1 1.1 Latar Belakang Masalah
Kebutuhan akan informasi yang cepat, tepat dan akurat sangatlah mutlak, terutama dalam era globalisasi dalam skala luas maupun era otonomi daerah dalam lingkup yang lebih sempit. Dalam era otonomi daerah sekarang ini sangat disyaratkan bagi suatu daerah untuk mampu bersaing dengan daerah yang lain, sehingga perlu bagi suatu daerah untuk memaksimalkan kelebihan yang dimilikinya.
Bidang statistika kesehatan, seperti halnya bidang-bidang lainnya membutuhkan tersedianya informasi yang cepat dan akurat, guna melakukan pengambilan keputusan dalam menghadapi era globalisasi yang penuh persaingan. Pengambilan suatu keputusan terkadang membutuhkan ketersediaan informasi yang mendukung, yang mana informasi tersebut berasal dari data yang diperoleh dan telah diolah. Untuk itu perlu dilakukan suatu usaha memperoleh data yang mampu memberikan informasi yang cepat dan akurat. Dalam hal ini diperlukan suatu penelitian, terhadap obyek yang ingin diambil informasinya, dimana populasi mengenai informasi yang diinginkan memang terbatas dan ditentukan batasnya (finite and delimited). Karena apabila permasalahan penggalian informasi yang berhubungan dengan kumpulan besar unit-unit populasi yang ada, maka suatu survei sampel dilakukan terhadap suatu populasi dengan melakukan penarikan sampel unit-unit populasi tersebut. Hal ini dilakukan untuk memperoleh hasil ketepatan informasi yang diinginkan dengan mengeluarkan biaya yang relatif rendah, karena jika dibandingkan dengan melakukan suatu pencacahan lengkap akan memerlukan biaya yang besar dan waktu yang lama. Informasi yang diperoleh dari hasil suatu survei kadang-kadang mempunyai ketepatan yang rendah, sehingga perlu ditentukan tingkat ketepatan yang mencukupi. Dapat
dikatakan suatu survei pada populasi tertentu dilakukan untuk memperoleh infomasi maksimum per unit biaya.
Setelah diputuskan untuk melakukan suatu survei maka diperlukan suatu perencanaan survei dengan mempertimbangkan hal-hal sebagai berikut (Hansen,1953):
1. Populasi hendaknya digali informasinya. Informasi yang dibutuhkan pada survei ini berhubungan dengan pemakaian kontrasepsi dalam upaya KB yang mana peserta dari tiap-tiap kecamatan, kelurahan/desa merupakan unit-unit elementer dari populasi.
2. Informasi yang dibutuhkan dari unit-unit populasi. Informasi yang dibutuhkan berupa data yang terdiri dari angka-angka yang merupakan nilai sesungguhnya dari populasi dan biasanya merupakan suatu kumpulan atau rata-rata nilai dari individu-individu anggota populasi. 3. Ketepatan hasil yang diinginkan. Perkiraan atau estimasi dari suatu
sampel umumnya akan berbeda dari nilai yang sesungguhnya (nilai dari populasi yang diestimasi) tetapi diharapkan perbedaan yang ditimbulkan cukup kecil sehingga tujuan yang hendak dicapai dari penelitian tersebut terpenuhi.
Untuk itu diperlukan suatu metode penarikan sampel (Sampling Method) yang benar-benar sesuai, yang dengan sampel relatif kecil mampu memberikan hasil yang mendekati karakteristik dari suatu populasi yang besar. Yang artinya mampu memberikan ketepatan (precision) yang tinggi terhadap karakteristik suatu populasi, akan tetapi ketepatan hasil yang diperoleh dari suatu survei sampel tidak hanya tergantung pada ukuran dari sampel tetapi juga pada hal-hal lain yang terkait pada rancangan sampel, seperti bagaimana sampel dipilih dan cara bagaimana hasil survei sampel diestimasi. Rancangan sampel yang efisien dalam hal ini adalah yang mampu memanfaatkan sumber-sumber informasi statistik dan pengetahuan lain yang berkenaan dengan populasi secara efektif bersama dengan teori dan metode sampling.
Pada umumya ada banyak alternatif pilihan rancangan sampel serta teknik penarikan sampel yang dapat diterapkan pada suatu permasalahn survei tertentu. Dengan memahami serta membandingkan efisiensi dari masing-masing alternatif rancangan sampel yang akan didapat pilihan rancangan sampel yang tepat. Dalam memahami dan membandingkan alternatif rancangan yang ada diperlukan kriteria pemilihan sampel yang sesuai dengan permasalahan yang dihadapi. Kriteria yang digunakan adalah untuk merancang sampel sehingga akan memberikan hasil dengan ketepatan yang diperlukan pada biaya yang minimal atau sebaliknya dengan biaya terbatas diperoleh hasil yang mampu mengestimasi karakteristik populasi yang diinginkan dengan ketepatan maksimal.
Oleh karena itu dipilih sebuah metode penarikan sampel yang sesuai dengan kriteria pemilihan rancangan sampel yang tepat, seperti telah disebutkan diatas bahwa perbedaan rancangan sampel beserta metode estimasinya tanpa ada perubahan ukuran sampel dapat memberikan hasil dengan ketepatan yang berbeda. Rancangan atau teknik ini dipilih karena berdasarkan teori memiliki keunggulan dalam meminimumkan biaya, sebab biaya perunit sampel yang dikeluarkan akan berkurang dengan dilakukannya penggelompokkan unit-unit sampel.
Akan tetapi penerapan suatu metode sampling tertentu tidak sepenuhnya dapat dilakukan sama persis dengan teori yang ada. Keadaan obyek penelitian akan sangat menentukan pelaksanaan penelitian dilapangan. Metode sampling yang digunakan dapat berubah untuk menyesuaikan keadaan obyek penelitian. Penggunaan teknik klaster dua tahap di DIY ini juga dilakukan penyesuaian dengan keadaan dilapangan, antara lain sub penarikan sampel dimana unit-unitnya bervariansi dalam ukuran.
Pengelompokan data populasi ini juga masih dirasa akan sangat menyulitkan dalam pengambilan sampel, sehingga dikembangkan pengambilan sampel kluster hingga dua tahap. Dengan pengambilan sampel klaster dua tahap ini, maka bias yang ada tidak terlalu besar dan sampel yang harus diambil juga tidak besar.
Dalam hal ini, akan dipaparkan mengenai teknik pengambilan sampel klaster dua tahap dengan pendekatan estimator HH dan HT . Estimator HH dan HT ini bisa digunakan untuk berbagai jumlah tahapan dalam pengambilan sampel klaster.
1.2 Perumusan Batasan Masalah
Berdasarkan uraian diatas, kita mengenal berbagai macam metode pengambilan sampel untuk memperoleh data dan informasi yang akuntable. Semua metode yang kita kenal memiliki kelebihan dan kekurangan masing-masing. Dalam skripsi ini, pembahasan akan dibatasi pada Perbandingan antara Estimator Hansen-Hurwitz dan Horvitz-Thompson pada klaster dua tahap pps dengan pengembalian sampling untuk mengestimasi total dan rata-rata populasi dari pengambilan sampling
1.3 Tujuan Penelitian
Skripsi ini di susun sebagai salah satu syarat untuk memperoleh gelar sarjana sains di Program Studi Statistika pada Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Gadjah Mada. Tujuan yang ingin dicapai dari penulisan skripsi ini adalah :
1. Mempelajari konsep metode pengambilan sampel klaster dua tahap sebagai metode survei yang efektif dan efisien untuk karakteristik populasi yang heterogen.
2. Menentukan estimator populasi dalam pengambilan sampel klaster dua tahap menggunakan pendekatan estimator Hurvitz-Thompson dan Hansen-Hurwitz.
3. Mengaplikasikan metode pengambilan sampel klaster dua tahap untuk mengestimasi rata-rata dan jumlah data.
1.4 Manfaat Penulisan
1. Menambah keilmuan statistika terutama pada bidang survei sampel. 2. Mempopulerkan salah satu metode survei sampel dalam statistika untuk
mengefisienkan proses survei.
1.5 Tinjauan Pustaka
Penulisan skripsi ini berangkat dari banyak penulisan skripsi dengan tema pengambilan sampel klaster yang telah dilakukan. Karya tulis tersebut adalah sebagi berikut :
1. Nurvianto (2005) dengan judul “Penarikan Sampel Berkelompok Satu Tahap dengan kelompok Berukuran Tidak Sama”
2. Adi (2005) dengan judul “Penarikan Sampel Klaster Tiga tahap dalam Survei Produktivitas Padi di Kabupaten Bantul”
Karya tulis ini lebih membahas mengenai metode pengambilan sampel dalam dunia pertanian. Metode tiga tahap yang digunakan pun menggunakan estimator pengambilan sampel sederhana.
Perbedaan skripsi ini dengan karya tulis lainnya yang ditemui pada tema pengambilan sampel klaster sebelumnya adalah karya tulis ini membahas pengambilan sampel klaster dua tahap dengan pendekatan Estimator Hansen-Hurwitz dan Hurwitz-Thompson dengan pps sampling pengembalian.
Literatur yang digunakan dalam skripsi ini adalah tulisan Mohammad Salehi M (2002) dengan judul “Comparison beetween Hansen-Hurwitz and Horvitz-Thompson Estimator for Adaptive Cluster Sampling” dan tulisan George A.F.Seber (1997) dengan judul “Two Stage Adaptive Cluster Sampling” sebagai tinjauan pustaka dalam teknik pengambilan sampel klaster dua tahap.
1.6 Metode Penulisan
Metode Penulisan dalam skripsi ini adalah berdasarkan studi literatur yang didapat dari perpustakaan serta jurnal-jurnal dan buku-buku yang berhubungan dengan tema skripsi ini. Sumber lainnya juga diperoleh melalui situs-situs pendukung yang tersedia di internet. Pengerjaan skripsi ini juga ditunjang dengan beberapa perangkat lunak diantaranya R versi 3.2.2 dan Microsoft Office Excel.
