10
LANDASAN TEORI
2.1 Artificial Intelligence / Intelegensia Semu (IS )
Kecerdasan buatan atau IS merupakan salah satu bagian ilmu komputer yang membuat agar mesin (komputer) dapat melakukan pekerjaan seperti dan sebaik yang dilakukan manusia. Komputer pada saat sekarang ini sangat penting bagi manusia dan diharapkan untuk dapat diberdayakan untuk mengerjakan segala sesuatu yang bisa dikerjakan oleh manusia.
M anusia dapat menyelesaikan permasalahan karena dibekali pengetahuan disertai dengan pengalaman yang cukup. Namun dengan bekal pengetahuan dan pengalaman saja tidak akan bisa menyelesaikan masalah dengan baik apabila tidak disertai dengan bekal penalaran serta pengambilan kesimpulan berdasarkan pengetahuan dan pengalaman yang mereka miliki. Agar komputer dapat bertindak seperti dan sebaik manusia, maka komputer juga dibekali pengetahuan, dan kemampuan untuk menalar.
Untuk membekali komputer dengan kecerdasan buatan ada dua bagian utama yang sangat dibutuhkan diantaranya :
1. Basis Pengetahuan (Knowledge Base)
Basis pengetahuan tersebut berisi fakta-fakta, teori, pemikiran dan hubungan antara satu dengan lainnya.
2. M otor Inferensi (Inference Engine)
Kemampuan untuk menarik kesimpulan berdasarkan pengetahuan (fakta dan teori) yang ada.
Dalam pengertian kecerdasan buatan, terdapat beberapa sudut pandang, antara lain:
1. Sudut pandang kecerdasan
Kecerdasan buatan akan membuat mesin menjadi ‘cerdas’ (mampu berpikir dan berbuat seperti apa yang dipikirkan dan dilakukan oleh manusia).
2. Sudut pandang penelitian
Kecerdasan buatan adalah suatu studi yang mempelajari bagaimana membuat agar komputer dapat melakukan sesuatu sebaik yang dikerjakan oleh manusia.
3. Sudut pandang bisnis
Kecerdasan buatan adalah kumpulan peralatan yang sangat powerful dan metodologis dalam menyelesaikan permasalahan-permasalahan bisnis dan ekonomi.
4. Sudut pandang pemrograman
Kecerdasan buatan meliputi studi tentang pemrograman simbolik (symbolic programming), penyelesaian masalah (problem solving) dan pencarian (searching).
2.1.1 Kecerdasan Buatan dan Kecerdasan Alami
M eskipun kecerdasan buatan berasal dari kecerdasan alami, kecerdasan buatan juga memiliki kelebihan disamping kekurangannya (Kusumadewi,2003,p3-p4).
Kelebihan dan kekurangan kecerdasan buatan dibandingkan kecerdasan alami, yaitu :
1. Kecerdasan buatan lebih bersifat permanen dibandingkan kecerdasan alami. Kecerdasan buatan tidak akan berubah sepanjang sistem komputer dan program tidak mengubahnya.
2. Kecerdasan buatan lebih mudah diduplikasi dan disebarkan. Pengetahuan pada suatu sistem komputer dapat disalin dan dipindahkan dengan mudah ke komputer yang lain, sedangkan mentransfer pengetahuan manusia kepada manusia yang lainnya membutuhkan proses yang sangat lama; selain itu, suatu keahlian yang ditransfer antarmanusia tidak akan pernah dapat diduplikasi secara sempurna (khususnya dari sisi pengalaman dan faktor pengaruh emosional yang berbeda-beda).
3. Kecerdasan buatan lebih murah dibanding dengan kecerdasan alami. M enyediakan layanan komputer akan jauh lebih mudah dan murah dibandingkan harus mendatangkan seseorang atau beberapa ahli untuk mengerjakan sejumlah pekerjaan dengan jangka waktu yang lebih lama dan biaya yang lebih mahal.
4. Kecerdasan buatan bersifat konsisten. Hal ini disebabkan karena kecerdasan buatan adalah bagian dari teknologi komputer, sedangkan kecerdasan alami akan senantiasa berubah-ubah.
5. Kecerdasan buatan dapat didokumentasikan sedangkan kecerdasan alami sangat sulit untuk direproduksi.
6. Kecerdasan buatan dapat mengerjakan pekerjaan yang relatif jauh lebih cepat apabila dibandingkan dengan kecerdasan alami, karena kecerdasan buatan dijalankan dalam mesin / komputer.
