55 4.1 Arsitekur Data Mining
Gambar 4.1 Arsitektur Data Mining
Gambar 4.1 menjelaskan arsitektur data mining yang akan dibuat. Pertama data yang didapat dari hasil pengumpulan data dilakukan data selection untuk memilih data atau atribut yang relevan. Setelah proses cleaning dilakukan data transformation, yaitu data diubah ke dalam bentuk yang lebih berkualitas dengan cara dilakukan Generalization dan Discritization. Lalu dilakukan proses mining menggunakan algoritma Naïve Bayes dan Decision Tree J48. Setelah proses mining selesai, dilakukan perbandingan antara kedua algoritma tersebut, dipilih algoritma mana yang paling baik dalam mengklasifikasikan pola penyakit.
56
4.2 Functional DataWarehouse
Dalam membangun Data Mining membutuhkan suatu Data Warehouse, untuk itu akan dibangun Data Warehouse sederhana guna memenuhi kebutuhan proses Data Mining. Data warehouse yang dibangun bukan merupakan data warehouse yang menyimpan seluruh data transaksional,hanya merupakan data warehouse yang menunjang pembangunan data mining, sehingga data dan formatnya pun disesuaikan dengan kebutuhan data mining.
Data warehouse merupakan sebuah sistem yang mengambil dan menggabungkan data secara periodik dari sistem sumber data ke penyimpanan data bentuk dimensional atau normal, untuk menyimpan data dalam bentuk nonvolatile sebagai pendukung manajemen dalam proses pengambilan keputusan.
Data warehouse menyatukan dan menggabungkan data dalam bentuk multidimensi. Pembangunan data warehouse meliputi pembersihan data, penyatuan data dan transformasi data, dan dapat dilihat sebagai preprocessing yang penting untuk digunakan dalam Data Mining. Selain itu data warehouse mendukung Online Analytical Processing (OLAP) yaitu sebuah alat yang digunakan untuk menganalisis secara interaktif dari bentuk multidimensi yang mempunyai data yang rinci, sehingga dapat memfasilitasi secara efektif data generalization dan Data Mining.
4.2.1 Data Selection
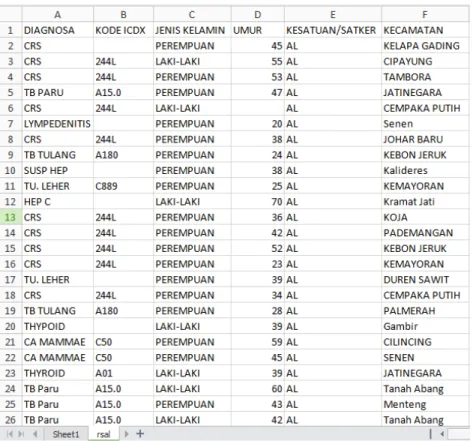
Database dapat menyimpan terabyte data sehingga kemungkinan data akan menjadi besar. Analisis data yang kompleks dan proses mining pada data dalam jumlah besar dapat memakan waktu yang lama dan membuat analisis menjadi tidak layak. Untuk itu dibutuhkan tahap data selection. Dalam tahap ini dilakukan pemilihan data atau atribut yang relevan pada tabel karena tidak semua data digunakan, hanya data atau atribut yang sesuai untuk dianalisis yang akan dipilih dari tabel. Seleksi data dapat diterapkan untuk memperoleh kumpulan data yang memiliki volume lebih kecil namun tetap mempertahankan integritas data asli.
Gambar 4.2 Data setelah Tahap Selection
Tahap data selection sangat penting untuk mendapatkan data atau atribut yang relevan sebelum dilakukan proses Data mining berikutnya seperti pada gambar 4.2. Prosedur dimulai dengan atribut lengkap lalu menghilangkan atribut yang tidak relevan. Pemilihan atribut melalui proses eliminasi dilakukan setelah melakukan wawancara dengan pihak RSAL Dr. Mintohardjo terkait dengan atribut apa saja yang berguna untuk menjadi acuan dalam menentukan pola penyakit.
Data Rekam Medis Pasien Rawat Jalan selama triwulan pertama tahun 2012 menjadi sumber dari data yang akan diolah dan mempunyai ekstensi .xls dengan jumlah record sebanyak 1985 records. Setelah dilakukan tahap data selection, jumlah atribut yang terpilih setelah dieliminasi menjadi sebanyak 6 atribut dari 12 atribut di dalam tabel Rekam Medis Pasien.
4.2.2 Data Cleaning
Data Cleaning merupakan suatu proses untuk membersihkan data kotor. Data kotor yang dimaksud adalah data yang mengandung missing value pada atribut-atribut, data yang tidak konsisten dan tidak relevan.
58
Gambar 4.3 Data yang mengandung Missing Value
Data yang mengandung missing values, noise dan inconsistencies dapat menjadikan data tidak akurat dan berkualitas sehingga akan menghasilkan proses mining yang tidak baik. Proses dalam data cleaning adalah menemukan ketidaksesuaian data yang dapat disebabkan oleh beberapa faktor, termasuk data yang hilang atau kosong, kekurangan atribut yang sesuai, berisi data yang outlier, rancangan formulir data entry yang memiliki banyak pilihan fields, human error dalam penginputan data, kesalahan yang disengaja seperti responden tidak ingin untuk informasi tentang dirinya disebarkan dan kerusakan data. Proses untuk membersihkan data dapat dilakukan dengan beberapa teknik, yaitu dengan memperkecil noise, memperbaiki data yang tidak konsisten, mengisi missing value dan mengidentifikasi atau membuang outlier.
Dalam menyelesaikan masalah dalam gambar 4.3 terdapat berbagai macam cara yaitu elimination, inspection, identification dan substitution. Yang diterapkan dalam penelitian ini adalah dengan cara elimination, yaitu membuang semua data yang mempunyai satu atau lebih atribut yang hilang. Proses ini dilakukan didalam Microsoft Excel, dimana data masukan awal yang mengandung nilai yang tidak
lengkap akan dihapus semua data nya. Data ini kemudian digunakan pada proses mining di penelitian ini.
Untuk memperbaiki data missing values pada gambar 4.3 dilakukan dengan cara mengabaikan record yang memiliki label klasifikasi yang kosong, dan dengan mengisi data secara manual. Setelah dilakukan proses data cleaning, maka data yang dapat diolah adalah 1759 records.
4.2.3 Data Transformation
Tahap Data Transformation dilakukan agar dapat merubah data untuk kepentingan analisis, dengan mengubah data yang telah diseleksi sehingga menghasilkan data yang berkualitas. Tahap dari Data Transformation yang dilakukan antara lain menghilangkan meng-agregasi data, generalisasi data, normalisasi data, dan pembentukan atribut.
• Discretization
Discretization dilakukan dengan mengganti nilai atribut yang berbentuk numeric dengan interval labels atau conceptual labels. Dari 6 atribut yang dipilih untuk dianalisa, atribut umur dapat di kategorikan dengan menggunakan strategi discretization. Proses pengelompokan umur untuk kesehatan berdasarkan pada WHO (World Health Organization) yaitu teknik pengelompokkan umur sesuai dengan jenjang (bayi dan anak-anak, remaja dan dewasa, tua).
