Segmentasi Nasabah Tabungan Menggunakan Model RFM
(
Recency, Frequency,Monetary
) dan
K-Means
Pada Lembaga Keuangan Mikro
Tikaridha Hardiani*), Selo Sulistyo**), Rudy Hartanto***) Teknik Elektro dan Teknologi Informasi, Universitas Gadjah Mada E-Mail: *[email protected], **[email protected], ***[email protected]
Abstrak
Persaingan yang ketat dalam lembaga keuangan, mengharuskan BMT (Baitul Maal Wat Tamwil) untuk mengelola nasabah secara maksimal. Mengetahui nasabah yang loyal akan membantu perusahaan menentukan strategi pemasaran yang tepat. Penelitian ini bertujuan untuk menentukan nasabah potensial, nasabah yang loyal kepada perusahaan. Nasabah potensial ditentukan dengan segmentasi nasabah. Studi kasus dalam penelitian ini yaitu di salah satu BMT di Yogyakarta. Metode yang digunakan yaitu CRISP DM (CRoss Industry Standard Process for Data Mining) dengan melalui proses business understanding, data understanding, data preparation, modeling dan evaluasi. Model yang digunakan untuk segmentasi yaitu RFM (Recency, Frequency dan Monetary) serta teknik data mining yaitu teknik clustering dengan algoritma K-Means. Software yang digunakan SPSS versi 22 untuk model RFM dan
Rapidminer 5.3. Hasil dari segmentasi ini membagi menjadi 3 cluster. Jumlah cluster
terbaik berdasarkan davies bouldin index. Cluster pertama terdiri dari 100 nasabah. RFM score antara 112-255 termasuk kelompok occational customer. Cluster ke dua terdiri dari 69 nasabah, memiliki RFM score antara 441-544 dan termasuk kelompok
superstar.Cluster ke tiga terdiri dari 79 nasabah, memilki RFM score antara 313-435 dan termasuk kelompok typical customer.
Kata kunci: segmentasi nasabah, RFM, K-Means, data mining, clustering, davies bouldin index
PENDAHULUAN
Setiap perusahaan dituntut untuk siap menghadapi persaingan yang semakin ketat dengan perusahaan lain. Fokus perusahaan modern telah berubah dari strategi yang mengutamakan produk (product/service oriented) menjadi strategi yang
mengutamakan pelanggan (customer
oriented)[1].
Dalam lembaga keuangan mikro,
nasabah yang berbeda mempunyai nilai yang berbeda pula. Salah satu tantangan yang
terpenting bagi perusahaan yaitu
pengetahuan tentang nasabah, memahami perbedaan nasabah, mengenali nasabah potensial sehingga nasabah loyal terhadap perusahaan [2]. BMT sulit mengenali nasabah yang loyal dan yang tidak. Dengan jumlah nasabah yang lebih dari dari 50.000 membuat perusahaan kesulitan untuk mengelompokkan nasabah secara manual.
Dengan menerapkan strategi Customer Relationship Management (CRM),
perusahaan dapat mengenali karakteristik nasabah dengan segmentasi nasabah. Manfaat
segmentasi nasabah yaitu mengetahui
perilaku nasabah dan menerapkan strategi marketing atau pemasaran yang tepat
sehingga perusahaan mendapatkan
keuntungan[3]. Segmentasi nasabah dalam penelitian ini menggunakan model RFM
(Recency, Frequency, Monetary). Model RFM merupakan model yang membedakan pelanggan penting dari data yang besar oleh tiga variabel yaitu recency, frequency dan
monetary.
Teknik data mining untuk segmentasi nasabah yaitu teknik clustering. Algoritma yang digunakan pada clustering yaitu K-Means. Data transaksi nasabah dianalisis
menggunakan model RFM lalu
dikelompokkan dengan algoritma K-Means. Penentuan jumlah cluster yang paling optimal menggunakan davies bouldin index.
Dalam paper ini dijelaskan lebih lanjut mengenai tinjauan pustaka pada bagian 2,
metode penelitian pada bagian 3 dan kesimpulan pada bagian 4.