1.7 Sistematika Penulisan
Agar penulisan skripsi ini terarah dan sistematis, maka secara garis besar skripsi ini disusun dengan sistematika sebagai berikut :
BAB I PENDAHULUAN
Bab ini membahas Latar Belakang Masalah, Perumusan dan Batasan Masalah, Tujuan Penulisan, Manfaat Penelitian, Tinjauan Pustaka, Metode Penulisan dan Sistematika Penulisan.
BAB II LANDASAN TEORI
Bab ini membahas mengenai konsep-konsep dasar yang berkaitan dengan skripsi. Diantaranya adalah konsep dasar tentang metode survei sampel yang berkaitan dengan pembahasan pokok permasalahan.
BAB III PEMBAHASAN
Bagian ini menguraikan tentang konsep pengambilan sampel klaster dua tahap dalam meningkatkan efektifitas dan efisiensi survei. Di sini juga akan dibahas bagaimana membentuk klaster data populasi sehingga diperoleh klaster yang homogen. Lebih jauh akan dibahas mengenai kelebihan estimator Hansen Hurwitz dan Horvitz-Thompson dengan pps pengembalian.
BAB IV STUDI KASUS
Bab ini menguraikan tentang penerapan metode pengambilan sampel klaster dua tahap pada data
BAB V PENUTUP
Bab ini berisi beberapa kesimpulan yang diperoleh dari hasil pembahasan pada bab-bab sebelumnya dan juga saran-saran atas permasalahan yang dihadapi.
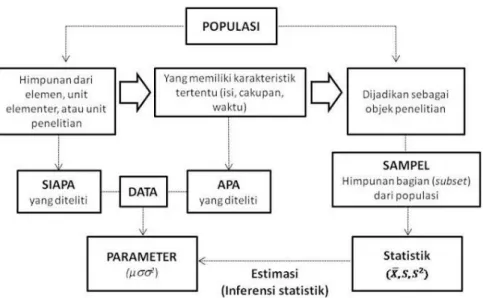
8 2.1 Populasi dan Sampel
Gambar 2.1 Populasi dan Sampel
2.1.1 Populasi
Definisi 2.1.1 (Walpole, 1995)
Populasi adalah keseluruhan pengamatan yang menjadi perhatian kita. Di waktu lampau, istilah “populasi” mengandung pengamatan yang diperoleh dari penelitian statistik yang berhubungan dengan orang banyak. Di masa kini, statistikawan menggunakan istilah itu bagi sembarang pengamatan yang menarik perhatian kita, misalnya sekelompok orang, binatang atau benda apa saja dimana sifat-sifat yang ada padanya dapat diukur atau diamati. Banyaknya pengamatan atau anggota suatu populasi disebut ukuran populasi. Populasi yang tidak pernah diketahui dengan pasti jumlahnya disebut populasi tak hingga, sedangkan populasi yang jumlahnya diketahui dengan pasti disebut populasi terhingga.
Dalam inferensi statistika, kita ingin memperoleh kesimpulan mengenai populasi, meskipun kita mungkin atau tidak praktis untuk mengamati keseluruhan individu yang menyusun populasi. Misalnya saja dalam usaha menentukan umur rata-rata suatu mesin jenis tertentu, adalah tidak mungkin untuk menguji semua mesin yang ada kalau kita masih ingin menjualnya. Biaya yang besar lebih sering menjadi faktor penghalang untuk mengamati semua anggota populasi. Oleh karena itu, kita terpaksa menggantungkan pada sebagian anggota populasi untu membantu kita menarik kesimpulan mengenai populasi tersebut.
2.1.2 Sampel
Definisi 2.1.2 (Walpole,1995)
Sampel adalah suatu himpunan bagian dari populasi.
Jika kita menginginkan kesimpulan dari sampel terhadap populasi, maka kita harus mempunyai sampel yang dapat mewakili populasi. Seringkali kita tergoda untuk mengambil anggota populasi yang memudahkan kita. Cara demikian ini dapat membawa pada kesimpulan yang salah mengenai populasi. Prosedur pengambilan sampel yang menghasilkan kesimpulan yang konsisten terlalu tinggi atau terlalu rendah mengenai suatu ciri populasi dikatakan berbias. Untuk menghilangkan bias ini, muncullah berbagai jenis metode pengambilan sampel dari populasi.
2.2 Variabel Random
Istilah percobaan statistika telah digunakan untuk menjelaskan sembarang proses/aktivitas yang menghasilkan data/hasil yang dikumpulkan dalam ruang sampel. Seringkali, kita tidak tertarik pada keterangan rinci tentang titik sampel, tetapi hanya pada suati keterangan numerik hasi percobaan, sehingga kita membutuhkan variabel random.
2.2.1 Variabel Random
Definisi 2.2.1 (Bain dan Engelhardt,1992)
“Variabel Random X adalah fungsi yang didefinisikan pada ruang sampel yang dipetakan ke bilangan riil; ( ) , untuk setiap hasil yang mungkin pada S”.
Huruf kapital X, Y, Z digunakan untuk menotasikan suatu variabel random dan huruf kecilnya x,y,z untuk menyatakan nilai yang mungkin dari setiap hasil observasi pada ruang sampel.
2.2.2 Variabel Random Diskrit
Definisi 2.2.2 (Bain dan Engelhardt,1992)
Variabel random X disebut variabel random diskrit jika himpunan semua nilai yang mungkin muncul dari X merupakan himpunan terhitung (countable)
Fungsi :
( ) dimana
Disebut fungsi kepadatan probabilitas diskrit (discrete pdf)
Fungsi distribusi kumulatif dan variabel random X didefinisikan sebagai :
( )
2.2.3 Variabel Random Kontinu
Definisi 2.2.3 (Bain dan Engelhardt,1992)
Variabel random X disebut variabel random kontinu jika terdapat fungsi ( ) yang merupakan fungsi kepadatan probabilitas dari X, dimana fungsi distribusi kumulatifnya dapat ditunjukkan sebagai :
( ) ∫ ( )
(2.1)
(2.2)
2.3 Ekspektasi dan Variansi 2.3.1 Ekspektasi
Definisi 2.3.1 Ekspektasi
Jika X adalah variabel random dengan fungsi kepadatan probabilitas
( ) maka nilai ekspektasi dari X didefinisikan sebagai :
( ) ∑ ( )
( ) ∫ ( )
( ) seringkali ditulis dengan notasi dan ̅.
2.3.2 Variansi
Definisi 2.3.2 Variansi
Variansi dari variabel random X ditunjukkan oleh :
( ) ( ̅) ( ) ̅
Notasi untuk variansi adalah , sehingga didapatkan:
( ) ̅
2.4 Distribusi Normal
Distribusi normal pertama kali diperkenalkan oleh Abraham de Moivre pada tahun 1733 sebagai pendekatan untuk distribusi dari jumlahan variabel random binomial. Distribusi normal merupakan distribusi terpenting dalam probabilitas dan statistika
Definisi 2.9 (Bain dan Engelhardt,1992:118).
Suatu variabel random X mengikuti distribusi normal dengan mean dan variansi , dinotasikan ( ), dengan pdf
( ) √ ( ( ) ) (2.4) (2.5) (2.6) (2.7) (2.8)
2.5 Teori Dasar Pengambilan Sampel
2.5.1 Kegunaan metode pengambilan sampel
Berikut adalah keuntungan dari pengambilan sampel sebagai perbandingan dalam pencacahan lengkap.
a. Mengurangi Biaya
Jika data yang telah diperoleh berasal dari sebagian kecil populasi, maka pengeluaran atau biaya akan lebih murah daripada melakukan sensus lengkap. Dengan populasi besar, hasil yang cukup akurat dapat diperoleh dari sampel yang didapatkan dengan fraksi yang kecil dari populasi.
b. Kecepatan Lebih Besar
Data dapat dikumpulkan dan diringkas lebih cepat dengan sebuah sampel daripada dengan perhitungan lengkap. Hal ini merupakan sebuah pertimbangan yang penting bila membutuhkan informasi yang lebih cepat.
c. Cakupan Lebih Besar
Survei-survei yang bertumpu pada pengembalian sampel haruslah lebih besar cakupannya dan fleksibel mengenai jenis informasi yang dapat diperoleh.
d. Tingat Ketelitian Lebih Besar
Sebuah sampel mungkin memberikan hasil yang lebih teliti daripada pencacahan lengkap, jika dipakai tenaga-tenaga yang berkualitas baik dan diberi latihan yang intensif, serta pengawasan terhadap pekerjaan lapangan diperketat.
2.5.2 Tahap-tahap dalam survei sampel
Tahap dalam pengambilan sampel merupakan metode dalam memilih sampel dari populasi yang digunakan untuk suatu penelitian atau studi kasus tertentu. Berikut adalah tahap-tahap dalam sebuah survei
a. Memilih populasi
Proses awal adalah menentukan populasi yang menarik untuk dipelajari. Suatu populasi yang baik adalah yang mencakup rancangan eksplisit semua elemen yang terlibat, biasanya meliputi beberapa komponen diantaranya yaitu, elemen, unit sampling, keluasan skop dan waktu. b. Memilih unit-unit sampling
Unit-unit sampling adalah unit analisa dari sampel yang diambil atau berasal, karena kompleksitas penelitian dan banyaknya desain sampel, maka pemilihan unit-unit sampling harus dilakukan dengan seksama. c. Memilih Kerangka Sampling
Pemilihan kerangka sampling merupakan tahap yang penting karena jika kerangka sampling dipilih secara memadai tidak mewakili populasi, maka generalisasi hasil penelitian meragukan. Kerangka sampling dapat berupa daftar nama populasi seperti buku telepon atau database nama lainnya.
d. Memilih Desain Sampel
Desain sampel merupakan tipe metode atau pendekatan yang digunakan untuk memilih unit-unit analisa studi. Desain sampel sebaiknya dipilih sesuai dengan tujuan penelitian.
e. Memilih Ukuran Sampel
Ukuran sampel tergantung beberapa faktor yang mempengaruhi diantaranya adalah :
- Homogenitas unit-unit sampel
Secara umum semakin mirip unit-unit sampel. Dalam suatu populasi semakin kecil sampel yang dibutuhkan untuk memperkirakan parameter-parameter populasi.
