i
DETEKSI OUTLIER MENGGUNAKAN ALGORITMA LOCAL
OUTLIER FACTOR
(STUDI KASUS DATA AKADEMIK MAHASISWA TI UNIVERSITAS
SANATA DHARMA)
Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika
Oleh:
Daniel Tomi Raharjo 095314058
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
OUTLIER DETECTION USING LOCAL OUTLIER FACTOR
ALGORITHM
(STUDY CASE ACADEMIC DATA OF STUDENTS OF INFORMATICS
ENGINEERING DEPARTMENT OF SANATA DHARMA UNIVERSITY)
A Thesis
Presented as Partial Fullfillment of the Requirements To Obtain the Sarjana Komputer Degree In Study Program of Informatics Engineering
By:
Daniel Tomi Raharjo 095314058
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
HALAMAN PERSEMBAHAN
“Apa yang tidak pernah dilihat oleh mata, dan tidak pernah
didengar oleh telinga, dan yang tidak pernah timbul di dalam
hati manusia: semua disediakan Allah untuk mereka yang
mengasihi Dia” ( 1 Korintus 2:9)
Kupersembahkan Untuk :
Tuhan Yesus Kristus
vii ABSTRAK
Dalam dunia data mining keberadaan data outlier tidak bisa dipandang sebelah mata, data outlier yang dulunya hanya sebuah noise, ternyata memiliki informasi penting yang terkandung di dalamnya. Proses deteksi outlier ternyata dapat di aplikasikan ke dalam berbagai bidang, salah satunya dalam bidang pendidikan. Penelitian tugas akhir ini dimaksudkan untuk mengembangkan sebuah perangkat lunak yang mampu mendeteksi sebuah outlier dari berbagai macam jenis data, dimana algoritma yang digunakan adalah algoritma local outlier factor dengan pendekatan density based. Pada penelitian tugas akhir ini digunakan data akademik mahasiswa program studi Teknik Informatika Universitas Sanata Dharma angkatan 2007-2008 yang diperoleh dari hasil penelitian gudang data mahasiswa (Rosa dkk), data akademik ini meliputi data nilai tes masuk dan data nilai IPS Semester 1-4. Dalam penelitian tugas akhir ini dilakukan pengujian terhadap 3 jenis data yaitu : data mahasiswa 2007-2008 jalur test, data mahasiswa 2007-2008 jalur prestasi, dan data mahasiswa jalur test & prestasi. Pengujian ini bertujuan untuk menguji validitas dari perangkat lunak yang dibuat dalam penelitian tugas akhir ini. Hasil pengujian dari ketiga jenis data tersebut menunjukkan bahwa perangkat lunak yang dibuat dapat menemukan data outlier dari data akademik mahasiswa secara valid.
viii
ABSTRACT
On data mining, outlier cannot be underestimated. Yesterday, outlier data can be look to be a noise but today outlier data is proven to have many important information. Detection outlier proses can be applied to many various field, one of which it can be applied on field of education. The aim of this study to develop a software, who can detect an outlier from many data variation. Where the algorithm used is the local outlier factor algorithm with the density-based approach.. This thesis use student academic data Informatics Engineering study program of Sanata Dharma University year 2007-2008, who is been research by Rosa and other, This data is including selection test value data and IPS value data. In this study, researchersused three types of data. The first 2007 – 2008 student admission data from regular tracks, second 2007 – 2008 student admission data from outstanding tracks, and the last data from joined from student admission data from regular tracks and student admission data from outstanding tracks. This test aims to test the validity of the software that is made in this thesis. The result of research from this 3 data is showing this software can find the data outlier from student data is valid
x
KATA PENGANTAR
Puji dan syukur kepada TuhanYesus Kristus, karena pada akhirnya penulis dapat menyelesaikan penelitian tugas akhir ini yang berjudul “ Deteksi Outlier Menggunakan Algoritma Local Outlier Factor(Studi Kasus Data Akademik Mahasiswa Ti Universitas Sanata Dharma)”
Penelitian ini tidak akan selesai dengan baik tanpa adanya dukungan, semangat, dan motivasi yang telah diberikan oleh banyak pihak. Untuk itu, penulis ingin mengucapkan terima kasih kepada:
1. Ibu P.H. Prima Rosa, S.Si., M.Sc. selaku Dekan Fakultas Sains dan Teknologi dan juga sebagai Dosen pengguji atas kritik dan saran yang telah diberikan.
2. Ibu Ridowati Gunawan, S.Kom.,M.T. selaku Ketua Program Studi Teknik Informatika dan dosen pembimbing akademik yang telah memberikan kesabaran, waktu dan kebaikan.
3. IbuSri Hartati Wijono S.Si., M.Kom. selaku dosen penguji atas kritik dan saran yang telah diberikan.
xi
6. Teman-Teman ACC : Robert, Anton, Ade, Pujo, Brahu, Githa, Nisa, Tri, Sintia, Risma, Febri, Grace yang selalu ada di samping saya, saat suka maupun duka.
7. Fio, Setyo dan Ratna teman sekerja saya dalam mengerjakan tugas akhir ini selama 6 bulan.
8. Seluruh teman-teman TI 09 yang telah bersama-sama menjalani perkuliahan selama 4 tahun.
9. Serta semua pihak yang telah membantu saya, yang tidak bisa saya sebutkan satu persatu
Penelitian tugas akhir ini masih memiliki banyak kekurangan. Untuk itu, penulis sangat membutuhkan saran dan kritik untuk perbaikan di masa yang akan datang. Semoga penelitian tugas akhir ini dapat membawa manfaat bagi semua pihak
Yogyakarta, 23 Agustus 2013
xii DAFTAR ISI
Halaman Judul ... i
Halaman Judul(Bahasa Inggris) ... ii
Halaman Persetujuan ... iii
Halaman Pengesahan ... iv
Halaman Persembahan ... v
Halaman Pernyataan... vi
Abstrak ... vii
Abstract ... viii
Halaman Persetujuan Publikasi Karya Ilmiah... ix
Kata Pengantar ... x
Daftar Isi... xii
Daftar Gambar ... xvii
Daftar Tabel ... xx
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 4
1.3 Batasan ... 4
1.4 Manfaat Penelitian ... 4
1.5 Tujuan Penelitian ... 5
1.6 Luaran Penelitian ... 5
xiii
1.8 Sistematika Penulisan ... 5
BAB II LANDASAN TEORI ... 2
2.1 Pengertian Data Mining ... 2
2.2 Pengertian Outlier ... 10
2.2.1 Statistical Distribution Based Local Outlier Detection ... 11
2.2.2 Distance Based Local Outlier Detection ... 11
2.2.3 Deviation Based Local Outlier Detection ... 12
2.2.4 Density Based Local Outlier Detection ... 12
2.2.5 Algoritma LOF ... 13
2.2.5.1 Contoh Perhitungan LOF... 13
BAB III METODOLOGI PENELITIAN... 18
3.1 Sumber Data ... 18
3.2 Seleksi Data ... 19
3.3 Transformasi Data ... 21
3.4 Penambangan Data ... 24
3.5 Evaluasi Pola ... 32
3.6 Presentasi Pengetahuan ... 33
BAB IV ANALISIS DAN PERANCANGAN SISTEM ... 34
4.1 Identifikasi Sistem ... 34
4.1.1 Diagram Use Case ... 35
4.1.2 Narasi Use Case ... 36
4.2 Perancangan Sistem Secara Umum ... 36
xiv
4.2.2 Proses Sistem ... 3
4.2.3 Output Sistem ... 39
4.3 Perancangan Sistem ... 40
4.3.2 Diagram Kelas Analisis ... 41
4.3.3 Diagram Sequence ... 44
4.3.4 Diagram Kelas Desain ... 45
4.3.5 Rincian Algoritma Setiap Method ... 46
4.4 Perancangan Struktur Data ... 63
4.4.1 Graf ... 63
4.4.2 Matriks Dua Dimensi ... 64
4.5 Perancangan Antarmuka ... 66
4.5.1 Tampilan Halaman Awal ... 66
4.5.2 Tampilan Halaman Utama ... 67
4.5.3 Tampilan Halaman Bantuan ... 70
4.5.4 Tampilan Menu Keluar ... 71
4.5.5 Tampilan Halaman Pilih Database ... 72
4.5.6 Tampilan Halaman Pilih Tabel ... 73
4.5.7 Tampilan Halaman Distribusi Atribut ... 74
BAB V IMPLEMENTASI PENAMBANGAN DATA ... 75
5.1 Implementasi Antarmuka... 75
