ABSTRAK
Kebutuhan untuk pengolahan data merupakan hal yang sangat penting untuk
era saat ini. Dalam bidang pendidikan, data mining sangat berguna untuk mengembangkan sebuah metode yang dapat menemukan keunikan dari sebuah data
yang berasal dari sistem pendidikan tersebut, dan menggunakan metode tersebut
untuk lebih memahami siswa, sehingga dapat mengembangkan sebuah sistem yang
sesuai (Barker & Yacef, 2009).
Salah satu metode dalam data mining untuk mengenali data yang bersifat unik di sebut deteksi outlier. Teknik deteksi outlier di kategorikan menjadi beberapa kelompok, yaitu Statistical Approaches, Proximity-based Approaches, Clustering-based Approaches, dan Classification Approaches.
Akan di buat sebuah aplikasi atau perangkat lunak untuk mendeteksi data
yang unik tersebut menggunakan salah satu algoritma data mining yaitu algoritma Connectivity-based Outlier Factor dengan pendekatan density based. Data yang di gunakan dalam penelitian ini adalah data akademik mahasiswa Teknik Informatika
Universitas Sanata Dharma angkatan 2007-2008 yang berupa hasil test penerimaan
mahasiswa baru, nilai final dan nilai Indeks Prestasi Semester (IPS) dari semester
satu sampai semester empat.
Pengujian akan di lakukan untuk menemukan data yang dinyatakan sebagai
outlier. Penelitian ini bertujuan untuk membantu Kaprodi TI Universitas Sanata Dharma dalam mendeteksi kejadian langka atau yang menyimpang dari pola umum
data akademik mahasiswa.
ABSTRACT
The need for data processing is very important for the current era. In
education, data mining is very useful to develop a method that can discover the
uniqueness of a data derived from the education system, and using these methods
to better understand the students, so that they can develop an appropriate system
(Barker & Yacef, 2009).
One method in data mining to identify data that is unique is called outlier
detection. Outlier detection techniques categorized into several groups, Statistical
Approaches, Proximity-based Approaches, Clustering-based Approaches, and
Classification Approaches.
It will be created an application or software to detect the unique data using
one of the data mining algorithm is an algorithm-based Outlier Factor Connectivity
with density-based approach. The data used in this study were student academic
data Sanata Dharma University of Information Engineering 2007-2008 force in the
form of new admissions test results, final value and the value of their GPA (IPS)
from one semester to semester four.
Tests will be done to find the data that is declared as outliers. This research
aims to help the chair person of Computer Science of Sanata Dharma University in
detecting rare events or that deviate from the general pattern of student academic
data.
DETEKSI
OUTLIER
MENGGUNAKAN ALGORITMA
CONNECTIVITY BASED OUTLIER FACTOR
(STUDI KASUS: DATA AKADEMIK MAHASISWA TEKNIK
INFORMATIKA UNIVERSITAS SANATA DHARMA)
Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika
Dosen Pengampu : Ridowati Gunawan, S.Kom., M.T.
Oleh:
Yustina Ayu Ruwidati
105314061
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
OUTLIER DETECTION USING CONNECTIVITY
BASED OUTLIER FACTOR ALGORITHM
(CASE STUDY: ACADEMIC DATA OF STUDENTS OF INFORMATICS
ENGINEERING DEPARTMENT OF SANATA DHARMA UNIVERSITY)
A Thesis
Presented as Partial Fullfillment of the Requirements
To Obtain the Barchelor of Computer Science
In Study Program of Informatics Engineering
By:
Yustina Ayu Ruwidati
105314061
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iii
HALAMAN MOTTO DAN PERSEMBAHAN
“Let it be”
-The Beatles-
iv
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak
memuat karya atau bagian karya orang lain, kecuali yang telah saya sebutkan
dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 14 Januari 2015
Penulis
v
ABSTRAK
Kebutuhan untuk pengolahan data merupakan hal yang sangat penting
untuk era saat ini. Dalam bidang pendidikan, data mining sangat berguna untuk mengembangkan sebuah metode yang dapat menemukan keunikan dari sebuah
data yang berasal dari sistem pendidikan tersebut, dan menggunakan metode
tersebut untuk lebih memahami siswa, sehingga dapat mengembangkan sebuah
sistem yang sesuai (Barker & Yacef, 2009).
Salah satu metode dalam data mining untuk mengenali data yang bersifat unik di sebut deteksi outlier. Teknik deteksi outlier di kategorikan menjadi beberapa kelompok, yaitu Statistical Approaches, Proximity-based Approaches, Clustering-based Approaches, dan Classification Approaches.
Akan di buat sebuah aplikasi atau perangkat lunak untuk mendeteksi data
yang unik tersebut menggunakan salah satu algoritma data mining yaitu algoritma Connectivity-based Outlier Factor dengan pendekatan density based. Data yang di gunakan dalam penelitian ini adalah data akademik mahasiswa Teknik
Informatika Universitas Sanata Dharma angkatan 2007-2008 yang berupa hasil
test penerimaan mahasiswa baru, nilai final dan nilai Indeks Prestasi Semester
(IPS) dari semester satu sampai semester empat.
Pengujian akan di lakukan untuk menemukan data yang dinyatakan sebagai outlier. Penelitian ini bertujuan untuk membantu Kaprodi TI Universitas Sanata Dharma dalam mendeteksi kejadian langka atau yang menyimpang dari
pola umum data akademik mahasiswa.
vi
ABSTRACT
The need for data processing is very important for the current era. In
education, data mining is very useful to develop a method that can discover the
uniqueness of a data derived from the education system, and using these methods
to better understand the students, so that they can develop an appropriate system
(Barker & Yacef, 2009).
One method in data mining to identify data that is unique is called outlier
detection. Outlier detection techniques categorized into several groups, Statistical
Approaches, Proximity-based Approaches, Clustering-based Approaches, and
Classification Approaches.
It will be created an application or software to detect the unique data using
one of the data mining algorithm is an algorithm-based Outlier Factor
Connectivity with density-based approach. The data used in this study were
student academic data Sanata Dharma University of Information Engineering
2007-2008 force in the form of new admissions test results, final value and the
value of their GPA (IPS) from one semester to semester four.
Tests will be done to find the data that is declared as outliers. This
research aims to help the chair person of Computer Science of Sanata Dharma
University in detecting rare events or that deviate from the general pattern of student academic data.
vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH
UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma
Nama : Yustina Ayu Ruwidati
Nomor Mahasiswa : 105314061
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan
Universitas Sanata Dharma karya ilmiah saya yang berjudul:
DETEKSI OUTLIER MENGGUNAKAN ALGORITMA
CONNECTIVITY BASED OUTLIER FACTOR
(STUDI KASUS: DATA AKADEMIK MAHASISWA TEKNIK
INFORMATIKA UNIVERSITAS SANATA DHARMA)
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya
memberikan kepada Perpustakaan Sanata Dharma hak untuk menyimpan,
mengalihkan dalam bentuk media lain, mengelolanya di internet atau media lain
untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun
memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai
penulis.
Demikian pernyataan ini saya buat dengan sebenarnya
Dibuat di Yogyakarta
Pada tanggal: 14Januari 2015
Yang menyatakan,
viii
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yesus Kristus, atas
berkat yang luar biasa dan kehendakNya penulis dapat menyelesaikan penelitian
tugas akhir ini yang berjudul “Deteksi Outlier Menggunakan Algoritma
Connectivity-based Outlier Factor (Studi Kasus: Data Akademik Mahasiswa
Teknik Informatika Universitas Sanata Dharma)”
Penulis mengucapkan terimakasih yang sebesar-besarnya kepada semua
pihak yang berperan dalam pengerjaan tugas akhir ini:
1. Tuhan Yesus Kristus dan Bunda Maria yang telah memberikan berkat dan
anugrah yang luar biasa sehingga tugas akhir ini bisa selesai.
2. Ibu P.H. Prima Rosa, S.Si., M.Sc selaku Dekan Fakultas Sains dan
Teknologi dan dosen penguji atas semua masukan dan dukungan yang
telah di berikan.
3. Ibu Ridowati Gunawan, S.Kom., M.T selaku dosen pembimbing akademik
atas kesabaran, bantuan, kritik, masukan, dan dorongan semangat selama
penulis menyelesaikan tugas akhir ini.
4. Ibu Sri Hartati Wijono, S.Si., M.Kom selaku dosen penguji atas kritik dan
saran yang di berikan.
5. Seluruh dosen dan karyawan Universitas Sanata Dharma Yogyakarta atas
kontribusinya dalam membantu penulis.
6. Kedua orang tua saya Bapak E. Ruwido dan Ibu Sumirah yang tanpa henti
memberikan dukungan baik secara moral maupun materi. Terima kasih
atas doa yang tanpa henti Bapak dan Ib panjatkan.
