(Studi Kasus: Pembuatan Situs Informasi Perfilman)
LINKED DATA USAGE AS DATASET RESOURCE FOR WEB BASED APPLICATION
(Case Study: Building Movie Sites )
Ahmad Muiz Lidinillah 08/273420/EPA/00928
PROGRAM STUDI S1 SWADAYA ILMU KOMPUTER JURUSAN ILMU KOMPUTER DAN ELEKTRONIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS GADJAH MADA
YOGYAKARTA
i
(Studi Kasus: Pembuatan Situs Informasi Perfilman)
LINKED DATA USAGE AS DATASET RESOURCE FOR WEB BASED APPLICATION
(Case Study: Building Movie Sites )
Diajukan untuk memenuhi salah satu syarat memperoleh derajat Sarjana Ilmu Komputer
Ahmad Muiz Lidinillah 08/273420/EPA/00928
PROGRAM STUDI S1 SWADAYA ILMU KOMPUTER JURUSAN ILMU KOMPUTER DAN ELEKTRONIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS GADJAH MADA
ii
PENGGUNAAN LINKED DATA SEBAGAI SUMBER DATA PADA APLIKASI BERBASIS WEB
(Studi Kasus: Pembuatan Situs Informasi Perfilman)
Telah dipersiapkan dan disusun oleh
Ahmad Muiz Lidinillah 08/273420/EPA/00928
Telah dipertahankan di depan Tim Penguji pada tanggal 18 Juli 2011
Susunan Tim Penguji
Pembimbing Penguji I
Khabib Mustofa, Dr., S.Si., M.Kom Ahmad Ashari, Dr., M.Kom
Penguji II
iii
atau pendapat yang pernah ditulis atau diterbitkan oleh orang lain, kecuali yang secara tertulis diacu dalam naskah ini dan disebutkan dalam daftar pustaka.
Yogyakarta, Juli 2011
iv
Untuk kedua orang tuaku dan ketiga adikku yang tercinta
Penulis menyadari bahwa penulisan tugas akhir ini tidak terlepas dari bimbingan dan bantuan dari berbagai pihak. Untuk itu penulis menyampaikan ucapan terima kasih kepada :
1. Ayahku dan Ibuku tersayang yang senantiasa mendoakan serta memberikan dukungan, juga untuk ketiga adikku, Faza Karimatul Akhlaq, Zahriyyatul Humairah,dan Himayatus Shalihah.
2. Bapak Retantyo Wardoyo, Drs., M.Sc, Ph.D, selaku dosen wali yang telah memberikan bimbingan selama penulis mengikuti masa studi di S1 Swadaya Ilmu Komputer UGM.
3. Bapak Khabib Mustofa, Dr., S.Si, M.Kom, selaku dosen pembimbing yang telah memberikan bimbingan, arahan, dan dorongan selama menyusun skripsi.
4. Bapak dan Ibu Dosen, serta seluruh karyawan Fakultas MIPA yang telah memberikan banyak ilmu dan pelajaran yang sangat berharga.
5. Special thank’s for: Huda, Topik, Falaq (thank’s buat koreksi dan perbaikannya), dan Diko (thank’s for sharing idea). Terima kasih atas kerja samanya selama ini.
6. Teman-teman Ilkom ’08: Lelet, Rinu, Anung, Munir, Tri, Wahyu, Mita, Okta, dan semua sahabat Ilkom ’08.
7. Teman-teman CIS ‘05 Satya, Taufik T, Hafiz, Ivan, dan teman-teman KOMSI lainnya yang telah memberi dukungan kepada penulis, baik secara langsung maupun tidak.
8. Teman-teman kos and others (‘Rip, ‘Qon, ‘Beng), teman-teman alumni Ali Maksum ‘04, serta semua pihak yang tidak dapat disebutkan satu persatu yang telah memberikan nasihat dan semangat dalam mengarungi perjalanan penulis di Jogja ini dan dalam penulisan tugas akhir ini.
Penulis menyadari dalam skripsi ini, masih terdapat banyak kekurangan dan kelemahannya. Untuk itu penulis sangat mengharapkan masukan berupa kritik dan saran yang bersifat membangun.
Akhirnya penulis berharap semoga tugas akhir ini dapat memberikan manfaat bagi penulis, pembaca, dan semua pihak yang berkepentingan dengan tugas akhir ini.
Yogyakarta, Juli 2011
vi
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metode Penelitian 3
1.7 Sistematika Penulisan 4
BAB II. TINJAUAN PUSTAKA 6
BAB III. LANDASAN TEORI 9
3.1 Semantic Web 9
3.1.1 Arsitektur semantic web 9 3.1.2 Perkembangan semantic web saat ini 11 3.2 RDF (Resource Descriptor Framework) 12
3.2.1 Model data RDF 13
3.2.2 Blank nodes 14
3.2.3 Format serialisasi RDF 14
3.3 RDFSchema 17
3.3.1 Class 17
3.3.2 Property 18
3.4 OWL (Ontology Web Language) 19
3.4.1 Jenis-jenis OWL 20
3.4.2 Elemen OWL 22
3.5 SPARQL 24
3.6 Linked Data 26
3.6.1 Prinsip dasar linked data 28
3.6.2 Content negotiation 28
3.6.3 Vocabulary pada linked data 30 3.6.4 Sumber dataset di linked data 31 3.6.5 Open World Assumption dan No Uniques Name
3.8.2 Struts 37 BAB IV. ANALISIS DAN PERANCANGAN SISTEM 39
4.1 Gambaran Umum Sistem 39
4.2 Spesifikasi Kebutuhan 39
4.2.1 Kebutuhan fungsional 39
4.2.2 Kebutuhan non-fungsional 40
4.3 Perancangan Ontologi 40
4.4 Perancangan Aplikasi Situs Perfilman Berbasis Web 43
4.4.1 Gambaran umum aplikasi 43
4.4.2 Perancangan model sistem 44
4.4.3 Perancangan antarmuka 54
BAB V. IMPLEMENTASI 63
5.1 Implementasi Fungsi Penarikan Data dari DBPedia 63 5.2 Implementasi Fungsi Pencarian Artis dan Film 66
5.2.1 Pencarian quick search 66
5.2.2 Pencarian artis 68
5.2.3 Pencarian film 69
5.3 Implementasi fungsi reasoning data 70 5.4 Implementasi Fungsi Penyajian Informasi 72
5.4.1 Halaman daftar artis 72
5.4.2 Halaman kategori artis 74
5.4.3 Halaman daftar film 75
5.4.4 Halaman kategori film 76
5.4.5 Form pembuatan berita 78
BAB VI. HASIL PENELITIAN DAN PEMBAHASAN 80 6.1 Penarikan Data ke DBPedia Endpoint 80
6.2 Reasoning Data 83
6.3 Pembuatan Berita 85
6.4 Pencarian Data 87
6.4.1 Pencarian data film 87
6.4.2 Pencarian data artis 90
6.4.3 Penelusuran hypertext link pada halaman depan
viii
3. Gambar 3.3 Skema rancangan URI 13 4. Gambar 3.4 Contoh relasi antar node pada model graf 15
5. Gambar 3.5 Contoh format RDF/XML 15
6. Gambar 3.6 Contoh statemen menggunakan format Turtle 16 7. Gambar 3.7 Penulisan beberapa statemen menggunakan format
Turtle 16
8. Gambar 3.8 Deklarasi tipe class pada resource 17 9. Gambar 3.9 Contoh pendeklarasian property menggunakan
RDF Schema 18
10. Gambar 3.10 Pendeklarasian class ex:Manusia 22 11. Gambar 3.11 Kumpulan dataset yang tergabung dalam linked data 27 12. Gambar 3.12 Mekanisme content negotiation 30 13. Gambar 3.13 Contoh baris kode untuk proses inferensi 35
14. Gambar 3.14 Alur pemrosesan pada JSP 36
15. Gambar 3.15 Diagram alur MVC pada Struts 37 16. Gambar 4.1 Potongan hirarki class ontologi DBPedia 40
17. Gambar 4.2 Gambaran umum aplikasi 43
18. Gambar 4.3 Diagram use-case pada pengguna umum sistem 44 19. Gambar 4.4 Diagram use case pada administrator sistem 45 20. Gambar 4.5 Diagram aktifitas pencarian quick search 46 21. Gambar 4.6 Diagram aktifitas pencarian kategori artis
dan kategori film 48
22. Gambar 4.7 Diagram aktifitas login 49
23. Gambar 4.8 Diagram aktifitas penarikan sumber data dari luar 50 24. Gambar 4.9 Diagram aktifitas proses inferensi pada graf data
sumber 51
25. Gambar 4.10 Diagram aktifitas pembuatan halaman berita 52 26. Gambar 4.11 Diagram aktifitas pengaturan pada aplikasi 53 27. Gambar 4.12 Diagram aktifitas pengubahan username dan
