BAB 2
LANDASAN TEORI
2.1 Jenis dan Elemen Statistika
Statistika adalah ilmu yang berkaitan dengan data (Gunawan Santosa, 2004). Hal-hal yang tercakup dalam statistika adalah pengumpulan, klasifikasi, peringkasan, organisasi, analisis dan interpretasi informasi numerik. Kata statistik pertama kali diperkenalkan oleh Gottingen Ashewall (1719-1772) dan kata statistika digunakan oleh Zimmerman yang dipopulerkan oleh Sir Jhon Sinclair dalam bukunya berjudul Statistical Account of Scotland (1791-1799).
Menurut R. Gunawan Santosa (2004), elemen-elemen dasar dalam statistika yaitu:
1. Populasi, yaitu himpunan unit-unit (orang, obyek, transaksi) yang menarik untuk diselidiki.
2. Variabel, yaitu karakteristik atau sifat dari unit individual populasi.
3. Pengukuran, yaitu proses yang digunakan untuk memasangkan bilangan-bilangan kepada variabel dari unit populasi individual.
4. Sensus dari populasi, yaitu kegiatan mengukur variabel untuk setiap unit populasi.
5. Sampel, yaitu himpunan bagian dari populasi.
6. Inferensi statistik, yaitu estimasi, prediksi atau generalisasi terhadap populasi yang didasarkan pada informasi yang terkandung pada sampel.
Statistika dibedakan menjadi 2 (dua) jenis, yaitu: 1. Statistika Deskriptif
Statistika deskriptif yaitu statistika yang menggunakan metode numerik dan grafik untuk mencari pola dalam suatu kumpulan data, meringkas informasi yang terkandung dalam kumpulan data dan menghadirkan informasi dalam bentuk yang diinginkan.
2. Statistika Inferensia (Induktif)
Statistika inferensia yaitu statistika yang menggunakan data sampel untuk membuat estimasi, keputusan, prediksi, dan generalisasi terhadap kumpulan data yang lebih besar. Menurut Richard Lungan (2006), statistika inferensia mempersoalkan tentang tatacara pengambilan kesimpulan/keputusan, termasuk penentuan ukuran keandalan dari kesimpulan/keputusan tersebut.
2.2 Jenis-Jenis Data
Data adalah bahan mentah yang perlu diolah sehingga menghasilkan informasi keterangan, baik kualitatif maupun kuantitatif yang menunjukkan fakta (Nana Danapriatna dan Rony Setiawan, 2005). Menurut Richard Lungan (2006), data adalah keterangan-keterangan atau fakta-fakta yang dikumpulkan dari suatu populasi atau lebih yang akan digunakan untuk menerangkan ciri-ciri dari populasi yang bersangkutan.
Data kategorik adalah informasi yang memberikan keterangan, gambaran, atau fakta mengenai suatu persoalan dalam bentuk kategori, huruf, atau lambang. Menurut Elfriede Mahulae (2010), manfaat menggunakan data kategorik adalah:
1. Ruang yang diperlukan untuk menyimpan data menjadi sangat sempit/kecil dibandingkan dengan data aslinya atau data primernya.
2. Waktu yang dilakukan untuk menganalisis data akan menjadi lebih singkat. 3. Hasil analisis data kategorik dapat dilakukan atau dipertanggungjawabkan
atas dasar pemikiran sebagai berikut:
a) Pada dasarnya, analisis statistik dilakukan dengan tujuan untuk mempelajari perbedaan atau persamaan kelompok-kelompok individu
lain perbedaan proporsi, prevalensi atau insiden suatu peristiwa tertentu antara kelompok individu yang ditinjau.
b) Mempelajari asosiasi ganda antar variabel kategorik dengan menerapkan model loglinier atau model regresi logistik yang meliputi penerapan statistik Rasio Kesamaan atau Rasio Kecenderungan.
c) Model asosiasi atau korelasi antar variabel kategorik dinyatakan telah mempunyai pola yang standard atau baku sehingga lebih mudah dapat dipahami dan diulang kembali dengan memakai berbagai macam data kategorik sesuai dengan bidangnya masing-masing.
d) Kesimpulan yang diambil berdasarkan model asosiasi (empiris) antara variabel numerik kerap kali tidak dapat dipertanggungjawabkan, karena data yang dipakai pada umumnya bukanlah data yang sesuai.