7. Kedua kakak saya Wing Budi Wiratmoko dan Sunaringtyas Nugraheni
atas semua semangat, doa, dan bantuan untuk penulis. Terima kasih pula
untuk keponakan kecilku, Randu Sekar Kinanthi yang dengan
kelucuannya dapat menghibur penulis selama pengerjaan tugas akhir ini.
8. Terima kasih untuk kamu, yang selama 10 tahun kehadiranmu telah
memberikan motivasi terbesar dalam hidupku untuk mewujudkan satu
ix
9. Sahabat-sahabat terbaikku, Verena Pratita Adji, Venti Trimuryatin, Fidelis
Asterina Surya Prasetya, dan Yohanes Advent Arinatal atas
kebersamaanya dari semester 1 hingga semester akhir ini. Terima kasih
atas semua canda, tawa, dukungan, doa yang telah kalian berikan.
10.Felisitas Brillianti dan Erlita Octaviani selaku teman sekelompok dalam
pengerjaan tugas akhir ini. Terima kasih atas kerja sama, bantuan, dan
semangatnya.
11.Daniel Tomi Rahardjo dan H. Roy Wiranata yang tidak pernah bosan
untuk membantu penulis dalam menyelesaikan tugas akhir ini.
12.Sahabat PPG, Erlin Kristiyanti, Patricia Puspita Wahyujati, Chatarina
Windar Herlita Swari, dan Vivi Yulisetyani atas keceriaan dan dukungan
dalam mengerjakan tugas akhir ini.
13.Teman-teman HMPS yang tidak bisa saya sebutkan satu persatu, terima
kasih atas kehadiran, doa, semangat, dan tawa kalian.
14.Serta semua pihak yang berperan dalam penyelesaian tugas akhir ini.
Tugas akhir ini masih kurang dari kata sempurna, oleh karena itu penulis
dengan rendah hati memohon untuk memberikan kritik dan saran untuk
perbaikan tugas akhir ini. Semoga penulisan tugas akhir ini dapat bermanfaat
bagi semua pihak. Terima kasih
Yogyakarta, Desember 2014
x
Daftar Isi
Halaman Judul ...
Halaman Persetujuan ... i
Halaman Pengesahan ... ii
Halaman Motto dan Persembahan ... iii
Pernyataan Keaslian Karya ... iv
Abstrak ... v
Abstract ... vi
Lembar Pernyataan Persetujuan ... vii
Kata Pengantar ... viii
Daftar Isi ... x
Daftar Gambar ... xiv
Daftar Tabel ... xvi
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang... 1
1.2 Rumusan Masalah ... 2
1.3 Batasan Masalah ... 2
1.4 Tujuan ... 3
1.5 Manfaat Penelitian ... 3
1.6 Metodologi Penelitian ... 3
1.7 Sistematika Penulisan ... 4
BAB II LANDASAN TEORI ... 6
2.1 Pengertian Data Mining ... 6
2.2 Outlier... 8
2.2.1 Jenis Outlier ... 9
2.2.1.1 Statistical Distribution-based Outlier Detection 9 2.2.1.2 Distance-based Outlier Detection ... 10
2.2.1.3 Density-based Local Outlier Approach ... 11
2.2.1.4 Deviation-based Approach ... 11
xi
2.4 Contoh Jalannya Algoritma ... 14
BAB III METODOLOGI PENELITIAN... 17
3.1 Data yang Dibutuhkan ... 17
3.2 Pengolahan Data ... 17
BAB IV ANALISIS DAN PERANCANGAN SISTEM ... 30
4.1 Gambaran Umum Sistem ... 30
4.1.1 Diagram Use Case ... 31
4.1.2 Narasi Use Case ... 32
4.2 Perancangan Sistem Secara Umum ... 32
4.2.1 Input Sistem ... 32
4.2.2 Proses Sistem ... 35
4.2.3 Output Sistem ... 37
4.3 Perancangan Sistem ... 37
4.3.1 Diagram Aktivitas ... 37
4.3.2 Diagram Kelas Analisis ... 38
4.3.3 Diagram Sequence ... 43
4.3.4 Diagram Kelas Desain ... 43
4.3.5 Rincian Algoritma ... 44
4.4 Perancangan Struktur Data ... 70
4.5 Perancangan Antarmuka ... 72
4.5.1 Tampilan Halaman Awal ... 72
4.5.2 Tampilan Halaman Menu Utama ... 73
4.5.3 Tampilan Halaman Pilih Database ... 75
4.5.4 Tampilan Halaman Pilih Tabel ... 76
4.5.5 Tampilan Halaman About ... 77
4.5.6 Tampilan Halaman Help ... 78
BAB V IMPLEMENTASI SISTEM ... 79
5.1 Implementasi Antarmuka ... 79
5.1.1 Implementasi Halaman Awal ... 79
5.1.2 Implementasi Halaman Menu Utama ... 80
xii
5.1.4 Implementasi Halaman About ... 89
5.1.5 Implementasi Halaman Help ... 90
5.1.6 Implementasi Halaman Exit ... 91
5.1.7 Implementasi Pengecekan Masukan ... 91
5.2 Implementasi Kelas ... 94
5.3 Implementasi Struktur Data ... 95
5.3.1 Implementasi Kelas Vertex.java ... 95
5.3.2 Implementasi Kelas Graph.java ... 96
BAB VI PENGUJIAN DAN ANALISA HASIL PENGUJIAN ... 99
6.1 Rencana Pengujian ... 99
6.1.1 Hasil Pengujian Blackbox ... 102
6.1.1.1 Pengujian Input Data ... 102
6.1.1.2 Pengujian Koneksi Database ... 103
6.1.1.3 Pengujian Seleksi Atribut ... 105
6.1.1.4 Pengujian Deteksi Outlier ... 106
6.1.1.5 Pengujian Simpan Hasil Deteksi Outlier 107 6.1.2 Kesimpulan Hasil Pengujian Blackbox ... 108
6.1.3 Hasil Pengujian Dengan Perubahan Nilai Parameter k 109 6.1.4 Kesimpulan Hasil Pengujian Dengan Perubahan Nilai Parameter k ... 115
6.1.5 Hasil Pengujian Validitas dan Review oleh Pengguna 115 6.1.5.1 Perbandingan Perhitungan Manual dengan Perhitungan Sistem ... 115
6.1.5.2 Kesimpulan Perbandingan Perhitungan Manual dengan Perhitungan Sistem ... 117
6.1.5.3 Hasil Review Oleh Pengguna ... 117
6.1.5.4 Kesimpulan Hasil Pengujian Validitas dan Review oleh Pengguna... 120
6.2 Kelebihan dan Kekurangan Sistem ... 123
6.2.1 Kelebihan Sistem ... 123
xiii
BAB VII KESIMPULAN DAN SARAN ... 125
7.1 Kesimpulan ... 125
7.2 Saran ... 126
DAFTAR PUSTAKA ... 127
LAMPIRAN 1 ... 128
LAMPIRAN 2 ... 129
LAMPIRAN 3 ... 137
LAMPIRAN 4 ... 144
LAMPIRAN 5 ... 150
LAMPIRAN 6 ... 159
LAMPIRAN 7 ... 194
xiv
DAFTAR GAMBAR
Gambar 2.1 Proses KDD(Knowledge Discovery in Database) ... 7
Gambar 2.2 Obyek pada daerah R adalah outlier ... 9
Gambar 3.1 Database gudangdata ... 18
Gambar 3.2 Isi tabel fact_lengkap2 ... 19
Gambar 3.3 Isi tabel fact_lengkap2 untuk mahasiswa Teknik Informatika 20 Gambar 3.4 Isi tabel fact_lengkap2 setelah seleksi ... 20
Gambar 3.5 Contoh Data angkatan 2007 jalur reguler ... 25
Gambar 4.1 Proses umum Sistem Deteksi Outlier Menggunakan Algoritma Connectivity-based Outlier Factor ... 36
Gambar 4.2 Diagram Kelas Analisis Sistem Deteksi Outlier Menggunakan Algoritma Connectivity-based Outlier Factor ... 38
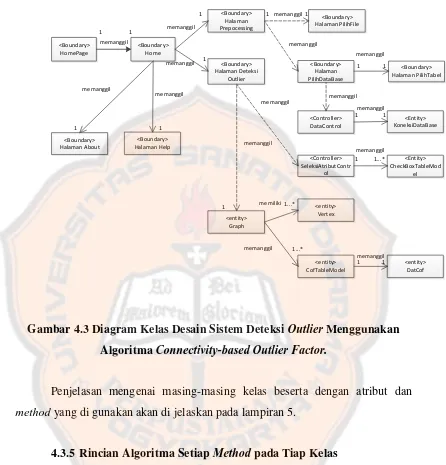
Gambar 4.3 Diagram Kelas Desain Sistem Deteksi Outlier Menggunakan Algoritma Connectivity-based Outlier Factor ... 44
Gambar 4.4 Ilustrasi Struktur Data Graf ... 71
Gambar 4.5 Tampilan Halaman Awal(HomePage) ... 72
Gambar 4.6 Tampilan Halaman Utama(Home) pada tab Prepocessing 74 Gambar 4.7 Tampilan Halaman Utama(Home) pada tab Deteksi Outlier 75 Gambar 4.8 Tampilan Halaman Pilih Database ... 76
Gambar 4.9 Tampilan Halaman Pilih Tabel ... 76
Gambar 4.10 Tampilan Halaman About ... 77
Gambar 4.11 Tampilan Halaman Help... 78
Gambar 5.1 Antarmuka atau Interface Halaman Awal(HomePage) ... 80
Gambar 5.2 Antarmuka atau Interface Halaman Menu Utama(Home) 81 Gambar 5.3 Kotak Dialog Pilih File ... 81
