IMPLEMENTASI ALGORITMA WINNOWING DAN PORTER
STEMMER MENDETEKSI KEMIRIPAN DUA DOKUMEN
BERBASIS WEB
SKRIPSI
LIDIA ARTA FERARI
081401077
PROGRAM STUDI S1 ILMU KOMPUTER
DEPARTEMEN ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
IMPLEMENTASI ALGORITMA WINNOWING DAN PORTER
STEMMER MENDETEKSI KEMIRIPAN DUA DOKUMEN
BERBASIS WEB
SKRIPSI
Diajukan untuk melengkapi tugas akhir dan memenuhi syarat mencapai gelar Sarjana Komputer
LIDIA ARTA FERARI 081401077
PROGRAM STUDI SARJANA ILMU KOMPUTER DEPARTEMEN ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMATIKA UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : IMPLEMENTASI ALGORITMA WINNOWING
DAN PORTER STEMMER MENDETEKSI KEMIRIPAN DUA DOKUMEN BERBASIS WEB
Kategori : SKRIPSI
Nama : LIDIA ARTA FERARI
NomorIndukMahasiswa : 081401077
Program Studi : SARJANA (S1) ILMU KOMPUTER
Departemen : ILMU KOMPUTER
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI Diluluskan di
Medan, Agustus 2014 Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Marihat Situmorang, M.Kom Syahriol Sitorus, S.Si, MIT
NIP. 196312141986031001 NIP. 197103101997031004
Diketahui/Disetujui oleh
Program Studi S1 IlmuKomputer Ketua,
Dr. Poltak Sihombing, M.Kom
PERNYATAAN
IMPLEMENTASI ALGORITMA WINNOWING DAN PORTER STEMMER MENDETEKSI KEMIRIPAN DUA DOKUMEN
BERBASIS WEB
SKRIPSI
Saya menyatakan bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Agustus 2014
PENGHARGAAN
Puji dan syukur penulis ucapkan kepada Tuhan Yang Maha Kuasa atas segala berkat dan kasih karuniaNya sehingga penulis dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer, pada Program Studi S1 Ilmu Komputer Departemen Ilmu Komputer Universitas Sumatera Utara.
Ucapan terima kasih penulis sampaikan kepada :
1. Bapak Dr. Poltak Sihombing, M.Kom, selaku Ketua Departemen Ilmu Komputer Universitas Sumatera Utara.
2. Ibu Maya Silvi Lydia, B.Sc, M.Sc, selaku Sekretaris Departemen Ilmu Komputer Universitas Sumatera Utara
3. Dekan dan Pembantu Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara, semua dosen pada Departemen Ilmu Komputer Fasilkom-TI USU, dan pegawai di Ilmu Komputer Fasilkom-TI USU.
4. Bapak Syahriol Sitorus, S.Si, MIT dan bapak Drs. Marihat Situmorang, M.Kom selaku pembimbing skripsi yang telah banyak memberikan bantuan, arahan, petunjuk, serta kesabaran dalam pengerjaan skripsi ini. 5. Bapak Prof. Dr. Muhammad Zarlis dan bapak Dr. Poltak Sihombing,
M.Kom selaku pembanding skripsi yang telah banyak memberikan kritik dan saran serta arahan dalam pengerjaan skripsi ini.
6. Papa dan mama kami tercinta, Nukman Siahaan dan Erline Madeline Listerine Hutagaol untuk semua keringat dan jerih payah yang begitu tulus. 7. Zonny Mega Siahaan beserta keluarga, Yannuke Patricia Siahaan beserta
keluarga, Sephilda Kristi Siahaan beserta keluarga, Decerwin Charsten Benediksta Siahaan, untuk semua dukungan hebatnya.
8. Hawe Numerouno yang telah memberi semangat di setiap kondisi.
9. Seluruh teman-teman Program Studi S1 Ilmu Komputer Departemen Ilmu Komputer Universitas Sumatera Utara yang telah memberikan bantuan dan dukungan selama penulisan skripsi ini.
Semoga Tuhan Yang Maha Kuasa memberikan berkat yang berlimpah kepada semua pihak yang telah memberikan bantuan, perhatian, serta dukungan kepada penulis dalam menyelesaikan skripsi ini.
Medan, Agustus 2014 Penulis
IMPLEMENTASI ALGORITMA WINNOWING DAN PORTER STEMMER MENDETEKSI KEMIRIPAN DUA DOKUMEN
BERBASIS WEB
ABSTRAK
Skripsi ini membahas tentang perancangan aplikasi penerapan algoritma Stemmer Porter dan Winnowing. Penelitian yang dilakukan bertujuan untuk mengetahui tingkat kemiripan antara satu file dengan file yang lain. Stemmer Porter merupakan suatu algoritma yang pertama kali ditemukan oleh Martin Porter pada tahun 1980 untuk stemming bahasa inggris, kemudian karena proses stemming bahasa inggris berbeda dengan bahasa indonesia maka, dikembangkan algoritma porter khusus untuk bahasa indonesia (Porter Stemmer for Bahasa Indonesia) oleh W.B. Frakes pada tahun 1992. Stemming adalah salah satu cara yang digunakan untuk meningkatkan performa IR dengan cara mentransformasi kata-kata dalam sebuah dokumen teks ke kata dasarnya. Sedangkan winnowing sendiri merupakan Algoritma Winnowing merupakan algoritma yang digunakan untuk deteksi tingkat kemiripan file. Dengan menggunakan kedua algoritma ini diharapkan mampu mengetahui tingkat kemiripan satu file dengan yang lain.
IMPLEMENTATION WINNOWING ALGORITHM AND PORTER STEMMER DETECT TWO DOCUMENT SIMILARITY
WEB-BASED ABSTRACT
This thesis discusses the application design and implementation Winnowing Porter Stemmer algorithm. Research conducted aimed to determine the degree of similarity between a file with another file. Porter Stemmer is an algorithm that was first discovered by Martin Porter in 1980 for stemming English, and because the process is different from English Stemming Indonesian then, algorithms developed specifically for Indonesian porter (Porter Stemmer for Indonesian) by WB Frakes in 1992. Stemming is one of the means used to improve the performance of the IR by transforming the way the words in a text document to word basically. While Winnowing Winnowing algorithm itself is an algorithm used for file similarity detection. By using the two algorithms is expected to determine the level of similarity of one file to another.
