Fakultas Ilmu Komputer
Universitas Brawijaya
622
Klasifikasi Penyakit Diabetes menggunakan Metode Support Vector
Machine
Abu Wildan Mucholladin1, Fitra Abdurrachman Bachtiar2, Muhammad Tanzil Furqon3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Diabetes mellitus (DM) adalah penyakit kronis yang berhubungan dengan tingginya kadar gula atau glukosa dalam darah. Diabetes disebabkan oleh salah satu dari dua penyebab, yaitu reaksi autoimun (sistem pertahanan tubuh menyerang sel-sel yang memproduksi insulin) atau resistensi insulin (tubuh tidak sepenuhnya menanggapi insulin). Tujuan penelitian ini adalah membuat model machine learning yang dapat mendeteksi dini penyakit diabetes. Ada banyak cara untuk mendiagnosis diabetes, salah satu metodenya adalah menggunakan machine learning. Support Vector Machine (SVM) adalah salah satu metode machine learning yang dikenal cukup efektif untuk kasus klasifikasi. Dataset dibersihkan dan dinormalisasi terlebih dahulu sehingga siap untuk dimasukkan ke dalam model SVM. Model SVM diproses dan diuji sehingga mendapatkan model terbaik untuk melakukan diagnosis. Keluaran dari model SVM akan mendiagnosis pasien yang menderita diabetes ataupun yang tidak menderita diabetes. Model SVM dibagi menjadi dua jenis yaitu model benchmark yang diimplementasikan menggunakan algoritme Sequential Minimal Optimization (SMO) dan model scratch yang diimplementasikan menggunakan algoritme Sequential Learning. Masing-masing model dioptimasi menggunakan algoritme Grid Search sehingga dapat menemukan hyperparameters optimal yang dapat digunakan oleh model. Model yang sudah optimal diuji kembali pada beberapa metrik menggunakan 10-fold cross
validation. Hasil pengujian menunjukkan bahwa model benchmark memiliki nilai 0,87 mean accuracy,
0,82 mean precision, 0,78 mean sensitivity, dan 0,92 mean specificity. Model scratch memiliki nilai 0,78
mean accuracy, 0,69 mean precision, 0,59 mean sensitivity, dan 0,87 mean specificity. Hasil eksperimen
menunjukkan bahwa metode Support Vector Machine memiliki potensi untuk digunakan sebagai alat deteksi dini penyakit diabetes.
Kata kunci: klasifikasi, diabetes, Support Vector Machine, Sequential Learning
Abstract
Diabetes mellitus (DM) is a chronic disease associated with high levels of sugar or glucose in the blood. Diabetes is caused by one of two causes, autoimmune reactions (the body's defense system attacks insulin-producing cells) or insulin resistance (the body does not fully respond to insulin). The purpose of this research is to create a machine learning model that can detect diabetes early. There are many ways to diagnose diabetes, one of the methods is using machine learning. Support Vector Machine (SVM) is a machine learning method that is known to be quite effective for classification cases. The dataset is cleaned and normalized before so it can be ready to input in the SVM model. The SVM model is processed and tested in order to find the best model for making a diagnosis. The output of the SVM model will diagnose patients who suffer diabetes or not. The SVM model is divided into two types, the benchmark model which is implemented using the Sequential Minimal Optimization (SMO) algorithm and the scratch model which is implemented using the Sequential Learning algorithm. Each model is optimized using the Grid Search algorithm so that it can find optimal hyperparameters that can be used by the model. The optimal model is retested on several metrics using 10-fold cross validation. The test results show that the benchmark model has 0,87 mean accuracy, 0,82 mean precision, 0,78 mean sensitivity, and 0,92 mean specificity. The scratch model has 0,78 mean accuracy, 0,69 mean precision, 0,59 mean sensitivity, dan 0,87 mean specificity. The experimental results show that the Support Vector Machine method has the potential to be used as an early detection tool for diabetes.
Fakultas Ilmu Komputer, Universitas Brawijaya
1. PENDAHULUAN
Diabetes adalah salah satu masalah kesehatan utama di seluruh dunia. Ini adalah suatu kondisi ketika tubuh tidak cukup untuk menghasilkan atau menggunakan hormon insulin yang membawa glukosa ke dalam sel-sel tubuh dan memungkinkan glukosa untuk masuk dan menjadi bahan bakar mereka. Diabetes mellitus umumnya disebut sebagai "diabetes" yaitu penyakit kronis yang berhubungan dengan tingginya kadar glukosa (gula) dalam darah (Devi, Bai, & Nagarajan, 2019).
Penyakit diabetes ini merupakan penyakit yang cukup berbahaya. Komplikasi jangka panjang diabetes berkembang secara bertahap. Semakin lama orang menderita diabetes dan semakin tidak terkontrolnya gula darahnya, semakin tinggi risiko komplikasi. Akhirnya, komplikasi diabetes mungkin melumpuhkan atau bahkan mengancam jiwa. Kemungkinan komplikasi termasuk penyakit kardiovaskular, kerusakan pada saraf, ginjal, mata, kaki, kulit, pendengaran, dan bahkan dapat menyebabkan depresi (Mayo Clinic, 2018).
Pada tahun 2019, International Diabetes
Federation mempublikasikan penelitiannya mengenai jumlah penderita penyakit diabetes di seluruh dunia. Indonesia menempati peringkat ke-2 setelah China di wilayah pasifik barat dengan jumlah penderita 10,7 juta orang dari total populasi dewasa 172,2 juta. Itu artinya ada sekitar 6,2% orang dewasa di Indonesia menderita penyakit diabetes. Dari jumlah penderita tersebut, sebanyak 115,6 ribu orang meninggal. Itu artinya ada sekitar 1,1% dari total penderita diabetes meninggal dunia. Terdapat 73,7% orang yang belum terdiagnosis diabetes di Indonesia, artinya orang-orang tersebut memiliki peluang menderita penyakit diabetes.
Deteksi dini merupakan salah satu langkah preventif yang bisa dilakukan oleh penderita diabetes. Dalam banyak kasus, informasi awal yang terkait dengan penderita diabetes membantu dalam menghindari penyakit, penyembuhan dan pengobatan penyakit yang relevan. Banyak sistem komputer dibangun dengan menanamkan kecerdasan manusia yang berguna bagi para penderita dalam pengelolaan penyakit. Dalam implementasinya dapat diciptakan sebuah sistem berbasis kecerdasan buatan menggunakan metode machine learning seperti Support Vector Machine yang dapat ditanamkan pada aplikasi yang dirancang khusus
untuk diagnosis penyakit diabetes.
Penelitian yang dilakukan oleh (Devi, Bai, & Nagarajan, 2019) mencoba mendiagnosis penyakit diabetes menggunakan metode data
mining. Metode yang digunakan adalah Farthest First (FF) dan Sequential Minimal Optimization
Support Vector Machine (SMO-SVM).
Algoritme Farthest First digunakan untuk mengelompokkan data ke dalam sejumlah
cluster, keluaran pengelompokan diberikan
sebagai masukan untuk pengklasifikasi SVM. Ini akan mengklasifikasikan pasien menjadi diabetes dan non-diabetes. Dataset yang digunakan untuk diagnosis diabetes mencakup 768 sampel dari pasien diabetes yang diambil dari Pima Indians Dataset. Hasil percobaan menunjukkan bahwa pendekatan terpadu yang diusulkan mencapai akurasi klasifikasi 99,4% untuk memprediksi diabetes mellitus.
