i
PENGELOMPOKAN KABUPATEN/KOTA DI PROVINSI JAWA TENGAH BERDASARKAN INDIKATOR PENDAPATAN DAN BELANJA
DAERAH MENGGUNAKAN K-MEANS CLUSTERING
Tugas Akhir
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Matematika
Program Studi Matematika
Oleh:
Brigita Novika Pratiwi NIM: 173114016
PROGRAM STUDI MATEMATIKA, JURUSAN MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
2021
ii
REGENCY/CITY GROUPING IN CENTRAL JAVA PROVINCE BASED ON REGIONAL INCOME AND EXPENDITURE INDICATORS USING
THE K-MEANS CLUSTERING
Thesis
Presented as Partial Fulfillment of the
Requirements to Obtain the Degree of Sarjana Matematika Mathematics Study Program
Written by:
Brigita Novika Pratiwi Student Number: 173114016
MATHEMATICS STUDY PROGRAM, DEPARTMENT OF MATHEMATICS
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
YOGYAKARTA 2021
vi MOTTO
“Janganlah takut, sebab Aku menyertai engkau, janganlah bimbang, sebab Aku ini Allahmu; Aku akan meneguhkan, bahkan akan menolong engkau; Aku akan memegang engkau dengan tangan kanan-Ku yang membawa kemenangan”
(Yesaya 41:10)
“do what you can, with what you have, where you are.” –theodore Roosevelt-
vii
HALAMAN PERSEMBAHAN
Karya ini kupersembahkan untuk:
Tuhan Yesus Kristus, Ibuku tercinta dan Bapakku di Surga, serta almamaterku
ix ABSTRAK
Tugas akhir ini membahas tentang pengelompokan Kabupaten/Kota di Provinsi Jawa Tengah pada tahun 2016-2018 berdasarkan indikator pendapatan dan belanja daerah. Berdasarkan data dari Badan Pusat Statistik Jawa Tengah menunjukkan bahwa pendapatan dan belanja tiap daerah bervariasi jumlahnya.
Untuk itu diperlukan pengelompokan daerah untuk mengetahui daerah mana saja yang mewakili kategori tinggi, sedang ataupun rendah. Penelitian ini menggunakan metode K-Means Clustering untuk melakukan pengelompokan berdasarkan variabel pendapatan dan belanja daerah menjadi kategori tinggi, sedang, dan rendah. Pengujian MANOVA dilakukan untuk memvalidasi hasil pengelompokan.
Kata kunci: Pendapatan dan belanja daerah, K-Means Clustering, MANOVA.
x ABSTRACT
This final project discusses the grouping of Regencies/Cities in Central Java Province in 2016-2018 based on indicators of regional income and expenditure.
Based on data from the Central Java Statistics Agency, it shows that the income and expenditure of each region varies in number. For this reason, regional grouping is needed to find out which areas represent the high, medium or low categories. This study uses the K-Means Clustering method to group based on regional income and expenditure variables into high, medium, and low categories. MANOVA test was conducted to validate the grouping results.
Keywords: Regional Income and Expenditure, K-Means Clustering, MANOVA.
xi
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa karena berkat dan rahmat-Nya penulis dapat menyelesaikan tugas akhir yang berjudul
“Pengelompokan Kabupaten/Kota di Provinsi Jawa Tengah Berdasarkan Indikator Pendapatan dan Belanja Daerah Menggunakan K-Means Clustering”. Penyusunan tugas akhir ini merupakan salah satu syarat untuk memperoleh gelar Sarjana Matematika pada Fakultas Sains dan Teknologi, Universitas Sanata Dharma.
Penulis menyadari bahwa penulisan Tugas Akhir ini tidak lepas dari bantuan banyak pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih kepada:
1. Bapak Ir. Ig. Aris Dwiatmoko, M.Sc. selaku dosen pembimbing yang dengan semangat dan sabar, serta membantu penulis dalam proses perkuliahan dan menyusun tugas akhir ini, hingga penulis dapat menyelesaikan tugas akhir ini dengan baik.
2. Bapak Prof. Ir. Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D. selaku Dekan Fakultas Sains dan Teknologi, Universitas Sanata Dharma.
3. Bapak Hartono, S.Si., M.Sc., Ph.D. selaku Dosen Pembimbing Akademik dan Ketua Program Studi Matematika, Fakultas Sains dan Teknologi, Universitas Sanata Dharma.
4. Romo Prof. Dr. Frans Susilo, SJ., Ibu Any Herawati, S.Si., M.Si., Bapak Ig. Aris Dwiatmoko, M.Sc., Bapak Dr. rer. nat. Herry P. Suryawan, M.Si., Ibu Dr. Lusia Krismiyati Budiasih, S.Si., M.Si., dan Bapak Ricky Aditya M.Sc. selaku dosen-dosen Program Studi Matematika yang telah memberikan banyak ilmu pengetahuan serta wawasan kepada penulis selama belajar di Program Studi Matematika.
5. Orang tua saya tercinta yaitu Bapak yang sudah bersama Bapa di Surga dan Ibu yang selalu memberikan semangat, doa, cinta, bantuan dan motivasi kepada penulis.
6. Adik saya tercinta Yulius Kurniawan yang selalu mendengarkan cerita penulis dan memberikan semangat selama ini.
7. Sahabat-sahabat saya Aryo Adi N, Witrianandha, Caecilia Austin, Maria
xiii DAFTAR ISI
HALAMAN JUDUL...i
TITLE PAGE ... ii
HALAMAN PERSETUJUAN PEMBIMBING ... iii
HALAMAN PENGESAHAN ...iv
PERNYATAAN KEASLIAN KARYA ... v
MOTTO ...vi
HALAMAN PERSEMBAHAN ... vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI... viii
ABSTRAK ...ix
ABSTRACT... x
KATA PENGANTAR ...xi
DAFTAR ISI... xiii
BAB I PENDAHULUAN ... 1
A. Latar Belakang ... 1
C. Batasan Masalah ... 2
D. Tujuan Penulisan... 2
E. Manfaat Penelitian ... 3
F. Metode Penelitian ... 3
G. Sistematika Penulisan ... 3
BAB II TINJAUAN PUSTAKA ... 5
A. Pendapatan Asli Daerah (PAD) ... 5
B. Belanja Daerah... 5
C. Data Multivariat dan Karakteristiknya ... 7
D. Konsep Kesamaan antar Obyek ... 13
E. MANOVA ... 22
BAB III ANALISIS CLUSTER ... 27
A. Pengertian Cluster... 27
B. Pengelompokan (Clustering) ... 29
C. Metode Analisis Cluster ... 36
D. Metode Pengelompokan ... 38
xiv
BAB IV K-MEANS CLUSTERING ... 48
A. K-Means Clustering ... 48
B. Sumber Data ... 57
C. Tahap Penelitian ... 57
D. Statistik Deskriptif dan Hasil Clustering ... 59
E. Validasi Cluster ... 63
BAB V KESIMPULAN dan SARAN ... 66
A. Kesimpulan ... 66
B. Saran ... 66
DAFTAR PUSTAKA ... 67
LAMPIRAN... 69
1 BAB I PENDAHULUAN
Pada bab ini akan dibahas latar belakang, rumusan masalah, batasan masalah, tujuan penulisan, manfaat penulisan, metode penelitian dan sistematika penulisan.
A. Latar Belakang
Pertumbuhan ekonomi merupakan salah satu indikator penting guna menilai keberhasilan pembangunan ekonomi yang terjadi di suatu daerah. Perekonomian akan mengalami pertumbuhan apabila total jumlah output produksi barang dan penyedia jasa tahun tertentu lebih besar daripada tahun sebelumnya, atau jumlah total alokasi output tahun tertentu lebih besar daripada tahun sebelumnya. Pada dasarnya pembangunan ekonomi daerah merupakan suatu proses di mana pemerintah daerah bersama-sama dengan masyarakat mengelola sumberdaya yang ada dan membentuk suatu pola hubungan kemitraan antara pemerintah daerah dengan sektor swasta untuk menciptakan suatu lapangan kerja baru sehingga dapat merangsang pertumbuhan kegiatan ekonomi dalam wilayah tersebut.
Oleh karena itu pemerintah daerah mempunyai hak dan kewenangan yang luas untuk menggunakan sumber-sumber keuangan yang dimilikinya sesuai dengan kebutuhan dan aspirasi masyarakat yang berkembang di daerah. Pemerintah daerah mengalokasikan dana dalam bentuk anggaran belanja daerah dalam APBD untuk menambah aset tetap. Alokasi belanja daerah ini didasarkan pada kebutuhan daerah akan sarana dan prasarana, baik untuk kelancaran pelaksanaan tugas pemerintahan maupun untuk fasilitas publik.
Provinsi Jawa Tengah terdiri dari 35 Kabupaten/Kota yang memiliki karakteristik pendapatan dan belanja daerah yang berbeda di setiap wilayahnya.
