2010 International Conference
on Asian Language
Processing
IALP 2010
Table of Contents
Message from General Chairs
...xiMessage from Program Chairs
...xiiiConference Committees
...xivProgram Committee
...xvOrganizers and Sponsors
...xviiInvited Talks
...xixLexicon and Morphology
A Survey on Rendering Traditional Mongolian Script
...3Biligsaikhan Batjargal, Fuminori Kimura, and Akira Maeda
A Combination of Statistical and Rule-Based Approach for Mongolian
Lexical Analysis
...7Lili Zhao, Jia Men, Congpin Zhang, Qun Liu, Wenbin Jiang, Jinxing Wu, and Qing Chang
A Letter Tagging Approach to Uyghur Tokenization
...11Batuer Aisha
Development of Analysis Rules for Bangla Root and Primary Suffix
for Universal Networking Language
...15Md. Nawab Yousuf Ali, Shahid Al Noor, Md. Zakir Hossain, and Jugal Krishna Das
A Suffix-Based Noun and Verb Classifier for an Inflectional Language
...19Navanath Saharia, Utpal Sharma, and Jugal Kalita
Behavior of Word ‘kaa’ in Urdu Language
...23Muhammad Kamran Malik, Aasim Ali, and Shahid Siddiq
Methods to Divide Uygur Morphemes and Treatments for Exceptions
...27Pu Li and Hao Zhao
Rules for Morphological Analysis of Bangla Verbs for Universal
Networking Language
...31Md. Nawab Yousuf Ali, Mohammad Zakir Hossain Sarker, Ghulam Farooque Ahmed, and Jugal Krishna Das
Discussion on Collation of Tibetan Syllable
...35 Heming Huang and Feipeng DaA Dictionary Mechanism for Chinese Word Segmentation Based on
the Finite Automata
...39 Wu Yang, Liyun Ren, and Rong TangDevelopment of Templates for Dictionary Entries of Bangla Roots
and Primary Suffixes for Universal Networking Language
...43 Md. Zakir Hossain, Shaikh Muhammad Allayear, Md. Nawab Yousuf Ali,and Jugal Krishna Das
A Study on "Worry" Separable Words & Its Separable Slots
...47 Chunling Li and Xiaoxiao WangSyntax and Parsing
Improving Dependency Parsing Using Punctuation
...53 Zhenghua Li, Wanxiang Che, and Ting LiuA Tree Probability Generation Using VB-EM for Thai PGLR Parser
...57 Kanokorn Trakultaweekoon, Taneth Ruangrajitpakorn, Prachya Boonkwan,and Thepchai Supnithi
Research on Verb Subcategorization-Based Syntactic Parsing Postprocess
for Chinese Language
...61 Jinyong Wang and Xiwu HanIdentification of Maximal-Length Noun Phrases Based on Maximal-Length
Preposition Phrases in Chinese
...65 Guiping Zhang, Wenjing Lang, Qiaoli Zhou, and Dongfeng CaiUrdu Noun Phrase Chunking - Hybrid Approach
...69 Shahid Siddiq, Sarmad Hussain, Aasim Ali, Kamran Malik, and Wajid AliThe Function of Fixed Word Combination in Chinese Chunk Parsing
...73 Liqun Wang and Shoichi YokoyamaProblems and Review of Statistical Parsing Language Model
...77 Faguo Zhou, Fan Zhang, and Bingru YangA General Comparison on Sentences Analysis and Its Teaching
Significance between Traditional and Structural Grammars
...81 Jiaying YuSemantics
Two Cores in Chinese Negation System: A Corpus-Based View
...87 Hio Tong Chan and Chunyu KitFinding Semantic Similarity in Vietnamese
...91 Dat Tien Nguyen and Son Bao PhamAutomatic Metaphor Recognition Based on Semantic Relation Patterns
...95 Xuri Tang, Weiguang Qu, Xiaohe Chen, and Shiwen YuEvent Entailment Extraction Based on EM Iteration
...101 Zhen Li, Hanjing Li, Mo Yu, Tiejun Zhao, and Sheng LiOn the Semantic Orientation and Computer Identification of the Adverb
“Jiù”
...105 Lin He and Jiaqin WuSemantic Genes and the Formalized Representation of Lexical Meaning
...110 Dan HuAcquisition of Hypernymy-Hyponymy Relation between Nouns
for WordNet Building
...114 Gunawan and Erick PranataAlgorithm for Conversion of Bangla Sentence to Universal Networking
Language
...118 Md. Nawab Yousuf Ali, M. Ameer Ali, Abu Mohammad Nurannabi,and Jugal Krishna Das
Construction of the Paradigmatic Semantic Network Based on Cognition
