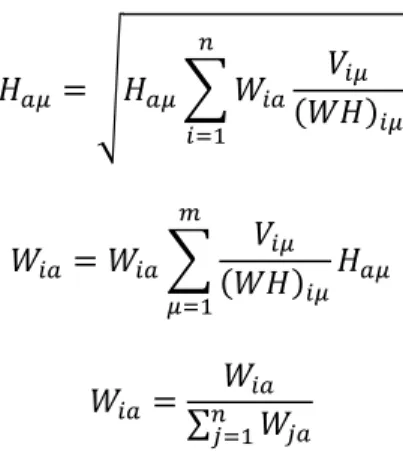BAB II
TINJAUAN PUSTAKA
2.1. Pengenalan
Ekspresi Wajah Manusia
Pengenalan ekspresi wajah manusia oleh mesin dapat dideskripsikan sebagai interpretasi terhadap karakteristik ekspresi wajah manusia melalui algoritma matematis yang dilakukan dengan bantuan mesin (Raheja & Kumar, 2010).
Penelitian untuk dapat mengenali ekspresi wajah manusia dengan bantuan komputer sudah dimulai sejak dua dekade lalu. Mase (1991) menggunakan teknik opticalflow untuk pengenalan ekspresi wajah. Lanitis, Taylor, dan Cootes (1995) menggunakan model bentuk fleksibel untuk mengenali identitas, jenis kelamin, dan ekspresi seseorang. Black dan Yacoob (1995) menggunakan localparametricmodelyang digunakan untuk mengikuti pergerakan wajah yang kemudian digunakan pada rule-based classifier untuk mengenali ekspresi. Kemudian Essa dan Pentland (1997) juga menggunakan opticalflow dengan pendekatan berbasis regional untuk mengenali ekspresi wajah. Otsuka dan Ohya (1997) menggunakan opticalflow dan Hidden Markov Model (HMM) untuk mengidentikasi ekspresi. Tian, Kanade, dan Cohn (2001) menggunakan action unit dan neural network, dimana action unit tersebut dapat menggambarkan pergerakan komponen wajah dalam berbagai ekspresi
seperti yang ditulis oleh Ekman dan Friesen (1978). Cohen etal. (2003) menggunakan Bayesian network dan multilevel HMM sebagai classifier.
Di lain pihak, teknik reduksi dimensi seperti contohnya PCA jugatelah berhasil digunakan untuk merepresentasikan dan mengenali ekspresi wajah seperti yang telah berhasil dilakukan oleh Cottrell dan Metcalfe (1991) serta Calder et al. (2001).ICA yang merupakan generalisasi dari PCA juga berhasil diterapkan oleh Fasel dan Luettin (2000) untuk pengenalan ekspresi wajah. Berikutnya Lee dan Seung (1999) mengembangkan algoritma NMF yang dinyatakan dapat merepresentasikan basisimage secara lokal. Namun Li etal. (2001) menemukan bahwa NMF ternyata memiliki tingkat akurasi yang lebih buruk dibandingkan dengan PCA. Li juga menawarkan metode LNMF untuk mengatasi masalah yang ada pada NMF. Bociu dan Pitas (2004) lalu menggunakan kedua metode tersebut serta menawarkan metode DNMF yang terbukti lebih baik untuk mengenali ekspresi wajah.
2.2. Algoritma Reduksi Dimensi
Koleksi data semakin berkembang bukan hanya ukurannya yang bertambah besar tetapi juga kompleksitas data yang digunakan. Kompleksitas data ini menentukan jumlah dimensi data. Dimensi data merupakan jumlah variabel atau fitur yang diukur pada setiap observasi. Data dengan dimensi yang tinggi dapat menyebabkan tantangan baru dalam pengolahan data tersebut. Salah satu hal yang menjadi masalah pada data berdimensi tinggi adalah biasanya tidak semua fitur yang ada
menyediakan informasi yang penting mengenai objek yang akan diamati. Tingginya jumlah dimensi pada data juga menyebabkan proses pengolahan data menjadi tidak efisien (Fodor, 2002).