password 54
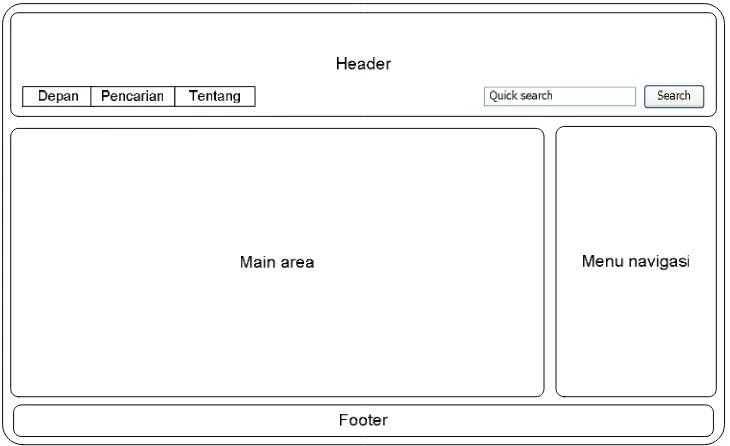
28. Gambar 4.13 Antamuka halaman depan 55
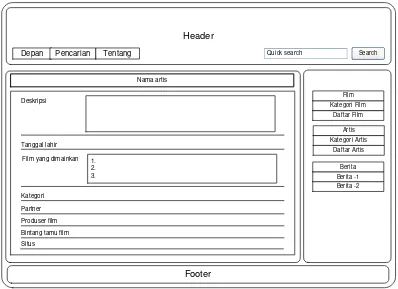
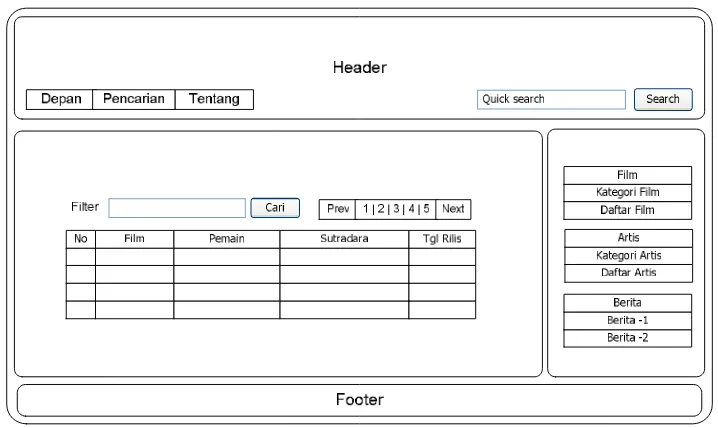
29. Gambar 4.14 Antarmuka halaman kategori film 56 30. Gambar 4.15 Antarmuka halaman deskripsi film 56 31. Gambar 4.16 Antarmuka halaman deskripsi artis 57 32. Gambar 4.17 Antarmuka halaman daftar film 58 33. Gambar 4.18 Antamuka halaman daftar artis 58
34. Gambar 4.19 Antarmuka halaman login 59
x
43. Gambar 5.6 Tampilan halaman depan 68
44. Gambar 5.7 Cuplikan kode pada pencarian aktor/artis 68 45. Gambar 5.8 Tampilan halaman pencarian aktor/artis 69 46. Gambar 5.9 Cuplikan kode pada pencarian film 70 47. Gambar 5.10 Tampilan halaman pencarian film 70 48. Gambar 5.11 Tampilan halaman form reasoning data 71 49. Gambar 5.12 Cuplikan kode pada proses inferensi data 72 50. Gambar 5.13 Tampilan halaman daftar artis 73 51. Gambar 5.14 Cuplikan kode untuk menampilkan
daftar artis 73
52. Gambar 5.15 Tampilan halaman kategori artis 74 53. Gambar 5.16 Cuplikan kode untuk daftar artis per kategori 75 54. Gambar 5.17 Tampilan halaman daftar film 75 55. Gambar 5.18 Cuplikan kode untuk menampilkan daftar film 76 56. Gambar 5.19 Tampilan halaman kategori film 77 57. Gambar 5.20 Cuplikan kode untuk daftar film per kategori 78
58. Gambar 5.21 Form pembuatan berita 78
59. Gambar 5.22 Cuplikan kode untuk menyimpan input pada
form pembuatan berita 79
xii Oleh
Ahmad Muiz Lidinillah 08/273420/EPA/00928
World Wide Web telah mengubah cara manusia dalam berinteraksi dan berbagi pengetahuan terhadap sesama. Kumpulan informasi yang ada disajikan dalam format yang mudah dipahami seperti HTML, sedangkan proses penelusuran dilakukan dengan memanfaatkan link hyperteks yang terkandung didalamnya. Namun sayangnya, proses yang demikian tidak memungkinkan komputer untuk memproses informasi tersebut secara semantik. Jenis format yang digunakan saat ini lebih menekankan pada layout supaya mudah dipahami oleh manusia, bukan komputer. Dibutuhkan sebuah format yang dapat merepresentasikan informasi tersebut tanpa harus kehilangan nilai semantik yang terkandung di dalamnya. Selain itu, perlu adanya keterlibatan dari banyak pihak agar pemakaiannya dapat diterapkan secara meluas.
Linked data ditujukan untuk mengatasi permasalahan tersebut dengan menyediakan sejumlah petunjuk bagaimana mempublikasikan informasi tersebut tanpa harus kehilangan nilai semantik yang ada. Informasi yang ada diidentifikasi menggunakan URI dan disajikan dalam dua format , yaitu format HTML untuk manusia dan format RDF untuk komputer. Selain itu terdapat mekanisme pengaturan konten untuk memilih format pada saat proses request dilakukan. Hingga tahun 2009 diperkirakan lebih dari 4,7 milyar RDF triples tersedia pada
linked data dan bebas dikonsumsi oleh siapa saja.
Pada penelitian ini akan dibangun sebuah aplikasi web yang menggunakan dataset yang bersumber dari linked data dengan studi kasus berupa situs informasi perfilman. Adapun library yang digunakan diantaranya Jena untuk memproses data RDF dan Struts sebagai framework pembuatan sistem. Tujuannya adalah mengeksplorasi sekaligus menunjukkan pemanfaatan linked data sebagai sumber data utama pada aplikasi yang dibangun.
by
Ahmad Muiz Lidinillah 08/273420/EPA/00928
The World Wide Web has altered the way human interact and share knowledge with others. Every information is available in format that easy to understand like HTML, while navigating process can be done by traversing a hypertext link inside the document. Unfortunately, the way information is provided make a computer unable to process the information semantically. The format to represent information impress to the layout that can be understood by human, not computer. Therefore, we need an alternative format to keep the semantic value inside. Besides, a lot of participants are needed to implement it on a global scale.
Linked data aimed to solve this problem by providing a set of guidence on how to publish this information without losing the semantic values. Every information identified by URI and provided in two format, HTML for human and RDF for computer. Also, there is a content negotiation mechanism to handle the right format while a request is coming. Estimated by 2009, more than 4.7 billion RDF triples available in linked data and free consumed by anyone.
In this research, we will build a web application about movie sites by using dataset from linked data. We used Jena library for RDF processing and Struts as framework for building system. The purpose is to explore and show the benefit from linked data while implemented as dataset resource for application.
1
1.1. Latar Belakang
Teknologi internet telah merubah cara manusia dalam berbagi pengetahuan. Beragam informasi tentang berbagai macam hal kini tersedia dan dapat diakses oleh setiap orang dimanapun dia berada. Untuk mengakses informasi tersebut, pengguna cukup menelusuri link yang disediakan. Apabila dirasa masih kurang, layanan pencarian yang ditawarkan oleh sejumlah search engine seperti Google atau Yahoo dapat dimanfaatkan untuk membantu operasi pencarian yang lebih spesifik.
Umumnya informasi yang beredar saat ini disajikan dalam format yang hanya dapat dipahami oleh manusia, salah satunya HTML. Format ini disajikan dalam bentuk kumpulan tag terstruktur untuk merepresentasikan layout dari halaman web yang ada sehingga informasi yang disajikan dapat dengan mudah dipahami manusia, namun tidak oleh mesin. Struktur yang ada menghilangkan nilai semantik pada informasi. Apabila semantik tersebut tetap dipelihara, maka sejumlah keuntungan dapat diperoleh seperti proses otomatisasi, integrasi, dan penggunaan kembali data pada berbagai aplikasi.
Beberapa pendekatan dilakukan untuk tetap mempertahankan semantik pada format HTML yang digunakan, salah satunya dengan menyediakan metadata berupa tag <META>. Dengan tag ini dapat disediakan sejumlah kata kunci terkait dengan informasi pada halaman web tersebut. Namun sayangnya, kata kunci yang dapat disertakan sifatnya masih umum dan terbatas. Selain itu, pada tag ini tidak dimungkinkan untuk menyertakan link ke sumber lain untuk memperkaya kata kunci yang disajikan (Hebeler, 2009).
beserta link RDF yang menuju ke sumber data lain, sehingga tersedia suatu kumpulan sumber data besar dengan beragam domain informasi mulai dari orang, musik, film, buku, komunitas online, dan lain-lain.