- Kepercayaan
Kepercayaan mengacu pada suatu tingkat dimana peneliti merasa yakin bahwa yang bersangkutan memperkirakan secara nyata parameter populasi yang benar. Semakin tinggi tingkat kepercayaan yang diinginkan, maka semakin besar ukuran sampel yang diperlukan.
- Presisi
Presisi mengacu pada ukuran kesalahan standar estimasi. Untuk mendapatkan presisi yang besar dibutuhkan ukuran sampel yang besar pula.
- Kekuatan Statistik
Istilah ini mengacu pada adanya kemampuan mendeteksi perbedaan dalam istilah pengujian hipotesis. Untuk mendapatkan kekuatan yang tinggi, peneliti memerlukan sampel yang besar
- Prosedur Analisa
Tipe prosedur analisa yang dipilih untuk menganalisa data dapat juga mempengaruhi seleksi ukuran sampel.
- Biaya, waktu dan Personil
Pemilihan ukuran sampel juga harus mempertimbangkan biaya, waktu dan personil. Sampel besar akan menuntut biaya besar, waktu banyak dan personil besar juga.
f. Memilih Rancangan Sampling
Rancangan sampling menentukan prosedur operasional dan metode untuk mendapatkan sampel yang diinginkan. Jika dirancang dengan baik, rancangan sampling akan menuntun peneliti dalam memilih sampel yang digunakan dalam studi, sehingga kesalahan yang akan muncul dapat ditekan sekecil mungkin
g. Memilih Sampel
Tahap akhir dalam proses ini adalah penentuan sampel untuk digunakan pada proses penelitian berikutnya, yaitu koleksi data
2.5.3 Bias dan pengaruhnya
Dalam teori survei sampel, estimator bias perlu dipertimbangkan untuk dua alasan yaitu :
a. Pada beberapa masalah yang sangat umum, khususnya dalam estimasi rasio, estimator yang disenangi dan cocok didapat ternyata menjadi bias.
b. Dalam estimator yang tak bias dalam pengambilan sampel berpeluang, kesalahan pengukuran dan kesalahan non respons menghasilkan bias yang jumlahnya dapat dihitung dari data.
Syarat-syarat estimator yang sebaik-baiknya adalah : 1. Estimator Tak Bias
Suatu estimator ( ̂) dikatakan tidak bias bagi parameternya ( ) apabila nilai estimator tersebut sama dengan nilai yang diduganya (parameternya). Jadi, penduga tersebut secara tepat dapat mengestimasi nilai dari parameternya.
2. Estimator Efisien
Suatu estimator dikatakan efisien bagi parameternya ( ) apabila estimator tersebut memiliki variansi yang kecil. Apabila terdapat lebih dari satu estimator, estimator yang efisien adalah estimator yang memiliki variansi terkecil. Dua buah estimator dapat dibandingkan efisiensinya dengan menggunakan efisiensi relatif (relative efficiency) 3. Estimator Konsisten
Suatu estimator dikatakan konsisten apabila memenuhi syarat berikut : a. Jika ukuran sampel semakin bertambah maka estimator akan
mendekati parameternya. Jika besarnya sampel menjadi tak terhingga maka estimatornya konsisten harus dapat memberi suatu estimator titik yang sempurna terhadap parameternya.
b. Jika ukuran sampel bertambah tak terhingga maka distribusi sampling estimator akan mengecil menjadi suatu garis tegak lurus diatas parameter yang sebenarnya dengan probabilitas sama dengan satu.
Estimator ( ̂) adalah suatu estimasi untuk suatu nilai populasi ( ) . Misalkan nilai ekspektasi dari ̂ adalah , maka bias didefinisikan sebagai . Pengaruh bias terhadap ketelitian suatu estimasi diabaikan jika biasnya kurang dari sepersepuluh simpangan baku
estimasinya. Jika kita mempunyai metode bias dimana dan B
merupakan nilai absolut dari biasnya, ini dapat dinyatakan bahwa bias tidak merugikan metode tersebut.
Karena kesulitan dalam menjamin bahwa bias masuk dalam estimasi tanpa diduga, biasanya lebih menyatakan ketepatan (precision) suatu estimasi daripada ketelitiannya (accuracy). Ketelitian menunjukkan besar simpangan dibanding dengan parameter sebenarnya ( ) , sedangkan ketepatan menunjukkan besar simpangan dari ekspektasi atau nilai angka harapan yang diperoleh dengan melakukan pengulangan dari prosedur pengambilan sampel.
2.5.4 Rata-rata kesalahan kuadrat
Untuk membandingkan sebuah estimator bias dengan estimator tak bias, atau dua estimator dengan jumlah bias yang berbeda, maka suatu kriteria yang berguna adalah dengan menghitung rata-rata kesalahan kuadrat (Mean Square Error) pada estimator yang diukur dari nilai populasi yang diperkirakan. Secara umum,
( ) ( ̂ )
[( ̂ ) ( )]
( ̂ ) ( ) ( ̂ ) ( ) ( ̂) ( ̂)
2.6 Pengambilan Sampel Acak Sederhana
Pengambilan sampel acak sederhana (simple random sampling) adalah sebuah metode untuk memilih n unit dari N sehingga setiap elemen dari NCn
sampel yang berbeda mempunyai kesempatan yang sama untuk dipilih. (2.9)
Pada sampel acak sederhana (simple random sampling) N menyatakan ukuran unit populasi dan n menyatakan ukuran unit sampel. Dalam praktek, pengambilan sampel yang berbeda mempunyai kesempatan yang sama untuk dipilih. Dalam praktek, pengambilan sampel acak sederhana dipilih unit per unit. Unit-unit dalam populasi diberi nomor dari 1 sampai N. Serangkaian bilangan acak antara 1 sampai N kemudian dipilih, dengan cara menggunakan sebuah tabel bilangan acak atau dengan cara menggunakan sebuah program komputer yang menghasilkan tabel bilangan acak. Pada setiap pengambilan proses, proses yang digunakan harus memberikan kesempatan dipilih yang sama untuk setiap bilangan dalam populasi. Unit-unit yang terpilih ini sebanyak n yang merupakan sampel.
Untuk membuktikan bahwa seluruh NCn sampel yang berbeda mempunyai kesempatan yang sama untuk terpilih dengan metode berikut. Dengan memperhatikan sampel yang berbeda, yaitu himpunanan unit-unit tertentu. Pada pengambilan pertama, probabilitas bahwa satu dari n unit-unit tertentu akan terpilih adalah . Pada pengambilan kedua, probabilitas bahwa satu dari ( ) unit-unit sisanya yang akan terpilih adalah ( ) ( ), dan seterusnya. Sehingga probabilitas seluruh n unit-unit tertentu yang terpilih dalam n
pengambilan adalah : ( ) ( ) ( ) ( ) ( ) ( )
Karena untuk bilangan yang telah diambil / dipindahkan dari populasinya untuk seluruh pengambilan berikutnya, metode ini disebut metode pengambilan sampel acak tanpa pengembalian (without replacement). Pengambilan sampel acak dengan pengembalian (with replacement) secara keseluruhan dapat dilakukan pada setiap pengambilan, seluruh anggota dari populasi memberikan kesempatan yang sama untuk dipilih, tanpa melihat sudah berapa kali unit-unit telah dipilih.
2.6.1 Penarikan Sampel Acak dengan Pengembalian
Pendekatan yang sama diterapkan bila penarikan sampel dengan pengembalian. Dalam kejadian ini, unit ke-i dapat muncul 0,1,2,3,..., kali dalam sampel. Misalkan merupakan jumlah unit ke-i muncul dalam sampel. Maka,
̅ ∑
Karena probabilitas bahwa unit ke-i terambil adalah , variansi berdistribusi binomial dengan jumlah sukses dari n percobaan dengan . Karenanya
( ) ( ) ( ) ( )
Secara bersamaan, variansi mengikuti distribusi multinomial. Untuk ini, ( )
Dengan menggunakana (2.11),(2.12) dan (2.13), untuk penarikan sampel dengan pengembalian, kita peroleh,
( ̅) [∑ ( ) ∑ ] ∑( ̂)
Akibatnya, ( ̅) dalam penarikan sampel tanpa pengembalian adalah ( ) ( ) kali nilainya dalam penarikan sampel dengan pengembalian. Jika bukan ̅ tetapi rata-rata ̅ dari unit-unit yang berbeda dalam sampel yang digunakan sebagai perkiraan, dan seandainya penarikan sampelnya dengan pengembalian, Murthy (1967) menunjukkan bahwa suku yang penting dalam rata-rata varians dari ̅ adalah ( ) .
(2.11)
(2.12)
(2.13)
2.6.2 Sifat-sifat Perkiraan/Estimasi
Ketelitian setiap estimasi yang dibuat berdasarkan sebuah sampel tergantung pada metode estimasinya yang dihitung dari data sampel dan rencana pengambilan sampelnya. Sebuah metode estimasi dikatakan tidak bias (unbiased) jika nilai rata-rata estimasinya yang diambil dari seluruh sampel yang mungkin berukuran sama dengan nilai populasi sebenarnya. Bila metode tersebut menjadi tidak bias tanpa adanya syarat tertentu, hasil ini harus berlaku untuk setiap nilai populasi terbatas dan untuk setiap n. Untuk mengetahui apakah ̅ tidak bias dalam pengambilan sampel acak sederhana, maka kita menghitung nilai ̅ untuk NCn sampel dan menetukan rata-ratanya.