Data yang baik, benar dan sesuai dengan model menentukan kualitas kebijakan/keputusan yang akan diambil terhadap suatu masalah dari populasi yang akan dikaji. Menurut sifatnya data terbagi 2 (dua) jenis, yaitu:
1. Data Kualitatif yaitu data yang disajikan bukan dalam bentuk angka yang berhubungan dengan kategorisasi, karakteristik berupa pertanyaan atau kata-kata. Contohnya sembuh, rusak dan sebagainya.
2. Data Kuantitatif yaitu data yang berbentuk bilangan. Contohnya jumlah mahasiswa di FMIPA USU, jumlah penjualan barang setiap bulannya dan lain sebagainya.
Data kuantitatif terbagi 2 (dua) jenis, yaitu:
1. Data Diskrit yaitu data kuantitatf yang nilainya merupakan hasil penghitungan dan berupa bilangan bulat. Contohnya jumlah anak tiga orang.
2. Data Kontinu yaitu data kuantitatif yang nilainya berdasarkan pengukuran yang nilainya berbentuk interval berupa bilangan pecahan dan bilangan bulat. Contohnya tinggi badan seseorang 160 cm, 165 cm dan sebagainya.
Menurut Richard Lungan (2006), berdasarkan sumbernya, data terbagi 2 (dua), yaitu:
1. Data Internal
Data internal merupakan data yang dikumpulkan oleh unit kerja tertentu dalam lingkungannya untuk keperluan sendiri. Misalnya data mahasiswa, dosen, pegawai, keuangan dan peralatan di FMIPA USU.
2. Data Eksternal
Data eksternal merupakan data yang diambil dari unit lain. Misalnya data dari FMIPA USU digunakan oleh BPS, maka data tersebut merupakan data eksternal bagi BPS.
Menurut Gunawan Santosa (2004), data dalam statistika dapat diperoleh dari 4 (empat) jenis sumber yang berbeda, yaitu:
1. Sumber terpublikasi 2. Rancangan percobaan
3. Survei (pertanyaan pada responden) 4. Observasi
Menurut cara memperolehnya, data terbagi atas 2 (dua) jenis, yaitu: 1. Data Primer
Data primer adalah data yang langsung diperoleh dari lapangan melalui percobaan, survei dan observasi. Misalnya seorang peneliti ingin mengetahui hubungan antara besarnya biaya yang dikeluarkan untuk promosi dan volume penjualan atas komoditi tertentu. Data biaya promosi dan volume penjualan tersebut merupakan data primer bagi peneliti bersangkutan.
2. Data Sekunder
Data sekunder diperoleh dari data primer, biasanya dalam publikasi berupa tabel-tabel, seperti data harga, data impor dan ekspor dan data produksi. Data yang dipublikasikan oleh Badan Pusat Statistik (BPS) selalu berupa data sekunder.
Data menurut waktu dibedakan atas 2 (dua) jenis, yaitu: 1. Data Silang
Data silang merupakan data yang dikumpulkan dalam waktu yang sifatnya temporer. Misalnya data hasil penelitian pemasaran pakaian jadi di Jakarta tahun 2004.
2. Data Berkala
Data berkala merupakan data yang dikumpulkan setiap periode tertentu. Misalnya jumlah impor mobil mewah menurut tahun, dari tahun 1995 sampai tahun 2010.
2.2.1 Metode Pengumpulan Data
Menurut Richard Lungan (2006), teknik pengumpulan data meliputi: 1. Pengumpulan langsung
Pengumpulan data secara langsung dilakukan dengan cara mengamati dan mencatat semua hasil pengamatan dari sumber pertama dilakukan dengan cara percobaan, survei dan observasi.
2. Pengumpulan tak langsung
Pengumpulan data tak langsung dilakukan dengan cara menghimpun data yang dipelukan dari orang-orang atau unit unit-unit kerja lain yang telah mengumpulkan data tersebut secara langsung.
2.2.2. Kriteria Data
Agar data dapat menerangkan ciri populasi dengan benar, data harus memenuhi kriteria-kriteria sebagai berikut:
1. Objektif, yaitu data yang benar-benar sama dengan keadaan yang sebenarnya (apa adanya).
3. Galat baku (standard error) kecil. 4. Tepat waktu.
5. Relevan.
2.2.3 Tujuan Pengumpulan Data
Menurut Richard Lungan, (2006) bahwa tujuan pengumpulan data yaitu: 1. Memperbaiki atau menyederhanakan teori atau hipotesa yang ada. 2. Menciptakan teori atau hipotesis yang baru.
