BAB 2
LANDAS AN TEORI
2.1 Basis Data
2.1.1 Pengertian Data
M enurut Turban (2003, p15), data adalah fakta mentah atau deskripsi dasar dari benda, peristiwa, aktivitas, dan transaksi yang didapatkan, direkam, disimpan, diklasifikasi tapi belum terorganisir untuk menyampaikan suatu arti spesifik. Contoh dari data, yaitu : nilai ujian, daftar gaji karyawan, dan saldo terakhir tabungan.
M enurut Laudon (2004, p7), data adalah fakta mentah yang menggambarkan kejadian – kejadian yang terjadi dalam sebuah organisasi atau sebuah lingkungan fisik sebelum mereka mengatur dan menyususnnya ke dalam bentuk yang dapat dimengerti dan digunakan orang lain.
M enurut O’brien (2005, p38), data adalah fakta atau observasi mentah yang biasanya banyak data yang menjelaskan kegiatan tersebut.
Berdasarkan definisi tersebut, dapat disimpulkan bahwa data adalah fakta mentah atau observasi tidak berarti yang menggambarkan kejadian-kejadian dalam sebuah lingkungan fisik sebelum diatur dan disusun ke dalam bentuk yang dapat dimengerti dan digunakan orang lain.
2.1.2 Pengertian Database
M enurut O’brien (2005, p211), database adalah kumpulan terintegrasi dari elemen data yang secara logika saling berhubungan.
M enurut Connolly dan Begg (2005, p15), “Database is a shared collection of logically related data, and a description of this data, designed to meet the information needs of an organization”, yang artinya database adalah kumpulan relasi-relasi logikal dari data, dan deskripsi dari data, yang dapat digunakan bersama dan dibuat untuk memperoleh informasi yang dibutuhkan oleh perusahaan.
M enurut Williams dan Sawyer (2005, p116), “Database is a collection of interrelated files in a computer system”, yang artinya database adalah kumpulan dari file-file yang saling berhubungan pada sistem komputer.
Berdasarkan definisi tersebut, dapat disimpulkan bahwa database adalah kumpulan dari elemen, relasi atau file-file yang saling terintegrasi untuk digunakan bersama dan dapat digunakan untuk memperoleh informasi yang dibutuhkan oleh perusahaan.
2.1.3 Metodologi Analisis Object Oriented Data Modeling 2.1.3.1 Object Oriented Data Modeling
M enurut Whitten (2004, p430) object-oriented analysis (OOA) adalah suatu pendekatan yang digunakan untuk (1)mempelajari objek-objek yang ada dengan melihat apakah mereka dapat digunakan kembali atau diadaptasi untuk penggunaan baru dan (2)menentukan objek baru atau objek yang diubah yang akan digabungkan dengan objek yang ada menjadi sebuah aplikasi komputasi bisnis yang berguna.
M enurut Whitten (2004, p430) object modeling adalah sebuah tehnik untuk mengidentifikasi objek di dalam system environment dan mengidentifikasi hubungan antara objek-objek tersebut.
M enurut Connolly dan Begg (2005, p813) object oriented data modeling merupakan sebuah (logikal) model data yang dapat menangkap objek semantik didukung dalam pemrograman berorientasi objek.
Keuntungan object-orientation menurut M athiassen (2000, p5) adalah sebagai berikut :
1. M enurut konsep umum yang dapat digunakan untuk memodelkan hampir semua fenomena dan dapat dinyatakan dalam bahasa umum (natural language)
• verb menjadi behavior • Adjective menjadi attributes
2. Dalam proses analisis, developers dapat menggunakan objek untuk menentukan system requirements.
3. Objek menawarkan developers cara alami berpikir tentang masalah-masalah yang mendukung abstraksi tanpa memaksa satu sisi sudut pandang teknis.
2.1.3.2 Proses Object Modeling
M enurut Whitten (2004, p442) terdapat 3 aktivitas umum dalam melakukan object oriented analysis :
1. Modeling fungsi sistem
2. M enemukan dan mengidentifikasi business objects.
3. M engorganisasikan objek-objek dan mengidentifikasi hubungannya.
Dari tiga proses umum tersebut maka akan dilakukan system definition dan dalam memodelkan fungsi dan mengidentifikasi business objects dan class diagram dalam mengorganisasikan objects dan mengidentifikasi hubungannya.
2.1.4 System Definition
M enurut M athiassen (2000, p23), System Definition merupakan sebuah penjelasan singkat dari sistem terkomputerisasi yang diungkapkan dengan bahasa alamiah. Di dalam system definiton juga dijelaskan mengenai rich picture.
M enurut M athiassen (2000, p.26) rich picture merupakan sebuah gambaran yang berisi informasi, yang menggambarkan pemahaman dari sebuah situasi. Rich picture berisi sebuah pandangan meneyeluruh dari people, object process, structure, dan problem dalam problem domain dan application domain. People dapat berupa system developer, user, pelanggan, atau pemain lainnya. Object dapat berupa banyak benda seperti mesin, dokumen, lokasi, departemen, dan lain sebagainya. Process menguraikan aspek dari sebuah situasi yang berubah, tidak stabil, atau di bawah pengembangan. Secara grafik, process diilustrasikan dengan simbol panah. Structure menguraikan aspek dari sebuah situasi yang terlihat atau sulit diubah.
2.1.5 Class Diagram
Class Diagram menurut Whitten (2004, p455) merupakan sebuah gambaran grafis dari objek statis sistem struktur, menunjukkan bahwa sistem terdiri dari object classes, serta hubungan antara object classes tersebut.
M enurut M athiassen (2000, p4), objek adalah suatu entitas yang mempunyai identitas, state dan behavior.
M enurut M athiassen (2000, p49) Class adalah sebuah deskripsi dari kumpulan objek-objek yang memiliki struktur behavior pattern dan atribut yang sama. Abstraksi, klasifikasi, dan seleksi adalah tugas utama dalam aktifitas class. Class merupakan tujuan utama dalam mendefinisikan dan membatasi problem domain. Kelas terdiri dari tiga bagian yaitu:
a. Nama class yaitu yang mendefinisikan class itu sendiri. b. Atribut
Atribut memiliki beberapa sifat antara lain: • Private
Private memiliki sifat yang tidak bisa dipanggil dari luar kelas itu sendiri.
• Protected
M erupakan suatu sifat yang hanya dapat dipanggil di class itu sendiri dan dan hanya bisa diwarisi pada sub class yang bersangkutan.
• Public
Public merupakan sebuah sifat dalam kelas yang dapat dipanggil oleh dan digunakan oleh kelas yang lain
c. Operasi
M erupakan sesuatu kegiatan yang dilakukan oleh sebuah kelas.
Di dalam class diagram terdapat struktur antara classes. Aktifitas structure difokuskan pada hubungan antara classes dan objek. Struktur antar class terdiri dari empat tipe yaitu :
a. Struktur Generalisasi
Generalisasi adalah super class yang menjelaskan sub class b. Struktur Crluster
Cluster adalah sebuah kumpulan dari classes yang berhubungan. Kelas didalam Cluster biasanya berhubungan secara struktur generalisasi atau struktur agregasi.
c. Struktur Aggregasi
Struktur aggregasi adalah sebuah hubungan antara dua atau lebih objek d. Struktur Assosiasi
Struktur asosiasi adalah sebuah hubungan antara dua atau lebih objek tetapi berbeda dengan aggregasi di mana hubungan objek-objek yang terasosiasi tersebut tidak mendefinisikan property dari suatu objek.
2.2 Konsep Data Warehouse
2.2.1 Pengertian Data Warehouse
M enurut Inmon (2007, p7), data warehouse ialah suatu basis untuk proses informasi yang didefinisikan sebagai subject oriented, integrated, nonvolatile, time variant dan a collection of data in support of management’s decision.
M enurut Lane (2005, p1-1), data warehouse adalah suatu basis data relasional yang dirancang untuk query dan analisis dibandingkan untuk proses transaksi.
Kemudian menurut Imhoff (2003, p13), menyatakan bahwa data warehouse berperan sebagai pusat integrasi. Dimana data yang terintegrasi menjadi langkah awal dalam menghasilkan sebuah informasi. Dari definisi – definisi tersebut adapun tujuan yang ingin dicapai data warehouse, yaitu : 1. Data warehouse menyediakan suatu pandangan (view) umum, sehingga data warehouse akan memiliki keleluasaan untuk mengakomodasi bagaimana data akan ditafsirkan atau dianalisis selanjutnya.
