vii ABSTRAK
Penambangan data (data mining) merupakan proses penemuan informasi otomatis dengan mengidentifikasi pola dari set data atau basis data besar. Proses penemuan informasi tersebut dapat dilakukan dengan metode pengelompokan data ke dalam beberapa kelompok dari sebuah set data yang dalam penambangan data disebut metode clustering. Clustering merupakan proses mempartisi data-set menjadi beberapa sub-set atau kelompok berdasarkan kesamaan karakteristik masing-masing data pada kelompok-kelompok yang ada. Salah satu algoritma clustering yaitu Agglomerative Hierarchical Clustering (AHC) di mana algoritma ini merupakan algoritma pengelompokan berbasis hirarki dengan pendekatan bottom up, yaitu proses pengelompokan dimulai dari masing-masing data sebagai satu buah cluster, kemudian secara rekursif mencari cluster terdekat sebagai pasangan untuk bergabung sebagai satu cluster yang lebih besar.
Pada tugas akhir ini diimplementasikan algoritma Agglomerative Hierarchical Clustering metode single linkage, complete linkage, dan average linkage untuk mengelompokkan Sekolah Menengah Atas di Provinsi DIY berdasarkan nilai Ujian Nasional tahun 2015. Hasil pengelompokan dapat digunakan untuk membantu penugasan pengawas sekolah untuk mendampingi sekolah. Dalam melakukan proses mengubah data mentah menjadi suatu informasi yang lebih bermanfaat, penulis menggunakan proses Knowledge Discovery in Database (KDD) yang terdiri dari pembersihan data, integrasi data, seleksi data, transformasi data, penambangan data, evaluasi pola, dan presentasi pengetahuan. Pada tahap awal KDD akan dilakukan pembersihan data dan integrasi data secara manual melalui aplikasi spreadsheet. Selanjutnya dilakukan seleksi data, tranformasi data, dan penambangan data dengan menggunakan perangkat lunak yang dibuat. Tahap selanjutnya yaitu evaluasi pola dan presentasi pengetahuan.
Berdasarkan penelitian yang telah dilakukan, dapat diketahui bahwa algoritma Agglomerative Hierarchical Clustering (AHC) dapat digunakan untuk mengelompokkan Sekolah Menengah Atas di Provinsi DIY berdasarkan nilai Ujian Nasional. Hasil evaluasi cluster menunjukkan bahwa pengelompokan menggunakan algoritma AHC dengan metode single linkage memiliki struktur yang kuat. Sedangkan hasil pengelompokan menggunakan metode complete linkage dan average linkage memiliki struktur pengelompokan yang baik.
Berdasar peraturan Mentri Pendidikan dan Kebudayaan no.143 tahun 2014 tentang petunjuk teknis pelaksanaan jabatan fungsional pengawas sekolah dan angka kreditnya di mana pengawas bertugas untuk mendampingi minimal 7 sekolah, pada kasus ini tidak dapat menggunakan metode single linkage karena selalu menghasilkan kelompok yang memiliki 1 anggota. Metode complete linkage memberikan hasil yang efektif jika kelompok pendampingan dibagi menjadi 2 dan 3 kelompok untuk jurusan IPA, sedangkan untuk jurusan IPS dibagi menjadi 2 sampai 6 kelompok. Metode average linkage memberikan hasil yang efektif jika kelompok pendampingan dibagi menjadi 2 kelompok untuk jurusan IPA, sedangkan untuk jurusan IPS dibagi menjadi 2 sampai 4 kelompok.
▸ Baca selengkapnya: pernyataan di atas, pengelompokan daerah pada fenomena di atas menggunakan konsep....
(2)ABSTRACT
Data mining is a process to find information by identifying pattern from data set or big database automatically. The finding process can be done by clustering data to some clusters from data set in data mining called clustering method. Clustering is known as a partition process of data set into some sub-sets or clusters, based on the same characateristics of each data in clusters. One of clustering algorithm is Agglomerative Hierarchical Clustering (AHC), which is a clustering algorithm based on hierarchy with bottom up approach. Bottom up approach is a clustering process that start from each data as one cluster, then find the closest cluster in recursive to be merged into one bigger cluster.
This undergraduate thesis implemented Agglomerative Hierarchical Clustering algorithm by using single linkage method, complete linkage method, and average method to cluster Senior High Schools in Special Region of Yogyakarta Province based on the score of national examination in 2015. The clustering result can be used to help the assigment of school supervisors in assisting schools. In the process of converting raw data into useful information, the writer used Knowledge Discovery in Database (KDD) process which consist of data cleansing, data integration, data selection, data transformation, data mining, pattern of evaluation, and knowledge presentation. In the early stage of KDD process, the writer performed data cleansing and data integration manually by using spreadsheet application. The next processes are data selection, data transformation, and data mining, which were done by using the invented software. The last steps are pattern evaluation and knowledge presentation.
Based on the research that has been done, it can be concluded that Knowledge Discovery in Database (KDD) algorithm can be used for clustering Senior High School in Special Region of Yogyakarta Province based on the score of national examination. The result of cluster evaluation showing that the clustering process using AHC algorithm with single linkage method has a strong clustering structure, while complete linkage and average linkage have a good clustering structure.
Based on the regulation of Ministry of Education and Culture no. 143/2014 one school supervisor should observe seven schools at minimum. Therefore, the single linkage method is not appropriate because there always be a cluster that have one member. For natural science major, the complete linkage method gives effective result when the schools are divided into 2 and 3 clusters, while for social science major the schools are divided into 2 until 6 clusters. The average linkage method gives effective result when the schools are divided into 2 clusters for natural science major and 2 up to 4 clusters for social science major.
i
PENGELOMPOKAN SEKOLAH MENENGAH ATAS
DI PROVINSI DAERAH ISTIMEWA YOGYAKARTA
BERDASARKAN NILAI UJIAN NASIONAL MENGGUNAKAN
ALGORITMA AGGLOMERATIVE HIERARCHICAL CLUSTERING
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun Oleh :
Vina Puspitasari
125314025
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
CLUSTERING OF SENIOR HIGH SCHOOL IN
SPECIAL REGION OF YOGYAKARTA PROVINCE
BASED ON THE SCORE OF NATIONAL EXAM USING
AGGLOMERATIVE HIERARCHICAL CLUSTERING ALGORITHM
FINAL PROJECT
Presented as Partial Fulfillment of the Requirements to Obtain the Sarjana Komputer Degree in Informatics Engineering Study Program
By:
Vina Puspitasari
125314025
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
HALAMAN PERSEMBAHAN
“
Orang yang ingin bergembira harus menyukai
kelelahan akibat bekerja”
~ Plato ~
“Bersabar dalam pencobaan, berjaga
-jaga dalam doa
dan jangan pernah berhenti bekerja”
~ St. Fransiskus dari Asisi ~
Karya ini kupersembahkan kepada :
Tuhan Yesus Kristus
Bunda Maria
vii ABSTRAK
Penambangan data (data mining) merupakan proses penemuan informasi otomatis dengan mengidentifikasi pola dari set data atau basis data besar. Proses penemuan informasi tersebut dapat dilakukan dengan metode pengelompokan data ke dalam beberapa kelompok dari sebuah set data yang dalam penambangan data disebut metode clustering. Clustering merupakan proses mempartisi data-set menjadi beberapa sub-set atau kelompok berdasarkan kesamaan karakteristik masing-masing data pada kelompok-kelompok yang ada. Salah satu algoritma clustering yaitu Agglomerative Hierarchical Clustering (AHC) di mana algoritma ini merupakan algoritma pengelompokan berbasis hirarki dengan pendekatan bottom up, yaitu proses pengelompokan dimulai dari masing-masing data sebagai satu buah cluster, kemudian secara rekursif mencari cluster terdekat sebagai pasangan untuk bergabung sebagai satu cluster yang lebih besar.
Pada tugas akhir ini diimplementasikan algoritma Agglomerative Hierarchical Clustering metode single linkage, complete linkage, dan average linkage untuk mengelompokkan Sekolah Menengah Atas di Provinsi DIY berdasarkan nilai Ujian Nasional tahun 2015. Hasil pengelompokan dapat digunakan untuk membantu penugasan pengawas sekolah untuk mendampingi sekolah. Dalam melakukan proses mengubah data mentah menjadi suatu informasi yang lebih bermanfaat, penulis menggunakan proses Knowledge Discovery in Database (KDD) yang terdiri dari pembersihan data, integrasi data, seleksi data, transformasi data, penambangan data, evaluasi pola, dan presentasi pengetahuan. Pada tahap awal KDD akan dilakukan pembersihan data dan integrasi data secara manual melalui aplikasi spreadsheet. Selanjutnya dilakukan seleksi data, tranformasi data, dan penambangan data dengan menggunakan perangkat lunak yang dibuat. Tahap selanjutnya yaitu evaluasi pola dan presentasi pengetahuan.
