ABSTRAK
Penambangan data merupakan ekstraksi pola terhadap data yang menarik dalam jumlah yang besar. Pola tersebut dikatakan menarik apabila tidak diketahui sebelumnya dan berguna bagi perkembangan ilmu pengetahuan. Data tersebut dapat diolah dengan berbagai teknik penambangan data seperti asosiasi, klasifikasi, clustering dan deteksi outlier. Deteksi outlier merupakan salah satu bidang penelitian yang penting dalam penambangan data. Penelitian tersebut bermanfaat untuk menemukan outlier yang mungkin berguna bagi pengguna. Outlier merupakan sebuah data yang berbeda dibandingkan dengan sifat umum yang dimiliki data lain pada suatu kumpulan data. Pada tugas akhir ini, pendeteksian outlier dilakukan menggunakan algoritma Local Outlier Probability (LoOP). Data yang digunakan adalah data akademik mahasiswa program studi Teknik Informatika Universitas Sanata Dharma, Yogyakarta tahun angkatan 2007 dan 2008. Data tersebut terdiri dari data numerik nilai hasil seleksi masuk mahasiswa yang diterima melalui jalur tes tertulis maupun jalur prestasi dan nilai indeks prestasi dari semester satu sampai empat. Hasil dari penelitian ini adalah sebuah perangkat lunak yang dapat digunakan sebagai alat bantu untuk mendeteksi outlier menggunakan algoritma Local Outlier Probability (LoOP).
ABSTRACT
Data mining is the extraction of the data are interesting patterns in large quantities. The pattern is said to be interesting if a previously unknown and useful for the development of science. Such data can be processed by a variety of data mining techniques such as association, classification, clustering and outlier detection. Outlier detection is one of the important research in the field of data mining. The study is useful for finding outliers that may be useful to the user. Outlier is a different data than the common properties owned by other data in a data set. In this thesis, outlier detection is done using algorithms Local Outliers Probability (Loop). The data used is the academic student of Computer Science Sanata Dharma University, Yogyakarta years of 2007 and 2008. The data consists of numeric data value of the student admission data from regular tracks and outstanding tracks and accomplishments of the
semester index value of one to four. The results of this study is a software that can be used as a tool to detect outliers using Local Outliers Probability algorithm (LOOP).
i
DETEKSI OUTLIER MENGGUNAKAN ALGORITMA LOCAL OUTLIER PROBABILITY (LoOP)
(STUDI KASUS DATA AKADEMIK MAHASISWA PROGRAM STUDI TEKNIK INFORMATIKA
UNIVERSITAS SANATA DHARMA) Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika
Oleh : Erlita Octaviani
105314019
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
OUTLIER DETECTION USING LOCAL OUTLIER PROBABILITY (LoOP) ALGORITHM
(STUDY CASE STUDENTS ACADEMIC DATA OF INFORMATICS ENGINEERING STUDY PROGRAM OF
SANATA DHARMA UNIVERSITY) A Thesis
Presented as Partial Fullfillment of the Requirements To Obtain the Sarjana Komputer Degree In Study Program of Informatics Engineering
By : Erlita Octaviani
105314019
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
iii
H ALAMAN PERSETUJUAN
SKRIPSI
DETEKSI OUTLIER MENGGUNAKAN ALGORITMA LOCAL OUTLIER
PROBABILITY (LoOP)
(STUDI KASUS DATA AKADEMIK MAHASISWA PROGRAM STUDI TEKNIK INFORMATIKA
UNIVERSITAS SANATA DHARMA)
Oleh :
Erlita Octaviani
105314019
Telah disetujui oleh :
Dosen Pembimbing
iv
HALAMAN PENGESAHAN SKRIPSI
DETEKSI OUTLIER MENGGUNAKAN ALGORITMA LOCAL OUTLIER
PROBABILITY (LoOP)
(STUDI KASUS DATA AKADEMIK MAHASISWA PROGRAM STUDI TEKNIK INFORMATIKA
UNIVERSITAS SANATA DHARMA)
Yang dipersiapkan dan disusun oleh :
Erlita Octaviani
105314019
Telah dipertahankan di depan Panitia Penguji
Pada tanggal 15 Desember 2014
Dan dinyatakan me menuhi syarat
Susunan Panitia Penguji
Tanda Tangan
Ketua : P.H. Prima Rosa, S.Si., M.Sc. ………
Sekretaris : Sri Hartati Wijono, S.Si., M.Kom. ………
Anggota : Ridowati Gunawan, S.Kom., M.T. ………
Yogyakarta, ….. Januari 2015
Fakultas Sains dan Teknologi
Universitas Sanata Dharma
Dekan,
v
HALAMAN PERSEMBAHAN
“
Ada 7 hal yang menghancurkan kita : kekayaan tanpa kerja keras,
kesenangan tanpa kesadaran, pengetahuan tanpa karakter, bisnis tanpa
moralitas, ilmu pengetahuan tanpa kemanusiaan, ibadah tanpa pengorbanan,
dan politik tanpa prinsip
”
(Mahatma Gandhi)
“Dan bersabarlah, karen
a sesungguhnya Allah tiada menyia-nyiakan pahala
orang-
orang yang berbuat kebaikan”
(Al-Qur
’an 11:115)
“Hidup adalah ‘pilihan’, segeralah tentukan ‘pilihanmu’ atau ‘pilihan’ akan
menentukan hidupmu” (Nicholas Cage)
-
JUST DO IT -
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah saya sebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 14 Januari 2015 Penulis,
vii
ABSTRAK
Penambangan data merupakan ekstraksi pola terhadap data yang menarik dalam jumlah yang besar. Pola tersebut dikatakan menarik apabila tidak diketahui sebelumnya dan berguna bagi perkembangan ilmu pengetahuan. Data tersebut dapat diolah dengan berbagai teknik penambangan data seperti asosiasi, klasifikasi, clustering dan deteksi outlier. Deteksi outlier merupakan salah satu bidang penelitian yang penting dalam penambangan data. Penelitian tersebut bermanfaat untuk menemukan outlier yang mungkin berguna bagi pengguna. Outlier merupakan sebuah data yang berbeda dibandingkan dengan sifat umum yang dimiliki data lain pada suatu kumpulan data. Pada tugas akhir ini, pendeteksian outlier dilakukan menggunakan algoritma Local Outlier Probability (LoOP). Data yang digunakan adalah data akademik mahasiswa program studi Teknik Informatika Universitas Sanata Dharma, Yogyakarta tahun angkatan 2007 dan 2008. Data tersebut terdiri dari data numerik nilai hasil seleksi masuk mahasiswa yang diterima melalui jalur tes tertulis maupun jalur prestasi dan nilai indeks prestasi dari semester satu sampai empat. Hasil dari penelitian ini adalah sebuah perangkat lunak yang dapat digunakan sebagai alat bantu untuk mendeteksi outlier menggunakan algoritma Local Outlier Probability (LoOP).
viii
ABSTRACT
Data mining is the extraction of the data are interesting patterns in large quantities. The pattern is said to be interesting if a previously unknown and useful for the development of science. Such data can be processed by a variety of data mining techniques such as association, classification, clustering and outlier detection. Outlier detection is one of the important research in the field of data mining. The study is useful for finding outliers that may be useful to the user. Outlier is a different data than the common properties owned by other data in a data set. In this thesis, outlier detection is done using algorithms Local Outliers Probability (Loop). The data used is the academic student of Computer Science Sanata Dharma University, Yogyakarta years of 2007 and 2008. The data consists of numeric data value of the student admission data from regular tracks and outstanding tracks and accomplishments of the semester index value of one to four. The results of this study is a software that can be used as a tool to detect outliers using Local Outliers Probability algorithm (LOOP).
ix
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPERLUAN KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dhama Nama : Erlita Octaviani
Nomor Mahasiswa : 105314019
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
DETEKSI OUTLIER MENGGUNAKAN ALGORITMA LOCAL OUTLIER PROBABILITY
(STUDI KASUS DATA AKADEMIK MAHASISWA PROGRAM STUDI TEKNIK INFORMATIKA
UNIVERSITAS SANATA DHARMA)
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya Dibuat di Yogyakarta
Pada tanggal 14 Januari 2015 Yang menyatakan,
x
KATA PENGANTAR
Puji syukur penulis haturkan ke hadirat Tuhan Yang Maha Esa atas segala rahmat dan karunia-Nya, sehingga dapat menyelesaikan penelitian tugas akhir yang berjudul “Deteksi Outlier Menggunakan Algoritma Local Outlier Probability (Studi Kasus Data Akademik Mahasiswa Program Studi Teknik Informatika Universitas Sanata Dharma)”.