2. Data warehouse merupakan tempat penyimpanan seluruh data historis. Data Warehouse akan tumbuh menjadi sangat besar sehingga harus dirancang untuk mengakomodasikan pertumbuhan data.
3. Data warehouse dirancang untuk menyediakan data bagi berbagai teknologi analisis dalam komunitas bisnis.
2.2.2 Karakteristik Data Warehouse
M enurut Inmon (2007, p7), Data warehouse didefinisikan dengan karakteristik sebagai berikut :
1. Subject oriented
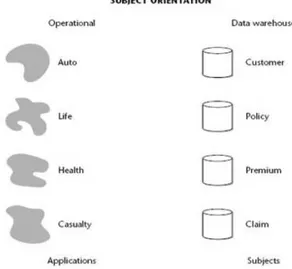
Subject oriented berarti bahwa data warehouse dibuat atau disusun berdasarkan pada subjek utama dalam lingkungan perusahaan, bukan berorientasi pada proses atau fungsi aplikasi seperti yang terjadi pada lingkungan operasional. Sebagai contoh adalah sebuah perusahaan asuransi, aplikasi terdiri dari mobil, kesehatan, jiwa, dan kehilangan. Sedangkan pada data warehouse diatur berdasarkan pelanggan, polis, premi dan klaim.
Gambar 2.1 Aspek Subject Oriented dari Data Warehouse (Sumber : Inmon, 2005, p30)
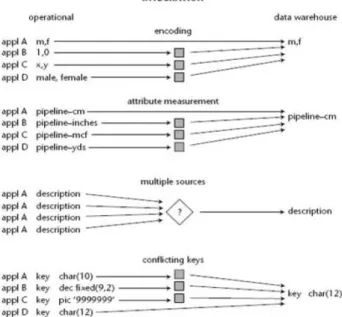
2. Integrated
Data dalam data warehouse bersifat terintegrasi karena bersumber dari sistem – sistem aplikasi yang berbeda dalam perusahaan. Sumber data demikian sering tidak konsisten, misalnya karena berbeda format. Sumber data yang terintegrasi ini harus dibuat konsisten untuk memberikan data yang seragam pada para pengguna.
Gambar 2.2 Aspek Integrated dari Data Warehouse (Sumber : Inmon, 2005, p31)
3. Non-volatile
Data dalam data warehouse tidak di-update dalam real time melainkan diperbarui secara periodic dari sistem operasional. Data baru selalu ditambahkan sebagai tambahan bagi database, bukan sebagai pengganti. Database secara terus–menerus mengambil data
baru, menambahnya, dan mengintegrasikannya dengan data sebelumnya.
Gambar 2.3 Aspek Non-volatile dari Data Warehouse (Sumber : Inmon, 2005, p32)
4. Time Variant
Data dalam data warehouse bersifat tepat dan valid dalam jangka waktu tertentu. Data dalam data warehouse terdiri dari serangkaian snapshot, masing–masing menunjukkan data operasional yang diambil pada suatu waktu tertentu.
Gambar 2.4 Aspek Time Variancy dari Data warehouse (Sumber : Inmon, 2005, p31)
5. A collection of data in support of management’s decision
Fungsi dari data historis dan manfaat dari data warehouse ialah untuk mendukung keputusan keputusan manajemen perusahaan. Sehingga dalam perancangan data warehouse harus disesuaikan dengan kebutuhan–kebutuhan tersebut.
2.2.3 S truktur Data Warehouse
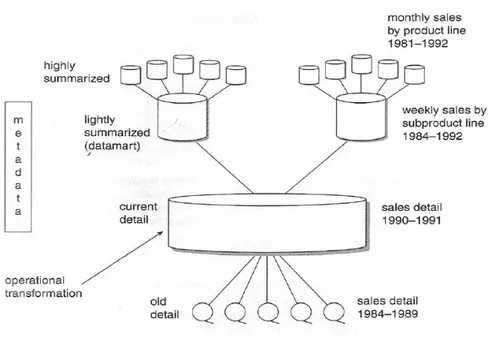
Berdasarkan Inmon (2005, p33-34), struktur data warehouse menunjukan level detil yang berbeda dalam data warehouse. Terdapat older level of detail, current level of detail, level of lightly summarized data (level data mart), dan level of highly summarized data. Data mengalir ke dalam data warehouse dari lingkaran operasional. Biasanya transformasi penting dari data terjadi pada jalur dari level data operasional ke level data warehouse.
Gambar 2.5 S truktur Data Warehouse
Sekali data disimpan, data melalui current detail ke older detail. Selama data diringkas, data melalui current detail ke older detail. Selama data diringkas, data melalui current detail ke lightly summarixed data, kemudian dari lightly summarized data ke highly summarized data.
1. Current Detail Data
Current detail data adalah data detail yang sedang aktif saat ini, mencerminkan keadaan yang sedang berjalan saat ini dan merupakan tingkat terendah dalam data warehouse. Current detail data ini biasanya memerlukan media penyimpanan data yang cukup besar. Alasan perlu diperhatikan current detail data adalah sebagai berikut :
• M enggambarkan kejadian yang baru terjadi dan selalu menjadi perhatian utama.
• Hampir selalu disimpan di media penyimpanan karena cepat diakses tetapi mahal dan kompleks dalam pengaturannya.
• Dapat digunakan dalam membuat rekapitulasi sehingga current detail dataharus akurat.
• Jumlahnya sangat banyak dan disimpan pada tingkat penyimpanan rendah.
2. Old Detail Data
Old detail data adalah data historis dapat berupa hasil back-up yang dapat disimpan dalam media penyimpanan yang terpisah dan dapat diakses kembali pada saat tertentu. Data ini jarang diakses sehingga disimpan dalam media penyimpanan alternatif seperti tape dan disk.
Data ini biasanya memiliki tingkat frekuensi akses yang rendah. Penyusunan file atau directory dari data ini disusun berdasarkan umur dari data yang bertujuan mempermudah untuk pencarian atau pengaksesan kembali.
3. Lightly Summarized data
Data ini merupakan ringkasan atau rangkuman dari current detail data. Data ini dirangkum berdasarkan periode atau dimensi lainnya sesuai dengan kebutuhan.
Ringkasan dari current detail data belum bersifat total summary. Data-data ini memiliki detil tingkatan yang lebih tinggi dari current detail data dan mendukung kebutuhan warehouse pada tingkat departemen. Tingkatan data ini disebut juga dengan data mart. Akses terhadap data jenis ini banyak digunakan untuk view suatu kondisi yang sedang atau sudah berjalan.
4. Highly Summarized Data
Data ini merupakan tingkat lanjutan dari lightly summarized data, yang merupakan hasil ringkasan yang bersifat totalitas, dapat diakses misalnya untuk melakukan analisis perbandingan data berdasarkan urutan waktu tertentu dan analisis menggunakan data multidimensi.
5. Metadata
M etadata adalah data mengenai data yang berisi lokasi dan deskripsi sistem komponen data warehouse seperti nama, definisi, struktur, dan isi dari data warehouse, identifikasi dari sumber data yang berwenang, dan lainnya (Berson, 1999, p27)
M etadata merupakan data yang menjelaskan tentang data dan merupakan suatu bentuk jaringan yang sangat penting bagi penggunaan data warehouse. M etadata dibuat untuk menjawab kebutuhan dari suatu fungsi tertentu karena setiap departemen biasanya menggunakan struktur data yang spesifik meskipun sumber datanya sama.
Peranan metadata yaitu :
• Sebagai directory untuk membantu penggunaan data warehouse menempatkan isi data dan mengetahui lokasi data dalam data warehouse.
• Sebagai panduan untuk menempatkan (mapping) data pada saat data ditransformasikan dari OLTP ke dalam lingkungan data warehouse.
• Sebagai panduan untuk menghasilkan rangkuman dari current detailed data menjadi lightly summarized data dan dari lightly summarized data menjadi highly summarized data.
2.2.4 Aliran Data dalam Data Warehouse
M enurut Connoly dan Begg (2005, p1161-1165), data warehouse fokus pada manajemen lima arus data primer, yaitu :
1. Inflow
M erupakan proses ekstraksi, pembersihan, dan pengisian data dari sumber data ke dalam data warehouse. Proses inflow ini berkonsentrasi pada proses mengambil data dari sumber sistem dan memasukannya ke dalam data warehouse. Cara lainnya yaitu data dimasukan ke dalam operational data store (ODS) sebelum dikirim ke data warehouse.
Proses rekontruksi data meliputi : • M embersihkan data yang kotor
• Restrukturisasi data untuk dicocokan dengan kebutuhan dari data warehouse, contohnya menambah atau membuang field-field, dan denormalisasi data.
