ABSTRAK
Penambangan data adalah proses mengekstrak informasi atau pengetahuan dari data dalam jumlah yang besar. Secara umum, penambangan data dapat diklasifikasikan dalam empat kategori yaitu deteksi dependensi, identifikasi kelas, deskripsi kelas dan deteksi outlier. Tiga kategori pertama berkaitan dengan pola yang dimiliki oleh banyak objek, atau pada objek dengan persentase yang besar dalam dataset. Sebaliknya, kategori keempat berfokus pada objek dengan persentase yang kecil, yang umumnya sering diabaikan atau dihilangkan karena dianggap noise (Knorr & Ng, 1998).
Pada tugas akhir ini algoritma Block-based Nested-Loop digunakan untuk deteksi outlier pada data numerik. Data yang digunakan adalah data akademik mahasiswa Universitas Sanata Dharma Prodi Teknik Informatika Angkatan 2007 dan 2008. Data tersebut terdiri dari data nilai tes masuk mahasiswa yang diterima melalui jalur tes tertulis maupun jalur prestasi dan nilai indeks prestasi dari semester satu sampai empat.
Hasil penelitian ini yaitu sebuah perangkat lunak yang dapat digunakan sebagai alat bantu untuk mendeteksi outlier menggunakan algoritma Block-based Nested-Loop. Pengujian terhadap sistem ini terdiri dari pengujian blackbox, pengujian review dan validitas oleh pengguna, pengujian efek perubahan nilai atribut penambangan data dan pengujian waktu deteksi outlier berdasarkan jumlah blok.
Berdasarkan hasil pengujian blackbox yang dilakukan, disimpulkan bahwa sistem pendeteksi outlier ini dapat menghasilkan keluaran yang sesuai dengan yang diharapkan pengguna dan mampu menangani error terhadap fungsi – fungsi yang tidak berjalan sesuai aturan. Berdasarkan hasil pengujian review dan validitas oleh pengguna disimpulkan bahwa sistem dapat menghasilkan data yang dinyatakan sebagai outlier. Berdasarkan hasil pengujian efek perubahan nilai atribut penambangan data disimpulkan bahwa pemilihan nilai atribut M dan D mempengaruhi hasil deteksi outlier. Dari hasil pengujian waktu deteksi outlier berdasarkan jumlah blok disimpulkan bahwa penggunaan blok-blok data dapat mempercepat proses deteksi outlier.
ABSTRACT
Data mining is the process of extracting information or knowledge from large amounts of data. In general, data mining can be classified into four categories: dependency detection, identification of classes, class descriptions and outlier detection. The first three categories correspond to the pattern that applied to many objects, or to a large percentage of objects in the dataset. The fourth category, in contrast focuses on a very small percentage of data objects, which are often ignored or discarded as noise (Knorr & Ng, 1998).
In this thesis, the Block-based Nested-Loop algorithm was used to perform outlier detections on numerical data. The data used in this thesis are academic data of students batch 2007 and 2008 of Informatics Engineering Study Program of Sanata Dharma University. The data consists of student admission data from regular admission track as well as students from outstanding track, and student academic data (Grade Point Average) of those students from first semester until fourth semester.
The results of this research is a software that can be used as a tool to detect outliers using Block-based Nested-Loop algorithm. The testing of this system consists of blackbox testing, validation testing by users, investigation of the effects of attribute changes of M and D, and investigation of time needed to detect outliers based on the number of blocks. M is the maximum number of objects within the D-neighbourhood of an outlier, whereas D is the maximum distance between any pair of objects that define as a neighbor.
Based on blackbox testing, it can be concluded that the outlier detection‟s system could produce output as expected and handle any incorrect functions. Based on user‟s validation, it can be concluded that the results of the system are confirmed as outliers. Based on the investigation of the effects of attribute changes, it can be concluded that the value of M dan D influence the number of generated outliers. Based on investigation of time needed to detect outliers, it can be concluded that data blocks usage could speed up the process of outlier detection.
i
DETEKSI OUTLIER
MENGGUNAKAN ALGORITMA BLOCK-BASED NESTED-LOOP STUDI KASUS : DATA AKADEMIK MAHASISWA
PROGRAM STUDI TEKNIK INFORMATIKA UNIVERSITAS SANATA DHARMA
SKRIPSI
Diajukan untuk Memenuhi salah Satu Syarat
Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika
Disusun Oleh : Fiona Endah Kwa
NIM : 095314041
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
OUTLIER DETECTION
USING BLOCK-BASED NESTED-LOOP ALGORITHM CASE STUDY : STUDENT ACADEMIC DATA OF INFORMATICS ENGINEERING STUDY PROGRAM,
SANATA DHARMA UNIVERSITY
A THESIS
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Komputer Degree In Informatics Engineering Study Program
By :
Fiona Endah Kwa NIM : 095314041
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
v
HALAMAN PERSEMBAHAN
“I can do all things through Christ who strengthens me.”
(Philippians 4:13)
~ IF IT’S EASY, IT WON’T BE AMAZING~
Karya saya ini saya persembahkan teristimewa untuk :
Keluarga, Dosen & Sahabat
Terima kasih untuk kasih sayang, doa, motivasi, semangat serta bantuan yang kalian berikan baik di saat susah
vii
ABSTRAK
Penambangan data adalah proses mengekstrak informasi atau pengetahuan dari data dalam jumlah yang besar. Secara umum, penambangan data dapat diklasifikasikan dalam empat kategori yaitu deteksi dependensi, identifikasi kelas, deskripsi kelas dan deteksi outlier. Tiga kategori pertama berkaitan dengan pola yang dimiliki oleh banyak objek, atau pada objek dengan persentase yang besar dalam dataset. Sebaliknya, kategori keempat berfokus pada objek dengan persentase yang kecil, yang umumnya sering diabaikan atau dihilangkan karena dianggap noise (Knorr & Ng, 1998).
Pada tugas akhir ini algoritma Block-based Nested-Loop digunakan untuk deteksi outlier pada data numerik. Data yang digunakan adalah data akademik mahasiswa Universitas Sanata Dharma Prodi Teknik Informatika Angkatan 2007 dan 2008. Data tersebut terdiri dari data nilai tes masuk mahasiswa yang diterima melalui jalur tes tertulis maupun jalur prestasi dan nilai indeks prestasi dari semester satu sampai empat.
Hasil penelitian ini yaitu sebuah perangkat lunak yang dapat digunakan sebagai alat bantu untuk mendeteksi outlier menggunakan algoritma Block-based Nested-Loop. Pengujian terhadap sistem ini terdiri dari pengujian blackbox, pengujian review dan validitas oleh pengguna, pengujian efek perubahan nilai atribut penambangan data dan pengujian waktu deteksi outlier berdasarkan jumlah blok.
Berdasarkan hasil pengujian blackbox yang dilakukan, disimpulkan bahwa sistem pendeteksi outlier ini dapat menghasilkan keluaran yang sesuai dengan yang diharapkan pengguna dan mampu menangani error terhadap fungsi – fungsi yang tidak berjalan sesuai aturan. Berdasarkan hasil pengujian review dan validitas oleh pengguna disimpulkan bahwa sistem dapat menghasilkan data yang dinyatakan sebagai outlier. Berdasarkan hasil pengujian efek perubahan nilai atribut penambangan data disimpulkan bahwa pemilihan nilai atribut M dan D mempengaruhi hasil deteksi outlier. Dari hasil pengujian waktu deteksi outlier berdasarkan jumlah blok disimpulkan bahwa penggunaan blok-blok data dapat mempercepat proses deteksi outlier.
viii
ABSTRACT
Data mining is the process of extracting information or knowledge from large amounts of data. In general, data mining can be classified into four categories: dependency detection, identification of classes, class descriptions and outlier detection. The first three categories correspond to the pattern that applied to many objects, or to a large percentage of objects in the dataset. The fourth category, in contrast focuses on a very small percentage of data objects, which are often ignored or discarded as noise (Knorr & Ng, 1998).
In this thesis, the Block-based Nested-Loop algorithm was used to perform outlier detections on numerical data. The data used in this thesis are academic data of students batch 2007 and 2008 of Informatics Engineering Study Program of Sanata Dharma University. The data consists of student admission data from regular admission track as well as students from outstanding track, and student academic data (Grade Point Average) of those students from first semester until fourth semester.
The results of this research is a software that can be used as a tool to detect outliers using Block-based Nested-Loop algorithm. The testing of this system consists of blackbox testing, validation testing by users, investigation of the effects of attribute changes of M and D, and investigation of time needed to detect outliers based on the number of blocks. M is the maximum number of objects within the D-neighbourhood of an outlier, whereas D is the maximum distance between any pair of objects that define as a neighbor.