Teorema 2.1
Rata rata ̅ adalah estimasi yang tidak bias dari ̅. Dibuktikan menurut definisi : ( ̅) ∑ ̅ ( ̅) ∑ ̅ ∑ ( ) [ ] ( ) ( ) ( ) ( ) ( ) ( ) ̅ (2.15)
Dimana jumlahnya ada sebanyak NCn sampel. Untuk menghitung jumlah ini, kita menentukan berapa banyak nilai-nilai yang muncul dari sampel . Karena ada ( ) unit sampel lainnya yang tersedia untuk sisa sampel, dan di sisi lain ada ( ) untuk mengisi sampel, jumlah sampel yang berisi adalah:
N-1
C
n-1 ( ) ( ) ( ) Sehingga ∑( ) ( ) ( ) ( ) ( )Dari persamaan (2.15) memberikan hasil
( ̅) ( ) ( ) ( ) ( ) ( ) ( ) ̅
Kesimpulan yang didapat ̅ ̅ adalah estimasi yang tidak bias dari jumlah populasi Y. Pembuktian dari teorema 2.1 dapat juga diperoleh sebagai berikut. Karena setiap unit muncul dalam jumlah sampel yang sama, maka
( ) merupakan perkalian dari ( )
Pengalinya adalah , karena ruas kiri mempunyai suku dan ruas kanan mempunyai N suku.
2.6.3 Variansi Perkiraan/Estimasi
Variansi dalam sebuah populasi terbatas biasanya ditetapkan sebagai ∑ ( ̅) (2.16) (2.17) (2.18) (2.19) (2.20)
Dengan adanya sedikit perubahan pada notasi yang memakai teori pengambilan sampel dengan maksud menganalisis variansi, pembagian N
diganti menjadi ( ) jika didapatkan variansi tidak diketahui dari suatu populasi. Dan diperoleh
∑ ( ̅)
Keuntungan yang diperoleh adalah hasilnya di dapat dari bentuk yang lebih sederhana. Sekarang dengan memperhatikan variansi ̅, yang dimaksud adalah ( ̅ ̅) yang diperoleh untuk seluruh NCn sampel.
Teorema 2.2
Variansi dari ̅ dari sampel acak sederhana adalah
( ̅) ( ̅ ̅) ( ) ( )
Di mana adalah fraksi pengambilan sampel. Bukti :
( ̅ ̅) ( ̅) ( ̅) ( ̅) Dengan alasan yang sama digunakan dalam (2.19), maka
( ̅) ( ̅) ( ̅) ( ̅) Dan juga bahwa
( ̅)( ̅) ( ̅)( ̅) ( ̅)( ̅)
( ) ( )[
( ̅)( ̅) ( ̅)( ̅) ( ̅)( ̅)]
Pada (2.25) jumlahnya terdiri dari seluruh pasangan unit-unit dalam sampel dan populasi. Penjumlahan dari kiri terdiri atas ( ) suku, dan dikanan terdiri atas ( ) suku.
(2.21)
(2.22)
(2.23)
(2.24)
Kemudian dengan mengkuadratkan (2.23) dan rata-ratakan seluruh sampel acak sederhana. Dengan menggunakan rumus (2.24) serta (2.25) maka diperoleh ( ̅ ̅) {( ̅) ( ̅) ( ) [ ( ̅)( ̅) ( ̅)( ̅)]}
Kuadrat selengkapnya atas perkalian silangnya, maka didapatkan
( ̅ ̅) {(
) ( ̅) ( ̅)
( ̅) ( ̅) }
Suku kedua dalam tanda kurung akan hilang dikarenakan jumlah dari sama dengan ̅. Setelah dibagi menjadi
( ̅) ( ̅ ̅)
( ) ∑( ̅ ̅)
Kesimpulan 1. Kesalahan baku (standard error) ̅ adalah
̅
√ √
√ √
Kesimpulan Variansi ̂ ̅ merupakan estimasi jumlah populasi dengan variansi adalah ( ) ( ̂ ) ( ) (2.26) (2.27) (2.28) (2.29) (2.30)
Kesimpulan 3. Kesalahan baku (standard error) dari ̂ adalah ̂ √ √ √ √
2.6.4 Koreksi Populasi terbatas
Untuk sebuah sampel yang berukuran n yang diambil secara acak dari populasi tidak terbatas, kita mengetahui bahwa variansi dari rata-ratanya adalah . Hasil ini akan berubah jika populasi terbatas dengan menambahkan faktor ( ) . Faktor ( ) untuk variansi dari √( ) untuk kesalahan baku disebut koreksi populasi terbatas (kpt). Untuk estimasi variansi proporsi kpt-nya adalah ( ) ( ).
Teorema 2.3
Jika adalah sebuah pasangan yang bervariansi ditetapkan pada unit dalam populasi dan ̅ ̅ adalah rata-rata dari sampel acak sederhana berukuran n, maka kovariansinya
( ̅ ̅)( ̅ ̅)
∑( ̅)( ̅)
Teorema ini dikurangkan ke teorema 2.2 untuk variansinya
. Rata-rata populasi dari adalah ̅ ̅ ̅dan teorema 2.2 memberikan
( ̅ ̅) ∑ ( ̅) yaitu ( ̅ ̅) ( ̅ ̅) ∑ ( ̅ ̅) ( ̅ ̅)
Suku-suku yang dikuadratkan dan disederhanakan pada kedua ruas. dengan teorema 2.2 ( ̅ ̅) ∑( ̅ ̅) (2.31) (2.32) (2.33) (2.34) (2.35)
Dengan sebuah hubungan yang sama untuk ( ̅ ̅) . Karenanya dua suku saling menghilangkan pada ruas kiri dan kanan dari (2.34). Hasil persamaan (2.32) mengikuti dari hasil sukunya.
2.6.5 Perkiraan/Estimasi Kesalahan Baku dari Sampel
Rumus kesalahan baku dari estimasi rata-rata populasi dan jumlah populasi dipergunakan untuk tujuan :
a. Membandingkan ketelitian yang diperoleh dari pengembalian sampel acak sederhana dengan metode pengambilan sampel lainnya.
b. Untuk memperkirakan ukuran sampel yang dibutuhkan dalam suatu survei yang telah direncanakan, dan
c. Untuk memperkirakan ketelitian sebenarnya yang didapat dalam suatu survei yang dilaksanakan.
Rumus-rumusnya mencakup variansi populasi. Dalam praktek hal ini tidak dapat diketahui, tetapi dapat diperkirakan dari data sampel. Hasil yang relevan dapat dinyatakan sebagai teorema berikut.
Teorema 2.4
Untuk sebuah sampel acak sederhana
∑ ( ̅)
adalah sebuah estimasi yang tak bias dari
∑ ( ̅) Dibuktikan : ∑ ( ̅)
adalah sebuah estimasi yang tak bias dari ∑
( ̅)
(2.36)
∑ ( ̅) ( ̅ ̅) [∑( ̅) ( ̅ ̅) ] [∑( ̅ ̅) ] ∑( ̅ ̅) ( ) ( ) ( ) ( ) ( ) dapat dituliskan ∑ ( ̅) ( ̅ ̅) [∑( ̅) ( ̅ ̅) ]
Sekarang merata-ratakan seluruh sampel acak sederhana berukuran n. Dengan menggunakan alasan yang sama dalam teorema 2.2
[∑( ̅ ̅) ] ∑( ̅ ̅) ( )
Dengan definisi . Selanjutnya, dengan teorema 2.2, ( ̅ ̅) , maka
(2.38)
( )
( ) ( ) ( )
Kesimpulan estimasi yang tidak bias dari variansi ̅ dan ̂ ̅ adalah
( ̅) ̅ ( )
( ̂) ̂ ( ) ( ) Untuk kesalahan bakunya diperoleh
̅ √ √ ,
dan
̂
√ √
2.6.6 Perkiraan/Estimasi Ukuran Sampel
Keputusan dalam menentukan besarnya jumlah sampel sangat penting dalam perencanaan sampel survei. Jika sampel yang diambil terlalu besar, maka merupakan pemborosan sumber-sumber dan jika yang diambil terlalu kecil akan mengurangi manfaat hasilnya.
Ukuran sampel n dalam sampel random sederhana dapat ditentukan kaitannya dengan batas-batas kesalahan dalam estimasi. Menentukan besarnya ukuran sampel juga dipertimbangkan besarnya tingkat ketelitian yang diinginkan peneliti. Dalam meperkirakan total populasi atau rata-rata, (2.40)
(2.41)
(2.41)
(2.42)
biasanya inigin mengontrol kesalahan relatif r dengan tingkat konfidensi ( ) Dengan acak sederhana didapatkan rata-rata ̅, akan mendapatkan
(| ̅ ̅ ̅ | ) (| ̅ ̅| ̅) ̅ ̅ √ √
Penyelesaian untuk n memberikan
(
̅ ) [ (
̅) ]
Perlu diperhatikan bahwa karakteristik populasi tempat n tergantung adalah koefisien variansi ̅ . Sebagai pendekatan pertama diambil
( ̅ )
Jika cukup besar maka rumus untuk n seperti
2.7 Sampling Klaster
Sampling klaster adalah pengambilan sampel dari populasi yang dikelompokkan menjadi sub-sub populasi secara bergerombol (klaster), dari sub populasi selanjutnya dirinci lagi menjadi sub-populasi yang lebih kecil. Anggota dari sub populasi terakhir dipilih secara acak sebagai sampel penelitian.
(2.44)
(2.45)
(2.46)
Dalam pembentukan klaster seperti ini, maka keadaan didalam klaster relatif heterogen dan antar klaster relatif homogen. Oleh karena itu, dalam pembentukan klaster didasarkan pada area atau daerah administratif. Tujuan penggunaan sampling klaster adalah untuk mengurangi biaya dengan meningkatkan efisensi penarikan sampel. Selain itu sampling klaster memiliki beberapa keuntungan diantaranya adalah paling murah biayanya dibandingkan dengan metode lainnya serta kerangka sampel yang hanya diperlukan untuk klaster-klaster yang dipilih, bukan untuk semua populasi. Suatu klaster dikatakan baik jika mempunyai heterogenitas yang tinggi antar anggota dalam satu klaster (within cluster) dan juga homogenitas yang tinggi antara klaster yang satu dengan klaster yang lainnya (between cluster).
