BAB VI
HETEROSKEDASTISITAS
Model regresi menghendaki tidak adanya masalah heteroskedastisitas. Jika varian dari galat suatu pengamatan ke pengamatan yang lain tetap, maka disebut homoskedastisitas. Jika varian berbeda, disebut heteroskedastisitas. Heteroskedastisitas tidak merusak sifat ketidakbiasan dan konsistensi dari penaksir Metode Kuadrat Terkecil. Tetapi, penaksir ini tidak lagi mempunyai varian minimum atau efisien. Dengan kata lain, mereka tidak lagi BLUE (Best Linear Unbiased Estimator / Penaksir tak bias linier terbaik). Penaksir yang BLUE diberikan olaeh Metode Kuadrat Terkecil Tertimbang. Contoh masalah heteroskedastisitas adalah orang kaya akan bervaraiasi dalam membelanjakan uangnya, sedangkan orang miskin hanya bisa sedikit bervariasi dalam berbelanja. Hal ini menunjukkan variasi yang tidak sama antara kedua golongan tersebut, yang berarti timbul masalah heteroskedastisitas.
Contoh :
Data berikut menyajikan rata-rata produktivitas tenaga kerja dan standar deviasi dari produktivitas tenaga kerja untuk sembilan kelas jumlah karyawan
Jumlah karyawan Rata-rata Produktivitas Standar Deviasi Produktivitas
1 – 4 9355 2487 5 – 9 8584 2642 10 -19 7962 3055 20 – 49 8275 2706 50 – 99 8389 3119 100 – 249 9418 4493 250 – 499 9795 4910 500 – 999 10281 5893 1000 - 2499 11750 5550
Apa yang dapat anda katakan mengenai sifat heteroskedastisitas, jika ada dalam data tadi ? Jawab :
Dari menu utama SPSS, pilih menu Analyze Regression Linear…. Dependent : Y
Independent(s) : X Method : Enter
Gambar 6.1 Kotak Dialog Statistik Masukkan variabel SRESID pada sumbu (pilihan) Y
Masukkan variabel ZPRED pada sumbu (pilihan) X Continue, OK
Catatan :
Deteksi adanya heteroskedastisitas
Deteksi dengan melihat ada tidaknya pola tertentu pada grafik yang dihasilkan, dimana sumbu X adalah Y yang telah diprediksi, dan sumbu X adalah residual (Y prediksi – Y sesungguhnya) yang telah distudentized.
Dasar pengambilan keputusan :
· Jika ada pola tertentu, seperti titik-titik (point-point) yang ada membentuk suatu pola tertentu yang teratur (bergelombang, melebar kemudian menyempit), maka telah terjadi heteroskedastisitas
· Jika tidak ada pola yang jelas, serta titik-titik menyebar di atas dan di bawah angka 0 pada sumbu Y , maka tidak terjadi heteroskedastisitas.
Hasil Analisa :
(Hanya tampilan grafik saja)
Scatterplot
Dependent Variable: Y
2.0 1.5 1.0 .5 0.0 -.5 -1.0 -1.5 -2.0 -1.5 -1.0 -.5 0.0 .5 1.0 1.5 2.0 2.5Regression Standardized Predicted Value
Interpretasi :
Dari grafik di atas, terlihat titik-titk menyebar dengan membentuk pola tertentu. Hal ini berarti terjadi heteroskedastisitas pada model regresi, sehingga model regresi tidak layak dipakai untuk prediksi.
Langkah untuk menghilangkan heteroskedastisitas.
Transformasi Log seringkali akan mengurangi heteroskedastisitas. Hal ini disebabkan karena transformasi yang memampatkan skala untuk pengukuran variabel, menguragi perbedaan antara kedua nilai tadi dari sepuluh kali lipat menjadi perbedaan dua kali lipat. Misal, angka 80 adalah 10 kali angka 8, tetapi ln 80 (= 4.3820) hanya dua kali besarnya ln 8 (= 2.0794).
Perhatikan dua model regresi berikut :
Yi = β0 + β1Xi + ui (persamaan 6.1)
Ln Yi = β0 + β1 ln Xi + ui (persamaan 6.2)
Manfaat tambahan dari transformasi log bahwa koefisien kemiringan β1 mengukur elastisitas dari Y terhadap X, yaitu persentase perubahan dalam Y untuk persentase perubahan dalam X. Misalnya, jika Y adalah konsumsi dan X adalah pendapatan, maka β1 (dalam persamaan 6.2) akan mengukur elastisitas pendapatan, sedangkan dalam model regresi asli (persamaan 6.1) β1, hanya mengukur tingkat rata-rata pertumbuhan konsumsi untuk satu unit perubahan dalam pendapatan.
