IMPLEMENTASI ALGORITMA PARTITIONING AROUND MEDOIDS (PAM) UNTUK PENGELOMPOKAN SEKOLAH MENENGAH ATAS DI DIY BERDASARKAN NILAI
DAYA SERAP UJIAN NASIONAL
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun Oleh: Astri Widiastuti Setiyawati
125314076
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
IMPLEMENTATION OF PARTITIONING AROUND MEDOIDS (PAM) ALGORITHM FOR CLUSTERING OF SENIOR HIGH SCHOOL IN DIY BASED ON VALUE ABSORPTION
DATA OF NATIONAL EXAM SCORE
FINAL PROJECT
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Komputer Degree In Informatics Engineering Study Program
By:
Astri Widiastuti Setiyawati 125314076
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATIC ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
YOGYAKARTA 2017
v
HALAMAN PERSEMBAHAN
”Sesungguhnya bersama kesulitan pasti ada kemudahan.
Maka apabila engkau telah selesai (dari suatu urusan),
tetaplah bekerja keras (untuk urusan yang lain)”
(QS 94: 6-7)
Karya ini, penulis persembahkan untuk : Allah SWT
Keluarga Sahabat
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah saya sebutkan dalam kutipan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 2 Februari 2017 Penulis,
vii
ABSTRAK
Penambangan data (data mining) merupakan proses penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data dalam jumlah besar. Salah satu metode dalam data mining adalah clustering. Clustering adalah proses mengelompokan sejumlah sejumlah data/obyek ke dalam klaster (group) sehingga dalam setiap klaster akan berisi data yang semirip mungkin. Salah satu algoritma clustering adalah Partitioning Around Medoids (PAM). PAM adalah metode clustering menggunakan metode partisi untuk mengelompokan sekumpulan n obyek menjadi sejumlah k cluster. Algoritma PAM menggunakan obyek pada kumpulan obyek untuk mewakili sebuah cluster. Obyek yang terpilih untuk mewakili sebuah cluster disebut dengan medoids.
Pada tugas akhir ini akan diimplementasikan algoritma PAM untuk mengelompokan data Sekolah Menengah Atas di DIY berdasarkan nilai daya serap ujian nasional mata pelajaran matematika tahun ajaran 2014/2015 menjadi beberapa kelompok sehingga diperoleh informasi mengenai kelompok-kelompok sekolah di DIY. Proses penambangan data yang dilakukan adalah proses KDD (Knowledge Discovery in Database) yaitu pembersihan data, integrasi data, seleksi data, transformasi data, penambangan data, evaluasi pola, dan presentasi pengetahuan.
Penambangan data dan evaluasi dalam penelitian menggunakan dua jenis data yaitu data nilai daya serap 29 kompetensi dan data rata-rata dari nilai daya serap 29 kompetensi. Berdasarkan evaluasi menggunakan nilai daya serap 29 kompetensi dapat disimpulkan bahwa algoritma ini dapat digunakan untuk mengelompokan data sekolah dengan nilai k yang diberikan. Berdasarkan evaluasi menggunakan rata-rata dari nilai daya serap 29 kompetensi dapat disimpulkan bahwa algoritma ini dapat mengelompokan nilai rata-rata daya serap ke dalam tiga kelompok yaitu kelompok dengan standar deviasi tinggi, sedang, dan rendah.
Kata kunci : penambangan data, clustering, Partitioning Around Medoids (PAM), medoids, KDD, nilai daya serap ujian nasional.
viii
ABSTRACT
Data mining is a mining process or extracting information by getting pattern or specific rules from a large amount of data. One of the data mining method is clustering. Clustering is a process of grouping data/objects into a cluster (group) so in that every cluster contains data as closely as possible. One of clustering algorithm is Partitioning Around Medoids (PAM). PAM is a clustering method that used partitioning method for cluster some n object to k cluster. PAM algorithm used object on the set of objects for representing a cluster. The choosen object for representing a cluster called as medoids.
This thesis will implement of PAM algorithm for clustering high school data in DIY based on the value of absorption data of national exam score mathematics subject in 2014/2015 become some of group so that obtained the information about high school groups in DIY. Process of data mining which is conducted is KDD (Knowledge Discovery in Database) process that is data cleaning, data integration, selection data, transformation data, data mining, pattern evaluation, and knowledge presentation.
Data mining and evaluation in research using two types of data that is value of absorption data 29 comprehension, and data of the average of value of absorption data 29 comprehension. Based on the evaluation using value of absorption data 29 comprehension can be concluded that the algorithm can be used to classify the data of high school by giving the value of k. Based on the evaluation using the average of value of absorption data 29 comprehension can be concluded that this algorithm can be used for grouping the value of the average of absorption data into three groups which is group with high, medium, and low standard deviation.
Keyword : Data mining, Clustering, Partitioning Around Medoids (PAM), Medoids, KDD, value of absorption data of national exam score.
ix
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA
ILMIAH UNTUK KEPERLUAN KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Astri Widiastuti Setiyawati
Nomor Mahasiswa : 125314076
Demi pengembagnan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
IMPLEMENTASI ALGORITMA PARTITIONING AROUND MEDOIDS (PAM) UNTUK PENGELOMPOKAN SEKOLAH MENENGAH ATAS DI DIY
BERDASARKAN NILAI DAYA SERAP UJIAN NASIONAL
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya. Dibuat di Yogyakarta
Pada tanggal : 2 Februari 2017 Yang menyatakan,
x
KATA PENGATAR
Puji dan syukur kepada Tuhan Yang Maha Esa, karena pada akhirnya penulis dapat menyelesaikan peneitian tugas akhie ini yang berjudul ”IMPLEMENTASI ALGORITMA PARTITIONING AROUND MEDOIDS (PAM) UNTUK PENGELOMPOKAN SEKOLAH MENENGAH ATAS DI DIY BERDASARKAN NILAI DAYA SERAP UJIAN NASIONAL”.
Dalam menyelesaikan seluruh penyusunan tugas akhir ini, penulis tak lepas dari doa, bantuan, dukungan, dan motivasi dari banyak pihak. Oleh karena itu, pada kesempatan kali ini penulis menyampaikan rasa penghargaan dan terima kasih yang terdalam kepada:
1. Allah SWT yang selalu memberikan anugrah, rahmat, kekuatan yang berlimpah sehingga penulis dapat menyelesaikan tugas akhi ini.
2. Kedua orang tua penulis, Drs. Setiawan dan Sumarwi atas doa, kasih sayang, perhatian, kepercayaan, dukungan baik moral maupun financial yang telah diberikan kepada penulis.
3. Bapak Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D. selaku Dekan Fakultas Sains dan Teknologi.
4. Ibu Dr. Anastasia Rita Widiarti selaku Ketua Program Studi Teknik Informatika Universitas Sanata Dharma Yogyakarta.
5. Romo Dr. C. Kuntoro Adi, S.J., M.A., M.Sc. selaku Dosen Pembimbing Akademik penulis.
6. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku Dosen Pembimbing skripsi yang telah memberikan waktu, bimbingan, nasihat, dan motivasi kepada penulis.
7. Seluruh Dosen dan Karyawan jurusan Teknik Informatika Universitas Sanata Dharma Yogyakarta, yang telah membimbing dan membantu selama proses perkuliahan.
xi
8. Para sepupu penulis Arin, Dwi, Ayu, dan Bagas serta keluarga besar Marsoedi yang selalu memberikan semangat, doa, dan motivasi dalam penyusunan tugas akhir ini.
9. Vinna Marcelia Tamaela, Yohanes Ragil Purnomo, Laurensius Praba Atmaja, Yosep Dwi N. selaku teman dekat penulis.
10. Untuk sahabat-sahabat penulis Nita, Dhesty, Prilly, Imas, Itha terima kasih untuk persahabata yang terjalin selama perkuliahan.
11. Seluruh teman-teman TI angkatan 2012 untuk bantuan, kebersamaan selama pengerjaan tugas akhir ini dan menjalani masa perkuliahan.
12. Serta semua pihak yang telah membantu penyusunan tugas akhir ini yang tidak dapat disebutkan satu persatu.
Penulis menyadari bahwa masih banyak kekurangan-kekurangan yang perlu diperbaiki dalam skripsi ini, untuk itu penulis mengharapkan masukan dan kritik, serta saran dari berbagai pihak untuk menyempurnakannya. Semoga skripsi ini dapat bermanfaat, baik bagi penulis maupun pembaca. Terima kasih.
