8
LANDASAN TEORI
2.1
Teori-teori Dasar
Merupakan teori-teori pokok yang merupakan landasan bagi teori-teori lainnya
yang terdapat dalam skripsi ini.
2.1.1
Pengertian Database
Menurut Connoly dan Begg (2005, p15), “database is a shared collection of
logically related data, and a description of this data, designed to meet the information
needs of an organization.” Yang dapat diartikan bahwa database
adalah suatu
kumpulan dari data yang terselubung secara logis, dan deskripsi dari data ini,
dirancang untuk memenuhi kebutuhan informasi dari sebuah organisasi. Database
bersifat tunggal, memiliki tempat penyimpanan data yang besar di mana dapat
digunakan secara bersama-sama oleh banyak departemen dan user.
Menurut Inmon (2005, p493), database adalah kumpulan dari data yang saling
berhubungan yang disimpan berdasarkan skema.
Dapat disimpulkan bahwa database adalah kumpulan dari data yang dimiliki
perusahaan yang berhubungan secara logikal dan disimpan berdasarkan skema yang
dirancang untuk memenuhi kebutuhan informasi perusahaan.
2.1.2
Pengertian Online Transaction Processing (OLTP)
Menurut Connolly dan Begg (2005, p1149), OLTP adalah sebuah sistem yang
telah dirancang untuk menangani pemrosesan transaksi tingkat tinggi, dengan transaksi
yang secara umum membuat perubahan kecil pada data operasional organisasi, yang
dibutuhkan oleh organisasi untuk menangani operasi sehari – hari.
Menurut Kimball dan Ross (2002, p408), OLTP adalah penjelasan dari semua
aktivitas dan sistem yang berhubungan dengan memasukkan data yang dapat diandalkan
ke dalam database.
Dapat disimpulkan bahwa OLTP adalah sebuah sistem yang berfungsi untuk
menangani pemrosesan transaksi dan semua aktivitas dari sistem yang berhubungan
dengan memasukkannya ke dalam database, dimana database-nya bersifat relational
dan sudah ternormalisasi.
2.1.3
Pengertian Online Analytical Processing (OLAP)
OLAP (Online Analytical Processing) adalah sebuah pendekatan untuk
menjawab multi- dimensional analytic queries. Menurut Depak Pareek (2007, p294)
OLAP sering dikategorikan sebagai sebuah Business Intelligence, yang juga
mencakup
relational reporting dan
data mining.
Terminology
dari OLAP sendiri
dicantumkan dalam OLAP Council White Paper (1997) sebagai modifikasi terhadap
terminology database pada umumnya (OLTP).
OLAP menggambarkan sebuah kelas teknologi yang dirancang untuk analisa
dan akses data secara khusus. Apabila pada proses transaksi pada umumnya
semata-mata pada relasional database, OLAP muncul dengan sebuah cara pandang
multidimensi data. Cara pandang multidimensi ini didukung oleh teknologi
multidimensi database. Cara ini memberikan teknik dasar untuk kalkulasi dan analisa
oleh sebuah aplikasi bisnis.
2.1.4
Pengertian Entity Relationship (ER) Modeling
Menurut Connolly dan Begg (2005, p342), Entity Relationship (ER) Modeling
adalah pendekatan top-down untuk mendesain database yang diawali dengan
mengidentifikasikan data penting yang disebut dengan entities
dan relationships di
antara data-data yang harus direpresentasikan dalam model. Kemudian ditambahkan
detail-detail seperti informasi yang ingin ditambahkan tentang entities dan relationships
yang disebut attributes
dan berbagai constrains pada entities, relationships dan
attributes.
2.1.5
Pengertian Data Warehouse
Menurut Inmon (2005, p29), data warehouse adalah sekumpulan dari data yang
subject-oriented, integrated, time-variant, dan non-volatile
untuk mendukung proses
pembuatan keputusan manajemen.
Berdasarkan Connoly dan Begg (2005, p1151), “
Data Warehouse is a
subject-oriented, integrated, time-variant, and non-volatile collection of data in
support of management’s decision-making process.” Yang artinya Data Warehouse
adalah koleksi data yang mempunyai sifat berorientasi pada subjek, terintegrasi,
rentang waktu, dan koleksi datanya tidak mengalami perubahan dalam menudukung
proses pengambilan keputusan di manajamen.
Dari pengertian-pengertian di atas, dapat disimpulkan bahwa data
warehouse
adalah sekumpulan data yang diperoleh dari berbagai sumber yang di
2.1.6
Karakteristik Data Warehouse
Menurut Inmon (2005, p29), data warehouse memiliki beberapa karakteristik
yaitu:
1.
Subject-Oriented, data warehouse diorganisasikan berdasarkan subjek utama
dari perusahaan (seperti pelanggan, produk, dan penjualan) dari pada
berdasarkan area aplikasi utama (seperti pembuatan faktur pelanggan,
pengendalian persedianm dan penjualan produk). Hal ini manggambarkan data
yang ada di dalam data warehouse merupakan data untuk pengambilan
keputusan, bukan data yang berorientasi aplikasi.