...122 Xiaofang OuyangThe Research of Sentence Testing Based on HNC Analysis System
of Sentence Category
...126 Zhiying LiuSemantic Patterns of Chinese Post-Modified V+N Phrases
...130 Likun Qiu and Wenxian ZhangInformation Extraction
A Grammar-Based Unsupervised Method of Mining Volitive Words
...137 Jianfeng Zhang, Yu Hong, Yuehui Yang, Jianmin Yao, and Qiaoming ZhuUsing Feature Selection to Speed Up Online SVM Based Spam Filtering
...142 Yuewu Shen, Guanglu Sun, Haoliang Qi, and Xiaoning HeA Semi-supervised Method for Classification of Semantic Relation
between Nominals
...146 Yuan Chen, Yue Lu, Man Lan, Jian Su, and Zhengyu NiuXPath-Wrapper Induction for Data Extraction
...150 Nam-Khanh Tran, Kim-Cuong Pham, and Quang-Thuy HaA Block Segmentation Based Approach for Web Information Extraction
...154 Chanwei Wang, Chengjie Sun, Lei Lin, and Xiaolong WangLinguistic Features for Named Entity Recognition Using CRFs
...158 R. Vijay Sundar Ram, A. Akilandeswari, and Sobha Lalitha DeviResearch on Domain-Adaptive Transfer Learning Method and Its
Applications
...162 Geli Fei and Dequan ZhengInformation Theory Based Feature Valuing for Logistic Regression
for Spam Filtering
...166 Haoliang Qi, Xiaoning He, Yong Han, Muyun Yang, and Sheng LiAutomatic Named Entity Set Expansion Using Semantic Rules
and Wrappers for Unary Relations
...170 Mai-Vu Tran, Tien-Tung Nguyen, Thanh-Son Nguyen, and Hoang-Quynh LeAnaphora Resolution of Malay Text: Issues and Proposed Solution Model
...174 Noorhuzaimi Karimah Mohd Noor, Shahrul Azman Noah, Mohd Juzaidin Ab. Aziz,and Mohd Pouzi Hamzah
Combining Multi-features with Conditional Random Fields for Person
Recognition
...178 Suxiang ZhangComparison between Typical Discriminative Learning Model
and Generative Model in Chinese Short Messages Service Spam Filtering
...182 Xiaoxia Zheng, Chao Liu, Chengzhe Huang, Yu Zou, and Hongwei YuChinese Spam Filter Based on Relaxed Online Support Vector Machine
...185 Yong Han, Xiaoning He, Muyun Yang, Haoliang Qi, and Chao SongComment Target Extraction Based on Conditional Random Field &
Domain Ontology
...189 Shengchun Ding and Ting JiangText Understanding and Summarization
Topic-Driven Multi-document Summarization
...195 Hongling Wang and Guodong ZhouMultiple Factors-Based Opinion Retrieval and Coarse-to-Fine Sentiment
Classification
...199 Shu Zhang, Wenjie Jia, Yingju Xia, Yao Meng, and Hao YuChinese Sentence-Level Sentiment Classification Based on Sentiment
Morphemes
...203 Xin Wang and Guohong FuExtracting Phrases in Vietnamese Document for Summary Generation
...207 Huong Thanh Le, Rathany Chan Sam, and Phuc Trong NguyenUser Interest Analysis with Hidden Topic in News Recommendation
System
...211 Mai-Vu Tran, Xuan-Tu Tran, and Huy-Long UongDependency Tree-Based Anaphoricity Determination for Coreference
Resolution
...215 Fang Kong, Jianmei Zhou, Guodong Zhou, and Qiaoming ZhuText Clustering Based on Domain Ontology and Latent Semantic Analysis
...219 Yaxiong Li, Jianqiang Zhang, and Dan HuSocial Network Mining Based on Wikipedia
...223 Fangfang Yang, Zhiming Xu, Sheng Li, and Zhikai XuRetrospective Labels in Chinese Argumentative Discourses
...227 Donghong LiuImprove Search by Optimization or Personalization, A Case Study in Sogou
Log
...231 Jingbin Gao, Muyun Yang, Sheng Li, Tiejun Zhao, and Haoliang QiMachine Translation
Conditional Random Fields for Machine Translation System Combination
...237 Tian Xia, Shandian Zhe, and Qun LiuA Method of Automatic Translation of Words of Multiple Affixes
in Scientific Literature
...241 Lei Wang, Baobao Chang, and Janet HarknessHierarchical Pitman-Yor Language Model for Machine Translation
...245 Tsuyoshi Okita and Andy WayTraining MT Model Using Structural SVM
...249 Tiansang Du and Baobao ChangEnglish-Hindi Automatic Word Alignment with Scarce Resources