5.1.1 Implementasi Halaman Awal ... 75
5.1.2 Implementasi Halaman Utama ... 76
xv
5.1.4 Implementasi Antarmuka Halaman Pilih Basis Data ... 84
5.1.5 Implementasi Halaman Bantuan ... 88
5.1.6 Implementasi Antarmuka Halaman Tentang ... 89
5.1.7 Implementasi Antarmuka Konfirmasi Keluar ... 90
5.1.8 Implementasi Pengecekan Masukan ... 91
5.2 Implementasi Kelas ... 95
5.3 Implementasi Struktur Data ... 96
5.3.1 Implementasi Kelas Vertex.java ... 97
5.3.2 Implementasi Kelas Graph.java ... 98
BAB VI PENGUJIAN DAN ANALISIS HASIL PENGUJIAN ... 101
6.1 Rencana Pengujian... 101
6.1.1 Hasil Pengujian Blackbox ... 103
6.1.2 Kesimpulan Pengujian Blackbox... 111
6.1.3 Hasil Pengujian Perubahan NIlai Atribut MinPts Terhadap Nilai LOF ... 111
6.1.4 Kesimpulan Hasil Pengujian Efek perubahan nilai Atribut minPts Terhadap Niai LOF ... 119
6.1.5 Hasil Pengujian Review Dan Validitas Pengguna ... 120
6.1.5.1 Perbandingan Perhitungan Manual dan Hasil Sistem... 120
6.1.5.2 Kesimpulan Hasil Perbandingan Perhitungan Manual dengan Perhitungan Menggunakan Sistem ... 122
xvi
Pengguna... 125
6.2 Kelebihan Dan Kekurangan Sistem ... 129
6.2.1 Kelebihan Sistem ... 129
6.2.2 Kekurangan Sistem ... 130
BAB VII KESIMPULAN DAN SARAN ... 131
7.1 Kesimpulan ... 132
7.2 Saran ... 131
DAFTAR PUSTAKA ... 133
LAMPIRAN 1 ... 134
LAMPIRAN 2 ... 142
LAMPIRAN 3 ... 149
LAMPIRAN 4 ... 155
LAMPIRAN 5 ... 156
xvii
DAFTAR GAMBAR
Gambar 2.1 Proses KDD ... 9
Gambar 2.2 Dataset Dengan Outlier ... 11
Gambar 3.1 Database “gudangdata” ... 19
Gambar 3.2 Tabel “fact_lengkap2”... 20
Gambar 3.3 Isi Tabel “fact_lengkap2”... 20
Gambar 3.4 Perhitungan Jarak Mahasiswa 2007 Jalur Test ... 26
Gambar 3.5 Pencarian kdistance data Mahasiswa 2007 Jalur Test ... 27
Gambar 4.1 Diagram Use Case ... 35
Gambar 4.2 Proses Umum Sistem Pendeteksi Outlier Menggunakan Algoritma Local Outlier Factor ... 38
Gambar 4.3 Diagram Kelas Analisis ... 41
Gambar 4.4 Diagram Kelas Desain ... 45
Gambar 4.5 Ilustrasi Struktur Data Graf ... 64
Gambar 4.6 Tampilan Halaman Awal ... 66
Gambar 4.7 Tampilan Halaman Utama Tab Preposesing ... 68
Gambar 4.8 Tampilan Halaman Utama Tab Deteksi Outlier ... 69
Gambar 4.9 Tampilan Halaman Bantuan ... 70
Gambar 4.10 Tampilan Dialog Keluar ... 71
Gambar 4.11 Tampilan Halaman Pilih Database ... 72
Gambar 4.12 Tampilan Halaman Pilih Tabel ... 73
xviii
Gambar5.1 Implementasi Halaman Awal ... 76
Gambar 5.2 Implementasi Halaman Utama Tab Preposesing ... 77
Gambar 5.3 Implementasi jFileChosser ... 78
Gambar 5.4 Implementasi Halaman Utam Tab Deteksi Outlier ... 78
Gambar 5.5 Kotak Seleksi Atribut ... 79
Gambar 5.6 Proses Input Data ... 80
Gambar 5.7 Proses Deteksi Outlier ... 80
Gambar 5.8 Tampilan Hasil Outlier ... 81
Gambar 5.9 Tampilan Hasil Seleksi LOF ... 81
Gambar 5.10 Tampilan Save Dialog ... 82
Gambar 5.11 Tampilan Halaman Distribusi Atribut ... 83
Gambar 5.12 Tampilan Distribusi Per Atribut ... 83
Gambar 5.13 Tampilan Diagram Batang Persebaran Atribut ... 84
Gambar 5.14 Implementasi Halaman Pilih Koneksi ... 85
Gambar 5.15 Proses Konfigurasi Basis Data ... 85
Gambar 5.16 Proses Koneksi Berhasil ... 86
Gambar 5.17 Implementasi Halaman Pilih Tabel ... 87
Gambar 5.18 Hasil Input Dari Database... 88
Gambar 5.19 Implementasi Halaman Bantuan ... 89
Gambar 5.20 Implementasi Halaman Tentang... 90
Gambar 5.21 Implementasi Halaman Konfirmasi keluar ... 91
Gambar 5.22 Pesan Kesalahan Input Data ... 91
xix
Gambar 5.24 Pesan Kesalahan Input Parameter Database ... 92
Gambar 5.25 Pesan Kesalahan nilai minPtskosong ... 93
Gambar 5.26 Pesan Kesalahan nilai minPts0 ... 93
Gambar 5.27 Pesan Kesalahan nilai minPtsnegative atau mengandung karakter Huruf ... 94
Gambar 5.28 Pesan Kesalahan Nilai Batas Outlier Kosong ... 94
Gambar 5.29 Pesan Kesalahan nilai Batas Outliernegative atau mengandung karakter Huruf... 95
Gambar 6.1 Grafik Pengujian Angkatan 2007-2008 Jalur Test ... 113
Gambar 6.2 Grafik Pengujian Data Angkatan 2007-2008 Jalur Prestasi ... 115
xx
DAFTAR TABEL
Tabel 3.1 Tabel Range Nilai Atribut ... 21
Tabel 3.2 Tabel Contoh Data Atribut nil-nil5 ... 22
Tabel 3.3 Tabel Contoh Data Nilai Atribut nil1-nil 5 Setelah Normalisasi ... 23
Tabel 3.4 Tabel Contoh Data Atribut Nilai Final ... 23
Tabel 3.5 Tabel Contoh Data Nilai Atribut Nilai Final Setelah Normalisasi ... 24
Tabel 3.6 Tabel Data Mahasiswa 2007 Jalur Tes ... 25
Tabel 3.7 Tabel Data kDistancedata Mahasiswa 2007 Jalur Test ... 27
Tabel 3.8 Tabel Data kDistance Neighborhood Data Mahasiswa 07 Jalur Test ... 28
Tabel 3.9 Tabel Data Reachbility Distance Data Mahasiswa 2007 Jalur Test ... 29
Tabel 3.10 Tabel Data Reachbility Density Data Mahasiswa 2007 Jalur Test ... 31
Tabel 3.11 Tabel Data LOF Data Mahasiswa 2007 Jalur Test ... 31
Tabel 4.1 Tabel Keterangan Diagram Kelas Analisis ... 42
Tabel 4.2 Ilustrasi Struktur Data Matriks Dua Dimensi ... 65
Tabel 4.3 Ilustrasi Struktur Data Matriks Dua Dimensi Setelah Dilakukan Perhitungan Jarak antar Vertex... 65
Tabel 5.1 Implementasi Kelas ... 95
Tabel 6.1 Tabel Rencana Pengujian BlackBox ... 102
Tabel 6.2 Tabel Pengujian Input Data... 103
Tabel 6.3 Tabel Pengujian Koneksi Database ... 105
Tabel 6.4 Tabel Pengujian Seleksi Atribut ... 107
xxi
Tabel 6.6 Tabel Pengujian Lihat Grafik Atribut ... 110
Tabel 6.7 Tabel Pengujian Simpan Hasil Deteksi Outlier ... 110
Tabel 6.8 Tabel Pengujian Data Mahasiswa 2007-2008 Jalur Test ... 112
Tabel 6.9 Tabel Pengujian Data Mahasiswa 2007-2008 Jalur Prestasi ... 113
Tabel 6.10 Tabel Pengujian Data Mahasiswa 2007-2008 ... 115
Tabel 6.11 Tabel Data Set Perbandingan Perhitungan Manual Dan Sistem ... 120
Tabel 6.12 Tabel Hasil Perhitungan Manual... 121
Tabel 6.13 Tabel Hasil Perhitungan Sistem ... 121
Tabel 6.14 Tabel Hasil Perhitungan Sistem 2007-2008 Jalur Test ... 123
Tabel 6.15 Tabel Hasil Perhitungan Sistem 2007-2008 Jalur Prestasi ... 123
1 BAB I
PENDAHULUAN
1.1 Latar belakang Masalah
Data adalah sesuatu yang sangat penting pada saat ini, seiring dengan berjalannya waktu data-data tersebut terkumpul dan menjadi gabungan data yang sangat besar.Dengan melimpahnya data tersebut dibutuhkan sebuah metode yang efektif dan efisien untuk menggali informasi yang terkandung di dalamnya. Berbagai teknik dan metode telah ada dalam ilmu data mining, kebanyakan dari metode tersebut mencoba untuk menemukan sebuah pola yang umum dari sebuah data set, namun karena jumlahnya yang begitu besar dan bervariatif mengakibatkan munculnya data-data yang tidak konsisten dengan data set yang lain, yang biasa disebut dengan outlier.
Karena keanomaliannya seringkali data tersebut hanya dipandang sebagai noise atau data yang mengganggu, padahal data-data tersebut sebenarnya tidak dapat diabaikan begitu saja, karena data-data tersebut kemungkinan mempunyai informasi yang sangat penting.
tersebut memiliki dimensi yang tinggi atau memiliki atribut yang banyak, salah satu algoritma yang ada adalah algoritma LOF (Local Outlier Factor) algoritma ini digunakan dalam pendekatan Density Based, algoritma ini tidak secara eksplisit menyatakan bahwa suatu obyek adalah sebuah outlier, namun algoritma memberikan bobot / derajat outlier terhadap suatu obyek nilai.
