EKSPANSI KUERI MENGGUNAKAN METODE SEMANTIC
SIMILARITY RETRIEVAL MODEL (SSRM)
SRI RAHAYU ISMANI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2012
EKSPANSI KUERI MENGGUNAKAN METODE SEMANTIC
SIMILARITY RETRIEVAL MODEL (SSRM)
SRI RAHAYU ISMANI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2012
ABSTRACT
SRI RAHAYU ISMANI. Query Expansion Method Using Semantic Similarity Retrieval Model (SSRM). Supervised by JULIO ADISANTOSO.
The main objective of this study was to applied the method of semantic similarity in the proccesed of query expansion in information retrieval systems in the Indonesian language. Selection of partners in selecting candidates expansion will be used phrase pairs that have been made In research Kartina (2010) in which the phrase pairs with the largest value of similarity between the words that will be selected. Used by 10 groups of queries not clear who obtained manually and 30 groups of queries in 2000 agricultural document, document search results will be compared with the addition one-term of expansion, two-term of expansion, and three-term of expansion.
The results of this study suggest five things. The first that the expansion of the query by added one term produces better results than the addition of two terms and three terms. The second that query expansion used by 10 groups of queries produces a higher precision values than using 30 groups of queries. The third that the used of the semantic similarity method produces better performance than the use of a thesaurus on the method of similarity retrieval Vektor Space Model (VSM). The fourth that the used of semantic similarity methods have not been able to produce better performance than the used of the method of conditional probabilities in the selection of expansion terms resulting from the translation of bilingual dictionary. The fifth that the used of the phrase paired in determining the candidate expansion terms can not maximize the search results using the method of semantic similarity of documents, because each pair selected does not necessarily have a semantic relationship with a given query.
Judul : Ekspansi Kueri Menggunakan Metode Semantic Similarity Retrieval Model (SSRM) Nama : Sri Rahayu Ismani
NRP : G64062227
Menyetujui:
Pembimbing,
Ir. Julio Adisantoso, M. Kom NIP. 19620714 198601 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta, 04 Februari 1988. Penulis merupakan anak kedua dari empat bersaudara dari pasangan Bapak Hamdi Ismani dan Ibu Rum Sari.
Penulis memulai pendidikan sekolah dasar di SD Negeri Sukatani 1 pada tahun 1994. Setelah lulus pada tahun 2000, penulis melanjutkan ke pendidikan menengah di SMP Negeri 233 Jakarta pada tahun yang sama dan kemudian dilanjutkan ke SMU Negeri 105 Jakarta pada tahun 2003. Tahun 2006 penulis lulus dari SMU dan diterima menjadi salah satu mahasiswa Institut Pertanian Bogor memalui jalur Undangan Seleksi Masuk IPB (USMI). Setahun kemudian penulis berhasil diterima menjadi salah satu mahasiswa Program Studi Ilmu Komputer IPB.
Selama mengikuti perkuliahan, penulis aktif di organisasi Himpunan Mahasiswa Ilmu Komputer (HIMALKOM) dan bergabung dengan divisi multimedia tahun kepengurusan 2008/2009. Tahun 2009 penulis menjalankan Praktek Kerja Lapangan (PKL) di Direktorat Komunikasi dan Sistem Informasi (DKSI) Institut Pertanian Bogor selama kurang lebih dua bulan.
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah SWT atas segala rahmat dan karunia-Nya sehingga tugas akhir dengan judul Ekspansi Kueri Menggunakan Metode Semantic Similarity
Retrieval Model (SSRM) dapat diselesaikan dengan baik.
Penyelesaian tugas akhir ini tidak lepas dari bantuan berbagai pihak, untuk itu ucapan terima kasih penulis sampaikan kepada:
1. Ayah, Ibu, Kakak, Adik, serta segenap keluarga besar yang selalu mendukung, mengingkatkan dan memberikan semangat selama proses pembuatan tugas akhir ini.
2. Bapak Ir. Julio Adisantoso, M. Kom selaku dosen pembimbing tugas akhir. Terima kasih atas kesabaran, bimbingan dan dukungan dalam penyelesaian tugas akhir ini.
3. Bapak Ahmad Ridha, S. Kom, MS dan Bapak Sony Hartono Wijaya, S. Kom, M. Kom selaku dosen penguji, Ibu Dr. Sri Nurdiati, M.Sc selaku Kepala Departemen Ilmu Komputer serta seluruh staf Departemen Ilmu Komputer FMIPA IPB.
4. Teman-teman satu bimbingan Ka Mutia, Hendrex, Awet, Tina, Rio, Iyam, Wildan, Eka, Adit, Devi, Nova, Dina, Woro, Isna, Agus, Yoga, dan Ade. Terima kasih atas bantuan, semangat dan kebersamaannya selama melakukan penelitian.
5. Sahabat-sahabatku Inez, Yuli, Ardan, Prames, Uut, Irawan, Roni, Wendhy dan seluruh sahabatku Ilkomerz43. Terima kasih atas motivasi, kebersamaan dan kenangan selama tiga tahun yang tak terlupakan.
6. Sahabat-sahabat baikku, Hana, Ziffy, Della, Nagi, Vely, terima kasih atas nasihat dan dukungan yang selalu diberikan.
7. Teman-teman Wisma Arini 3 Mba Titi, Uni, Aron, Tia, terima kasih atas dukungan dan candaan-candaan yang menghibur.
8. Seluruh pihak yang membantu baik secara langsung maupun tidak langsung dalam pelaksaan tugas akhir ini.
Penulis berharap tulisan ini dapat bermanfaat di masa yang akan datang.