2.
Integrated, data di dalam data warehouse berasal dari sumber data yang berbeda
dari sistem aplikasi yang berbeda diseluruh perusahaan. Sumber data biasanya
digunakan secara tidak konsisten, contohnya format yang berbeda. Sumber data
yang terintegrasi harus dibuat konsisten untuk menampilkan pandangan
terintegrasi dari data kepada user.
3.
Time variant, data didalam data warehouse hanya akurat dan valid dalam suatu
waktu tertentu atau dalam interval waktu tertentu.
4.
Non-volatile, data didalam data warehouse tidak diupdate secara real time tetapi
diperbaharui dari sistem operasional secara berkala. Data baru selalu
ditambahkan sebagai tambahan kedalam database bukan sebagai penggantian.
2.1.7
Keuntungan Data Warehouse
Menurut Connolly dan Begg (2005, p1152),
data warehouse dapat memberikan
beberapa keuntungan bagi perusahaan, diantaranya :
Sebuah organisasi harus menangani sumber daya dalam jumlah besar untuk
memastikan implementasi data warehouse yang berhasil dan biayanya bisa
sangat bervariasi. Berdasarkan penelitian dari International Data Corporation
(IDC) pada 1996 rata – rata tingkat pengembalian investasi data warehouse
dalam 3 tahun mencapai 401%.
•
Kentungan kompetitif
Pengembalian dari investasi yang tinggi bagi perusahaan yang
mengimplementasikan
data warehouse dengan berhasil akan memberikan
mereka keuntungan kompetitif. Keuntungan tersebut didapat dengan
mengizinkan pembuat keputusan mengakses data yang sebelumnya tidak
tersedia, tidak diketahui dan informasi yang belum dimanfaatkan, contohnya,
tren dan permintaan.
•
Meningkatkan produktivitas para pembuat keputusan perusahaan
Data warehouse meningkatkan produktivitas dari pembuat keputusan
perusahaan dengan menciptakan database yang terintegrasi, konsisten,
berorientasi subjek dan data historis. Dengan merubah data menjadi informasi
yang berarti, data warehouse memungkinkan manajer untuk melakukan analisis
dengan lebih akurat dan konsisten.
2.1.8
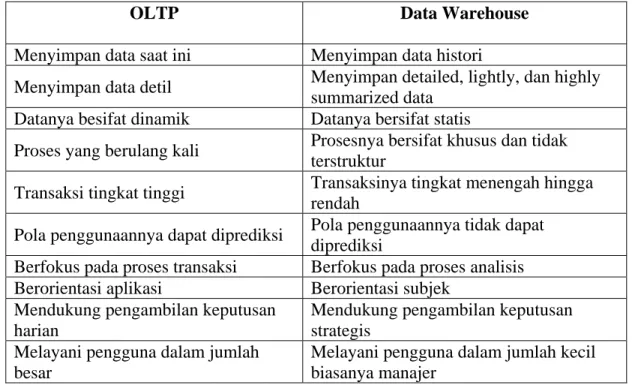
Perbandingan Data Warehouse dan OLTP
Menurut Connolly dan Begg (2005, p1153) Secara umum perbedaan antara data
warehouse dan OLTP adalah
OLTP Data
Warehouse
Menyimpan data saat ini
Menyimpan data histori
Menyimpan data detil
Menyimpan detailed, lightly, dan highly
summarized data
Datanya besifat dinamik
Datanya bersifat statis
Proses yang berulang kali
Prosesnya bersifat khusus dan tidak
terstruktur
Transaksi tingkat tinggi
Transaksinya tingkat menengah hingga
rendah
Pola penggunaannya dapat diprediksi
Pola penggunaannya tidak dapat
diprediksi
Berfokus pada proses transaksi
Berfokus pada proses analisis
Berorientasi aplikasi
Berorientasi subjek
Mendukung pengambilan keputusan
harian
Mendukung pengambilan keputusan
strategis
Melayani pengguna dalam jumlah
besar
Melayani pengguna dalam jumlah kecil
biasanya manajer
Tabel 2.1 Perbedaan antara OLTP dan Data Warehouse
Sumber: Connolly dan Begg (2005, p1153)
2.1.9
Struktur Data Warehouse
Menurut Inmon (2005, p33), data warehouse memiliki beberapa tingkat kedetilan
yaitu
older level of detail (biasanya terdapat dalam tempat penyimpanan alternatif),
current level of detail,
lightly summarized data (tingkat data mart), dan highly
summarized
data. Aliran data ke dalam data warehouse dari lingkungan operasional.
Biasanya terjadinya transformasi data dari tingkat operasional ke tingkat data
warehouse.