Untuk mereduksi jumlah dimensi dari data yang akan diolah, diperkenalkan beberapa algoritma untuk mereduksi dimensi. Algoritma yang dibuat dirancang sedemikian rupa sehingga informasi penting yang terdapat dalam data tidak hilang ketika dimensinya direduksi. Beberapa contoh algoritma reduksi dimensi yang cukup sering digunakan dan memiliki hasil yang cukup baik adalah PCA, ICA, LDA, dan NMF.
2.2.1. Principal Component Analysis
Menurut Turk dan Pentland (1991), PCA melibatkan prosedur matematis yang mentransformasi beberapa variabel yang memiliki korelasi menjadi kumpulan fitur yang tidak berkolerasi yang jumlahnya lebih sedikit yang disebut principalcomponent. Proses ini akan menghasilkan beberapa eigenvector yang merupakan kombinasi seluruh variasi fitur yang terdapat dalam seluruh data. Jika objek yang digunakan berupa gambar wajah, eigenvector tersebut sering disebut juga eigenfaces.
Untuk melakukan hal ini, data atau gambar yang akan direduksi dimensinya harus diubah menjadi kumpulan matriks kolom D1, D2, …, Dm
dimana m merupakan jumlah dari sampel yang tersedia. Rata-rata dari setiap data dapat dihitung dengan
Selisih antara setiap data dengan rata-ratanya dapat direpresentasikan dengan
Dari matriks N, matriks covariance dapat dihitung untuk kemudian digunakan dalam mencari eigenvector. Matriks covariance dapat dihitung dengan
1
Langkah berikutnya adalah menghitung eigenvector dan eigenvalue dari matriks covariance tersebut. Dari eigenvector dan eigenvalue yang dihasilkan, dipilih k eigenvector yang memiliki eigenvalue terbesar. Kumpulan k eigenvector tersebut merupakan eigenfaces yang dapat digunakan untuk memproyeksikan data ke dalam eigenspace.
Selain digunakan untuk mereduksi dimensi, PCA juga dapat digunakan untuk melakukan pengenalan. Untuk melakukan hal tersebut, data yang memiliki dimensi tinggi harus diproyeksi ke eigenspace dengan menggunakan eigenvector yang telah dihitung sebelumnya. Hal ini dilakukan dengan rumus
Dimana F merupakan hasil proyeksi data ke eigenspace. Cara yang sama juga digunakan terhadap data yang ingin dikenali. Tingkat kemiripan kemudian dapat dihitung dengan Euclidean distance.
Menurut Li etal. (2001), reduksi dimensi pada PCA dilakukan dengan membuang komponen-komponen yang paling tidak penting. Hal ini menyebabkan PCA memiliki sifat holistik. Oleh karena itu PCA tidak
dapat mengambil fitur yang bersifat lokal dari sebuah data. Tetapi dalam kasus tertentu, terutama dalam pengenalan objek, fitur yang bersifat lokal dapat menghasilkan akurasi pengenalan yang lebih baik. Fitur lokal dapat mengatasi masalah seperti perbedaan pencahayaan, localdeformation, dan partialocclusion yang sulit diatasi oleh metode holistik.
Gambar 2.1 Eigenface dari Metode PCA
2.2.2. Independent Component Analysis
Menurut Bartlett, Movellan, dan Sejnowski (2002), ICA merupakan pengembangan selanjutnya dari PCA. Berbeda dengan PCA yang bersifat holistik, ICA dapat memisahkan sinyal yang tercampur secara acak dari koefisien PCA sehingga hasil yang dihasilkan bersifat lebih independen. Sifat independen dari ICA dapat dilihat berdasarkan minimalisasi dari Mutual Information atau dari Maksimalisasi dari non-Gaussianity. Ada berbagai macam algoritma yang dapat digunakan untuk ICA, di antaranya adalah infomax dan FastICA.
