LANDASAN TEORI
2.1 Analisis Regresi
Analisis regresi adalah salah satu metode yang dapat digunakan untuk menentukan hubungan antara variabel independen (x) dengan variabel dependen (y). Untuk n pengamatan dengan p variabel independen, maka model regresi tersebut dapat ditulis sebagai berikut:
)
1
.
2
(
,
...
,
3
,
2
,
1
;
1 0x
i
n
y
i p k ik k i=
+
∑
+
=
=ε
β
β
Keterangan :yi = variabel dependen pada pengamatan ke-i (i = 1, 2, ... , n)
β0
= konstantaβk
= koefisien regresi ke – k (k = 1,2, … , p)xik = variabel independen ke-k pada pengamatan ke-i (i = 1, 2, ... , n)
i
ε
= error yang diasumsikan identik, independen, dan berdistribusi normaldengan mean nol dan varians σ2
Persamaan 2.1 dapat ditransformasikan ke dalam matriks:
) 2 . 2 ( ε + =Xβ y
▸ Baca selengkapnya: nilai jumlah kuadrat selisih variabel independen x terhadap rata-ratanya dan variabel y terhadap rata-ratanya adalah
(2)Dimana, = nk n n k k x x x x x x x x x L M O M M M L L 2 1 2 22 21 1 12 11 1 1 1 X = n y y y M 2 1 y = p β β β M 1 0 β
Penaksiran parameter model regresi dapat dilakukan dengan menggunakan metode Ordinary Least Square (OLS). Metode ini dilakukan dengan meminimumkan jumlah kuadrat errornya dan hasil penaksiran parameternya adalah sebagai berikut:
y
X
X
X
β
ˆ
=
(
T)
−1 T (2.3)Uji signifikansi parameter regresi dilakukan dengan 2 cara, yaitu uji serentak dan uji parsial. Hipotesis yang digunakan untuk uji serentak adalah sebagai berikut:
H0 :
β1 =
β2 = ... =
βk = ... =
βp = 0
H1 : paling tidak ada satu
βk
≠ 0, k = 1, 2, ... pStatistik uji: Fhitung = MSE MSR = ) 1 /( ) ˆ ( ) /( ) ˆ ( 1 2 1 2 − − − −
∑
∑
= = p n y y p y y n i i i n i i (2.4) Keterangan:MSR = Mean Square Regression MSE = Mean Square Error
Pengambilan keputusan adalah apabila Fhitung > Fα (p, n-p-1) dengan p adalah
parameter maka H0 ditolak pada tingkat signifikansi α. Artinya paling sedikit ada satu βk
yang tidak sama dengan nol. Pengambilan keputusan juga dapat melalui p-value dimana H0 ditolak jika p-value < α.
Hipotesis yang digunakan untuk uji parsial adalah sebagai berikut:
H0 :
βk
= 0 H1 :βk
≠ 0, k = 1, 2, ... p Statistik uji:)
(
k k hitungb
S
b
t
=
(2.5)Dengan S(bk) adalah akar diagonal matriks
MSE
b
S
2(
k)
=
(
X
TX
)
−1 (2.6)Pengambilan keputusannya yaitu apabila |thitung| > t(1-α/2, n-p-1) dengan p adalah
parameter dan MSE adalah Mean Square Error maka H0 ditolak pada tingkat
signifikansi α, artinya ada pengaruh xi terhadap model. Pengambilan keputusan juga
Uji Asumsi Residual
Residual memiliki asumsi identik, independen, dan berdistribusi normal (Hill, Griffiths dan Lim, 2011, p172). Pengujian masing–masing asumsi tersebut adalah sebagai berikut:
1. Uji Asumsi Identik
Uji asumsi identik dapat dilakukan dengan uji Glejser. Uji Glejser dilakukan dengan melakukan regresi antara nilai variabel independen dan absolute residual sebagai dependen.