Gambar 5.4 File Inputan Tertampil pada Tabel ... 82
Gambar 5.5 Daftar Atribut pada Tabel Seleksi Atribut... 83
xv
Gambar 5.8 Hasil Deteksi Outlier ... 84
Gambar 5.9 Hasil Deteksi Outlier Setelah Diberi Batas Outlier ... 85
Gambar 5.10 Kotak Dialog Simpan Hasil Deteksi Outlier ... 85
Gambar 5.11 Kotak Dialog Simpan Hasil Deteksi Outlier Saat Memberi Nama File ... 86
Gambar 5.12 Pesan Sukses Hasil Deteksi Outlier Berhasil Disimpan.. 86
Gambar 5.13 Antarmuka atau Interface Halaman PilihDatabase ... 87
Gambar 5.14 Memasukan Username, Password, Database Name, dan Url 87 Gambar 5.15 Pesan Sukses Konfigurasi ke Database Berhasil ... 88
Gambar 5.16 Antarmuka atau Interface Halaman PilihTabel ... 88
Gambar 5.17 Tabel Inputan dari Database Tertampil pada Halaman Utama pada tab Prepocessing ... 89
Gambar 5.18 Antarmuka atau Interface Halaman About ... 90
Gambar 5.19 Antarmuka atau Interface Halaman Help ... 91
Gambar 5.20 Antarmuka atau Interface Halaman Exit ... 91
Gambar 5.21 Pesan Kesalahan k Kosong ... 92
Gambar 5.22 Pesan Kesalahan k Mengandung Karakter Selain Angka 92 Gambar 5.23 Pesan Kesalahan Batas Outlier Kosong ... 93
Gambar 5.24 Pesan Kesalahan Batas Outlier Mengandung Karakter Selain Angka ... 93
Gambar 5.25 Pesan Kesalahan Username, Password, Database Name, dan Url Ada yang Kosong ... 93
Gambar 5.26 Pesan Kesalahan Username, Password, Database Name, dan Url Ada yang Salah ... 94
Gambar 5.27 Pesan Kesalahan Format File Tidak Sesuai ... 94
Gambar 6.1 Grafik Hasil Pengujian Data Akademik Mahasiswa Teknik Informatika Angkatan 2007-2008 Jalur Tes ... 109
Gambar 6.2 Grafik Hasil Pengujian Data Akademik Mahasiswa Teknik Informatika Angkatan 2007-2008 Jalur Prestasi ... 111
xvi
DAFTAR TABEL
Tabel 2.1 Simbol dan definisi... 13 Tabel 3.1 Contoh perhitungan min-max normalization untuk atribut nil11, nil12,
nil13, nil14, dan15 ... 22
Tabel 3.2 Setelah di hitung menggunakan rumus min-max normalization untuk atribut nil11, nil12, nil13, nil14, dan15 ... 22
Tabel 3.3 Contoh perhitungan min-max normalization untuk atribut final 23 Tabel 3.4 Setelah di hitung menggunakan rumus min-max normalization untuk
atribut final ... 24
Tabel 4.1 Tabel Penjelasan dari Diagram Kelas Analisis ... 39
Tabel 4.2 Ilustrasi Struktur Data Matriks Dua Dimensi ... 71
Tabel 4.3 Ilustrasi Struktur Data Matriks Dua Dimensi Setelah dilakukan
Perhitungan dengan Ecluidian Distance ... 72 Tabel 6.1 Rencana Pengujian Blackbox ... 102 Tabel 6.2 Hasil Pengujian Input Data pada Kelas Home ... 104 Tabel 6.3 Hasil Pengujian Input Data pada Kelas Koneksi Database . 105 Tabel 6.4 Hasil Pengujian Seleksi Atribut pada Kelas Home ... 107 Tabel 6.5 Hasil Pengujian Deteksi Outlier pada Kelas Home ... 108 Tabel 6.6 Hasil Pengujian Simpan Hasil Deteksi Outlier pada Kelas Home109 Tabel 6.7 Daftar Nilai Per Atribut ... 118 Tabel 6.8 Hasil Deteksi Outlier Data Akademik Mahasiswa Teknik Informatika
Angkatan 2007-2008 Jalur Tes ... 120
Tabel 6.9 Hasil Deteksi Outlier Data Akademik Mahasiswa Teknik Informatika Angkatan 2007-2008 Jalur Prestasi ... 120
BAB I
PENDAHULUAN
1.1
Latar Belakang
Di era globalisasi saat ini, pendidikan merupakan kebutuhan primer bagi
setiap individu. Pendidikan yang di maksud adalah usaha sadar dan terencana
untuk mewujudkan suasana belajar dan proses pembelajaran agar peserta didik
secara aktif mengembangkan potensi dirinya untuk memiliki kekuatan
spiritual keagamaaan, pengendalian diri, kepribadian, kecerdasan, akhlak
mulia, serta ketrampilan yang diperlukan dirinya, masyarakat, bangsa, dan
Negara (UU No. 20 Tahun 2003).
Universitas Sanata Dharma Yogyakarta adalah sebuah institusi pendidikan
yang tentunya memiliki banyak data. Sebagai contoh adalah data akademik.
Data-data akademik yang dapat di ambil adalah data PMB (berupa nilai test
penerimaan mahasiswa baru ataupun nilai rapor SMA) dan nilai semester.
Pada akhir semester IV, akan di analisa apakah mahasiswa tersebut layak
untuk melanjutkan studi di program studi Teknik Informatika ataukah tidak.
Apakah mahasiswa tersebut perlu untuk di drop out atau tidak. Dalam mengambil keputusan, seorang Kaprodi harus memperhatikan berbagai
faktor-faktor nilai.
Apabila nilai test penerimaan mahasiswa baru dan nilai semester seorang
mahasiswa bagus, tentunya mahasiswa tersebut di nilai berprestasi. Begitu
juga sebaliknya. Tetapi, ada kemungkinan apabila seorang mahasiswa memiliki nilai test penerimaan mahasiswa baru yang bagus, namun ia tidak
berprestasi dibuktikan dengan nilai semesternya yang jelek.
Kebutuhan untuk pengolahan data pun di rasa sangat penting untuk era
saat ini. Dalam bidang pendidikan, data mining sangat berguna untuk mengembangkan sebuah metode yang dapat menemukan keunikan dari sebuah
data yang berasal dari sistem pendidikan tersebut, dan menggunakan metode
sebuah sistem yang sesuai (Barker & Yacef, 2009).
Salah satu metode dalam Data Mining untuk mengenali data yang bersifat
unik di sebut Deteksi Outlier. Teknik Deteksi Outlier di kategorikan menjadi beberapa kelompok, yaitu Statistical Approaches, Proximity-based Approaches, Clustering-based Approaches, dan Classification Approaches. Dan salah satu algoritma yang ada adalah algoritma Connectivity-based Outlier Factor (COF). Algoritma COF ini merupakan algoritma dengan pendekatan Density Based. Algoritma COF digunakan untuk mendeteksi outlier segera setelah outlier tersebut muncul dalam database. COF dapat menangani outlier atau pola yang menyimpang dari low density pattern. Ide utama dari algoritma COF adalah untuk menentukan setiap record data yang dapat setingkat atau sederajat untuk menjadi outlier atau data yang menyimpang dari suatu pola yang umum.
Dengan demikian, dapat disimpulkan bahwa mahasiswa tersebut memiliki
pola yang menyimpang dari pola atau di kenal sebagai outlier. Data mahasiswa yang termasuk outlier ini dapat di gunakan oleh Kaprodi untuk lebih memperhatikan mahasiswa tersebut agar prestasinya bisa naik.
1.2Rumusan Masalah
Rumusan masalah dari penelitian ini adalah :
1.2.1 Bagaimana algoritma Connectivity-based Outlier Factor dapat mendeteksi outlier dari data nilai akademik mahasiswa Teknik Informatika Universitas Sanata Dharma?
1.2.2 Mahasiswa manakah yang memiliki data nilai akademik yang unik atau
menyimpang dari pola umum berdasarkan indeks prestasi semester?