Penelitian mengenai penyakit diabetes juga dilakukan oleh (Sisodia & Sisodia, 2018) yang bertujuan untuk merancang model yang dapat memprediksi kemungkinan terjadinya diabetes pada pasien dengan ketelitian yang maksimal. Metode yang digunakan sebagai pengklasifikasi adalah Decision Tree, Support Vector Machine
dan Naive Bayes. Eksperimen dilakukan pada Pima Indians Diabetes Database (PIDD) yang
bersumber dari UCI machine learning repository. Hasil yang diperoleh menunjukkan
akurasi masing-masing algoritme adalah Naive
Bayes 76,30%, Support Vector Machine 65,10%, Decision Tree 73,82%.
Penelitian ini dilakukan atas dasar kekhawatiran dengan banyaknya orang yang terkena dampak negatif dari diabetes mellitus dengan angka kejadian yang terus meningkat. Sebagian besar pasien diabetes tidak menyadari risiko pra-diabetes yang mengarah pada penyakit yang sebenarnya. Dalam penelitian ini, tujuan utama penelitian ini adalah mengklasifikasi penyakit diabetes dengan metode machine
learning. Tantangan utama yang ingin diselesaikan dalam penelitian ini adalah meningkatkan akurasi model estimasi dan membuat model adaptif ke lebih dari satu
dataset. Tugas utama yang terkait dengan
penelitian ini adalah pengumpulan data, pra-pemrosesan data, dan pengembangan model klasifikasi. Dataset yang menjadi patokan terkait diabetes dalam penelitian ini diperoleh dari situs web Kaggle.
Fakultas Ilmu Komputer, Universitas Brawijaya
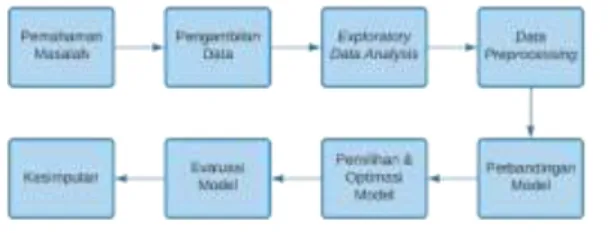
Gambar 2.1 Metodologi Penelitian
Metodologi penelitian ini secara umum digambarkan pada Gambar 2.1. Penelitian ini dimulai dengan memahami obyek masalah terlebih dahulu, kemudian mengambil data yang sesuai dengan kebutuhan masalah. Selanjutnya dilakukan proses exploratory data analysis, data
preprocessing, perbandingan model, pemilihan
& optimasi model, evaluasi model, dan terakhir pengambilan kesimpulan dari penelitian ini. 3. PENGAMBILAN DATA
Pengambilan data merupakan suatu aktivitas pencarian data yang akan diolah dan digunakan sebagai input dari machine learning. Pada penelitian ini, data didapatkan dari situs web Kaggle dengan nama Pima Indians
Diabetes Database. Dalam dataset ini, sampel
diambil dari populasi perempuan Pima Indian yang berada di dekat Phoenix, Arizona. Populasi tersebut telah diteliti secara terus menerus sejak tahun 1965 oleh National Institute of Diabetes
and Digestive and Kidney Diseases karena
tingginya angka kejadian diabetes (Smith, Everhart, Dickson, Knowler, & Johannes, 1988).
Dataset ini memiliki 9 atribut dan 768 sampel
dengan 268 sampel didiagnosis penyakit diabetes dan 500 sampel didiagnosis sehat dari penyakit diabetes. Berikut merupakan atribut yang ada di dalam dataset ini
Tabel 3.1 Atribut Dataset
No. Atribut Deskripsi Satuan Tipe
1 Pregnancies Number of
times pregnant times Numeric
2 Glucose Plasma Glucose Concentration at 2 Hours in an Oral Glucose Tolerance Test (GTT) mg/dL Numeric 3 Blood Pressure Diastolic Blood Pressure mm Hg Numeric 4 Skin Thickness Triceps Skin
Fold Thickness mm Numeric
5 Insulin 2-Hour Serum
Insulin µU/ml Numeric
6 BMI Body Mass
Index kg/m 2 Numeric 7 Diabetes Pedigree Function Diabetes Pedigree Function - Numeric
8 Age Age years Numeric
9 Outcome Diagnosis - Nominal
4. EXPLORATORY DATA ANALYSIS Exploratory Data Analysis merupakan
pendekatan yang digunakan untuk menganalisis kumpulan data agar mendapatkan pengetahuan dari dataset itu sendiri sehingga dapat memperkuat hipotesis awal yang mendukung penelitian. Analisis data yang dilakukan adalah seperti melihat sebaran titik data, melihat distribusi data, analisis univariate, melihat
skewness dan kurtosis masing-masing atribut,
dan melihat korelasi antar atribut. Analisis tersebut dilakukan dengan metode visual. Analisis ini juga berguna sebagai gambaran mengenai hal apa yang dapat dilakukan pada saat
data preprocessing.
Proses peninjauan penyebaran titik data merupakan salah satu proses exploratory data
analysis yang dilakukan dalam penelitian ini.
Proses tersebut melihat penyebaran titik data jika ditinjau menggunakan dua variabel, contohnya variabel glucose dan blood_pressure. Ditinjau dari dua variabel tersebut, kecenderungan seseorang terkena penyakit diabetes semakin besar ketika kedua nilai variabel juga besar. Penyebaran titik data juga cenderung mengumpul di tengah sehingga data ini tidak bisa dipisahkan secara linier. Pada kedua variabel juga memiliki nilai nol, ini merupakan anomali karena tidak mungkin nilai glucose dan
blood_pressure seseorang bernilai nol.
Pendekatan statistika juga dilakukan dalam proses exploratory data analysis, contohnya uji
skewness & kurtosis dan uji Pearson correlation.
Uji skewness & kurtosis digunakan untuk membuktikan tingkat kenormalan suatu distribusi data. Uji korelasi atribut menggunakan
Pearson correlation juga untuk memastikan
apakah terdapat korelasi antar atribut dataset. Proses exploratory data analysis yang dilakukan dalam penelitian ini menghasilkan pengetahuan bahwa masing-masing fitur masih belum terdistribusi secara normal sehingga perlu dilakukan normalisasi fitur. Terdapat beberapa fitur juga yang masih memiliki nilai skewness dan kurtosis yang tinggi sehingga menunjukkan bahwa masih ada fitur yang memiliki outlier.
Fakultas Ilmu Komputer, Universitas Brawijaya Fitur pregnancies juga dihapus karena tidak menjelaskan apakah pada saat disurvei seseorang sedang hamil atau tidak (informasi ini dibutuhkan untuk mendiagnosis diabetes gestasional) dan fitur ini juga berkorelasi kuat dengan fitur age sehingga dapat mengganggu proses pelatihan model.
5. DATA PREPROCESSING 5.1 Penanganan Anomali
Gambar 5.1 Deteksi Outlier
Grafik di atas menunjukkan bahwa masing-masing fitur memiliki outlier dan fitur insulin yang paling banyak memiliki outlier. Saat uji
kurtosis, fitur blood_pressure, insulin, bmi, dan
dpf memiliki nilai kurtosis yang cukup tinggi, ini menunjukkan fitur-fitur ini memang memiliki banyak outlier. Hal ini juga didukung dengan distribusi fitur-fitur ini yang memiliki ekor panjang. Oleh karena itu, perlu dilakukan pembersihan outlier dengan bantuan nilai IQR. Semua titik data yang memiliki nilai kurang dari (1,5 ∙ 𝐼𝑄𝑅) di bawah kuartil pertama atau lebih dari (1,5 ∙ 𝐼𝑄𝑅) di atas kuartil ketiga akan dihapus.