Pendapatan dan belanja daerah untuk setiap wilayah juga berbeda pada setiap tahun terutama pada tahun 2016 sampai dengan tahun 2018. Sehingga dapat dilakukan proses pengelompokan untuk setiap Kabupaten/ Kota di Provinsi Jawa Tengah dengan indikator yang digunakan adalah pendapatan dan belanja daerah.
Dari beberapa teknik Clustering, metode yang akan digunakan adalah K-
Means Clustering. K-Means merupakan salah satu metode data clustering non hirarki yang mempartisi data ke dalam cluster sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang memiliki karakteristik yang berbeda dikelompokkan ke dalam kelompok lain.
Implementasi K-Means Clustering berguna untuk menemukan partisi dari n individu ke dalam kelompok k untuk meminimalkan jumlah kelompok (Everitt, 2011). Dengan menggunakan K-Means, Kabupaten/Kota akan dikelompokan menjadi 3 kelompok sesuai dengan pendapatan dan belanja tiap daerahnya yaitu kelompok 3 mewakili kategori tinggi, kelompok 2 mewakili kategori sedang dan kelompok 1 mewakili kategori rendah.
B. Rumusan Masalah
Berdasarkan uraian di atas, perumusan masalah dalam tugas akhir ini, yaitu bagaimana hasil pengelompokan K-Means Clustering untuk menentukan kelompok Kabupaten/Kota dengan 3 kategori kelompok yang berbeda pada tahun 2016 - 2018 di Provinsi Jawa Tengah.
C. Batasan Masalah
Batasan masalah tugas akhir ini adalah sebagai berikut:
1. Data yang dianalisis adalah sekumpulan data dari Badan Pusat Statistik yang berisi pendapatan dan belanja daerah untuk setiap Kabupaten/Kota di Provinsi Jawa Tengah pada tahun 2016 - 2018.
2. Metode yang digunakan adalah K-Means Clustering.
3. Perancangan program menggunakan R.
D. Tujuan Penulisan
Berdasarkan rumusan masalah di atas, tujuan dari penulisan tugas akhir ini adalah:
1. Mengelompokan Kabupaten/Kota di Provinsi Jawa Tengah berdasarkan
indikator pendapatan dan belanja daerah pada tahun 2016 sampai dengan tahun 2018.
2. Menerapkan metode K-Means Clustering dalam menentukan kelompok Kabupaten/ Kota di Provinsi Jawa Tengah.
E. Manfaat Penelitian
Dengan melakukan penelitian ini diharapkan dapat memperoleh manfaat yaitu dapat memberikan informasi tentang hasil pengelompokan Kabupaten/Kota di Provinsi Jawa Tengah berdasarkan indikator pendapatan dan belanja daerah menggunakan metode K-Means Clustering, dan dapat memberikan informasi kepada pemeritah untuk mengetahui daerah mana saja yang tergolong kategori kurang sehingga dapat mendorong pemerintah Provinsi Jawa Tengah untuk melakukan pembangunan terhadap daerah yang kurang.
F. Metode Penelitian
Metode penulisan dalam tugas akhir ini adalah studi pustaka, yaitu dengan membaca dan mempelajari jurnal-jurnal dan buku-buku yang berkaitan dengan metode K-Means Clustering.
G. Sistematika Penulisan
Tugas akhir ini akan menggunakan sistematika penulisan sebagai berikut:
BAB I PENDAHULUAN A. Latar Belakang B. Rumusan Masalah C. Batasan Masalah D. Tujuan Penulisan E. Manfaat Penulisan F. Metode Penelitian G. Sistematika Penulisan
BAB II TINJAUAN PUSTAKA A. Pendapatan Asli Daerah (PAD) B. Belanja Daerah
C. Data Multivariat dan Karakteristiknya D. Konsep Kesamaan antar Obyek E. MANOVA
BAB III ANALISIS CLUSTER A. Pengertian Cluster
B. Pengelompokan Clustering C. Metode Analisis Cluster D. Metode Pengelompokan BAB IV K-MEANS CLUSTERING
A. K-Means Clustering B. Sumber Data
C. Tahap Penelitian
D. Statistik Deskriptif dan Hasil Clustering E. Validasi Cluster
BAB V PENUTUP A. Kesimpulan B. Saran
DAFTAR PUSTAKA LAMPIRAN
5 BAB II
TINJAUAN PUSTAKA
Pada bab ini akan dibahas mengenai dasar teori yang akan dipergunakan dalam bab selanjutnya, yaitu definisi pendapatan asli daerah, belanja daerah, data multivariat dan beberapa pokok bahasan yang terkait dengan konsep kedekatan jarak antar obyek dan MANOVA.
Pendapatan asli daerah dan belanja daerah merupakan dua indikator pentingdalam pertumbuhan ekonomi yang menunjukkan kemajuan pembangunan suatu daerah.
A. Pendapatan Asli Daerah (PAD)
Pendapatan asli daerah adalah penerimaan yang diperoleh daerah dari sumber-sumber dalam wilayahnya sendiri yang dipungut berdasarkan Peraturan daerah sesuai dengan peraturan perundangan yang berlaku. Selanjutnya sumber- sumber PAD terdiri dari beberapa unsur yaitu: pajak daerah, retribusi daerah, hasil perusahaan milik daerah dan hasil pengelolaan kekayaan daerah lainnya yang dipisahkannya dan lain-lain. Upaya meningkatkan pendapatan asli daerah pada dasarnya ditempuh melalui upaya intensifikasi yang pelaksanaannya diantaranya melalui kegiatan sebagai berikut, penyederhanaan prosedur administrasi yang dimaksudkan untuk memberi kemudahan bagi masyarakat membayar pajak dan retribusi daerah. Peningkatan dan pengawasan yang efektif agar tidak terjadi penyimpangan dari prosedur pungutan dan pembayaran pajak dan retribusi daerah.
Peningkatan sumber daya manusia dengan mengerahkan sumber daya aparatur dalam pengelolaan pendapatan daerah. Meningkatkan kegiatan penyuluhan kepada masyarakat, untuk menumbuhkan kesadaran masyarakat membayar retribusi dan pajak.
B. Belanja Daerah
Pengeluaran dan penerimaan daerah disebut Anggaran Pendapatan dan Belanja Daerah (APBD) yang merupakan rencana keuangan tahunan pemerintah
daerah yang dibahas dan disetujui bersama oleh pemerintah daerah dan Dewan Perwakilan Rakyat Daerah (DPRD) dan ditetapkan dengan peraturan daerah.
Tujuan dan fungsi APBD pada prinsipnya, sama dengan tujuan dan fungsi APBN.
APBD terdiri dari pendapatan daerah, belanja daerah dan pembiayaan daerah.
Belanja daerah biasanya direalisasikan digunakan untuk belanja pegawai, barang dan jasa, dan untuk belanja modal. Tiga komponen APBD yaitu belanja daerah, pendapatan daerah dan pembiayaan daerah, sangat mempengaruhi keberhasilan perekonomian suatu daerah. Jika ketiganya diolah dengan baik maka akan memberikan dampak yang baik pula bagi perekonomian daerah.
Belanja daerah dikelompokkan menjadi dua jenis yaitu belanja tidak langsung dan belanja langsung, belanja tidak langsung seperti belanja pegawai, belanja bunga, belanja subsidi, belanja hibah, belanja bantuan sosial belanja bagi hasil kepada Provinsi/Kabupaten dan pemerintah desa, belanja bantuan keuangan kepada Provinsi/Kabupaten dan pemerintah desa. Sedangkan belanja langsung meliputi belanja pegawai barang dan jasa, belanja modal. Untuk meningkatkan belanja daerah, jumlah Produk Domestik Reginal Bruto (PDRB) harus besar. Karena semakin besar PDRB, maka akan semakin besar pula pendapatan yang diterima oleh Kabupaten/Kota dengan semakin besar pendapatan yang diperoleh daerah, maka pengalokasian belanja oleh pemerintah pusat akan lebih besar untuk meningkatkan 3 berbagai potensi lokal di daerah tersebut untuk kepentingan pelayanan publik.
Pengeluaran belanja daerah dilihat dari perkembangan jumlah penduduk di suatu daerah, apabila perkembangan jumlah penduduk semakin besar akan memerlukan anggaran yang semakin besar. Karena meningkatnya jumlah penduduk menuntut konsekuensi logis adanya peningkatan sarana dan prasarana umum, baik dari aspek kuantitas maupun kualitas. Perkembangan jumlah penduduk yang semakin besar akan memerlukan anggaran yang semakin besar, supaya kualitas pertumbuhan ekonomi lebih baik, pertumbuhan penduduk harus selalu dikendalikan.