Berdasarkan penelitian yang telah dilakukan, dapat diketahui bahwa algoritma Agglomerative Hierarchical Clustering (AHC) dapat digunakan untuk mengelompokkan Sekolah Menengah Atas di Provinsi DIY berdasarkan nilai Ujian Nasional. Hasil evaluasi cluster menunjukkan bahwa pengelompokan menggunakan algoritma AHC dengan metode single linkage memiliki struktur yang kuat. Sedangkan hasil pengelompokan menggunakan metode complete linkage dan average linkage memiliki struktur pengelompokan yang baik.
Berdasar peraturan Mentri Pendidikan dan Kebudayaan no.143 tahun 2014 tentang petunjuk teknis pelaksanaan jabatan fungsional pengawas sekolah dan angka kreditnya di mana pengawas bertugas untuk mendampingi minimal 7 sekolah, pada kasus ini tidak dapat menggunakan metode single linkage karena selalu menghasilkan kelompok yang memiliki 1 anggota. Metode complete linkage memberikan hasil yang efektif jika kelompok pendampingan dibagi menjadi 2 dan 3 kelompok untuk jurusan IPA, sedangkan untuk jurusan IPS dibagi menjadi 2 sampai 6 kelompok. Metode average linkage memberikan hasil yang efektif jika kelompok pendampingan dibagi menjadi 2 kelompok untuk jurusan IPA, sedangkan untuk jurusan IPS dibagi menjadi 2 sampai 4 kelompok.
ABSTRACT
Data mining is a process to find information by identifying pattern from data set or big database automatically. The finding process can be done by clustering data to some clusters from data set in data mining called clustering method. Clustering is known as a partition process of data set into some sub-sets or clusters, based on the same characateristics of each data in clusters. One of clustering algorithm is Agglomerative Hierarchical Clustering (AHC), which is a clustering algorithm based on hierarchy with bottom up approach. Bottom up approach is a clustering process that start from each data as one cluster, then find the closest cluster in recursive to be merged into one bigger cluster.
This undergraduate thesis implemented Agglomerative Hierarchical Clustering algorithm by using single linkage method, complete linkage method, and average method to cluster Senior High Schools in Special Region of Yogyakarta Province based on the score of national examination in 2015. The clustering result can be used to help the assigment of school supervisors in assisting schools. In the process of converting raw data into useful information, the writer used Knowledge Discovery in Database (KDD) process which consist of data cleansing, data integration, data selection, data transformation, data mining, pattern of evaluation, and knowledge presentation. In the early stage of KDD process, the writer performed data cleansing and data integration manually by using spreadsheet application. The next processes are data selection, data transformation, and data mining, which were done by using the invented software. The last steps are pattern evaluation and knowledge presentation.
Based on the research that has been done, it can be concluded that Knowledge Discovery in Database (KDD) algorithm can be used for clustering Senior High School in Special Region of Yogyakarta Province based on the score of national examination. The result of cluster evaluation showing that the clustering process using AHC algorithm with single linkage method has a strong clustering structure, while complete linkage and average linkage have a good clustering structure.
Based on the regulation of Ministry of Education and Culture no. 143/2014 one school supervisor should observe seven schools at minimum. Therefore, the single linkage method is not appropriate because there always be a cluster that have one member. For natural science major, the complete linkage method gives effective result when the schools are divided into 2 and 3 clusters, while for social science major the schools are divided into 2 until 6 clusters. The average linkage method gives effective result when the schools are divided into 2 clusters for natural science major and 2 up to 4 clusters for social science major.
KATA PENGANTAR
Puji syukur kepada Tuhan Yesus Kristus, atas segala berkat dan karunia sehingga penulis dapat menyelesaikan tugas akhir yang berjudul
“PENGELOMPOKAN SEKOLAH MENENGAH ATAS DI PROVINSI
DAERAH ISTIMEWA YOGYAKARTA BERDASARKAN NILAI UJIAN
NASIONAL MENGGUNAKAN ALGORITMA AGGLOMERATIVE
HIERARCHICAL CLUSTERING”. Tugas akhir ini ditulis sebagai salah satu syarat memperoleh gelar sarjana program studi Teknik Informatika, Fakultas Sains dan Teknologi Universitas Sanata Dharma.
Penulisan tugas akhir ini berjalan dengan baik dari awal hingga akhir karena adanya dukungan doa, semangat dan motivasi yang diberikan oleh banyak pihak. Untuk itu, penulis ingin mengucapkan terima kasih kepada :
1. Tuhan Yesus Kristus dan Bunda Maria yang selalu memberikan berkat dan kekuatan sehingga penulis dapat menyelesaikan tugas akhir ini.
2. Kedua orang tua penulis, Yohanes Albertus Santoso, S.E. dan Maria Goretti
Giyarni atas doa, kasih sayang, perhatian, kepercayaan, dukungan baik moral maupun finansial yang diberikan kepadaku.
3. Adik penulis, Elisabeth Griselda Petrina yang selalu mendoakan dan memberi dukungan dalam penyusunan tugas akhir.
4. Bapak Sudi Mungkasi, S.Si., M.Math.Sc.,Ph.D selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma.
5. Ibu Dr. Anastasia Rita Widiarti selaku Ketua Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
6. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku Dosen Pembimbing yang telah dengan sabar membimbing dan memberikan motivasi.
7. Bapak Puspaningtyas Sanjoyo Adi, S.T.,M.T. selaku Dosen Pembimbing Akademik penulis.
DAFTAR ISI
HALAMAN JUDUL ... i
TITLE PAGE ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ...iv
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ...vi
ABSTRAK ... vii
ABSTRACT ... viii
PERSETUJUAN PUBLIKASI KARYA ILMIAH ... ix
KATA PENGANTAR ... x
1.6 SISTEMATIKA PENULISAN ... 3
BAB IILANDASAN TEORI ... 5
2.1. PENAMBANGAN DATA ... 5
2.1.1. Pengertian Penambangan Data ... 5
2.1.2. Fungsi Penambangan Data ... 5
2.1.3. Knowledge Discovery in Database (KDD) ... 6
2.2. Ujian Nasional (UN)... 7
2.3 Analisis Cluster ... 8
2.3.1. Konsep Clustering ... 8
2.3.2. Silhouette Coefficient ... 10
2.4 Algoritma Agglomerative Hierarchical Clustering (AHC) ... 13
BAB IIIMETODOLOGI PENELITIAN ... 15
xiii
3.2. SPESIFIKASI ALAT ... 15
3.2.1. Hardware ... 15
3.2.2. Software ... 15
3.3. TAHAP-TAHAP PENELITIAN ... 15
3.3.1. Studi Kasus ... 15
3.3.2. Penelitian Pustaka... 16
3.3.3. Knowledge Discovery in Database (KDD) ... 16
3.3.4. Pengembangan Perangkat Lunak ... 16
BAB IV PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK 18 4.1 PEMROSESAN AWAL ... 18
4.1.1 Pembersihan Data (Data Cleaning) ... 18
4.1.2 Integrasi Data (Data Integration) ... 18
4.1.3 Seleksi Data (Data Selection) ... 18
4.1.4 Transformasi Data (Data Transformation) ... 20
4.2 PERANCANGAN PERANGKAT LUNAK ... 21
4.2.1 Perancangan Umum ... 21
4.2.3 Diagram Aktivitas ... 24
4.2.4 Diagram Kelas Analisis ... 25
4.2.5 Diagram Kelas Desain ... 25
4.2.6 Diagram Sekuen ... 25
4.2.7 Perancangan Struktur Data ... 25
4.2.8 Algoritma Setiap Method ... 27
4.2.9 Perancangan Antarmuka ... 27
4.2.9.1 Perancangan Halaman Beranda ... 27
4.2.9.2 Perancangan Halaman AHC ... 28
4.2.9.3 Perancangan Halaman Bantuan ... 29
BAB V IMPLEMENTASI DAN EVALUASI HASIL ... 30