Gambar 5.2 Fitur-Fitur Anomali
Grafik di atas menunjukkan fitur-fitur yang memiliki anomali nilai nol. Artinya, fitur-fitur tersebut tidak seharusnya memiliki nilai nol. Pada saat proses pembersihan outlier, anomali nilai nol pada fitur glucose, blood_pressure, dan
bmi sudah ikut terhapus, namun tidak pada fitur
skin_thickness dan insulin. Untuk mengatasi hal
ini, maka perlu dilakukan imputasi fitur dengan nilai mediannya. Jadi semua nilai nol yang terkandung pada kedua fitur akan digantikan dengan nilai median masing-masing fitur. Nilai median dipilih sebagai pengganti nilai nol karena nilai median lebih kuat (robust) terhadap
outlier.
5.2 Penskalaan Fitur
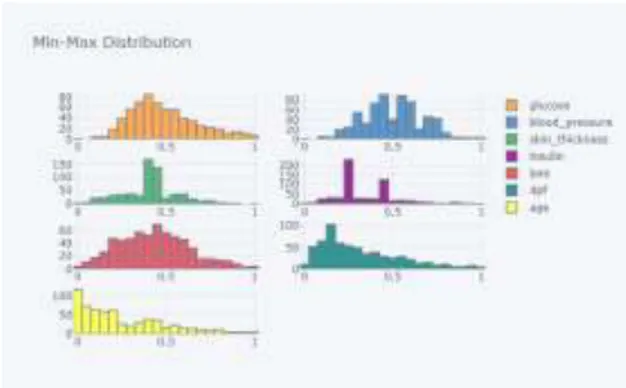
Gambar 5.3 Distribusi Min-Max
Pada penelitian ini, metode penskalaan fitur yang dipilih adalah metode min-max normalization. Alasan pemilihan metode ini
karena distribusi yang dihasilkan setelah pembersihan outlier dan anomali sudah cukup mendekati distribusi normal sehingga hanya perlu penskalaan ulang saja. Metode min-max
normalization merupakan metode penskalaan
ulang yang cukup sederhana dan cocok diterapkan dalam kasus ini. Pada grafik di atas juga menunjukkan bahwa distribusi data setelah diterapkan metode min-max normalization tidak mengubah distribusi sebelumnya secara signifikan dan masih tetap terlihat mendekati distribusi normal.
6. PERBANDINGAN MODEL
Gambar 6.1 Perbandingan Model
Fakultas Ilmu Komputer, Universitas Brawijaya menemukan model yang cocok digunakan dalam penelitian ini. Terdapat lima model yang diuji yaitu Naive Bayes (NB), K-Nearest Neighbor (KNN), Logistic Regression (LR), Support
Vector Machine (SVM), dan Multi Layer Perceptron (MLP). Masing-masing model diuji
nilai akurasinya pada data latih dan data uji. Pengujian model dilakukan menggunakan metode 10-fold cross validation. Hasil yang didapatkan menunjukkan bahwa model Support
Vector Machine memiliki performa yang paling
baik dibandingkan model yang lain baik dari segi akurasi pada data latih maupun data uji. Nilai akurasi yang didapatkan adalah 0,90 pada data latih dan 0,86 pada data uji. Oleh karena itu, model Support Vector Machine dipilih untuk digunakan dalam penelitian ini.
7. SUPPORT VECTOR MACHINE
Algoritme Support Vector Machine (SVM) ditemukan oleh Vladimir N. Vapnik dan Alexey Ya. Chervonenkis pada tahun 1963. Pada tahun 1992, Bernhard E. Boser, Isabelle M. Guyon dan Vladimir N. Vapnik mengusulkan cara untuk membuat nonlinear classifier dengan menerapkan trik kernel pada maximum-margin
hyperplanes (Boser, Guyon, & Vapnik, 1992).
Kemudian konsep standar SVM saat ini diajukan oleh Corinna Cortes dan Vapnik pada tahun 1993 dan diterbitkan pada tahun 1995 (Cortes & Vapnik, 1995).
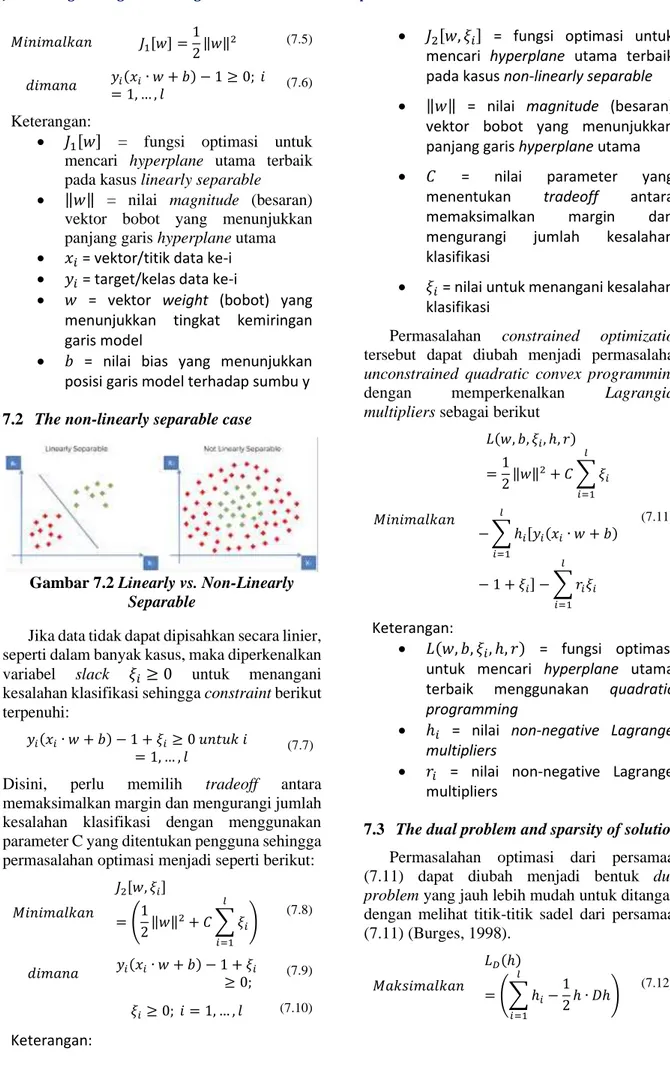
7.1 The linearly separable case
Gambar 7.1 Linear Hyperplane
Pertama, pertimbangkan kasus ketika data dapat dipisahkan secara linier. Masalah klasifikasi dapat dirumuskan kembali sebagai salah satu menemukan hyperplane 𝑓(𝑤, 𝑏) = 𝑥𝑖∙ 𝑤 + 𝑏 yang memisahkan sampel positif dan negatif:
𝑥𝑖∙ 𝑤 + 𝑏 ≥ 1 𝑢𝑛𝑡𝑢𝑘 𝑦𝑖= 1 (7.1)
𝑥𝑖∙ 𝑤 + 𝑏 ≤ 1 𝑢𝑛𝑡𝑢𝑘 𝑦𝑖= −1 (7.2)
ini setara dengan persamaan berikut
𝑦𝑖(𝑥𝑖∙ 𝑤 + 𝑏) − 1 ≥ 0 𝑢𝑛𝑡𝑢𝑘 𝑖 = 1, … , 𝑙 (7.3)
Keterangan:
• 𝑥𝑖 = vektor/titik data ke-i • 𝑦𝑖 = target/kelas data ke-i
• 𝑤 = vektor weight (bobot) yang menunjukkan tingkat kemiringan garis model
• 𝑏 = nilai bias yang menunjukkan posisi garis model terhadap sumbu y 𝑎 ∙ 𝑏 ≡ ∑ 𝑎𝑖 𝑖𝑏𝑖 menunjukkan dot product. Semua titik yang ada pada persamaan (7.1) terletak pada hyperplane 𝐻1∶ 𝑥𝑖∙ 𝑤 + 𝑏 = 1 dengan 𝑤 normal dan jarak tegak lurus dari titik asal hyperplane 𝐻1 yaitu 𝑑𝐻1=
(1−𝑏)
‖𝑤‖. Demikian pula, semua titik yang ada pada persamaan (7.2) terletak pada hyperplane 𝐻2∶ 𝑥𝑖∙ 𝑤 + 𝑏 = −1 dengan jarak dari titik asal hyperplane 𝐻2 yaitu 𝑑𝐻2 =