C. Data Multivariat dan Karakteristiknya
Pada bagian ini akan dibahas mengenai data multivariat karena pembahasan analisis cluster melibatkan konsep data multivariat. Data multivariat adalah data yang diperoleh dari hasil pengukuran, terhadap 𝑝 variabel pada n unit sampel . Data multivariat dapat dinyatakan dalam bentuk matriks. Dalam data multivariat ini sering kali dihadapkan pada masalah pengamatan yang dilakukan pada suatu periode waktu untuk 𝑝 ≥ 1 variabel. Misalkan dalam suatu pengukuran terhadap n individu dengan 𝑝 variabel yang dinyatakan dengan vektor 𝒀 = (𝒚𝟏, 𝒚𝟐, … , 𝒚𝒑).
Sehingga data multivariat disajikan dalam bentuk matriks Y berukuran 𝑛𝑥𝑝 dengan n baris dan p kolom sebagai berikut:
𝒀𝒏𝒙𝒑= [
𝑦11 𝑦12 … 𝑦1𝑝 𝑦21
⋮ 𝑦𝑛1
𝑦22 … 𝑦2𝑝
⋮ ⋱ ⋮ 𝑦𝑛2 … 𝑦𝑛𝑝
]
dengan:
𝑦𝑖𝑗 = elemen matriks, yaitu pengamatan ke-𝑖 untuk variabel ke-𝑗, dimana 𝑖 = 1,2, … , 𝑛 dan 𝑗 = 1,2, … , 𝑝.
𝑛 = banyaknya obyek pengamatan dan 𝑝 = banyaknya variabel
Setiap variabel dalam matriks data multivariat dapat dihitung rata-ratanya dalam bentuk vektor yaitu vektor rata-rata. Vektor rata-rata populasi dari variabel acak 𝑦 didefinisikan sebagai rata-rata dari semua nilai y dan vekor rata-rata ini dinotasikan dengan 𝜇. Rata-rata sering kali disebut sebagai nilai harapan dari 𝑦, yang dapat dinotasikan dengan 𝐸(𝑦). Vektor rata-rata populasi 𝜇 tidak diketahui, sehingga diduga dengan vektor rata-rata sampel yang dinotasikan dengan 𝒚
̅. Elemen-elemen vektor rata-rata 𝒚̅ adalah rata-rata dari 𝑝 variabel multivariat.
Definisi 2.31 Vektor Rata-Rata Sampel
Misalkan 𝒚 mewakili vektor acak dari 𝑝 variabel dan jika terdapat 𝑛 individu dalam sampel, maka 𝑛 vektor pengamatan dinotasikan dengan 𝒚𝟏, 𝒚𝟐, … , 𝒚𝒑, di mana
𝒚𝒊 = ( 𝑦𝑖1 𝑦𝑖2
⋮ 𝑦𝑖𝑝
)
Sehingga diperoleh vektor rata-rata sampel 𝒚̅ yang didefinisikan sebagai berikut:
𝒚
̅ =1 𝑛∑ 𝒚𝒊
𝑛
𝑖=1
= ( 𝑦̅1 𝑦̅2
⋮ 𝑦̅𝑝
)
di mana:
𝑦̅1 = rata-rata sampel 𝑛 pengamatan variabel pertama 𝑦̅2 = rata-rata sampel 𝑛 pengamatan variabel kedua
𝑦̅𝑝 = rata-rata sampel 𝑛 pengamatan variabel pertama ke-𝑝.
Dalam setiap 𝑛 vektor pengamatan 𝒚𝟏, 𝒚𝟐, … , 𝒚𝒑 diubah ke dalam bentuk vektor kolom dan ditulis dalam bentuk matriks 𝒀 sebagai berikut:
(variabel)
1 2 𝑗 𝑝
𝒀 = (
𝒚𝟏′ 𝒚𝟐′
⋮ 𝒚𝒊′
⋮ 𝒚𝒑′)
= (𝑢𝑛𝑖𝑡) 1 2 𝑖 𝑛 (
𝑦11 𝑦12 ⋯ 𝑦1𝑗 ⋯ 𝑦1𝑝 𝑦21 𝑦22 ⋯ 𝑦2𝑗 ⋯ 𝑦2𝑝
⋮ 𝑦𝑖1
⋮ 𝑦𝑛1
⋮ 𝑦𝑖2
⋮ 𝑦𝑛2
⋯
⋯
⋮ 𝑦𝑖𝑗
⋮ 𝑦𝑛𝑗
⋯
⋯
⋮ 𝑦𝑖𝑝
⋮ 𝑦𝑛𝑝)
Sehingga diperoleh 𝒚̅ dari matriks 𝒀 dengan menjumlahkan 𝑛 elemen di setiap kolom matriks 𝒀 dan membagi dengan 𝑛. Selanjutnya mendefinisikan 𝒚̅′ sebagai berikut:
𝒚̅′ = 1 𝑛𝒋′𝒀,
di mana 𝒋 merupakan vektor kolom dengan setiap elemennya adalah 1, dan 𝒋′ merupakan transpose dari 𝒋. Sebagai contoh dari elemen kedua pada 𝒋′𝒀 adalah sebagai berikut
(1, 1, … , 1) ( 𝑦12 𝑦22
⋮ 𝑦𝑛2
) = ∑ 𝑦𝑖2
𝑛
𝑖=1
.
Definisi 2.32 Kovarians Populasi
Kovarians Populasi didefinisikan sebagai berikut:
𝐶𝑜𝑣(𝑦𝑖, 𝑦𝑗) = 𝐸[(𝑦𝑖− 𝜇𝑖)(𝑦𝑗− 𝜇𝑗)]
di mana 𝜇𝑖 dan 𝜇𝑗 masing-masing adalah rata-rata dari 𝑦𝑖 dan 𝑦𝑗. Sedangkan varians populasi pada variabel 𝑦𝑖 didefinisikan sebagai 𝑣𝑎𝑟(𝑦𝑖) = 𝜎𝑖2 = 𝐸(𝑦𝑖− 𝜇𝑖)2.
Definisi 2.33 Matriks Kovarians Populasi
Pada umumnya matriks kovarians populasi didefinisikan sebagai berikut:
∑ = (
𝜎11 𝜎12 ⋯ 𝜎1𝑝 𝜎21 𝜎22 ⋯ 𝜎2𝑝
⋮ 𝜎𝑝1
⋮
𝜎𝑝2 ⋮
⋯ 𝜎𝑝𝑝 )
dengan elemen diagonal 𝜎𝑗𝑗 = 𝜎𝑗2 merupakan varians populasi dan 𝜎12 merupakan kovarians populasi untuk variabel kesatu dan kedua yang didefinisikan sebagai 𝐶𝑜𝑣(𝑦1, 𝑦2). Kovarians populasi biasanya tidak diketahui, sehingga diduga dengan kovarians sampel. Karena matriks kovarians populasi (∑) tidak diketahui maka diduga dengan matriks kovarians sampel 𝑺.
Definisi 2.34 Matriks Kovarians Sampel
Pada umumnya matriks kovarians sampel disimbolkan dengan 𝑺, yang
didefinisikan sebagai berikut:
𝑺 = 1
𝑛 − 1∑(𝒚𝑖− 𝒚̅)(𝒚𝑖− 𝒚̅)′
𝑛
𝑖=1
untuk 𝑖 = 1,2, … , 𝑛
Matriks kovarians sampel 𝑺 = (𝑠𝑗𝑘) dapat ditulis dalam bentuk matriks sebagai berikut:
𝑺 = (𝑠𝑗𝑘) = (
𝑠11 𝑠12 ⋯ 𝑠1𝑝 𝑠21 𝑠22 ⋯ 𝑠2𝑝
⋮ 𝑠𝑝1
⋮
𝑠𝑝2 ⋮
⋯ 𝑠𝑝𝑝 ).
Varians sampel dari variabel ke- 𝑗 merupakan elemen-elemen matriks 𝑺 dan didefinisikan sebagai berikut:
𝑠𝑗𝑗 = 𝑠𝑗2 = 1
𝑛 − 1∑(𝑦𝑖𝑗−
𝑛
𝑖=1
𝑦̅𝑗)2
= 1
𝑛 − 1(∑ 𝑦𝑖𝑗2 −
𝑖
𝑛𝑦̅𝑗2)
Kovarians sampel dari variabel ke- 𝑗 dan ke-𝑘 didefinisikan sebagai berikut:
𝑠𝑗𝑘 = 1
𝑛 − 1∑(𝑦𝑖𝑗− 𝑦̅𝑗)(𝑦𝑖𝑘− 𝑦̅𝑘)
𝑛
𝑖=1
= 1
𝑛 − 1(∑ 𝑦𝑖𝑗𝑦𝑖𝑘−
𝑖
𝑛𝑦̅𝑗𝑛𝑦̅𝑘)
Matriks 𝑺 merupakan matriks yang simetris sehingga 𝑠𝑗𝑘= 𝑠𝑘𝑗. Sebagai contoh 𝑠12= 𝑠21, 𝑠13 = 𝑠31dan seterusnya.