Dari data yang sama di atas, kita akan hitung nilai Ln X dan Ln Y, didapat :
10281 5893 9.24 8.68
11750 5550 9.37 8.62
Dari menu utama SPSS, pilih menu Analyze Regression Linear….
Dependent : Ln Y
Independent(S) : Ln X
Method : Enter
Tekan tombol Plot …, dan masukkan variabel SRESID pada sumbu (pilihan) Y dan masukkan variabel ZPRED pada sumbu (pilihan) X.
Continue, OK Hasil Analisa :
Scatterplot
Dependent Variable: LN_Y
1.5 1.0 .5 0.0 -.5 -1.0 -1.5 -2.0 -1.5 -1.0 -.5 0.0 .5 1.0 1.5 2.0Regression Standardized Predicted Value Interpretasi :
Dari grafik di atas, terlihat titik-titk menyebar secara acak dan tidak berpola. Hal ini berarti tidak terjadi problem heteroskedastisitas pada model regresi, sehingga model regresi layak dipakai untuk prediksi.
BAB VII
AUTOKORELASI
Dalam analisis regresi diasumsikan bahwa galat acaknya tidak saling berkorelasi satu sama lain. Kalau asumsi ini tidak terpenuhi berarti ada korelasi diantara galat acaknya, maka estimasi koefisiennya tetap tidak bebrbias tetapi variasi dari koefisien itu tidak minimal lagi. Autokorelasi didefinisikan sebagi terjadinya korelasi diantara data-data pengamatan, atau dengan kata lain munculnya suatu data dipengaruhi data sebelumnya. Artinya, ada korelasi antar anggota sampel yang diurutkan berdasar waktu. Tentu saja model regresi yang baik adalah regresi yang bebas dari autokorelasi. Autukorelasi pada sebagian besar kasus ditemukan pada regresi yang datanya adalah time series, atau berdasarkan waktu berkala, seperti bulanan, tahunan, dan sebagainya.
Contoh :
Y (nilai penjualan) : 64 61 84 70 88 92 72 77 X (biaya promosi) : 20 16 34 23 27 32 18 22 Buktikan apakah terdapat autokorelasi dari data di atas ? Jawab :
Dari menu utama SPSS, pilih menu Analyze Regression Linear Dependent : Y
Independent (s) : X Method : Enter
Tekan tombol, Statistics …, dan aktifkan pilihan Durbin-Watson pada bagian residuals
Continue, OK
Catatan :
Deteksi adanya autokorelasi
Ada tidaknya autokorelasi dapat dilihat dari statistik d Durbin-Watson. Nilai statistik d
terletak antara 0 dan 4. Bila :
D-W < 1.10 1.10 – 1.54 1.55 – 2.46 2.47 – 2.90 > 2.91 Kesimpulan Ada autokorelasi positif
Tanpa Kesimpulan Tidak Ada Autokorelasi
Tanpa Kesimpulan Ada Autokorelasi Negatif
Jika ada masalah autokorelasi, maka model regresi yang seharusnya signifikan (lihat angka F dan signifikansinya), menjadi tidak layak untuk dipaklai. Autokorelasi bisa diatasi dengan beberapa cara antara lain :
Variables Entered/Removedb
Variables Variables
Model Entered Removed Method
1 Xa . Enter
a.
All requested variables entered.
b. Dependent Variable: Y
Model Summaryb
Adjusted Std. Error of Durbin-W
Model R R Square R Square the Estimate atson
1 .862a .743 .700 6.16 .830
a.
Predictors: (Constant), X b. Dependent Variable: Y ANOVAb Sum ofModel Squares df Mean Square F Sig.
1 Regression 658.503 1 658.503 17.367 .006a Residual 227.497 6 37.916 Total 886.000 7
a.
Predictors: (Constant), X b. Dependent Variable: Y Coefficientsa Standardi zed Unstandardized Coefficien Coefficients tsModel B Std. Error Beta t Sig.
1 (Constant) 40.082 8.890 4.509 .004
X 1.497 .359 .862 4.167 .006
a.
Dependent Variable: Y
Interpretasi :
Pada bagian model summary, terlihat angka Durbin-Watson sebesar +0.830. Hal ini berarti model regresi di atas terdapat masalah autokorelasi positif, sehingga model regresi yang didapat menjadi tidak layak untuk dipakai.