Hipotesis untuk uji Glejser adalah sebagai berikut: H0 : residual identik
H1 : residual tidak identik
Statistik uji: Fhitung = ) 1 /( ) | | | (| ) /( ) | | | | ( 1 2 ^ 1 2 ^ − − − − =
∑
∑
= = − p n e e p e e MSE MSR n i i i n i i (2.7)Pengambilan keputusan adalah apabila Fhitung > Fα (p, n-p-1) maka H0 ditolak
pada tingkat signifikansi α, artinya residual tidak identik atau terjadi heterokedastisitas. Pengambilan keputusan juga dapat melalui p-value dimana H0 ditolak jika p-value < α.
2. Uji Asumsi Independen
Uji asumsi independen dengan menggunakan Durbin-Watson. Hipotesis untuk uji Durbin-Watson adalah sebagai berikut:
H0 : ρ = 0 tidak ada korelasi residual
H1 : ρ > 0 ada korelasi residual
Statistik uji:
(
)
∑
∑
= = − − = n i i n i i i hitung e e e d 1 2 1 2 1 (2.8)Daerah keputusan yang dapat diambil adalah jika dhitung ≤ dL,α maka H0
ditolak.
3. Uji Asumsi Normal
Uji kenormalan data dapat dengan uji Kolmogorov–Smirnov. Hipotesis untuk uji Kolmogorov–Smirnov adalah sebagai berikut:
H0 : Residual berdistribusi normal
H1 : Residual berdistribusi tidak normal
Statistik Uji: ) ( ) ( 0 x S x F maks D= − N (2.9)
F0(x) adalah fungsi distribusi kumulatif teoritis sedangkan SN(x)=i/n merupakan fungsi peluang kumulatif pengamatan dari suatu sampel random dengan i adalah pengamatan dan n adalah banyaknya pengamatan. Pengambilan keputusan adalah H0 ditolak jika D >q(1-α) dimana q adalah nilai berdasarkan Tabel Kolmogorov-Smirnov. Selain itu juga dapat melalui Pvalue , dimana H0 ditolak jika Pvalue kurang dari α.
Coefficient of Determination (R2)
Nilai R2 menunjukkan hubungan linear, goodness of fit antara data sampel dengan nilai prediksinya. Nilai R2 juga menunjukkan nilai proporsi varian variabel dependen yang dapat dijelaskan oleh variabel independennya (Hill, Griffiths dan Lim, 2011, p137).
SST
SSE
R
2=
1
−
(2.10) Keterangan :SSE = Sum Square Error SST = Sum Square Total
2.2 Geographically Weighted Regression (GWR)
Model GWR adalah suatu model regresi sederhana yang diubah menjadi model regresi yang terboboti (Fotheringham, Brunsdon, Charlton, 2002). Setiap nilai parameter akan dihitung pada setiap titik lokasi geografis sehingga setiap titik lokasi geografis mempunyai nilai parameter regresi yang berbeda-beda. Hal ini akan memberikan variasi pada nilai parameter regresi di suatu kumpulan wilayah geografis. Jika nilai parameter
regresi konstan pada tiap-tiap wilayah geografis, maka model GWR adalah model global. Artinya tiap-tiap wilayah geografis mempunyai model yang sama.
Model umum untuk model GWR adalah
(
)
∑
(
)
=+
+
=
p k i ik i i k i i iu
v
u
v
x
y
1 0,
β
,
ε
β
(2.11) Keterangan:yi = variabel dependen pada lokasi ke-i (i = 1, 2, ... , n)
xik = variabel independen ke-k pada lokasi ke-i (i = 1, 2, ... , n)
(ui,vi) = koordinat longitude latitude dari titik ke-i pada suatu lokasi geografis.
βk (ui
,vi) = koefisien regresi ke-k pada masing-masing lokasii
ε
= error yang diasumsikan identik, independen, dan berdistribusi Normaldengan mean nol dan varians konstan σ2
Model GWR di persamaan 2.11 dapat ditransformasikan ke dalam bentuk matriks seperti di bawah ini :
)
12
.