ICA memiliki dua jenis arsitektur yang berbeda dalam merepresentasikan gambar pada matriks X. Pada arsitektur I, setiap baris
pada matriks X merupakan representasi dari gambar yang berbeda dan setiap kolom mewakili satu pixel dari gambar-gambar tersebut. Sedangkan pada arsitektur II, matriks X merupakan transpos dari matriks X pada arsitektur I sehingga setiap kolom mewakili satu gambar dan setiap baris mewakili setiap 1 pixel pada setiap gambar.
Gambar 2.2 Perbandingan Basis Image ICA Arsitektur I(kiri) dan Arsitektur II(kanan)
2.2.3. Non-negative Matrix Factorization
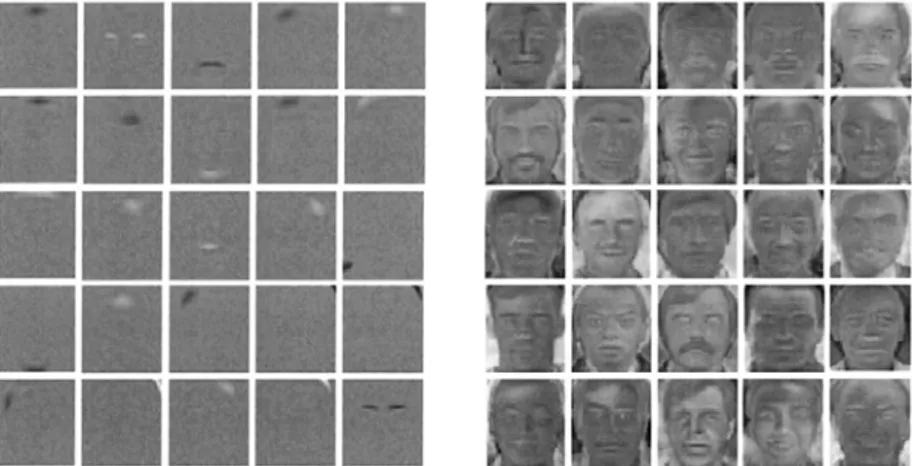
Menurut Lee dan Seung (1999), NMF merupakan suatu metode faktorisasi matriks seperti halnya PCA, dimana kedua memiliki bentuk faktorisasi V≈WH. W merupakan basisimage sedangkan H merupakan encoding atau kombinasi koefisien dari setiap basisimage. Kedua metode tersebut menghasilkan representasi basisimage yang berbeda. PCA menghasilkan eigenfaces yang merupakan representasi terdistorsi dari keseluruhan wajah sedangkan NMF menghasilkan representasi fitur-fitur
lokal dari setiap wajah. Bentuk basisimage dari NMF ini memungkinkan wajah direkonstruksi hanya dengan bagian-bagian tertentu dari wajah. Hal ini dimungkinkan dengan adanya batasan non-negatif yang diterapkan pada kedua faktor yang dihasilkan.
Pada NMF, database gambar direpresentasikan dengan matriks V yang memiliki dimensi n × m dimana n merupakan jumlah pixel pada setiap gambar dan m merupakan jumlah gambar wajah yang terdapat dalam database tersebut.Matriks V difaktorisasi sehingga memenuhi bentuk
Proses faktorisasi tersebut menghasilkan matriks W dan H yang masing-masing berdimensi n × r dan r × m. Nilai r dipilih sedemikian sehingga persamaan (n + m)r < nm terpenuhi. Dengan demikian maka terjadilah kompresi atau pengurangan terhadap dimensi database gambar.