3. Mengetahui keadaan atau hipotesis yang ada.
4. Memecahkan masalah yang mencakup inter-relasi antara beberapa kasus (kelompok data).
2.3 Variabel (Peubah)
Variabel (peubah) adalah sesuatu yang nilainya berubah-ubah menurut waktu atau berbeda menurut elemen atau tempat (Supranto, 2004). Contohnya apabila objek yang diteliti adalah suatu perusahaan, peubahnya ialah jumlah modal, jumlah karyawan, jumlah produksi, jumlah penjualan, jumlah pajak perusahaan dan sebagainya.
Variabel (peubah) dibedakan menjadi 2 (dua) jenis, yaitu:
1. Variabel (peubah) Bebas yaitu variabel (peubah) yang dapat berdiri sendiri dan sifatnya dapat mempengaruhi variabel lain.
2. Variabel (peubah) Terikat yaitu variabel (peubah) yang tidak dapat berdiri sendiri sehingga sifatnya dipengaruhi oleh variabel (peubah) lain.
2.4 Skala Pengukuran
Skala pengukuran adalah suatu skala yang digunakan untuk mengklasifikasikan peubah yang diukur supaya tidak terjadi kesalahan dalam menentukan analisis data
dan langkah-langkah penelitian selanjutnya (Nana Danapriatna dan Rony Setiawan, 2005). Menurut Sam Kash Kachigan (1986), skala pengukuran terdiri dari 4 (empat) jenis, yaitu:
1. Skala Nominal
Skala nominal yaitu skala yang paling sederhana disusun berdasarkan kategori. Contohnya jenis kelamin yaitu laki-laki dan perempuan.
2. Skala Ordinal
Skala ordinal yaitu skala berdasarkan ranking/urutan, tidak mempunyai skor yang sama dan data yang diperoleh tidak mempunyai arti mutlak. Contohnya status sosial terdiri dari kelas bawah, kelas menengah dan kelas atas.
3. Skala Interval
Skala interval yaitu skala yang menunjukkan jarak antara satu data dengan data lain dan mempunyai bobot yang sama. Contohnya suhu dan lain-lain.
4. Skala Rasio
Skala rasio yaitu skala yang mempunyai nilai nol mutlak dan mempunyai jarak yang sama. Contohnya berat badan seseorang 50 kg.
2.5 Model Loglinier
Model loglinier merupakan suatu model statistik yang berguna untuk menentukan dependensi atau kecenderungan antara beberapa peubah yang berskala nominal atau kategorikal (Agresti, 1990). Model loglinier merupakan metode statistik yang dapat digunakan untuk mendeskripsikan pola hubungan antar beberapa variabel (peubah) kategorik.
Dengan analisis model loglinier diperoleh persamaan yang menggambarkan ada tidaknya hubungan antara dua atau lebih peubah dan pola hubungannya sekaligus
untuk mengetahui sel-sel mana yang memberikan distribusi sehingga terjadi kontribusi.
Beberapa kelebihan dari model loglinier adalah:
1. Dapat menentukan model matematika yang cocok untuk dependensi lebih dari dua peubah.
2. Model loglinier dapat digunakan untuk menentukan besarnya interaksi yang menyebabkan peubah tersebut dependen atau tidak.
