Imputasi Missing data Menggunakan Algoritma
Pengelompokan Data K-Harmonic Means
Abidatul Izzah 1), Nur Hayatin2) 1)
Jurusan Teknik Informatika ITS Surabaya Jl. Teknik Kimia Kampus Teknik Informatika ITS Surabaya
2)
Teknik Informatika Universitas Muhammadiyah Malang Jl. Raya Tlogomas 246, Malang Indonesia
1)
Abstract— Missing data adalah hilangnya suatu nilai
atribut tertentu pada suatu instance dataset. Permasalahan ini disebabkan oleh tidak adanya data di lapangan atau adanya kesalahan dalam pencacahan. Metode yang sering digunakan untuk mengatasi permasalahan ini adalah dengan mengisi nilai dari rataan atribut yang ada atau menghilangkan instance yang mengandung missing data. Penggunaan metode ini dirasa kurang efektif karena dapat menghilangkan informasi penting yang mungkin terdapat pada data yang dibuang. Metode lain yang digunakan adalah dengan mengestimasi nilai missing data atau yang dikenal dengan imputasi data. Salah satu teknik imputasi yang digunakan adalah algoritma pengelompokan data K-Means (KM). Dalam perkembangannya, KM telah disempurnakan untuk menghindari pengaruh dari data-data yang ada di sekitar titik tengah klaster, metode pengelompokan data ini disebut dengan K-Harmonic Means (KHM). KHM merupakan variasi model KM dalam hal fungsi obyektif yang digunakan. Penelitian ini bertujuan untuk mengimputasi nilai yang hilang pada suatu data menggunakan K-Harmonic Means. Algoritma KHM digunakan untuk menentukan titik centroid yang digunakan untuk mengestimasi nilai missing data. Data yang digunakan dalam penelitian ini adalah lima dataset yang diperoleh dari UCI Machine Learning. Dengan menggunakan pendekatan metode ini diharapkan hasil imputasi missing data yang diperoleh memiliki Mean Square Error (MSE) sekecil mungkin.
Keywords— Imputasi, Harmonic Means,
K-Means, Missing data
I. PENDAHULUAN
Dalam kasus nyata, banyak sekali ditemukan dataset yang setengah dari fiturnya hilang. Permasalahan ini disebut dengan missing data.
Missing data dapat diakibatkan oleh kesalahan
sistem maupun human error. Dalam banyak kasus yang berkaitan dengan pengenalan pola maupun klasifikasi, missing data merupakan permasalahan yang dapat mempengaruhi hasil klasifikasi.
Missing data menjadi kelemahan umum dalam
klasifikasi dimana hampir semua metode klasifikasi hanya dapat bekerja pada data yang lengkap. Hal ini yang mendorong perlunya dicari metode khusus untuk penanganan terhadap
permasalahan yang berkaitan dengan missing data. Metode yang umum digunakan adalah dengan cara membuang data yang mengandung missing (case
deletion). Beberapa metode telah dikembangkan
khusus untuk menangani missing data. Salah satu metode tersebut adalah teknik imputasi. Teknik imputasi sendiri dibedakan menjadi beberapa metode, yang paling popular adalah: mean,
median, modus, dan klasterisasi.
Imputasi missing data pernah dilakukan oleh Malarvizhi menggunakan KM. Dalam penelitian tersebut dilakukan analisa kinerja KM dan
K-Nearest Neighbour (KNN) untuk imputasi missing
data. Analisa dilakukan dengan cara membandingkan akurasi dari hasil klasterisasi kedua metode tersebut. Hasil pengujian menunjukkan bahwa KM menunjukkan akurasi kurang baik dibanding KNN. Hal ini dimungkinkan karena KM memiliki kelemahan pada inisialisasi centroid (Malarvizhi dkk, 2012).