Based on blackbox testing, it can be concluded that the outlier detection‟s system could produce output as expected and handle any incorrect functions. Based on user‟s validation, it can be concluded that the results of the system are confirmed as outliers. Based on the investigation of the effects of attribute changes, it can be concluded that the value of M dan D influence the number of generated outliers. Based on investigation of time needed to detect outliers, it can be concluded that data blocks usage could speed up the process of outlier detection.
x
KATA PENGANTAR
Puji syukur kepada Tuhan Yesus Kristus, atas segala berkat dan karunia
sehingga penulis dapat menyelesaikan skripsi ini dengan judul “Deteksi Outlier Menggunakan Algoritma Block-based Nested-Loop Studi Kasus : Data Akademik Mahasiswa Program Studi Teknik Informatika Universitas Sanata Dharma”.
Penelitian ini berjalan dengan baik dari awal hingga akhir karena adanya
dukungan doa, semangat dan motivasi yang diberikan oleh banyak pihak. Untuk
itu, penulis ingin mengucapkan terima kasih kepada:
1. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku Dekan Fakultas
Sains dan Teknologi.
2. Ibu Ridowati Gunawan, S.Kom., M.T., selaku Ketua Program Studi
Teknik Informatika.
3. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku Dosen
Pembimbing yang telah dengan sabar membimbing dan memberikan
motivasi.
4. Ibu Ridowati Gunawan, S.Kom., M.T. dan Ibu Sri Hartati Wijono, S.Si.,
M.Kom. selaku dosen penguji atas kritik dan saran yang telah diberikan.
5. Bapak Iwan Binanto, M.Cs. selaku Dosen Pembimbing Akademik.
6. Seluruh Dosen yang telah mendidik dan memberikan ilmu pengetahuan
selama penulis menjalani studi di Universitas Sanata Dharma Yogyakarta.
7. Pihak sekretariat dan laboran yang turut membantu penulis menyelesaikan
xi
8. Kedua orang tua terkasih, Papa Alex Kwa, BE, SE dan Mama Selvina
Yarangga untuk setiap doa, kasih sayang, perhatian serta dukungan yang
selalu diberikan kepada penulis.
9. Semua saudara tersayang, Kak Victor, Kak Sherli, Kak Febby, Kak Vani
dan Kak Jenie. Terima kasih sudah memberikan motivasi dan berbagai
masukan yang sangat membantu penulis dalam menyelesaikan skripsi ini.
10.Para sahabat tersayang, Nidya, Friska, Margaretha, Cristy, Phebe,
Mayanti dan Rico. Terima kasih untuk persahabatan yang indah dan doa
serta dukungan kalian bagi penulis.
11.Kedua rekan kerja skripsi ini, Setyo dan Tomy. Terima kasih telah saling
berbagi ilmu serta suka dan duka dari awal hingga akhir penyelesaian
skripsi ini.
12.Seluruh teman-teman kuliah TI 2009, terima kasih untuk kebersamaan
kita selama menjalani masa perkuliahan.
13.Teman-teman Tim Usher GKI Gejayan, terima kasih karena selalu
mendukung perjuangan penulis lewat doa setiap minggunya.
14.Pihak-pihak lain yang turut membantu penulis dalam menyelesaikan tugas
akhir ini, yang tidak dapat disebutkan satu per satu.
Penelitian skripsi ini masih memiliki banyak kekurangan. Untuk itu,
penulis sangat membutuhkan saran dan kritik untuk perbaikan di masa yang akan
datang. Semoga penelitian skripsi ini dapat membawa manfaat bagi semua pihak.
Yogyakarta, 23 Agustus 2013
xii
DAFTAR ISI
HALAMAN JUDUL………...i
HALAMAN JUDUL (INGGRIS)………...ii
HALAMAN PERSETUJUAN………..iii
HALAMAN PENGESAHAN………iv
HALAMAN PERSEMBAHAN………..v
PERNYATAAN KEASLIAN KARYA………vi
DAFTAR TABEL………...xvii
DAFTAR GAMBAR………...xix
Bab 1………...1
1.6 Sistematika Penulisan ... 6
1.6.1 Bab 1 Pendahuluan ... 6
1.6.2 Bab 2 Landasan Teori ... 6
1.6.3 Bab 3 Metode Penelitian ... 6
1.6.4 Bab 4 Analisis dan Perancangan Sistem ... 7
1.6.5 Bab 5 Implementasi Sistem ... 7
1.6.6 Bab 6 Pengujian dan Analisis Hasil Pengujian ... 7
1.6.7 Bab 7 Kesimpulan dan Saran ... 8
1.6.8 Daftar Pustaka ... 8
Bab 2………...9
LANDASAN TEORI………..9
xiii
2.2.5.1 Algoritma Block-based Nested-Loop ... 16
Bab 3……….19
METODE PENELITIAN……….19
3.1 Data ... 19
3.2 Pengolahan Data ... 20
3.2.1 Pemrosesan Awal Data ... 20
3.2.2 Seleksi Data ... 20
3.2.3 Transformasi Data ... 21
3.2.4 Penambangan Data ... 22
3.2.5 Evaluasi Pola yang Ditemukan ... 23
3.2.6 Presentasi Pengetahuan ... 24
3.3 Contoh Implementasi Algoritma Block-based Nested-Loop ... 24
Bab 4……….34
ANALISIS DAN PERANCANGAN SISTEM………34
4.1 Identifikasi Sistem ... 34
4.2 Input Sistem, Proses Sistem dan Output Sistem ... 35
4.2.1 Input Sistem ... 35
4.2.2 Proses Sistem ... 37
4.2.3 Output Sistem ... 39
4.3 Perancangan Struktur Data ... 40
4.4 Diagram Use Case ... 45
4.5 Perancangan Sistem ... 46
4.5.1 Diagram Konteks ... 46
4.5.2 Diagram Aktivitas ... 46
4.5.3 Diagram Kelas Analisis ... 47
4.5.4 Diagram Sequence ... 48
4.5.3 Diagram Kelas Desain ... 49
xiv
4.5.6.1 Detail Algoritma Pada Method di Kelas HalamanUtama ... 56
4.5.6.2 Detail Algoritma Pada Method di Kelas HalamanPilihDB ... 67
4.5.6.3 Detail Algoritma Pada Method di Kelas HalamanPilihTabel ... 68
4.5.6.4 Detail Algoritma Pada Method di Kelas DistribusiAtribut ... 69
4.5.6.5 Detail Algoritma Pada Method di Kelas Graph ... 71
4.5.6.6 Detail Algoritma Pada Method di Kelas DatabaseConnection ... 78
4.5.6.7 Detail Algoritma Pada Method di Kelas Database ... 80
4.5.6.8 Detail Algoritma Pada Method di Kelas CheckBoxTableModel .. 81
4.6 Perancangan Antarmuka ... 82
4.6.1 Halaman Awal ... 83
4.6.2 Halaman Utama (Preprocess) ... 83
4.6.3 Halaman Utama (Deteksi Outlier) ... 85
4.6.4 Halaman Distribusi Atribut ... 86
4.6.5 Halaman Pilih DB ... 87
4.6.6 Halaman Pilih Tabel ... 88
4.6.7 Halaman Bantuan ... 88
4.6.8 Halaman Konfirmasi Keluar ... .89
BAB 5……….…...90
IMPLEMENTASI SISTEM………..…90
5.1 Implementasi Antarmuka ... 91
5.1.1 Implementasi Halaman Awal ... 91
5.1.2 Implementasi Halaman Utama ... 92
5.1.3 Implementasi Halaman Pilih DB ... 96
5.1.4 Implementasi Halaman Pilih Tabel ... 97
5.1.5 Implementasi Halaman Distribusi Atribut ... 99
5.1.6 Implementasi Halaman Bantuan ... 100
5.1.7 Implementasi Halaman Konfirmasi Keluar ... 100
5.1.8 Implementasi Pengecekan Masukan ... 101
5.1.9 Implementasi Halaman Open File ... 104
5.2 Implementasi Struktur Data ... 105
5.2.1 Implementasi Kelas Vertex ... 105
5.2.2 Implementasi Kelas Graph ... 107
xv
5.3 Implementasi Kelas ... 110
5.3.1 Implementasi Kelas HalamanUtama ... 110
5.3.2 Implementasi Kelas HalamanPilihDB ... 123
5.3.3 Implementasi Kelas HalamanPilihTabel ... 124
5.3.4 Implementasi Kelas HalamanDistribusiAtribut ... 126
5.3.5 Implementasi Kelas SeleksiAtribut ... 127
5.3.6 Implementasi Kelas DatabaseConnection ... 128
5.3.7 Implementasi Kelas Database ... 130
5.3.8 Implementasi Kelas CheckBoxTableModel ... 132
5.3.9 Implementasi Kelas BarChart ... 134
5.3.10 Implementasi Kelas GraphController ... 135
BAB 6………..136
PENGUJIAN DAN ANALISIS HASIL PENGUJIAN………..136
6.1 Fase Implementasi Pengujian ... 136
6.1.1 Rencana Pengujian ... 136
6.1.1.1 Pengujian Blackbox ... 137
6.1.1.1.1 Pengujian DatabaseConnection ... 137
6.1.1.1.2 Pengujian HalamanUtama ... 138
6.1.1.1.3 Pengujian HalamanDistribusiAtribut ... 141
6.1.1.1.5 Pengujian HalamanPilihTabel ... 142
6.1.1.1.6 Kesimpulan Hasil Pengujian Blackbox ... 142
6.1.1.2 Pengujian Review dan Validitas oleh Pengguna ... 143
6.1.1.2.1 Perbandingan Perhitungan Manual dan Sistem ... 143