Tabel 4.1 Kategori Umur
Range Umur Kategori Jumlah
<=11 tahun Bayi dan Anak-Anak 30 >=12 tahun dan <= 45
tahun
Remaja dan Dewasa 452
>=46 tahun Tua 1292
Untuk mempermudah pengelompokkan umur, maka data excel di export ke SQL SERVER 2008 untuk dilakukan manipulasi data menggunakan
60
syntax queries. Tabel 4.1 menggambarkan range umur <=11 tahun maka pasien akan dikategorikan ke Bayi dan Anak-anak, >12tahun dan <=45 tahun merupakan kategori Remaja dan Dewasa, dan >=46 tahun merupakan kategori Tua. Dari 1759 records rekam medis, kategori Bayi dan Anak berjumlah 30 pasien, kategori Remaja dan Dewasa berjumlah 452 pasien dan kategori Tua berjumlah 1292 pasien. Query yang digunakan untuk meng-kategorikan umur di sql server 2008 dapat dilihat di Gambar 4.4.
Gambar 4.4 SQL Query Pengelompokkan Umur
• Generalization
Generalization bertujuan untuk mengubah data atribut low level menjadi atribut high level. Atribut-atribut yang ada diubah ke dalam bentuk categorical. Berikut adalah hasil dari tahap Generalization berdasarkan atribut-atribut yang sudah terpilih
- ICDX (ICD-10)
Pengelompokkan ICDX (International Statistical Classiication of Diseases and Related Health Problem) adalah pengkodean penyakit, tanda-tanda, gejala, temuan yang abnormal, keluhan, keadaan sosial dan eksternal yang menyebabkan cedera atau penyakit, seperti yang diklasifikasikan oleh WHO. Pengkodean ini menetapkan lebih dari 155.000 yang memungkinkan berbagai kode dan memungkinkan yang banyak berasal dari pelacakan diagnosis dan prosedur baru dengan perluasan yang signifikan. Tabel 4.2 akan menjelaskan pengelompokkan ICDX berdasarkan WHO.
Tabel 4.2 Pengelompokkan ICDX
Kode ICDX Keterangan Jumlah
A00-B99 Penyakit Infeksi dan Parasit 104
C00-D48 Neoplasma 65
D50-D89 Penyakit Darah dan Organ Pembentuk Darah Termasuk Gangguan Sistem Imun
5
E00-E90 Endokrin, Nutrisi, dan Gangguan Metabolik 350 G00-G99 Penyakit yang Mengenai Sistem Syaraf 176 I00-I99 Penyakit Pada Sistem Sirkulasi 250 J00-J99 Penyakit Pada Sistem Pernapasan 87 K00-K93 Penyakit Pada Sistem Pencernaan 171 L00-L99 Penyakit Pada Kulit dan Jaringan
Subcutaneous
21
M00-M99 Penyakit Pada Sistem Musculoskletat 149 N00-N99 Penyakit Pada Sistem Saluran Kemih dan
Genital
229
O00-O99 Kehamilan dan Kelahiran 1
Q00-Q99 Malformasi Kongenital, Deformasi dan Kelainan Chromosom
5
R00-R99 Gejala, tanda, Kelainan klinik dan kelainan lab yang tidak ditemukan pada klasifikasi lain
11
S00-T98 Keracunan, cedera dan beberapa yang berasal dari luar
83
V01-Y98 Penyebab morbiditas dan kematian external 4 Z00-Z99 Faktor-faktor yang memengaruhi status
kesehatan dan hubungannya dengan jasa kesehatan
63
− Wilayah
Pengelompokkan atribut ‘Kecamatan’ menjadi kelompok wilayah dimaksudkan untuk mempermudah dalam melakukan analisa, sehingga hasil yang ada nantinya dapat memberikan
62
informasi berdasarkan lokasi/ wilayah kotamadya yang bersangkutan. Pengelompokkan wilayah dilakukan di SQL SERVER untuk dilakukan manipulasi data menggunakan syntax queries. Berikut adalah tabel untuk mengelompokkan kecamatan berdasarkan wilayah kotamadya nya :
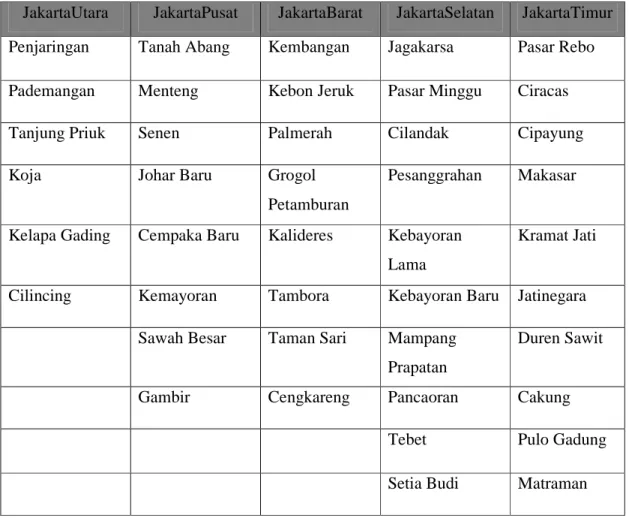
Tabel 4.3 Pengelompokkan Wilayah
JakartaUtara JakartaPusat JakartaBarat JakartaSelatan JakartaTimur Penjaringan Tanah Abang Kembangan Jagakarsa Pasar Rebo Pademangan Menteng Kebon Jeruk Pasar Minggu Ciracas
Tanjung Priuk Senen Palmerah Cilandak Cipayung
Koja Johar Baru Grogol
Petamburan
Pesanggrahan Makasar
Kelapa Gading Cempaka Baru Kalideres Kebayoran Lama
Kramat Jati
Cilincing Kemayoran Tambora Kebayoran Baru Jatinegara Sawah Besar Taman Sari Mampang
Prapatan
Duren Sawit
Gambir Cengkareng Pancaoran Cakung
Tebet Pulo Gadung
Setia Budi Matraman
Pengelompokkan wilayah dari kecamatan ke kotamadya menggunakan sql server 2008. Gambar 4.5 di bawah ini merupakan query dari pengelompokkan tersebut.
Gambar 4.5 SQL Query Pengelompokkan Wilayah
Gambar 4.6 Hasil Data Transformation
Gambar 4.6 merupakan hasil dari diterapkannya proses Data Transformation, dimana umur sudah dikategorikan menurut jenjang nya sesuai dengan WHO, kode ICDX juga dikategorikan berdasarkan diagnosa
64
yang diberikan kepada pasien dan kotamadya didapat dari penggolongan kecamatan. Tahap berikutnya adalah dengan mengkonversi data yang semula menggunakan Microsoft Excel lalu menjadi format CSV (Command Separated Values) atau arff yang dikenali oleh WEKA 3.6.