Dalam perkembanganya teknik data mining juga digunakan untuk meneliti dalam berbagai bidang, mulai dari ekonomi, bisnis dan juga dalam bidang pendidikan, banyak sekali penelitian dilakukan dalam bidang pendidikan, menurut Ryan dan Kalina salah satu fungsi Data Mining dalam dunia pendidikan adalah untuk mengembangkan sebuah metode yang dapat menemukan keunikan dari sebuah data yang berasal dari sistem pendidikan tersebut, dan menggunakan metode tersebut untuk lebih memahami siswa, sehingga dapat mengembangkan sebuah sistem yang sesuai (Barker & Yacef, 2009).
maka seorang kaprodi harus memperhatikan riwayat akademik setiap mahasiswa, yaitu berupa nilai test masuk dan juga nilai akademik dari semester 1 sampai semester 4, mahasiswa yang memiliki nilai test masuk tinggi maka akan memiliki potensi prestasi / nilai akademik yang tinggi, begitu pula sebaliknya mahasiswa yang memiiki nilai test masuk yang rendah maka akan memiliki potensi prestasi / nilai akademik yang rendah juga. Namun prediksi tersebut tidak selalu tepat, karena bisa saja mahasiswa yang memiliki nilai test masuk tinggi namun ternyata prestasinya biasa saja atau rendah, begitu pula sebaliknya. Dengan demikian dapat dikatakan mahasiswa yang memiliki pola tidak umum dapat dikatakan sebagai outlier, maka dengan mengetahui mana saja mahasiswa yang berpotensi menjadi outlier akan sangat membantu seorang kaprodi untuk memutuskan mahasiswa mana saja yang bisa dipertahankan dan mahasiswa mana saja yang harus dikeluarkan(DO).
1.2 Rumusan Masalah
1. Bagaimana algoritma Local Outlier Factor dapat mendeteksi outlier dari data nilai akademik mahasiswa?
2. Apakah algoritma Local Outlier Factor dapat mendeteksi Outlier data nilai akademik mahasiswa?
1.3 Batasan
1. Data yang dipakai adalah data nilai akademik mahasiswa program Studi teknik informatika tahun angkatan 2007-2008
2. Algoritma yang dipakai dalam penelitian ini adalah algoritma Local Outlier Factor dengan menggunakan pendekatan Density Based.
1.4 Manfaat Penelitian
Manfaat penelitian ini adalah :
1. Memberikan analisis sejauh mana algoritma Local Outlier Factor dapat mendeteksi sebuah outlier
1.5 Tujuan Penelitian
Tujuan Penelitian ini adalah menerapkan algoritma Local Outlier Factorke dalam sebuah sistem untuk mendeteksi outlierdari data akademik mahasiswa.
1.6 Luaran Penelitian
Luaran penelitian ini adalah sebuah aplikasi berbasis desktop yang mampu memberikan hasil deteksi outlier menggunakan algoritma Local Outlier Factor.
1.7 Metodologi Penelitian
Metodologi yang digunakan untuk menyelesaikan tugas akhir ini adalah menggunakan metode KDD (Knowledge Discovery in Database), yang
dikemukakan oleh Jiawei Han dan Kamber.
1.8 Sistematika Penulisan
Bab I Pendahuluan
Bab ini berisi latar belakang pemilihan judul tugas akhir, rumusan masalah, batasan masalah, tujuan penelitian dilakukan, metodologi penelitian, dan sistematika penulisan tugas akhir.
Bab ini merupakan dasar teoritis yang digunakan untuk menyusun tugas akhir ini. Teori mengenai data-mining, outlier, dan Local Outlier Factor sebagai metode dalam perhitungan nilai LOF.
Bab III Metodologi Penelitian
Bab ini berisi penjelasan metodologi penelitian yang akan digunakan untukmetode LOFdalamanalisis outlier untuk studi kasus data akademik mahasiswa Teknik Informatika Universitas Sanata Dharma.
Bab IV Analisis Dan Perancangan Sistem
Bab ini berisi mengenai proses analisa dan perancangan sistem yang akan dibangun dalam penelitian ini.
Bab V Implementasi Sistem
Bab ini berisi mengenai implementasi sistem deteksi outlier menggunakan algoritma Local Outlier Factor.
Bab VIPengujian Dan Analisis Hasil Pengujian
Pada bab ini, Analisis hasil penelitian yang dilakukan dijelaskan secara lengkap.
Bab VII Kesimpulan dan Saran
8 BAB II
LANDASAN TEORI
2.1 Pengertian Data Mining
Data Miningadalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Handriyadi dkk, 2009).Secara sederhana data mining merujuk pada ektraksi atau penambangan pengetahuan dari data dalam jumlah yang besar (Santosa, 2007).Karena ketersediaan data dalam jumlah yang besar, data mining telah menarik perhatian dalam industri informasi dan masyarakat secara keseluruhan dalam beberapa tahun terakhir, data mining dapat dipandang sebagai akibat dari evolusi alami dari informasi teknologi. Data mining hadir untuk menjawab kebutuhan menganalisis data dalam jumlah yang besar, dimana hal ini didasari oleh terbatasnya kemampuan manusia untuk menganalisis dan mengolah data, yang mengakibatkan data-data tersebut hanya disimpan dalam
sebuah repository yang besar dan hanya menjadi sebuah “kuburan data” (Santosa,
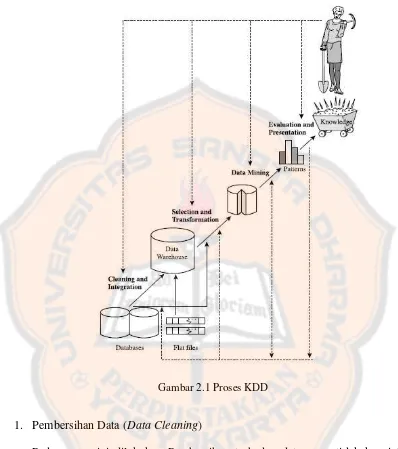
2007). Banyak orang berpendapat bahwa data mining adalah sinonim dari KDD (Knowledge Discovery in Database), namun lebih tepatnya data mining adalah sebuah bagian yang sangat penting dalam proses KDD
Gambar 2.1 Proses KDD
1. Pembersihan Data (Data Cleaning)
Pada proses ini dilakukan Pembersihan terhadap data yang tidak konsisten atau data yang menggangu
2. PenggabunganData (Data Integration)
Pada proses ini dilakukan penggabungan data dari berbagai sumber 3. Seleksi Data ( Data Selection)
4. Transformasi Data (Data Transformation)
Data ditransformasi atau dikonsolidasikan ke dalam bentuk yang tepat untuk di tambang.
5. Penambangan Data (Data Mining)
Proses yang paling penting dimana teknik penambangan data diterapkan untuk mengekstrak Pola Data
6. Evaluasi Pola (Pattern Evaluation)
Yaitu proses mengidentifikasi pola-pola yang benar-benar menarik yang mewakili pengetahuan
7. Presentasi Pengetahuan (Knowledge Presentation)
Pola yang didapat direpresentasikan kepada pengguna dalam bentuk visualisasi
2.2 Pengertian Outlier
Gambar2.2 Dataset dengan Outlier
Menurut jiawei Han dan Kamber dalam pendeteksian sebuah outlier dikategorikan menjadi 4 pendekatan/metode antara lain : Statistical Distribution Based, Distance Based, Deviation Based,Density Based
2.2.1 Statistical Distribution BasedLocal Outlier Detection
Dalam metode ini data diasumsikan sebagai sebuahhipotesis kerja.
Setiap data obyek di dalam dataset dibandingkan terhadap hipotesis kerja. Data yang dapat diterima maka akan masuk dalam hipotesis kerja, sedangkan data yang ditolak atau tidak sesuai dengan hipotesis kerja maka ditetapkan menjadi hipotesis alternatif (outlier).
2.2.2 Distance Based Local Outlier Detection
pada obyek tetangga terdekat (nearest neighbor). Di dalam pendekatan ini sebuah obyek melihat obyek-obyek local neighborhod yang didefinisikan sebagai k-nearest neighbor.Jika ketertanggan sebuah obyek relatif dekat maka obyek tersebut dikatakan normal, namun jika ketertangaan antar obyek relative jauh maka obyek tersebut dikatakan tidak normal (outlier)(Handriyandi dkk, 2009).
2.2.3 Deviation Based Local Outlier Detection
Metode deviation basedtidakmenggunakan pengujian statistik ataupun perbandingan jarak untuk mengidentifikasi sebuah outlier. Sebaliknya metode ini mengidentifikasi sebuah outlier dengan memeriksa karakteristik utama dari obyek dalam sebuah kumpulan. Obyek yang memiliki karakteristik diluar karakteristik utama maka akan dianggap sebagai oulier (Han dan Kamber, 2006).