K-Means (KM) adalah salah satu algoritma
pengelompokan data yang dapat digunakan untuk melakukan imputasi pada missing data. Algoritma KM mengelompokkan data (klasterisasi) berdasarkan titik pusat klaster (centroid). Pen (1999) telah melakukan perbandingan empat teknik inisialisasi centroid, yaitu random, Forgy, MacQueen dan Kaufman. Proses inisialisasi
centroid sangat mempengaruhi hasil klasterisasi sehingga permasalahan sensitifitas terhadap penentuan titik awal menjadi kelemahan metode ini Jika inisialisasi centroid kurang optimal, maka hasil klasterisasi juga akan kurang optimal. Disamping itu titik awal pusat klaster yang ditentukan secara random sangat memungkinkan hasil klaster konvergen pada lokal optimal Hal inilah yang menjadi salah satu kelemahan KM (Pen, 1999). Untuk mengatasi masalah yang terjadi pada inisialisasi pusat klaster, Zhang, Hsu, dan Dayal (Zhang dkk, 1999) mengusulkan sebuah metode baru yang diberi nama K-Harmonic Means (KHM) yang kemudian dimodifikasi oleh Hammerly dan Elkan (Hammerly, 2002).
Penelitian ini bertujuan untuk menerapkan algoritma KHM sebagai algoritma untuk imputasi
missing data agar didapatkan estimasi nilai untuk
sebenarnya. Penelitian ini juga membandingkan beberapa metode imputasi yang lain (KM, Mean, dan Median) untuk mengetahui kinerja dari metode tersebut dengan menganalisa klasterisasi data yang dihasilkan.
II. STUDI PUSTAKA
A. Pengelompokan Data
Pengelompokkan data dalam data mining dibedakan menjadi 2, yaitu klasifikasi dan klasterisasi. Klasifikasi adalah pengelompokkan data yang membutuhkan data latih (supervised). Sedangkan klasterisasi adalah pengelompokkan data tanpa membutuhkan data latih (unsupervised). Du (2010) menjelaskan bahwa klasterisasi adalah proses membagi data yang tidak berlabel menjadi kelompok-kelompok data yang memiliki kemiripan. Setiap kelompok data (klaster) terdiri dari obyek yang memiliki kemiripan satu sama lain dan setiap klaster memiliki ketidakmiripan dengan klaster lain. Klasterisasi lazim digunakan dalam analisis data multivariat.
Misalkan K adalah jumlah klaster, C
merupakan label klaster, dan P merupakan dataset. Klasterisasi harus memenuhi kriteria sebagai berikut: } ,..., 2 , 1 { , i K Ci (1) j i C Ci j , and i,j{1,2,...,K} (2) P Ci K i
1 (3)B. Imputasi Missing Data
Missing data adalah suatu kondisi hilangnya
sebagian fitur pada dataset. Missing data dapat disebabkan oleh kesalahan sistem seperti tidak adanya respon terhadap sensor atau perangkat penerima input. Dapat pula disebabkan oleh human
error seperti ketidaklengkapan memasukkan data
pada database atau ketidakpahaman responden dalam pengisian kuisioner pada survey skala besar sehingga melewati form isian yang telah disediakan. Metode yang ada pada data mining hanya dapat memroses data yang memiliki kelengkapan fitur sehingga dibutuhkan penanganan khusus terhadap permasalahan ini. Ada 3 metode yang digunakan untuk penanganan
missing data, yaitu : Case Deletion, Parameter Estimation, dan Imputation Techniques (Little dan
Rubin, 2002).
Case deletion merupakan metode yang paling
mudah yaitu dengan cara menghapus data yang mengandung missing. Kelemahan dari metode ini adalah dimungkinkan informasi-informasi penting ikut terhapus ketika missing data dihapus. Teknik imputasi merupakan metode penanganan missing data yang lebih banyak diteliti. Imputasi data adalah memperkirakan nilai pada missing data
dengan cara mendapatkan pola dari data yang memiliki fitur lengkap. Beberapa metode imputasi yang populer adalah: Mean, Median/Modus dan klasterisasi.
Missing data adalah suatu kondisi dimana
data tidak ada atau data hilang. Terdapat 3 mekanisme penghilangan data, antara laon
Missing Completely at Random (MCAR), yaitu
jika distribusi data yang hilang pada suatu atibut tidak tergantung pada data pengamatan atau
missing data. Metode ini akan menggunakan
dataset komplit kemudian membangkitkan missing
data secara acak berdasarkan proporsi tertentu.
