IDENTIFIKASI PENCILAN DAN PETA PENCILAN PADA ANALISIS
KOMPONEN UTAMA UNTUK DATA MENJULUR
ANNA FAUZIYAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2012
untuk Data Menjulur. Dibimbing oleh KUSMAN SADIK dan I MADE SUMERTAJAYA. Analisis Komponen Utama (AKU) merupakan salah satu analisis peubah ganda yang pada dasarnya mentransformasikan secara linier peubah asal menjadi peubah baru yang dinamakan komponen utama. Akan tetapi, AKU yang didasarkan pada matriks ragam peragam ini sangat sensitif terhadap keberadaan pencilan. Sensitifitas terhadap pencilan pada AKU-Klasik dapat diatasi dengan AKU yang kekar (AKU-K) yang bekerja sangat baik pada data yang memiliki sebaran simetrik atau tidak menjulur. Apabila data peubah asal menjulur maka banyak titik data yang sebenarnya bukan pencilan dianggap sebagai pencilan atau sebaliknya. Kemudian dikembangkanlah pendekatan AKU-K yang cocok untuk data menjulur dengan mendefinisikan berbagai kriteria baru untuk menggambarkan pencilan yaitu AKU-KAO. Penelitian ini menggunakan empat metode yaitu AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO untuk mengetahui perbandingan efektifitas keempat metode tersebut dalam mengidentifikasi pencilan pada data menjulur. Keempat metode tersebut dicobakan pada dua set data yang dikontaminasi pencilan dengan proporsi 0%, 5%, 10%, dan 15%. Hasil yang diperoleh dari penelitian ini menunjukkan bahwa metode AKU-KAO mampu mengatasi pengaruh kehadiran pencilan pada data menjulur karena memiliki tingkat kesalahan identifikasi yang paling kecil. Hal tersebut diperkuat dengan adanya peta pencilan yang memberikan gambaran secara visual dalam pengidentifikasian pencilan.
ANNA FAUZIYAH
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2012
NIM : G14080036
Menyetujui,
Pembimbing I,
Dr. Ir. Kusman Sadik, M.Si
NIP : 196909121997021001
Pembimbing II,
Dr. Ir. I Made Sumertajaya, MS
NIP : 196807021994021001
Mengetahui : Ketua Departemen,
Dr. Ir. Hari Wijayanto, M.Si
NIP : 196504211990021001
Pencilan pada Analisis Komponen Utama untuk Data Menjulur” ini dapat terselesaikan.
Ucapan terima kasih tak lupa penulis ucapkan kepada berbagai pihak yang telah membantu sehingga karya ilmiah ini selesai dengan baik, yaitu :
1. Bapak Dr. Ir. Kusman Sadik, M.Si dan Bapak Dr. Ir. I Made Sumertajaya, MS atas kesabarannya dalam membimbing, memberi saran, serta motivasi sehingga karya ilmiah ini dapat diselesaikan
2. Seluruh dosen pengajar di Departemen Statistika
3. Ayahanda Yayat Suryatna, Ibunda Eeng Emalia serta kakak-kakak Dewi Noviyanti dan Nisa Sofianti yang selalu memberikan kasih sayang, semangat, dan doa
4. Ibu Markonah, Ibu Tri, Ibu Aat, Bang Ibay, Bang Iyus dan staf tata usaha lainnya yang telah banyak membantu
5. Rekan-rekan di Departemen Statistika IPB angkatan 45 khususnya Keluarga Pandhewi (Dinia Wihansah, Mulya Sari, Hanik Aulia, dan Hana Maretha), Ramadhiyan Firdan, Iin Puspitasari, Ratih Noviani, dan Hadi Septian atas segala kebersamaan, canda tawa, kenangan indah, dan masukan-masukan yang telah mengisi kehidupan penulis selama di kampus
6. Teman bimbingan skripsi yaitu Aji Setyawan, Tri Hardi Putra, dan Arni Nurwida atas semangat dan kebersamaannya
7. Teman-teman kostan SQ yaitu Mega, Delvi, Fatchah, Nengsih, Hilma, Ulan, Puji, Putri, Yuang, Fitri, Irma, Feby, Lia, Reffa dan Devi atas dukungan, semangat dan doa kepada penulis
8. Semua pihak yang tidak mungkin disebutkan satu persatu yang telah membantu penulis selama ini.
Semoga karya ilmiah ini dapat bermanfaat bagi semua pihak yang membutuhkan. Penulis mohon maaf atas segala kekurangan dan kesalahan yang terdapat dalam karya ilmiah ini.
Bogor, November 2012
Eeng Emalia. Penulis merupakan putri ketiga dari tiga bersaudara.
Penulis memulai pendidikannya di SD Negeri 1 Jambar dan lulus pada tahun 2002. Kemudian penulis melanjutkan pendidikan di SMP Negeri 2 Kuningan hingga tahun 2005. Setelah menyelesaikan studinya di SMA Negeri 1 Kuningan pada tahun 2008, penulis diterima sebagai mahasiswa Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB (USMI) pada tahun yang sama. Selama satu tahun pertama di IPB, penulis melalui Tahap Persiapan Bersama (TPB). Pada tahun 2009, penulis diterima sebagai mahasiswa Departemen Statistika dengan minor Ilmu Ekonomi dan Studi Pembangunan.
Selama kuliah, penulis aktif dalam organisasi kemahasiswaan yaitu sekretaris divisi Komunikasi dan Informasi Lembaga Struktural Bina Desa BEM KM IPB selama dua periode pada tahun 2009-2010, anggota Departemen Sains Himpunan Profesi Gamma Sigma Beta Departemen Statistika FMIPA IPB Periode 2011. Penulis juga aktif dalam kegiatan kemahasiswaan yang diadakan oleh Departemen Statistika maupun Fakultas Matematika dan Ilmu Pengetahuan Alam, antara lain Spirit FMIPA 2010 (Divisi Medis), The 6th Statistika Ria 2010 (Divisi LO), Pesta Sains
FMIPA 2010 (Divisi K4), Welcome Ceremony Statistics (WCS) 2011 serta Lomba Jajak Pendapat Statistika 2011 (Sekretaris Umum). Pada bulan Februari-April 2012 penulis diberikan kesempatan untuk praktik lapang di PT. Infomedia Nusantara.
DAFTAR ISI
Halaman
DAFTAR TABEL ... viii
DAFTAR GAMBAR ... viii
DAFTAR LAMPIRAN ... viii
PENDAHULUAN 1 Latar Belakang ... 1 Tujuan ... 1 TINJAUAN PUSTAKA 1 Data Menjulur ... 1 Pencilan ... 2
Analisis Komponen Utama ... 3
Analisis Komponen Utama Kekar ... 3
Analisis Komponen Utama Kekar untuk Data Menjulur ... 4
Peta Pencilan ... 4
METODOLOGI 5
Data ... 5
Metode ... 5
HASIL DAN PEMBAHASAN 6
Karakteristik Data ... 6
Identifikasi Pencilan pada n1=500 ... 6
Identifikasi Pencilan pada n2=100 ... 8
Peta Pencilan ... 9
Penerapan AKU-Klasik dan AKU-KAO ... 10
KESIMPULAN DAN SARAN 11
Kesimpulan ... 11
Saran... 11
DAFTAR PUSTAKA ... 11
LAMPIRAN ... 13
DAFTAR TABEL
Halaman
1. Nilai medcouple tiap peubah ... 6
2. Persentase kesalahan identifikasi pencilan pada data menjulur n1=500, p=10 dan k=2 ... 7
3. Persentase kesalahan identifikasi pencilan pada data menjulur n2=100, p=10 dan k=2 ... 8
4. Ringkasan hasil komponen utama pada berbagai metode ... 10
DAFTAR GAMBAR
Halaman 1. Peta pencilan ... 52. Persentase Kesalahan I pada n1=500 ... 7
3. Persentase Kesalahan II pada n1=500 ... 7
4. Persentase Kesalahan I pada n2=100 ... 8
5. Persentase Kesalahan II pada n2=100 ... 8
6. Peta pencilan data menjulur n1=500, p=10 dan k=2 dengan proporsi pencilan 5% pada (a) AKU-Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO ... 9
7. Peta pencilan data menjulur n2=100, p=10 dan k=2 dengan proporsi pencilan 5% pada (a) AKU-Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO ... . 10
DAFTAR LAMPIRAN
Halaman 1. Skema algoritma penelitian ... 142. Rumus adjusted outlyingness (AO) ... 15
3. Histogram data hasil pembangkitan ... 15
4. Nilai korelasi antar peubah pada n1=500 dan p=10 ... 15
5. Nilai korelasi antar peubah pada n2=100 dan p=10 ... 16
6. Kesalahan identifikasi pencilan pada data menjulur n1=500, p=10, dan k=2 ... 17
7. Kesalahan identifikasi pencilan pada data menjulur n2=100, p=10, dan k=2 ... 18
8. Peta pencilan data menjulur n1=500, p=10 dan k=2 dengan proporsi pencilan 0% (a) AKU- Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO ... 19
9. Peta pencilan data menjulur n1=500, p=10 dan k=2 dengan proporsi pencilan 10% (a) AKU- Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO ... 20
10. Peta pencilan data menjulur n1=500, p=10 dan k=2 dengan proporsi pencilan 15% (a) AKU- Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO ... 21
11. Peta pencilan data menjulur n2=100, p=10 dan k=2 dengan proporsi pencilan 0% (a) AKU- Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO ... 22
12. Peta pencilan data menjulur n2=100, p=10 dan k=2 dengan proporsi pencilan 10% (a) AKU- Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO ... 23
13. Peta pencilan data menjulur n2=100, p=10 dan k=2 dengan proporsi pencilan 15% (a) AKU- Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO ... 24
PENDAHULUAN Latar Belakang
Konsep dasar dari Analisis Komponen Utama (AKU) adalah pereduksian dimensi sekumpulan peubah asal menjadi peubah baru yang berdimensi lebih kecil yang saling bebas dan tetap mempertahankan informasi yang terkandung di dalamnya. Peubah baru tersebut disebut komponen utama. Akan tetapi, AKU yang didasarkan pada matriks ragam peragam ini sangat sensitif terhadap keberadaan pencilan. Hubert et al. (2005) memperkenalkan pendekatan Analisis Komponen Utama Kekar (AKU-K) atau
Robust Principal Component Analysis
(ROBPCA) yang menghasilkan komponen utama yang tidak dipengaruhi oleh pencilan. AKU-K menggabungkan konsep Projection
Pursuit (PP) dengan Minimum Covariance Determinant (MCD). PP digunakan untuk
inisiasi reduksi dimensi awal sedangkan MCD digunakan sebagai penduga matriks ragam peragam yang kekar. Pada tahap akhir AKU-K dilakukan pembobotan ulang dengan menggunakan penduga MCD. Jika pembobotan ulang tersebut tidak dilakukan maka metode tersebut dinamakan AKU-KMCD. AKU-KMCD menghasilkan subruang AKU yang sama dengan AKU-K tetapi tidak dengan nilai dari akar ciri dan vektor cirinya.
