LECTURE NOTES #5
Model Regresi Linier Berganda Dengan Variabel Kualitatif I. Pendahuluan
Hingga saat ini, modal regresi yang dipelajari adalah yang memiliki variabel (bebas dan tergantung) berbentuk kuantitatif (numeris). Variabel semacam ini misalnya konsumsi per kapita (dalam IDR), gaji (dalam USD), usia, dsb. Dalam penelitian yang sebenarnya akan sangat mungkin kita berinteraksi dengan variabel yang bersifat kualitatif (kategorik). Variabel semacam ini misalnya jenis kelamin, agama, suku, kategori pendidikan, dsb.
Terdapat perlakukan khusus jika suatu model regresi memiliki variabel kualitatif (dummy variabel atau kategorik). Hal ini disebabkan sifat non continuity dari variabel ini. Sebagai contoh jika kita mengkategorikan variabel jenis kelamin sebagai bernilai 1 untuk laki-laki dan 0 untuk perempuan, maka angka 0.5 tidak memiliki arti dan relevansi dalam penelitian.
Seperti yang dilihat nanti perlakuan yang diberikan untuk model regresi semacam ini hanyalah merupakan perluasan langsung dari regresi standar yang telah dipelajari selama ini. Tidak ada perbedaan pada perhitungan koefisien maupun statistik uji, yang berbeda adalah pada intrepretasi dan spesifikasi.
Perlu diperhatikan bahwa dalam bagian ini, pembahasan hanya dilakukan pada model regresi dengan variabel kualitatif sebagai regressor. Penggunaan variabel kualitatif sebagai regresand memiliki teknik estimasi yang intrepretasi yang sangat berbeda. Kita akan mengkategorikan model semacam ini sebagai model regresi probabilistic yang dibahas pada bagian tersendiri.
II. Model Paling Sederhana
Disini akan diuraikan suatu model yang paling sederhana, yakni variabel kategorik binary. Seperti namanya variabel ini hanya memiliki 2 kategori. Variabel semacam ini misalnya jenis kelamin, variabel kepemilikian (memiliki dan tidak memiliki), dan variabel lainnya yang hanya memiliki 2 jawaban (ya dan tidak).
Permasalahan lebih disederhanakan lagi dengan mengasumsikan dampak dari perbedaan kategori hanya bersifat konstan pada setiap tingkat variabel bebas lainnya. Dalam model ini dampak variabel kualitatif ditunjukkan melalui intersep.
Sebagai ilustrasi, misalnya kita ingin menduga adanya diskriminasi berdasarkan gender pada suatu institusi. Salah satu cara untuk melihatnya
Jika kita mengasumsikan adanya diskriminasi maka hipotesis akan disusun sbb:
Perhitungan parameter OLS serta uji statistik tidak berbeda dengan model regresi standar. Dengan menggunakan rejection rule, maka kita dapat mengambil kesimpulan apakah data mendukung/menolak hipotesis null. Seandainya kita memperoleh hasil yang menolak hipotesis null, δ0 adalah lebih kecil dari nol (negatif), maka dapat dikatakan bahwa data mendukung dugaan adanya diskriminasi. Hal ini terjadi karena gaji wanita adalah lebih kecil dari pria pada setiap level educ, dengan kata lain
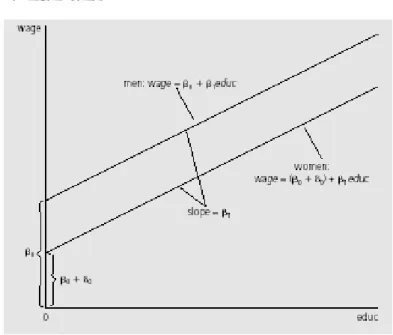
Secara grafis
Grafik 1. Regresi Kualitatif Variabel Kategorik=2
0 0 1
wage
=
β δ
+
female
+
β
educ u
+
………1)0 0 1 0
:
0
:
0
H
H
δ
δ
≥
<
………2) 0 0 1 0 1(
)
(
)
; untuk wanita
(
)
; untuk pria
E wage
educ
E wage
educ
β δ
β
β
β
=
+
+
=
+
………3)Sebagaimana ditunjukkan oleh grafik, gaji yang diterima oleh wanita pada setiap level pendidikan adalah lebih rendah dari pria. Selisih antara gaji pria dan wanita untuk suatu tingkat pendidikan tertentu adalah sebesar δ0.
