obyek dapat ditentukan (Santosa, 2007).
Gambar 3. Contoh penggunaan metode Decision Tree untuk menentukan jenis buah
Walaupun banyak variasi model decision tree dengan tingkat kemampuan dan syarat yang berbeda, pada umumnya beberapa ciri kasus cocok untuk diterapkan decision tree (Santosa, 2007) :
1. Data dinyatakan dengan pasangan atribut dan nilainya. Misalnya atribut satu data adalah temperatur dan nilainya adalah dingin. Biasanya untuk satu data nilai dari satu atribut tidak terlalu banyak jenisnya. Dalam contoh atribut warna buah ada beberapa nilai yang mungkin yaitu hijau, kuning, merah.
2. Label/output data biasanya bernilai diskrit. Output ini bisa bernilai ya atau tidak, sakit atau tidak sakit, diterima atau ditolak. Dalam beberapa kasus mungkin saja outputnya tidak hanya dua kelas, tetapi penerapan decision tree lebih banyak untuk kasus binary.
3. Data mempunyai missing value. Misalkan untuk beberapa data, nilai dari suatu atributnya tidak diketahui. Dalam keadaan seperti ini decision tree masih mampu memberi solusi yang baik.
Algoritme C5.0
Algoritme C5.0 adalah salah satu algoritme yang terdapat dalam klasifikasi data mining disamping algoritme CART, yang khususnya diterapkan pada teknik decision tree. C5.0 merupakan penyempurnaan algoritme terdahulu yang dibentuk oleh Ross Quinlan pada tahun 1987, yaitu ID3 dan C4.5. Dalam algoritme C5.0, pemilihan atribut yang akan diproses menggunakan information gain. Secara heuristik akan dipilih atribut yang menghasilkan simpul yang paling bersih (purest). Kalau dalam cabang suatu decision tree anggotanya berasal dari satu kelas maka cabang ini disebut pure. Kriteria yang digunakan adalah information gain. Jadi dalam memilih atribut untuk memecah obyek dalam beberapa kelas harus kita pilih atribut yang menghasilkan information gain paling besar.
Ukuran information gain digunakan untuk memilih atribut uji pada setiap node di dalam tree. Ukuran ini digunakan untuk memilih atribut atau node pada pohon. Atribut dengan nilai information gain tertinggi akan terpilih sebagai parent bagi node selanjutnya. Formula untuk information gain adalah (Kantardzic, 2003):
( ) ∑
=
−
= m
i
i i
m p p
s s s I
1
2 2
1, ,...., log ( ) (2.1)
S adalah sebuah himpunan yang terdiri dari s data sampel. Diketahui atribut class adalah m dimana mendefinisikan kelas-kelas di dalamnya, Ci (for i= 1, …, m), si adalah jumlah sampel pada S dalam class Ci. untuk mengklasifikasikan sampel yang digunakan maka diperlukan informasi dengan menggunakan aturan seperti di atas (2.1). Dimana pi adalah proporsi kelas dalam output seperti pada kelas Ci dan diestimasikan dengan si /s. Atribut A memiliki nilai tertentu {a1, a2,
…, av}. Atribut A dapat digunakan pada partisi S ke dalam v subset, {S1, S2, …, Sv}, dimana Sj berisi sample pada S yang bernilai aj pada A. Jika A dipilih sebagai atribut tes (sebagai contoh atribut terbaik untuk split), maka subset ini akan berhubungan pada cabang dari node himpunan S. Sij adalah jumlah sample pada class Ci dalam sebuah subset Sj. Untuk mendapatkan informasi nilai subset dari atribut A tersebut maka digunakan formula,
(
j mj)
y j
mj
j I s s
s s A s
E ... ,...