Dalam menyelesaikan keseluruhan penyusunan tugas akhir ini, penulis telah banyak mendapatkan bantuan yang ternilai dari berbagai pihak. Oleh karena itu, pada kesempatan ini penulis dengan segala kerendahan hati ingin mengucapkan banyak terima kasih kepada :
1. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku Dekan Fakultas Sains dan Teknologi dan juga sebagai dosen penguji atas kritik dan saran yang telah diberikan..
2. Ibu Ridowati Gunawan, S.Kom., M.T. selaku Ketua Program Studi Teknik Informatika serta selaku dosen pembimbing akademik yang selalu memberikan kesabaran, waktu, saran, dan motivasi kepada penulis.
3. Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku Wakil Ketua Program Studi Teknik Informatika serta selaku dosen penguji atas kritik dan saran yang telah diberikan.
4. Ibu Agnes Maria Polina, S.Kom., M.Sc. selaku Dosen Pembimbing Akademik.
5. Semua dosen yang sudah membimbing penulis dan memberikan begitu banyak ilmu yang bermanfaat untuk penulis selama penulis belajar di Universitas Sanata Dharma Yogyakarta.
6. Pihak sekretariat dan laboran yang turut membantu penulis menyelesaikan tugas akhir ini.
xi
8. Adik-adik tersayang, Ernanda Rully Novrisanti dan Erwinsyah Rico Agusta yang telah memberikan semangat dan motivasi kepada penulis
9. Chandra Nurseta, terima kasih untuk selalu ada saat suka maupun duka, selalu memberikan semangat, doa dan motivasi kepada penulis
10. Ibu Chatarina Eny Murwaningtyas, M.Si. terima kasih banyak atas bantuan bimbingannya.
11. Daniel Tomi Raharjo, Setyo Resmi Probowati, Agustinus Dwi Budi, Queen Aurellia, terima kasih atas segala bantuan kepada penulis.
12. Felisitas Brillianti, Verena Pratita Aji, Yustina Ayu Ruwidati dan Fidelis Asterina. Terima kasih untuk persahabatan yang indah dan saling mendukung satu sama lain.
13. Kedua rekan skripsi ini, Felisitas Brillianti dan Yustina ayu Ruwidati. Terima kasih telah saling berbagi ilmu serta suka duka dari awal hingga akhir penyelesaian tugas akhir ini.
14. Seluruh teman-teman TI 2010 (HMPS 2010) terima kasih atas kebersamaan dan persaudaraan kita selama menjalani perkuliahan ini.
15. Semua pihak yang berperan baik secara langsung maupun tidak langsung yang tidak bisa disebutkan satu per satu.
Penulis berharap, semoga tugas akhir ini dapat memberikan tambahan pengetahuan yang berguna kepada pembaca pada umumnya. Penulis menyadari tugas akhir ini masih memiliki kekurangan, oleh karena itu penulis mengharapkan kritik dan saran yang membangun demi kesempurnaan tugas akhir ini.
Yogyakarta, 14 Januari 2015
xii
DAFTAR ISI
Halaman Judul ... i
Halaman Judul (Bahasa Inggris) ... ii
Halaman Persetujuan ... iii
Halaman Pengesahan ... iv
Halaman Persembahan ... v
Halaman Pernyataan ... vi
Abstrak ... vii
Abstract ... viii
Halaman Persetujuan Publikasi Karya Ilmiah ... ix
Kata Pengantar ... x
Daftar Isi ... xii
Daftar Gambar ... xv
Daftar Tabel ... xvii
Daftar Rumus ... xix
Daftar Lampiran ... xx
BAB I PENDAHULUAN 1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 4
1.3 Batasan Masalah ... 4
1.4 Tujuan Penelitian ... 4
1.5 Manfaat Penelitian ... 5
1.6 Metodologi Penelitian ... 5
1.7 Sistematika Penulisan ... 6
BAB II LANDASAN TEORI 2.1 Data Mining ... 8
xiii
2.1.2 Tahap Data Mining ... 10
2.1.3 Teknik Data Mining ... 13
2.2 Outlier ... 17
2.2.1 Pengertian Outlier ... 17
2.2.2 Dampak Outlier ... 18
2.2.3 Metode Pendekatan Outlier ... 19
2.3 Algoritma Local Outlier Probability ... 21
2.3.1 Contoh Perhitungan LoOP ... 24
BAB III METODOLOGI PENELITIAN 3.1 Data yang dibutuhkan ... 28
3.2 Pengolahan Data ... 29
BAB IV ANALISIS DAN PERANCANGAN SISTEM 4.1 Identifikasi Sistem ... 46
4.1.1 Diagram Use Case ... 47
4.1.2 Narasi Use Case ... 47
4.2 Perancangan Sistem Secara Umum ... 47
4.2.1 Input Sistem ... 47
4.2.2 Proses Sistem ... 51
4.2.3 Output Sistem ... 52
4.3 Perancangan Sistem ... 52
4.3.1 Diagram Aktivitas ... 52
4.3.2 Diagram Kelas Analisis ... 53
4.3.3 Diagram Sequence ... 56
4.3.4 Diagram Kelas Desain ... 56
4.3.5 Rincian Algoritma Setiap Method ... 57
4.4 Perancangan Struktur Data ... 77
4.4.1 Graf ... 78
4.4.2 Matriks Dua Dimensi ... 79
xiv
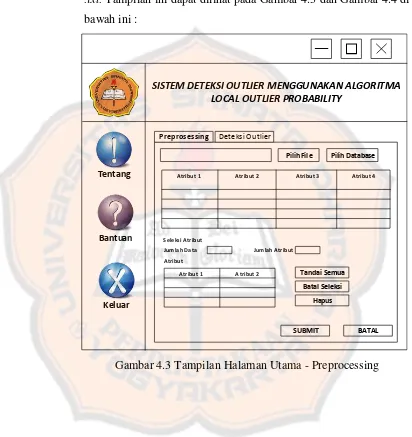
4.5.1 Tampilan Halaman Awal ... 80
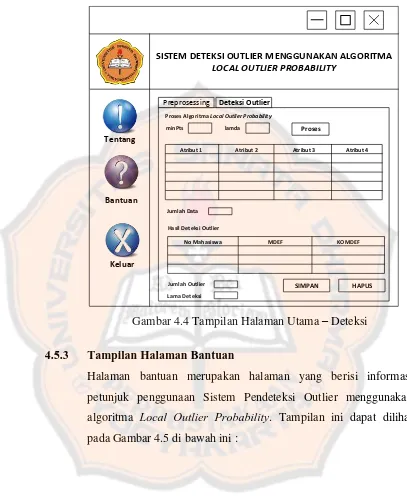
4.5.2 Tampilan Halaman Utama ... 80
4.5.3 Tampilan Halaman Bantuan ... 82
4.5.4 Tampilan Halaman Tentang ... 83
4.5.5 Tampilan Halaman Keluar ... 84
4.5.6 Tampilan Halaman Pilih Database ... 84
4.5.7 Tampilan Halaman Pilih Tabel ... 85
4.5.8 Tampilan Halaman Pilih File ... 85
BAB V IMPLEMENTASI PENAMBANGAN DATA 5.1 Implementasi Antarmuka ... 86
5.2 Implementasi Kelas ... 99
5.3 Implementasi Struktur Data ... 100
BAB VI PENGUJIAN DAN ANALISIS HASIL PENGUJIAN 6.1 Rencana Pengujian ... 104
6.2 Kelebihan dan Kekurangan Sistem ... 125
BAB VII PENUTUP 7.1 Kesimpulan ... 127
7.2 Saran ... 127
DAFTAR PUSTAKA ... 129
xv
DAFTAR GAMBAR
Gambar 2.1 Tahap data mining dalam proses KDD ... 10
Gambar 2.2 Data set outlier ... 17
Gambar 3.1 Database “gudangdata” ... 29
Gambar 3.2 Tabel fact_lengkap2 dalam database gudangdata ... 30
Gambar 3.3 Isi tabel fact_lengkap2 dalam database gudangdata ... 31
Gambar 3.4 Perhitungan jarak mahasiswa angkatan 2007 jalur tes ... 38
Gambar 3.5 Pencarian kdistance pada data mahasiswa angkatan 2007 jalur tes ... 38
Gambar 3.6 Pencarian kdistance neighborhood dari data mahasiswa angkatan 2007 jalur tes ... 39
Gambar 3.7 Perhitungan standard distance dari data mahasiswa angkatan 2007 jalur tes ... 40
Gambar 3.8 Pencarian probability set distance dari data mahasiswa angkatan 2007 jalur tes ... 41
Gambar 3.9 Perhitungan probability local outlier factor dari data mahasiswa angkatan 2007 jalur tes ... 42
Gambar 3.10 Perhitungan agregat probability local outlier factor dari data mahasiswa angkatan 2007 jalur tes ... 43
Gambar 3.11 Perhitungan local outlier probability dari data mahasiswa angkatan 2007 jalur tes ... 44
Gambar 4.1 Ilustrasi struktur data graf ... 78
Gambar 4.2 Tampilan Halaman Awal ... 80
Gambar 4.3 Tampilan Halaman Utama - Preprocessing ... 81
Gambar 4.4 Tampilan Halaman Utama - Deteksi ... 82
Gambar 4.5 Tampilan Halaman Bantuan ... 83
Gambar 4.6 Tampilan Halaman Tentang ... 83
Gambar 4.7 Tampilan Halaman Konfirmasi Keluar ... 84
xvi
Gambar 4.9 Tampilan Halaman Pilih Tabel ... 85
Gambar 4.10 Tampilan Halaman Pilih File ... 85
Gambar 5.1 Implementasi halaman awal ... 86