Contoh 1.
Dari data wage1.raw kita menggunakan gaji (wage) sebagai variabel tergantung, pendidikan (educ), pengalaman kerja (exper), lama penugasan (tenure) sebagai variabel penjelas yang relevan serta satu variabel kategorik jenis kelamin (female, dimana female=1 jika ybs adalah wanita dan 0 jika pria). Regresi dengan menggunakan 526 sampel diperoleh hasil sbb:
Dependent Variable: WAGE Method: Least Squares Date: 06/06/08 Time: 07:49 Sample: 1 526
Included observations: 526
Variable Coefficient Std. Error t-Statistic Prob. C -1.567939 0.724551 -2.164014 0.0309 FEMALE -1.810852 0.264825 -6.837915 0.0000 EDUC 0.571505 0.049337 11.58362 0.0000 EXPER 0.025396 0.011569 2.195083 0.0286 TENURE 0.141005 0.021162 6.663225 0.0000 R-squared 0.363541 Mean dependent var 5.896103 Adjusted R-squared 0.358655 S.D. dependent var 3.693086 S.E. of regression 2.957572 Akaike info criterion 5.016075 Sum squared resid 4557.308 Schwarz criterion 5.056619 Log likelihood -1314.228 F-statistic 74.39801 Durbin-Watson stat 1.794400 Prob(F-statistic) 0.000000
Tabel 1. Print Out Regresi Contoh 1
Seperti yang dapat dilihat pada tabel 1, dugaan terdapatnya diskriminasi melalui variabel gaji tampaknya memperoleh dukungan data. Disini koefisien variabel dummy adalah sebesar –1.81. Dengan kata lain setelah mengontrol/memperhitungkan variabel educ, exper dan tenure, wanita memperoleh gaji lebih rendah 1.81 unit daripada pria.
Suatu variasi yang banyak ditemui pada aplikasi empiris adalah jika variabel tergantung adalah berupa log (model semi elasticity). Disini dengan sedikit modifikasi, maka koefisien variabel dummy dapat diintrepretasikan sebagai persentase perbedaan antar kategori.
Contoh 2.
Masih menggunakan data pada contoh 1, misalnya kita merubah spesifikasi model menjadi
Estimasi OLS untuk model ini memberikan hasil sbb:
Dependent Variable: LOG(WAGE) Method: Least Squares
Date: 06/06/08 Time: 08:16 Sample: 1 526
Included observations: 526
Variable Coefficient Std. Error t-Statistic Prob. C 0.416691 0.098928 4.212066 0.0000 FEMALE -0.296511 0.035805 -8.281169 0.0000 EDUC 0.080197 0.006757 11.86823 0.0000 EXPER 0.029432 0.004975 5.915866 0.0000 EXPER^2 -0.000583 0.000107 -5.430528 0.0000 TENURE 0.031714 0.006845 4.633036 0.0000 TENURE^2 -0.000585 0.000235 -2.493365 0.0130 R-squared 0.440769 Mean dependent var 1.623268 Adjusted R-squared 0.434304 S.D. dependent var 0.531538 S.E. of regression 0.399785 Akaike info criterion 1.017438 Sum squared resid 82.95065 Schwarz criterion 1.074200 Log likelihood -260.5861 F-statistic 68.17659 Durbin-Watson stat 1.795726 Prob(F-statistic) 0.000000
Tabel 2. Print Out Regresi Contoh 2
Disini koefisien variabel dummy (female) adalah –0.297, intrepretasi yang tepat terhadap koefisien ini dilakukan dengan perhitungan berikut:
2
0 0 1 2 3
2
4 5
log(
)
exper
exper
+
+
wage
female
educ
tenure
tenure
u
β δ
β
β
β
β
β
=
+
+
+
+
Dengan demikian persentase selisih antara gaji wanita dan pria, setelah memperhitungkan variabel bebas pada model adalah sebesar -25.7%.