Berdasarkan uraian di atas, pada penelitian ini akan difokuskan pada bagaimana memanfaatkan linked data sebagai sumber data pada sistem untuk memperoleh informasi yang diperlukan.
1.2. Rumusan Masalah
Berdasarkan latar belakang di atas, maka rumusan permasalahannya adalah bagaimana membangun sebuah sistem yang dapat menyajikan informasi dengan memanfaatkan linked data sebagai sumber data sistem dan disertai fitur pencarian data.
1.3. Batasan Masalah
Untuk memfokuskan arah penelitian serta memperjelas penyelesaian penelitian, maka diperlukan adanya pembatasan masalah, yaitu sebagai berikut:
1. Penelitian difokuskan pada bagaimana menggunakan sumber data dari luar sistem berupa linked data dalam format triple RDF untuk disertakan ke dalam aplikasi sistem. Hal lain yang terkait seperti isu trust didalam pemakaian data tersebut tidak dibahas.
2. Data yang digunakan bersumber dari DBPedia.
3. Pada aplikasi disediakan fungsi pencarian agar didapat informasi yang lebih relevan.
4. Domain data yang digunakan dibatasi seputar dunia perfilman.
1.4. Tujuan Penelitian
Tujuan penelitian ini adalah membuat sebuah aplikasi berbasis web yang didalamnya disajikan informasi seputar perfilman dengan memanfaatkan sumber data dari luar berupa linked data dalam format RDF.
1.5. Manfaat Penelitian
Manfaat yang diharapkan dari penulisan tugas akhir ini adalah:
1. Mengkaji dan mengeksplorasi pemanfaatan teknologi semantic web yang berkembang saat ini, terutama di bidang Linked Data.
2. Sebagai salah satu model alternatif dalam pembangunan aplikasi berbasis web saat ini, dimana sumber data tidak semata-mata berasal dari dalam sistem melainkan memanfaatkan sumber data dari luar. Hal ini bertujuan untuk memperkaya informasi yang akan disajikan oleh sistem.
3. Sebagai bahan referensi untuk penelitian yang serupa di masa mendatang.
1.6. Metode Penelitian
Metode penelitian yang digunakan dalam penulisan skripsi ini adalah :
1. Metode Studi Literatur
Studi literatur dilakukan dengan mempelajari sejumlah referensi yang berkaitan erat dengan materi penelitian baik melalui buku atau media internet.
2. Analisis dan Perancangan Sistem
3. Implementasi dan Pengujian
Pembuatan aplikasi dilakukan dengan menggunakan librari Jena sebagai
engine sistem untuk memparsing data dalam format RDF dan SPARQL sebagai bahasa query untuk menampilkan data.
4. Pembahasan dan Penulisan Tugas Akhir
Meliputi pembahasan dari analisis sistem hingga pembuatan aplikasi berbasis teknologi semantic web untuk dijadikan dasar dalam penulisan skripsi.
1.7. Sistematika Penulisan
Sistematika penulisan laporan ini meliputi :
BAB 1 PENDAHULUAN
Bab ini menjelaskan tentang latar belakang masalah, rumusan masalah, batasan masalah, maksud dan tujuan penelitian, metode pengumpulan data, dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini memuat uraian sistematis tentang informasi hasil penelitian terdahulu yang berhubungan dengan penelitian yang dilakukan saat ini. Informasi hasil penelitian tersebut digunakan sebagai acuan dalam penelitian ini.
BAB III LANDASAN TEORI
Bab ini menjelaskan tentang berbagai hal umum dan mendasar yang mendukung penelitian ini.
BAB IV ANALISIS DAN PERANCANGAN SISTEM
Bab ini menjelaskan tentang analisis terhadap kebutuhan sistem dan perancangan sistem yang akan dibuat.
BAB V IMPLEMENTASI
BAB VI HASIL PENELITIAN DAN PEMBAHASAN
Bab ini membahas hasil penelitian yang telah dilakukan beserta pengujian terhadap sistem yang telah dibangun.
BAB VII PENUTUP
BAB II
TINJAUAN PUSTAKA
Saat ini penelitian mengenai aplikasi terkait semantic web berbasis linked data sudah mulai banyak dilakukan. Penelitian ini umunya berfokus pada pemanfaatan sekumpulan dataset di luar sistem untuk diintegrasikan ke dalam sistem yang dibangun. Salah satunya penelitian tentang Researchers Map Application yang dilakukan oleh Hartig dkk (2009) dimana aplikasi tersebut dapat menunjukkan peta lokasi tempat kerja para professor Jerman serta menampilkan profil dan daftar karya mereka yang telah dipublikasikan. Tak hanya itu, aplikasi ini juga menyediakan fungsi filtering dalam menampilkan daftar nama professor tersebut berdasarkan bidang penelitiannya, semisal query optimization atau data warehousing. Adapun data yang digunakan berasal dari file RDF dipublikasikan oleh professor tersebut di blog miliknya. Aplikasi ini sendiri memanfaatkan API Google Maps dalam menampilkan peta lokasi para professor tersebut di wilayah Jerman.
domain musik. Aplikasi gFacet ini dibangun menggunakan Adobe Flex, yaitu framework untuk membangun Rich Internet Application (RIA) berbasis platform Adobe Flash.
Selanjutnya mengenai paper yang ditulis oleh Hausenblas (2009). Disini Hausenblas menggambarkan contoh nyata penggunaan linked data sebagai sumber data pada situs BBC Music beta. Situs ini memanfaatkan sumber data dari DBpedia untuk menyediakan informasi biografi artis musik dan MusicBrainz sebagai metadata sekaligus identifier yang merujuk ke artis musik tertentu. Selain itu, dijelaskan pula secara singkat tahapan-tahapan yang harus dilakukan di dalam memanfaatkan linked data sebagai sumber data pada aplikasi yang dibangun.
Mengenai penelitian yang berasal dari UGM, penulis menemukan beberapa yang membahas tentang semantic web, namun sejauh pengamatan penulis sumber data yang digunakan masih bersifat lokal belum memanfaatkan dataset dari luar sistem. Contohnya mengenai penelitian yang dilakukan oleh Nurkamid (2009) dengan membangun sebuah aplikasi pencarian untuk bibliografi perpustakaan dengan menggunakan RDF/OWL sebagai bagian dari teknologi
semantic web. Nurkamid menggunakan pendekatan SKOS (Simple Knowledge Organization System) untuk membantu merepresentasikan dan mengatur kosakata di dalam teknologi semantic web. Untuk membangun ontologi beserta instance
data yang diperlukan, digunakan tool Protege. Ontologi dan instance data ini nantinya yang menjadi sumber data bagi aplikasi yang dibuat.
Selain itu penelitian yang dilakukan oleh Bendi (2010) tentang sistem
berbasis bahasa alami yang dipakai direpresentasikan dalam bentuk triple, yang terdiri dari subyek, predikat dan obyek. Sementara pemodelan data dalam
semantic web juga menyatakan suatu statement dalam bentuk triple: resources,
9
BAB III
LANDASAN TEORI
3.1 Semantic Web
Berners-Lee menggambarkan teknologi semantic web sebagai perluasan dari web yang ada saat ini, dimana informasi memiliki arti yang terdefinisi secara lebih baik dengan mengupayakan persamaan persepsi antara konsep-konsep yang ada, sehingga memungkinkan manusia dan komputer untuk bekerjasama secara lebih optimal (Berners-Lee, 2001). Hal ini dilakukan dengan cara menyediakan metadata yang diperuntukkan khusus untuk mesin, sehingga mesin mampu memproses nilai semantik yang terkandung dalam dokumen tersebut.
Umumnya informasi yang ada saat ini disajikan dalam format yang dapat dibaca oleh manusia, tidak oleh komputer. Komputer lebih ditujukan untuk memproses struktur tampilan dalam menyajikan suatu informasi, bukan untuk memproses nilai semantik dari informasi tersebut. Contohnya pada format halaman web seperti HTML, yang merepresentasikan layout halaman web berdasarkan kumpulan tag element yang didefinisikan oleh W3C (World Wide Web Consortium). Format ini ditujukan agar informasi yang disajikan dapat dipahami oleh manusia, namun tidak oleh mesin. Andaikata disediakan mekanisme untuk menyimpan sekaligus memproses semantik dari informasi yang ada, sejumlah keuntungan dapat diperoleh seperti automatic reasoning atau
inference deduction untuk membentuk informasi baru.