5.1 IMPLEMENTASI RANCANGAN PERANGKAT LUNAK ... 30
5.1.2 Implementasi Kelas Kontrol ... 31
5.2 EVALUASI HASIL ... 32
5.2.1 Pengujian Perangkat Lunak (Black Box) ... 32
5.2.1.1 Rencana Pengujian Black Box ... 32
5.2.1.2 Prosedur Pengujian Black Box dan Kasus Uji ... 32
5.2.1.3 Evaluasi Pengujian Hasil Black Box ... 32
5.2.2 Pengujian Perbandingan Hasil Hitung Manual dengan Hasil Perangkat Lunak ... 33
5.2.2.1 Perhitungan Manual ... 33
5.2.2.2 Perhitungan Perangkat Lunak ... 34
5.2.2.3 Evaluasi Pengujian Perbandingan Hitung Manual dengan Hasil Perangkat Lunak ... 35
5.2.3 Pengujian Perbandingan Hasil Perangkat Lunak dengan Hasil Perangkat Lunak Lainnya (Orange) ... 36
5.2.3.1 Perhitungan Perangkat Lunak ... 36
5.2.3.2 Perhitungan Perangkat Lunak Lainnya (Orange) ... 36
5.2.3.3 Evaluasi Pengujian Perbandingan Perhitungan Hasil Perangkat Lunak dengan Perangkat Lunak Lainnya (Orange). ... 37
5.2.4 Pengujian Perangkat Lunak dengan Menggunakan Dataset ... 38
5.2.4.1 Evaluasi Hasil Clustering ... 38
5.3 KELEBIHAN DAN KEKURANGAN PERANGKAT LUNAK ... 53
5.3.1 Kelebihan Perangkat Lunak ... 53
5.3.2 Kekurangan Perangkat Lunak ... 53
BAB VI PENUTUP ... 54
6.1 SIMPULAN ... 54
6.2 SARAN ... 55
DAFTAR PUSTAKA ... 56
xv
DAFTAR GAMBAR
Gambar 2. 2 Tahapan Proses KDD ... 6
Gambar 4. 1 Diagram Konteks... 21
Gambar 4. 2 Flowchart ... 22
Gambar 4. 3 Diagram Use Case ... 23
Gambar 4. 4 Diagram Kelas Analisis ... 25
Gambar 4. 5 Perancangan Array ... 26
Gambar 4. 6 Ilustrasi Konsep Arraylist ... 26
Gambar 4. 7 Perancangan Halaman Beranda ... 28
Gambar 4. 8 Perancangan Halaman AHC... 28
Gambar 4. 9 Perancangan Halaman Bantuan ... 29
Gambar 5. 1 Interface View_Beranda ... 30
Gambar 5. 2 Interface View_AHC ... 31
Gambar 5. 3 Interface View_Bantuan ... 31
Gambar 5. 4 Hasil Penambangan Data Metode Single linkage Menggunakan Perangkat Lunak ... 34
Gambar 5. 5 Hasil Penambangan Data Metode Complete linkage Menggunakan Perangkat Lunak ... 35
Gambar 5. 6 Hasil Penambangan Data Metode Average linkage Menggunakan Perangkat Lunak ... 35
Gambar 5. 7 Hasil Perhitungan Metode Single linkage Menggunakan Aplikasi Orange ... 37
Gambar 5. 8 Hasil Perhitungan Metode Complete linkage Menggunakan Aplikasi Orange ... 37
Gambar 5. 9 Hasil Perhitungan Metode Average linkage Menggunakan Aplikasi Orange ... 37
Gambar 5. 10 Grafik Perhitungan Nilai Silhouette Coefficient Terhadap Jumlah Cluster SMA Jurusan IPA Pada Metode Single linkage... 42
Gambar 5. 11 Grafik Perhitungan Nilai Silhouette Coefficient Terhadap Jumlah Cluster SMA Jurusan IPA Pada Metode Complete linkage ... 43
Gambar 5. 12 Grafik Perhitungan Nilai Silhouette Coefficient Terhadap Jumlah Cluster SMA Jurusan IPA Pada Metode Average linkage ... 44
Gambar 5. 13 Grafik Perhitungan Nilai Silhouette Coefficient Terhadap Jumlah Cluster SMA Jurusan IPS Pada Metode Single linkage ... 50
Gambar 5. 14 Grafik Perhitungan Nilai Silhouette Coefficient Terhadap Jumlah Cluster SMA Jurusan IPS Pada Metode Complete linkage ... 51
DAFTAR TABEL
Tabel 3. 1 Kriteria subjetif pengukuran pengelompokan berdasarkan Silhouette
Coefficient (SC) ... 12
Tabel 4.1 Atribut dari data asli nilai Ujian Nasional SMA jurusan IPA... 18
Tabel 4. 2 Atribut dari data asli nilai Ujian Nasional SMA jurusan IPS ... 19
Tabel 4. 3 Atribut terseleksi dari data nilai Ujian Nasional SMA jurusan IPA .... 20
Tabel 4. 4 Atribut terseleksi dari data nilai Ujian Nasional SMA jurusan IPS ... 20
Tabel 4. 5 Gambaran Umum Use Case ... 24
Tabel 4. 6 Perancangan HashMap ... 27
Tabel 5. 1 Implementasi kelas view ... 30
Tabel 5. 2 Implementasi kelas Controler ... 31
Tabel 5. 3 Rencana Pengujian Black Box... 32
Tabel 5. 4 Dataset Pengujian ... 33
Tabel 5. 5 Perhitungan Hasil Silhouette Coefficient (SC) Jurusan IPA ... 38
1 BAB I
PENDAHULUAN
1.1 LATAR BELAKANG
Penambangan data (data mining) merupakan proses penemuan informasi otomatis dengan mengidentifikasi pola dari set data atau basis data besar. Penambangan data dapat diterapkan dalam bidang apapun, salah satunya pada bidang pendidikan. Dalam bidang pendidikan, data-data pendidikan dapat diterapkan dalam penambangan data untuk dilakukan proses penemuan informasi dalam waktu yang singkat.
Proses penemuan informasi tersebut dapat dilakukan dengan metode pengelompokkan data ke dalam beberapa kelompok dari sebuah set data atau dalam data mining disebut metode clustering. Clustering merupakan proses mempartisi data-set menjadi beberapa sub-set atau kelompok berdasarkan kesamaan karakteristik masing-masing data pada kelompok-kelompok yang ada. Data-data
yang masuk ke dalam batas kesamaan dengan kelompoknya akan bergabung dengan kelompok tersebut, dan akan terpisah dalam kelompok yang berbeda jika keluar dari batas kesamaan kelompok tersebut. Salah satu algoritma clustering adalah Agglomerative Hierarchical Clustering (AHC).
Agglomerative Hierarchical Clustering (AHC) adalah metode pengelompokan berbasis hirarki dengan pendekatan bottom up, yaitu proses pengelompokan dimulai dari masing-masing data sebagai satu buah cluster, kemudian secara rekursif mencari cluster terdekat sebagai pasangan untuk bergabung sebagai satu cluster yang lebih besar. Agglomerative hierarchical Clustering (AHC) dapat diimplementasikan pada sekumpulan data numerik dalam proses pengelompokan data. Salah satu contoh data numerik adalah data sekolah yang meliputi data nilai Ujian Nasional (UN).
meningkatkan mutu pendidikan dan melakukan pengawasan terhadap sekolah-sekolah (http://un.kemdikbud.go.id/). Maka dari itu Ujian Nasional merupakan hal penting yang harus dilaksanakan demi terciptanya pendidikan yang bermutu .
Sesuai dengan konsep clustering yang membagi set data besar ke dalam kelompok-kelompok maka dapat dilakukan pengelompokan Sekolah Menengah Atas di Provinsi Daerah Istimewa Yogyakarta berdasarkan Ujian Nasional menjadi beberapa kelompok untuk membantu penugasan pengawas sekolah untuk mendampingi sekolah sesuai dengan peraturan Mentri Pendidikan dan Kebudayaan no 143 tahun 2014 tentang petunjuk teknis pelaksanaan jabatan fungsional pengawas sekolah dan angka kreditnya di mana satu pengawas untuk jenjang pendidikan SMA mengawasi minimal 7 sekolah .
Berdasarkan hal di atas, maka penulis tertarik untuk membuat sistem pengelompokan data Sekolah Menengah Atas di Provinsi DIY berdasarkan nilai Ujian Nasional (UN) menggunakan algoritma Agglomerative Hierarchical Clustering (AHC) untuk mengelompokan Sekolah Menengah Atas di Provinsi DIY menggunakan algoritma Agglomerative Hierarchical Clustering (AHC).
1.2 RUMUSAN MASALAH
Berdasarkan Latar Belakang yang ada dapat dirumuskan masalah yaitu : 1. Apakah algoritma Agglomerative Hierarchical Clustering (AHC) dapat
dipergunakan untuk mengelompokan Sekolah Menengah Atas di provinsi DIY berdasarkan nilai Ujian Nasional?
2. Bagaimana hasil evaluasi clustering dari pengelompokan yang dihasilkan menggunakan Silhouette Index (SI)?
3. Apakah hasil pengelompokan SMA di Provinsi DIY dengan algoritma Agglomerative Hierarchical Clustering (AHC) dapat dipergunakan untuk membantu menentukan jumlah pengawas sekolah sesuai dengan peraturan Mentri Pendidikan dan Kebudayaan?
Tujuan dari penelitian ini adalah membangun sistem untuk mengelompokan Sekolah Menengah Atas di Provinsi Daerah Istimewa Yogyakarta berdasarkan nilai Ujian Nasional menggunakan Agglomerative Hierarchical Clustering (AHC).