TINJAUAN PUSTAKA
2.1 Customer Relationship Management
(CRM)
CRM adalah filosofi operasi bisnis untuk memperoleh dan mempertahankan pelanggan, meningkatkan nilai pelanggan, loyalitas dan retensi, dan menerapkan strategi
customer-centric. CRM, dikhususkan untuk meningkatkan hubungan dengan pelanggan, berfokus pada gambaran yang komprehensif tentang bagaimana untuk mengintegrasikan nilai pelanggan, persyaratan, harapan dan perilaku melalui analisa data dari transaksi
pelanggan[5]. Perusahaan dapat
memperpendek siklus penjualan dan
meningkatkan loyalitas pelanggan serta menambah pendapatan dengan CRM yang baik.
2.2 Model RFM (Recency, Frequency, Monetary)
Model RFM adalah model berbasis perilaku digunakan untuk menganalisis perilaku pelanggan dan kemudian membuat prediksi berdasarkan perilaku database[6]. Model RFM ini merupakan metode yang sudah lama dan populer untuk mengukur hubungan dengan pelanggan[7]. Definisi model RFM [4]: Recency yaitu kapan terakhir transaksi dilakukan. Frequency yaitu jumlah transaksi yang dilakukan pelanggan. Misalkan, dua kali dalam setahun atau tiga kali dalam satu bulan.Dan monetary ialah besarnya nilai transaksi yang dilakukan.
Nilai recency, frequency, monetary
dibagi menjadi lima bagian dengan nilai 5, 4, 3, 2 dan 1. Nilai recency dihitung berdasarkan tanggal transaksi terakhir atau interval waktu transaksi terakhir dengan saat ini. Nasabah dengan tanggal transaksi terbaru mempunyai nilai 5 sedangkan nasabah dengan tanggal transaksi terjauh di masa lalu mempunyai nilai 1. Begitu juga dengan nilai
frequency, nasabah yang sering bertransaksi mempunyai nilai frequency yang tinggi, yaitu
5. Sedangkan nasabah yang jarang
bertransaksi mempunyai nilai 1. Nasabah yang mempunyai saldo simpanan yang banyak mempunyai nilai monetary yang tinggi, dengan nilai 5. Sebaliknya nasabah yang mempunyai saldo simpanan yang kecil mempunyai nilai monetary yang rendah yaitu
1 [8][9][4]. Penghitungan RFM score pada SPSS yaitu[8]:
RFM score = (nilai Recency x 100)+(nilai Frequency x 0)+nilai monetary (1)
Terdapat 125 (5x5x5) kombinasi RFM score. RFM score tertinggi 555 dan yang terendah 111. Nasabah dengan score 555 merupakan nasabah yang dengan tingkat keloyalan yang tinggi sedangkan nasabah dengan score 111 merupakan nasabah dengan tingkat keloyalan yang rendah.
2.3 Segmentasi Pelanggan
Segmentasi adalah proses membagi pelanggan menjadi beberapa cluster dengan
kategori loyalitas pelanggan untuk
membangun strategi pemasaran. Segmentasi pelanggan dibagi menjadi 6 karakteristik berdasarkan nilai RFM[10][11] sebagai berikut:
Tabel 1. Karakter Pelanggan Berdasarkan Nilai RFM
Kelas pelanggan
Karakteristik
Superstar a. Pelanggan dengan loyalti yang tinggi. b. Mempunyai nilai monetary yang tinggi. c. Mempunyai frekuensi yang tinggi. d. Mempunyai transaksi paling tinggi. Golden customer a. Mempunyai nilai monetary tertinggi yang ke dua. b. Frekuensi yang tinggi. c. Mempunyai rata-rata transaksi. Typical customer
Mempunyai rata-rata nilai
monetary dan rata-rata transaksi. Occational customer a. Nilai monetary terendah kedua setelah dormant customer. b. Nilai recency paling rendah.
c. Transaksi paling tinggi. Everyday shopper a. Memiliki peningkatan transaksi. b. Transaksi yang rendah. c. Mempunyai nilai monetary sedang sampai rendah Dormant customer a. Mempunyai frekuensi dan monetary yang paling rendah.
b. Nilai recency yang paling rendah. 2.4 Algoritma K-Means
K-means adalah salah satu algoritma yang terkenal untuk clustering dan telah digunakan secara luas di berbagai bidang termasuk data mining, data statistik, analisis dan aplikasi bisnis lainnya[4]. Penelitian ini
mengusulkan algoritma K-Means
membangun cluster dengan atribut R-F-M. Langkah-langkah algoritma K-Means[4]: 1. Menentukan jumlah cluster k
2. Inisialisasi k pusat cluster ini bisa dilakukan dengan berbagai cara. Namun yang paling sering dilakukan adalah dengan cara random. Pusat-pusat cluster diberi nilai awal dengan angka-angka
random.