3.1.1 Arsitektur semantic web
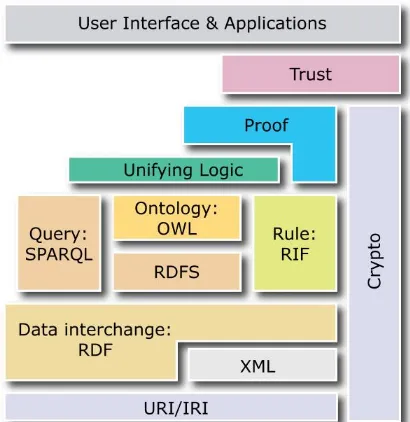
Gambar 3.1 Semantic web layer cake (Bratt, 2007)
W3C merekomendasikan didalam semantic web activity terdapat beberapa layer arsitektur dari semantic web. Pada bagian paling bawah adalah layer
Unicode dan URI (Uniform Resource Identifiers) yang memastikan penggunaan sekumpulan karakter yang telah disepakati secara internasional dan menyediakan alat untuk mengidentifikasi obyek di semantic web. Jenis URI yang paling umum dan banyak digunakan yaitu URL (Uniform Resource Locator).
Diatas layer Unicode dan URI (Uniform Resource Identifier) terdapat XML dan RDF sebagai format pertukaran data. RDF digunakan untuk merepresentasikan knowledge base yang ada dalam bentuk triple statement dan tersedia dalam beberapa macam format serialisasi seperti RDF/XML, Turtle, N-Triples dan N3.
saat ini SWRL (Semantic Web Rule Languange) merupakan bahasa rule yang banyak digunakan dan direkomendasikan oleh W3C.
Selanjutnya untuk ketiga layer diatasnya yaitu Unifying Logic, Proof dan
Trust, hingga saat ini masih dalam proses perkembangan. Layer Proof dan Trust
bertujuan untuk memastikan keabsahan dan derajat kepercayaan didalam pemakaian informasi tersebut.
Mengenai layer paling atas yaitu User Interface & Application, hal ini mengacu pada aplikasi atau software agent yang dibangun tepat diatas semantic web dan bagaimana layout yang disajikan dalam mewadahi interaksi dengan para penggunanya. Hal ini penting mengingat ekspresi kaya yang dapat dimunculkan serta eksploitasi yang dapat dilakukan terhadap struktur data dari semantic web
tersebut.
3.1.2 Perkembangan semantic web saat ini
Ide dari semantic web adalah dimungkinkannya proses inferensi oleh mesin komputer terhadap data-data yang tersebar di internet. Untuk itu diperlukan adanya publikasi data oleh berbagai pihak dalam format yang disepakati, yaitu RDF. Selanjutnya upaya tersebut mulai diwujudkan oleh sejumlah pihak, seperti DBPedia yang mempublikasikan data-data dari Wikipedia ke dalam format RDF. Ada pula layanan jejaring sosial seperti LiveJournal.com dan Tribe yang mengekspor data para anggotanya menjadi file FOAF (Friend of a Friend) dalam format RDF (Golbeck dan Rothstein, 2008). Semuanya ini berujung pada penyediaan data yang dapat diakses via web menggunakan format RDF.
Meskipun upaya penyediaan data ini mulai membuahkan hasil, namun dalam perkembangannya semantic web masih menghadapi sejumlah tantangan (Heath dkk, 2009). Beberapa isu yang dihadapi saat ini diantaranya seperti
isu trust dan quality, bagaimana menentukan derajat keabsahan data yang diterima serta seberapa relevan data tersebut sesuai dengan kebutuhan.
3.2 RDF (Resource Descriptor Framework)
RDF adalah bahasa yang digunakan untuk merepresentasikan informasi pada web dan direkomendasikan W3C sebagai format standar penyimpanan data pada teknologi semantic web (Brickley dan Guha, 2004). Tiap dokumen RDF merupakan kumpulan statemen yang terdiri dari subyek, predikat dan obyek yang disebut juga sebagai triples. Kumpulan statemen ini apabila digambarkan membentuk sekumpulan node yang saling terhubung oleh edge berbentuk arah panah sehingga membentuk suatu graf. Hal ini dapat dilihat pada Gambar 3.2.
John
Gambar 3.2 Contoh representasi data dalam bentuk graf
3.2.1 Model data RDF
RDF mendeskripsikan segala sesuatu yang ada di sekitar sebagai sebuah
resource. Tiap-tiap resource ini diberi pengenal unik berupa URI (Universal Resource Identifier). URI berfungsi seperti URL, namun lebih luas dimana seluruh hal yang dapat ditelusuri baik secara eletronik ataupun tidak diberikan pengenal ini. Dengan URI, agen atau mesin dapat merujuk kepada resource yang direfer oleh URI tersebut secara konsisten dan bersifat global tidak terbatas hanya pada ruang lingkup sistem dimana resource tersebut dideskripsikan. Aplikasi atau dataset di luar sistem dapat merefer ke resource menggunakan URI yang didefinisikan oleh sistem tersebut.
URI pada dasarnya merupakan untaian string yang tersusun dari URI schema, lalu diikuti titik dua dan dua garis miring (://), lalu hostname dan port number (opsional) dan terakhir alamat spesifik berupa hierarchical path yang mengarah ke resource yang direpresentasikan (Segaran, 2009). URI scheme
mengidentifikasi protokol yang digunakan oleh URI dan kebanyakan berupa http atau https. Pada bagian alamat atau path yang merefer ke resource, masing-masing organisasi bebas menentukan penamaan sekaligus hirarki pada path tersebut berdasarkan pada hostname yang mereka pegang, sehingga mencegah adanya URI yang sama untuk dua entitas yang berbeda. Dengan demikian URI dapat juga dikatakan sebagai strong identifier. Gambar 3.3 menampilkan contoh skema rancangan pada URI.
Gambar 3.3 Skema rancangan URI
Dalam format RDF, subyek pada statemen terdiri dari resource atau blank node, predikat selalu terdiri dari resource dan obyek pada statemen terdiri dari
merepresentasikan anonymous node alias resource yang tidak memiliki identifier berupa URI.
3.2.2 Blank nodes
Tidak semua node pada graf RDF memiliki URI sebagai identifiernya. Terdapat kemungkinan suatu node yang merepresentasikan resource tertentu tidak diberikan URI karena tidak dimungkinkannya pemberian URI yang cocok untuk mengalamati resource tersebut (Segaran, 2009). Node yang demikian disebut sebagai anonymous node atau blank node. Pada blank node ini nantinya diberikan penamaan unik yang bersifat lokal, hanya berlaku pada konteks dokumen RDF dimana resource tersebut didefinisikan sehinga tidak dapat direfer diluar dokumen RDF tersebut.
Blank node pada dasarnya digunakan untuk merepresentasikan existential variable (Hebeler, 2009). Hal ini dapat diibaratkan dalam kehidupan disekitar dimana terdapat pernyataan “terdapat pasangan hidup untuk setiap orang dimuka bumi”. Disini “pasangan hidup” dapat dianggap sebagai sebuah existential variable yang menggambarkan keberadaan seseorang namun tidak dapat diidentifikasi dengan pasti siapa orang tersebut sebenarnya. Entitas yang hendak direpresentasikan disini tidaklah sepenuhnya jelas melainkan masih bersifat abstrak.
3.2.3 Format serialisasi RDF
Model data RDF berguna dalam menyajikan informasi, namun masih dalam bentuk abstrak. Serialisasi menjadikan model RDF yang tadinya masih bersifat abstrak ke dalam persistent form seperti text file, sehingga dimungkinkannya proses pertukaran data antar komputer yang berbeda. Adapun format serialisasi RDF yang cukup populer dan banyak digunakan diantaranya:
1. RDF/XML
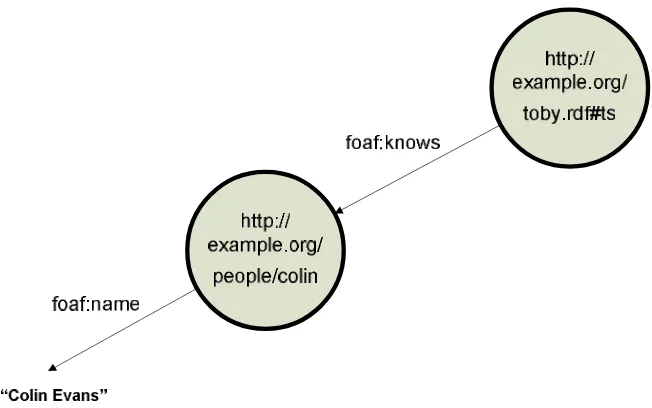
atribut rdf:about yang berisi URI yang merefer pada node graf. Apabila node yang direfer merupakan blank node, maka digunakan atribut rdf:NodeID. Selanjutnya tiap edge/predikat pada graf yang terhubung dengan node tersebut menjadi sub-elemen dari <rdf:Description>. Untuk lebih jelasnya dapat dilihat pada Gambar 3.4.
Gambar 3.4 Contoh relasi antar node pada model graf
Gambar graf diatas dapat dinyatakan dalam format RDF/XML sebagaimana yang tersaji pada Gambar 3.5.