...253 Eknath Venkataramani and Deepa GuptaSentence Similarity-Based Source Context Modelling in PBSMT
...257 Rejwanul Haque, Sudip Kumar Naskar, Andy Way, Marta R. Costa-jussà,and Rafael E. Banchs
Verb Transfer in a Tamil to Hindi Machine Translation System
...261 Sobha Lalitha Devi, Pravin Pralayankar, S. Menaka, T. Bakiyavathi,R. Vijay Sundar Ram, and V. Kavitha
Lexical Gap in English - Vietnamese Machine Translation: What to Do?
...265 Le Manh Hai and Phan Thi TuoiNominal Transfer from Tamil to Hindi
...270 Sobha Lalitha Devi, V. Kavitha, Pravin Pralayankar, S. Menaka, T. Bakiyavathi,and R. Vijay Sundar Ram
Language Resources
Building Thai FrameNet through a Combination Approach
...277 Dhanon Leenoi, Sawittree Jumpathong, and Thepchai SupnithiEvaluating the Quality of Web-Mined Bilingual Sentences Using Multiple
Linguistic Features
...281 Xiaohua Liu and Ming ZhouA Semi-Supervised Approach on Using Syntactic Prior Knowledge
for Construction Thai Treebank
...285 Taneth Ruangrajitpakorn, Prachya Boonkwan, Thepchai Supnithi,and Phiradet Bangcharoensap
A Proposed Model for Constructing a Yami WordNet
...289 Meng-Chien Yang, D. Victoria Rau, and Ann Hui-Huan ChangAnnotation Guidelines for Hindi-English Word Alignment
...293 Rahul Kumar Yadav and Deepa GuptaBuilding Synsets for Indonesian WordNet with Monolingual Lexical
Resources
...297 Gunawan and Andy SaputraA Study of Unique Words in Hawks’ Translation of Hong Lou Meng
in Comparison with Yang’s Translation
...301 Yunfang Liang, Lixin Wang, and Dan YangKazakh Noun Phrase Extraction Based on N-gram and Rules
...305 Gulila Altenbek and Ruina SunSpoken Language Processing
Feature Smoothing and Frame Reduction for Speaker Recognition
...311 Santi Nuratch, Panuthat Boonpramuk, and Chai WutiwiwatchaiImproved Cantonese Tone Recognition with Approximated F0 Contour:
Implications for Cochlear Implants
...315 Meng Yuan, Haihong Feng, and Tan LeeCombining Sub-bands SNR on Cochlear Model for Voice Activity
Detection
...319 Qibo Liu, Yi Liu, and Yanjie LiPrecedence of Emotional Features in Emotional Prosody Processing:
Behavioral and ERP Evidence
...323 Xuhai Chen and Yufang YangAcoustic Space of Vowels with Different Tones: Case of Thai Language
...327 Vaishna Narang, Deepshikha Misra, Ritu Yadav, and Sulaganya PunyayodhinA Study of F1 Correlation with F0 in a Tone Language: Case of Thai
...330 Sulaganya Punyayodhin, Deepshikha Misra, Ritu Yadav, and Vaishna NarangA Contrastive Study of F3 Correlation with F2 and F1 in Thai and Hindi
...334 Ritu Yadav, Deepshikha Misra, Sulaganya Punyayodhin, and Vaishna NarangDurational Contrast and Centralization of Vowels in Hindi and Thai
...339 Deepshikha Misra, Ritu Yadav, Sulaganya Punyayodhin, and Vaishna NarangA Study in Comparing Acoustic Space: Korean and Hindi Vowels
...343 Hyunkyung Lee and Vaishna NarangAuthor Index
...347Acquisition of Hypernymy-Hyponymy Relation
between Nouns for WordNet Building
Gunawan*
,**
)and Erick Pranata**)
*) Dept. of Electrical Engineering Faculty of Industrial Technology Institut Teknologi Sepuluh Nopember
Surabaya, East Java, Indonesia **) Dept. of Computer Science Sekolah Tinggi Teknik Surabaya
Surabaya, East Java, Indonesia [email protected], [email protected]
Abstract—Automatic extraction of hypernym-hyponym pairs has been done in many researches. But none is described as an automatic method to incorporate the result to WordNet or on WordNet building. This paper proposes a method to automatically acquire hypernym-hyponym pairs for WordNet building by utilizing a monolingual dictionary and Lesk Word Sense Disambiguation or Lesk WSD to deliver tagged pairs. This method is implemented on an Indonesian monolingual dictionary and produces 70% accuracy.