Untuk mendapatkan hasil faktor yang paling mendekati V ≈ WH, Kullback-Leibler (KL) divergence digunakan sebagai costfunction seperti yang disebutkan oleh Lee (2001).Nilai terendah yang dapat dihasilkan KL divergence adalah nol.
log
Masalah berikut yang muncul adalah bagaimana cara meminimalkan nilai dengan tetap memenuhi syarat W, H ≥ 0.Untuk mendapatkan W dan H yang tidak negatif, diterapkan multiplicativeupdaterules pada setiap iterasi. Dengan
∑ ∑ ∑
∑
Dengan adanya batasan non-negatif yang diberikan pada setiap faktor, setiap komponen yang berhasil dipelajari oleh NMF dapat dikombinasikan tanpa perlu melakukan pengurangan seperti yang terjadi pada ICA. Namun Li etal. (2001) menemukan bahwa bagian-bagian yang dipelajari oleh NMF ternyata tidak terlokalisasi seperti yang ditunjukkan oleh Lee dan Seung (1999). Li juga menemukan bahwa NMF bahkan menghasilkan akurasi yang lebih buruk dari PCA. NMF juga memerlukan iterasi yang lebih banyak untuk mencapai konvergensi.
2.2.4. Local Non-negative Matrix Factorization
Untuk mengatasi masalah pada NMF, Li etal. (2001) mengajukan metode baru yang disebut LNMF. Metode ini ditujukan untuk memperkuat sifat lokal pada basisimage sehingga fitur yang dihasilkan lebih cocok untuk digunakan pada kasus yang membutuhkan fitur lokal. Hal ini dilakukan dengan menambahkan batasan pada costfunction yang dapat menimbulkan sifat lokal dari faktor yang terbentuk.
log
Dimana α, β> 0, dan . Perubahan nilai W dan H yang terjadi pada LNMF didefinisikan sebagai
∑
Dengan menggunakan rumus tersebut, akan didapatkan hasil basisimage yang terlokalisasi dengan baik.
Gambar 2.3Perbandingan Basis Image pada LNMF(kiri) dan NMF(kanan)
Dari hasil penelitian yang dilakukan oleh Li etal. (2001), ditemukan bahwa LMNF menghasilkan akurasi yang lebih baik dibandingkan dengan PCA maupun NMF. Namun demikian, algoritma ini umumnya membutuhkan jumlah iterasi yang lebih banyak dibandingkan dengan NMF seperti yang dikatakan oleh Zhang etal. (2005).
2.2.5. Two Dimensional Non-negative Matrix Factorization
2DNMF merupakan salah satu variasi dari metode NMF yang dibuat oleh Zhang etal. (2005). Perbedaan yang menjadi kunci utama dari metode 2DNMF adalah pada representasi gambar yang digunakan. Pada NMF tradisional, matriks gambar yang digunakan harus terlebih dahulu diubah menjadi vektor 1 dimensi. Vektor yang dihasilkan dari proses tersebut biasanya akan menghasilkan fitur dengan dimensi yang sangat tinggi, dimana dalam kondisi seperti itu akan sulit untuk mencari faktor yang baik untuk merekonstruksi gambar. Zhang etal. (2005) juga mengatakan bahwa proses pengubahan matriks ke vektor tersebut mungkin dapat mengakibatkan hilangnya informasi struktur yang tersembunyi pada gambar 2D.
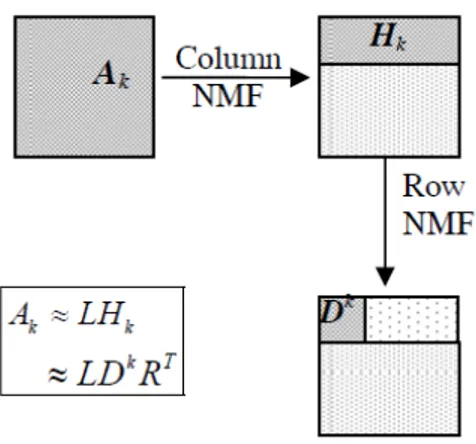
Proses yang terjadi pada metode 2DNMF dapat dibagi menjadi dua tahap. Pada tahap pertama, m gambar yang berukuran p × q dibentuk menjadi p × qm matrik X = [A1,A2,…,Am] dimana setiap Ak mewakili
sebuah gambar wajah. Metode NMF kemudian diterapkan pada matriks X sehingga
L merupakan basis image yang berukuran p × d, sedangkan H merupakan kombinasi koefisien yang berukuran d × qm. Karena setiap kolom dari matriks X mewakili satu kolom pada gambar Ak, maka matriks
L berisi informasi kolom dari setiap gambar sehingga sering disebut juga columnbases.