6.1.1.2.2 Hasil Deteksi dari Sistem untuk Pengujian Review dan Validitas oleh Pengguna ... 144
6.1.1.2.3 Kesimpulan Pengujian Review dan Validitas oleh ... 147
Pengguna ... 147
6.1.1.3 Pengujian Efek Perubahan Nilai Atribut Penambangan Data ... 150
6.1.1.3.1 Kesimpulan Pengujian Efek Perubahan Nilai Atribut Penambangan Data ... 154
xvi
6.1.1.4.1 Kesimpulan Pengujian Perbandingan Waktu Deteksi Outlier
Berdasarkan Jumlah Blok ... 157
6.2 Kelebihan dan Kekurangan Sistem ... 158
6.2.1 Kelebihan Sistem ... 158
6.2.2 Kekurangan Sistem ... 158
BAB 7………..159
KESIMPULAN DAN SARAN………...159
7.1 Kesimpulan ... 159
7.2 Saran ... 159
DAFTAR PUSTAKA……….161
LAMPIRAN………162
Lampiran 1 : Tabel Ringkasan Use Case ... 162
Lampiran 2 : Skenario Use Case ... 162
Lampiran 3 : Diagram Aktivitas ... 166
Lampiran 4 : Tabel Diagram Kelas Analisis ... 169
Lampiran 5 : Diagram Sequence ... 171
xvii
DAFTAR TABEL
Tabel 3.1 Data Mentah dibagi ke dalam 4 Blok………... 26
Tabel 4.1 Tabel Nama Atribut pada Data Akademik Mahasiswa……… 37
Tabel 4.2 Tabel Kelas HalamanUtama………. 56
Tabel 4.3 Tabel Kelas HalamanPilihDB………... 67
Tabel 4.4 Tabel Kelas HalamanPilihTabel………... 68
Tabel 4.5 Tabel Kelas DistribusiAtribut………... 69
Tabel 4.6 Tabel Kelas Graph……… 71
Tabel 4.7 Tabel Kelas DatabaseConnection………. 78
Tabel 4.8 Tabel Kelas Database……… 80
Tabel 4.9 Tabel Kelas CheckBoxTableModel……….. 81
Tabel 4.10 Tabel Kelas BarChart………..82
Tabel 5.1 Tabel Nama Kelas yang Diimplementasikan dalam Sistem………. 90
Tabel 6.1 Tabel Rencana Pengujian………..137
Tabel 6.2 Tabel Pengujian Kelas DatabaseConnection………... 138
Tabel 6.3 Tabel Pengujian Kelas HalamanUtama……… 138
Tabel 6.4 Tabel Pengujian Kelas HalamanDistribusiAtribut………... 141
Tabel 6.5 Tabel Pengujian Kelas HalamanPilihDB……….. 141
Tabel 6.6 Tabel Pengujian Kelas HalamanPilihTabel……….. 142
xviii
Tabel 6.8 Tabel Nilai per Atribut Hasil Outlier Mahasiswa Angkatan 2007 Jalur
Tes Tertulis………. 144
Tabel 6.9 Tabel Jumlah Outlier Berdasarkan Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1
dengan Nilai M dan D yang Berubah-ubah (54 Mahasiswa)…….. 151
Tabel 6.10 Tabel Jumlah Outlier Berdasarkan Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Prestasi Semester 1 dengan
Nilai M dan D yang Berubah-ubah (72 mahasiswa)……….152
Tabel 6.11 Tabel Jumlah Outlier Berdasarkan Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Tes dan Jalur Prestasi
dengan Nilai M dan D yang Berubah-ubah (126 Mahasiswa)…… 153
Tabel 6.12 Tabel Perbadingan Lama Deteksi Outlier Berdasarkan Jumlah Blok pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Tes dan Jalur
xix
DAFTAR GAMBAR
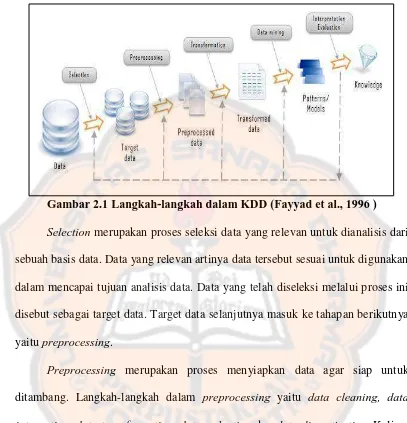
Gambar 2.1 Langkah-langkah dalam KDD (Fayyad et al., 1996 )…………... 10
Gambar 3.1 Gudang data „data_mahasiswa‟……… 20
Gambar 3.2 Data mentah untuk implementasi algoritma Block-based Nested-Loop……… 25
Gambar 3.3 Pengecekan tetangga pada first array antara blok 1 dan blok 1... 27
Gambar 3.4 Hasil akhir pengecekan blok 1 dan blok 1 dalam first array…… 28
Gambar 3.5 Pencarian tetangga dari data first array pada second array…….. 28
Gambar 3.6 Hasil akhir pengecekan blok 1 (first array) dan blok 2 (second array)……….. 29
Gambar 3.7 Pencarian tetangga dari data first array pada second array…….. 30
Gambar 3.8 Hasil akhir pengecekan blok 1 (first array) dan blok 3 (second array)……….. 31
Gambar 3.9 Hasil akhir pengecekan blok 1 (first array) dan blok 4 (second array)……….. 32
Gambar 4.1 Proses Umum Sistem Pendeteksi Outlier Menggunakan Algoritma Block-based Nested-Loop…………...……… 39
Gambar 4.2 Diagram Use Case………. 45
Gambar 4.3 Diagram Konteks……….. 46
Gambar 4.4 Diagram Kelas Analisis……… 47
Gambar 4.5 Diagram Kelas Desain……….. 49
Gambar 4.6 Tampilan Antarmuka Halaman Awal………... 83
xx
Gambar 4.8 Tampilan Antarmuka Halaman Utama (Tab Deteksi Outlier)…..85 Gambar 4.9 Tampilan Antarmuka Halaman Distribusi Atribut………86
Gambar 4.10 Tampilan Antarmuka Halaman Pilih DB……… 87
Gambar 4.11 Tampilan Antarmuka Halaman Pilih Tabel……… 88
Gambar 4.12 Tampilan Antarmuka Halaman Bantuan………. 89
Gambar 4.13 Tampilan Antarmuka Halaman Konfirmasi Keluar……… 89
Gambar 5.1 Antarmuka Halaman Awal………91
Gambar 5.2 Antarmuka Halaman Utama, tab Preprocess……… 92 Gambar 5.3 Antarmuka Halaman Utama, tab Preprocess(File .xls atau .csv)..93 Gambar 5.4 Antarmuka Halaman Utama, tab Preprocess (Seleksi atribut)…. 94 Gambar 5.5 Antarmuka Halaman Utama, tab Deteksi Outlier...95 Gambar 5.6 Antarmuka Halaman Utama, tab Deteksi Outlier (hasil deteksi
outlier)……… 95
Gambar 5.7 Dialog Untuk Menyimpan Hasil Deteksi Outlier………. 96 Gambar 5.8 Pesan Sukses Menyimpan File Hasil Deteksi Outlier………….. 96
Gambar 5.9 Antarmuka Halaman Pilih DB……….. 97
Gambar 5.10 Pesan Sukses Melakukan Koneksi Ke Basis data………... 97
Gambar 5.11 Antarmuka Halaman Pilih Tabel……….98
Gambar 5.12 Antarmuka Halaman Utama, tab Preprocess (input tabel dari basis
data)……… 98
Gambar 5.13 Antarmuka Halaman Distribusi Atribut……….. 99
Gambar 5.14 Antarmuka Grafik Distribusi Atribut……….. 99
xxi
Gambar 5.16 Antarmuka Halaman Konfirmasi Keluar……… 101
Gambar 5.17 Pesan Kesalahan (1)……… 101
Gambar 5.18 Pesan Kesalahan (2)……… 102
Gambar 5.19 Pesan Kesalahan (3)………... 102
Gambar 5.20 Pesan Kesalahan (4)……… 102
Gambar 5.21 Pesan Kesalahan (5)……… 103
Gambar 5.22 Pesan Kesalahan (6)……… 103
Gambar 5.23 Pesan Kesalahan (7)……… 103
Gambar 5.24 Pesan Kesalahan (8)……… 104
Gambar 5.25 Antarmuka Open File……….. 105
Gambar 6.1a Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1 dengan Nilai M=4 dan D
Berubah-ubah………. 151
Gambar 6.1b Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1 dengan Nilai M=5 dan D
Berubah-ubah………. 151
Gambar 6.2a Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1 dengan Nilai D=1 dan M
Berubah-ubah………. 151
Gambar 6.2b Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1 dengan Nilai D=2 dan M
Berubah-ubah………. 151
Gambar 6.3a Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Prestasi Semester 1 dengan Nilai M=4 dan D
xxii
Gambar 6.3b Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Prestasi Semester 1 dengan Nilai M=5 dan D
Berubah-ubah………. 152
Gambar 6.4a Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Prestasi Semester 1 dengan Nilai D=1 dan M
Berubah-ubah………. 152
Gambar 6.4b Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Jalur Prestasi Semester 1 dengan Nilai D=2 dan M
Berubah-ubah………. 152
Gambar 6.5a Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Semester 1dengan Nilai M=4 dan D Berubah-ubah. 153
Gambar 6.5b Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Semester 1dengan Nilai M=5 dan D Berubah-ubah.. 153
Gambar 6.6a Grafik Hasil Deteksi Outlier pada Data Mahasiswa Angkatan 2007 dan 2008 Semester 1 dengan Nilai D=1 dan M Berubah-ubah.. 153
1
Bab 1 PENDAHULUAN
1.1 Latar Belakang
Penelitian dalam bidang pendidikan menggunakan teknik penambangan
data telah banyak dilakukan saat ini. Penambangan data dalam bidang pendidikan
(educational data mining) berfokus pada pengembangan metode-metode untuk mengekstrak knowledge dari data-data pendidikan. Data pendidikan dapat berupa data pribadi atau akademik. Selain itu data pendidikan juga dapat berasal dari e-learning system yang memiliki data dalam jumlah besar yang digunakan oleh banyak institusi (Tair & El-Halees, 2012).