Contoh 2.31
Misalkan diketahui data dalam sebuah penelitian tentang pengukuran kalsium dengan tiga jenis tanah yang berbeda dan akan dilakukan penelitian di 10 lokasi yang berbeda di Indonesia.
Tabel 2.31 Tabel kadar kalsium pada setiap jenis tanah
Nomor Lokasi 𝒚𝟏 𝒚𝟐 𝒚𝟑
1 35 3.5 2.8
2 35 4.9 2.7
3 40 30 4.38
4 10 2.8 3.21
5 6 2.7 2.73
6 20 2.8 2.81
7 35 4.6 2.88
8 35 10.9 2.9
9 35 8 3.28
10 30 1.6 3.2
Berikut adalah variabel-variabel yang akan digunakan:
𝒚𝟏= kadar kalsium pada tanah aluvial 𝒚𝟐= kadar kalsium pada tanah vulkanis 𝒚𝟑= kadar kalsium pada tanah humus
Untuk menentukan rata-rata vektor 𝒚̅ , yaitu dengan cara menghitung rata-rata dari setiap variabelnya. Sehingga diperoleh perhitungan sebagai berikut:
𝒚̅𝟏= 35 + 35 + 40 + 10 + 6 + 20 + 35 + 35 + 35 + 30 10
= 281
10 = 28.1
𝒚
̅𝟐= 3.5 + 4.9 + 30 + 2.8 + 2.7 + 2.8 + 4.6 + 10.9 + 8 + 1.6
10 = 7.18
𝒚
̅𝟑= 2.8 + 2.7 + 4.38 + 3.21 + 2.73 + 2.81 + 2.88 + 2.9 + 3.28 + 3.2 10
= 3.089
diperoleh vektor rata-rata 𝒚
̅ = (𝒚̅̅̅𝟏, 𝒚̅𝟐, 𝒚̅𝟑)
𝒚̅ = (28.1 7.18 3.089)
Selanjutnya akan dicari matriks kovarians dengan menentukan nilai dari elemen matriks kovarians terlebih dahulu
∑ 𝑦𝑖1𝑦𝑖1= (35)(35) + (35)(35) + ⋯ + (30)(30) = 9161
10
𝑖=1
𝑠11= 1
10 − 1[(9161 − 10(28.1)(28.1))] =1264.9
9 = 140.54
dengan perhitungan yang sama diperoleh:
𝑠12= 𝑠21= 49.68 𝑠13= 𝑠31= 1.9412 𝑠22 = 72.24844 𝑠32 = 𝑠23= 3.67608 𝑠33 = 0.2501
Sehingga matriks kovarians sampelnya adalah sebagai berikut:
𝑺 = (
140.54 49.68 1.94 49.68 72.24 3.67 1.94 3.67 0.25
)
D. Konsep Kesamaan antar Obyek
Konsep kesamaan antar obyek atau ukuran kedekatan merupakan hal yang paling mendasar dalam analisis cluster. Kesamaan antar obyek adalah sebuah ukuran untuk kesesuaian atau kemiripan diantara obyek-obyek yang akan dipilah menjadi beberapa cluster. Ukuran kesamaan mempertimbangkan dua sifat yaitu variabel (diskrit, kontinu) atau skala pengukuran (nominal, ordinal, rasio, interval).
Terdapat tiga metode yang dapat diterapkan dalam konsep kesamaan antar obyek yaitu ukuran korelasi, ukuran jarak, dan ukuran asosiasi. Pemilihan metode tergantung pada tujuan dan jenis data. Ukuran korelasi dan ukuran jarak digunakan untuk data dengan skala metrik, sedangkan ukuran asosiasi digunakan untuk data dengan tipe non metrik. Di mana tipe data non metrik merupakan data yang tidak berupa angka atau seringkali disebut sebagai data kualitatif, data ini bisa berupa atribut atau karakteristik. Sedangkan data metrik adalah data yang berupa angka atau data kuantitatif, variabel yang diukur dalam data ini menggunakan skala interval dan rasio.
1. Ukuran Korelasi
Ukuran ini dapat diterapkan pada data dengan skala metrik. Kesamaan antar obyek dapat dilihat dari koefisien korelasi antar pasangan obyek yang diukur dengan beberapa variabel. Korelasi juga sering disebut sebagai kovarians standar.
Koefisien korelasi populasi dua variabel acak x dan y didefinisikan sebagai berikut:
𝑟𝑥𝑦= 𝑠𝑥𝑦
√𝑠𝑥𝑥𝑠𝑦𝑦 = 𝑠𝑥𝑦
𝑠𝑥𝑠𝑦 = ∑𝑛𝑖=1(𝑥𝑖− 𝑥̅)(𝑦𝑖− 𝑦̅)
√∑𝑛𝑖=1(𝑥𝑖− 𝑥̅)2∑𝑛𝑖=1(𝑦𝑖− 𝑦̅)2
Matriks koefisien korelasi sampel pada umumnya disimbolkan dengan 𝑹 dan didefinisikan sebagai berikut:
𝑹 = (𝑟𝑥𝑦) = (
1 𝑟12 ⋯ 𝑟1𝑝 𝑟21 1 ⋯ 𝑟2𝑝
⋮ 𝑟𝑝1
⋮
𝑟𝑝2 ⋮
⋯ 1 )
Di mana setiap elemen diagonal pada matriks 𝑹 adalah 1 karena berkorelasi dengan dirinya sendiri. Matriks 𝑹 adalah matriks yang simetris sehingga 𝑟𝑥𝑦=𝑟𝑦𝑥.
Dalam korelasi populasi matriks koefisien korelasi didefinisikan sebagai berikut:
𝑷𝝆 = (𝜌𝑥𝑦) = (
1 𝜌12 ⋯ 𝜌1𝑝 𝜌21 1 ⋯ 𝜌2𝑝
⋮ 𝜌𝑝1
⋮
𝜌𝑝2 ⋮
⋯ 1
),
di mana:
𝜌𝑥𝑦= 𝜎𝑥𝑦 𝜎𝑥𝜎𝑦
Contoh 2.41
Data pada contoh ini menggunakan data dan perhitungan yang ada dalam contoh 2.31 dan selanjutnya akan ditentukukan matriks koefisien korelasi sampel:
𝑟12 = 𝑟21= 𝑠12
√𝑠11𝑠22= 49.68
√(140.54)(72.24) = 0.49
dengan perhitungan yang sama diperoleh:
𝑟31 = 𝑟31= 0.32 𝑟32 = 𝑟32= 0.86
Sehingga diperoleh matriks koefisien korelasi sampel sebagai berikut:
𝑹 = (
1 0.49 0.32
0.49 1 0.86
0.32 0.86 1 )
Dalam perhitungan ini bisa dilakukan menggunakan Microsoft excel dan Perangkat lunak R jika diketahui data yang banyak.
2. Ukuran Jarak
Menurut Kamus Besar Bahasa Indonesia (KBBI) jarak pada umumnya merupakan ruang sela (panjang atau jauh) antara dua benda atau tempat. Teknik multivariat didasarkan pada konsep jarak yang sederhana. Misalkan terdapat titik 𝑃 = (𝑥1, 𝑥2) di dalam bidang, sehingga jarak garis lurus dari titik 𝑃 ke titik asal 𝑂 = (0,0) adalah sebagai berikut
Menurut Teorema Phytagoras:
𝑑(𝑂, 𝑃) = √𝑥12+ 𝑥22 (2.2)
Secara umum, jika titik 𝑃 memiliki koordinat 𝑃 = (𝑥1, 𝑥2, … , 𝑥𝑃) yang terdapat dalam ruang dimensi 𝑝 maka jarak dari 𝑃 ke titik asal 𝑂 = (0,0, … ,0) adalah
𝑑(𝑂, 𝑃) = √𝑥12 + 𝑥22+ ⋯ + 𝑥𝑝2 (2.3)
Sehingga jarak garis lurus antara dua titik sembarang 𝒙 dan 𝒚 dengan koordinat 𝒙′= (𝑥1, 𝑥2, … , 𝑥𝑃) dan 𝒚′= (𝑦1, 𝑦2, … , 𝑦𝑃) adalah sebagai berikut
𝑑(𝒙, 𝒚) = √(𝑥1− 𝑦1)2+ (𝑥2− 𝑦2)2+ ⋯ + (𝑥𝑝− 𝑦𝑝)2 (2.4)
Oleh karena itu persamaan ini akan mendasari dalam ukuran kesamaan obyek dalam analisis cluster. Ukuran kesamaan tersebut dinyatakan dalam bentuk ukuran similaritas atau disimilaritas. Tipe data untuk ukuran similaritas atau disimilaritas dibagi menjadi dua yaitu data bersifat metrik dan koefisien asosiasi, dimana data yang bersifat metrik dalam ukuran similaritas atau disimilaritas meliputi data kontinu dan data biner. Berdasarkan skala pengukurannya data kontinu meliputi
skala interval dan rasio sedangkan untuk data biner skala pengukuran dapat menggunakan skala nominal dan ordinal.