Bogor, Januari 2012
v
DAFTAR ISI
Halaman DAFTAR GAMBAR ... vi DAFTAR TABEL ... vi DAFTAR LAMPIRAN ... vi PENDAHULUAN ... 1 Latar belakang... 1 Tujuan ... 1 Ruang Lingkup... 1 TINJAUAN PUSTAKA ... 1Temu Kembali Informasi ... 1
Ekspansi Kueri ... 2
Semantic Similarity Retrieval Model (SSRM) ... 2
Evaluasi Sistem Temu Kembali Informasi ... 3
METODE PENELITIAN ... 3
Koleksi Dokumen... 4
Indexing ... 4
Matriks Kesamaan ... 4
Ekspansi Kueri ... 5
Pengujian Kinerja Sistem ... 5
Analisis Pembandingan Metode Ekspansi ... 5
Asumsi-asumsi ... 5
Lingkungan Implementasi ... 5
HASIL DAN PEMBAHASAN... 6
Koleksi Dokumen... 6
Indexing ... 6
Ekspansi Kueri ... 7
Pencarian Dokumen ... 7
Pengujian Kinerja Sistem ... 8
Analisis Pembandingan Metode Ekspansi ... 9
KESIMPULAN DAN SARAN... 10
Kesimpulan ... 10
Saran... 10
DAFTAR PUSTAKA ... 11
vi
DAFTAR GAMBAR
Halaman
1 Gambaran umum sistem temu kembali informasi ... 3
2 Grafik recall terhadap precision pada QE0 ... 8
3 Grafik recall terhadap precision pada QX0 ... 8
4 Grafik recall terhadap precision pada QE0, QE1, QE2, dan QE3 ... 8
5 Grafik recall terhadap precision pada QX0, QX1, QX2, dan QX3 ... 9
DAFTAR TABEL
Halaman 1 Ilustrasi perhitungan recall & precision ... 32 Deskripsi dokumen pengujian ... 6
3 Hasil proses tokenisasi ... 6
4 Contoh pasangan kata ... 7
5 Normalisasi peluang pasangan kata ... 7
6 Perbandingan nilai presisi sistem pada 1000 dan 2000 dokumen... 9
7 AVP berdasarkan penelitian Paiki (2006) ... 10
8 AVP berdasarkan penelitian Samana (2011) ... 10
DAFTAR LAMPIRAN
Halaman 1 Contoh dokumen dalam koleksi ... 132 Daftar 30 kueri dan jumlah dokumen relevan ... 14
1
PENDAHULUAN
Latar belakang
Search Engine atau mesin pencari adalah
salah satu contoh aplikasi dalam penggunaan sistem temu kembali informasi. Mesin pencari melakukan pencarian informasi dari sekumpulan dokumen berdasarkan kebutuhan informasi pengguna yang dimasukkan dalam bentuk kueri. Kueri tersebut bisa berupa kata atau serangkaian kata yang berkaitan dengan topik tertentu. Terdapat masalah yang sering ditemui dalam pencarian informasi tersebut, yaitu pengguna tidak mampu merepresentasikan kebutuhan informasi yang diinginkan ke dalam bentuk kueri. Untuk memecahkan masalah tersebut perlu dilakukan ekspansi kueri, yaitu kueri yang diberikan pengguna akan dimodifikasi, kemudian kueri yang baru tersebut akan digunakan untuk pencarian berikutnya (kueri akhir).
Paiki (2006) telah melakukan penelitian mengenai ekspansi kueri dengan menggunakan metode similarity thesaurus. Dalam penelitian tersebut diberikan bobot yang sama untuk setiap istilah-istilah yang berkaitan dengan kueri. Hal ini tidak dapat meningkatkan kinerja sistem khususnya pada saat ekspansi kueri. Sedangkan Rusidi (2008) melakukan ekspansi kueri dengan mengambil istilah ekspansi berdasarkan keeratan hubungan istilah dalam kueri dengan istilah lain yang berada dalam indeks. Keeratan hubungan antar istilah ini diukur dengan menggunakan metode peluang bersyarat. Hasil dalam penelitian tersebut menunjukkan jumlah istilah ekspansi yang lebih sedikit lebih baik dibandingkan dengan mengunakan jumlah istilah kueri yang lebih banyak.
Sitohang (2009) telah mengimplementasikan metode penerjemahan kueri dengan menggunakan kamus dwibahasa dalam mencari istilah ekspansi. Dalam kamus dwibahasa tersebut akan dicari istilah kata yang memiliki makna hampir sama dengan kueri yang telah diberikan dan akan dipilih istilah untuk ekspansi dengan menggunakan nilai idf istilah yang dihasilkan dari penerjemahan. Tetapi dalam penggunaan metode ini hanya dapat meningkatkan relevansi hasil temu kembali untuk beberapa kueri tertentu. Sedangkan Samana (2011) melakukan penelitian mengenai ekspansi kueri dengan berfokus pada pemilihan istilah ekspansi yang dihasilkan oleh penerjemahan dwibahasa menggunakan metode peluang bersyarat. Ekspansi kueri yang dilakukan pada penelitian tersebut mengakibat menurunnya nilai presisi.
Hliaoutakis et al. (2006) melakukan penelitian untuk membuat sistem temu kembali informasi menggunakan WordNet dengan
metode semantic similarity. WordNet
merupakan sebuah database kamus bahasa Inggris yang dikembangkan oleh Princeton University. Pada penelitian tersebut WordNet digunakan untuk mencari ekspansi kata dari kueri yang telah diberikan. Selain penelitian tersebut, penelitian yang menggunakan metode
semantic similarity juga dilakukan pada data
medis. Dalam penelitiannya, Hliaoutakis telah membuat database yang berisi hubungan kesamaan makna antara kata-kata mengenai medis dalam bahasa Inggris. Database tersebut bernama MeSH, kemudian digunakan metode
semantic similarity retrieval model (SSRM)
untuk perhitungan bobot dari kueri (Hliaoutakis
et al. 2006).
Oleh karena belum adanya database kamus bahasa Indonesia, maka pada penelitian ini akan dicari istilah yang berkaitan dengan kata dalam kueri dengan cara menghitung peluang antar kata yang terdapat dalam dokumen dengan menggunakan teknik pembentukan frase yang dihasilkan pada penelitian Kartina (2010). Tujuan
Tujuan utama dari penelitian adalah mengimplementasikan metode Semantic Similarity Retrieval Model (SSRM) dalam
proses pembobotan ekspansi kueri dalam sistem temu kembali informasi untuk koleksi dokumen teks berbahasa Indonesia.
Ruang Lingkup
Ruang lingkup penelitian ini adalah:
Penelitian ini menggunakan dokumen serta kueri berbahasa Indonesia.
Menggunakan frase yang terdiri atas dua kata yang dihasilkan pada penelitian Kartina (2010) sebagai kandidat istilah ekspansi.
TINJAUAN PUSTAKA
Temu Kembali InformasiInformation retrieval atau temu kembali
informasi merupakan pencarian material, yang biasanya dokumen, dari sesuatu yang tidak terstruktur, biasanya teks, yang memenuhi kebutuhan informasi dari sekumpulan koleksi yang besar yang biasanya disimpan di komputer (Manning et al. 2008). Untuk menemukembalikan informasi terdapat proses
indexing yang bertujuan menentukan kata mana
2 dokumen diwujudkan sebagai sebuah vektor
dengan elemen sebanyak kata yang berhasil dikenali dari proses pemisahan kata. Vektor tersebut beranggotakan bobot dari tiap kata yang dihitung berdasarkan metode tf-idf. Metode tf-idf ini merupakan metode pembobotan dalam bentuk sebuah metode yang merupakan integrasi antar term frequency (tf), dan inverse document frequency (idf)
t t d t Df N Tf W, .log [1] dengan wt,d adalah bobot dari kata t dalam dokumen d sedangkan tft adalah frekuensi kata t dalam dokumen d(tf) dengan N merupakan
ukuran data training yang digunakan untuk penghitungan idf. Adapun dft adalah jumlah dari dokumen yang di-training yang mengandung nilai t.