1.4 BATASAN MASALAH
Batasan masalah dalam penelitian ini adalah :
1 Metode yang digunakan adalah metode clustering algoritma Agglomerative Hierarchical Clustering (AHC).
2 Aplikasi dibuat berbasis desktop dan menggunakan bahasa pemrograman Java.
3 Set data yang digunakan adalah data nilai Ujian Nasional (UN) di Provinsi Daerah Istimewa Yogyakarta pada tahun 2015.
1.5 MANFAAT PENELITIAN
Manfaat yang didapat dari penelitian ini adalah :
1 Memberikan gambaran implementasi algoritma Agglomerative
Hierarchical Clustering (AHC) dalam mengelompokan Sekolah Menengah Atas berdasarkan nilai Ujian Nasional.
2 Memberikan referensi bagi penelitian yang berkaitan dengan pengelompokan sekolah.
3 Memberikan masukan untuk Dinas Pendidikan dalam pengambilan kebijakan perbaikan mutu pendidikan Sekolah Menengah Atas di Provinsi Daerah Istimewa Yogyakarta.
1.6 SISTEMATIKA PENULISAN
Sistematika Penulisan dibagi menjadi beberapa bab, yaitu : 1. BAB I : PENDAHULUAN
Pendahuluan berisi tentang latar belakang, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, dan sistematika penulisan tugas akhir
Landasan Teori berisi tentang teori yang terkait dengan perancangan dan pembuatan sistem.
3. BAB III. METODOLOGI PENELITIAN
Metodologi penelitian ini berisi penjelasan gambaran umum penelitian, data, spesifikasi alat, dan tahap-tahap penelitian.
4. BAB IV : PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA
Pemrosesan awal dan perancangan perangkat lunak penambangan data ini berisi pemrosesan awal dalam proses Knowledge Discovery in Database (KDD) yaitu pembersihan data, integrasi data, seleksi data, dan transformasi data. Pada bab ini juga berisi perancangan perangkat lunak yang terdiri dari perancangan umum, diagram use case, diagram aktivitas, diagram sekuen, diagram kelas analisis, diagram kelas desain, algoritma per method, struktur data, dan perancangan
antarmuka.
5. BAB V : IMPLEMENTASI DAN EVALUASI HASIL
Implementasi dan evaluasi hasil ini berisi implementasi rancangan perangkat lunak dan evaluasi hasil yang terdiri dari pengujian perangkat lunak (black box), pengujian perbandingan perhitungan manual dengan hasil sistem, pengujian perbandingan hasil sistem dengan sistem lain (Orange) dan kelebihan dan kekurangan sistem.
6. BAB VI : PENUTUP
Penutup berisi tentang simpulan umum yang diperoleh dari pembuatan sistem serta rancangan pengembangan sistem ke depan.
5 BAB II
LANDASAN TEORI
2.1. PENAMBANGAN DATA
2.1.1. Pengertian Penambangan Data
Penambangan data adalah kegiatan yang meliputi pengumpulan dan pemakaian data historis untuk menemukan keteraturan, pola, atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Santosa, 2007).
2.1.2. Fungsi Penambangan Data
Fungsi penambangan data digunakan untuk menentukan macam-macam pola yang dapat ditemukan dalam tugas-tugas penambangan data
(Han dkk, 2006). Tugas-tugas yang berkaitan dengan penambangan data dibagi menjadi empat kelompok, yaitu :
a. Model Prediksi (Prediction Modelling)
Model prediksi merupakan pembuatan sebuah model yang dapat melakukan pemetaan dari setiap himpunan variabel ke setiap targetnya, kemudian menggunakan model tersebut untuk memberikan nilai target pada himpunan baru yang didapat. Ada 2 jenis model prediksi, yaitu klasifikasi dan regresi. Klasifikasi digunakan untuk variabel target diskret, sedangkan regresi digunakan untuk variabel target kontinu.
b. Analisis Cluster (Cluster Analysis)
Analisis cluster merupakan pengelompokan data ke dalam sejumlah kelompok berdasarkan kesamaan karakteristik masing-masing data pada kelompok-kelompok yang ada. Data-data yang masuk dalam batas kesamaan dengan kelompoknya akan bergabung dalam kelompok tersebut, dan akan terpisah dalam kelompok yang berbeda jika keluar dari batas kesamaan kelompok tersebut.
Analisis asosiasi digunakan untuk menemukan pola yang menggambarkan kekuatan hubungan fitur dalam data. Pola yang ditemukan biasanya merepresentasikan bentuk aturan implikasi atau subset fitur. Tujuannya adalah untuk menemukan pola yang menarik dengan cara yang efisien.
d. Deteksi Anomali (Anomaly Detection)
Deteksi anomali merupakan proses pengamatan sebuah data dari sejumlah data yang secara signifikan mempunyai karakteristik yang berbeda dari sisa data yang lain. Data-data yang karakteristiknya menyimpang (berbeda) dari data yang lain disebut sebagai outlier. (Prasetyo, 2014)
2.1.3. Knowledge Discovery in Database (KDD)
Gambar 2. 1 Tahapan Proses KDD
Tahapan Proses dalam penggunaan data mining yang merupakan proses Knowledge Discovery in Database (KDD) adalah :
1. Pembersihan Data (Data Cleaning)
Tahap ini merupakan tahap menghilangkan data yang tidak diperlukan dan data yang tidak konsisten.
2. Integrasi Data (Data Integration)
Tahap ini merupakan tahap menggabungkan data dari berbagai sumber.
3. Seleksi Data (Data Selection)
Tahap ini merupakan tahap untuk menganalisis data yang relevan yang diperoleh dari database.
4. Transformasi Data (Data Transformation)
Tahap ini merupakan proses dimana data diubah atau digabungkan sehingga menjadi tepat untuk dilakukan penambangan data.
5. Penambangan Data (Data Mining)
Tahap ini merupakan proses utama dimana metode cerdas diterapkan untuk mengekstrak pola data.
6. Evaluasi Pola (Patern Evaluation)
Tahap ini merupakan tahap untuk mengidentifikasi pola-pola yang sungguh-sungguh menarik yang mewakili pengetahuan berdasarkan beberapa langkah penting.
7. Presentasi Pengetahuan (Knowledge Presentation)
Tahap ini merupakan teknik visualisasi dan gambaran pengetahuan yang digunakan untuk memberikan pengetahuan hasil penambangan kepada pengguna.
2.2. Ujian Nasional (UN)
Adapun tujuan UN sebagai berikut :
a) Untuk memperoleh informasi tentang mutu hasil pendidikan secara nasional
b) Mengukur pencapaian hasil belajar siswa baik sekolah/madrasah negri maupun swasta
c) Memperoleh gambaran perbandingan mutu pendidikan pada sekolah madrasah, antar sekolah/madrasah, dan antar wilayah dari tahun ke tahun.
d) Menjadi bahan penentuan kebijakan pembinaan sekolah/madrasah e) Sebagai bahan pertimbangan dalam memberikan Surat Tanda Tamat
Belajar dan seleksi masuk ke jenjang pendidikan yang lebih tinggi. (Kartowagiran, 2008)
2.3 Analisis Cluster
2.3.1. Konsep Clustering
Clustering adalah proses mempartisi data–set menjadi beberapa sub-set atau kelompok sedemikian rupa sehingga elemen-elemen dari suatu kelompok tertentu memiliki set properti yang dishare bersama , dengan tingkat similaritas yang tinggi dalam satu kelompok dan tingkat similaritas antar kelompok yang rendah (Hermawati & Astuti, 2009).
Menurut keanggotaan data dalam cluster, clustering dapat dibagi menjadi dua, yaitu eksklusif dan tumpang-tindih. Dalam kategori eksklusif, sebuah data bisa dipastikan hanya menjadi anggota satu cluster dan tidak menjadi anggota di cluster yang lain. Metode clustering yang masuk kedalam kategori ini adalah K-Means, DBSCAN, dan SOM. Sementara yang termasuk kategori tumpang tindih adalah metode clustering yang membolehkan sebuah data menjadi anggota dilebih dari satu cluster, misalnya Fuzzy C-Means dan pengelompokan berbasis hirarki (Prasetyo, 2014).
Sementara menurut kategori kekompakan, clustering terbagi menjadi dua, yaitu komplet dan parsial. Jika semua data bisa bergabung menjadi satu (dalam konteks partisi) maka bisa dikatakan semua data kompak menjadi satu cluster, tapi jika ada satu atau dua (sedikit) data yang tidak ikut bergabung dalam cluster mayoritas maka data tersebut dikatakan data yang mempunyai perilaku yang menyimpang. Data yang menyimpang ini dikenal dengan sebutan outlier, noise (Prasetyo, 2004).
Isu yang juga penting dalam clustering adalah matrik yang digunakan
untuk mengukur ketidakmiripan data yang dikelompokkan. Penggunaan matrik yang berbeda dapat memberikan hasil yang berbeda tergantung kasus yang diselesaikan. Matrik yang paling banyak digunakan adalah Euclidean. Secara geometris metrik ini memberikan jarak terpendek antara dua data. Selain Euclidian, ada pula pengukuran jarak dengan menggunakan manhattan. Pengukuran jarak dengan menggunakan manhattan memberikan jarak sesungguhnya antara dua data. Formula manhattan yaitu :
D1(x,y)=||x-y||1=∑��=�|| �− �|| ...(2.1)
di mana :
� = indeks data
= nilai fitur ke-i dari x. = nilai fitur ke-i dari y.