Keuntungan dari metode ini adalah memudahkan para peneliti untuk estimasi komputasi dari model yang diusulkan Mekanisme lain adalah Missing at
Random (MAR), yaitu jika distribusi data yang
hilang pada suatu atribut tergantung pada data pengamatan tetapi tidak tergantung pada missing
data. Yang terakhir adalah Not Missing at Random (NMAR), jika distribusi data yang hilang
pada suatu atribut tergantung pada missing data (Pigott dan Therese, 2011)..
C. K-Means
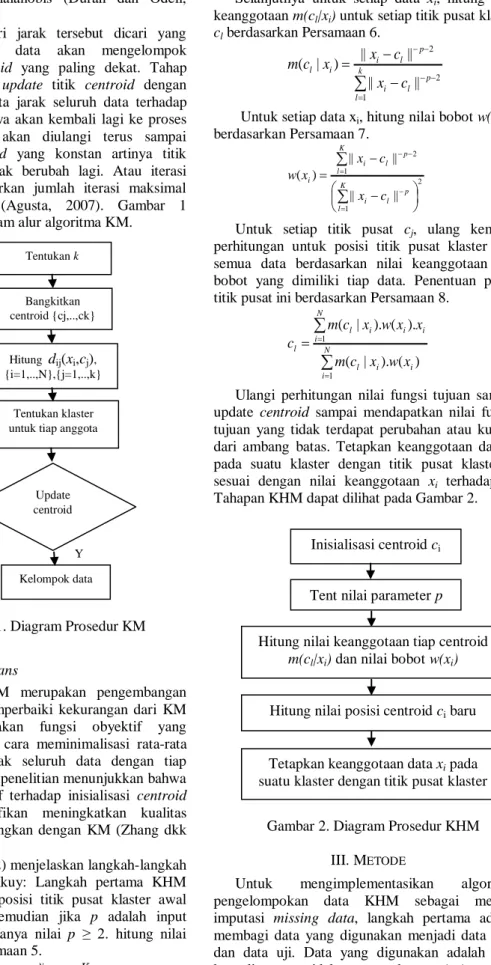
Algoritma KM merupakan algoritma klasterisasi yang mengelompokkan data berdasarkan titik pusat klaster (centroid) terdekat dengan data. Tujuan dari KM adalah pengelompokkan data dengan memaksimalkan kemiripan data dalam satu klaster dan meminimalkan kemiripan data antar klaster. Ukuran kemiripan yang digunakan dalam klaster adalah fungsi jarak. Sehingga pemaksimalan kemiripan data didapatkan berdasarkan jarak terpendek antara data terhadap titik centroid.
Tahapan awal yang dilakukan pada proses klasterisasi data dengan menggunakan algoritma KM adalah pembentukan titik awal centroid cj
Pada umumnya pembentukan titik awal centroid dibangkitkan secara acak. Jumlah centroid cj yang
dibangkitkan sesuai dengan jumlah klaster yang ditentukan di awal. Setelah k centroid terbentuk kemudian dihitung jarak tiap data xi dengan
centroid ke-j sampai k, dinotasikan dengan d(xi,cj).
Terdapat beberapa ukuran jarak yang digunakan sebagai ukuran kemiripan suatu instance data, salah satunya adalah jarak Euclid. Perhitungan jarak Euclidean seperti pada Persamaan 4.
Jika semakin kecil, kesamaan antara dua unit pengamatan semakin dekat. Syarat menggunakan jarak Euclid adalah jika semua fitur dalam dataset tidak saling berkorelasi. Jika terdapat fitur yang berkorelasi maka menggunakan
konsep jarak Mahalanobis (Duran dan Odell, 1974).
Selanjutnya dari jarak tersebut dicari yang terdekat sehingga data akan mengelompok berdasarkan centroid yang paling dekat. Tahap berikutnya adalah update titik centroid dengan menghitung rata-rata jarak seluruh data terhadap
centroid. Selanjutnya akan kembali lagi ke proses
awal. Iterasi ini akan diulangi terus sampai didapatkan centroid yang konstan artinya titik
centroid sudah tidak berubah lagi. Atau iterasi
dihentikan berdasarkan jumlah iterasi maksimal yang ditentukan (Agusta, 2007). Gambar 1 menunjukkan diagram alur algoritma KM.
