i
DETEKSI OUTLIER MENGGUNAKAN ALGORITMA NAIVE NESTED LOOP
(STUDI KASUS : DATA AKADEMIK MAHASISWA PROGRAM STUDI TEKNIK INFORMATIKA, UNIVERSITAS SANATA DHARMA, YOGYAKARTA)
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
Setyo Resmi Probowati NIM : 095314039
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
OUTLIER DETECTION USING NAÏVE NESTED LOOP ALGORITHM (CASE STUDY : STUDENT ACADEMIC DATA OF INFORMATICS
ENGINEERING STUDY PROGRAM,
SANATA DHARMA UNIVERSITY, YOGYAKARTA)
A Thesis
Presented as Partial Fullfillment of the Requirements To Obtain Sarjana Komputer Degree
in Informatics Engineering Study Program
By :
Setyo Resmi Probowati NIM : 095314039
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
v
HALAMAN PERSEMBAHAN
And now these three remain :
faith, hope and love.
But the greatest of these is love
~ 1 Corinthians 13:13 ~
vii ABSTRAK
Penambangan data merupakan ekstraksi pola terhadap data yang menarik dalam jumlah yang besar. Pola tersebut dikatakan menarik apabila tidak diketahui sebelumnya dan berguna bagi perkembangan ilmu pengetahuan. Data tersebut dapat diolah dengan berbagai teknik penambangan data seperti asosiasi, klasifikasi, clustering dan deteksi outlier.
Deteksi outlier merupakan salah satu bidang penelitian yang penting dalam penambangan data. Penelitian tersebut bermanfaat untuk menemukan outlier yang mungkin berguna bagi pengguna. Outlier merupakan sebuah data yang berbeda dibandingkan dengan sifat umum yang dimiliki data lain pada suatu kumpulan data
Pada tugas akhir ini, pendeteksian outlier dilakukan menggunakan algoritma Naïve Nested Loop. Data yang digunakan adalah data akademik mahasiswa program studi Teknik Informatika Universitas Sanata Dharma, Yogyakarta tahun angkatan 2007 dan 2008. Data tersebut terdiri dari data numerik nilai hasil seleksi masuk mahasiswa yang diterima melalui jalur tes tertulis maupun jalur prestasi dan nilai indeks prestasi dari semester satu sampai empat.
Hasil dari penelitian ini adalah sebuah perangkat lunak yang dapat digunakan sebagai alat bantu untuk mendeteksi outlier menggunakan algoritma Naïve Nested Loop. Pengujian terhadap sistem ini meliputi tiga metode pengujian, yaitu pengujian blackbox, pengujian efek perubahan nilai atribut penambangan data, dan pengujian review dan validitas oleh pengguna.
Berdasarkan pengujian blackbox yang telah dilakukan dapat disimpulkan bahwa sistem pendeteksi outlier ini secara fungsional dapat berjalan dengan baik dan menghasilkan keluaran yang sesuai dengan yang diharapkan. Dari hasil pengujian efek perubahan nilai atribut penambangan data disimpulkan bahwa penentuan nilai parameter pada algoritma Naïve Nested Loop yaitu nilai M dan dmin berpengaruh terhadap jumlah outlier yang dihasilkan. Berdasarkan hasil pengujian review dan validitas oleh pengguna dapat disimpulkan bahwa sistem dapat menghasilkan data yang dinyatakan sebagai outlier.
viii ABSTRACT
Data mining is an extraction of interesting pattern in large numbers of data. The pattern is said to be interesting if the data is previously unknown and it is useful for the development of knowledge in data mining. The data can be processed by a variety of data mining techniques such as association, classification, clustering and outlier detection.
Outlier detection is one of important researches in data mining. This research is useful to discover outliers which might be useful for users. Outlier is a data which is different from other data in a dataset.
In this thesis, Naïve Nested Loop algorithm was used to perform outlier detection. The data used in this thesis are academic data of students batch 2007 and 2008 of Informatics Engineering Department of Sanata Dharma University. The dataset consists of student admission data from regular admission track as well as students from outstanding track, and student academic data (Grade Point Average) of those students from first semester until fourth semester.
The results of this research is a software that can be used as a tool to determine outliers using Naïve Nested Loop algorithm. The testing of this system includes three testing methods, namely blackbox testing, the effects of attribute changes of M (the maximum number of objects within the dmin neighbourhood of an outlier) and dmin (the maximum distance between any pair of objects that define as a neighbour), and validation testing by users.
Based on blackbox testing, it can be concluded that the outlier detection‟s system could perform properly and produce output as expected. Based on the second testing, it can be concluded that the value of M and dmin influence the number of generated outliers. Based on the user‟s validation, it can be concluded that the results of the system are confirmed as outliers.
x
KATA PENGANTAR
Puji dan syukur penulis panjatkan atas Kehadirat Tuhan Yang Maha Esa, karena atas limpahan berkat dan rahmat-Nya penulis dapat menyelesaikan tugas akhir yang berjudul “Deteksi Outlier Menggunakan Algoritma Naïve Nested Loop (Studi Kasus : Data Akademik Mahasiswa Teknik Informatika Universitas Sanata Dharma, Yogyakarta)“ dan selalu memberikan kekuatan untuk berkembang menjadi lebih baik. Tugas akhir ini ditulis sebagai salah satu syarat memperoleh gelar sarjana komputer program studi Teknik Informatika, Fakultas Sains dan Teknologi Universitas Sanata Dharma.
Penulis mengucapkan terima kasih sebesar-besarnya kepada semua pihak yang turut memberikan dukungan, semangat, dan bantuan dalam bentuk apapun sehingga tugas akhir ini dapat terselesaikan :
1. Tuhan Yesus Kristus, Bunda Maria, dan Santa Natalia yang telah memberikan anugerah sehingga penulis dapat menyelesaikan tugas akhir ini dengan tepat waktu.
2. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku dosen pembimbing atas kesabaran, bimbingan, waktu, saran dan terlebih dukungan serta semangat yang diberikan.
xi
4. Oto Lelono Prabowo adik saya dan semua anggota keluarga besar yang telah memberikan semangat, doa, dan perhatian sehingga penulis dapat menyelesaikan tugas akhir ini.
5. Sahabat dan teman-teman seperjuangan, TI angkatan 2009 yang selalu memberikan keceriaan, semangat, doa, dan dukungan dalam menyelesaikan tugas akhir ini
6. Semua pihak yang berperan baik secara langsung maupun tidak langsung yang tidak bisa disebutkan satu per satu sehingga penulis dapat menyelesaikan tugas akhir ini.
Dengan rendah hati, penulis menyadari bahwa tugas akhir ini masih memiliki banyak kekurangan dan jauh dari sempurna, oleh karena itu diperlukan saran dan kritik yang penulis harapkan untuk perbaikan-perbaikan tugas akhir ini. Akhir kata, penulis berharap semoga tugas akhir ini memberikan banyak manfaat bagi semua pihak. Terima Kasih.