i. Skala Nominal
Skala nominal merupakan skala pengukurang yang tujuannya memberikan informasi untuk membedakan benda atau obyek yang diteliti. Pengukuran dengan skala ini dilakukan dengan memberikan angka atau simbol. Pemberian angka ini bertujuan untuk menunjukkan karakteristik pada obyek tersebut. Contoh dari skala ini yaitu seperti jenis kelamin, laki-laki diberi simbol 0 dan perempuan diberi simbol 1 atau angka lainnya.
ii. Skala Ordinal
Skala ordinal merupakan skala pengukuran yang mengkategorikan suatu obyek berdasarkan urutan atau tingkatan. Skala ini menggunakan bilangan-bilangan atau lambang-lambang untuk meunjukkan urutan atau tingkatan obyek yang diukur berdasarkan karakteristik tertentu. Sebagai contoh misalnya dilakukan pengukuran mengenai tingkat kepuasan seseorang terhadap sebuah produk. Dalam kasus ini dapat diberikan angka 5,4,3,2,1 di mana masing-masing memberikan rasa sangat puas, puas, kurang puas, tidak puas dan sangat tidak puas.
iii. Skala Interval
Skala interval merupakan skala pengukuran seperti skala nominal dan ordinal, di mana adanya urutan tertentu dalam hasil suatu pengukuran. Perbedaanya adalah bahwa pada skala interval, selisih antar nilai pengukuran terdefinisi dengan jelas.
Misalkan jarak suhu antara 5°C dengan 10°C memiliki arti yang sama dengan jarak antara 15°C dengan 20°C. Tetapi tidak demikian dengan jarak antara sangat tidak puas dan tidak puas dibandingkan dengan sangat puas dan puas pada skala ordinal, di mana jaraknya tidak terdefinisi dengan jelas. Skala ini biasanya digunakan dalam pengukuran data numerik. Sebagai contoh variabel berskala interval adalah suhu dalam derajat celcius.
iv. Skala Rasio
Skala rasio hampir sama dengan skala interval yang membedakan skala ini yaitu terletak pada nilai nol. Nilai nol pada skala interval tidak bersifat mutlak sedangkan pada skala rasio nilai nolnya bersifat mutlak, dalam hal ini nilai nol mutlak menunjukkan ketiadaan karakteristik yang diukur. Sebagai contoh misalnya tinggi dan berat badan seseorang.
a) Ukuran jarak data kontinu
Analisis cluster didasarkan pada ukuran kesamaan atau ketidaksamaan antar data. Ukuran kesamaan atau ketidaksamaan yang digunakan adalah jarak (distance). Ukuran ini disajikan dalam bentuk matriks D (nxn) sebagai berikut:
𝑫 = [
𝑑11 𝑑12 … 𝑑1𝑛 𝑑21
⋮ 𝑑𝑛1
𝑑22 … 𝑑2𝑛
⋮ ⋱ ⋮ 𝑑𝑛2 … 𝑑𝑛𝑛
]
di mana ukuran ketidaksamaan atau ukuran disimilaritas memenuhi 4 sifat berikut:
1) 𝑑(𝒙, 𝒚) ≥ 0 2) 𝑑(𝒙, 𝒚) = 0 3) 𝑑(𝒙, 𝒚) = 𝑑(𝒚, 𝒙),
4) 𝑑(𝒙, 𝒚) ≤ 𝑑(𝒙, 𝒛) + 𝑑(𝒛, 𝒚)
Ukuran tersebut dapat dinyatakan dalam jarak antar dua obyek yang pengukurannya menggunakan beberapa konsep ukuran jarak berikut:
1) Jarak Euclidean (Euclidean Distance)
Jarak Euclidean merupakan salah satu metode perhitungan jarak yang digunakan untuk mengukur jarak antara 2 (dua) buah titik dalam ruang Euclidean (meliputi bidang Euclidean dua dimensi, tiga dimensi, atau bahkan lebih) dan juga digunakan untuk mengukur tingkat kemiripan data. Jarak Euclidean merupakan
jarak terpendek yang didapat antara dua titik dalam perhitungan.
Berikut adalah rumus jarak Euclidean:
𝑑
𝑒𝑢𝑐(𝒙, 𝒚) = √∑
𝑝𝑖=1|𝑥
𝑖− 𝑦
𝑖|
2(2.11)
2) Jarak Kuadrat Euclidean (KE)
Jarak Kuadrat Euclidean adalah jumlah kuadrat yang berbeda dari nilai antara dua nilai pada seluruh variabel.
𝑑
𝐾𝐸(𝒙, 𝒚) = ∑
𝑝𝑖=1(𝑥
𝑖− 𝑦
𝑖)
2(2.12)
3) Jarak Manhattan (Manhattan Distance)
Jarak Manhattan atau jarak City-Block adalah jumlah nilai selisih mutlak untuk setiap variabel. Ukuran jarak ini menghasilkan jarak yang serupa dengan jarak Euclid untuk beberapa kasus tertentu.
Berikut adalah rumus jarak Manhattan:
𝑑
𝑀𝑎𝑛(𝒙, 𝒚) = ∑
𝑝𝑖=1|𝑥
𝑖− 𝑦
𝑖|
(2.13)4) Jarak Minkowski (Minkowski Distance)
Jarak Minkowski merupakan sebuah metrik dalam ruang vektor di mana suatu norma didefinisikan (normed vector space) sekaligus dianggap sebagai generalisasi dari jarak Euclidean dan jarak Manhattan.
𝑑
𝑀𝑖𝑛(𝒙, 𝒚) = [∑
𝑝𝑖=1|𝑥
𝑖− 𝑦
𝑖|
𝑚]
1⁄𝑚 (2.14)dengan m adalah parameter dan untuk m=1.
5) Jarak Canberra (Canberra Distance)
Jarak Canberra adalah jumlah nilai perbedaan mutlak dibagi dengan jumlah antara dua variabel. Jarak ini dapat dinyatakan dalam bentuk sebagai berikut:
𝑑
𝐶𝑎𝑛(𝒙, 𝒚) = ∑
|𝑥𝑖−𝑦𝑖|(𝑥𝑖+𝑦𝑖) 𝑝
𝑖=1 (2.15)
Ukuran jarak Canberra digunakan hanya untuk variabel yang bernilai positif.
Contoh 2.5.1
Misalkan diketahui 𝒙 = (1,1) dan 𝒚 = (0,1) , akan dicari jarak dengan beberapa rumus jarak dibawah ini.
dengan menggunakan jarak Euclidean pada persamaan (2.11) diperoleh, 𝑑𝑒𝑢𝑐(𝒙, 𝒚) = √(𝑥1− 𝑦1)2+ (𝑥2− 𝑦2)2
𝑑𝑒𝑢𝑐(𝒙, 𝒚) = √(1 − 0)2+ (1 − 1)2
= √1 + 0 = 1
dengan menggunakan jarak kuadrat Euclidean pada persamaan (2.12) diperoleh, 𝑑𝐾𝐸(𝒙, 𝒚) = (𝑥1− 𝑦1)2+ (𝑥2− 𝑦2)2
𝑑𝐾𝐸(𝒙, 𝒚) (1 − 0)2+ (1 − 1)2
= 1 + 0 = 1
dengan menggunakan jarak Manhattan pada persamaan (2.13) diperoleh, 𝑑𝑀𝑎𝑛(𝒙, 𝒚) = (|𝑥1− 𝑦1| + |𝑥2− 𝑦2|)
= (|1 − 0| + |1 − 1|) = 1
b) Ukuran similaritas untuk data biner
Salah satu contoh ukuran similaritas atau ukuran kesamaan obyek berskala nominal adalah bentuk ukuran biner. Dalam hal ini setiap obyek diberi kode 0 atau 1, di mana nilai 0 untuk obyek yang tidak memiliki karakteristik dan nilai 1 untuk data yang memiliki karakteristik yang ditentukan. Sebagai contoh misalnya terdapat variabel jenis kelamin, di mana 0 untuk laki-laki dan 1 untuk perempuan, atau misalnya untuk variabel kelulusan, di mana 0 untuk yang tidak lulus dan 1 untuk lulus. Apabila terdapat dua buah obyek yang variabel datanya bertipe biner, maka ukuran similaritas atau ukuran kesamaan antara dua buah obyek didefinisikan berdasarkan frekuensi data dalam tabel kontingensi pada nilai yang sama (matches) dan nilai yang tidak sama (mismatces).