Perhitungan ini dapat digeneralisir. Untuk sembarang model dimana variabel dependen adalah berbentuk log(y), maka persentase perbedaan antara variabel kualitatif xi=1 versus xi=0 (dengan koefisien regresi βi) adalah
III. Variabel Multi Kategori
Dalam banyak kasus variabel kategori dispesifikasi sebagai bentuk multikategori. Daripada mengklasifikasikan pendidikan sebagai terdidik versus tidak terdidik, variabel ini biasanya dispesifikasikan berdasarkan tingkat pendidikan formal terakhir (<SD, SMA, Akademi, S1 dan Pasca Sarjana). Kebutuhan variabel multi kategori juga dapat timbul dari upaya meng”kualitatif”kan suatu variabel kuantitatif, misalnya usia yang dirubah menjadi interval-interval misalnya untuk menunjukkan pra remaja, remaja, dewasa, mature, dan senior.
Salah satu aplikasi yang umum digunakan adalah berkenaan dengan variabel ordinal. Untuk mengingatkan, variabel ordinal adalah variabel kualitatif dimana setiap kategori memiliki arti urutan (tinggi-rendah). Aplikasi seperti ini misalnya untuk melihat dampak dari credit rating terhadap suku bunga surat hutang suatu institusi. Perlakukan sebagai variabel numeris biasanya kurang didukung teori atau menyebabkan kesulitan intrepretasi.
Jika variabel bersifat multi kategori sejumlah k maka biasanya akan dibuat variabel dummy sebanyak k-1, dimana satu kategori akan dijadikan sebagai benchmark. Sebagai contoh jika kita ingin mengetahui suku bunga bagi obligasi dengan rating A, B, C, dan D (A terbaik, dan D terburuk), maka
^ ^
log( ) log( ) 0.297 log( ) 0.297
exp log( ) exp( 0.297)
exp( 0.297) exp( 0.297) 1 0.257 F M F M F M F M F M M wage wage wage wage wage wage wage wage wage wage wage − = − = − ⎛ ⎞ = − ⎜ ⎟ ⎝ ⎠ = − − = − − ≈ −
(
)
100
×
exp(
β
i) 1
−
………5)yang dilakukan pertama kali adalah menetapkan kategori benchmark (misalnya D). Model regresi selanjutnya dapat disusun sbb;
Dimana brate adalah suku bunga obligasi, CRA: variabel dummy yang bernilai 1 jika obligasi ybs memiliki credit rating A dan 0 jika lainnya, CRB: variabel dummy yang bernilai 1 jika obligasi ybs memiliki credit rating B dan 0 jika lainnya, CRC: variabel dummy yang bernilai 1 jika obligasi ybs memiliki credit rating C dan 0 jika lainnya. Dengan pemodelan semacam ini maka suku bunga setiap kategori dapat dihitung sbb:
Tentu saja jika kita mengharapkan tidak ada perbedaan suku bunga antara credit rating i (I=A,B dan C) dengan D maka δi =0.
Contoh 3.
Suatu penelitian dilakukan untuk melihat ranking suatu perguruan tinggi ilmu hukum (law school) terhadap gaji awal (salary) lulusannya. Adapun kategori variabel dummy terdiri atas top_10, r11_25, r26_r40, r41_60 dan r61_100. Benchmark yang digunakan adalah r61_100 dan variabel kontrol lain adalah nilai SAT (LSAT), indeks prestasi (GPA), koleksi perpustakaan (libvol) dan biaya kuliah (cost). Model dispesifikasikan sebagai bentuk log pada regressan dan regressor libvol dan cost. Hasil estimasi dari data Lawsch85.raw memberikan hasil sbb:
Dependent Variable: LOG(SALARY) Method: Least Squares
Date: 06/06/08 Time: 09:14 Sample (adjusted): 1 155
Included observations: 136 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. C 8.363104 0.445731 18.76265 0.0000 TOP10 0.539343 0.053542 10.07326 0.0000 R11_25 0.471620 0.039092 12.06433 0.0000 R26_40 0.279098 0.034697 8.043818 0.0000 R41_60 0.182382 0.028310 6.442362 0.0000 0 0 A 1 B 2 C
brate
=
β δ
+
CR
+
δ
CR
+
δ
CR
+
u
………6) 0 0 0 0 1 0 2(
)
; untuk credit rating = D
(
)
; untuk credit rating = A
(
)
; untuk credit rating = B
(
)
; untuk credit rating = C
E brate
E brate
E brate
E brate
β
β δ
β δ
β δ
=
=
+
=
+
=
+
………7)LSAT 0.006048 0.003492 1.732075 0.0857 GPA 0.130589 0.081868 1.595124 0.1132 LOG(LIBVOL) 0.072552 0.028921 2.508605 0.0134 LOG(COST) 0.024917 0.028322 0.879763 0.3806 R-squared 0.883295 Mean dependent var 10.54149 Adjusted R-squared 0.875944 S.D. dependent var 0.277240 S.E. of regression 0.097648 Akaike info criterion -1.751006 Sum squared resid 1.210967 Schwarz criterion -1.558257 Log likelihood 128.0684 F-statistic 120.1523 Durbin-Watson stat 1.990396 Prob(F-statistic) 0.000000
Tabel 3. Print Out Regresi Contoh 3
Dengan menggunakan formula persamaan 5, maka selisih starting salary bagi lulusan sekolah dengan ranking top10 terhadap ranking 61-100 adalah 71.6% (=100x(exp(0.54)-1)). Secara statistik koefisien variabel dummy ini adalah signifikan pada p-value 0.00.