Yogyakarta, Agustus 2013 Penulis
xii DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL (INGGRIS) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN ILMIAH ... vi
ABSTRAKSI ... vii
ABSTRACT ... viii
LEMBAR PERNYATAAN PERSETUJUAN ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR TABEL ... xviii
DAFTAR GAMBAR ... xix
DAFTAR LISTING PROGRAM ... xxiii
BAB I ... 1
PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Batasan Masalah... 4
1.4 Tujuan Penelitian ... 4
1.5 Luaran ... 5
1.6 Manfaat Penelitian ... 5
1.7 Metodologi Penelitian ... 6
1.8 Sistematika Penulisan ... 7
BAB II ... 10
LANDASAN TEORI ... 10
2.1 Penambangan Data ... 10
xiii
2.1.2 Permasalahan dalam Penambangan Data ... 10
2.1.3 Fungsionalitas Penambangan Data ... 11
2.2 Knowledge Discovery in Databases (KDD) ... 14
2.2.1 Kaitan Penambangan Data dengan KDD ... 14
2.2.2 Tahapan dalam Knowledge Discovery in Databases (KDD) ... 14
2.3 Analisa Outlier ... 16
2.3.1 Definisi Outlier ... 16
2.3.2 Hubungan Antara Penambangan Data dengan Outlier ... 17
2.3.3 Penyebab Outlier ... 18
2.3.4 Manfaat Outlier ... 18
2.3.5 Berbagai Macam Pendekatan Pendeteksi Outlier ... 19
2.4 Metode Pendeteksi Outlier dengan Pendekatan Distance-Based ... 23
2.4.1 Algoritma Naïve Nested Loop ... 24
BAB III ... 26
METODOLOGI PENELITIAN ... 26
3.1 Data ... 26
3.2 Pengolahan Data... 27
3.3 Contoh Implementasi Deteksi Outlier dengan Algoritma Naïve Nested Loop 32 BAB IV ... 37
ANALISIS DAN PERANCANGAN SISTEM ... 37
4.1 Identifikasi Sistem ... 37
4.1.1 Diagram Use Case ... 39
4.1.2 Narasi Use Case ... 41
4.2 Perancangan Sistem Secara Umum ... 41
4.2.1 Pemrosesan Data Awal ... 41
4.2.2 Input Sistem ... 47
xiv
4.2.4 Output Sistem ... 52
4.3 Perancangan Sistem ... 52
4.3.1 Diagram Konteks ... 52
4.3.2 Diagram Aktivitas ... 53
4.3.3 Diagram Kelas Analisis ... 54
4.3.4 Diagram Sequence ... 56
4.3.5 Perancangan Struktur Data ... 56
4.3.5.1 Matriks Dua Dimensi ... 57
4.3.5.2 Graf ... 59
4.3.6 Diagram Kelas Desain ... 60
4.3.7 Rincian Algoritma Setiap Method Pada Tiap Kelas ... 62
4.3.7.1 Rincian Algoritma pada Method di Kelas DatabaseConnection ... 62
4.3.7.2 Rincian Algoritma pada Method di Kelas Graph_NaiveNL ... 63
4.3.7.3 Rincian Algoritma pada Method di Kelas CheckBoxTableModel 65 4.3.7.4 Rincian Algoritma pada Method di Kelas DatabaseController ... 65
4.3.7.5 Rincian Algoritma pada Method di Kelas DiagramBatang ... 66
4.3.7.6 Rincian Algoritma pada Method di Kelas HalamanUtama ... 67
4.3.7.7 Rincian Algoritma pada Method di Kelas HalamanDistribusiAtribut ... 76
4.3.7.8 Rincian Algoritma pada Method di Kelas HalamanPilihDatabase 78 4.3.7.9 Rincian Algoritma pada Method di Kelas HalamanTampilTabel.. 80
4.4 Perancangan Antarmuka ... 82
BAB V ... 92
IMPLEMENTASI PENAMBANGAN DATA ... 92
5.1 Implementasi Antarmuka ... 92
5.1.1 Implementasi Halaman Awal ... 92
5.1.2 Implementasi Halaman Utama ... 93
xv
5.1.4 Implementasi Halaman Pilih Database ... 102
5.1.5 Implementasi Halaman Tampil Tabel ... 104
5.1.6 Implementasi Halaman Bantuan ... 105
5.1.7 Implementasi Antarmuka Halaman Missing Values ... 106
5.1.8 Implementasi Halaman Konfirmasi Keluar ... 107
5.1.9 Implementasi Pengecekan Masukan ... 108
5.2 Implementasi Dataset yang Akan Diuji ... 112
5.3 Implementasi Kelas ... 113
5.3.1 Implementasi Kelas DatabaseConnection ... 114
5.3.2 Implementasi Kelas Graph_NaiveNL ... 115
5.3.3 Implementasi Kelas CheckBoxTableModel ... 118
5.3.4 Implementasi Kelas DatabaseController ... 120
5.3.5 Implementasi Kelas DiagramBatang ... 121
5.3.6 Implementasi Kelas HalamanUtama ... 122
5.3.7 Implementasi Kelas HalamanDistribusiAtribut ... 135
5.3.8 Implementasi Kelas HalamanPilihDatabase ... 137
5.3.9 Implementasi Kelas HalamanTampilTabel ... 141
5.4 Implementasi Struktur Data ... 143
5.4.1 Implementasi Kelas Vertex_NaiveNL.java ... 143
5.4.2 Implementasi Kelas Graph_ NaiveNL.java ... 144
BAB VI ... 147
PENGUJIAN DAN ANALISA HASIL PENGUJIAN ... 147
6.1 Fase Implementasi Pengujian ... 147
6.1.1 Rencana Pengujian ... 147
6.1.1.1 Hasil Pengujian Blackbox ... 149
xvi
6.1.1.1.2 Pengujian Koneksi Database ... 150
6.1.1.1.3 Pengujian Seleksi Atribut ... 152
6.1.1.1.4 Pengujian Deteksi Outlier ... 153
6.1.1.1.5 Pengujian Lihat Grafik Distribusi Atribut... 153
6.1.1.1.6 Pengujian Simpan Hasil Deteksi Outlier ... 154
6.1.1.1.7 Kesimpulan Hasil Pengujian Blackbox ... 155
6.1.1.2 Hasil Pengujian Efek Perubahan Nilai Atribut Penambangan Data ... 155
6.1.1.2.1 Pengujian Dengan Data Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 Jalur Tes Tertulis ... 156
6.1.1.2.2 Pengujian Dengan Data Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 Jalur Tes Prestasi ... 157
6.1.1.2.3 Pengujian Dengan Data Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 ... 158
6.1.1.2.4 Kesimpulan Hasil Pengujian Efek Perubahan Nilai Atribut Penambangan Data ... 159
6.1.1.3 Hasil Pengujian Validitas dan Review oleh Pengguna ... 159
6.1.1.3.1 Perbandingan Perhitungan Manual dan Hasil Sistem ... 159
6.1.1.3.2 Hasil Deteksi dari Sistem untuk Pengujian Review dan Validitas oleh Pengguna ... 162
6.1.1.3.3 Kesimpulan Hasil Pengujian Review dan Validitas oleh Pengguna ... 164
6.2 Kelebihan dan Kekurangan Sistem ... 168
6.2.1 Kelebihan Sistem ... 168
6.2.2 Kekurangan Sistem ... 169
BAB VII ... 170
KESIMPULAN DAN SARAN ... 170
7.1 Kesimpulan ... 170
7.2 Saran ... 171
DAFTAR PUSTAKA ... 172
LAMPIRAN I Deskripsi Usecase ... 174
xvii
LAMPIRAN III Diagram Aktivitas ... 184
LAMPIRAN IV Diagram Sequence ... 193
LAMPIRAN V Diagram Kelas ... 200
xviii
DAFTAR TABEL
Tabel 4.1 Tabel Nama Kelas ... 55
Tabel 5.1 Tabel Implementasi Kelas ... 113
Tabel 6.1 Tabel Rencana Pengujian ... 148
Tabel 6.2 Tabel Pengujian Input Data ... 149
Tabel 6.3 Tabel Pengujian Koneksi Database ... 151
Tabel 6.4 Tabel Pengujian Seleksi Atribut ... 152
Tabel 6.5 Tabel Pengujian Deteksi Outlier ... 153
Tabel 6.6 Tabel Pengujian Lihat Grafik Distribusi Atribut ... 154
Tabel 6.7 Tabel Pengujian Simpan Hasil Deteksi Outlier ... 154
Tabel 6.8 Tabel Jumlah Outlier Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1 dengan Nilai M dan dmin yang berubah-ubah ... 156
Tabel 6.9 Tabel Jumlah Outlier Mahasiswa Teknik InformartikaAngkatan 2007 dan 2008 Jalur Prestasi Semester 1 dengan Nilai M dan dmin yang berubah-ubah ………..157
Tabel 6.10 Tabel Jumlah Outlier Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 Jalur Tes dan Jalur Prestasi Semester 1 dengan nilai M dan dmin yang berubah-ubah ... 158
Tabel 6.11 Tabel Perbandingan Hasil Outlier Mahasiswa Program Studi Teknik Informatika Angkatan 2007 Jalur Tes Tertulis ... 160
Tabel 6.12 Tabel Nilai per Atribut Hasil Outlier Mahasiswa Program Studi Teknik Informatika Angkatan 2007 Jalur Tes Tertulis ... 160
Tabel 6.13 Tabel Hasil Outlier untuk Data Mahasiswa Program Studi Teknik Informatika angkatan 2007 dan 2008 Jalur Tes Tertulis ... 162
xix
Tabel 6.15 Tabel Hasil Outlier untuk Data Mahasiswa Program Studi Teknik
Informatika angkatan 2007 dan 2008 Jalur Tes Tertulis dan Prestasi ... 163
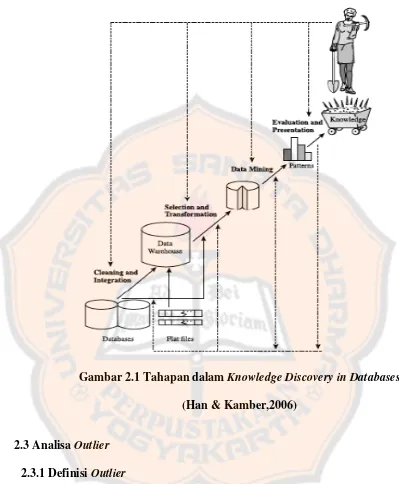
DAFTAR GAMBAR Gambar 2.1 Tahapan dalam Knowledge Discovery in Databases (Han & Kamber,2006)... 16
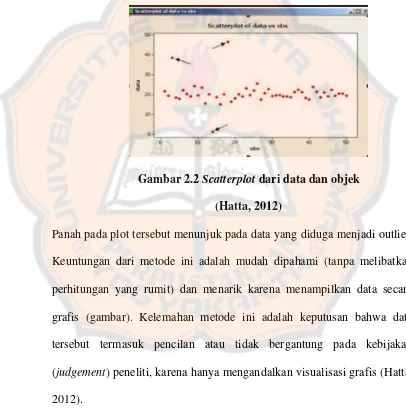