Sebelum melakukan studi lebih lanjut ada baiknya memperhatikan segi asumsi yang harus dipenuhi dalam analisis klaster ini yaitu
1. Data yang representatif, sampel yang diambil benar-benar mewakili populasi yang ada.
2. Multikolinearitas, yaitu kemungkinan adanya korelasi antar objek, sebaiknya tidak ada. Tapi jika ada, besarnya multikolinearitas tersebut tidaklah tinggi. Proses sampling klaster :
a. Membuat klaster. Proses ini adalah proses pengelompokkan data yaitu populasi keseluruhan dibagi ke dalam beberapa kelompok atau klaster berdasarkan area atau daerah administratif.
b. Setelah klaster terbentuk maka selanjutnya melakukan interpretasi terhadap klaster yang telah terbentuk, yang pada intinya adalah memberi nama spesifik untuk menggambarkan isi klaster.
c. Melakukan validasi dan profiling klaster. Klaster yang terbentuk kemudian diuji apakah valid atau tidak, kemudian dilakukan proses profiling untuk menjelaskan karakteristik tiap klaster berdasarkan profil tertentu.
29
3.1 Deskripsi Pengambilan Sampel Klaster Dua Tahap
Pada penarikan acak sederhana hanya didasarkan pada nomor unit dalam populasi. Penarikan acak ini menjadi kurang baik jika unit dalam populasi ukurannya bervariansi. Oleh karena itu digunakan variansi pendukung (auxiliary variable) sebagai pertimbangan di dalam penarikan sampel agar diperoleh estimator yang lebih efisien. Variabel pendukung yang digunakan sebagai dasar penarikan sampel adalah variabel yang memiliki korelasi yang erat dengan variabel yang diteliti. Variabel pendukung yang dipertimbangkan sebagai dasar penarikan sampel selanjutnya disebut ukuran(size). Prosedur penarikan sampel dimana peluang terpilihnya suatu unit sampel sebanding dengan ukuran disebut sebagai sampling berpeluang sebanding dengan ukuran atau sampling with probability proportional to size (pps).
Pengambilan sampel klaster adalah pengambilan sampel random sederhana dimana setiap pengambilan sampel unit terdiri dari klaster atau kelompok. Pada metode pengambilan sampling klaster satu tahap ini, populasi dikelompokkan dalam beberapa klaster. Klaster yang ada kemudian dipilih untuk dijadikan sampel klaster. Selanjutnya, semua elemen dalam klaster yang terpilih akan diteliti. Pada metode ini memiliki elemen yang terpilih dalam klaster cukup banyak sehingga kurang efisien karena memakan waktu yang banyak dan membutuhkan biaya yang lebih banyak. Kemudian metode ini dikembangkan dengan pengambilan klaster dua tahap.
Dalam metode pengambilan sampling klaster dua tahap ini memiliki dua tahap pengambilan. Tahap pertama memilih sebuah sampel dari unit-unit primer(utama) dan tahap kedua memilih sebuah sampel dari subunit dari setiap
unit primer yang terpilih. Keuntungan dari pengambilan sampling klaster dua tahap ini adalah bahwa cara ini lebih fleksibel daripada pengambilan sampel satu tahap. Dalam pengambilan sampel dua tahap ini, peneliti dihadapkan pada pemilihan klaster yang tepat. Sebagai pedoman, banyaknya klaster dalam sampel usahakan cukup banyak. Hal ini mengingat bahwa biaya pengukuran karakteristik elemen sangat mahal. Elemen dalam suatu kelompok secara fisik sebenarnya mirip dengan antar satu dengan yang lainnya. Oleh karena itu sebisa mungkin dalam pembentukan klaster harus memperhatikan kehomogenan elemen-elemen yang akan diteliti dalam klaster tersebut. Suatu populasi yang homogen akan menghasilkan sampel dengan tingkat kesalahan sampling yang lebih kecil dibandingkan dengan suatu populasi yang heterogen. Dalam hal ini, ukuran sampel harus ditentukan terlebih dahulu jika jumlah klaster ditingkatkan maka jumlah elemen dalam suatu klaster harus dikurangi begitu pula sebaliknya.
Pengambilan sampel klaster dua tahap dan sampel acak berlapis hampir sama. Dalam sampel acak berlapis, klaster diperlakukan sebagai strata, sedangkan perbedaannya klaster harus dipilih dari populasi klaster sebagai sampel klaster. Tidak semua klaster diteliti, tetapi semua klaster dalam sampel acak berlapis diteliti melalui sampel yang dipilih dari strata. Sehingga sampel yang diambil tidak terlalu besar dengan tingkat keakuaratan tinggi.
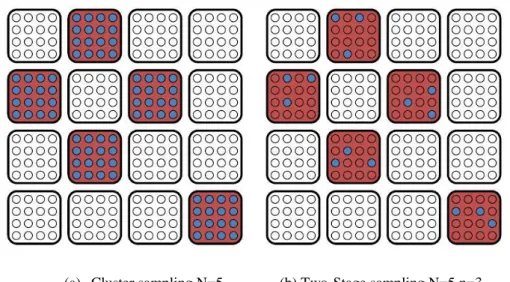
Secara umum pengambilan sampel klaster dua tahap dapat dijelaskan pada gambar sebagai berikut dengan perbandingan pengambilan sampel klaster satu tahap.
(a) Cluster sampling N=5 (b) Two-Stage sampling N=5 n=3
Gambar 3.1 Ilustrasi Cluster Sampling dan Two-Stage Cluster Sampling
Didalam pemilihan sampel klaster maupun elemen yang tepat dilakukan secara acak menggunakan tabel bilangan random. Pembagian populasi dalam klaster juga didasarkan pada kehomogenan antar klaster. Karakteristik antar klaster adalah homogen dan didalam klaster adalah heterogen
3.2 Estimasi Pengambilan Sampel Klaster Dua Tahap 3.2.1 Estimator rata-rata populasi dan variansi populasi
Pada penarikan sampel klaster dua tahap, rencana penarikan sampelnya pertama memberikan sebuah metode pemilihan n unit. Kemudian untuk setiap unit terpilih, diberikan metode untuk memilih sejumlah tertentu subunit-subunit. Dalam mencari rata-rata dan variansi estimasi, rata-ratanya harus meliputi seluruh sampel yang dapat diturunkan dengan proses dua tahap.
Menurut teorema 2.1 dalam sampel random sederhana, rata-rata ̅ adalah estimasi tak bias dari ̅ sehingga estimator rata-rata dalam populasi dinotasikan dengan ̂ ̅ bila n unit dan subunit dari masing-masing unit yang telah diambil dan dipilih dengan pengambilan sampel acak sederhana, maka ̅ adalah estimator tak bias untuk ̅
Untuk memperkirakan rata-rat dan populasi dalam sampel klaster, kebanyakan statistik survei menggunakan bobot sampling dari estimator
diatas, bobot sampling untuk unit sekunder (subunit) / dan unit primer (utama) i adalah nilai bobot ini bisa kita peroleh dengan menghitung probabilitas inklusi untuk sampel klaster.
= P (unit sekunder j terpilih di unit primer i)
= P(unit sekunder i terpilih ) P (unit sekunder j terpilih| unit primer i)
=
sehingga
Jadi estimator untuk ̂ dan ̅ dapat dihitung dengan
∑ ∑
∑ ∑
Sehingga ̅ diestimasi dengan
̅ ̅
∑
∑ ̅ Dan ̿ diestimasi dengan
̿ ̅ ∑ ∑ ̅
∑ ∑
Untuk variansi dari rata-rata populasi pada pengambilan sampel klaster dua tahap dapat dijabarkan sebagai berikut (Cochran, 1991)
( ̿) [ ( ̿)] [ ( ̿)]
Karena
( ̿) ∑
̅ , suku pertama pada ruas kanan adalah variansi dari rata-rata per subunit untuk sebuah sampel acak sederhana berukuran n unit. Oleh karena itu, dengan teorema 2.2[ ( ̿)] ̅
(3.1)
(3.2)
Selanjutnya, dengan
̿ ∑
̅ dan pengambilan sampel acak sederhana digunakan pada tahap kedua,( ̿) ∑ ( )
Seluruh sampel pada tahap pertama juga dirata-ratakan sehingga diperoleh [ ( ̿)]
̅ ∑ ( )
Kemudian variansi dari rata-rata populasi dinyatakan dalam ( ̿) ( )
̅ ̅ ∑ ( )
Oleh karena variansi populasi tidak diketahui dan variansi dari populasi adalah merupakan estimator tak bias untuk variansi populasi karena [ ( ) ]. Estimator variansi dari rata-rata populasi dapat dinyatakan dalam bentuk berikut
( ̿) ( )
̅ ̅ ∑ ( )
3.2.2 Estimator Total Populasi
Memperkirakan total populasi diperlukan dalam pengambilan klaster dua tahap ini karena kita tidak mengamati setiap unit sekunder dalam sampel unit primer. Dengan mengguakan bobot sampling pada (3.1) total populasi dalam klaster i dapat diestimasi dengan
̂
̅
∑∑
∑
∑
∑
Sedangkan variansi dari total populasi adalah
( )
( ̿)
∑
(
)
∑
(
)
( ̂)
( ̿)
(
)
∑
(
)
(
)
∑
(
)
Dimana adalah variansi populasi di klaster unit primer dan adalah variansi populasi antar elemen di dalam klaster i. Oleh karena variansi dari total populasi tidak dapat dihitung maka perlu di estimasi menggunakan data sampel. Sehingga variansi dari total populasi dapat dinyatakan dalam
̂( ̂) ( ) ∑ ( )
Dengan standar deviasi dari total populasi sebesar ̂ √ ( )
3.3 Pendekatan Hansen Hurwitz
Hansen-Hurwitz (HH) memperkenalkan notasi ukuran klaster sampling yang tak seimbang/tak sama dengan estimasi probabilitas proporsi (pps) untuk mengestimasi nilai , jumlahan dari Y-variate yang melewati/melampaui populasi tak hingga dari elemen . Akan dijelaskan prosedur atau metode untuk penarikan klaster sampling dengan menggunakan pps dan dengan pengembalian. Pertama, klaster menandai interval yang berurutan dengan panjang yang sama dengan ukuran klaster (jumlah elemen populasi dalam sebuah klaster). Kedua, sasaran sampel dari elemen populasi yang telah diberi nomor berurutan diambil menggunakan pengambilan sampel acak sederhana dengan pengembalian. Ketiga,
(3.6)
klaster tersebut yang memberikan jarak (range) yang besar, dipilih lagi dengan pengembalian.