• M emastikan bahwa sumber data konsisten ddengan dirinya sendiri dan dengan data lainnya yang sudah ada di data warehouse. 2. Upflow
M erupakan penambahan nilai ke dalam data di dalam data warehouse melalui peringkasan, pemaketan, dan distribusi data. Aktifitas yang berhubungan dengan upflow yaitu sebagai berikut : • M eringkas data dengan proses memilih, memperhitungkan,
menggabungkan dan mengelompokan data relasional ke dalam tampilan yang lebih berguna bagi user.
• Pengepakan data dengan mengubah data detail ke dalam format yang lebih berguna seperti spreadsheets, teks dokumen, diagram, tampilan grafik yang lain, database pribadi dan animasi.
• M endistribusikan data ke kelompok-kelompok yang tepat untuk meningkatkan ketersediaan dan dapat diakses.
3. Downflow
M erupakan proses mengambil dan mem-backup data dalam data warehouse. M enyimpan data lama memainkan peranan yang penting di dalam mempertahankan penampilan dan efektifitas dari warehouse dengan mengirimkan data lama dengan nilai yang terbatas ke sebuah tempat penyimpanan seperti magnetic tape dan optical disk.
Downflow dari data juga meliputi proses yang memastikan bahwa kondisi yang sekarang dari data warehouse dapat dibangun
kembali jika terjadi kehilangan data, kegagalan software atau hardware.
4. Outflow
M erupakan proses membuat data agar tersedia bagi end-user. Outflow merupakan kondisi dimana manfaat dari data
warehouse benar-benar dirasakan oleh sebuah organisasi.
Dua aktifitas kunci terdapat pada outflow yaitu sebagai berikut : • Pengaksesan, dimana berhubungan dengan proses memuaskan
pemakai akhir dengan menyediakan data yang dibutuhkan oleh mereka. Yang menjadi perhatian utama yaitu membuat suatu lingkungan jadi user dapat dengan efektif menggunakan query tool untuk mengakses sumber data yang paling tepat. Frekuensi dari pengaksesan ini dapat bervariasi mulai dari ad hoc, secara rutin, sampai real time. Selain itu juga harus dipastikan bahwa sumber sistem digunakan dengan cara yang paling efektif di dalam menjadwalkan pengeksekusian terhadap query dan user. • Pengiriman, dimana berhubungan dengan secara aktif
mengirimkan informasi ke workstation dari user. Ini merupakan area yang baru dari data warehouse dan sering dihubungkan dengan proses publish dan subcribe. Warehouse akan mem-publish objek bisnis bermacam-macam dan user akan men-subcribe terhadap objek bisnis yang dibutuhkan mereka.
5. Metaflow
M erupakan proses manajemen metadata. Metaflow merupakan proses yang memindahkan metadata (data tentang flow yang lainnya). Metadata merupakan deskripsi dari data yang ditampung di dalam data warehouse, apa yang telah dilakukan terhadap data tersebut dengan cara cleansing, integrating, dan summarizing.
2.2.5 Anatomi Data Warehouse
a. Data Warehouse Fungsional
Tiap data warehouse fungsional mencakup sebuah grup tersendiri yang terpisah (seperti divisi), area fungsional, unit geografis, atau grup pemasaran produk.
(http://www.etfinancial.com/dataglossary.htm).
Data warehouse fungsional berfokus pada kebutuhan dari sebuah fungsi bisnis, misalkan departemen, divisi, dan sebagainya. Keuntungan dari data warehouse ini adalah memberikan fleksibilitas karena dapat disesuaikan dengan permasalahan bisnis spesifik dan kemungkinan dari departemen atau lini bisnis tertentu, disamping relatif lebih murah dan lebih sederhana untuk diimplementasikan. Perusahaan umumnya membangun beberapa rangkaian data warehouse fungsional untuk mendukung area yang berbeda-beda, dan hal ini memberikan pengembangan yang cepat. Perusahaan juga dapat memberikan respon yang lebih cepat terhadap kesempatan pasar. Namun, terdapat resiko hilangnya konsistensi data di luar lingkungan
fungsi bisnis bersangkutan. Apabila pendekatan ini lingkupnya diperbesar dari lingkungan fungsional menjadi lingkup perusahaan, konsistensi data perusahaan tidak dapat dijamin. (www.freesoft.hu/download.emt?id=76).
b. Data Warehouse Terpusat
Data Warehouse terpusat adalah sebuah database yang diciptakan dari pengekstraksian operasional yang menganut pada sebuah model data tunggal enterprise yang konsisten untuk memastikan konsistensi atas data pendukung dalam perusahaaan. M erupakan penerapan gaya komputerisasi dimana semua sistem informasi dilokasikan dan dimanajemen dari sebuah lokasi fisikal tunggal. (http://www.etfinancial.com/dataglossary.htm).
Data warehouse terpusat adalah sebuah database fisikal tunggal yang menyimpan semua data untuk area fungsional spesifik, departemen, divisi atau perusahaan (enterprise). Pendekatan ini umumnya digunakan saat terdapat banyak end-user yang sudah terhubung dengan sebuah komputer atau jaringan pusat. Data warehouse terpusat biasanya menyimpan data dari sistem operasi yang berbeda-beda. Data yang disimpan didalamnya dapat diakses dari sebuah lokasi dan harus di-load dan dipelihara pada basis data regular.(http://www.kenorrinst.com/pg%2033%2Dd)
Data warehouse terpusat melingkupi sebuah data warehouse tunggal yang melayani semua kebutuhan perusahaan. Tujuan dari
pendekatan ini adalah untuk memecahkan permasalahan organisasional yang membatasi operasi perusahaan. Jadi,membangun sebuah data warehouse terpusat yang terunifikasi sangat kompleks, membutuhkan biaya besar dan waktu lebih banyak. Namun, keuntungan dari data warehouse terpusat yang menyediakan gambaran yang komprehensif, tingkat control dan reliabilitas yang tinggi karena keterpaduan data di dalamnya.
(http://www.freesoft.hu/download.emt?id=76)
c. Data Warehouse Terdistribusi
Data warehouse terdistribusi adalah sebuah sumber data terpisah yang dapat diakses user via gateway pusat menyediakan view logical atas data corporate dalam gambaran yang dapat dipahami oleh user. Gateway tersebut akan melakukan parse dan mendistribusikan query secara real-time ke sumber data terpisah dan mengembalikan result set-nya ke user.
Data warehouse terdistribusi adalah data warehouse yang komponennya didistribusikan ke beberapa database fisikal yang berbeda. Pendekatan ini umumnya dipilih saat perusahaan besar ingin mengikutsertakan level organisasinya yang lebih rendah dalam pengambilan keputusan, sehingga diperlukan penurunan data untuk pembuatan keputusan ke komputer lokal tempat pengambilan keputusan lokal. Umumnya, data warehouse terdistribusi melibatkan data yang paling redundan dan konsekuensinya adalah proses load
dan update yang sangat kompleks. Pendekatan ini memerlukan biaya yang sangat besar karena setiap sistem pengumpul data fungsional dan sistem operasinya dikelola secara terpisah. Disamping itu, supaya berguna bagi perusahaan, data harus disinkronisasikan untuk memelihara keterpaduannya.
(http://www.kenorrinst.com/pg%2033%20d.w.%20whitepaper.htm)
2.2.6 Arsitektur Data Warehouse
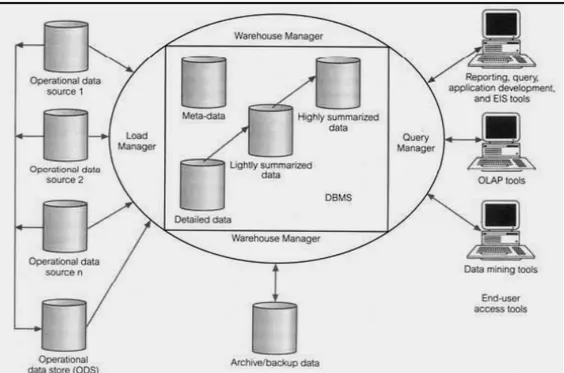
M enurut Connolly (2002, p1052), komponen – komponen utama sebuah data warehouse antara lain :
1. Operational Data
Data untuk data warehouse berasal dari :
• Mainframe data operasional yang berada pada tingkatan database generasi pertama dan database jaringan. Diperhatikan sebagian besar data operasional perusahaan disimpan pada sistem tersebut. • Data departemen yang berada di sistem file DBM S relasional
(seperti SQL Server 2008).