Knowledge Discovery in Databases (KDD) adalah proses mengekstrak informasi dari data berdasarkan pada analisis dan interpretasi tertentu. KDD
terdiri dari empat proses utama yaitu preprocessing, data mining, pattern evaluation, dan knowledge presentation (Han & Kamber, 2006). Dari keempat tahap tersebut, penambangan data (data mining) merupakan tahapan yang menjadi fokus dalam pengolahan data mentah (training dataset) menjadi bentuk yang dapat dievaluasi. Ada dua jenis pendekatan dalam melakukan penambangan
data yaitu supervised dan unsupervised. Pendekatan supervised artinya penambangan dilakukan pada data yang telah diketahui label kelasnya.
pendekatan unsupervised antara lain clustering, binning, dan histogram analysis. Data yang telah ditambang menggunakan salah satu dari metode-metode di atas
selanjutnya akan dievaluasi untuk menghasilkan sebuah informasi (knowledge). Salah satu metode penambangan data yaitu analisis klaster. Klaster
merupakan kumpulan objek atau data dalam sebuah kelompok yang serupa satu
sama lain tetapi berbeda atau tidak mirip dengan objek atau data pada klaster lain.
Data diklaster atau dikelompokkan dengan prinsip memaksimalkan kemiripan
intraclass dan meminimalkan kemiripan interclass. Artinya, data-data yang berada dalam sebuah klaster memiliki tingkat kemiripan yang tinggi satu sama
lain, tetapi memiliki tingkat kemiripan yang rendah dengan data pada klaster
lainnya. Klastering sering disebut sebagai segmentasi data karena klastering
membagi sejumlah besar data ke dalam grup berdasarkan kemiripannya.
Algoritma Block-based Nested-Loop merupakan contoh algoritma yang memiliki kemampuan untuk mendeteksi outlier dalam sekumpulan data. Tidak seperti klastering, deteksi outlier dilakukan untuk menemukan data yang tidak konsisten dengan data lainnya. Data dianggap tidak konsisten (outlier) apabila data tersebut tidak memiliki tingkat kemiripan yang sesuai dengan data lainnya
(Han & Kamber, 2006). Dengan adanya deteksi outlier, kita dapat mengenali adanya kesalahan dalam memasukkan data, kecurangan dalam menggunakan data
dengan jumlah atribut yang banyak atau high dimensional datasets (Ghoting et al., 2006).
Algoritma Block-based Nested-Loop dapat diimplementasikan pada sekumpulan data numerik untuk mendeteksi adanya outlier. Salah satu contoh data numerik yaitu data akademik mahasiswa yang berupa hasil tes masuk
universitas dan indeks prestasi semester (IPS). Sejumlah mahasiswa yang
memiliki data akademik yang serupa satu sama lain berarti masuk ke dalam
kelompok bukan outlier. Mahasiswa yang tidak memiliki kemiripan data akademik dengan mahasiswa manapun berarti memiliki data akademik yang unik
dibandingkan mahasiswa lainnya. Mahasiswa ini akan dianggap sebagai outlier. Berdasarkan hasil deteksi outlier, pihak universitas dapat memperoleh informasi mengenai mahasiswa dengan data akademik yang berbeda atau unik
dibandingkan mahasiswa lainnya. Data akademik yang unik dapat dihasilkan dari
nilai IPS mahasiswa yang sangat tinggi atau sangat rendah pada setiap semester.
Selain itu, data akademik yang unik juga berasal dari tinggi rendahnya nilai tes
masuk mahasiswa. Sebagai contoh, sejumlah mahasiswa dengan nilai IPS dan
nilai tes masuk yang tinggi akan tergabung dalam sebuah kelompok yang sama.
Kemudian sejumlah mahasiswa yang memiliki nilai IPS dan nilai tes masuk yang
rendah juga akan tergabung dalam sebuah kelompok yang sama. Pihak
universitas dapat menganalisis data diri mahasiswa tersebut untuk menemukan
faktor tertentu yang berpengaruh pada keunikan data akademik mahasiswa
1.2 Rumusan Masalah
Pada penelitian ini, deteksi outlier akan dilakukan berdasarkan nilai tes masuk dan IPS. Mahasiswa dengan data akademik yang unik atau tidak memiliki
kemiripan dengan mahasiswa lainnya akan masuk ke dalam kelompok outlier. Pada penelitian ini juga dilakukan analisis mengenai penggunaan blok-blok data
terhadap lama deteksi outlier. Jadi, rumusan masalah dalam penelitian ini adalah : 1. Mahasiswa manakah yang memiliki data akademik yang unik atau
berbeda pada tiap semester berdasarkan nilai tes masuk dan IPS?
2. Bagaimanakah pengaruh penggunaan blok-blok data terhadap waktu
deteksi outlier?
1.3 Tujuan Penelitian
Tujuan penelitian ini yaitu :
1. Melakukan deteksi outlier pada data akademik mahasiswa Prodi Teknik Informatika Universitas Sanata Dharma berupa hasil tes masuk dan IPS
semester satu sampai semester empat menggunakan algoritma Block-based Nested-Loop.
2. Menganalisis hasil deteksi outlier yang dihasilkan oleh algoritma Block-based Nested-Loop.
1.4 Batasan Masalah
Batasan masalah pada penelitian ini yaitu :
1. Algoritma deteksi outlier yang digunakan yaitu algoritma Block-based Nested-Loop.
2. Data yang digunakan dalam penelitian ini merupakan data akademik
mahasiswa Prodi Teknik Informatika angkatan 2007 dan 2008 di
Universitas Sanata Dharma berupa hasil tes penerimaan mahasiswa baru
(nilai penalaran mekanik, nilai penalaran verbal, nilai hubungan ruang, nilai Bahasa Inggris, nilai kemampuan numerik), nilai final dan nilai indeks prestasi semester dari semester satu sampai semester empat.
3. Hasil penelitian ini berupa kelompok mahasiswa outlier, jika ada.
1.5 Manfaat Penelitian
Manfaat penelitian ini, antara lain:
1. Memperkenalkan salah satu algoritma penambangan data khususnya
untuk mendeteksi outlier yaitu algoritma Block-based Nested-Loop serta keunggulannya dalam mendeteksi outlier.
2. Membantu pihak Universitas Sanata Dharma dalam mendeteksi kejadian
1.6 Sistematika Penulisan 1.6.1 Bab 1 Pendahuluan
Bab ini berisi latar belakang, rumusan masalah, tujuan penelitian, batasan
masalah, manfaat penelitian dan sistematika penulisan
1.6.2 Bab 2 Landasan Teori
Bab ini berisi teori yang digunakan dalam penulisan tugas akhir ini. Teori
pertama yang digunakan yaitu Knowledge Discovery in Databases (KDD). Teori kedua yang digunakan yaitu Outlier Detection. Outlier Detection terdiri dari pengertian outlier, penyebab outlier, manfaat deteksi outlier, metode deteksi outlier, Distance-Based Outlier Detection dan Algoritma Block-based Nested-Loop
1.6.3 Bab 3 Metode Penelitian
Bab ini berisi penjelasan mengenai langkah atau metode yang dilakukan
untuk menyelesaikan masalah dalam penelitian ini. Hal pertama yang dibahas
yaitu mengenai data. Kedua yaitu mengenai pengolahan data yang terdiri dari
pemrosesan awal data, seleksi data, penambangan data, evaluasi pola yang
ditemukan dan presentasi pengetahuan. Ketiga yaitu mengenai contoh
1.6.4 Bab 4 Analisis dan Perancangan Sistem
Bab ini berisi pembahasan tentang beberapa komponen. Komponen
pertama yaitu identifikasi sistem. Komponen kedua yaitu input sistem, proses
sistem dan output sistem. Komponen ketiga yaitu perancangan struktur data.