Apabila data dalam data warehouse sudah menua, maka data akan berpindah dari
current detail ke older detail. Jika data sudah dirangkum maka data akan berpindah dari
current detail ke lightly summarized data dan kemudian dari lightly summarized data ke
highly summarized data.
a.
Current Detailed Data
Berisi data yang mencerminkan keadaan sekarang yang sedang berjalan saat
ini yang diperoleh dari database
operasional. Data tersebut mempunyai ukuran yang
sangat besar karena merupakan level terendah dan menyimpan semua informasi dan
data yang ada dalam perusahaan.
Current detail data selalu menjadi perhatian utama. Hal ini di sebabkan karena:
•
Jumlah datanya sangat banyak dan disimpan pada tingkat penyimpanan
terendah.
•
Merefleksikan kejadian yang sedang berlangsung dalam sebuah perusahaan.
•
Digunakan untuk merekapitulasi data, sehingga current detail data harus
akurat.
•
Disimpan dalam media penyimpanan agar cepat diakses, tapi membutuhkan
biaya yang mahal dan pengaturannya kompleks.
b.
Old Detailed Data
Data ini merupakan data historis dari current detail data, dapat berupa hasil
bakcup atau arsip dari data yang disimpan dalam tempat penyimpanan yang terpisah.
Karena bersifat cadangan, maka biasanya data disimpan dalam tempat penyimpanan
alternatif seperti tape-disk.
Data ini biasanya jarang di akses. Penyusunan file dari data ini disusun
berdasarkan umur dari data yang bertujuan mempermudah pencarian atau pengaksesan
kembali.
c.
Lightly Summarized Data
Data ini merupakan ringkasan atau rangkuman dari current detail data. Data
ini dirangkum berdasar periode atau dimensi lainnya sesuai dengan kebutuhan.
Ringkasan dari
current detail data belum bersifat total summary.Data-data ini
memiliki detil tingkatan yang lebih tinggi dan mendukung kebutuhan
warehouse
pada tingkat departemen. Tingkatan data ini di sebut juga dengan data
mart.
Akses terhadap data jenis ini banyak digunakan untuk view suatu kondisi yang
sedang atau sudah berjalan.
d.
Highly Summarized Data
Data ini merupakan tingkat lanjutan dari Lightly summarized data,
merupakan
hasil ringkasan yang bersifat total, dapat di akses untuk melakukan analisis
perbandingan data berdasarkan urutan waktu tertentu dan analisis multidimensi.
2.1.10
Pengertian Data Mart
Menurut Inmon (2005, p494), data mart adalah struktur data per departemen
yang berasal dari data warehouse dimana data di denormalisasi berdasarkan kebutuhan
informasi tiap departemen.
Menurut Turban et al.(2005, p73), data mart adalah data warehouse kecil yang
dirancang untuk unit bisnis strategis atau departemen. Keuntungan dari data mart
adalah biayanya rendah, waktu untuk implementasinya singkat , pengendaliannya lokal
bukan terpusat.
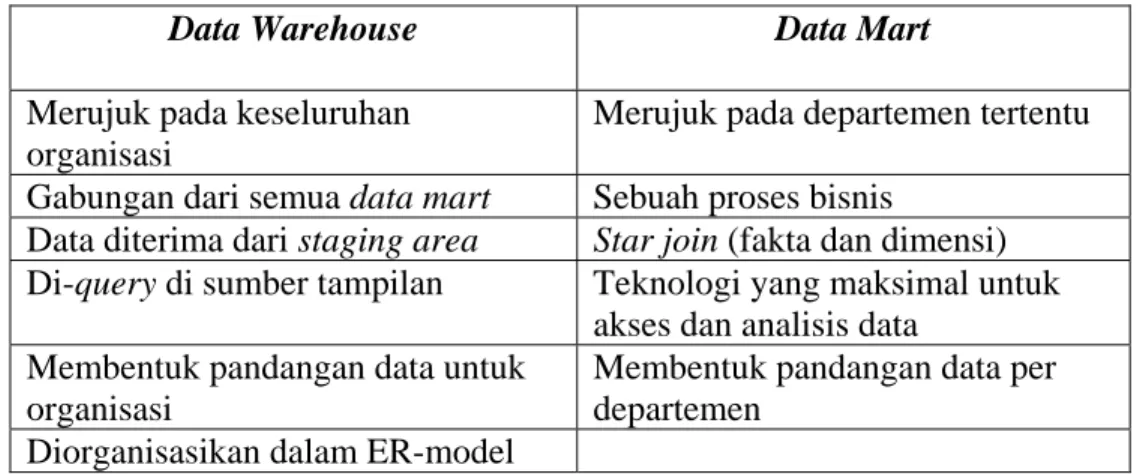
Menurut Ponniah (2001, p26), data mart dan data warehouse memiliki beberapa
perbedaan, yaitu :
Data Warehouse
Data Mart
Merujuk pada keseluruhan
organisasi
Merujuk pada departemen tertentu
Gabungan dari semua data mart
Sebuah proses bisnis
Data diterima dari staging area
Star join (fakta dan dimensi)
Di-query di sumber tampilan
Teknologi yang maksimal untuk
akses dan analisis data
Membentuk pandangan data untuk
organisasi
Membentuk pandangan data per
departemen
Diorganisasikan dalam ER-model
Tabel 2.2 Perbedaan antara Data Warehouse dan Data Mart
Sumber:
Ponniah (2001, p26)
2.1.11
Metadata
Area dari data warehouse yang menyimpan semua definisi meta-data yang
digunakan oleh semua proses di dalam data warehouse.