Gambar 5.2 Implementasi halaman utama tab preprocessing ... 87
Gambar 5.3 Implementasi JFileChooser ... 88
Gambar 5.4 Proses input data ... 88
Gambar 5.5 Implementasi seleksi atribut ... 89
Gambar 5.6 Implementasi halaman utama tab deteksi outlier ... 89
Gambar 5.7 Tampilan deteksi outlier ... 90
Gambar 5.8 Tampilan hasil seleksi LoOP ... 90
Gambar 5.9 Tampilan save dialog ... 91
Gambar 5.10 Implementasi halaman pilih database ... 91
Gambar 5.11 Proses konfigurasi database ... 92
Gambar 5.12 Proses koneksi berhasil ... 92
Gambar 5.13 Implementasi halaman pilih tabel ... 93
Gambar 5.14 Hasil input data dari database ... 93
Gambar 5.15 Implementasi halaman bantuan ... 94
Gambar 5.16 Implementasi halaman tentang ... 94
Gambar 5.17 Implementasi halaman konfirmasi keluar ... 95
Gambar 5.18 Error message input data ... 95
Gambar 5.19 Error message konfigurasi database ... 96
Gambar 5.20 Error message input data ... 96
Gambar 5.21 Error message input data minpts kosong ... 97
Gambar 5.22 Error message input data minpts non numerik ... 97
Gambar 5.23 Error message input data lamda kosong ... 97
Gambar 5.24 Error message input data lamda non numerik ... 98
Gambar 5.25 Error message input data batas outlier kosong ... 98
xvii
DAFTAR TABEL
Tabel 3.1 Contoh data atribut nil1 – nil5 sebelum dinormalisasi ... 32
Tabel 3.2 Contoh data atribut nil1 – nil5 sesudah dinormalisasi ... 33
Tabel 3.3 Contoh data atribut nilai final sebelum dinormalisasi ... 34
Tabel 3.4 Contoh data atribut nilai final sesudah dinormalisasi ... 35
Tabel 3.5 Data akademik mahasiswa angkatan 2007 jalur tes tertulis ... 37
Tabel 4.1 Tabel keterangan diagram kelas analisis ... 53
Tabel 4.2 Ilustrasi matriks 2 dimensi ... 79
Tabel 4.3 Ilustrasi matriks 2 dimensi setelah perhitungan jarak antar verteks ... 79
Tabel 5.1 Implementasi kelas ... 99
Tabel 6.1 Tabel rencana pengujian blackbox ... 105
Tabel 6.2 Tabel pengujian input data ... 106
Tabel 6.3 Tabel pengujian koneksi basis data ... 107
Tabel 6.4 Tabel pengujian seleksi atribut ... 108
Tabel 6.5 Tabel pengujian deteksi outlier ... 109
Tabel 6.6 Tabel pengujian simpan hasil deteksi outlier ... 111
Tabel 6.7 Tabel jumlah outlier mahasiswa Teknik Informatika angkatan 2007 dan 2008 jalur tes tertulis semester 1 dengan nilai minpts dan lamda yang berubah-ubah ... 112
Tabel 6.8 Tabel Data Outlier Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1 dengan Nilai k yang berubah-ubah, Lamda = 1 dan batas outlier = 0,8 ... 112
Tabel 6.9 Tabel jumlah outlier mahasiswa Teknik Informatika angkatan 2007 dan 2008 jalur prestasi semester 1 dengan nilai minpts dan lamda yang berubah-ubah ... 113
xviii
Tabel 6.11 Tabel jumlah outlier mahasiswa Teknik Informatika angkatan 2007 dan 2008 jalur tes tertulis dan prestasi semester 1 dengan nilai minpts dan lamda yang berubah-ubah ... 114 Tabel 6.12 Tabel Data Outlier Mahasiswa Teknik Informatika Angkatan
2007 dan 2008 Jalur Tes Tertulis dan Jalur Prestasi Semester 1 dengan Nilai k yang berubah-ubah, Lamda = 1 dan batas
outlier = 0,8 ... 114 Tabel 6.13 Data nilai akademik mahasiswa Teknik Informatika angkatan
Tahun 2007 yang diterima melalui jalur tes tertulis yang
digunakan untuk perbandingan perhitungan manual dan sistem 116 Tabel 6.14 Hasil perhitungan manual ... 116 Tabel 6.15 Tabel hasil perhitungan sistem ... 117 Tabel 6.16 Tabel hasil outlier untuk data mahasiswa Teknik Informatika
Angkatan 2007 dan 2008 jalur tes tertulis ... 118 Tabel 6.17 Tabel hasil outlier untuk data mahasiswa Teknik Informatika
Angkatan 2007 dan 2008 jalur prestasi ... 119 Tabel 6.18 Tabel hasil outlier untuk data mahasiswa Teknik Informatika
xix
DAFTAR RUMUS
Rumus 2.1 Rumus jarak Euclidean distance ... 21
Rumus 2.2 Rumus standard distance ... 22
Rumus 2.3 Rumus probabilistic set distance ... 23
Rumus 2.4 Rumus probabilistic local outlier factor ... 23
Rumus 2.5 Rumus agregat probabilistic local outlier factor ... 23
Rumus 2.6 Rumus local outlier probability ... 23
Rumus 2.7 Rumus error function ... 23
xx
DAFTAR LAMPIRAN
Lampiran 1 Diagram use case ... 132 Lampiran 2 Deskripsi use case ... 133 Lampiran 3 Narasi use case ... 134 Lampiran 4 Proses umum sistem pendeteksi outlier ... 139 Lampiran 5 Diagram aktivitas ... 140 Lampiran 6 Diagram kelas analisis ... 145 Lampiran 7 Diagram sequence ... 146 Lampiran 8 Diagram kelas desain ... 150 Lampiran 9 Diagram kelas ... 151 Lampiran 10 Listing Program ... 157 Lampiran 11 Data set ... 224 Lampiran 12 Outlier Plot Data Akademik Mahasiswa Teknik
Informatika Angkatan 2007-2008 Jalur Tes Tertulis ... 238 Lampiran 13 Outlier Plot Data Akademik Mahasiswa Teknik
Informatika Angkatan 2007-2008 Jalur Prestasi ... 240 Lampiran 14 Outlier Plot Data Akademik Mahasiswa Teknik
1 BAB I PENDAHULUAN
1.1 Latar Belakang
Kebutuhan akan informasi yang akurat sangat dibutuhkan dalam kemajuan teknologi informasi sekarang ini. Namun kebutuhan informasi yang tinggi kadang tidak diimbangi dengan penyajian informasi yang memadai, sehingga sering kali informasi tersebut masih perlu digali ulang dari kumpulan data yang luas. Kemampuan teknologi informasi untuk mengumpulkan dan menyimpan berbagai jenis data jauh meninggalkan kemampuan untuk menganalisis, meringkas, dan mengekstrak knowledge dari data tersebut. Metode tradisional untuk menganalisis data yang ada tidak dapat menangani data dalam jumlah besar.
Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi dalam database. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengindentifikasi informasi pengetahuan potensial dan berguna yang tersimpan di dalam database besar (Turban et al. 2005).
Data mining adalah bagian dari proses KDD (Knowledge Discovery in Databases) yang terdiri dari beberapa tahapan seperti pemilihan data, pra pengolahan, transformasi, data mining, dan evaluasi hasil (Maimon & Last, 2000).
Deteksi outlier pada sekumpulan data adalah salah satu bidang penelitian yang terus berkembang dalam topik data mining. Penelitian ini sangat bermanfaat untuk mendeteksi adanya perilaku atau kejadian yang tidak normal seperti deteksi penipuan penggunaan kartu kredit, penggelapan asuransi, diagnosa medis, dan sebagainya.
based, density based, clustering based, subspace based, dan lain-lain (Han & Kamber, 2006). Metode density based merupakan gagasan outlier berdasarkan bobot / derajat outlier berdasarkan nilai. Salah satu algoritma dengan metode density based adalah algoritma Local Outlier Probability (LoOP).