2.3.2. Silhouette Coefficient
Silhouette Coefficient adalah metode yang digunakan untuk memvalidasi baik sebuah cluster yang menggabungkan nilai kohesi dan separasi. Silhouette Coefficient (SC) dapat digunakan untuk memvalidasi baik sebuah data, cluster tunggal (satu cluster dari sejumlah cluster), atau bahkan keseluruhan cluster. Untuk menghitung nilai SC, terlebih dahulu menghitung nilai Silhouette Index (SI) dari sebuah data ke-i. Perhitungan nilai SI terdapat 2 komponen yaitu ai dan bi. ai adalah rata-rata jarak data ke-i terhadap semua data lainnya dalam satu cluster, sedangkan bi didapatkan dengan menghitung rata-rata jarak data ke-i terhadap semua data dari cluster yang lain yang tidak dalam satu cluster dengan data ke-i, kemudian diambil yang terkecil (Prasetyo, 2014).
Berikut formula untuk menghitung : Berikut formula untuk menghitung :
=�=1,…,
d : jarak data ke-i dengan data ke-r dalam satu cluster j
x : data
: nilai minimum dari rata-rata jarak data ke-i terhadap semua
Untuk mendapatkan Silhouette Index (SI) data ke-i menggunakan persamaan berikut :
�� = ax{ , } − ...(2.4) di mana :
a : rata-rata jarak data ke-i terhadap semua data lainnya dalam satu cluster.
b : nilai minimum dari rata-rata jarak data ke-i terhadap semua data dari cluster yang lain tidak dalam satu cluster dengan data ke-i.
max{ , } : nilai maksimum dari nilai a dan b dari satu data SI : Silhouette Index
Nilai mengukur seberapa tidak mirip sebuah data dengan cluster yang diikutinya, nilai yang semakin kecil menandakan semakin tepatnya data tersebut
berada dalam cluster tersebut. Nilai yang besar menandakan seberapa jeleknya data terhadap cluster yang lain. Nilai SI yang didapat dalam rentang (-1, +1). Nilai SI yang mendekati 1 menandakan bahwa data tersebut semakin tepat berada dalam
cluster tersebut. Nilai SI negatif ( > ) menandakan bahwa data tersebut tidak tepat berada dalam cluster tersebut (karena lebih dekat ke cluster yang lain). SI bernilai 0 (atau mendekati 0) berarti data tersebut posisinya berada di perbatasan di antara dua cluster.
Untuk nilai SI dari sebuah cluster didapatkan dengan menghitung rata-rata nilai SI semua data yang bergabung dalam cluster tersebut, seperti persamaan berikut :
�� = 1 ∑=1�� ...(2.5) di mana :
i : indeks data j : cluster
mj : banyaknya data dalam cluster j
Sementara nilai SI global didapatkan dengan menghitung rata-rata nilai SI dari semua Cluster seperti pada persamaan berikut :
�� = 1∑ =1�� ...(2.6)
di mana :
j : cluster
k : jumlah cluster
�� : Silhouette Index cluster SI : Silhouette Index global
Untuk memvalidasi seberapa baik sebuah cluster digunakan metode Silhouette Coefficient (SC). Nilai SC didapatkan dengan mencari nilai maksimum SI Global dari jumlah cluster 2 sampai jumlah cluster n-1, seperti persamaan berikut:
�� = � �� � ...(2.7) di mana :
SC : Silhouette Coefficient SI : Nilai Silhouette Global k : jumlah cluster
Kriteria subjektif pengukuran baik atau tidaknya pengelompokan berdasarkan Silhouette Coefficient (SC) menurut Kauffman dan Roesseeuw (1990) disajikan dalam Tabel 3.1
Tabel 3. 1 Kriteria subjetif pengukuran pengelompokan berdasarkan Silhouette Coefficient (SC)
Nilai SC Interpretasi SC
0,71 - 1,00 Struktur kuat
0,51 - 0,70 Struktur baik
0,26 - 0,50 Struktur Lemah
2.4 Algoritma Agglomerative Hierarchical Clustering (AHC)
Agglomerative Hierarchical Clustering (AHC) adalah metode pengelompokan berbasis hirarki dengan pendekatan bottom up, yaitu proses pengelompokan dimulai dari masing-masing data sebagai satu buah cluster, kemudian secara rekursif mencari cluster terdekat sebagai pasangan untuk bergabung sebagai satu cluster yang lebih besar. (Prasetyo, 2014)
Algoritma Agglomerative Hierarchical Clustering (AHC) dapat dijelaskan sebagai berikut (Prasetyo, 2014) :
1. Hitung matriks kedekatan berdasarkan jenis jarak yang digunakan 2. Ulangi langkah 3 sampai 4, hingga hanya satu cluster yang tersisa
3. Gabungkan dua cluster terdekat berdasarkan parameter kedekatan yang ditentukan
4. Perbarui matriks kedekatan untuk merefleksikan kedekatan diantara cluster- cluster baru dan cluster yang tersisa
Pengelompokan berbasis hirarki sering ditampilkan dalam bentuk grafis menggunakan diagram yang mirip pohon (tree) yang disebut dengan dendogram. Dendogram merupakan diagram yang menampilkan hubungan cluster dan subcluster-nya dalam urutan yang mana cluster yang digabung (agglomerative view) atau dipecah (divisive view).
Ada tiga teknik kedekatan yang digunakan Agglomerative Hierarchical Clustering (AHC) yaitu:
1. Single linkage (jarak terdekat)
Single linkage memberikan hasil bila cluster-cluster digabungkan menurut jarak antara anggota-anggota yang paling dekat diantara dua cluster. Pengukuran jarak cluster dalam single linkage menggunakan formula jarak minimal. Teknik ini bagus untuk menangani set data yang distribusi datanya non-elips, tapi sangat sensitif terhadap noise dan outlier.
d(U,V) = min {d(U,V)}; d(U,V) ϵ D ... (2.6)
d(U,V) : jarak antar-cluster U dan V
min{d(U,V)} : nilai minimum dari dari cluster U dan V
2. Complete linkage (jarak terjauh)
Complete linkage terjadi bila kelompok-kelompok digabungkan menurut jarak antara anggota-anggota yang paling jauh di antara dua cluster. Pengukuran jarak cluster dalam complete linkage menggunakan formula jarak maksimal. Teknik ini kurang peka terhadap noise dan outlier, tetapi bagus untuk data yang mempunyai distribusi bentuk bulat.
d(U,V) = max {d(U,V)}; d(U,V) ϵ D ... (2.7)
Keterangan :
d(U,V) : jarak antar-cluster U dan V
max{d(U,V)} : nilai maksimum dari dari cluster U dan V
3. Average linkage (jarak rerata)
Average linkage digabungkan menurut jarak-rata-rata antara pasangan-pasangan anggota masing-masing pada himpunan diantara dua cluster. Pengukuran jarak cluster dalam average linkage menggunakan formula jarak rerata. Teknik ini merupakan pendekatan yang mengambil pertengahan di antara single linkage dan complete linkage.
d(U,V) = 1
x {d(U,V)}; d(U,V) ϵ D ... (2.8)
Keterangan :
15 BAB III
METODOLOGI PENELITIAN
3.1. SUMBER DATA
Data yang akan digunakan untuk penelitian ini berupa i berekstensi .xls yang diperoleh dari situs milik Kementrian Pendidikan dan kebudayaan yang dapat diakses melalui alamat http://un.kemdikbud.go.id/r-hasilun.html
Data sumber merupakan data nilai Ujian Nasional SMA jurusan IPA dan IPS di Daerah Istimewa Yogyakarta tahun 2015. Pada penelitian ini data mata pelajaran yang digunakan adalah seluruh mata pelajaran yang digunakan untuk Ujian Nasional jurusan IPA (Bahasa Indonesia, Bahasa Inggris, Matematika, Fisika, Kimia, dan Biologi) dan IPS (Bahasa Indonesia, Bahasa Inggris, Matematika, Geografi, Sosiologi, dan Ekonomi).
3.2. SPESIFIKASI ALAT
3.2.1. Hardware
Perangkat keras yang digunakan untuk membuat aplikasi ini adalah Laptop dengan spesifikasi prosessor Intel Core i3, RAM 2GB, HDD 300GB.
3.2.2. Software
Perangkat lunak yang digunakan dalam pembuatan aplikasi ini adalah Sistem Operasi Windows 8.1 Enterprise 64-bit, JDK 1, 7, dan NetBeans 7.2 .