4.3 Star Schema
Gambar 4.7 Star Schema
Gambar 4.7 menjelaskan table fakta dan dimensi yang ada pada rekam medis. Tiap table dimensi memiliki Surrogate key dan Natural key. Table fakta berisi summary rekam medis harian. Measure pada table fakta yaitu jumlah rekam medis, menunjukkan jumlah banyaknya rekam medis dalam satu hari. Di dalam star schema ini berisi 6 table dimensi, yaitu Dimensi Waktu, kodya, kategori umur, ICD, Pekerjaan dan Jenis Kelamin.
4.4 Data Mining
Pada tahapan ini, menjelaskan mengenai pembuatan model data mining, yang terdiri dari teknik-teknik data mining. Pada penelitian ini aplikasi yang digunakan adalah Weka 3.6.10, yang digunakan untuk mengolah data rekam medis.
Weka (Waikato Environment for Knowledge Analysis) merupakan aplikasi data mining yang berbasis open source dan berengine java. Weka dipilih karena teknik yang digunakan pada Weka, didasarkan pada asumsi bahwa data tersedia sebagai hubungan dimana data digambarkan oleh sejumlah atribut yang tetap, biasanya atribut nya numerik atau nominal.
Dalam proses ini, digunakan 2 algoritma yaitu Naïve Bayes dan Decision Tree J48. Hasil dari 2 algoritma ini akan dibandingkan sehingga menghasilkan algoritma yang paling baik diantara Naive Bayes dan Decision Tree J48.
Langkah pertama yang dilakukan adalah membuka aplikasi Weka (Waikato Environment for Knowledge Analysis), tampilannya seperti pada gambar 2.19. File yang akan di olah Weka harus memiliki ekstensi file csv (Command Separated Values) atau arff , jika data belum berbentuk arff atau csv data harus di konversi ke format arff atau csv. Setelah format data berbentuk csv atau arff, data siap untuk ke proses pengolahan.
4.3.1 Decision Tree J48
Decision Tree J48 merupakan implemetasi dari algoritma C4.5 yang memproduksi decision tree. Ini merupakan standar algoritma yang digunakan dalam machine learning. Decision Tree merupakan salah satu algoritma klasifikasi dalam data mining. Algoritma klasifikasi merupakan algoritma yang secara induktif dalam pembelajaran dalam mengkonstruksikan sebuah model dari dataset yang belum diklasifikasikan. Setiap data dari item berdasarkan dari nilai setiap atribut. Klasifikasi dapat dilihat sebagai mapping dari sekelompok set dari atribut kelas tertentu. Decision Tree mengklasifikasikan data yang diberikan menggunakan nilai atribut. Dataset dengan atribut pilihan pada Gambar 4.2 kemudian diklasifikasikan menggunakan Decision Tree J48.
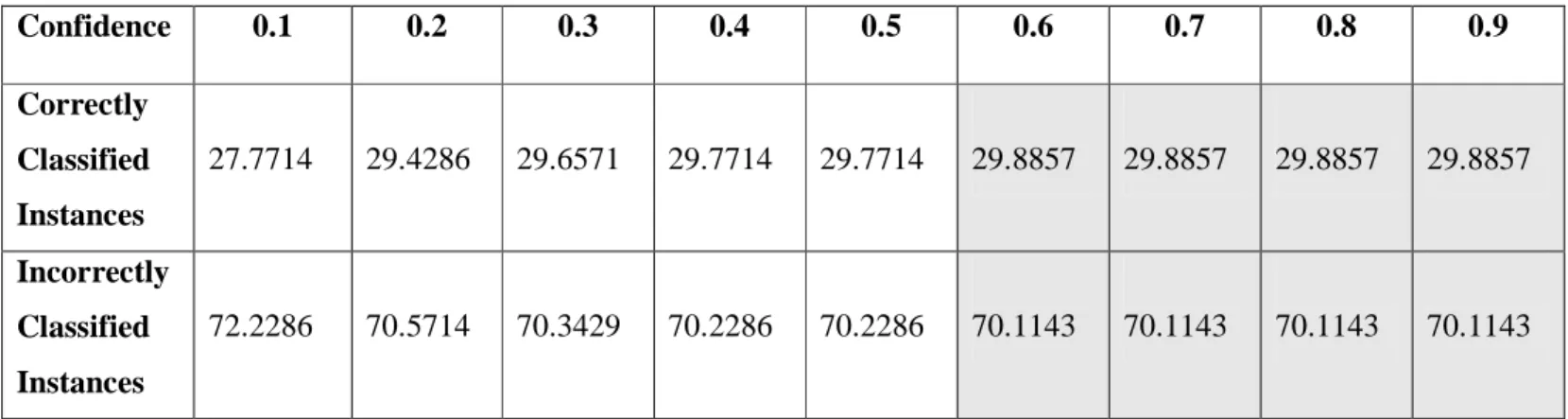
4.3.1.1 Confidence
Confidence adalah ukuran yang menilai tingkatkepastian bersyarat, yaitu probabilitas bahwa transaksi yang mengandung X juga akan mengandung Y. Hasil Confidence dari Decision Tree J48 akan ditampilkan pada tabel 4.4
Tabel 4.4 Hasil Confidence Decision Tree J48
4.3.1.2 Cross Validation dan Confusion Matrix
Tabel 4.5 Decision Tree J48 menggunakan K-Fold Cross Validation
Cross Validation 2 3 4 5 6 7 8 9 10 Correctly Classified Instances 25.2571 26.1143 25.6 25.9429 25.8286 26.4 26.5143 26.1143 26.3429 Incorrectly Classified Instances 74.7429 73.8857 74.4 74.0571 74.1714 73.6 73.4857 73.8857 73.6571 Confidence 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Correctly Classified Instances 27.7714 29.4286 29.6571 29.7714 29.7714 29.8857 29.8857 29.8857 29.8857 Incorrectly Classified Instances 72.2286 70.5714 70.3429 70.2286 70.2286 70.1143 70.1143 70.1143 70.1143
Berdasarkan tabel 4.5 K-Fold Cross Validation, data pengujian dipisah secara acak ke dalam k himpunan atau folds (lipatan), D1, D2, Dk, yang masing-masing kurang lebih berukuran sama. Data Training dan Testing dilakukan sebanyak k kali. Pada iterasi ke-1, partisi D1 digunakan sebagai data tes, dan partisi sisanya digunakan bersama untuk melatih model. Dalam iterasi pertama, yang diuji pada D1; iterasi kedua dilatih pada himpunan bagian D1, D2,D3,....Dk dan diuji pada D2; dan seterusnya. Dalam penelitian ini menggunakan 10-fold Cross Validation dan 8 fold merupakan hasil yang paling baik karena memiliki correctly classified instances terbesar dibanding jumlah fold lain.