• Data pribadi yang berada di server dan workstation pribadi.
• Sistem – sistem eksternal seperti internet, database yang tersedia secara komersil, dan database yang berhubungan dengan pemasok atau pelanggan perusahaan.
2. Operational Datastore
Sebuah operational datastore (ODS) adalah sebuah tempat penyimpanan data operasional terkini dan terintegrasi, yang digunakan untuk kebutuhan analisis. ODS memiliki struktur dan sumber data yang sama dengan data warehouse, berperan sebagai tempat penyimpanan data sebelum dipindahkan ke data warehouse. ODS menyimpan data yang telah di-extract dari sistem sumber dan telah dibersihkan. Dengan demikian, proses pengintegrasian dan rekontruksi data untuk data warehouse menjadi lebih sederhana. 3. Load Manager
Load Manager melakukan semua operasi yang berhubungan dengan fungsi extracting / mengambil data dan fungsi loading / meletakkan data ke dalam data warehouse. Data dapat di-extract dari sumber – sumber data atau pada umumnya diambil dari operational datastore. Operasi yang dilakukan load manager dapat berupa transformasi data yang sederhana untuk mempersiapkan pemasukan data ke dalam data warehouse. Ukuran dan kompleksitas komponen ini akan berbeda sesuai dengan data warehouse yang dirancang dan dapat dibangun menggunakan kombinasi antara vendor loading dan custom-build programs.
4. Warehouse Manager
Warehouse manager melakukan semua operasi yang berhubungan dengan manajemen data dalam data warehouse. Komponen ini dibangun menggunakan vendor dan management tools dan custom-build programs. Operasi yang dilakukan oleh data warehouse manager berupa :
a. M elakukan analisis data untuk menjaga konsistensi data.
b. M elakukan transformasi dan penggabungan sumber data dari penyimpanan sementara ke dalam table – table data warehouse. c. M enciptakan index dan view pada base tables.
d. M elakukan denormalisasi (jika diperlukan). e. M elakukan agregasi (jika diperlukan)
f. M elakukan back-up dan archive / back-up data 5. Query Manager
Query manager melakukan semua operasi yang berhubungan dengan management user queries. Komponen ini dibangun menggunakan vendorend-user data access tools, data warehouse monitoring tools, fasilitas database, dan custom build-in programs. Kompleksitas queries manager ditentukan oleh fasilitas yang disediakan end-user access tools dan database. Operasi yang
dilakukan komponen ini berupa pengarahan query pada table – table yang tepat dan penjadwalan eksekusi query.
6. Detailed Data
Komponen ini menyimpan semua detil dalam skema basis data. Pada umumnya beberpa data tidak disimpan secara fisik, tetapi dapat dilakukan dengan cara agregasi. Secara periodik data detil ditambahkan ke data warehouse untuk mendukung agregasi data. 7. Lighly and Highly Summarized Data
Komponen ini menyimpan semua data yang diringkas oleh warehouse manager. Data perlu diringkas dengan tujuan untuk mempercepat performa query. Ringkasan data terus diperbaharui seiring dengan adanya data yang baru yang masuk ke dalam data warehouse.
8. Archive / Backup Data
Komponen ini menyimpan data detil dan ringkasan data dengan tujuan untuk menyimpan dan backup data. Walaupun ringkasan yang diperoleh dari data mendetil, ringkasan perlu di backup juga apabila data tersebut disimpan melampaui periode penyimpanan data detil. Data kemudian dipindahkan ke media penyipanan seperti magnetic tape atau optical disc.
9. Meta-data
Komponen ini menyimpan semua definisi meta-data(informasi mengenai data) yang digunakan dalam proses dalam data warehouse. Meta-data digunakan untuk berbagai tujuan, antara lain :
• Proses extracting dan loading, meta-data digunakan untuk memetakan sumber data dalam data warehouse.
• Pross manajemen warehouse, meta-data digunakan untuk menghasilkan tabel ringkasan (summarized tables).
• Sebagai bagian dari proses manajemen query, meta-data digunakan untuk mengarahkan sebuah query pada sumber data yang tepat.
10. End-User Access Tools
Tujuan utama dari data warehouse adalah dengan menyediakan informasi bagi pengguna untuk pembuatan keputusan yang strategis dalam berbisnis. Para pengguna berinteraksi dengan data warehouse menggunakan end-user access tools. Berdasarkan kegunaan data warehouse, terdapat lima kategori end-user access tools, yaitu : • Reporting and Query Tools
Reporting tools meliputi production reporting tools dan reports writers. Production reporting tools digunakan untuk menghasilkan laporan operasional secara berkala.
Query tools untuk relasional data warehouse dirancang untuk menerima SQL atau menghasilkan SQL statements untuk proses query data yang tersimpan di warehouse.
• Application Development Tools
Application development tools menggunakan graphical data acsesss tools yang dirancang khusus untuk lingkungan client-server. Beberapa aplikasi perlu diintegrasikan dengan OLAP tools, dan dapat mengakses semua sistem basis data utama.
• Executive Information System (EIS) Tools
EIS sering dikenal sebagai ‘everyone’s information systems’ (sistem informasi setiap orang). Awalnya dikembangkan untuk mendukung pembuatan kebutuhan top-level yang strategis. Akan tetapi, kemudian meluas mendukung semua tingkat manajemen. EIS tools pada awalnya berhubungan dengan mainframes yang memungkinkan para pengguna untuk membangun aplikasi pendukung keputusan yang bersifat grafik untuk menyediakan sebuah overview mengenai data perusahaan dan akses pada sumber data eksternal. Kini, EIS banyak dilengkapi dengan fasilitas query dan menyediakan custom-build applications untuk area bisnis seperti penjualan, pemasaran, dan keuangan.
• Online Analytical Processing (OLAP) Tools
OLAP tools didasarkan pada konsep basis data yang bersifat multi-dimensi dan memperbolehkan pengguna untuk menganalisis data dari sudut pandang yang kompleks dan multi-dimensi. Alat bantu ini mengasumsikan bahwa data diatur dengan model multi-dimensi yang khusus (M DDB) atau oleh sebuah relational basis data yang dirancang untuk memungkinkan query multi-dimensi.
• Data Mining Tools
Data mining adalah proses menemukan kolerasi, pola, dan tren yang baru yaitu dengan melakukan penggalian pada sejumlah data menggunakan teknik statistik, matematis, dan artificial intelligenten (AI). Data mining memiliki potensi untuk menggantikan kemampuan OLAP tools.
Gambar 2.6 Arsitektur Data Warehouse
(Sumber : Connolly dan Begg, 2005, p1157)
2.2.7 Keuntungan Data Warehouse
M enurut Connoly dan Begg (2005, p1157), keuntungan data warehouse adalah :
1. Potensial ROI (Returns On Investment) yang tinggi. Organisasi harus menjalankan jumlah yang besar dari sumber untuk menjamin kesuksesan implementasi dari data warehouse dan biaya yang sangat besar bagi solusi teknikal support yang tersedia. Penyelidikan dari International Data Corporation (IDC) pada tahun 1996 menjalankan rata-rata ROI dalam 2 tahun dengan data warehousing mencapai 401% diatas 90% perusahaan yang disurvei mencapai di atas 160% ROI, dan seperempatnya lebih dari 600% ROI.
2. Competitive advantage. ROI yang besar bagi perusahaan-perusahaan diperoleh dari kesuksesan data warehouse merupakan fakta bahwa competitive advantage yang besar menyertai teknologi ini. Competitive advantage diperoleh dengan menyediakan pembuatan keputusan ke data yang dapat mengungkapkan ketidaksediaan, ketidaktahanan, dan ketidakterbukaan informasi sebelumnya, sebagai contoh customer, trend dan permintaan.
3. M eningkatkan produktifitas pembuatan keputusan perusahaan. Data warehouse meningkatkan produktifitas pembuatan keputusan perusahaan dengan menciptakan integrasi database yang konsisten, subject oriented, data historical.
M enurut M allach (2000, p181-182), keuntungan data warehouse adalah :
1. Kinerja perangkat keras DSS dapat dioptimalkan untuk tujuan tertentu.
2. Response time dari DSS tetap terjaga
3. Lingkungan data warehouse lebih sederhana dan lebih baik dibandingkan client-server.
2.2.8 Istilah-Istilah dalam Data Warehouse
Beberapa istilah-istilah yang berhubungan dengan data warehouse antara lain :
1. Decision Support System (DSS )
M enurut O'Brien (2005, p448), DSS atau sistem pendukung keputusan adalah sistem informasi berbasis komputer yang menyediakan dukungan informasi yang interaktif bagi manajer dan praktisi bisnis selama proses pengambilan keputusan. Sistem pendukung keputusan menggunakan model analitis, database khusus, penilaian dan pandangan pembuatan keputusan, dan proses pemodelan berbasis komputer yang interaktif untuk mendukung pembuatan keputusan bisnis yang semitersetruktur dan tersetruktur.