2
(
1
)
(
⊗
+
ε
=
β
X
y
Pada model GWR diasumsikan bahwa data observasi yang dekat dengan titik ke-i mempunyai pengaruh yang besar pada penaksiran dari βk(ui,vi) daripada data yang berada jauh dari titik ke-i. Menurut Fotheringham, Brunsdon dan Charlton (2002), lokal parameter βk(ui,vi) ditaksir menggunakan Weighted Least Squared (WLS). Pada GWR sebuah observasi diboboti dengan nilai yang berhubungan dengan titik ke-i. Bobot wij, untuk j = 1, 2, ... , n, pada tiap lokasi (ui,vi) diperoleh sebagai fungsi yang kontinu dari jarak antara titik ke-i dan titik data lainnya.
Penaksiran parameter
Penaksiran parameter pada masing-masing lokasi ke-I melalui WLS adalah sebagai berikut :
βˆ(i)=
(
XTW(i)X)
−1XTW(i)y (2.13) Keterangan :X = matrik data dari variabel bebas y = vektor variabel respon
W(i) = matriks pembobot
= n i i i W W W i ... 0 0 0 ... 0 0 ... 0 ) ( 2 1 M M M M W = nk n n k k x x x x x x x x x L M O M M M L L 2 1 2 22 21 1 12 11 1 1 1 X = n y y y M 2 1 y
(
)
(
)
(
)
(
)
(
)
(
)
= n n p n n n n p v u v u v u v u v u v u , β ... , β , β . . . . . . . . . , β ... , β , β 1 0 1 1 1 1 1 1 1 0 βUji signifikansi
Uji signifikansi dapat dilakukan dengan hipotesis sebagai berikut (Sugiyanto, 2008, p26): 0 ) , ( : H0
β
k ui vi = p , ... , 2 , 1 k ; 0 ) , ( : H1β
k ui vi ≠ = Statistik uji: ) 14 . 2 ( )) , ( βˆ ( se ) , ( βˆ i i k i i k hit v u v u T =Pengambilan keputusan adalah H0 ditolak jika nilai
>
2 2 1 ; 2 /|
T
|
δ δ αt
hit dimana:(
(I L) (I L))
1= − − T trδ
(
)
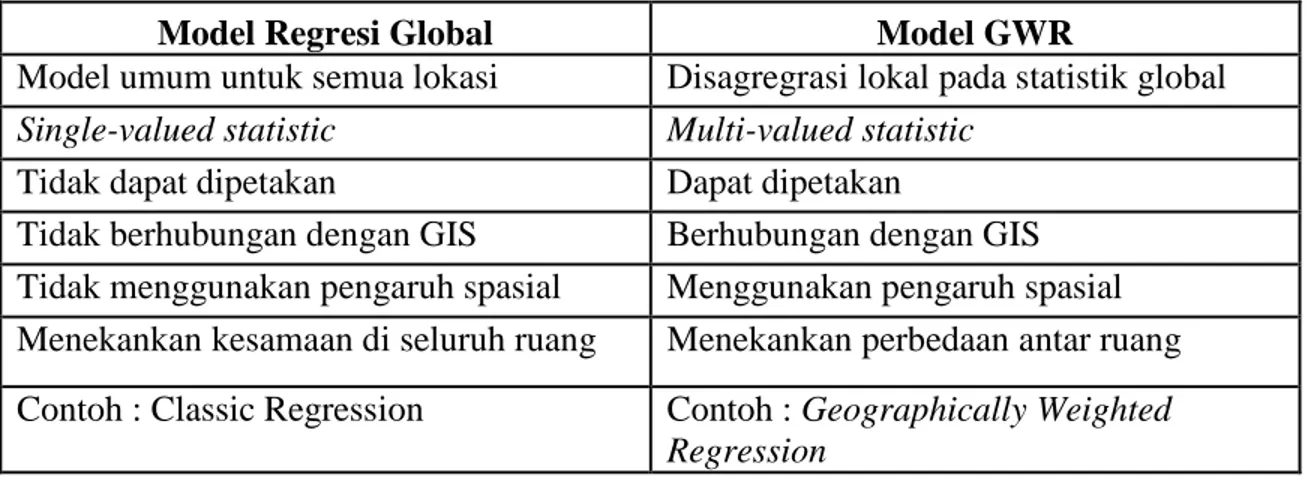
2 2= (I−L) (I−L) T tr δ = 1 ... 0 0 ... ... ... ... 0 ... 1 0 0 ... 0 1 I = − − − ) , ( W X ] X ) , ( W X [ ) , ( W X ] X ) , ( W X [ ) , ( W X ] X ) , ( W X [ L 1 2 2 1 2 2 2 1 1 1 1 1 1 n n T n n T T n T T T T T T v u v u x v u v u x v u v u x MFotheringham, Brunsdon dan Charlton (2002, p6) menyebutkan adanya beberapa perbedaan antara model regresi global dengan model GWR. Perbedaan tersebut disajikan pada Tabel 2.1.