3. Memasukkan setiap item dataset yang jaraknya paling dekat dengan nilai
centroid ke dalam centroid cluster
tersebut..
4. Menghitung rata-rata nilai item dalam setiap cluster untuk dijadikan sebagai
centroid yang baru.
5. Melakukan pengulangan langkah 2 dan langkah 3 hingga nilai centroid sama dengan nilai rata-rata item dalam
cluster.
Perhitungan jarak antar titik dengan menggunakan euclidean distance. Formula
euclidean distance:
d(p,q) = (2)
METODE PENELITIAN
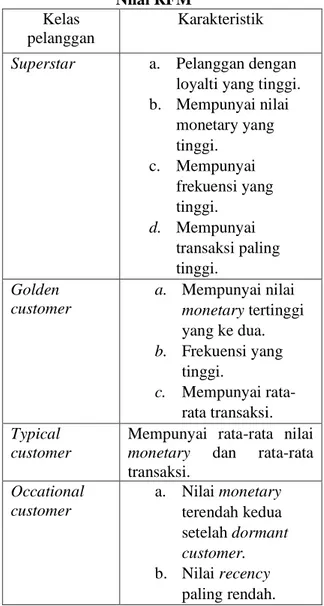
Metode yang digunakan yaitu CRISP-DM (CRoss Industry Standard Process for Data Mining). Ada 6 tahap pada CRISP-DM, yaitu[12]:
1. Business Understanding
Memahami tujuan dan kebutuhan dalam lingkup bisnis atau unit penelitian, menerjemahkan pengetahuan ini ke dalam permasalahan data mining.
2. Data Understanding
Mengumpulkan data, jika data berasal dari lebih dari satu database maka dilakukan proses integrasi data. Selanjutnya memahami data, mengidentifikasi kualitas data, memeriksa data dan membersihkan data yang tidak valid atau proses data cleaning.
3. Data Preparation
Pada tahap ini, mengumpulkan data yang akan digunakan untuk tahap selanjutnya atau proses data selection. Memilih variabel yang akan dianalisis, menyiapkan data awal sehingga siap untuk pemodelan atau data transformation.
4. Modelling
Tahap ini meliputi pemilihan dan penerapan berbagai teknik permodelan untuk mendapatkan nilai yang optimal. Ada beberapa teknik berbeda yang diterapkan untuk masalah data mining yang sama dan
ada pula teknik pemodelan yang
membutuhkan format data khusus.
5. Evaluation
Menetapkan apakah model terebut sudah sesuai dengan tujuan pada tahap awal
(business understanding).
6. Deployment
Dalam tahap ini pengetahuan atau
informasi yang telah diperoleh
dipresentasikan.
Gambar 1. Siklus proses CRISP-DM Sumber: Wikipedia [13]
4. PEMBAHASAN
4.1. Business UnderstandingStudi kasus penelitian ini dilakukan di salah satu BMT (Baitul Maal Wat Tamwil) di Yogyakarta. BMT XYZ berdiri tahun 1994, memiliki total nasabah sebesar 52.011. BMT XYZ melayani simpanan dan pembiayaan. Pemahaman terhadap tujuan bisnis dalam
penelitian ini meningkatkan dan
mempertahankan jumlah nasabah terutama nasabah potensial.
Menerjemahkan tujuan bisnis ke dalam tujuan data mining dalam penelitian ini ialah
customer segmentation dapat digunakan oleh
pihak manajemen untuk menemukan
segmen-segmen nasabah yang bertujuan untuk membangun profil nasabah yang terkait dengan sejarah simpanan nasabah dan menentukan pemasaran yang tepat pada setiap segmen yang terbentuk.
4.2. Data Understanding
Penelitian ini menggunakan data
transaksi simpanan dari Januari 2013-Juli 2015. Data diambil dari database BMT dengan formalt xls. Jumlah data transaksi terdiri dari 248 nasabah. Data transaksi simpanan yang digunakan dibatasi transaksi nasabah setor atau menyetor uang dan tarik atau mengambil uang.