Yogyakarta, 2 Februari 2017
xii
DAFTAR ISI
HALAMAN JUDUL ... i
TITLE PAGE ... ii
HALAMAN PERSETUJUAN ... Error! Bookmark not defined. HALAMAN PENGESAHAN ... Error! Bookmark not defined. HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... vi
ABSTRAK ... vii
ABSTRACT ... viii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPERLUAN KEPENTINGAN AKADEMIS ... ix
KATA PENGATAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xvi
DAFTAR TABEL ... xvii
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 4
1.3 Batasan Masalah ... 4
1.4 Tujuan dan Manfaat ... 5
1.5 Metodologi Penelitian ... 6
1.6 Sistematika Penulisan ... 8
BAB II LANDASAN TEORI ... 10
2.1 Knowledge Discovery in Database (KDD) ... 10
2.1.1 Definisi Knowledge Discovery in Database (KDD) ... 10
2.1.2 Tahapan Knowledge Discovery in Database (KDD) ... 10
2.2 Penambangan Data (Data Mining) ... 14
2.2.1 Definisi Penambangan Data (Data Mining) ... 14
2.2.2 Teknik Penambangan Data (Data Mining) ... 14
xiii
2.3.1 Definisi Clustering ... 15
2.3.2 Tipe Clustering ... 16
2.4 Partitioning Around Medoids (PAM) ... 17
2.4.1 Algoritma Partitioning Around Medoids (PAM) ... 17
2.4.2 Contoh Penerapan Algoritma Partitioning Around Medoids (PAM) ... 18
2.5 Silhouette ... 19
2.5.1 Silhouette Index (SI) ... 19
2.5.2 Silhouette Coefficient (SC) ... 22
BAB III METODOLOGI PENELITIAN... 23
3.1 Data ... 23
3.2 Data yang Digunakan ... 28
3.3 Spesifikasi Alat ... 32
3.3.1 Spesifikasi Software ... 32
3.3.2 Spesifikasi Hardware ... 32
BAB IV PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA... 33
4.1 Pemrosesan Awal Sumber Data ... 33
4.1.1 Pembersihan Data... 33
4.1.2 Integrasi Data ... 33
4.1.3 Seleksi Data ... 33
4.1.4 Transformasi Data ... 34
4.2 Perancangan Perangkat Lunak Penambangan Data ... 35
4.2.1 Perancangan Umum ... 35
4.2.1.1 Input ... 35
4.2.1.2 Proses ... 35
4.2.1.3 Output ... 36
4.2.2 Diagram Konteks (Context Diagram) ... 37
4.2.3 Diagram Usecase ... 37
4.2.4 Diagram Aktivitas (Activity Diagram) ... 38
4.2.5 Diagram Kelas (Class Diagram) ... 40
xiv
4.2.6.1 Halaman Awal ... 40
4.2.6.2 Halaman Bantuan ... 41
4.2.6.3 Halaman Informasi ... 42
4.2.6.4 Halaman Input Data ... 42
4.2.6.5 Halaman K-Medoids ... 43
BAB V IMPLEMENTASI DAN EVALUASI HASIL ... 45
5.1 Implementasi Rancangan Perangkat Lunak Penambangan Data ... 45
5.1.1 Implementasi Tampilan Antarmuka ... 46
5.1.1.1 Halaman Utama ... 46
5.1.1.2 Halaman Bantuan ... 47
5.1.1.3 Halaman Informasi ... 47
5.1.1.4 Halaman Input Data ... 48
5.1.1.5 Halaman K-Medoids ... 51
5.2 Evaluasi Hasil ... 52
5.2.1 Uji Coba Perangkat Lunak (Black Box) ... 52
5.2.1.1 Rencana Pengujian Black Box ... 52
5.2.1.2 Prosedur Pengujian Black Box dan Kasus Uji ... 53
5.2.1.3 Evaluasi Pengujian Black Box ... 53
5.2.2 Pengujian Perbandingan Hasil Hitung Manual dengan Hasil Perangkat Lunak... 54
5.2.2.1 Perhitungan Manual ... 54
5.2.2.2 Perhitungan Perangkat Lunak... 54
5.2.2.3 Evaluasi Pengujian Perbandingan Hitung Manual dengan Hasil Perangkat Lunak... 55
5.2.2.4 Pengujian Perangkat Lunak Dengan Menggunakan Dataset ... 57
5.2.2.5 Evaluasi Hasil Clustering ... 57
BAB VI PENUTUP ... 63
6.1 Kesimpulan ... 63
6.2 Saran ... 65
DAFTAR PUSTAKA ... 66
LAMPIRAN 1 : Contoh Perhitungan K-Medoids ... 68
xv
LAMPIRAN 3 : Prosedur Pengujian dan Kasus Uji ... 73
LAMPIRAN 4 : Data Uji Algoritma K-Medoids ... 77
LAMPIRAN 5 : Perhitungan Manual ... 80
LAMPIRAN 6 : Hasil Pengujian Dataset ... 99
xvi
DAFTAR GAMBAR
Gambar 2.1 Proses Knowledge Discovery in Database (Han&Kamber, 2006) ... 11
Gambar 4.1 Data awal nilai daya serap ... 34
Gambar 4.2 Data setelah proses transformasi ... 35
Gambar 4.3 Proses Umum Sistem ... 36
Gambar 4.4 Diagram Konteks... 37
Gambar 4.5 Diagram Usecase... 37
Gambar 4.6 Diagram Aktivitas Input Berkas ... 38
Gambar 4.7 Diagram Aktivitas Seleksi Atribut ... 39
Gambar 4.8 Diagram Aktivitas Proses Clustering ... 39
Gambar 4.9 Diagram Aktivitas Simpan Hasil... 40
Gambar 4.10 Rancangan Antarmuka Halaman Awal ... 41
Gambar 4.11 Rancangan Antarmuka Halaman Bantuan ... 42
Gambar 4.12 Rancangan Antarmuka Halaman Tentang ... 42
Gambar 4.13 Rancangan Antarmuka Halaman Input Data ... 43
Gambar 4.14 Rancangan Antarmuka Halaman K-Medoids ... 44
Gambar 5.1 Halaman Awal ... 46
Gambar 5.2 Halaman Bantuan ... 47
Gambar 5.3 Halaman Informasi ... 48
Gambar 5.4 Halaman Input Data ... 49
Gambar 5.5 Halaman Input Data (berkas .xls) ... 49
Gambar 5.6 Halaman Input Data (hapus atribut) ... 50
Gambar 5.7 Halaman Input Data (Hapus Atribut) ... 50
Gambar 5.8 Halaman K-Medoids ... 51
Gambar 5.9 Halaman K-Medoids (Clustering) ... 52
Gambar 5.10 Hasil Penambangan Data Menggunakan Perangkat Lunak ... 55
xvii
DAFTAR TABEL
Tabel 2.1 Data Contoh ... 19
Tabel 2.2 Kriteria subjektif pengukuran pengelompokan berdasarkan Silhouette Coefficient (SC) ... 22
Tabel 3.1 Atribut nilai daya serap ujian nasional pelajaran matematika tahun 2014/2015. ... 23
Tabel 3.2 Atribut nilai daya serap ujian nasional pelajaran matematika tahun 2014/2015 yang digunakan dalam penelitian ... 28
Tabel 5.1 Nama kelas yang diimpelentasikan ... 45
Tabel 5.2 Rencana Pengujian Black Box ... 53
Tabel 5.3 Uji Perbandingan Algoritma K-Medoids Secara Manual dan Sistem ... 56
Tabel 5.4 Hasil Uji Perbandingan Anggota Cluster Secara Manual dan Sistem ... 56
Tabel 5.5 Hasil Perhitungan Silhouette Coefficient (SC) ... 57
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Penambangan data (data mining) adalah proses yang memperkerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan (knowledge) secara otomatis. Data mining berisi pencarian trend atau pola yang diinginkan dalam database besar untuk membantu pengambilan keputusan di waktu yang akan datang. Pola-pola ini dikenali oleh perangkat tertentu yang dapat memberikan suatu analisa data yang berguna dan berwawasan yang kemudian dapat dipelajari dengan lebih teliti, yang mungkin saja menggunakan perangkat pendukung keputusan yang lainnya (Hermawati, 2013).
Clustering merupakan salah satu teknik dalam penambangan data. Clustering bertujuan untuk mengelompokkan sejumlah data/obyek ke dalam klaster (group) sehingga dalam setiap klaster akan berisi data yang semirip mungkin. Salah satu algoritma clustering adalah Partitioning Around Medoids (PAM). Algoritma Partitioning Around Medoids (PAM) lebih dikenal dengan algoritma K-Medoids. Algoritma ini merupakan teknik partisi klasik untuk clustering yang melakukan klasterisasi data dari n obyek ke dalam k cluster yang dikenal dengan apriori. Perbedaan antara K-Means dan K-Medoids terletak pada cara kedua metode tersebut menghentikan perhitungan dan melakukan perulangan. Jika pada K-Means berpatokan pada kondisi konvergen, pada K-Medoids tergantung pada kualitas kluster yang didapat pada perulangan terakhir (Tiwari, 2012). Algoritma K-Medoids lebih kuat daripada algoritma K-Means bila dihadapkan dengan noise dan outliers, karena medoid kurang dipengaruhi oleh outliers atau nilai-nilai ekstrim yang lain daripada sebuah mean (Yusupa, 2015).
Ujian Nasional merupakan penilaian pada akhir proses pembelajaran di sekolah. Penilaian merupakan serangkaian kegiatan untuk memperoleh, menganalisis,
2
dan menafsirkan data tentang proses dan hasil belajar siswa yang dilakukan secara sistematis dan berkesinambungan sehingga menjadi informasi yang bermaksa dalam mengambil keputusan (Depdikbud, 1994). Ujian Nasional bertujuan untuk menilai pencapaian kompetensi lulusan secara nasional pada mata pelajaran tertentu. Ujian Nasional diadakan sekurang-kurangnya satu kali dan sebanyak-banyaknya dua kali dalam satu tahun pelajaran (PP No. 19 tahun 2005, ps. 66).