2.5.1 Model Loglinier Tiga Dimensi
Andaikan
mijk adalah frekuensi harapan. Anggap semua mijk 0, dan andaikanijk ijk lnm
. Tanda dot yang mengikuti indeks merupakan rata-rata yang berkenaan
dengan indeks tersebut, sebagai contoh
I i ijk jk
. Sehingga diperoleh: ... ... .. i X i ... . . Y j j ... .. k Z k ... . . .. . XY ij i j ij ... .. .. . XZ ik i k ik ... .. . . . YZ jk j k jk ... .. . . .. . . . XYZ ijk ij ik jk i j k ijk .Jumlah dari parameter tersebut sama dengan nol, yaitu:
i j Y j X i =
k i j k XYZ ijk XY ij XY ij Z k ... 0 Dengan model loglinear, angka-angka pada sel tabel kontingensi dapat dimodelkan sedemikian hingga pada tabel kontingensi tiga dimensi, model loglinear adalah (Agresti, 1990): YZ jk XZ ik XY ij Z k Y j X i ijk m Lnˆ +ijkXYZ (1) Keterangan: ijk
mˆ nilai harapan dari Xijk
= rata-rata dari seluruh logaritma nilai harapan
X i
efek utama kategori ke-i peubah X untuk i =1,2,3…I
Y j
efek utama kategori ke-j peubah Y untuk j =1,2,3,…J
Z k
= efek utama kategori ke-k peubah Z untuk k =1,2,3,…K
XY ij
= efek interaksi antara kategori ke-i peubah X dan kategori ke-j peubah Y untuk i=1,2,3…I dan j=1,2,3,…J
XZ ik
efek interaksi antara kategori ke-i peubah X dan kategori ke-k peubah Z untuk i = 1,2,3…I dan k = 1,2,3,…K
YZ jk
efek interaksi antara kategori ke-j peubah Y dan kategori ke-k peubah Z untuk j = 1,2,3,…J dan k = 1,2,3,…K
XYZ ijk
= pengaruh interaksi ke tiga peubah terhadap model.
Dengan model loglinier ini diperoleh persamaan yang menggambarkan ada tidaknya hubungan antara dua peubah atau lebih dan pola hubungannya. Untuk menginterpretasi model loglinier, dijelaskan asosiasi marginal dan asosiasi parsial dari model dengan menggunakan odds rasio yaitu ukuran untuk melihat hubungan antara nilai peubah penjelas x dengan peluang terjadinya suatu kategorik pada peubah respon (Agresti, 1990). Analisis loglinier dari suatu tabel frekuensi multivariat yang pada dasarnya menyelesaikan analisis tersebut disebut odds atau odds rasio (Hagenaars, 1993). Beberapa model loglinier untuk tabel kontingensi tiga dimensi disajikan dalam tabel berikut:
Tabel 2.1 Model Loglinier untuk Tabel Kontingensi Tiga Dimensi
Nomor Model Loglinier Tiga Dimensi Simbol
1 Z k Y j X i ijk m Lnˆ (X, Y, Z) 2 XY ij Z k Y j X i ijk m Ln ˆ (XY, Z) 3 YZ jk XY ij Z k Y j X i ijk m Ln ˆ (XY, YZ) 4 XZ ik YZ jk XY ij Z k Y j X i ijk m Lnˆ (XY, YZ, XZ) 5 XYZ ijk XZ ik YZ jk XY ij Z k Y j X i ijk m Ln ˆ (XYZ) 2.6 Tabel Kontingensi
Penggunaan tabel kontingensi merupakan teknik penyusunan data yang cukup sederhana untuk melihat hubungan antara beberapa peubah dalam satu tabel (Abdul Hakim, 2002). Peubah yang dianalisis merupakan peubah kategorikal, yang memiliki skala nominal atau ordinal. Jumlah seluruh frekuensi sel yang diharapkan harus sama dengan jumlah seluruh pengamatan.
Data sering terdiri dari sejumlah objek yang terhitung dengan atribut tertentu yang dimiliki oleh kategori-kategori tertentu yang disusun dalam tabel satu dimensi, dua dimensi, tiga dimensi atau bahkan lebih biasanya disebut tabel kontingensi satu arah, dua arah dan tiga arah (Elfriede Mahulae, 2010).
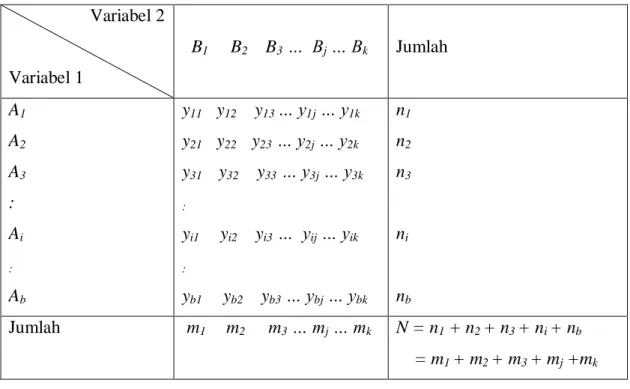
Misalnya suatu eksperimen yang terdiri dari n observasi yang diklasifikasikan menurut dua peubah atau lebih peubah kategorik. Peubah pertama mempunyai b tingkat (b kategori) ditulis dengan A1, A2, A3,…,Ab. dan peubah ke dua
mempunyai k tingkat (k kategori) ditulis dengan B1, B2, B3,…, Bk (Agresti, 1990).