4.3. Data Preparation
Persiapan data merupakan salah satu aspek yang paling penting dan sering memakan waktu proyek data mining. Fase ini terdiri dari reduksi data, seleksi fitur dan
data transformation[2]. Segmentasi nasabah ini berdasarkan model RFM, maka seleksi fitur dari model RFM yaitu tanggal terakhir transaksi, jumlah transaksi nasabah dan jumlah saldo nasabah. Tabel 2 menjelaskan hasil dari seleksi fitur.
Tabel 2. Hasil seleksi fitur Data awal Data akhir Tanggal terakhir
transaksi (tipe:date)
Recency
(type:number)
Jumlah transaksi Frequency
Jumlah saldo Monetary
Langkah selanjutnya yaitu data
transformation. Pada data transformation
dilakukan normalisasi. Normalisasi adalah proses transformasi dimana sebuah atribut numerik diskalakan dalam jarak yang lebih kecil seperti -1 sampai 1, atau 0 sampai
1[14]. Normalisasi dilakukan agar skala dari data tidak terlalu jauh. Ada beberapa
metode/teknik yang diterapkan untuk
normalisasi data, salah satunya yaitu normalisasi z score. Disebut juga zero-mean normalization, dimana nilai dari sebuah atribut A dinormalisasi berdasarkan nilai rata-rata dan standar deviasi dari atribut A. Sebuah nilai v dari atribut A dinormalisasi menjadi v' [14]:
(3) adalah nilai rata-rata dan adalah standar deviasi dari atribut A
Normalisasi z score dan penentuan RFM
score pada data transaksi simpanan menggunakan software SPSS.
4.4. Modelling
Teknik data mining yang digunakan yaitu clustering, dengan algoritma K-Means. Dalam K-Means jumlah cluster harus ditentukan oleh pengambil keputusan. Untuk mengidentifikasi k optimal, berbagai pengujian dapat digunakan. Dalam penelitian ini, menggunakan davies bouldin index[14]:
DB = (4)
D (i,j) = minx€Si,y€Sj dist (x,y) (5)
∆(i) = maxx, y€Si dist(x,y) (6)
∆(j) = maxx, y€Sj dist(x,y) (7)
Nilai davies bouldin index yang kecil merupakan jumlah cluster yang baik[15]. Semakin kecil nilai davies boulden index
semakin optimal hasil cluster.
Proses clustering dan pengujian davies bouldin index menggunakan framework rapidminer 5.3. Dari hasil clustering yang dilakukan, seperti yang ditunjukkan di tabel 3 didapatkan jumlah cluster 3 yang paling baik. Hal ini disebabkan nilai davies bouldin index
pada 3 cluster menunjukkan yang paling kecil[15][16]. Nilai negatif yang tinggi menunjukkan kinerja yang baik dari indeks [16].
Tabel 3. Perbandingan Hasil Pengujian
Davies Bouldin Index
Jumlah cluster Davies Bouldin
Index 2 -0.505 3 -0.535 4 -0.459 5 -0.248 6 -0.323 7 -0.376 8 -0.444 9 -0.447 10 -0.476
Tabel 4. Hasil Segmentasi Berdasarkan RFM Clust er Jumlah nasabah Avg R Avg F Avg M RFM score C1 100 1.505 2.97 0 3.009 112-255 C2 69 4.710 3.46 4 2.630 441-544 C3 79 3.383 2.63 0 3.049 313-435
Pada tabel 4 dan gambar 2 dijelaskan
cluster pertama terdiri dari 100 nasabah. RFM score antara 112-255 termasuk dalam
kelompok occational customer karena
memiliki recency yang paling rendah,
monetary dan frequency yang bagus. Cluster
ke dua terdiri dari 69 nasabah. RFM score
antara 441-544 termasuk dalam kelompok
superstar dengan loyalti yang tinggi. Cluster ke tiga terdiri dari 79 nasabah. RFM score
antara 313-435 termasuk kelompok typical customer karena memiliki rata-rata frequency
dan monetary.
4.5.Evaluation
Evaluasi dari model yang digunakan dengan pengujian davies bouldin index. Dari
pengujian tersebut dihasilkan
pengelompokan dengan 3 cluster mempunyai nilai davies boulden index yang paling kecil. Maka dari itu, nasabah dikelompokkan menjadi 3 cluster.
4.6. Deployment
Proses deployment belum dilakukan.
5.