2.2.4 Density Based Local Outlier Detection
2.2.5 Algoritma LOF
Pada penelitian ini akan menggunakan algoritma LOF, ide utama dari LOF adalah membandingkan kepadatan lokal lingkungan sebuah obyek dengan kepadatan lokal tetangganya, dalam algoritma LOF sebuah obyek dikatakan sebagai outlier apabila memiliki nilai LOF yang tinggi atau menjauhi 1, sedangkan obyek yang memiliki nilai LOF rendah atau mendekati 1 maka obyek tersebut tidak dapat dikategorikan sebagai outlier. Nilai LOF yang tinggi mengindikasikan bahwa obyek tersebut memiliki kepadatan yang rendah terhadap lingkungannya sehingga berpotensi menjadi sebuah outlier. Langkah –langkah untuk menemukan outlier di deskripsikan sebagai berikut :
1. Menghitung k-distance dari setiap obyek p
Tujuan dari perhitungan k-distance ini adalah untuk menentukan tetangga dari p, secara sederhana k-distancedari sebuah obyek p, adalah jarak maksimal dari P terhadap. tetangga terdekatnya. dan di notasikan dengan k-distance(p), k-distance didefinisikan d(p,o) dimana antara P dan object o D memiliki :
(i) untuk setidaknya k objects o‟ D | {p} dan dinyatakan bahwa d(p,o‟) ≤ d(p,o)
2. Menghitung jumlah tetangga terdekat(k-distance neighborhood
dari setiap obyek p)
k-distance neighborhoodsuatu objek p dinotasikan Nk-distance(p), atau Nk(p) dimana berisi setiap objek dengan jarak tidak lebih besar dari kdistance (p).
3. Menghitung Reachbility Distance dari p
Reachability distance dari suatu obyek p terhadap obyek o adalah distance(p, o)atau kdistance(o), dengan membandingkan keduanya dan dicari nilai yang maksimum sehingga,reach-distk(p, o) = max{kdistance (o), distance(p,
o)). Tujuan dari perhitungan ini adalah untuk memastikan bahwasemua bendaberada dalam lingkungan yang homogen. Selain itu, nilai LOF akan stabil jika sebuah obyek berada dalam lingkungan yang seragam sekalipun jika MinPts(k) berubah.
Fluktuasi darireachabilitydistance dapat dikontrol dengan memilih nilai maksimum untuk k.
4. Menghitung kepadatan local dari setiap obyek
local reachbility density dari p di definisikan sebagai berikut :
…….. (2.1)
lrdMinPts(p) : Kepadatan local dari obyek p
reachdistMinPts(p,o) : Reacbility Distance dari obyek p ke obyek o
NMinPts(p) : Jumlah tetangga p dalam suatu minPts
Secara intuitif, local reachbility density p adalah kebalikan dari rata-rata reachability distance baseddi dalam minPts-tetangga terdekat dari obyek p.
5. Menghitung LOF untuk setiap obyek data
Local outlier factor dari P di definisikan sebagaiberikut :
……(2.2)
Keterangan :
LOFMinPts(p) : Derajat outlier dari obyek p
lrdMinPts(o) : Kepadatan local obyek o
lrdMinPts(p) : Kepadatan local obyek p
NMinPts(p) : Jumlah tetangga p dalam suatu minPts
merupakan rata-rata rasio kepadatan reachability lokal p dan tetangga p dalam satu jangkauan.
2.2.5.1 Contoh Perhitungan LOF
Misalkan Sebuah database D memiliki 4 buah obyek dan dilambangkan sebagai P1, P2, P3 dan P4 dimana masing-masing obyek memiliki jarak sebagai
berikut : P1P2 = 4 , P1P3 = 3 , P1P4 = 7 , P2P3 = 5 , P2P4 = 6 , dan P3P4 = 8 dan
minPts(k) = 2
1. Mencari k-distance
Maka untuk contoh diatas langkah untuk menemukan k-distance dari obyek P1 adalah sebagai berikut :
a. Hitung jarak P1 terhadap semua obyek dengan menggunakan fungsi
jarak, untuk contoh diatas jarak P1 terhadap obyek yang lain telah di
didefinisikan yaitu : P1P2 = 4, P1P3 = 3, P1P4 = 7
b. Pilih 2 jarak minimum yang berbeda dari P1, semua jarak dari P1
diurutkan dan dipilih 2 minimum pertama, maka diperoleh 2 minimum pertama yaitu P1P3 = 3 , P1P2 = 4
c. kemudian dari 2 jarak tersebut pilih yang paling maksimum, dimana ini nanti akan menjadi kdistance dari P1 maka :
k-distance(P1) = max(3,4) , sehingga k-distance(P1) = 4
2. Menemukan k-distanceneighborhoodyang k-distance<= 4
Selanjutnya dicari k-distanceneighborhooddari P1, maka obyek data yang
4 dan jarak dari P2 dan P3 dari P1 masing-masing tidak lebih dari 4 (yaitu, P1P2 =
4, P1P3 = 3)
3. Menghitung Reachbility Distance
Jarak reachability dari P1 adalahdihitung sebagai berikut: Pertama,
mengidentifikasi lingkungan kdistance P1 (yaitu, Nk (P1) = (P2, P3)). reachbility
distance P1 dihitung sehubungan dengan P2 dan P3 karena mereka merupakan
tetangga dariP1.Untuk P2 dalam lingkungan P1: reachdistk (P1, P2) = max
(k-distance (P2), distance((P1, P2)) = max(5,4) = 5. Sejak kdistance (P2) = 5 dan
jarak (P1, P2) = 4. Untuk P3 dalam lingkungan P1: reachdistk (P1, P3) = max
{k-distance (P3), jarak (P1, P3)} =max (5, 3) = 5. Oleh karena itu, reachdistk (P1, o) =
(5, 5), yang merupakan kombinasi dari jarak reachability daritetangga dari P1.
4. Menghitung Reachbility Density
Kepadatan reachability lokal untuk P1 dihitung sebagai berikut:
lrdk (P1) = 1 / {(5 +5) / 2} = 2/10, karena (5,5) merupakan jarak reachability lokal
P1 dan jumlah tetangga kdistance adalah 2.makalrdk (P2) = 2/9, lrdk (P3) = 2/9 dan
lrdk (P4) = 2/13.
5. Menghitung LOF
Selanjutnya dilakukan perhitungan LOF untuk obyek P1, nilai LOF P1
sebagai berikut :
18 BAB III
METODOLOGI PENELITIAN
Pada bagian ini akan dijelaskan mengenai metodologi penambangan data yang akan digunakan dalam penelitian ini, yaitu KDD(Knowledge Discovery in Database) yang dikemukakan oleh Jiawei Han dan Kamber.
3.1 Sumber Data
Sumber data dalam penelitian skripsi ini adalah Data akademik mahasiswa Teknik Informatika Universitas Sanata Dharma tahun angkatan 2007-2008, data ini berupa script query yang berisi sebuah gudang data dan berformat .sql. Data ini diperoleh dari Gudang Data akademik mahasiswa USD hasil penelitian Rosa, dkk (2011).Data yang telah terkumpul kemudian diolah.Pada tahap ini data yang tadinya berupa file mentah di extrak ke dalam database, hasil ekstrakan tersebut
menghasilkan sebuah basis data yang bernama “gudangdata”, dalam basis data ini
Gambar 3.1 Database“gudangdata”
3.2 Seleksi Data (Data Selection)
Gambar 3.2 Tabel “fact_lengkap2”.
Setelah dilakukan seleksi terhadap tabel dalam database gudangdata, selanjutnya dilakukan seleksi terhadap data dalam tabel fact_lengkap2, yaitu dengan menyeleksi data mahasiswa yang bukan program studi Teknik Informatika, yaitu data mahasiswa yang memiliki data sk_prodi selain 27
Gambar 3.3 Isi tabel “fact_lengkap2”.
jummsttb, jumnem, jummtnem, sttb, sk_jeniskelamin, sk_status, sk_kabupaten, sk_daftarsmu, sk_prodi
3.3 Transformasi Data (Data Tranformation)
Pada tahap ini dilakukan proses normalisasi atribut, proses ini dilakukan agar data tersebut memiliki bentuk yang tepat untuk ditambang, hal itu dikarenakan perbedaan range nilai antar atribut satu dengan yang lainnya,
sehingga atribut-atribut tersebut nantinya akan memiliki range nilai sama dengan atribut IPS. Untuk melakukan proses normalisasi tersebut digunakan metode min max normalization, dengan rumus sebagai berikut :
, …..(3.1)
Nilai1, nilai2, nilai3, nilai4 dan nilai 5 0-10
Nilai Final 0-100
IPS 0-4
Keterangan
v’ : nilai yang sudah ternormalisasi
v : nilai lama yang belum ternormalisasi
minA : minimum nilai dari atribut a
maxA : maksimum nilai dari atribut a
newMinA : nilai minimum baru dari atribut a
newMaxA : nilai maksimum baru dari atribut a
1. Normalisasi Atribut nilai1, nilai2, nilai3, nilai4 dan nilai 5
Contoh data dibawah ini menggambarkan proses transformasi dari atribut nilai1, nilai2, nilai3, nilai 4 dan nilai 5
Nomor nil11 nil12 nil13 nil14 nil15 ips1
1 8.00 6.00 6.00 7.00 5.00 3.72
Nomor nil11 nil12 nil13 nil14 nil15 ips1
2. Normalisasi Atribut Nilai Final
Contoh data dibawah ini mengambarkan proses transformasi atribut nilai final
Nomor ips1 ips2 ips3 ips4 final
1 2.06 2.32 2.91 3.00 67.80
10 3.89 3.75 3.00 3.62 77.00
11 2.89 3.68 2.88 3.76 72.99
Tabel 3.3 Contoh data atribut nil1-nil5 setelah normalisasi
12 3.11 3.08 2.78 3.48 68.17
13 2.00 2.00 2.29 3.00 77.10
Nomor ips1 ips2 ips3 ips4 final Final1
1 2.06 2.32 2.91 3.00 67.80 2.712
2 2.72 2.50 2.96 2.38 67.75 2.71
3 3.33 3.48 3.78 3.48 69.41 2.7764
4 2.39 3.00 2.43 2.82 71.60 2.864
5 2.11 2.71 2.43 2.45 73.75 2.95
6 3.00 2.96 2.61 3.29 67.57 2.7028
7 3.72 3.56 3.43 3.67 78.67 3.1468
8 3.44 3.04 2.88 3.48 71.33 2.8532
9 2.17 2.70 3.09 3.63 72.00 2.88
10 3.89 3.75 3.00 3.62 77.00 3.08
11 2.89 3.68 2.88 3.76 72.99 2.9196
12 3.11 3.08 2.78 3.48 68.17 2.7268
13 2.00 2.00 2.29 3.00 77.10 3.084
3.4 Penambangan Data (Data Mining)
Data-data yang telah diolah akan dianalis menggunakan algoritma Local Outlier Factor, data yang akan diteliti dibatasi yaitu data akademik mahasiswa Teknik Informatika Universitas Sanata Dharma dengan Tahun akademik 2007 – 2008, selama 4 semester. pada tahap ini ditentukan beberapa variable yang digunakan untuk pengujian variable tersebut antara lain :
1. Variabel Input
Nim_mhs, nama_mhs, ips1, ips2, ips3, ips4, nil1,nil2,nil3, nil4, nil5, nil6, final, statusTes, kd21, kd22, kd23, kd24, kd25, kd26, kd27, kd28, nem
2. Output
Output yaitu data mahasiswa yang menjadi outlier.