(−1−𝑏)
‖𝑤‖ . Jarak antara dua hyperplane 𝐻1 dan 𝐻2 disebut sebagai margin dan memiliki persamaan:
𝑀𝑎𝑟𝑔𝑖𝑛 = |𝑑𝐻1− 𝑑𝐻2| =
2
‖𝑤‖ (7.4)
Keterangan:
• 𝑑𝐻1 = jarak dari hyperplane positif ke
hyperplane utama
• 𝑑𝐻2 = jarak dari hyperplane negatif ke
hyperplane utama
• ‖𝑤‖ = nilai magnitude (besaran) vektor bobot yang menunjukkan panjang garis hyperplane utama Secara umum, ada banyak hyperplane yang memenuhi kondisi yang diberikan dalam persamaan (7.3) untuk kumpulan data yang dapat dipisahkan. Untuk memilih salah satu
hyperplane dengan kemampuan generalisasi
terbaik, maka perlu memaksimalkan margin di antara hyperplane kanonik (𝐻1 dan 𝐻2) (lihat Gambar 7.1) (Burges, 1998). Hal ini dibenarkan dari perspektif teori komputasi karena memaksimalkan margin sesuai dengan meminimalkan dimensi Vapnik–Chervonenkis (V-C) dari pengklasifikasi yang dihasilkan (Vapnik, 1997).
Oleh karena itu, permasalahan optimasi yang harus diselesaikan menjadi seperti berikut
Fakultas Ilmu Komputer, Universitas Brawijaya 𝑀𝑖𝑛𝑖𝑚𝑎𝑙𝑘𝑎𝑛 𝐽1[𝑤] = 1 2‖𝑤‖ 2 (7.5) 𝑑𝑖𝑚𝑎𝑛𝑎 𝑦𝑖(𝑥𝑖∙ 𝑤 + 𝑏) − 1 ≥ 0; 𝑖 = 1, … , 𝑙 (7.6) Keterangan:
• 𝐽1[𝑤] = fungsi optimasi untuk mencari hyperplane utama terbaik pada kasus linearly separable
• ‖𝑤‖ = nilai magnitude (besaran) vektor bobot yang menunjukkan panjang garis hyperplane utama • 𝑥𝑖 = vektor/titik data ke-i • 𝑦𝑖 = target/kelas data ke-i
• 𝑤 = vektor weight (bobot) yang menunjukkan tingkat kemiringan garis model
• 𝑏 = nilai bias yang menunjukkan posisi garis model terhadap sumbu y
7.2 The non-linearly separable case
Gambar 7.2 Linearly vs. Non-Linearly Separable
Jika data tidak dapat dipisahkan secara linier, seperti dalam banyak kasus, maka diperkenalkan variabel slack 𝜉𝑖 ≥ 0 untuk menangani kesalahan klasifikasi sehingga constraint berikut terpenuhi:
𝑦𝑖(𝑥𝑖∙ 𝑤 + 𝑏) − 1 + 𝜉𝑖≥ 0 𝑢𝑛𝑡𝑢𝑘 𝑖
= 1, … , 𝑙 (7.7)
Disini, perlu memilih tradeoff antara memaksimalkan margin dan mengurangi jumlah kesalahan klasifikasi dengan menggunakan parameter C yang ditentukan pengguna sehingga permasalahan optimasi menjadi seperti berikut:
𝑀𝑖𝑛𝑖𝑚𝑎𝑙𝑘𝑎𝑛 𝐽2[𝑤, 𝜉𝑖] = (1 2‖𝑤‖ 2+ 𝐶 ∑ 𝜉 𝑖 𝑙 𝑖=1 ) (7.8) 𝑑𝑖𝑚𝑎𝑛𝑎 𝑦𝑖(𝑥𝑖∙ 𝑤 + 𝑏) − 1 + 𝜉𝑖 ≥ 0; (7.9) 𝜉𝑖≥ 0; 𝑖 = 1, … , 𝑙 (7.10) Keterangan:
• 𝐽2[𝑤, 𝜉𝑖] = fungsi optimasi untuk mencari hyperplane utama terbaik pada kasus non-linearly separable • ‖𝑤‖ = nilai magnitude (besaran)
vektor bobot yang menunjukkan panjang garis hyperplane utama • 𝐶 = nilai parameter yang
menentukan tradeoff antara memaksimalkan margin dan mengurangi jumlah kesalahan klasifikasi
• 𝜉𝑖 = nilai untuk menangani kesalahan klasifikasi
Permasalahan constrained optimization
tersebut dapat diubah menjadi permasalahan
unconstrained quadratic convex programming,
dengan memperkenalkan Lagrangian multipliers sebagai berikut
𝑀𝑖𝑛𝑖𝑚𝑎𝑙𝑘𝑎𝑛 𝐿(𝑤, 𝑏, 𝜉𝑖, ℎ, 𝑟) =1 2‖𝑤‖ 2+ 𝐶 ∑ 𝜉 𝑖 𝑙 𝑖=1 − ∑ ℎ𝑖[𝑦𝑖(𝑥𝑖∙ 𝑤 + 𝑏) 𝑙 𝑖=1 − 1 + 𝜉𝑖] − ∑ 𝑟𝑖𝜉𝑖 𝑙 𝑖=1 (7.11) Keterangan: • 𝐿(𝑤, 𝑏, 𝜉𝑖, ℎ, 𝑟) = fungsi optimasi untuk mencari hyperplane utama terbaik menggunakan quadratic programming
• ℎ𝑖 = nilai non-negative Lagrange
multipliers
• 𝑟𝑖 = nilai non-negative Lagrange multipliers
7.3 The dual problem and sparsity of solution
Permasalahan optimasi dari persamaan (7.11) dapat diubah menjadi bentuk dual
problem yang jauh lebih mudah untuk ditangani
dengan melihat titik-titik sadel dari persamaan (7.11) (Burges, 1998). 𝑀𝑎𝑘𝑠𝑖𝑚𝑎𝑙𝑘𝑎𝑛 𝐿𝐷(ℎ) = (∑ ℎ𝑖 𝑙 𝑖=1 −1 2ℎ ∙ 𝐷ℎ) (7.12)
Fakultas Ilmu Komputer, Universitas Brawijaya 𝑑𝑖𝑚𝑎𝑛𝑎 ∑ 𝑦𝑖ℎ𝑖 𝑙 𝑖=1 = 0; (7.13) 0 ≤ ℎ𝑖≤ 𝐶; 𝑖 = 1, … , 𝑙 (7.14) Keterangan:
• 𝐿𝐷(ℎ) = fungsi optimasi untuk mencari hyperplane utama terbaik menggunakan dual problem
• 𝐷𝑖𝑗 = 𝑦𝑖𝑦𝑗𝑥𝑖∙ 𝑥𝑗
Solusi untuk dual problem ini secara tradisional ditemukan dengan menggunakan
standard quadratic programming packages.