Dalam Permendiknas No. 63 tahun 2009 tentang Sistem Penjaminan Mutu Pendidikan (SPMP) pasal 20 menyatakan bahwa salah satu jenis kegiatan penjaminan mutu pendidikan adalah evaluasi dan pemetaan mutu satuan atau program pendidikan oleh Pemerintah, Pemerintah Provinsi, dan Pemerintah Kabupaten atau Kota. Pemerintah telah menentukan kebijakan dalam meningkatkan standar mutu pendidikan dengan melakukan Ujian Nasional (UN) dan Ujian Sekolah (US) setiap tahunnya.
Hasil Ujian Nasional tersedia di web kemdikbud dengan berbagai format. Salah satu format yang disajikan adalah mengenai daya serap. Daya serap memuat informasi mengenai proporsi atau presentase jawaban benar yang bisa dipilih berdasarkan kelompok maupun SKL. Daya serap memberikan gambaran tentang kemampuan peserta didik dalam penguasaan indikator dari kompetensi/pokok bahasan mata pelajaran. Mengetahui nilai daya serap dapat menjadikan sebagai tolak ukur untuk mengetahui sejauh mana pemahaman peserta didik terhadap mata pelajaran yang diajarkan oleh gurunya.
Dalam Permendikbud No. 143 tahun 2014 tentang Petunjuk Tekniks Pelaksanaan Jabatan Fungsional Pengawas Sekolah dan Angka Kreditnya, beserta lampirannya yang merupakan satu kesatuan utuh. Menurut permendikbud ini bahwa tugas pokok pengawas sekolah adalah melaksanakan tugas pengawasan akademik dan manajerial pada satuan pendidikan yang meliputi penyusunan program pengawasan, peniliaian, pembimbingan, dan pelatiahan profesional guru, evaluasi hasil pelaksanaan program pengawasan, dan pelaksanaan tugas pegawasan didaerah khusus. Adapun beban kerja pengawas sekolah dalam melaksanakan tugas pengawasan adalah 37.50 jam perminggu. Dengan sasaran untuk SMP/MTs, SMA/MA, dan SMK/MAK paling sedikit 7 (tujuh) satuan pendidikan.
3
Clustering berpotensi sebagai alat untuk menganalisis nilai daya serap ujian nasional, karena clustering memiliki konsep membagi data menjadi kelompok-kelompok agar dapat membantu dalam proses pengelompokan SMA khususnya yang berada di Provinsi DIY berdasarkan nilai daya serap ujian nasional.
Pada penelitian ini, penulis mengkhususkan melakukan pengelompokan Sekolah Menengah Atas berdasarkan pada mata pelajaran matematika. Hal ini didasari karena pentingnya peranan pelajaran matematika dalam kehidupan sehari-hari. Dengan mempelajari matematika, manusia dapat memecahkan suatu permasalahan. Baik memecahkan masalah dalam pengerjaan soal-soal maupun memecahkan permasalahan yang lain dalam kehidupan nyata. Selain itu mempelajari matematika dapat membuat manusia menjadi lebih teliti, cermat, dan tidak ceroboh dalam bertindak.
Penelitian serupa telah dilakukan oleh Megawati (2015) yang berjudul “Implementasi Algoritma Fuzzy C-Means untuk Pengelompokan Sekolah Menengah Atas di DIY Berdasarkan Nilai Ujian Nasional dan Ujian Sekolah” yang bertujuan untuk mengelompokkan Sekolah Menengah Atas berdasarkan nilai ujian nasional dan nilai sekolah dengan menggunakan algoritma Fuzzy C-Means. Sedangkan, pada penelitian ini hanya menggunakan nilai daya serap Ujian Nasional dengan lokasi penelitian yang sama yaitu pada Provinsi DIY. Jika pada penelitian sebelumnya menggunakan algoritma Fuzzy C-Means sebagai algoritma untuk mengelompokan Sekolah Menengah Atas pada penelitian penulis saat ini adalah menggunakan algoritma Partitioning Around Medoids sebagai algoritma untuk mengelompokkan Sekolah Menengah Atas. Hasil pengelompokan sekolah menengah atas selanjutnya dapat dipergunakan untuk membantu Departemen Pendidikan Provinsi dan juga penyelenggara pendidikan untuk melihat dan mengevaluasi sekolah-sekolah yang termasuk ke dalam kelompok nilai daya serap tinggi, sedang, dan rendah. Dengan demikian Departemen Pendidikan Provinsi dapat mengambil langkah perbaikan yang tepat.
Berdasarkan hal diatas, maka penulis tertarik untuk mengimplementasikan algoritma Partitioning Around Medoids (PAM) dan mengambil judul untuk tugas akhir yaitu “Implementasi Algoritma Partitioning Around Medoids (PAM) untuk
4
Pengelompokkan Sekolah Menengah Atas di DIY berdasarkan Nilai Daya Serap Ujian Nasional” untuk membantu dalam proses pengelompokan data Sekolah Menengah Atas dengan algoritma Partitioning Around Medoids (PAM).
1.2 Rumusan Masalah
Berdasarkan permasalahan yang telah dikemukakan diatas, maka rumusan masalah yang akan penulis bahas adalah :
1. Bagaimana menerapkan algoritma Partitioning Around Medoid (PAM) untuk mengelompokkan sekolah menengah atas di Provinsi DIY berdasarkan nilai daya serap ujian nasional matapelajaran matematika? 2. Bagaimana hasil evaluasi dari pengelompokan sekolah berdasarkan nilai
daya serap 29 kompetensi dalam mata pelajaran matematika dengan menggunakan algoritma Partitioning Around Medoid (PAM) berdasarkan Silhouette Index (SI)?
3. Bagaimana hasil evaluasi dari pengelompokan sekolah berdasarkan rata-rata nilai daya serap 29 kompetensi dalam mata pelajaran matematika dengan algoritma Partitioning Around Medoid (PAM) menggunakan 3 cluster sesuai peringkat akreditasi?
1.3 Batasan Masalah
Adapun batasan masalah dalam tugas akhir ini adalah :
1. Algoritma yang digunakan adalah menggunakan algoritma Partitioning Around Medoid (PAM) atau K-Medoids.
2. Data yang digunakan adalah data nilai daya serap ujian nasional mata pelajaran matematika siswa SMA jurusan IPA di Provinsi DIY tahun ajaran 2014/2015.
5
3. Atribut clustering yang digunakan adalah data nilai daya serap ujian nasional mata pelajaran matematika di Provinsi DIY yang meliputi atribut nama sekolah dan jumlah kompetensi daya serap mata pelajaran matematika.
1.4 Tujuan dan Manfaat
Tujuan dari penulisan tugas akhir ini adalah :
1. Mengetahui hasil pengelompokan Sekolah Menengah Atas berdasarkan nilai daya serap mata pelajaran matematika dengan menggunakan 29 kompetensi pada tahun ajaran 2014/2015 dengan menggunakan algoritma Partitioning Around Medoid (PAM).
2. Mengevaluasi hasil pengelompokan Sekolah Menengah Atas berdasarkan mata pelajaran matematika dengan menggunakan algoritma Partitioning Around Medoid (PAM) berdasarkan nilai Silhouette Index (SI) untuk jumlah cluster k=2 hingga k=(1/2)*n.
3. Mengetahui hasil pengelompokan Sekolah Menengah Atas berdasarkan nilai daya serap mata pelajaran matematika dengan menggunakan rata-rata dari 29 kompetensi pada tahun ajaran 2014/2015.
4. Mengevaluasi hasil pengelompokan Sekolah Menengah Atas berdasarkan rata-rata nilai daya serap mata pelajaran matematika dengan menggunakan 3 cluster sesuai peringkat akreditasi.
Manfaat dari penulisan tugas akhir ini adalah :
1. Diharapkan menjadi bahan evaluasi bagi Sekolah Menengah Atas khususnya di DIY agar bisa meningkatkan kualitas pembelajaran mata pelajaran matematika bagi siswanya.
6
2. Dapat memberikan gambaran mengenai implementasi dari algoritma Partitioning Around Medoids dalam menghasilkan pengelompokan Sekolah Menengah Atas berdasarkan nilai daya serap ujian nasional.
1.5 Metodologi Penelitian
Metode penelitian yang digunakan penulis dalam menyelesaikan tugas akhir adalah sebagai berikut :
1. Studi Pustaka
Pada tahapan ini merupakan proses pengumpulan data dan pengumpulan informasi algoritma yang akan digunakan dengan cara mempelajari berbagai referensi (buku, laporan, hasil penelitian, jurnal, ataupun artikel) yang berhubungan dengan masalah yang diteliti.
2. Pembersihan data (data cleaning)
Pada tahapan ini merupakan proses pembuangan data yang tidak relevan atau tidak konsisten terhadap data lainnya.
3. Integrasi data (data integration)
Pada tahapan integrase data ini akan dilakukan penggabungan data dari berbagai sumber/database yang ada.
4. Seleksi data (data selection)
Pada tahapan seleksi data ini merupakan tahapan menyeleksi data yang akan digunakan dalam penelitian.
5. Transformasi data (data transformation)
Pada tahapan ini akan dilakukan format data asli ke dalam format data yang sesuai dengan penelitian.
7 6. Penambangan data (data mining)
Pada tahapan ini akan dilakukan proses penambangan data menggunakan algoritma Partitioning Around Medoids (PAM) dengan menggunakan metode Waterfall dengan tahap-tahap sebagai berikut:
a. Analisa
Pada tahapan ini merupakan tahapan menganalisis hal-hal yang diperlukan dalam pelaksanaan proses pembuatan perangkat lunak penambangan data.
b. Desain
Tahapan desain ini merupakan tahapan penerjemahan dari data yang dianalisis kedalam bentuk yang mudah dimengerti oleh user.
c. Coding
Tahapan coding merupakan tahapan pemecahan masalah yang telah dirancang ke dalam bahasa pemrograman tertentu.
d. Testing atau pengujian
Pada tahapan ini merupakan tahap pengujian terhadap perangkat lunak penambangan data yang telah dibangun.