Misalkan terdapat dua obyek i dan k masing-masing diamati n variabel random, maka tabel kontingensi dapat disajikan dalam tabel 2.32. Dalam tabel 2.32 a menunjukkan frekuensi obyek i dan k yang sama-sama memiliki karakteristik 1 dan d menunjukkan frekuensi obyek i dan k yang sama-sama memiliki karakteristik 0 sedangkan untuk b menunjukkan frekuensi obyek i dan k yang memiliki karakteristik berbeda yaitu obyek ke-i memiliki karakteristik 1 dan obyek ke-k memiliki karakteristik 0 dan c menunjukkan frekuensi obyek i dan k yang memiliki karakteristik berbeda yaitu obyek ke-i memiliki karakteristik 0 dan obyek ke-k memiliki karakteristik 1 (Johnson & Wichern, 2007).
Tabel 2.32 Tabel kontingensi data biner untuk dua obyek.
Obyek Obyek k
Jumlah
1 0
Obyek i 1 a b a+b
0 c d c+d
Jumlah a+c b+d n=a+b+c+d
Tabel 2.33 Tabel beberapa koefisien similaritas
Nama Koefisien Similritas Definisi Koefisien Similaritas Jaccard coefficient (Jaccard, 1908) 𝑎
(𝑎 + 𝑏 + 𝑐)
Rogers dan Tanimoto (1960) (𝑎 + 𝑑)
[𝑎 + 2(𝑏 + 𝑐) + 𝑑]
Sneath dan Sokal (1973) 𝑎
[𝑎 + 2(𝑏 + 𝑐)]
Gower dan Legendre (1986)
(𝑎 + 𝑑) [𝑎 +1
2(𝑏 + 𝑐) + 𝑑]
Gower dan Legendre (1986)
𝑎 [𝑎 +1
2(𝑏 + 𝑐)]
3. Ukuran Asosiasi
Ukuran asosiasi dipakai untuk mengukur data berskala nonmetrik (nominal dan ordinal) dimana data ini merupakan data kualitatif, dengan cara mengambil bentuk-bentuk dari koefisien korelasi pada tiap obyeknya. Ketika variabelnya biner, data dapat kembali disusun dalam bentuk tabel kontingensi. Untuk setiap pasangan variabel, terdapat n obyek yang dikategorikan dalam tabel dengan memberikan kode 0 dan 1, yang dapat dilihat pada tabel 2.51.
Misalnya, variabel i bernilai 1 sebanyak a dan variabel k bernilai 0 sebanyak b. Rumus korelasi product moment yang biasa diterapkan ke dalam variabel biner adalah sebagai berikut:
𝑟 =
𝑎𝑑−𝑏𝑐[(𝑎+𝑏)(𝑐+𝑑)(𝑎+𝑐)(𝑏+𝑑)]1⁄2 (2.16)
Nilai ini dapat diambil sebagai ukuran kesamaan antara dua variabel koefisien korelasi (2.16) untuk menguji independensi dua variabel. Di dalam koefisien asosiasi skala pengukuran yang digunakan yaitu data berskala nominal dan data
berskala ordinal.
E. MANOVA
Dalam Tugas Akhir ini Multivariate Analysis of Variance (MANOVA) digunakan untuk memvalidasi hasil clustering. MANOVA merupakan perluasan dari konsep dan teknik Analysis of Variance (ANOVA) yang terdiri dari beberapa variabel dependen (variabel tak bebas). Penggunaan lebih dari satu variabel tak bebas ini sering dijumpai pada kasus-kasus yang ingin mengamati atau melihat karakteristik suatu obyek yang dalam hal ini tidak cukup jika hanya menggunakan variabel tak bebas.
Dalam pengujian MANOVA terdapat beberapa asumsi yang harus dipenuhi.
Adapun asumsi yang harus dipenuhi sebelum melakukan pengujian dengan MANOVA yaitu asumsi data berdistribusi normal multivariat dan matriks varian/kovarian homogen. Statistik uji yang dapat digunakan untuk pengambilan hipotesis, antara lain Pillai’s Trace, Wilks Lamda, Hotelling Trace. Uji homogenitas matriks varian/kovarian berguna untuk melihat apakah matriks kovarian dari dependen variabel sama untuk grup-grup yang ada (independen).
Berikut model MANOVA untuk membandingkan vektor rata-rata g populasi.
𝑿𝑖𝑗= 𝝁 + 𝝉𝑖+ 𝒆𝑖𝑗
(2.17)
dengan:
𝑗 = 1,2, … , 𝑛𝑖 dan 𝑖 = 1,2, … , 𝑔, di mana 𝒆𝑖𝑗 adalah variabel bebas 𝑁𝑝(𝟎, ∑).
Parameter vektor 𝝁 adalah rata-rata keseluruhan dan 𝝉𝑖 merepresentasikan efek perlakuan ke-i dengan
∑ 𝑛𝑖
𝑔
𝑖=1
𝝉𝑖= 0
Sehingga pengamatan vektor
𝑿
𝑖𝑗 dapat diuraikan menjadi𝒙
𝑖𝑗= 𝑥̅ + (𝑥̅
𝑖− 𝑥̅) + (𝑥
𝑖𝑗− 𝑥̅
𝑖)
di mana:
𝒙
𝑖𝑗=
pengamatan ke-j dari populasi ke-i𝒙
̅
= rata-rata sampel penduga 𝝁 (𝒙̅𝑖− 𝒙̅) = penduga efek perlakuan 𝝉𝑖 (𝒙𝑖𝑗− 𝒙̅𝑖) = penduga galat 𝒆𝑖𝑗Matriks jumlah kuadrat dan perkalian silang dapat dinyatakan sebagai berikut
𝑾 = ∑ ∑
(𝒙
𝑖𝑗− 𝒙
̅𝑖)(𝒙
𝑖𝑗− 𝒙
̅𝑖)
′𝑛𝑖
𝒋=𝟏 𝒈
𝑖=1
= (𝑛1− 1)𝑺𝟏+ (𝑛2− 1)𝑺𝟐+ ⋯ + (𝑛𝑔− 1)𝑺𝒈
dimana 𝑺𝒊 adalah sampel matriks kovarians untuk sampel ke-i. Berikut adalah tabel MANOVA untuk membandingkan vektor rata-rata populasi.
Tabel 2.34 Tabel MANOVA membandingkan vektor rata-rata populasi Sumber
Variasi
Matriks Jumlah Kuadrat dan Perkalian Silang
Derajat Bebas
Perlakuan
𝑩 = ∑ 𝑛𝑖(𝒙̅𝑖− 𝒙̅)
(
𝒙̅𝑖− 𝒙̅)
′𝑔
𝒊=𝟏
𝑔 − 1
Galat
𝑾 = ∑ ∑
(𝒙
𝑖𝑗− 𝒙
̅𝑖)(𝒙
𝑖𝑗− 𝒙
̅𝑖)
′𝑛𝑖
𝒋=𝟏 𝒈
𝑖=1
∑ 𝑛𝑖− 𝑔
𝑔
𝒊=𝟏
Total
𝑩 + 𝑾 = ∑ ∑
(𝒙
𝑖𝑗− 𝒙
̅𝑖)(𝒙
𝑖𝑗− 𝒙
̅𝑖)
′𝑛𝑖
𝒋=𝟏 𝒈
𝑖=1
∑ 𝑛𝑖− 1
𝑔
𝒊=𝟏
Berikut langkah-langkah dalam pengujian hipotesis MANOVA:
1. Merumuskan hipotesis nol dan alternatif 𝐻0: 𝝁𝟏= 𝝁𝟐= ⋯ = 𝝁𝒈
𝐻1: ∃𝝁𝒊 ≠ 𝝁𝒋, 𝑖 ≠ 𝑗
2. Pilih tingkat signifikansi 𝛼 3. Statistik uji :
Terdapat beberapa asumsi-asumi yang harus dipenuhi dalam pengujian MANOVA, yaitu variabel pengamatan berdistribusi normal multivariat dan matriks kovarian homogen. Berikut ini merupakan statistik uji Wilk’s Lambda 𝜆 = |𝑾|
|𝑩 + 𝑾|
dengan:
𝑾 = ∑ ∑(𝒙𝑖𝑗− 𝒙̅𝑖)(𝒙𝑖𝑗− 𝒙̅𝑖)′
𝑛𝑖
𝒋=𝟏 𝒈
𝑖=1
𝑩 = ∑ 𝑛𝑖(𝒙̅𝑖− 𝒙̅)(𝒙̅𝑖− 𝒙̅)′
𝑔
𝒊=𝟏
Dalam pengujian MANOVA jika asumsi matriks kovarian homogen dipenuhi maka statistik uji yang digunakan yaitu Wilk’s Lambda, sedangkan jika asumsi matriks kovarian homogen tidak dipenuhi maka statistik uji yang dapat digunakan yaitu Pillai’s Trace.