Misalkan yij adalah banyaknya kejadian peubah pertama pada tingkat ke-i dan peubah
ke dua pada tingkat ke-j, untuk i = 1, 2, 3, … , b dan j = 1, 2, 3, … , k. Data tersebut dapat disusun seperti tabel berikut:
Tabel 2.2 Tabel Kontingensi bxk Variabel 2 Variabel 1 B1 B2 B3 … Bj … Bk Jumlah A1 A2 A3 : Ai : Ab y11 y12 y13 … y1j … y1k y21 y22 y23 … y2j … y2k y31 y32 y33 … y3j … y3k : yi1 yi2 yi3 … yij … yik : yb1 yb2 yb3 … ybj … ybk n1 n2 n3 ni nb Jumlah m1 m2 m3 … mj … mk N = n1 + n2 + n3 + ni + nb = m1 + m2 + m3 + mj +mk
Hal-hal yang yang berlaku dalam uji independensi untuk tabel kontingensi k
b yaitu:
1. Sebanyak n trial dilakukan dan tiap-tiap hasilnya diklasifikasikan menurut 2 (dua) sifat (A1, A2, A3,…,Ab dan B1, B2, B3,…, Bk). Jadi, ada sebanyak bk
peristiwa yang mungkin (Ai dan Bj) pada setiap percobaan. Setiap trial bebas
artinya percobaan pertama tidak mempengaruhi percobaan ke dua, dan seterusnya.
2. Probabilitas peristiwa Ai dan Bj untuk setiap satu eksperimen adalah pij yaitu
peluang Ai dan Bj. Nilai atau besarnya pij tidak diketahui.
3. yij adalah banyaknya frekuensi dengan peristiwa Ai dan Bj terjadi dalam n
percobaan=frekuensi sel ij.
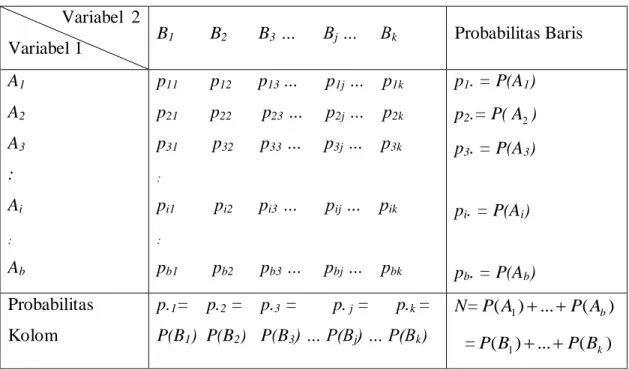
Dengan demikian diperoleh suatu model yang menghasilkan tabel probabilitas sel seperti tabel berikut ini:
Tabel 2.3 Tabel Probabilitas bxk Variabel 2
Variabel 1 B1 B2 B3 … Bj … Bk Probabilitas Baris A1 A2 A3 : Ai : Ab p11 p12 p13 … p1j … p1k p21 p22 p23 … p2j … p2k p31 p32 p33 … p3j … p3k : pi1 pi2 pi3 … pij … pik : pb1 pb2 pb3 … pbj … pbk p1. = P(A1) p2.= P(A ) 2 p3. = P(A3) pi. = P(Ai) pb. = P(Ab) Probabilitas Kolom p.1= p.2 = p.3 = p. j = p.k = P(B1) P(B2) P(B3) … P(Bj) … P(Bk) N=P(A1)...P(Ab) =P(B1)...P(Bk) pi. = pi1 + pi2 + pi3 + … + pik = P(A ) i p.j = p1j + p2j + p3j + … + pbj = P(Bj)
Jika nilai pi. tidak diketahui, maka dicari nilai p ˆi.
N n
p i
i.