Komponen keempat yaitu diagram use case. Komponen kelima yaitu perancangan sistem yang terdiri dari diagram konteks, diagram aktivitas, diagram
kelas analisis, diagram sequence, diagram kelas desain dan detail algoritma tiap method pada tiap kelas. Komponen keenam yaitu perancangan antarmuka.
1.6.5 Bab 5 Implementasi Sistem
Bab ini berisi tentang implementasi antarmuka, implementasi pengecekan
masukan, implementasi struktur data dan implementasi kelas serta analisis dari
masing-masing tampilan program.
1.6.6 Bab 6 Pengujian dan Analisis Hasil Pengujian
Bab ini berisi pengujian serta analisis terhadap pengujian yang dilakukan
serta kelebihan dan kekurangan sistem. Pengujian terbagi menjadi tiga jenis yaitu
pengujian blackbox serta kesimpulannya, pengujian review dan validitas oleh pengguna serta kesimpulannya, pengujian efek perubahan nilai atribut
penambangan data serta kesimpulannya dan pengujian perbandingan waktu
1.6.7 Bab 7 Kesimpulan dan Saran
Kesimpulan dan saran berisi tentang kesimpulan dan saran dari penulis
tugas akhir mengenai penelitian yang dilakukan.
1.6.8 Daftar Pustaka
Daftar pustaka berisi tentang referensi yang digunakan dalam penyusunan
9
Bab 2
LANDASAN TEORI
Bab ini berisi penjelasan mengenai teori atau konsep yang terkait dengan
rumusan masalah dalam penelitian ini. Konsep yang dijelaskan yaitu Knowledge Discovery in Databases (KDD) dan Outlier Detection. Setiap konsep atau teori akan berisi penjelasan mengenai definisi, bagian-bagian serta peran
masing-masing bagian tersebut dalam penelitian ini. Hal-hal tersebut akan diuraikan
dalam dua sub bab di bawah ini.
2.1 Knowledge Discovery in Databases (KDD)
Knowledge Discovery in Databases (KDD) adalah proses mengambil informasi penting yang tersembunyi dalam sekumpulan data. KDD membantu
seseorang dalam mengambil keputusan berdasarkan informasi yang ditemukan
tersebut (Baradwaj & Pal, 2011). KDD terbagi menjadi lima tahap yaitu
Gambar 2.1 Langkah-langkah dalam KDD (Fayyad et al., 1996 ) Selection merupakan proses seleksi data yang relevan untuk dianalisis dari sebuah basis data. Data yang relevan artinya data tersebut sesuai untuk digunakan
dalam mencapai tujuan analisis data. Data yang telah diseleksi melalui proses ini
disebut sebagai target data. Target data selanjutnya masuk ke tahapan berikutnya
yaitu preprocessing.
Preprocessing merupakan proses menyiapkan data agar siap untuk ditambang. Langkah-langkah dalam preprocessing yaitu data cleaning, data integration, data transformation, data reduction dan data discretization. Kelima langkah tersebut dilakukan secara berurutan. Langkah tertentu boleh dilewati saat
kondisi data telah memenuhi syarat yang ditentukan masing-masing langkah
tersebut. Saat telah melewati tahap preprocessing, data siap untuk ditambang. Data mining atau penambangan data adalah proses mengekstrak informasi atau pengetahuan dari data dalam jumlah yang besar. Secara umum,
penambangan data dapat diklasifikasikan dalam empat kategori yaitu deteksi
pertama berkaitan dengan pola yang dimiliki oleh banyak obyek atau pada obyek
dengan persentase yang besar dalam dataset. Berbagai penelitian penambangan data mengenai aturan asosiasi, klasifikasi, klastering dan generalisasi konsep
termasuk dalam tiga kategori tersebut. Sebaliknya, kategori keempat berfokus
pada obyek dengan persentase yang kecil, yang umumnya sering diabaikan atau
dihilangkan karena dianggap noise (Knorr & Ng, 1998).
Evaluation merupakan tahap pembuatan pola atau pemetaan berdasarkan hasil penambangan data. Tujuan dilakukannya tahap ini untuk membantu
pihak-pihak yang berkepentingan terhadap data yang dianalisis untuk memperoleh
gambaran tentang data tersebut. Pembuatan diagram atau pohon keputusan
merupakan contoh visualisasi hasil penambangan data. Visualisasi dapat
memberikan gambaran yang lebih mudah dipahami dibandingkan hasil sebuah
penambangan data. Setelah tahap visualisasi selesai maka akan diperoleh hasil
akhir analisis data yaitu knowledge.
2.2 Outlier Detection
2.2.1 Pengertian Outlier
Outlier dalam sekumpulan data merupakan data yang dianggap tidak mirip atau tidak konsisten dengan data lainnya. Outlier merupakan hasil observasi (data pengukuran) dalam suatu kumpulan data yang nilainya sangat
berbeda jika dibandingkan dengan sekumpulan data dari pengukuran lain
terlihat berbeda jauh dan tidak konsisten dengan data lain (Han & Kamber,
2006).
2.2.2 Penyebab Outlier
Pertama, munculnya outlier dapat disebabkan oleh data pengukuran yang salah. Sebagai contoh, munculnya data umur seseorang yaitu 999 tahun dapat
disebabkan oleh pengaturan otomatis (default) program. Pengaturan otomatis ini diberlakukan pada data umur yang tidak direkam (missing values) (Han & Kamber, 2006).
Kedua, kemunculan outlier juga dapat dikarenakan data pengukuran berasal dari populasi lain. Contohnya yaitu gaji seorang pimpinan perusahaan
dapat dianggap sebagai outlier di antara gaji para karyawan di perusahaan tersebut (Han & Kamber, 2006). Hal ini disebabkan adanya perbedaan yang
sangat mencolok antara gaji seorang pimpinan dan gaji karyawan di sebuah
perusahaan.
Ketiga, outlier berasal dari data pengukuran yang benar tetapi mewakili peristiwa atau keadaan unik yang jarang terjadi. Sebagai contoh, terdapat sebuah
sekolah yang selalu menghasilkan lulusan dengan nilai yang sangat rendah setiap
tahun. Ketika terdapat seorang siswa yang lulus dari sekolah tersebut dengan nilai
yang sangat tinggi, maka siswa itu akan dianggap sebagai outlier.
2.2.3 Manfaat Deteksi Outlier
Sebagian besar algoritma penambangan data berfokus untuk
dapat mengakibatkan hilangnya informasi penting yang tersembunyi dibalik
outlier tersebut. Outlier sebenarnya dapat menjadi hal yang menarik untuk dianalisis lebih lanjut.
Deteksi outlier (outlier detection) adalah deteksi yang dilakukan pada sekumpulan obyek untuk menemukan obyek yang memiliki tingkat kemiripan
yang sangat rendah dibandingkan dengan obyek lainnya. Deteksi outlier umumya digunakan untuk menemukan kejanggalan dalam data, deteksi kecurangan data
atau untuk mengetahui adanya pola khusus dalam sekumpulan data. Deteksi
outlier sering dimanfaatkan untuk mendeteksi kecurangan penggunaan kredit atau layanan telekomunikasi. Deteksi outlier juga berguna dalam bidang pemasaran, yaitu untuk mengidentifikasi perilaku belanja konsumen dengan
tingkat pendapatan yang tinggi atau rendah. Dalam dunia kesehatan, deteksi
outlier digunakan untuk menemukan respon yang tidak biasanya atau berbeda terhadap berbagai perawatan kesehatan (Han & Kamber, 2006). Di bidang
pendidikan, deteksi outlier dapat digunakan untuk mengetahui prestasi akademik mahasiswa yang berbeda secara signifikan dari mahasiswa lainnya dalam
universitas yang sama (Tair & El-Halees, 2012).
3.2.4 Metode Deteksi Outlier
Algoritma klastering umumnya menghilangkan outlier dari data karena dianggap noise, tetapi algoritma deteksi outlier justru menjadikan outlier menjadi hasil dari eksekusinya. Ada beberapa metode yang dapat digunakan untuk
yaitu: pendekatan statistical distribution-based, pendekatan distance-based, pendekatan density-based local outlier dan pendekatan deviation-based (Han & Kamber, 2006).