Keywords-WordNet; Hypernymy; Hyponymy; WSD; Dictionary
I. INTRODUCTION
WordNet [1] is a lexical reference system which was first built in 1985 by Princeton University, known as Princeton WordNet, and until now it’s already in its 3.0 version. WordNet building is a resource and time consuming process in which this process was done seriously by Princeton University and produced a reliable lexical reference system. Many attempts were done to automatically or semi-automatically build WordNet for other languages than English such as researches done by Barbu et al. [2], Lee et al. [3], Elkateb et al. [4], Putra et al. [5], and many more.
WordNet can be built in various methods, whether by expanding existing initial WordNet data, or merging existing data. Acquisition of hypernymy-hyponymy relation is an instance of the latter method. Many attempts were done to acquire hypernymy-hyponymy relation, e.g. Hearst [6], Sombatsrisomboon et al. [7], and Costa et al. [8], but none of the research exposes a method to automatically incorporate the result acquired to an already sense-distinguished data or WordNet. This paper proposes a method to automatically acquire hypernymy-hyponymy relation from Kamus Besar Bahasa Indonesia or KBBI (Indonesian monolingual dictionary) along with the definition for each lemma constructing the relation to distinguish the sense.
The input which is used as the acquisition source is described in section 2. The strategy used to utilize input data to acquire hypernymy-hyponymy relation along with the
definitions is described in section 3. The result of the approach is then described in section 4, followed by the incorporation in section 5 and further researches in section 6.
II. KAMUS BESAR BAHASA INDONESIA
The input data used in this paper is KBBI [9], the most standard dictionary for Bahasa Indonesia. KBBI was first published in 1988 and kept being improved until the 4th edition in 2008. This dictionary becomes the chosen input data because of the credibility of the producer, which is the Language Center of Indonesia. The editions were improving for every edition, whether in the amount of lemmas, or in the structure.
KBBI contains records of lemma, part-of-speech, definition, examples in sentences, and proverbs. But in the acquisition process, only lemma, part-of-speech, and definition which are taken, as shown in Fig. 1. This decision is done, considering that only those three elements are related to WordNet structure and WSD algorithm. These elements then can be used whether for the acquisition source or the Lesk WSD source where the latter topic is described in detail in section 3.
Figure 1. Example of Different Sense in KBBI
Lemma papan (board) and lemma papan atas (high class) are lemmas which are given in the Fig. 1 and have their own definitions, where the first lemma contains two definitions which means lemma papan has two senses. The KBBI structure where every record contains lemmas, and every lemma contains definitions, implies that the iteration on the acquisition will be done for every lemma and every definition. Therefore, the objective of the acquisition is to find hypernym, which consists of lemma, part-of-speech, and definition, for every
Papan n
1 kayu (besi, batu, dsb) yg lebar dan tipis (broad and thin wood (iron, rock, etc))
2 tempat tinggal; rumah (place to stay; house) Papan atas n
lemma in KBBI which is delivered in records, where the records are denoted as hyponyms which also consists of lemma, part-of-speech, and definition.
KBBI which is used in the hypernymy-hyponymy acquisition on Bahasa Indonesia is KBBI in its 3rd edition, where this version is available in HTML-like format, where lemmas, and sense numbers are indicated in bold, and part-of-speech is indicated in italic. These tags can be used to extract KBBI into records of fields consisting of lemma, part-of-speech, and definition, where the example of KBBI raw data is shown in Fig. 2. The 4th edition of KBBI cannot be used because it is still not available in machine readable format.