Dalam bahasan ini penulis akan membatasi pada pembahasan metode pengambilan sampling dengan menggunakan penggembalian serta menghitung estimator Hansen-Hurwitz dan Hurvitz-Thompson dari .
3.3.1 Metode Pemilihan Hansen-Hurwitz (HH)
Metode pemilihan Hansen-Hurwitz (HH) untuk sampling klaster berukuran tak sama dengan pps dan dengan pengembalian pada dasarnya memiliki 3 langkah, yaitu :
Langkah pertama :
Unit sekunder (elemen) M populasi (j=1,2,...,M) ditandai dengan bilangan bulat secara berurutan dengan jarak yang sama dengan ukuran klaster Langkah Kedua :
Ukuran tetap target sampel dari elemen m populasi digambarkan dengan sebuah populasi seragam/sama yang memutar dari bilangan bulat 1 sampai M
melalui pengambilan sampel acak sederhana dengan pengembalian Langkah Ketiga :
Klaster yang didalamnya memberikan range (jarak) jumlah acak dari target sampel yang hilang/gugur ditarik atau diambilkan dengan pengembalian. 3.3.2 Estimator Hansen-Hurwitz
Berdasarkan pada sampel berukuran n klaster dari unit populasi yang dipilih dengan pps dan pengembalian dari elemen populasi dan klaster yang dikelan luas dengan unbiased HH estimator dari Y, begitu juga dikenal dengan pps estimator yaitu
∑ ∑
( ) ∑ ∑ ̅
Keterangan
n = ukuran klaster sampel
m = ukuran sampel elemen populasi = pengukuran untuk unit ke i
= probabilitas bahwa nilai ke i ada dalam sampel
Untuk nilai ∑
Jika sebuah sampel berukuran n unit primer dan unit sekunder diambil dengan probabilitas proporsional terhadap dengan metode pengambilan klaster dua tahap.
Modifikasi estimator Hansen-Hurwitz untuk total populasi adalah:
∑ ∑
Untuk = { Mean variansi dari estimator Hansen-Hurwitz adalah sebagai berikut :
[
] *
∑
+
*∑
+
[∑ ̅ ] [ ( ̅) ( ̅) ( ̅ )] (3.9)( ̅ ̅ ̅ )
̅ ̅
̅ ̅
Oleh karena itu dapat dibuktikan bahwa ̂ adalah estimator tak
bias untuk Y pada pengambilan sampel klaster dua tahap. Variansi dari Y untuk estimator Hansen-Hurwitz adalah
[ ] [ ∑ ̅ ] (∑ ̅ ) ∑[ ( ̅)] ( ̅) ∑( ̅ ̅) ( )∑( ̅ ̅) Dimana ̅
3.4 Pendekatan Estimator Horvitz-Thompson
Estimator Horvitz-Thompson adalah estimator yang umumnya digunakan untuk menghitung total populasi yang dapat digunakan untuk banyak jenis metode pengambilan sampel. Estimator ini dapat digunakan untuk pengambilan sampel dengan pengembalian maupun tanpa pengembalian. Estimator Horvitz-Thompson untuk total populasi (Cochran, 1991)
̂ ∑
Dimana adalah pengukuran untuk unit ke- = Probabilitas bahwa unit ke- ada dalam sampel
Untuk nilai ∑
Sebuah sampel penduga berukuran n unit primer dan unit sekunder diilih tanpa pengembalian dengan metode pengambilan klaster dua tahap. Modifikasi estimator Horvitz-Thompson untuk total populasi adalah
̂ ∑ ̂ ∑ ̂ Untuk { Berikut ( ) ( ) ( ) ( ) Jika , maka ( ) ( ) [ ( )] ( ) Untuk , nilai ( ) ( ) ( ) ( )
( ̂ ) [∑ ̂ ] [∑ ̂ ] { [∑ ̂ | ]} [∑ ] ∑
Oleh karena itu, dapat dibuktikan bahwa ̂ adalah estimator tak bias untuk pada pengambilan sampel klaster dua tahap. Sedangkan variansi dari estimator tak bias total populasi Horvitz-Thompson adalah
( ̂ ) (Unit primer) + (Unit sekunder)
[ (∑ ̂ | )] [ (∑ ̂ | )] [∑ ] [∑ ( ̂) ] ∑ ( ) ∑ ∑ ( ) ∑ ( ̂) ∑ ( ) ∑ ∑( ) ∑ ( ̂) ∑ ∑ ∑ ∑ ( ̂)
Dengan estimator variansinya dinyatakan seperti dibawah ini :
̂( ̂ ) ∑( ) ̂ ∑ ∑ ̂ ̂ ∑ ̂( ̂)
Untuk perhitungan estimator rata-rata populasi menggunakan estimator Horvitz-Thompson, maka estimator total populasi di atas cukup dibagi dengan jumlah populasi. Sehingga rata-rata populasi dapat diestimasi dengan
̂
̂
.
Sedangkan untuk perhitungan variansi, berarti variansi dari totalpopulasi dibagi dengan total populasi dikuadratkan atau ( ̂ ) ( ̂ )
Perhitungan ini hampir sama dengan perhitungan untuk estimator pada pengambilan klaster dua tahap dengan metode pengambilan sampel random sederhana.
Jika unit primer terpilih dengan probabilitas sama, maka
( ) dan ( )
Kemudian kita dapat menerapkan rumus (diatas) dengan
( ̂) ∑ ∑ ∑ ∑ ( ) ( ) ∑ ∑ [ ( ) ] ( ) ( ) [∑ ∑ ∑ ] ( )( ) [( ) ∑ ∑ ∑ ∑ ] ( )( ) [ ∑ ]
( )( ) [∑( )
]
( )
Menggunakan teori pengambilan sampel sederhana pada (3.6), diperoleh
( ̂) ∑ ( ) Sehingga ( ̂) ∑ ( ̂) ∑ ( ) Jadi, ( ̂) ( ̂) ( ̂) ( ) ∑ ( ) ( ) ∑ ( )
Jadi estimator tak bias untuk total populasi menggunkan pengambilan sampel sederhana merupakan kasus khusus dari estimator Horvitz-Thompson dengan probabilitas sama unit primer dan unit sekunder . Oleh karena itu kita akan memperoleh rumus (3.5) jika nilai pada estimator Horvitz-Thompson diganti dengan probabilitas terpilihnya unit primer dan sekunder dalam populasi. Dengan cara yang sama, estimator dari variansi populasi untuk penggambilan sampel klaster
dua tahap juga dapat diperoleh meggunakan estimator Horvitz-Thompson. Metode Horvitz-Thompson ini dapat digunakan untuk pengambilan sampel klaster dalam banyak tahap bergantung pada probabilitas unit yang terpilih dalam sampel.
Beberapa kasus khusus lainnya dengan menggunakan estimator Horvitz-Thompson seperti pada pengambilan sampel random sederhana dengan . Diperoleh ̂ ∑ ∑ ∑ ̅ ̂
Hasil serupa juga akan diperoleh untuk pengambilan berstrata dengan jika unit i ada dalam strata h.
̂ ∑ ∑
∑ ̅ ̂
Begitu juga untuk semua jenis metode pengambilan sampel lainnya, nilai estimator Horvitz-Thompson untuk total populasi akan bergantung pada probabilitas terpilihnya sampel.
3.5 Fungsi Biaya
Dalam menerapkan rancangan pengambilan sampel klaster dua tahap, selain mempertimbangkan faktor-faktor teknis statistik yang meliputi presisi dan tingkat kepercayaan, juga harus mempertimbangkan faktor biaya. Dalam hal ini anggaran terbatas, kita perlu mempertimbangkan biaya dari penelitian yang diusulkan. Menggunakan metode pengambilan sampel tanpa pengembalian, fungsi biaya menurut Cochran (1991) adalah
∑
Dengan
= fungsi biaya, tidak termasuk overhead cost
Biaya pendaftaran (listing) per sub unit dalam sebuah unit yang dipilih Biaya per sub unit dan pengawasannya.
Fungsi biaya diatas mengabaikan biaya perjalanan antara unit. Istilah dimasukkan karena pengambilan sampel biasanya harus mendaftar elemen-elemen dalam setiap unit terpilih dan memeriksa jumlahnya agar diambil sebuah subsampel.
44 BAB IV STUDI KASUS
Penulis memberikan sebuah studi kasus pengambilan sampel klaster dua tahap dengan perbandingan metode estimasi Hansen-Hurwitz dan Horvitz-Thompson dengan populasi pengguna alat kontrasepsi (IUD, MOP, MOW, Kondom, Susuk, Suntik, dan Pil) yang digunakan dalam upaya program Keluarga Berencana di Provinsi Daerah Istimewa Yogyakarta. Metode pertama yang dilakukan adalah menentukan populasi, kemudian tahapan selanjutnya adalah pengambilan sampel dengan menggelompokkannya berdasarkan klaster yang terbagi berdasarkan wilayah administratif supaya terjaga kehomogenitasannya antar klaster.
Dengan studi kasus tersebut, ingin diketahui jumlah pengguna alat kontrasepsi yang mengikuti KB dalam sebuah daerah. Berkaitan dengan tema besar penulisan, penulis ingin mengestimasikan jumlah peserta KB di DIY. Manfaat dari studi kasus ini adalah memperdalam metode pengambilan sampel dengan metode Hansen-Hurwitz dan Hurvitz-Thompson.