Gambar 2.2 Scatterplot dari data dan objek (Hatta, 2012) ... 19
Gambar 3.1 Dekripsi Tabel pada Gudang Data „data_mahasiswa‟ ... 27
Gambar 3.2 Dekripsi Tabel „fact_lengkap2‟ ... 28
Gambar 3.3 Data pada Tabel „fact_lengkap2‟ ... 29
Gambar 3.4 Gambar Data Akademik Mahasiswa ... 33
Gambar 3.5 Perhitungan jarak antar objek dengan rumus euclidean distance .... 34
Gambar 3.6 Pencarian jumlah tetangga dalam radius D dan penentuan outlier . 35 Gambar 3.7 Hasil Pencarian Outlier... 36
Gambar 4.1 Diagram Use Case ... 40
Gambar 4.2 Dekripsi Tabel pada Basisdata „data_mahasiswa‟ ... 42
Gambar 4.3 Dekripsi Tabel „fact_lengkap2‟ ... 42
Gambar 4.4 Data pada Tabel „fact_lengkap2‟ ... 43
Gambar 4.5 Proses Umum Sitem Pendeteksi Outlier Menggunakan Algoritma Naïve Nested Loop ... 51
Gambar 4.6 Diagram Konteks ... 52
Gambar 4.7 Diagram Kelas Analisis ... 54
Gambar 4.8 Ilustrasi Struktur Data Matriks Dua Dimensi ... 58
xx
Gambar 4.10 Ilustrasi Struktur Data Graf ... 59
Gambar 4.11 Diagram Kelas Desain ... 61
Gambar 4.12 Tampilan Halaman Awal ... 83
Gambar 4.13 Tampilan Halaman Awal (Bagian Preprocess) ... 85
Gambar 4.14 Tampilan Halaman Utama (Bagian Deteksi Outlier) ... 86
Gambar 4.15 Tampilan Halaman Pilih Database ... 87
Gambar 4.16 Tampilan Halaman Tampil Tabel ... 88
Gambar 4.17 Tampilan Halaman Distribusi Atribut ... 89
Gambar 4.18 Tampilan Halaman Konfirmasi Keluar ... 90
Gambar 4.19 Tampilan Halaman Bantuan ... 91
Gambar 5.1 Antarmuka Halaman Awal ... 93
Gambar 5.2 Antarmuka Halaman Utama (tabbed pane Preprocess) ... 94
Gambar 5.3 Antarmuka Halaman Utama (tabbed pane Deteksi Outlier) ... 94
Gambar 5.4 Kotak Dialog Saat Memilih File .xls ... 95
Gambar 5.5 Antarmuka Halaman Utama (data file .xls tertampil) ... 95
Gambar 5.6 Kotak Dialog Saat Memilih File .csv ... 96
Gambar 5.7 Antarmuka Halaman Utama (data file .csv tertampil) ... 96
Gambar 5.8 Antarmuka Halaman Utama (sebelum dilakukan fungsi Seleksi Atribut) ... 97
Gambar 5.9 Antarmuka Detail Fungsi Seleksi Atribut (pada Halaman Utama) . 98 Gambar 5.10 Antarmuka Halaman Utama (setelah dilakukan fungsi Seleksi Atribut) ... 98
Gambar 5.11 Antarmuka Halaman Utama (tabbed pane Deteksi Outlier) ... 99
Gambar 5.12 Kotak Dialog Simpan Hasil Outlier ... 100
Gambar 5.13 Pesan Ketika Proses Penyimpanan Hasil Outlier Berhasil Dilakukan ... 100
Gambar 5.14 Antarmuka Halaman Distribusi Atribut ... 101
Gambar 5.15 Antarmuka Grafik Distribusi Atribut ... 102
xxi
Gambar 5.17 Antarmuka Halaman Pilih Database (Setelah pengguna memilih
basisdata) ... 103
Gambar 5.18 Pesan Koneksi Berhasil ... 104
Gambar 5.19 Antarmuka Halaman Tampil Tabel ... 104
Gambar 5.20 Antarmuka Halaman Utama Beserta Data dari Tabel dalam Basisdata ... 105
Gambar 5.21 Antarmuka Halaman Bantuan ... 106
Gambar 5.22 Antarmuka Halaman Missing Values ... 107
Gambar 5.23 Antarmuka Halaman Konfirmasi Keluar ... 107
Gambar 5.24 Pesan Berhasil Keluar dari Sistem ... 108
Gambar 5.25 Pesan Kesalahan (1) ... 108
Gambar 5.26 Pesan Kesalahan (2) ... 109
Gambar 5.27 Pesan Kesalahan (3) ... 109
Gambar 5.28 Pesan Kesalahan (4) ... 110
Gambar 5.29 Pesan Kesalahan (5) ... 110
Gambar 5.30 Pesan Kesalahan (6) ... 111
Gambar 5.31 Pesan Kesalahan (7) ... 111
Gambar 5.32 Pesan Kesalahan (8) ... 111
Gambar 5.33 Pesan Kesalahan (9) ... 112
Gambar 6.1a Grafik Jumlah Outlier Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1 dengan Nilai M = 1 dan dmin berubah-ubah ... 156
Gambar 6.1b Grafik Jumlah Outlier Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1 dengan Nilai M = 2 dan dmin berubah-ubah ... 156
Gambar 6.2a Grafik Jumlah Outlier Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1 dengan Nilai M berubah-ubah dan dmin = 1 ... 156
Gambar 6.2b Grafik Hasil Outlier Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Masuk Semester 1 dengan Nilai M berubah-ubah dan dmin = 2 ... 156
Gambar 6.3a Grafik Jumlah Outlier Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Prestasi Semester 1 dengan Nilai M = 2 dan dmin berubah-ubah ... 157
Gambar 6.3b Grafik Jumlah Outlier Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Prestasi Semester 1 dengan Nilai M = 3 dan dmin berubah-ubah ... 157
xxii
xxiii
DAFTAR LISTING PROGRAM
Listing Program 5.1 Kelas DatabaseConnection.java ... 114 Listing Program 5.2 Kelas Graph_NaiveNL.java ... 116 Listing Program 5.3 Kelas CheckBoxTableModel.java ... 118 Listing Program 5.4 Kelas DatabaseController.java ... 120 Listing Program 5.5 Kelas DiagramBatang.java ... 121 Listing Program 5.6 Kelas HalamanUtama.java... 122 Listing Program 5.7 Kelas HalamanDistribusiAtribut.java ... 135 Listing Program 5.8 Kelas HalamanPilihDatabase.java ... 138 Listing Program 5.9 Kelas HalamanTampilTabel.java. ... 141 Listing Program 5.10 Kelas Vertex_NaiveNL.java ... 143 Listing Program 5.11 Implementasi Pembentukan Matriks Dua Dimensi ... 145 Listing Program 5.12 Method addVertex ... 145 Listing Program 5.13 Method addEdge ... 146 Listing Program 5.14 Method euclideanDistance ... 146
1 BAB I PENDAHULUAN 1.1 Latar Belakang
Data merupakan sesuatu yang belum mempunyai arti bagi penerimanya dan masih memerlukan adanya suatu pengolahan. Data bisa berwujud suatu keadaan, gambar, suara, huruf, angka, bahasa ataupun simbol-simbol lainnya yang bisa kita gunakan sebagai bahan untuk melihat lingkungan, obyek, kejadian ataupun menemukan suatu konsep dan pengetahuan baru. Perkembangan teknologi informasi memungkinkan kita untuk menyimpan data dalam jumlah yang besar tetapi dari sekumpulan data tersebut belum tentu kita mengetahui informasi yang tersembunyi di dalamnya.
Penambangan data adalah ekstraksi pola yang menarik dari data dalam jumlah besar. Suatu pola dikatakan menarik apabila pola tersebut tidak sepele, implisit, tidak diketahui sebelumnya, dan berguna. Penambangan data merupakan salah satu dari rangkaian KDD (Knowledge Discovery in Databases). Tahapan proses dalam KDD adalah pembersihan data, integrasi data, pemilihan data, transformasi data, evaluasi pola, dan penyajian pola (Han & Kamber 2006). Setelah tahap preprocessing, data dapat diolah dengan berbagai teknik dalam penambangan data untuk menemukan asosiasi, klasifikasi, clustering (pengelompokan), maupun untuk mendeteksi adanya outlier.
perilaku langka seperti penipuan menggunakan kartu kredit, deteksi penyusupan pada jaringan komunikasi, diagnosa medis, dan lain-lain. Outlier sendiri merupakan sebuah data pada sekumpulan data yang sangat berbeda dibandingkan dengan sifat umum dari sekumpulan data lainnya. Pendeteksian outlier berusaha untuk mengenali data yang langka tersebut karena kemungkinan memiliki informasi yang bermanfaat.
Banyak cara yang digunakan untuk mendeteksi outlier dengan pendekatan penambangan data antara lain metode grafis, metode statistik, metode distance based, metode density based, dan metode deviation based. Pendekatan distance based merupakan sebuah metode pencarian outlier yang populer dengan menghitung jarak pada objek tetangga terdekat. Dalam pendekatan ini, satu objek melihat objek-objek lain dalam lokal ketetanggaannya. Apabila ketetanggaannya relatif dekat maka dikatakan sebagai objek normal, akan tetapi jika ketetanggaan antar objek relatif sangat jauh maka dikatakan objek tersebut tidak normal.