Meta-data digunakan untuk
beberapa tujuan diantaranya :
•
Dalam proses ekstraksi dan loading,
meta-data digunakan untuk memetakan
sumber data ke view dari data di dalam data warehouse.
•
Dalam proses manajemen warehouse, meta-data digunakan untuk menghasilkan
tabel ringkasan secara otomatis.
•
Sebagai bagian dari proses manajemen query,
meta-data digunakan untuk
melakukan query langsung ke sumber data yang sesuai.
2.1.12
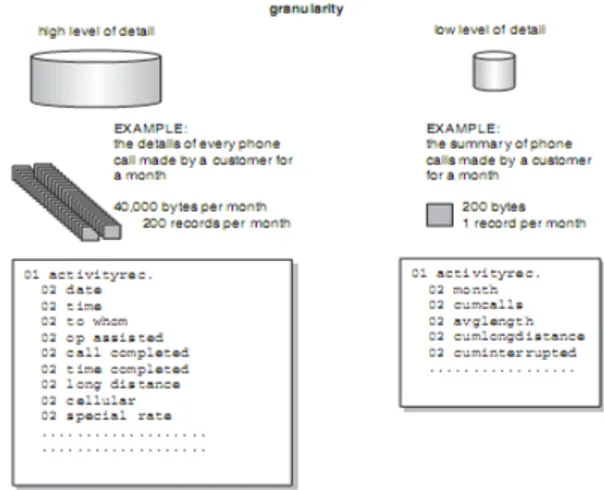
Granularity
Menurut Inmon (2005, p41), Granularity merupakan suatu level dari detil atau
ringkasan pada unit data di dalam data warehouse. Semakin banyak detil atau ringkasan
pada unit data maka akan semakin rendah level pada granularity.
Contohnya adalah sebuah transaksi yang sederhana akan berada pada timgkat
granularity yang rendah, sedangkan keseluruhan dari transaksi dalam satu bulan akan
berada pada level granularity yang tinggi.
Granularity merupakan permasalah utama dalam mendesain lingkungan data
warehouse karena berpengaruh besar pada volume dari data yang terletak didalam data
warehouse.
Granularity memiliki beberapa keuntungan diantaranya :
1.
Dapat digunakan kembali
Dikatakan dapat digunakan kembali karena dapat digunakan oleh banyak orang
dengan berbagai cara yang berbeda. Contohnya data yang sama dapat digunakan
untuk memenuhi kebutuhan dalam bidang pemasaran, penjualan dan keuangan.
Pemasaran menginginkan melihat data bulanan berdasarkan area geografi,
penjualan ingin melihat data penjualan setiap agen berdasarkan area geografi tiap
minggu, dan keuangan melihat pendapatan setiap kuarter berdasarkan produk.
2.
Kemampuan untuk mencocokkan data
Jika memiliki satu dasar yang sama untuk semuanya, maka jika terjadi perbedaan
dalam analisis antara dua atau lebih departemen, proses pencocokan akan menjadi
sederhana.
3.
Fleksibel
Dimana para pengguna dapat merubah data sesuai dengan tampilan yang mereka
inginkan sehingga pekerjaan dapat diselesaikan dengan mudah.
4.
Granularity terdiri dari sebuah history dari aktifitas – aktifitas dan kejadian pada
perusahaan.
5.
Kebutuhan yang tidak jelas dimasa yang akan datang dapat diakomodasi. Saat ada
kebutuhan baru dan ada kebutuhan informasi, data warehouse sudah siap untuk
melakukan analisis dan organisasi disiapkan untuk menangani kebutuhan yang
baru.
Gambar 2.1 Contoh dari Granularity
Sumber: Inmon (2005, P44)
Dalam jangka waktu yang panjang, efisiensi sangat dibutuhkan dalam
menyimpan dan mengakses data serta kemampuan dalam menganalisa data dalam detil
data yang tepat. Sehingga data warehouse membutuhkan sesuatu yang lebih dari satu
tingkat granularity tetapi dua tingkat granularity.
Keuntungan dari granularity dua tingkat adalah kita dapat memproses
permintaan utama dengan sangat efisien dan dapat menjawab berbagai pertanyaan yang
ada. Karena biaya, efesiensi, kemudahan dalam mengakses, dan kemampuan dalam
menjawab berbagai query, dual of level data merupakan arsitektur terbaik dalam detail
level pada data warehouse.