DAFTAR ISI
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 4
1.6 Metodologi Penelitian 4
1.7 Sistematika Penulisan 5
Bab 2 LandasanTeori 7
2.1 Pengertian Stemming 7
2.2 Stemming Porter 8
2.3 Winnowing 16
2.3.1 Hashing 17
2.3.2 K-gram 18
2.4 Jaccard’s Similarity Coefficient 19
Bab 3 Analisis dan Perancangan Sistem 20
3.1 Analisis Sistem 20
3.3.1 Analisis persyaratan fungsional 22
Bab 4 Implementasi dan Pengujian Sistem 47 4.1 Implementasi Sistem 47 4.1.1 Tampilan halaman form home (awal) 4.1.2 Tampilan halaman form journal 49 4.1.3 Tampilan halaman form similarity 50 4.1.4 Tampilan halaman form about 51 4.2 Pengujian Sistem 52 4.2.1 Pengujian Sistem Pilih File 52 4.2.2 Pengujian Hasil Proses Pilih File 59 Bab 5 Kesimpulan dan Saran 65 5.1 Kesimpulan 65 5.2 Saran 66
DAFTAR TABEL
Nomor Tabel
Nama Tabel Halaman
2.1 Kelompok rule pertama : inflectional particles 9 2.2 Kelompok rule kedua :inflectional possesive pronouns 9 2.3 Kelompok rule ketiga: first order of derivational prefixes 10 2.4 Kelompok rule keempat: second order of derivational
prefixes
10
2.5 Kelompok rule kelima: derivational suffixes 11
3.1 Usecase Penghitungan Kemiripan File 24
3.2 Kombinasi Awalan Akhiran Yang Tidak Diijinkan 31
3.3 Cara Menentukan Tipe Awalan Untuk awalan “te-” 31
DAFTAR GAMBAR
Nomor
Gambar Nama Gambar Halaman
3.6
Tampilan hasil open file jurnal Tampilan hasil pilih file
Tampilan Show Content Tampilan hasil proses
IMPLEMENTASI ALGORITMA WINNOWING DAN PORTER STEMMER MENDETEKSI KEMIRIPAN DUA DOKUMEN
BERBASIS WEB
ABSTRAK
Skripsi ini membahas tentang perancangan aplikasi penerapan algoritma Stemmer Porter dan Winnowing. Penelitian yang dilakukan bertujuan untuk mengetahui tingkat kemiripan antara satu file dengan file yang lain. Stemmer Porter merupakan suatu algoritma yang pertama kali ditemukan oleh Martin Porter pada tahun 1980 untuk stemming bahasa inggris, kemudian karena proses stemming bahasa inggris berbeda dengan bahasa indonesia maka, dikembangkan algoritma porter khusus untuk bahasa indonesia (Porter Stemmer for Bahasa Indonesia) oleh W.B. Frakes pada tahun 1992. Stemming adalah salah satu cara yang digunakan untuk meningkatkan performa IR dengan cara mentransformasi kata-kata dalam sebuah dokumen teks ke kata dasarnya. Sedangkan winnowing sendiri merupakan Algoritma Winnowing merupakan algoritma yang digunakan untuk deteksi tingkat kemiripan file. Dengan menggunakan kedua algoritma ini diharapkan mampu mengetahui tingkat kemiripan satu file dengan yang lain.
IMPLEMENTATION WINNOWING ALGORITHM AND PORTER STEMMER DETECT TWO DOCUMENT SIMILARITY
WEB-BASED ABSTRACT
This thesis discusses the application design and implementation Winnowing Porter Stemmer algorithm. Research conducted aimed to determine the degree of similarity between a file with another file. Porter Stemmer is an algorithm that was first discovered by Martin Porter in 1980 for stemming English, and because the process is different from English Stemming Indonesian then, algorithms developed specifically for Indonesian porter (Porter Stemmer for Indonesian) by WB Frakes in 1992. Stemming is one of the means used to improve the performance of the IR by transforming the way the words in a text document to word basically. While Winnowing Winnowing algorithm itself is an algorithm used for file similarity detection. By using the two algorithms is expected to determine the level of similarity of one file to another.
BAB 1
PENDAHULUAN
1.1Latar Belakang
Pemanfaatan kecanggihan di jaman globalisasi menjadi salah satu hal yang sangat penting dalam penggunaan di kehidupan sehari-hari. Pemanfaatan-pemanfaatan teknologi dalam kehidupan sehari-hari adalah untuk mencari, mengolah, atau dapat juga menyimpan informasi dengan menggunakan kecanggihan komputer. Informasi yang diperoleh biasanya berupa dokumen teks. Kemudahan mengakses informasi dalam berupa dokumen teks bisa menimbulkan sifat manusia yang negatif, yaitu dengan meniru atau mencontoh hasil karya orang lain melebihi batas normal tolerir. Jika hanya mencontoh sedikit bagian atau mengutip untuk dijadikan referensi mungkin tidak begitu masalah. Namun banyak juga kasus tingkat kemiripan dua dokumen tersebut bisa sama hampir sepenuhnya. Kita dapat mengetahui berapa tingkat kemiripan antara dua dokumen yang di sinyalir memiliki kesamaan dengan bantuan suatu sistem.
digunakan untuk meningkatkan performa IR dengan cara mentransformasi kata-kata dalam sebuah dokumen teks ke kata dasarnya. Algoritma Stemming untuk bahasa yang satu berbeda dengan algoritma stemming untuk bahasa lainnya.
Contoh salah satu Stemming adalah Stemming Porter. Algoritma Porter ditemukan oleh Martin Porter 1980. Algoritma tersebut digunakan untuk stemming bahasa inggris, kemudian karena proses stemming bahasa inggris berbeda dengan bahasa indonesia maka, dikembangkan algoritma porter khusus untuk bahasa indonesia (Porter Stemmer for Bahasa Indonesia) oleh W.B. Frakes pada tahun 1992. untuk pendeteksian kesamaan dokumen itu sendiri menggunakan algoritma Winnowing. Winnowing adalah suatu algoritma yang dipakai untuk melakukan proses pengecekkan kesamaan suatu kata (document fingerprinting).
1.2Rumusan Masalah
Jurnal mahasiswa pada program studi S1 Ilmu Komputer Fasilkom TI USU yang memiliki ekstensi (.pdf), akan dicek tingkat kemiripan dari judul antar jurnal, sehingga didapatkan nilai kemiripan pada setiap jurnal. Setelah itu, dihitung kemiripan dari isi jurnal yang di indikasikan sama. Sebelum dihitung tingkat kemiripan, maka teks pada jurnal, akan dilakukan proses stemming, yaitu penghapusan imbuhan. Teks yang digunakan untuk proses penghitungan tingkat kemiripan adalah teks yang sudah dilakukan proses stemming. Bahasa pemrograman yang digunakan adalah PHP dengan menggunakan database MySql .
1.3Batasan Masalah
Yang menjadi batasan masalah dalam penelitian ini ialah;
1. Data digunakan adalah jurnal mahasiswa S1 Ilmu Komputer Fasilkom TI USU yang berbahasa Indonesia
2. File yang akan di input adalah berekstensi (.pdf) yang tidak di kunci dan bukan hasil scann.
3. Pengindikasian kemiripan dilihat dari judul jurnal tersebut.
4. Algoritma yang digunakan adalah algoritma Winnowing dan Porter Stemmer. 5. Aplikasi yang dibuat menggunakan Bahasa Pemrograman PHP.
1.4Tujuan Penelitian
Tujuan penelitian ini adalah sebagai berikut:
1. Untuk merancang suatu aplikasi yang dapat memisahkan kalimat dalam bahasa Indonesia menjadi beberapa suku kata yang sesuai dengan kata dasarnya. 2. Untuk mengimplementasikan algoritma Winnowing dan Stemming Potter dalam
pendeteksian kemiripan dua dokumen.
1.5 Manfaat Penelitian
Manfaat penelitian ini adalah untuk mengetahui sejauh mana kemiripan satu dokumen dengan dokumen yang lain, dengan cara memisahkan sesuai kata dasarnya. Algoritma Stemming Potter sendiri untuk memisahkan sesuai suku kata nya. Sehingga dapat diketahui kata asli nya. Dan Winnowing melakukan proses pengecekkan kesamaan suatu kata (document fingerprinting). Dengan adanya penelitian seperti ini, diharapkan dapat mengetahui kecurangan-kecurangan yang terjadi, sehingga para oknum jera dan tidak ada lagi yang berani atau tega menjiplak hasil karya orang tanpa seijin dari orang tersebut .
1.6 Metodologi Penelitian
Tahapan yang dilakukan dalam penelitian ini adalah: 1. Studi Literatur
2. Perancangan Sistem
Pada tahap ini akan di susun perancangan sistem dengan menerapkan algoritma Stemming Potter sebagai algoritma stemmer untuk pendeteksian kemiripan dokumen.
3. Implementasi Sistem
Tahap ini merupakan tahap pengimplementasian sistem yang telah dibangun ke dalam bahasa pemrograman.
4. Pengujian dan Penganalisaan Sistem
Dalam tahap ini dilakukan pengujian aplikasi yang sudah dibangun.