Untuk memudahkan perhitungan, matriks H dibagi menjadi m sub-matriks sehingga menjadi H = [H1, H2, …, Hm] dimana setiap Hk
merupakan koefisien dari gambar Ak. Sehingga setiap gambar Ak dapat
ditulis sebagai
, 1,2, … ,
Tahap pertama dari 2DNMF ini disebut juga Column NMF.
Tahap kedua atau yang disebut juga Row NMF merupakan proses untuk mendapatkan informasi baris dari matriks H yang dihasilkan dari tahap sebelumnya. Untuk melakukan hal tersebut, matriks H dibentuk menjadi matriks H’ = [H1T, H2T, …, HmT] yang berukuran q × dm.Metode
NMF kemudian diterapkan kembali pada matriks H’ sehingga
R merupakan basis image yang berukuran q × g, sedangkan C merupakan kombinasi koefisien yang berukuran g×dm. Karena setiap kolom dari matriks H’ mewakili informasi baris pada gambar Ak, maka
matriks R disebut juga sebagai rowbases. Untuk memudahkan, matriks C juga dibagi menjadi m sub-matriks C = [C1, C2, …, Cm] sehingga HkT
dapat ditulis sebagai
, 1,2, … , Dengan melakukan substitusi maka dihasilkan
L , 1,2, … ,
Jika diketahui bahwa L = [l1, l2, …, ld] dan R = [r1, r2, …, rg] maka
2D bases dapat dihasilkan dengan menggunakan outer product dari column base li dan row base rj.
· , 1 , 1
Eij merupakan matriks dengan ukuran yang sama dengan ukuran
gambar asli. Dengan asumsi bahwa , 1,2, … , maka didapatkan
L
Secara sederhana, algoritma 2DNMF dapat digambarkan sebagai
Gambar 2.4 Ilustrasi Algoritma 2DNMF
Untuk melakukan pengenalan terhadap sebuah gambar, dataset gambar harus diproyeksikan ke dalam bilinear space sehingga menjadi featurematrix.
, 1,2, … ,
Cara yang sama juga dapat dilakukan terhadap gambar A yang akan dikenali
Pengenalan dapat dilakukan dengan menghitung Frobenius norm setiap Fk dengan FA. Gambar yang dikenali akan diprediksi sebagai
anggota dari kelompok yang anggotanya memiliki Frobenius norm paling minimal.
,
Ukuran kemiripan antara kedua gambar juga dapat dihitung berdasarkan Frobenius norm antara koefisien gambar yang telah dilatih dengan dengan gambar yang akan dikenali. Dalam hal ini gambar yang akan dikenali tidak terdapat pada data pelatihan sehingga koefisiennya tidak diketahui. Tetapi koefisien tersebut dapat dihitung dengan
Dimana merupakan pseudoinverse dari matriks L, merupakan pseudoinverse dari matriks R, dan A merupakan matriks 2D dari gambar yang akan dikenali.
Gambar 2.5 Perbandingan Basis Image pada NMF(kiri) dan 2DNMF(kanan)
Dari hasil eksperimen yang dilakukan oleh Zhang etal. (2005) dapat disimpulkan bahwa 2DNMF menghasilkan akurasi pengenalan objek yang lebih tinggi dibandingkan dengan NMF dan LNMF serta dengan rasio kompresi data yang mirip dan dengan efisiensi waktu yang jauh melebihi NMF dan LNMF.