Kelebihan dari kecerdasan alami diantaranya :
1. Kreatif, kemampuan untuk menambah ataupun memenuhi pengetahuan sangat melekat pada jiwa dan otak manusia. Pada kecerdasan buatan, untuk menambah pengetahuan harus dilakukan melalui sistem yang dibangun.
2. Kecerdasan alami memungkinkan orang untuk mendapatkan dan menggunakan pengalaman secara langsung, sedangkan pada kecerdasan buatan harus bekerja dengan input-input simbolik.
3. Pemikiran manusia dapat digunakan secara luas, sedangkan kecerdasan buatan sangat terbatas. Kecerdasan buatan yang dibuat untuk menyelesaikan suatu bidang permasalahan tidak akan dapat digunakan dalam bidang permasalahan yang berbeda, sementara kecerdasan alami (otak manusia) dapat digunakan untuk menyelesaikan berbagai bidang permasalahan.
2.1.2 Lingkup Kecerdasan Buatan
Pesatnya perkembangan teknologi menyebabkan adanya perkembangan dan perluasan lingkup yang dibutuhkan di berbagai disiplin ilmu dan teknologi.
Di samping bidang komputer, kecerdasan buatan juga telah dikembangkan untuk memenuhi kebutuhan disiplin ilmu lainnya. Hingga saat ini kecerdasan buatan telah memiliki banyak cabang yang banyak digunakan dalam memenuhi berbagai kebutuhan disiplin ilmu yang lain, cabang-cabang tersebut antara lain:
1. Sistem Pakar.
Komputer digunakan sebagai sarana untuk menyimpan pengetahuan para pakar. Dengan demikian komputer akan memiliki keahlian untuk menyelesaikan permasalahan dengan meniru keahlian yang dimiliki oleh pakar.
2. Pengolahan Bahasa Alami.
Dengan pengolahan bahasa alami ini diharapkan user dapat berkomunikasi dengan komputer dengan menggunakan bahasa sehari-hari dan bukan dengan menggunakan bahasa komputer atau bahasa mesin.
3. Jaringan Syaraf Tiruan.
Pengaplikasian kecerdasan buatan dengan meniru cara kerja otak manusia dan membuat sistem arsitektur jaringan yang dapat bekerja seperti otak manusia
4. Pengenalan Ucapan.
M elalui pengenalan ucapan diharapkan manusia dapat berkomunikasi dengan komputer menggunakan suara.
5. Robotika dan sistem sensor.
Dalam disiplin ilmu ini, komputer dan mesin dapat dipakai untuk melakukan pekerjaan-perkerjaan yang berjalan dalam lingkungan
berbahaya bagi manusia sementara manusia cukup memantau dari tempat lain.
6. Computer Vision.
Cabang kecerdasan buatan ini mencoba untuk dapat menginterpretasikan gambar yang diproses melalui komputer untuk dapat mengenali bentuk-bentuk objek dalam gambar tersebut.
7. Intelligent Computer-aided Instruction.
Komputer dapat digunakan sebagai tutor yang dapat melatih dan mengajar.
8. Game Playing.
Permainan game hampir tidak pernah terlepas dari kecerdasan buatan, misalnya dalam permainan catur (pengaplikasian heuristic searching).
2.2 Forex
Trading forex merupakan pasar terbesar di dunia diukur berdasarkan nilai
total transaksi. M enurut survei BIS (Bank International for Settlement – bank sentralnya bank-bank sentral seluruh dunia, www.bis.com), yang dilakukan pada akhir tahun 2004, nilai transaksi forex mencapai USD 1,900 miliar per hari. Dengan demikian, prospek investasi di perdagangan forex adalah sangat bagus. Pasar valas/forex berjalan selama 24 jam, berputar mulai dari pasar New Zealand & Australia yang berlangsung pukul 05.00 – 14.00 WIB, terus ke pasar Asia yaitu Jepang & Singapura yang berlangsung pukul 07.00 – 16.00 WIB, ke pasar Eropa yaitu Jerman & Inggris yang berlangsung pukul 13.00 – 22.00, sampai ke pasar Amerika yang berlangsung pukul 20.30 – 10.30. Dalam perkembangan
sejarahnya, bank sentral milik negara-negara dengan cadangan mata uang asing yang besar sekalipun dapat dikalahkan oleh kekuatan pasar forex yang bebas. Forex Online Adalah perdagangan / pertukaran mata uang asing dengan mata uang asing lainnya dengan satu satuan kontrak yang disebut dengan lot. Tidak melibatkan bentuk fisik dari mata uang tersebut secara langsung melainkan hanya nilainya saja.