)
( 1
1
∑
1=
+
= + (2.2)
s
s s1j+ ..+ mj
adalah jumlah subset j yang dibagi dengan jumlah sampel pada S, maka untuk mendapatkan nilai gain, selanjutnya digunakan formula
Gain(A)=I(s1,s2,...,sm)–E(A) (2.3)
C5.0 memiliki fitur penting yang membuat algoritme ini menjadi lebih unggul dibandingkan dengan algoritme terdahulunya dan mengurangi kelemahan yang ada pada algoritme decision tree sebelumnya. Fitur tersebut adalah (Quinlan, 2004) :
1. C5.0 telah dirancang untuk dapat menganalisis basis data subtansial yang berisi puluhan sampai ratusan record dan satuan hingga ratusan field numerik dan nominal.
2. untuk memaksimumkan tingkat penafsiran pengguna terhadap hasil yang disajikan, maka klasifikasi C5.0 disajikan dalam dua bentuk, menggunakan pohon keputusan dan sekumpulan aturan IF-then yang lebih mudah untuk dimengerti dibandingkan neural network.
3. C5.0 mudah digunakan dan tidak membutuhkan pengetahuan tinggi tentang statistik atau machine learning.
K-Nearest Neighbor Algorithm
Seperti halnya decision tree, K-Nearest Neighbor sangat sering digunakan dalam klasifikasi dengan tujuan dari algoritme ini adalah untuk mengklasifikasi objek baru berdasarkan atribut dan training samples (Larose, 2002 ).
Algoritme k-nearest neighbor (k-NN atau KNN) adalah sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut. Teknik ini sangat sederhana dan mudah diimplementasikan. Mirip dengan teknik klastering, pengelompokkan suatu data baru berdasarkan jarak data baru itu ke beberapa data/tetangga
(neighbor) terdekat. Dalam hal ini jumlah data/tetangga terdekat ditentukan oleh user yang dinyatakan dengan k. Misalkan ditentukan k=5, maka setiap data testing dihitung jaraknya terhadap data training dan dipilih 5 data training yang jaraknya paling dekat ke data testing. Lalu periksa output atau labelnya masing-masing, kemudian tentukan output mana yang frekuensinya paling banyak. Lalu masukkan suatu data testing ke kelompok dengan output paling banyak. Misalkan dalam kasus klasifikasi dengan 3 kelas, lima data tadi terbagi atas tiga data dengan output kelas 1, satu data dengan output kelas 2 dan satu data dengan output kelas 3, maka dapat disimpulkan bahwa output dengan label kelas 1 adalah yang paling banyak. Maka data baru tadi dapat dikelompokkan ke dalam kelas 1. Prosedur ini dilakukan untuk semua data testing (Santosa, 2007). Gambar 4 berikut ini adalah bentuk representasi K-NN dengan 1, 2 dan 3 tetangga data terhadap data baru x (Pramudiono, 2003).
(a)1-nearest neighbor (b)2-nearest neighbor (c)3-nearest neighbor Gambar 4. Ilustrasi 1-, 2-, 3-nearest neighbor terhadap data baru (x)
Untuk mendefinisikan jarak antara dua titik yaitu titik pada data training (x) dan titik pada data testing (y) maka digunakan rumus Euclidean,
∑
=−
=
ni
i
i
y
x y
x d
1
) (
) ,
(
2 (2.4)dengan d adalah jarak antara titik pada data training x dan titik data testing y yang akan diklasifikasi, dimana x=x1,x2,…,xi dan y=y1,y2,…,yi dan I merepresentasikan nilai atribut serta n merupakan dimensi atribut (Han &
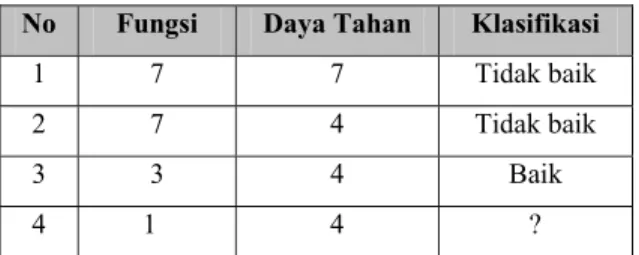
Kamber, 2001). Sebagai ilustrasi, pada Tabel 1 berikut ini disajikan contoh penerapan rumus Euclidean, pada empat data klasifikasi kualitas baik dan tidak baik sebuah kertas tisu yang dinilai berdasarkan daya tahan kertas tersebut dan fungsinya. Sebanyak tiga data yang sudah terklasifikasi yaitu data no 1,2, dan 3
- - - - - - - - - - + +
- + - - + +
- + - x
- - - - - - - - - + +
- + - - + +
+ - x + - - - -
- - - + + - + - - + +
- x
masing-masing data dihitung jaraknya ke data no 4 untuk mendapatkan kelas yang sesuai bagi data no 4 maka k=1 (Teknomo, 2006).