Sensitifitas terhadap pencilan pada AKU-Klasik dapat diatasi dengan AKU-K yang bekerja sangat baik pada data yang memiliki sebaran simetrik atau tidak menjulur. Apabila data peubah asal menjulur maka banyak titik data yang sebenarnya bukan pencilan dianggap sebagai pencilan atau sebaliknya. Hubert et al. (2009) mengembangkan pendekatan AKU-K yang cocok untuk data menjulur dengan mendefinisikan berbagai kriteria baru untuk menggambarkan pencilan. Pendekatan ini terdiri dari langkah-langkah yang sama dengan AKU-K sebelumnya akan tetapi pada pendekatan baru ini dilakukan beberapa modifikasi. Perbedaan mendasar dari pendekatan AKU-K baru ini dengan pendekatan AKU-K sebelumnya yaitu terletak pada penggantian perhitungan keterpencilan pada AKU-K yang menggunakan rumus Stahel-Donoho (AKU-K) dengan menggunakan rumus perhitungan keterpencilan baru yaitu adjusted outlyingness (AKU-KAO).
Tujuan
Penelitian ini bertujuan untuk:
1. Membandingkan efektifitas metode Klasik, KMCD, K, dan AKU-KAO dalam mengidentifikasi pencilan pada data menjulur yang memiliki berbagai proporsi pencilan
2. Menerapkan peta pencilan pada data menjulur
3. Menerapkan AKU-Klasik dan AKU-KAO pada data menjulur.
TINJAUAN PUSTAKA Data Menjulur
Bentuk dan ketidaksimetrian dari sebuah sebaran dapat diukur dari kemiringannya. Sebaran yang simetrik memiliki kemiringan nol, sebaran yang tidak simetrik yang ekornya menjulur ke kanan memiliki kemiringan positif, sedangkan sebaran yang ekornya menjulur ke kiri memiliki kemiringan negatif. Koefisien kemiringan klasik b1 dari kumpulan
data peubah tunggal Xn={x1, x2, ... , xn} diambil
dari sebaran kontinu yang didefinisikan sebagai berikut:
b1 Xn =
m3(Xn)
m2(Xn)
3 2
dimana 𝑚2 merupakan momen empiris kedua
dan 𝑚3 merupakan momen empiris ketiga dari
data. Akan tetapi, b1 sangat sensitif terhadap
pencilan dalam data sehingga harus menggunakan koefisien kemiringan yang kekar.
Brys et al. (2004) memperkenalkan ukuran kemiringan yang kekar terhadap pencilan yaitu
medcouple. Nilai medcouple berkisar antara -1
sampai 1. Jika nilainya 0 maka sebarannya tidak menjulur (simetrik). Misalkan Xn={x1, x2,
... , xn} diambil dari sebaran kontinu dan
kemudian diurutkan sehingga x1 ≤ x2 ≤ ... ≤ xn
, maka median untuk Xn adalah:
mn =
(xn 2+x(n 2)+1))/2, jika n genap x(n+1)/2 , jika n ganjil
berikut nilai MCn (medcouple):
MCn = medxi≤mn≤xjh(xi, xj) jika 𝑥𝑖 ≠ 𝑥𝑗 maka: h xi, xj = xj- mn - mn - xi xj− xi
jika xi=xj=mn maka diberikan fungsi kernel
h. Misalkan m1 < ... < mk melambangkan
indeks dari pengamatan yang kembar dengan median mn dan 𝑥𝑚𝑙 = 𝑚𝑛 untuk l = 1, ..., k maka: h(𝑚𝑖, 𝑚𝑗) = -1 jika i + j - 1 < k 0 jika i + j - 1 = k +1 jika i + j - 1 > k Salah satu contoh sebaran menjulur adalah sebaran normal inverse Gaussian (NIG). Sebaran tersebut merupakan kasus khusus dari sebaran generalized hyperbolyc (GH) yang didefinisikan sebagai Gaussian generalized
inverse Gaussian mixing distribution yang
sering digunakan pada bidang keuangan. Jika
X~N µ, σ2 maka 1/X bukan sebaran NIG.
Sebaran GH didefinisikan sebagai berikut: gh x:λ,α,β,δ,µ = a λ,α,β,δ δ2+ x-μ 2 x - 12 2 × Kλ-1 2(α δ 2 + x-μ 2) exp β x-μ 𝑎 𝜆, 𝛼, 𝛽, 𝛿 = 𝛼 2− 𝛽2 𝜆 2 2𝜋𝛼𝜆−1 2𝛿𝜆𝐾 𝜆 𝛿 𝛼2− 𝛽2 dengan: 𝛿 ≥ 0, 𝛽 < 𝛼 jika 𝜆 > 0 𝛿 > 0, 𝛽 < 𝛼 jika 𝜆 = 0 𝛿 > 0, 𝛽 ≤ 𝛼 jika 𝜆 < 0
Misalkan peubah acak X menyebar
X~NIG α, β, δ,μ yang memiliki fungsi
kepekatan peluang, nilai harapan, dan ragam sebagai berikut : fx x = αδ π exp δ α2-β 2 +β x-μ K1(α δ 2 + x-μ 2 δ2 + x-μ 2 E X = μ+δ β α (1-( β α)2)1 2 Var X = δ2α-1 β α 1-( β α)2 3 2 dengan 𝑥, µ 𝜖 ℝ, 0 ≤ 𝛿, 0 ≤ 𝛽 ≤ 𝛼 dimana: µ : parameter lokasi δ : parameter skala
α, β : parameter bentuk yang menentukan
panjang ekor dan kemenjuluran
𝐾1 merupakan fungsi modifikasi Bassel dari
persamaan: Kn+1 2 x = π2 x-1 2e-x (1+ n+i ! n-i i! n i=1 (2𝑥)−𝑖) dengan 𝑥, µ 𝜖 ℝ, 0 ≤ 𝛿, 𝛽 < 𝛼 dimana: Kλ x = K-λ x maka K-1 2 x = K1 2 x = π 2 x-1/2e-x λ = n+1 2, n = 0, 1, 2, …
Fungsi modifikasi Bassel hanya memperbolehkan pada kasus ketika 𝜆=-1/2 dan λ=1. Pada λ=-1/2 diperoleh sebaran NIG sedangkan pada λ=1 diperoleh sebaran
hyperbolic (HYP).
Peubah acak NIG ganda menyebar
NIGp α, β, tδ,tμ,∆ untuk t > 0, berikut adalah
fungsi kepekatan peluang, nilai harapan, dan ragamnya: fx(x) = 2δ α 2π p+1 2 exp δα K(p+1)/2(α δ 2 +x'∆-1x (δ2+x'∆-1x(p+1)/4 E X = μ+δ ζ Π∆1 2 Var X = δ2 ζ-1 ζ ∆+x-1 ζ Π∆1 2 ' Π∆1 2 dengan 𝒙, µ, 𝜷 𝜖 ℝ𝑝, 𝛿 > 0, 𝜶2> 𝜷′∆𝜷, ∆ ϵ ℝ𝑝, ζ = δ α2-β'∆β, Π = β∆1 2 (α2-β'∆β)1 2, dan = 𝛿2∆ dimana:
∆ : matriks definit positif 𝜻 : parameter kemenjuluran
Π : parameter yang menentukan panjang ekor
Σ : matriks ragam peragam
(Prause 1999)
Pencilan
Pencilan adalah pengamatan ekstrim dan merupakan titik data yang tidak khas dari seluruh pengamatan data (Montgomery & Peck 1992). Dengan cara yang sama, Johnson (2007) mendefinisikan pencilan sebagai suatu pengamatan pada rangkaian data yang terlihat tidak konsisten terhadap sisaan dari data tersebut. Menurut Draper dan Smith (1992), pencilan merupakan pengamatan yang nilai mutlak sisaannya jauh lebih besar daripada sisaan-sisaan lainnya dan bisa jadi terletak tiga atau empat simpangan baku atau lebih jauh lagi dari rata-rata sisaannya.
