Parallel CBIR implementations with load balancing algorithms
José L. Bosque
a,∗, Oscar D. Robles
a, Luis Pastor
a, Angel Rodríguez
b aDpto. de Informática, Estadística y Telemática, U. Rey Juan Carlos, C. Tulipán, s/n, 28933 Móstoles, Madrid, SpainbDept. de Tecnología Fotónica, UPM, Campus de Montegancedo s/n, 28660 Boadilla del Monte, Spain Received 22 December 2003; received in revised form 23 February 2005; accepted 7 April 2006
Available online 13 June 2006
Abstract
The purpose of content-based information retrieval (CBIR) systems is to retrieve, from real data stored in a database, information that is relevant to a query. When large volumes of data are considered, as it is very often the case with databases dealing with multimedia data, it may become necessary to look for parallel solutions in order to store and gain access to the available items in an efficient way.
Among the range of parallel options available nowadays, clusters stand out as flexible and cost effective solutions, although the fact that they are composed of a number of independent machines makes it easy for them to become heterogeneous. This paper describes a heterogeneous cluster-oriented CBIR implementation. First, the cluster solution is analyzed without load balancing, and then, a new load balancing algorithm for this version of the CBIR system is presented.
The load balancing algorithm described here is dynamic, distributed, global and highly scalable. Nodes are monitored through a load index which allows the estimation of their total amount of workload, as well as the global system state. Load balancing operations between pairs of nodes take place whenever a node finishes its job, resulting in a receptor-triggered scheme which minimizes the system’s communication overhead. Globally, the CBIR cluster implementation together with the load balancing algorithm can cope effectively with varying degrees of heterogeneity within the cluster; the experiments presented within the paper show the validity of the overall strategy.
Together, the CBIR implementation and the load balancing algorithm described in this paper span a new path for performant, cost effective CBIR systems which has not been explored before in the technical literature.
© 2006 Elsevier Inc. All rights reserved.
Keywords:Parallel implementations; CBIR systems; Load balancing algorithms
1. Introduction
The tremendous improvements experimented by computers in aspects such as price, processing power and mass storage capabilities have resulted in an explosion of the amount of information available to people. But this same wealth makes finding the “best” information a very hard task. CBIR1systems try to solve this problem by offering mechanisms for selecting the data items which resemble most a specific query among all the available information [12,34], although the complexity
∗Corresponding author.
E-mail addresses:[email protected](J.L. Bosque),
[email protected](O.D. Robles),[email protected](L. Pastor), [email protected](A. Rodríguez).
1Content-based information retrieval.
0743-7315/$ - see front matter © 2006 Elsevier Inc. All rights reserved. doi:10.1016/j.jpdc.2006.04.014
of this task depends heavily on the volume of data stored in the system. As usual, parallel solutions can be used to alleviate this problem, given the fact that the search operations present a large degree of data parallelism.
can easily become heterogeneous, requiring load distributions that take into consideration each node’s computational features
[33]. This way, one of the critical parameters to be fixed in order to keep the efficiency high for this architectures is the workload assigned to each of the cluster nodes. Even though load balancing has received a considerable amount of interest, it is still not definitely solved, particularly for heterogeneous systems [10,18,41,45]. Nevertheless, this problem is central for minimizing the applications’ response time and optimizing the exploitation of resources, avoiding overloading some proces-sors while others are idling.
This paper describes the architecture, implementation and performance achieved by a parallel CBIR system implemented on a heterogeneous cluster that includes load balancing. The flexibility of the architecture herein presented allows the dy-namical addition or removal of nodes from the cluster between two user queries, achieving reconfigurability, scalability and an appreciable degree of fault tolerance. This approach allows a dynamic management of specific databases that can be incor-porated to or removed from the CBIR system in function of the desired user query. The heterogeneity of the system is managed by a new dynamic and distributed load balancing algorithm, introducing a new load index that takes into account the com-putational nodes capabilities and a more accurate measure of their workload. The proposed method introduces a very small system overhead when departing from a reasonably balanced starting point.
As mentioned before, the amount of data to be managed in CBIR systems is so huge nowadays that it is almost manda-tory to use parallelism in order to achieve a reasonable user re-sponse times. Two alternatives were tested in a previous work: a shared-memory multiprocessor and a cluster [6]. Since the cluster implementation has given better results, it seems ad-visable to introduce load balancing strategies to improve the efficiency in heterogeneous clusters. The selected approach is based on a dynamic, distributed, global and highly scalable load balancing algorithm. An heterogeneous load index based on the number of running tasks and the computational power of each node is defined to determine the state of the nodes. The algorithm automatically turns itself off in global overloading or under-loading situations.
Together, the CBIR implementation and the load balancing algorithm described in this paper open a new path for perfor-mant, cost effective CBIR systems which has not been explored before in the technical literature.
The rest of this article is organized as follows: Section 2 presents an overview of parallel CBIR systems and load bal-ancing algorithms. Section 3 presents an analysis of a sequen-tial version of the CBIR algorithm and a brief description of its parallel implementation on a cluster (without load balancing). Section 4 describes the distributed load balancing algorithm ap-plied to the parallel CBIR system and Section 5 details its im-plementation on a heterogeneous cluster. Section 6 shows the tests performed in order to measure the improvement achieved by the heterogeneous cluster version with load balancing and the results achieved. Finally, Section 7 presents the conclusions and ongoing work.
2. Previous work
The technological development experimented during the last 20 years has turned into a spectacular increase in the volume of data managed by information systems. This fact has lead to the search for methods to automate the process of extracting structured information from these systems[12,31]. The poten-tial importance of CBIR systems has been reflected in the va-riety of approaches taken while dealing with different aspects of CBIR systems. The multidisciplinary nature of this problem has often resulted in partial advances that have been integrated later on in new prototypes and commercial systems. For exam-ple, it is possible to find research work that takes into consider-ation man–machine interaction issues [32]; the users’ behavior from a psychological modeling standpoint [27]; multidimen-sional indexing techniques [5]; multimedia database manage-ment system issues [19]; pattern recognition algorithms [17]; multimedia signal processing [39]; object representation and modeling techniques [21]; benchmarks for testing the perfor-mance of CBIR systems [16,24]; etc.
In any case, most of the research effort for CBIR sys-tems has been focused on the search for powerful repre-sentation techniques for discriminating elements among the global database. Although the data nature is a crucial factor to be taken into consideration, most often the final repre-sentation is a feature vector2 extracted from the raw data, which reflects somehow its content. While dealing with 2D images, it is possible to find techniques using color, shape, or texture-based primitives. Other techniques use spatial relation-ships among the image components or a combination of the above-mentioned approaches. For higher-dimensionality input data, it is possible to find proposals dealing with 3D images or video sequences. Nowadays, one of the most promising research lines is to increase the abstraction level of the se-mantics associated to the primitives managed, representing high-level concepts derived from the images or the multimedia data.