Pendekatan statistical distribution-based mengasumsikan sebuah model distribusi atau probabilitas dari sejumlah data yang diidentifikasi outliernya menggunakan discordancy test. Pendekatan distance-based menentukan outlier berdasarkan jarak antar obyek serta jumlah obyek menggunakan parameter pct dan dmin. Pendekatan density-based local outlier, berfokus pada menemukan outlier pada sejumlah data berdasarkan kedekatan atau kepadatan antara satu obyek dengan obyek lainnya. Pendekatan density-based hampir sama dengan distance-based tetapi mampu membedakan antara local outlier dan global outlier. Pendekatan deviation-based tidak menggunakan perhitungan secara statistik maupun jarak untuk mengidentifikasi obyek yang diduga sebagai outlier. Pendekatan ini mengidentifikasi adanya outlier dengan menguji karakteristik utama dari obyek dalam sebuah kelompok. Setiap outlier yang ditemukan menggunakan pendekatan-pendekatan tersebut selanjutnya perlu diperiksa
kembali untuk diyakini kebenarannya. Pada penelitian ini, penulis menggunakan
pendekatan distance-based untuk melakukan deteksi outlier.
2.2.5 Distance-Based Outlier Detection
antar obyek dalam T. Untuk sebuah obyek O, D-neighbourhood dari O memuat sekumpulan obyek � ∈ � yang terletak pada jarak kurang dari D terhadap O sehingga { Q ∈ T| F (O, Q) ≤ D}. Nilai fractionp merupakan persentase jumlah obyek minimum dalam T yang harus ada di luar D-neighbourhood dari sebuah outlier. Diasumsikan M merupakan jumlah obyek maksimum dalam D-neighbourhood dari sebuah outlier sehingga M = N(1 - p) (Knorr & Ng, 1998). Sebagai contoh, terdapat sebuah dataset T dengan jumlah obyek N sebanyak 100 dan persentase jumlah outlier dalam data sekitar 10%. Berdasarkan data tersebut maka persentase data bukan outlier p adalah 100 – 10% yaitu 90% atau 0.9. Untuk memperoleh nilai M maka menggunakan perhitungan N(1 – p) sehingga M = 100(1-0.9) yaitu 10. Artinya, pada dataset T jumlah obyek maksimum dalam D-neighbourhood sebuah outlier adalah 10 obyek. Apabila sebuah obyek A dalam datasetT dapat menemukan lebih dari 10 obyek yang jaraknya kurang dari D terhadap dirinya maka A akan menjadi data bukan outlier sebaliknya A akan menjadi outlier. Nilai M adalah jumlah obyek maksimum dalam D-neighbourhood sebuah outlier sehingga dapat dikurangi menjadi 9, 8, 7 atau bahkan 1 sampai diperoleh hasil outlier yang dianggap paling tepat. Pada pendekatan distance-based terdapat beberapa algoritma yang dapat digunakan antara lain Index-Based, Block-based Nested-Loop dan Cell-Based (Han & Kamber, 2006).
Jarak antar dua obyek dalam sebuah kumpulan data memiliki arti yang
Untuk menghitung jarak antar obyek harus disesuaikan dengan tipe variabel yang
dimiliki. Tipe variabel yang berupa nilai numerik dan sifatnya multidimensi,
dapat dihitung jaraknya menggunakan pengukuran Euclidean distance (Han & Kamber, 2006).
Euclidean distance didefinisikan sebagai berikut
�( , ) = (�1− �1 )2+ (�2− �2 )2+ …. +(�� − �� )2 (2.1)
di mana i = obyek pertama, j= obyek kedua, xi = nilai obyek pertama, xj = nilai obyek kedua dan n = dimensi obyek.
Pendekatan distance-based melibatkan penggunaan dua buah parameter sebagai input. Penentuan nilai parameter p dan D dapat melibatkan beberapa kali percobaan (trial and error) hingga mendapatkan nilai yang paling tepat. Pemilihan nilai parameter p dan D dapat mempengaruhi hasil deteksi outlier.
2.2.5.1 Algoritma Block-based Nested-Loop
Algoritma Block-based Nested-Loop merupakan pengembangan dari algoritma deteksi outlier lain yaitu Index-Based. Algoritma ini menghindari penggunaan memori dalam membentuk indeks untuk menemukan seluruh
DB(p,D)-outliers. Algoritma ini menggunakan prinsip block-oriented, nested-loop design.
dalam dua bagian yang disebut first array sebanyak ½B dan second array sebanyak ½B. Data kemudian dibagi ke dalam blok-blok tertentu. Algoritma Block-based Nested-Loop akan mengatur proses masuk keluarnya blok ke dalam memori. Setiap data yang ada dalam blok tertentu akan secara langsung dihitung
jaraknya dengan data lainnya. Untuk setiap data t dalam first array, jumlah tetangganya akan dihitung. Dua data dikatakan saling bertetangga apabila jarak
keduanya kurang dari atau sama dengan D. Perhitungan jumlah tetangga untuk setiap obyek akan berhenti saat nilainya telah melebihi M (Knorr & Ng, 1998). M merupakan jumlah tetangga maksimum dalam D-neighbourhood sebuah outlier. Jika jumlah tetangga sebuah data telah melebihi M artinya data tersebut tidak termasuk outlier.
Pseudocode algoritma Block-based Nested-Loop adalah sebagai berikut (Knorr & Ng, 1998):
1. Isi first array (½B) dengan sebuah blok dari T 2. Untuk setiap obyek ti, pada first array, do :
a. counti 0
b. Untuk setiap obyek tj dalam first array, jika dist(ti ,tj) ≤ D;
Tambahkan nilai countidengan 1. Jika counti > M, tandai ti sebagai
non-outlier dan proses dilanjutkan ke ti berikutnya.
3. Selama masih ada blok yang tersisa untuk dibandingkan dengan first array, do:
belum pernah dimasukkan ke dalam first array berada pada urutan terakhir)
b. Untuk setiap obyek ti dalam first array yang belum ditandai (unmarked) do:
Untuk setiap obyek tj dalam second array, jika dist(ti ,tj) ≤ D:
Tambahkan nilai countidengan 1. Jika counti > M, tandai ti sebagai non-outlier dan proses dilanjutkan ke ti berikutnya.
4. Untuk setiap obyek ti dalam first array yang belum ditandai (unmarked), tandai ti sebagai outlier.
19
Bab 3
METODE PENELITIAN
Bab ini berisi penjelasan mengenai langkah atau metode yang dilakukan
untuk menyelesaikan masalah dalam penelitian ini. Langkah penyelesaian
masalah tersebut meliputi data yang digunakan dalam penelitian, cara mengolah
data dan contoh implementasi algoritma Block-based Nested-Loop. Hal-hal tersebut akan diuraikan dalam tiga sub bab di bawah ini.
3.1 Data
Pada penelitian ini data yang digunakan adalah data akademik mahasiswa
Universitas Sanata Dharma Prodi Teknik Informatika Angkatan 2007 dan 2008.
Data ini diperoleh dari gudang data akademik mahasiswa hasil penelitian Rosa
dkk (2011). Data diperoleh dalam bentuk skrip .sql. Dari skrip tersebut, data yang digunakan dalam penelitian ini adalah data nilai hasil seleksi masuk mahasiswa
(jalur tes dan jalur prestasi) dan nilai indeks prestasi semester (IPS) pada
semester satu sampai semester empat. Total data akademik yang digunakan
3.2 Pengolahan Data
Pengolahan data akademik dalam penelitian ini meliputi beberapa langkah
yaitu :
3.2.1 Pemrosesan Awal Data
Data mentah yang digunakan dalam penelitian ini dalam bentuk skrip .sql. Sebelum mengolah data yang ada dalam skrip tersebut, skrip dijalankan terlebih
dahulu menggunakan SQLyog. Hasil yang diperoleh yaitu terdapat gudang data dengan nama data_mahasiswa dan di dalamnya terdapat beberapa tabel yaitu
dim_angkatan, dim_daftarsmu, dim_fakultas, dim_jeniskel, dim_kabupaten,
dim_prodi, dim_prodifaks, dim_statustes dan fact_lengkap2. Setelah semua tabel
berhasil dibuat, proses pengolahan data dilanjutkan ke seleksi data.
Gambar 3.1 Gudang data ‘data_mahasiswa’
3.2.2 Seleksi Data
Pada tahap ini dilakukan seleksi terhadap data yang relevan dengan
penelitian. Berdasarkan data yang diperoleh, data yang akan dipakai adalah
kolom ips1, ips2, ips3, ips4, ips4, nil11, nil12, nil13, nil14, nil15 dan final.
kolom tersebut seluruhnya berada pada tabel fact_lengkap2.
dengan sk_prodi = 27. Baris dengan sk_prodi = 27 merupakan data mahasiswa
yang berasal dari Prodi Teknik Informatika. Data ini yang dipilih karena dapat
digunakan sebagai variabel numerik untuk mendeteksi outlier dan sesuai untuk mencapai tujuan penelitian.