Ekspansi Kueri
Selberg (1997) dalam Paiki (2006) menyatakan bahwa ekspansi kueri adalah sekumpulan teknik untuk memodifikasi kueri dengan tujuan untuk memenuhi sebuah kebutuhan informasi. Ekspansi kueri dapat berarti penambahan maupun pengurangan kata pada kueri.
Terdapat tiga cara yang dapat digunakan dalam melakukan ekspansi kueri yakni: manual,
interaktif, dan automatic. Terkadang pengguna
tidak dapat memberikan informasi yang cukup untuk melakukan ekspansi kueri (manual dan
interaktif), maka dibutuhkan suatu metode
ekspansi yang tidak memerlukan keterlibatan pengguna di dalamnya (Automatic). Automatic
Queri Ekspansion (AQE) merupakan proses
penambahan istilah atau frase pada kueri asli untuk meningkatkan kinerja temu kembali tanpa intervensi dari pengguna (Imran & Sharan 2009, dalam Samana 2011).
Pada ekspansi kueri terdapat dua metode analisis yang digunakan, yaitu analisis lokal dan analisis global. Ekspansi kueri dengan analisis lokal hanya menggunakan kueri dan dokumen-dokumen yang sudah dutemukembalikan pada pencarian awal. Dalam hal ini, analisis lokal digunakan untuk menentukan istilah-istilah yang tepat untuk ekspansi kueri. Sedangkan analisis global, prinsip dasarnya adalah dengan memanfaatkan konteks suatu kata untuk menentukan kesamaannya dengan kata yang lain (Baeza-Yates & Ribeiro-Neto dalam Paiki 2006).
Semantic Similarity Retrieval Model (SSRM) Umumnya pada temu kembali informasi, sebuah dokumen direpresentasikan oleh vektor kata dan setiap kata dihitung dengan menggunakan pembobot tf-idf. SSRM bekerja dalam tiga tahap :
1 Pembobotan ulang kata
Bobot qi dari kata i pada kueri ditetapkan berdasarkan hubungannya dengan persamaan semantik kata j dalam vektor yang sama
j i t j) sim(i, j i i q q.sim(i,j) q [2] dengan t didefinisikan sebagai threshold. Persamaan semantik antar kata yang dihitung berdasarkan persamaan cosine) ( ) ( ) ( ). ( ) , ( j V i V j V i V j i sim [3]
dengan merupakan dot product vektor i dan vektor j, merupakan panjang vektor kata i, dan merupakan panjang vektor kata j.
2 Ekspansi kata
Pertama-tama akan dicari pasangan kata dari setiap kata dalam kueri awal yang memiliki nilai kesamaan paling besar. Kemudian, setiap kata i dalam kueri akhir diberikan bobot sebagai berikut
j i Q j and T j) sim(i, j i i q.sim(i,j) n 1 q q' [4]dengan n adalah jumlah pasangan frase dari setiap kata yang yang ada dalam kueri, qi merupakan bobot kata i sebelum dilakukan ekspansi, dan Q merupakan subset dari sekumpulan kata yang asli pada kueri yang menuju ke kata baru yang akan ditambahkan ke dalam kata yang sudah diekspansi. Jika kata i tidak berada pada kueri awal, maka nilai qi = 0. 3 Kesamaan Dokumen
Persamaan antara ekspansi dan pembobotan ulang sebuah kueri q dan sebuah dokumen d dihitung dengan ukuran kesamaan dokumen sebagai berikut
i j i j i j i j d q j i sim d q d q sim . ) , ( . . ) , ( [5]3 dengan i dan j merupakan kata dalam kueri dan
dokumen secara berurutan dalam satu dokumen. Ukuran kesamaan pada persamaan [3] rata-rata bobotnya telah dinormalisasikan pada batas [0,1].
Evaluasi Sistem Temu Kembali Informasi Dalam sistem temu kembali informasi diperlukan suatu ukuran untuk mengevaluasi kinerja sistem dalam menemukembalikan dokumen-dokumen yang relevan. Terdapat enam jenis ukuran yang dapat digunakan untuk mengukur kinerja sistem yaitu coverage, time
lag, presentation, effort, recall, dan precision
(Cleverdon dalam Paiki 2006). Recall dan
precision merupakan salah satu ukuran yang
paling sering digunakan dalam mengevaluasi sistem.
Recall merupakan rasio jumlah dokumen
relevan yang ditemukembalikan terhadap jumlah seluruh dokumen relevan dalam koleksi.
Precision merupakan rasio jumlah dokumen
relevan yang ditemukembalikan terhadap
jumlah seluruh dokumen yang
ditemukembalikan. Ilustrasi perhitungan Recall dan precision dapat dilihat pada Tabel 1 (Manning et al. 2008).
Tabel 1 Ilustrasi perhitungan recall & precision Relevant Non-relevant Retrieved tp fp Non-retrieved fn tn Sehingga: ) ( Re fp tp tp call [6] ) ( Pr fn tp tp ecision [7]
Average precision (AVP) adalah suatu
ukuran evaluasi kinerja temu-kembali yang diperoleh dengan menghitung average precision menggunakan eleven standard recall yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9 dan 1 (Manning et al. 2008).
METODE PENELITIAN
Penelitian ini akan dilakukan melalui beberapa tahap yaitu : (1) indexing, (2) matriks kesamaan, (3) ekspansi kueri, (4) pengujian kinerja sistem, dan (5) analisis pembandingan kinerja sistem. Alur kerja dari sistem dapat dilihat pada Gambar 1.4 Gambar 1 menunjukkan alur dari sistem yang
dilakukan secara offline (1, 2, 3) dan online (4, 5, 6, 7) dengan penjelasan sebagai berikut: Masukan: Query q, Dokumen d.
Keluaran: Top-N dokumen. 1. Menghitung frekuensi kata.
2. Menghitung bobot dari seluruh kata yang terdapat dalam dokumen dengan perhitungan tf.idf
3. Menghitung nilai sim dari pasangan kata yang nilai peluangnya ≥ 0.3
4. Mencari kandidat untuk kueri ekspansi dengan memilih pasangan kata yang memiliki nilai sim terbesar
5. Menghitung bobot baru kueri dengan perhitungan SSRM tahap 1
j i t j) sim(i, j i i q q.sim(i,j) q6. Menghitung bobot dari kueri ekspansi yang didapatkan dengan perhitungan SSRM tahap 2
j i Q j and T j) sim(i, j.sim(i,j) q n 1 'i q , i adalah kueri baru
j i Q j and T j) sim(i, j i i q.sim(i,j) n 1 q q' , i adalah kueri dalam qi7. Menghitung nilai kesamaan dokumen dengan kueri dengan perhitungan SSRM tahap 3
i j i j i j i j d q j i sim d q d q sim . ) , ( . . ) , ( Koleksi DokumenDokumen yang digunakan adalah dokumen berita dalam bidang pertanian berbahasa Indonesia sebanyak 2000 dokumen. Dokumen berita yang digunakan merupakan koleksi berita dari beberapa sumber di Internet.