7. Evaluasi pola (pattern evaluasi)
Pada tahapan ini akan dilakukan proses evaluasi terhadap hasil data mining yang telah dilakukan pada proses sebelumnya.
8. Presentasi pengetahuan (knowledge presentation)
Pada tahapan ini akan dilakukan presentasi hasil data mining yang telah dikerjakan sebelumnya.
8
1.6 Sistematika Penulisan
Sistematika penulisan dibagi menjadi beberapa bab, sebagai berikut : BAB I : Pendahuluan
Bab ini berisi tentang latar belakang, rumusan masalah, batasan masalah, tujuan dan manfaat, metodologi penelitian, dan sistematika penulisan tugas akhir.
BAB II : Landasan Teori
Bab ini membahas tentang teori-teori yang digunakan guna menunjang penelitian dan menjadi dasar atau sumber tertulis dari apa yang akan dilakukan yaitu, Knowledge Discovery in Database (KDD), Penambangan Data (data mining), Clustering, Partitioning Around Medoids (PAM), dan Silhouette Index (SI).
BAB III : Metodologi Penelitian
Bab ini akan menjelaskan tentang penelitian pustaka yang berisikan data, data yang digunakan, dan spesifikasi alat.
BAB IV : Pemrosesan Awal dan Perancangan Perangkat Lunak Penambangan Data
Bab ini membahas tentang pemrosesan awal dari data yang akan digunakan dan perancangan dari perangkat lunak penambangan data yang akan dibangun.
BAB V : Implementasi Penambangan Data dan Evaluasi Hasil
Bab ini berisi mengenai implementasi sistem yang dibangun dan analisis hasil dari sistem yang telah dibuat.
9 BAB VI : Penutup
Bab ini berisi mengenai kesimpulan dan saran mengenai sistem yang dibuat.
10
BAB II
LANDASAN TEORI
2.1 Knowledge Discovery in Database (KDD)
2.1.1 Definisi Knowledge Discovery in Database (KDD)
Knowledge Discovery in Database (KDD) adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola, atau hubungan dalam set data berukuran besar. Penambangan data (data mining) merupakan bagian dari Knowledge Discovery in Database yang merupakan kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola, atau hubungan dalam data yang berukuran besar (Santosa, 2007).
2.1.2 Tahapan Knowledge Discovery in Database (KDD)
Menurut Han and Kamber (2006), penambangan data tidak dapat dipisahkan dari proses Knowledge Discovery in Database (KDD). KDD merupakan sebuah proses mengubah data mentah menjadi suatu informasi yang berguna. Tahapan KDD merupakan suatu rangkaian proses penambangan data (data mining) dan dapat dibagi menjadi beberapa tahap. Tahap-tahap tersebut bersifat interaktif di mana pemakai terlibat langsung atau melalui perantara knowledge base. Ilustrasi proses KDD dapat dilihat pada gambar 2.1.
11
Gambar 2.1 Proses Knowledge Discovery in Database
(Han&Kamber, 2006)
Tahapan proses Knowledge Discovery in Database (KDD) adalah sebagai berikut :
1. Pembersihan data (data cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak relevan dengan hipotesa data mining yang dimiliki. Data-data yang tidak relevan itu juga lebih baik dibuang. Pembersihan data juga akan mempengaruhi performasi dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
12 2. Integrasi data (data integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru. Tidak jarang data yang diperlukan untuk data mining tidak hanya berasal dari satu database tetapi juga berasal dari beberapa database atau file teks. Integrasi data dilakukan pada atribut-aribut yang mengidentifikasikan entitas-entitas yang unik seperti atribut nama, jenis produk, nomor pelanggan dan lainnya. Integrasi data perlu dilakukan secara cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya. Sebagai contoh bila integrasi data berdasarkan jenis produk ternyata menggabungkan produk dari kategori yang berbeda maka akan didapatkan korelasi antar produk yang sebenarnya tidak ada. 3. Seleksi data (data selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database. Sebagai contoh, sebuah kasus yang meneliti faktor kecenderungan orang membeli dalam kasus market basket analysis, tidak perlu mengambil nama pelanggan, cukup dengan id pelanggan saja.
4. Transformasi data (data transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining. Beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clustering hanya bisa menerima input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagi-bagi menjadi beberapa interval. Proses ini sering disebut transformasi data.
13 5. Penambangan data (data mining)
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi pola (pattern evaluation)
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan. Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai hipotesa ada beberapa alternatif yang dapat diambil seperti menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba metode data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
7. Presentasi pengetahuan (knowledge presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan dalam proses data mining. Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan hasil data mining.
Tahap 1 sampai dengan tahap 4 merupakan berbagai bentuk dari data preprocessing, dimana data disiapkan untuk dilakukan penambangan (mining). Data mining hanya salah satu langkah dari keseluruhan proses dalam Knowledge Discovery in Database (KDD).
14
2.2 Penambangan Data (Data Mining)
2.2.1 Definisi Penambangan Data (Data Mining)
Penambangan data (Data mining) adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan teknik statistic, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban, dkk, 2005).
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual (Pramudiono, 2006).
Data mining merupakan analisis dari peninjauan kumpulan data untuk menemukan hubungan tidak diduga dan meringkas data dengan cara yang berbeda dengan sebelumnya, yang dapat dipahami dengan bermanfaat bagi pemilik data (Larose, 2005).
2.2.2 Teknik Penambangan Data (Data Mining)
Teknik dalam penambangan data adalah sebagai berikut (Hermawati, 2013): 1. Classification (klasifikasi)
Klasifikasi adalah menentukan sebuah record data baru ke salah satu dari beberapa kategori (atau klas) yang telah didefinisikan sebelumnya. Disebut juga dengan ‘supervised learning’.
2. Clustering (klasterisasi)
Klasterisasi adalah mempartisi data-set menjadi beberapa sub-set atau kelompok sedemikian rupa sehingga elemen-elemen dari suatu kelompok tertentu memiliki set property yang dishare bersama, dengan tingkat similaritasyang tinggi dalam satu kelompok dan tingkat similaritas antar kelompok yang rendah. Disebut juga dengan ‘unsupervised learning’.
15
3. Association Rule Discovery (kaidah asosiasi)
Mendeteksi kumpulan atribut-atribut yang muncul bersamaan (co-occur) dalam frekuensi yang sering, dan membentuk sejumlah kaidah dari kumpulan-kumpulan tersebut.
2.3 Clustering
2.3.1 Definisi Clustering
Clustering yaitu menemukan kumpulan obyek hingga obyek-obyek dalam satu kelompok sama (atau punya hubungan) dengan yang lain dan berbeda (atau tidak berhubungan) dengan obyek-obyek dalam kelompok lain. Tujuan dari clustering adalah untuk meminimalkan jarak di dalam cluster dan memaksimalkan jarak antar cluster.
Dalam mengukur jarak dalam clustering dapat dilakukan dengan menggunakan Euclidean Distance. Euclidean distance merupakan pengukuran jarak obyek dan pusat cluster yang banyak digunakan secara luas dalam berbagai kasus pattern matching, termasuk clustering. Eucludean distance dinyatakan dengan persamaan :
𝑑𝑖𝑠𝑡 = √∑𝑛𝑘=1(𝑝𝑘− 𝑞𝑘)2 ……….(2.1)
Dimana :
n = jumlah fitur dalam suatu data. k = indeks data.
pk = nilai atribut (fitur) ke-k dari p.
16
2.3.2 Tipe Clustering
Clustering merupakan suatu kumpulan dari keseluruhan cluster. Beberapa tipe penting dari clustering adalah sebagai berikut (Hermawati, 2013):
1. Partitional vs Hierarchical
Partitional clustering adalah pembagian obyek data ke dalam subhimpunan (cluster) yang tidak overlap sedemikian hingga tiap obyek data berada dalam tepat satu sub-himpunan.
Hierarchical clustering merupakan sebuah himpunan cluster bersarang yang diatur sebagai suatu pohon hirarki. Tiap simpul (cluster) dalam pohon (kecuali simpul daun) merupakan gabungan dari anaknya (subcluster) dan simpul akar berisi semua obyek.
2. Exclusive vs non-exclusive
Exclusive clustering adalah bila setiap obyek yang ada berada tepat di dalam satu cluster.
Overlapping atau non-exclusive clustering adalah bila sebuah obyek dapat berada di lebih dari satu cluster secara bersamaan.
3. Fuzzy vs non-fuzzy
Dalam fuzzy clustering, sebuah titik termasuk dalam setiap cluster dengan suatu nilai bobot antara 0 dan 1. Jumlah dari bobot-bobot tersebut sama dengan 1. Clustering probabilitas mempunyai karakteristik yang sama. 4. Partial vs complete
Dalam complete clustering, setiap obyek ditempatkan dalam sebuah cluster. Tetapi dalam partial clustering, tidak semua obyek ditempatkan dalam sebuah cluster. Kemungkinan ada obyek yang tidak tepat untuk ditempatkan di salah satu cluster, misalkan berupa outlier atau noise.