Pada umumnya pendeteksian pencilan untuk peubah ganda berbasis pada asumsi sebaran yang simetrik. Menurut Hubert dan Van der Veeken (2008), pada data yang
sebarannya tidak simetrik atau menjulur pendeteksian pencilan dilakukan dengan menggunakan adjusted outlyingness (AO) dari data peubah ganda. Pada prakteknya AO tidak dapat dihitung dengan memproyeksikan pengamatan pada semua vektor peubah tunggal a. Oleh karena itu, harus dibatasi dengan cara memilih satu set arah acak. Simulasi menunjukkan bahwa banyaknya arah yang efisien dan hemat dalam waktu komputasi adalah sebanyak m=250p arah. Arah acak dihasilkan sebagai arah yang tegak lurus terhadap subruang yang direntang oleh
p-pengamatan secara acak yang diambil dari
kumpulan data.
Setelah AO dihitung untuk setiap pengamatan, maka tahap selanjutnya yaitu memutuskan apakah pengamatan tersebut adalah pencilan atau bukan. Sebaran AO pada umumnya tidak diketahui (tetapi biasanya miring ke kanan karena dibatasi oleh nol). Oleh karena itu, dihitunglah diagram kotak garis yang disesuaikan (adjusted boxplot) dari nilai AO dan mendeklarasikan pencilan jika AO melebihi batas atas diagram kotak garis yang disesuaikan.
cut off = Q3 + 1.5 e3MC IQR
dimana:
Q3 : kuartil ketiga dari AOi
IQR : jangkauan antar kuartil MC : nilai medcouple.
Analisis Komponen Utama
Jollife (2002) mendefinisikan bahwa ide sentral dari analisis komponen utama adalah untuk memperkecil dimensi dari peubah asal sehingga diperoleh peubah baru yang disebut komponen utama. Komponen tersebut tidak saling berkorelasi dan tetap mempertahankan sebagian besar informasi yang terkandung pada peubah asalnya. Menurut Johnson (2007), komponen utama merupakan kombinasi linear terboboti dari p peubah acak
X1, X2, ... , Xp yang mampu menerangkan data
secara maksimum. Vektor acak x’=[x1, x2, ... ,
xp]menyebar menurut sebaran tertentu dengan
vektor nilai tengah µ dan matriks ragam peragam Σ.
Komponen utama ke-j dari p peubah dapat dinyatakan sebagai:
Yj=a1j x1+a2j x2+…+apj xp= a'x
dan keragaman komponen utama ke-j adalah :
Var Yj = λj ; j = 1,2,…, p
λ1, λ2, …, λp adalah akar ciri dimana
λ1 ≥ λ2 ≥ …≥ λp ≥ 0. Total keragaman
komponen utama adalah
λ1 + λ2 +…+ λp = tr (Σ). Vektor ciri 𝒂 sebagai
pembobot dari transformasi linear peubah asal diperoleh dari persamaan:
𝜮 − 𝜆𝑗𝑰 𝒂𝒋= 0 ; 𝑗 = 1, 2, … , 𝑝
Analisis Komponen Utama Kekar
Analisis Komponen Utama Klasik berbasis pada matriks ragam peragam yang sangat sensitif terhadap pencilan. Hubert et al. (2005) memperkenalkan analisis komponen utama yang kekar terhadap pencilan. AKU-K merupakan kombinasi dua ide yaitu antara
Projection Pursuit (PP) dan penduga ragam
peragam yang kekar. Konsep PP digunakan dalam tahap inisiasi reduksi dimensi awal. Konsep penduga ragam peragam yang kekar menggunakan Minimum Covariance Determinant (MCD) kemudian diterapkan
pada data dengan dimensi yang lebih rendah. Secara umum algoritma AKU-K terdiri dari tahap-tahap berikut:
1. Mereduksi ruang data, terutama ketika
p≥n, dimana p merupakan jumlah peubah
penjelas dan n adalah jumlah observasi. Langkah ini dilakukan dengan Metode Dekomposisi Nilai Singular terhadap
mean-centered data matriks dengan rumus:
Xn,p− 1nμ0
' = U
n,r0Dr0,r0Vr0,p' '
dengan 𝜇 0 merupakan vektor rataan klasik,
r0=rank(Xn,p− 1nμ0 '
), D adalah matriks diagonal berukuran r0 x r0, dan
U’U=Iro=V’V, dimana Ir0 adalah matriks
identitas berukuran r0 x r0
2. Menemukan h keterpencilan terkecil (least
outlyingness), tahap ini dilakukan dengan
memilih ½ < α < 1 untuk mendapatkan nilai h=max{[αn],[(n+kmax+1)/2]}, dimana
kmax merupakan jumlah maksimum
komponen yang akan dihitung. Selanjutnya keterpencilan dihitung dengan rumus Stahel-Donoho:
OutlO(xi) = max𝑣𝜖𝐵
xi'v-μMCD(xj'v)
∑MCD(xj'v)
dengan 𝝁𝑀𝐶𝐷 dan 𝑀𝐶𝐷 merupakan
penduga nilai tengah dan simpangan baku MCD, h pengamatan dengan nilai keterpencilan terkecil dihitung vektor nilai
tengah (𝝁𝟏) dan matriks ragam
peragamnya ( 𝟎)
3. Matriks ragam peragam didekomposisi sehingga diperoleh komponen utamanya. Sebanyak k komponen utama pertama dipilih dan semua data diproyeksikan pada subruang 𝑉0 berdimensi-k yang direntang
oleh k vektor ciri pertama sehingga diperoleh Xn,k
4. Untuk setiap pengamatan, dihitung jarak ortogonalnya (OD):
ODi
(0)
= xi- x i,k
dengan 𝑥 𝑖,𝑘 merupakan proyeksi dari 𝑥𝑖
pada subruang 𝑉0. Kemudian diperoleh
subruang kekar penduga 𝑉1 sebagai
subruang yang direntang oleh k vektor ciri dominan dari 𝟏, yang mana matriks
ragam peragam semua pengamatan 𝑥𝑖
ODi
(0)≤ c
OD. Nilai cut off sebesar cOD = (μ
+ 𝜎 𝑧0.975)3 2 dimana 𝜇 dan 𝜎 diduga dari
MCD dan 𝑧0.975 adalah 97.5% kuantil dari
sebaran gaussian. Selanjutnya, semua data diproyeksikan pada subruang V1
5. Menghitung kembali penduga nilai tengah dan matriks ragam peragam pada subruang berdimensi-k dengan menggunakan pembobot MCD pada data yang diproyeksikan. Pendugaan ini menggunakan algoritma FAST-MCD yang diadaptasi (Rousseeuw 1999). Komponen utama akhir adalah vektor ciri dari matriks ragam peragam tersebut.
AKU Kekar MCD (AKU-KMCD) merupakan analisis dimana tahap akhir pada algoritma AKU-K di atas tidak dilakukan. Akar ciri kekar yang dihasilkan saling berkorespondensi dengan vektor ciri kekar dari matriks ragam peragam dari h
pengamatan yang memiliki keterpencilan terkecil. Hal tersebut menghasilkan subruang AKU yang sama dengan AKU-K tetapi tidak dengan nilai dari akar ciri dan vektor cirinya.
Analisis Komponen Utama Kekar untuk Data Menjulur
AKU Klasik dan AKU-K keduanya digunakan pada data yang simetrik. Hal tersebut mengharuskan data peubah asal memiliki sebaran yang simetrik. Jika tidak terpenuhi maka dapat dilakukan transformasi terhadap peubah asal misalnya dengan menggunakan transformasi Box-Cox, tetapi peubah yang ditransformasi akan lebih sulit diinterpretasikan. Pada situasi seperti itu maka dilakukan analisis pada peubah asal dengan
menggunakan teknik AKU yang cocok untuk data yang tidak simetrik. Pada AKU-K dilakukan modifikasi dimana analisis tersebut dapat digunakan pada data menjulur dengan mendefinisikan berbagai kriteria baru untuk menggambarkan pencilan. Menurut Hubert et
al. (2009), terdapat tiga modifikasi yang
dilakukan pada AKU-K untuk data menjulur yaitu:
1. Mengganti perhitungan keterpencilan pada AKU-K sebelumnya dengan perhitungan keterpencilan baru yang disebut AO. Perhitungan tersebut berdasarkan pada
adjusted boxplot. AO memiliki penyebut
yang berbeda untuk memberi tanda pada data menjulur. Rumus AO disajikan pada Lampiran 1
2. Mengubah nilai cut off jarak ortogonal
yaitu menggunakan nilai terbesar dari OD yang lebih kecil dari Q3({OD}) + 1.5
e3MC({OD})IQR({OD})
3. Selain menerapkan pembobotan pada penduga MCD, dilakukan juga perhitungan AO pada AKU-K untuk data menjulur pada subruang 𝑉1 berdimensi-k kemudian
menghitung nilai tengah dan matriks ragam peragam dari h pengamatan dengan AO terkecil.