Setelah optimal multipliers ℎ𝑖 ditemukan, maka pengklasifikasi menjadi seperti berikut
𝑓(𝑥) = 𝑠𝑖𝑔𝑛 (∑ ℎ𝑖𝑦𝑖𝑥𝑖∙ 𝑥 𝑖
+ 𝑏0) (7.15)
Keterangan:
• 𝑓(𝑥) = fungsi classifier untuk mengklasifikasikan data uji
• ℎ𝑖 = nilai Lagrange multipliers • 𝑦𝑖 = target/kelas data latih ke-i • 𝑥𝑖 = vektor/titik data latih ke-i • 𝑥 = vektor/titik data uji
• 𝑏0 = nilai bias yang menunjukkan posisi garis model terhadap sumbu ordinat
Berdasarkan kondisi optimal Kuhn-Tucker, jumlah non-zero Lagrange multipliers ℎ𝑖 jauh lebih kecil daripada jumlah data, karena jenis perluasan untuk pengklasifikasi yang diberikan oleh persamaan (7.15) sangat jarang. Titik data yang sesuai dengan non-zero Lagrangians ini disebut sebagai support vectors. Nilai bias 𝑏0 dapat ditemukan menggunakan support vectors 𝑥𝑠𝑣 apapun
𝑏0= 𝑦𝑠𝑣− ∑ ℎ𝑖𝑦𝑖𝑥𝑖∙ 𝑥𝑠𝑣 𝑖∈𝑆𝑉
(7.16)
Keterangan:
• 𝑏0 = nilai bias yang menunjukkan posisi garis model terhadap sumbu ordinat
• ℎ𝑖 = nilai Lagrange multipliers • 𝑦𝑖 = target/kelas data latih ke-i • 𝑥𝑖 = vektor/titik data latih ke-i • 𝑥𝑠𝑣 = vektor/titik data latih yang
menjadi support vectors
• 𝑦𝑠𝑣 = target/kelas dari data latih yang menjadi support vectors
7.4 Extension to non-linear decision surfaces
Gambar 7.3 Implementasi Kernel
Kekuatan linear decision surfaces sangat terbatas. SVM menyediakan cara yang mudah untuk memperluas analisis dari ruang input ke ruang fitur nonlinier dengan menggunakan pemetaan dimensi tinggi Φ(𝑥). Menemukan
hyperplane pemisah linier dalam ruang fitur ini
setara dengan menemukan non-linear decision
boundary di ruang input.
Perlu dicatat bahwa vektor input hanya muncul dalam bentuk dot product Φ(𝑥𝑖) ∙ Φ(𝑥𝑗) dalam dual problem dan solusinya. Dengan menggunakan kernel yang mereproduksi ruang Hilbert, maka dot product dari dua vektor fitur ini dapat ditulis ulang menjadi kernel asalkan beberapa kondisi terpenuhi
(Φ(𝑥𝑖) ∙ Φ(𝑥𝑗)) = 𝐾(𝑥𝑖, 𝑥𝑗)
≡ ∑ 𝜙𝑘(𝑥𝑖)𝜙𝑘(𝑥𝑗) 𝑘
(7.17)
Keterangan:
• 𝑥𝑖 = vektor/titik data latih ke-i • 𝑥𝑗 = vektor/titik data latih/uji ke-j • (Φ(𝑥𝑖) ∙ Φ(𝑥𝑗)) = 𝐾(𝑥𝑖, 𝑥𝑗) = fungsi
kernel yang memetakan data dari
ruang input (berdimensi rendah) ke ruang Hilbert (berdimensi tinggi) Beberapa contoh umum dari kernel adalah
Gaussian RBF dan polynomial of degree d Gaussian RBF : 𝐾(𝑥, 𝑥′) ≡ 𝑒−‖𝑥−𝑥′‖ 2⁄2𝜎2 (7.18) Polynomial of degree d : 𝐾(𝑥, 𝑥′) ≡ (𝑥 ∙ 𝑥′+ 1)𝑑 (7.19) Keterangan:
• 𝐾(𝑥, 𝑥′) = fungsi kernel yang memetakan data dari ruang input
Fakultas Ilmu Komputer, Universitas Brawijaya (berdimensi rendah) ke ruang Hilbert (berdimensi tinggi)
• 𝑥 = vektor/titik data latih • 𝑥′ = vektor/titik data latih/uji • 𝑒 ≈ 2,718 = konstanta Euler
• ‖𝑥 − 𝑥′‖ = vector norm / jarak antar vektor data
• 𝜎 = nilai parameter sigma yang nilainya diatur bebas oleh pengguna • 𝑑 = nilai parameter degree yang
nilainya diatur bebas oleh pengguna Penggunaan kernel sebagai pengganti dot
product dalam masalah optimasi menyediakan
implementasi otomatis untuk merepresentasikan
hyperplane di ruang fitur, bukan di ruang input
(lihat Gambar 7.3).
7.5 Mendapatkan balanced classifier
Dalam kasus ketika data dapat dipisahkan secara linier, balanced classifier didefinisikan sebagai hyperplane (𝑓(𝑤, 𝑏) = 𝑥 ∙ 𝑤 + 𝑏) yang terletak di tengah dua kelas, atau lebih tepatnya, variabel bias 𝑏 didefinisikan sebagai berikut:
𝑏 = −1 2(𝑥𝑖
+∙ 𝑤 + 𝑥
𝑖−∙ 𝑤) (7.20)
𝑥𝑖+ dan 𝑥𝑖− adalah dua support vector dari dua kelas. Tentu saja, balanced classifier lebih unggul daripada unbalanced classifier. Untuk permasalahan asli (lihat persamaan (7.5)),
balanced classifier dapat diperoleh secara
otomatis. Namun, saat memaksimalkan margin yang dimodifikasi, balanced classifier tidak bisa diperoleh secara otomatis. Batasan pada besaran w harus dipenuhi.