Gugus kueri dan dokumen yang digunakan dalam penelitian ini menggunakan 30 kueri yang diambil dari koleksi yang ada di Laboratorium Temu Kembali Informasi Departemen Ilmu Komputer IPB dan 10 kueri tidak jelas yang didapatkan secara manual.
Indexing
Tahap indexing merupakan kumpulan dari beberapa langkah awal dalam melakukan tahap pemodelan temu kembali informasi, yang diantaranya: tokenisasi, pembuangan stopwords, dan pembobotan kata dalam seluruh dokumen. Dalam penelitian ini, proses indexing dijalankan secara offline.
Pada tahap tokenisasi akan dilakukan pembacaan karakter yang bertujuan membedakan karakter-karakter yang bersifat separator dan yang bukan. Dalam penelitian ini, karakter angka akan dianggap sebagai separator, karena karakter angka dianggap kurang representatif dalam menggambarkan suatu dokumen tertentu.
Sebelum memasuki tahap pembobotan kata, masing-masing token tersebut akan diperiksa keberadaannya di dalam stopwords. Jika token tersebut terdapat dalam daftar stopwords, maka akan dibuang dan sebaliknya jika tidak, maka token tersebut akan digunakan dalam tahap pembobotan.
Setelah itu, akan dilakukan pembobotan kata, tujuan dari pembobotan ini adalah untuk menentukan tingkat kepentingan suatu token di dalam dokumen. Metode yang digunakan adalah tf-idf dan Semantic Similarity Retrieval
Model. Pembobotan tf-idf digunakan pada
proses indexing, sedangkan pembobotan menggunakan Semantic Similarity Retrieval
Model digunakan pada saat ekspansi kueri.
Matriks Kesamaan
Berdasarkan indeks yang sudah dibuat akan dihasilkan matriks kesamaan secara automatis. Ukuran kesamaan yang digunakan adalah ukuran kesamaan cosine.
Semakin besar jumlah istilah unik yang didapatkan dalam indeks, maka semakin besar pula ukuran matriks kesamaannya. Untuk mengatasi besarnya ukuran matriks kesamaan, setiap pasangan frase yang dihasilkan pada penelitian Kartina (2010) akan dihitung nilai kedekatannya dengan menggunakan persamaan [3]. Jika pasangan frase tersebut memiliki jumlah yang sedikit pada dokumen yang sama, secara otomatis akan dibuang. Dengan demikian, diharapkan jumlah pasangan frase yang digunakan sebagai kandidat kueri ekspansi akan berkurang, sehingga waktu komputasi dapat dipersingkat.
5 Ekspansi Kueri
Pemilihan kandidat kueri ekspansi pada penelitian ini akan menggunakan pasangan frase yang dihasilkan pada penelitian Kartina (2010) yang telah dihitung nilai nilai kedekatannya. Pasangan frase dengan nilai kesamaan antarkata terbesar akan dijadikan kueri ekspansi dan ditambahkan pada kueri awal yang diberikan pengguna (kueri akhir), untuk kemudian dilakukan pembobotan ulang dengan menggunakan metode Semantic Similarity
Retrieval Model.
Pengujian Kinerja Sistem
Hal utama yang akan diuji dari sistem ini yakni presisi dari hasil pencarian dokumen berdasarkan kueri masukan. Metode evaluasi yang digunakan untuk menghitung presisi dari sistem ialah metode recall-precision. nilai
recall dan precision dari setiap pencarian
dengan kueri tertentu akan dihitung dan selanjutnya diambil nilai rata-ratanya untuk mendapatkan nilai average precision dari sistem. Dengan menghitung nilai average
precision dari sistem, nilai presisi sistem secara
keseluruhan akan dapat diketahui. Terdapat delapan asumsi kondisi pengujian presisi sistem, yakni:
1. Kondisi pertama (QE0): evaluasi proses temu kembali 30 kueri tanpa menggunakan ekspansi kueri.
2. Kondisi kedua (QE1): evaluasi proses temu kembali 30 kueri dengan menambahkan satu istilah pada masing-masing kata dalam kueri.
3. Kondisi ketiga (QE2): evaluasi proses temu kembali 30 kueri dengan menambahkan dua istilah pada masing-masing kata dalam kueri.
4. Kondisi keempat (QE3): evaluasi proses temu kembali 30 kueri dengan menambahkan tiga istilah pada masing-masing kata dalam kueri.
5. Kondisi pertama (QX0): evaluasi proses temu kembali 10 kueri tanpa menggunakan ekspansi kueri.
6. Kondisi keempat (QX1): evaluasi proses temu kembali 10 kueri dengan menambahkan satu istilah pada masing-masing kata dalam kueri.
7. Kondisi keempat (QX2): evaluasi proses temu kembali 10 kueri dengan menambahkan dua istilah pada masing-masing kata dalam kueri.
8. Kondisi keempat (QX3): evaluasi proses temu kembali 10 kueri dengan
menambahkan tiga istilah pada masing-masing kata dalam kueri.
Evaluasi presisi pencarian sistem akan diuji pada dua jenis koleksi dokumen pengujian. Koleksi pertama ialah menguji sistem pada pengolah 1000 dokumen dan membandingkan hasil presisi dengan hasil penelitian Paiki (2006). Koleksi kedua ialah koleksi dokumen yang memiliki ukuran lebih yakni 2000 dokumen.
Analisis Pembandingan Metode Ekspansi Penelitian ini menggunakan metode
semantic similarity dalam proses pembobotan
pada ekspansi kueri, ekspansi kueri dengan 30 kueri akan dibandingkan dengan penelitian yang telah dilakukan oleh Paiki (2006) yang melakukan ekspansi kueri dengan menggunakan metode similarity thesaurus yang diimplementasikan pada temu kembai vektor dan ekspansi kueri dengan 10 kueri akan dibandingkan dengan penelitian yang telah dilakukan oleh Samana (2011) yang melakukan ekspansi kueri dengan menggunakan metode peluang bersyarat dalam pemilihan istilah ekspansi dalam penerjemahan kamus dwibahasa. Analisis lebih jauh diperlukan untuk mengetahui metode mana yang lebih baik digunakan dalam ekspansi kueri.