2. Data Mart
M enurut Connoly and Begg (2005, p1171), “Data mart is subset of data warehouse that support the requirements of a particular department of business function”, yang artinya data mart adalah subset dari data warehouse yang mendukung kebutuhan informasi dari suatu departemen atau fungsi bisnis tertentu. Data mart merupakan suatu bagian dari data warehouse yang dapat mendukung pembuatan laporan dan analisis data pada suatu unit, bagian atau operasi perusahaan.
Perbedaan antara data mart dan data warehouse adalah : • Data mart hanya berfokus pada kebutuhan user yang berkaitan
• Data mart tidak mengandung data operasional secara detil, tidak seperti data warehoiuse.
• Data yang ada dalam data mart lebih sedikit daripada yang ada dalam data warehouse, data mart juga lebih mudah dimengerti karena lebih sederhana.
3. OLAP (OnLine Analytical Processing)
M enurut M allach (2000,p531), “OLAP is a category of software that enables analyst, mangers, and executive to gain insight into data through fast, consistent, interactive access to a wide variety of posible views of information that has been transformed from raw data to reflect the real demensionality of the enterprise as understood by the user”, yang artinya OLAP adalah kategori teknologi software yang dapat memungkinkan penganalisa, manager, dan eksekutif untuk melihat data yang ada dengan akses cepat, konsisten dan interaktif sehingga dapat melihat informasi yang sudah ditransformasi dan data mentah menjadi dimensi keadaan nyata yang dapat dimengerti dengan mudah oleh user.
OLAP juga merupakan suatu pemrosesan database yang menggunakan tabel fakta dan dimensi untuk dapat menampilkan berbagai bentuk laporan, query dari data yang berukuran besar.
Berikut ini bebrapa keuntungan yang diperoleh dengan menerpakan OLAP (Connoly dan Begg, 2005, p1208), yaitu :
a. M eningkatkan produktivitas dari end-users bisnis dan pengembang teknologi informasi.
b. M eningkatkan penghasilan dan keuntungan potensial dengan memungkinkan perusahaan untuk merespon permintaan lebih cepat.
c. mengurangi back-log dari pengembang aplikasi untuk staf teknologi informasi dengan membuat end-user bebas untuk membuat perubahan skema dan memungkinkan organisasi untuk merespon permintaan pasar lebih cepat.
b. mengurangi lalu lintas jaringan dalam sistem OLTP dan dalam data warehouse.
4. OLTP (Online transaction Processing)
M enurut Connoly dan Begg (2005, p1149), “Online Transaction Processing (OLTP) is the systems that have been designed to handle high transaction throughput, with transactions typically making small changes to the organization's operational data, that is, data that the organization requires to handle it day-to-day ooperations”, yang berarti OLTP adalah suatu sistem yang telah dirancang untuk menangani jumlah hasil transaksi yang tinggi, dengan transaksi yang pada umumnya membuat perubahan yang kecil bagi data operasional organisasi. Oleh karena itu, data organisasi memerlukan penanganan operasinya setiap hari.
Ukuran database OLTP dapat berkisar dari database berukuran kecil (beberapa megabytes (M b)), database berukuran menengah/medium (Gigabytes (Gb)), database berukuran besar (Terabytes (Tb)), atau bahkan sampai penyimpanan yang sangat besar hingga Petabytes(Pb).
5. Dimensional Table ( Tabel Dimensi )
M enurut Inmon (2005, p495) tabel dimensi adalah tempat dimana data-data yang tidak berhubungan yang berelasi dengan tabel fakta yang ditempatkan di dalam tabel multidimensional.
Disebut juga tabel kecil (minor tabel), biasanya lebih kecil dan memegang data deskriptif yang mencerminkan dimensi suatu bisnis. Tabel dimensi adalah tabel yang berisikan kategori dengan ringkasan data detil yang dapat dilaporkan seperti laporan keuntungan pada tabel fakta dapat dilaporkan sebagai dimensi waktu (yang berupa perbulan, perkuartal, dan pertahun).
M enurut Connoly dan Begg (2005, p1183), “a set of smaller tables called dimension tables”, yang berarti tabel dimensi adalah sekumpulan tabel-tabel yang lebih kecil dari tabel fakta pada dimensional model (DM ). Setiap tabel dimensi mempunyai non-composite PK.
6. Fact Table (Tabel Fakta)
M enurut Inmon (2005, p497), tabel fakta adalah tabel pusat dari skema bintang dimana data yang sering muncul akan ditempatkan disini.
Disebut juga tabel utama (major table), merupakan inti dari skema bintang dan berisi data aktual yang akan dianalisis (data kumulatif dan transaksi). Tabel fakta adalah tabel yang umumnya mengandung angka dan data historis dimana key (kunci) yang dihasilkan sangat unik karena key nya merupakan kumpulan foreign key dan primary key yang ada pada masing-masing tabel dimensi yang berhubungan atau merupakan tabel terpusat dari skema bintang. Tabel fakta menyimpan tipe-tipe measure yang berbeda, seperti measure, yang secara langsung terhubung dengan tabel dimensi dan measure, yang secara langsung terhubung dengan tabel dimensi dan measure yang tidak berhubungan dengan tabel dimensi.
M enurut Connolly dan Begg (2005, p1183), “Every dimensional model (DM) is composed of one table with composite primary key, called the fact table”, yang berarti tabel fakta adalah satu tabel pada dimensional model (DM) yang isinya composite promary key (PK). Jadi PK pada tabel fakta merupakan beberapa Foreign Key (FK).
7. Data Transformation Service (DTS
M enurut Peterson (2001, p6), DTS dalam microsoft SQL 2008 adalah sebuah alat yang dapat digunakan untuk memindahkan data. DTS juga merupakan alat fleksibel yang dapat diukur untuk mendapatkan kendali tertinggi atas trnsformasi dari data. DTS merupakan sebuah alat untuk meng-copy, memindahkan, memperkuat, membersihkan, dan memvalidasi data. Transfer data memuat tiap kolom dari sumber data, memanipulasi nilai ke dalam kolom tersebut, dan memasukan kolom tersebut ke tujuan data.
8. Extract, Transform, Load (ETL)
ETL (Extract, Transform, Load) adalah proses-proses dalam data warehouse yang meliputi :
• M engekstrak data dari sumber-sumber eksternal.
• M entransformasikan data ke bentuk yang sesuai dengan keperluan bisnis.
• M emasukan data ke target akhir, yaitu data warehouse.
ETL merupakan proses yang sangat penting, dengan ETL data dapat dimasukan ke dalam data wareehouse. ETL juga dapat dgunakan untuk mengintegrasikan data dengan sistem yang sudah ada sebelumnya.
Tujuan ETL adalah mengumpulkan, menyaring, mengolah, danmenggabungkan data-data yang relevan dari berbagai sumber
untuk disimpan ke dalam data warehouse. Hasil dari proses ETL, adalah dihasilkannya data yang memenuhi kriteria data warehouse seperti historis, terpadu, terangkum, statis, dan memiliki struktur yang dirancang untuk keperluan proses analisis.
¾ Extract
Langkah pertama pada proses ETL, adalah mengekstrak data dari sumber-sumber data. Kebanyakan proyek data warehouse menggabungkan data dari sumber-sumber yang berbeda. Pada hakekatnya, proses ekstraksi adalah proses penguraian, pembersihan dari data yang diekstrak untuk mendapatkan struktur atau pola data yang diharapkan.
¾ Transform
Tahapan transformasi menggunakan serangkaian aturan atau fungsi untuk mengekstrak data dari sumber dan selanjutnya akan dimasukan ke dalam data warehouse. Berikut adalah hal-hal yang dapat dilakukan dalam tahapan transformasi :
• Hanya memilih kolom tertentu saja untuk dimasukan ke dalam data warehouse.
• M enterjemahkan nilai-nilai yang berupa kode (contohnya apabila database sumber menyimpan nilai 1 untuk laki-laki dan nilai 2 untuk perempuan, tetapi data warehouse yang telah ada menyimpan M untuk laki-laki dan F untuk perempuan, ini disebut dengan automated data cleansing,
tidak ada pembersihan secara manual yang ditunjukan ETL).