Misalkan ada unbalanced classifier
𝑓(𝑤′, 𝑏′). Tanpa kehilangan generality, maka asumsinya adalah classifier akan lebih dekat ke kelas negatif, yaitu:
𝑥𝑖+∙ 𝑤′+ 𝑏′= 𝑐; 𝑐 > 1
𝑥𝑖−∙ 𝑤′+ 𝑏′= −1
Hal tersebut mudah untuk diperiksa dengan menggunakan transformasi 𝑤∗= 2
1+𝑐𝑤′ dan 𝑏∗= 2
1+𝑐𝑏 ′+1−𝑐
1+𝑐 bahwa bisa didapatkan
balanced classifier 𝑓(𝑤∗, 𝑏∗) yang sejajar dengan unbalanced classifier
𝑥𝑖+∙ 𝑤∗+ 𝑏∗= 1
𝑥𝑖−∙ 𝑤′+ 𝑏′= −1
Jadi, dapat dibangun parallel classifier yang diparameterisasi oleh 𝑐, untuk 𝑐 ≥ 1 dengan cara berikut: 𝑤(𝑐) =1 + 𝑐 2 𝑤 ∗ (7.21) 𝑏(𝑐) =1 + 𝑐 2 𝑏 ∗−1 − 𝑐 2 (7.22) 𝑥𝑖+∙ 𝑤(𝑐) + 𝑏(𝑐) = 𝑐; 𝑐 > 1 (7.23) 𝑥𝑖−∙ 𝑤(𝑐) + 𝑏(𝑐) = −1 (7.24)
Disini, 𝑓(𝑤(1), 𝑏(1)) memberikan balanced
classifier, yang sesuai dengan 𝑐 = 1 dan 𝑓(𝑤∗, 𝑏∗). Untuk 𝑐 > 1, diperoleh unbalanced
classifier yang lebih dekat ke kelas negatif.
Demi kesederhanaan, maka diasumsikan
augmenting factor menjadi 1. Kemudian,
SVMseq meminimalkan ‖𝑤‖2+ 𝑏2. Jadi ketika 𝐿(𝑐) = ‖𝑤(𝑐)‖2+ 𝑏(𝑐)2 (7.25)
mengambil nilai minimum pada 𝑐 = 1, SVMseq akan menyediakan balanced classifier. Untuk menghitung turunan dari 𝐿(𝑐) terhadap 𝑐, dapat menggunakan persamaan berikut
𝑑𝐿(𝑐) 𝑑𝑐 = 1 + 𝑐 2 [‖𝑤 ∗‖2− 1 (1 + 𝑐)2] +1 + 𝑐 2 [𝑏 ∗+ 𝑐 1 + 𝑐] 2 (7.26)
Perhatikan bahwa 𝑐 ≥ 1 dan ‖𝑤∗‖2>1 4 memastikan 𝑑𝐿(𝑐)
𝑑𝑐 > 0, untuk setiap 𝑐. Jadi, ‖𝑤∗‖2>1
4 adalah kondisi yang cukup untuk memperoleh balanced classifier dalam metode ini. Dalam praktiknya, hal ini mudah dipenuhi hanya dengan menskalakan data input ke nilai yang lebih kecil, otomatis hasilnya mengarah ke nilai 𝑤 yang lebih besar.
Bekerja di sepanjang garis pada poin 7.3, dan menyelesaikan permasalahan hyperplane di ruang fitur dimensi tinggi, maka permasalahan optimasi yang dimodifikasi dapat diubah menjadi bentuk dual problem:
𝑀𝑎𝑘𝑠𝑖𝑚𝑎𝑙𝑘𝑎𝑛 𝐿′𝐷(ℎ) = (∑ ℎ𝑖 𝑙 𝑖=1 −1 2ℎ ∙ 𝐷′ℎ) (7.27) 𝑑𝑖𝑚𝑎𝑛𝑎 0 ≤ ℎ𝑖≤ 𝐶; 𝑖 = 1, … , 𝑙 (7.28) 𝐷𝑖𝑗′ = 𝑦𝑖𝑦𝑗𝐾(𝑥𝑖, 𝑥𝑗) + 𝜆2𝑦 𝑖𝑦𝑗 (7.29)
Fakultas Ilmu Komputer, Universitas Brawijaya Disini, dalam kasus non-linier, perlu menambah vektor input dengan dimensi ekstra dalam ruang fitur, yaitu, 𝛷(𝑥′) = (𝛷(𝑥)𝜆)𝑇.
Non-linear classifier yang dihasilkan dihitung
menggunakan persamaan berikut 𝑓(𝑥) = 𝑠𝑖𝑔𝑛 ( ∑ ℎ𝑖𝑦𝑖𝐾(𝑥𝑖, 𝑥)
𝑖∈𝑆𝑉
+ ℎ𝑖𝑦𝑖𝜆2)
(7.30)
Keterangan:
• 𝑓(𝑥) = fungsi classifier untuk mengklasifikasikan data uji
• ℎ𝑖 = nilai Lagrange multipliers • 𝑦𝑖 = target/kelas data latih ke-i • 𝑥𝑖 = vektor/titik data latih ke-i • 𝑥 = vektor/titik data uji
• 𝐾(𝑥𝑖, 𝑥) = fungsi kernel yang memetakan data dari ruang input (berdimensi rendah) ke ruang Hilbert (berdimensi tinggi)
• 𝜆 = nilai augmenting factor sebagai pengganti nilai bias
7.6 Sequential Learning Algorithm
Berikut adalah algoritme Sequential Learning SVM (SVMseq) yang diusulkan oleh
(Vijayakumar & Wu, 1999):
1. Inisialisasi ℎ𝑖 = 0. Hitung matriks 𝐷𝑖𝑗= 𝑦𝑖𝑦𝑗(𝐾(𝑥𝑖, 𝑥𝑗) + 𝜆2) untuk 𝑖, 𝑗 = 1, … , 𝑙 2. Pada setiap pola, dari 𝑖 = 1 sampai dengan
𝑙, hitung
• 𝐸𝑖 = ∑𝑙𝑗=1ℎ𝑗𝐷𝑖𝑗
• 𝛿ℎ𝑖 = 𝑚𝑖𝑛{𝑚𝑎𝑥[𝛾(1 − 𝐸𝑖), −ℎ𝑖], 𝐶 − ℎ𝑖} • ℎ𝑖= ℎ𝑖+ 𝛿ℎ𝑖
3. Jika hasil pelatihan sudah converged, maka hentikan pelatihan, jika belum maka ulangi langkah ke-2
8. PEMILIHAN & OPTIMASI MODEL
Pengujian hyperparameters merupakan pengujian yang menguji kombinasi nilai
hyperparameters untuk mencari nilai
hyperparameters yang optimal. Proses optimasi hyperparameters ini menggunakan algoritme Grid Search. Algoritme ini akan mencoba satu
per satu setiap kombinasi nilai yang diberikan
untuk dimasukkan ke dalam model dan mengevaluasi model. Evaluasi model tersebut menggunakan metode 10-fold cross validation sehingga nanti algoritme Grid Search akan menghasilkan 10 nilai akurasi untuk setiap fold. Kemudian 10 nilai akurasi ini akan dihitung rata-ratanya untuk mendapatkan nilai
hyperparameters mana yang paling optimal.
Algoritme Grid Search juga akan menghasilkan model sebanyak banyaknya kombinasi dikali 10
fold (n_grid * n_fold), kemudian dari banyaknya
model tersebut dipilih satu model yang paling optimal.