Tabel 2.1 Perbandingan Model Regresi Global dengan GWR
Model Regresi Global Model GWR
Model umum untuk semua lokasi Disagregrasi lokal pada statistik global
Single-valued statistic Multi-valued statistic
Tidak dapat dipetakan Dapat dipetakan
Tidak berhubungan dengan GIS Berhubungan dengan GIS Tidak menggunakan pengaruh spasial Menggunakan pengaruh spasial Menekankan kesamaan di seluruh ruang Menekankan perbedaan antar ruang Contoh : Classic Regression Contoh : Geographically Weighted
Regression
2.3 Bandwidth
Bandwidth adalah ukuran jarak fungsi pembobot dan sejauh mana pengaruh
lokasi terhadap lokasi lain. Secara teoritis bandwidth merupakan lingkaran dengan radius b dari titik pusat lokasi, dimana digunakan sebagai dasar menentukan bobot setiap pengamatan terhadap model regresi pada lokasi tersebut. Untuk pengamatan-pengamatan yang terletak dekat dengan lokasi i maka akan lebih berpengaruh dalam membentuk parameter model pada lokasi i. (Fotheringham, Brunsdon, dan Charlton, 2002, p45).
Untuk mendapatkan bandwidth optimum, dapat dilakukan dengan menghitung
optimum (Fotheringham, Brunsdon, dan Charlton, 2002, p60) dengan menggunakan rumus sebagai berikut:
[
]
2 1)
(
ˆ
∑
= ≠−
=
n i i iy
b
y
CV
(2.15) Keterangan: i = lokasi ke-i b = bandwidth ) ( ˆ by≠i = nilai prediksi dari model regresi tanpa pengamatan ke-i
2.4 Pembobot
Pembobot W(i) dihitung untuk tiap i dan wij mengindikasikan kedekatan atau
bobot tiap titik data dengan lokasi i. Hal ini yang membedakan GWR dengan WLS pada umumnya yang mempunyai matrik bobot yang konstan. Peran pembobot sangat penting karena nilai pembobot tersebut mewakili letak data observasi satu dengan lainnya sehingga sangat dibutuhkan ketepatan cara pembobotan.
Beberapa jenis fungsi pembobot yang dapat dipergunakan menurut Fotheringham, Brunsdon, dan Charlton (2002, p56-57) antara lain:
1 Fungsi Inverse Jarak
Fungsi tersebut dapat dinotasikan sebagai berikut:
)
16
.
2
(
b
d
jika
,
0
b
d
jika
,
1
)
v
,
(u
w
ij ij i i j
≥
<
=
Fungsi inverse jarak akan memberi bobot nol ketika lokasi j berada diluar radius b dari lokasi i, sedangkan apabila lokasi j berada didalam radius b maka akan mendapat bobot satu.