Pendekatan distance based menyediakan beberapa algoritma pencarian outlier, salah satunya adalah algoritma Naïve Nested Loop. Algoritma Naïve Nested Loop mencari tetangga dari masing-masing objek dalam radius jarak yang ditentukan di sekitar objek tersebut.
untuk mencari mahasiswa dengan permasalahan pembelajarannya. Data yang digunakan adalah data mahasiswa dan memakai pendekatan distance based dan density based. Hasil yang diperoleh berupa pengetahuan mengenai outlier yang menggambarkan kejadian langka, contohnya beberapa outlier adalah mahasiswa dengan nilai indeks prestasi tinggi namun terletak pada kumpulan yang berbeda dengan kebanyakan mahasiswa lain yang juga memiliki indeks prestasi tinggi. Maka pada penelitian ini akan dilakukan pendeteksian outlier menggunakan algoritma Naïve Nested Loop pada kumpulan data mahasiswa Universitas Sanata Dharma, Yogyakarta. Data tersebut diperoleh dari gudang data akademik mahasiswa Universitas Sanata Dharma, Yogyakarta hasil penelitian Rosa, dkk (2013). Data mahasiswa terdiri atas data nilai hasil seleksi masuk dan data indeks prestasi selama empat semester pertama dan pendeteksian outlier dilakukan untuk melihat mahasiswa mana saja yang menjadi anggota outlier pada setiap semesternya. Hasil penelitian diharapkan dapat memberikan pengetahuan baru pada bidang pendidikan untuk melihat kejadian langka dari data akademik mahasiswa. Setelah menemukan outlier dari sekumpulan data akademik tersebut, selanjutnya hasil outlier akan dianalisa.
1.2 Rumusan Masalah
Berdasarkan latar belakang di atas, rumusan masalah yang diidentifikasi adalah :
1.3 Batasan Masalah
Batasan masalah pada penelitian ini adalah sebagai berikut :
1. Penggunaan algoritma Naïve Nested Loop yang digunakan sebagai sarana untuk mendeteksi outlier pada kumpulan data numerik nilai hasil seleksi masuk dan nilai indeks prestasi semester satu sampai empat mahasiswa Teknik Informatika Universitas Sanata Dharma, Yogyakarta. 2. Data yang digunakan adalah kumpulan data numerik nilai hasil seleksi masuk dan nilai indeks prestasi semester satu sampai empat mahasiswa Teknik Informatika Universitas Sanata Dharma, Yogyakarta tahun angkatan 2007 dan 2008. Nilai hasil seleksi masuk terdiri dari dua macam yaitu nilai hasil penerimaan mahasiswa yang masuk melalui jalur prestasi dan tes tertulis. Untuk mahasiswa yang menempuh jalur prestasi, nilai terdiri dari nilai kognitif rapor SMA yang telah dihitung rata-ratanya. Sedangkan untuk mahasiswa yang menempuh jalur masuk tes tertulis, nilai tes terdiri dari nilai penalaran numerik, nilai penalaran verbal, nilai hubungan ruang, nilai bahasa Inggris, dan nilai kemampuan numerik.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah sebagai berikut :
prestasi semester satu sampai empat mahasiswa Teknik Informatika Universitas Sanata Dharma, Yogyakarta.
2. Menganalisis hasil deteksi outlier pada kumpulan data numerik nilai hasil seleksi masuk dan nilai indeks prestasi semester satu sampai empat mahasiswa Teknik Informatika Universitas Sanata Dharma, Yogyakarta.
1.5 Luaran
Sebuah sistem berbasis teknologi informasi yang mampu mendeteksi outlier pada sekumpulan data numerik nilai hasil seleksi masuk dan nilai indeks prestasi semester satu sampai empat mahasiswa Teknik Informatika Universitas Sanata Dharma, Yogyakarta menggunakan algoritma Naïve Nested Loop.
1.6 Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut :
3. Penelitian ini dapat memberikan pengetahuan baru kepada pembaca mengenai kemungkinan adanya kejadian langka pada data nilai seleksi masuk dan nilai indeks prestasi semester mahasiswa Teknik Informatika Universitas Sanata Dharma, Yogyakarta.
1.7 Metodologi Penelitian
Dalam penyelesaian tugas akhir ini, langkah-langkah kerja yang akan ditempuh adalah sebagai berikut :
1. Studi Pustaka
Studi pustaka, yaitu salah satu metode penelitian yang dilakukan dengan cara mempelajari hal-hal yang berkaitan dengan deteksi outlier menggunakan algoritma Naïve Nested Loop dan mengumpulkan informasi yang didapat dari buku, artikel, karya ilmiah, dan website internet.
2. Teknik Penambangan Data
Metodologi kedua dilakukan dengan menggunakan teknik penambangan data yang langkah-langkahnya seperti di bawah ini (Han & Kamber 2006):
a. Penggabungan Data ( Data Integration )
Proses menggabungkan data dari beberapa sumber agar data dapat terangkum ke dalam tempat penyimpanan / satu tabel yang utuh. b. Seleksi Data ( Data Selection )
dihilangkan karena atribut yang diperlukan adalah atribut yang saling bergantung.
c. Transformasi Data (Data Transformation)
Pada proses ini, data yang sudah diseleksi selanjutnya ditransformasikan ke dalam bentuk yang sesuai untuk ditambang. d. Penambangan Data ( Data Mining )
Proses mengaplikasikan metode yang tepat untuk mendapatkan pola pada suatu kumpulan data. Dalam penelitian ini, metode yang digunakan adalah metode analisis outlier dengan menggunakan pendekatan distance based. Algoritma yang digunakan untuk mendeteksi outlier adalah algoritma Naïve Nested Loop.
e. Evaluasi Pola ( Pattern Evaluation )
Tahap ini merupakan bagian dari proses pencarian pengetahuan yang mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya.
f. Presentasi Pengetahuan ( Knowledge Presentation )
Pada tahap ini pola yang telah didapat selanjutnya direpresentasikan kepada pengguna ke dalam bentuk yang lebih mudah untuk dipahami.
1.8 Sistematika Penulisan
- BAB I PENDAHULUAN
Bab ini menjelaskan latar belakang peneltian, rumusan masalah yang digunakan sebagai acuan, batasan-batasan masalah, tujuan penelitian, luaran, manfaat, metodologi penelitian dan sistematika penulisan.
- BAB II LANDASAN TEORI
Bab ini menjelaskan dasar-dasar teori yang digunakan sebagai referensi dan acuan dalam penulisan Tugas Akhir, meliputi : pengertian penambangan data, pengertian tentang analisis outlier, hubungan outlier dengan penambangan data, teori-teori yang digunakan untuk penentuan outlier dalam berbagai pendekatan, rangkaian proses KDD (Knowledge Discovery in Databases) kaitannya dengan penambangan data, dan algoritma pedeteksi outlier yaitu, Naïve Nested Loop.
- BAB III METODOLOGI PENELITIAN
Bab ini menjelaskan mengenai metode yang dipakai dalam penelitian dan pembuatan aplikasi sebagai implementasi. Juga disebutkan pengertian dan hal-hal yang terkait dengan metode yang dipakai tersebut. - BAB IV ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi tentang indentifikasi sistem, pemrosesan data awal, input, proses, dan output, perancangan sistem, perancangan struktur data serta perancangan antarmuka yang akan dibuat.
Bab ini dapat berisi mengenai listing program dari hasil implementasi yang telah dibuat beserta penjelasan singkat dan output hasil dari implementasi tersebut.
- BAB VI PENGUJIAN DAN ANALISIS HASIL PENGUJIAN
Bab ini berisi tentang pembahasan pengujian program dan analisis dari hasil pengujian program yang telah diimplementasikan.
- BAB VII KESIMPULAN DAN SARAN
10 BAB II
LANDASAN TEORI
Pada bab ini akan dipaparkan pengertian penambangan data, pengertian tentang analisis outlier, hubungan outlier dengan penambangan data, teori-teori yang digunakan untuk penentuan outlier dalam berbagai pendekatan. Dibahas pula serangkaian proses KDD (Knowledge Discovery in Databases) kaitannya dengan penambangan data. Teori penentuan outlier yang dipaparkan akan secara khusus membahas algoritma pedeteksi outlier Distance-Based, khususnya algoritma Naïve Nested Loop.
2.1 Penambangan Data 2.1.1 Definisi
Definisi umum dari penambangan data adalah serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data (Iko, 2007). Penambangan data mengekstraksi pola yang menarik dari data dalam jumlah besar. Suatu pola dikatakan menarik apabila pola tersebut tidak sepele, implisit, tidak diketahui sebelumnya, dan berguna.
2.1.2 Permasalahan dalam Penambangan Data
Dengan diperolehnya informasi-informasi yang berguna dari data-data yang ada, hubungan antar item dalam transaksi maupun informasi potensial lain yang ada di dalamnya dapat diekstrak dan dianalisa serta diteliti secara lebih lanjut dari berbagai sudut pandang.