17
2.4 Partitioning Around Medoids (PAM)
Algoritma Partitioning Around Medoids (PAM) atau dikenal juga dengan K-Medoids adalah algoritma pengelompokan yang berkaitan dengan algoritma K-Means dan algoritma medoidshift. Algoritma K-Medoids ini diusulkan pada tahun 1987.
Algoritma Partitioning Around Medoids (PAM) dikembangkan oleh Leonard Kaufman dan Peter J. Rousseeuw. Algoritma ini sangat mirip dengan algoritma K-Means, terutama karena kedua algoritma ini partitional. Dengan kata lain, kedua algoritma ini memecah dataset menjadi kelompok-kelompok dan kedua algoritma ini berusaha untuk meminimalkan kesalahan. Tetapi algoritma Partitioning Around Medoids (PAM) bekerja dengan menggunakan Medoids, yang merupakan entitas dari dataset yang mewakili kelompok dimana ia dimasukkan.
Algoritma Partitioning Around Medoids (PAM) menggunakan metode partisi clustering untuk mengelompokkan sekumpulan n obyek menjadi sejumlah kcluster. Algoritma ini menggunakan obyek pada kumpulan obyek untuk mewakili sebuah cluster. Obyek yang terpilih untuk mewakili sebuah cluster disebut dengan medoid. Cluster dibangun dengan menghitung kedekatan yang dimiliki antara medoid dengan obyek non-medoid.
2.4.1 Algoritma Partitioning Around Medoids (PAM)
Algoritma dari Partitioning Around Medoids (PAM) atau K-Medoids adalah sebagai berikut (Han & Kamber, 2006):
1. Secara acak pilih k obyek pada sekumpulan n obyek sebagai medoid. 2. Ulangi langkah 3 hingga langkah 6.
3. Tempatkan obyek non-medoid ke dalam cluster yang paling dekat dengan medoid.
18
5. Hitung total biaya, S, dari pertukaran medoid oj dengan orandom.
6. Jika S < 0 maka tukar ojdengan orandom untuk membentuk sekumpulan k obyek
baru sebagai medoid.
7. Hingga tidak ada perubahan.
Nilai total biaya/cost dinyatakan dengan persamaan:
Total 𝑐𝑜𝑠𝑡 = ∑ 𝑑𝑖𝑠𝑡 ……….(2.2) Dimana :
dist = merujuk pada rumus 2.1
Nilai S dinyatakan dengan persamaan:
S = Total 𝑐𝑜𝑠𝑡 baru − Total 𝑐𝑜𝑠𝑡 lama ……….(2.3) Dimana :
Total cost baru = jumlah biaya/cost non-medoids. Total cost baru = jumlah biaya/cost medoids.
K-medoids sangat mirip dengan K-means, perbedaan utama diantara dua algoritma tersebut adalah jika pada K-Means cluster diwakili dengan pusat dari cluster, sedangkan pada K-Medoids cluster diwakili oleh obyek terdekat dari pusat cluster.
2.4.2 Contoh Penerapan Algoritma Partitioning Around Medoids (PAM)
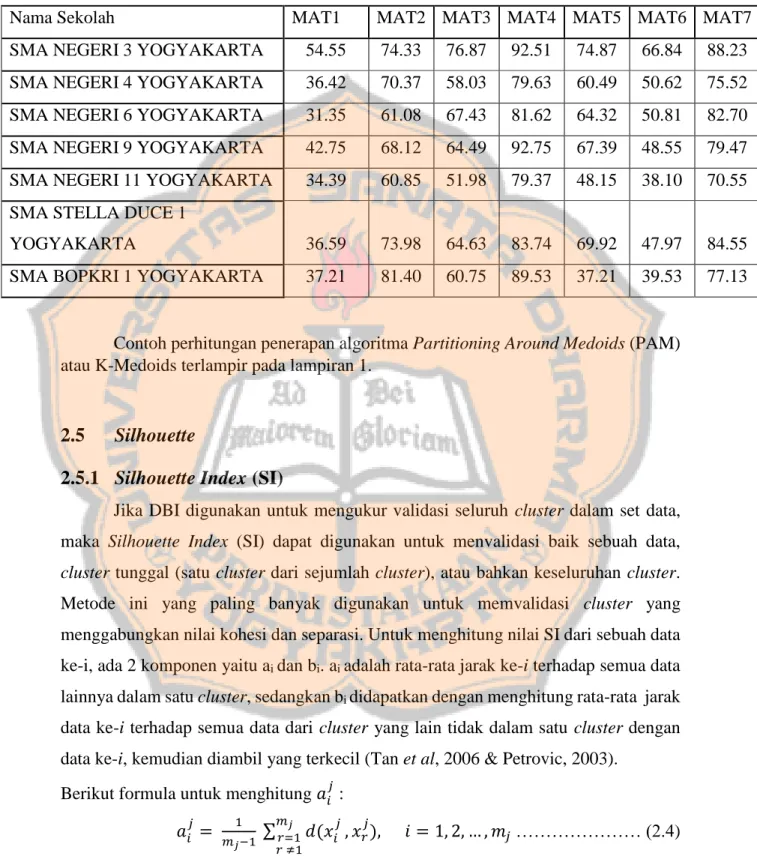
Berikut adalah contoh penerapan algoritma PAM atau K-Medoids pada kasus nilai daya serap ujian nasional di provinsi DIY, dengan data sampel yang digunakan adalah mata pelajaran matematika pada tahun ajaran 2013/2014.
19
Tabel 2.1 Data Contoh
Nama Sekolah MAT1 MAT2 MAT3 MAT4 MAT5 MAT6 MAT7
SMA NEGERI 3 YOGYAKARTA 54.55 74.33 76.87 92.51 74.87 66.84 88.23 SMA NEGERI 4 YOGYAKARTA 36.42 70.37 58.03 79.63 60.49 50.62 75.52 SMA NEGERI 6 YOGYAKARTA 31.35 61.08 67.43 81.62 64.32 50.81 82.70 SMA NEGERI 9 YOGYAKARTA 42.75 68.12 64.49 92.75 67.39 48.55 79.47 SMA NEGERI 11 YOGYAKARTA 34.39 60.85 51.98 79.37 48.15 38.10 70.55 SMA STELLA DUCE 1
YOGYAKARTA 36.59 73.98 64.63 83.74 69.92 47.97 84.55
SMA BOPKRI 1 YOGYAKARTA 37.21 81.40 60.75 89.53 37.21 39.53 77.13
Contoh perhitungan penerapan algoritma Partitioning Around Medoids (PAM) atau K-Medoids terlampir pada lampiran 1.
2.5 Silhouette
2.5.1 Silhouette Index (SI)
Jika DBI digunakan untuk mengukur validasi seluruh cluster dalam set data, maka Silhouette Index (SI) dapat digunakan untuk menvalidasi baik sebuah data, cluster tunggal (satu cluster dari sejumlah cluster), atau bahkan keseluruhan cluster. Metode ini yang paling banyak digunakan untuk memvalidasi cluster yang menggabungkan nilai kohesi dan separasi. Untuk menghitung nilai SI dari sebuah data ke-i, ada 2 komponen yaitu ai dan bi. ai adalah rata-rata jarak ke-i terhadap semua data
lainnya dalam satu cluster, sedangkan bi didapatkan dengan menghitung rata-rata jarak
data ke-i terhadap semua data dari cluster yang lain tidak dalam satu cluster dengan data ke-i, kemudian diambil yang terkecil (Tan et al, 2006 & Petrovic, 2003).
Berikut formula untuk menghitung 𝑎𝑖𝑗 : 𝑎𝑖𝑗 = 𝑚1 𝑗−1 ∑ 𝑑(𝑥𝑖 𝑗 𝑚𝑗 𝑟=1 𝑟 ≠1 , 𝑥𝑟𝑗), 𝑖 = 1, 2, … , 𝑚𝑗 ……… (2.4)
20 Dimana :
j = cluster i = index data
𝑎𝑖𝑗 = rata-rata jarak data ke–i terhadap semua data lainnya dalam satu cluster. mj = jumlah data dalam cluster ke-j.
𝑑(𝑥𝑖𝑗, 𝑥𝑟𝑗) adalah jarak data ke-i dengan data ke-r dalam satu cluster j.
Berikut formula untuk menghitung 𝑏𝑖𝑗 : 𝑏𝑖𝑗 = 𝑛=1,…,𝑘 𝑚𝑖𝑛 𝑛 ≠𝑗 { 1 𝑚𝑛 ∑ 𝑑(𝑥𝑖 𝑗, 𝑥 𝑟𝑛) 𝑚𝑛 𝑟=1 𝑟 ≠1 } , 𝑖 = 1, 2, … , 𝑚 𝑗 ……….. (2.5) Dimana : j = cluster n = cluster i = index data
mn = banyak data dalam satu cluster
𝑏𝑖𝑗 = nilai terkecil dari rata-rata jarak data ke-i terhadap semua data dari cluster yang lain tidak dalam satu cluster dengan data ke-i
𝑑(𝑥𝑖𝑗, 𝑥𝑟𝑛) adalah jarak data ke-i dalam satu cluster j dengan data ke-r dalam suatu
cluster n.