ˆ
Jika nilai p.j tidak diketahui, maka dicari nilai pˆ.j
N m pˆ.j j N m n p p N Eij ˆi.ˆj. i j H0: Pij= P(A dan i Bj) = P(A ) . P(i Bj) = PiPj 1 H :Pij P(A dan i Bj)P(A ) . P(i Bj) PiPj
Tabel 2.4 Tabel Kontingensi Model Loglinier Tiga Dimensi VAR 3 VARIABEL 2 Jumlah 1 … J … 1 … K Jumlah … 1 … K Jumlah V A R 1 1 2 3 . . . I X111 X.11 X11k X.1k X11. Xij. X1j1 Xij1 … … X1jk Xijk X1j. Xij. X1.. Xi.. Jumlah X.11 X.1k X1j. X.j1 X.jk X.j. X…
Taksiran nilai harapan masing-masing sel dinyatakan sebagai:
2 .. . . .. .. . . .. ) )( )( ( ˆ ˆ N X X X m N N X N X N X m k j i ijk k j i ijk 2.7 Uji Chi-Kuadrat
Untuk menginterpretasikan data pada tabel kontingensi, salah satu yang dapat dipakai adalah uji Chi-Kuadrat (Agresti, 1990). Uji Chi-Kuadrat adalah pengujian hipotesis mengenai perbandingan antara frekuensi observasi yang benar-benar terjadi dengan frekuensi harapan/ekspektasi. Frekuensi observasi adalah nilai yang didapat dari hasil observasi sedangkan frekuensi harapan adalah nilai yang didapat dari penghitungan secara teoritis. Uji Chi-Kuadrat digunakan untuk mengetahui adanya hubungan antara peubah yang diukur tersebut signifikan atau tidak.
Kegunaan uji Chi-Kuadrat adalah:
1. Untuk menguji apakah ada perbedaan yang cukup berarti antara pengamatan suatu objek (respon tertentu) terhadap nilai harapan.
2. Untuk menguji apakah ada hubungan antara satu peubah berdasarkan pengkategorian (klasifikasi) terhadap peubah lainnya yang juga diberikan pengkategorian (klasifikasi).
Hipotesa yang dipergunakan adalah:
k j i ijk k j i ijk P P P P H P P P P H .. . . .. 1 .. . . .. 0 : :
Hipotesa ini berlaku untuk semua peubah yang bebas. Statistik uji Chi-Kuadrat untuk tabel kontingensi (R.S.N Pillai and V. Bagavathi, 2000) dirumuskan sebagai berikut:
I i J j K k ijk ijk ijk e e n 1 1 1 2 2 ( ) (2) Keterangan: ijkn observasi untuk kasus-kasus yang dikategorikan pada peubah ke-i, j dan k
ijk
e banyak kasus yang diharapkan untuk dikategorikan pada peubah ke-i, j dan k
2
= sebuah nilai peubah acak uji Chi-Kuadrat.
Dengan kriteria pengujian adalah: Jika hitung2 tabel2 maka TolakH0
Jika hitung2 tabel2 maka Terima H 0
Uji Chi-Kuadrat banyak digunakan di berbagai bidang yang menyangkut kesesuaian (goodness of fit) maupun uji kebebasan tentang distribusi empiris dan teoritis (Yusuf Wibisono, 2005). Uji ini didasarkan pada seberapa baik kesesuaian antara frekuensi pengamatan (observasi) dan frekuensi yang diharapkan dari distribusi teoritis yang dihipotesiskan. Pengujian tentang kebebasan antara dua peubah atau lebih, ke homogenitas proporsi, bahkan sebagai alternatif dalam pengujian beberapa
nilai lokasi sekaligus yang analog dengan uji keragaman juga menjadi fokus dari uji Chi-Kuadrat ini.
Beberapa karakteristik uji Chi-Kuadrat (R.S.N Pillai and V. Bagavathi, 2000) yaitu:
1. Pengujian berdasarkan pada kejadian-kejadian atau frekuensi-frekuensi, di mana dalam teori-teori distribusi, pengujian berdasarkan rata-rata dan standard deviasi.
2. Untuk menemukan kesimpulan, pengujian Chi-Kuadrat harus diaplikasikan terutama pengujian hipotesis tetapi tidak digunakan untuk estimasi.
3. Pengujian dapat digunakan antara semua himpunan dari observasi dan ekspektasi frekuensi.
4. Untuk semua penambahan nilai derajat kebebasan, distribusi Chi-Kuadrat baru harus dibentuk.
5. Pengujian Chi-Kuadrat merupakan tujuan pengujian umum dan sering digunakan dalam penelitian.
Beberapa asumsi dari pengujian Chi-Kuadrat (R.S.N Pillai and V. Bagavathi, 2000) adalah:
1. Semua observasi harus independen. 2. Semua kejadian harus mutually exclusive. 3. Terdapat observasi yang besar.
4. Untuk tujuan perbandingan, data tersebut harus dalam bentuk yang asli.
2.8 Uji Hipotesis
Pengujian hipotesis merupakan bagian dari statistika inferensia yang mempersoalkan tentang kebenaran suatu anggapan atau teori. Hipotesis statistik adalah suatu asumsi atau pernyataan, dapat benar atau salah, terhadap parameter atau ciri satu atau beberapa populasi yang dihadapi (Richard Lungan, 2006).