Permasalahan dalam penambangan data dilatarbelakangi oleh kondisi dimana data ada pada jumlah yang sangat besar sehingga menimbulkan ledakan informasi yang dialami oleh perusahaan, institusi atau organisasi. Kondisi data dalam jumlah yang besar tersebut merupakan salah satu akumulasi dari data yang terekam bertahun-tahun dalam suatu transaksi. Peranan penambangan data dibutuhkan dalam menangani ledakan volume data, dengan menggunakan teknik penambangan data yang dapat digunakan untuk menghasilkan informasi tertentu yang dibutuhkan dari kumpulan data tersebut.
2.1.3 Fungsionalitas Penambangan Data
Berikut fungsionalitas dan tipe pola yang dapat ditemukan dengan penambangan data (Han & Kamber,2006) :
a. Deskripsi konsep / kelas : Karaterisasi dan diskriminasi
atau diskriminasi data dengan membandingkan target kelas dengan satu atau lebih kelas lain.
b. Analisis Asosiasi (Korelasi dan kausalitas)
Analisis asosiasi adalah pencarian aturan-aturan asosiasi yang menunjukkan kondisi-kondisi nilai atribut yang sering terjadi bersama-sama dalam sekumpulan data. Analisis asosiasi sering digunakan untuk menganalisa data transaksi.
c. Klasifikasi dan Prediksi
Klasifikasi adalah proses menemukan model atau fungsi yang menjelaskan dan membedakan kelas-kelas atau konsep, dengan tujuan agar model yang diperoleh dapat digunakan untuk memprediksi kelas atau objek yang memiliki label kelas yang tidak diketahui. Model yang diturunkan didasarkan pada analisis dari data training (objek data yang memiliki label kelas yang diketahui). Model yang diturunkan dapat direpresentasikan dalam berbagai bentuk seperti aturan IF-THEN klasifikasi, pohon keputusan, formula ,matematika atau jaringan syaraf tiruan.
d. Analisis Klaster
clustering adalah memaksimalkan kemiripan intra-class dan meminimumkan kemiripan inter-class. Clustering sering disebut segmentasi data karena clustering mempartisi data yang besar ke dalam grup sesuai dengan kesamaannya. Clustering dapat digunakan untuk deteksi outlier, dimana outlier adalah suatu nilai yang jauh dari semua klaster lain.
e. Analisis Outlier
Database dapat mengandung objek data yang tidak sesuai dengan sifat umum atau model data. Objek data tersebut adalah outlier. Outlier merupakan objek data yang tidak mengikuti perilaku umum dari data. Outlier dapat dianggap sebagai pengecualian atau noise. Analisis data outlier dinamakan outlier mining. Teknik ini berguna untuk fraud detection (deteksi penipuan) dan rare events analysis (analisis kejadian langka). Outlier dapat dideteksi dengan menggunakan tes statistik yang mengasumsikan distribusi atau probabilitas model data menggunakan distance measures, dimana objek yang memiliki jarak yang jauh dari klaster-klaster lainnya dianggap outlier atau anomali.
f. Analisis Trend dan Evolusi
2.2 Knowledge Discovery in Databases (KDD) 2.2.1 Kaitan Penambangan Data dengan KDD
Penambangan data merupakan salah satu dari rangkaian Knowledge Discovery in Database (KDD) yang umumnya meliputi data preprocessing, data mining, dan post processing (Han & Kamber, 2006). Knowledge Discovery in Databases berhubungan dengan teknik integrasi dan penemuan ilmiah, interpretasi dan visualisasi dari pola-pola pada sejumlah data.
2.2.2 Tahapan dalam Knowledge Discovery in Databases (KDD)
Berikut ini merupakan serangkaian proses yang dalam tahapan KDD (Tan, 2005):
1. Pembersihan data dan integritas data (Cleaning & Integration)
Proses ini digunakan untuk menghilangkan data yang tidak konsisten dan bersifat noise dari data yang terdapat di berbagai basisdata yang mungkin berbeda format maupun platform yang kemudian diintegrasikan dalam satu tempat penyimpanan yang utuh.
2. Seleksi dan transformasi data (Selection and Transformation)
Data yang ada dalam basisdata kemudian direduksi untuk mendapatkan hasil yang akurat. Beberapa cara seleksi, antara lain:
Sampling, adalah seleksi subset yang mewakili suatu sifat populasi
data yang besar
Denoising, adalah proses menghilangkan noise dari data yang akan
Feature extraction, adalah proses mengekstraksi spesifikasi data yang
sesuai dengan konteks tertentu.
Transformasi data diperlukan sebagai tahap pre-processing agar data siap untuk ditambang.
3. Penambangan data (Data Mining)
Data yang telah ditransformasi, kemudian ditambang dengan berbagai teknik. Proses penambangan data adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan fungsi-fungsi tertentu. Fungsi atau algoritma dalam data mining sangat bervariasi, dimana pemilihannya bergantung pada tujuan dan proses pencarian pengetahuan secara menyeluruh.
4. Evaluasi pola dan presentasi pengetahuan
Gambar 2.1 Tahapan dalam Knowledge Discovery in Databases (Han & Kamber,2006)
2.3 Analisa Outlier 2.3.1 Definisi Outlier
Dalam analisis outlier terdapat dua masalah besar yaitu penentuan data apa yang dapat dipertimbangkan sebagai outlier dan menemukan metode yang efisien untuk menggali outlier yang ditetapkan.
2.3.2 Hubungan Antara Penambangan Data dengan Outlier
Kecanggihan dan kemungkinan otomatisasi algoritma penambangan data dibutuhkan untuk mendukung kinerja ilmuwan dan ahli statistika. Sekumpulan data yang ada dapat meningkat secara drastis, hal ini memperjelas bahwa perangkat penambangan data yang baik akan dibutuhkan untuk pemanfaatan data dalam kebutuhan strategi penelitian (Knoor,2002).
Walaupun secara tradisional ilmuwan mampu menyelesaikan pengolahan data dengan jumlah atribut yang sedikit secara efektif, namun ukuran kumpulan data dan jumlah dimensi dalam jumlah yang besar telah terbukti menjadi kunci penghambat pada analisis data (Han & Kamber, 2006). Salah satu permasalahan dalam penambangan data adalah identifikasi outlier secara efisien pada sekumpulan data yang memiliki lebih dari satu jumlah atribut. Permasalahan lain adalah jumlah informasi tambahan yang dapat disediakan oleh algoritma pendeteksi outlier.
persetujuan yang menyatakan seperti apakah ketentuan outlier yang bermakna (Knorr, 2002).
2.3.3 Penyebab Outlier
Outlier dapat disebabkan karena data berasal dari sumber yang berbeda, variasi alami dari data itu sendiri, dan kesalahan saat pengukuran atau eksekusi data. Adanya data outlier ini akan membuat analisis terhadap serangkaian data menjadi bias, atau tidak mencerminkan fenomena yang sebenarnya. Istilah outlier juga sering dikaitkan dengan nilai esktrem, baik ekstrem besar maupun ekstrem kecil. Sebagai ilustrasi, jika ada empat mahasiswa, mahasiswa pertama mempunyai uang saku per bulan Rp. 500 ribu, mahasiswa kedua Rp. 600 ribu, mahasiswa ketiga Rp. 700 ribu, dan mahasiswa keempat karena merupakan anak orang kaya, mempunyai uang saku per bulan sampai dengan Rp. 5 juta. Secara sekilas tampak bahwa nilai 5 juta relatif jauh dibandingkan uang saku ketiga mahasiswa yang lain.
2.3.4 Manfaat Outlier
2.3.5 Berbagai Macam Pendekatan Pendeteksi Outlier 1. Metode Grafis
Metode ini dilakukan dengan cara memotong data dengan observasi ke-i (i=1, 2, 3,…,n). Dalam beberapa software statistika, metode ini dilakukan dalam menu scatterplot. Dari plot tersebut, pencilan akan nampak memisahkan diri dari kumpulan sebagian besar data.
Gambar 2.2 Scatterplot dari data dan objek (Hatta, 2012)
Panah pada plot tersebut menunjuk pada data yang diduga menjadi outlier. Keuntungan dari metode ini adalah mudah dipahami (tanpa melibatkan perhitungan yang rumit) dan menarik karena menampilkan data secara grafis (gambar). Kelemahan metode ini adalah keputusan bahwa data tersebut termasuk pencilan atau tidak bergantung pada kebijakan (judgement) peneliti, karena hanya mengandalkan visualisasi grafis (Hatta, 2012).
2. Metode Statistik
tersebut dibuat fungsi threshold yang berpotensi untuk dinyatakan sebagai outlier.
Pendekatan distribusi statistik untuk deteksi outlier mengasumsikan model distribusi dan probabilitas untuk sekumpulan data (misalnya, distribusi normal atau Poisson) untuk selanjutnya mengidentifikasi outlier menggunakan model tes discordancy (kejanggalan). Pengujian membutuhkan pengetahuan dari parameter kumpulan data (seperti distribusi data), pengetahuan distribusi parameter (seperti rata-rata), dan perkiraan jumlah outlier.