Asumsi-asumsi
Asumsi-asumsi yang digunakan dalam penelitian ini antara lain:
Token hasil tokenizing merupakan istilah yang belum tentu bernilai benar secara bahasa
Setiap token hasil tokenizing telah memiliki pasangan frase masing-masing
Setiap pasangan frase yang didapatkan sebagai kandidat istilah ekspansi memiliki makna semantik yang ambigu
Jumlah dokumen relevan untuk tiap kueri telah diketahui sebelumnya
Pilihan istilah yang didapatkan pada hasil ekspansi kueri belum tentu bernilai benar secara bahasa
Lingkungan Implementasi
Perangkat lunak yang digunakan dalam melakukan penelitian yaitu:
Windows 7 Starter sebagai sistem operasi
ActivePerl-5.10.1.1007 sebagai interpreter bahasa pemrograman Perl yang digunakan
6
Notepad++ v.5.9
Microsoft Excel 2007 sebagai aplikasi yang digunakan untuk melakukan perhitungan dalam mengevaluasi sistem
Perangkat keras yang digunakan untuk penelitian meliputi:
AMD Dual-Core Processor E-350 CPU @ 1,6 GHz
RAM 2 GB
Harddisk dengan kapasitas 320 GB
HASIL DAN PEMBAHASAN
Koleksi DokumenTahapan pengumpulan dokumen telah menghasilkan koleksi yang terdiri atas 2000 dokumen pertanian yang seluruhnya berasal dari lab Temu Kembali Informasi dan merupakan dokumen berita dalam bidang pertanian berbahasa Indonesia. Deskripsi dari dokumen yang digunakan dapat dilihat pada Tabel 2. Tabel 2 Deskripsi dokumen pengujian
Uraian Nilai (byte) Ukuran keseluruhan dokumen
Ukuran rata-rata dokumen Ukuran dokumen terbesar Ukuran dokumen terkecil
6438425 3219 53309 412 Seluruh isi dokumen yang dikumpulkan menggunakan Bahasa Indonesia semi-formal/formal. Jumlah stopword yang diperoleh dari 2000 dokumen adalah sebanyak 1074 kata, diantaranya adalah kata-kata umum, tetapi, tersebut, tanpa, dan setelah.
Contoh dari dokumen pengujian dapat dilihat pada Lampiran 1, dan format dokumen yang terkumpul diformat dengan susunan tag sebagai berikut :
<DOC>
<DOCNO> nomor dokumen </DOCNO> <TITLE> judul dokumen </TITLE>
<AUTHOR> nama/inisial penulis </AUTHOR> <DATE> tanggal dokumen </DATE>
<TEXT> isi teks lengkap </TEXT> </DOC>
Selain itu untuk mengevaluasi sistem yang dihasilkan dari penelitian ini digunakan 30 kueri yang diambil dari koleksi yang ada di Laboratorium Temu Kembali Informasi Departemen Ilmu Komputer IPB dan 10 kueri tidak jelas yang didapatkan oleh penulis secara manual. Daftar kueri dan jumlah dokumen relevan dapat dilihat pada Lampiran 2 dan Lampiran 3.
Indexing
Tahap indexing berjalan secara offline dan dilakukan untuk menghasilkan kata-kata yang akan digunakan sebagai penciri dokumen. Dari
indexing yang dilakukan tercatat 31454 buah
istilah unik. Berikut lima istilah dengan frekuensi tertinggi adalah :
Pertanian (1472 dokumen, 8946 kata) Petani (1091 dokumen, 5477 kata) Tanaman (954 dokumen, 3695 kata) Tahun (1148 dokumen, 3507 kata) Indonesia (921 dokumen, 3315 kata)
Tahap tokenisasi dilakukan dengan memilah kata tertentu berdasarkan frekuensi kemunculannya dalam setiap dokumen, sehingga diperoleh sebanyak 259460 kata dengan frekuensi kemunculan yang bervariasi. Penjelasan hasil tokenisasi ditunjukkan oleh Tabel 3.
Tabel 3 Hasil proses tokenisasi
Uraian Nilai
Rata-rata token tiap dokumen Jumlah token keseluruhan Jumlah token terbesar Jumlah token terkecil
130 259460 8946 1
Stopword yang diperoleh sebanyak 1074
kata sehingga menunjukkan bahwa frekuensi kemunculannya sangat banyak dalam dokumen.
Stopword merupakan daftar kata umum yang
mempunyai fungsi tapi tidak mempunyai arti yang ditemukan dalam seluruh dokumen sehingga perlu dibuang untuk efisiensi, seperti : adalah, akan, atau, dan bagi.
Setelah tahap pembuangan stopword
kemudian dilakukan pembobotan terhadap kata. Tahap ini dilakukan untuk mendapatkan hasil sejumlah kata yang sering muncul pada suatu dokumen sehingga dapat diketahui pentingnya kata tersebut untuk dokumen yang
7 bersangkutan. Pendekatan yang digunakan
adalah dengan term frequency (tf) dan inverse
document frequency (idf), dalam penelitian ini
kata yang akan dihitung bobotnya hanya kata dengan nilai idf >= 0.3, dari hasil kali terhadap keduanya sehingga diperoleh nilai bobot setiap
term t pada dokumen d.
Seluruh hasil dari tahap indexing disimpan dalam table hash frek.dat untuk kemudian dipakai dalam tahap perhitungan bobot dari seluruh kata dalam dokumen dengan menggunakan persamaan [1]. Sedangkan hasil dari perhitungan bobot kata disimpan dalam
table hash tfIdf.dat.
Ekspansi Kueri
Sejumlah 270262 pasangan kata beserta dengan masing-masing peluangnya telah didapatkan dari penelitian Kartina (2010). Pasangan kata yang akan digunakan dalam penelitian ini akan dibatasi dengan hanya mengambil pasangan kata yang memiliki nilai peluang lebih dari sama dengan 0.3, sehingga didapat 31014 pasangan kata yang akan disimpan dan dihitung kesamaan antar kata dengan menggunakan persamaan [3] untuk disimpan dalam table hash cosineKata.dat untuk kemudian dijadikan kandidat istilah pada ekspansi kueri. Contoh pasangan kata yang telah dihitung nilai kedekatannya dapat dilihat pada Tabel 4.
Tabel 4 Contoh pasangan kata Pasangan kata Ukuran Matriks Kesamaan Nilai Peluang Asam Lemak 0.0880 0.4078 Proyek Stadion 0.0774 0.4193 Pupuk Kandang 0.0267 0.6580 Jalan Tol 0.0304 0.5833 Bawang Bombai 0.0012 1
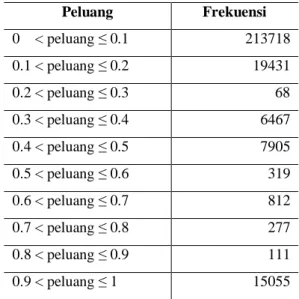
Nilai peluang dari pasangan kata yang dinormalisasikan dalam batas [0,1] dapat dilihat pada Tabel 5.