IV. Komponen Interaksi
Suatu komponen interaksi cukup sering digunakan dalam penelitian empiris. Komponen ini menunjukkan dampak bersama 2 atau lebih variabel bebas individual terhadap variabel tergantung yang bersifat interaksi. Dalam bagian ini dampak bersama yang hendak diamati adalah pengaruh terhadap slope dan uji perbedaan antara model regresi.
Variabel dummy sering digunakan untuk melihat apakah dampak suatu kategori dapat bersifat variabel. Dengan kata lain perbedaan antar kategori semakin besar (semakin kecil) dengan berubahnya nilai variabel bebas. Pembahasan akan dibatasi pada dampak yang bersifat perubahan konstan dan monoton (meningkat atau menurun searah dengan pergerakan variabel bebas).
Masih dengan menggunakan contoh diskriminasi gaji misalnya dihipotesakan bahwa perbedaan gaji adalah tidak konstan pada setiap tingkat pendidikan. Terdapat dua kemungkinan bahwa dengan meningkatnya pendidikan maka (1) selisih gaji seorang wanita akan semakin kecil atau (2) selisih gaji seorang wanita akan semakin besar. Kondisi ini dapat dimodelkan sbb:
Komponen female*educ disebut dengan komponen interaksi, ia adalah hasil perkalian antara variabel dummy female dan educ. Pada intinya dengan mengestimasi persamaan 8, kita akan memperoleh 2 model regresi sbb:
0 0 1 1
Hipotesis disusun melalui pengenaan restriksi yang relevan terhadap δ0 dan
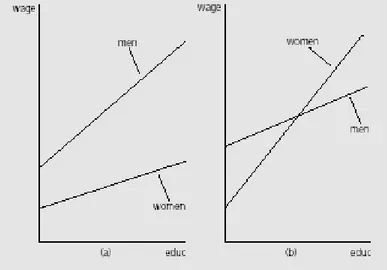
δ1. Sebagai contoh jika kita menghipotesakan bahwa gaji wanita adalah lebih kecil dengan perbedaan yang semakin besar (secara linier) terhadap pria, maka δ0<0 dan δ1<0 dan sebaliknya jika gaji wanita awalnya adalah lebih kecil tetapi perbedaan akan semakin kecil maka δ0<0 dan δ1>0. Secara grafis
Grafik 2. Grafik persamaan 8: (a) δ0<0 dan δ1<0 dan (b) δ0<0 dan δ1>0
Seperti biasa signifikansi dampak perbedaan slope dapat dilihat melalui apakah koefisien variabel interaksi memenuhi criteria rejection rule yang sesuai (t statistik atau p value).
Contoh 4.
Disini kita melakukan modifikasi pada contoh 2, dimana disini ditambahkan variabel interaksi female*educ pada variabel yang sudah ada. Estimasi dengan menggunakan Eviews ver. 5.1 diperoleh hasil sbb:
Dependent Variable: LOG(WAGE) Method: Least Squares
Date: 06/07/08 Time: 07:43 Sample: 1 526
Included observations: 526
Variable Coefficient Std. Error t-Statistic Prob.