<rdf:RDF xmlns:rdf=”http://www.w3.org/1999/02/22-rdf-syntax-ns#” xmlns:foaf=”http://xmlns.com/foaf/0.1/”>
<rdf :Description rdf :About=”http://example.org/toby.rdf #ts> <foaf:knows>
<rdf :Description rdf :About=”http://example.org/people/colin”> <foaf:name>Colin Evans</foaf:name>
</rdf :Description> </foaf:knows> </rdf :Description> </rdf :RDF >
Gambar 3.5 Contoh format RDF/XML
Pada RDF/XML, untuk menyingkat penulisan URI digunakan aliasing
mudah dibaca. Dari contoh diatas, terlihat pada bagian rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" prefix RDF digunakan sebagai namespace untuk URI dari sintak RDF.
2. Turtle (Terse RDF Triple Languange)
Format serialisasi RDF selanjutnya adalah Turtle. Turtle menyajikan tatacara penulisan sintak yang lebih simple dan mudah dibaca bagi manusia. Pada Turtle tiap statemen ditulis dalam satu baris dan diakhiri dengan tanda titik. Gambar 3.6 menampilkan contoh statemen menggunakan format Turtle.
people:Ryan ext :w orksWit h people:John .
Gambar 3.6 Contoh statemen menggunakan format Turtle
Apabila terdapat kumpulan statemen yang memiliki bagian subyek yang sama, maka penulisan dapat dipersingkat. Pada baris pertama cukup ditulis subyek statemen, lalu pada baris selanjutnya cukup ditulis predikat dan obyek dari statemen. Masing-masing baris kecuali pada baris terakhir diakhiri dengan tanda titik koma (;) untuk menandakan statemen tersebut merefer ke subyek yang sama dengan statemen diatasnya. Adapun contohnya dapat dilihat pada Gambar 3.7.
people:Andrew
foaf:knows people:Matt ; foaf:surname "Perez-Lopez" .
Gambar 3.7 Penulisan beberapa statemen menggunakan format Turtle
Sedangkan apabila kumpulan statemen RDF hanya berbeda pada obyeknya saja, maka penulisan dapat dipersingkat menjadi satu baris dengan urutan subyek, predikat, lalu kumpulan obyek dari masing-masing statemen dipisah oleh tanda koma dan terakhir ditutup dengan tanda titik. 3. N-Triples
lengkap tanpa ada penyingkatan seperti pada RDF/XML atau Turtle. Apabila subyek atau obyek merupakan blank node, maka dituliskan dalam format _:name, dimana name terdiri dari karakter alfanumerik dan diawali dengan huruf. Sedangkan pada obyek literal, nilai dari obyek tersebut disertai dengan tanda petik.
3.3 RDF Schema
RDF Schema merupakan perluasan semantik pada RDF untuk menggambarkan resource yang ada. Pada RDF Schema disediakan mekanisme untuk mengelompokkan sekumpulan resource yang sejenis ke dalam class-class
tertentu serta relationship pada masing-masing resource tersebut dapat ditentukan (Brickley dan Guha, 2004). Sekumpulan vocabulary pada RDF Schema nantinya digunakan untuk mendeskripsikan karakteristik dari resource dalam konteks domain tertentu, seperti rdfs:range, rdfs:domain dan lain-lain.
3.3.1 Class
Untuk mengelompokkan resource ke dalam ke dalam class-class tertentu, dapat digunakan vocabulary rdf:class. Dimisalkan terdapat statemen yang menyatakan bahwa Andi adalah manusia. Statemen ini dapat dinyatakan ke dalam format RDF Turtles sebagaimana yang tersaji pada Gambar 3.8.
@prefix ex: <http://example.org/>. ex:Manusia rdf :type rdfs:Class . ex:Andi rdf :type ex:Manusia .
Gambar 3.8 Deklarasi tipe class pada resource
Beberapa vocabulary yang digunakan untuk mendefinisikan class
3.3.2 Property
Property pada RDF dapat dianggap sebagai sekumpulan atribut yang menggambarkan karakteristik dari resource. Property tersebut juga merepresentasikan relasi yang terjadi antara satu resource dan resource lainnya. Untuk menyatakan relationship pada suatu resource, dapat digunakan sejumlah vocabulary yang berasal dari RDF Schema, diantaranya rdf:range atau rdf:domain. rdf:range digunakan untuk menentukan instance dari class apa saja yang dapat menjadi obyek suatu statemen berpasangan dengan predikat yang disebutkan oleh rdf:type. Adapun rdf:domain digunakan untuk menentukan instance dari class apa saja yang dapat menjadi subyek suatu statemen berpasangan dengan predikat yang disebutkan oleh rdf:domain. Pada Gambar 3.9 disajikan contoh relationship yang muncul antara manusia dengan hewan.
ex:makan rdf:type rdf :Property . ex:makan rdfs:domain ex:Manusia . ex:makan rdfs:range ex:Hewan . ex:Ayam rdf:type ex:Hewan . ex:Andi ex:makan ex:Ayam .
Gambar 3.9 Contoh pendeklarasian property menggunakan RDF Schema
Vocabulary yang disebutkan diatas hanyalah beberapa dari sekian
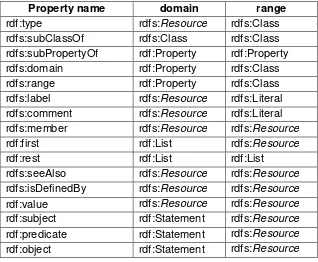
vocabulary yang terdapat pada RDF Schema. Tabel 3.1 dan Tabel 3.2 memuat kumpulan vocabulary yang tersedia pada RDF Schema.
Tabel 3.1 Kumpulan class pada RDF (Brickley dan Guha, 2004)
Class name
Tabel 3.2 Kumpulan property pada RDF (Brickley dan Guha, 2004)
Property name domain range
rdf:type rdfs:Resource rdfs:Class
rdfs:subClassOf rdfs:Class rdfs:Class
rdfs:subPropertyOf rdf:Property rdf:Property
rdfs:domain rdf:Property rdfs:Class
rdfs:range rdf:Property rdfs:Class
rdfs:label rdfs:Resource rdfs:Literal
rdfs:comment rdfs:Resource rdfs:Literal
rdfs:member rdfs:Resource rdfs:Resource
rdf:first rdf:List rdfs:Resource
rdf:rest rdf:List rdf:List
rdfs:seeAlso rdfs:Resource rdfs:Resource
rdfs:isDefinedBy rdfs:Resource rdfs:Resource
rdf:value rdfs:Resource rdfs:Resource
rdf:subject rdf:Statement rdfs:Resource
rdf:predicate rdf:Statement rdfs:Resource
rdf:object rdf:Statement rdfs:Resource
3.4 OWL (Ontology Web Language)
OWL adalah bahasa yang dibangun sebagai perluasan dari RDF Schema dengan beberapa tambahan yang dapat meningkatkan ekspresi ontologi pada web (Hebeler, 2009). Ontologi sendiri merupakan istilah yang dipinjam dari ilmu filsafat yang merujuk pada disiplin ilmu yang mendeskripsikan entitas yang ada didunia dan bagaimana entitas tersebut saling berelasi antara satu sama lain. OWL lebih ekspresif dibandingkan dengan RDF Schema dalam mendefinisikan suatu
class beserta property-nya sehingga dimungkinkkan proses reasoning yang lebih
powerfull.
OWL umumnya disimpan dalam bentuk dokumen pada web. Tiap dokumen ini terdiri dari ontology header, annotation dan definisi dari class dan
memuat ontologi yang mendeskripsikan sekumpulan class beserta property-nya dengan dokumen yang memuat instance data dari class tersebut.
Pada OWL, vocabulary yang ada didefinisikan pada namespace
http://www.w3c.org/2002/07/owl# dan umumnya menggunakan prefix owl.
Vocabulary tersebut menyediakan perluasan fungsi yang tidak dimiliki oleh
vocabulary pada RDF Schema. Beberapa fungsi tersebut diantaranya (Antoniou dan Hermelen, 2008):
1. Property Restriction, yaitu menentukan class apa saja yang merupakan bagian dari range suatu property secara lebih ketat. Pada RDF Schema, batasan yang diberikan bersifat global, tidak dapat diterapkan hanya untuk
class-class tertentu saja. Sedangkan pada OWL, batasan yang diberikan dapat bersifat lokal.
2. Cardinality Restrictions, yaitu menentukan berapa banyak jumlah suatu
property yang dapat digunakan pada instance dari class tertentu. Misalnya diberikan suatu statemen bahwa sesorang memiliki maksimal dua orang tua. Dengan cardinality restrictions, batasan tersebut dapat diberikan menggunakan owl:maxCardinality.
3. Disjointness of Classes, yaitu menyatakan bahwa suatu class merupakan himpunan saling asing dengan class lainnya. Contohnya pada class male dan female, dimana tiap orang hanya bisa menjadi instance dari salah satu
class tersebut, tidak kedua-duanya.