Tabel 5 Normalisasi peluang pasangan kata
Peluang Frekuensi 0 < peluang ≤ 0.1 213718 0.1 < peluang ≤ 0.2 19431 0.2 < peluang ≤ 0.3 68 0.3 < peluang ≤ 0.4 6467 0.4 < peluang ≤ 0.5 7905 0.5 < peluang ≤ 0.6 319 0.6 < peluang ≤ 0.7 812 0.7 < peluang ≤ 0.8 277 0.8 < peluang ≤ 0.9 111 0.9 < peluang ≤ 1 15055 Pencarian Dokumen
Pencarian dokumen dilakukan dengan menghitung ukuran kesamaan antara kueri yang diberikan dan tiap dokumen. Semakin tinggi nilai ukuran kesamaan dengan suatu dokumen maka dapat diartikan dokumen relevan dengan kueri yang diberikan.
Proses awal pencarian dokumen dilakukan dengan cara menghitung bobot dari kueri yang dimasukan oleh pengguna (kueri awal) dengan menggunakan rumus tfIdf. Setelah didapatkan bobot dari kueri yang diberikan, sistem akan mencari kandidat kueri ekspansi dalam table
hash cosineKata.dat untuk kemudian dipilih
yang memiliki nilai kesamaan antarkata paling besar yang akan dijadikan kueri ekspansi (kueri akhir).
Metode SSRM bekerja dalam tiga tahap yaitu: pembobotan ulang kata, ekspansi kueri, dan kesamaan dokumen. Tahap pembobotan ulang kata dimulai dengan menghitung bobot dari kueri awal dengan menambahkan jumlah dari seluruh nilai kesamaan pasangan kata yang telah dipilih dengan menggunakan persamaan [2] dengan nilai threshold 0,001.
Kueri akhir yang didapatkan akan masuk ke tahap kueri ekspansi untuk kemudian dihitung kembali bobotnya dengan menggunakan persamaan [4] dengan nilai threshold 0,001. Pasangan kata yang dipakai pada persamaan ini menggunakan pasangan kata yang telah dicari dari table hash cosineKata.dat.
Ukuran kesamaan dokumen pada metode SSRM menggunakan persamaan [5], untuk setiap i dan j (i dan j merupakan pasangan kata yang telah dicari pada tahap ekspansi kueri)
8 akan dihitung jumlah vektor kueri i dikalikan
dengan vektor dokumen yang mengandung kata
j dan dikalikan dengan ukuran kesamaan antara
kata i dan j.
Pengujian Kinerja Sistem
Proses evaluasi dilakukan untuk mengetahui seberapa baik kinerja dari suatu sistem temu kembali informasi. Proses evaluasi dalam penelitian ini menggunakan 30 macam kueri yang diambil dari Laboratorium Temu Kembali Informasi Departemen Ilmu Komputer IPB dan 10 macam kueri tidak jelas yang ditentukan secara manual oleh pengguna dan telah diketahui dokumen-dokumen relevannya, dan kinerja dari sistem pada penelitian ini akan diuji dengan menggunakan nilai recall dan precision sebagai tolok ukur yang menggambarkan seberapa baik sistem yang telah dibangun, setelah itu dilakukan interpolasi untuk mengetahui nilai Average Precision.
Tahap awal akan dilakukan pengujian untuk pencarian dokumen tanpa melakukan ekspansi kueri menggunakan pembobotan VSM. Hasil pengujian untuk QE0 dan QX0 dapat dilihat pada Gambar 2 dan Gambar 3.
Gambar 2 Grafik recall terhadap precision pada QE0.
Gambar 3 Grafik recall terhadap precision pada QX0.
Nilai recall dan precision dari pencarian tanpa ekspansi dengan menggunakan metode
Vector Space Model (VSM) akan digunakan
sebagai pembanding oleh pencarian yang menggunakan ekspansi, baik satu, dua, maupun pencarian yang menggunakan tiga buah ekspansi dari setiap kata dalam kueri awal. Nilai
average precision (AVP) dari menu pencarian
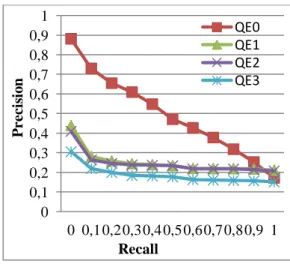
untuk gugus 30 kueri dan gugus 10 kueri masing-masing adalah sebesar 0.495 dan 0.796. Kondisi pengujian lainnya, QE1, QE2, dan QE3 yang merupakan pengujian untuk pencarian 30 kueri yang dilakukan dengan menambahkan istilah ekspansi pada kueri awal. Hasil dari pengujian tersebut akan dibandingkan dengan pencarian tanpa ekspansi (QE0).
Gambar 4 Grafik recall terhadap precision pada QE0, QE1, QE2, dan QE3. 0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 P r e c is io n Recall 0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 P r e c is io n Recall 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 P r e c is io n Recall QE0 QE1 QE2 QE3
9 Gambar 5 Grafik recall terhadap precision
pada QX0, QX1, QX2, dan QX3. Perbandingan untuk tiga pengujian dengan ekspansi kueri dapat dilihat pada Gambar 4 dan Gambar 5. Dari grafik terlihat bahwa penggunaan metode semantic similarity dalam menghitung pembobotan kueri pada pengujian yang dilakukan untuk 30 kueri hanya mampu meningkatkan nilai precision untuk dua kueri masukan dari 30 kueri yang diujikan, dan peningkatan terjadi pada saat penambahan satu istilah ekspansi (QE1). Sedangkan pada pengujian yang dilakukan untuk 10 kueri hanya mampu meningkatkan nilai precision untuk empat kueri masukan dari 10 kueri yang diujikan, dan peningkatan terjadi pada saat penambahan satu istilah ekspansi (QX1).
Pada Tabel 6 dapat dilihat perbandingan nilai AVP dari pengujian QE0, QE1, QE2, QE3, QX0, QX1, QX2, dan QX3. Pada pengujian untuk hasil temu kembali yang menggunakan ekspansi kueri (QE1, QE2, QE3, QX1, QX2, QX3) menghasilkan nilai AVP yang lebih kecil dibandingkan tanpa menggunakan ekspansi kueri (QE0, QX0) dan nilai AVP semakin menurun dengan penambahan istilah ekspansi. Hal ini dikarenakan dalam tahap kesamaan antar dokumen, setiap kandidat pasangan kata kueri yang terpilih sangat mempengaruhi perhitungan kedekatan antara kueri ekspansi dan dokumen. Sedangkan kandidat pasangan kata yang didapatkan pada proses pemilihan pasangan ekspansi cukup banyak, dan beberapa diantaranya tidak sesuai dengan konteks pencarian dan juga belum tentu setiap kandidat pasangan kata yang terpilih berada dalam satu dokumen. Masalah tersebut mengakibatkan hasil temu kembali yang diperoleh tidak sesuai dengan yang diharapkan. Akan tetapi untuk beberapa kueri masukan, hasil pencarian menggunakan ekspansi kueri dapat menghasilkan hasil pencarian yang lebih baik.