Untuk mendapatkan Silhouette Index (SI) data ke-i menggunakan persamaan berikut: 𝑆𝐼𝑖𝑗 = 𝑏𝑖𝑗− 𝑎𝑖𝑗
max{𝑎𝑖𝑗,𝑏𝑖𝑗} ……….………(2.6)
Dimana :
𝑆𝐼𝑖𝑗 = Silhouette Index data ke-i dalam satu cluster
𝑏𝑖𝑗 = nilai terkecil dari rata-rata jarak data ke-i terhadap semua data dari cluster yang lain tidak dalam satu cluster dengan data ke-i
21
Nilai ai mengukur seberapa tidak mirip sebuah data dengan cluster yang
diikutinya, nilai yang semakin kecil menandakan semakin tepatnya data tersebut berada dalam cluster tersebut. Nilai bi yang besar menandakan seberapa jeleknya data terhadap
cluster yang lain. Nilai SI yang didapat dalam rentang [-1, +1]. Nilai SI yang mendekati 1 menandakan bahwa data tersebut semakin tepat berada dalam cluster tersebut. Nilai SI negatif (ai > bi) menandakan bahwa data tersebut tidak tepat berada di dalam cluster
tersebut (karena lebih dekat ke cluster yang lain). SI bernilai 0 (atau mendekati 0) berarti data tersebut posisinya berada di perbatasan di antara dua cluster.
Untuk nilai SI dari sebuah cluster didapatkan dengan menghitung rata-rata nilai SI semua data yang bergabung dalam cluster tersebut, seperti pada persamaan berikut : 𝑆𝐼𝑗 = 𝑚1 𝑗 ∑ 𝑆𝐼𝑖 𝑗 𝑚𝑗 𝑖=1 ……….……… (2.7) Dimana :
𝑆𝐼𝑗 = Rata-rata Silhouette Index cluster j
mj = jumlah data dalam cluster ke-j
𝑆𝐼𝑖𝑗 = Silhouette Index data ke-i dalam satu cluster i = index
Sementara nilai SI global didapatkan dengan menghitung rata-rata nilai SI dari semua cluster seperti pada persamaan berikut:
𝑆𝐼 = 1𝑘 ∑𝑘𝑗=1𝑆𝐼𝑗 ………(2.8)
Dimana :
SI = Rata-rata Silhouette Index dari dataset k = jumlah cluster
22
2.5.2 Silhouette Coefficient (SC)
Silhouette Coefficient adalah suatu metode yang digunakan untuk mengetahui apakah cluster yang terbentuk adalah cluster yang memiliki struktur kuat, struktur baik, struktur lemah, maupun struktur yang buruk. Untuk menghitung nilai Silhouette Coefficient, terlebih dahulu mengghitung nilai Silhouette Index dari sebuah data ke-i. Nilai Silhouette Coefficient didapatkan dengan mencari nilai maksimal dari nilai Silhouette Index Global dari jumlah cluster 2 sampai jumlah cluster n-1, seperti pada persamaan berikut:
𝑆𝐶 = 𝑀𝑎𝑘𝑠𝑘 𝑆𝐼(𝑘) ………(2.9) Dimana :
SC = Silhouette Coefficient SI = Silhouette Index Global k = jumlah cluster
Kriteria subjektif pengukuran baik atau tidaknya pengelompokan berdasarkan Silhouette Coefficient (SC) menurut Kauffman dan Roesseeuw (1990) dapat dilihat pada tabel 2.2.
Tabel 2.2 Kriteria subjektif pengukuran pengelompokan berdasarkan Silhouette
Coefficient (SC)
Nilai SC Intepretasi oleh Kauffman dan Roesseeuw
0.71 – 1.00 Struktur kuat
0.51 – 0.70 Struktur baik
0.26 – 0.50 Struktur lemah
23
BAB III
METODOLOGI PENELITIAN
3.1 Data
Data yang digunakan diperoleh dari situs http://litbang.kemdikbud.go.id/. Data yang digunakan pada penelitian ini adalah data nilai daya serap ujian nasional siswa SMA jurusan IPA tahun ajaran 2014/2015. Data nilai daya serap yang digunakan adalah mata pelajaran matematika. Pada setiap mata pelajaran terdapat beberapa nilai kompetensi daya serap Ujian Nasional. Berikut ini adalah nilai kompetensi nilai daya serap Ujian Nasional pada mata pelajaran matematika
Tabel 3.1 Atribut nilai daya serap ujian nasional pelajaran matematika tahun 2014/2015.
No Nama Atribut Keterangan
1 KODE SEKOLAH Kode Sekolah
2 NAMA SEKOLAH Nama Sekolah
3 JNS SEKOLAH Jenis Sekolah (SMA)
4 STS SE Status Sekolah (Negeri/Swasta)
5 MAT1 Kompetensi 1 daya serap
matematika: Menentukan penarikan kesimpulan dari beberapa premis.
6 MAT2 Kompetensi 2 daya serap
matematika: Menentukan ingkaran atau kesetaraan dari pernyataan majemiuk atau pernyataan
berkuator.
7 MAT3 Kompetensi 3 daya serap
24
Menggunakan aturan pangkat, akar, dan logaritma.
8 MAT4 Kompetensi 4 daya serap
matematika:
Menggunakan rumus jumlah dan hasil kali akar-akar persamaan
kuadrat.
9 MAT5 Kompetensi 5 daya serap
matematika:
Menyelesaikan masalah persamaan atau fungsi kuadrat dengan menggunakan diskriminan.
10 MAT6 Kompetensi 6 daya serap
matematika:
Menyelesaikan masalah sehari-hari yang berkaitan dengan sistem
persamaan linier.
11 MAT7 Kompetensi 7 daya serap
matematika:
Menentukan persamaan lingkaran atau garis singgung lingkaran.
12 MAT8 Kompetensi 8 daya serap
matematika:
Menyelesaikan masalah yang berkaian dengan teorema sisa atau
teorema faktor.
13 MAT9 Kompetensi 9 daya serap
25
Menyelesaikan masalah program linier.
14 MAT10 Kompetensi 10 daya serap
matematika:
Menyelesaikan operasi matriks.
15 MAT11 Kompetensi 11 daya serap
matematika:
Menyelesaikan operasi aljabar beberapa vektor dengan syarat
tertentu.
16 MAT12 Kompetensi 12 daya serap
matematika:
Menyelesaikan masalah yang berkaitan dengan besar sudut/nilai
perbandingan trigonometri sudut antara 2 vektor.
17 MAT13 Kompetensi 13 daya serap
matematika:
Menyelesaikan masalah yang berkaitan dengan panjang proyeksi
atau vektor proyeksi.
18 MAT14 Kompetensi 14 daya serap
matematika:
Menentukan bayangan titik atau kurva karena dua transformasi atau
lebih.
19 MAT15 Kompetensi 15 daya serap
26
Menentukan penyelesaian pertidaksamaan eksponen atau
logaritma.
20 MAT16 Kompetensi 16 daya serap
matematika:
Menyelesaikan masalah yang berkaitan dengan fungsi eksponen
atau fungsi logaritma.
21 MAT17 Kompetensi 17 daya serap
matematika:
Menyelesaikan masalah deret aritmetika.
22 MAT18 Kompetensi 18 daya serap
matematika:
Menyelesaikan masalah deret geometri.
23 MAT19 Kompetensi 19 daya serap
matematika:
Menghitung jarak dan sudut antara dua obyek (titik, garis, dan bidang)
di ruang dimensi tiga.
24 MAT20 Kompetensi 20 daya serap
matematika:
Menyelesaikan masalah geometri dengan menggunakan aturan sinus
atau kosinus.
25 MAT21 Kompetensi 21 daya serap
27
Menyelesaikan persamaan trigonometri.
26 MAT22 Kompetensi 22 daya serap
matematika:
Menyelesaikan masalah yang berkaitan dengan nilai perbandingan
trigonometri yang menggunakan rumus jumlah dan selisih sinus, kosinus, dan tangen serta jumlah
dan selisih dua sudut.
27 MAT23 Kompetensi 23 daya serap
matematika:
Menghitung nilai limit fungsi aljabar dan fungsi trigonometri.
28 MAT24 Kompetensi 24 daya serap
matematika:
Menyelesaikan soal aplikasi turunan fungsi.
29 MAT25 Kompetensi 25 daya serap
matematika:
Menentukan integral tak tentu dan integral tentu fungsi aljabar dan
fungsi trigonometri.
30 MAT26 Kompetensi 26 daya serap
matematika:
Menghitung luas daerah dan volume benda putar dengan menggunakan
28
31 MAT27 Kompetensi 27 daya serap
matematika:
Menghitung ukuran pemusatan atau ukuran letak dari data dalam bentuk
tabel, diagram, atau grafik.
32 MAT28 Kompetensi 28 daya serap
matematika:
Menyelesaikan masalah sehari-hari dengan menggunakan kaidah
pencacahan, permutasi, atau kombinasi.
33 MAT29 Kompetensi 29 daya serap
matematika:
Menyelesaikan masalah yang berkaitan dengan peluang suatu
kejadian.
3.2 Data yang Digunakan
Data yang akan digunakan dalam penelitian ini adalah 31 atribut, yaitu kode sekolah, nama sekolah, jns sek, sts sek, mat1, mat2, mat3, mat4, mat5, mat6, mat7, mat8, mat9, mat10, mat11, mat12, mat13, mat14, mat15, mat16, mat17, mat18, mat19, mat20, mat21, mat22, mat23, mat24, mat25, mat26, mat27, mat28, mat29, mat30. Atribut jns sek, dan sts sek tidak digunakan pada penelitian ini. Sehingga atribut yang digunakan menjadi 31 atribut yaitu :
Tabel 3.2 Atribut nilai daya serap ujian nasional pelajaran matematika tahun 2014/2015 yang digunakan dalam penelitian.