KESIMPULAN
Fokus dari penelitian ini ialah segmentasi nasabah dengan studi kasus di BMT XYZ. Setelah dilakukan segmentasi, dihasilkan 3 cluster yang paling optimal. Pengujian jumlah cluster yang optimal, menggunakan davies bouldin index. Cluster
pertama terdiri dari 100 nasabah. RFM score
antara 112-255 termasuk kelompok
occational customer. Cluster ke dua terdiri dari 69 nasabah, memiliki RFM score antara 441-544 dan termasuk kelompok superstar. Cluster ke tiga terdiri dari 79 nasabah, memilki RFM score antara 313-435 dan termasuk kelompok typical customer. Hasil
segmentasi tersebut dapat digunakan BMT XYZ untuk menetukan strategi pemasaran yang tepat untuk setiap segmen.
6.
DAFTAR PUSTAKA
[1] Miguéis, V. L., Camanho, A. S., Cunha, João Falcão e., “Customer data mining for life style segmentation”,Expert Syst. Appl. 39(10): 9359-9366, 2012.
[2] K. Mahboubeh, J.T Mohammad,”
Estimating customer future value of different customer segments based on adapted RFM model in retail banking Gambar 2. Grafik hasil clustering
context”, Procedia Computer Science 31327–1332, 2011.
[3] A.S Reza, F. Ebrahim, “Customer Segmentation based on Modified RFM Model in the Insurance Industry”,
IPCSIT vol .25, 2012.
[4] Cheng, Ching-Hsue dan Chen, You-Shyang, “Classifiying the segmentation of customer value via RFM model and RS Theory”, Expert Systems with Applications 36, pp. 4176–4184, 2009. [5] Peppard, J, “Customer relationship
management(CRM) in financial
services”, European Management
Journal, 18(3),2000, pp. 312–327. [6] Hughes AM, “Boosting reponse with
RFM”, Mark. Tools, 5: 4-10
[7] Schijns, J. M. C., & Schroder, G. J,”Segment selection by relationship strength”, Journal of Direct Marketing, 10, pp. 69–79, 1996.
[8] Direct Marketing. URL:
http://www.cc.uoa.gr/fileadmin/cc.uoa.g r/uploads/files/manuals/SPSS22/IBM_S
PSS_Direct_Marketing.pdf, diakses
pada tanggal 2 September 2015
[9] Hosseini, Muhammad, M. Anahita,
“Cluster analysis using data mining approach to develop CRM methodology to assess the customer loyalty”, Expert Systems with Applications 37, pp.5259– 5264, 2010.
[10]Yuliari, Putri, Putra, Rusjayanti,
“Customer Segmentation Through
Fuzzy C-Means and Fuzzy RFM Method”, Journal of Theoretical and Applied Information Technology, vol. 78 No. 3, 2015.
[11]Tsiptsis Antonios Chorianopoulos, “Data Mining Techniques in CRM:
Inside Customer Segmentation”,
NewCaledonia: Antony Rowe Ltd, Chippenham, Wiltshire. 2009.
[12]Chapman, P., Clinton, J., Kerber, R., Khabaza, T., Reinartz, T., Shearer, C., Wirth, R, ”CRISP-DM 1.0 : Step-by-Step Data Mining Guide”,Edited by SPSS,2000.URL:http://www-
staff.it.uts.edu.au/~paulk/teaching/dmkd d/ass2/readings/methodology/CRISPWP -0800.pdf, diakses pada 2 September 2015.
[13]Wikipedia. URL:
www.en.wikipedia.org, diakses pada 1 September 2015
[14]Junaedi, Hartanto, Herman, Indra, “Data Transformasi pada Data Mining”, Konferensi Nasional “Inovasi dalam Desain dan Teknologi”, IDeaTech, 2011.
[15]Qiao, Haiyan, Brandon, “A Data Clustering Tool with Cluster Validity Indices”, International Conference on
Computing, Engineering and
Information IEEE, 2009.
[16]Thomas, Juan, “New Version of
Davies-Bouldin Index for Clustering
Validation Based on Cylindrical
![Gambar 1. Siklus proses CRISP-DM Sumber: Wikipedia [13]](https://thumb-ap.123doks.com/thumbv2/123dok/3753834.2461614/3.893.128.449.122.469/gambar-siklus-proses-crisp-dm-sumber-wikipedia.webp)