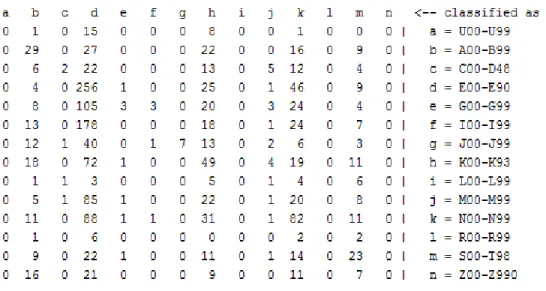
Gambar 4.8 Hasil Confusion Matrix Decision Tree J48 di WEKA
68
Confusion Matrix merupakan sebuah metode untuk evaluasi yang menggunakan tabel matrix Pada gambar 4.8 dapat dilihat bahwa jika dataset terdiri dari 14 class. Evaluasi dengan Confusion Matrix menghasilkan nilai accuracy, precision dan recall.. Nilai accuracy merupakan persentase jumlah record data yang diklasifikasikan secara benar oleh sebuah algoritma dapat membuat klasifikasi setelah dilakukan pengujian pada hasil klasifikasi tersebut. Confusion Matrix berisi informasi aktual dan prediksi yang dilakukan oleh sistem klasifikasi. Beberapa persyaratan standar yang telah didefinisikan untuk matriks ini adalah :
1. True Positive (TP) : Jika hasil dari prediksi adalah positive dan nilai aktual juga positive, maka disebut True Positive (TP).
2. False Positive (FP) : Namun, jika nilai sebenarnya negative, maka dikatakan False Positive (FP).
3. False Negative (FN) :Jumlah record positif yang diklasifikasikan secara negative.
4. True Negative (TN) : Jumlah record negative yang diklasifikasikan sebagai negative.
5. Precision dan Recall : Precision adalah sebagian kecil dari contoh diambil yang relevan, sementara recall adalah sebagian kecil dari contoh yang relevan yang diambil.
6. Precision dapat dilihat sebagai ukuran ketepatan atau kualitas, sedangkan recall adalah ukuran dari kelengkapan atau kuantitas. Recall dengan nilai tinggi berarti bahwa algoritma memiliki hasil yang lebih relevan dibanding tidak relevan.
7. Recall digunakan untuk membandingkan jumlah t_pos terhadap jumlah record yang posiitf, sedangkan Precision adalah perbandingan jumlah t_neg terhadap jumlah record yang negative.
Gambar 4.8 diatas merupakan Confusion Matrix yang mengkalkulasikan nilai aktual dan prediksi. Jumlah True Positive dari class a adalah 0, sedangkan False Positive nya adalah 5. Jumlah True Positive dari class b adalah 8, sedangkan False Positive nya adalah 42. Jumlah True Positive dari class c adalah 4, sedangkan False Positive nya adalah 28. Jumlah True Positive dari class d adalah 238, sedangkan False Positive nya
adalah 817. Jumlah True Positive dari class e adalah 1, sedangkan False Positive nya adalah 24. Jumlah True Positive dari class f adalah 45, sedangkan False Positive nya adalah 139. Jumlah True Positive dari class g adalah 7, sedangkan False Positive nya adalah 19. Jumlah True Positive dari class h adalah 25, sedangkan False Positive nya adalah 155. Jumlah True Positive dari class i adalah 0, sedangkan False Positive nya adalah 0. Jumlah True Positive dari class j adalah 0, sedangkan False Positive nya adalah 8. Jumlah True Positive dari class k adalah 105, sedangkan False Positive nya adalah 332. Jumlah True Positive dari class l adalah 0, sedangkan False Positive nya adalah 0. Jumlah True Positive dari class m adalah 22, sedangkan False Positive nya adalah 124. Jumlah True Positive dari class n adalah 9, sedangkan False Positive nya adalah 57.
Perhitungan precision, recall, f-measure yang telah dilakukan dengan menggunakan rumus pada confusion matrix berturut-turut ditunjukkan pada tabel 4.6, 4.7 dan 4.8.
Tabel 4.6 Hasil Perhitungan Precision Decesion Tree J48 KODE ICD-X Precision= TP
TP+FP Hasil U00-U99 0/0 0 A00-B99 8/42 0.19047 C00-D48 4/28 0.14285 E00-E90 238/817 0.29130 G00-G99 1/24 0.04167 I00-I99 45/139 0.32374 J00-J99 7/19 0.36842 KOO-K93 25/155 0.16129 L00-L99 0/0 0
70 MOO-M99 0/8 0 NOO-N99 105/332 0.31626 R00-R99 0/0 0 S00-T98 22/124 0.17741 Z00-Z990 9/57 0.15789
Tabel 4.7 Hasil Perhitungan Recall Decesion Tree J48
KODE ICD-X Recall = TP
TP+FN Hasil U00-U99 0/25 0 A00-B99 8/103 0.07766 C00-D48 4/64 0.0625 E00-E90 238/342 0.69590 G00-G99 1/170 0.00588 I00-I99 45/241 0.186722 J00-J99 7/85 0.08235 KOO-K93 25/174 0.14367 L00-L99 0/21 0 MOO-M990 0/143 0 NOO-N99 105/226 0.46460 R00-R99 0/11 0 S00-T98 22/81 0.27160 Z00-Z990 9/64 0.140625
Tabel 4.8 Hasil Perhitungan F-Measure Decesion Tree J48
KODE ICD-X F-Measure = 2.P.R
P+R Hasil U00-U99 0/0 0 A00-B99 0.02958/0.26813 0.11031 C00-D48 0.01785/0.20535 0.08677 E00-E90 0.40543/0.9872 0.41068 G00-G99 0.00049/0.04755 0.01030 I00-I99 0.12089/0.51046 0.23684 J00-J99 0.06067/0.45077 0.13461 KOO-K93 0.046660/0.30496 0.15281 L00-L99 0/0 0 MOO-M990 0/0 0 NOO-N99 0.29386/0.78086 0.3763 R00-R99 0/0 0 S00-T98 0.09636/0.44901 0.21462 Z00-Z990 0.04440/0.298515 0.14875 .
4.3.2 Naive Bayes
Naive Bayes adalah metode pembelajaran yang didasarkan pada hipotesis sederhana. Pada Naive Bayes ada atau tidaknya dari fitur tertentu dari kelas tidak berhubungan dengan ada atau tidaknya dari fitur lainnya. Namun, meskipun Naive Bayes terlihat kuat dan efisien, kinerjanya tetap sebanding dengan teknik data mining lainnya. Naive Bayes classifier adalah linear classifier , serta analisis diskriminan linier, regresi logistik atau linier SVM ( support vector mesin). Perbedaannya terletak pada metode estimasi parameter dari classifier nya. Naïve Bayes classifier secara luas digunakan dalam dunia penelitian. Para peneliti mengemukakan bahwa Naive Bayes sangat mudah untuk program dan penerapannya, parameter yang mudah untuk diperkirakan, metode pembelajaran yang cepat bahkan pada database yang sangat besar, akurasinya cukup baik dibandingkan dengan teknik data mining yang lain. Di sisi lain , pengguna akhir tidak mendapatkan model mudah untuk menafsirkan dan menyebarkan. Dalam menguji kinerja Naive Bayes dapat menggunakan tools WEKA, yang dapat diihat pada tabel 4.9 adalah hasil dari perhitungan algoritma Naive Bayes dengan menggunakan test option Cross Validation.