3.2.3 Transformasi Data
Data yang telah diseleksi masih berupa data yang belum tepat untuk
ditambang. Data tersebut belum tepat ditambang karena masih terdapat
perbedaan rentang nilai antara atribut nilai final, nilai tes masuk dan ips. Nilai
final memiliki rentang nilai antara 0-100. Nilai tes masuk memiliki rentang nilai
antara 0-10. Ips memiliki rentang nilai antara 0-4. Perbedaan rentang nilai ini
akan disamakan melalui proses transformasi data.
Transformasi data dilakukan dengan menggunakan metode normalisasi.
Metode normalisasi dilakukan dengan cara membuat skala pada data atribut.
Salah satu jenis metode normalisasi yaitu min-max normalization (Han & Kamber, 2006).
Min-max normalization didefinisikan sebagai berikut :
di mana v = nilai awal, minA = nilai minimum atribut A sebelum normalisasi,
maksimum atribut A setelah normalisasi dan new_minA = nilai minimum atribut A setelah normalisasi.
Penelitian ini menggunakan data berupa nilai tes masuk, nilai final dan
ips. Range data nilai tes masuk dan data nilai final disamakan dengan range data
ips. Contoh normalisasi data nilai final adalah sebagai berikut. Diketahui nilai
final awal v = 77.10, nilai minimum awal minA = 0, nilai maksimum awal maxA = 100, nilai minimum baru new_minA = 0 dan nilai maksimum baru new_minA = 4, maka nilai final setelah normalisasi v’ = 77.10−0
100 −0 4−0 + 0 = 3.08
Contoh normalisasi data nilai tes masuk adalah sebagai berikut. Diketahui nilai
tes awal v = 8.00, nilai minimum awal minA = 0, nilai maksimum awal maxA = 10, nilai minimum baru new_minA = 0 dan nilai maksimum baru new_minA = 4, maka nilai tes setelah normalisasi v’ = 8.00 − 0
10 −0 4−0 + 0 = 3.20
3.2.4 Penambangan Data
Data yang telah melalui proses transformasi data selanjutnya dicari
outliernya menggunakan algoritma deteksi outlier yaitu algoritma Block-based Nested-Loop. Data yang diteliti akan dibatasi pada data dua tahun angkatan di Universitas Sanata Dharma yaitu tahun angkatan 2007 dan 2008. Pada tahap ini,
akan ditentukan juga variabel-variabel yang akan digunakan untuk menambang
data. Variabel-variabel tersebut antara lain :
1. Input, yang terdiri dari :
Untuk mahasiswa yang mengikuti jalur tes, nilai hasil seleksi yang
digunakan berasal dari lima jenis mata tes yaitu nilai penalaran
mekanik, nilai penalaran verbal, nilai hubungan ruang, nilai
Bahasa Inggris dan nilai kemampuan numerik serta nilai final.
Untuk mahasiswa yang mengikuti jalur prestasi, nilai hasil seleksi
yang digunakan berasal dari nilai final.
b. Nilai Indeks Prestasi Semester (IPS) pada semester 1 sampai
semester 4.
2. Output, yaitu sejumlah data yang masuk ke dalam kelompok outlier, jika ada
3.2.5 Evaluasi Pola yang Ditemukan
Pada tahap ini, pengetahuan atau pola berupa outlier yang didapat dari proses deteksi outlier akan dievaluasi dengan hipotesa yang telah dibentuk sebelumnya. Hipotesa awal mengenai mahasiswa yang masuk ke dalam kategori
3.2.6 Presentasi Pengetahuan
Tahap ini merupakan tahap akhir dari penelitian. Pola khusus yang
dihasilkan (outlier) perlu ditampilkan ke dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Oleh sebab itu, pada tahap ini akan dilakukan
pembuatan sistem dengan antarmuka pengguna yang mudah dimengerti oleh
pihak universitas.
3.3 Contoh Implementasi Algoritma Block-based Nested-Loop
Pada penelitian ini, dilakukan deteksi outlier menggunakan algoritma Block-based Nested-Loop dengan data akademik yang berasal dari gudang data data akademik mahasiswa yang berasal dari penelitian Rosa dkk (2011). Data
yang awalnya dalam bentuk skrip .sql diubah ke dalam format .xls agar lebih mudah untuk diolah. Data yang akan diolah berasal dari tabel fact_lengkap2.
Jumlah data yang digunakan sebanyak 13 baris. Data tersebut telah diseleksi
khusus untuk mahasiswa yang memiliki sk_prodi = 27 (Prodi Teknik
Informatika), angkatan 2007 dan statustes = T (jalur tes). Data yang digunakan
Gambar 3.2 Data mentah untuk implementasi algoritma Block-based Nested-Loop
Pada bagian ini, penjelasan mengenai langkah-langkah deteksi outlier menggunakan algoritma Block-based Nested-Loop hanya akan ditampilkan menggunakan data mahasiswa di atas pada semester satu saja. Untuk semester
tiga hingga semester empat hanya akan ditampilkan hasil deteksi outliernya saja. Proses deteksi outlier menggunakan algoritma Block-based Nested-Loop adalah sebagai berikut:
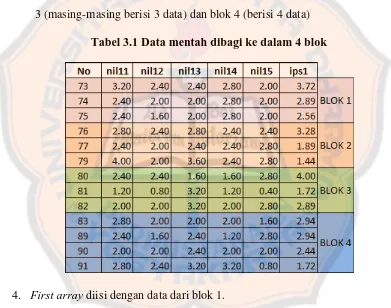
3. Membagi seluruh data ke dalam sejumlah blok. Jumlah blok = 4, maka
setiap 13
4 = 3 data dan sisa 1 data. Berdsarkan perhitungan tersebut, setiap
blok akan berisi 3 buah data. Perhitungan ini menyisakan 1 data yang belum
masuk ke dalam sebuah blok. Sisa data dapat dimasukkan ke dalam blok
yang mana saja. Dalam contoh ini, sisa data dimasukkan ke dalam blok ke-4.
Dengan demikian diperoleh hasil pembagian blok yaitu blok 1, blok 2, blok
3 (masing-masing berisi 3 data) dan blok 4 (berisi 4 data)
Tabel 3.1 Data mentah dibagi ke dalam 4 blok
4. First array diisi dengan data dari blok 1.
5. Setiap data dalam first array dihitung jaraknya terhadap setiap data lainnya dalam first array menggunakan Euclidean distance dan nilainya dimasukkan pada kolom Eucliden dist.
Setiap kali jarak telah dihitung, nilai jarak langsung dibandingkan dengan
tetangga dan ditandai dengan angka 1 pada kolom Neighbor. Jika jarak > D, maka dinyatakan sebagai bukan tetangga dan ditandai dengan angka 0.
Gambar 3.3 Pengecekan tetangga pada first array antara blok 1 dan blok 1
Menurut analisis di atas, pada data mahasiswa dengan nomor 73 ditemukan
tetangga sebanyak 2 buah yaitu mahasiswa dengan nomor 74 dan 75.
6. Setelah jumlah tetangga ditemukan, lalu dibandingkan dengan nilai parameter
M. Jika jumlah tetangga > M maka data tersebut dinyatakan sebagai bukan outlier, jika sebaliknya maka data masih dinyatakan sebagai unmarked. Pada contoh di atas, karena diperoleh jumlah tetangga = 2 yang artinya < M, maka data masih diberi keterangan unmarked.
7. Selanjutnya, pengecekan dilakukan terhadap data lainnya dalam blok 1 yaitu
mahasiswa nomor 74 dan 75 (kembali ke langkah 5).
Gambar 3.4 Hasil akhir pengecekan blok 1 dan blok 1 dalam first array
Selanjutnya blok 2 dimasukkan ke second array.
8. Setiap data dalam first array yang masih unmarked, dicari tetangganya yang berada dalam second array. Jumlah tetangga yang diperoleh pada perhitungan sebelumnya akan ditambahkan ke dalam pengecekan ini.
Pada gambar di atas, terlihat bahwa mahasiswa nomor 73 mendapatkan 1 orang
tetangga pada pengecekan dengan blok 2. Jumlah tetangga ini dijumlahkan
dengan jumlah tetangga sebelumnya yaitu 2 orang sehingga menjadi 3 orang.
Mahasiswa nomor 73 masih berstatus unmarked pada tahap ini karena jumlah tetangganya masih < M. Maka data mahasiswa ini akan dimasukkan lagi ke dalam pengecekan selanjutnya.
9. Selanjutnya, pengecekan dilakukan terhadap data lainnya dalam blok 1 yaitu
mahasiswa nomor 74 dan 75 (kembali ke langkah 8).
Hasil akhir pengecekan antara blok 1 (first array) dan blok 2 (second array) diperoleh mahasiswa nomor 73, 74 dan 75 akan dimasukkan ke dalam
pengecekan dengan blok selanjutnya karena masih ditandai sebagai unmarked.
Selanjutnya blok 3 dimasukkan ke second array.