Uji hipotesis menggunakan data untuk menilai kebenaran suatu anggapan mengenai parameter populasi yang sedang dipelajari. Data kemudian diolah guna mendapatkan penduga bagi parameter populasi. Nilai penduga ini tidak harus sama dengan nilai parameter yang diduga.
Untuk memperoleh kesimpulan yang benar, perlu disusun suatu kaidah pengambilan keputusan. Dalam penyusunan suatu kaidah pengambilan kesimpulan, hal yang pertama harus dilakukan yaitu menyusun anggapan sementara yang disebut hipotesis nol, dengan simbol H , misalnya: 0
0
H : Peubah bebas tidak berpengaruh nyata terhadap peubah tak bebas. Dalam penelitian ini hipotesis nol yaitu:
0
H : Tidak ada hubungan antara jenis maskapai penerbangan, harga tiket pesawat terbang dan tingkat pemesanan tiket pesawat terbang berdasarkan tujuan penerbangan.
Untuk menguji kebenaran H tersebut perlu dipertanyakan, apakah hasil 0
pengamatan contoh dapat menunjang anggapan sementara tersebut atau tidak? Hipotesis tandingan dari H adalah 0 H , misalnya: 1
1
H : Peubah bebas berpengaruh nyata terhadap peubah tak bebas. Dalam tulisan ini hipotesis tandingan dari H yaitu: 0
1
H : Ada hubungan antara jenis maskapai penerbangan, harga tiket pesawat terbang dan tingkat pemesanan tiket pesawat terbang berdasarkan tujuan penerbangan.
Uji hipotesis bertujuan untuk membuktikan kebenaran salah satu di antara
0
H dan H terhadap nilai parameter populasi. Artinya, jika statistik uji yang 1
diperoleh dari data mendukung H , maka 0 H diterima, dan menolak 0 H . Sebaliknya 1 jika statistik uji tersebut mendukung H , maka terima 1 H dan menolak kebenaran 1
0
2.9 Derajat Kebebasan (Degree of Freedom)
Derajat kebebasan berarti jumlah kelas yang akan ditempatkan tanpa melanggar batasan-batasan. Apabila akan dibandingkan penghitungan dari nilai Chi-Kuadrat dengan nilai dari tabel Chi-Kuadrat, maka derajat kebebasan harus jelas.
Derajat kebebasan dari uji Chi-Kuadrat dirumuskan sebagai berikut (R.S.N Pillai and V. Bagavathi, 2000):
V = n – k (3) Keterangan:
V = derajat kebebasan
k = jumlah dari batasan independen n = jumlah dari kelas frekuensi
Untuk tabel kontingensi22derajat kebebasan adalah:
V = (c-1)(r-1) (4) Keterangan:
c = jumlah kolom r = jumlah baris
Untuk tabel kontingensi i jk derajat kebebasan adalah:
(i-1)(j-1)+(i-1)(k-1)+(j-1)(k-1)+(i-1)(j-1)(k-1) (5)
2.10 Uji Kesesuaian (Goodness of Fit)
Uji kesesuaian adalah pengujian untuk mengetahui apakah dua atau lebih populasi adalah sama atau homogen (Abdul Hakim, 2002). Menurut Richard Lungan (2006), uji kesesuaian merupakan suatu uji yang akan menentukan apakah secara teoritis suatu populasi mempunyai sebaran tertentu atau tidak.
Uji kesesuaian populasi pertama kali diperkenalkan oleh Karl Pearson pada tahun 1900-an (Yusuf Wibisono, 2005). Karl Pearson mempertanyakan kesesuaian
data yang teramati dengan data frekuensi teoritis yang didasarkan pada hipotesisnya. Ternyata banyak nilai statistik dari penarikan contoh yang dipilih secara acak tidak tepat atau sesuai dengan hasil teoritisnya.
Uji kesesuaian bertujuan untuk mengetahui tentang sebaran populasi. Suatu contoh acak dipilih dari populasi yang bersangkutan, kemudian informasi contoh tersebut digunakan untuk menguji kebenaran sebaran populasi tersebut.