Figure 2. Tagged KBBI Raw Data
Tags in KBBI raw data holds the biggest part in the extraction process. Look at the <br> tag. This tag separates lemmas in canonical (e.g. sakit (sick)), derived (e.g. penyakit
(illness)), or compound form (e.g. rumah sakit (hospital)). Inconsistency that appears in this format, where there are several records without this tag, would decrease the performance of the extraction, which is an error in the output. The percentage of the error cannot be calculated precisely for it needs thorough analysis for every record extracted. The result of the extraction is structured KBBI records.
III. ACQUISITION STRATEGY
Acquiring hypernym-hyponym pairs from KBBI is done by several processes. The first process is to disambiguate every word in the definition. The process is intended to find the appropriate part-of-speech and definition for every word in definition. Thus, the result from the first process is used in the second process where the definition is refined so that only the part of the definition which contains the information of hypernym of a lemma is taken. The last process is to acquire hypernym from the simplified definition. The overall process of these processes is described in Fig. 3.
Figure 3. Overall Hypernym-Hyponym pairs Acquisition Process
A. Lesk Algorithm
A simple WSD algorithm used in this paper is Lesk algorithm [10]. This algorithm is applied considering the availability of lexical resources in Bahasa Indonesia, i.e. KBBI. KBBI is the appropriate lexical resource for this WSD, as the source itself contains lemma, part-of-speech, and definition which match the requirements of the algorithm.
The input for Lesk WSD is a sentence, and the output is a tagged definition, where the tags are part-of-speech and definition which is attached to every word in input definition. Thus, every word in the definition will have the proper part-of-speech and definition for the given definition. These elements can be illustrated in Fig. 4, where the sentence is taken from the first definition of papan (board).
Figure 4. Example of WSD’s input and output
Lemma bisa in Bahasa Indonesia generally has two meanings or senses. The first sense is be able to, and the second sense is poison. From Fig. 4, one can conclude that bisa
kayu (besi, batu, dsb) yg lebar dan tipis
kayu - n - bagian batang cabang dahan pokok keras biasa dipakai untuk bahan bangunan dsb (part of branch; hard material usually used as building material, etc.)
besi - n - logam keras kuat serta banyak sekali gunanya bahan pembuat senjata mesin ferum (strong and hard metal with many functions; material used to make weapon; ferum) batu - n - akik untuk mata cincin dsb (gemstone for rings) dsb - null - null
yg - null - null
lebar - a - lapang tidak sempit (spacious; not narrow) dan - p - penghubung satuan kata frasa klausa kalimat setara
termasuk tipe sama serta memiliki fungsi tidak berbeda (conjuction of phrase, clause, sentence with same type and function)
<b><sup>1</sup>ceng·kung</b><i>a</i> cekung (tt mata, pipi, dsb);<br>--<b> mengkung</b> sangat cekung
<b><sup>2</sup>ceng·kung</b><i>n</i> bunyi keras besar (spt bunyi anjing menyalak);<br>--<b> cengking</b> berbagai bunyi (spt bunyi anjing)
<b><sup>3</sup>ceng·kung</b>, <b>ber·ceng·kung</b> <i>v</i>
in the phrase bisa ular (snake poison) takes the latter sense of
bisa as the proper sense. The senses are provided in part-of-speech and definition which is more than enough to express sense of a lemma.
B. Definition Simplification
The tagged definition is then processed further. The process is done by analyzing the definition format delivered by KBBI. KBBI delivers every concept in the definition by dividing them by semicolon (;). This definition should be simplified by taking the first concept which doesn’t express synonymy, considering that KBBI may contain synonyms in its definitions.
Synonymy in definition can be identified by counting the word count in the concept taken, where a concept with less than three words will be identified as a synonym for the lemma. This decision is based on the analysis on every record in KBBI where concepts which contain one or two words always resemble synonym. Fig. 5 shows the example of concepts in definitions where blue-marked concepts express synonym.
Figure 5. Example of Synonym Concepts
Lemmas anjing (dog), udang (shrimp), and kamerad
(comrade) have implicit synonym on the definitions. But only
anjing and udang which are taken into consideration because the first concept of the lemmas doesn’t express synonymy. Therefore, lemma kamerad is disposed of from the acquisition process, while the first concept from the chosen lemmas is taken by splitting the definition on semicolon.