5. Pembuatan laporan skripsi bertujuan untuk dijadikan sebagai dokumentasi hasil penelitian.
6. Penyusunan Laporan
7. Menyusun laporan hasil analisis dan perancangan kedalam bentuk format skripsi.
1.7 Sistematika Penulisan
Sistematika penulisan dalam penyusunan tulisan ini adalah sebagai berikut :
Bab 1 : Pendahuluan
Membahas tentang Latar Belakang, Identifikasi Masalah, Rumusan Masalah, Batasan Masalah, Tujuan Penelitian, Manfaat Penelitian, Metodologi Penelitian dan Sistematika Penulisan.
Membahas tentang teori-teori yang berkaitan dengan information retrieval, natural language processing, dan sistem penghitung kemiripan file.
Bab 3 : Analisa dan Perancangan
Bab ini mendeskripsikan fase-fase awal dalam pengembangan suatu sistem, sehingga terdapat gambaran yang jelas terhadap sistem yang akan dibangun.
Bab 4 : Implementasi dan Pengujian
Bab ini akan membahas tentang hasil dari pengimplementasian analisa yang sudah dirancang sebelumnya, sehingga pada bab ini akan ditampilkan perancangan antar muka serta pengujiannya.
Bab 5 : Kesimpulan dan Saran
Bab terakhir akan memuat kesimpulan isi dari keseluruhan uraian bab-bab sebelumnya dan saran-saran dari hasil yang diperoleh dan diharapkan dapat bermanfaat dalam pengembangan selanjutnya.
BAB 2
LANDASAN TEORI
2.1 Pengertian Stemming
Stemming merupakan suatu proses atau cara dalam menemukan kata dasar dari suatu kata. Stemming sendiri berfungsi untuk menghilangkan variasi-variasi morfologi yang melekat pada sebuah kata dengan cara menghilangkan imbuhan-imbuhan pada kata tersebut, sehingga nantinya di dapat suatu kata yang benar sesuai struktur morfologi bahasa Indonesia yang benar.
2.2 Stemming Porter
Algoritma yang diimplementasikan dalam aplikasi ini menggunakan algoritma Porter. Algoritma Porter ditemukan oleh Martin Porter 1980. Algoritma tersebut digunakan untuk stemming bahasa inggris, kemudian karena proses stemming bahasa inggris berbeda dengan bahasa indonesia maka, dikembangkan algoritma porter khusus untuk bahasa indonesia (Porter Stemmer for Bahasa Indonesia) oleh W.B. Frakes pada tahun 1992. Algoritma ini terkenal digunakan sebagai stemmer untuk bahasa Inggris. Porter Stemmer dalam bahasa Indonesia akan menghasilkan keambiguan karena aturan morfologi bahasa Indonesia. Bila dibandingkan, untuk teks berbahasa Indonesia, Porter stemmer lebih cepat prosesnya daripada algoritma stemming yang lain. Tidak banyak algoritma yang dikhususkan untuk stemming bahasa Indonesia dengan berbagai keterbatasan didalamnya. Algoritma Porter salah satunya, algoritma ini membutuhkan waktu yang lebih singkat dibandingkan dengan stemming menggunakan algoritma lainnya [7].
Langkah-langkah algoritma Stemming Porter adalah sebagai berikut:
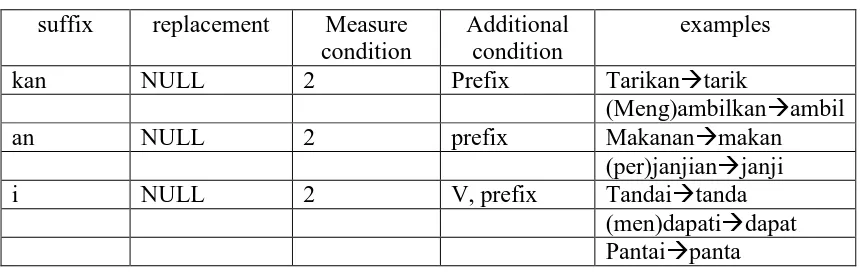
1. Periksa pada kata yang akan di Stemm jika terdapat partikel (kah”, lah”, “-pun”), maka hapus partikel yang melekat.
2. Hapus kata ganti kepemilikan seperti “-ku”, “-mu”, “-nya”, jika ada.
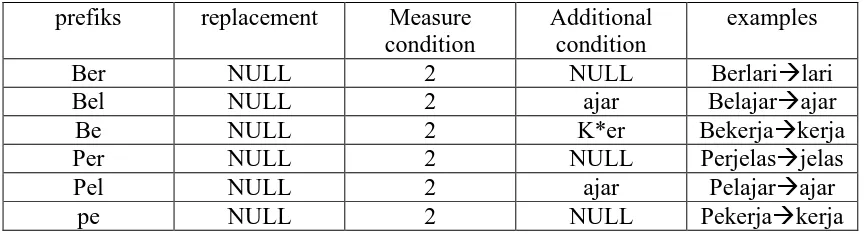
3. Hapus first order prefiks (awalan pertama) seperti “-meng”, “-meny”, “-men”, “-mem”, “-me”, “-peng”, “-peny”, “-pen”, “-pem”, “-di”, “-ter”, “-ke”.
Tabel 2.1 Kelompok rule pertama : inflectional particles
Tabel 2.2 Kelompok rule kedua :inflectional possesive pronouns
Suffix Replacement Measure Condition
Additional
Condition examples
Ku NULL 2 NULL Bukuku buku
Mu NULL 2 NULL bukumu buku
nya NULL 2 NULL Bukunyabuku
Suffix Replacement Measure Condition
Additional
Condition examples
Kah NULL 2 NULL Bukukah
buku
Lah NULL 2 NULL Adalah ada
Tabel 2.3 Kelompok rule ketiga: first order of derivational prefixes
Prefiks Replacement Measure condition
Additional
Tabel 2.4 Kelompok rule keempat: second order of derivational prefixes prefiks replacement Measure
Tabel 2.5 Kelompok rule kelima: derivational suffixes suffix replacement Measure
condition
Stemming adalah proses untuk menggabungkan atau memecahkan setiap varian-varian suatu kata menjadi kata dasar [7]. Stem (akar kata) adalah bagian dari kata yang tersisa setelah dihilangkan imbuhannya (awalan dan akhiran). Contoh : connect adalah stem dari connected, connecting, connection, dan connections. Metode stemming memerlukan input berupa term yang terdapat dalam dokumen. Sedangkan outputnya berupa stem.
Ada tiga jenis metode stemming, antara lain :
1. Successor Variety (SV) : lebih mengutamakan penyusunan huruf dalam kata dibandingkan dengan pertimbangan atas fonem. Contoh untuk kata-kata : corpus, able, axle, accident, ape, about menghasilkan SV untuk kata apple :
1. Karena huruf pertama dari kata “apple” adalah “a”, maka kumpulan kata yang ada substring “a” diikuti “b”, “x”, “c”, “p” disebut SV dari “a” sehingga “a” memiliki 4 SV.
2. N-Gram Conflation : ide dasarnya adalah pengelompokan kata-kata secara bersama berdasarkan karakter-karakter (substring) yang teridentifikasi sepanjang N karakter.
3. Affix Removal : membuang suffix dan prefix dari term menjadi suatu stem. Yang paling sering digunakan adalah algoritma Porter Stemmer karena modelnya sederhana dan effisien.