Langkah untuk menghilangkan autokorelasi :
Autokorelasi dapat timbul karena berbagai alasan. Jika terjadi autokorelasi, maka diperlukan tindakan perbaikan. Jika koefisien autokorelasi diketahui, masalah autokorelasi dapat diatasi dengan transformasi data mengikuti prosedur persamaan perbedaan yang digeneralisasikan. Namun tidak selalu dengan transformasi, dapat menyelesaikan masalah autokorelasi. Untuk data kita di atas, dicoba dengan transformasi ln.
Y X Ln Y Ln X
64 20 4.16 3.00 61 16 4.11 2.77 84 34 4.43 3.53 70 23 4.25 3.14 88 27 4.48 3.30 92 32 4.52 3.47 72 18 4.28 2.89 77 22 4.34 3.09
Dari menu utama SPSS, pilih menu Analyze Regression Linear …. Dependent : Y
Independent (s) : X2 Method : Enter
Tekan tombol Statistics…, dan aktifkan pilihan Durbin- Watson pada bagian residuals. Continue, OK.
Hasil Analisa :
Variables Entered/Removedb
Variables Variables
Model Entered Removed Method
1 LN_Xa . Enter
a.
All requested variables entered.
b. Dependent Variable: LN_Y
Model Summaryb
Adjusted Std. Error of Durbin-W
Model R R Square R Square the Estimate atson
1 .873a .763 .723 7.832E-02 .876
a.
Predictors: (Constant), LN_X
b. Dependent Variable: LN_Y
ANOVAb Sum of
Model Squares df Mean Square F Sig.
1 Regression .118 1 .118 19.270 .005a
Residual 3.680E-02 6 6.134E-03
Total .155 7
a.
Predictors: (Constant), LN_X
Coefficientsa
Standardi zed
Unstandardized Coefficien
Coefficients ts
Model B Std. Error Beta t Sig.
1 (Constant) 2.791 .350 7.982 .000
LN_X .486 .111 .873 4.390 .005
a.
Dependent Variable: LN_Y
Interpretasi :
Meskipun telah dicoba untuk melakukan transformasi data dengan transformasi ln, namun angka Durbin-Watson (0.876) tetap menunjukkan adanya autokorelasi positif. Hal ini berarti model regresi di atas terdapat masalah autokorelasi, sehingga model regresi yang didapat menjadi tidak layak untuk dipakai. Perlu dicoba cara lain untuk menghilangkan masalah autokorelasi misalnya dengan menambah data observasi.
BAB VIII MULTIKOLINIERITAS
Satu asumsi dari analisis regresi adalah tidak adanya korelasi antar variabel independen (variabel bebas). Jika terjadi korelasi, maka dinamakan terdapat problem multikolinieritas. Tanda yang paling jelas dari multikolinieritas adalah adalah ketika R2 sangat tinggi (0.7 – 1), tetapi tidak satu pun koefisien regresi yang signifikan (nyata) secara statistik. Salah satu cara untuk mengatasi multikolinieritas adalah dengan transformasi data dan mengeluarkan satu dari variabel yang berkolinier.
Contoh :
Data hipotetik mengenai belanja konsumsi Y, pendapatan X2 dan kekayaan X3.
Y X2 X3 70 80 810 65 100 1009 90 120 1273 95 140 1425 110 160 1633 115 180 1876 120 200 2052 140 220 2201 155 240 2435 150 260 2686
Uji apakah terdapat multikolinieritas dari data di atas ! Jawab :
Dari menu utama SPSS, pilih menu Analyze Regression Linear …. Dependent : Y
Independent (s) : X2, X3 Method : Enter
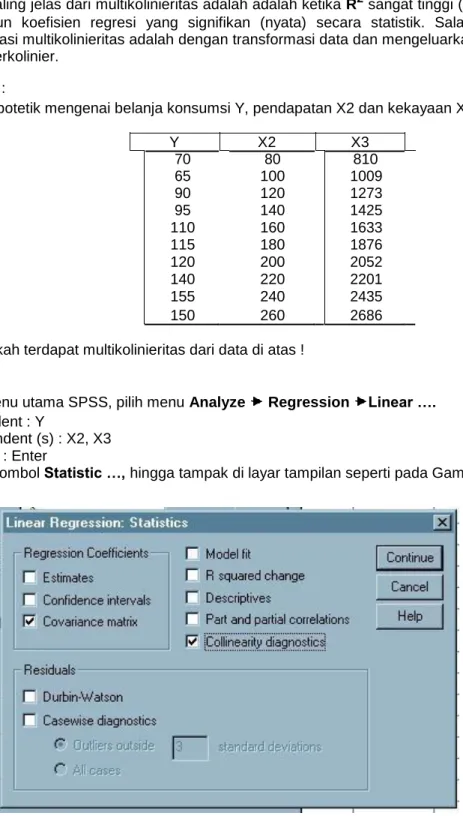
Tekan tombol Statistic …, hingga tampak di layar tampilan seperti pada Gambar 8.1 berikut ini.