3.4.1 Jenis-jenis OWL
Berikut ini penjelasan tentang ketiga jenis sub-bahasa tersebut:
1. OWL-Lite
Dilihat dari sintaksnya, OWL-Lite paling sederhana. Jenis ini digunakan jika pengguna hanya membutuhkan hirarki class yang sederhana dengan batasan yang sederhana pula. Contohnya, pada OWL-Lite ini disediakan dukungan cardinality constraint dengan batasan nilai yang diizinkan hanya 0 atau 1. OWL-Lite menyediakan cara yang cepat untuk berpindah dari thesaurus dan hirarki sederhana yang sudah ada. Kelemahan utama dari OWL-Lite ini terletak pada derajat ekspresi yang ditawarkan sangat terbatas.
2. OWL-DL
OWL-DL jauh lebih ekspresif dibanding OWL-Lite. Proses komputasi di OWL-DL sangat lengkap dan pasti selesai dalam hitungan waktu tertentu. OWL-DL dapat menghasilkan hirarki klasifikasi secara otomatis dan mampu mengecek konsistensi dalam suatu ontologi karena OWL-DL mendukung reasoning.
3. OWL-Full
3.4.2 Elemen OWL 3.4.2.1Class dan individual
Class merupakan suatu resource tertentu yang merepresentasikan sekumpulan resource dengan karakteristik yang sama. Adapun resource yang merupakan anggota dari class disebut sebagai individual dan bertindak sebagai instance dari class tersebut. Untuk menyatakan suatu class baru beserta instance-nya, digunakan owl:Class dan rdf:type seperti yang tersaji pada Gambar 3.10.
@prefix ex: <http://example.org/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix owl: <http://www.w3c.org/2002/07/owl#> .
ex:Manusia rdf:type owl:Class . ex:Andi rdf:type ex:Manusia .
Gambar 3.10 Pendeklarasian class ex:Manusia
Selanjutnya untuk memberikan batasan mengenai keanggotaan suatu class
dapat dilakukan dengan membentuk relasi taksonomi dengan class lainnya menggunakan rdfs:subClassOf. Dengan relasi ini, dapat dinyatakan bahwa class A merupakan spesialisasi dari class B sehingga tiap instance dari class A juga merupakan instance dari class B.
3.4.2.2Property
Property digunakan untuk mendefinisikan relasi yang ada pada sekumpulan resource. Terdapat dua jenis property pada OWL:
1. datatype properties, digunakan pada relasi antara instance suatu class
dengan obyek bertipe literal.
3.4.2.3Property characteristics
OWL menyediakan sejumlah tambahan vocabulary yang menyediakan tambahan semantik untuk mendeskripsikan karakteristik suatu property. Beberapa
vocabulary tersebut diantaranya adalah:
1. owl:TransitiveProperty
Apabila terdapat statemen (A p B) dan (B p C), maka secara implisit menyatakan statemen (A p C).
2. owl:SymmetricProperty
Apabila terdapat statemen (A p B), maka secara implisit menyatakan statemen (B p A).
3. owl:FunctionalProperty.
Apabila terdapat statemen (A p X) dan (A p Y), maka X =Y. 4. owl:InverseFunctionalProperty
Apabila terdapat statemen (A p B) dan (C p B), maka A = C. 3.4.2.4Property restrictions
Property restriction digunakan untuk mendeskripsikan suatu property
dalam konteks class tertentu, sehingga dapat ditentukan bagaimana suatu property
digunakan pada saat berpasangan dengan instance dari class tertentu. Proses ini dilakukan dengan menggunakan owl:Restriction serta property dimana batasan tersebut hendak diterapkan diidentifikasi menggunakan owl:onProperty.
Terdapat dua jenis propertyrestriction pada OWL, yaitu:
1. Value Restrictions, yaitu batasan untuk menentukan range suatu property
pada saat berpasangan dengan instance dari class tertentu. Vocabulary
yang digunakan yaitu: owl:allValuesFrom, owl:someValuesFrom dan owl:hasValue.
2. Cardinality Restrictions, yaitu batasan untuk menentukan berapa banyak suatu property dapat muncul pada saat berpasangan dengan instance dari
3.5 SPARQL
SPARQL (SPARQL Protocol and RDF Query language) adalah bahasa
query yang digunakan untuk menelusuri data pada graf RDF sekaligus sebagai
data access protocol pada semantic web (Doods, 2005). Proses pencarian dilakukan berdasarkan pattern yang diajukan oleh query kemudian hasi pencarian ditampilkan dalam model RDF . Kebanyakan query pada SPARQL mengandung sekumpulan triple pattern yang disebut juga sebagai basic graph pattern. Triple tersebut mirip dengan triple pada RDF , kecuali pada tiap-tiap subyek, predikat dan obyek dapat berupa variabel. Penamaan variabel ini bersifat bebas, terdiri dari string dan diawali oleh tanda “?” atau tanda “$” seperti ?name atau $address (Prud'hommeaux, 2008). Variabel ini nantinya berisi data hasil dari pencarian
query yang hendak ditampilkan ke client.
Selain sebagai bahasa query, SPARQL juga berfungsi sebagai data access protocol yang menggambarkan mekanisme bagaimana mengakses sekumpulan repository data RDF secara remote (Doods, 2005). Protokol ini mendefinisikan bagaimana cara user mengajukan query ke SPARQL endpoint menggunakan protokol HTTP. SPARQL endpoint sendiri merupakan layanan yang disediakan untuk melayani request data dalam bentuk query SPARQL. Beberapa situs menyediakan layanan ini, seperti DBPedia dan LinkedMDB.
Berdasarkan spesifikasi dari W3C 26 Januari 2010 tentang SPARQL versi 1.1, query yang dikembangkan masih terbatas hanya untuk operasi yang bersifat
read only. Operasi lainnya seperti insert, update, atau delete belum tersedia sehingga tidak dimungkinkan memodifikasi dataset RDF menggunakan query
tersebut. Query ini terdiri atas empat bentuk query, yaitu SELECT, CONSTRUCT, ASK dan DESCRIBE. Fungsi dari masing-masing bentuk query
1. Query SELECT
Query SELECT digunakan untuk menampilkan data hasil pencarian berdasarkan triple pattern yang disebutkan setelah klausa WHERE. Data-data ini nantinya disertakan (binding) ke dalam variabel yang terletak sesudah klausa SELECT. Contoh sintak query SELECT sebagai berikut :
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?name ?mbox
WHERE
{ ?x foaf:name ?name .
?x foaf:mbox ?mbox }
2. Query CONSTRUCT
Query CONSTRUCT digunakan untuk mengembalikan data hasil pencarian ke dalam bentuk graf. Penggunaannya mirip dengan query
SELECT. Contohnya sebagai berikut :
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX org: <http://example.com/ns#>
CONSTRUCT { ?x foaf:name ?name }
WHERE { ?x org:employeeName ?name }
3. Query ASK
Query ASK digunakan untuk menentukan apakah graph pattern yang dicari ditemukan atau tidak. Hasil dari query ini bisa bernilai true atau false.
4. Query DESCRIBE
Query DESCRIBE bersifat deskriptif, digunakan untuk menampilkan informasi terkait dengan resource yang diminta.
1. ORDER BY
Klausa ORDER BY digunakan untuk mengurutkan kumpulan hasil query, baik secara menaik ataupun menurun.
2. DISTINCT
Klausa DISTINCT digunakan untuk menghapus duplikasi yang ada dari tiap hasil query. Klausa ini diletakkan tepat di depan variabel dari query
SPARQL.
3. OFFSET
OFFSET digunakan untuk menampilkan subset dari hasil query pada urutan tertentu. Biasanya digunakan berpasangan dengan klausa LIMIT. 4. LIMIT
LIMIT digunakan untuk membatasi hasil query yang hendak ditampilkan. Jumlah dari hasil query yang akan ditampilkan sebanyak nilai yang ditentukan oleh LIMIT. Nilai dari LIMIT sendiri tidak boleh bernilai negatif.
3.6 Linked Data
Linked data adalah sekumpulan langkah/metode terbaik untuk mempublikasikan sekaligus menghubungkan kumpulan data terstruktur pada Web (Heath dkk, 2009). Hal ini didasarkan pada asumsi dimana nilai dan kegunaan suatu data akan meningkat apabila terhubung dengan sumber data lainnya. Untuk itu, model RDF digunakan sebagai format representasi data beserta RDF link untuk menghubungkan sekumpulan data dari sumber yang berbeda.
kesatuan membentuk global data space atau yang dikenal juga sebagai Web of Data.