Tabel 4.9 Naïve Bayes menggunakan K-Fold Cross Validation
Cross Validation 2 3 4 5 6 7 8 9 10 Correctly Classified Instances 27.7714 29.4286 29.6571 29.7714 29.7714 29.8857 29.8857 29.8857 29.8857 Incorrectly Classified Instances 72.2286 70.5714 70.3429 70.2286 70.2286 70.1143 70.1143 70.1143 70.1143
Pada Cross Validation data yang ada pada data sampel mempunyai peluang yang sama untuk menjadi data training dan data tes. Dapat dilihat pada tabel 4.9, algoritma Naive Bayes menggunakan model pengujian Cross Validation, yang dapat dihasilkan nilai terbaik pada 7 fold sampai 10 fold dengan nilai 29.8857. Indeks berisi sama ( atau kira-kira sama ) proporsi dari bilangan bulat 1 sampai K yang mendefinisikan partisi dari pengamatan N ke K menguraikan subset . Panggilan berulang kembali partisi dibuat secara acak dan berbeda. Pada K - fold Cross Validation, K - 1 lipatan digunakan untuk pelatihan dan lipatan terakhir digunakan untuk evaluasi. Proses ini diulang K kali , meninggalkan satu nilai yang berbeda untuk evaluasi setiap kalinya . Data pada cross validation yang digunakan untuk membentuk hasil klasifikasi dan untuk mengetesnya pun berbeda. Walaupun, merupakan satu kesatuan data. Fungsi Cross Validation menciptakan partisi acak, yang tergantung pada keadaan default nilai acak . Maka dari itu, hasil yang didapat akan berbeda dengan nilai yang berbeda pula.
Gambar 4.9 Hasil Confusion Matrix Naïve Bayes di WEKA
Pada gambar 4.9 merupakan Confusion Matrix yang mengkalkulasikan nilai aktual dan prediksi. Jumlah True Positive dari class a adalah 0, sedangkan False Positive nya adalah 0. Jumlah True Positive dari class b adalah 29, sedangkan False Positive nya adalah 150. Jumlah True Positive dari class c adalah 2, sedangkan False Positive nya adalah 5. Jumlah True Positive dari class d adalah 256, sedangkan False
74
Positive nya adalah 337. Jumlah True Positive dari class e adalah 3, sedangkan False Positive nya adalah 8. Jumlah True Positive dari class f adalah 0, sedangkan False Positive nya adalah 5. Jumlah True Positive dari class g adalah 7, sedangkan False Positive nya adalah 7. Jumlah True Positive dari class h adalah 49, sedangkan False Positive nya adalah 246. Jumlah True Positive dari class i adalah 0, sedangkan False Positive nya adalah 0. Jumlah True Positive dari class j adalah 1, sedangkan False Positive nya adalah 20. Jumlah True Positive dari class k adalah 82, sedangkan False Positive nya adalah 281. Jumlah True Positive dari class l adalah 0, sedangkan False Positive nya adalah 0. Jumlah True Positive dari class m adalah 23, sedangkan False Positive nya adalah 104. Jumlah True Positive dari class n adalah 0, sedangkan False Positive nya adalah 0.
Perhitungan precision, recall, f-measure yang telah dilakukan dengan menggunakan rumus pada confusion matrix berturut-turut ditunjukkan pada tabel 4.10, 4.11 dan 4.12.
Tabel 4.10 Hasil Perhitungan Precision Naïve Bayes
KODE ICD-X Precision= TP TP+FP Hasil U00-U99 0/0 0 A00-B99 29/134 0.2164 C00-D48 2/5 0.4 E00-E90 256/940 0.2723 G00-G99 3/8 0.375 I00-I99 0/5 0 J00-J99 7/7 1 K00-K93 49/246 0.1991 L00-L99 0/0 0
M00-M99 1/20 0.05
N00-N99 82/281 0.2918
R00-R99 0/0 0
S00-T98 23/104 0.2211
Z00-Z990 0/0 0
Tabel 4.11 Hasil Perhitungan Recall Naïve Bayes
KODE ICD-X Recall = TP TP+FN Hasil U00-U99 0/25 0 A00-B99 29/103 0.2815 C00-D48 2/64 0.0312 E00-E90 256/342 0.7485 G00-G99 3/173 0.0173 I00-I99 0/241 0 J00-J99 7/85 0.0823 K00-K93 49/174 0.2816 L00-L99 0/21 0 M00-M990 1/143 0.0069 N00-N99 82/226 0.3628 R00-R99 0/11 0 S00-T98 23/81 0.2839 Z00-Z990 0/64 0
76
Tabel 4.12 Hasil Perhitungan F-Measure Naïve Bayes
KODE ICD-X F-Measure = 2.P.R P+R Hasil U00-U99 0/0 0 A00-B99 0.121824/0.498 0.245 C00-D48 0.0248/0.431 0.058 E00-E90 0.4074/1.021 0.399 G00-G99 0.0135/0.393 0.034 I00-I99 0/0 0 J00-J99 0.164/1.082 0.152 KOO-K93 0.1122/0.481 0.233 L00-L99 0/0 0 MOO-M990 0.0007/0.057 0.012 NOO-N99 0.2119/0.655 0.323 R00-R99 0/0 0 S00-T98 0.1255/0.505 0.249 Z00-Z990 0/0 0
Dari perhitungan Precision dan Recall dapat dihasilkan F-Measure tertinggi pada Kode ICDX E00-E90, sebesar 0.399. Dapat diartikan pada teknik Naïve Bayes, penyakit yang paling banyak diderita pada triwulan tahun 2012 adalah pasien yang menderita pada diagnosa Endokrin, Nutrisi dan Gangguan Metabolik dengan kode ICDX E00-E90.
4.4 Perbandingan Algoritma Decision Tree J48 dan Naïve Bayes
Pemecahan suatu masalah tidak hanya dapat diselesaikan oleh satu metode. Penyelesaian masalah bisa diselesaikan dengan menggunakan beberapa metode dan logika yang berlainan. Membandingkan metode mana yang dapat dinilai baik dalam penyelesaian masalah dapat dilihat dari berbagai aspek. Diantaranya :
1. Tingkat Kepercayaan tinggi (realibility). Hasil yang diperoleh dari proses memiliki akurasi yang tinggi dan benar
2. Proses yang efisien yaitu proses harus diselesaikan secepat mungkin dan frekuensi kalkulasi yang sependek mungkin.
3. Bersifat general, maksudnya tidak hanya menyelesaikan satu kasus saja, tetapi kasus lain yang lebih general.
4. Bisa dikembangkan (expendable). Harus menjadi sesuatu yang dapat dikembangkan lebih jauh bedasarkan requirement yang ada.
5. Mudah dimengerti, Siapa saja yang melihat, orang itu akan dapat dengan mudah memahami algoritma tersebut. Karena jika sulit untuk dimengerti, maka akan suliit untuk dikelola.