From the computational complexity point of view, CBIR sys-tems are potentially expensive and have user response times growing with the ever-increasing sizes of the databases associ-ated to them. One of the most common approaches followed to reach acceptable price/performance ratios has been to exploit the algorithms’ inherent parallelism at implementation time. However, the novelty of CBIR systems hinders finding refer-ences dealing with this aspect. Some contributions that can be cited are Zaki’s compilation [43], and the contributions of Srakaew et al. [37] and Bosque et al. [6]. Another reason that has made difficult widespread parallel CBIR system develop-ment is that prototype analysis demands a manual image clas-sification stage that limits in practice the number of images used in the tests. Nevertheless, the volume of data managed by current DBs, and obviously those with multimedia infor-mation, will demand parallel optimizations for commercial im-plementations of CBIR systems. In those cases, load balancing operations preventing the coexistence of idling and overloaded
processors will be almost required, since total response times are usually considerably improved with the introduction of even simple load balancing approaches.
Load balancing techniques can be classified according to different criteria[8]. First, algorithms can be labeled asstatic or dynamic. Static methods perform workload distribution at compilation time, not taking into consideration the system state variations. Dynamic methods are able to redistribute workload among nodes at run time, depending on changes in the system state. The work of Rajagopalan et al. [28] and Obeloer et al. [25] are agent-based techniques. These are flexible and con-figurable approaches but the amount of resources needed for agent implementation is considerably large. Grosu et al. [15] present a very different cooperative approach to the load bal-ancing problem, considering it as a game in which each clus-ter node is a player and must minimize its job execution time. Banicescu et al. propose a load balancing library for scientific applications on distributed memory architectures. The library integrates dynamic loop scheduling as an object migration pol-icy with the object migration mechanism provided by the data movement and control substrate which is extended with a mo-bile object layer [2].
Load balancing algorithms can also be classified as central-ized or distributed. In the first case, there is a single central node in charge of keeping the system’s information updated, making decisions and actually performing the load balancing opera-tions. In distributed methods, every node takes part in the load balancing operations; Zaki et al. [44] show that distributed al-gorithms yield better results than their centralized counterparts. Last, load balancing algorithms can be classified as global or local. In the first case, a global view of the system state is kept [10]. In the second case, nodes are arranged in sets or domains, and distribution decisions are made only within each domain [9,40]. Other approaches mix this taxonomy by combining sev-eral features that could be considered mutually exclusive, like the work of Ahmad and Ghafoor [1], where a semidistributed algorithm with a two level hierarchy is presented; their work focus on static networks where communication latency is very important and depends on node placement. In this type of net-works, distributed algorithms may produce instability, scala-bility and bottleneck problems. The improvement of dynamic network technologies solves these problems with broadcast so-lutions and very low latencies. The technique proposed by Ahmad and Ghafoor [1], although interesting, is not easily applicable to general, unrestricted distributed systems: it was developed for static network environments, where latency is de-pendent on node location and where broadcast operations are very costly in terms of system performance. Clusters, which in the present work appear as a very attractive option for CBIR systems in terms of cost/performance ratio, present very dif-ferent communication features, and therefore, advise using a different approach.
Although a set of projects have been developed to implement CBIR systems on clusters like the IRMA project for medical images [14] and the DISCOVIR project (distributed content-based visual information retrieval system on peer-to-peer net-work) [13], none of them include a load balancing algorithm to
distribute the workload of the cluster nodes and therefore they cannot manage system heterogeneity.
3. CBIR system description
The experimental work presented in this paper has been per-formed on a test CBIR system containing information from 29.5 million color pictures. The system provides the user with a data set containing thepimages considered most similar to the query one. If the result does not satisfy the user, he/she can choose one of the selected images or enter a new one that presents some kind of similarity with the desired image.
The following sections describe the heart of the CBIR sys-tem, where the signature is extracted from each image (a feature vector describing the image content), as well as the processes involved in serving a user’s query. More detailed analysis of the retrieval techniques involved in the CBIR system and the method’s stages from the standpoint of parallel optimization can be found elsewhere[30,29,6], respectively.
3.1. Signature computation
Many different approaches can be used for computing the images’ signatures, as mentioned in Section 2. In the work presented here, a primitive that represents the color information of the original image at different resolution levels has been selected. To achieve a multiresolution representation, a wavelet transform is first applied to the image [22,11].
3.2. Analysis of the sequential CBIR algorithm
The search for images contained in a CBIR system can be broken down into the following stages:
(1) Input/query image introduction: The user first selects a 128×128 pixel bidimensional image to be used as a search reference. Then the system computes its signature as de-scribed above. The whole process can be efficiently im-plemented using anO(i_s)order algorithm,i_sbeing the image’s size[38]. This stage does not require high com-putational resources since the system deals with just one image.
(2) Query and DB image’s signature comparison and sorting: The signature obtained in the previous stage is compared with all of the DB images’ signatures using an Euclidean distance-based metric. After this process, the identifiers of thepimages most similar to the input image are extracted, ranked by their similarity. Even though this process of signature comparison, selection and ranking is not very demanding from the computational point of view, it has to be performed with all of the images within the DB. (3) Results display: The following step is to assemble a mosaic
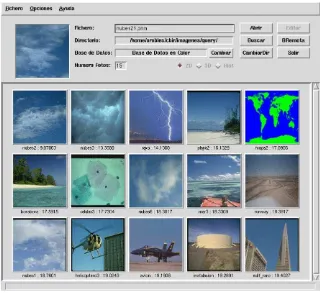
made up of the selectedpimages which has to be presented to the user as the search result (see Fig.1).
Fig. 1. Visual result of a query.
Upon observing the operations involved, it is possible to notice that the comparison and sorting stage involves a much larger computational load than the others. Luckily, the exploitation of data parallelism can be done just by dividing the workload amongn independent nodes, since there are no dependencies. This can be accomplished by distributing off-line the CBIR im-age’s signatures across the processing nodes. Then, each node can compare the image query’s signature with every available signature. In order to ease also the storage requirements, it is possible to distribute images, signatures and computation over all of thenavailable nodes.
3.3. Parallel implementations without load balancing
3.3.1. Global strategy
A remarkable feature of the signature comparison and sorting stage is the problem’s fine granularity: it is possible to perform an efficient data-oriented parallelization by combining the sig-nature comparison and sorting stages, and distributing among the different nodes only the data needed to perform this stage, which are the signatures of the DB images assigned to each node as well as a scalar defining the total number of signatures to be returned,p. It has to be noted that the amount of com-munications among the corresponding processes is very small, since only the input image’s signature and thepidentifiers from the most similar images which have been found at each node, together with their corresponding similarity measures, have to be exchanged among the processes involved, as we will see below.
The programmed optimization strategy is based on a farm
model, in which a master process distributes the data to be dealt with upon a set ofslaveprocesses which analyze the data and return the partial results to themasteronce they have fin-ished their computations. Since this approach makes it possible to maintain a large degree of data handling locality, it is well suited for distributed memory multiprocessors with message passing communication. Further advantages of this solution are its good price/performance ratio and its high level of scalabil-ity, whenever the number of images stored in the database is increased. In our case, the following solution has been adopted:
(1) The master process computes the signature of the input image and broadcasts it to then slaveprocesses.