4.1 Pengumpulan Data
Untuk studi kasus pada skripsi ini, penulis menggunakan data Pengguna Alat Kontrasepsi pada peserta KB tahun 2013 pada kecamatan dan desa terpilih yang bersumber pada “Kecamatan dalam Angka tahun 2014” di tiap Kabupaten. Data yang dipergunakan terdiri dari kecamatan, desa (data terlampir).
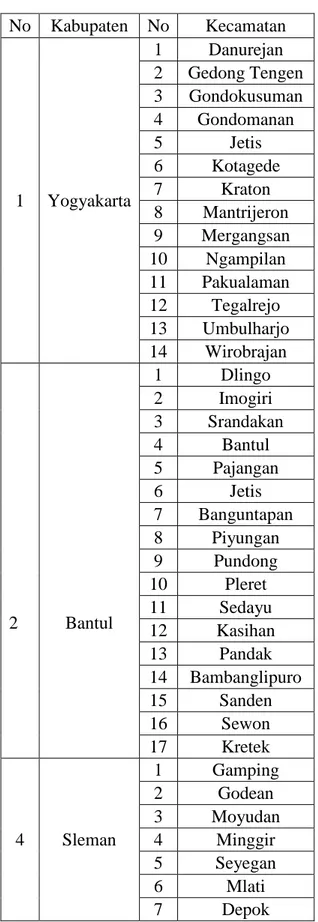
Tabel 4.1 Kecamatan di tiap Kabupaten No Kabupaten No Kecamatan 1 Yogyakarta 1 Danurejan 2 Gedong Tengen 3 Gondokusuman 4 Gondomanan 5 Jetis
6 Kotagede 7 Kraton 8 Mantrijeron 9 Mergangsan 10 Ngampilan 11 Pakualaman 12 Tegalrejo 13 Umbulharjo 14 Wirobrajan 2 Bantul 1 Dlingo 2 Imogiri 3 Srandakan 4 Bantul 5 Pajangan 6 Jetis 7 Banguntapan 8 Piyungan 9 Pundong 10 Pleret 11 Sedayu 12 Kasihan 13 Pandak 14 Bambanglipuro 15 Sanden 16 Sewon 17 Kretek 3 Gunungkidul 1 Wonosari 2 Nglipar 3 Playen 4 Patuk 5 Paliyan 6 Panggang 7 Tepus 8 Semanu 9 Karangmojo 10 Ponjong 11 Rongkop 12 Semin 13 Ngawen
14 Gedangsari 15 Saptosari 16 Girisubo 17 Tanjungsari 18 Purwosari 4 Sleman 1 Gamping 2 Godean 3 Moyudan 4 Minggir 5 Seyegan 6 Mlati 7 Depok 8 Berbah 9 Prambanan 10 Kalasan 11 Ngemplak 12 Ngaglik 13 Sleman 14 Tempel 15 Turi 16 Pakem 17 Cangkringan 5 Kulon Progo 1 Wates 2 Temon 3 Sentolo 4 Samigaluh 5 Pengasih 6 Panjatan 7 Nanggulan 8 Lendah 9 Kokap 10 Kalibawang 11 Girimulyo 12 Galur
4.2 Pengambilan Sampel 4.2.1 Sampel Unit primer
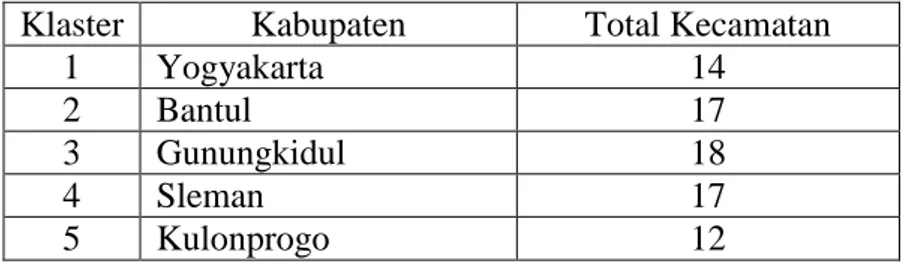
Dalam penelitian survei ini, populasi terbagi ke dalam 78 kecamatan yang ada di Daerah Istimewa Yogyakarta. Pada tiap kecamatan memiliki sejumlah kelurahan atau desa. Dari 78 kecamatan tersebut, kemudan dibentuk menjadi 5 klaster unit primer (N) yang berdasarkan pada daerah administratifnya yaitu kabupaten. Faktor tersebut digunakan untuk menjaga kehomogenan variabel variabel yang terdapat pada antar klaster serta keheterogenan di dalam klaster.
Tabel 4.2 Populasi Terkluster
Klaster Kabupaten Total Kecamatan
1 Yogyakarta 14
2 Bantul 17
3 Gunungkidul 18
4 Sleman 17
5 Kulonprogo 12
Setelah pembentukan klaster, maka langkah selanjutnya untuk pengambilan klaster dua tahap adalah dengan melakukan pengambilan klaster secara acak atau secara random dengan menggunakan software R versi 3.2.2 . Selanjutnya 5 unit klaster (N) yang telah terbentuk diambil sampel 3 klaster unit primer untuk diteliti. Kemudian dipilih 3 (n) klaster unit primer secara random dengan kesalahan standar sebesar 95%.
4.2.2 Sampel Unit Sekunder
Untuk pengambilan sampel unit sekunder, juga dilakukan dengan pengambilan sampel menggunakan data jumlah kecamatan yang ada pada setiap klaster unit primer yang terpilih kemudian dilakukan pengambilan acak kecamatan tersebut dan meneliti jumlah kelurahan/desa dari kecamatan yang terpilih pada tiap klaster yang terbentuk.
Tabel 4.3 Sampel Unit Sekunder No Kabupaten No Kecamatan 1 Yogyakarta 1 Danurejan 2 Gedong Tengen 3 Gondokusuman 4 Gondomanan 5 Jetis 6 Kotagede 7 Kraton 8 Mantrijeron 9 Mergangsan 10 Ngampilan 11 Pakualaman 12 Tegalrejo 13 Umbulharjo 14 Wirobrajan 2 Bantul 1 Dlingo 2 Imogiri 3 Srandakan 4 Bantul 5 Pajangan 6 Jetis 7 Banguntapan 8 Piyungan 9 Pundong 10 Pleret 11 Sedayu 12 Kasihan 13 Pandak 14 Bambanglipuro 15 Sanden 16 Sewon 17 Kretek 4 Sleman 1 Gamping 2 Godean 3 Moyudan 4 Minggir 5 Seyegan 6 Mlati 7 Depok
8 Berbah 9 Prambanan 10 Kalasan 11 Ngemplak 12 Ngaglik 13 Sleman 14 Tempel 15 Turi 16 Pakem 17 Cangkringan
Hasil pengacakan pada cluster 1, 2 dan 3 pada observasi pertama adalah sebagai berikut :
Cluster 1 : Kota Yogyakarta
Cluster 2 : Kabupaten Bantul
Cluster 3 : Kabupaten Sleman
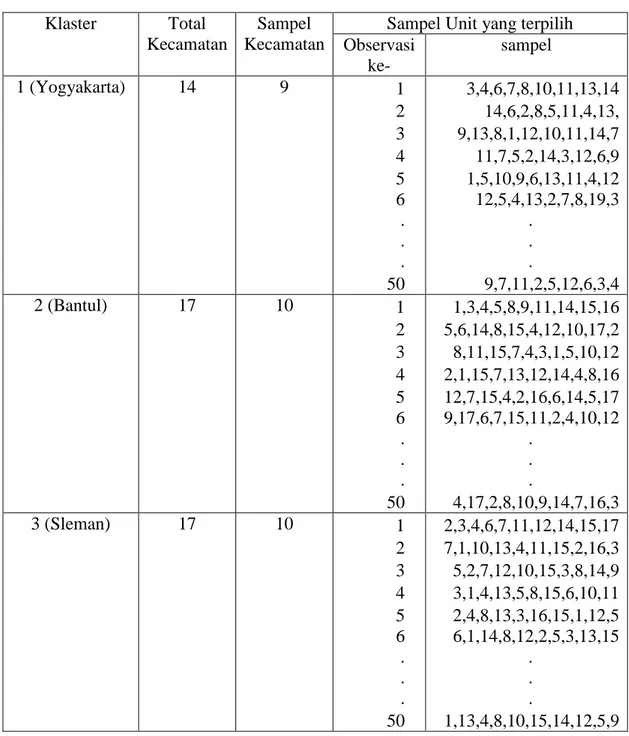
Dengan menggunakan R 3.2.2 untuk pengacakan sampel, pada observasi pertama dan klaster pertama yaitu kota Yogyakarta ini didapatkan sampel dengan nomor 8,7,6,3,4,13,11,10,14. Kemudian pada klaster dua Kabupaten Bantul didapatkan sampel dengan nomor 4,8,14,9,16,11,15,3,5,1. Dan pada klaster tiga Kabupaten Sleman diperoleh nomor sampel 14,7,15,6,2,11,17,3,4.12.
Tabel 4.4 Sampel Unit yang Terpilih Klaster Total
Kecamatan
Sampel Kecamatan
Sampel Unit yang terpilih Observasi ke- sampel 1 (Yogyakarta) 14 9 1 2 3 4 5 6 . . . 50 3,4,6,7,8,10,11,13,14 14,6,2,8,5,11,4,13, 9,13,8,1,12,10,11,14,7 11,7,5,2,14,3,12,6,9 1,5,10,9,6,13,11,4,12 12,5,4,13,2,7,8,19,3 . . . 9,7,11,2,5,12,6,3,4 2 (Bantul) 17 10 1 2 3 4 5 6 . . . 50 1,3,4,5,8,9,11,14,15,16 5,6,14,8,15,4,12,10,17,2 8,11,15,7,4,3,1,5,10,12 2,1,15,7,13,12,14,4,8,16 12,7,15,4,2,16,6,14,5,17 9,17,6,7,15,11,2,4,10,12 . . . 4,17,2,8,10,9,14,7,16,3 3 (Sleman) 17 10 1 2 3 4 5 6 . . . 50 2,3,4,6,7,11,12,14,15,17 7,1,10,13,4,11,15,2,16,3 5,2,7,12,10,15,3,8,14,9 3,1,4,13,5,8,15,6,10,11 2,4,8,13,3,16,15,1,12,5 6,1,14,8,12,2,5,3,13,15 . . . 1,13,4,8,10,15,14,12,5,9
Pada tahap ini dilakukan observasi pengacakan sampel sebanyak 50 kali yang bertujuan supaya sampel yang diambil benar-benar dapat mewakili tiap sub unit. Kemudian dari masing-masing sampel kecamatan yang terpilih, akan diteliti rata-rata dan jumlah pengguna alat kontrasepsi peserta KB di Provinsi Daerah Istimewa Yogyakarta.