6. Portabilitas yang tinggi (portability). Bisa dengan mudah diimplementasikan dimana saja.
7. Precise(tepat, benar, teliti). Setiap instruksi harus ditulis dengan baik dan tidak ada keragu-raguan, dengan demikian setiap instruksi harus dinyatakan secara eksplisit dan tidak ada bagian yang dihilangkan karena user dianggap sudah mengerti.
Sedangkan Kriteria algoritma yang dinilai baik menurut Donald E. Knuth yaitu: 1. Input : algoritma memiliki nol atau lebih inputan dari luar.
2. Output : algoritma harus memiliki minimal satu buah output keluaran. 3. Definiteness : algoritma harus memiliki instruksi-instruksi yang jelas dan
tidak ambigu.
78
5. Efectiveness : algoritma harus sebisa mungkin harus dapat dilakukan secara efektif.
Dari hal tersebut, dapat dilakukan perbandingan algoritma Decision Tree J48 dan Naïve Bayes dari beberapa aspek yang bisa dibandingkan, seperti seberapa efektif algoritma tersebut dapat mengelompokkan pola penyakit, tingkat keakuratan dan aspek lainnya. Berikut perbandingan Algoritma Decision Tree dan J48 naive bayes.
Tabel 4.13 Perbandingan Precision Decision Tree J48 dan Naïve Bayes
Gambar 4.10 Grafik Perbandingan Precision DT J48 dan Naïve Bayes
Dari tabel 4.13 dapat dilihat sebarapa baik tingkat Precision dari hasil komputasi menggunakan algoritma Decision Tree J48 dan Naïve Bayes. Pada hasil komputasi precision dengan kode icdx U00-099 kedua algoritma tersebut sama-sama menghasilkan precision 0. Hasil komputasi pada kode icdx A00-B99 algoritma Naïve Bayes menghasilkan hasil yang lebih baik, yaitu 0.2164 sedangkan decision tree j48 hanya 0.19047. Hasil komputasi kode icdx C00-D48 algoritma Naïve Bayes menghasilkan hasil yang lebih baik, yaitu 0,4 sedangka decision Tree J48 hanya 0,14285. Hasil komputasi pada kode icdx E00-E90 algoritma Decision Tree J48 menghasilkan hasil yang lebih baik, yaitu 0,29310 sedangkan naïve bayes hanya 0,2723. Hasil komputasi kode icdx G00-G99 algoritma yang menghasilkan hasil
80
yang lebih baik yaitu Naïve Bayes, yaitu 0.375 sedangkan Decision Tree J48 hanya 0.375.
Hasil komputasi pada kode icdx I00-I99 algoritma yang menghasilkan hasil yang lebih baik yaitu Decision Tree J48, yaitu 0.32374 sedangkan Naïve Bayes menghasilkan 0. Hasil komputasi kode icdx J00-J99 algoritma yang menghasilkan hasil yang lebih baik yaitu naïve bayes, yaitu 1 sedangkan decision tree j48 hanya 0,36842. Hail komputasi pada kode icdx K00-K93 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes, yaitu 0,1991 sedangkan decision tree j48 hanya 0,16129. Hasil komputasi pada kode icdx L00-L99 kedua algoritma sama-sama menghasilkan 0. Hasil komputasi pada kode icdx M00-M99 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes, dengan hasil 0,05 sedangkan decision tree j48 hanya menghasilkan 0. Hasil komputasi pada kode icdx N00-N99 algoritma yang menghasilkan hasil yang lebih baik yaitu Decision tree J48 sedangkan Naïve Bayes hanya menghasilkan 0,2918. Hasil komputasi pada kode icdx R00-R99 kedua algoritma sama-sama menghasilkan hasil 0. Hasil komputasi pada kode icdx S00-T98 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes, dengan hasil 0,2211 sedangkan Decision tree J48 hanya menghasilkan 0,17741. Hasil komputasi pada kode icdx Z00-Z99.
Algoritma yang menghasilkan hasil yang lebih baik yaitu Decision tree J48 dengan hasil 0,15789 sedangkan Naïve bayes hanya menghasilkan 0. Dari data diatas dapat dilihat ke dalam bentuk grafiknya pada gambar 4.10, dimana Naïve Bayes rata-rata memiliki precision lebih unggul (terlebih pada class dengan kode icdx J00-J99),dibanding dengan Decision Tree J48. Dapat disimpulkan algoritma yang menghasilkan tingkat precision yang lebih baik dalam pengkalsifikasian pola penyakit yaitu Naïve Bayes, karena kedua algoritma tersebut menghasilkan confusion matrix yang berbeda. Karena confusion Matrix berisi informasi actual dan prediksi yang dilakukan oleh algoritma tersebut. Naïve Bayes lebih baik dalam memprediksikan kejadian positive yaitu dimana nilai actual dan prediksi bernilai positive.
Tabel 4.14 Perbandingan Recall Decision Tree J48 dan Naïve Bayes
82
Dari tabel 4.14 dapat dilihat sebarapa baik tingkat Recall dari hasil komputasi menggunakan algoritma Decision Tree J48 dan Naïve Bayes. Pada hasil komputasi Recall dengan kode icdx U00-099 kedua algoritma tersebut sama-sama menghasilkan recall 0. Hasil komputasi pada kode icdx A00-B99 algoritma Naïve Bayes menghasilkan hasil yang lebih baik, yaitu 0.2815 sedangkan decision tree j48 hanya 0.07766. Hasil komputasi kode icdx C00-D48 algoritma Decision Tree menghasilkan hasil yang lebih baik, 0.0625 sedangkan Naïve Bayes hanya 0.0312. Hasil komputasi pada kode icdx E00-E90 algoritma Naïve Bayes menghasilkan hasil yang lebih baik, yaitu 0.7485 sedangkan Decision Tree J48 hanya 0.69590. Hasil komputasi kode icdx G00-G99 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes, yaitu 0.0173sedangkan Decision Tree J48 hanya 0.00588.
Hasil komputasi pada kode icdx I00-I99 algoritma yang menghasilkan hasil yang lebih baik yaitu Decision Tree J48, yaitu 0.186722 sedangkan Naïve Bayes menghasilkan 0. Hasil komputasi kode icdx J00-J99 kedua algoritma menghasilkan hasil yang sama yaitu 0.0823. Hail komputasi pada kode icdx K00-K93 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes, yaitu 0.2816 sedangkan decision tree J48 hanya 0.14367. Hasil komputasi pada kode icdx L00-L99 kedua algoritma sama-sama menghasilkan 0. Hasil komputasi pada kode icdx M00-M99 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes, dengan hasil 0.0069 sedangkan decision tree j48 hanya menghasilkan 0. Hasil komputasi pada kode icdx N00-N99 algoritma yang menghasilkan hasil yang lebih baik yaitu Decision tree J48 dengan hasil 0.46460 sedangkan Naïve Bayes hanya menghasilkan 0.3628. Hasil komputasi pada kode icdx R00-R99 kedua algoritma sama-sama menghasilkan hasil 0. Hasil komputasi pada kode icdx S00-T98 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes, dengan hasil 0.2839 sedangkan Decision tree J48 hanya menghasilkan 0.27160. Hasil komputasi pada kode icdx Z00-Z99 algoritma yang menghasilkan hasil yang lebih baik yaitu Decision tree J48 dengan hasil 0.140625 sedangkan Naïve bayes hanya menghasilkan 0.