0 1
0 0 1 1
(log(
))
; untuk laki-laki
(log(
))
(
) (
)
; untuk wanita
E
wage
educ
E
wage
educ
β
β
β δ
β δ
=
+
=
+
+
+
………9)C 0.388806 0.118687 3.275892 0.0011 FEMALE -0.226789 0.167539 -1.353643 0.1764 EDUC 0.082369 0.008470 9.724919 0.0000 FEMALE*EDUC -0.005565 0.013062 -0.426013 0.6703 EXPER 0.029337 0.004984 5.885973 0.0000 EXPER^2 -0.000580 0.000108 -5.397767 0.0000 TENURE 0.031897 0.006864 4.646956 0.0000 TENURE^2 -0.000590 0.000235 -2.508901 0.0124 R-squared 0.440964 Mean dependent var 1.623268 Adjusted R-squared 0.433410 S.D. dependent var 0.531538 S.E. of regression 0.400100 Akaike info criterion 1.020890 Sum squared resid 82.92160 Schwarz criterion 1.085761 Log likelihood -260.4940 F-statistic 58.37084 Durbin-Watson stat 1.795466 Prob(F-statistic) 0.000000
Tabel 4. Print Out Regresi Contoh 4
Seperti yang dapat dilihat pada tabel 4, baik melalui criteria t statistik maupun p value tampaknya data tidak mendukung adanya perbedaan pada slope (koefisien return to education) antara model gaji pria versus wanita.
Wald Test: Equation: Untitled
Test Statistic Value df Probability F-statistic 34.32555 (2, 518) 0.0000 Chi-square 68.65110 2 0.0000
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err. C(2) -0.226789 0.167539 C(4) -0.005565 0.013062 Restrictions are linear in coefficients.
Tabel 5. Print Out Wald Test Contoh 4
Namun demikian kesimpulan yang lebih kuat mengenai hal ini (tidak adanya perbedaan slope) masih harus dilihat melalui pengujian Wald test. Dengan melakukan retriksi pada koefisien variabel dummy dan interaksi dapat diuji hipotesa apakah koefisien dimaksud dapat dikeluarkan dari model. Hasil pengujian yang diberikan pada tabel 5 menunjukkan hal ini
significant. Dugaan terhadap rendahnya signifikansi komponen interaksi dengan demikian berasal dari multikolinearitas.
Komponen interaksi juga dapat digunakan untuk melihat apakah satu atau lebih model regresi adalah sama. Sebagai ilustrasi jika kita mengasumsikan bahwa tidak terdapat diskriminasi atas gaji wanita versus pria, maka kita dapat mengharapkan bahwa model gaji adalah identik diantara kedua jenis kelamin tersebut.
Misalnya kita ingin mengetahui apakah terdapat perbedaan antara model regresi bagi dua group sample: g=1 dan g=2. Model regresi memiliki k variabel dengan intersep, sbb:
jika tidak terdapat perbedaan model regresi maka hipotesis null bahwa β1,i =
β2,i untuk semua i = 0,…, k adalah tidak dapat ditolak.
Pengujian dilakukan dengan membagi sample menjadi dua bagian sesuai dengan groupnya (n1 untuk g=1 dan n2 untuk g=2). Terhadap masing-masing sub sample (n1 dan n2) dilakukan estimasi terpisah atas persamaan 10, dan peroleh SSR1 dan SSR2. SSRUR adalah jumlah dari keduanya (SSRUR=SSR1+SSR2). SSRR diperoleh dari pooled data, yang menunjukkan bahwa model regresi adalah identik bagi setiap group dengan demikian data bisa dijadikan satu (pooled).
Pengujian hipotesis null tidak ada perbedaan antara kedua group dilakukan melalui suatu versi F test yang disebut Chow Test. Adapun formulasi dapat diberikan sbb:
Contoh 5.
Dengan menggunakan GPA3.raw khususnya data dari spring semester, kita ingin melihat apakh ada perbedaan antara indeks prestasi kumulatif antara atlet mahasiswa pria versus wanita dengan mengontrol variabel nilai SAT (sat), ranking persentile waktu high school (hsprc), jumlah jam kehadiran kuliah (tothrs). Sesuai dengan kerangka kerja Chow Test maka kita pertama kali mengestimasi nilai SSRR, yakni pooled data. Regresi yang relevan diberikan pada tabel 6.
,0 ,1 1 ,2 2
...