4. Wilayah kritis 𝐻0 ditolak apabila 𝜆 ≤ 𝜆𝛼,𝑝,𝑣𝐵,𝑣𝑊 di mana:
𝑣𝐵 = 𝑔 − 1 𝑣𝑊= 𝑔(𝑛 − 1) 5. Perhitungan
Dalam tahap ini perhitungan dapat dilakukan dengan menggunakan perangkat lunak R maupun perangkat lunak yang lain.
6. Membuat kesimpulan
Setelah diperoleh hasil maka selanjutnya dapat ditarik kesimpulan apakah vektor rata-rata dari dua atau lebih populasi berbeda secara signifikan.
Berikut contoh dalam pengujian hipotesis MANOVA.
Contoh 2.6.1
Andrew dan Heszberg (1985) melaporkan hasil penelitiannya terhadap 6 ladang apel yang berbeda. Masing-masing ladang diteliti 8 pohon apel di mana setiap subyek dikenakan 4 pengukuran yang meliputi:
1) 𝑌1 : ukuran lilitan batang pohon berumur 4 tahun (dalam 10cm), 2) 𝑌2 : pertumbuhan pohon berumur 4 tahun (dalam m),
3) 𝑌3 : lilitan batang pohon berumur 15 tahun (dalam 10cm) dan,
4) 𝑌4 : berat batang di atas permukaan tanah pada pohon berumur 15 tahun (dalam 1000 pounds).
Kemudian akan diuji apakah ada perbedaan rata-rata ukuran yang signifikan dari ke-8 ladang yang diteliti. Hasil pengukuran disajikan pada Lampiran 1:
Penyelesaian:
1. Merumuskan hipotesis nol dan alternatif 𝐻0: 𝝁𝟏= 𝝁𝟐= ⋯ = 𝝁𝟔
𝐻1: ∃𝝁𝒊 ≠ 𝝁𝒋, 𝑖 ≠ 𝑗
2. Pilih tingkat signifikansi 𝛼 = 0.05 3. Statistik uji :
Statistik uji yang digunakan yaitu statistik uji Wilk’s Lambda . data diasumsikan berdistribusi normal multivariat dan matriks kovarians homogen
𝜆 = |𝑾|
|𝑩 + 𝑾|
4. Wilayah kritis 𝑝 = 4, 𝑔 = 6, 𝑛 = 8 𝑣𝐻= 6 − 1 = 5 𝑣𝐸 = 6(8 − 1) = 42
𝐻0 ditolak apabila 𝜆 ≤ 𝜆.05,4,5,40= 0.455 5. Menghitung statistik uji
𝑩 = ( 0.074 0.537 0.332 0.208
0.537 4.200 2.355 1.637
0.332 2.355 6.114 3.781
0.208 1.637 3.781 2.493
)
𝑾 = ( 0.020 1.697 0.554 0.217
1.697 12.143
4.364 2.110
0.554 4.364 4.291 2.482
0.217 2.110 2.482 1.723
)
𝑩 + 𝑾 = ( 0.394 2.234 0.886 0.426
2.234 16.342
6.719 3.747
0.886 6.719 10.405
6.263
0.426 3.747 6.263 4.216
)
𝜆 = |𝑾|
|𝑩 + 𝑾|=0.6571
4.2667 = 0.154
Karena 0.154 = 𝜆 ≤ 𝜆0.05,4,5,40= 0.455, maka dapat disimpulkan bahwa 𝐻0 ditolak.
6. Membuat kesimpulan
𝐻0 ditolak sehingga dapat disimpulkan bahwa terdapat perbedaan vektor rata- rata ukuran dari keenam ladang yang diteliti secara signifikan.
27 BAB III
ANALISIS CLUSTER
Pada bab ini akan dibahas mengenai konsep dasar dari analisis cluster dan beberapa metode dalam pengelompokan (clustering).
A. Pengertian Cluster
Cluster adalah sekelompok titik (obyek) di mana sebuah titik pada kelompok itu lebih dekat atau mirip dengan semua titik (obyek) yang ada pada kelompok tersebut daripada titik-titik lain yang tidak terdapat pada kelompok itu. Cluster juga didefinisikan sebagai sekelompok titik (obyek) dimana semua titik pada kelompok itu lebih dekat dengan pusat dari kelompok tersebut daripada pusat pada kelompok yang lain. Pada umumnya pusat cluster disebut sebagai centroid, yaitu rata-rata dari semua titik dalam cluster tersebut.
Misalkan terdapat kumpulan titik (obyek) yang mewakili nomor alamat rumah di sebuah perumahan, dimana titik-titik ini memiliki kedekatan jarak yang berbeda- beda antar rumah di perumahan tersebut yang dapat dilihat pada gambar berikut:
Gambar 3.11 Gambar sekumpulan titik(obyek)
Kumpulan titik(obyek) tersebut akan dikelompokkan berdasarkan jarak terdekat antar rumah atau titik. Sehingga akan didapatkan 3 cluster yang mewakili 3 blok di perumahan tersebut sesuai dengan kedekatan jarak antar rumah.
Gambar 3.12 Gambar hasil pengelompokan
Dalam hal ini pengelompokan berhasil sesuai dengan kedekatan jarak antar obyek.
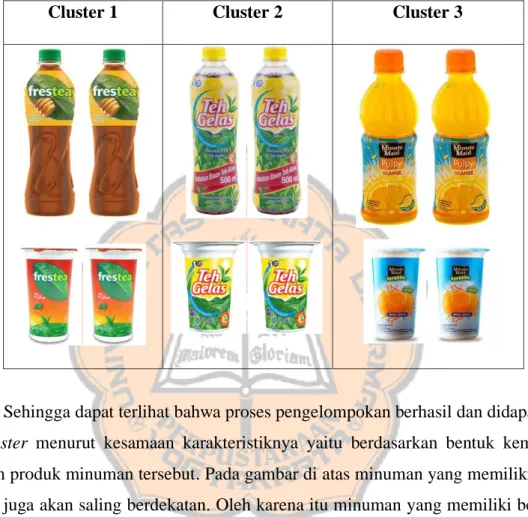
Selanjutnya misalkan terdapat sekelompok obyek minuman dengan beberapa karakteristik (X1= bentuk kemasan, X2= rasa minuman, X3= merk produk) sebagai berikut:
Gambar 3.13 Gambar minuman sebelum dikelompokkan
Pada gambar 3.13 obyek minuman akan dikelompokkan bentuk kemasan,
sehingga obyek yang memiliki bentuk kemasan yang sama atau mirip akan menjadi satu kelompok, sedangkan obyek yang berbeda terdapat pada kelompok lain.
Tabel 3.11 Tabel minuman yang berhasil dikelompokkan
Cluster 1 Cluster 2 Cluster 3
Sehingga dapat terlihat bahwa proses pengelompokan berhasil dan didapatkan 3 cluster menurut kesamaan karakteristiknya yaitu berdasarkan bentuk kemasan dalam produk minuman tersebut. Pada gambar di atas minuman yang memiliki rasa sama juga akan saling berdekatan. Oleh karena itu minuman yang memiliki bentuk kemasan sama akan berdekatan dan menjadi satu kelompok dan yang memiliki bentuk kemasan yang berbeda berada pada kelompok lain. Ukuran kedekatan karakteristik ini akan menjadi pertimbangan untuk menghasilkan pengelompokan yang optimal.
B. Pengelompokan (Clustering)
Pada dasarnya clustering merupakan suatu metode untuk mencari dan mengelompokkan obyek yang memiliki kemiripan karakteristik (similarity) antar satu obyek dengan obyek yang lain. Selain itu clustering juga merupakan metode
segmentasi data yang sangat berguna dalam prediksi dan analisis masalah. Sebagai contoh misalkan terdapat sekumpulan obyek masker seperti pada gambar berikut:
Gambar 3.16 Gambar sekumpulan masker sebelum dikelompokkan
Pada gambar 3.16 sekumpulan masker tersebut akan dikelompokkan berdasarkan karakteristiknya, yaitu bentuk dan warna. Sehingga proses pengelompokan ini dimulai dengan mengambil satu buah bentuk masker dan mencari bentuk yang sama untuk dijadikan satu kelompok, selanjutnya dengan mencari bentuk masker yang sama dengan warna berbeda untuk dijadikan satu kelompok, dan selanjutnya mencari bentuk dan warna masker yang berbeda untuk dijadikan satu kelompok dalam kelompok yang lain.
Hasil dari pengelompokan ini dapat dilihat pada tabel berikut:
Tabel 3.12 Tabel Hasil Pengelompokan
Cluster 1 Cluster 2 Cluster 3
Pada tabel 3.12 dapat terlihat bahwa proses pengelompokan berhasil, sehingga didapatkan 3 cluster menurut kesamaan karakteristiknya yaitu berdasarkan bentuk dan warna masker. Masker yang memiliki bentuk dan warna yang sama akan menjadi satu kelompok dan bentuk masker yang berbeda berada pada kelompok lain.