No Nama Atribut Keterangan
1 KODE SEKOLAH Kode Sekolah
29
3 MAT1 Kompetensi 1 daya serap matematika:
Menentukan penarikan kesimpulan dari beberapa premis.
4 MAT2 Kompetensi 2 daya serap matematika:
Menentukan ingkaran atau kesetaraan dari pernyataan majemiuk atau pernyataan
berkuator.
5 MAT3 Kompetensi 3 daya serap matematika:
Menggunakan aturan pangkat, akar, dan logaritma.
6 MAT4 Kompetensi 4 daya serap matematika:
Menggunakan rumus jumlah dan hasil kali akar-akar persamaan kuadrat.
7 MAT5 Kompetensi 5 daya serap matematika:
Menyelesaikan masalah persamaan atau fungsi kuadrat dengan menggunakan
diskriminan.
8 MAT6 Kompetensi 6 daya serap matematika:
Menyelesaikan masalah sehari-hari yang berkaitan dengan sistem persamaan linier.
9 MAT7 Kompetensi 7 daya serap matematika:
Menentukan persamaan lingkaran atau garis singgung lingkaran.
10 MAT8 Kompetensi 8 daya serap matematika:
Menyelesaikan masalah yang berkaian dengan teorema sisa atau teorema faktor.
11 MAT9 Kompetensi 9 daya serap matematika:
Menyelesaikan masalah program linier. 12 MAT10 Kompetensi 10 daya serap matematika:
30
Menyelesaikan operasi matriks. 13 MAT11 Kompetensi 11 daya serap matematika:
Menyelesaikan operasi aljabar beberapa vektor dengan syarat tertentu. 14 MAT12 Kompetensi 12 daya serap matematika:
Menyelesaikan masalah yang berkaitan dengan besar sudut/nilai perbandingan
trigonometri sudut antara 2 vektor. 15 MAT13 Kompetensi 13 daya serap matematika:
Menyelesaikan masalah yang berkaitan dengan panjang proyeksi atau vektor
proyeksi.
16 MAT14 Kompetensi 14 daya serap matematika: Menentukan bayangan titik atau kurva
karena dua transformasi atau lebih. 17 MAT15 Kompetensi 15 daya serap matematika:
Menentukan penyelesaian pertidaksamaan eksponen atau logaritma.
18 MAT16 Kompetensi 16 daya serap matematika: Menyelesaikan masalah yang berkaitan
dengan fungsi eksponen atau fungsi logaritma.
19 MAT17 Kompetensi 17 daya serap matematika: Menyelesaikan masalah deret aritmetika. 20 MAT18 Kompetensi 18 daya serap matematika: Menyelesaikan masalah deret geometri. 21 MAT19 Kompetensi 19 daya serap matematika:
31
Menghitung jarak dan sudut antara dua obyek (titik, garis, dan bidang) di ruang
dimensi tiga.
22 MAT20 Kompetensi 20 daya serap matematika: Menyelesaikan masalah geometri dengan menggunakan aturan sinus atau kosinus. 23 MAT21 Kompetensi 21 daya serap matematika: Menyelesaikan persamaan trigonometri. 24 MAT22 Kompetensi 22 daya serap matematika: Menyelesaikan masalah yang berkaitan dengan nilai perbandingan trigonometri yang menggunakan rumus jumlah dan selisih sinus, kosinus, dan tangen serta
jumlah dan selisih dua sudut. 25 MAT23 Kompetensi 23 daya serap matematika:
Menghitung nilai limit fungsi aljabar dan fungsi trigonometri.
26 MAT24 Kompetensi 24 daya serap matematika: Menyelesaikan soal aplikasi turunan
fungsi.
27 MAT25 Kompetensi 25 daya serap matematika: Menentukan integral tak tentu dan integral tentu fungsi aljabar dan fungsi
trigonometri.
28 MAT26 Kompetensi 26 daya serap matematika: Menghitung luas daerah dan volume
benda putar dengan menggunakan integral.
32
Menghitung ukuran pemusatan atau ukuran letak dari data dalam bentuk tabel,
diagram, atau grafik.
30 MAT28 Kompetensi 28 daya serap matematika: Menyelesaikan masalah sehari-hari dengan menggunakan kaidah pencacahan,
permutasi, atau kombinasi. 31 MAT29 Kompetensi 29 daya serap matematika:
Menyelesaikan masalah yang berkaitan dengan peluang suatu kejadian.
3.3 Spesifikasi Alat
Sistem dibuat dengan menggunakan hardware dan software sebagai berikut :
3.3.1 Spesifikasi Software
Spesifikasi software yang dibutuhkan dalam pembuatan sistem ini adalah: 1. Sistem Operasi Windows 7
2. Compiler IDE Netbeans 7.2.
3.3.2 Spesifikasi Hardware
Spesifikasi hardware yang dibutuhkan dalam pembuatan sistem ini adalah: 1. Processor Intel Core i5.
2. RAM 4 GB. 3. HDD 500 GB.
33
BAB IV
PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT
LUNAK PENAMBANGAN DATA
4.1 Pemrosesan Awal Sumber Data
4.1.1 Pembersihan Data
Sebelum melakukan proses data mining perlu melakukan proses cleaning data terlebih dahulu. Proses cleaning meliputi membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Kemudian dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal. Pada penelitian ini terdapat 2 data sekolah yang dihapus karena kedua sekolah ini tidak memiliki nilai untuk tiap atribut. Kedua sekolah tersebut adalah SMA Piri 2 Yogyakarta dan SMA Proklamasi’45 Yogyakarta.
4.1.2 Integrasi Data
Tahap integrasi ini merupakan tahap penggabungan data dari berbagai sumber. Pada penelitian ini penulis menggunakan data yang diambil dari situs kemendikbud. Data yang diambil dari situs kemendikbud yaitu data nilai daya serap Ujian Nasional mata pelajaran matematika tahun ajaran 2014/2015, data tersebut memiliki 29 kompetensi. Data dari kemendikbud kemudian digabungkan menjadi 1 file excel berekstensi .xls.
4.1.3 Seleksi Data
Tahap seleksi ini merupakan tahap pemilihan (seleksi) data dari sekumpulan data, tahap ini perlu dilakukan sebelum tahap data mining dalam KDD. Data hasil seleksi yang akan digunakan untuk proses penambangan data akan disimpan dalam
34
suatu berkas. Pada data nilai daya serap terdapat 2 atribut tetap yaitu KODE SEKOLAH dan NAMA SEKOLAH. Sisanya merupakan atribut nama kompetensi yang jumlahnya berbeda untuk tiap tahun ajaran. Daftar atribut yang digunakan dapat dilihat pada tabel 3.2.
4.1.4 Transformasi Data
Pada tahap transformasi data adalah mengubah format data asli ke dalam format data yang sesuai untuk penelitian, yaitu mengubah data dari kolom nilai daya serap per sekolah menjadi baris per sekolah untuk mempermudah proses penambangan data. Kemudian, mengubah format data yang sesuai untuk penelitian ini yaitu pada baris pertama dalam excel adalah nama kolom dari data yang digunakan dan baris berikutnya adalah data tersebut seperti pada gambar 4.2.
35
Gambar 4.2 Data setelah proses transformasi
4.2 Perancangan Perangkat Lunak Penambangan Data
4.2.1 Perancangan Umum 4.2.1.1 Input
Data input dari sistem yang akan dibangun berasal dari file dengan ekstensi .xls atau .csv yang dipilih langsung oleh user (pengguna) dari direktori komputer. Sebelum melakukan proses clustering, pengguna diharuskan mengisi jumlah cluster yang dikehendaki pada textfield yang telah disediakan.
4.2.1.2 Proses
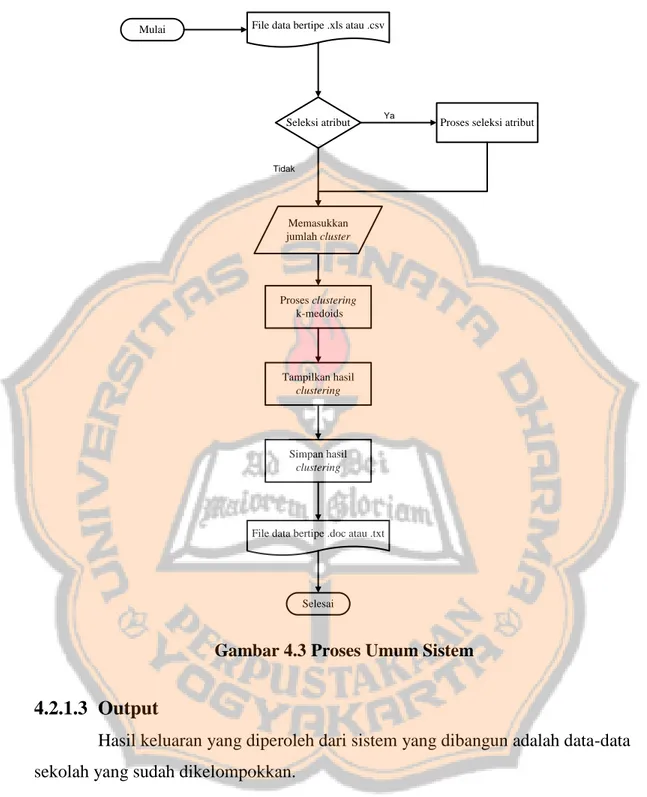
Sistem ini akan mengimplementasikan algoritma Partitioning Around Medoids untuk mengelompokan data sekolah berdasarkan nilai daya serap ujian nasional mata pelajaran matematika pada tahun ajaran 2014/2015. Pada gambar 4.1 diperlihatkan proses dari sistem membuka berkas atau data dengan tipe .xls atau .csv kemudian sistem akan menyeleksi atribut yang tidak akan digunakan untuk proses clustering. Kemudian jika telah selesai menyeleksi atribut yang tidak akan digunakan, maka akan dilanjutkan dengan menginputkan nila untuk jumlah cluster. Kemudian akan di lakukan proses clustering dengan menggunakan algoritma k-medoids atau Partitioning Around Medoids. Kemudian sistem akan menampilkan hasil proses clustering. Setelah itu, hasil clustering dapat disimpan ke dalam direktori computer dengan tipe data berupa .doc atau .txt.