3. Metode Distance-based
Objek data dikatakan sebagai outlier apabila objek tersebut memiliki objek tetangga yang sangat sedikit pada jarak tertentu dan memiliki jarak jauh dibandingkan dengan jarak rata-rata objek data tetangga terdekat.
Kelebihan dari Metode Distance-Based adalah pendekatannya yang cukup sederhana. Sedangkan, kekurangan Metode Distance-Based adalah
a. Untuk basisdata yang besar akan memakan biaya yang besar b. Sangat tergantung pada nilai parameter yang dipilih
c. Tidak dapat menangani kasus himpunan data yang memiliki kepadatan berbeda pada daerah yang berbeda
d. Waktu proses deteksi dan hasil deteksi kurang akurat dibandingkan dengan metode Density-Based (Handriyani et al., 2009)
4. Metode Density-Based
local neighborhood suatu objek. MinPts diasumsikan sebagai jangkauan dari nilai batas bawah dan batas atas parameter MinPts. Untuk selanjutnya semua objek dalam sekumpulan data akan dihitung nilai LOF-nya.
Objek data akan dianggap memiliki nilai outlier yang tinggi jika pada jarak k tetangga terdekat memiliki kepadatan yang sangat kecil. Semakin banyak objek – objek tetangga dalam jarak k-tetangga terdekat, objek ini memiliki nilai LOF mendekati 1 dan tidak seharusnya diberi label sebagai outlier.
Kelebihan Metode Density Based adalah dapat digunakan untuk data yang kepadatannya berbeda. Sedangkan, kekurangan Metode Density Based adalah :
a. Pemilihan parameter juga menjadi satu penentu yang kuat dalam menentukan nilai kepadatan
b. Tanpa LOF maka objek yang berada pada klaster yang berbeda dapat dianggap outlier
5. Metode Deviation Based
dari deskripsi tersebut akan dianggap sebagai outlier (Han & Kamber, 2006).
Terdapat dua teknik yang digunakan dalam pendekatan deviation based, yaitu
a. Teknik Sequential Exception, dengan mensimulasikan cara manusia membedakan objek yang berbeda dari sederetan objek normal
b. Teknik OLAP (OnLine Analysis Processing) data cube : menggunakan data cube untuk mengindentifikasi daerah-daerah outlier pada data multidimensional yang besar
Data preprocessing dalam deteksi outlier merupakan hal yang penting untuk diperhatikan karena data yang akan dihasilkan dalam deteksi outlier ini khusus pada kasus data berdimensi sangat tinggi. Reduksi dimensi merupakan satu hal yang sangat menarik untuk diteliti lebih lanjut.
2.4 Metode Pendeteksi Outlier dengan Pendekatan Distance-Based
dibalik pengujian discordancy (kejanggalan) untuk berbagai macam standar distribusi. Deteksi outlier berbasis jarak menghindari perhitungan yang berlebihan yang dapat dikaitkan dengan ketepatan distribusi yang diamati ke dalam beberapa distribusi standar dan dalam memilih pengujian discordancy (kejanggalan) (Han & Kamber, 2006).
Deteksi outlier berbasis jarak mengharuskan pengguna untuk mengatur kedua parameter pct dan dmin. Menemukan pengaturan yang cocok untuk parameter tersebut dapat melibatkan banyak percobaan dan kesalahan. Dalam penentuan parameter pct dan dmin keterlibatan pengguna diperlukan untuk mengubahnya secara berkelanjutan dalam menentukan outlier diberbagai variasi pengujian.
Terdapat tiga algoritma pendeteksi outlier dalam pendekatan Distance Based, yaitu algoritma index based, naïve nested loop, block-based nested loop dan cell based. Pada penelitian tugas akhir ini akan menggunakan algoritma naïve nested loop.
2.4.1 Algoritma Naïve Nested Loop
dihentikan saat jumlah tetangga objek o dalam radius dmin sudah mencapai M+1, selanjutnya beralih ke objek selanjutnya.
Dalam penelitian yang dilakukan oleh Knoor (2002) nilai M juga dinyatakan sebagai n(1-p), dimana n merupakan jumlah data, p atau disebut juga pct merupakan jumlah minimum objek yang terletak lebih jauh dari jarak o ke dmin.
Berikut merupakan cara kerja algoritma Naïve Nested Loop (Jian Pei, 2009) :
for j = 1 to n do - set countj = 0 ;
- for k=1 to n do if (dist(j,k)<D) then countj++ ; - if countj <= |n(1-p)| then output j as an outlier
26 BAB III
METODOLOGI PENELITIAN
Pada bab ini akan dipaparkan mengenai perancangan penelitian yang digunakan untuk mencapai tujuan dalam penelitian tugas akhir ini. Tujuan dari penelitian ini adalah menerapkan algoritma Naïve Nested Loop untuk mendeteksi outlier pada kumpulan data numerik hasil seleksi masuk mahasiswa dan nilai indeks prestasi semester satu sampai empat. Kemudian dilanjutkan dengan penjelasan mengenai pengolahan data, penyelesaian data yang ada dengan algoritma Naïve Nested Loop, analisis dan evaluasi hasil outlier yang diperoleh.
3.1 Data
Data akademik mahasiswa program studi Teknik Informatika angkatan 2007-2008 terdiri dari 126 buah. Mahasiswa tersebut telah diterima di Universitas Sanata Dharma melalui dua macam jalur seleksi masuk yaitu, jalur prestasi dan jalur tes tertulis.
3.2 Pengolahan Data
Berikut merupakan tahapan yang dilakukan dalam pengolahandata: 1. Penggabungan Data ( Data Integration )
Data yang telah terkumpul akan diolah ke dalam database, data mentah tersebut berbentuk skrip .sql sehingga diolah terlebih dahulu menggunakan perangkat lunak SQLyog agar diketahui data dan tabel apa saja yang ada dalam database tersebut. Setelah skrip dijalankan melalui SQLyog , diketahui bahwa gudang data yang digunakan
bernama “data_mahasiswa” dan terdiri dari tabel dim_angkatan,
dim_daftarsmu, dim_fakultas, dim_jeniskel, dim_kabupaten, dim_prodi, dim_prodifaks, dim_statustes, dan fact_lengkap2.
Gambar 3.1 Dekripsi Tabel pada Gudang Data ‘data_mahasiswa’
Setelah dilakukan proses penggabungan data tabel dalam gudang
data „data_mahasiswa‟. Selanjutnya dilakukan seleksi data untuk
mengambil data dalam tabel „fact_lengkap2‟ karena dalam tabel inilah memuat atribut nilai hasil seleksi tes masuk dan nilai indeks prestasi semester satu hingga empat disimpan. Sedangkan tabel-tabel selain
„fact_lengkap2‟ tidak digunakan.
Gambar 3.2 Dekripsi Tabel ‘fact_lengkap2’
Pada tabel „fact_lengkap2‟ terdiri atas data akademik mahasiswa
Gambar 3.3 Data pada Tabel ‘fact_lengkap2’
3. Transformasi Data (Data Transformation)
Pada proses ini, data yang sudah diseleksi untuk selanjutnya ditransformasikan ke dalam bentuk yang sesuai untuk ditambang. Data ditransformasikan dengan metode normalisasi. Dalam tahap ini, diketahui bahwa atribut yang akan digunakan dalam perhitungan deteksi outlier adalah ips1, ips2, ips3, ips4, nil11, nil12, nil13, nil14, nil15, dan final. Jangkauan nilai atribut ips1, ips2, ips3,dan ips4 adalah 0.00 sampai dengan 4.00. Sedangkan untuk jangkauan nilai atribut nil11, nil12, nil13, nil14, dan nil15 adalah 0 sampai 10. Sementara itu, jangkauan nilai final adalah 0 sampai 100. Sehingga perlu dilakukan normalisasi data untuk menyamaratakan persebaran nilai keseluruhan atribut dengan menggunakan rumus min-max normalization :
Tahapan normalisasi data untuk atribut nil11, nil12, nil13, nil14, nil15, dan final dilakukan untuk menyamakan jangkauan nilai terhadap
atribut ips1, ips2, ips3, ips4. Sehingga pada saat perhitungan deteksi outlier persebaran nilai atribut hanya berkisar antara 0.00 sampai 4.00.
Proses normalisasi data berikut ini berlaku untuk atribut nil11, nil12, nil13, nil14, dan nil15 menggunakan min-max normalization, semisal nil11 adalah 7.00 maka proses normalisasinya adalah :
maxA = 10, minA= 0, new_maxA = 4, new_minA= 0, dan v = nil11
dalam hal ini bernilai 7.00 , sehingga proses perhitungannya v1 = (7-0)/(10-0)*(4-0)+0 = 7/10*4 = 2.80. Sehingga hasil normalisasi nil11 yang awalnya bernilai 7.00 sekarang menjadi 2.80.
Berikutnya adalah proses normalisasi data berikut berlaku untuk atribut final menggunakan min-max normalization, semisal nilai final adalah 61.00 maka proses normalisasinya adalah :
maxA = 100, minA= 0, new_maxA = 4, new_minA= 0, dan v = final
dalam hal ini bernilai 61.00 , sehingga proses perhitungannya v1= (61-0)/(100-0)*(4-0)+0 = 61/100*4 = 2.44. Sehingga hasil normalisasi nilai final yang awalnya bernilai 61.00 sekarang menjadi 2.44.