• M engkodekan nilai-nilai ke dalam bentuk bebas (contohnya memetakan “Male”, “1” dan “Mr” ke dalam M ).
• M elakukan perhitungan nilai-nilai baru (contohnya sale_amount = qty * unit_price).
• M enggabungkan data secara bersama-sama dari berbagai sumber.
• M embuat ringkasan dari sekumpulan baris data (contohnya total penjualan untuk setiap toko atau setiap bagian).
¾ Loading
Fase load merupakan tahapan yang berfungsi untuk memasukan data ke dalam target akhir, yang biasanya ke dalam suatu data warehouse. Jangka waktu proses ini tergantung pada kebutuhan organisasi. Beberapa data warehouse dapat setiap minggu menulis keseluruhan informasi yang ada secara kumulatif, data diubah, sementara data warehouse yang lain (atau bagian lain dari data warehouse yang sama) dapat menambahkan data baru dalam bentuk historikal, contohnya setiap jam. Waktu dan jangkauan untuk mengganti atau
menambah data tergantung dari perancangan data warehouse pada waktu menganalisis keperluan informasi.
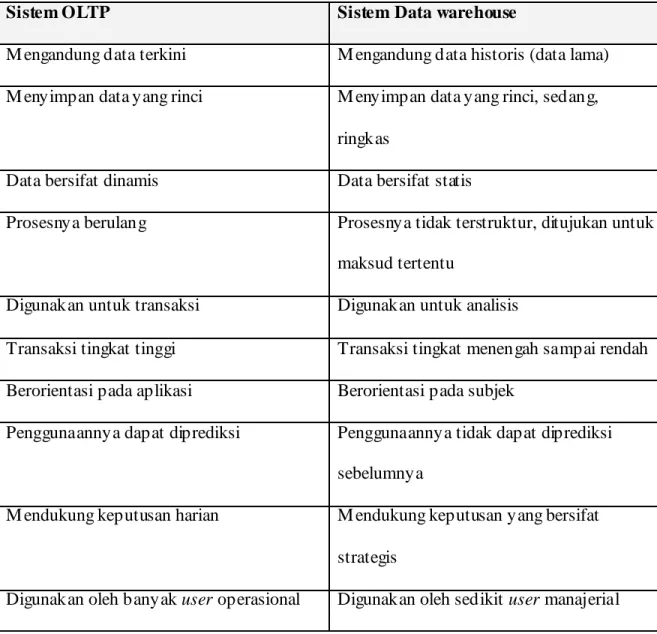
2.2.9 Perbandingan Data Warehouse dengan OLTP
M enurut Connoly dan begg (2005, p1153), biasanya sebuah organisasi mempunyai beberapa sistem Online Transaction Processing (OLTP) yang berbeda untuk setiap proses bisnis, seperti pengawasan persediaan (inventory control), pesanan pelanggan (invoicing customer) dan tingkat penjualan. Sistem ini menghasilkan data operasional yang detil, terbaru, dan selalu berubah. Sistem OLTP optimal jika digunakan untuk sejumlah transaksi yang dapat diramalkan (predictable), berulang (repetitive), dan sering diperbaharui (update intensive). Data OLTP diorganisasikan berdasarkan syarat-syarat dari transaksi dihubungkan dengan aplikasi bisnis dan mendukung keputusan per hari dalam sejumlah besar operasional user yang konkruen.
Umumnya organisasi hanya mempunyai satu data warehouse yang menyimpan data secara historis, detil, dan ringkasan dengan beberapa tingkatan dan sangat jarang berubah. Data warehouse didesain untuk mendukung transaksi yang tidak dapat diramalkan (unpredictable), dan memerlukan jawaban untuk query khusus (ad hoc), tidak terstruktur dan heuristic. Data warehouse diorganisasikan berdasarkan pada syarat-syarat query yang potensial dan mendukung keputusan strategis jangka panjang dari sejumlah kecil user tingkat manajerial.
Di bawah ini adalah tabel perbandingan antara sistem OLTP dengan sistem data warehouse (Connolly dan Begg, 2005, p1153) :
Tabel 2.1 Perbandingan Sistem OLTP dan S istem Data Warehouse
Sistem OLTP Sistem Data warehouse
M engandung data terkini M engandung data historis (data lama) M enyimpan data yang rinci M enyimpan data yang rinci, sedang,
ringkas
Data bersifat dinamis Data bersifat statis
Prosesnya berulang Prosesnya tidak terstruktur, ditujukan untuk maksud tertentu
Digunakan untuk transaksi Digunakan untuk analisis
Transaksi tingkat tinggi Transaksi tingkat menengah sampai rendah Berorientasi pada aplikasi Berorientasi pada subjek
Penggunaannya dapat diprediksi Penggunaannya tidak dapat diprediksi sebelumnya
M endukung keputusan harian M endukung keputusan yang bersifat strategis
2.3 Metodologi Percancangan Data Warehouse
Berdasarkan kutipan dari Connolly dan Begg (2005, p1187-1193), metodologi yang dikemukakan oleh Kimball dalam membangun data warehouse ada 9 tahapan , yang dikenal dengan Nine-step Methodology. Sembilan tahap tersebut adalah :
2.3.1 Pemilihan proses (Choosing the Process)
Proses menunjuk pada subyek yang ada dari sebuah bagian data mart. Data mart pertama yang akan dibangun harus tepat waktu, disesuaikan dengan anggaran dan menjawab pertanyaan bisnis yang banyak diutarakan. Data mart adalah bagian dari data warehouse yang mendukung kebutuhan pada suatu unit departemen dari perusahaan atau fungsi bisnis.
2.3.2 Pemilihan Grain (Choosing the Grain)
M emilih grain berarti menentukan secara tepat apa yang direpresentasikan oleh record pada tabel fakta. Sebagai contoh PropertySale merepresentasikan fakta mengenai setiap penjualan properti dan menjadi tabel fakta dari skema bintang PropertySale. Oleh karena itu, grain dari tabel fakta PropertySale adalah penjualan properti itu sendiri.
Ketika grain dari tabel fakta dipilih, dimensi dapat diidentifikasikan dari tabel fakta. Sebagai contoh Branch, Staff, Owner, ClientBuyer,
PropertyForSale, dan Promotion entity akan digunakan untuk tabel dimensi utama yang selalu ada dalam skema bintang.
M emutuskan grain untuk tabel fakta juga menentukan grain untuk setiap tabel dimensi. M isalnya, grain pada tabel fakta PropertySale adalah setiap penjualan properti itu sendiri, kemudian grain pada dimensi Client adalah detil dari klien yang membeli properti.
2.3.3 Identifikasi dan penyesuaian dimensi (identifying and conforming the dimension)
Dimensi menetapkan konteks pertanyaan mengenai fakta dalam tabel fakta. Kumpulan dimensi yang baik membuat data mart mudah dimengerti dan digunakan. Dimensi diidentifikasikan dengan detil untuk menjelaskan suatu hal seperti client dan properti pada grain yang tepat. Sebagai contoh dimensi client buyer mendeskripsikan atribut ID, nama , tipe, kota, area, dan negara.
Jika dimensi apapun ada di dalam dua data mart, maka dimensi tersebut merupakan dimensi yang sama, atau diomensi yang satu merupakan suatu perhitungan matematikan dari dimensi yang lainnya. Hanya dengan ciri ini, dua data mart dapat berbagi satu atau lebih data mart, dimensi tersebut harus sesuai. Sebagai contoh, dimensi-dimensi yang sesuai dengan penjualan properti dan periklanan properti adalah dimensi Time, PropertyForSlae, Branch, dan Promotion. Jika dimensi-dimensi tersebut tidak sesuai, maka data warehouse akan gagal untuk
dibangun, sebab dua data mart tersebut tidak akan dapat digunakan secara bersamaan.
2.3.4 Pemilihan fakta (Choosing the Facts)
Grain dari tabel fakta menentukan fakta yang bisa digunakan. M isalnya, grain dari tabel fakta adalah setiap penjualan properti, kemudian semua fakta numerik harus menunjuk pada penjualan ini. Fakta-fakta tersebut harus numerik dan dapat ditambah.
2.3.5 Menyimpan pre-calculation pada table fakta (Storing pre calculation in the fact table)
Setelah fakta-fakta dipilih maka dilakukan pengkajian ulang untuk menentukan apakah fakta-fakta yang dapat diterapkan untuk pre-calculation (kalkulasi awal) dan melakukan peyimpanan pada tabel fakta. Contoh umum dari kebutuhan untuk penyimpanan pre-calculation muncul ketika fakta berisi pernyataan untung atau rugi. Situasi ini akan meningkat ketika tabel fakta didasarkan pada invoice atau sales.