1. Jika suatu kata diakhiri dengan “ies” tetapi bukan “eies” atau “aies”, maka “ies” direplace dengan “y”
2. Jika suatu kata diakhiri dengan “es” tetapi bukan “aes” atau “ees” atau “oes”, maka “es” direplace dengan “e”
3. Jika suatu kata diakhiri dengan “s” tetapi bukan “us” atau “ss”, maka “s” direplace dengan “NULL”
Gambar 2.1 Diagram Stemming Algoritma Stemming
Successor Variety Affix Removal N-Grams Conflation
Stemming adalah proses pemetaan dari penguraian berbagai bentuk kata baik itu prefik sufik, maupun gabungan antara prefik dan sufik,menjadi bentuk kata dasarnya atau stem.Algoritma Stemming yang digunakan adalah Potter Stemmer untuk bahasa Indonesia. Algoritma stemming dapat mengatasi akhiran yang berupa partikel, akhiran yang menunjukkan kata ganti kepemilikan, prefiks (imbuhan), sufiks (akhiran), dan gabungan antara prefiks dan sufiks. Sebelum melakukan proses penghilangan imbuhan pada Potter Stemmer, dilakukan perhitungan measure. Stemming itu proses pemotongan (pemangkasan) kata untuk mendapatkan bentuk dasar (kata dasar) dari kata tersebut. Misal terdapat kata mempermainkan, maka dari kata tersebut bisa dipilah-pilah menjadi mem + per + main + kan.
Prefiks 1 + Prefiks 2 + Kata dasar + Sufiks 3 + Sufiks 2 + Sufiks 1
Gambar 2.2 Flowchart Stemmer Porter
Pada proses stemmer porter, pertama-tama masukkan kata yang akan di stem, lalu memeriksa apakah terdapat partikel, jika ada maka hapus partikel, jika tidak maka lanjutkan memeriksa apakah terdapat kata kepemilikan, jika ada maka hapus, jika tidak maka lanjutkan. Periksa apakah terdapat prefix, jika ada maka hapus, jika tidak maka lanjutkan memeriksa apakah terdapat sufiks.Jika terdapat sufiks maka hapus. Jika pemeriksaan berhasil maka proses dinyatakan selesai dan tidak perlu melanjutkan proses pemotongan imbuhan selanjutnya. Dokumen dalam bahasa indonesia mempunyai keunikan tersendiri, karena kata - kata dalam bahasa indonesia dapat berubah bentuk saat mendapatkan imbuhan. Akibat dari hal proses Stemmer dari dokumen berbahasa Indonesia, yaitu proses mengembalikan kata ke bentuk dasar, memerlukan teknik tersendiri yang berbeda dengan teknik Stemmer pada bahasa - bahasa lain.
Fungsi Stemmer yang didesain berdasarkan algoritma Porter Stemmer for Bahasa Indonesia adalah inti dari tahap pre-processing yang dibuat. Guna dari fungsi ini adalah sebagai berikut:
1. Dengan mengembalikan kata menjadi kata dasarnya, akan sangat mengurangi macam kata yang perlu diperiksa dan dibandingkan dengan tabel Stopword maupun tabel Keyword. Hal ini akan mempercepat proses perbandingan kata serta mengurangi isi tabel Stopword dan tabel Keyword.
dapat meningkatkan kemungkinan terbentuknya sebuah Rule Assosiasi, atau dapat meningkatkan kualitas Rule Assosiasi yang dihasilkan.
2.3 Winnowing
fingerprint tiap dokumen. Nilai-nilai fingerprint inilah yang digunakan untuk menemukan tingkat presentase kesamaan sebuah dokumen dengan dokumen lain. Input dari algoritma ini sendiri adalah string dari dokumen tersebut, dan output nya berupa nilai-nilai hash yang dinamakan fingerprints dari dokumen tersebut.
Syarat dari algoritma deteksi penjiplakan seperti whitespace insensitivity, yaitu
pencocokan teks file seharusnya tidak terpengaruh oleh spasi, jenis huruf kapital,
tanda baca dan sebagainya,noise surpression yaitu menghindari pencocokan teks file
dengan panjang kata yang terlalu kecil atau kurang relevan dan bukan merupakan
kata yang umum digunakan, dan position independence yaitu pencocokan teks file
seharusnya tidak bergantung pada posisi kata-kata sehingga kata dengan urutan posisi
berbeda masih dapat dikenali jika terjadi kesamaan. Winnowing telah memenuhi
syarat-syarat tersebut dengan cara membuang seluruh karakter-karakter yang tidak
relevan misal: tanda baca, spasi dan juga karakter lain, sehingga nantinya hanya
Algoritma winnowing lebih cepat waktu komputasinya daripada algoritma rabin-karp karena fingerprint dari algoritma rabin-karp lebih banyak sedangkan winnowing dipilih nilai minimum dari window nya. keunggulan algoritma winnowing bisa memberikan informasi posisi fingerprint. Penggunaan nilai window yang semakin besar dapat mempengaruhi dalam waktu proses, karena semakin besar nilai dari suatu window mempengaruhi proses pembentukan nilai-nilai hashing yang semakin kecil. Selain itu, nilai k-gram dan basis juga mempengaruhi dalam memberikan persentasi kemiripan yang diperoleh sistem itu sendiri [3].
2.3.1 Hashing
Hashing adalah mengubah serangkaian karakter menjadi suatu kode atau nilai yang
menjadi penanda dari rangkaian karakter tersebut. Dengan adanya pengubahan
inilah, maka tercipta penanda sebagai indeks untuk digunakan dalam mencari
informasi kembali atau information retrieval. Fungsi untuk menghasilkan nilai ini
disebut fungsi hash, sedangkan nilai yang dihasilkan disebut nilai hash [11].
Nilai hash pada umumnya digambarkan sebagai fingerprint yaitu suatu string
pendek yang terdiri atas huruf dan angka yang terlihat acak. Fungsi Hash adalah
suatu cara menciptakan “fingerprint” dari berbagai data masukan. Fungsi Hash akan
mengganti atau mentranspose-kan data tersebut untuk menciptakan fingerprint, yang
biasa disebut hash value. Hash value biasanya digambarkan sebagai suatu string
pendek yang terdiri atas huruf dan angka yang terlihat random (data biner yang
ditulis dalam notasi hexadecimal). Algoritma fungsi hash yang baik adalah yang
menghasilkan sedikit hash collision. Hash collision merupakan kejadian dua atau
2.3.2 K-gram
K-gram adalah rangkaian substring yang bersebelahan dengan panjang. Metode ini
menghasilkan rangkaian substring sejumlah k-grams, dimana k adalah parameter
yang dipilih oleh user. K-gram mengambil substring karakter huruf sejumlah k dari
sebuah kata yang secara kontinuitas dibaca dari teks sumber hingga akhir dari
dokumen [9]. Dibawah ini salah satu contoh k-gram dengan k=5:
Text: pohon anggur, dan melon
Kemudian dilakukan penghilangan spasi :
pohonanggurdanmelon
Sehingga dihasilkan rangkaian 5-grams yang diturunkan
dari text :
Pohon|| ohona || honan ||onang|| nanggu ||anggu ||nggur
ggurd ||gurda|| urdan|| rdanm|| danme|| anmel|| nmelo
2.4 Jaccard’s Similarity Coefficient
Jaccard’s Similarity Coefficient (Jaccard 1912) merupakan indeks umum untuk variabel biner. Hal ini didefinisikan sebagai hasil bagi antara persimpangan dan serikat variabel dibandingkan berpasangan antara dua benda.