Algoritma Local Outlier Probability (LoOP) adalah metode local density based yang menggunakan beberapa konsep statistik untuk menghasilkan skor akhir. Algoritma ini menggabungkan keunggulan dari kedua pendekatan tersebut. Metode local density based tidak menganggap data mengikuti setiap distribusi dan penalaran matematika pada model statistik. Skor LoOP merupakan probabilitas bahwa suatu titik tertentu adalah local density outlier. Probabilitas ini memungkinkan perbandingan yang mudah dari titik data dengan data yang sama ditetapkan serta seluruh set data yang berbeda (Kriegel et al. 2009).
Dalam perkembangannya, teknik data mining juga digunakan untuk meneliti dalam berbagai bidang. Salah satunya adalah di bidang pendidikan. Banyak sekali penelitian dilakukan dalam bidang pendidikan. Universitas Sanata Dharma merupakan salah satu perguruan tinggi di kota Yogyakarta yang memiliki banyak data seperti data akademik mahasiswa yang meliputi data nilai tes Penerimaan Mahasiswa Baru (PMB) dan data nilai Indeks Prestasi per Semester (IPS). Untuk menjamin dan mempertahankan mutu, setiap prodi Universitas Sanata Dharma secara rutin melakukan evaluasi sisip program. Evaluasi ini untuk mengetahui kemampuan setiap mahasiswa dan untuk memutuskan apakah mahasiswa tersebut harus dipertahankan atau harus dikeluarkan (DO). Dalam memutuskan hasil evaluasi tersebut maka seorang Kaprodi harus memperhatikan riwayat akademik setiap mahasiswa dengan membandingkan nilai hasil tes PMB dengan nilai akademik semester 1 sampai 4.
ditargetkan oleh pihak universitas sebagai tindakan mengembangkan strategi untuk meningkatkan prestasi mahasiswa dan meningkatkan kinerja akademik dengan cara memantau perkembangan kinerja mereka. Oleh karena itu, evaluasi kinerja merupakan salah satu dasar untuk memantau perkembangan prestasi mahasiswa.
Algoritma Local Outlier Probability dapat diimplementasikan pada sekumpulan data numerik untuk mendeteksi adanya outlier. Salah satu contoh data numerik adalah data akademik mahasiswa yang berupa nilai hasil tes PMB dan nilai IPS. Sejumlah mahasiswa yang memiliki data akademik serupa satu sama lain berarti masuk ke dalam kelompok bukan outlier. Mahasiswa yang tidak memiliki kemiripan data akademik dengan mahasiswa manapun berarti memiliki data akademik yang unik dibandingkan mahasiswa lainnya. Mahasiswa ini akan dianggap sebagai outlier.
Berdasarkan hasil deteksi outlier, pihak universitas dapat memperoleh informasi mengenai mahasiswa dengan data akademik yang berbeda atau unik dibandingkan mahasiswa lainnya. Data unik ini dapat dihasilkan dari nilai IPS mahasiswa yang sangat tinggi atau sangat rendah di tiap semester. Selain itu data akademik yang unik juga berasal dari tinggi rendahnya nilai tes PMB mahasiswa. Sebagai contoh, sejumlah mahasiswa dengan nilai IPS dan nilai tes PMB yang tinggi akan tergabung dalam sebuah kelompok yang sama. Kemudian sejumlah mahasiswa yang memiliki nilai IPS dan nilai PMB yang rendah juga akan tergabung dalam sebuah kelompok yang sama. Pihak universitas dapat menganalisis data diri mahasiswa tersebut untuk menemukan faktor tertentu yang berpengaruh pada keunikan data akademik mahasiswa tersebut.
mahasiswa Teknik Informatika Universitas Sanata Dharma angkatan 2007-2008.
1.2 Rumusan Masalah
Berdasarkan latar belakang di atas, rumusan masalah dalam penelitian ini adalah :
1. Bagaimana algoritma Local Outlier Probability (LoOP) dapat mendeteksi outlier dari data nilai akademik mahasiswa?
1.3 Batasan Masalah
Batasan masalah pada penelitian ini adalah sebagai berikut :
1. Penggunaan algoritma Local Outlier Probability (LoOP) yang digunakan sebagai sarana untuk mendeteksi outlier pada kumpulan data numerik nilai PMB dan nilai IPS mahasiswa Teknik Informatika Universitas Sanata Dharma.
2. Data yang digunakan adalah kumpulan data numerik nilai PMB dan nilai IPS mahasiswa Teknik Informatika Universitas Sanata Dharma angkatan 2007-2008.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah sebagai berikut :
1.5 Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut :
1. Menambah pengetahuan tentang kemampuan algoritma Local Outlier Probability (LoOP) dalam mendeteksi outlier dengan studi kasus data akademik mahasiswa Teknik Informatika Universitas Sanata Dharma. 2. Memberikan informasi kepada pihak Universitas dalam mendeteksi
anomali data yang ada pada data akademik mahasiswa.
1.6 Metodologi Penelitian
Metodologi yang digunakan dalam penelitian ini adalah : 1. Studi Pustaka
Metode ini merupakan salah satu metode penelitian yang dilakukan dengan cara mempelajari hal-hal yang berkaitan dengan deteksi outlier menggunakan algoritma Local Outlier Probability (LoOP) dan mengumpulkan informasi yang didapat dari berbagai sumber, diantaranya adalah artikel, karya ilmiah terdahulu, dan website internet. 2. Teknik Data Mining
Pada metode ini menggunakan metode KDD (Knowledge Discovery in Databases) yang dikemukakan oleh Jiawei Han dan Kamber. Langkah-langkahnya adalah sebagai berikut :
a. Penggabungan Data (Data Integration)
Proses menggabungkan data dari beberapa sumber agar data dapat terangkum ke dalam tempat penyimpanan atau satu tabel yang utuh. b. Seleksi Data (Data Selection)
Proses pemilihan atribut-atribut yang relevan untuk dilakukan penambangan data. Sedangkan, atribut yang tidak sesuai akan dihilangkan.
c. Transformasi Data (Data Transformation)
d. Penambangan Data (Data Mining)
Proses mengaplikasikan metode yang tepat untuk mendapatkan pola pada suatu kumpulan data. Dalam penelitian ini, metode yang digunakan adalah metode analisis outlier dengan menggunakan pendekatan density based. Algoritma yang digunakan untuk mendeteksi outlier adalah algoritma Local Outlier Probability (LoOP).
e. Evaluasi Pola (Pattern Evaluation)
Tahap ini merupakan bagian dari proses pencarian pengetahuan yang mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya. f. Presentasi Pengetahuan (Knowledge Presentation)
Pada tahap ini pola yang telah didapat selanjutnya direpresentasikan kepada pengguna ke dalam bentuk yang lebih mudah untuk dipahami.
1.7 Sistematika Penulisan
Untuk mengetahui secara ringkas permasalahan dalam penulisan tugas akhir ini, maka digunakan sistematika penulisan yang bertujuan untuk mempermudah pembaca menelusuri dan memahami tugas akhir ini.
BAB I PENDAHULUAN
Pada bab ini penulis menguraikan tentang latar belakang secara umum, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian serta sistematika penulisan secara keseluruhan.
BAB II LANDASAN TEORI
BAB III METODOLOGI PENELITIAN
Bab ini menjelaskan tentang metode yang dipakai dalam penelitian dan pembuatan aplikasi sebagai implementasi
BAB IV ANALISIS DAN PERANCANGAN SISTEM
Bab ini menjelaskan tentang analisa sistem dan perancangan sistem yang akan dibangun dalam penelitian ini.
BAB V IMPLEMENTASI SISTEM
Bab ini menjelaskan tentang implementasi sistem pendeteksi outlier menggunakan algoritma Local Outlier Probability menggunakan java.
BAB VI PENGUJIAN DAN ANALISIS HASIL PENGUJIAN
Bab ini menjelaskan pengujian setiap proses yang ada dalam sistem kemudian menjelaskan analisa dari hasil pengujian tersebut.
BAB VII KESIMPULAN DAN SARAN
8 BAB II
LANDASAN TEORI
2.1 Data Mining
2.1.1 Pengertian Data Mining
Data mining adalah serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data (Pramudiono, 2007). Data mining didefinisikan sebagai proses menemukan pola-pola dalam data. Proses ini otomatis atau seringnya semi otomatis. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan, biasanya keuntungan secara ekonomi. Data yang dibutuhan dalam jumlah besar (Witten & Frank, 2005). Secara sederhana, data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar (Davies & Beynon, 2004). Data mining sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Santosa, 2007).
Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa faktor antara lain (Larose, 2005) : a. Pertumbuhan yang cepat dalam kumpulan data.
b. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses ke dalam database yang handal.
c. Adanya peningkatan akses data melalui navigasi web dan intranet. d. Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar
dalam globalisasi ekonomi.
e. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi).
f. Perkembangan yang hebat dalam kemampuan komputasi dan dan pengembangan kapasitas media penyimpanan.
Hubungan yang dicari dalam data mining dapat berupa hubungan antara dua atau lebih dalam satu dimensi, misalnya dalam dimensi produk, kita dapat melihat keterkaitan pembelian suatu produk dengan produk yang lain. Selain itu hubungan juga dapat dilihat antara 2 atau lebih atribut dan 2 atau lebih obyek (Ponniah, 2001).
statistik, machine learning, information retrieval, dan komputasi tingkat tinggi. Selain itu data mining didukung oleh ilmu lain seperti neural network, pengenalan pola, spatial data analysis, image database, signal processing (Han & Kamber, 2006). Penggunaan teknik data mining diharapkan dapat memberikan pengetahuan-pengetahuan yang sebelumnya tersembunyi di dalam gudang data sehingga menjadi informasi yang berharga.
Menurut Bonnie O’Neil (1997, p522), Data mining adalah suatu proses yang mengubah data menjadi informasi dimana ini merupakan proses pencarian data dan relasi yang tersembunyi dalam data.
2.1.2 Tahap Data Mining
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap yang diilustrasikan di Gambar 2.1. Tahap-tahap tersebut bersifat interaktif, pemakai terlibat langsung atau dengan perantaraan knowledge base.
[image:32.595.97.515.223.732.2]Menurut Jiawei Han dan Kamber, proses KDD digambarkan sebagai berikut :
Menurut para ahli, data mining merupakan sebuah analisa dari observasi data dalam jumlah besar untuk menemukan hubungan yang tidak diketahui sebelumnya dan metode baru untuk meringkas data agar mudah dipahami serta kegunaannya untuk pemilik data. Data-data yang ada, tidak dapat langsung diolah dengan menggunakan sistem data mining. Data terebut harus dipersiapkan terlebih dahulu agar hasil yang diperoleh dapat lebih maksimal, dan waktu komputasinya lebih minimal. Proses persiapan data ini sendiri dapat mencapai 60% dari keseluruhan proses dalam data mining. Adapun tahapan-tahapan yang harus dilalui dalam proses data mining antara lain :
1. Pembersihan data (Data Cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak relevan dengan hipotesa data mining yang dimiliki. Data-data yang tidak relevan itu juga lebih baik dibuang. Pembersihan data juga akan mempengaruhi performasi dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
2. Integrasi Data (Data Integration)
menghasilkan hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya. Sebagai contoh bila integrasi data berdasarkan jenis produk ternyata menggabungkan produk dari kategori yang berbeda maka akan didapatkan korelasi antar produk yang sebenarnya tidak ada.
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database. Sebagai contoh, sebuah kasus yang meneliti faktor kecenderungan orang membeli dalam kasus market basket analysis, tidak perlu mengambil nama pelanggan, cukup dengan id pelanggan saja.
4. Transformasi Data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining. Beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clustering hanya bisa menerima input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagi-bagi menjadi beberapa interval. Proses ini sering disebut transformasi data.
5. Penambangan Data (Data Mining)
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data. 6. Evaluasi Pola (Pattern Evaluation)
umpan balik untuk memperbaiki proses data mining, mencoba metode data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat. 7. Presentasi Pengetahuan (Knowledge Presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan dalam proses data mining. Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan hasil data mining.
2.1.3 Teknik Data Mining
Dengan definisi data mining yang luas, ada banyak jenis metode analisis yang dapat digolongkan dalam data mining. Pada dasarnya penggalian data dibedakan menjadi dua fungsionalitas, yaitu deskripsi dan prediksi. Berikut ini beberapa fungsionalitas penggalian data yang sering digunakan:
1. Association Rule Mining
Association rules (aturan asosiasi) atau affinity analysis (analisis
afinitas) berkenaan dengan studi tentang “apa bersama apa”.
memberikan informasi tersebut dalam bentuk hubungan “if-then”
atau “jika-maka”. Aturan ini dihitung dari data yang sifatnya probabilistik (Santosa, 2007). Dengan pengetahuan tersebut pemilik pasar swalayan dapat mengatur penempatan barangnya atau merancang strategi pemasaran dengan memakai kupon diskon untuk kombinasi barang tersebut.
Analisis asosiasi dikenal juga sebagai salah satu metode data mining yang menjadi dasar dari berbagai metode data mining lainnya. Khususnya salah satu tahap dari analisis asosiasi yang disebut analisis pola frekuensi tinggi (frequent pattern mining) menarik perhatian banyak peneliti untuk menghasilkan algoritma yang efisien. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support (nilai penunjang) yaitu prosentase kombinasi item tersebut. dalam database dan confidence (nilai kepastian) yaitu kuatnya hubungan antar item dalam aturan assosiatif. Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan assosiatif yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence (minimum confidence) (Pramudiono, 2007). 2. Classification
mencukupi model ini dapat dipakai untuk prediksi kelas data yang belum diketahui.
3. Clustering
Clustering termasuk metode yang sudah cukup dikenal dan banyak dipakai dalam data mining. Sampai sekarang para ilmuwan dalam bidang data mining masih melakukan berbagai usaha untuk melakukan perbaikan model clustering karena metode yang dikembangkan sekarang masih bersifat heuristic. Usaha-usaha untuk menghitung jumlah cluster yang optimal dan pengklasteran yang paling baik masih terus dilakukan. Dengan demikian menggunakan metode yang sekarang, tidak bisa menjamin hasil pengklasteran sudah merupakan hasil yang optimal. Namun, hasil yang dicapai biasanya sudah cukup bagus dari segi praktis.
Tujuan utama dari metode clustering adalah pengelompokan sejumlah data/obyek ke dalam cluster (group) sehingga dalam setiap cluster akan berisi data yang semirip mungkin. Dalam clustering metode ini berusaha untuk menempatkan obyek yang mirip (jaraknya dekat) dalam satu klaster dan membuat jarak antar klaster sejauh mungkin. Ini berarti obyek dalam satu cluster sangat mirip satu sama lain dan berbeda dengan obyek dalam cluster-cluster yang lain. Dalam metode ini tidak diketahui sebelumnya berapa jumlah cluster dan bagaimana pengelompokannya (Santosa, 2007).
4. Outlier Analysis
menggunakan tes statistik yang mengasumsikan distribusi atau probabilitas model data menggunakan distance measures, dimana obyek yang memiliki jarak yang jauh dari klaster-klaster lainnya dianggap outlier atau anomali.
5. Decision Tree
Dalam decision tree tidak menggunakan vector jarak untuk mengklasifikasikan obyek. Seringkali data observasi mempunyai atribut-atribut yang bernilai nominal. Sebagai contoh obyeknya adalah sekumpulan buah-buahan yang bisa dibedakan berdasarkan atribut bentuk, warna, ukuran dan rasa. Bentuk, warna, ukuran dan rasa adalah besaran nominal, yaitu bersifat kategoris dan tiap nilai tidak bisa dijumlahkan atau dikurangkan. Dalam atribut warna ada beberapa nilai yang mungkin yaitu hijau, kuning, merah. Dalam atribut ukuran ada nilai besar, sedang dan kecil. Dengan nilai-nilai atribut ini, kemudian dibuat decision tree untuk menentukan suatu obyek termasuk jenis buah apa jika nilai tiap-tiap atribut diberikan (Santosa, 2007). Decision tree sesuai digunakan untuk kasus-kasus yang keluarannya bernilai diskrit. Walaupun banyak variasi model decision tree dengan tingkat kemampuan dan syarat yang berbeda, pada umumnya beberapa ciri yang cocok untuk diterapkannya decision tree adalah sebagai berikut :
1.) Data dinyatakan dengan pasangan atribut dan nilainya 2.) Label/keluaran data biasanya bernilai diskrit
3.) Data mempunyai missing value (nilai dari suatu atribut tidak diketahui)
Dengan cara ini akan mudah mengelompokkan obyek ke dalam beberapa kelompok. Untuk membuat decision tree perlu memperhatikan hal-hal berikut ini :
4. Kriteria pemberhentian. 5. Pruning.
2.2 Outlier
2.2.1 Pengertian Outlier
Outlier merupakan kumpulan data yang dianggap memiliki sifat yang berbeda, tidak konsisten dibandingkan dengan kebanyakan data lainnya (Han & Kamber, 2006). Adanya data outlier ini akan membuat analisis terhadap serangkaian data menjadi bias, atau tidak mencerminkan fenomena yang sebenarnya.