The results of this process are lemmas, with simplified definition which doesn’t express synonymy. Through this process, the next process will be easier, because the data processed are a lot smaller.
C. The Acquisition
Acquiring hypernym from the result of the previous process can be done by extracting the first noun phrase. The extraction utilizes the part-of-speech information from the tagged lemma formed from the Lesk WSD. The result from this extraction can be a canonical or derived word, or a compound form of word. But in this paper, only the first output used as the final result, as the latter result needs refinement on the definition.
Lemma abu (dust), as an example which is shown in Fig. 6, after being processed using Lesk WSD will produce tagged definition which can be used in acquisition process whereas from the example in Fig. 6, the first noun phrase is taken. Noun phrase is identified by taking sequenced nouns before lemma with part-of-speech p or null, where it will be then identified as hypernym for lemma abu. From the example in Fig. 6, one can
conclude that the hypernym for abu is sisa (remains). This process is then done through every KBBI record to acquire every hypernym existing in KBBI definitions for the given lemma.
Figure 6. Example of Acquisition Input
The results of this process are hypernym-hyponym pairs where each lemma, whether it is hypernym or hyponym, is attached with proper part-of-speech and definition. This information then can be used in the incorporation process with WordNet or glossed synset, where in this process part-of-speech and definition hold the biggest part on determining the proper sense for hypernym and hyponym.
IV. RESULT
The method proposed in this paper successfully acquired 24,256 pairs from 54,395 possible pairs in 91029 records in KBBI, where the other possible pairs consist of compound forms, synonyms, and invalid pairs. Hypernym-hyponym pairs in compound forms can be acquired through a further process in defining the sense using WSD, while the other pairs cannot be considered as results, as they don’t express hypernymy.
Counting the accuracy is done by an Indonesian native speaker in two steps. The first step didn’t take the sense of hypernym and hyponym into account. Therefore, a pair scores if native speaker of Bahasa Indonesia accepts the pair as a valid hypernym-hyponym pairs without regard to each sense. This step produces 92% accuracy. The second step is done by taking account the sense of hypernym or hyponym. Therefore, a pair scores if native speaker of Bahasa Indonesia accepts the pair as a valid hypernym-hyponym pairs if it is a valid pairs with valid sense for each lemma constructing the pairs. From this step, 70% accuracy is produced. The result is satisfying, but it fully depends on the input data and the WSD algorithm used.
Several limitations that affect the implementation of the method proposed are the availability of lexical resource in fully machine readable format. KBBI is not delivered in a consistent format, which results in some errors on the KBBI extraction. The WSD algorithm used is also the simplest one, while the effort to implement more powerful algorithm is restricted by the limitation of the lexical resources existed.
abu n sisa yg tinggal setelah suatu barang mengalami pembakaran lengkap (remain that is left after a thing is fully burned)
sisa n apa tertinggal dimakan diambil lebihan saldo (things
which are left, eaten, taken; excessed balance)
yg null null
tinggal v sbg keterangan kata majemuk berarti didiami (as remark of compund which means inhabited)
setelah adv sesudah (after)
suatu num satu hanya satu untuk menyatakan benda kurang tentu (one; only one; to express uncertain object)
barang n semua perkakas rumah perhiasan dsb (every housing tool; jewelry)
mengalami v merasai menjalani menanggung suatu peristiwa dsb (feeling such as bearing an event)
pembakaran n tempat membakar bata genting kapur dsb (place to burn brick; roof tile; chalk)
lengkap a tidak ada kurangnya genap (not less; complete)
anjing - n - binatang menyusui yg biasa dipelihara untuk menjaga rumah, berburu, dsb; Canis familiaris; (mammal which is cared to guard houses or hunt, etc.)
udang - n - binatang tidak bertulang, hidup dl air, berkulit keras, berkaki sepuluh, berekor pendek, dan bersepit dua, pd kaki depannya; Crustacea; (invertebrate that live in the water, hard-skinned, has 10 legs, short tail)
V. INCORPORATION
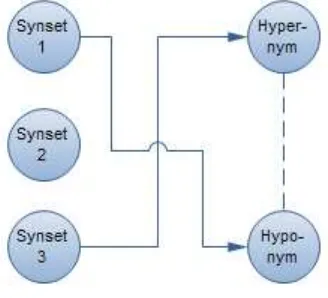
The results of the acquisition are tagged hypernym-hyponym pairs. The information provided in the pairs can be incorporated to WordNet which has already existed or a glossed synset. The technique used is word match similarity, where the main concept of this incorporation is finding the best synset for every hypernym and hyponym, so that the hypernymy-hyponymy relation can be incorporated to the synsets.