Untuk menghitung kemiripan dari dua dokumen , diperlukan Jaccard’s Similarity Coefficient, dengan rumus :
│ Aᴖ B│
D(A,B) = ________________ X 100% │ AᴗB│- │ Aᴖ B│
Keterangan:
D(A,B) merupakan nilai similarity ,
│ Aᴖ B│ jumlah dari fingerprints dokumen 1 dan 2 yang sama,
BAB 3
ANALISIS DAN PERANCANGAN
3.1 Analisis Sistem
Di dalam merancang suatu sistem diperlukan sebuah analisis sistem untuk membangun sistem tersebut. Analisis sistem ini bertujuan membantu pemodelan rancang bangun sistem yang akan di implementasikan secara konkret nantinya. Tahap ini mendeskripsikan fase-fase awal dalam pengembangan suatu sistem, sehingga terdapat gambaran yang jelas terhadap sistem yang akan dibangun.
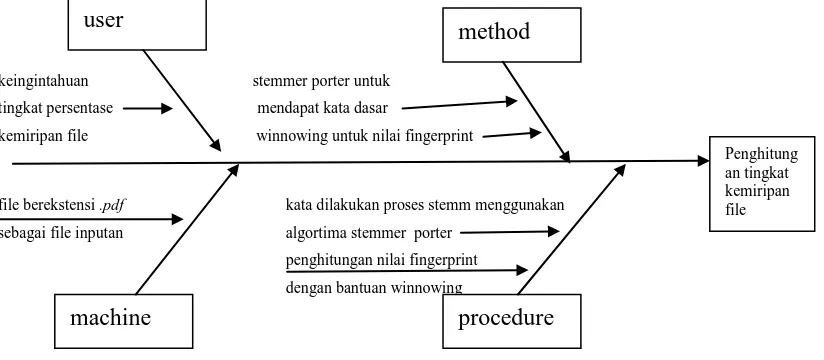
3.2 Analisis Masalah
Pemodelan diagram Ishikawa dapat dilihat pada Gambar 3.1 dibawah ini.
keingintahuan stemmer porter untuk
tingkat persentase mendapat kata dasar
kemiripan file winnowing untuk nilai fingerprint
file berekstensi .pdf kata dilakukan proses stemm menggunakan
sebagai file inputan algortima stemmer porter
penghitungan nilai fingerprint dengan bantuan winnowing
Gambar 3.1 Diagram Ishikawa
Pada diagram Ishikawa diatas, segi empat paling kanan (kepala ikan) menunjukkan masalah utama yaitu user atau admin ingin mengetahui tingkat kesamaan dari suatu file yang akan di cek, sedangkan aspek ditunjukkan oleh segi empat yang dihubungkan oleh sebuah garis ke tulang utama (garis horizontal yang terhubung ke kepala ikan). Selanjutnya, tulang-tulang kecil yang diwakili oleh garis
panah yang mengarah ke tulang-tulang kategori masalah menunjukkan sebab akibat yang muncul pada permasalahan tersebut.
3.3 Analisis Persyaratan (Requirement Analysis)
Analisis persyaratan pada fase ini mempunyai kegunaan untuk menentukan syarat-syarat yang dibutuhkan dalam membangun sistem bentuk fungsional dan non-fungsional yang akan dijelaskan pada tahap selanjutnya. Berikut penjabarannya :
3.3.1 Analisis persyaratan fungsional
Pada fase ini dapat diketahui hal-hal apa saja yang dapat dikerjakan oleh sistem. Hal-hal tersebut antara lain :
1. Sistem ini dilakukan pada file yang berekstensi (.pdf). 2. Sistem akan membaca judul file sesuai dengan nama file.
3. Sistem akan melakukan proses stemming dan mencari nilai fingerprint dari judul file yang di input.
4. Sistem akan memeriksa tingkat kemiripan dengan judul-judul file yang ada dalam database.
5. Sistem akan kembali melakukan proses stemming dan mencari nilai fingerprint isi teks.
7. Sistem akan memberitahu tingkat kemiripan file tersebut dengan file yang lain.
3.3.2Analisis persyaratan non-fungsional
Analisis persyaratan fungsional meliputi ; 1. Perfoma
Sistem yang akan dibangun dapat menghitung tingkat kemiripan antara satu file dengan file yang lain setelah sebelumnya dilakukan dulu proses stemming dan mencari nilai fingerprintnya.
2. Mudah digunakan (user friendly)
Sistem yang akan dibangun memiliki cara penggunaan yang mudah dan tampilan menarik, sehingga lebih memudahkan pengguna untuk
mengoperasikannya. 3. Hemat biaya
Sistem yang akan dibangun tidak memerlukan lagi perangkat tambahan atau perangkat pendukung lain, sehingga tidak perlu lagi mengeluarkan biaya tambahan.
4. Dokumentasi
Sistem yang akan dibangun dapat menyimpan file yang sudah diproses.
3.4 Pemodelan Sistem dengan Usecase dan Activity Diagram
Gambar 3.2 Usecase Diagram
Pada diagram di atas, admin dapat berperan juga sebagai user. Admin menginput file yang akan diproses. File-file tersebut hanya berekstensi (.pdf). Setelah itu, file tersebut diproses dengan menggunakan algoritma-algoritma yang berperan.
Usecase penghitungan kemiripan file dapat dilihat pada table 3.1.
Table 3.1 Usecase Penghitungan Kemiripan File Na me Algortima stemmer porter dan winowing Actors Admin /user
Trigger Admin menginput file yang akan diproses Preconditions File yang akan diproses dibandingkan dengan
file-file yang sebelumnya sudah disimpan di database
Post Conditions Admin dapat melihat hasil penghitungan kemiripan file
2. User mengakses tombol tampilkan isi 3. Sistem akan mengecek berdasar judul yang
memiliki kemiripan
4. Sistem akan membandingkan hanya dengan file-file yang memiliki kemiripan judul
5. Sistem akan kembali melalukan proses pada isi file menggunakan algortima-algoritma yang terkait
6. Sistem akan menampilkan hasil persentase kemiripan
Alternative Flows -
Berikut ini penjelasan untuk table 3.1 :
1. Nama algoritma yang digunakan adalah Stemmer Porter dan Winowing 2. User/admin sebagai actor
3. Tidak tersedia preconditions
4. Pada post conditions, user dapat melihat hasil penghitungan kemiripan file
5. Pada success scenario terdapat proses:
a. User telah menginputkan file yang akan diproses b. User mengakses tombol tampilkan isi
d. Sistem akan membandingkan hanya dengan file-file yang memiliki kemiripan judul
e. Sistem akan kembali melalukan proses pada isi file menggunakan algortima-algoritma yang terkait
f. Sistem akan menampilkan hasil persentase kemiripan
User Sistem
Selesai Input file
Tampilkan hasil kemiripan judul(persentase≥5%)
Tampilkan hasil kemiripan isi file
Memroses judul dengan judul dalam database
Cek isi file tidak
Gambar 3.3 Activity Diagram
Dari activity diagram tersebut, dapat dijelaskan pertama-tama user menginput file yang akan diproses. Setelah itu, sistem akan melakukan pengecekan melalui judul. Judul yang memiliki kemiripan di ambang batas ( ≥5% ), maka sistem akan meneruskan pemrosesan, jika tidak maka user langsung menghentikan pemrosesan. File akan dibandingkan dengan file-file yang memiliki judul hampir sama yang sudah tersimpan di database. Selanjutnya, sistem akan melakukan proses pada isi file tersebut. Stemming porter dilakukan untuk mendapat kata dasar. Lalu dilakukan pembentukan gram dan mencari nilai-nilai hash nya menggunakan winnowing. Setelah itu, didapat nilai fingerprint. Nilai-nilai fingerprint inilah yang nantinya yang akan dibandingkan dengan nilai fingerprint pada file lain. Lalu akan dihitung persentase kemiripan nya. Untuk menghitung kemiripan dari dua dokumen tersebut, diperlukan Jaccard’s Similarity Coefficient.