(2) The slaveprocesses then proceed to compare the signa-ture of the input image with the signasigna-tures of the images assigned to their corresponding process node. Once each comparison has been performed, a check is then carried out to ascertain whether the result obtained is one of the bestp images and, should that be the case, it is then in-corporated into the set which is repeatedly sorted using a bubble sorting algorithm.
(3) The slaveprocesses forward the p image identifiers and similarity measurements to themasterprocess after com-paring and selecting thepimages which are most similar within each process node.
selected images’ + identifiers (if any)
selected images’ + identifiers (if any) selected images’
+ identifiers (if any)
SLAVE 2
Query Image Signature
Query Image Signature
MASTER
Requested images to show
SLAVE 1
Query Image Signature
+
Requested images to show
Requested images to show
+
SLAVE n
+
p more similar list p more similar list
p more similar list
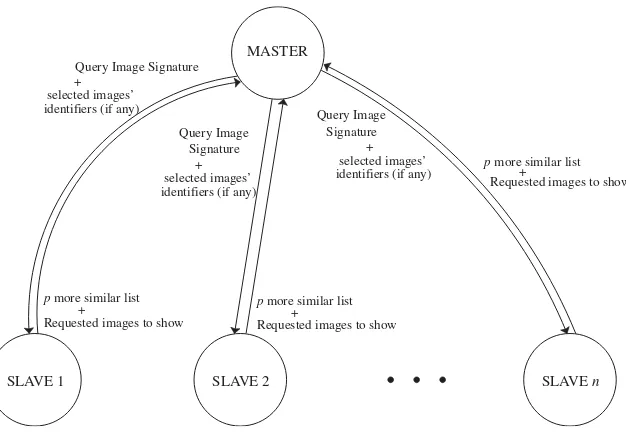
Fig. 2. Process communication in the cluster implementation without load balancing.
(5) Finally, themasterprocess requests the process nodes that contain the previously selected images to forward them so that they may be presented to the user and, once available, proceeds to compose a mosaic that is then displayed to the user.
Fig.2 represents a schematic diagram of the communication between the processes involved in the unbalanced system. It must be noticed that each node of the heterogeneous cluster runs two processes: amaster to attend the user queries and a
slaveto provide the local results achieved by each process node to themasterprocess of the cluster node where the query has been generated. This situation is very similar to that found on a grid.
3.3.2. MPI cluster implementation
The application has been programmed using the MPI libraries as communication primitives between themasterandslave pro-cesses. MPI has been selected given that it currently constitutes a standard for message passing communications on parallel ar-chitectures, offering a good degree of portability among paral-lel platforms [23]. The MPI version used is 6.5.6 LAM, from the Laboratory for Scientific Computing of Notre Dame Uni-versity, a free distribution of MPI [36].
The pseudo-code corresponding to the implementation of the
masterandslaveprocesses is shown below.
Master
loop
Request an image to the user Compute its signature
Forward the signature to each of then slaveprocesses using the MPI_BCAST
(broadcast) primitive
Receive the results of then slaveprocesses using the MPI_-RECV (receive) primitive
Sort the partialn·p comparisons selecting the topp
Request the p most similar images to theslave processes where the corresponding images are stored
Receive thepmore similar images from the nodes containing them using the MPI_RECV primitive
Compose the mosaic to be presented to the user end loop
Slavej (1jn)
Mbeing the number of images stored in process nodej
loop
Receive the signature of the query image for-warded from themasterusing the
MPI_BCAST (reception from a previous broad-cast) primitive
Initialize the Pj set which shall contain thep better results of the comparisons
fork=1 toMdo
Find the signature of the imagek
Compare the query signature with that of the current image obtaining the similarity measure-mentmsj k
ifmsj k ∈Pj then
Eliminate the worst result ofPj
Incorporate the result corresponding to the imagek
toPj
SortPj using a bubble sorting algorithm end if
end for
ForwardPj to themaster
if the master requests images to compose the mosaicthen
Forward the requested images endif
The size of the data corresponding to each one of thepbest results that are transferred from every slave to themaster is around 336 bytes. Therefore, eachslaveprocess transfers 336·p
bytes per query. For example, for p = 20 and n = 25, the traffic involved in the response will be less than 165 kB.3
4. Description of the load balancing algorithm
A dynamic, distributed, global and highly scalable load bal-ancing algorithm has been developed for CBIR application and tested with the CBIR parallel application previously described. A more detailed description of the load balancing algorithm can also be found in [7]. A load index based on the number of run-ning tasks and the computational power of each node is used to determine the nodes’ state, which is exchanged among all of the cluster nodes at regular time intervals. The initiation rule is receiver-triggered and based on workload thresholds. Finally, the distribution rule takes into account the heterogeneous nature of the cluster nodes as well as the communication time needed for the workload transmission in order to divide the amount of workload between a pair of nodes in every load balancing op-eration. These ideas are detailed along the following sections.
4.1. State rule
The load balancing algorithm is based on aload indexwhich estimates how loaded a node is in comparison to the rest of the nodes that compose the cluster. Many approaches can be taken to compute the load index. Like in any estimation process, it is necessary to find a trade-off between accuracy and cost, since keeping frequently updated node rankings according to their workload might be costly.
The index is based on the number of tasks in the run-queue of each CPU [20]. These data are exchanged among all of the nodes in the cluster to update the global state information. Moreover, each node takes into account the following informa-tion about the rest of the cluster nodes:
• Cluster heterogeneity: each node can have a different com-putational powerPi, so this factor is an important parameter to take into account for computing the load index. It is de-fined as the inverse of the time taken by nodeito process a single signature.
• Total amount of workload for each node: it is evaluated when the application begins its execution and it is updated if there are any changes in a node.
• Percentage of the workload performed by each node,Wi: it is defined in function of the total workload, the computational power and the number of tasks in this node.
• Period of time from the last update,D, and total execution time,T.
3These figures do not take into consideration either the data corresponding to the images presented to the user or the overheads originated by the communication primitives, although the latter could be considered negligible.
Therefore, the updates of the number of tasks are performed as
Nave=
(Nlast·T )+(Ncur·D)
T +D , (1)
whereNcuris the number of current running tasks in the node,
Nlast is the average of the number of tasks running from the
last update, T is the total execution time of the Nlast tasks
considered, andDis the interval of time since the last update. This expression gives the average number of tasks of the node during the execution time of the application. So, the percentage of workload processed in each node,Wi, is evaluated as
Wi =
Pi·T
W·Nave
×100. (2)
4.2. Information rule
Given that the load balancing approach described here is dynamic, distributed and global, every node in the system needs updated information about how loaded the remaining system nodes are[42]. The selected information rule is periodic: each node broadcasts its own load index to the rest of the nodes at specific time instants. A periodic rule is necessary because each node has to compute the amount of workload processed by the rest of the cluster nodes, based on the average number of tasks per node. To evaluate the average number of tasks it is necessary that the information is updated periodically, which makes other information rules such as event driven or under demand not suitable.