, g g g g k ky
=
β
+
β
x
+
β
x
+ +
β
x
+
u
………..……10) 1 2 1 2(
(
)) /
1
/(
2(
1))
r htSSR
SSR
SSR
k
F
SSR
SSR
n
k
−
+
+
=
+
−
+
………..……11)Dependent Variable: CUMGPA Date: 06/07/08 Time: 08:42 Sample: 1 732 IF SPRING=1 Included observations: 366
Variable Coefficient Std. Error t-Statistic Prob. C 1.490850 0.183678 8.116641 0.0000 SAT 0.001185 0.000165 7.191040 0.0000 HSPERC -0.009957 0.001245 -8.000114 0.0000 TOTHRS 0.002343 0.000755 3.101564 0.0021 R-squared 0.351636 Mean dependent var 2.334153 Adjusted R-squared 0.346263 S.D. dependent var 0.601126 S.E. of regression 0.486034 Akaike info criterion 1.405794 Sum squared resid 85.51507 Schwarz criterion 1.448446 Log likelihood -253.2603 F-statistic 65.44289 Prob(F-statistic) 0.000000
Tabel 6. Pooled regression contoh 5
Dapat dilihat disini nilai SSRR=85.515, estimasi model pada sub sample (group wanita, g=1 dan group pria, g=2) memberikan SSR1=19.603 dan SSR2=58.752 sehingga SSRUR=78.355 (lihat tabel 7 dan 8).
Dependent Variable: CUMGPA Date: 06/07/08 Time: 08:39
Sample: 1 732 IF SPRING=1 AND FEMALE=1 Included observations: 90
Variable Coefficient Std. Error t-Statistic Prob. C 1.127326 0.361595 3.117646 0.0025 SAT 0.001802 0.000347 5.195036 0.0000 HSPERC -0.009001 0.002908 -3.095606 0.0027 TOTHRS 0.002228 0.001409 1.581710 0.1174 R-squared 0.401430 Mean dependent var 2.666000 Adjusted R-squared 0.380550 S.D. dependent var 0.606606 S.E. of regression 0.477430 Akaike info criterion 1.402628 Sum squared resid 19.60279 Schwarz criterion 1.513731 Log likelihood -59.11826 F-statistic 19.22525 Prob(F-statistic) 0.000000
Dependent Variable: CUMGPA Method: Least Squares
Date: 06/07/08 Time: 08:41
Sample: 1 732 IF SPRING=1 AND FEMALE=0 Included observations: 276
Variable Coefficient Std. Error t-Statistic Prob. C 1.480812 0.205971 7.189434 0.0000 SAT 0.001052 0.000180 5.845756 0.0000 HSPERC -0.008452 0.001361 -6.208219 0.0000 TOTHRS 0.002344 0.000857 2.736217 0.0066 R-squared 0.316852 Mean dependent var 2.225942 Adjusted R-squared 0.309317 S.D. dependent var 0.559225 S.E. of regression 0.464757 Akaike info criterion 1.319782 Sum squared resid 58.75172 Schwarz criterion 1.372252 Log likelihood -178.1299 F-statistic 42.05226 Prob(F-statistic) 0.000000
Tabel 8. Group 2 regression contoh 5
Dengan demikian statistik F dapat diperoleh sbb:
Nilai F ini lebih besar F kritis pada α=5%, df numerator=4, df denominator=358 yakni 2.37, dengan demikian hipotesis null bahwa β1,i = β2,i untuk semua i = 0,…, k adalah ditolak. Dengan kata lain paling tidak terdapat satu parameter yang membedakan antara kedua group tersebut.
Pengujian model yang baru dilakukan (Chow Test) bersifat sangat restriktif, tidak boleh ada perbedaan pada satu parameter pun. Adakalanya kita lebih memperhatikan pada adakah perbedaan slope dengan tetap memperbolehkan perbedaan pada intersep. Kita dapat menguji hipotesa ini dengan memodelkan suatu regresi dengan variabel interaksi dan menguji apakah komponen interaksi tersebut adalah signifikan secara statistik (Wald test). Masih dengan data yang sama, regresi dengan variabel interaksi dapat dilihat pada tabel 9.