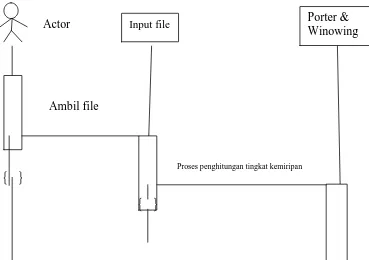
Sequence diagram untuk proses ini dapat dilihat pada gambar 3.4 dibawah ini.
Gambar 3.4 Sequence Diagram
Dari sequence diagram dapat dilihat bahwa file diproses dengan algoritma Porter dan Winowing dengan menginput file terlebih dahulu . Setelah proses stemming dan fingerprint dilakukan, maka di dapat hasil akhir persentase kemiripan file yang satu dengan yang lain.
3.5 Perancangan algoritma
Flow chart merupakan langkah awal pembuatan program. Dengan adanya flowchart urutan poses kegiatan menjadi lebih jelas. Jika ada penambahan proses maka dapat dilakukan lebih mudah. Setelah flowchart selesai disusun, selanjutnya
menerjemahkannya ke bentuk program dengan bahasa pemrograman.
3.5.1 Flow chart Porter
Gambar 3.5 Flow Chart Stemmer Porter
Pada flowchart winnowing pertama tentukan gram yang akan di bentuk, lalu bentuk gram dan hash. Setelah hash terbentuk, maka langkah selanjutnya window pun di bentuk. Nilai-nilai dari minimal dari masing-masing window inilah yang akan menjadi nilai fingerprint untuk menghitung nilai kesamaan dokumen tersebut.
Gambar 3.6 Flow chart Winnowing mulai
Tentukan gram
Bentuk gram
Bentuk window Buat hash
Bentuk fingerprint
3.5.3 Algoritma Porter Stemmer
Awalan-awalan pada stemmer ditentukan dengan langkah-langkah berikut.
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe awalannya secara berturut-turut adalah “di-”, “ke-”, atau “se-”.
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”, “be-”, “me-”, atau “pe-” maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan adalah bukan “none” maka awalan dapat dilihat pada Tabel 2. Hapus awalan jika ditemukan.
Tabel 3.2 Kombinasi Awalan Akhiran Yang Tidak Diijinkan
Awalan Akhiran yang tidak diizinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
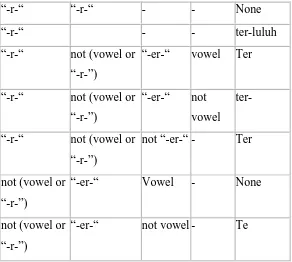
Tabel 3.3 Cara Menentukan Tipe Awalan Untuk awalan “te-”
Following Characters Tipe
Awalan
“-r-“ “-r-“ - - None
Tabel 3.4 Jenis Awalan Berdasarkan Tipe Awalannya
Tipe Awalan Awalan yang harus dihapus
di- di-
1. Aturan untuk reduplikasi.
1. Jika kedua kata yang dihubungkan oleh tanda penghubung adalah kata yang sama maka root word adalah bentuk tunggalnya, contoh : “buku-buku” root word-nya adalah “buku”.
2. Kata lain, misalnya “bolak-balik”, “berbalas-balasan, dan ”seolah-olah”. Untuk mendapatkan root word-nya, kedua kata diartikan secara terpisah. Jika keduanya memiliki root word yang sama maka diubah menjadi bentuk tunggal, contoh: kata “berbalas-balasan”, “berbalas” dan “balasan” memiliki root word yang sama yaitu “balas”, maka root word “berbalas-balasan” adalah “balas”. Sebaliknya, pada kata “bolak-balik”, “bolak” dan “balik” memiliki root word yang berbeda, maka root word-nya adalah “bolak-balik”.
2. Tambahan bentuk awalan dan akhiran serta aturannya.
1. Untuk tipe awalan “mem-“, kata yang diawali dengan awalan “memp-” memiliki tipe awalan “mem-”.
2. Tipe awalan “meng-“, kata yang diawali dengan awalan “mengk-” memiliki tipe awalan “meng-”.
Berikut contoh-contoh aturan yang terdapat pada awalan sebagai pembentuk kata dasar.
1. Awalan SE-
1. Se + bungkus = sebungkus
2. Se + nasib = senasib
3. Se + arah = searah
4. Se + ekor = seekor
2. Awalan ME-
Me + vokal (a,i,u,e,o) menjadi sengau “meng”
Contoh :
Me + konsonan b menjadi “mem”
Contoh :
1. Me + beri = member
2. Me + besuk = membesuk
Me + konsonan c menjadi “men”
Contoh :
1. Me + cinta = mencinta
Me + konsonan d menjadi “men”
Contoh :
1. Me + didik = mendidik
2. Me + dengkur = mendengkur
Me + konsonan g dan h menjadi “meng”
Contoh :
1. Me + gosok = menggosok
2. Me + hukum = menghukum
Me + konsonan j menjadi “men”
Contoh :
1. Me + jepit = menjepit
2. Me + jemput = menjemput
Me + konsonan k menjadi “meng” (luluh)
Contoh :
1. Me + kukus = mengukus 2. Me + kupas = mengupas
Contoh :
1. Me + pesona = mempesona
2. Me + pukul = memukul
Me + konsonan s menjadi “meny” (luluh)
Contoh :
1. Me + sapu = menyapu
2. Me + satu = menyatu
Me + konsonan t menjadi “men” (luluh)
Contoh :
1. Me + tanama = menanam
2. Me + tukar = menukar
Me + konsonan (l,m,n,r,w) menjadi tetap “me”
Contoh :
Contoh :
1. Ke + bawa = kebawa
2. Ke + atas = keatas
4. Awalan PE-
Pe + konsonan (h,g,k) dan vokal menjadi “per”
Contoh :
1. Pe + hitung + an = perhitungan
2. Pe + gelar + an = pergelaran
3. Pe + kantor + = perkantoran
Pe + konsonan “t” menjadi “pen” (luluh)
Contoh :
1. Pe + tukar = penukar
2. Pe + tikam = penikam
Pe + konsonan (j,d,c,z) menjadi “pen”
Contoh :
1. Pe + jahit = penjahit
2. Pe + didik = pendidik
Pe + konsonan (b,f,v) menjadi “pem”
Contoh :
1. Pe + beri = pemberi
2. Pe + bunuh = pembunuh
Pe + konsonan “p” menjadi “pem” (luluh)
Contoh :
1. Pe + pikir = pemikir
2. Pe + potong = pemotong
Pe + konsonan “s” menjadi “peny” (luluh)
Contoh :
1. Pe + siram = penyiram 2. Pe + sabar = penyabar
Contoh :
1. Pe + lamar = pelamar
2. Pe + makan = pemakan
3. Pe + nanti = penanti
4. Pe + wangi = pewangi
3.5.4 Algoritma Winowing
Langkah-langkah algoritma Winnowing :
1. Penghapusan karakter-karakter yang tidak relevan (whitespace insensitivity), antara lain spasi atau tanda baca.
2. Pembentukan rangkaian gram dengan ukuran k.
3. Penghitungan nilai hash dari setiap gram.
4. Membagi ke dalam window tertentu.
5. Pemilihan beberapa nilai hash menjadi document fingerprinting.
Winnowing memiliki rumus sebagai berikut:
Berikut salah satu contoh untuk menghitung nilai fingerprints dari suatu kata;
1. Saya belajar
Hapus spasi = sayabelajar
Ditentukan Gram : 3 , Window : 3
Bentuk Gram Say | aya | yab | abe | bel | ela | laj | aja | jar Nilai Hash:
H(say | b=2 | k=3) ascii(s) * 2(3−1) + ascii(a) * 2(2−1) + ascii(y) * 2(1−1) 115 * 22 + 97 * 21 + 121 * 20 = 460 + 194 + 121 = 775 H(aya | b=2 | k=3) ascii(a) * 2(3−1) + ascii(y) * 2(2−1) + ascii(a) * 2(1−1)
97 * 22 + 105 * 21 + 110 * 20 = 388 + 210 + 110 = 708
Dari kalimat pertama dan kedua didapat nilai fingerprint nya sebagai berikut: Fingerprint1 : [727, 1] [685,2][702,5] [697,6]
Fingerprint2 : [727,1] [685,2] [708,5][735,6]
3.5.5 Perhitungan kemiripan
Untuk menghitung kemiripan dari dua dokumen tersebut, diperlukan Jaccard’s Similarity Coefficient, dengan rumus :
│ Aᴖ B│
│ Aᴖ B│ jumlah dari fingerprints dokumen 1 dan 2 yang sama,
│ AᴗB│ ialah jumlah fingerprints dokumen 1 dan 2 dikurangi jumlah yang sama.