4.3. Initiation rule
The initiation rule determines the current times for perform-ing load balancperform-ing operations. It is a receiver initiated rule, where load balancing operations involve pairs of idling and heavily loaded nodes: whenever a processor finishes its as-signed workload, it looks for a busy node and asks it to share part of its remaining workload. Since each node keeps informa-tion about the amount of pending work of the remaining nodes, the selection of busy nodes is simple.
The initiation rule described above minimizes the number of load balancing operations, reducing the algorithm overhead. Also, all the operations improve the system performance, be-cause the total response time of the nodes involved in the load balancing operation are equalized, provided that there are not any additional changes in their state or they are not involved in other load balancing operations.
4.4. Load balancing operation
4.4.1. Localization rule
Whenever a node finishes its workload, it looks for a sender node to start a load balancing operation. The receiver node checks the state of the rest of the cluster nodes and com-putes a node list, ordered by the amount of pending work. To select the sender node, the receiver checks its own posi-tion in the list and selects the node which is in the symmetric position; for example, if nodes are ranked according to their workload, the node less loaded will look for the most loaded; the second less loaded node will look for the second most loaded, and so on. In consequence, each pair of sender–receiver nodes will have between both of them a similar amount of workload.
Apart from being very simple to implement, this approach gives good results since whenever a node finishes its work it is placed in one end of the list, selecting a heavily loaded (in the other end of the list). This way, the selection of the sender node is very coherent: the underloaded nodes take workload from the overloaded nodes, while the nodes in middle positions in the list do not receive a load balancing request (since it is very unlikely that a node placed in an intermediate position starts a load balancing operation).
Additionally, if several nodes are looking for a sender at the same time, it is unlikely that they address their requests to the same sender. This way, situations where a loaded node receives several load balancing petitions and the rest of the loaded nodes do not receive any are avoided. Finally, this approach is not time consuming, because the nodes have always up-to-date state information to make their own list.
Whenever a node receives a load balancing request, it can accept or reject it. In order to accept it, the sender node should have a minimum amount of work left. Otherwise, the sender node is near to complete its workload and the cost of the load balancing operation can be higher than finishing the remaining workload locally. In that case, the receiver node will select another node from the list using the same proce-dure until an adequate node is found or the end of the list is reached.
4.4.2. Distribution rule
The distribution rule computes the amount of work that has to be moved from the sender to the receiver node. An appropriate rule should take into consideration the relative nodes’ capabilities and availabilities, so that they finish pro-cessing their jobs at the same time (provided that no additional operations change their processing conditions). The commu-nication time to transfer the workload among the nodes is also taken into consideration because thereceivernode cannot run the new assigned task until it receives the correspond-ing load, havcorrespond-ing an additional delay. The global equilibrium is obtained through successive operations between couples of nodes.
The proposed distribution rule is based on two parameters: the number of running tasksNTi and the computational power
Piof the nodes which take part in the operation. This reflects the fact that the contribution of a powerful node might be hampered
by a large amount of external workload. Both parameters will be included in thenodes’ actual computational power,Pacti, which is obtained as
P acti =
Pi
N Ti
. (3)
This is a multi-phase application within two different phases: comparison and sorting. Whenever the load balancing opera-tion is finished, the sender node has to finish the comparison phase with the remaining workload. Then, it must sort all the processed workload. The receiver should compare and sort the new workload. Additionally, the communication time has to be taken into account, because the receiver cannot continue the processing until it receives the new workload. Then, the distri-bution rule is determined by the following expressions:
Ts=
whereTs andTr are the response times of the sender and re-ceiver processors, since the load balancing operation is finished.
Wis the total workload of the sender which has not still been processed, Ws is the remaining workload in the sender node
after the load balancing operation and Wr the workload sent
to the receiver. P acts andP actr are the sender and receiver
current computational power. Finally,Pcis the communication
power expressed in units of workload per second. The commu-nication power is obtained by computing offline the number of signatures that can be exchanged between two of the cluster nodes per second.
This model takes into consideration two assumptions:
• The computational power for a node is the same in both the comparison and sorting phases.
• The response time in both phases and the communication time are linear with respect to the workload.
Solving these expressions, the amount of both sender and re-ceiver workload can be computed as
Wr=
2W P actrPc
2PcP acts+2P actrPc+P actsP actr
,
Ws=W−Wr. (5)
The values for both workloads Wr andWs take into account
the heterogeneity of the nodes, their current state, the commu-nication times and the two different phases of the application.
5. Distributed load balancing implementation on a heterogeneous cluster
5.1. Process structure of the load balance implementation
Two replicated processes are distributed among each one of the cluster nodes:
(1) Load daemon: This process implements both the state and the information rules.
(2) Distribution daemon: It collects requests fromslavenodes demanding workload and proceeds with the transference.
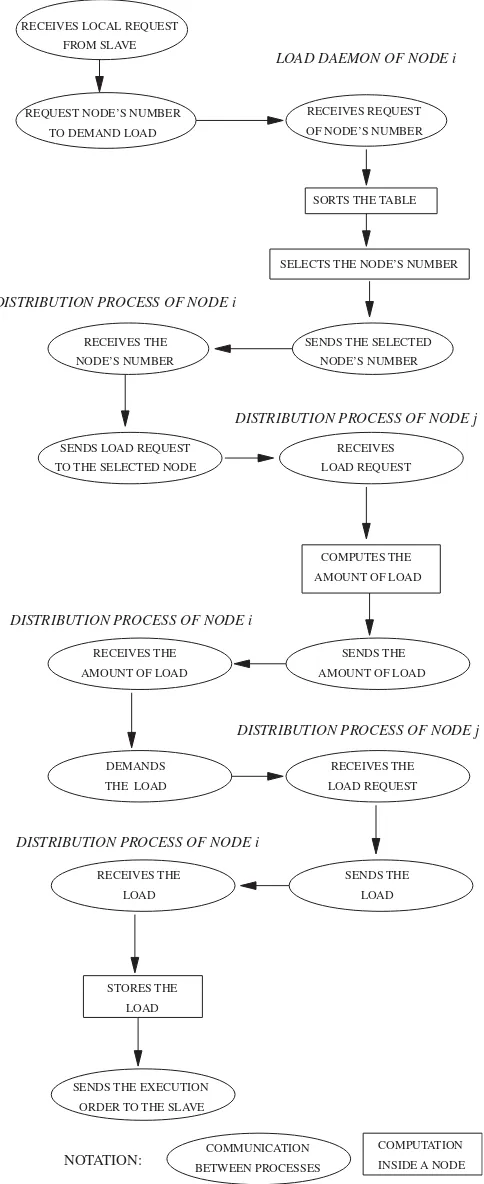
Fig.3 shows a decomposition of all the actions that must be carried out when aslavenode finishes its local workload and triggers the initiation rule. First, it demands new load to the dis-tribution process, which obtains the demanded load and sends it to theslavenode with the purpose to allow the continuation of the computations. The following section describes the struc-ture of the group of processes and their functions.