2.1.13
Aliran Informasi Data Warehouse
Menurut Connolly dan Begg (2005, p1161-1165), data warehouse fokus pada
manajemen lima arus data primer, yaitu :
a.
Inflow
Menurut Connolly dan Begg (2005, p1162), inflow adalah proses yang
berhubungan dengan ekstraksi, pembersihan, dan loading dari data dari sistem sumber
ke dalam data warehouse. Agar data dapat masuk ke dalam data warehouse maka data
harus direkonstruksi terlebih dahulu. Proses rekonstruksi ini melibatkan proses :
•
Pembersihan data yang kotor
•
Membentuk kembali data agar sesuai dengan persyaratan data warehouse yang
baru, misalnya menambah atau mengurangi field dan denormalisasi data.
•
Memastikan sumber data konsisten dengan sumber itu sendiri dan data yang
sudah ada di data warehouse.
b.
Upflow
Menurut Connolly dan Begg (2005, p1163), upflow adalah proses yang
berhubungan dengan menambah nilai data di dalam data warehouse melalui
merangkum, mempaket, dan mendistribusikan data.
Aktivitas yang berhubungan dengan upflow yaitu:
•
Meringkas data dengan memilih, memproyeksikan,
menggabungkan, dan
mengelompokkan data relasional
menjadi
view yang lebih baik dan berguna
untuk pengguna akhir.
•
Membungkus data dengan merubah detil atau ringkasan data menjadi format
yang lebih berguna, seperti spreadsheets, dokumen teks, grafik, tampilan grafik
yang lain, database privat, dan animasi.
•
Mendistribusikan data untuk kelompok yang tertentu untuk meningkatkan
ketersediaannya dan pengaksesannya.
c.
Downflow
Menurut Connolly dan Begg (2005, p1164), downflow adalah proses yang
berhubungan dengan pengarsipan dan melakukan backup data dalam data warehouse.
Menyimpan data lama mempunyai peranan yang penting dalam mempertahankan
penampilan dan efektifitas dari warehouse dengan mmengirimkan data lama dengan
nilai terbatas ke sebuah tempat penyimpanan seperti magnetic tape atau optical disc.
Downflow
dari data juga meliputi proses yang memastikan bahwa kondisi
sekarang dari data warehouse dapat dibangun kembali jika terjadi kehilangan data,
kegagalan software atau hardware.
d.
Outflow
Menurut Connolly dan Begg (2005, p1164), outflow adalah proses yang
berhubungan dengan pembuatan data agar tersedia untuk pengguna akhir.
Dua aktivitas kunci yang terlibat dalam outflow mencakup:
•
Pengaksesan, yang berfokus pada kepuasan permintaan pengguna untuk data
yang mereka perlukan.
•
Pengiriman, yang berfokus dengan pengiriman informasi yang proaktif untuk
workstation pengguna akhir.
e.
Meta-flow
Menurut Connolly dan Begg (2005, p1165), meta-flow adalah proses yang
berhubungan dengan manajemen meta-data. Meta-data adalah penjelasan dari isi data
dari data warehouse, apa yang ada di dalamnya, darimana berasal dan apa yang sudah
dilakukan dengan pembersihan, peringkasan dan integrasi.
2.1.14
Arsitektur Data Warehouse
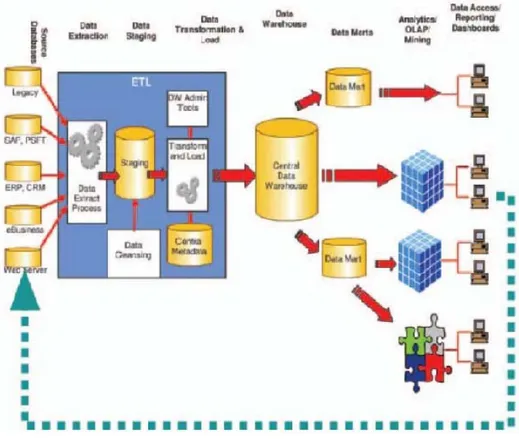
Gambar 2.2 Arsitektur Data Warehouse
Sumber: Connolly dan Begg (2005, P1157)
Menurut Connoly dan Begg (2002, p1056-p1161), komponen Data Warehouse
yang terdapat pada arsitektur Data Warehouse, adalah sebagai berikut :
1.
Operasional Data
Sumber data Data Warehouse berasal dari :
-
Mainframe
data operasinal yang berada pada tingkat basis data generasi
pertama dan basis data jaringan. Diperhatikan sebagian besar data
operasional perusahaan disimpan pada sistem tersebut.
-
Data departemen berada di sistem penyimpanan file departemental seperti
VSAM, RMS, dan relational DMBS seperti Informix dan Oracle.
-
Data pribadi yang tersimpan dalam workstation dan server pribadi.
-
Sistem eksternal seperti internet, database
komersial, atau database
yang
berhubungan dengan supplier dan consumer.