1.3Batasan Masalah
Batasan masalah dari penelitian ini adalah :
1.3.2 Data yang di gunakan adalah data akademik mahasiswa TI Universitas
Sanata Dharma angkatan 2007-2008 yang berupa hasil test penerimaan
mahasiswa baru, nilai final dan nilai Indeks Prestasi Semester (IPS) dari
semester satu sampai semester empat.
1.3.3 Hasil penelitian ini berupa kelompok mahasiswa outlier, jika ditemukan.
1.4Tujuan
Tujuan dari penelitian ini adalah :
1.4.1 Melakukan deteksi outlier pada data akademik Mahasiswa Teknik Informatika Universitas Sanata Dharma dengan menerapkan algoritma
Connectivity-based Outlier Factor.
1.4.2 Menganalisis hasil deteksi outlier pada data akademik yang di hasilkan oleh algoritma Connectivity-based Outlier Factor.
1.5Manfaat Penelitian
Manfaat dari penelitian ini adalah :
1.5.1 Memberikan analisis sejauh mana algoritma Connectivity-based Outlier Factor dapat mendeteksi sebuah outlier serta keunggulan algoritma ini dalam mendeteksi outlier.
1.5.2 Membantu Kaprodi TI Universitas Sanata Dharma dalam mendeteksi
kejadian langka atau yang menyimpang dari pola umum data akademik
mahasiswa.
1.6Metodologi Penelitian
Metode yang di gunakan dalam penelitian ini adalah Knowledge Discovery in Database (KDD), yaitu proses yang dibantu oleh komputer untuk menggali dan menganalisis sejumlah besar himpunan data dan mengekstrak informasi
dan pengetahuan yang berguna. Langkah-langkah KDD menurut Jiawei Han
adalah sebagai berikut :
1.6.1 Pembersihan Data (Data Cleaning)
1.6.2 Integrasi Data (Data Integration)
Menggabungkan data dari berbagai sumber data yang berbeda.
1.6.3 Pemilihan Data (Data Selection)
Mengambil data yang relevan dengan tugas analisis yang di ambil dari
database.
1.6.4 Transformasi Data (Data Transformation)
Mentransformasi atau menggabungkan data ke dalam bentuk yang sesuai
untuk penggalian lewat operasi summary atau aggregation. 1.6.5 Penambangan Data (Data Mining)
Proses penting dimana metode cerdas di aplikasikan untuk mengekstrak
suatu pola data.
1.6.6 Evaluasi Pola (Pola Evaluation)
Mengidentifikasi pola yang menarik dan merepresentasikan pengetahuan
berdasarkan interestingness measures.
1.6.7 Presentasi Pengetahuan (Knowledge Presentation)
Penyajian pengetahuan yang di gali kepada pengguna dengan
menggunakan visualisasi dan teknik representasi pengetahuan.
1.7 Sistematika Penulisan
Sistematika penulisan proposal tugas akhir ini adalah sebagai berikut:
BAB I PENDAHULUAN
Pada bab ini di jelaskan latar belakang penelitian dan latar
belakang secara umum, rumusan masalah penelitian, batasan
masalah penelitian, tujuan penelitian, manfaat penelitian,
metodologi penelitian, dan sistematika penulisan.
BAB II LANDASAN TEORI
Pada bab ini di jelaskan landasan teori dari penelitian ini. Dasar
Database), pengertian outlier, jenis-jenis outlier, dan algoritma Connectivity-based Outlier Factor.
BAB III METODOLOGI PENELITIAN
Pada bab ini akan di jelaskan mengenai metode yang dipakai
dalam penelitian dan pembuatan aplikasi dalam analisis outlier untuk studi kasus data akademik mahasiswa Teknik Informatika
Universitas Sanata Dharma.
BAB IV ANALISIS DAN PERANCANGAN SISTEM
Pada bab ini akan di jelaskan analisis sistem yang meliputi
gambaran umum sistem, data yang di butuhkan untuk penelitian,
dan pengolahan data. Akan di jelaskan pula perancangan sistem
yang meliputi perancangan umum dari sistem tersebut,
perancangan struktur data, dan perancangan interface atau antarmuka sistem.
BAB V IMPLEMENTASI SISTEM
Pada bab ini akan di jelaskan implementasi dari sistem deteksi
outlier menggunakan algoritma Connectivity-based Outlier Factor. Akan di jelaskan pula listingprogram dari sistem ini.
BAB VI PENGUJIAN DAN ANALISA HASIL PENGUJIAN
Pada bab ini akan di jelaskan hasil pengujian dari sistem deteksi
outlier menggunakan algoritma Connectivity-based Outlier Factor beserta dengan analis dari hasil pengujian.
BAB VII KESIMPULAN DAN SARAN
Pada bab ini akan di jelaskan kesimpulan dari hasil pengujian yang
telah dilakukan dan saran yang berguna untuk pengembangan
6
BAB II
LANDASAN TEORI
2.1
Pengertian
Data Mining
Data Mining adalah acuan untuk mengekstrak atau menambang pengetahuan dari data yang jumlahnya sangat besar (Han & Kamber, 2006).
Data Mining adalah suatu proses menemukan hubungan yang berarti, pola, dan kecenderungan dengan memeriksa dalam sekumpulan besar data yang
tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola
seperti teknik statistik dan matematika (Gartner, 2007).
Selain itu, data mining juga di definisikan oleh beberapa ahli seperti Data Mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan dana machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang
bermanfaat yang tersimpan dalam database besar (Turban et al, 2005). Data Mining merupakan bidang dari beberapa keilmuan yang menyatukan teknik dari pembelajaran mesin, pengenalan pola, statistik, database, dan visualisasi untuk penanganan permasalahan pengambilan informasi dari database yang besar (Larose, 2006).
Dari pengertian-pengertian di atas, dapat di simpulkan bahwa data mining mewarisi dari banyak bidang ilmu seperti kecerdasan buatan (artificial intellegent), machine learning, statistik, database, dan juga pemerolehan informasi (information retrieval). Dengan kemajuan saat ini, Data Mining bertujuan untuk mendapatkan hubungan atau pola yang mungkin memberikan
indikasi yang bermanfaat. Saat ini, hampir semua bidang membutuhkan data mining. Hal ini di karenakan oleh terbatasnya kemampuan manusia untuk menganalisis dan mengolah data.
istilah tersebut memiliki konsep yang berbeda tapi berhubungan satu sama lain
atau memiliki keterkaitan satu sama lain, Data Mining merupakan salah satu tahapan yang terdapat di dalam KDD (Knowledge Discovery in Database). Menurut Jiawei Han dan Kamber, langkah untuk menemukan pengetahuan
atau KDD pada data mining adalah sebagai berikut:
Gambar 2.1 Proses KDD (Knowledge Discovery in Database)
Langkah-langkah KDD adalah sebagai berikut:
1. Data Cleaning atau Pembersihan Data
Di dalam tahapan ini, di lakukan penghilangan noise, memeriksa data yang tidak konsisten, membuang duplikasi data dan memperbaiki kesalahan
2. Data Integration atau Penggabungan Data
Di dalam tahapan ini di lakukan penggabungan data dari berbagai sumber
data yang ada agar mudah di pilih dan di proses nantinya.
3. Data Selection atau Seleksi Data
Di dalam tahapan ini di lakukan pemilihan data yang di butuhkan dalam
database dan di gunakan untuk proses analisis. 4. Data Transformation atau Transformasi Data
Di dalam tahapan ini, di lakukan pengubahan dan penggabungan data dari
berbagai macam bentuk menjadi satu bentuk yang sama agar mudah di
proses.
5. Data Mining atau Penambangan Data
Di dalam tahapan ini, merupakan proses yang sangat penting dimana
metode cerdas di lakukan dan di terapkan untuk mengekstrak pola data.
6. Pattern Evaluation atau Evaluasi Pola
Di dalam tahapan ini, melakukan evaluasi terhadap pattern yang telah di proses, aspek-aspek yang di evaluasi adalah hasil output yang di dapat setelah proses data mining dilakukan.
7. Knowledge Presentation atau Presentasi Pengetahuan
Di dalam tahapan ini, di lakukan penyajian hasil dari proses data mining yang sudah di proses.
2.2
Outlier
Meskipun data yang berjumlah besar yang di kumpulkan di banyak ilmu
pengetahuan dan aplikasi komersial, peristiwa tertentu yang khusus masih
sangat langka terjadi. Peristiwa langka ini, sangat sering di sebut sebagai
outlier. Yang di definisikan sebagai peristiwa yang sangat jarang terjadi. Menurut Hawkins, Outlier adalah kejadian yang menyimpang sangat jauh dari kejadian lainnya yang menimbulkan kecurigaan bahwa hal tersebut terjadi
di karenakan oleh mekanisme yang berbeda. Sedangkan menurut Jiawei Han
dari obyek data lain pada umumnya.