5.2. Groups of processes
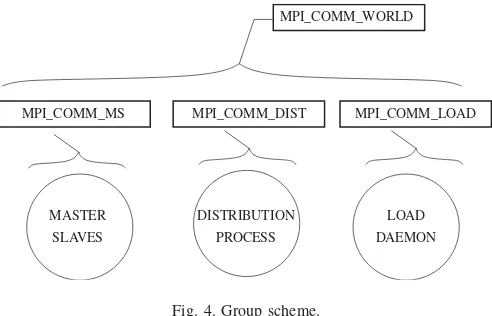
As mentioned in Section 3.3.2, communication and synchro-nization between processes is based on MPI. A structure of groups of processes based on communicators [23,26,35] has been implemented, where the groups allow to establish commu-nication structures between processes and to use global com-munication functions over subsets of processes. This way, each type of process belongs to his own group:
• MPI_COMM_MS: this group is composed by the master
process and all of theslaveprocesses.
• MPI_COMM_DIST: this group is formed by the distribution processes.
• MPI_COMM_LOAD: this group is composed by the load daemonof each of the nodes.
The group concept is the more natural way to implement this process scheme, because most often the messages transmitted involve processes that belong to the same group. Fig.4 presents this communication hierarchy.
5.3. Load daemon
The main function of this process is to compute the local load index, to send this information to the load daemons of the other nodes and to transmit all of the information available to the local distribution process, whenever it is required to do so. Also, it is in charge of initializing and managing a table that stores the state of the other nodes. The table stores the follow-ing information for each of the nodes: computational power, average number of active tasks while the application is running, percentage of completed work, time of the last update, total ex-ecution time with some load level and number of signatures to be processed.
At predetermined fixed intervals, the process evaluates the load index of the node where it is running and sends the state
NOTATION:
OF NODE’S NUMBER RECEIVES REQUEST
SORTS THE TABLE
SELECTS THE NODE’S NUMBER
SENDS THE SELECTED NODE’S NUMBER NODE’S NUMBER
RECEIVES THE
SENDS LOAD REQUEST TO THE SELECTED NODE
RECEIVES LOAD REQUEST
SENDS THE AMOUNT OF LOAD AMOUNT OF LOAD
RECEIVES THE
THE LOAD
DEMANDS RECEIVES THE LOAD REQUEST
SENDS THE LOAD LOAD
RECEIVES THE
LOAD DAEMON OF NODE i
COMPUTES THE AMOUNT OF LOAD
LOAD STORES THE
SENDS THE EXECUTION ORDER TO THE SLAVE FROM SLAVE
REQUEST NODE’S NUMBER TO DEMAND LOAD RECEIVES LOCAL REQUEST
DISTRIBUTION PROCESS OF NODE i
DISTRIBUTION PROCESS OF NODE j
COMMUNICATION
BETWEEN PROCESSES INSIDE A NODE COMPUTATION
DISTRIBUTION PROCESS OF NODE i
DISTRIBUTION PROCESS OF NODE i
DISTRIBUTION PROCESS OF NODE i
DISTRIBUTION PROCESS OF NODE j
Fig. 3. General overview of the whole load balancing algorithm.
summa-MPI_COMM_WORLD
MPI_COMM_MS
MASTER SLAVES
DISTRIBUTION PROCESS
LOAD DAEMON MPI_COMM_DIST MPI_COMM_LOAD
Fig. 4. Group scheme.
Table 1
Messages and associated functions of the load daemon Message Associated tasks
identifier
0 Task information
1 The distribution process has finished and demands the iden-tifier of a transmitter node
2 The distribution process informs about the number of sig-natures delivered to other node
3 The distribution process notifies that there are no available nodes to transfer load
4 The distribution process shows the number of signatures obtained from other node
5 Another load daemon informs about its new number of signatures because their transference to other node 6 Another load daemon reports about the new number of
signatures assigned to
7 Another load daemon tells that there are no nodes to transfer load
rizes the messages involved with the load daemon and the tasks associated with each one.
5.4. Distribution process
The main function of the load distribution process is to im-plement the initiation rule and the load balancing operation. Whenever a particularslavefinishes its local work, the distribu-tion process is then alerted, evaluating therefore the initiadistribu-tion rule, finding a candidate node, establishing the negotiation and delivering the load to theslave. On the other hand, if the node receives a load balancing request, the distribution rule must be triggered and the appropriate workload is sent to the remote node.
6. Analysis of the CBIR implementation with load balancing in a heterogeneous cluster
A set of experiments have been performed for testing the behavior of the parallel CBIR system implemented on the het-erogeneous cluster using the above distributed load balancing algorithm. To compare the results achieved by the parallel CBIR system with and without the distributed load balancing
200 250 300 350 400 450 500
0 5 10 15 20 25
Computational P
o
w
er
Processor
Fig. 5. Computational power of the cluster nodes, measured in workload units/second.
rithm, the total response time of the CBIR system, with and without load balance, has been measured. Additionally, two classical load balancing algorithms have been implemented as reference: the random algorithm[3] and the Probin algorithm [9]. The random algorithm is the one of the most simple and distributed load balancing algorithms because each node makes decisions based on local information. A node is considered sender if the queue length of the CPU exceeds a predetermined and constant threshold. The receiver is selected randomly be-cause the nodes do not share any information about the status system. The Probin algorithm is a diffusion-based algorithm, where the information is locally exchanged defining commu-nication domains between neighbor nodes. Several levels of coordination can be established varying the domains’ size.
The experiments have been executed on a heterogeneous cluster composed of 25 nodes, linked through a 100 MB/s Eth-ernet. Each of the process nodes features 4 GB of storage ca-pacity in an IDE hard disk linked through DMA with 16.6 MB/s transfer speed. The PC’s operating system is Linux v. 2.2.12. The heterogeneity is determined by the hard disk features. It has to be noted that this component determines each node’s re-sponse, as shown in Fig. 5, since in this CBIR system (as in many others),I/Ooperations are predominant with respect to CPU operations.
4000 6000 8000 10000 12000 14000
5 10 15 20 25 5 10 15 20 25
Ex
ecution time (seconds)
Number of processes
Without algorithm Random algorithm Probin algorithm Proposed algorithm
1 1.02 1.04 1.06 1.08 1.1 1.12 1.14 1.16 1.18 1.2
Speedup
Number of processors
Random algorithm Probin algorithm Proposed algorithm
(a) (b)
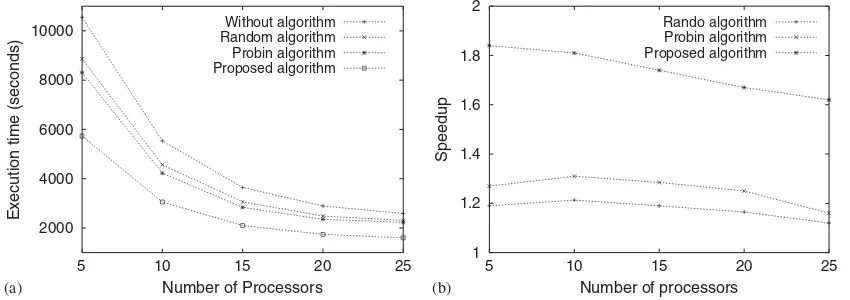
Fig. 6. Results without external tasks (speedup with respect to the algorithm without load balancing): (a) response time and (b) speedup.