Setelah nilai atribut nil11, nil12, nil13, nil14, nil15, dan final di normalisasikan dalam kisaran nilai 0.00 - 4.00 maka nilai yang sudah dinormalisasikan inilah yang nantinya akan digunakan sebagai input dalam proses deteksi outlier.
4. Penambangan Data ( Data Mining )
Teknik Informatika, Universitas Sanata Dharma tahun angkatan 2007 dan 2008 selama empat semester. Pada tahap ini, akan ditentukan pula input dan output yang akan digunakan untuk menambang data, antara lain sebagai berikut :
1. Input terdiri dari :
a. Nilai hasil seleksi masuk mahasiswa, baik mahasiswa yang menempuh jalur prestasi maupun jalur tes tertulis. Masukan tersebut diperoleh dari atribut yang ada pada tabel
„fact_lengkap2‟ yaitu nil11, nil12, nil13, nil14, nil15, dan final. Atribut nil11, nil12, nil13, nil14, dan nil15 hanya dimiliki oleh mahasiswa yang masuk melalui jalur tes tertulis. Sedangkan atribut final dimiliki oleh mahasiswa yang masuk melalui jalur tes tertulis maupun jalur prestasi.
b. Indeks prestasi mahasiswa dari semester satu hingga empat. Masukan tersebut diperoleh dari atribut yang ada pada tabel
„fact_lengkap2‟ yaitu ips1, ips2, ips3, dan ips4.
2. Output, yaitu data mahasiswa yang menjadi outlier dari perhitungan yang diambil dari data numerik nilai hasil seleksi masuk dan nilai indeks prestasi selama empat semester.
5. Evaluasi Pola ( Pattern Evaluation )
sebelumnya. Melalui sistem pendeteksi outlier akan diperoleh luaran berupa data-data outlier menggunakan algoritma Naïve Nested Loop dan dianalisa kembali oleh pemilik data itu apakah hipotesa outlier yang mereka miliki sama atau tidak dengan hasil yang diperoleh sistem, sehingga dapat diketahui seperti apa tingkat keberhasilan pencarian outlier tersebut.
6. Presentasi Pengetahuan ( Knowledge Presentation )
Pada tahap ini pola yang telah didapat selanjutnya direpresentasikan kepada pengguna ke dalam bentuk sistem pendeteksi dengan antarmuka yang lebih mudah untuk dipahami. Melalui sistem pendeteksi outlier ini diharapkan pengguna dalam hal ini pihak internal Universitas Sanata Dharma dapat mencari tahu data-data yang bersifat langka dan berbeda dari kebanyakan data lainnya untuk selanjutnya dianalisa mengapa data-data tersebut bisa muncul. Tidak bisa dipungkiri bahwa outlier sendiri akan didefinisikan dan dianalisa oleh orang yang ahli dan mengerti tentang data itu.
3.3 Contoh Implementasi Deteksi Outlier dengan Algoritma Index Based Setelah melalui proses pengumpulan dan pengolahan data, pada tahap ini akan dilakukan perhitungan menggunakan algoritma Naïve Nested Loop kemudian melihat hasil outlier pada sekumpulan data mahasiswa tersebut.
1. Pencarian outlier akan dilakukan pada sekumpulan data mahasiswa yang masuk melalui jalur tes tertulis. Dalam hal ini adalah data akademik mahasiswa program studi teknik informatika tahun angkatan 2007. Atribut yang akan digunakan terdiri dari ips1, ips2, ips3, ips4, nil11, nil12, nil13, nil14, nil15. Sehingga akan dilihat kaitan nilai tes masuk dengan nilai indeks prestasi dari semester satu sampai 4 dan akan dicari mahasiswa dengan pola apa saja yang akan masuk sebagai outlier.
Gambar 3.4 Data Akademik Mahasiswa
Sehingga diperoleh jarak satu objek dengan objek yang lainnya dan perhitungan jarak memakai iterasi sebanyak tiga belas kali. Atribut yang dimasukkan ke dalam perhitungan jarak ini adalah atribut nil11, nil12, nil13, nil14, nil15, ips1, ips2, ips3, dan ips4. Nilai tes masuk dikaitankan dengan nilai indeks prestasi masing-masing semester sehingga perhitungan jarak dengan atribut ips1 dilakukan pada perhitungan semester 1, sampai atribut ips4 pada perhitungan semester 4.
Gambar 3.5 Perhitungan jarak antar objek dengan rumus euclidean distance
3. Selanjutnya menentukan nilai dmin dan nilai M. Di mana dmin adalah radius atau jarak maksimum ketetanggaan antar objek o. Sedangkan M merupakan jumlah maksimum tetangga objek dalam radius dmin. Dalam kasus ini nilai dmin adalah 2 dan M adalah 4. Satu per satu objek mahasiswa akan dicari jumlah tetangganya dalam radius dmin
jika jarak kedua objek tersebut ≤ 2 dan jumlah tetangganya sudah
mahasiswa selanjutnya. Dalam simulasi ini dilakukan perhitungan jumlah tetangga hingga objek terakhir untuk memastikan jumlah total tetangga pada masing-masing objek mahasiswa.
Pada iterasi 1 dilakukan pengecekan jarak pada data mahasiswa pertama terhadap keduabelas data mahasiswa lainnya. Dan diperoleh jumlah tetangga dalam radius dmin sebanyak 2 tetangga karena jumlah tetangga mahasiswa pertama lebih dari M, yaitu 9 maka dapat disimpulkan mahasiswa pertama bukan outlier. Perhitungan serupa dilakukan hingga data ke-13 dan berakhir pada iterasi 13 berlaku untuk perhitungan jarak menggunakan atribut ips1, ips2, ips3, dan ips4.
Gambar 3.6 Pencarian jumlah tetangga dalam radius D dan penentuan outlier
Gambar 3.7 Hasil Pencarian Outlier
37 BAB IV
ANALISIS DAN PERANCANGAN SISTEM
Pada bab ini akan dipaparkan mengenai analisa dan perancangan sistem. Analisa sistem dimulai dari idenfitikasi sistem yang akan dibuat, berlanjut pada pemrosesan data awal yang akan digunakan dalam penelitian lalu pembahasan mengenai input, proses, dan output sistem. Selain itu akan dipaparkan pula perancangan sistem yang terdiri dari perancangan struktur data, pembuatan diagram usecase, diagram kelas, diagram aktivitas, atribut dan method yang akan dipakai, model analisis, dan perancangan antar muka.
4.1 Identifikasi Sistem
hubungan ruang, nilai bahasa Inggris, dan nilai kemampuan numerik. Calon mahasiswa yang masuk melalui jalur tes tertulis juga akan memiliki nilai final berdasarkan rata-rata lima komponen tes tersebut. Nilai final ini juga digunakan sebagai pertimbangan calon mahasiswa tersebut diterima atau tidak sebagai mahasiswa Universitas Sanata Dharma.
Calon mahasiswa yang berhasil lolos seleksi penerimaan mahasiswa baru baik yang melalui jalur prestasi maupun jalur tes tertulis akan menjadi mahasiswa yang harus mengikuti kegiatan perkuliahan dan setiap semesternya akan memperoleh nilai indeks prestasi sebagai kalkulasi dari prestasi akademiknya. Namun, akan muncul pertanyaan apakah nilai indeks prestasi mahasiswa yang tinggi juga dipengaruhi oleh nilai hasil seleksi masuk yang tinggi pula atau apakah ada mahasiswa yang memiliki nilai indeks prestasi rendah tetapi nilai hasil seleksi masuknya tinggi. Hal ini menjadi sesuatu yang menarik untuk dicari kejadian langkanya atau dalam hal ini berkaitan dengan deteksi outlier. Dari nilai hasil seleksi masuk dan nilai indeks prestasi selama empat semester diharapkan dapat digunakan sebagai bahan untuk melihat kejadian langka pada data akademik mahasiswa.
4.1.1 Diagram Use Case
Sebuah sistem membutuhkan pengguna sebagai pelaku utama untuk melakukan aksinya supaya sistem dapat menjalankan fungsi yang sesuai dengan keinginan pengguna tersebut. Diagram use case berikut menggambarkan interaksi terdapat pada Sistem Pendeteksi Outlier Menggunakan Algoritma Naïve Nested Loop ini. Pelaku utama dari sistem ini hanya satu yaitu pengguna.