Selain itu, hal yang menyebabkan kecilnya nilai AVP dapat dikarenakan kondisi dokumen pada korpus, dimana terdapat kesalahan penulisan isi pada koleksi dokumen. Selain itu penyebab dari kecilnya nilai AVP dikarenakan untuk setiap pasang kueri dengan dokumen relevan, terdapat banyak kueri dan pasangannya yang memiliki sedikit jumlah dokumen yang relevan sehingga jika dibandingkan dengan jumlah dokumen yang besar akan menghasilkan nilai recall dan
precision yang kecil.
Tabel 6 Perbandingan nilai presisi sistem pada 1000 dan 2000 dokumen Kondisi Pengujian Average Precision 1000 dokumen 2000 dokumen QE0 0.544 0.495 QE1 0.262 0.253 QE2 0.257 0.246 QE3 0.197 0.187 QX0 0.712 0.796 QX1 0.604 0.744 QX2 0.600 0.739 QX3 0.589 0.739
Pengujian juga dilakukan pada 1000 dokumen pertanian. Pada Tabel 6 terlihat bahwa hasil perbandingan pengujian 30 kueri pada 1000 dokumen dengan 2000 dokumen memperlihatkan penurunan presisi pencarian. Hal ini dapat dikarenakan jumlah dokumen yang dibandingkan dengan dengan dokumen yang relevan lebih sedikit. Sedangkan hasil perbandingan pengujian 10 kueri pada 1000
dokumen dengan 2000 dokumen
memperlihatkan adanya kenaikan nilai presisi. Analisis Pembandingan Metode Ekspansi
Pada penelitian sebelumnya Paiki (2006) telah menggunakan similarity thesaurus pada ekspansi kueri yang diimplementasikan pada temu kembali berbasis vektor. Pengujian untuk melihat kinerja sistem akan dilakukan dengan membandingkan antara temu kembali dengan menggunakan metode similarity thesaurus dan temu kembali dengan menggunakan metode
semantic similarity. Perbandingan dilakukan
pada dua kegiatan temu kembali, yaitu temu kembali lima istilah dan sepuluh istilah pada penggunan similarity thesaurus dan temu 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 P r e ci si o n Recall QX0 QX1 QX2 QX3
10 kembali satu istilah dan dua istilah pada
penggunaan semantic similarity. Tabel 7 menunjukkan AVP dari hasil pengujian yang dilakukan dalam penelitian sebelumnya. Tabel 7 AVP berdasarkan penelitian Paiki
(2006) Pengujian Average Precision Similarity Thesaurus Semantic Similarity TH5-1 0.201 0.253 TH10-1 0.166 0.246
Penelitian ini menunjukkan hasil yang relatif lebih baik daripada ekspansi kueri menggunakan similarity thesaurus (Paiki, 2006). Hal ini karena terdapat perbedaan saat pembobotan ulang kata yang terjadi setelah ekspansi kueri. Pembobotan ulang kata yang dilakukan dalam penelitian ini sangat dipengaruhi oleh setiap kandidat ekspansi kueri, sedangkan pada penelitian sebelum kandidat ekspansi tidak mempengaruhi pembobotan ulang. Sehingga bobot kueri pada penelitian ini lebih besar dibandingkan dengan penelitian yang dilakukan sebelumnnya.
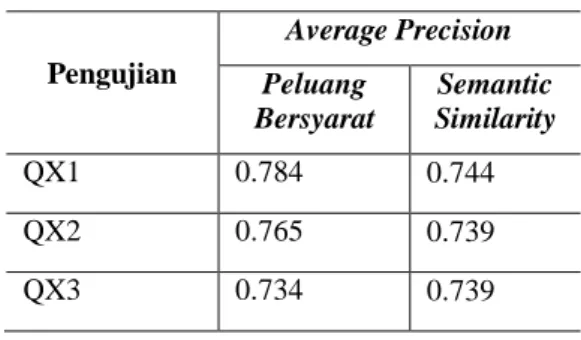
Pengujian metode ekspansi selanjutnya akan dibandingkan dengan penelitian yang telah dilakukan oleh Samana (2011). Dalam penelitian tersebut digunakan metode peluang bersyarat dalam pemilihan istilah ekspansi yang dihasilkan dari penerjemahan kamus dwibahasa. Pengujian untuk melihat kinerja sistem akan dilakukan perbandingan antara temu kembali menggunakan peluang bersyarat dengan temu kembali 10 kueri dengan menggunakan metode
semantic similarity.
Tabel 8 menunjukkan bahwa pada pengujian penambahan satu istilah ekspansi, dua istilah ekspansi, dan penambahan tiga istilah ekspansi pada penelitian sebelumnya menghasilkan nilai AVP yang lebih besar dibandingkan dengan penelitian ini. Hal tersebut dapat terjadi karena terdapat perbedaan teknik dalam pemilihan kandidat ekspansi. Dalam penelitian sebelumnya pemilihan kandidat ekspansi dipilih dengan mengggunakan nilai peluang yang tertinggi dari penerjemahan kamu dwibahasa dan pada saat ekspansi kueri dan tidak terjadi pembobotan ulang kata. Sedangkan dalam penelitian ini terjadi pembobotan ulang kata dimana pembobotan ulang kata sangat dipengaruhi oleh kandidat ekspansi yang dipilih. Teknik pemilihan kandidat ekspansi yang digunakan dalam penelitian ini masih
kurang baik dibandingkan teknik yang dilakukan dalam penelitian sebelumnya sehingga pembobotan ulang kata menghasilkan bobot yang lebih kecil dibandingkan dengan penelitian sebelumnya.
Tabel 8 AVP berdasarkan penelitian Samana (2011) Pengujian Average Precision Peluang Bersyarat Semantic Similarity QX1 0.784 0.744 QX2 0.765 0.739 QX3 0.734 0.739
KESIMPULAN DAN SARAN
KesimpulanHasil penelitian menunjukkan:
1. Ekspansi kueri dengan penambahan satu istilah ekspansi menghasilkan nilai AVP dengan nilai lebih tinggi daripada penambahan dua istilah dan penambahan tiga istilah.
2. Kinerja sistem yang didapatkan sudah cukup baik bila dilakukan pengujian pada 10 kueri tidak jelas karena nilai AVP yang dihasilkan masih lebih dari 50%, dibandingkan dengan pengujian pada 30 kueri yang menghasilkan nilai AVP kurang dari 50%.