10.Setiap data dalam first array yang masih unmarked, dicari tetangganya yang berada dalam second array. Jumlah tetangga yang diperoleh pada perhitungan sebelumnya akan ditambahkan ke dalam pengecekan ini.
Gambar 3.7 Pencarian tetangga dari data first array pada second array
Pada gambar di atas, terlihat bahwa mahasiswa nomor 73 mendapatkan 1
tetangga. Jumlah tetangga ini dijumlahkan dengan jumlah tetangga sebelumnya
yaitu 3 orang sehingga menjadi 4 orang. Mahasiswa nomor 73 masih berstatus
unmarked pada tahap ini karena jumlah tetangganya masih kurang dari M. Maka data mahasiswa ini akan dimasukkan lagi ke dalam pengecekan selanjutnya.
11.Selanjutnya, pengecekan dilakukan terhadap data lainnya dalam blok 1 yaitu
mahasiswa nomor 74 dan 75 (kembali ke langkah 10).
Hasil akhir pengecekan antara blok 1 (first array) dan blok 3 (second array) diperoleh 2 data yang ditandai sebagai bukan outlier yaitu mahasiswa dengan nomor 74 dan 75. Ketika mahasiswa 74 dicek dengan mahasiswa nomor 80,
mahasiswa nomor 74 adalah 4 dari pengecekan sebelumnya dan ditambah 1 pada
tahap ini sehingga menjadi 5 orang. Data yang diberi label biru menunjukkan
data yang tidak ikut serta ditambahkan sebagai tetangga mahasiswa nomor 74
karena pengecekan berhenti saat M > 4. Kedua data ini tidak akan disertakan lagi dalam pengecekan berikutnya pada iterasi selanjutnya.
Gambar 3.8 Hasil akhir pengecekan blok 1 (first array) dan blok 3 (second array)
Selanjutnya blok 4 dimasukkan ke dalam second array.
Gambar 3.9 Hasil akhir pengecekan blok 1 (first array) dan blok 4 (second array)
Hasil akhir pengecekan antara blok 1 (first array) dan blok 4 (second array) diperoleh data mahasiswa 73 yang ditandai sebagai bukan outlier yaitu. Ketika mahasiswa 73 dicek dengan mahasiswa nomor 83, jumlah tetangga mahasiswa
nomor 73 telah mencapai M > 4. Jumlah tetangga mahasiswa nomor 73 adalah 4 dari pengecekan sebelumnya dan ditambah 1 pada tahap ini sehingga menjadi 5
orang. Data yang diberi label biru menunjukkan data yang tidak ikut serta
ditambahkan sebagai tetangga mahasiswa nomor 73 karena pengecekan berhenti
saat M > 4. Karena seluruh data dalam blok 1 telah dicek dengan seluruh blok lainnya maka iterasi pegecekan outlier untuk data dalam blok 1 telah selesai.
Urutan pengecekan data pada kasus di atas adalah sebagai berikut:
1. Blok 1 dan Blok 1, kemudian dengan Blok 2, Blok 3, Blok 4
total ada 4 blok yang dibaca
2. Blok 4 dan Blok 4 (tidak perlu dibaca, sudah berada dalam array), kemudian dengan Blok 1 (tidak perlu dibaca, sudah berada dalam array), Blok 2, dan Blok 3
total ada 2 blok yang dibaca
3. Blok 3 dan Blok 3, kemudian dengan Blok 4, Blok 1, dan Blok 2
total ada 2 blok yang dibaca
4. Blok 2 dan Blok 2, kemudian dengan Blok 3, Blok 4, Blok 1
total ada 2 blok yang dibaca
34
Bab 4
ANALISIS DAN PERANCANGAN SISTEM
4.1 Identifikasi Sistem
Universitas Sanata Dharma melakukan seleksi penerimaan mahasiswa
baru setiap tahun. Seleksi penerimaan mahasiswa baru terbagi menjadi dua jalur
yaitu jalur prestasi dan jalur tes. Kedua jalur penerimaan mahasiswa baru tersebut
memiliki persyaratan yang harus dipenuhi oleh calon mahasiswa. Calon
mahasiswa yang mengikuti jalur prestasi diwajibkan melampirkan nilai raport
SMA saat kelas XI semester 1 dan semester 2. Untuk calon mahasiswa yang
mengikuti jalur tes, diwajibkan mengikuti tes tertulis yang terdiri dari lima jenis
tes yaitu tes penalaran mekanik, tes penalaran verbal, tes hubungan ruang, tes
kemampuan numerik dan tes Bahasa Inggris. Berdasarkan nilai final untuk jalur
prestasi dan nilai final serta nilai lima tes untuk jalur tes tersebut, dapat
ditentukan calon mahasiswa yang diterima menjadi mahasiswa di Universitas
Sanata Dharma.
Mahasiswa di Universitas Sanata Dharma menjalani masa perkuliahan
yang dibagi ke dalam beberapa semester. Setiap semester dilakukan evaluasi
untuk mengetahui tingkat pemahaman setiap mahasiswa. Tingkat pemahaman
mahasiswa ditunjukkan oleh Indeks Prestasi Semester (IPS). Setiap mahasiswa
memiliki IPS yang bervariasi terhadap mahasiswa lainnya. Selain itu setiap
mahasiswa juga dapat memiliki IPS yang sama atau berbeda-beda di setiap
Deteksi outlier bermanfaat dalam membantu pihak universitas dalam menemukan data akademik yang unik. Mahasiswa yang memiliki nilai tinggi saat
mengikuti seleksi penerimaan mahasiswa baru belum tentu akan memiliki IPS
yang tinggi di setiap semester, demikian juga sebaliknya. Tetapi tidak menutup
kemungkinan juga bahwa ada mahasiswa yang selalu memiliki nilai tinggi atau
rendah sejak seleksi penerimaan mahasiswa baru hingga di setiap semester
selama perkuliahan. Dengan demikian, ada kemungkinan munculnya mahasiswa
dengan data akademik yang unik di setiap semester. Mahasiswa dengan data
akademik yang unik ini selanjutnya disebut sebagai outlier.
Sistem ini menggunakan pendekatan distance-based dengan algoritma Block-based Nested-Loop untuk melakukan deteksi outlier. Data yang digunakan penelitian ini untuk diolah menggunakan sistem deteksi outlier yaitu data akademik mahasiswa Prodi Teknik Informatika angkatan 2007 dan 2008 di
Universitas Sanata Dharma berupa hasil tes penerimaan mahasiswa baru (nilai
penalaran mekanik, nilai penalaran verbal, nilai hubungan ruang, nilai Bahasa
Inggris dan nilai kemampuan numerik), nilai final dan nilai indeks prestasi
semester dari semester satu sampai semester empat. Data diperoleh dari gudang
data akademik mahasiswa hasil penelitian Rosa dkk (2011).
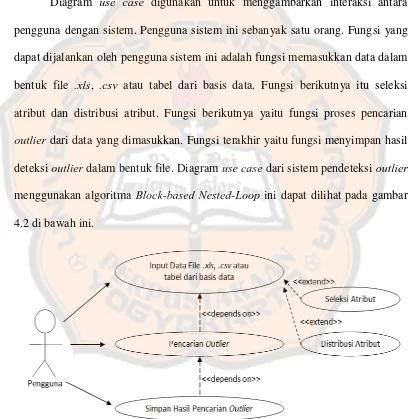
4.2 Input Sistem, Proses Sistem dan Output Sistem 4.2.1 Input Sistem
data yang diinputkan sehingga proses deteksi outlier yang dilakukan oleh sistem dapat berjalan dengan benar dan keluaran yang dihasilkan juga tepat.
Sistem Pendeteksi Outlier Menggunakan Algoritma Block-based Nested-Loop ini juga memerlukan masukan data berupa nilai M dan D. Nilai M dan D ini diperlukan untuk melakukan deteksi outlier terhadap data file .xls, .csv atau tabel dari basis data yang diinputkan pengguna. Penjelasan lebih lanjut dari nilai M dan
D dapat dijelaskan sebagai berikut:
1. Nilai M menunjukkan jumlah tetangga atau obyek maksimum dari
sebuah outlier dalam ketetanggaan-D (Knorr & Ng, 1998). Sebuah data akan dinyatakan sebagai outlier apabila jumlah tetangganya kurang dari atau sama dengan M. Sebaliknya, data yang jumlah
tetangganya lebih dari M akan dinyatakan sebagai bukan outlier. Penentuan nilai M disesuaikan dengan jumlah data yang digunakan
serta persentase data yang diperkirakan sebagai outlier.
2. Nilai D menunjukkan jangkauan (range) nilai yang menjadi dasar penentuan dua buah data merupakan tetangga atau tidak berdasarkan
jarak (euclidean distance) kedua data tersebut. Perhitungan jarak akan dilakukan oleh sistem. Jika jarak dua data bernilai kurang dari atau
sama dengan D, maka keduanya merupakan tetangga. Pengguna