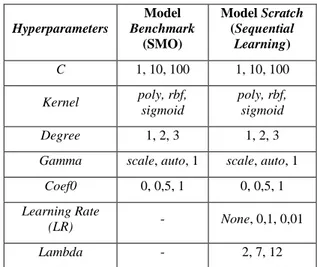
Tabel 8.1 Kombinasi Nilai Hyperparameters
Hyperparameters Model Benchmark (SMO) Model Scratch (Sequential Learning) C 1, 10, 100 1, 10, 100 Kernel poly, rbf, sigmoid poly, rbf, sigmoid Degree 1, 2, 3 1, 2, 3
Gamma scale, auto, 1 scale, auto, 1
Coef0 0, 0,5, 1 0, 0,5, 1
Learning Rate
(LR) - None, 0,1, 0,01
Lambda - 2, 7, 12
Tabel di atas menunjukkan kombinasi nilai
hyperparameters yang akan diuji. Setiap
parameter mempunyai tiga nilai yang akan diuji pada model benchmark dan model scratch. Model benchmark mengimplementasikan algoritme Sequential Minimal Optimization (SMO), sedangkan model scratch
mengimplementasikan algoritme Sequential
Learning. Model benchmark tidak menguji
parameter learning rate dan lambda sehingga kombinasi nilai yang diuji pada model ini sebanyak 243 kombinasi, sedangkan model
scratch menguji parameter learning rate dan lambda sehingga kombinasi nilai yang diuji pada
model ini sebanyak 2187 kombinasi.
Tabel 8.2 Hyperparameters Tuning (Model Benchmark)
C 100 1 10
Kernel poly poly poly
Degree 3 2 2
Fakultas Ilmu Komputer, Universitas Brawijaya Coef0 0,5 0 0 Fold 1 Score 0,8615 0,8769 0,8769 Fold 2 Score 0,8615 0,8615 0,8615 Fold 3 Score 0,8308 0,8308 0,8308 Fold 4 Score 0,8438 0,8125 0,8125 Fold 5 Score 0,8281 0,8281 0,8281 Fold 6 Score 0,8906 0,8906 0,8906 Fold 7 Score 0,8750 0,8438 0,8438 Fold 8 Score 0,8906 0,8906 0,8906 Fold 9 Score 0,8750 0,9063 0,9063 Fold 10 Score 0,8906 0,9063 0,9063 Mean Score 0,8648 0,8647 0,8647 Rank 1 2 3
Model benchmark diuji menggunakan 243 kombinasi (atau 35 kombinasi) nilai hyperparameters. Masing-masing nilai
hyperparameters akan dimasukkan ke dalam
model dan diukur tingkat akurasinya menggunakan metode 10-fold cross validation. Metode cross validation ini akan menghasilkan 10 nilai akurasi dengan 10 nilai akurasi ini akan dihitung rata-ratanya untuk digunakan sebagai metrik model. Nilai rata-rata akurasi akan diurutkan dari yang terbesar ke yang terkecil dengan nilai terbesar menandakan bahwa nilai
hyperparameters tersebut yang paling optimal
untuk digunakan oleh model. Dalam kasus ini, nilai hyperparameters yang paling optimal adalah C=100, kernel=’poly’, degree=3, gamma=’auto’, dan coef0=0,5 dengan nilai
rata-rata akurasinya adalah 0,8648. Proses
hyperparameters tuning menggunakan
algoritme Grid Search ini akan menghasilkan model sebanyak 243 kombinasi dikali 10 fold (n_grid * n_fold) yaitu 2430 model, dari banyaknya model tersebut dipilih satu model yang paling optimal yaitu model pada rank 1 dan
fold 6.
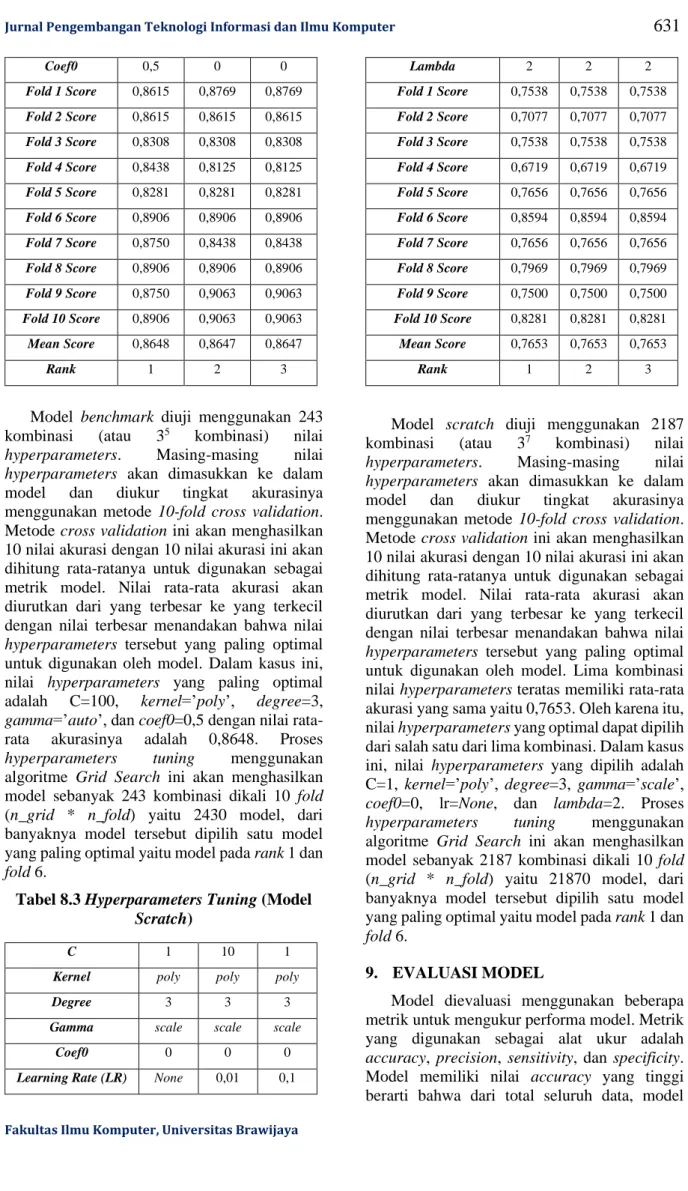
Tabel 8.3 Hyperparameters Tuning (Model Scratch)
C 1 10 1
Kernel poly poly poly
Degree 3 3 3
Gamma scale scale scale
Coef0 0 0 0
Learning Rate (LR) None 0,01 0,1
Lambda 2 2 2 Fold 1 Score 0,7538 0,7538 0,7538 Fold 2 Score 0,7077 0,7077 0,7077 Fold 3 Score 0,7538 0,7538 0,7538 Fold 4 Score 0,6719 0,6719 0,6719 Fold 5 Score 0,7656 0,7656 0,7656 Fold 6 Score 0,8594 0,8594 0,8594 Fold 7 Score 0,7656 0,7656 0,7656 Fold 8 Score 0,7969 0,7969 0,7969 Fold 9 Score 0,7500 0,7500 0,7500 Fold 10 Score 0,8281 0,8281 0,8281 Mean Score 0,7653 0,7653 0,7653 Rank 1 2 3
Model scratch diuji menggunakan 2187 kombinasi (atau 37 kombinasi) nilai hyperparameters. Masing-masing nilai
hyperparameters akan dimasukkan ke dalam
model dan diukur tingkat akurasinya menggunakan metode 10-fold cross validation. Metode cross validation ini akan menghasilkan 10 nilai akurasi dengan 10 nilai akurasi ini akan dihitung rata-ratanya untuk digunakan sebagai metrik model. Nilai rata-rata akurasi akan diurutkan dari yang terbesar ke yang terkecil dengan nilai terbesar menandakan bahwa nilai
hyperparameters tersebut yang paling optimal
untuk digunakan oleh model. Lima kombinasi nilai hyperparameters teratas memiliki rata-rata akurasi yang sama yaitu 0,7653. Oleh karena itu, nilai hyperparameters yang optimal dapat dipilih dari salah satu dari lima kombinasi. Dalam kasus ini, nilai hyperparameters yang dipilih adalah C=1, kernel=’poly’, degree=3, gamma=’scale’,
coef0=0, lr=None, dan lambda=2. Proses
hyperparameters tuning menggunakan
algoritme Grid Search ini akan menghasilkan model sebanyak 2187 kombinasi dikali 10 fold (n_grid * n_fold) yaitu 21870 model, dari banyaknya model tersebut dipilih satu model yang paling optimal yaitu model pada rank 1 dan
fold 6.