Gambar 1. Diagram Prosedur KM
D. K-Harmonic Means
Algoritma KHM merupakan pengembangan dari KM yang memperbaiki kekurangan dari KM dengan menggunakan fungsi obyektif yang didapatkan dengan cara meminimalisasi rata-rata harmonik dari jarak seluruh data dengan tiap
centroid. Dari hasil penelitian menunjukkan bahwa
KHM tidak sensitif terhadap inisialisasi centroid dan secara signifikan meningkatkan kualitas klasterisasi dibandingkan dengan KM (Zhang dkk 1999).
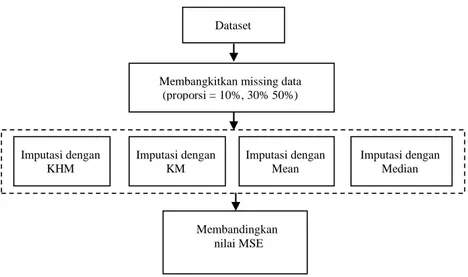
Widiartha (2012) menjelaskan langkah-langkah KHM sebagai berikuy: Langkah pertama KHM adalah inisialisasi posisi titik pusat klaster awal secara random. Kemudian jika p adalah input parameter dan biasanya nilai p ≥ 2. hitung nilai fungsi tujuan Persamaan 5.
N i K l xi cl p K C X KHM 1 1|| || 1 ) , ( (5)
Selanjutnya untuk setiap data xi, hitung nilai keanggotaan m(cl|xi) untuk setiap titik pusat klaster
cl berdasarkan Persamaan 6.
k l p l i p l i i l c x c x x c m 1 2 2 || || || || ) | ( (6)Untuk setiap data xi, hitung nilai bobot w(xi) berdasarkan Persamaan 7. 2 1 1 2 || || || || ) ( K l p l i K l p l i i c x c x x w (7) Untuk setiap titik pusat cj, ulang kembali perhitungan untuk posisi titik pusat klaster dari semua data berdasarkan nilai keanggotaan dan bobot yang dimiliki tiap data. Penentuan posisi titik pusat ini berdasarkan Persamaan 8.
N i i i l N i i i i l l x w x c m x x w x c m c 1 1 ) ( ). | ( ). ( ). | ( (8) Ulangi perhitungan nilai fungsi tujuan sampai update centroid sampai mendapatkan nilai fungsi tujuan yang tidak terdapat perubahan atau kurang dari ambang batas. Tetapkan keanggotaan data xi pada suatu klaster dengan titik pusat klaster cj sesuai dengan nilai keanggotaan xi terhadap cj. Tahapan KHM dapat dilihat pada Gambar 2.III. METODE
Untuk mengimplementasikan algoritma pengelompokan data KHM sebagai metode imputasi missing data, langkah pertama adalah membagi data yang digunakan menjadi data latih dan data uji. Data yang digunakan adalah data komplit yang tidak mengandung missing data. Langkah berikutnya adalah melakukan pengelompokan data dari data latih tersebut menggunakan KHM. Dari proses pengelompokan
Inisialisasi centroid ci
Tent nilai parameter p
Hitung nilai keanggotaan tiap centroid
m(cl|xi) dan nilai bobot w(xi)
Hitung nilai posisi centroid ci baru
Tetapkan keanggotaan data xi pada suatu klaster dengan titik pusat klaster
cj
Gambar 2. Diagram Prosedur KHM Y N Bangkitkan centroid {cj,..,ck} Hitung dij(xi,cj), {i=1,..,N},{j=1,..,k} Tentukan klaster untuk tiap anggota
Kelompok data Update centroid Tentukan k
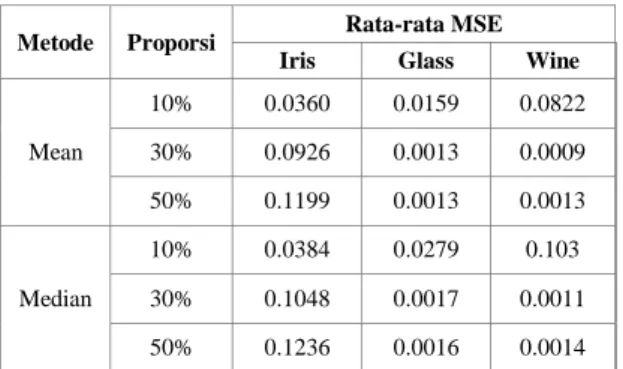
Gambar 3. Bagan Penelitian Membandingkan nilai MSE Imputasi dengan KM Imputasi dengan Median Imputasi dengan Mean Imputasi dengan KHM
Membangkitkan missing data (proporsi = 10%, 30% 50%)
Dataset
ini akan diperoleh masing-masing centroid untuk setiap kelompok data.