Langkah selanjutnyadilakukan penambangan terhadap data tersebut dengan menggunakan algoritma Local Outlier Factor. Pada penambangan ini digunakan tools Ms.Excel untuk membantu perhitungan menggunakan algoritma Local Outlier Factor. Berikut merupakan cotoh tahap penambangan data :
1. perhitungan data mahasiswa angkatan 2007 pendaftar jalur regular dengan membandingkan nilai per komponen dan IPS semester 1
Tabel 3.6 Tabel Data Mahasiswa 2007 Jalur Tes
Nomor
Alias ips1 nil11 nil12 nil13 nil14 nil15
P1 3.72 8.00 6.00 6.00 7.00 5.00
P2 2.89 6.00 5.00 5.00 7.00 5.00
P3 2.56 6.00 4.00 5.00 7.00 5.00
P4 3.28 7.00 6.00 7.00 6.00 6.00
P5 1.89 6.00 5.00 6.00 6.00 7.00
P6 1.44 10.00 5.00 9.00 6.00 7.00
P7 4.00 6.00 6.00 4.00 4.00 7.00
P8 1.72 3.00 2.00 8.00 3.00 1.00
P9 2.89 5.00 5.00 8.00 5.00 7.00
P10 2.94 7.00 5.00 5.00 5.00 4.00
P11 2.94 6.00 4.00 6.00 3.00 7.00
P12 2.44 5.00 5.00 6.00 5.00 5.00
dari data diatas kemudian dicari jarak setiap obyek dengan menggunakan fungsi jarak ecludian, dengan menggunakan rumus :
………(3.2)
Gambar 3.4 Perhitungan Jarak Mahasiswa 2007 Jalur Test
Gambar 3.5 Pencarian kdistance data mahasiswa 2007 jalur test
Sehingga k-distance untuk masing-masing obyek didapati sebagai berikut :
Tabel 3.7 Tabel Data kdistancedata mahasiswa 2007 jalur test
k-distance
P1 2.052897681
P2 1.697056275
P3 1.775130668
P4 1.602823512
P5 1.741861145
P6 4.088663943
P7 2.428321068
P8 3.278382054
P9 1.876987014
P11 1.873810407
P12 2.538025382
P13 2.404140462
Kemudian dicari setiap tetangga setiap obyek yang jaraknya tidak melebihi dari k-distance dari obyek tersebut
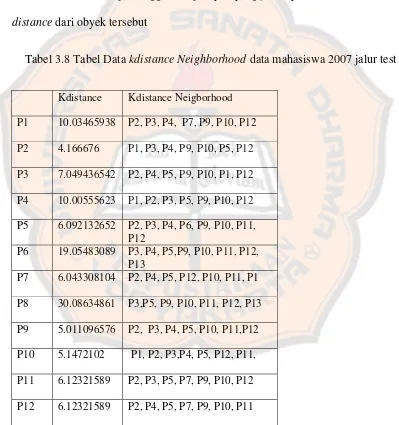
Tabel 3.8 Tabel Data kdistance Neighborhood data mahasiswa 2007 jalur test
Kdistance Kdistance Neigborhood
P1 10.03465938 P2, P3, P4, P7, P9, P10, P12
P2 4.166676 P1, P3, P4, P9, P10, P5, P12
P3 7.049436542 P2, P4, P5, P9, P10, P1, P12
P4 10.00555623 P1, P2, P3, P5, P9, P10, P12
P5 6.092132652 P2, P3, P4, P6, P9, P10, P11, P12
P6 19.05483089 P3, P4, P5,P9, P10, P11, P12, P13
P7 6.043308104 P2, P4, P5, P12, P10, P11, P1
P8 30.08634861 P3,P5, P9, P10, P11, P12, P13
P9 5.011096576 P2, P3, P4, P5, P10, P11,P12
P10 5.1472102 P1, P2, P3,P4, P5, P12, P11,
P11 6.12321589 P2, P3, P5, P7, P9, P10, P12
Kemudian dicari reachbility distance setiap obyek yaitu dengan membandingkan jarak suatu obyek ke tetangga dari obyek tersebut dengan k-distance dari tetangganya
Tabel 3.9 Tabel Data Reachbility Distance data mahasiswa 2007 jalur test
P2 P4 P12 P3 P7 P9 P10
P1 1.2862305 0.91515 1.967936 1.6736056 1.8539614 2.0528977 1.372943131
Reachbility Distance 1.6970563 1.60282 2.538025 1.7751307 2.4283211 2.0528977 1.741861145
Reachbility Density 0.5059223
P3 P9 P10 P1 P4 P5 P12
P2 0.520662 1.6971 0.98137 1.28623 1.19635 1.4 1.075909034
Reachbility Distance 1.775131 1.877 1.74186 2.0529 1.60282 1.741861 2.538025382
Reachbility Density 0.525148
P2 P4 P5 P9 P10 P1 P4
P3 0.520662 1.2508 1.2508 1.77513 1.12746 1.673606 1.510487617
Reachbility Distance 1.697056 1.6028 1.74186 1.87699 1.74186 2.052898 2.538025382
Reachbility Density 0.528242
P1 P2 P3 P5 P9 P10 P12
P4 0.915146 1.1963 1.51049 1.60282 1.19635 1.308111 1.405188799
Reachbility Distance 2.052898 1.6971 1.77513 1.74186 1.87699 1.741861 2.538025382
Reachbility Density 0.521461
P2 P3 P10 P9 P4 P11 P12
P5 1.4 1.2508 1.74186 1.4 1.60282 1.647447 1.126312679
Reachbility Distance 1.697056 1.7751 1.74186 1.87699 1.60282 1.87381 2.538025382
Reachbility Density 0.465269
P10 P5 P3 P4 P9 P12 P13
P6 2.801785 2.7046 2.70458 4.08866 2.53112 2.690725 2.545029045
Reachbility Distance 2.801785 2.7046 2.70458 4.08866 2.53112 2.690725 2.545029045
Reachbility Density 0.34983
P2 P4 P5 P12 P10 P11 P1
P7 1.906448 1.7093 2.42832 2.04448 1.78726 1.598215 1.853961391
Reachbility Density 0.489647
P3 P5 P9 P10 P11 P12 P13
P8 3.05525 3.2784 3.13707 3.00229 3.15813 2.538025 3.046309242
Reachbility Distance 3.05525 3.2784 3.13707 3.00229 3.15813 2.538025 3.046309242
Reachbility Density 0.329948
P2 P3 P5 P4 P12 P10 P11
P9 1.697056 1.7751 1.4 1.19635 1.21556 1.876987 1.266128054
Reachbility Distance 1.697056 1.7751 1.74186 1.60282 2.53803 1.876987 1.873810407
Reachbility Density 0.534119
P2 P3 P5 P12 P11 P1 P4
P10 0.981367 1.1275 1.74186 1.1 1.6 1.741861 1.308111448
Reachbility Distance 1.697056 1.7751 1.74186 2.53803 1.87381 2.052898 1.602823512
Reachbility Density 0.527045
P5 P3 P12 P7 P9 P10 P4
P11 1.647447 1.8738 1.36015 1.59822 1.26613 1.6 1.308111448
Reachbility Distance 1.741861 1.8738 2.53803 2.42832 1.87699 1.741861 1.602823512
Reachbility Density 0.507111
P2 P3 P5 P4 P9 P10 P11
P12 1.075909 1.0641 1.12631 1.40519 1.21556 1.1 1.360147051
Reachbility Distance 1.697056 1.7751 1.74186 1.60282 1.87699 1.741861 1.873810407
Reachbility Density 0.568665
P1 P2 P3 P4 P5 P10 P12
P13 2.529822 2.1728 2.12945 2.40414 2.3723 2.274593 2.200357435
Reachbility Distance 2.529822 2.1728 2.12945 2.40414 2.3723 2.274593 2.538025382
Reachbility Density 0.426279
Tabel 3.10 Tabel Data Reachbility Density data mahasiswa 2007 jalur test
Kdistance Kdistance Neigborhood reachability density of p
P1 2.052897681 P2, P3, P4, P7, P9, P10, P12 0.51
P2 1.697056275 P1, P3, P4, P9, P10, P5, P12 0.53
P3 1.775130668 P2, P4, P5, P9, P10, P1, P12 0.53
P4 1.602823512 P1, P2, P3, P5, P9, P10, P12 0.52
P5 1.741861145 P2, P3, P4, P6, P9, P10, P11, P12 0.47
P6 4.088663943 P3, P4, P5,P9, P10, P11, P12, P13 0.35
P7 2.428321068 P2, P4, P5, P12, P10, P11, P1 0.49
P8 3.278382054 P3,P5, P9, P10, P11, P12, P13 0.33
P9 1.876987014 P2, P3, P4, P5, P10, P11,P12 0.53
P10 1.741861145 P1, P2, P3,P4, P5, P12, P11, 0.53
P11 1.873810407 P3, P4, P5, P7, P9, P10,P12 0.51
P12 2.538025382 P2, P3,P4, P5, P9, P10, P11 0.57
P13 2.404140462 P1, P2. P3, P4, P5, P10, P12 0.43
Setelah itu dilakukan perhitungan derajat outlier dari setiap obyek atau yang disebut sebagai LOF dengan menggunakan rumus (2.2) :
Tabel 3.11 Tabel Data LOF data mahasiswa 2007 jalur test
Kdistance Kdistance Neigborhood reachability density of p LOF
P1 2.052897681 P2, P3, P4, P7, P9, P10, P12 0.51 1.04
P2 1.697056275 P1, P3, P4, P9, P10, P5, P12 0.53 0.99
P4 1.602823512 P1, P2, P3, P5, P9, P10, P12 0.52 1.00
P5 1.741861145 P2, P3, P4, P6, P9, P10, P11, P12 0.47 1.09
P6 4.088663943 P3, P4, P5,P9, P10, P11, P12, P13 0.35 1.46
P7 2.428321068 P2, P4, P5, P12, P10, P11, P1 0.49 1.06
P8 3.278382054 P3,P5, P9, P10, P11, P12, P13 0.33 1.54
P9 1.876987014 P2, P3, P4, P5, P10, P11,P12 0.53 0.97
P10 1.741861145 P1, P2, P3,P4, P5, P12, P11, 0.53 0.98
P11 1.873810407 P3, P4, P5, P7, P9, P10,P12 0.51 0.99
P12 2.538025382 P2, P3,P4, P5, P9, P10, P11 0.57 0.91
P13 2.404140462 P1, P2. P3, P4, P5, P10, P12 0.43 1.22