Non aktifkan pilihan Estimates dan Model Fit
Aktifkan pilihan Covariance matrix dan Collinearity diagnostics Continue, OK.
Catatan :
Deteksi adanya multikolinieritas
a. Besaran VIF (Variance Inflation Factor) dan Tolerance
Pedoman suatu model regresi yang bebas multikolinieritas adalah : · Mempunyai nilai VIF di sekitar angka 1
· Mempunyai angka TOLERANCE mendekati 1. b. Besaran korelasi antar variabel independent
Pedoman suatu model regresi yang bebas multikolinieritas adalah koefisien korelasi antar variabel independen haruslah lemah (di bawah 0.5). Jika korelasi kuat, maka terjadi problem multikolinieritas. c. Pengujian pada eigen value, jika eigen value mendekati nol maka terjadi multikolinieritas.
Hasil Analisa :
Variables Entered/Removedb
Variables Variables
Model Entered Removed Method
1 X3, X2a . Enter
a.
All requested variables entered.
b. Dependent Variable: Y Model Summarya
a.
Dependent Variable: Y Coefficientsa Collinearity StatisticsModel Tolerance VIF
1 X2 .002 482.128 X3 .002 482.128
a.
Dependent Variable: Y Coefficient Correlationsa Model X3 X2 1 Correlations X3 1.000 -.999 X2 -.999 1.000Covariances X3 6.507E-03 -6.63E-02
X2 -6.63E-02 .677
a.
Dependent Variable: Y
Collinearity Diagnosticsa
Condition Variance Proportions
Model Dimension Eigenvalue Index (Constant) X2 X3
1 1 2.930 1.000 .01 .00 .00
2 6.971E-02 6.483 .98 .00 .00
3 1.060E-04 166.245 .00 1.00 1.00
a.
Dependent Variable: Y Interpretasi :Pada bagian COEFFICIENT terlihat angka untuk kedua variabel bebas angka VIF = 482.128 yang jauh lebih besar dari 1. Demikian juga nilai TOLERANCE = 0.002 yang jauh lebih kecil dari 1. Dengan demikian dapat disimpulkan bahwa pada model regresi tersebut terdapat problem multikolinieritas. Koefisien korelasi antar variabel bebas (X2 dan X3) sangat kuat, yaitu sebesar – 0.999. Hal ini menunjukkan adanya problem multikolinieritas dalam model regresi di atas.
Langkah untuk menghilangkan multikolinieritas.
Salah satu cara untuk menghilangkan problem multikolinieritas adalah dengan mengeluarkan salah satu variabel dan melakukan transformasi data. Berikut ini dicoba untuk menghilangkan problem multikolinieritas dengan mengeluarkan salah satu variable. Dari soal di atas, dicoba untuk membuat model regresi baru tanpa melibatkan X3 (kekayaan).
Dari menu utama SPSS, pilih menu Analyze Regression Linear …. Dependent : Y
Independent (s) : X2Method : Enter
Tekan tombol Statistics…, non aktifkan pilihan Estimates dan Model Fit dan aktifkan pilihan Covariance matrix dan Collinearity diagnostics
Continue, OK. Hasil Analisa :
Variables Entered/Removedb
Variables Variables
Model Entered Removed Method
1 X2a . Enter
a.
All requested variables entered.
b.
Dependent Variable: Y
Coefficientsa
Collinearity Statistics
Model Tolerance VIF
Collinearity Diagnosticsa
Condition Variance Proportions Model Dimension Eigenvalue Index (Constant) X2
1 1 1.947 1.000 .03 .03
2 5.263E-02 6.083 .97 .97
a.
Dependent Variable: Y Interpretasi :
Pada bagian COEFFICIENT terlihat angka VIF dan TOLERANCE untuk variable bebas X2 = 1.000. Dengan demikian dapat disimpulkan bahwa pada model regresi tanpa melibatkan X3 tidak terdapat problem multikolinieritas, sehingga model tersebut layak untuk digunakan untuk menduga Y = belanja konsumsi.