9. EVALUASI MODEL
Model dievaluasi menggunakan beberapa metrik untuk mengukur performa model. Metrik yang digunakan sebagai alat ukur adalah
accuracy, precision, sensitivity, dan specificity.
Model memiliki nilai accuracy yang tinggi berarti bahwa dari total seluruh data, model
Fakultas Ilmu Komputer, Universitas Brawijaya berhasil memprediksi banyak data dengan benar sesuai dengan label aslinya. Model memiliki nilai precision yang tinggi berarti bahwa dari total seluruh data pasien yang diprediksi menderita diabetes, model berhasil memprediksi banyak data pasien yang menderita penyakit diabetes dengan benar dibandingkan pasien yang sehat tetapi diprediksi sebagai penderita diabetes. Model memiliki nilai sensitivity yang tinggi berarti bahwa dari total seluruh data pasien penderita diabetes, model berhasil memprediksi banyak data pasien yang menderita penyakit diabetes dengan benar. Model memiliki nilai specificity yang tinggi berarti bahwa dari total seluruh data pasien yang sehat, model berhasil memprediksi banyak data pasien yang sehat dengan benar.
Gambar 9.1 Cross Validation Metrics – Accuracy & Precision (Benchmark)
Gambar di atas menunjukkan hasil pengujian metrik accuracy dan precision pada model
benchmark. Hasilnya menunjukkan bahwa pada
setiap fold, model berhasil mencapai nilai diatas 0,70 untuk metrik accuracy dan precision. Nilai rata-rata accuracy dan precision yang dicapai oleh model yang sudah dioptimasi ini adalah 0,87 dan 0,82.
Gambar 9.2 Cross Validation Metrics – Sensitivity & Specificity (Benchmark)
Gambar di atas menunjukkan hasil pengujian metrik sensitivity/recall dan specificity pada model benchmark. Hasilnya menunjukkan bahwa pada setiap fold, model berhasil mencapai nilai diatas 0,70 untuk metrik sensitivity dan
specificity. Nilai rata-rata sensitivity dan specificity yang dicapai oleh model yang sudah
dioptimasi ini adalah 0,78 dan 0,92.
Gambar 9.3 Cross Validation Metrics – Accuracy & Precision (Scratch)
Gambar di atas menunjukkan hasil pengujian metrik accuracy dan precision pada model
scratch. Hasilnya menunjukkan bahwa pada
setiap fold, model berhasil mencapai nilai diatas 0,55 untuk metrik accuracy dan precision. Nilai rata-rata accuracy dan precision yang dicapai oleh model yang sudah dioptimasi ini adalah 0,78 dan 0,69.
Gambar 9.4 Cross Validation Metrics – Sensitivity & Specificity (Scratch)
Gambar di atas menunjukkan hasil pengujian metrik sensitivity/recall dan specificity pada model scratch. Hasilnya menunjukkan bahwa pada setiap fold, model berhasil mencapai nilai diatas 0,45 untuk metrik sensitivity dan
specificity. Nilai rata-rata sensitivity dan specificity yang dicapai oleh model yang sudah
dioptimasi ini adalah 0,59 dan 0,87.
Fakultas Ilmu Komputer, Universitas Brawijaya Pada penelitian ini, riset dilakukan menggunakan berbagai sumber medis untuk menentukan batasan nilai pada faktor-faktor risiko penyakit diabetes. Batasan nilai ini kemudian dianalisis untuk mendapatkan pengetahuan pada batas nilai berapa sebuah faktor dapat mempengaruhi seseorang terkena penyakit diabetes.
Data dilakukan pemrosesan terlebih dahulu sebelum dimasukkan ke dalam model Support
Vector Machine seperti menghapus fitur yang
tidak relevan, menangani nilai outlier & anomali nilai nol, dan menormalisasi fitur-fitur.
Kedua model dioptimasi menggunakan algoritme Grid Search untuk mencari
hyperparameters yang optimal digunakan oleh
model. Hyperparameters optimal untuk digunakan model benchmark adalah C=100,
kernel=’poly’, degree=3, gamma=’auto’, dan coef0=0,5. Hyperparameters optimal untuk
digunakan model scratch adalah C=1,
kernel=’poly’, degree=3, gamma=’scale’, coef0=0, lr=None, dan lambda=2.
Kedua jenis model yang sudah optimal diuji menggunakan cross validation pada beberapa metrik. Hasil pengujian menunjukkan bahwa model benchmark memiliki nilai mean accuracy sebesar 0,87, mean precision sebesar 0,82, mean
sensitivity sebesar 0,78, dan mean specificity
sebesar 0,92. Model scratch memiliki nilai mean
accuracy sebesar 0,78, mean precision sebesar
0,69, mean sensitivity sebesar 0,59, dan mean
specificity sebesar 0,87
DAFTAR REFERENSI
Boser, B. E., Guyon, I. M., & Vapnik, V. N. (1992). A Training Algorithm for Optimal Margin Classifiers. Pittsburgh: Association for Computing Machinery. Burges, C. (1998). A Tutorial on Support Vector
Machines for Pattern Recognition. Data
Mining and Knowledge Discovery, 2,
121–167.
Cortes, C., & Vapnik, V. (1995). Support-Vector Networks. Machine Learning, 20, 273-297.
Devi, R. D., Bai, A., & Nagarajan, N. (2019). A Novel Hybrid Approach for Diagnosing Diabetes Mellitus using Farthest First and Support Vector Machine Algorithms.
Obesity Medicine.
International Diabetes Federation. (2020). What
is diabetes. Dipetik Agustus 6, 2020, dari
https://www.idf.org/aboutdiabetes/what-is-diabetes.html
Mayo Clinic. (2018). Diabetes. Dipetik Agustus
6, 2020, dari
https://www.mayoclinic.org/diseases- conditions/diabetes/symptoms-causes/syc-20371444
Sisodia, D., & Sisodia, D. S. (2018). Prediction of Diabetes using Classification Algorithms. Procedia Computer Science,
132, 1578-1585.
Smith, J. W., Everhart, J., Dickson, W., Knowler, W., & Johannes, R. (1988). Using the ADAP Learning Algorithm to Forecast the Onset of Diabetes Mellitus.
Proceedings of the Symposium on Computer Applications and Medical Care, 261–265.
Vapnik, V. (1997). Statistical Learning Theory. New York: John Wiley and Sons Inc. Vijayakumar, S., & Wu, S. (1999). Sequential
Support Vector Classifiers and Regression. Proc. International
Conference on Soft Computing