Apabila data populasi atau data contoh diklasifikasikan menurut satu atribut tunggal atau apabila akan menguji distribusi probabilitas populasi teoritis, maka digunakan uji kesesuaian (Yusuf Wibisono, 2005). Apabila hasil pengukuran menunjukkan bahwa ada kesesuaian atau tidak terlalu menyimpang antara data frekuensi yang teramati dengan frekuensi teoritis, maka hipotesis nol diterima. Tetapi, jika tidak ada kesesuaian antara data frekuensi yang teramati dengan frekuensi teoritis, maka hipotesis nol ditolak. Sesuai tidaknya frekuensi teramati dengan frekuensi teoritis ditentukan dengan cara membandingkan ukuran kesesuaian dengan suatu nilai distribusi Chi-Kuadrat.
2.11 Uji Kebebasan (Uji Independensi)
Uji independensi adalah menguji hipotesis bahwa 2 (dua) sifat tidak berhubungan (Abdul Hakim, 2002). Uji kebebasan mencakup uji kebebasan dua faktor yang terdiri dari beberapa kategori atau level. Dalam hal ini, hasil pengamatan contoh acak diklasifikasi menjadi 2 (dua) faktor yaitu baris dan kolom, masing-masing terdiri dari beberapa kategori. Klasifikasi dapat dilihat pada tabel kontingensi bxk seperti berikut ini:
Tabel 2.5 Tabel Kontingensi untuk Pengamatan Dua Faktor bk Faktor I
Kategori Ke-i
Faktor II
Kategori Ke-j Jumlah Pi
1 2 … j … k 1 2 . . i . b n 11 n … 12 n1j … n1k n 21 n … 22 n2j … n2k . . n i1 n … i2 nij … n ik . n b1 n … b2 nbj … n bk n 1. n 2. n i. n b. . 1 p . 2 p . i p . b p Jumlah n .1 n … .2 n.j … n.k n 1 P p .1 p … .2 p.j … p.k 1
Apabila antara dua peubah tidak mempunyai keterkaitan, maka dikatakan bahwa ke duanya bebas atau tidak saling mempengaruhi.
2.12 Uji K-Way
Uji K-Way terdiri dari 2 (dua) tahap (Fazahadu Syuraifah, 2010), yaitu: 1. Uji untuk interaksi K-suku atau lebih adalah nol.
Uji ini berdasarkan pada hipotesa bahwa efek order ke-K atau lebih sama dengan nol. Uji ini dimulai dari order tertinggi hingga order terendah.
2. Uji untuk interaksi K-suku adalah nol.
Uji ini didasarkan pada hipotesa bahwa efek order ke-K sama dengan nol. Uji ini dimulai dari order terendah hingga order tertinggi.
2.13 Uji Asosiasi Parsial
Tujuan dari uji asosiasi parsial adalah untuk menguji hubungan ketergantungan antara dua peubah dalam setiap level peubah lainnya. Dari uji asosiasi parsial ini diketahui peubah yang akan dimasukkan ke dalam model.
2.14 Koefisien Kontingensi
Setelah diketahui ada tidaknya hubungan antar peubah kategorik pada pengujian Chi-Kuadrat, selanjutnya yang akan dilakukan adalah penghitungan nilai ukuran keeratan hubungan antar peubah dengan menggunakan koefisien kontingensi (Dergibson Siagian dan Sugiarto, 2000). Jika nilai Chi-Kuadrat sudah diperoleh, maka penghitungan koefisien kontingensi sangat mudah dan biasanya pengitungan harga koefisien kontingensi setelah menemukan harga Chi-Kuadrat. Uji signifikan yang digunakan adalah tabel kritik Chi-Kuadrat dengan derajat kebebasan adalah (c-1)(r-1).
Nilai koefisien kontingensi dapat dicari dengan menggunakan rumus:
) ( 2 2 hitung hitung N C (6) m m Cmax 1 (7)
Dengan memperhatikan rumus di atas, dapat diketahui besarnya nilai koefisien kontingensi yaitu 0CCmax.
Keterangan:
C = koefisien kontingensi
2
hitung
= hasil penghitungan Chi-Kuadrat N = banyak data
m = min (baris; kolom), dalam penelitian ini nilai m adalah nilai minimal dari semua variabel yaitu min (X;Y;Z).