2.3.6 Melengkapi table dimensi (Rounding out the dimension tables)
Dalam langkah ini, kembali pada tabel dimensi dan menambahkan gambaran teks terhadap dimensi yang memungkinkan. Gambaran teks harus mudah digunakan dan dimengerti oleh user. Kegunaan suatu data mart ditentukan oleh lingkup dan atribut tabel dimensi.
2.3.7 Pemilihan durasi Basis Data (Choosing the duration of the database) Durasi mengukur waktu dari pembatasan data yang diambil dan dipindahkan ke dalam tabel fakta. Sebagai contoh, perusahaan asuransi memiliki kebutuhan untuk menyimpan data dalam jangka waktu 5 tahun atau lebih. Tabel fakta yang besar menimbulkan dua persoalan. Pertama, semakin lama umur data, akan muncul masalah pembacaan dan interpretasi terhadap file yang lama. Kedua, terdapat kemungkinanan digunakannya versi dimensi yang lama, bukan versi terbarunya.
2.3.8 Melacak perubahan dari dimensi secara perlahan (Tracking slowly changing dimension)
M engamati perubahan dari dimensi pada tabel dimensi khususnya data history yang lama atau data lama yang sudah berubah. Ada tiga tipe dasar dari perubahan dimensi yang perlahan, yaitu :
• Perubahan data dimensi langsung dilakukan pada tabel dimensinya • Perubahan data dimensi mengakibatkan pembentukan record baru. • Perubahan data dimensi mengakibatkan sebuah atribut atau kolom
alternatif dibuat, jadi antara record yang lama dan baru diakses secara bersama-sama.
2.3.9 Memutuskan prioritas dan mode dari query (Deciding the query priorities and the query modes)
M empertimbangkan pengaruh dari rancangan fisik, seperti penyortiran urutan tabel fakta pada disk dan keberadaan dari penyimpanan awal ringkasan (summaries) atau penjumlahan (aggregate). Selain itu, masalah administrasi, backup, kinerja indeks, dan keamanan juga merupakan faktor yang harus diperhatikan.
2.4 Dimensionality Modeling
M enurut Connolly dan Begg (2005, p1183), pemodelan dimensi (dimensionality modeling) adalah tehnik desain logikal yang bertujuan untuk menampilkan dalam bentuk standar dan intuitif yang memungkinkan untuk menampilkan akses tingkat tinggi.
Pemodelan dimensional model (DM ) dibuat dari satu tabel dengan composite priimary key yang disebut tabel fakta (fact table) dan seperangkat tabel dengan composite primary key yang disebut tabel deimensi (dimension table). Setiap tabel dimensi memiliki sebuah primary key sederhana (non-composite) yang berhubungan secara langsung dengan satu dari komponen dalam composite key dalam tabel fakta. Dengan kata lain , primary key dari tabel fakta dibuat dari dua atau lebih foreign key. Struktur karakteristik ’seperti bintang’ ini disebut skema bintang (star schema atau star join).
Fitur penting lain dari DM adalah seluruh key alami yang digantikan dengan surrogate key. Hal ini berarti setiap penggabungan antara tabel fakta dan tabel dimensi didasarkan pada surrogate key, bukan key alami. Setiap surrogate key
harus memiliki struktur tergeneralisasi yang didasarkan pada integer sederhana. Kegunaan dari surrogate key memungkinkan data dalam warehouse untuk mempunyai independensi dari data yang digunakan dan dihasilkan oleh sistem OLTP.
2.5 Skema Bintang (S tar schema)
2.5.1 Pengertian Skema Bintang (S tar schema)
M enurut Connoly dan Begg (2005, p1183), skema bintang (star schema) adalah struktur logikal yang mempunyai sebuah tabel fakta berisi data faktual yang ditempatkan di tengah, dikelilingi oleh tabel dimensi berisi data referensi (yang dapat didenormalisasi).
Gambar 2.7 S kema Bintang (Star Schema)
(Sumber : Connolly dan Begg, 2005, p1184)
2.5.2 Keuntungan Skema Bintang (S tar schema)
Skema bintang memiliki beberapa keuntungan yang tidak terdapat dalam struktur relasional biasa. Keuntungan menggunakan skema bintang yaitu :
1. Efisiensi, struktur database yang konsisten sehingga lebih efisien dalam mengakses data dengan menggunakan alat atau tool utnuk menampilkan data termasuk laporan tertulis dan query.
2. kemampuan untuk mengatasi perubahan kebutuhan, skema bintang dapat beradaptasi terhadap perubahan kebutuhan pengguna, karena semua tabel dimensi memiliki kesamaan dalam menyediakan akses tabel fakta.
3. Extensibility, model dimensional dapat dikembangkan. Seperti menambah tabel fakta selama data masih konsisten, menambah tabel dimensi selama ada nilai tunggal di tabel dimensi tersebut yang mendefinisikan setiap record tabel fakta yang ada, menambahkan attribute tabel dimensi, dan memecah record tabel dimensi yang ada menjadi level yang lebih rendah dari level sebelumnya.
4. Kemampuan untuk menggambarkan situasi bisnis pada umumnya, pendekatan standar untuk menangani situasi umum di dunia bisnis yang terus bertambah.
5. Proses query yang bisa diprediksi, aplikasi data warehouse yang mencari data dari level yang dibawahnya akan dengan mudah menambah jumlah atribut pada tabel dimensi dari sebuah skema bintang. Aplikasi yang mencari data dari level yang setara akan menghubungkan tabel fakta yang terpisah melalui tabel dimensi yang dapat diakses bersama.
2.6 Skema Snowflake (Snowflake Schema)
2.6.1 Pengertian Skema Snowflake (Snowflake Schema)
M enurut Connolly dan Begg (2005, p1185), skema snowflake (snowflake schema) adalah variasi lain dari skema bintang dimana tabel dimensi tidak berisi data yang dinormalisasi. Suatu tabel dimensi dapat memiliki tabel dimensi lainnya.
Gambar 2.8 S kema Snowflake (Snowflake Schema)
2.6.2 Keuntungan dan Kerugian Skema Snowflake (Snowflake)
Keuntungan dari skema snowflake (snowflake schema adalah :
1. Kecepatan memindahkan data dari data OLTP ke dalam metadata. 2. Sebagai kebutuhan dari alat pengambil keputusan tingkat tinggi
dimana dengan tipe yang seperti ini, seluruh struktur dapat digunakan sepenuhnya.
3. Banyak yang beranggapan lebih nyaman merancang dalam bentuk normal ketiga.
Sedangkan kerugiannya adalah mempunyai masalah yang besar dalam hal kinerja (performance), hal ini disebabkan semakin banyaknya join antar tabel-tabel yang dilakukan dalam skema snowflake ini, maka semakin lambat juga kinerja yang dilakukan.
2.7 Agregasi
M enurut M allach (2000, p514), agregasi merupakan kumpulan dari elemen-elemen pada beberapa dimensi dari database. Toko dapat diagregasikan ke dalam daerah; hari dapat diagregasikan ke dalam minggu, bulan, dan kuartal; dan produk dapat diagregasikan ke dalam kategori.
2.8 Denomarlisasi
Denormalisasi ini bertentangan dengan aturan normalisasi. Normalisasi sendiri berarti melakukan pemecahan tabel menjadi beberapa tabel sesuai dengan aturan yang ada sehingga menghasilkan tabel yang lebih ringkas dan lebih stabil.
M enurut Adelham (2000, p244), denormalisasi adalah suatu prosedur regrouping normalisasi data untuk menspesifikasikan kumpulan proses menjadi lebih efisien. Proses denormalisasi ini sangat berlawanan dengan proses normalisasi yang biasa dilakukan dalam pendesainan database.
Hal-hal utama yang membuat kita melakukan proses denormalisasi adalah : • Untuk mengurangi jumlah hubungan antar tabel yang harus diproses
dari query pengguna.
• M embuat struktur database fisik semakin dekat dengan pandangan model bisnis pengguna. M embuat struktur tabel sesuai dengan yang ingin ditanyakan oleh pemakai dan memungkinkan terjadinya akan langsung, yang sekali lagi akan meningkatkan performa.
• M empercepat proses agregasi serta memudahkan pengaksesan data secara langsung pada bagian yang hendak dianalisis.
Namun penggunaan denormalisasi memiliki kelemahan, dimana tempat penyimpanan data haruslah besar, ini juga akan mempengaruhi kinerja kerja secara fisik.