Dari analisis data diatas menggunakan algoritma local outlier factor maka ditemukan 3 data yang berpotensi menjadi sebuah outlier, dimana 2 data dengan outlier yang sangat tinggi yaitu mahasiswa dengan no P6 dimana mahasiswa tersebut memiliki nilai tes masuk yang tinggi, tetapi memiliki nilai IPS yang rendah di semester 1, dan mahasiswa dengan no P8, dimana mahasiswa tersebut memiliki nilai final yang rendah dan memiliki IPS yang rendah juga.
3.5 Evaluasi Pola (Pattern Evaluation)
3.6 Presentasi Pengetahuan (Knowledge Presentation)
34 BAB IV
ANALISIS DAN PERANCANGAN SISTEM
4.1 Identifikasi Sistem
Deteksi outlier merupakan sebuah teknik di dalam data mining yang bertujuan untuk menemukan sebuah data yang berbeda/anomali dari keseluruhan set yang ada, dalam pendekteksian outlier ini terdapat beberapa pendekatan antara lain Statistical Distribution Based, Distance Based, Deviation Based dan Density Based
Dalam metode density based,outlier tidak diklasifikasn secara eksplisit tetapi lebih kepada pemberian nilai kepada setiap obyek dengan sebuah ukuran derajat outlier atau yang disebut LOF (Local Outlier Factor). Dalam tugas akhir ini akan dijelaskan bagaimana proses mendeteksi sebuah outlier dan proses pembuatan aplikasi untuk mendeteksi outlier menggunakan algoritma Local Outlier Factor. Proses pendeteksian outlier dapat mencakup keanekaragaman bentuk data, sehingga nantinya aplikasi yang akan dikembangkan dapat mendeteksi outlier dari berbagai jenis data
Dalam penelitian ini data yang digunakan adalah data yang bertipe file excel dan data dari Basis Data.dan hasil keluaran (output) disimpan dalam file Ms Word (.doc) dan.txt
4.1.1 Diagram Use Case
Dalam sebuah sistem selalu ada interaksi antara pengguna dan Sistem, dimana interaksi tersebut dapat menggambarkan bagaimana proses dan cara kerja sistem tersebut. Untuk mengambarkan interaksi di dalam sistem yang akan dikembangkan pada tugas akhir ini digunakan sebuah diagram usecaseseperti berikut
Gambar 4.1 Diagram Use Case
Dalam diagram usecase diatas terdapat satu orang pengguna yang nantinya dapat berinteraksi dengan Sistem. Pengguna tersebut dapat menjalankan 3 fungsi utama dalam Sistemyaitu : menginputkan data, mencari outlier dan menyimpan Pengguna
Cari Outlier Input data excel atau
database
Simpan
Seleksi Atribut <<Extends>> <<Depends
On>>
<<Depends On>>
hasil outlier. Ketiga fungsi tersebut saling berhubungan sehingga fungsi-fungsi tersebut harus dijalankan secara berurutan, fungsi yang harus dijalankan terlebih dahulu adalah menginputkan data, mencari outlier dan kemudian simpan data. Selain itu terdapat juga fungsi tambahan fungsi ini merupakan fungsi tambahan yang terdapat pada fungsi input data. fungsi tersebut adalah fungsi seleksi atribut dan fungsi lihat grafik distribusi atribut. Kedua fungsi tersebut merupakan perluasan dari fungsi input data.
4.1.2 Narasi Use Case
Untuk mengetahui detail Narasi Use Case secara keseluruhan dapat dilihat pada bagian lampiran 1.
4.2 Perancangan Sistem Secara Umum
4.2.1 Input Sistem
Sistem yang dibuat pada penelitian ini dapat menerima masukan berupa data bebas dari pengguna yang bertipe file excel (.xls) atau data dalam table yang terdapat di dalam basis data .dalam penelitian ini data yang digunakan adalah data dengan ukuran bebas, karena aplikasi yang akan dikembangkan bersifat universal, sehingga dapat mencari outlier di semua jenis data.
4.2.1.1minPts
minPts adalah jangkauan atau jumlah tetangga terdekat yang digunakan untuk mendefinisikan local Neighborhood suatu obyek.
4.2.2 Proses Sistem
Sisitem Deteksi outlier berjalan dengan beberapa tahapan yaitu sebagai berikut
4.2.2.1 Pengambilan Data
Pada tahap ini Sistem akan mengambil data sesuai dengan pilihan user, data yang akan dibaca dapat berupa file xls, csv atau mengambil data yang terdapat di dalam database, data ini kemudian akan ditampilkan di dalam interface, kemudian dilakukan seleksi oleh user, dalam seleksi ini userakan memilih atribut mana saja yang sesuai untuk dilakukan proses Deteksi outlier
4.2.2.2 Perhitungan jarak obyek data
Selanjutnya setiap obyek data dicari jarak ketetanggan antar obyek, proses perhitungan ini menggunakan rumus Euclidean distance. Sehingga setiap obyek akan memiliki nilai jarak dengan satu dan lainnya
4.2.2.3 Pencarian outlier berdasarkan parameter minPts
Gambar 4.2 Proses Umum Sitem Pendeteksi Outlier Menggunakan Algoritma Local Outlier Factor
4.2.3 Output Sistem
Sistem yang kan dibuat ini adalah Sistem untuk mendeteksi outlier, hasil keluaran dari Sistem ini adalah sebagai berikut :
4.2.3.1 Jumlah data row
Sistemakan menampilkan jumlah baris, hal ini bertujuan untuk memastikan bahwa setiap data yang di import terbaca oleh Sistem dengan benar
4.2.3.2 Label serta derajad LOF
4.3 Perancangan Sistem
4.3.1 Diagram Aktivitas
Diagram aktivitas berfungsi untuk menunjukan aktivitas antara pengguna dengan Sistem. Detail dari diagram aktivitas per use case dapat dilihat di lampiran 2. Berikut adalah diagram aktivitas dari setiap use case:
1. Diagram Aktivitas Inputdata dari file .xls
2. Diagram Aktivitas Inputdata dari tabel dalam basisdata 3. Diagram Aktivitas Deteksi Outlier
4.3.2 Diagram Kelas Analisis
Gambar 4.3 Diagram Kelas Analisis Pengguna
Halaman Awal
Halaman Utama
Halaman Distribusi Atribut
DiagramBatang
Halaman PilihDatabase Halaman TampilTabel
DatabaseConnectio
n DatabaseControll
er
CheckBoxTableModel
Seleksi Atribut
Graph Vertex HalamanBantuan
HalamanKonfirmasiKeluar
Kontroller lof
Data LofTableModel
Tabel 4.1 Tabel keterangan diagram kelas analisis
No Nama Kelas Jenis Keterangan
1 DatabaseConnection Entity Kelas ini adalah kelas yang berfungsi untuk
melakukan koneksi antara Sistem dengan
basis data, dalam kelas ini juga terdapat
atribut-atribut yang digunakan untuk
melakukan koneksi tersebut
2 Graph Entity Kelas ini berfungsi untuk membentuk
sebuah graph beserta dengan edge anta
setiap verteks
3 Vertex Entity Kelas ini berfungsi untuk membentuk
sebuah verteks, dalam kelas ini terdapat
atribut-atribut yang digunakan untuk proses
perhitunngan outlier
4 SeleksiAtribut Entity Kelas ini berfungsi untuk menyimpan
atribut yang digunakan untuk table pada
seleksi atribut
5 CheckBoxTableModel Entity Kelas ini adalah kelas yang berfungsi untuk
membentuk seleksi atribut menjadi sebuah
table model
6 DataLof Entity Kelas ini adalah kelas yang berfungsi untuk
menyimpan data hasil deteksi outlier
7 DataLofTableModel Entitiy Kelas ini berfungsi untuk membentuk
DataLof menjadi kedalam sebuah Tabel
8. DiagramBatang Entity Kelas ini berfungsi untuk menampikan
rincian data atribut ke dalam sebuah
Diagram
9 DatabaseController Controller Kelas ini berfungsi untuk mengatur koneksi
antara Sistem dengan database, serta berisi
method-method yang digunakan untuk
query database.