Outlier adalah suatu data yang menyimpang dari sekumpulan data yang lain dan juga merupakan pengamatan yang tidak mengikuti sebagian besar pola dan terletak jauh dari pusat data (Soemartini, 2007).
[image:39.595.97.514.167.666.2]Analisis outlier dikenal juga dengan analisis anomali atau deteksi anomali atau deteksi outlier (nilai atributnya obyek tsb, signifikan berbeda dengan nilai atribut obyek lainnya ) atau exception mining.
Gambar 2.2 data set outlier Beberapa penyebab adanya outlier, yaitu :
Data berasal dari sumber yang berbeda
Variasi natural data itu sendiri
Memang ada data-data ekstrim yang tidak dapat dihindarkan keberadaannya
Sebagai ilustrasi, pada pendapatan toko roti “Amanah” pada bulan Januari sampai Agustus. Pada bulan Januari pendapatan sekitar Rp 150 ribu, Febuari Rp 300 ribu, Maret Rp 200 ribu, April Rp 150 ribu, Mei Rp 130 ribu, Juni Rp 200 ribu, Juli Rp 300 ribu, dan Agustus Rp 1 juta. Dari data tersebut sangat tampak bahwa nilai 1 juta relatif jauh dibandingkan pendapatan di bulan-bulan sebelumnya.
2.2.2 Dampak Outlier
Deteksi outlier merupakan suatu teknik untuk mencari obyek dimana obyek tersebut mempunyai perilaku berbeda dibandingkan obyek-obyek pada umumnya. Deteksi outlier merupakan salah satu bidang penelitian yang penting dalam topik penambangan data. Penelitian ini bermanfaat untuk mendeteksi penyalahgunaan kartu kredit, deteksi adanya penyusupan pada jaringan komunikasi, analisis medis, segmentasi data pelanggan yang berkaitan dengan pemasaran barang.
Keberadaan data outlier akan mengganggu dalam proses analisis data dan harus dihindari dalam banyak hal. Outlier dapat menyebabkan hal-hal berikut ini :
Residual yang besar dari model yang terbentuk
Varians pada data tersebut menjadi lebih besar
2.2.3 Metode Pendekatan Outlier
Menurut Jiawei Han dan Kamber, teknik data mining dapat digunakan untuk mendeteksi adanya suatu outlier pada sebuah dataset. Teknik data mining yang digunakan adalah metode deteksi outlier dengan menggunakan metode statistical distribution based, distance based, density based, dan deviation based.
1.) Statistical Distribution based
Dalam metode ini data diasumsikan sebagai sebuah hipotesis kerja. Setiap data obyek di dalam dataset dibandingkan terhadap hipotesis kerja. Data yang dapat diterima maka akan masuk dalam hipotesis kerja, sedangkan data yang ditolak atau tidak sesuai dengan hipotesis kerja maka ditetapkan menjadi hipotesis alternatif (outlier).
Kelebihan metode ini jika pengetahuan data akan jenis distribut data dan jenis uji yang diperlukan sudah cukup, maka pendekatan statistik sangat efektif. Akan tetapi kekurangan dari metode pendekatan ini adalah sulit untuk menemukan fungsi distribusi dan jenis uji yang tepat untuk data dikarenakan kebanyakan uji hanya cocok untuk single atribut. Selain itu juga ditemukan kesulitan dalam menentukan fungsi distribusi dan uji yang tepat untuk data berdimensi tinggi.
2.) Distance based
Kelebihan dari metode pendekatan ini adalah sederhana. Akan tetapi untuk menangani basis data yang besar akan memakan biaya besar, sangat bergantung dengan nilai parameter yang dipilih dan juga tidak dapat menangani kasus himpunan data yang memiliki kepadatan berbeda pada daerah berbeda.
3.) Density based
Metode density-based tidak secara eksplisit mengklasifikasikan sebuah obyek adalah outlier atau bukan, akan tetapi lebih kepada pemberian nilai kepada obyek sebagai derajat kekuatan obyek tersebut dapat dikategorikan sebagai outlier. Ukuran derajat kekuatan ini adalah local outlier factor (LOF). Pendekatan untuk pencarian outlier ini hanya membutuhkan sebuah parameter yaitu k, k adalah jangkauan atau jumlah tetangga terdekat yang digunakan untuk mendefinisikan local Neighborhood suatu obyek.
4.) Deviation based
Metode deviation based tidak menggunakan pengujian statistik ataupun perbandingan jarak untuk mengidentifikasi sebuah outlier. Sebaliknya metode ini mengidentifikasi sebuah outlier dengan memeriksa karakteristik utama dari obyek dalam sebuah kumpulan. Obyek yang memiliki karakteristik diluar karakteristik utama maka akan dianggap sebagai outlier.
2.3 Algoritma Local Outlier Probability
Pada penelitian ini, penulis menggunakan algoritma Local Outlier Probability (LoOP) untuk mendeteksi adanya outlier dalam data akademik mahasiswa TI Universitas Sanata Dharma angkatan 2007-2008. Algoritma ini bekerja pada k-neighborhood obyek. LoOP adalah metode local density based yang menggunakan beberapa konsep statistik untuk menghasilkan skor akhir. Ini menggabungkan keunggulan dari kedua pendekatan tersebut. Metode local density based tidak menganggap data mengikuti setiap distribusi dan penalaran matematika pada model statistik. Skor LoOP merupakan probabilitas bahwa suatu titik tertentu adalah local density outlier. Probabilitas ini memungkinkan perbandingan yang mudah dari titik data dengan data yang sama ditetapkan serta seluruh set data yang berbeda (Kriegel et al. 2009).
Langkah-langkah perhitungan LoOP adalah sebagai berikut. Normalisasi Faktor dinotasikan dengan .
1. Menghitung k-distance dari setiap obyek (o)
Tujuan dari perhitungan k-distance ini adalah untuk menentukan tetangga dari o, secara sederhana k-distance dari sebuah obyek o adalah jarak maksimal dari obyek tertentu terhadap tetangga terdekatnya dan di notasikan dengan k-distance(o).
Untuk menghitung k-distance, langkah awal adalah menghitung jarak masing-masing obyek dengan menggunakan rumus euclidean distance seperti di bawah ini :
d(i,j) =
……(2.1)2. Menghitung jumlah tetangga terdekat (k-distance neighborhood) dari setiap obyek o
k-distance neighborhood suatu obyek o dinotasikan Nk-distance(o), atau Nk(o) dimana berisi setiap obyek dengan jarak tidak lebih besar dari k-distance (o).
3. Menghitung standard distance σ(o,S) atau standar deviasi dari jarak disekitar o
Untuk konteks lokal o dalam S. Jika kita gunakan = erf-1 sebaliknya (galat), di mana erf menunjukkan kesalahan fungsi Gaussian, dalam estimasi kepadatan S, kita dapat mensimulasikan gagasan statistik klasik dan notasi outlier didefinisikan sebagai obyek yang menyimpang. Nilai-nilai secara empiris adalah 68-95-99.7 aturan
(“three sigma”), nilai empiris itu adalah = 1 = 68%, = 2 = 95%, dan = 3 = 99,7%. Jadi semakin besar nilai lamda maka akan semakin memperkecil ditemukan error / noise. Dalam hal ini disarankan menggunakan lamda 2. Untuk menghitung standard distance dari obyek di Nk(o) dengan rumus =
σ(o,S)
=
……(2.2)
Keterangan :
σ : standard distance / standar deviasi S : himpunan tetangga dari obyek o s : tetangga dari obyek o / anggota dari S |S| : banyak anggota dari himpunan S
4. Menghitung Probabilistic set distance (pdist) pdist(, o, S)
kepadatan. Bagaimanapun, normalization factor () memberikan pengaruh terhadap skore LoOP. Rumus Probabilistic set distance (pdist) pdist(, o, Nk(o)) sebagai berikut :
pdist(
,o,S) =
.σ(o, S)
……(2.3)
5. Menghitung Probabilistic Local Outlier Factor yang merupakan ratio perkiraan kepadatan
plof(
,S(o)) =
-1
……(2.4)6. Menghitung agregat Probabilistic Local Outlier Factor
nPLOF(
) =
nPLOF() = . ……(2.5) keterangan :
D : jumlah dataset dari obyek o
7. Menghitung Local Outlier Probability (LoOP)
LoOP
S(o) = max (0,
))
……(2.6)Rumus erf tersebut adalah
erf(x) = dt ……(2.7)
Pendekatan ini didasarkan pada dua asumsi sebagai berikut: 1. titik poinnya adalah pusat set neighborhood.