36
Mulai File data bertipe .xls atau .csv
Seleksi atribut Proses seleksi atribut
Memasukkan jumlah cluster Proses clustering k-medoids Tampilkan hasil clustering Simpan hasil clustering
File data bertipe .doc atau .txt
Selesai Tidak
Ya
Gambar 4.3 Proses Umum Sistem
4.2.1.3 Output
Hasil keluaran yang diperoleh dari sistem yang dibangun adalah data-data sekolah yang sudah dikelompokkan.
37
4.2.2 Diagram Konteks (Context Diagram)
Pengguna Clustering dengan
K-Medoids Data daya serap, jumlah cluster
Pengelompokan data sekolah
Gambar 4.4 Diagram Konteks
4.2.3 Diagram Usecase
Diagram usecase merupakan sebuah gambaran kebutuhan sistem dari sudut pandang di luar sistem. Pengguna sistem dalam diagram usecase disebut dengan actor. Pada sistem ini actor yang digunakan hanya satu actor. Fungsi yang dapat dilakukan oleh actor pada sistem ini adalah memilih data, seleksi atribut, proses clustering dengan memasukkan nilai jumlah cluster ,dan menyimpan hasil. Gambar dari usecase ditunjukkan pada gambar 4.3 berikut.
actor
Seleksi atribut
Proses clustering dengan algoritma PAM
Simpan hasil clustering Input berkas <<include>> <<include>> <<ex tends >>
38
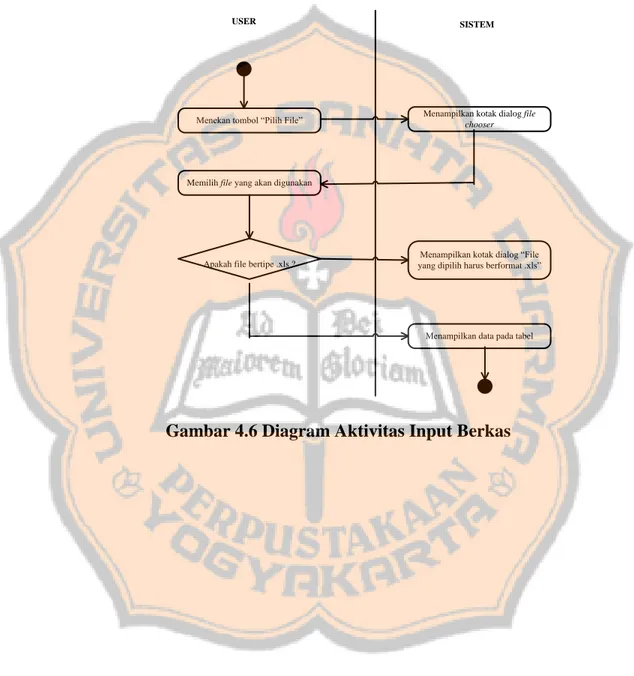
4.2.4 Diagram Aktivitas (Activity Diagram)
Diagram aktivitas digunakan untuk menunjukkan aktivitas yang dikerjakan oleh pengguna dan sistem dalam setiap usecase yang disebutkan dalam gambar 4.3. Berikut adalah diagram aktivitas dari setiap usecase :
USER SISTEM
Menampilkan kotak dialog “File yang dipilih harus berformat .xls”
Menampilkan data pada tabel Menampilkan kotak dialog file
chooser
Menekan tombol “Pilih File”
Memilih file yang akan digunakan
Apakah file bertipe .xls ?
39
USER SISTEM
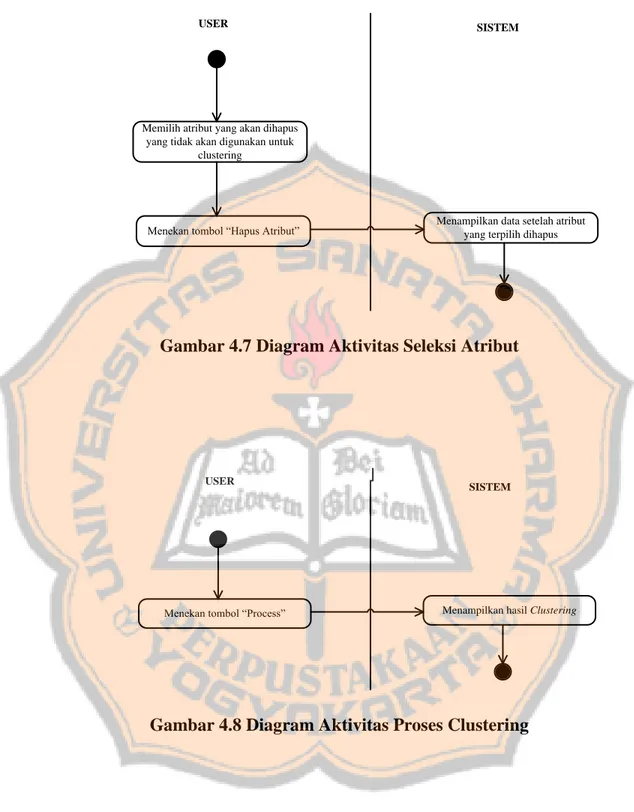
Menampilkan data setelah atribut yang terpilih dihapus Memilih atribut yang akan dihapus
yang tidak akan digunakan untuk clustering
Menekan tombol “Hapus Atribut”
Gambar 4.7 Diagram Aktivitas Seleksi Atribut
USER
SISTEM
Menampilkan hasil Clustering Menekan tombol “Process”
40
USER SISTEM
Menekan tombol “Simpan Hasil”
Memilih lokasi dan tipe file untuk menyimpan hasil
Menampilkan kotak save dialog
File berhasil disimpan pada direktori komputer yang telah ditentukan
Gambar 4.9 Diagram Aktivitas Simpan Hasil
4.2.5 Diagram Kelas (Class Diagram)
Diagram kelas berguna untuk memperlihatkan hubungan antar kelas. Diagram kelas dapat membantu menvisualisasikan struktur kelas-kelas dari suatu sistem. Diagram kelas dapat dilihat pada lampiran 2.
4.2.6 Rancangan Antarmuka 4.2.6.1 Halaman Awal
Halaman awal adalah halaman yang digunakan sebagai halaman yang akan muncul pertama kali ketika sistem dijalankan. Halaman ini berisi empat tombol yaitu BERANDA, BANTUAN, TENTANG, dan MASUK SISTEM. Tombol BERANDA akan menghubunkan pada halaman awal sistem, tombol BANTUAN akan menghubungkan dengan halaman bantuan, tombol TENTANG akan menghubungkan
41
dengan halaman tentang, dan tombol MASUK SISTEM akan menghubungkan dengan halaman prepocessing.
Gambar 4.10 Rancangan Antarmuka Halaman Awal
4.2.6.2 Halaman Bantuan
Halaman bantuan adalah halaman yang akan ditampilkan ketika pengguna menekan tombol BANTUAN. Pada halaman ini berisi mengenai pentujuk
42
Gambar 4.11 Rancangan Antarmuka Halaman Bantuan
4.2.6.3 Halaman Informasi
Halaman tentang adalah halaman yang akan ditampilkan ketika pengguna menekan tombol TENTANG. Pada halaman ini berisi mengenai informasi dari sistem.
Gambar 4.12 Rancangan Antarmuka Halaman Tentang
4.2.6.4 Halaman Input Data
Halaman input berkas adalah halaman yang akan ditampilkan ketika pengguna menekan tombol MASUK SISTEM pada halaman awal. Halaman ini berfungsi sebagai sarana pengguna memilih data atau memasukkan data. Pada halaman ini pengguna bisa memilih atribut yang akan digunakan dalam men-cluster dan pengguna juga bisa menghapus atribut yang tidak dibutuhkan ketika akan men-cluster.
43
Gambar 4.13 Rancangan Antarmuka Halaman Input Data
4.2.6.5 Halaman K-Medoids
Halaman clustering adalah halaman yang akan ditampilkan ketika pengguna menekan tombol CLUSTERING pada halaman preprocessing. Pada halaman ini pengguna diminta untuk menginputkan jumlah cluster. Kemudian pengguna menekan tombol PROCESS untuk melakukan clustering. Setelah proses clustering selesai, pengguna bisa menyimpan hasil clustering.
44