Sehingga dari rumus bisa dihitung tingkat kemiripan dari kalimat pertama dan kedua ;
Kesamaan : (2 / 6 ) * 100% = 33,3 %
Penggunaan nilai window yang semakin besar dapat mempengaruhi dalam waktu proses, karena semakin besar nilai dari suatu window mempengaruhi proses pembentukan nilai-nilai hashing yang semakin kecil. Selain itu, nilai k-gram dan basis juga mempengaruhi dalam memberikan persentasi kemiripan yang diperoleh sistem itu sendiri.
3.6 Perancangan Sistem
3.6.1 Perancangan Antar Muka Form Home
Pada tampilan perancangan home terdapat “choose file” untuk memilih file yang kan diproses, “show content” untuk menampilkan isi dari file tersebut, “title” untuk menampilkan judul dari file tersebut, “content” memuat isi dari file jurnal tersebut, serta “process” untuk memroses jurnal tersebut ke dalam sistem.
Similarity Of Journal
Home Journal Similarity About
Gambar 3.7 Tampilan Form Home Choose file
Show content
title
content
3.6.2 Perancangan Antar Muka Form Journal
Pada perancangan form journal, menampilkan jurnal-jurnal yang telah masuk ke dalam database.
Similarity Of Journal
No Journal … ….
Gambar 3.8 Tampilan Form Journal
Pada perancangan form similarity, menampilkan tingkat kemiripan judul dan kemiripan isi dari jurnal-jurnal yang telah diproses.
Similarity Of Journal
Home Journal Similarity About
No Title Similarity of title Similarity of
content
… … .. ..
… … .. ..
3.6.4 Perancangan Antar Muka Form About
Pada perancangan form about, berisikan informasi dasar dari pembuat aplikasi.
Similarity Of Journal
Home Journal Similarity About
About
BAB 4
IMPLEMENTASI DAN PENGUJIAN
4.1 Implementasi Sistem
Implementasi sistem merupakan tahap lanjutan dari perancangan sistem. Dalam tahap ini, mengimplementasikan hasil analisis dan perancangan sistem ke dalam suatu bahasa pemrograman. Dengan adanya implementasi sistem, akan lebih terlihat nyata hasil akhir dari perancangan sistem yang sudah di analisis sebelumnya.
Pada bab ini akan di tunjukkan implementasi dari penggabungan algoritma Stemmer Porter dan Winnowing serta penghitungan rumus Jaccard’s Similarity Coefficient. Bab sebelumnya sudah di bahas tenteng cara kerja algortima Stemmer dan Winnowing. Sistem ini akan dibangun menggunakan bahasa pemrograman PHP. Pada aplikasi ini akan terdapat 4(empat) halaman utama, yaitu:
4.1.1 Tampilan halaman form home (awal)
Gambar 4.1 Form home
Pada tampilan form home terdapat tombol choose fil, show content, kotak title yang berisi judul jurnal, dan kotak content yang memuat isi jurnal yang akan di proses.
4.1.2 Tampilan halaman form journal
Gambar 4.2 Form journal
4.1.3 Tampilan halaman form similarity
Halaman form similarity atau dengan kata lain menampilkan hasil kemiripan dari jurnal-jurnal yang sudah diproses oleh sistem. Form similarity dapat di lihat pada Gambar 4.3 .
Pada tampilan halaman ini, terdapat tabel yang berisi title, similarity of title, dan similarity of content. Dari tampilan ini dapat diketahui tingkat kesamaan judul antar jurnal yang paling mirip dan ditampilkan juga beserta tingkat kemiripan dari isi-isi jurnal tersebut.
4.1.4 Tampilan halaman form about
Gambar 4.4 Form about
4.2 Pengujian Sistem
Tahapan pengujian sistem merupakan tahapan lanjutan dari implementasi sistem. Tahapan ini memiliki kegunaan untuk membuktikan bahwa hasil dari pengimplementasian analisis dan perancangan sistem telah berhasil.
4.2.1 Pengujian sistem pilih file
Gambar 4.5 Tampilan hasil open file jurnal
Gambar 4.6 Tampilan hasil pilih file
Judul jurnal yang sudah dipilih akan ditampilkan seperti pada gambar di atas.
Gambar 4.7 Tampilan show content
Gambar 4.8 Tampilan hasil proses
Gambar 4.9 Tampilan hasil fingerprint judul
Gambar 4.10 Tampilan hasil fingerprint isi
Setelah judul dari jurnal tersebut di dapat nilai fingerprintnya, maka selanjutnya di cari nilai fingerprint dari isi jurnal. Semua proses judul maupun isi, mengalami algoritma yang sama sehingga di dapat nilai fingerprint masing-masing.
Gambar 4.11 Tampilan hasil kemiripan jurnal
Pada form similarity di atas, diketahui bahwa jurnal yang berjudul “Analisis Perbandingan Metode Simple Additive Weighting dan Metode Fuzzy Multi Criteria Decision Making Untuk Menentukan Lokasi Pengabdian” memiliki kesamaan dengan beberapa jurnal yang lain. Dapat dilihat jurnal tersebut di bandingkan dengan jurnal yang berjudul “ Analisis Perbandingan Algoritma Ant Colony dengan Algoritma A dalam Menentukan Rute Terpendek” memiliki tingkat kesamaan judul sebesar 8.77 %, sedangkan untuk kesamaan isi memiliki tingkat kesamaan sebesar 11.89 %.
Untuk Menentukan Lokasi Pengabdian” memiliki tingkat kemiripan judul paling besar dengan jurnal yang berjudul “Analisis Perbandingan Metode Low Bit Coding dan Least Significant Bit untuk Digital Watermarking pada File WMA” sebesar 11.94 %, sedangkan untuk isi jurnal nya memiliki tingkat kemiripan paling besar 11.89 % terhadap jurnal yang berjudul “Analisis Perbandingan Algoritma Ant Colony dengan Algoritma A dalam Menentukan Rute Terpendek”
4.2.2 Pengujian hasil proses judul file
Aplikasi ini mempunyai langkah-langkah sebagai berikut: 1. Ambil teks dan titik yang terdapat pada file
2. Ubah semua huruf menjadi huruf kecil (lowerchase) 3. Hapus stopword dan yang kurang dari 3 karakter 4. Teks mulai diproses dengan stemming porter 5. Pisahkan kalimat berdasarkan titik
6. Pembentukan grams 7. Pembentukan hash 8. Pembentukan window 9. Pembentukan fingerprint 10.Penghitungan kesamaan
Berikut merupakan contoh penghitungan pada kedua file jurnal yang terdapat dalam database.
Jurnal I:
Jurnal II :
Algoritma Ant Colony System dalam Penjadwalan Kegiatan Belajar Mengajar di Sekolah Dasar.
Kedua judul jurnal tersebut akan diproses sesuai algoritma diatas.