Table 2
Response time without external workload, measured in seconds
No. nodes Without alg. Random alg. Probin alg. Proposed alg.
5 14 362 14 070 13 771 12 628
10 7285 7044 6784 6362
15 5110 4970 4863 4432
20 4639 4320 4295 3799
25 4168 4114 4128 3593
6.1. Tests considering cluster heterogeneity and load balancing overhead
The main purposes of these tests were to detect the amount of overhead introduced by the load balancing algorithm, and how the algorithm can manage the system heterogeneity. The tests were performed on clusters with 5, 10, 15, 20 and 25 slave nodes plus a master node, in order to evaluate the algorithm scalability. The results are presented in Table2 and in Fig. 6.
Table 2 shows that the response times are always shorter with some load balancing algorithm, which means that the overhead introduced by the algorithm is smaller than the improvements achieved by using any of the implemented load balancing al-gorithms. From these results two main considerations can be pointed out:
• The tested load balancing algorithms improved always the response times between 10% and 15%. The best results were achieved by the proposed algorithm.
• The proposed approach proved to be more stable, while the results obtained with the other algorithms were less consis-tent.
Fig.6(b) and Table 3 present the speedup of these algorithms, where the speedup refers to the improvements.
An interesting parameter for estimating the methods’ behav-ior is the standard deviation of the response times of the differ-ent cluster nodes, shown in Table 4 and in Fig. 7. The standard deviation of the nodes’ response times is a measurement di-rectly related to idling times of nodes waiting for other nodes to finish their assignments.
Table 3
Speedup without external tasks
No. nodes Speedup Speedup Speedup
random alg. Probin alg. proposed alg.
5 1.021 1.047 1.137
10 1.034 1.073 1.145
15 1.028 1.051 1.153
20 1.019 1.029 1.158
25 1.013 1.01 1.16
Table 4
Standard deviation of the cluster nodes without external tasks
No. nodes Without alg. Random alg. Probin alg. Proposed alg.
5 2620 1127 743.53 355
10 1198 787 482 145
15 763 571.94 85.73 73
20 620 430 317 46
25 575 333.25 198.08 37
0 500 1000 1500 2000 2500 3000
5 10 15 20 25
Time (seconds)
Number of processors Without algorithm Random algorithm Probin algorithm Proposed algorithm
2000 4000 6000 8000 10000
Ex
ecution time (seconds)
Number of Processors Without algorithm Random algorithm Probin algorithm Proposed algorithm
1 1.2 1.4 1.6 1.8 2
5 10 15 20 25
5 10 15 20 25
Speedup
Number of processors Rando algorithm Probin algorithm Proposed algorithm
(a) (b)
Fig. 8. Results with external tasks: (a) response time and (b) speedup.
Table 5
Response time with external tasks on a node, measured in seconds
No. nodes Without alg. Random alg. Probin alg. Proposed alg.
5 10 548 8864 8305 5732
10 5535 4562 4225 3054
15 3645 3063 2836 2099
20 2893 2483 2352 1739
25 2589 2311 2231 1601
The load balancing algorithm presented here decreases the standard deviation, equilibrating the response times, while with the random algorithm a slight reduction is achieved but with the Probin algorithm this value is erratic, depending highly on the probed nodes. Finally, the proposed algorithm achieves the best values of all the load balancing algorithms tested, ranging from a reduction of the standard deviation from 86.45% with 5 nodes to 93.56% with 25 nodes with respect to the response times without a load balancing algorithm.
6.2. Results with system overload
For these experiments the system is slightly overloaded, hav-ing one of the nodes heavily loaded. The goal of this test is to measure the algorithm’s ability to distribute the work of the loaded node among the remaining cluster nodes, without af-fecting the system performance. The tests were performed on a heterogeneous cluster with 5, 10, 15, 20, and 25 slave nodes and a master node, using a database of 12.5 million images. Table
5 and Fig. 8 present the results achieved in this experiment. For these tests, the differences obtained between executions with or without load balancing were very strong. The reductions in response times range from 45% with 5 nodes to 38% with 25 nodes. As the number of nodes increases, the differences in response times decrease. Again, the best results are achieved with the proposed algorithm. Table 6 and Fig. 8(b) show the speedup achieved in these tests.
Finally, Table 7 and Fig. 9 present the standard deviation results.
In these tests, the reduction of the standard deviation ranged from 90% to 95%. An interesting point to be remarked is the lack of consistency of the results provided by the random
algo-Table 6
Speedup with external tasks
No. nodes Speedup Speedup Speedup
random alg. Probin alg. proposed alg.
5 1.19 1.27 1.84
10 1.213 1.31 1.81
15 1.19 1.285 1.74
20 1.165 1.25 1.67
25 1.12 1.16 1.62
Table 7
Standard deviation with external tasks
No. nodes Without alg. Random alg. Probin alg. Proposed alg.
5 2809 1232 305 127
10 1117 821 296 83
15 565 490 452 54
20 375 345 321 32
25 308 291 217 16
0 500 1000 1500 2000 2500 3000
5 10 15 20 25
Time (seconds)
Number of processors
Without algorithm Random algorithm Probin algorithm Proposed algorithm
Fig. 9. Standard deviation with external tasks.
rithm. This method provides only marginal improvements with respect to the algorithm without load balancing for more than 10–15 nodes.
0 500 1000 1500 2000 2500 3000 3500 4000
0 0.5 1 1.5 2
Response time (seconds
.)
Number of tasks per node Without algorithm Proposed algorithm
Fig. 10. Response time considering a loaded node for a 25 node cluster.
Table 8
Response time increasing the number of external tasks, measured in seconds for a 25 node cluster
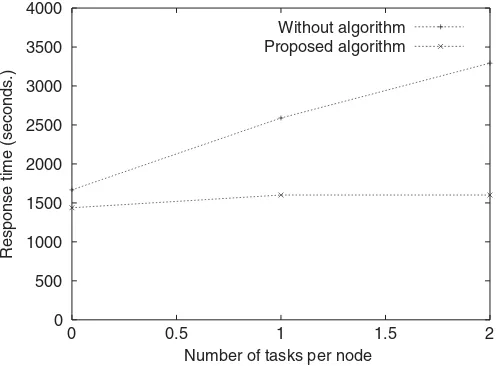
No. tasks Without alg. Proposed alg.