Dependent Variable: CUMGPA Method: Least Squares
Date: 06/07/08 Time: 08:33 Sample: 1 732 IF SPRING=1 Included observations: 366
(85.515 78.355) / 4
8.18
78.355 / 358
htF
=
−
≈
Variable Coefficient Std. Error t-Statistic Prob. C 1.480812 0.207334 7.142168 0.0000 FEMALE -0.353486 0.410529 -0.861050 0.3898 SAT 0.001052 0.000181 5.807324 0.0000 FEMALE*SAT 0.000751 0.000385 1.948755 0.0521 HSPERC -0.008452 0.001370 -6.167404 0.0000 FEMALE*HSPERC -0.000550 0.003162 -0.173878 0.8621 TOTHRS 0.002344 0.000862 2.718228 0.0069 FEMALE*TOTHRS -0.000116 0.001628 -0.071164 0.9433 R-squared 0.405927 Mean dependent var 2.334153 Adjusted R-squared 0.394311 S.D. dependent var 0.601126 S.E. of regression 0.467833 Akaike info criterion 1.340203 Sum squared resid 78.35451 Schwarz criterion 1.425507 Log likelihood -237.2572 F-statistic 34.94562 Prob(F-statistic) 0.000000
Tabel 9. Model dengan komponen interaksi: contoh 5
Seperti yang terlihat pada tabel 9, koefisien interaksi umumnya adalah tidak signifikan (kecuali female*sat, yang secara marginal sedikit lebih besar dari 5%). Apakah ini berarti komponen interaksi tidak diperlukan didalam model? Belum tentu, kita masih harus mengujinya dengan menggunakan Wald Test yang diberikan oleh tabel 10.
Wald Test: Equation: Untitled
Test Statistic Value df Probability F-statistic 1.533898 (3, 358) 0.2054 Chi-square 4.601693 3 0.2034
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err. C(4) 0.000751 0.000385 C(6) -0.000550 0.003162 C(8) -0.000116 0.001628 Restrictions are linear in coefficients.
Wald test pada tabel 10 menunjukkan bahwa hipotesis null resctriction exclusion tidak dapat ditolak. Dengan demikian tampaknya data memungkinkan kita untuk mengestimasi model yang lebih sederhana, yakni model tanpa variabel interaksi (tabel 11).
Dependent Variable: CUMGPA Method: Least Squares
Date: 06/07/08 Time: 09:23 Sample: 1 732 IF SPRING=1 Included observations: 366
Variable Coefficient Std. Error t-Statistic Prob. C 1.328541 0.179827 7.387861 0.0000 FEMALE 0.310098 0.058613 5.290611 0.0000 SAT 0.001214 0.000159 7.634963 0.0000 HSPERC -0.008441 0.001234 -6.838671 0.0000 TOTHRS 0.002464 0.000729 3.379269 0.0008 R-squared 0.398291 Mean dependent var 2.334153 Adjusted R-squared 0.391623 S.D. dependent var 0.601126 S.E. of regression 0.468869 Akaike info criterion 1.336582 Sum squared resid 79.36167 Schwarz criterion 1.389896 Log likelihood -239.5944 F-statistic 59.73935 Prob(F-statistic) 0.000000
Tabel 11. Model tanpa komponen interaksi: contoh 5
V. Dummy Variable Trap (Suatu Catatan)
Dalam penggunaan variabel kategorik k kategori, kita akan menambahkan k-1 variabel dummy kedalam model regresi jika dampak kategori hanya melalui intersep dan 2(k-1) jika dampak kategori terdapat pada intersep dan slope. 1 kategori akan digunakan sebagai bench mark (base) yang dipilih sepenuhnya berdasarkan pertimbangan peneliti.
Perlu diperhatikan bahwa kesalahan spesifikasi berupa penggunaan k variabel dummy (dan bukannya k-1) akan menimbulkan masalah perfect colinearity. Sebagai konsekuensinya model tidak akan dapat diestimasi. Hal ini disebabkan oleh masalah singular matriks karena dengan menggunakan k variabel dummy, maka salah satu variabel dummy adalah kombinasi linier dari variabel dummy lainnya.
Sebagai contoh jika kita menggunakan variabel dengan kategori=3 dan dispesifikasikan melalui variabel dummy C1, C2 dan C3 maka akan berlaku C1+C2+C3 =1, atau C1 =1-C2-C3 yang merupakan kolinearitas sempurna. Estimasi OLS adalah suatu penyelesaian atas system persamaan simultan melalui teknik matriks, dari kuliah matematika diketahui apabila terdapat
satu atau lebih kolom/baris yang tidak bebas linier maka determinan matriks tersebut adalah nol dan sebagai konsekuensinya penyelesaian yang unik terhadap system tidak akan dapat diperoleh.
Dengan demikian sangat penting bagi kita untuk menspesifikasikan model secara benar.