Dalam sejarahnya, linked data mulanya berasal dari upaya untuk mewujudkan visi dari semantic web dimana perkembangan teknologi semantic web yang tadinya masih terbatas hanya pada ruang lingkup penelitian agar dapat diimplementasikan ke dalam dunia nyata. Hal ini dapat terjadi apabila data yang digunakan tersedia dalam jumlah besar, tidak saling terisolir satu sama lain dan direpresentasikan menggunakan format standar yang disepakati bersama, yaitu format RDF. Selanjutnya upaya ini diwujudkan secara nyata oleh komunitas
Semantic Web Education and Outreach (SWEO) yang merupakan bagian dari W3C dengan meluncurkan proyek Linking Open Data di tahun 2007. Tujuannya adalah mengupayakan tersedianya sekumpulan dataset di web dalam format RDF serta menghubungkan item data dari dataset yang berbeda menggunakan RDF link. Gambar 3.11 menampilkan kumpulan dataset yang tergabung dalam proyek
Linking Open Data.
3.6.1 Prinsip dasar linked data
Berners-Lee (2006) menyatakan terdapat empat prinsip dasar dalam mempublikasikan data sebagai bagian dari Web of Data, yaitu :
1. Semua item harus diidentifikasi menggunakan URI.
2. URI yang dipakai harus bersifat dereferenceable, yaitu HTTP URI dapat menelusuri item yang ditunjuk oleh URI tersebut.
3. Ketika URI tersebut ditelusuri - yaitu pada saat menggunakan property
RDF sebagai hyperlink - hal ini membawa ke lebih banyak data.
4. Sertakan link yang menuju ke URI lainnya agar dimungkinkan penemuan ke lebih banyak data.
Pada linked data, tiap item data yang ada terbagi atas dua macam, yaitu
information resources (berupa data atau dokumen digital) dan non-information resources (berupa entitas di dunia nyata). Pada information resources, apabila item tersebut ditelusuri, maka server akan merespon dengan HTTP response code
200 OK dan mengirimkan ke client item data tersebut. Sedangkan pada non-information resources, HTTP redirecting dilakukan untuk mengarahkan request ke dokumen metadata yang mendesripsikan item/entitas tersebut. Server cukup merespon dengan HTTP respon code 303 See Other. Selanjutnya client akan diarahkan ke file RDF yang mendeskripsikan item/entitas yang diminta.
3.6.2 Content negotiation
server dapat merespon dengan format serialisasi RDF yang didukung, seperti RDF/XML, Turtle, N3 dan lain sebagainya.
Sebagai contoh, dimisalkan terdapat request untuk item non-information resources tentang sesorang bernama John dengan URI
http://www.example.com/resources/john. Untuk itu, disediakan URI tambahan berupa http://www.example.com/html/john (information resources dalam format representasi HTML) dan URI http://www.example.com/RDF /john (information resources dalam format representasi RDF/XML). Selanjutnya tahapan proses yang terjadi pada saat menelusuri item tersebut dijelaskan sebagai berikut:
1. Client melakuan HTTP GET request pada URI
http://www.example.com/resources/john. Apabila client berupa manusia, maka baris Accept: text/html ditambahkan pada HTTP header untuk secara spesifik meminta representasi dalam format HTML. Sedangkan apabila client berupa mesin, maka baris Accept: application/rdf+xml ditambahkan pada HTTP header untuk secara spesifik meminta representasi dalam format RDF/XML. Dimisalkan dalam contoh ini client adalah mesin. 2. Server menerima request URI yang diminta, merespon dengan HTTP
respon code 303 See Other dan mengirimkan ke client URI dari
information resources yang mendeskripsikan non-information resources yang diminta. Proses ini dikenal sebagai HTTP redirecting.
3. Client melakukan request kembali menggunakan URI yang diterima, masih dalam format RDF/XML. Adapun URI yang diminta yaitu
http://www.example.com/RDF /john.
4. Server merespon dengan mengirimkan ke client file RDF/XML yang mendeskripsikan John tersebut.
Gambar 3.12 Mekanisme content negotiation (Berrueta dan Phipps, 2008) 3.6.3 Vocabulary pada linked data
Pada linked data, disarankan untuk menggunakan vocabulary yang telah dibuat sebelumnya. Pembuatan vocabulary baru dilakukan apabila vocabulary
yang sudah ada dianggap tidak cocok untuk digunakan. Beberapa vocabulary
yang cukup terkenal diantaranya seperti FOAF (Friend of a Friend), Dublin Core, SKOS (Simple Knowledge Organization System), dan Music Ontology.
Berikut ini sejumlah petunjuk terkait dengan penggunaan vocabulary pada
linked data (Bizer dkk, 2007):
1. Jangan ciptakan kembali vocabulary yang serupa dari nol, tapi lengkapi yang telah ada untuk merepresentasikan data yang digunakan.
2. Sediakan dalam format yang dapat dikonsumsi oleh manusia dan mesin. 3. Pastikan URI yang digunakan bersifat dereferenceable. Ini penting agar
client dapat menelusuri definisi dari vocabulary tersebut.
4. Jika memungkinkan, gunakan vocabulary yang dipakai oleh orang lain. 5. Nyatakan seluruh informasi yang disajikan secara eksplisit.
3.6.4 Sumber dataset di linked data 3.6.4.1DBPedia
DBPedia merupakan hasil dari upaya komunitas untuk mengekstrak kumpulan informasi di Wikipedia ke dalam bentuk dataset RDF meliputi berbagai macam domain informasi. Tujuannya adalah agar dapat dimanfaatkan di dalam pengembangan aplikasi semantic web serta menghubungkannya dengan dataset lainnya dari luar sehingga menciptakan apa yang dikenal sebagai Web of Data. Tak hanya itu, DBPedia juga menyediakan fasilitas untuk melakukan operasi query terhadap dataset tersebut via SPARQL endpoint .
Diperkirakan sat ini terdapat lebih dari 274 juta triple RDF yang terkandung di DBPedia tersedia dalam 14 jenis bahasa. Kumpulan triple ini mendeskripsikan setidaknya 2,6 juta resource yang ada, terdiri dari 213.000 orang, 328.000 tempat, 57.000 album musik, 36.000 film, 20.000 perusahaan dan masih banyak lagi. Selain itu, tersedia 609.000 link untuk gambar, 3.150.000 link ke halaman situs luar dan 4.878.100 link ke dataset RDF di luar. Hal ini menjadikan DBPedia sebagi sebuah sumber dataset RDF yang kaya akan data dan berfungsi sebagai hubs bagi sumber dataset lainnya yang tergabung dalam komunitas Open Linked Data.
Mengenai operasi query data pada DBPedia, fasilitas ini disediakan oleh DBPedia dengan menggunakan bahasa SPARQL dan didukung oleh OpenlinkVirtuoso. Format representasi hasil query yang didukung pun bermacam-macam, mulai dari HTML, RDF/XML, JSON dan CSV. Hal ini bertujuan untuk memudahkan para pengguna apabila hendak mengintegrasikan data tersebut ke dalam aplikasi mereka. Selain itu, proses penjelajahan data juga dapat dilakukan menggunakan Semantic web browser seperti Disco, Tabulator, atau Marbles.
3.6.4.2LinkedMDB
dengan sepuluh ribu link yang terhubung ke sumber data lainnya. Untuk tugas penciptaan dan pemeliharaan link dalam kuantitas besar, digunakan tool ODDLinker (Open Data Dataset Linker) yang menyediakan teknik penggabungan terbaru untuk menemukan sejumlah link dari kumpulan sumber data yang berbeda.
Sebagai basis penciptaan linknya, LinkedMDB menggunakan sumber data Freebase dengan lisensi Creative Commons Attribution. LinkedMDB juga memanfaatkan sumber dataset lainnya seperti RDFBookMashup (menyediakan link terhadap sejumlah buku yang terkait dengan film), Musicbrainz (link ke album terkait soundtrack film) dan Reyvu.com (link terkait review film). Adapun mengenai publikasi data, LinkedMDB menggunakan situs www.linkedmdb.org
sebagai halaman utamanya, http://data.linkedmdb.org/resource/ untuk merefer ke
tiap entitas yang dipublikasikan dalam bentuk RDF dan
http://data.linkedmdb.org/sparql untuk SPARQL endpointnya.
3.6.5 Open World Assumption dan No Uniques Name Assumption
Teknologi semantik web dirancang untuk menjadikan world wide web yang ada saat ini menjadi lebih bersifat machine-understandable. Resource yang ada disajikan dalam bentuk terdistribusi, begitu pula deskripsi dari resource
tersebut, dalam hal ini OWL. OWL mendukung hal semacam ini dikarenakan model representasi yang digunakan menggunakan RDF yang memanfaatkan link dalam merepresentasikan relasi yang ada. Selain itu OWL juga menyediakan mekanisme untuk meng-import dan mempergunakan ontologi yang sudah ada dalam lingkungan sistem yang terdistribusi.
pada ketidak-lengkapan informasi yang ada pada lingkungan sistem terdistribusi. Berbeda dengan closed world assumption yang menyatakan bahwa suatu statement dapat dianggap bernilai salah bila tidak diketahui dengan pasti kebenarannya. Semua informasi yang diperlukan dianggap lengkap dan tersimpan di dalam sistem. Contoh dari closed world assumption dapat dilihat pada sistem database relasional yang ada saat ini.