Dari data diatas dapat dilihat ke dalam bentuk grafiknya pada gambar 4.11, dimana hasil recall Decision Tree J48 bersaing dengan hasil recall Naïve Bayes. Dapat disimpulkan algoritma yang menghasilkan tingkat recall yang lebih baik dalam pengkalsifikasian pola penyakit yaitu Naïve Bayes, karena kedua algoritma tersebut menghasilkan confusion matrix yang berbeda. Karena confusion Matrix
berisi informasi actual dan prediksi yang dilakukan oleh algoritma tersebut. Hal ini disebabkan naïve bayes lebih banyak memiliki record yang positif tetapi diklasifikasikan negative.
84
Gambar 4.12 Grafik Perbandingan F-Measure Decision Tree J48 dan Naïve Bayes
Dari tabel 4.15 dapat dilihat sebarapa baik tingkat F-Measure dari hasil komputasi menggunakan algoritma Decision Tree J48 dan Naïve Bayes. Pada hasil komputasi F-Measure dengan kode icdx U00-099 kedua algoritma tersebut sama-sama menghasilkan recall 0. Hasil komputasi pada kode icdx A00-B99 algoritma Naïve Bayes menghasilkan hasil yang lebih baik, yaitu 0.11031 sedangkan decision tree j48 hanya 0.245. Hasil komputasi kode icdx C00-D48 algoritma Decision Tree menghasilkan hasil yang lebih baik, 0.08677 sedangkan Naïve Bayes hanya 0.058. Hasil komputasi pada kode icdx E00-E90 algoritma Decision Tree J48 menghasilkan hasil yang lebih baik, yaitu 0.41068 sedangkan Naïve Bayes hanya 0.399. Hasil komputasi kode icdx G00-G99 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes, yaitu 0.034 sedangkan Decision Tree J48 hanya 0.01030.
Hasil komputasi pada kode icdx I00-I99 algoritma yang menghasilkan hasil yang lebih baik yaitu Decision Tree J48, yaitu 0.23684 sedangkan Naïve Bayes menghasilkan 0. Hasil komputasi kode icdx J00-J99 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes yaitu 0.152 sedangkan decision tree J48 hanya 0.152. Hasil komputasi pada kode icdx K00-K93 algoritma yang
menghasilkan hasil yang lebih baik yaitu Naïve Bayes, yaitu 0.233sedangkan decision tree j48 hanya 0.15281. Hasil komputasi pada kode icdx L00-L99 kedua algoritma sama-sama menghasilkan 0. Hasil komputasi pada kode icdx M00-M99 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes, dengan hasil 0.012 sedangkan decision tree j48 hanya menghasilkan 0. Hasil komputasi pada kode icdx N00-N99 algoritma yang menghasilkan hasil yang lebih baik yaitu Decision tree J48 dengan hasil 0.3763 sedangkan Naïve Bayes hanya menghasilkan 0.323. Hasil komputasi pada kode icdx R00-R99 kedua algoritma sama-sama menghasilkan hasil 0. Hasil komputasi pada kode icdx S00-T98 algoritma yang menghasilkan hasil yang lebih baik yaitu Naïve Bayes, dengan hasil 0.249 sedangkan Decision tree J48 hanya menghasilkan 0.21462. Hasil komputasi pada kode icdx Z00-Z99 algoritma yang menghasilkan hasil yang lebih baik yaitu Decision tree J48 dengan hasil 0.14875 sedangkan Naïve bayes hanya menghasilkan 0.
Dari data diatas dapat dilihat ke dalam bentuk grafiknya pada gambar 4.12, dimana hasil F-measure Naïve Bayes dan Decision Tree berbeda tipis, tetapi Naïve Bayes tetap unggul dengan banyak class yang menghasilkan hasil lebih tinggi dibanding dengan Decision Tree J48. Dapat disimpulkan algoritma yang menghasilkan tingkat F-Measure yang lebih baik dalam pengkalsifikasian pola penyakit yaitu Naïve Bayes, karena kedua algoritma tersebut menghasilkan confusion matrix yang berbeda. Karena confusion Matrix berisi informasi actual dan prediksi yang dilakukan oleh algoritma tersebut.
4.4.1 ROC AREA
Untuk menentukan kinerja identifikasi, ROC (Receiver Operating Characteristic) adalah analisis yang digunakan. Berdasarkan kurva yang dibentuk oleh ROC kesalahan dalam distribusi dapat diidentifikasi oleh algoritma dengan baik.
86
• U00-U99
Gambar 4.13 Kurva ROC UOO-U99
Grafik pada gambar 4.13, menggambarkan, ROC area Class U00-U99 yang menggunakan classifier Naïve Bayes menghasilkan kurva yang lebih baik, sebab terlihat classifier naïve bayes lebih menghasilkan kurva yang lebih stabil dan mengalami kenaikan yang konstan. Sedangkan kurva yang dihasilkan menggunakan classifier Decision Tree J48 hasilnya tidak lebih baik dibandingkan dengan kurva yang dihasikan menggunakan naïve bayes. Terlihat pada kurva yang dihasilkan Decision Tree J48 garis kurva mengalami kenaikan, tetapi kenaikannya tidak konstan dan garis yang dihasilkan lebih tipis dibandingkan dengan garis yang dihasilkan pada kurva yang menggunakan classifier Naïve
• A00-B99
Grafik pada gambar 4.14 menggambarkan ROC class A00-B99, kurva yang dihasilkan menggunakan classifier Naïve Bayes memiliki Kurva yang lebih baik, Kurva yang dihasilkan lebih stabil dibandingkan kurva yang menggunakan classifier Decision Tree J48 yang lebih fluktuatif. Dan dapat dilihat juga garis kurva yang dihasilkan Naïve Bayes lebih tebal dibandingkan yang dihasilkan Decision Tree J48.
• C00-D48
Gambar 4.15 Kurva ROC C00-D48
Grafik pada gambar 4.15 menggambarkan kurva yang dihasilkan menggunakan classifier Naïve Bayes lebih baik dibandingkan menggunakan classifier Decision Tree J48. Kurva yang dihasilkan Classifier decision tree J48 memiliki garis lebih tipis dan kurva yang lebih landau dibandingkan dengan yang mengguanakan classifier Decision Tree J48.