3.3. TAHAP-TAHAP PENELITIAN
3.3.1. Studi Kasus
Ujian Nasional sehingga nantinya dapat dipergunakan untuk evaluasi dalam meningkatkan mutu pendidikan.
3.3.2. Penelitian Pustaka
Penulis melakukan penelitian ini dengan mencari literatur-literatur sebagai referensi untuk mengetahui teori-teori yang berkaitan dengan penelitian. Literatur-literatur yang digunakan berasal dari buku, jurnal, dan karya ilmiah.
3.3.3. Knowledge Discovery in Database (KDD)
Penulis melakukan penelitian ini bertujuan untuk mengubah data mentah menjadi suatu informasi yang lebih bermanfaat, dalam penelitian ini penulis menggunakan proses Knowledge Discovery in Database (KDD) di mana proses KDD tersebut terdiri dari pembersihan data, integrasi data, seleksi data, transformasi data, penambangan data, evaluasi pola, dan presentasi pengetahuan. (Han dkk, 2006)
Pada penelitian ini, penulis melakukan pembersihan data dan integrasi data
secara manual yaitu dengan menggunakan aplikasi spreadsheet. Tahap seleksi data, transformasi data, dan penambangan data dilakukan di dalam perangkat lunak yang dikembangkan oleh penulis sebagai alat bantu untuk mempermudah tahap-tahap tersebut. Pada tahap evaluasi pola dan presentasi pengetahuan, penulis melakukan evaluasi hasil dari perangkat lunak yang telah dibangun dan kemudian memberikan penjelasan atas hasil evaluasi agar informasi yang didapat dapat bermanfaat bagi pihak-pihak yang membutuhkan.
3.3.4. Pengembangan Perangkat Lunak
Metode yang digunakan penulis dalam mengembangakan sistem penambangan data ini adalah metode waterfall. Waterfall adalah sebuah model pengembangan perangkat lunak yang dilakukan secara sekuensial, dimana satu tahap dilakukan setelah tahap sebelumnya selesai dilakukan. Metode ini merupakan metode yang paling umum digunakan oleh para pengembang perangkat lunak. Metode waterfall memiliki langkah-langkah sebagai berikut :
Langkah ini merupakan langkah untuk menganalisis kebutuhan dari sistem yang akan dibangun.
2. Desain
Langkah ini merupakan langkah untuk merancang sebuah perangkat lunak sesuai dengan kebutuhan dari sistem yang telah dianalisis. Pada langkah ini dilakukan perancangan antarmuka, struktur data, dan algoritma yang akan digunakan pada sistem ini. 3. Implementasi
Implementasi merupakan penerapan dari hasil desain ke dalam bahasa pemrograman yang nantinya akan menghasilkan sebuah perangkat lunak.
4. Pengujian Perangkat Lunak
Langkah terakhir yang perlu dilakukan adalah pengujian perangkat lunak yang telah selesai dibuat. Pengujian perangkat lunak yang dilakukan adalah dengan menggunakan pengujian blackbox, pengujian membandingkan hasil perhitungan manual dengan hasil
BAB IV
PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK
4.1PEMROSESAN AWAL
4.1.1 Pembersihan Data (Data Cleaning)
Pembersihan data adalah proses membersihkan data dari data yang tidak diperlukan (noise) dan data yang tidak konsisten. Data yang memiliki noise seperti beberapa sekolah nilai ujian nasionalnya kosong maka sekolah tersebut akan dihapus dari tabel data.
4.1.2 Integrasi Data (Data Integration)
Integrasi data adalah melakukan penggabungan data dari berbagai macam sumber. Dalam penelitian ini peneliti menggunakan 8 data yaitu data nilai Ujian Nasional tahun 2015 jurusan IPA dan data nilai Ujian Nasional tahun
2015 jurusan IPS. Data penelitian ini diperoleh dari satu sumber sehingga tidak dilakukan integrasi data.
4.1.3 Seleksi Data (Data Selection)
Seleksi atribut merupakan tahap yang perlu dilakukan sebelum proses penambangan data. Pada data asli nilai Ujian Nasional terdapat 4 atribut tetap yaitu atribut KODE_SEKOLAH, NAMA_SEKOLAH, dan 6 mata pelajaran Ujian Nasional yang tertera pada tabel 4.1 dan tabel 4.2. Atribut yang dibuang adalah atribut KODE_SEKOLAH karena KODE_SEKOLAH tidak dibutuhkan informasinya dalam pengelompokan dan Atribut yang akan digunakan untuk proses penambangan data yaitu NAMA_SEKOLAH dan 6 mata pelajaran Ujian Nasional yang tertera pada tabel 4.3 dan tabel 4.4
Tabel 4.1 Atribut dari data asli nilai Ujian Nasional SMA jurusan IPA
No. Atribut Keterangan
2 NAMA_SEKOLAH Nama Sekolah
3 UN_BIN_15 Rata-rata nilai Ujian Nasional Bahasa Indonesia
4 UN_BING_15 Rata-rata nilai Ujian Nasional Bahasa Inggris
5 UN_MTK_15 Rata-rata nilai Ujian Nasional Matematika
6 UN_FSK_15 Rata-rata nilai Ujian Nasional Fisika
7 UN_KMA_15 Rata-rata nilai Ujian Nasional Kimia
8 UN_BIO_15 Rata-rata nilai Ujian Nasional Biologi
Tabel 4. 2 Atribut dari data asli nilai Ujian Nasional SMA jurusan IPS
No. Atribut Keterangan
1 KODE_SEKOLAH Kode Sekolah
2 NAMA_SEKOLAH Nama Sekolah
3 UN_BIN_15
Rata-rata nilai Ujian Nasional Bahasa Indonesia
4 UN_BING_15
Rata-rata nilai Ujian Nasional Bahasa Inggris
5 UN_MTK_15
Rata-rata nilai Ujian Nasional Matematika
6 UN_EKO_15
Rata-rata nilai Ujian Nasional Ekonomi
7 UN_SOS_15
Rata-rata nilai Ujian Nasional Sosiologi
8 UN_GEO_15
Tabel 4. 3 Atribut terseleksi dari data nilai Ujian Nasional SMA jurusan IPA
No. Atribut Keterangan
1 NAMA_SEKOLAH Nama Sekolah
2 UN_BIN_15
Rata-rata nilai Ujian Nasional Bahasa
Indonesia
3 UN_BING_15
Rata-rata nilai Ujian Nasional Bahasa Inggris
4 UN_MTK_15
Rata-rata nilai Ujian Nasional Matematika
5 UN_FSK_15 Rata-rata nilai Ujian Nasional Fisika
6 UN_KMA_15 Rata-rata nilai Ujian Nasional Kimia
7 UN_BIO_15 Rata-rata nilai Ujian Nasional Biologi
Tabel 4. 4 Atribut terseleksi dari data nilai Ujian Nasional SMA jurusan IPS
No. Atribut Keterangan
1 NAMA_SEKOLAH Nama Sekolah
2 UN_BIN_15
Rata-rata nilai Ujian Nasional Bahasa Indonesia
3 UN_BING_15
Rata-rata nilai Ujian Nasional Bahasa Inggris
4 UN_MTK_15 Rata-rata nilai Ujian Nasional Matematika
5 UN_EKO_15 Rata-rata nilai Ujian Nasional Ekonomi
6 UN_SOS_15 Rata-rata nilai Ujian Nasional Sosiologi 7 UN_GEO_15 Rata-rata nilai Ujian Nasional Geografi
4.1.4 Transformasi Data (Data Transformation)
terseleksi ke dalam bentuk Array sehingga data siap dilakukan proses penambangan data.
4.2 PERANCANGAN PERANGKAT LUNAK
4.2.1 Perancangan Umum
4.2.1.1 Input Sistem
Sistem pengelompokan dengan menggunakan algoritma Agglomerative Hierarchical Clustering hanya dapat menerima masukan dari pengguna berupa file bertipe .xls yang dapat dipilih langsung oleh pengguna dari direktori penyimpanan di komputer. Sebelum melakukan proses pengelompokan, pengguna juga harus memilih atribut yang akan digunakan, memilih metode, dan mengisi jumlah kelompok yang ingin didapatkan pada texfield yang telah disediakan. Perancangan input sistem secara umum digambarkan pada Gambar 4.1.
Gambar 4. 1 Diagram Konteks
4.2.1.2 Proses Sistem
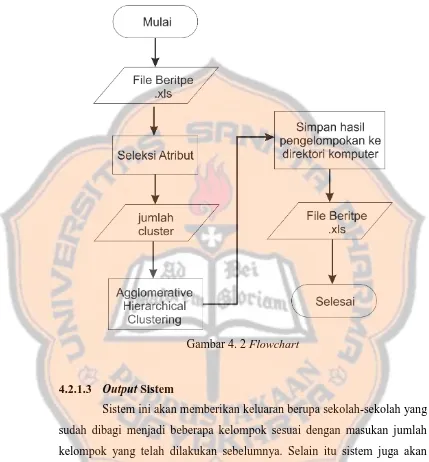
Proses yang dilakukan oleh sistem yang akan dibangun terdiri dari beberapa tahapan untuk mendapatkan kelompok sekolah-sekolah. Tahapan-tahapan tersebut yaitu :
1. Pemilihan atribut yang akan digunakan untuk pemrosesan pengelompokan data.
2. Pemilihan metode pengelompokan yang akan digunakan.
3. Menentukan jumlah kelompok yang akan dihasilkan oleh sistem. 4. Proses pengelompokan untuk mendapatkan kelompok
sekolah-sekolah sesuai dengan jumlah kelompok yang dimasukan.