2.
Operasional Data Store (ODS)
Operasional Data Store (ODS) adalah tempat penyimpanan sementara
dari data operasional saat ini yang terintegrasi yang digunakan untuk
analisis. ODS memiliki sumber data dan struktur yang sama seperti Data
Warehouse, bertindak secara sederhana sebagai tempat penampungan
sementara sebelum data dipindahkan ke Data Warehouse. Membangun ODS
merupakan tahap yang berguna dalam membangun Data Warehouse, karena
sebuah ODS dapat menyuplai data yang sudah diekstrak dari sistem sumber
dan dibersihkan. Intergrasi dan restrukturisasi data untuk
Data Warehouse
menjadi lebih sederhana.
3.
Load Manager
Load manager melakukan semua operasi yang berhubungan dengan
Extract
dan Load data ke dalam Data Warehouse. Data di Extract dari
sumber-sumber data atau pada umumnya dari penyimpanan data operasional. Operasi
yang dilakukan Load manager
dapat berupa Transformasi data yang
sederhana untuk mempersiapkan data tersebut agar dapat dimasukkan kedalam
Data Warehouse .
4.
Warehouse Manager
Warehouse
Manager melakukan semua operasi yang berhubungan
dengan management data dalam Data Warehouse. Operasi yang dilakukan
oleh warehouse manager meliputi :
•
Analisis data untuk memastikan konsistensi.
•
Perbahan bentuk dan penggabungan data sumber dari gudang
penyimpanan sementara ke dalam table Data Warehouse.
•
Membuat indeks dan mengacu pada tabel dasar.
•
Pembuatan denormalisasi.
•
Pembuatan agrerasi.
•
Melakukan back-up dan archive/backup data
5.
Query Manager
Query Manager melakukan semua operasi yang berhubungan dengan
pengaturan
user query. Komponen ini dibangun menggunakan vendor
enduser data access tools, Data Warehouse monitoring tools, fasilitas basis
data, dan custom build-in program. Kompleksitas
queries manager
ditentukan oleh fasilitas yang disediakan oleh end user access tools dan
database. Operasi yang dilakukan komponen ini berupa pengarahan
query
6.
Detailed Data
Detailed data menyimpan semua data detail di dalam skema database.
Data detail terbagi 2 yaitu :
•
Current detail data Data ini berasal langsung dari operasional
database, dan selalu mengacu pada data perusahaan sekarang. Current
detail
data diatur sepanjang sisi-sisi subyek seperti data profil
pelanggan , data aktifitas pelanggan, data
sales, data demografis,
dan lain-lain.
•
Old detail data Data ini menampilkan current detail data yang berumur
atau histori dari subyek area. Data ini yang dipakai untuk menganilisis
trend yang akan dihasilkan.
7.
Lightly and Highly Summarized Data
Lighly and Highly Summarized Data menyimpan semua data yang
diringkas oleh warehouse manager. Data perlu diringkas untuk
mempercepat performa query. Ringkasan data terus diperbaharui seiring
dengan adanya data baru yang masuk ke dalam Data Warehouse.
8.
Archive/Backup Data
Archive/backup
data menyimpan data detil dan ringkasan data
dengan tujuan untuk menyimpan dan
backup
data. Walaupun ringkasan data
dibangun dari detil data, akan memungkinkan untuk membuat cadangan
ringkasan data secara online
jika data ini ditunjukkan melebihi penyimpanan
waktu untuk detil data. Data ditransfer ke arsip penyimpanan seperti
magnetic tape atau optical disk.
9.
Metadata
Metadata menyimpan semua definisi metadata yang digunakan oleh
semua proses didalam warehouse. Tujuan metadata adalah sebagai berikut :
-
Proses Extract dan Load – metadata digunakan untuk memetakan sumber data
ke dalam pandangan umum data dalam warehouse.
-
Proses manajemen warehouse
metadata digunakan untuk mengotomatisasi
pembuatan tabel ringkasan.
-
Sebagai proses manajemen query metadata digunakan untuk mengarahkan
suatu query dengan sumber data yang tepat.
10. End-user Access Tools
Tujuan
utama
Data Warehouse adalah menyediakan informasi bagi
pengguna untuk pembuatan keputusan yang strategis dalam berbisnis. Para
pengguna ini berinteraksi dengan Data Warehouse menggunakan peralatan
akses
users. Berdasarkan kegunaan Data Warehouse, ada 5 kategori
end-users access tools , yaitu :
-
Reporting and query tool.
-
Application development tool.
-
Executive information system (EIS) tool.
-
Online analytical processing (OLAP) tool.
-
Data mining tool.
2.1.15
Anatomi Data Warehouse
Penerapan awal dari arsitektur data warehouse dibuat berdasarkan konsep
bahwa data warehouse mengambil data dari berbagai sumber dan memindahkannya ke
dalam pusat pengumpulan data yang besar.