10 KontrollerLof Controller Kelas ini berfungsi untuk mengatur proses
deteksi outlier, mulai dari proses
penginputan data hingga proses
penyimpana data outlier
8 HalamanUtama Boundary Kelas ini berisi tampilan halaman utama
dari dari Sistem, yaitu proses seleksi atribut
dan juga deteksi outlier
9 HalamanDistribusiAtribut Boundary Kelas ini berisi tampilan untuk memilih
atribut yang akan dicari persebaran
distribusinya.
10 HalamanPilihDatabase Boundary Kelas ini berisi tampilan untuk memilih
jenis database serta melakukan
konfigurasinya.
11 HalamanTampilTabel Boundary Kelas ini berisi tampilan untuk memilih
tabel yang akan digunakan untuk proses
deteksi outlier
12 HalamanAwal Boundary Kelas ini berisi tampilan awal yang
4.3.3 Diagram Sequence
Berikut merupakan diagram sequence yang terdapat dalam proses perancanganSistem Pendeteksi Outlier Menggunakan Algoritma local Outlier Factor.
1. Diagram Sequence Inputdata dari file .xls 2. Diagram Sequence Inputdata dari file .csv
3. Diagram Sequence Inputdata dari tabel dalam basisdata 4. Diagram Sequence Deteksi Outlier
5. Diagram Sequence Simpan hasil deteksi outlier
6. Diagram Sequence Lihat Distribusi Atribut per Atribut 7. Diagram Sequence Seleksi Atribut
Untuk penjelasan rinci dari masing – masing diagram sequence dapat dilihat pada lampiran 2 yang terdapat pada tugas akhir ini.
tampilan utama
13 HalamanBantuan Boundary Kelas ini berisi tampilan mengenai petunjuk
penggunaan Sistem
14 HalamanTentangKami Boundary Kelas ini berisi tampilan informasi
mengenai Sistem.
15 HalamanKonfirmasiKeluar Boundary Kelas ini digunakan untuk menampilkan
konfirmasi apakah pengguna benar-benar
4.3.4 Diagram Kelas Desain
Diagram kelas desainmenunjukkan daftar kelas yang nantinya akan dipakai dalam pembuatan sistem. Diagram kelas memuat semua kelas untuk menjalankan semua fungsi pada sistem.Untuk rincian atribut dan methodmasing-masing kelas dapat dilihat padalampiran 4 dalam tugas akhir ini.
<<boundary >>
4.3.5 Rincian Algoritma Setiap Method Pada Tiap Kelas
4.3.5.1 Rincian Algoritma pada Method di koneksi Database
Nama method Fungsi method Algoritma method
KoneksiDatabase(
String, String, String, String) lakukan langkah dibawah ini
a. Buat koneksi MySql dengan lakukan langkah dibawah ini
a. Buat obyek ds dari oracleDataSource kemudian dengan obyek tersebut setting alamat url dari database
c. Apabila koneksi berhasi
tampilkan pesan “koneksi
Berhasil”
d. Apabila koneksi gagal tampilkan
pesan “Koneksigagal”
isConnectedSQL() Mengecek apakah koneksi dengan terhubung atau tidak dengan memanghil method is Connected 2. Jika hasilnya true putuskan
koneksi
4.3.5.2 Rincian Algoritma pada Method di Kelas Kontroller LOF Nama method Fungsi method Algoritma method
inputData Menginputkan data dari Jtable ke dalam matrix dalam graf
1. Selama i = 0 dan I tidak lebih dari jumlah baris dari jTable lakukan langkah dibawah ini :
2. Buat variable label bertipe string 3. Buat variable listNilai yang bertipe
arraylist double
4. Selama j = 0 dan j tidak lebih dari jumlah kolom jTable lakukan langkah dibawah ini
a. Cek apakah j = 0 jika iya maka set label = data yang ada di dalam baris dan kolom table tersebut,
b. Jika tidak maka lakukan langkah c dan d
c. Cek apakah data tersebut merupakan data numeric, jika masukan data pada baris (i,j) kedalam arraylist nilai
0.0 kedalam arrayList nilai 5. panggil method addVerteks dari kelas
graph dengan inputan label, dan list nilai
6. selama i = 0 dan i tidak lebih dari jumlah baris jTable lakukan langkah dibawah ini :
a. selama j = i + 1 dan j tidak lebih dari jumlah baris dari jTable lakukan langkah dibawah ini : b. cek apakah i=j jika iya panggil
method addEdge yang terdapat di kelas graph dengan memasukan inputan i, j dan hasil perhitungan jarak Ecludian I dan J dengan memanggil method ecludian antar setiap obyek
1. Buat dua buah variabel yaitu a dan b dengan tipe ArrayList double
2. Set arrayList a sebagai arrayList yang menyimpan nilai dari obyek awal 3. Set arrayListb sebagai array yang akan
yang akan dicari jarakanya terhadap obyek awal
4. Kemudian hitung jarak setiap nilai dari obyek awal terhadap obyek tujuan dengan menggunakan rumus ecludian distance
cariKdistance mencariKdistance dari setiap obyek
1. Set semua flagKunjungan dari semua obyek(vertex ) menjaid false
2. buat sebuah variable array a bertipe double, dimana array ini memiliki panjang sesuai jumlah dari minPts / jangkauan
3. buat variable kDistance dengan tipe double
4. buat variable temp1 bertipe double 5. buat variable tamping bertipe string 6. masukan data jarak dari setiap
tetangga dengan menggunakan perulangan, selama t tidak lebih dari panjang array a lakukan langkah dibawah ini
maka lakukan langkah dibawah ini : b. cek apakah edge dari indeks tersebut
terhadap i != -1 dan !=0 dan flahKunjungannya == false jika ya lakukan langkah dibawah c dan d: c. jika edge dari indeks terhadap
verteksList ke i< dari temp1 maka d. set temp1 = garis[indeks][i]
e. set array a ke t = temp1;
f. kemudian ubah flagKunjungan dari arraylis tersebut menjadi true dengan memanggil method search2 dengan inputan (temp1, indeks) String, array ini berfungsi untuk menyimpan label yang menjadi tetangga terhadap obyek yang akan dicari tetangganya
3. Jika jarak indeks terhadap I kurang <= kDIstance , maka tambahkan
verteksList[i] kedalam array a 4. Kembaikan a nilai dari array a
1. Buat variable reachbilityDistance bertipe List Double
2. Buat variable indexTujuan dengan tipe integer, variable ini berfungsi untuk menyimpan label, dari kDistance Neighborhood suatu obyek
3. Buat variable kDistance bertipe double 4. Inisialisasikan i = 0, selama i < size
tujuan lakukan langkah dibawah ini a. Cari index obyek tujuan dengan
memanggil method Search dengan inputan label dari List Tujuan ke i, kemudian inisialisasikan kedalam variable indexTujuan
b. Setelah itu cari kDistance dari obyek tujuan tersebut dengan memanggil verteksList[indexTujuan].getKdistanc( )
garis[indexAwal][indexTujuan] Maka tambahkan kDistance kedalam array reachbiltyDistance
d. Jika tidak maka tambahkan garis[indexAwal[indexTujuan] kedalam array reachbiltyDistance e. Kembalikan nilai reachbiltyDistance
reachBilityDensity(
1. Buat variable ReachbilityDensity bertipe double
2. Buat variable
jumlahReachbiltyDistance bertipe double dan inisialisasikan = 0.0 3. Inisialisasikan i=0, selama
i<reachbilityDistance.size lakukan langkah dibawah ini :
a. Jumlahkan JumlahreachBIlityDistance dengan reachBilityDistance ke i, kemudian inisialisasikan kedalam variabek jumlahReachBilityDIstance b. Kembalikan nilai ReachBilityDensity
reachBilityDistance.size()
getLof(List<Doubl e>, Double)
Mencari nilai LOF setiap obyek
1. Buat variable LOF bertipe double 2. Buat variable
jumlahReachbilityDensity dan insialisasikan 0.0;
3. Inisialisasikan i=0, selama i< reachbilityDensity.size lakukan langkah dibawah ini
a. Inisialisasikan
1. Buat variable index bertipe int 2. lakukan insisialisasi variable index
dalam Verteks dengan inputan label 3. set variable kDIstance pada
vertekslidt[index] dengan inputan yaitu hasil balik dari method cariKdistance dengan inputan index dan jangkauan
1. Buat variable index bertipe int 2. lakukan insisialisasi variable index
dengan memanggil method search dengan inputan label