Proses clustering memiliki 6 langkah sebagai berikut:
1. Merumuskan Masalah
Merumuskan masalah pengelompokan yaitu dengan menetapkan karakteristik yang akan dijadikan dasar dari pengelompokan. Karakteristik yang dipakai dalam dasar pengelompokan disebut sebagai variabel. Variabel yang akan dipilih menggambarkan kesamaan antar obyek yang relevan dengan masalah yang akan dilakukan dalam proses clustering.
2. Memilih Ukuran Kesamaan/Kemiripan Obyek
Pada dasarnya tujuan dari analisis cluster yaitu mengelompokkan obyek-obyek yang serupa, sehingga perlu dilakukan beberapa ukuran kesamaan untuk menilai seberapa mirip atau berbedanya obyek tersebut. Ukuran kesamaan dalam analisis cluster dibagi menjadi tiga yaitu ukuran korelasi, ukuran kedekatan dan ukuran
asosiasi. Ukuran asosiasi digunakan untuk mengukur data berskala non metrik yaitu ordinal atau nominal, sedangkan ukuran korelasi biasanya digunakan untuk mengukur data berskala matriks, dan ukuran kedekatan yang sering kali digunakan yaitu ukuran jarak dan ukuran kemiripan, obyek dapat dikatakan berdekatan apabila memiliki jarak yang kecil dan kemiripan yang besar. Jika variabel dalam data adalah kontinu maka kedekatan antar obyek dapat diukur menggunakan ukuran jarak di mana ukuran jarak yang paling umum digunakan yaitu jarak Euclidean atau kuadrat jarak Euclidean.
3. Memilih Metode Pengelompokan
Metode dalam pengelompokan dibagi menjadi dua yaitu bersifat hirarki atau non hirarki, pembahasan mengenai metode hirarki dan non hirarki ini akan dibahas pada sub bab berikutnya. Selanjutnya pemilihan metode pengelompokan ini didasarkan sesuai dengan kebutuhan penguji.
4. Menentukan Banyaknya Cluster
Dalam hal ini penentuan banyaknya cluster merupakan masalah utama dalam analisis cluster. Tidak ada aturan yang tegas dalam penentuan banyaknya cluster, namun diperlukan beberapa petunjuk yang dapat digunakan dalam menentukan banyaknya cluster:
a. Diperlukan pertimbangan teoritis dan konseptual untuk menentukan banyaknya cluster. Misalkan tujuan pengclusteran digunakan untuk mengenali atau mengidentifikasi segmen pasar, mungkin manajemen pasar menghendaki banyaknya cluster dalam jumlah tertentu (3, 4 atau 5 cluster).
b. Banyaknya cluster seharusnya disesuaikan dengan kebutuhan analisis bagi penguji.
5. Menginterpretasikan dan Membuat Profil Cluster
Setelah banyaknya cluster terbentuk langkah selanjutnya yaitu dengan melakukan interpretasi terhadap cluster yang sudah terbentuk. Tahap ini dilakukan dengan memberi nama spesifik untuk menggambarkan isi dalam cluster tersebut.
Pemberian nama dari profil cluster dibuat berdasarkan tujuan pengelompokan.
Misalkan jika tujuan suatu pengelompokan bersifat kualitatif maka pemberian nama juga bersifat kualitatif. Tahap interpretasi meliputi pengujian tiap cluster. Proses ini dimulai dengan suatu ukuran yang sering kali digunakan yaitu centroid, dimana centroid mewakili nilai rata-rata dari obyek-obyek yang terdapat dalam cluster untuk masing-masing variabel.
6. Validasi dari Proses Clustering
Tujuan dari validasi cluster yaitu untuk menjamin dan memastikan bahwa hasil dari clustering dapat mewakili populasi dan dapat digeneralisasi untuk obyek yang lain. Cluster yang terbentuk akan diuji apakah hasil dari pengelompokan valid.
Selanjutnya melakukan proses profiling untuk menjelaskan karakteristik dari setiap cluster berdasarkan profil tertentu. Titik berat dalam tahap ini yaitu pada karakteristik yang secara signifikan berbeda antar cluster. Contoh validasi clustering dapat menggunakan ANOVA atau MANOVA tujuannya untuk memastikan bahwa pembentukan cluster tersebut berhasil.
Berikut akan diberikan contoh penggunaan algoritma K-Means melalui animasi menurut (Xie, 2013). Contoh ini diberikan disini untuk memberikan ilustrasi bagaimana langkah-langkah tersebut diimplementasikan, sedangkan untuk pembahasan K-Means dibahas secara rinci pada bab 4.
Contoh 3.12:
Data yang diperoleh pada perhitungan berikut akan diplot menggunakan algoritma K-Means untuk mengidentifikasi 4 buah cluster (k=4). Perhitungan algoritma K-Means ini menggunakan software R dan diperoleh plot pertama sebagai berikut:
Gambar 3.21 Plot 1 Algoritma K-Means
Plot pertama tersebut menunjukkan alokasi titik secara acak ke salah satu dari 4 cluster. Titik-titik tersebut kemudian dipetakan berdasarkan jarak terdekatnya untuk menentukan empat cluster. Dalam plot tersebut dapat dilihat bahwa setiap cluster memiliki centroid masing-masing, di mana centroid yang diperoleh pada plot pertama akan digunakan pada iterasi kedua untuk memperoleh plot yang kedua.
Berikut adalah plot yang kedua
Gambar 3.22 Plot 2 Algoritma K-Means
Pada plot 2 dapat terlihat bahwa setiap cluster memiliki centroid baru yang dapat digunakan untuk iterasi berikutnya. Perhitungan ini dilakukan berulang kali
sampai diperoleh cluster dan centroid yang konvergen. Dalam proses ini diperoleh centroid yang konvergen setelah melakukan 22 kali plot yang dapat dilihat pada gambar berikut:
Gambar 3.23 Plot 21 Algoritma K-Means
Gambar 3.24 Plot 22 Algoritma K-Means
Pada plot 21 dan plot 22 tidak ditemukan anggota yang berpindah dan centroid yang dihasilkan sama, sehingga dengan demikian iterasi selesai.
Clustering digunakan hampir dalam semua bidang. Berikut adalah contoh dari clustering dalam bidang:
a) Biologi
Dalam bidang biologi pengelompokan digunakan berdasarkan karakter tertentu secara hirarkis. Sebagai contoh dalam bidang ini yaitu misalkan terdapat sekumpulan
hewan: kambing, kucing, sapi, ayam, bebek. Kumpulan hewan-hewan tersebut akan dikelompokkan berdasarkan karakteristik yang sama, oleh karena itu kambing, kucing dan sapi akan menjadi satu kelompok karena merupakan hewan berkaki empat, selanjutnya ayam dan bebek akan berada pada kelompok lain karena merupakan hewan berkaki dua.
b) Bisnis
Dalam bidang bisnis pengelompokan biasa digunakan untuk mengelompokkan karakteristik dalam bisnis tertentu. Sebagai contoh misalkan terdapat sekumpulan bisnis teh, indomaret, sawit dan alfamart. Kumpulan bisnis tersebut akan dikelompokkan berdasarkan karakteristik bisnisnya masing-masing, sehingga teh dan sawit akan menjadi satu kelompok karena merupakan bisnis perkebunan, selanjutnya indomaret dan alfamart berada pada kelompok lain karena merupakan bisnis waralaba.
C. Metode Analisis Cluster
Analisis cluster merupakan teknik multivariat yang mempunyai tujuan utama untuk mengelompokkan obyek-obyek berdasarkan karakteristik yang dimilikinya.
Analisis cluster mengklasifikasikan obyek sehingga obyek yang paling dekat kesamaannya dengan obyek lain berada dalam cluster yang sama. Karakteristik obyek-obyek dalam suatu kelompok memiliki tingkat kemiripan (homogenitas) yang tinggi, sedangkan karakteristik antar obyek pada suatu kelompok dengan kelompok lain memiliki kemiripan yang rendah. Homogenitas dan heterogenitas merupakan dua hal yang baik dan harus dimiliki dalam sebuah cluster. Pembentukan kelompok- kelompok ini didasarkan pada jarak. Analisis cluster juga merupakan salah satu analisis yang berguna untuk meringkas data atau sejumlah variabel. Proses meringkas data ini dapat dilakukan dengan mengelompokkan obyek-obyek berdasarkan kesamaan karakteristik tertentu diantara obyek-obyek yang hendak diteliti. Selain itu analisis cluster dapat digunakan untuk menganalisis data kontinu atau data biner dengan penyesuaian pada ukuran similaritasnya. Dalam pembentukan