4.3 Analisis dan Pembahasan
4.3.1 Estimasi rata-rata populasi
Untuk mendapatkan nilai dari estimasi rata-rata dan jumlah pengguna alat kontrasepsi peserta KB yang tersedia di tiap klaster kabupaten terpilih pada setiap provinsi di Indonesia, maka dapat dihitung menggunakan rumus 3.2 yaitu :
̅ ∑ Keterangan :
: observasi ke j pada sampel dari klaster ke i (banyak peserta KB terpilih
didalam klaster i)
: jumlah unit sekunder dalam sampel dari unit primer i (jumlah kecamatan terpilih dari masing-masing klaster)
Dan hasil perhitungan seperti tabel dibawah ini
Tabel 4.5 Estimasi Rata-rata populasi
Klaster Sampel Kabupaten Rata-rata Jumlah pengguna KB
1 Yogyakarta 2550,0
2 Bantul 6012,2
3 Sleman 6983,4
Berdasarkan tabel diatas, dapat dijelaskan bahwa kita ambil sebagai contoh pada sampel klaster nomor 1. Terdapat rata-rata pengguna alat kontrasepsi sebanyak 2550 peserta. Melihat pada tabel 4.5 tersebut klaster 1 merupakan klaster wilayah Kota Yogyakarta yang beranggotakan 9 kecamatan terpilih. Berdasarkan informasi data diatas bisa menjadi pedoman
pemerintah yang ingin menekan jumlah ledakan penduduk di provinsi DIY. Jumlah kelurahan dan rata-rata jumlah peserta KB di setiap klaster diatas dapat dimanfaatkan untuk memperkirakan jumlah peserta KB yang akan dibutuhkan pemerintah dalam kependudukan.
Sedangkan rata-rata total peserta KB yang tersedia di provinsi DIY dapat diestimasi menggunakan persamaan (3.3)
̿
∑ ∑
Dengan mengunakan perhitungan pada R diperoleh estimasi rata-rata populasi sebesar 4579,17241 4580 pengguna alat kontrasepsi. Artinya terdapat rata-rata 4580 peserta KB pada masing-masing kecamatan di DIY. Estimasi rata-rata total peserta KB ini tersedia untuk semua wilayah kecamatan di DIY.
Berdasarkan nilai estimator rata-rata total peserta KB diprovinsi DIY diatas, dapat pula dihitung persebaran rata-rata total peserta KB. Nilai estimator variansi dari total peserta KB di DIY menggunakan rumus
( ̿) ( )
̅ ̅ ∑ ( )
Diperoleh hasil sebesar 515056,7159 dengan tingkat kesalahan baku sebesar 717,6745. Dengan nilai variansi yang tidak terlalu besar ini menunjukkan bahwa data masih menyebar disekitar rata-rata. Sehingga peneliti dapat mengambil kesimpulan bahwa pengambilam sampel ini sudah cukup baik dengan tingkat kesalahan standar kecil.
4.3.2 Estimasi Total Populasi Horvitz-Thompson
Nilai estimasi dari total pengguna alat kontrasepsi peserta KB yang terdapat di tiap sampel klaster kebupaten di DIY dapat dihitung dengan menggunakan rumus
∑
Dengan : jumlah kecamatan dalam klaster ke-i
Hasil perhitungannya dapat dilihat pada tabel ini
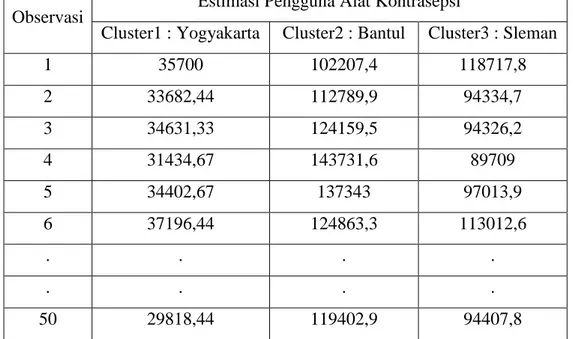
Tabel 4.6 Estimasi Total Populasi Horvitz-Thompson
Observasi Estimasi Pengguna Alat Kontrasepsi
Cluster1 : Yogyakarta Cluster2 : Bantul Cluster3 : Sleman
1 35700 102207,4 118717,8 2 33682,44 112789,9 94334,7 3 34631,33 124159,5 94326,2 4 31434,67 143731,6 89709 5 34402,67 137343 97013,9 6 37196,44 124863,3 113012,6 . . . . . . . . 50 29818,44 119402,9 94407,8
Berdasarkan tabel diatas, dapat dijelaskan bahwa pada klaster 2 terdapat jumlah pengguna alat kontrasepsi sebanyak 102207,4 102207 peserta. Dari tabel 4.6 klaster 2 adalah klaster kabupaten Bantul yang memiliki anggota 17 kecamatan. Berdasarkan data diatas pemerintah daerah yang ingin melihat kependudukan kelurga berencana, jumlah kecamatan dan estimasi total jumlah pengguna alat kontrasepsi peserta KB yang tersedia dapat dimanfaatkan.
Untuk mengestimasi total jumlah peserta KB di provinsi DIY secara keseluruhan, dapat menggunakan persamaan (3.5)
∑ ∑
Dari hasil perhitungan persamaan diatas, kemudian diperoleh nilai estimasi total populasi sebesar 28147,56 28148 yang artinya terdapat 28148 jumlah keseluruhan pengguna alat kontrasepsi peserta KB di Provinsi DIY.
Berdasarkan nilai estimator total pengguna alat kontrasepsi di atas, selanjutnya ingin melihat seberapa besar persebaran data. Diperoleh nilai estimasi variansi dari total populasi secara keseluruhan pengguna alat kontrasepsi menggunakan persamaan (3.6)
( ) ( ) ∑ ( )
Tabel 4.7 Variansi dan Kesalahan Baku Estimasi Horvitz-Thompson Observasi Variansi HT Kesalahan baku HT
1 403310698 20082,6 2 506514490 22505,88 3 429242717 20718,17 4 502003443 22405,43 5 536113019 23154,11 6 527884343 22975,73 . . . . . . 50 528039931 22979,12
Pada Observasi pertama diperoleh variansi sebesar 403310698 dengan kesalahan baku 20082,6.
4.4 Estimasi Total Populasi Hansen-Hurwitz
Untuk menghitung nilai dari estimator Hansen-Hurwitz pada masing-masing klaster, dapat menggunakan rumus (3.8)
∑
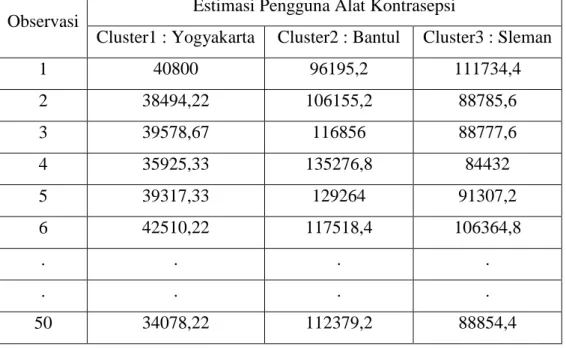
Tabel 4.8 Estimasi Total Populasi Hansen-Hurwitz Observasi Estimasi Pengguna Alat Kontrasepsi
Cluster1 : Yogyakarta Cluster2 : Bantul Cluster3 : Sleman
1 40800 96195,2 111734,4 2 38494,22 106155,2 88785,6 3 39578,67 116856 88777,6 4 35925,33 135276,8 84432 5 39317,33 129264 91307,2 6 42510,22 117518,4 106364,8 . . . . . . . . 50 34078,22 112379,2 88854,4
Berdasarkan tabel diatas, dapat dijelaskan bahwa dengan menggunakan estimator Hansen-Hurwitz untuk klaster 3 dengan wilayah Kota Yogyakarta, terdapat jumlah peserta pengguna Alat kontrasepsi sebanyak 111734,4 111734 peserta yang tersebar di 17 kecamatan.
Untuk mengestimasi total jumlah peserta pengguna alat kontrasepsi program KB di Provinsi DIY secara keseluruhan menggunakan estimator Hansen-Hurwitz, dapat dihitung menggunakan persamaan (3.9)
∑
∑
Dari hasil perhitungan persamaan diatas, kemudian diperoleh nilai dari estimator total populasi Hansen-Hurwitz sebesar 391048,9 391049. Artinya bahwa dengan menggunakan estimator Hansen-Hurwitz diperoleh estimasi untuk total pengguna alat kontrasepsi di Provinsi DIY sebesar 391049 peserta. Untuk menghitung nilai variansi dari estimator HH dapat menggunakan rumus.
( )
( )∑( ̅ ̅)
Tabel 4.9 Variansi dan Kesalahan Baku Estimasi Hansen-Hurwitz
Observasi Variansi Kesalahan Baku
1 294509585 17161,28 2 330725444 18185,86 3 310006319 17607 4 322564355 17960,08 5 293127690 17120,97 6 259803876 16118,43 . . . . . . 50 342339079 18502,41
Pada Observasi pertama diperoleh variansi sebesar 294509585 dengan kesalahan baku 17161,28.