Tabel 1. Tabel klasifikasi kualitas baik atau tidak baik sebuah kertas tisu No Fungsi Daya Tahan Klasifikasi
1 7 7 Tidak baik
2 7 4 Tidak baik
3 3 4 Baik
4 1 4 ?
Berikut ini disajikan pula perhitungan yang dilakukan terhadap tiga data yang sudah terklasifikasi dengan data yang belum terklasifikasi pada Tabel 1 di atas.
Jarak data no satu ke data no empat:
07 . 6 45 3
6 ) 4 7 ( ) 1 7
( 2 2 2 2
4 ,
1 = − + − = + = =
d
Jarak data no dua ke data no empat:
6 36 0
6 ) 4 4 ( ) 1 7
( 2 2 2 2
4 ,
2 = − + + = + = =
d
Jarak data no tiga ke data no empat:
2 4 0
2 )
4 4 ( ) 1 3
( 2 2 2 2
4 ,
3 = − + + = + = =
d
Dari hasil perhitungan di atas diperoleh jarak antara data no tiga dan data no empat adalah jarak yang terdekat maka kelas data no empat adalah baik.
Teknik ini akan diujicobakan terhadap dataset akademik yang belum terklasifikasi atau data yang belum dikenal, untuk menemukan kelas yang sesuai dengan berdasarkan pada data tetangga terdekatnya yang sudah terklasifikasi.
Tingkat ketepatan klasifikasi terhadap data dari kedua algoritma yang digunakan menjadi titik fokus analisa dalam penelitian.
Membangun Model Prediksi
Secara umum, proses dasar dalam membangun model prediksi adalah sama, terlepas dari teknik data mining yang akan digunakan. Keberhasilan dalam membangun model lebih banyak tergantung pada proses bukan pada teknik yang
digunakan, dan proses tersebut sangat tergantung pada data yang digunakan untuk menghasilkan model. Hal ini terkait dengan tahapan praproses data dalam data mining yaitu pembersihan data (data cleaning) yang harus dikerjakan sebelum melakukan tahap pengolahan data dengan tujuan membersihkan data yang akan diolah dari redudancy dan missing value.
Tantangan utama dalam membangun model prediksi adalah mengumpulkan data awal yang cukup banyak jumlahnya. Data preclassified, hasilnya sudah diketahui, dan oleh karena itu data preclassified digunakan untuk melatih model, sehingga disebut model set. Data dibagi secara acak menggunakan teknik 3-fold cross validation ke dalam kelompok data training dan data testing. Masing- masing kelompok akan diujicobakan ke dalam kedua algoritma yang dipakai.