Deteksi outlier, baru-baru ini telah mendapatkan perhatian dari berbagai pihak. Karena saat ini outlier bukan hanya di anggap sebagai noise untuk di hilangkan, namun bisa di anggap memiliki informasi yang sama pentingnya
dengan data yang lain. Karena bisa saja menurut suatu pihak, suatu kelompok
data di anggap sebagai noise namun untuk pihak lain sekelompok data tersebut dianggap sebagai informasi yang sangat berguna. Noise adalah kesalahan atau random error dari sebuah variabel yang terukur.
Gambar 2.2 Obyek pada daerah R adalah outlier.
Deteksi outlier dapat di kategorikan menjadi empat pendekatan menurut Jiawei Han dan Kamber. Yaitu Statistical approach, Distance-based approach, Density-based local outlier approach, dan Deviation-based approach.
2.2.1 Jenis
Outlier
2.2.1.1
Statistical Approach / Statistical Distribution-based Outlier
Detection
Metode Statistik mengasumsikan distribusi atau pemodelan
probabilitas untuk satu set data (distribusi normal atau Poisson Distribution) dan kemudian mengidentifikasi outlier sehubungan dengan model yang menggunakan discordancy test. Aplikasi dari kebutuhan pengetahuan dari parameter sejumlah data (seperti di
asumsikan sejumlah data yang di distribusikan), pengetahuan
yang diharapkan.
Sebuah obyek data yang normal yang di hasilkan oleh
model statistik (Statistical Approach) dan data yang tidak mengikuti model tersebut adalah outlier. Keefektivan dari metode statistik tergantung pada asumsi apakah yang akan di pakai atau di
buat untuk metode statistik yang berlaku untuk sejumlah data yang
di berikan. (Han dan Kamber, 2006)
2.2.1.2
Distance-based
Approach
/
Distance-based
Outlier
Detection
Distance-based Outlier Detection ini merupakan salah satu tipe dari Proximity-based Approach yang mana mengasumsikan bahwa proximity dari sebuah outlier pada tetangga terdekatnya secara signifikan menyimpang dari proximity pada obyek untuk sebagian besar obyek pada data set. Pada Distance-based sebuah obyek di sebut sebagai outlier jika neighborhoodnya tidak memiliki titik lain yang cukup.
Gagasan dari distance-based outlier detection adalah untuk mengatasi keterbatasan dari metode statistik. Sebuah obyek o pada
sebuah kumpulan data, D adalah Distance-based(DB) outlier dengan parameter pct dan dmin yaitu DB(pct;dmin)-outlier, jika
setidaknya fraksi, pct, dari obyek D terletak pada jarak terbesar
pada dmin dari o. Dengan kata lain, daripada mengandalkan uji
statistik, kita bisa memikirkan distance-based outlier sebagai obyek yang tidak cukup memiliki tetangga, dimana tetangga di
definisikan berdasar pada jarak pada obyek yang di berikan.
yang berkaitan dengan distribusi yang cocok ke dalam distribusi
standar dan dalam memilih tes discordancy. (Han dan Kamber, 2006)
2.2.1.3
Density-based Local Outlier Approach
Metode Density-based menyelidiki kepadatan dari sebuah obyek dan tetangganya. Sebuah obyek di identifikasi sebagai
outlier jika kepadatannya relativ lebih rendah dari tetangganya. Asumsi dari metode Density-based adalah bahwa kepadatan di sekeliling obyek yang bukan outlier mirip dengan kepadatan di sekeliling tetangganya, sedangkan kepadatan di sekeliling obyek
outlier adalah signifikan berbeda dari jarak di sekitar tetangganya.
Metode Density-based menggunakan kepadatan relatif dari sebuah obyek terhadap tetangganya untuk menunjukan sejauh
mana sebuah obyek disebut sebagai oulier. (Han dan Kamber,
2006)
2.2.1.4
Deviation-based Approach
Metode Deviation-based tidak menggunakan uji statistik atau Distance-based untuk mengidentifikasi obyek yang tidak biasa. Sebaliknya, metode Deviation-based mengidentifikasi outlier dengan memeriksa karakter utama obyek dari sebuah grup. Obyek yang menyimpang atau memiliki karakteristik di luar
karakter utama dianggap sebagai outlier. Oleh karena itu, pendekatan deviasi biasanya di gunakan untuk merujuk pada
2.3
Algoritma
Connectivity-based Outlier Factor
Ide utama dari algoritma Connectivity-based Outlier Factor (COF) adalah untuk menentukan masing-masing record data yang sederajat atau setingkat untuk menjadi outlier. Algoritma Connectivity-based Outlier Factor adalah algoritma pendeteksian outlier dengan pendekatan density based untuk menangani penyimpangan dari low density pattern. Algoritma COF ini merupakan varian dari algoritma LOF (Local Outlier Factor) yang juga menggunakan k-neighborhood. Gagasan dari algoritma Connectivity-based Outlier Factor adalah low density dari isolativity. Low density berarti jumlah obyek pada close neighborhood dari suatu obyek relatif kecil. Sedangkan isolativity berarti derajat atau tingkatan dimana sebuah obyek terkoneksi dengan obyek yang lain.
Record data dengan nilai COF yang tinggi biasanya di sebut strong outlier. Tidak seperti record data dari cluster yang normal yang biasanya cenderung memiliki nilai COF yang lebih rendah.
Algoritma untuk menghitung nilai COF untuk semua record data memiliki
langkah-langkah sebagai berikut:
1. Mencari Nk(p) untuk setiap record data p pada k nearest neighbours (k-NN);
2. Mencari set based nearest path (SBN-path) atau s. Di sini, set based nearest path (SBN-path) dari record data p1 pada set Nk (p) adalah urutan record dengan jarak terdekat masing-masing p, s={p1,p2,…,pr}
sehingga untuk semua 1≤ i ≤ r −1, pi+1 adalah tetangga terdekat dari {p1,…,pi} pada {pi+1,…,pr}.
3. Mencari set based nearest trail (SBN-trail) atau tr. SBN-trail adalah urutan edge terhadap s atau SBN-path di mana setiap tepi menghubungkan dua tetangga terdekat berturut-turut dari jalur SBN -path. Dapat dinotasikan SBN-trail = {e(1), ..., e(r-1)}.
5. Menghitung average chaining distance(ac-dist) dari p1 ke Nk - {p1}, dinotasikan dengan ac-distNk(p)∪p(p1) dan didefinisikan sebagai:
dimana dist(ei) dinotasikan jarak antara node yang terdiri dari tepi.
Average chaining distance dari p1 ke Nk-{p1} adalah jumlah bobot dari cost description sequence dari SBN trail untuk beberapa SBN path dari p1, dan juga dapat dilihat sebagai rata-rata jarak bobot dalam
cost description sequence SBN-trail.
6. Hitung connectivity-based outlier factor (COF) pada record data p
sehubungan dengan k- neigbourhood nya menggunakan rumus
berikut:
[image:33.595.103.518.191.754.2]COF dihitung sebagai rasio average chaining distance dari data record p untuk Nk(p) dan average chaining distance pada k-distance neighbors mereka sendiri.
Tabel 2.1 Simbol dan definisi
P Masing-masing record dari suatu set
data
Nk(p) Jumlah tetangga terdekat dari p
SBN-path atau s Jalur dari p ke p(r)
SBN-trail atau tr Urutan dari edge sesuai dengan
SBN-path
Cost Desciption Sequence Jarak dari masing-masing edge pada
SBN- trail
Average Chaining Distance Rata-rata dari bobot CDS(Cost
Description Sequence) pada SBN-... (1)
trail
Connectivity-based Outlier Factor Menunjukkan seberapa jauh titik
bergeser dari pola.
Perbandingan titik ke titik di
sekelilingnya yang mempengaruhi
outlier factor
2.4
Contoh Jalannya Algoritma
Di asumsikan terdapat titik yaitu 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 2,
dan 1. Titik 2 dan titik 1 terletak jauh dari titik lainnya yang berdekatan. Di
tentukan bahwa jarak dari titik 1 ke 2 adalah 5 ((dist(1,2) = 5)), jarak dari titik 2 ke titik 7 adalah 3 ((dist(2,7) = 3)), sedangkan jarak dari titik satu ke titik lainnya adalah 1. Di tentukan pula k = 10, r = 11.
1. Mencari Nk(p)
Dari contoh di atas akan di cari Nk(1) terhadap p=1.
Jarak terdekat dari titik 1 adalah 2, 9, 10, 8, 11, 7, 12, 6, 13, 5.
Jadi Nk(1) = {2, 9, 10, 8, 11, 7, 12, 6, 13, 5}. 2. Mencari SBN-path
Langkah selanjutnya adalah mencari SBN-path dari titik 1 pada Nk(1) ∪ {1}.
Pada langkah ini, di lakukan penggabungan antara p=1 dengan Nk(1). Perhitungan di lakukan secara berantai dengan ukuran jarak terdekat dari
titik tertentu (< p1, p2, ..., pr>).