Peta Pencilan
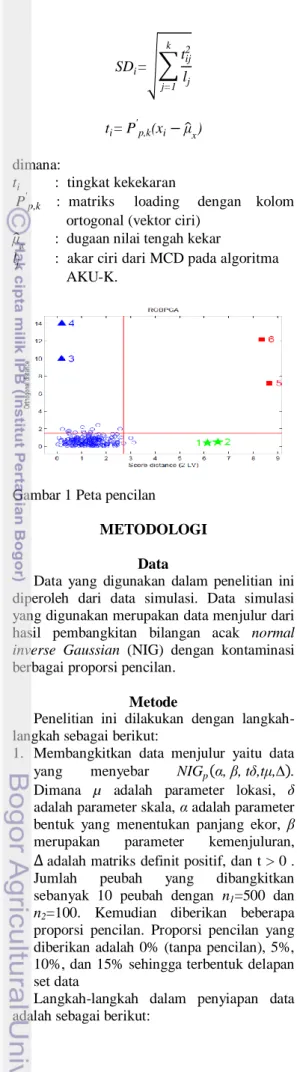
Selain menghitung komponen utama, AKU-K juga menggambarkan pencilan. Secara umum, pencilan merupakan pengamatan yang tidak mematuhi pola umum data. Pada Gambar 1 dapat dilihat bahwa dalam konteks AKU dapat dibedakan tiga jenis pencilan yaitu:
1. Amatan berpengaruh baik yaitu amatan yang terletak pada subruang komponen utama tetapi jauh dari pengamatan biasa (pengamatan 1 dan 2)
2. Pencilan ortogonal yaitu amatan yang memiliki jarak ortogonal yang besar ke subruang komponen utama sementara proyeksinya terletak pada subruang komponen utama (pengamatan 3 dan 4) 3. Amatan berpengaruh buruk yaitu amatan
yang memiliki jarak ortogonal yang besar dan proyeksi pada ruang komponen utama jauh dari pengamatan biasa (pengamatan 5 dan 6).
Jarak ortogonal adalah jarak antara pengamatan dan proyeksi dalam k-dimensi subruang V1. Peta pencilan memplotkan jarak
ortogonal dengan jarak skor (score distance). Garis ditarik untuk membedakan antara observasi yang memiliki jarak ortogonal antara jarak skor besar dan kecil.
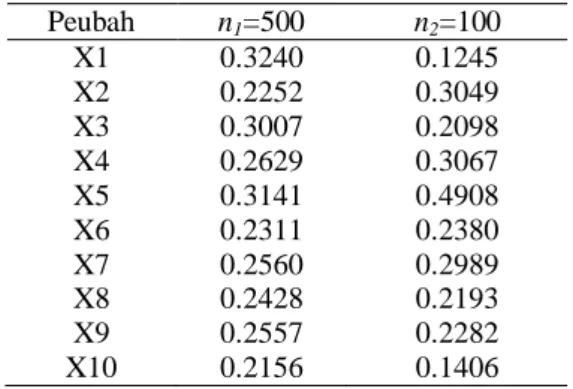
SDi= tij2 lj k j=1 ti= P ' p,k(xi− μ x) dimana: ti : tingkat kekekaran P'
p,k : matriks loading dengan kolom
ortogonal (vektor ciri)
μx : dugaan nilai tengah kekar
𝑙𝑗 : akar ciri dari MCD pada algoritma
AKU-K.
Gambar 1 Peta pencilan
METODOLOGI Data
Data yang digunakan dalam penelitian ini diperoleh dari data simulasi. Data simulasi yang digunakan merupakan data menjulur dari hasil pembangkitan bilangan acak normal
inverse Gaussian (NIG) dengan kontaminasi
berbagai proporsi pencilan.
Metode
Penelitian ini dilakukan dengan langkah-langkah sebagai berikut:
1. Membangkitkan data menjulur yaitu data yang menyebar NIGp α, β, tδ,tμ,∆ .
Dimana µ adalah parameter lokasi, δ adalah parameter skala, α adalah parameter bentuk yang menentukan panjang ekor, β merupakan parameter kemenjuluran, ∆ adalah matriks definit positif, dan t > 0. Jumlah peubah yang dibangkitkan sebanyak 10 peubah dengan n1=500 dan
n2=100. Kemudian diberikan beberapa
proporsi pencilan. Proporsi pencilan yang diberikan adalah 0% (tanpa pencilan), 5%, 10%, dan 15% sehingga terbentuk delapan set data
Langkah-langkah dalam penyiapan data adalah sebagai berikut:
1.1 Penyiapan data simulasi dengan membangkitkan data menjulur yaitu data yang menyebar NIG α, β, δ,μ . Proses pembangkitan dilakukan dengan algoritma sebagai berikut: a. Membangkitkan data menjulur
X~NIG(α, β, δ,μ) sebanyak n1 =
500 dan n2 = 100
b. Mengulangi langkah a sebanyak p atau 10 kali dengan parameter yang sama sehingga diperoleh 10 peubah X berukuran 500 dan 100 yaitu X1, X2, ..., X10
c. Peubah X1, X2, ..., X10 membentuk
matriks berdimensi 500 × 10 dan 100 × 10
d. Menentukan nilai korelasi awal pada peubah X1, X2, ..., X10
sehingga kesepuluh peubah tersebut saling berkorelasi e. Mengecek kemenjuluran dari dua
set data tersebut dengan melihat nilai medcouple dari masing-masing peubah
1.2 Penyiapan data pencilan dan set data. Pembangkitan pencilan dilakukan dengan cara pengekstriman data pengamatan biasa pada h peubah dari
p peubah pada setiap pengamatan
yang terpilih dimana h<p. Proses pembangkitan dilakukan dengan algoritma sebagai berikut:
a. Mempersiapkan dua set data menjulur X1, X2, ..., X10
berdimensi 500 × 10 dan 100 × 10 yang akan dikontaminasi oleh berbagai proporsi pencilan b. Melakukan identifikasi pencilan
pada dua set data tersebut dengan menggunakan adjusted
outlyingness (AO). Jika AOi ≥ cut
off yang ditentukan maka pengamatan tersebut dikatakan sebagai pencilan
c. Melakukan pengekstriman pada pengamatan yang memiliki nilai AOi terbesar sesuai dengan proporsi pencilan yang diinginkan yaitu 0%, 5%, 10%, dan 15% sehingga terdapat empat set data menjulur berukuran 500 × 10 dan empat set data menjulur berukuran 100 × 10.
2. Melakukan identifikasi pencilan dengan menggunakan metode Klasik, AKU-KMCD, AKU-K, dan AKU-KAO untuk setiap data pada langkah 1. Kemudian membandingkan hasil dari keempat
metode tersebut. Hal yang dibandingkan adalah jumlah pencilan yang teridentifikasi pada setiap metode
3. Membandingkan peta pencilan yang dihasilkan oleh metode AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO 4. Melakukan penerapan AKU-Klasik dan
AKU-KAO pada data menjulur dengan proporsi pencilan 5% untuk n=500, p=10 5. Melakukan penerapan AKU-Klasik pada
data menjulur dengan proporsi pencilan 5% untuk n=500, p=10 tetapi pencilan yang teridentifikasi dihilangkan
6. Membandingkan hasil AKU-Klasik dan AKU-KAO pada langkah 4 dan 5. Hal yang dibandingkan adalah akar ciri dan proporsi kumulatif komponen utama pertama.
Skema algoritma penelitian dapat dilihat pada Lampiran 1. Pengolahan data dilakukan dengan menggunakan perangkat lunak
MATLAB 7.7.0(R2008b) dan Microsoft Excel 2007. Metode AKU-Klasik, AKU-KMCD,
AKU-K, dan AKU-KAO dilakukan menggunakan program MATLAB yang
terdapat pada situs
http://www.wis.kuleuven.ac.be/stat/robust.htm l dan http://win-www.uia.ac.be/u/statis.
HASIL DAN PEMBAHASAN Karakteristik Data
Data yang dibangkitkan merupakan data menjulur dari sebaran NIG α, β, δ,μ dengan parameter lokasi µ=0, parameter skala σ=1, parameter panjang ekor γ=1 dan parameter kemenjuluran δ = 0.8. Data tersebut memiliki ukuran n1=500 dan n2=100 dengan p=10 untuk
setiap ukuran. Histogram dari data hasil pembangkitan dapat dilihat pada Lampiran 2. Histogram tersebut menggambarkan bahwa data menjulur ke kanan karena pada awal pembangkitan parameter kemenjuluran data telah ditetapkan dengan nilai positif.
Tabel 1 menunjukkan besarnya kemenjuluran data pada setiap peubah. Nilai
medcouple melebihi nilai 0 sehingga data
dapat dikatakan menjulur. Nilai medcouple berkisar antara -1 sampai 1. Jika nilainya 0 maka sebaran datanya tidak menjulur (simetrik). Besarnya korelasi antar peubah dapat dilihat pada Lampiran 3 dan 4. Lampiran 3 menunjukkan bahwa terdapat korelasi yang signifikan pada kesepuluh peubahnya (X1-X10). Sedangkan pada Lampiran 4 terdapat korelasi yang tidak signifikan antara peubah X2 dan X6 (0.146), antara peubah X3 dan X6
(0.165), antara peubah X4 dan X9 (0.235) serta peubah X6 dan X9 (0.133).