2 2
)
(
)
(
i j i j iju
u
v
v
d
=
−
+
−
(2.17) 2 Fungsi Kernel GaussBentuk fungsi kernel gauss adalah
]
)
/
(
2
/
1
[
exp
)
v
,
(u
w
j i i=
−
d
ijb
2 (2.18) Fungsi kernel gauss akan memberi bobot yang akan semakin menurun mengikuti fungsi gaussian ketika dij semakin besar.3 Fungsi Kernel Bi-square
Fungsi tersebut dapat dinotasikan sebagai berikut:
)
19
.
2
(
b
d
jika
,
0
b
d
jika
,
]
/b)
(d
[1
)
v
,
(u
w
ij ij 2 2 ij i i j
≥
<
−
=
Fungsi kernel bi-square akan memberi bobot nol ketika lokasi j berada pada atau diluar radius b dari lokasi i, sedangkan apabila lokasi j berada didalam radius b maka akan mendapat bobot yang mengikuti fungsi kernel bi-square.
2.5 Teori Angka Buta Huruf
Angka buta huruf (ABH) adalah proporsi penduduk usia tertentu yang tidak dapat membaca dan atau menulis huruf latin atau huruf lainnya terhadap penduduk usia tertentu (BPS, 2012). Kondisi ABH di Jawa Timur sudah masuk ke dalam tahap yang cukup memprihatinkan. Hal ini bisa dapat dilihat dari data BPS (2012) yang menyatakan
bahwa pada 2010, persentase penduduk yang buta huruf di provinsi Jawa Timur dengan usia 15 tahun ke atas bisa mencapai 11,66% penduduk, 15–44 tahun mencapai 2,39% dan di atas 45 tahun sebesar 26,22%. Angka ini merupakan ABH terbesar di pulau Jawa pada tahun 2010.
Menurut Dirjen Pendidikan Non Formal dan Informal (Dirjen PNFI) Depdiknas Hammid Muhammad ada beberapa faktor penyebab tingginya buta aksara antara lain tingginya angka putus sekolah dasar, beratnya geografis Indonesia, munculnya buta aksara baru, dan kembalinya seseorang menjadi buta aksara.
Menurut Firmansyah dan Sutikno (2011), faktor–faktor yang mempengaruhi tingkat ABH antara lain kepadatan penduduk, rasio penduduk miskin per jumlah penduduk, rasio anggaran pendidikan per APBD, rasio tenaga pendidik sekolah dasar per jumlah siswa sekolah dasar, rasio tenaga pendidik sekolah menengah pertama per jumlah siswa sekolah menengah pertama, rasio fasilitas fisik pendidikan sekolah dasar per jumlah siswa sekolah dasar, rasio fasilitas fisik pendidikan sekolah menengah pertama per jumlah siswa sekolah menengah pertama, angka partisipasi murni usia 7-12 tahun, dan angka partisipasi murni usia 13-15 tahun.
2.6 Teknologi Informasi dan Komunikasi (TIK)
TIK adalah rangkaian kegiatan yang difasilitasi peralatan elektronik yang mencakup pengolahan, transmisi, dan penyajian informasi. TIK merupakan konvergensi dari tiga wilayah yaitu teknologi informasi, data dan informasi, serta masalah-masalah sosiol ekonominya. Perkembangan TIK dapat diukur berdasarkan 4 dimensi yaitu keterhubungan, akses, kebijakan dan penggunaan (Hermana, 2007). Indikator – indikator yang mengukur TIK:
1. penggunaan komputer per 1000 penduduk. 2. penggunaan internet per 1000 penduduk. 3. penggunaan telepon per 100 penduduk.
4. penggunaan telepon selular per 100 penduduk.
Menurut Badan Pusat Statistik (2009), dalam survei sosial ekonomi nasional 2009, yang menjadi indikator TIK adalah
1. kepemilikan telepon rumah, 2. kepemilikan telepon selular, 3. kepemilikan komputer, dan
4. penggunaan internet sebulan terakhir.