Dari contoh di atas, jalur atau path dari titik 1, jarak terdekat adalah ke titik 2. Dari titik 2, jarak terdekat adalah titik 7. Dari titik 7, jarak terdekat
adalah titik 6. Dari titik 6, jarak terdekat adalah titik 5. Kemudian kembali ke titik 7, titik terdekat dari titik 7 selain titik 6 adalah titik 8. Dari titik 8,
jarak terdekat adalah titik 9. Dari titik 9, jarak terdekat adalah titik 10. Dari
titik 12. Dan yang terakhir dari titik 12, jarak terdekat adalah titik 13.
Jadi SBN-path atau s1 = <1, 2, 7, 6, 5, 8, 9, 10, 11, 12, 13>.
3. Mencari SBN-trail
Langkah yang berikutnya adalah mencari SBN-trail untuk s1 atau SBN-path terhadap titik 1.
SBN-trail adalah urutan edge terhadap s1 (< dist(e1), ..., dist(er-1)>). Dari jarak titik 1 ke titik 2, titik 2 ke titik 7, titik 7 ke titik 6, titik 6 ke titik 5,
titik 7 ke titik 8, titik 8 ke titik 9, titik 9 ke titik 10, titik 10 ke titik 11, titik
11 ke titik 12, dan titik 12 ke titik 13. Jarak dari masing-masing titik
tersebut adalah e.
Jadi SBN-trail atau tr1 = < (1,2), (2,7), (7,6), (6,5), (7,8), (8,9), (9,10), (10,11), (11,12), (12,13) >
4. Menghitung Cost Description
Langkah selanjutnya adalah menghitung Cost Description. Cost Description adalah jarak dari masing-masing edge pada SBN- trail.
Pada contoh data di atas sudah di tentukan bahwa jarak dari titik 1 ke 2
adalah 5 ((dist(1,2) = 5)), jarak dari titik 2 ke titik 7 adalah 3 ((dist(2,7) = 3)), sedangkan jarak dari titik satu ke titik lainnya adalah 1. Maka dapat di
hitung untuk tr1, dist(1,2) = 5, dist(2,7) = 3, dist(7,6) = 1, dist(6,5) = 1, dist(7,8) = 1, dist(8,9) = 1, dist(9,10) = 1, dist(10,11) = 1, dist(11,12) = 1, dan dist(12,13) = 1.
Maka Cost Desciption atau c1 terhadap tr1 : c1 = < 5, 3, 1, 1, 1, 1, 1, 1, 1, 1 >
5. Menghitung ac-dist atau Average Chaining Distance
ac-dist Nk (1) ∪ {1} 1 =( 2(11-1)*5)/(11(11-1)) + (2(11-2)*3)/(11(11-1)) + (2(11-3)*1)/(11(11-1)) + (2(11-4)*1)/(11(11-1)) +
5)*1)/(11(11-1)) + 6)*1)/(11(11-5)*1)/(11(11-1)) + 7)*1)/(11(11-5)*1)/(11(11-1)) +
(2(11-8)*1)/(11(11-1)) + (2(11-9)*1)/(11(11-1)) + (2(11-10)*1)/(11(11-1)) =
2,054545455
6. Menghitung COF (Connectivity-based Outlier Factor)
Langkah selanjutnya adalah menghitung Connectivity-based Outlier Factor (COF).
Jadi COFk(1) = 2,1
17
BAB III
METODOLOGI PENELITIAN
Pada bab ini akan di jelaskan mengenai metodologi penambangan
data yang di gunakan dalam penelitian sistem deteksi outlier menggunakan algoritma Connectivity-based Outlier Factor. Metodologi yang di gunakan adalah KDD (Knowledge Discovery in Database) menurut Jiawei Han dan Kamber. Akan di jelaskan pula penerapan dari algoritma Connectivity-based Outlier Factor pada kumpulan data atau data set akademik mahasiswa Teknik Informatika Universitas Sanata Dharma.
3.1Data yang dibutuhkan
Data yang di gunakan dalam penelitian ini adalah Data Akademik
Mahasiswa Teknik Informatika Universitas Sanata Dharma angkatan
2007-2008. Data akademik yang di gunakan adalah dari semester satu
sampai semester empat. Data ini berasal dari penelitian yang dilakukan
oleh Rosa, dkk (2011). Data ini berupa script query yang berisi tabel gudang data dan file ini berformat .sql.
3.2Pengolahan Data
Tahapan pengolahan data untuk data akademik Teknik Informatika
Universitas Sanata Dharma adalah sebagai berikut:
1. Data Integration atau Penggabungan Data
Di dalam tahapan ini di lakukan penggabungan data dari berbagai
sumber data yang ada agar mudah di pilih dan di proses nantinya. Sumber
data yang berupa file .sql (script query) dari penelitian Rosa, dkk (2011) ini kemudian di olah dengan di import ke dalam database dan akan terbuat satu database baru bernama gudangdata. Database gudangdata memiliki sembilan tabel, yaitu tabel dim_angkatan, tabel dim_daftarsmu, tabel
tabel dim_prodifaks, tabel dim_statustes, dan tabel fact_lengkap2.
Gambar 3.1 Database gudangdata.
2. Data Selection atau Seleksi Data
Setelah dilakukan proses Data Integration atau penggabungan data, selanjutnya di dalam tahapan ini akan di lakukan pemilihan data yang di
butuhkan dalam database dan di gunakan untuk proses analisis. Data yang di peroleh dari langkah sebelumnya akan di seleksi sesuai dengan
kebutuhan untuk penelitian ini. Tabel yang di gunakan untuk penelitian ini
adalah tabel fact_lengkap2. Tabel yang lainnya tidak di gunakan karena di
nilai kurang relevan dengan penelitian ini. Di dalam tabel fact_lengkap2
ini terdapat atribut nomor, jumsttb, jummtsttb, jumnem, nomor_mhs,
nama_mhs, ips1, ips2, ips3, ips4, nil11, nil12, nil13, nil14, nil15, final,
statustes, kd21, kd22, kd23, kd24, kd25, kd26, kd27, kd28, nem, sttb,
Gambar 3.2 Isi tabel fact_lengkap2
Langkah selanjutnya setelah seleksi tabel adalah menyeleksi data
dalam tabel. Data yang akan di gunakan adalah data mahasiswa Teknik
Informatika angkatan 2007-2008. Jadi data selain mahasiswa Teknik
Informatika akan di hilangkan. Data mahasiswa yang memiliki atribut
Gambar 3.3 Isi tabel fact_lengkap2 untuk mahasiswa Teknik Informatika
Setelah itu, di lakukan seleksi untuk atribut-atribut yang sesuai
untuk di gunakan dalam penelitian ini. Akan di lakukan penghilangan
atribut-atribut nomor, jumsttb, jummtsttb, jumnem, sttb, sk_jeniskel,
sk_status, sk_kabupaten, sk_daftarsmu, dan sk_prodi.
Gambar 3.4 Isi tabel fact_lengkap2 setelah seleksi
3. Data Transformation atau Transformasi Data
Di dalam tahapan ini, di lakukan pengubahan dan penggabungan
mudah di proses. Atribut-atribut yang di gunakan memiliki tipe atau jenis
yang berbeda sehingga membutuhkan transformasi data untuk
penyeragaman data sehingga datanya dapat lebih mudah untuk di tambang.
Contohnya atribut ips1, ips2, ips3, dan ips4 memiliki nilai maksimal 4.00.
Untuk atribut nil11, nil12, nil13, nil14, dan nil15 memiliki nilai maksimal
10.00. Sedangkan untuk atribut final memiliki nilai maksimal 100.00.
Karena perbedaan nilai maksimal masing-masing atribut tersebut,
maka harus di lakukan pengubahan nilai maksimal. Atribut nil11, nil12,
nil13, nil14, nil15, dan final akan di ubah nilai maksimalnya sehingga
menjadi satu bentuk dengan atribut ips1, ips2, ips3, dan ips4 yaitu 4.00.
Untuk penggabungan data dari berbagai macam bentuk menjadi
satu bentuk yang sama tersebut di gunakan rumus min-max normalization.
Keterangan :
v’ : Nilai yang di cari untuk di normalisasi. v : Nilai yang belum di normalisasi. minA : Nilai minimum dari atribut A. maxA : Nilai maksimum dari atribut A. new_maxA : Nilai maksimum baru dari atribut A. new_minA : Nilai minimum baru dari atribut A.
Contoh perhitungan menggunakan rumus min-max normalization untuk atribut nil11, nil12, nil13, nil14, dan nil15 adalah sebagai berikut.
nil11 adalah 8.00. Akan dilakukan transformasi untuk nil11 agar nilai
maksimumnya 4.00. Di notasikan v = 8.00, minA = 0.00, maxA = 10.00, new_maxA = 4.00, new_minA = 0.00. Jadi v’ = ((8.00 - 0.00) / (10.00 – 0.00)) * (4.00 - 0.00) + 0.00. v’ = (8 / 10) * 4. v’ = 3.20.