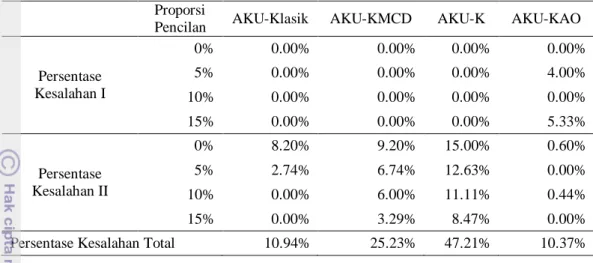
Tabel 1 Nilai medcouple tiap peubah Peubah n1=500 n2=100 X1 0.3240 0.1245 X2 0.2252 0.3049 X3 0.3007 0.2098 X4 0.2629 0.3067 X5 0.3141 0.4908 X6 0.2311 0.2380 X7 0.2560 0.2989 X8 0.2428 0.2193 X9 0.2557 0.2282 X10 0.2156 0.1406
Simulasi dilakukan dengan menggunakan metode AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO. Karena semua simulasi dilakukan pada set data yang mengandung pencilan sebesar 0%, 5%, 10%, dan 15%, maka α yang digunakan untuk setiap metode adalah sebesar 85%.
Identifikasi Pencilan pada n1=500
Tabel 2 menunjukkan kesalahan identifikasi pencilan pada data menjulur dengan n1=500 data, p=10 dimensi dan rank
k=2 (k adalah banyaknya komponen utama
yang diambil) dikontaminasi dengan data yang diekstrimkan. Kesalahan I merupakan kesalahan dimana pencilan teridentifikasi sebagai data bukan pencilan. Sedangkan, Kesalahan II merupakan kesalahan dimana data bukan pencilan teridentifikasi sebagai pencilan. Metode yang baik adalah metode yang mengidentifikasi data secara tepat. Pada data tanpa pencilan (proporsi pencilan 0%) dan data dengan proporsi 10% tidak terdapat Kesalahan I untuk keempat metode (Gambar 2). Artinya, keempat metode tersebut mengidentifikasi pencilan secara tepat. Pada proporsi pencilan 5%, AKU-KAO memiliki persentase Kesalahan I sebesar 4%. Artinya, AKU-KAO mengidentifikasi pencilan sebagai data bukan pencilan sebanyak 1 pencilan dari 25 pencilan yang dikontaminasikan. Sedangkan, pada data dengan proporsi pencilan 15%, AKU-KAO memiliki persentase Kesalahan I yaitu sebesar 5.33%.
Pada Tabel 2 terlihat bahwa keempat metode yaitu AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO memiliki persentase Kesalahan II yang beragam. Pada proporsi pencilan 0%, AKU-Klasik memiliki
Tabel 2 Persentase kesalahan identifikasi pencilan pada data menjulur n1=500, p=10 dan k=2
Gambar 2 Persentase Kesalahan I pada n1=500
persentasi Kesalahan II yang beragam. Pada proporsi pencilan 0%, AKU-Klasik memiliki Kesalahan II sebesar 8.20%. Artinya, Klasik mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 41 pencilan dari 500 data bukan pencilan (data pengamatan biasa). Pada AKU-KMCD terdapat Kesalahan II sebesar 9.20%. Artinya, AKU-KMCD mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 46 pencilan dari 500 data bukan pencilan. Sedangkan pada AKU-K terdapat Kesalahan II yang relatif tinggi yaitu sebesar 15%. Artinya, AKU-K mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 75 pencilan dari 500 data bukan pencilan. Berbeda dengan AKU-KAO yang memiliki Kesalahan II yang cukup kecil dibandingkan dengan ketiga metode yang lainnya yaitu sebesar 0.6%. Artinya, AKU-KAO mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 3 pencilan dari 500 data bukan pencilan.
Pada data dengan proporsi pencilan 5%, tidak terdapat Kesalahan II untuk AKU-KAO. Sedangkan pada ketiga metode lainnya yaitu AKU-Klasik, AKU-KMCD, dan AKU-K memiliki Kesalahan II masing-masing sebesar 2.74%, 6.74%, dan 12,63%. Ketika proporsi
pencilan ditambahkan menjadi 10% dan 15%, AKU-Klasik tidak mencatat Kesalahan II. Artinya, AKU-Klasik mengidentifikasi data bukan pencilan secara tepat. Pada AKU-KMCD terdapat Kesalahan II sebesar 6% ketika proporsi pencilan meningkat menjadi 10%. Pada AKU-K terdapat Kesalahan II sebesar 11.11%. Sedangkan pada AKU-KAO terdapat sedikit Kesalahan II yaitu sebesar 0.44%. Pada proporsi pencilan 15% AKU-KMCD dan AKU-K memiliki Kesalahan II masing-masing sebesar 3.29% dan 8.47%. Secara keseluruhan AKU-K memiliki Kesalahan II yang paling tinggi yaitu diatas 8% diikuti oleh KMCD dan AKU-Klasik. Sedangkan AKU-KAO memiliki Kesalahan II yang relatif kecil yaitu dibawah 1% (Gambar 3).
AKU-K memiliki Kesalahan Total terbesar yaitu sebesar 47.21% diikuti AKU-KMCD dan AKU-Klasik yang memiliki Kesalahan Total masing-masing sebesar 25.23% dan 10.94%. Berbeda dengan ketiga metode lainnya, AKU-KAO memiliki Kesalahan Total paling kecil yaitu sebesar 10.37%. Kesalahan I dan Kesalahan II pada data n1=500 dapat dilihat
lebih rinci pada Lampiran 5.
Gambar 3 Persentase Kesalahan II pada
n1=500
Proporsi
Pencilan AKU-Klasik AKU-KMCD AKU-K AKU-KAO
Persentase Kesalahan I 0% 0.00% 0.00% 0.00% 0.00% 5% 0.00% 0.00% 0.00% 4.00% 10% 0.00% 0.00% 0.00% 0.00% 15% 0.00% 0.00% 0.00% 5.33% Persentase Kesalahan II 0% 8.20% 9.20% 15.00% 0.60% 5% 2.74% 6.74% 12.63% 0.00% 10% 0.00% 6.00% 11.11% 0.44% 15% 0.00% 3.29% 8.47% 0.00%
Tabel 3 Persentase kesalahan identifikasi pencilan pada data menjulur n2=100, p=10 dan k=2
Proporsi
Pencilan AKU-Klasik AKU-KMCD AKU-K AKU-KAO
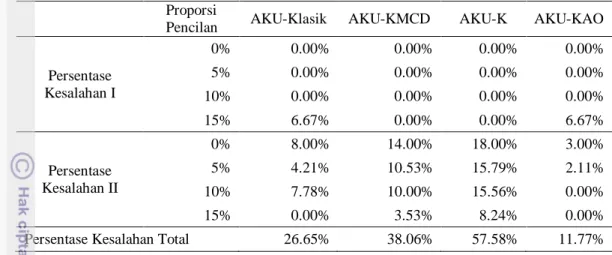
Persentase Kesalahan I 0% 0.00% 0.00% 0.00% 0.00% 5% 0.00% 0.00% 0.00% 0.00% 10% 0.00% 0.00% 0.00% 0.00% 15% 6.67% 0.00% 0.00% 6.67% Persentase Kesalahan II 0% 8.00% 14.00% 18.00% 3.00% 5% 4.21% 10.53% 15.79% 2.11% 10% 7.78% 10.00% 15.56% 0.00% 15% 0.00% 3.53% 8.24% 0.00%
Persentase Kesalahan Total 26.65% 38.06% 57.58% 11.77%
Identifikasi Pencilan pada n2=100
Pada Tabel 3 menunjukkan set data menjulur dengan n2=100, p=10 dan k=2. Data
dengan proporsi pencilan sebanyak 0%, 5%, dan 10% tidak mencatat Kesalahan I ketika menggunakan metode Klasik, AKU-KMCD, AKU-K, dan AKU-KAO. Artinya, keempat metode tersebut mengidentifikasi pencilan secara tepat pada proporsi pencilan 0%, 5%, dan 10%. Akan tetapi, AKU-Klasik mencatat Kesalahan I sebesar 6.67% pada proporsi pencilan 15%. Artinya, AKU-Klasik mengidentifikasi pencilan sebagai data bukan pencilan sebanyak 1 pencilan dari 15 pencilan yang dikontaminasikan. Selain itu AKU-KAO juga memiliki Kesalahan I sebesar 6.67%.
Gambar 4 Persentase Kesalahan I pada n2=100
Pada Tabel 3 terlihat bahwa keempat metode yaitu AKU-Klasik, AKU-KMCD,AKU-K, dan AKU-KAO memiliki persentasi Kesalahan II yang beragam sama seperti pada data n1=500. Pada proporsi
pencilan 0%, AKU-Klasik memiliki Kesalahan II sebesar 8%. Artinya, AKU-Klasik mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 8 pencilan dari 100 data bukan pencilan. Pada AKU-KMCD terdapat Kesalahan II sebesar 14.00%. Artinya, AKU-KMCD mengidentifikasi data
bukan pencilan sebagai pencilan sebanyak 14 pencilan dari 100 data bukan pencilan. Sedangkan pada AKU-K terdapat Kesalahan II yang relatif tinggi yaitu sebesar 18%. Artinya, AKU-K mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 18 pencilan dari 100 data bukan pencilan. AKU-KAO memiliki Kesalahan II sebesar 3%, lebih kecil bila dibandingkan dengan ketiga metode lainnya. Artinya, AKU-KAO mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 3 pencilan dari 100 data bukan pencilan.