2.6.1 Pengertian Telepon
Menurut Fauzi dan Suherman (2006, p1) telepon adalah alat pengirim suara (mikropon) dan alat penerima suara (speaker). Pesawat ini dihubungkan dengan sentral telepon menggunakan sepasang kabel tembaga yang dikenal sebagai saluran 2 kawat. Telepon secara konvensional adalah untuk komunikasi suara, namun demikian telah banyak telepon yang digunakan untuk komunikasi data. Secara umum, telepon dibagi menjadi 2, yaitu telepon rumah dan telepon selular.
2.6.2 Pengertian Komputer
Menurut BPS (2007) komputer adalah mesin penghitung elektronik yang cepat dan dapat menerima informasi input digital, kemudian memprosesnya sesuai dengan program yang tersimpan di memorinya, dan menghasilkan output berupa informasi. Untuk mewujudkan konsepsi komputer sebagai pengolah data untuk menghasilkan suatu informasi, maka diperlukan sistem komputer yang elemennya terdiri dari:
1. Hardware atau perangkat keras, yaitu peralatan komputer yang secara fisik
terlihat dan bisa dipegang, seperti monitor, CPU (Central Processing Unit),
keyboard mouse, dan printer.
2. Software atau perangkat lunak, yaitu program yang berisi instruksi / perintah
untuk melakukan pengolahan data, seperti macam – macam program windows, Microsoft Word, SPSS, CSPro, dan sebagainya.
3. Brainware, yaitu orang yang mengoperasikan dan mengendalikan sistem
komputer. Rumah tangga dikatakan mempunyai komputer bila menguasai perangkat keras komputer berupa monitor, CPU, keyboard, dan mouse (walaupun tidak menguasai printer) yang sudah dilengkapi dengan perangkat lunak.
2.6.3 Pengertian Internet
Internet adalah sebuah sistem komunikasi global yang menghubungkan komputer-komputer dan jaringan-jaringan komputer di seluruh dunia (BPS, 2007).
2.7 Pemetaan
Menurut Ukur, Ramadijanti dan Basofi (2010, p1), pemetaan adalah proses pengukuran dan penggambaran permukaan bumi dengan menggunakan metode tertentu sehingga didapatkan hasil berupa file yang berbentuk vektor atau raster. Pembuatan peta secara konvensional dapat dibantu dengan bantuan komputer, mulai dari pembacaan data di lapangan sampai proses download ke komputer untuk proses perhitungan poligon, perataan penghitungan (koreksi) dan lain-lain, bahkan sampai pada proses pembuatan pemisahan warna secara digital sebagai bagian dari proses pencetakan peta.
2.8 Berbasis Komputer
Yang dimaksud berbasis komputer dalam skripsi ini adalah membuat aplikasi program. Aplikasi program dibuat dengan menggunakan bahasa pemrograman Java dan R Language.
2.8.1 Java
Menurut Horton (2005, p1), Java adalah bahasa pemrograman inovatif yang telah menjadi pilihan untuk digunakan dalam hal menjalankannya pada berbagai sistem komputer yang berbeda. Java memungkinkan untuk menulis program kecil yang biasanya disebut applet dan kebanyakan digunakan di halaman web untuk menyediakan berbagai macam fungsi. Selain dapat merepresentasikan teks dan gambar, Java juga dapat menyertakan animasi game, aplikasi yang interaktif dan kemungkinan lainnya.
2.8.2 R Language
Menurut Torgo (2011, p1), R adalah bahasa pemrograman yang baik untuk komputasi statistik. Hal ini mirip dengan bahasa S yang dikembangkan oleh AT&T Bell
Laboratories oleh Rick Becker, John Chambers dan Allan Wilks. Ada beberapa macam
versi untuk R antara lain R untuk Unix, Windows, dan berbagai macam Mac. Selain itu R juga dapat berjalan di berbagai arsitektur komputer seperti Intel, PowerPC, Alpha sistem, dan sistem Sparc. Sumber kode dari setiap komponen R tersedia secara bebas sehingga dapat diadaptasikan dengan baik. R memiliki keterbatasan dalam penanganan dataset yang sangat besar karena semua perhitungan dilakukan dalam memori utama komputer.