2. nilai jarak mensimulasi nilai positif dari distribusi normal.
Asumsi pertama dilanggar terutama ketika titik poinnya adalah outlier. Pelanggaran ini akan mengakibatkan terlalu tinggi PLOF sebagai akibat dari peningkatan standard distance titik outlier. Efek ini sebenarnya diinginkan karena akan menekankan bahwa intinya adalah outlier.
Penambahan konsep statistik untuk metode kepadatan lokal membuat skor LoOP independen dari setiap distribusi. Hal ini membuat mampu menangani kelompok non-seragam seperti kelompok yang dihasilkan oleh model Gaussian yang ditangani buruk oleh LOF misalnya.
2.3.1 Contoh Perhitungan LoOP
Diketahui sebuah data D memiliki 4 buah obyek dan dilambangkan sebagai obyek P1, P2, P3, P4. Masing-masing obyek tersebut memiliki jarak sebagai berikut : (k = 2)
Berikut ini merupakan langkah penyelesaian persoalan di atas : 1. Mencari kdistance
Langkah mencari kdistance adalah sebagai berikut :
a. Menghitung jarak P1 terhadap semua obyek menggunakan rumus jarak ecluidean distance (tabel di atas merupakan data yang sudah dihitung jaraknya)
c. Kemudian dari 2 jarak terkecil tersebut, pilih yang paling besar jaraknya. Jarak terbesar tersebut adalah kdistance.
Obyek yang dekat dengan P1 urut dari kecil adalah P3 – P2. Jarak P1 ke P3 adalah 2 sedangkan jarak P1 ke P2 adalah 4. Maka kdistance(P1) = 4.
2. Menemukan kdistance neighborhood
Maksudnya adalah mencari tetangga terdekat dimana besar jaraknya tidak lebih dari sama dengan kdistance(o)
3. Menghitung standard distance
=
4. Menghitung probabilistic set distance
pdist(
disini adalah 2.
Maka pdist P1 = 2 x 2,236068 = 4,472136
5. Menghitung probabilistic PLOF
PLOF,Nk(o)(o) = -1
Untuk menghitung PLOF perlu menghitung terlebih dahulu nilai jumlah pdist dari setiap tetangga terkait.
Sebagai contoh menghitung ∑pdist P1. Perlu diingat bahwa tetangga P1 adalah P2 dan P3. Maka ∑pdist P1 = pdist P2 + pdist
P3.
6. Menghitung agregat PLOF (nPLOF)
nPLOF() = .
nPLOF = 2 .
= 0,794688
7. Menghitung derajat LoOP
LoOP
Nk(o)(o) = max (0,
))
28 BAB III
METODOLOGI PENELITIAN
Pada bab ini akan dijelaskan mengenai perancangan penelitian yang digunakan untuk mencapai tujuan dalam penelitian tugas akhir ini. Metodologi penelitian ini menggunakan metodologi penambangan data yaitu KDD (Knowledge Discovery in Database) yang dikemukakan oleh Jiawei Han dan Kamber.
3.1 Data yang dibutuhkan
Dalam Kamus Besar Bahasa Indonesia, data diartikan sebagai kenyataan yang ada yang berfungsi sebagai bahan sumber untuk menyusun suatu pendapat, keterangan yang benar, dan keterangan atau bahan yang dipakai untuk penalaran dan penyelidikan.
Data adalah catatan atas kumpulan fakta (Vardiansyah, 2008). Data merupakan bentuk jamak dari datum, berasal dari bahasa Latin yang berarti
“sesuatu yang diberikan”. Dalam penggunaan sehari-hari data berarti suatu pernyataan yang diterima secara apa adanya. Pernyataan ini adalah hasil pengukuran atau pengamatan suatu variabel yang bentuknya dapat berupa angka, kata-kata, atau citra.
Dalam tujuan pencarian fakta tersebut, pada penelitian ini penulis menggunakan data akademik mahasiswa teknik informatika Universitas Sanata Dharma Yogyakarta angkatan 2007-2008. Data ini bersifat numerik yang meliputi data nilai hasil seleksi masuk dan indeks prestasi semester satu sampai empat. Data tersebut diperoleh dari gudang data akademik mahasiswa Universitas Sanata Dharma Yogyakarta khususnya mahasiswa teknik informatika.
nilai indeks prestasi semester dari semester satu hingga empat. Data akademik mahasiswa program studi Teknik Informatika angkatan 2007-2008 terdiri dari 126 buah.
3.2 Pengolahan Data
Berikut ini merupakan tahap-tahap yang dilakukan dalam pengolahan data : 1. Penggabungan Data (Data Integration)
Data mentah dalam skrip sql diekstrak ke dalam database. Lalu hasil
ekstrak tersebut menghasilkan basis data bernama “gudangdata”. Dalam
[image:51.595.97.513.205.632.2]basis data ini terdiri dari beberapa tabel, yaitu tabel dim_angkatan, dim_daftarsmu, dim_fakultas, dim_jeniskel, dim_kabupaten, dim_prodi, dim_prodifaks, dim_statustes, dan factlengkap2.
Gambar 3.1 Database “gudangdata”
2. Seleksi Data (Data Selection)
Tahap selanjutnya adalah seleksi data dimana melakukan seleksi terhadap data yang relevan dengan penelitian. Dari database
“gudangdata” tersebut tabel data yang akan dipakai untuk penelitian
Gambar 3.2 Tabel fact_lengkap2 dalam database “gudangdata”
Setelah seleksi terhadap tabel dalam database “gudangdata”,
Gambar 3.3 Isi tabel fact_lengkap2 dalam database “gudangdata”
Selanjutnya dilakukan seleksi terhadap kolom yang berada dalam tabel fact_lengkap2, kolom-kolom yang tidak dipakai antara lain : nomor, jumsttb, jummsttb, jumnem, jummtnem, sttb, sk_jeniskelamin, sk_status, sk_kabupaten, sk_daftarsmu, sk_prodi
3. Transformasi Data (Data Transformation)
Pada tahap ini, data yang sudah diseleksi selanjutnya ditransformasikan kedalam bentuk yang sesuai untuk ditambang. Hal ini dikarenakan adanya perbedaan range nilai antara atribut satu dengan atribut lainnya. Nilai final memiliki range nilai antara 0-100. Nilai tes masuk memiliki range nilai antara 0-10. IPS memiliki range nilai antara 0-4. Perbedaan range nilai ini akan disamakan melalui proses transformasi data.
Transformasi data dilakukan dengan menggunakan metode normalisasi. Metode normalisasi dilakukan dengan cara membuat skala pada data atribut. Salah satu jenis metode normalisasi yaitu min-max normalization (Han & Kamber, 2006).
Normalisasi data untuk menyamaratakan persebaran nilai keseluruhan atribut dengan menggunakan rumus min-max normalization :
……(3.1)
Keterangan :
v = nilai lama yang belum dinormalisasi
minA = minimum nilai dari atribut a maxA = maksimum nilai dari atribut a
new_min = nilai minimum baru dari atribut a new_max = nilai maksimum baru dari atribut a
Proses normalisasi data berikut ini berlaku untuk atribut nil11, nil12, nil13, nil14, dan nil15 menggunakan min-max normalization, semisal nil11 adalah 8.00 maka proses normalisasinya adalah : maxA = 10, minA= 0, new_maxA = 4, new_minA= 0, dan v = nil11 dalam hal ini bernilai 8.00, sehingga proses perhitungannya v1 = (8-0)/(10-0)*(4-0)+0 = 3.20. Sehingga hasil normalisasi nil11 adalah 3.20.
1. Normalisasi atribut nil11, nil12, nil13, nil14, dan nil15
Contoh data dibawah ini menggambarkan proses transformasi dari atribut nilai1, nilai2, nilai3, nilai 4 dan nilai 5. Tabel 3.1 merupakan tabel yang berisi data atribut nil11 – nil15 sebelum normalisasi.