Akan di berikan satu contoh perhitungan dalam tabel untuk atribut
ips1, nil11, nil12, nil13, nil14, dan nil15. Atribut nil11, nil12, nil13, nil14, A A A A A A min new min new max new min max min v
v' ( _ _ ) _
dan nil15 akan di seragamkan nilai maksimumnya adalah 4.00.
Tabel 3.1 Contoh perhitungan min-max normalization untuk atribut
nil11, nil12, nil13, nil14, dan15.
Nomor ips1 nil11 nil12 nil13 nil14 nil15
1. 3.72 8.00 6.00 6.00 7.00 5.00
2. 2.89 6.00 5.00 5.00 7.00 5.00
3. 2.56 6.00 4.00 5.00 7.00 5.00
4. 3.28 7.00 6.00 7.00 6.00 6.00
5. 1.89 6.00 5.00 6.00 6.00 7.00
6. 1.44 10.00 5.00 9.00 6.00 7.00
7. 4.00 6.00 6.00 4.00 4.00 7.00
8. 1.72 3.00 2.00 8.00 3.00 1.00
9. 2.89 5.00 5.00 8.00 5.00 7.00
10. 2.94 7.00 5.00 5.00 5.00 5.00
11. 2.94 6.00 4.00 6.00 3.00 7.00
12. 2.44 5.00 5.00 6.00 5.00 5.00
13. 1.72 7.00 6.00 8.00 8.00 2.00
Tabel 3.2 Setelah di hitung menggunakan rumus min-max
normalization untuk atribut nil11, nil12, nil13, nil14, dan15.
Nomor ips1 nil11 nil12 nil13 nil14 nil15
1. 3.72 3.20 2.40 2.40 2.80 2.00
2. 2.89 2.30 2.00 2.00 2.80 2.00
3. 2.56 2.40 1.60 2.00 2.80 2.00
4. 3.28 2.80 2.40 2.80 2.40 2.40
5. 1.89 2.40 2.00 2.40 2.40 2.80
6. 1.44 4.00 2.00 3.60 2.40 2.80
7. 4.00 2.40 2.40 1.60 1.60 2.80
8. 1.72 1.20 0.80 3.20 1.20 0.40
10. 2.94 2.80 2.00 2.00 2.00 1.60
11. 2.94 2.40 1.60 2.40 1.20 2.80
12. 2.44 2.00 2.00 2.40 2.00 2.00
13. 1.72 2.80 2.40 3.20 3.20 0.80
Sedangkan untuk contoh perhitungan menggunakan rumus min-max normalization untuk atribut final adalah sebagai berikut. final = 67.80. Akan dilakukan transformasi untuk final agar nilai maksimumnya
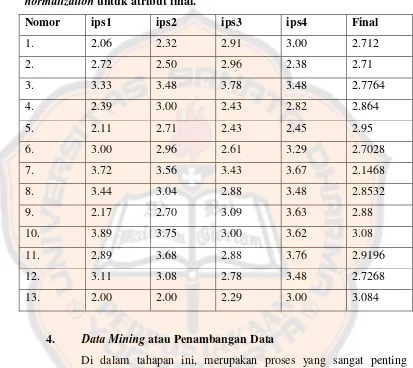
4.00. Di notasikan v = 67.80, minA = 0.00, maxA = 100.00, new_maxA = 4.00, new_minA = 0.00. Jadi v’ = ((67.80 - 0.00) / (100.00 – 0.00)) * (4.00 - 0.00) + 0.00. v’ = (67.80 / 100) * 4. v’ = 2.712.
Akan di berikan satu contoh perhitungan dalam tabel untuk atribut
ips1, ips2, ips3, ips4, dan final. Atribut final akan di seragamkan nilai
maksimumnya adalah 4.00.
Tabel 3.3 Contoh perhitungan min-max normalization untuk atribut
final.
Nomor ips1 ips2 ips3 ips4 Final
1. 2.06 2.32 2.91 3.00 67.80
2. 2.72 2.50 2.96 2.38 67.75
3. 3.33 3.48 3.78 3.48 69.41
4. 2.39 3.00 2.43 2.82 71.60
5. 2.11 2.71 2.43 2.45 73.75
6. 3.00 2.96 2.61 3.29 67.57
7. 3.72 3.56 3.43 3.67 78.67
8. 3.44 3.04 2.88 3.48 71.33
9. 2.17 2.70 3.09 3.63 72.00
10. 3.89 3.75 3.00 3.62 77.00
11. 2.89 3.68 2.88 3.76 72.99
[image:43.595.103.518.217.748.2]13. 2.00 2.00 2.29 3.00 77.10
Tabel 3.4 Setelah di hitung menggunakan rumus min-max
normalization untuk atribut final.
Nomor ips1 ips2 ips3 ips4 Final
1. 2.06 2.32 2.91 3.00 2.712
2. 2.72 2.50 2.96 2.38 2.71
3. 3.33 3.48 3.78 3.48 2.7764
4. 2.39 3.00 2.43 2.82 2.864
5. 2.11 2.71 2.43 2.45 2.95
6. 3.00 2.96 2.61 3.29 2.7028
7. 3.72 3.56 3.43 3.67 2.1468
8. 3.44 3.04 2.88 3.48 2.8532
9. 2.17 2.70 3.09 3.63 2.88
10. 3.89 3.75 3.00 3.62 3.08
11. 2.89 3.68 2.88 3.76 2.9196
12. 3.11 3.08 2.78 3.48 2.7268
13. 2.00 2.00 2.29 3.00 3.084
4. Data Mining atau Penambangan Data
Di dalam tahapan ini, merupakan proses yang sangat penting
dimana metode cerdas di lakukan dan di terapkan untuk mengekstrak pola
data. Data akademik Teknik Informatika angkatan 2007-2008 yang telah
di olah, akan di analisis menggunakan algoritma Connectivity-based Outlier Factor. Dalam tahap ini, akan di gunakan beberapa variabel untuk melakukan pengujian. Variabel-variabel yang di gunakan adalah sebagai
berikut:
1. Input
Variabel input yang di gunakan di ambil dari tabel
[image:44.595.103.516.183.551.2]tersebut adalah nomor_mhs, nama_mhs, ips1, ips2, ips3, ips4, nil1,
nil2, nil3, nil4, nil5, final, statustes, kd21, kd22, kd23, kd24, kd25,
kd26, kd27, kd28, dan nem.
2. Output
Variabel output yang di gunakan berupa mahasiswa yang di
anggap sebagai outlier setelah di lakukan pendeteksian
menggunakan algoritma Connectivity-based Outlier Factor.
Akan di berikan contoh penambangan data menggunakan algoritma
Connectivity-based Outlier Factor. Data yang di gunakan adalah sampel mahasiswa Teknik Informatika angkatan 2007-2008 berjumlah 13.
1. Perhitungan data mahasiswa angkatan 2007 pendaftar jalur reguler.
Dengan membandingan variabel ips1 dengan nil1, nil2, nil3,nil4, dan
nil5.
Gambar 3.5 Contoh Data angkatan 2007 jalur reguler.
Dari data di atas, kemudian di cari jarak perbandingan setiap obyek
Setelah di hitung jarak, maka tentukan k = 7. Cari 7 jarak paling dekat terhadap obyek p. Setelah mendapat 7 jarak terdekat, kemudian di cari jarak terbesar atau maksimum dari obyek p. Untuk obyek P1 dapat
diperoleh jangkauan terbesar adalah 1,7385. Jangkauan terbesar atau
maksimum juga di sebut sebagai k-distance.
2. Mencari Nk(p)
Dari contoh di atas akan di cari Nk(P1) terhadap p=P1. Jarak terdekat dari titik P1 adalah P3, P4, P5, P6, P9, P11, P12
Jadi Nk(P1) = { P3, P4, P5, P6, P9, P11, P12}.
3. Mencari SBN-path
∪ {P1}.
Pada langkah ini, di lakukan penggabungan antara p=P1 dengan Nk(P1). Perhitungan di lakukan secara berantai dengan ukuran jarak terdekat dari
titik tertentu (< p1, p2, ..., pr>).
Dari contoh di atas, jalur atau path dari titik P1.
Jadi SBN-path atau s1 = < P1, P12, P4, P3, P11, P9, P5, P6>.
4. Mencari SBN-trail
Langkah yang berikutnya adalah mencari SBN-trail untuk s1 atau SBN-path terhadap titik P1.
SBN-trail adalah urutan edge terhadap s1 (< dist(e1), ..., dist(er-1)>).
Jadi SBN-trail atau tr1 = <
(P1,P12),(P12,P4),(P4,P3),(P3,P11),(P11,P9),(P9,P5),(P5,P6) >
5. Menghitung Cost Description Sequence
Description Sequence adalah jarak dari masing-masing edge pada SBN- trail.