Jurnal I :
1. Analisis Perbandingan Algoritma Ant Colony dengan Algoritma A dalam Menentukan Rute Terpendek.
2. analisis perbandingan algoritma ant colony dengan algoritma a dalam menentukan rute terpendek.
3. Analisis perbandingan algoritma ant colony algoritma rute terpendek.
4. Teks di stemming sesuai kamus kata dasar : Analisis analisis
menentukan tentu rute-rute
5. analisis algoritma ant colony algoritma tentu rute. 6. Pembentukan grams = 5
Ditentukan Gram : 5 , Window : 3
Bentuk Gram anali | nalis | alisi | lisis | isisa | sisal | isalg | salgo | algor | lgori | gorit | oritm | ritma| itmaa| tmaan | maant | aantc | antco | ntcol | tcolo | colon | olony | lonya | onyal | nyalg | yalgo | algor | lgori | gorit | oritm | ritma | itmat | tmate | maten | atent | tentu | entur | nturu | turut | urute |
7. Pembentukan hash Nilai Hash:
H(anali | b=10 | k=5) ascii(a) * 10(5−1) + ascii(n) * 10(4−1) + ascii(a) * 10(3−1) + ascii(l) * 10(2−1) + ascii(i) * 10(1−1)
97 * 104 + 110* 103 + 97 * 102 + 108 * 101 + 105 * 100 1090885
H(nalis | b=10 | k=5 ) ascii(n) * 10(5−1) + ascii(a) * 10(4−1) + ascii(l) * 10(3−1) + ascii(i) * 10(2−1) + ascii(s) * 10(1−1)
Jurnal II :
Algoritma Ant Colony System dalam Penjadwalan Kegiatan Belajar Mengajar di Sekolah Dasar.
1. Algoritma Ant Colony System Penjadwalan Belajar Mengajar Sekolah Dasar. 2. algortima ant Colony system penjadwalan belajar mengajar sekolah dasar, 3. algoritmaantcolonysystempenjadwalanbelajarmengajarsekolahdasar,
4. algor| lgori| gorit| oritm | ritma| itmaa | tmaan | maant| aantc| antco| ntcol | tcolo | colon | olony | lonys | onysy | nysys| ysyst | syste| ystem| stemp| tempe | empen | mpenj | penja | enjad | njadw | jadwa | adwal | dwala | walan | alanb | nbela | belaj|elaja | lajar | ajarm | jarme| armen | rmeng | menga | engaj | ngaja | gajar | ajars| jarse | arsek | rseko | sekol | ekola | kolah | olahd |lahda |ahdas | hdasa | dasar|
Nilai fingerprint jurnal II :
1089524 1153566 1177967 1079259 1092701 1113020 1203325 1233371 1233825 1283761 1277296 1273057 1130670 1082978 1089447 1145957 1096857 1086937 1094857 1086955 1096617 1129277 1188497 1085085
Nilai fingerprint jurnal I :
Kesamaan dari kedua fingerprint nya :
1089524 1153566 1177967 1079259 1092701 1113020
Maka tingkat kemiripan :
│ Aᴖ B│
D(A,B) = ________________ X 100% │ AᴗB│- │ Aᴖ B│
= 6
───── X 100 38
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan pembahasan dan evaluasi dari bab terdahulu, maka dapat ditarik kesimpulan sebagai berikut:
1. Algoritma stemmer porter dan winnowing dapat digunakan dalam menghitung tingkat kemiripan suatu file dengan yang lain.
2. Aplikasi ini dapat digunakan dalam aktivitas yang terjadi pada lingkungan akademik.
3. Algoritma stemmer porter membantu mempercepat algoritma winnowing dalam menentukan nilai fingeprint dari suatu teks. Namun, algoritma winnowing dibantu oleh persamaan jaccard hanya menghitung tingkat kemiripan saja, bukan menentukan file tersebut termasuk plagiat atau tidak.
5.2 Saran
1. Dapat ditambahkan indikator lain yang lebih kompleks dalam setiap perspektif yang terdapat pada algoritma stemmer porter dan winnowing, sehingga dapat dilakukan penghitungan kemiripan file yang lebih detail dan akurat.
2. Sistem ini dapat dikembangkan lebih lanjut dengan menfokuskan pada mengembangkan fitur-fitur yang ada dikarenakan sistem yang dibuat lebih menfokuskan pada penghitungan kemiripan satu file dengan yang lain menggunakan dua algoritma.
DAFTAR PUSTAKA
[1] Djuandi, F., 2008, Jurus Baru Pemrograman SQL Server 2005, ElexMedia Komputindo, Jakarta.
[2]. Han , Jiawei, dan Micheline Kamber, “Data Mining : Concepts andTechniques Second Editions”, San Franscisco, Publish by Morgan Kaufmann Publisher, Copyright © 2006.
[3]. Kusmawan, P. Y., Yuhana, U. L., & Purwitasari, D. (2010). Aplikasi Pendeteksi Penjiplakan pada File Teks dengan Algoritma Winnowing. ITS-Undergraduate-3100010038856 , 1-11.
[4]. Kadir, Abdul. 2003. Dasar Pemrograman Web Dinamis Menggunakan PHP. Andi. Yogyakarta.
[5]. Ledy Agusta, Fakultas Teknologi Informasi; Universitas Kristen SatyaWacana; “Perbandingan Algoritma Stemming Porter Dengan Algoritma Nazief & Adriani Untuk Stemming Dokumen Teks Bahasa Indonesia ”,
http://yudiagusta.files.wordpress.com/2009/11/196-201-knsi09-036- perbandingan-algoritma-stemming-porter-dengan-algoritma-nazief-adriani-untuk-stemming-dokumen-teks-bahasa-indonesia.pdf , Tanggal Akses : 10 Maret 2013
[6]. Prasetyo, Didik. 2005. Solusi Menjadi Web Master Melalui Manajemen Web dengan PHP. PT Elex Media Komputindo. Jakarta.
[7]. Rachmansyah, 2009, Stemmer Kata Bahasa Indonesia 2009, Elex Media Komputindo, Jakarta.
[8]. Steven. (2009, September 14). PERANCANGAN PROGRAM APLIKASI PENDETEKSIAN PLAGIARISME DOKUMEN BERBASIS TEKS
Teknik-Informatika - Matematika Skripsi Sarjana Program Ganda Semester Ganjil 2008/2009, Universitas Bina Nusantara, Jakarta , 8-25.
[9]. Scheimer, Saul, Daniel S. Wilkerson, dan Alex Aiken. Winnowing: Local Algorithms for Document Fingerprinting. San Diego: In Proceedings of the ACM SIGMOD International Conference On Management Of Data. 2003
[10]. S.Pressman , Roger, Ph.D. , “ Rekayasa Perangkat Lunak : Pendekatan Praktisi” (Buku Satu).Penerbit ANDI Bekerja Sama McGraw-Hill Book Companies, Inc. Judul Asli : “Software Engineering: A Practitioner’s Approach ” , Copyright © 1997.
CURRICULUM VITAE
Nama : Lidia Arta Ferari Siahaan Alamat Sekarang : Komplek Pemda Tk.I , Medan Alamat Orang Tua : Puri Masurai II , Jambi
Telp/Hp : 081396632021
Email : [email protected] Riwayat Pendidikan
SD Negeri 196, Jambi dari Tahun 1995 s/d Tahun 2001 SMP Negeri 8, Jambi dari Tahun 2001 s/d Tahun 2004 SMA Negeri 5, Jambi dari Tahun 2004 s/d Tahun 2007 Universitas Sumatera Utara dari Tahun 2008 s/d Tahun 2014 Keterampilan
DAFTAR LAMPIRAN
Nomor
Lampiran Nama Lampiran Halaman
A Tabel ASCII A-1