Kemudian pada data uji dilakukan penghilangan nilai atribut menggunakan teknik MCAR hingga data uji terdiri dari data komplit Dc
dan data missing Dm. Proporsi penghilangan nilai
atribut ini sebesar 10%, 30%, dan 50%. Kemudian dilakukan tahap imputasi dengan menghitung jarak
Euclidean sesuai dengan Persamaan 1 antara
setiap data uji yang mengandung missing data Dm
dengan masing-masing titik centroid pada setiap kelompok data.
Centroid terdekat berdasarkan jarak tersebut
akan mengisi atribut yang hilang pada Dm. Proses
ini dilakukan sampai seluruh missing data terisi. Evaluasi dilakukan dengan menghitung nilai
Mean Square Error (MSE) antara nilai imputasi
dengan nilai real. Jika
merupakan dataset real dan
merupakan dataset hasil imputasi maka MSE dapat ditentukan dengan persamaan :
Bagan metode penelitian ini dapat dilihat pada Gambar 3.
IV. UJI COBA DAN ANALISIS
A. Data Uji Coba
Data yang digunakan dalam uji coba ini adalah dataset iris, wine, dan glass yang diambil dai UCI Machine Learning Repository. Dataset tersebut merupakan dataset yang lengkap yang tidak terdapat missing value pada data. Karakteristik dataset tersebut dapat dilihat pada Tabel 1.
TABEL 1. DATASET
Dataset Instance Atribut
Iris 150 4
Wine 178 13
Glass 214 10
B. Skenario Uji Coba
Pengujian dilakukan pada beberapa metode imputasi untuk menganalisa performa dari metode imputasi. Pada penelitian ini terdapat 4 metode yang akan diujicobakan yaitu KHM, KM, Mean, dan Median. Proses pertama yang akan dilakukan untuk imputasi data dari data komplit adalah membangkitkan missing data. Dengan cara menghilangkan beberapa instance secara acak, berturut-turut dengan proporsi 10%, 30%, dan 50%.
Setelah diperoleh dataset dengan missing data, proses imputasi dilakukan. Evaluasi dari hasil imputasi dilihat dari perhitungan MSE. Dalam setiap imputasi untuk masing-masing dataset dan proporsi dilakukan 10 kali replikasi. Dimana dari setiap replikasi akan dihitung nilai MSE sehingga dari 10 replikasi akan didapatkan nilai rata-rata MSE untuk tiap metode. Pada akhirnya uji one way ANOVA dilakukan untuk mengetahui performa terbaik dari metode yang diujikan
C. Hasil Uji Coba
Pada pengujian menggunakan metode KHM, parameter yang digunakan adalah p = 2. Berikut ini Tabel 2 menunjukkan nilai rata-rata MSE yang diperoleh dari 10 replikasi.
TABEL 2.HASILUJICOBA
Metode Proporsi Rata-rata MSE Iris Glass Wine
KHM 10% 0.0032 0.0032 0.0184 30% 0.029 0.0009 0.0006 50% 0.0557 0.0011 0.0008 KM 10% 0.0047 0.0114 0.016 30% 0.0622 0.0013 0.0007 50% 0.0716 0.0015 0.0009
Metode Proporsi Rata-rata MSE Iris Glass Wine
Mean 10% 0.0360 0.0159 0.0822 30% 0.0926 0.0013 0.0009 50% 0.1199 0.0013 0.0013 Median 10% 0.0384 0.0279 0.103 30% 0.1048 0.0017 0.0011 50% 0.1236 0.0016 0.0014
Dari pengamatan secara rata-rata metode imputasi pengelompokan data KHM memiliki MSE paling rendah. Dalam pengujian data hasil 10 replikasi antara metode KHM dengan KM,
Mean, dan Median diatas digunakan uji statistik
ANOVA dengan taraf kepercayaan 95%. Dengan menggunakan software SPSS 17, diperoleh nilai p-value untuk perbandingan metode KHM dengan metode imputasi KM, Mean, dan Median dapat dilihat pada Tabel 3. Nilai yang ditunjukkan adalah nilai p-value antara metode KHM dengan metode lainnya.