Tabel 3.1 Contoh Data Atribut nil11 sampai nil15 sebelum dinormalisasi
Data yang ada pada Tabel 3.1 kemudian dinormalisasi menggunakan rumus min-max normalization sehingga menghasilkan data seperti pada Tabel 3.2 di bawah ini :
Tabel 3.2 Contoh Data Atribut nil11 sampai nil15 setelah dinormalisasi
Nomor nil11 nil12 nil13 nil14 nil15 ips1 1 2,80 2,00 2,00 2,00 1,60 3,72 2 1,20 0,80 3,20 1,20 0,40 2,89 3 2,40 1,60 2,00 2,80 2,00 2,56 4 2,00 2,00 2,40 2,00 2,00 3,28 5 2,40 1,60 2,40 1,20 2,80 1,89 6 2,40 2,00 2,40 2,40 2,80 1,44 7 2,40 2,40 1,60 1,60 2,80 4,00 8 4,00 2,00 3,60 2,40 2,80 1,72 9 3,20 2,40 2,40 2,80 2,00 2,89 10 2,80 2,40 3,20 3,20 0,80 2,94 11 2,80 2,40 2,80 2,40 2,40 2,94 12 2,40 2,00 2,00 2,80 2,00 2,44 13 2,00 2,00 3,20 2,00 2,80 1,72
2. Normalisasi atribut nilai Final
Berikutnya adalah proses normalisasi data berikut berlaku untuk atribut final menggunakan min-max normalization, semisal nilai final adalah 67,80 maka proses normalisasinya adalah :
Contoh data dibawah ini mengambarkan proses transformasi atribut nilai final. Tabel 3.3 merupakan tabel yang berisi data atribut nilai final sebelum normalisasi.
Tabel 3.3 Contoh Data Atribut Nilai Final sebelum dinormalisasi
Nomor Ips1 Ips2 Ips3 Ips4 Final
1 2,94 3,27 2,96 2,81 54,00
2 1,72 1,65 1,53 1,68 28,00
3 2,56 2,77 2,52 3,13 52,00
4 2,44 2,63 2,00 2,67 51,00
5 2,94 2,59 1,55 2,35 53,00
6 1,89 2,20 2,21 1,95 59,00
7 4,00 3,52 3,43 3,70 58,00
8 1,44 2,42 2,53 1,96 74,00
9 3,72 3,48 3,36 3,65 65,00
10 1,72 2,65 2,43 2,24 59,00
11 3,28 2,75 2,90 3,00 64,00
12 2,89 3,21 3,33 3,36 55,00
13 2,89 3,18 3,04 2,95 57,00
Tabel 3.4 Contoh Data Atribut Nilai Final setelah dinormalisasi
Nomor Ips1 Ips2 Ips3 Ips4 Final
1 2,94 3,27 2,96 2,81 2,16
2 1,72 1,65 1,53 1,68 1,12
3 2,56 2,77 2,52 3,13 2,08
4 2,44 2,63 2,00 2,67 2,04
5 2,94 2,59 1,55 2,35 2,12
6 1,89 2,20 2,21 1,95 2,36
7 4,00 3,52 3,43 3,70 2,32
8 1,44 2,42 2,53 1,96 2,96
9 3,72 3,48 3,36 3,65 2,60
10 1,72 2,65 2,43 2,24 2,36
11 3,28 2,75 2,90 3,00 2,56
12 2,89 3,21 3,33 3,36 2,20
13 2,89 3,18 3,04 2,95 2,28
Setelah nilai atribut nil11, nil12, nil13, nil14, nil15, dan final di normalisasikan dalam kisaran nilai 0.00 - 4.00 maka nilai yang sudah dinormalisasikan inilah yang nantinya akan digunakan sebagai input dalam proses deteksi outlier.
4. Penambangan Data (Data Mining)
1.) Input, yang terdiri dari :
a. Nilai hasil seleksi masuk mahasiswa, baik melalui jalur tes maupun jalur prestasi. Masukan tersebut diperoleh dari atribut yang ada pada tabel fact_lengkap2 yaitu yaitu nil11, nil12, nil13, nil14, nil15, dan final. Atribut nil11, nil12, nil13, nil14, dan nil15 hanya dimiliki oleh mahasiswa yang masuk melalui jalur tes tertulis. Sedangkan atribut final dimiliki oleh mahasiswa yang masuk melalui jalur tes tertulis maupun jalur prestasi.
b. Indeks prestasi mahasiswa dari semester satu hingga empat. Masukan tersebut diperoleh dari atribut yang ada pada tabel fact_lengkap2 yaitu ips1, ips2, ips3, dan ips4.
2.) Output, yaitu : data mahasiswa yang menjadi outlier dari perhitungan yang diambil dari data numerik nilai hasil seleksi masuk dan nilai indeks prestasi selama empat semester.
Tabel 3.5 Data Akademik Mahasiswa Angkatan 2007 Jalur Tes Tertulis No ips1 ips2 ips3 ips4 nil11 nil12 nil13 nil14 nil15 1 2,94 3,27 2,96 2,81 2,80 2,00 2,00 2,00 1,60 2 1,72 1,65 1,53 1,68 1,20 0,80 3,20 1,20 0,40 3 2,56 2,77 2,52 3,13 2,40 1,60 2,00 2,80 2,00 4 2,44 2,63 2,00 2,67 2,00 2,00 2,40 2,00 2,00 5 2,94 2,59 1,55 2,35 2,40 1,60 2,40 1,20 2,80 6 1,89 2,20 2,21 1,95 2,40 2,00 2,40 2,40 2,80 7 4,00 3,52 3,43 3,70 2,40 2,40 1,60 1,60 2,80 8 1,44 2,42 2,53 1,96 4,00 2,00 3,60 2,40 2,80 9 3,72 3,48 3,36 3,65 3,20 2,40 2,40 2,80 2,00 10 1,72 2,65 2,43 2,24 2,80 2,40 3,20 3,20 0,80 11 3,28 2,75 2,90 3,00 2,80 2,40 2,80 2,40 2,40 12 2,89 3,21 3,33 3,36 2,40 2,00 2,00 2,80 2,00 13 2,89 3,18 3,04 2,95 2,00 2,00 3,20 2,00 2,80
Langkah 1 Menghitung k-distance
Perhitungan data mahasiswa angkatan 2007 melalui jalur tes dengan membandingkan nilai per komponen dan mulai dari indeks prestasi semester 1. Mencari jarak dengan menggunakan rumus jarak ecluidian distance, yaitu =
d(i,j)
=
……(2.1)
Gambar 3.4 Perhitungan jarak mahasiswa angkatan 2007 jalur tes
Setelah menghitung jarak setiap obyek, maka selanjutnya dicari kdistance dari setiap obyek, dengan asumsi k = 10, k melambangkan jangkauan suatu obyek terhadap tetangganya, sehingga dicari 10 jarak terdekat dari sebuah obyek. Caranya dengan mengurutkan jarak dari yang terkecil sampai jarak terbesar. Lalu memilih sebanyak k, yaitu 10 obyek dengan jarak terkecil. Kemudian pilih jarak terbesar dari kesepuluh jarak tersebut. jarak terbesar tersebut adalah kdistance. Gambar 3.5 merupakan pencarian kdistance dari setiap obyek mahasiswa angkatan 2007 jalur tes.
Langkah 2 Menghitung jumlah tetangga terdekat (kdistance neighborhood) dari setiap obyek
Setelah pencarian kdistance selesai, selanjutnya adalah mencari kdistance neighborhood dari data mahasiswa angkatan 2007 jalur tes. Gambar 3.6 merupakan pencarian kdistance neighborhood dari data mahasiswa angkatan 2007 jalur tes.
Gambar 3.6 Pencarian kdistance neighborhood dari data mahasiswa angkatan 2007 jalur tes
Langkah 3 Menghitung standard distance (σ)
= ……(2.2)
Gambar 3.7 di bawah ini merupakan perhitungan standard distance dari mahasiswa angkatan 2007 jalur tes. Perhitungan ini menggunakan Microsoft excel.
Gambar 3.7 Perhitungan standard distance dari mahasiswa angkatan 2007 jalur tes
Misal pada obyek P1, stdev dari P1 adalah 1,56582 didapat dari :
= ==
== 1,56582
Langkah 4 Menghitung Probabilistic set distance (pdist)
pdist( ……(2.3)
Gambar 3.8 Perhitungan probability set distance dari data akademik mahasiswa angkatan 2007 jalur tes
Contoh perhitungan pada obyek p1 adalah pdist(
== 2 * 1,56582 == 3,13164
Langkah 5 Menghitung Probabilistic Local Outlier Factor (PLOF)
PLOF,Nk(o)(o) = -1 ……(2.4)
Sebelum menghitung PLOF, langkah utama adalah mencari pdist dari obyek s dimana s tersebut adalah anggota dari Nk(o) dimana Nk(o) adalah tetangga dari obyek itu sendiri. Maksudnya, adalah
PLOF dari obyek P1 = -1
Nk(P1) = P3, P4, P5, P6, P7, P9, P10, P11, P12, P13
Gambar 3.9 Perhitungan probability local outlier factor dari data akademik mahasiswa angkatan 2007 jalur tes
Perhitungannya = PLOF P1
-1
= -0,13072