Alat ukur dalam evaluasi
Evaluasi model merupakan tahapan yang juga dikerjakan dalam penelitian dengan tujuan untuk memperoleh informasi yang terdapat pada hasil klasifikasi terhadap kedua algoritma yang digunakan. Dalam weka classifier hasil klasifikasi yang diperoleh disertakan dengan beberapa alat ukur yang tersedia di dalamnya, diantaranya adalah sebagai berikut :
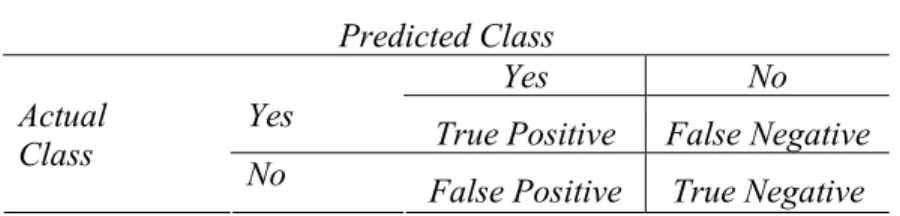
- Confusion matrix
Dalam penelitian ini dipilih alat ukur evaluasi berupa confusion matrix yang terdapat pada weka classifier dengan tujuan untuk mempermudah dalam menganilisis performa algoritma karena confusion matrix memberikan informasi dalam bentuk angka sehingga dapat dihitung rasio keberhasilan klasifikasi. Confusion matrix adalah salah satu alat ukur berbentuk matrik 2x2 yang digunakan untuk mendapatkan jumlah ketepatan klasifikasi dataset terhadap kelas aktif dan tidak aktif pada kedua algoritma yang dipakai. Dalam kasus dengan dua klasifikasi data keluaran seperti contoh : ya dan tidak, pinjam atau tidak pinjam, atau contoh lainnya, tiap kelas yang diprediksi memiliki empat kemungkinan keluaran yang berbeda, yaitu true positives (TP) dan true negatives (TN) menunjukkan ketepatan klasifikasi.
Jika prediksi keluaran bernilai positif sedangkan nilai aslinya adalah negatif
maka disebut dengan false positive (FP) dan jika prediksi keluaran bernilai negatif sedangkan nilai aslinya adalah positif maka disebut dengan false negative (FN). Berikut ini pada Tabel 2 disajikan bentuk confusion matrix seperti yang telah dijelaskan sebelumnya.
Tabel 2. Perbedaan hasil yang diperoleh dari dua kelas prediksi Predicted Class
Yes No Yes True Positive False Negative
Actual
Class No False Positive True Negative
Beberapa kegiatan yang dapat dilakukan dengan menggunakan data hasil klasifikasi dalam confusion matrix diantaranya :
- menghitung nilai rata-rata keberhasilan klasifikasi (overall success rate) ke dalam kelas yang sesuai dengan cara membagi jumlah data yang terklasifikasi dengan benar, dengan seluruh data yang diklasifikasi.
- Selain itu dilakukan pula penghitungan persentase kelas positif ( true positive & false positive ) yang diperoleh dalam klasifikasi, yang disebut dengan lift chart.
- Lift chart terkait erat dengan sebuah tehnik dalam mengevaluasi skema data mining yang dikenal dengan ROC (receiver operating characteristic) yang berfungsi mengekspresikan persentase jumlah proporsi positif dan negatif yang diperoleh.
- Recall precision berfungsi menghitung persentase false positive dan false negative untuk menemukan informasi di dalamnya .
Review Riset yang Relevan
Moertini (2003) melakukan penelitian menggunakan algoritma C4.5 yang merupakan algoritma pendahulu dari C5.0. Hasil dari penelitian tersebut menyebutkan bahwa algoritma C4.5 memiliki performa yang baik dalam
mengkonstruksi sebuah pohon keputusan dan menghasilkan aturan-aturan yang dapat digunakan pada waktu yang akan datang. Salah satu kesimpulan yang diperoleh mempertegas alasan bahwa algoritma ini digunakan untuk klasifikasi data yang memiliki atribut-atribut numerik dan kategorikal.
Sufandi (2007) melakukan penelitian untuk memprediksi kemajuan belajar mahasiswa aktif yaitu dengan melakukan pengujian menggunakan data dengan kategori mahasiswa aktif dengan metode Neural Network Multi Layer Perceptron namun tidak selesai dikejakan karena hasil klasifikasi mahasiswa aktif & tidak aktif tidak diperoleh dengan jelas .