Tabel 3. HASIL UJI STATISTIK
Metode Data Proporsi
p KM Mean Median KHM Iris 10% 0.994 0 0 30% 0.514 0.054 0.016 50% 0.919 0.065 0.046 Glass 10% 0.985 0.948 0.723 30% 0.887 0.89 0.457 50% 0.684 0.937 0.468 Wine 10% 1 0.76 0.567 30% 0.976 0.585 0.18 50% 0.983 0.029 0.009
Jika diambil nilai α = 0.05, maka hal ini menunjukkan bahwa metode imputasi KHM menunjukkan hasil yang baik secara signifikan jika dibandingkan dengan Mean dan Median, namun tidak untuk KM karena nilai yang ditunjukkan kurang dari nilai batas α. Dari sini bisa disimpulkan bahwa secara rata-rata metode KHM memiliki performa yang bagus dengan menghasilkan MSE yang paling kecil jika dibandingkan dengan tiga metode pembandingnya. Namun, pada kasus tertentu
KHM memberikan nilai MSE yang sama dengan metode imputasi KNN dan Median. Hal ini disebabkan proses pemilihan data hilang adalah secara random sehingga adakalanya nilai nilai yang hilang merupakan median itu sendiri.
V. KESIMPULAN
Hasil imputasi menggunakan KHM memberikan nilai MSE paling kecil untuk semua dataset yakni 0.0293 untuk dataset Iris, 0.001733 untuk dataset Glass, dan 0.0066 untuk dataset Wine. Jika dibandingkan dengan teknik imputasi KM, Mean, dan Median, secara rata-rata imputasi
missing data menggunakan algoritma pengelompokan data KHM menunjukkan hasil yang lebih baik. Namun hasil uji statistik menunjukkan bahwa perbedaan secara signifikan terjadi antara KHM dengan Mean dan Median, tidak dengan KM. Dari hasil yang telah didapatkan, dapat disimpulkan bahwa secara rata-rata KHM mampu memberikan nilai akurasi yang lebih baik jika dibandingkan dengan metode KM namun perbedaan ini tidak terlihat signifikan.
DAFTAR PUSTAKA
Agusta, Y, 2007, K-Means – Penerapan, Permasalahan dan Metode Terkait. Jurnal Sistem dan Informatika Vol. 3, 47-60
Du, K.L., 2010, Clustering A neural network approach. Neural Network, 23, pp.89-107
Duran, B.S., Odell, P.L.,1974, Cluster Analysis : A Survey, Springer-Verlag, Berlin and New York
Little, R. J. dan Rubin, D.B. 2002. Statistical analysis with missing data. Second Edition. John Wiley and Sons, New York.
Hammerly, G., dan Elkan, C., 2002, Alternatives to The K-Means Algorithm that Find Better Clusterings, Proceedings of the 11th international conference on information and knowledge management, hal. 600–607.
Malarvizhi, T. 2012, K-NN classifier performs better than k-means clustering in missing value imputation, IOSR Journal of Computer Engineering, Vol.6, No. 5, hal 12-15.
Pen, J.M., Lozano, J.A., dan Larranaga, P. (1999), An Empirical Comparison of Four Initialization Methods for The K-Means Algorithm, Pattern Recognition Letters, Vol. 20, hal. 1027-1040. Pigott D.T., 2011. A review of methods for missing data.
Educational Research and Evaluation, Vol. 7, No.4, hal. 353-383.
Widiartha, I.M, Arifin, A.Z., Yuniarti, A., 2012, Klasterisasi
Data Iris Menggunakan Metode Berbasis
Artificial Bee Colony Dan K-Harmonic Means Tesis Pascasarjana Jurusan T. Informatika, FTIF, Institut Teknologi Sepuluh Nopember, Surabaya. Zhang, B., Hsu, M., dan Dayal, U. 1999, K-Harmonic Means –
A Data Clustering Algorithm, Technical Report HPL-1999-124, Hewlett-Packard Laboratories.