Proses umum yang terjadi pada sistem digambarkan dalam diagram flowchart yang digambarkan pada Gambar 4.2 .
Gambar 4. 2 Flowchart
4.2.1.3 Output Sistem
4.2.2 Diagram Use Case
Gambar 4. 3 Diagram Use Case
Diagram use case digunakan untuk menggambarkan interaksi antara sistem dengan pengguna. Pengguna dari sistem yang akan dibangun ini adalah sebanyak satu pengguna. Fungsi yang dapat dilakukan oleh pengguna sistem ini adalah pengguna dapat menginputkan data dalam bentuk file .xls. Fungsi selanjutnya yaitu pengguna dapat menyeleksi atribut yang akan digunakan dan kemudian melakukan proses clustering dengan memilih metode perhitungan jarak dan melihat hasil clustering . Fungsi yang terakhir yaitu pengguna dapat menyimpan hasil clustering.
4.2.2.1Gambaran Umum Use Case
Tabel 4. 5 Gambaran Umum Use Case
Nama Use Case Deskripsi Aktor
Input berkas .xls
Use case ini merupakan proses memasukan data file bertipe .xls
User
Seleksi atribut
Use case ini merupakan proses pemilihan atribut dari data terpilih yang akan digunakan untuk proses clustering data
User
Proses clustering
Use case ini merupakan proses clustering data dari data yang telah terpilih
User
Simpan hasil clustering
Use case ini merupakan proses penyimpanan hasil clustering dalam bentuk file berekstensi .xls
User
4.2.2.2Narasi Use Case
Diagram use case pada Gambar 4.3 juga memiliki narasi yang merupakan penjelasan lebih lengkap dari masing-masing use case tersebut terlampir pada lampiran 1.
4.2.3 Diagram Aktivitas
4.2.4 Diagram Kelas Analisis
Diagram kelas berguna untuk memperlihatkan hubungan antar kelas yang dapat membantu memvisualisasikan struktur kelas-kelas dari suatu sistem. Diagram kelas desain dapat lihat pada Gambar 4.7.
Gambar 4. 4 Diagram Kelas Analisis
4.2.5 Diagram Kelas Desain
Diagram kelas desain terlampir pada lampiran 3.
4.2.6 Diagram Sekuen
Terdapat empat diagram sekuen yaitu input berkas .xls, seleksi atribut, proses clustering, dan simpan hasil clustering. Diagram sekuen terlampir pada lampiran 4.
4.2.7 Perancangan Struktur Data
Sistem pengelompokan data ini membutuhkan tempat penyimpanan yang tidak terlalu banyak dan tidak menghabiskan banyak waktu. Konsep penyimpanan data yang sesuai untuk sistem pengelompokan adalah dengan menggunakan konsep struktur data. Pada penelitian ini digunakan konsep struktur data array, ArrayList dan HashMap.
1. Array
tipe data yang sama. Setiap data disimpan dalam alamat memori yang berbeda-beda dan disebut dengan elemen array. Setiap elemen mempunyai nilai indek sesuai dengan urutannya. Melalui indek inilah kita dapat mengakses data-data tersebut.
Pada penelitian ini penulis menggunakan array untuk menyimpan data input dari file bertipe .xls.. Cara kerja array pada sistem ini adalah menyimpan nama sekolah dan keenam nilai mata pelajaran ujian nasional.
Gambar 4. 5 Perancangan Array
2. ArrayList
Arraylist merupakan penyimpanan sementara dimana ukuran tempat penyimpanannya bersifat dinamis yaitu dapat berubah ukurannya sesuai dengan inputan data yang dimasukkan pengguna.
Pada penelitian ini penulis menggunakan arraylist untuk membuat matriks jarak. Cara kerja array list pada sistem ini adalah yang pertama untuk menampung nilai jarak untuk satu sekolah dengan sekolah yang lainnya. Objek array list baru akan selalu dibuat untuk setiap sekolah .
Gambar 4. 6 Ilustrasi Konsep Arraylist
3. HashMap
HashMap merupakan penyimpanan sementara yang memiliki key dan value dalam penyimpanannya dimana satu key dipetakan ke suatu nilai.
Pada penelitian ini penulis menggunakan HashMap untuk menghitung nilai Silhouette Index pada suatu pengelompokan. Cara kerja HashMap pada sistem ini adalah mengeset size dari arraylist yang menampung nama sekolah sebagai key dan indeks data sekolah sebagai value. Sebagai contoh akan dijelaskan pada Tabel 4.6 berikut.
Tabel 4. 6 Perancangan HashMap
Key Value
0 [0]
1 [1 , 4]
2 [2 , 3]
4.2.8 Algoritma Setiap Method
Rincian algoritma per method terlampir pada Lampiran 5
4.2.9 Perancangan Antarmuka
Sistem Pengelompokan Sekolah menengah Atas di DIY berdasarkan nilai Ujian Nasional Menggunakan Agglomerative Hierarchical Clustering ini memiliki desain antarmuka yang digunakan untuk melakukan interaksi dengan pengguna. Antarmuka sistem terdiri dari 3 tampilan yang terdiri dari Halaman Beranda, Halaman AHC, dan Halaman Bantuan.
Gambar 4. 7 Perancangan Halaman Beranda
Halaman Beranda adalah halaman yang muncul pertama kali ketika aplikasi
dijalankan. Halaman ini berisi judul aplikasi, tombol “AHC”, tombol “BANTUAN”, dan identitas pembuat aplikasi.
4.2.9.2Perancangan Halaman AHC
Halaman Agglomerative Hierarchical Clustering merupakan halaman yang
ditampilkan ketika pengguna menekan tombol “AHC” pada halaman awal.
Halaman ini berfungsi untuk memasukkan data, memilih atribut yang akan digunakan, memasukkan jumlah cluster, dan mengcluster data, melihat hasil cluster, dan menyimpan hasil cluster.
4.2.9.3Perancangan Halaman Bantuan
Gambar 4. 9 Perancangan Halaman Bantuan
Halaman Bantuan ini ditampilkan saat pengguna menekan tombol
BAB V
IMPLEMENTASI DAN EVALUASI HASIL
5.1 IMPLEMENTASI RANCANGAN PERANGKAT LUNAK
Perangkat lunak pengelompokan data ini memiliki 4 kelas yang terdiri dari satu kelas control dan tiga kelas view;
5.1.1 Implementasi Kelas View
Berikut ini adalah tabel yang berisikan daftar kelas yang ada pada package view. Pada tabel tersebut disertakan pula nama file fisik dan file executable.
Tabel 5. 1 Implementasi kelas view
No. Nama Kelas Nama File Fisik Nama File
Executable Interface
1 View_Beranda View_Beranda.java View_Beranda.class Gambar 5.1
2 View_AHC View_AHC.java View_AHC.class Gambar 5.2
3 view_Bantuan view_Bantuan.java view_Bantuan.class Gambar 5.3
Gambar 5. 2 Interface View_AHC
Gambar 5. 3 Interface View_Bantuan
5.1.2 Implementasi Kelas Kontrol
Berikut ini adalah tabel yang berisikan daftar kelas yang ada pada package control. Pada tabel tersebut disertakan pula nama file fisik dan file executable.
Tabel 5. 2 Implementasi kelas Controler
No. Nama Kelas Nama File Fisik Nama File Executable
5.2 EVALUASI HASIL
5.2.1 Pengujian Perangkat Lunak (Black Box)
5.2.1.1Rencana Pengujian Black Box
Rencana pengujian menggunaan black box akan dijelakan pada tabel berikut.
Tabel 5. 3 Rencana Pengujian Black Box
No. Use Case Butir Uji Kasus Uji
1 Input Data
Pengujian memasukkan data dari file bertipe .xls
UC-01
Pengujian memasukkan data dari file selain bertipe .xls
UC-02
2 Seleksi Atribut Pengujian memilih
atribut UC-03
3 Proses Clustering Pengujian melakukan
proses pengelompokan UC-04
4 Simpan hasil Clustering
Pengujian menyimpan hasil pengelompokan ke dalam file bertipe .xls
UC-05
5.2.1.2Prosedur Pengujian Black Box dan Kasus Uji
Setelah menyusun rencana pengujian pada tabel 5.3 maka dilakukan prosedur pengujian serta kasus uji pada Lampiran 2.