0 1667 1438
1 2589 1601
2 3293 1601
above 15 nodes. Finally, the proposed algorithm has very stable values, achieving better results when the number of nodes is increased. The method takes advantage of the availability of additional nodes having them all finishing within a short time interval.
6.3. Results increasing the load of a heavily loaded node
The last experiment presented in this paper has been per-formed increasing the number of external tasks on a heavily loaded node. This way, the unbalance among different nodes is higher, and the algorithms’ behavior when confronted with highly overloaded nodes can be checked. Table8 and Fig. 10 present the results achieved.
From the results above it can be seen that the response times without any load balancing algorithm increase linearly with the external load. When the proposed load balancing algorithm is introduced, depending on the system’s external workload status, it is possible to achieve a small increment in the system’s response time. But globally, the response times remain almost invariant when the amount of external workload is increased, as it can be seen in Table 8 and Fig. 10. This behavior proves that if there are some underloaded nodes the extra workload can be split among them and the application response time can be kept constant.
7. Conclusions and future work
This paper begins with an analysis of the operations involved in a typical CBIR system. From the analysis of the sequential version it can be observed a lack of data or algorithmic
depen-dencies. This allows efficient cluster implementations of CBIR systems since it is a parallel architecture that meets very well the application needs[6].
Improvements on the cluster implementation have been made by introducing a dynamic, distributed, global and scalable load balancing algorithm which has been designed specifically for the parallel CBIR application implemented on a heterogeneous cluster. An additional important feature is that the load balanc-ing algorithm takes into account the system heterogeneity orig-inated both by the different node computational attributes and by external factors such as the presence of external tasks.
The experiments presented here show that the amount of overhead introduced by this method is very small. In fact, this overhead is hidden by the improvements achieved whenever any degree of system heterogeneity shows up, a common sit-uation in grid systems. All these experiments have also shown that using the load balancing algorithm results in large execu-tion time reducexecu-tions and in a more uniform distribuexecu-tion of the node’s response times, which can be detected through strong reductions in the response times’ standard deviation.
As it has been shown in the experiments presented here, another important aspect that should be stressed is the algorithm scalability: increasing the number of system nodes does not significantly change the execution time increments originated by the introduction of the load balancing algorithm. At this moment, considering a network with a much higher number of nodes is not possible with the available resources. In any case, it is feasible and even simple to extend the current implementation to define a hierarchical algorithm using MPI communicators. The cluster version of the CBIR system that includes the load balancing algorithm is nowadays fully operative.
Finally, further work will be devoted to the evaluation of the effects in the method’s performance of using more complex node load indices and initiation rules. New efforts will be made in order to refine the primitives used in the CBIR system, and to introduce fault tolerance mechanisms in order to increase the system robustness. Analysis on the system response will also be made after distributing the database of the CBIR system between different clusters. Future migration of the implemented CBIR system to a grid will also be performed.
Acknowledgments
This work has been partially funded by the Spanish Ministry of Education and Science (Grant TIC2003-08933-C02) and Government of the Community of Madrid (Grant GR/SAL/0940/2004).
References
[1]I. Ahmad, A. Ghafoor, Semi-distributed load balancing for massively parallel multicomputer systems, IEEE Trans. Software Engrg. 17 (10) (1991) 987–1004.
[2]I. Banicescu, R. Carino, J. Pabico, M. Balasubramaniam, Design and implementation of a novel dynamic load balancing library for cluster computing, Parallel Comput. 31 (7) (2005) 736–756.
[4]G. Bell, J. Gray, What’s next in high-performance computing?, Commun. ACM 45 (2) (2002) 91–95.
[5]A.P. Berman, L.G. Shapiro, A flexible image database system for content-based retrieval, Comput. Vision Image Understanding 75 (1/2) (1999) 175–195.
[6]J.L. Bosque, O.D. Robles, A. Rodríguez, L. Pastor, Study of a parallel CBIR implementation using MPI, in: V. Cantoni, C. Guerra (Eds.), Proceedings on International Workshop on Computer Architectures for Machine Perception, IEEE CAMP 2000, Padova, Italy, 2000, pp. 195–204, ISBN 0-7695-0740-9.
[7]J.L. Bosque, O.D. Robles, L. Pastor, Load balancing algorithms for CBIR environments, in: Proceedings on International Workshop on Computer Architectures for Machine Perception, IEEE CAMP 2003, The Center for Advanced Computer Studies, University of Louisiana at Lafayette, IEEE, New Orleans, USA, 2003, ISBN 0-7803-7971-3.
[8]T.L. Casavant, J.G. Kuhl, A taxonomy of scheduling in general-purpose distributed computing systems, in: T.L. Casavant, M. Singhal (Eds.), Readings in Distributed Computing Systems, IEEE Computer Society Press, Los Alamitos, CA, 1994, pp. 31–51.
[9]A. Corradi, L. Leonardi, F. Zambonelli, Diffusive load-balancing policies for dynamic applications, IEEE Concurrency 7 (1) (1999) 22–31. [10]S.K. Das, D.J. Harvey, R. Biswas, Parallel processing of adaptive meshes
with load balancing, IEEE Trans. Parallel Distributed Systems 12 (12) (2001) 1269–1280.
[11]I. Daubechies, Ten Lectures on Wavelets, vol. 61 of CBMS-NSF Regional Conference Series in Applied Mathematics, Society for Industrial and Applied Mathematics, Philadelphia, PA, 1992.
[12]A. del Bimbo, Visual Information Retrieval, Morgan Kaufmann Publishers, San Francisco, CA, 1999, ISBN 1-55860-624-6.
[13]Department of Computer Science and Engineering, The Chinese University of Hong Kong, DISCOVIR Distributed Content-based Visual Information Retrieval System on Peer-to-Peer(P2P) Network, Web, 2003. URL http://www.cse.cuhk.edu.hk/∼miplab/ discovir/.
[14]Department of Diagnostic Radiology and Department of Medical Informatics and Division of Medical Image Processing and Lehrstuhl für Informatik VI of the Aachen University of Technology RWTH Achen, IRMA: Image Retrieval in Medical Applications, Web, 2003. URL http://libra.imib.rwth-aachen.de/irma/ index_en.php.
[15]D. Grosu, A. Chronopoulos, M. Leung, Load balancing in distributed systems: an approach using cooperative games, in: 16th International Parallel and Distributed Processing Symposium IPDPS ’02, IEEE, 2002, pp. 52–53.
[16]N.J. Gunther, G. Beretta, A benchmark for image retrieval using distributed systems over the internet: birds-i, Technical Report HPL-2000-162, Imaging Systems Laboratory, Hewlett Packard, December 2000.
[17]R.M. Haralick, L.G. Shapiro, Computer and Robot Vision, vol. I, Addison-Wesley, Reading, MA, 1992, ISBN: 0-201-10877-1.
[18]C.-C. Hui, S.T. Chanson, Hydrodynamic load balancing, IEEE Trans. Parallel Distributed Systems 10 (11) (1999) 1118–1137.