Gambar 5 Persentase Kesalahan II pada
n2=100
Kesalahan II pada data dengan proporsi pencilan 5% tidak jauh berbeda dengan data yang memiliki proporsi pencilan 0%. Pada AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO memiliki Kesalahan II masing-masing sebesar 4.21%, 10.53%, 15.79%, dan 2.11%. Ketika proporsi pencilan ditambahkan menjadi 10% dan 15%, AKU-KAO tidak mencatat Kesalahan II. Artinya, AKU-KAO mengidentifikasi secara tepat data bukan pencilan. Begitu pula pada AKU-Klasik yang tidak mencatat Kesalahan II ketika proporsi pencilan meningkat menjadi 15%. Pada proporsi pencilan 10%, AKU-Klasik memiliki Kesalahan II sebesar 7.78%. Pada AKU-
KMCD terdapat kesalahan sebesar 10%. Sedangkan pada AKU-K terdapat Kesalahan II yaitu sebesar 15.56%. Pada proporsi pencilan 15%, AKU-KMCD dan AKU-K memiliki Kesalahan II masing-masing sebesar 3.53% dan 8.24%.
Secara keseluruhan AKU-K memiliki Kesalahan Total terbesar yaitu sebesar 57.58% diikuti AKU-KMCD dan AKU-Klasik yang memiliki Kesalahan Total masing-masing sebesar 38.06% dan 26.65%. Sedangkan, AKU-KAO memiliki Kesalahan Total paling kecil yaitu sebesar 11.77%. Hasil tersebut tidak berbeda jauh dengan hasil pada n1=500.
Persentase Kesalahan Total pada n1=500 dan
n2=100 menunjukkan bahwa AKU-KAO
memiliki kesalahan yang paling kecil dalam mengidentifikasi pencilan. Kesalahan I dan Kesalahan II pada data n2=100 dapat dilihat
lebih rinci pada Lampiran 6.
Peta pencilan
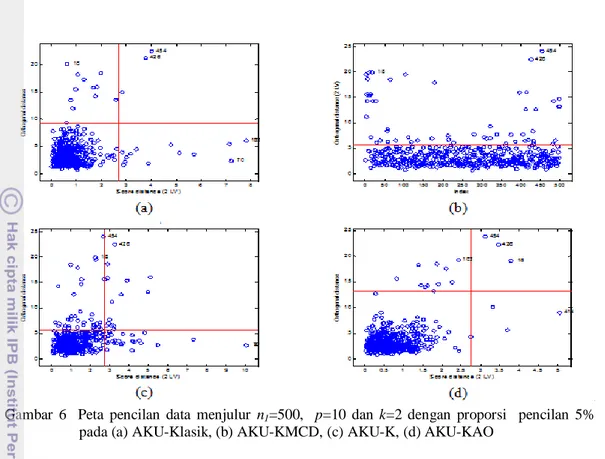
Peta pencilan merupakan peta yang memplotkan jarak ortogonal dengan jarak skor. Peta ini membedakan pencilan menjadi tiga jenis yaitu amatan berpengaruh baik, pencilan ortogonal, dan amatan berpengaruh buruk. Gambar 6 menunjukkan peta pencilan pada saat proporsi pencilan 5% pada n1=500,
p=10 dengan k=2 dimensi. Gambar 6(a)
merupakan peta pencilan untuk AKU-Klasik. Peta tersebut menggambarkan 13 amatan
berpengaruh baik, pencilan ortogonal sebanyak 12 pencilan, dan 3 amatan berpengaruh buruk. Peta pencilan AKU-KMCD pada Gambar 6(b) memplotkan jarak ortogonal dengan urutan pengamatannya dan hanya menggambarkan pencilan secara keseluruhan. Peta tersebut menggambarkan sebanyak 57 pencilan. Gambar 6(c) merupakan peta pencilan AKU-K. Peta ini menggambarkan 33 amatan berpengaruh baik, pencilan ortogonal sebanyak 36 pencilan, dan 16 amatan berpengaruh buruk. Peta pencilan AKU-KAO pada Gambar 6(d) menggambarkan 4 amatan berpengaruh baik, pencilan ortogonal sebanyak 12 pencilan, dan 16 amatan berpengaruh buruk. Peta pencilan dengan proporsi pencilan 0%, 10%, dan 15% terlampir pada Lampiran 7, 8, dan 9. Gambar 7 merupakan peta pencilan pada saat proporsi pencilan 5% pada n2=100, p=10
dengan k=2 dimensi. Peta pencilan AKU-Klasik pada Gambar 7(a) menggambarkan 4 amatan berpengaruh baik, pencilan ortogonal sebanyak 3 pencilan, dan 2 amatan berpengaruh buruk. Gambar 7(b) merupakan peta pencilan AKU-KMCD. Peta tersebut menggambarkan sebanyak 15 pencilan. Gambar 7(c) merupakan peta pencilan AKU-K yang menggambarkan 5 amatan berpengaruh baik, pencilan ortogonal sebanyak 9 pencilan, dan 6 amatan berpengaruh buruk. Peta pencilan AKU-KAO pada Gambar 7(d) Gambar 6 Peta pencilan data menjulur n1=500, p=10 dan k=2 dengan proporsi pencilan 5%
menggambarkan 3 amatan berpengaruh baik, pencilan ortogonal sebanyak 2 pencilan, dan 2 amatan berpengaruh buruk. Peta pencilan dengan proporsi pencilan 0%, 10%, dan 15% terlampir pada Lampiran 10, 11, dan 12. Secara keseluruhan peta pencilan AKU-Klasik, AKU- KMCD, dan AKU-K pada
n1=500 dan n2=100 hampir sama karena pada
peta pencilan ketiga metode tersebut terlalu banyak menggambarkan pengamatan biasa sebagai pencilan dan sebaliknya. Sedangkan pada peta pencilan AKU-KAO, pencilan yang
digambarkan cukup sesuai dengan proporsi pencilan yang dikontaminasikan.
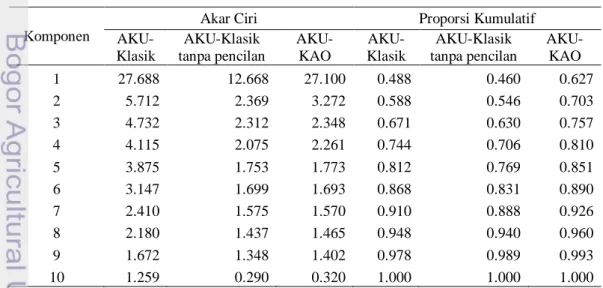
Penerapan AKU-Klasik dan AKU-KAO
AKU-Klasik dan AKU-K merupakan analisis yang digunakan untuk data simetrik. Oleh karena itu data peubah asal harus memiliki sebaran yang simetrik. Jika datanya tidak simetrik maka akan banyak titik data yang sebenarnya bukan pencilan dianggap sebagai pencilan dan sebaliknya. Pada penelitian ini dilakukan penerapan AKU-
Komponen
Akar Ciri Proporsi Kumulatif
AKU-Klasik AKU-Klasik tanpa pencilan AKU-KAO AKU-Klasik AKU-Klasik tanpa pencilan AKU-KAO 1 27.688 12.668 27.100 0.488 0.460 0.627 2 5.712 2.369 3.272 0.588 0.546 0.703 3 4.732 2.312 2.348 0.671 0.630 0.757 4 4.115 2.075 2.261 0.744 0.706 0.810 5 3.875 1.753 1.773 0.812 0.769 0.851 6 3.147 1.699 1.693 0.868 0.831 0.890 7 2.410 1.575 1.570 0.910 0.888 0.926 8 2.180 1.437 1.465 0.948 0.940 0.960 9 1.672 1.348 1.402 0.978 0.989 0.993 10 1.259 0.290 0.320 1.000 1.000 1.000
Gambar 7 Peta pencilan data menjulur n2=100, p=10 dan k=2 dengan proporsi pencilan 5% pada
(a) AKU-Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO
Tabel 4 Ringkasan hasil komponen utama pada AKU-Klasik, AKU-Klasik tanpa pencilan, dan AKU-KAO
p=10 yang dikontaminasi pencilan sebesar 5%.
Klasik pada data menjulur dengan n=500, Kemudian analisis tersebut juga diterapkan pada data ketika pencilan yang teridentifikasi dihilangkan. Pencilan yang dihilangkan adalah pencilan yang teridentifikasi yaitu sebanyak 38 pencilan (lihat Lampiran 4). Selain itu dilakukan juga penerapan analisis komponen utama kekar untuk data menjulur (AKU-KAO) pada n=500, p=10 yang dikontaminasi pencilan sebesar 5%.
Tabel 4 menunjukkan ringkasan hasil analisis komponen utama pada AKU- Klasik, AKU-Klasik tanpa pencilan, dan AKU-KAO. Hal yang dibandingkan yaitu akar ciri dan proporsi kumulatif komponen utama pertama. AKU-Klasik menghasilkan akar ciri pertama sebesar 27.688 dan mampu menerangkan keragaman data sebesar 0.488 atau 48.8%. Ketika pencilan yang teridentifikasi dihilangkan, AKU-Klasik menghasilkan akar ciri pertama yang nilainya lebih kecil yaitu sebesar 12.668 dan mampu menerangkan keragaman data sebesar 0.460 atau 46%. Proporsi kumulatif data yang diterangkan AKU-Klasik menurun ketika pencilan yang teridentifikasi dihilangkan. Hal tersebut terjadi karena data dengan pencilan memiliki keragaman lebih tinggi daripada data tanpa pencilan. Sedangkan AKU-KAO menghasilkan akar ciri pertama sebesar 27.100 dan proporsi kumulatif data yang diterangkannya yaitu sebesar 0,627 atau 62.7%. Nilai akar ciri pertama komponen utama pada AKU-KAO mampu menerangkan keragaman data yang lebih besar bila dibandingkan dengan nilai akar ciri pertama komponen utama pada AKU-Klasik dan AKU-Klasik tanpa pencilan.