3. Ekspansi kueri dengan metode semantic
Similarity mampu meningkatkan kinerja
pencarian jika dibandingkan metode
similarity thesaurus pada model temu
kembali vektor.
4. Ekspansi kueri dengan metode semantic
Similarity belum mampu meningkatkan
kinerja pencarian jika dibandingkan metode peluang bersyarat dalam pemilihan istilah ekspansi yang dihasilkan dari penerjemahan kamus dwibahasa.
5. Penggunaan pasangan frase dalam menentukan kandidat istilah ekspansi tidak dapat memaksimalkan hasil pencarian dokumen dengan metode semantic Similarity.
Saran
Untuk penelitian selanjutnya terdapat beberapa hal yang dapat ditambahkan atau diperbaharui:
1. Menggunakan koleksi dokumen yang lebih besar.
11 2. Menggunakan thesaurus dalam menentukan
istilah mana saja yang akan ditambahkan pada kueri awal.
DAFTAR PUSTAKA
Hliaoutakis A, Varelas G, Petrakis EGM, Milios E. 2006. MedSearch: A Retrieval for
Medical Information Based on Semantic Similarity. In: 10th ECDL European Conference on Research and Advanced Technology for Digital Libraries (ACDL 2006), Alicante, Spain 17-22.
Hliaoutakis A, Varelas G, Voutsakis E, Petrakis EGM, Milios E. 2006. Information
Retrieval by Semantic Similarity, Journal on
Semantic Web and Information System (IJSWIS), Special Issue of Multimedia Semantics, Vol.3, No.3, Juli/September, 2006, PP. 55-73, copyright 2006, Idea Group Inc. ww.idea-group.com. Posted by Permission of the Publisher.
Kartina. 2010. Analisis Pertanyaan Bernahasa Indonesia pada Question Answering System (QAS). [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Manning CD, Raghavan P, Schütze H. 2008.
Introduction to Information Retrieval.
America, New York.
Paiki FF. 2006. Evaluasi Penggunaan Similarity
Thesaurus Terhadap Ekspansi Kueri dalam
Sistem Temu Kembali Informasi Berbahasa Indonesia. [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Rusidi. 2008. Ekspansi Kueri dalam Sistem Temu Kembali Informasi Berbahasa Indonesia Menggunakan Peluang Bersyarat. [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Samana MA. 2011. Ekspansi kueri Berdasarkan Kamus Dwibahasa Menggunakan Peluang Bersayarat. [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Sitohang NL. 2009. Ekspansi Kueri pada Sistem Temu Kembali Informasi Menggunakan Kamus Dwibahasa. [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
13 Lampiran 1 Contoh dokumen dalam koleksi
<DOC>
<DOCNO> mediaindonesia 160110 </DOCNO>
<TITLE>Lawan Produk China dengan Pertanian </TITLE> <AUTHOR>Kasriadi</AUTHOR>
<DATE> Sabtu, 16 Januari 2010 </DATE> <TEXT>
PALU--MI: Ketua Umum Himpunan Pengusaha Muda Indonesia (HIPMI) Erwin Aksa mengatakan, untuk menghadapi gempuran pasar industri produk China yang saat ini telah membanjiri pasar domestik diperlukan penguatan sektor perkebunan dan pertanian.
Erwin mengakui, tantangan terbesar yang dihadapi Indonesia pasca ditandatanganinya perjanjian perdagangan bebas Indonesia-China saat ini adalah membanjirnya produk industri dari negara itu. "Ada empat hal yang diperkuat untuk menghadapi produk dari China, yakni pertambangan, perkebunan/pertanian, properti, dan infrastruktur," kata Erwin Aksa saat menghadiri Rapat Kerja HIPMI Sulteng dan Seminar Daerah Arah dan kebijakan Perkebunan Sulawesi Tengah di Palu, Sabtu (16/1).
Erwin mengatakan, empat sektor itu perlu diperhatikan oleh pengusaha dalam negeri karena Indonesia memiliki sumber daya yang cukup besar di sektor tersebut yang tidak dimiliki China. Sektor perkebunan, misalnya, Indonesia memiliki luas lahan yang besar. Hanya, saat ini tidak ada lagi kapling lahan dalam jumlah yang luas. Lahan dalam jumlah besar telah dikapling oleh
pengusaha-pengusaha besar.
Sektor perkebunan membutuhkan keterlibatan pengusaha lokal atau daerah karena pengusaha luar negeri kurang berminat dengan lahan yang kecil. "Investor luar negeri tidak tertarik dengan lahan yang kecil. Mereka membutuhkan lahan ratusan ribu hektare untuk mengembangkan investasi perkebunan. Di sinilah perlunya keterlibatan pengusaha lokal," kata Erwin.
Pemerintah daerah perlu fokus pada pembangunan perkebunan. Soalnya, untuk bersaing di sektor industri tekstil atau alas kaki, Indonesia sudah ketinggalan. Industri tersebut sudah dikuasai China. Industri tekstil di negara itu tumbuh 10 kali lipat dari industri dalam negeri. "Perkebunan rakyat perlu dikembangkan dengan memanfaatkan pengusaha-pengusaha di daerah," kata Erwin.
</TEXT> </DOC>
14 Lampiran 2 Daftar 30 kueri dan jumlah dokumen relevan
Kueri Jumlah Dokumen Relevan gagal panen 114 petani tebu 25 industri gula 30
perdagangan hasil pertanian 56
penerapan teknologi pertanian 99
pupuk organik 66
penyakit hewan ternak 30
penerapan bioteknologi 53
laboratorium pertanian 53
riset pertanian 84
harga komoditas pertanian 65
tanaman pangan 53
kelompok tani 43
musim panen 49
tanaman obat 31
gabah kering giling 37
impor beras indonesia 50
sistem pertanian organik 28
swasembada pangan 42 penyuluhan pertanian 38 tadah hujan 29 bencana kekeringan 44 peternak ayam 30 flu burung 37
institut pertanian bogor 62
pembangunan untuk sektor pertanian 103
upaya peningkatan pendapatan petani 61
produk usaha peternakan rakyat 35
kelangkaan pupuk 35
15 Lampiran 3 Daftar 10 kueri dan jumlah dokumen relevan
Kueri Jumlah Dokumen Relevan buah 157 bunga 66 ekonomi 303 hama 118 hujan 141 impor 221 lingkungan 191 panen 280 pupuk 149 tanaman 523
![Tabel 1 Ilustrasi perhitungan recall & precision Relevant Non-relevant Retrieved t p f p Non-retrieved f n t n Sehingga: )Re(fptpcalltp [6] )Pr(fntpecisiontp [7]](https://thumb-ap.123doks.com/thumbv2/123dok/4257723.2881564/11.892.473.766.146.361/ilustrasi-perhitungan-precision-relevant-retrieved-retrieved-fptpcalltp-fntpecisiontp.webp)