Maka Cost Desciption Sequence atau c1 terhadap tr1 :
c1 = < 0,9811; 0,1189; 0,0245; 0,1854; 0,0644; 0,2258; 0,1385>
6. Menghitung ac-dist atau Average Chaining Distance
Langkah berikutnya yaitu menghitung ac-dist. ac-dist adalah rata-rata dari bobot CDS(Cost Description Sequence) pada SBN-trail.
7. Menghitung COF (Connectivity-based Outlier Factor)
Langkah selanjutnya adalah menghitung Connectivity-based Outlier Factor (COF).
Jadi COFk(P1) = 0,966746822
Pada contoh di atas, dapat di tentukan bahwa P1 bukan outlier. Karena nilai COF tidak lebih dari 1.
5. Pattern Evaluation atau Evaluasi Pola
Di dalam tahapan ini, melakukan evaluasi terhadap pattern yang telah di proses, aspek-aspek yang di evaluasi adalah hasil output yang di dapat setelah proses data mining dilakukan.
.
6. Knowledge Presentation atau Presentasi Pengetahuan
Di dalam tahapan ini, di lakukan penyajian hasil dari proses data mining yang sudah di proses. Sehingga dalam tahapan ini akan di buat sebuah sistem berbasis desktop menggunakan bahasa pemrograman java
30
BAB IV
ANALISIS DAN PERANCANGAN SISTEM
Pada bab ini akan di jelaskan analisis dan perancangan sistem deteksi
outlier menggunakan algoritma Connectivity-based Outlier Factor.
6.1Gambaran Umum Sistem
Universitas Sanata Dharma adalah salah satu universitas swasta di
Yogyakarta yang setiap tahunnya akan melakukan seleksi penerimaan mahasiswa
baru. Terdapat dua jalur seleksi penerimaan mahasiswa baru, yaitu jalur prestasi
dan jalur tes tertulis. Untuk jalur prestasi, di gunakan nilai rata-rata kognitif dalam
raport kelas XI semester satu dan dua dengan rata-rata nilai minimal 75. Dari nilai
rata-rata kognitif tersebut dapat di peroleh nilai final sehingga calon mahasiswa
tersebut dapat di tentukan untuk di terima atau tidak di Universitas Sanata
Dharma. Sedangkan untuk jalur test tertulis, terdapat lima komponen nilai, yaitu
komponen nilai penalaran numerik, komponen nilai penalaran verbal, komponen
nilai hubungan ruang, komponen nilai bahasa inggris, dan komponen nilai
kemampuan numerik. Dari kelima komponen tersebut akan di rata-rata sehingga
dapat menghasilkan nilai final untuk penentuan apakah calon mahasiswa tersebut
dapat di terima di Universitas Sanata Dharma.
Setelah di lakukan seleksi penerimaan mahasiswa baru, maka akan di
dapat mahasiswa yang di nyatakan di terima di Universitas Sanata Dharma. Para
mahasiswa baru ini, akan mengikuti perkuliahan reguler dan setiap akhir semester
akan mendapat hasil nilai berupa Indeks Prestasi. Nilai Indeks Prestasi Semester
dari mahasiswa tersebut dari semester satu sampai empat akan di gunakan sebagai
pembanding dengan nilai masuk mahasiswa tersebut baik jalur tes tertulis maupun
jalur prestasi.
Pada akhir semester IV, akan di analisa apakah mahasiswa tersebut layak
Apabila seorang mahasiswa memiliki nilai masuk yang bagus, tentunya nilai
Indeks Prestasinya juga bagus. Namun tidak menutup kemungkinan terdapat
mahasiswa yang memiliki nilai masuk yang bagus tetapi indeks prestasi
semesternya jelek dan sebaliknya, hal ini menjadi sesuatu yang menarik untuk di
teliti karena berkaitan dengan deteksi outlier.
Sebuah sistem pendekteksi outlier akan di buat untuk mendeteksi kejadian langka tersebut. Sistem ini akan di buat berdasarkan algoritma Connectivity-based Outlier Factor dengan pendekatan density based. Sistem ini di harapkan dapat meneliti mahasiswa-mahasiswa mana saja yang di indikasikan sebagai outlier.
6.1.1 Diagram Use Case
Diagram Use case merupakan suatu model atau pemodelan yang di gunakan untuk menggambarkan kebutuhan fungsional yang di harapkan
dari sebuah sistem. Jadi, sebuah sistem terdapat pengguna atau user dan sistem yang berjalan yang saling berinteraksi. Diagram use case beserta penjelasannya akan di jelaskan pada lampiran 1.
Pada diagram use case, terdapat Pengguna atau user yang menggunakan sistem pendeteksian outlier ini. Pengguna dapat melakukan input data yang berupa file Excel atau file berekstensi .csv serta dari database. Pengguna selanjutnya dapat melakukan pencarian outlier. Fungsi utama yang lain adalah pengguna dapat menyimpan hasil
pendeteksian outlier. Ketiga fungsi di atas hanya bisa di lakukan secara berurutan karena terdapat depends on, dimana pengguna harus menginputkan data terlebih dahulu, kemudian melakukan proses pencarian
outlier, dan selanjutnya menyimpan data hasil pendeteksian.
Fungsi tambahan lain adalah pengguna dapat menyeleksi atribut.
Fungsi ini bisa berjalan apabila pengguna telah melakukan salah satu
6.1.2 Narasi Use Case
Untuk mengetahui detail keseluruhan dari narasi use case dapat dilihat pada bagian lampiran 2.
6.2Perancangan Sistem Secara Umum
4.2.1 Input Sistem
Input untuk sistem yang akan di bangun ini berupa data bebas dari
user dengan file berekstensi .xls atau file excel. Inputan dapat juga berupa data dalam suatu tabel dalam database. Di dalam sistem yang akan di bangun ini, data dapat berukuran apa saja sehingga user dapat mencari outlier pada semua jenis data.
Inputan untuk mencari outlier dalam sistem ini terdapat dua macam, yaitu:
1. k
k adalah jangkauan atau tetangga terdekat dari obyek p untuk mendefinisikan local neighbourhood.
Berikut ini merupakan rincian data yang akan di gunakan dalam
penelitian sistem deteksi outlier menggunakan algoritma Connectivity-based Outlier Factor:
a. Data Hasil Seleksi Masuk Jalur Tes
No. Nama
Atribut
Penjelasan Nilai
1. Nomor urut Atribut ini
merupakan
nama alias dari
nomor
mahasiswa
pada tiap obyek
1-126
atribut dari
komponen nilai
tes 1
3. Nil2 Merupakan
atribut dari
komponen nilai
tes 2
0-4.00
4. Nil3 Merupakan
atribut dari
komponen nilai
tes 3
0-4.00
5. Nil4 Merupakan
atribut dari
komponen nilai
tes 4
0-4.00
6. Nil5 Merupakan
atribut dari
komponen nilai
tes 5
0-4.00
b. Data Hasil Seleksi Masuk Jalur Prestasi
No. Nama
Atribut
Penjelasan Nilai
1. Nomor urut Atribut ini
merupakan
nama alias dari
nomor
mahasiswa
pada tiap obyek
1-126
atribut nilai dari
rata-rata nilai
kognitif pada
rapor
c. Data Hasil Seleksi Masuk (Gabung)
No. Nama
Atribut
Penjelasan Nilai
1. Nomor urut Atribut ini
merupakan
nama alias dari
nomor
mahasiswa
pada tiap obyek
1-126
2. Ips1 Merupakan
atribut nilai dari
Indeks Prestasi
mahasiswa
semester 1
0-4.00
3. Ips2 Merupakan
atribut nilai dari
Indeks Prestasi
mahasiswa
semester 2
0-4.00
4. Ips3 Merupakan
atribut nilai dari
Indeks Prestasi
mahasiswa
semester 3
0-4.00
atribut nilai dari
Indeks Prestasi
mahasiswa
semester 4
6. Final Merupakan
atribut nilai dari
rata-rata nilai
kognitif pada
rapor
0-4.00
4.2.2 Proses Sistem
Proses sistem deteksi outlier adalah sebagai berikut: 1. Pengambilan Data
Pada tahap ini, user dapat melakukan pengambilan data dengan memasukan data yang berekstensi .xls dan .csv. Selain itu, user dapat mengambil data pada tabel dalam database. Setelah itu akan di tampilkan atribut-atribut yang di gunakan, kemudian user akan memilih atau menyeleksi atribut-atribut yang sekiranya di perlukan
dalam proses pendeteksian outlier. 2. Perhitungan Jarak Obyek Data
Pada tahap ini akan di lakukan perhitungan jarak antar obyek
menggunakan rumus Euclidean Distance. Perhitungan ini di lakukan agar di dapatkan jarak masing-masing obyek dengan obyek lainnya.
3. Pencarian Outlier Berdasarkan Parameter k
Start
Data bertipe .xls
Data bertipe