Selanjutnya mengenai no unique names assumption yang menyatakan bahwa tidak dapat diasumsikan kumpulan resource yang diidentifikasi oleh URI yang berbeda benar-benar berbeda satu sama lain, kecuali bila dinyatakan sebaliknya secara eksplisit. Tidaklah dimungkinkan untuk mengasumsikan tiap user menggunakan URI yang sama dalam merepresentasikan resource tertentu dalam skala global. Yang terjadi adalah sebaliknya, dimana tiap user menggunakan URI miliknya masing-masing dalam merepresentasikan resource
yang digunakan. Duplikasi dianggap sebagai hal yang lumrah karena tidak ada kontrol penuh terhadap sumber informasi untuk mengatur pemberian URI pada
resource yang ada.
3.7 Jena Framework
Jena merupakan suatu framework yang cukup terkenal dan digunakan untuk membangun aplikasi semantic web. Jena dibangun menggunakan bahasa Java dan merupakan proyek open source. Pada Jena disediakan dukungan untuk RDF, RDF Schema, OWL API dan mesin inference untuk melakukan reasoning. Untuk query data, disediakan query engine yaitu ARQ untuk menelusuri data dalam bentuk graf. ARQ sendiri merupakan implementasi pada Jena untuk pemrosesan bahasa query SPARQ.
penyimpanannya. Beberapa server database yang didukung diantaranya seperti MySQL, PostgreSQL, Oracle dan Microsoft SQL Server.
3.7.1 Reasoner engine pada Jena
Pada Jena disediakan inference subsystem yang memungkinkan proses inferensi untuk dilakukan. Proses inferensi ini pada dasarnya terbagi atas dua macam, yaitu menggunakan ontologi yang disertakan ke dalam model atau menggunakan sekumpulan rule yang dimuat ke dalam reasoner. Inferensi memungkinkan sekumpulan statemen yang tadinya masih bersifat implisit untuk kemudian dinyatakan secara eksplisit. Beberapa built-in reasoner yang terdapat pada Jena disajikan dibawah ini:
1. Transitive reasoner
Menyediakan dukungan untuk penelusuran class dan property. Reasoner ini mendukung property transitive dan reflexive dari rdfs:subPropertyOf dan rdfs:subClassOf.
2. RDF Schema rule reasoner
Mengimplementasikan subset dari RDF Schema entailments. 3. OWL, OWL Mini dan OWL Micro Reasoner
Mengimplementasikan sebagian dari OWL/Lite yang merupakan subset dari OWL/Full language.
4. DAML micro reasoner
Menyediakan dukungan penggunakaan API DAML. 5. Generic rule reasoner
Merupakan reasoner yang mendukung user-defined rules. Beberapa jenis strategi yang didukungnya yaitu forward-chaining, backward-chaining
3.7.2 Contoh inferensi menggunakan Jena
Dimisalkan hendak dilakukan proses inferensi berbasis OWL. Disini kumpulan triple statement disimpan pada file DemoData.rdf sedangkan skema ontologi disimpan pada file schema.owl. Contoh baris kode untuk melakukan inferensi ditampilkan pada Gambar 3.13.
Model schema = FileManager.get().loadModel("file:data/schema.owl"); Model data = FileManager.get().loadModel("file:data/DemoData.rdf "); Reasoner reasoner = ReasonerRegistry.getOWLReasoner();
reasoner = reasoner.bindSchema(schema);
InfModel infmodel = ModelFactory.createInfModel(reasoner, data);
Gambar 3.13 Contoh baris kode untuk proses inferensi
Langkah pertama yang dilakukan adalah membuat instance model. Disini terdapat dua instance model dimana yang satu membaca file yang berisi asserted statement dan satunya lagi membaca file ontology. Pada Jena disediakan class
FileManager yang memudahkan dalam memuat file RDF ataupun file OWL ke dalam instance dari class Model. Setelah dibuat instance model, class
ReasoneRegistry dipanggil untuk membuat instance reasoner dengan berbagai
macam jenis (getTransitiveReasoner, getRDFSReasoner,
getRDFSSimpleReasoner, getOWLReasoner, getOWLMiniReasoner dan terakhir getOWLMicroreasoner). Instance reasoner ini disertakan pada instance model schema untuk menciptakan reasoner baru berbasiskan instance model schema tersebut. Selanjutnya langkah terakhir berupa proses inferensi dengan menempelkan instance reasoner tersebut ke instance model data. Hal ini akan menghasilkan instance dari class InfModel yang memuat statement pada instance
3.8 JSP dan Struts
3.8.1 JSP (Java Server Pages)
JSP merupakan teknologi yang dikembangkan oleh Sun Microsystem sebagai bagian dari J2EE (Java Enterprise Edition). JSP dibangun dengan tujuan untuk mempermudah para developer yang sebelumnya berkutat dengan servlet dalam membangun aplikasi berbasis web. Dengan JSP, proses perancangan aplikasi lebih mudah karena terdapat pemisahan yang jelas antara komponen view yang menampilkan layout dari aplikasi dan komponen kode yang mengurus
bussiness logic dari aplikasi. Selain itu, pada JSP disediakan JSTL yang meringkas penulisan kode ke dalam bentuk tag seperti HTML di layer view.
Dengan adanya pemisahan layer bussiness logic dari layer view, para developer dapat berfokus dalam penulisan kode aplikasi sementara untuk layout presentasi diserahkan kepada web designer. Hasilnya proses pengembangan aplikasi menjadi lebih produktif dan efisien. Apabila terjadi perubahan pada
bussiness logic code tidak mempengaruhi proses perancangan layout aplikasi. Untuk memproses halaman JSP, pada web server diperlukan JSP container. Container ini nantinya akan mengubah halaman JSP tersebut menjadi servlet, dimana tiap-tiap template text yang ada diubah menjadi string dan disertakan ke dalam println method, sedangkan elemen-elemen pada JSP diubah menjadi kode Java. Langkah terakhir container melakukan compiling pada class
3.8.2 Struts
Struts merupakan MVC framework yang dikembangkan oleh Craig McClanahan dengan tujuan untuk mempermudah didalam proses pengembangan aplikasi web. Dengan Struts, operasi-operasi umum yang terdapat dalam aplikasi web dapat diringkas seperti penanganan input pada form web, validasi input, error handling dan masih banyak lagi. Selain itu, disediakan pula sejumlah plug-in yang menyediakan fungsionalitas tambahan seperti Tiles (untuk menyederhanakan proses perancangan layout web). Hal ini menjadikan Struts sebagai salah satu framework yang cukup populer dan banyak dipakai dalam pengembangan aplikasi berbasis web.
MVC (Model View Controller) merupakan arsitektur yang dipakai oleh Struts dalam merancang sebuah aplikasi berbasis web (Cavaness, 2004). Model merupakan bagian yang menangani kontrol akses data dan bussiness logic, View untuk mengatur bagaimana data disajikan ke user dan Controller untuk menangani request dan alur data yang terjadi antara Model dan View. Gambaran mengenai alur proses yang terjadi disajikan pada Gambar 3.8.
Pada Struts, bagian Controller diterapkan menggunakan class Action.
39
4.1 Gambaran Umum Sistem
Sistem yang akan dibuat merupakan aplikasi penyajian informasi seputar dunia perfilman berbasis web dengan sumber data utama berasal situs DBPedia. Sumber data disediakan dalam format RDF dan menggunakan mekanisme content negotiation untuk memperoleh data yang diinginkan. Adapun ragam informasi yang disajikan terbagi atas dua macam kategori, yaitu kategori artis dan kategori film. Untuk memperoleh informasi yang lebih relevan, disediakan pula halaman pencarian berdasarkan kedua kategori tersebut.
4.2 Spesifikasi Kebutuhan Sistem
Dalam merancang sebuah sistem, perlu didefinisikan terlebih dahulu kebutuhan fungsional dan non-fungsional yang dibutuhkan.
4.2.1 Kebutuhan fungsional
Berikut ini daftar dari kebutuhan fungsional sistem yang sedang dibangun: 1. Sistem menyediakan informasi seputar perfilman yang terbagi atas dua
kategori, yaitu kategori artis dan kategori film.
2. Sistem menyediakan fungsi pencarian seputar artis dan film.
3. Sistem menyediakan halaman login untuk mengakses modul administrator. 4. Sistem menyediakan pengaturan terhadap konfigurasi sistem (khusus
administrator).
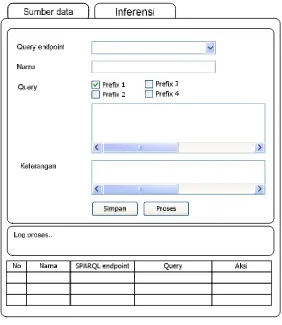
5. Sistem menyediakan form antarmuka yang berfungsi untuk me-retrieve
sekumpulan dokumen RDF dari luar (dataset source) beserta fasilitas pengelolaannya (khusus administrator).