Berikut ini adalah tiga jenis dasar dari sistem data warehouse :
a.
Data Warehouse Fungsional
Data Warehouse fungsional menggunakan pendekatan kebutuhan dari tiap
bagian fungsi bisnis, misalnya departement, divisi, dan sebagai nya. Setiap
fungsi dapat memiliki gambaran oleh sistem.Setiap unit fungsi dapat memiliki
gambaran data masing- masing. Pendekatan ini banyak digunakan karena sistem
memberikan solusi yang mudah untuk dibangun dengan biaya investasi yang
relatif rendah dan dapat memberikan kemampuan system pengumpulan data yang
terbatas kepada kelompok pemakai.Penerapan jenis sistem pengumpulan data
seperti ini beresiko kehilangan kosistensi data diluar lingkungan fungsi bisnis
bersangkutan. Bila lingkup pendekatan ini diperbesar dari lingkungan fungsional
menjadi lingkup perusahaan, konsistensi data perusahaan tidak lagi dapat dijamin.
b.
Data Warehouse Terpusat
Data Warehouse dibuat pada sebuah enterprise data model yang konsisten
dan berada pada suatu lokasi physical yang tetap, untuk menjamin konsistensi data
yang ada ketika dilakukan proses ETL pada database ke Data Warehouse.
Dengan data yang konsisten maka akan mempermudah dalam pengambilan atau
pembuatan keputusan.
c.
Data Warehouse Terdistribusi
Data warehouse
terdistribusi dikembangkan berdasarkan konsep gateway
data warehouse,
sehingga memungkinkan user
dapat langsung berhubungan denagn
sumber data atau pemasok data maupun dengan pusat pengumpulan data lainnya.
Gambaran
user
diatas adalah gambaran logikal karena data mungkin diambil dari
berbagai sumber yang berbeeda. Pendekatan ini menggunakan teknologi
client/server
untuk mengambil data dari berbagai sumber sehingga memungkinkan tiap
departement atau divis untuk membangun sistem operasionalnya sendiri serta
dapat membangun pengumpul data fungsionalnya masing masing dan
menggabungkan bagian-bagian tersebut dengan teknologi
client-server.
Pendekatan
ini akan menjadi efektif bila data tersedia dalam bentuk yang konsisten dan user
dapat menambahkan data tersebut dengan informasi baru apabila ingin membangun
gambaran baru atas informasi.
Penereapan
data warehouse
terdistribusi ini memerlukan biaya yang sangat
besar karena setiap pengumpul data fungsional dan sistem operasinya dikelola secara
terpisah. Selain itu, supaya berguna bagi perusahaan, data yang ada harus
disinkronisasikan untuk memelihara keterpaduan data.
2.1.16
Konsep Pemodelan Data Warehouse
Untuk pemodelan data warehouse, lebih digunakan teknik pemodelan
dimensional. Dengan teknik ini, dapat dibuat tabel fakta, tabel dimensi, dan
membangun relasi antara masing-masing tabel dimensi dan tabel fakta.
a.
Model Dimensional
Menurut Kimball (2003, p16), Dimensional modeling adalah suatu metode
desain yang merupakan peningkatan dari model relasional biasa dan teknik rekayasa
realitas data teks dan angka.
Menurut Kimball (2003, p18), Dalam membuat desain dimensional digunakan 4
langkah :
1)
Menentukan sumber data.
2)
Mendeklarasi grain dari tabel fakta.
3)
Masukkan dimensi untuk semua yang diketahui mengenai grain ini.
4)
Masukkan fakta ukuran numerik sebenarnya ke grain
tersebut.
b.
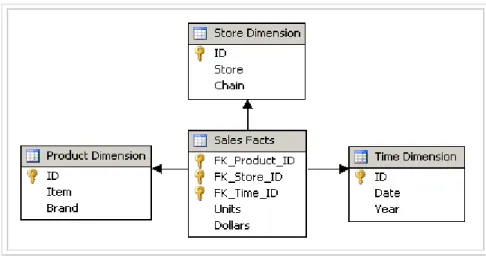
Skema Bintang
Menurut Connolly dan Begg (2005, p1018), skema bintang adalah sebuah
logikal struktur yang mempunyai sebuah tabel fakta berisi data terbaru di tengah, yang
dikelilingi tabel dimensi yang berisi data referensi (yang dapat didenormalisasi).
Sumber:
http://yoyonb.files.wordpress.com/2009/11/star-schema.png
Menurut Ponniah (2001, p220), Skema bintang memiliki beberapa keuntungan
diantaranya :
•
Pengguna mudah untuk mengerti
Saat user berinteraksi dengan data warehouse melalui alat query pihak ketiga,
user seharusnya mengetahui apa maksud pertanyaannya. Mereka harus
mengetahui data apa yang tersedia bagi mereka dalam data warehouse. Mereka
harus memahami struktur data dan bagaimana bermacam – macam bagian yang
saling berhubungan dalam seluruh skema. Skema bintang menampilkan
bagaimana user berpikir dan apa yang pengguna perlukan untuk meng-query dan
menganalisis.