Menurut Johnson (2007) salah satu kriteria penentuan banyaknya jumlah komponen utama yang digunakan adalah dengan mengambil sejumlah komponen utama yang mampu menjelaskan 80% total keragaman dari data. Peubah yang digunakan pada penelitian ini sebanyak 10 buah. Pada AKU-Klasik diperlukan sebanyak 5 komponen utama. Pada AKU-Klasik tanpa pencilan diperlukan sebanyak 6 komponen utama. Sedangkan pada AKU-KAO hanya diperlukan sebanyak 4 komponen utama.
KESIMPULAN DAN SARAN Kesimpulan
Analisis komponen utama kekar untuk data menjulur (AKU-KAO) menunjukkan hasil yang lebih baik dalam mengidentifikasi
pencilan pada data menjulur daripada Klasik, K, dan KMCD. AKU-KAO mengidentifikasi pencilan secara tepat dan konsisten dibandingkan dengan ketiga metode lainnya yang menganggap titik data pencilan sebagai pencilan (Kesalahan I) dan titik data bukan pencilan sebagai pencilan (Kesalahan II). AKU-Klasik, AKU-KMCD, dan AKU-K didesain untuk data simetrik sehingga kurang tepat jika digunakan pada data menjulur. AKU-KAO mampu mengatasi pengaruh kehadiran pencilan pada data menjulur dengan n1=500 maupun data dengan
n2=100 karena memiliki Kesalahan Total
paling kecil. Hal tersebut diperkuat dengan adanya peta pencilan yang memberikan gambaran secara visual dalam pendeteksian pencilan.
Saran
Penetapan α yang digunakan untuk setiap metode perlu ditetapkan secara tepat agar terdapat keseimbangan antara kekekaran dan efisiensi dalam komputasi karena semakin kecil α semakin kekar AKU-K tetapi semakin tidak akurat.
DAFTAR PUSTAKA
Brys G, Hubert M, Struyf A. 2004. A Robust Measure of Skewness. Journal of
Computational and Graphical Statistics. 13: 996-1017.
Draper NR, Smith H. 1992. Analisis Regresi
Terapan Edisi Kedua. Sumantri B.
penerjemah. Jakarta: Gramedia Pustaka Utama. Terjemahan dari: Applied Regression Analysis.
Hubert M, Rousseeuw PJ, Vanden-Branden K. 2005. ROBPCA: A New Approach to Robust Principal Component Analysis.
Technometrics. 47: 64-79.
Hubert M, Rousseeuw PJ, Verdonck T. 2009. Robust PCA for Skewed Data and Its Outlier Map. Computational Statistics &
Data Analysis. 53: 2264-2274.
Hubert M, Van der Veeken S. 2008. Outlier Detection for Skewed Data. Journal of
Chemometrics. 22: 235-246.
Johnson RA, Wichern DW. 2007. Applied
Multivariate Statistical Analysis. Ed
ke-6. New Jersey : Prentice Hall. Inc. Jolliffe IT. 2002. Principal Component
Analysis. Ed ke-2. New York:
Springer-Verlag. Inc.
Montgomery DC, Peck EA. 1992.
Analysis. Ed ke-2. New York: John
Wiley & Sons. Inc.
Prause K. 1999. The generalized hiperbolic model: estimation, financial derivatives, and risk measures [disertasi]. Freiburg: Albert-Ludwigs Universitat
Rousseeuw PJ. Driessen KV. 1999. A Fast Algorithm for the Minimum Covariance Determinant Estimator. Technometrics.
Lampiran 1 Skema algoritma penelitian
Bangkitkan data menjulur
X~NIG(0,0.8,1,0) sebanyak n1 = 500 dan n2 = 100
Ulangi sebanyak 10 kali dengan parameter yang sama sehingga diperoleh 10 peubah
X berukuran 500 dan 100 yaitu X1, X2, ..., X10 Peubah X1, X2, ..., X10 membentuk matriks berdimensi 500 × 10 dan 100 × 10
Tentukan nilai korelasi awal pada peubah X1, X2,
..., X10 sehingga kesepuluh
peubah tersebut saling berkorelasi
Cek kemenjuluran dari dua set data dengan melihat nilai medcouple dari masing-masing peubah
Melakukan pengekstriman pada pengamatan yang memiliki nilai AOi terbesar sesuai dengan proporsi pencilan yang diinginkan yaitu 0%, 5%, 10%, dan 15%
YA TIDAK
Hitung nilai adjusted
outlyingness (AO). Jika AOi ≥
cut off yang ditentukan maka
pengamatan tersebut dikatakan sebagai pencilan
Terdapat empat set data menjulur berukuran 500 × 10 dan empat set data menjulur berukuran 100 × 10 yang sudah dikontaminasi
Lakukan identifikasi pencilan dengan menggunakan metode AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO
Bandingkan hasilnya
Metode Klasik, KMCD, K, dan AKU-KAO menghasilkan peta pencilan
Bandingkan hasilnya
Persiapkan data menjulur dengan proporsi pencilan 5% untuk n=500, p=10
Persiapkan data menjulur dengan proporsi pencilan 5% untuk n=500,
p=10 tapi pencilan yang
teridentifikasi dihilangkan
Lakukan metode AKU-Klasik
dan AKU-KAO Lakukan metode AKU-Klasik
Bangkitkan data menjulur
X~NIG(0,0.8,1,0) sebanyak n1 = 500 dan n2 = 100
TIDAK Bangkitkan data menjulur
X~NIG(0,0.8,1,0) sebanyak n1 = 500 dan n2 = 100
1
-5 0 5 10 15 20 0 50 100 150 200 250 300 350 -2 0 2 4 6 8 10 12 14 16 0 10 20 30 40 50 60 70
Lampiran 2 Rumus adjusted outlyingness (AO)
AOi=maxv∈B |xi'v-med(xj'v)| c2-med xj ' v I[xi ' v>med xj ' v ]+(med xj ' v -c1 v I[xi ' v<med xj ' v ] dimana:
𝑐1 : pengamatan terkecil yang lebih besar dari Q1-1.5e
-4MCIQR
𝑐2 : pengamatan terbesar yang lebih kecil dari Q3+1.5e3MCIQR
𝑄1 : kuartil pertama
𝑄3 : kuartil ketiga
IQR : jangkauan antar kuartil MC : medcouple
Lampiran 3 Histogram data hasil pembangkitan
(a) Histogram data n1=500, p=10 (b) Histogram data n2=100, p=10
Lampiran 4 Nilai korelasi antar peubah pada n1=500 dan p=10
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X1 r 1.000 nilai-p 0.000 X2 r 0.680 1.000 nilai-p 0.000 0.000 X3 r 0.601 0.407 1.000 nilai-p 0.000 0.000 0.000 X4 r 0.661 0.435 0.408 1.000 nilai-p 0.000 0.000 0.000 0.000 X5 r 0.665 0.416 0.363 0.448 1.000 nilai-p 0.000 0.000 0.000 0.000 0.000 X6 r 0.643 0.424 0.359 0.424 0.454 1.000 nilai-p 0.000 0.000 0.000 0.000 0.000 0.000 X7 r 0.699 0.493 0.411 0.452 0.462 0.455 1.000 nilai-p 0.000 0.000 0.000 0.000 0.000 0.000 0.000 X8 r 0.697 0.497 0.385 0.469 0.465 0.402 0.498 1.000 nilai-p 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 X9 r 0.690 0.422 0.415 0.472 0.499 0.433 0.444 0.454 1.000 nilai-p 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 X10 r 0.671 0.504 0.434 0.523 0.422 0.432 0.443 0.418 0.458 1.000 nilai-p 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 Frekuensi Frekuensi N il ai N il ai
Lampiran 5 Nilai korelasi antar peubah pada n2=100 dan p=10 X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X1 r 1.000 nilai-p 0.000 X2 r 0.582 1.000 nilai-p 0.000 0.000 X3 r 0.659 0.445 1.000 nilai-p 0.000 0.000 0.000 X4 r 0.604 0.304 0.374 1.000 nilai-p 0.000 0.002 0.000 0.000 X5 r 0.564 0.406 0.332 0.347 1.000 nilai-p 0.000 0.000 0.001 0.000 0.000 X6 r 0.441 0.146 0.165 0.352 0.280 1.000 nilai-p 0.000 0.148* 0.102* 0.000 0.005 0.000 X7 r 0.713 0.425 0.405 0.442 0.378 0.429 1.000 nilai-p 0.000 0.000 0.000 0.000 0.000 0.000 0.000 X8 r 0.627 0.363 0.455 0.419 0.336 0.316 0.419 1.000 nilai-p 0.000 0.000 0.000 0.000 0.001 0.001 0.000 0.000 X9 r 0.539 0.576 0.390 0.235 0.364 0.133 0.377 0.411 1.000 nilai-p 0.000 0.000 0.000 0.019* 0.000 0.187* 0.000 0.000 0.000 X10 r 0.695 0.430 0.511 0.465 0.424 0.376 0.540 0.442 0.378 1.000 nilai-p 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 Keterangan. *Korelasi tidak signifikan pada taraf nyata 0.05