3. set variable kNeighborhood pada vertekslidt[index] dengan inputan yaitu hasil balik dari method cariNeigborhood dengan inputan
1. Buat variable index bertipe int 2. lakukan insisialisasi variable index
dengan memanggil method search dengan inputan label
yaitu hasil balik dari method
1. Buat variable index bertipe int 2. lakukan insisialisasi variable index
dengan memanggil method search dengan inputan label
3. set variable ReachbilityDensity pada vertekslidt[index] dengan inputan yaitu hasil balik dari method ReachbilityDensity dengan inputan
1. Buat variable index bertipe int 2. lakukan insisialisasi variable index
dengan memanggil method search dengan inputan label
3. buat variable tetangga bertipe List String
4. inisialisasikan tetangga =
5. buat variable rDensity dengan tipe List Double
6. insialisasikan variable i= 0 , selama i < tetangga.size lakukan langkah dibawah ini :
a. insialisasikan variable index1 bertipe integer
b. inisialisasikan variable index1 = search(tetangga.get(i) c. tambahkan nilai ke list
rDensity dengan menginputkan reachbiltyDensty dari
vertekslist[index1]
7. set lof pada vertekslist[index] dengan memanggil method getLof dengan inputan rDensity,
1. buat variable dlf dengan tipe list DataLOF
DaraLOFTableMode l
3. selama i = 0 dan I kurang dari vertekslist length lakukan langkah dibawah ini :
a. cek apakah nilai Lof dari vertekslist[i] >= 1.1 jika ya lakukan langkah
selanjutnya
b. insialisasikan dl sebagai obyek baru dari kelas DataLOF
c. set nilai atribut Label dari dl = label dari
verteksList[i]
d. set nilai atibut Lof dari dl = lof dari verteksList[i] e. tambahkan dl kedalam List
dlf
4. buat variable obyek dm yang bertipe DataLofTableModel, dengan
menginputkan dlf serta label sebagai inputan parameter
Search(String label)
Mthod ini berfungsi untuk mencari posisi indeks dari suatu vertekslist
1. insialisasikan i=0 selama ikurang dari verteksList length lakukan langkah dibawah ini :
a. jika label sama denga label dari verteksList[i] maka kembalikan nilai I dan proses pencarian berhenti
2. kembalikan nilai -1 yang berarti tidak terdapat data dalam verteksList
Search2 Method ini berfungsi untuk mencari vertekslist tertentu dan mengubah flag kunjungannya
menjadi true
1. insialisasikan i=0 selama ikurang dari verteksList length lakukan langkah dibawah ini :
a. jika garis[indeks][i] sama dengan jarak , maka set falg kunjungan dari verteksList[i] menjadi true
4.3.5.3 Rincian Algoritma pada Method di Kelas CheckBoxTableModel Nama method Fungsi method Algoritma method
add(int, SeleksiAtribut) Menambahkan data ke dalam CheckBoxTable Model
sebagai data di index ke-a ke dalam list
removeRow() Menghapus nama
atribut yang yang
5) Jika !seleksi.getPilih=true maka nilai seleksi ditambahkan ke list s 6) Set nilai lfm = s
4.3.5.4 Rincian Algoritma pada Method di Kelas DatabaseController
Nama method Fungsi
method
1. Buat variable stmt bertipe Statement 2. Buat variable rset bertipet ResultSet 3. Buat variable query bertipe String 4. Buat koneksi kedalam database
oracle, dan simpan koneksi tersebut ke dalam variable stnt
6. Kemudian eksekusi syntax tersebut yang terdapat di variable query dan eksekusi dengan menggunakan variable stmt
7. Kemudian simpan hasil eksekusi query tersebut kedalam variable rset 8. Kembalikan nilai rset
displayTableSQL(
1. Buat variable stmt bertipe Statement 2. Buat variable rset bertipet ResultSet 3. Buat variable query bertipe String
4. Buat koneksi kedalam database oracle, dan simpan koneksi tersebut ke dalam variable stnt
5. Set variable query = syntax untuk menampilkan seluruh table dalam oracle yaitu : "show tables "
6. Kemudian eksekusi syntax tersebut yang terdapat di variable query dan eksekusi dengan menggunakan variable stmt
7. Kemudian simpan hasil eksekusi query tersebut kedalam variable rset
8. Kembalikan nilai rset
Connection,String) isi tabel berdasarkan tabel yang dipilih
pengguna
2. Buat variable rset bertipet ResultSet 3. Buat variable query bertipe String
4. Buat koneksi kedalam database oracle, dan simpan koneksi tersebut ke dalam variable stnt
5. Set variable query = syntax untuk menampilkan seluruh table dalam oracle yaitu : " "select * from table "
6. Kemudian eksekusi syntax tersebut yang terdapat di variable query dan eksekusi dengan menggunakan variable stmt
7. Kemudian simpan hasil eksekusi query tersebut kedalam variable rset
8. Kembalikan nilai rset
4.3.5.5 Rincian Algoritma pada Method di Kelas DiagramBatang Nama method Fungsi method Algoritma method
tampil(int[][],
1. Membaca paramater input (array int v, array String n , dan array String t) 2. Inisialisasi i=0
terpenuhi
4.4 Perancangan Struktur Data
Dalam pengembangan sebuah Sistem atau aplikasi diperlukan adanya perancangan sebuah struktru data, perancangan struktur data ini berfungsi untuk menggambarkan bagaiman sebuah data diolah dan disimpan dalam program, pada penelitian tugas akhir ini konsep struktur data yang dipakai adalah konsep Graph tak berarah dengan menggunakan struktur data matriks 2 dimensi. Dengan menggunakan graf maka akan memudahkan dalam memetakan obyek data beserta jarak sebuah obyek data dengan obyek yang lainnya.
4.4.1 Graf
Gambar 4.5 Ilustrasi Struktur Data Graf
4.4.2 Matriks Dua Dimensi
Dalam penerapan konsep graph ini digunakan sebuah matriks 2 dimensi. Matriks ini akan menyimpanvertex dan edge dari graph tersebut. Dimana vertex adalah representasi dari obyek data dan edge adalah representasi dari jarak antar obyek data.
(Vertex) Mahasiswa1 (List) nilai
Vertex Mahasiswa 2
(List) nilai
Vertex Mahasiswa 3
(List) nilai edge : 3.21
edge :2.58
edge :2.58
edge : 3.21 edge : 1.05
Ketika graf pertama kali dibentuk, edge sebuah obyek dengan obyek yang lain dilambangkan dengan nilai -1, yang artinya obyek tersebut tidak terhubung, karena belum dilakukan perhitungan jarak obyek data, dan jarak sebuah obyek terhadap dirinya sendiri dilambangkan dengan nilai 0.
Tabel 4.2 Ilustrasi Struktur Data Matriks Dua Dimensi
Mahasiswa 1 Mahasiswa 2 Mahasiswa 3
Mahasiswa 1 0 -1 -1
Mahasiswa 2 -1 0 -1
Mahasiswa 3 -1 -1 0
Kemudian dilakukan perhitungan jarak setiap verteks dengan menggunakan rumus jarak Ecludian Distance.Ketika edgedari suatu verteks ke verteks yang lain sudah ditemukan maka nilai edge dari kedua verteks tersebut diubah menjadi sama dengan hasil perhitungan menggunakan rumus ecludian distance
Tabel 4.3 Ilustrasi Struktur Data Matriks Dua Dimensi Setelah Dilakukan Perhitungan Jarak antar Vertex
Mahasiswa 1 Mahasiswa 2 Mahasiswa 3
Mahasiswa 1 0 2.58 3.21
Mahasiswa 2 2.58 0 1.05
4.5 Perancangan Antarmuka
4.5.1 Tampilan Halaman Awal
Halaman awal adalah halaman pertama yang muncul saat user menjalankan Sistem ini dalam halaman awal ini dalam halaman awal in iterdapat tombol masuk, tombol masuk ini apabila di klik makan akan mengarah ke halaman selanjutnya yaitu halaman utama.
Gambar 4.6 Tampilan Halaman Awal SISTEM PENDETEKSI
OUTLIERMENGGUNAKAN ALGORITMA LOCAL OUTLIER FACTOR
Universitas Sanata Dharma Yogyakarta -Copyright 2013-
4.5.2 Tampilan Halaman Utama
Jumlah Data Seleksi Atribut
Atribut 1
Preposesing Deteksi Outlier
Pilih File Keluar
Pilih DB
Bantuan
Tentang
Unchek All
Submit Distribusi Atribut
Cek All Hapus
minPts
Jumlah Data Preposesing Deteksi
Outlier
Keluar Bantua n
Hasil Deteksi Outlier
Label Lof Rangking
Simpan
Proses Tentan
g
LOCAL OUTLIER FACTOR