The incorporation, which is shown in Fig. 7, is done for every hypernym-hyponym pairs where the process is done first on hypernym and then hyponym for next process. The word match technique is done for every synset until the synset which matches with the hypernym or hyponym is found. The results from this process are pairs of synset which bear the hypernymy-hyponymy relation. Thus, these results can be denoted as the prototype of a simple WordNet.
Figure 7. Incorporation Process
In Bahasa Indonesia itself, the incorporation is done by implementing the results acquired, to collection of Bahasa Indonesia synsets, which is gloss-less, from the current research [11] done on Bahasa Indonesia. The gloss-less synset should be processed further so that every lemma that constructs the synset is glossed. Gaining the gloss can be done by using WSD, where the result of this process would be tagged synset, where every lemma which constructs the synset would have definition with only noun part-of-speech. The glossed Bahasa Indonesia synset then would be ready for incorporation.
VI. FURTHER RESEARCH
Hypernym-hyponym pairs acquired fully depend on KBBI, while in WordNet, there are some categories in the root area that need special attention. Since the method proposed is still not able to determine a proper synset to complete the upper categories in the root area, there should be research on automatically or semi-automatically construct the upper category synsets.
Being limited in lexical resources, there is also a challenge in implementation of a better WSD. The WSD method being used in this paper is Lesk WSD which only needs a dictionary for the implementation, which matches the availability of Bahasa Indonesia lexical resources.
Considering the availability of lexical resources, researches on building Bahasa Indonesia lexical resources are encouraged. The result can be used to improve the acquisition of hypernym-hyponym pairs, Word Sense Disambiguation, Language Translation, or other Natural Language Processing Tasks. This research should be also implemented on other Asian languages which still lack lexical resources, so that they can be used for tasks like this.
REFERENCES
[1] Christiane Fellbaum, “WordNet: An Electronic Lexical Database,” Cambridge, MA: MIT Press, 1998.
[2] Eduard Barbu, Verginica Barbu Mititelu, “Automatic building of Wordnets,” Proc. RANLP conference Borovets, Bulgaria, 2005. [3] Changki Lee, Gunbae Lee, Seo Jung Yun, “Automatic WordNet
mapping using word sense disambiguation,” Proc. of the 2000 Joint SIGDAT conference on empirical methods in natural language processing and very large corpora: held in conjunction with the 38th Annual Meeting of the Association for Computational Linguistics, vol. 13, pp. 142-147, Hongkong, 2000.
[4] Sabri Elkateb, William Black, Horacio Rodríguez, Musa Alkhalifa, Piek Vossen, Adam Pease, Christiane Fellbaum, “Building a WordNet for Arabic,” Proc. of the Fifth International conference on Language Resources and Evaluation, 2005.
[5] Desmond Darma Putra, Abdul Arfan, Ruli Manurung, “Building an Indonesian WordNet,” 2007.
[6] Marti A. Hearst, “Automatic acquisition of hyponyms from large text corpora,” Proc. of the 14th conference on Computational Linguistics, vol. 2, pp. 539-545, Nantes, France, 1992.
[7] Ratanachai Sombatsrisomboon, Yutaka Matsuo, Mitsuru Ishizuka, “Acquisition of hypernyms and hyponyms from the WWW,” 2003. [8] Rui P. Costa, Nuno Seco, “Hyponymy extraction and web search
behavior analysis based on query reformulation,” Proc. of the 11th Ibero-American conference on AI: Advances in Artificial Intelligence, pp. 332-341, Lisbon, Portugal, 2008.
[9] Tim Penyusun Kamus Pusat Bahasa Departemen Pendidikan Nasional, Kamus Bahasa Indonesia, 2008.
[10] Michael Lesk, “Automatic sense disambiguation using machine readable dictionaries: how to tell a pine cone from an ice cream cone,” Proc. of the 5th annual international conference on Systems documentation, pp. 24-26, Toronto, Ontario, Canada, 1986.