5.2.1.3Evaluasi Pengujian Hasil Black Box
5.2.2 Pengujian Perbandingan Hasil Hitung Manual dengan Hasil Perangkat
Lunak
Salah sattu metode yang dilakukan oleh peneliti untuk menguji valid tidaknya alat uji yang dibuat , maka peneliti melakukan perbandingan hasil antara alat uji yang dibuat dengan perhitungan manual. Pengujian ini menggunakan dataset Ujian Nasional jurusan IPA tahun 2015 sejumlah 10 data dengan atribut NAMA SEKOLAH UN_BIN_15, UN BING_15, UN_MTK_15, UN_FSK_15, UN_KMA_15, UN_BIO_15. Dataset yang digunakan dapat dilihat pada tabel 5.4.
Tabel 5. 4 Dataset Pengujian
NAMA_SEKOLAH UN_BIN
pengelompokan 3 kelompok. Proses perhitungan manual beserta dengan hasilnya dapat dilihat pada Lampiran 6.
5.2.2.2Perhitungan Perangkat Lunak
Pengujian perhitungan perangkat lunak menggunakan dataset Ujian Nasional SMA jurusan IPA di DIY tahun 2015 sejumlah 10 data, Proses perhitungan perangkat lunak ini dilakukan dengan menggunakan perangkat lunak yang telah dibuat dengan menggunakan metode single linkage, complete linkage, dan average linkage.. Dalam perhitungan pengelompokan ini, perangkat lunak akan menghasilkan 3 kelompok. Hasil dari perhitungan perangkat lunak dapat dilihat pada Gambar 5.4, Gambar 5.5, dan Gambar 5.6 berikut ini.
Gambar 5. 5 Hasil Penambangan Data Metode Complete linkage Menggunakan
Perangkat Lunak
Gambar 5. 6 Hasil Penambangan Data Metode Average linkage Menggunakan Perangkat Lunak
5.2.2.3Evaluasi Pengujian Perbandingan Hitung Manual dengan Hasil
Perangkat Lunak
perangkat lunak yang dibuat sudah berjalan dengan baik dan sesuai dengan yang diharapkan.
5.2.3 Pengujian Perbandingan Hasil Perangkat Lunak dengan Hasil
Perangkat Lunak Lainnya (Orange)
5.2.3.1Perhitungan Perangkat Lunak
Pengujian perhitungan perangkat lunak menggunakan dataset Ujian Nasional SMA jurusan IPA di DIY tahun 2015 sejumlah 10 data, Proses perhitungan perangkat lunak ini dilakukan dengan menggunakan perangkat lunak yang telah dibuat dengan menggunakan metode single linkage, complete linkage, dan average linkage.. Dalam perhitungan pengelompokan ini, perangkat lunak akan menghasilkan 3 kelompok. Hasil dari perhitungan perangkat lunak dapat dilihat pada Gambar 5.4, Gambar 5.5, dan Gambar 5.6.
5.2.3.2Perhitungan Perangkat Lunak Lainnya (Orange)
Orange merupakan sebuah aplikasi penambangan data yang dapat
memberikan hasil terpercaya. Peneliti menggunakan aplikasi Orange ini untuk membandingkan perhitungan perangkat lunak yang dibuat untuk mengetahui hasil yang diperoleh dari perangkat lunak yang dibuat memliki hasil yang sama atau tidak.
Gambar 5. 7 Hasil Perhitungan Metode Single linkage Menggunakan Aplikasi Orange
Gambar 5. 8 Hasil Perhitungan Metode Complete linkage Menggunakan Aplikasi Orange
Gambar 5. 9 Hasil Perhitungan Metode Average linkage Menggunakan Aplikasi Orange
5.2.3.3Evaluasi Pengujian Perbandingan Perhitungan Hasil Perangkat Lunak
dengan Perangkat Lunak Lainnya (Orange).
5.2.4 Pengujian Perangkat Lunak dengan Menggunakan Dataset
Pada pengujian perangkat lunak ini dilakukan pengujian menggunakan dataset nilai Ujian Nasional Sekolah Menengah Atas di Daerah Istimewa Yogyakarta jurusan IPA dan IPS tahun 2015 menggunakan metode single linkage, complete linkage, dan average linkage .
5.2.4.1Evaluasi Hasil Clustering
Evaluasi clustering yang digunakan oleh peneliti yaitu menggunakan Silhouette Coefficient (SC). Berdasarkan seluruh pengujian yang telah dilakukan terhadap dataset rata-rata nilai Ujian Nasional di provinsi DIY tahun 2015, didapatkan hasil evaluasi clustering dari setiap metode yang terbentuk. Hasil evaluasi clustering terlampir pada Tabel 5.5.
Tabel 5. 5 Perhitungan Hasil Silhouette Coefficient (SC) Jurusan IPA
Berdasarkan pengujian dataset rata-rata nilai Ujian Nasional SMA jurusan IPA dengan menggunakan metode single linkage, complete linkage, dan average linkage yang dapat dilihat pada Tabel 5.5 didapatkan nilai maksimum dari pengujian k=2 sampai dengan k=139 yaitu 0,995 yang disebut dengan Silhouette Coefficient (SC). Nilai SC sebesar 0,995 berada pada interval 0,71 – 1,00 yang berarti hasil pengelompokan memiliki struktur yang kuat. Pada Tabel 5.7 dapat dilihat SI Global bernilai 0,995 ketika k=139. Pengelompokan dengan membagi dataset menjadi 139 kelompok tidak perlu dilakukan karena tidak ada manfaatnya mengelompokan data ke dalam 139 kelompok. Menurut peraturan Mentri Pendidikan dan Kebudayaan no.143 tahun 2014 tentang petunjuk teknis pelaksanaan jabatan fungsional pengawas sekolah dan angka kreditnya, setiap pengawas pendidikan tingkat SMA mengawasi minimal 7 sekolah berarti jumlah cluster yang rasional untuk 140 sekolah berkisar antara 2 sampai 20 cluster. Oleh karena itu dalam analisis selanjutnya difokuskan pada nilai k antara 2 sampai 20.
Gambar 5. 10 Grafik Perhitungan Nilai Silhouette Coefficient Terhadap Jumlah Cluster SMA Jurusan IPA Pada Metode Single linkage
Dari Gambar 5.10 dapat dilihat bahwa :
1. Ketika k=2 SI Global bernilai 0,662, ketika k=3 nilai SI Global naik menjadi 0,739, kemudian ketika k=4 nilai SI Global mengalami penurunan kembali menjadi 0,707. Nilai SI Global kembali naik ketika k=5 sampai dengan k=11, kemudian turun kembali ketika k=12 dengan
nilai SI Global sebesar 0,828. Ketika k=13 nilai SI Global kembali naik sampai k=19 menjadi 0,881 dan ketika k=20 nilai SI Global mengalami penurunan dengan nilai 0,849.
2. Nilai maksimum SI Global ketika k =2 sampai k =20 adalah 0,881 pada k =19 yang menunjukkan bahwa pengelompokan yang dilakukan dengan menggunakan metode single linkage memiliki struktur pengelompokan yang kuat.
Pada metode single linkage, untuk semua k selalu ditemukan cluster dengan jumlah anggota 1.
Gambar 5. 11 Grafik Perhitungan Nilai Silhouette Coefficient Terhadap Jumlah Cluster SMA Jurusan IPA Pada Metode Complete linkage
Dari Gambar 5.11 dapat dilihat bahwa :
1. Ketika k=2 nilai SI Global sebesar 0,543, ketika k=3 nilai SI Global turun menjadi 0,486 dan kemudian naik kembali menjadi 0,611 ketika k=4. Nilai SI Global mengalami penurunan kembali ketika k=5 dengan nilai 0,476 sampai k=10 dengan nilai 0,314 dan naik kembali ketika k=11 dengan nilai 0,382. Ketika k=12 nilai SI Global turun kembali sampai k=13 menjadi 0,342, ketika k=14 SI Global kembali naik dengan nilai 0,343, ketika k=15 nilai SI Global turun menjadi 0,319, dan naik kembali ketika k=16 dengan nilai SI Global 0,328. Nilai SI Global kembali mengalami penurunan ketika
k=17 sampai dengan k=19 dan kemudian naik kembali ketika k=20 dengan nilai SI Global 0,316
2. Nilai maksimum SI Global ketika k =2 sampai k=20 adalah 0,611 pada k=4 yang menunjukkan bahwa pengelompokan yang dilakukan dengan menggunakan metode complete linkage memiliki struktur pengelompokan yang baik.
Pada metode complete linkage, untuk semua k >3 selalu ditemukan cluster dengan jumlah anggota 1.
Gambar 5. 12 Grafik Perhitungan Nilai Silhouette Coefficient Terhadap Jumlah Cluster SMA Jurusan IPA Pada Metode Average linkage
Dari Gambar 5.12 dapat dilihat bahwa :