•
Optimasi navigasi
Hubungan digunakan untuk berpindah dari satu tabel ke yang lain untuk
mendapatkan informasi yang dicari. Hubungan menyediakan kemampuan untuk
melakukan navigasi melalui database.
User dapat berpindah dari tabel satu ke
tabel lain menggunakan join. Jika bagian dari proses join banyak dan rumit,
navigasi melalui database menjadi sulit dan lambat. Di sisi lain, jika bagian join
sederhana, maka navigasi yang ada menjadi optimal dan cepat. Keuntungan
utama dari skema bintang adalah mengoptimasi navigasi melalui database.
Bahkan ketika hasil dari query terlihat kompleks, navigasi akan tetap sederhana.
•
Cocok untuk pemrosesan Query
Karena skema bintang adalah struktur query-centric, maka skema bintang sangat
cocok untuk pemrosesan query.
•
STARjoin dan STARindex
Skema bintang mengizinkan software
pemroses
query untuk melakukan
pelaksanaan yang lebih baik. Itu dapat membuat perfoma skema spesifik yang
dapat diimplementasikan dalam query. Susunan skema bintang lebih cocok
untuk teknik perfoma yang khusus seperti STARjoin dan STARindex.
c.
Tabel Fakta
Menurut Whalen
et al.(2001, p236), tabel fakta adalah tabel di dalam data
warehouse yang menjelaskan ukuran data bisnis. Fakta berisi nilai dari sebuah kejadian
atau transaksi tertentu misalnya penyimpanan uang di bank, penjualan produk, atau
pesanan. Tabel fakta menyimpan nilai numerik daripada karakter. Contohnya tabel
fakta dapat berisi field seperti RegionID, SalespersonID, ItemID, dan CustomerID.
Tabel fakta dapat memiliki banyak foreign key yang berhubungan dengan tabel
dimensi. Tabel fakta menyimpan informasi penting dari data warehouse. Tabel fakta
dapat menyimpan jutaan hingga miliaran record dan memakan tempat penyimpanan
hingga satu terabyte.
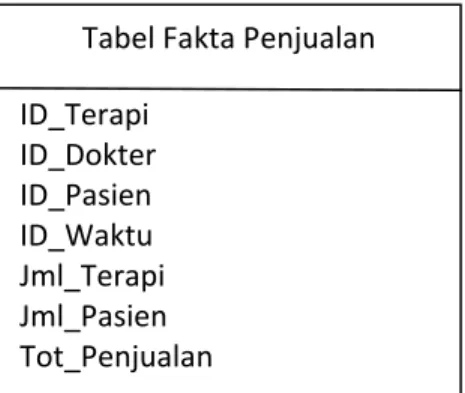
Tabel Fakta Penjualan ID_Terapi ID_Dokter ID_Pasien ID_Waktu Jml_Terapi Jml_Pasien Tot_Penjualan
Gambar 2.4 Contoh Tabel Fakta
Menurut Kimball (2008), tabel fakta merupakan dasar dari data warehouse, tabel
fakta mengandung pengukuran fundamental pada sebuah perusahaan
a.
Concatenated key
Baris dalam tabel fakta diidentifikasi dengan menggunakan primary key dari
tabel-tabel dimensi, maka primary key dari tabel-tabel fakta merupakan gabungan primary key
dari semua tabel dimensi.
b.
Data grain
Data
grain merupakan tingkat detail untuk pengukuran. Sebagai contoh, jumlah
pemesanan berhubungan berhubungan dengan jumlah produk tertentu pada suatu
pesanan, tanggal tertentu, untuk pelanggan spesifik dan diperloeh oleh seorang
perwakilan penjualan spesifik tertentu. Jika jumlah pesanan dilihat sebgai jumlah
untuk suatu produk perbulan, maka data grain-nya berbeda dan pada tingkat yang
lebih tinggi.
c.
Fully additive measures
Agregasi dari fully additive measures dilaksanakan dengan penjumlahan sederhana
nilai-nilai atribut tersebut.
d.
Semiadditive measures
Semiadditive measures merupakan nilai yang tidak dapat langsung dijumlahkan,
sebagai contoh persentase keuntungan.
Tabel fakta umumnya memiliki lebih sedikit atribut daripada tabel dimensi, namun
memiliki jumlah record yang lebih banyak.
f.
Sparse data
Tabel fakta tidak perlu menyimpan record yang nilainya null. Maka tabel fakta
dapat memiliki gap
g.
Degenerate dimensions
Terdapat elemen-elemen data dari sistem operasional yang bukan merupakan fakta
ataupun dimensi, seperti nomor pesanan, tagihan, dan lain-lain. Namun
atribut-atribut tersebut dapat berguna dalam jenis analisis tertentu.
d.
Tabel Dimensi