1
Lampiran 6 Kesalahan identifikasi pencilan pada data menjulur n1=500, p=10, dan k=2
Proporsi
pencilan Metode Data
Hasil Deteksi Total Kesalahan I Kesalahan II Pencilan Bukan Pencilan 0% AKU-Klasik Pencilan 0 0 Bukan Pencilan 41 459 500 0.00% 8.20% AKU-KMCD Pencilan 0 0 0 Bukan Pencilan 46 454 500 0.00% 9.20% AKU-K Pencilan 0 0 0 Bukan Pencilan 75 425 500 0.00% 15.00% AKU-KAO Pencilan 0 0 0 Bukan Pencilan 3 497 500 0.00% 0.60% 5% AKU-Klasik Pencilan 25 0 25 Bukan Pencilan 13 462 475 0.00% 2.74% AKU-KMCD Pencilan 25 0 25 Bukan Pencilan 32 443 475 0.00% 6.74% AKU-K Pencilan 25 0 25 Bukan Pencilan 60 415 475 0.00% 12.63% AKU-KAO Pencilan 24 1 25 4.00% 0.00% Bukan Pencilan 0 475 475 10% AKU-Klasik Pencilan 50 0 50 0.00% 0.00% Bukan Pencilan 0 450 450 AKU-KMCD Pencilan 50 0 50 Bukan Pencilan 27 423 450 0.00% 6.00% AKU-K Pencilan 50 0 50 Bukan Pencilan 50 400 450 0.00% 11.11% AKU-KAO Pencilan 50 0 50 Bukan Pencilan 2 448 450 0.00% 0.44% 15% AKU-Klasik Pencilan 75 0 75 0.00% 0.00% Bukan Pencilan 0 425 425 AKU-KMCD Pencilan 75 0 75 Bukan Pencilan 14 411 425 0.00% 3.29% AKU-K Pencilan 75 0 75 Bukan Pencilan 36 389 425 0.00% 8.47% AKU-KAO Pencilan 71 4 75 5.33% 0.00% Bukan Pencilan 0 425 425
Lampiran 7 Kesalahan identifikasi pencilan pada data menjulur n2=100, p=10, dan k=2
Proporsi
pencilan Metode Data
Hasil Deteksi Total Kesalahan I Kesalahan II Pencilan Bukan Pencilan 0% AKU-Klasik Pencilan 0 0 0 Bukan Pencilan 8 92 100 0.00% 8.00% AKU-KMCD Pencilan 0 0 0 Bukan Pencilan 14 86 100 0.00% 14.00% AKU-K Pencilan 0 0 0 Bukan Pencilan 18 82 100 0.00% 18.00% AKU-KAO Pencilan 0 0 0 Bukan Pencilan 3 97 100 0.00% 3.00% 5% AKU-Klasik Pencilan 5 0 5 Bukan Pencilan 4 91 95 0.00% 4.21% AKU-KMCD Pencilan 5 0 5 Bukan Pencilan 10 85 95 0.00% 10.53% AKU-K Pencilan 5 0 5 Bukan Pencilan 15 80 95 0.00% 15.79% AKU-KAO Pencilan 5 0 5 Bukan Pencilan 2 93 95 0.00% 2.11% 10% AKU-Klasik Pencilan 10 0 10 Bukan Pencilan 7 83 90 0.00% 7.78% AKU-KMCD Pencilan 10 0 10 Bukan Pencilan 9 81 90 0.00% 10.00% AKU-K Pencilan 10 0 10 Bukan Pencilan 14 76 90 0.00% 15.56% AKU-KAO Pencilan 10 0 10 Bukan Pencilan 0 90 90 0.00% 0.00% 15% AKU-Klasik Pencilan 14 1 15 6.67% 0.00% Bukan Pencilan 0 85 85 AKU-KMCD Pencilan 15 0 15 Bukan Pencilan 3 82 85 0.00% 3.53% AKU-K Pencilan 15 0 15 Bukan Pencilan 7 78 85 0.00% 8.24% AKU-KAO Pencilan 14 1 15 6.67% 0.00% Bukan Pencilan 0 85 85
0 50 100 150 200 250 300 350 400 450 500 0 1 2 3 4 5 6 7 8 9 10 Index O rt h o g o n a l d is ta n c e ( 2 L V ) 58 322 396 ROBPCA 0 1 2 3 4 5 6 0 1 2 3 4 5 6 7 8 9 Score distance (2 LV) O rt h o g o n a l d is ta n c e 346 322 130 431 58 396 CPCA 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 6 7 8 9 10 Score distance (2 LV) O rt h o g o n a l d is ta n c e 437 346 130 58 322 396 ROBPCA 0 0.5 1 1.5 2 2.5 0 1 2 3 4 5 6 7 8 9 Score distance (2 LV) O rt h o g o n a l d is ta n c e 111 130 322 431 58 396 ROBPCA
Lampiran 8 Peta pencilan data menjulur n1=500, p=10 dan k=2 dengan proporsi pencilan 0%
(a) AKU- Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO
(a) (b)
0 1 2 3 4 5 6 7 8 9 0 5 10 15 20 25 30 Score distance (2 LV) O rt h o g o n a l d is ta n c e 65 66 22 24 5 484 CPCA 0 50 100 150 200 250 300 350 400 450 500 0 5 10 15 20 25 30 35 Index O rt h o g o n a l d is ta n c e ( 2 L V ) 17 65 66 ROBPCA 0 2 4 6 8 10 12 0 5 10 15 20 25 30 35 Score distance (2 LV) O rt h o g o n a l d is ta n c e 24 21 22 17 65 66 ROBPCA 0 2 4 6 8 10 12 14 16 0 5 10 15 20 25 30 35 Score distance (2 LV) O rt h o g o n a l d is ta n c e 414 24 107 17 65 66 ROBPCA
Lampiran 9 Peta pencilan data menjulur n1=500, p=10 dan k=2 dengan proporsi pencilan 10%
(a) AKU-Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO
(a) (b)
0 1 2 3 4 5 6 7 8 0 5 10 15 20 25 30 35 40 Score distance (2 LV) O rt h o g o n a l d is ta n c e 20 25 22 65 66 104 CPCA 0 50 100 150 200 250 300 350 400 450 500 0 5 10 15 20 25 30 35 40 Index O rt h o g o n a l d is ta n c e ( 2 L V ) 103 20 25 ROBPCA 0 2 4 6 8 10 12 0 5 10 15 20 25 30 35 40 Score distance (2 LV) O rt h o g o n a l d is ta n c e 2 21 22 103 20 25 ROBPCA 0 2 4 6 8 10 12 0 5 10 15 20 25 30 35 40 Score distance (2 LV) O rt h o g o n a l d is ta n c e 401 485 10 103 20 25 ROBPCA
Lampiran 10 Peta pencilan data menjulur n1=500, p=10 dan k=2 dengan proporsi pencilan 15%
(a) AKU-Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO
(a) (b)
0 1 2 3 4 5 0 1 2 3 4 5 6 7 8 9 10 Score distance (2 LV) O rt h o g o n a l d is ta n c e 6 94 41 49 85 6 CPCA 0 10 20 30 40 50 60 70 80 90 100 0 2 4 6 8 10 12 14 Index O rt h o g o n a l d is ta n c e ( 2 L V ) 49 85 6 ROBPCA 0 1 2 3 4 5 6 7 8 0 2 4 6 8 10 12 14 Score distance (2 LV) O rt h o g o n a l d is ta n c e 48 41 94 49 85 6 ROBPCA 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 0 2 4 6 8 10 12 Score distance (2 LV) O rt h o g o n a l d is ta n c e 71 48 6 49 85 6 ROBPCA
Lampiran 11 Peta pencilan data menjulur n2=100, p=10 dan k=2 dengan proporsi pencilan 0%
(a) AKU- Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO
(a) (b)
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 0 5 10 15 20 25 30 35 40 Score distance (2 LV) O rt h o g o n a l d is ta n c e 14 8 12 10 7 6 CPCA 0 10 20 30 40 50 60 70 80 90 100 0 5 10 15 20 25 30 35 40 45 Index O rt h o g o n a l d is ta n c e ( 2 L V ) 7 12 6 ROBPCA 0 1 2 3 4 5 0 5 10 15 20 25 30 35 40 45 Score distance (2 LV) O rt h o g o n a l d is ta n c e 14 2 12 7 12 6 ROBPCA 0 5 10 15 20 0 5 10 15 20 25 30 35 40 45 50 Score distance (2 LV) O rt h o g o n a l d is ta n c e 12 17 3 10 7 6 ROBPCA
Lampiran 12 Peta pencilan data menjulur n2=100, p=10 dan k=2 dengan proporsi pencilan 10%
(a) AKU-Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO
(a) (b)
0 1 2 3 4 5 6 0 5 10 15 20 25 30 35 40 Score distance (2 LV) O rt h o g o n a l d is ta n c e 12 8 6 11 10 7 CPCA 0 10 20 30 40 50 60 70 80 90 100 0 5 10 15 20 25 30 35 40 45 Index O rt h o g o n a l d is ta n c e ( 2 L V ) 12 10 6 ROBPCA 0 2 4 6 8 10 12 0 5 10 15 20 25 30 35 40 45 Score distance (2 LV) O rt h o g o n a l d is ta n c e 6 7 9 12 10 6 ROBPCA 0 5 10 15 20 0 5 10 15 20 25 30 35 40 Score distance (2 LV) O rt h o g o n a l d is ta n c e 13 12 6 8 10 7 ROBPCA
Lampiran 13 Peta pencilan data menjulur n2=100, p=10 dan k=2 dengan proporsi pencilan 15%
(a) AKU-Klasik, (b) AKU-KMCD, (c) AKU-K, (d) AKU-KAO
(a) (b)