[19]S. Khoshafian, A.B. Baker, Multimedia and Imaging Databases, Morgan Kaufmann, San Francisco, CA, 1996.
[20]T. Kunz, The influence of different workload descriptions on a heuristic load balancing scheme, IEEE Trans. Software Engrg. 17 (7) (1991) 725–730.
[21]L.J. Latecki, R. Melter, A. Gross, et al., Special issue on shape representation and similarity for image databases, Pattern Recognition 35 (1).
[22]S. Mallat, A theory for multiresolution signal decomposition: the wavelet representation, IEEE Trans. Pattern Anal. Mach. Intell. 11 (7) (1989) 674–693.
[23]MPI Forum, A message-passing interface standard, 2003. URL
www.mpi-forum.org.
[24]H. Müller, W. Müller, D.M. Squire, S. Marchand-Maillet, T. Pun, Performance evaluation in content-based image retrieval: overview and proposals, Pattern Recognition Lett. 22 (2001) 593–601.
[25]W. Obeloer, C. Grewe, H. Pals, Load management with mobile agents, in: 24th Euromicro Conference, vol. 2, IEEE, 1998, pp. 1005–1012. [26]P.S. Pacheco, Parallel Programming with MPI, Morgan Kaufmann
Publishers Inc., San Francisco, 1997.
[27]J.S. Payne, L. Hepplewhite, T.J. Stonham, Evaluating content-based image retrieval techniques using perceptually based metrics, in: Proceedings of SPIE on Applications of Artificial Neural Networks in Image Processing IV, vol. 3647, SPIE, 1999, pp. 122–133.
[28]A. Rajagopalan, S. Hariri, An agent based dynamic load balancing system, in: International Workshop on Autonomous Decentralized Systems, IEEE, 2000, pp. 164–171.
[29]O.D. Robles, A. Rodríguez, M.L. Córdoba, A study about multiresolution primitives for content-based image retrieval using wavelets, in: M.H. Hamza (Ed.), IASTED International Conference On Visualization, Imaging, and Image Processing (VIIP 2001), IASTED, ACTA Press, Marbella, Spain, 2001, pp. 506–511, ISBN 0-88986-309-1.
[30]A. Rodríguez, O.D. Robles, L. Pastor, New features for content-based image retrieval using wavelets, in: F. Muge, R.C. Pinto, M. Piedade (Eds.), V Ibero-american Symposium on Pattern Recognition, SIARP 2000, Lisbon, Portugal, 2000, pp. 517–528, ISBN 972-97711-1-1. [31]S. Santini, Exploratory Image Databases: Content-based Retrieval,
Communications, Networking, and Multimedia, Academic Press, New York, 2001, ISBN 0-12-619261-8.
[32]S. Santini, A. Gupta, R. Jain, Emergent semantics through interaction in image databases, IEEE Trans. Knowledge Data Engrg. 13 (3) (2001) 337–351 ISSN: 1041-4347.
[33]B. Schnor, S. Petri, R. Oleyniczak, H. Langendörfer, Scheduling of parallel applications on heterogeneous workstation clusters, in: K. Yetongnon, S. Hariri (Eds.), Proceedings of the ISCA Ninth International Conference on Parallel and Distributed Computing Systems, vol. 1, ISCA, Dijon, 1996, pp. 330–337.
[34]A.W.M. Smeulders, M. Worring, S. Santini, A. Gupta, R. Jain, Content-based image retrieval at the end of the early years, IEEE Trans. PAMI 22 (12) (2000) 1349–1380.
[35]M. Snir, S.W. Otto, S. Huss-Lederman, D.W. Walker, J. Dongarra, MPI: The Complete Reference, The MIT Press, Cambridge, 1996.
[36]J.M. Squyres, K.L. Meyer, M.D. McNally, A. Lumsdaine, LAM/MPI User Guide, University of Notre Dame, lAM 6.3, 1998. URL
http://www.mpi.nd.edu/lam/.
[37]S. Srakaew, N. Alexandridis, P.P. Nga, G. Blankenship, Content-based multimedia data retrieval on cluster system environment, in: P. Sloot, M. Bubak, A. Hoekstra, B. Hertzberger (Eds.), High-Performance Computing and Networking. Seventh International Conference, HPCN Europe 1999, Springer, Berlin, 1999, pp. 1235–1241.
[38]E.J. Stollnitz, T.D. DeRose, D.H. Salesin, Wavelets for Computer Graphics, Morgan Kaufmann Publishers, San Francisco, 1996. [39]Y. Wang, Z. Liu, J.-C. Huang, Multimedia content analysis, IEEE Signal
Process. Mag. 16 (6) (2000) 12–36.
[40]M.H. Willebeek-LeMair, A.P. Reeves, Strategies for dynamic load balancing on highly parallel computers, IEEE Trans. Parallel Distributed Systems 4 (9) (1993) 979–993.
[41]L. Xiao, S. Chen, X. Zhang, Dynamic cluster resource allocations for jobs with known and unknown memory demands, IEEE Trans. Parallel Distributed Systems 13 (3) (2002) 223–240.
[42]C. Xu, F. Lau, Load Balancing in Parallel Computers: Theory and Practice, Kluwer Academic Publishers, Dordrecht, 1997.
[43]M.J. Zaki, Parallel and distributed association mining: a survey, IEEE Concurrency 7 (4) (1999) 14–25.
[44]M.J. Zaki, S. Pathasarathy, W. Li, Customized Dynamic Load Balancing, vol. 1, Architectures and Systems, Prentice-Hall PTR, Upper Saddle River, NJ, 1999 (Chapter 24).
[45]A.Y. Zomaya, Y.-H. Teh, Observations on using genetic algorithms for dynamic load-balancing, IEEE Trans. Parallel Distributed Systems 12 (9) (2001) 899–911.
in 2003. His Ph.D. was centered on theorical models and algorithms for heterogeneous clusters. He has been an associate professor at the Universidad Rey Juan Carlos in Madrid, Spain, since 1998. His research interest are parallel and distributed processing, performance and scalability evaluation and load balancing.
Oscar D. Roblesreceived his degree in Computer Science and Engineering and the Ph.D. degree from the Universidad Politécnica de Madrid in 1999 and 2004, respectively. His Ph.D. was centered on Content-based image and video retrieval techniques on parallel architectures. Currently he is Associate Professor in the Rey Juan Carlos University and has published works in the fields of multimedia retrieval and parallel computer systems. His research interests include content-based multimedia retrieval, as well as computer vision and computer grapyhics. He is an Eurographics member.
Luis Pastor received the B.S.EE degree from the Universidad Politécnica de Madrid in 1981, the M.S.EE degree from Drexel University in 1983, and the Ph.D. degree from the Universidad Politécnica de Madrid in 1985. Currently he is Professor in the university Rey Juan Carlos (Madrid, Spain). His research interests include image processing and synthesis, virtual reality, 3D modeling and and parallel computing.