• E00-E90
88
Grafik pada gambar 4.16 menggambarkan kurva yang dihasilkan menggunakan classifier Decision Tree J48 dan Naïve Bayes memiliki hasil yang tidak jauh berbeda. Tetapi yang menggunakan classifier Decision Tree J48 memiliki hasil yang lebih baik dibandingkan Naïve Bayes. Classifier Decision Tree J48 menghasilkan ROC area sebesar 0.6677 sedangkan ROC yang dihasilkan menggunakan classifier Naïve Bayes hanya sebesar 0.6564. • G00-G99
Gambar 4.17 Kurva ROC G00-G99
Grafik pada gambar 4.17 menggambarkan kurva yang dihasilkan dengan menggunakan classifier Decision Tree J48 dan Naïve Bayes. Dari dua classifier tersebut menghasilkan hasil ROC area yang sama, yaitu sebesar 0.5218.
• I00-I99
Grafik pada gambar 4.18 menggambarkan kurva yang dihasilkan dengan menggunakan classifier Decision Tree J48 dan Naïve Bayes. Dapat dilihat kedua classifier tersebut menghasilkan nilai ROC area yang relatif sama. Tetapi ROC area yang dihasilkan menggunakan classifier decision tree j48 lebih baik dibandingkan dengan menggunakan classifier naïve bayes. ROC area yang dihasilkan menggunakan Decision Tree J48 sebesar 0.6156 sedangkan yang menggunakan Naïve Bayes sebesar 0.6097
• J00-J99
Gambar 4.19 Kurva ROC J00-J99
Grafik pada gambar 4.19, menggambarkan kurva yang dihasilkan dengan menggunakan classifier Decision Tree J48 dan Naïve Bayes. Dapat dilihat kedua classifier tersebut menghasilkan nilai ROC area yang tidak jauh berbeda. ROC yang dihasilkan dengan menggunakan classifier Decision Tree J48 sebesar 0.5997 sedangkan ROC yang dihasilkan menggunakan Naïve Bayes hanya sebesar 0.5832.
• K00-K93
Gambar 4.20 Kurva ROC K00-K93
90
Grafik pada gambar 4.20 menggambarkan ROC area yang dihasilkan menggunakan dua classifier yaitu Decision Tree J48 dan Naïve Bayes. Classifier yang menghasilkan nilai ROC yang lebih baik yaitu yang menggunakan Naïve Bayes. Terlihat kurva yang dihasilkan menggunakan Naïve Bayes memiliki garis yang lebih tebal dan stabil.
• L00-L99
Gambar 4.21 Kurva ROC L00-L99
Grafik pada gambar 4.21 menggambarkan ROC area yang dihasilkan menggunakan dua classifier yaitu Decision Tree J48 dan Naïve Bayes. Classifier yang menggunakan Naïve Bayes menghasilkan kurva yang lebih baik, karena mengalami kenaikan yang konstan sehingga menghasilkan nila 0.6661 sedangkan Naïve Bayes memiliki kurva yang fluktuatif dan hanya menghasilkan nilai ROC sebesar 0.5943
• M00-M99
Gambar 4.22 Kurva ROC M00-M99
Grafik pada gambar 4.22 menggambarkan ROC area yang dihasilkan menggunakan dua classifier yaitu Decision Tree J48 dan Naïve Bayes. Classifier yang menggunakan Decision Tree J48 menghasilkan kurva yang lebih baik, karena mengalami kenaikan yang konstan sehingga menghasilkan nila 0.5878 sedangkan Naïve Bayes memiliki kurva yang fluktuatif dan hanya menghasilkan nilai ROC sebesar 0.5693
• N00-N99
Gambar 4.23 Kurva ROC N00-N99
Grafik pada gambar 4.23 menggambarkan ROC area yang dihasilkan menggunakan dua classifier yaitu Decision Tree J48 dan Naïve Bayes. Kurva yang dihasilkan Naïve Bayes lebih baik dibandingkan yang menggunakan Decision Tree J48. Hal tersebut dapat dilihat melalui kurva yang dihasilkan menggunakan Naïve Bayes, pada kurva ini Naïve Bayes menghasilkan kurva yang lebih stabil dibandingkan dengan Decision Tree J48.
• R00-R99
92
Grafik pada gambar 4.24 menggambarkan ROC area yang dihasilkan menggunakan dua classifier yaitu Decision Tree J48 dan Naïve Bayes. Kedua classifier menghasilkan nilai ROC yang tidak jauh berbeda. Kurva yang dihasilkan Decision Tree J48 memiliki nilai ROC 0.3453 sedangkan yang dihasilkan Naïve Bayes hanya bernilai 0.313
• S00-T98
Gambar 4.25 Kurva ROC S00-T98
Grafik pada gambar 4.25 menggambarkan ROC area yang dihasilkan menggunakan dua classifier yaitu Decision Tree J48 dan Naïve Bayes. Kurva yang dihasilkan menggunakan classifier Naïve Bayes mengasilkan ROC area yang lebih baik sebesar 0.7492 sedangkan ROC area yang dihasilkan menggunakan classifier Decision Tree J48 hanya sebesar 0.6576. Terlihat perbedaan kurva yang dihasilkan, kurva yang dihasilkan menggunakan Naïve Bayes mempunyai garis yang lebih tebal.
• Z00-Z990
Grafik pada gambar 4.26 menggambarkan ROC area yang dihasilkan menggunakan dua classifier yaitu Decision Tree J48 dan Naïve Bayes. Kedua classifier tersebut menghasilkan kurva yang tidak jauh berbeda. Naïve Bayes menghasilkan nilai ROC area sebesar 0.6179 dan kurva yang dihasilkan menggunakan Decision Tree J48 bernilai 0.6137.
Tabel 4.16 Perbandingan Algoritma Decision Tree J48 dan Naïve Bayes
KODE ICD-X
Decision Tree
Naïve Bayes
Better
U00-U99 0.5956 0.605 Naïve Bayes
A00-B99 0.715 0.735 Naïve Bayes
C00-D48 0.5169 0.5527 Naïve Nayes
E00-E90 0.6677 0.6564 Decision Tree
G00-G99 0.5128 0.5128 Both
I00-I99 0.6156 0.6097 Decision Tree
J00-J99 0.5997 0.5832 Decision Tree K00-K93 0.6189 0.6159 Decision Tree L00-L99 0.5943 0.6661 Naïve Bayes M00-M99 0.5878 0.5693 Decision Tree N00-N99 0.6527 0.6982 Naïve Bayes R00-R99 0.3453 0.313 Decision Tree S00-T98 0.6576 0.7492 Naïve Bayes Z00-Z990 0.6137 0.6179 Naïve Bayes
Dari data tabel 4.16 Algoritma naïve bayes lebih baik dalam melakukan pengklasifikasian penyakit. Algoritma Naïve Bayes lebih baik dalam mengklasifikasikan penyakit dengan kode U00-U99,A00-B99, C00-D48, L00-L99, N00-N99, S00-T98 dan Z00-Z99. Sedangkan Algoritma Decision Tree J48 hanya baik dalam mengklasifikasikan penyakit dengan kode E00-E90, I00-I99, J00-J99, K00-K93, M00-M99 dan R00-R99. Sedangkan pengklasifikasian penyakit dengan kode icdx G00-G99, kedua algoritma sama-sama dapat mengklasfikasikannya dengan nilai ROC area yang sama.