Terdapat tiga fungsi utama yang dapat dijalankan oleh pengguna yaitu fungsi input data, fungsi pendeteksian outlier , dan fungsi simpan hasil deteksi outlier. Ketiga fungsi tersebut saling berkaitan sehingga dalam menjalankan fungsi ini pengguna harus melakukannya secara beurutan. Pada fungsi input data, pengguna dapat memasukan berbagai jenis data yang akan diproses dalam deteksi outlier yaitu data berformat .xls , .csv , dan data yang berasal dari tabel dalam basisdata. Fungsi berikutnya adalah fungsi deteksi outlier terhadap data yang telah dimasukkan oleh pengguna. Dalam fungsi ini pengguna memasukan dua nilai paramater input yaitu M dan dmin. M adalah jumlah maksimum objek dalam ketetanggaan dmin dari sebuah outlier dan dmin adalah radius atau jarak maksimum ketetanggaan antar objek o. Setelah itu sistem akan menampilkan hasil deteksi outlier dan selanjutnya pengguna dapat menyimpan hasil tersebut ke dalam file yang berformat .txt atau .doc.
dan fungsi lihat grafik distribusi per atribut. Kedua fungsi ini hanya dapat dilakukan jika pengguna sudah memasukan input data. Fungsi seleksi atribut merupakan fungsi yang disediakan sistem jika pengguna akan menghapus beberapa atribut yang tidak dipakai dalam perhitungan deteksi outlier. Sedangkan fungsi lihat grafik distribusi per atribut dilakukan apabila pengguna ingin melihat distribusi data yang ada dalam satu atribut dalam bentuk diagram batang.
Diagram use case untuk sistem pendeteksi outlier menggunakan algoritma Naïve Nested Loop dapat dilihat pada gambar di bawah ini sedangkan deskripsinya dapat dilihat pada lampiran 1:
Gambar 4.1 Diagram Use Case Input data file .xls, csv
atau tabel basisdata
Deteksi outlier Pengguna
<<depends on>>
Simpan hasil deteksi outlier <<depends on>>
Seleksi atribut <<extends >>
Lihat grafik distribusi per
4.1.2 Narasi Use Case
Untuk detil narasi secara keseluruhan dari setiap use case dapat dilihat pada lampiran dalam tugas akhir ini pada lampiran 2.
4.2 Perancangan Sistem Secara Umum 4.2.1 Pemrosesan Data Awal
Dalam penelitian tugas akhir ini akan dipakai data numerik nilai hasil seleksi masuk mahasiswa dan nilai indeks prestasi semester satu hingga empat dari mahasiswa Teknik Informatika Universitas Sanata Dharma Yogyakarta tahun angkatan 2007 dan 2008. Data diperoleh dari gudang data akademik mahasiswa Universitas Sanata Dharma hasil penelitian Rosa, dkk (2013) dalam bentuk skrip kueri .sql.
Berikut merupakan tahapan yang dilakukan dalam pengolahan data: 1. Penggabungan Data ( Data Integration )
Data yang telah terkumpul akan diolah ke dalam database, data mentah tersebut berbentuk skrip .sql sehingga diolah terlebih dahulu menggunakan perangkat lunak SQLyog agar diketahui data dan tabel apa saja yang ada dalam database tersebut.Setelah skrip dijalankan melalui SQLyog , diketahui bahwa gudang data yang
digunakan bernama “data_mahasiswa” dan terdiri dari tabel
Gambar 4.2 Dekripsi Tabel pada Basisdata ‘data_mahasiswa’
2. Seleksi Data ( Data Selection )
Setelah dilakukan proses penggabungan data tabel dalam gudang data „data_mahasiswa‟. Selanjutnya dilakukan seleksi data untuk
mengambil data dalam tabel „fact_lengkap2‟ karena dalam tabel
inilah memuat atribut nilai hasil seleksi tes masuk dan nilai indeks prestasi semester satu hingga empat disimpan. Sedangkan
tabel-tabel selain „fact_lengkap2‟ tidak digunakan.
Pada tabel „fact_lengkap2‟ terdiri atas data akademik mahasiswa
diseluruh program studi , sedangkan dalam penelitian ini hanya akan memakai data mahasiswa prodi Teknik Informatika angkatan 2007 dan 2008. Atribut yang tidak dipakai adalah nomor, jumsttb, jummsttb, jumnem, jummtnem, sttb, sk_jeniskelamin, sk_status, sk_kabupaten, sk_daftarsmu, sk_prodi.
Gambar 4.4 Data pada Tabel ‘fact_lengkap2’
3. Transformasi Data (Data Transformation)
perlu dilakukan normalisasi data untuk menyamaratakan persebaran nilai keseluruhan atribut dengan menggunakan rumus min-max normalization :
Tahapan normalisasi data untuk atribut nil11, nil12, nil13, nil14, nil15, dan final dilakukan untuk menyamakan jangkauan nilai terhadap atribut ips1, ips2, ips3, ips4. Sehingga pada saat perhitungan deteksi outlier persebaran nilai atribut hanya berkisar antara 0.00 sampai 4.00.
Proses normalisasi data berikut ini berlaku untuk atribut nil11, nil12, nil13, nil14, dan nil15 menggunakan min-max normalization, semisal nil11 adalah 7.00 maka proses normalisasinya adalah : maxA = 10, minA= 0, new_maxA = 4, new_minA= 0, dan v = nil11
dalam hal ini bernilai 7.00 , sehingga proses perhitungannya v1 = (7-0)/(10-0)*(4-0)+0 = 7/10*4 = 2.80. Sehingga hasil normalisasi nil11 yang awalnya bernilai 7.00 sekarang menjadi 2.80.
Berikutnya adalah proses normalisasi data berikut berlaku untuk atribut final menggunakan min-max normalization, semisal nilai final adalah 61.00 maka proses normalisasinya adalah :
normalisasi nilai final yang awalnya bernilai 61.00 sekarang menjadi 2.44.
Setelah nilai atribut nil11, nil12, nil13, nil14, nil15, dan final dinormalisasikan dalam kisaran nilai 0.00 - 4.00 maka nilai yang sudah dinormalisasikan inilah yang nantinya akan digunakan sebagai input dalam proses deteksi outlier.
4. Penambangan Data ( Data Mining )
Data yang telah diolah akan dianalisa menggunakan algoritma Naïve Nested Loop. Data yang diteliti dibatasi pada data mahasiswa Teknik Informatika, Universitas Sanata Dharma tahun angkatan 2007 dan 2008 selama empat semester. Pada tahap ini, akan ditentukan pula input dan output yang akan digunakan untuk menambang data, antara lain sebagai berikut :
1. Input terdiri dari :
a. Nilai hasil seleksi masuk mahasiswa, baik mahasiswa yang menempuh jalur prestasi maupun jalur tes tertulis. Masukkan tersebut diperoleh dari atribut yang ada pada tabel
„fact_lengkap2‟ yaitu nil11, nil12, nil13, nil14, nil15, dan
b. Indeks prestasi mahasiswa dari semester satu hingga empat. Masukkan tersebut diperoleh dari atribut yang ada pada tabel
„fact_lengkap2‟ yaitu ips1, ips2, ips3, dan ips4.
2. Output, yaitu data mahasiswa yang menjadi outlier dari perhitungan yang diambil dari data numerik nilai hasil seleksi masuk dan nilai indeks prestasi selama empat semester.
5. Evaluasi Pola ( Pattern Evaluation )
Tahap ini merupakan bagian dari proses pencarian pengetahuan yang mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya. Melalui sistem pendeteksi outlier akan diperoleh luaran berupa data-data outlier menggunakan algoritma Naïve Nested Loop dan dianalisa kembali oleh pemilik data itu apakah hipotesa outlier yang mereka miliki sama atau tidak dengan hasil yang diperoleh sistem, sehingga dapat diketahui seperti apa tingkat keberhasilan pencarian outlier tersebut.
6. Presentasi Pengetahuan ( Knowledge Presentation )
data lainnya untuk selanjutnya dianalisa mengapa data-data tersebut bisa muncul. Tidak bisa dipungkiri bahwa outlier sendiri akan didefinisikan dan dianalisa oleh orang yang ahli dan mengerti tentang data itu.
4.2.2 Input Sistem
Data akademik mahasiswa Teknik Informatika angkatan 2007-2008 terdiri dari 126 buah. Mahasiswa tersebut telah diterima di Universitas Sanata Dharma melalui dua macam jalur seleksi masuk yaitu, jalur prestasi dan jalur tes. Untuk masing-masing jalur seleksi masuk tersebut akan dicari outlier-nya karena memiliki struktur data yang berbeda.
Berikut ini merupakan rincian data yang akan dalam penelitian antara lain sebagai berikut:
a. Data Hasil Seleksi Masuk Jalur Prestasi
No Nama Atribut Penjelasan Nilai
1 nomor urut Atribut ini merupakan nomor alias untuk
menunjukkan objek
mahasiswa
1 – 126
2 Final Atribut ini merupakan rata-rata dari nilai kognitif rapor siswa SMA/sederajat
0-4.00
b. Data Hasil Seleksi Masuk Jalur Tes Tertulis No Nama
Atribut
1 nomor urut Atribut ini merupakan nilai komponen tes 1
0-4.00
3 nil12 Atribut ini merupakan nilai komponen tes 2
0-4.00
4 nil13 Atribut ini merupakan nilai komponen tes 3
0-4.00
5 nil14 Atribut ini merupakan nilai komponen tes 4
0-4.00
6 nil15 Atribut ini merupakan nilai komponen tes 5
0-4.00
7 Final Atribut ini merupakan nilai akhir hasil kalkulasi semua nilai tes
0-4.00
c. Data Indeks Prestasi Semester No Nama
Atribut
Penjelasan Nilai