M enurut Connolly dan Begg (2005, p520), denormalisasi mengarah pada suatu situasi dimana 2 relasi digabungkan menjadi suatu relasi baru, dan relasi baru tersebut masih ternormalisasi, namun mengandung null yang lebih sedikit dari relasi yang lama. Denormalisasi biasanya digunakan pada saat kinerja tidak memuaskan dan suatu relasi yang memiliki tingkat update rendah serta tingkat query tinggi.
Dalam melakukan denormalisasi penyimpanan data dalam database akan melanggar ketentuan dalam normalisasi terutama Third Normal Form (3NF) yang bertujuan untuk menghilangkan redudansi data. Namun, jika normalisasi menghabiskan waktu dalam memberikan suatu informasi dari tabel yang diinginkan, dan akan lebih hemat jika disimpan dalam sebuah tabel.
2.9 Teknik Pencarian Data (Fact Finding)
M enurut Connolly dan Begg (2005, p 317-320), pencarian fakta (fact finding) dapat didefinisikan sebagai suatu proses formal yang menggunakan teknik seperti wawancara (interview) dan kuesioner untuk mengumpulkan fakta/kebenaran mengenai sistem, kebutuhan, dan berbagai pilihan.
Pada umumnya, database developer menggunakan beberapa teknik fact finding selama proyek database berlangsung. M enurut Connolly dan Begg (2005, p318), terdapat lima teknik fact finding yaitu :
1. M emeriksa Dokumentasi (Examining Documentation) 2. Wawancara (Interviewing)
3. M elakukan Observasi Aktivitas Operasional di dalam Organisasi (Observing the Enterprise in Operation)
4. M elakukan Riset (Research) 5. Kuesioner (Questionnaires)
Setiap teknik dalam fact finding masing-masing memiliki kelebihan dan kekurangan dalam mengumpulkan fakta mengenai sistem organisasi.
2.9.1 Memeriksa Dokumentasi (Examining Documentation)
Dokumentasi berguna untuk memperoleh beberapa pemahaman mengenai kebutuhan bagi database. Dokumentasi dapat membantu untuk menyediakan informasi pada suatu bagian perusahaan yang terkait dengan masalah. Dengan melakukan pemeriksaan dokumentasi, form, laporan, dan file yang berhubungan dengan sistem yang ada, dapat diperoleh pemahaman mengenai sistem.
2.9.2 Wawancara (Interviewing)
Teknik wawancara merupakan teknik yang paling banyak digunakan, dan pada umumnya sangat berguna dalam menampilkan fakta. Wawancara dilakukan untuk mengumpulkan informasi dari orang-orang (individu) secara tatap muka (face to face). Wawancara memiliki beberapa tujuan, seperti mencari fakta,
membenarkan fakta, mengklarifikasikan fakta, menghasilkan antusias, melibatkan end-user, mengidentifikasi kebutuhan, dan mengumpulkan ide dan pendapat. Wawancara memerlukan keahlian komunikasi yang baik untuk berhubungan dengan orang yang memiliki nilai, prioritas, pendapat, motivasi, dan kepribadian berbeda.
Ada dua jenis wawancara yaitu : • Wawancara yang tidak terstruktur
Pewawancara mengharapkan orang akan diwawancara untuk menyediakan kerangka kerja (framework) dan arahan untuk wawancara. Jenis wawancara ini tidak akan memberikan hasil yang tidak baik dalam analisis dan perancangan database.
• Wawancara yang terstruktur
Pewawancara mempersiapkan pertanyaan-pertanyaan tertentu yang akan ditanyakan kepada orang yang akan diwawancara. Ada dua jenis pertanyaan yaitu : open-ended question yaitu pertanyaan dengan jawaban berupa deskripsi yang luas dan closed-ended question yaitu pertanyaan dengan jawaban hanya ’ya’ atau ’tidak’.
2.9.3 Melakukan Observasi Aktivitas Operasional di dalam Organisasi (Observing the Enterprise in Operation)
Observasi merupakan salah satu teknik fact finding yang paling efektif dalam memahami sistem. Dengan menggunakan teknik ini, memungkinkan seseorang dapat mempelajari dan memahami sistem.
2.9.4 Melakukan Riset (Research)
Teknik fact finding ini sangat berguna untuk melakukan penelitian atau riset terhadap aplikasi dan masalah yang terjadi. Jurnal perdagangan komputer, buku referensi, dan internet (meliputi kelompok user dan bulletin board) merupakan sumber informasi yang baik.
2.9.5 Kuesioner (Questionnaires)
Teknik fact finding dengan melakukan survei melalui kuesioner. Kuesioner merupakan dokumen khusus yang memungkinkan fakta dikumpulkan dalam sejumlah besar orang.
2.10 Digital Dashboard
M enurut Few (2006, p2) Digital dashboard adalah tampilan visual dari informasi-informasi yang paling penting untuk memperoleh sebuah objektif atau lebih, tampilan visual tersebut di konsilidasikan dan diatur dalam sebuah layar sehingga semua informasi dapat diakses dengan mudah.
Sama seperti dashboard mobil yang menyediakan informasi yang dibutuhkan untuk berkendaraan, sebuah digital dashboard mempunyai fungsi yang sama. Apakah nantinya akan digunakan untuk mendukung keputusan strategis, atau dijalankan setiap hari untuk tim operasional. Semuanya ditampilkan dalam sebuah tampilan layar, dan tujuannya untuk memantau informasi yang dibutuhkan secara efisien untuk mencapai sebuah tujuan.
Sementara itu, digital dashboard dapat juga menyaring informasi yang tidak perlu, sehingga pada akhirnya dapat meningkatkan produktivitas dan efisiensi. Dengan demikian digital dashboard membantu penggunanya dapat lebih fokus dan menbuat keputusan berdasarkan informasi yang tepat.
Dashboard merupakan tampilan visual, Informasi yang di tampilkan biasanya kombinasi grafik dan teks, Namun lebih menekankan pada grafik. Dashboard ditampilkan secara grafis karena dapat mengkomunikasikan suatu keadaan secara lebih efisien daripada sebuah teks. Bagaimana anda menampilkan informasi dengan cara terbaik agar mata manusia dapat melihatnya secara cepat dan otak manusia dapat dengan mudah mencari informasi yang terpenting.
Dashboard memiliki mekanisme tampilan yang ringkas, jelas, dan intuitif. M ekanisme tampilan secara jelas memberikan informasi tanpa memerlukan banyak ruang. Sehingga kumpulan informasi akan tepat ditampilkan
dalam satu layar. Dashboard harus dapat ditampilkan secara spesifik untuk orang, kelompok atau fungsi yang dibutuhkan.
2.11 Teori-Teori Khusus yang Berhubungan dengan Topik yang Dibahas
2.11.1 Pengertian Penjualan Properti
Dalam kamus besar bahasa Indonesia, penjualan berarti proses, cara, perbuatan menjual. M enjual sendiri berarti memberikan sesuatu kepada orang lain untuk memperoleh uang pembayaran atau menerima uang. Sedangkan properti berarti harta berupa tanah dan bangunan serta sarana dan prasarana yang merupakan bagian yang tidak terpisahkan dari tanah dan/atau bangunan yang dimaksudkan. Dengan kata lain, penjualan properti ialah proses, cara tindakan memberikan harta berupa tanah bangunan serta sarana dan prasarana kepada orang lain untuk memperoleh uang pembayaran.
2.11.2 Pengertian Persediaan Properti
Dalam kamus besar bahasa Indonesia, persediaan ialah barang yang dimiliki untuk dijual atau untuk diproses selanjutnya dijual. Berdasarkan pengertian di atas, persediaan properti ialah barang berupa bangunan yang pemilik akan jual melalui perantara broker properti yang siap untuk dijual atau diproses selanjutnya.
2.11.3 Pengertian Komisi
Dalam kamus besar bahasa Indonesia, komisi adalah imbalan (uang) atau persentase tertentu yang dibayarkan karena jasa yang diberikan dalam jual beli dan sebagainya. Berdasarkan pengertian tersebut komisi disini berupa sejumlah uang yang diberikan kepada Member Broker dan Marketing Associate terhadap keberhasilannya akan suatu transaksi.
2.11.4 Pengertian Penghargaan
Dalam kamus besar bahasa Indonesia, penghargaan adalah perbuatan menghargai. Berdasarkan pengertian tersebut penghargaan disini berupa memberikan award dalam kategori tertentu dari perusahaan kepada Marketing Associate atau Member Broker atas sejumlah prestasi yang telah dicapai olehnya. Penghargaan dibagi ke dalam beberapa kategori dengan syarat-syarat pencapaian yang beragam.