Pertukaran mata uang merupakan pertukaran rupiah Indonesia menjadi mata uang dolar dari masing-masing negara. Adapun pertukaran mata uang Indonesia terhadap beberapa negara. Seperti pada saat sekarang ini pertukaran mata uang Indonesia terhadap 1 dolar Amerika yaitu dengan kurs jual Rp. 9135,- pada tanggal 1 September 2006; Rp. 9151,- pada tanggal 1 November 2006;. Rp. 9.186,- pada tanggal 1 Desember 2006.
Dalam penulisan skripsi ini penulis membatasi ruang lingkup dalam melakukan peramalan, yaitu hanya melakukan peramalan pertukaran mata uang Indonesia terhadap Dolar Amerika saja.
2.3 Computer Vision
Computer vision dapat dideskripsikan sebagai sebuah deduksi otomatik
dari struktur atau properti pada lingkungan dimensi-tiga baik dari satu atau banyak citra dua dimensi dari lingkungan dan pengenalan objek dengan bantuan properti ini. Tujuan dari computer vision adalah untuk menarik kesimpulan mengenai lingkungan fisik dari citra yang ambigu atau yang memiliki noise (Kulkarni, 2001, p27). Pengertian lain mengenai tujuan dari computer vision
adalah untuk menghasilkan keputusan yang berguna mengenai objek fisik nyata dan model berdasarkan pada citra yang didapatkan.
Salah satu pendekatan untuk menerapkan sistem computer vision adalah dengan mengemulasikan sistem vision pada manusia (human vision). Namun, permasalahan pada pendekatan ini adalah sistem vision pada manusia sangat kompleks dan sukar dipahami, sehingga pada saat ini tidaklah mungkin untuk mengemulasikan sistem human vision secara sempurna. M eskipun demikian, studi terhadap sistem biologis dapat memberikan petunjuk kepada kita unutk membangun sistem computer vision.
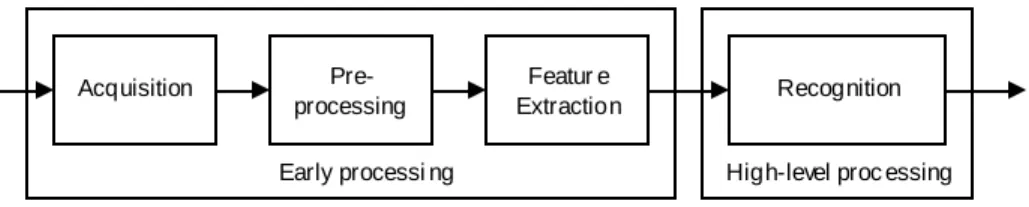
Tahapan dalam sistem computer vision secara umum seperti pada Gambar 2.1. Tiga tahap pertama -image acquisition, preprocessing, dan feature
extraction- mengimplementasikan pemrosesan tingkat rendah, sedangkan tahap
terakhir –recognition- berhubungan dengan pemrosesan tingkat tinggi.
2.4 Logika Fuzzy
Fuzzy Logic pada dasarnya merupakan logika bernilai banyak
(Multivalued logic) yang dapat mendefinisikan nilai diantara keadaan yang biasa dikenal seperti ya – tidak, hitam – putih, benar – salah dan nol – satu. logika fuzzy menirukan cara manusia mengambil keputusan dengan kemampuannya
Input Acquisition Pre- Output
processing
Gambar 2.1 Sistem Computer Vision
Featur e
Extraction Recognition
bekerja dari data yang samar atau tidak rinci dan menemukan penyelesaian yang tepat. Untuk masalah-masalah yang rumit, tidak cukup hanya berbasis pada logika False (0) atau True (1), masalah yang berhubungan dengan pemikiran manusia misalnya logika fuzzy menggunakan interval antara 0 sampai dengan 1.
Fuzzy Logic berangkat dari kenyataan bahwa dunia nyata adalah sangat
kompleks. Kompleksitas ini muncul dari ketidakpastian dalam bentuk ke tidak telitian (imprecision) informasi. Komputer dibuat manusia tidak mampu menangani persoalan yang kompleks dikarenakan komputer tidak mempunyai kemampuan untuk menalar (reasoning) sedangkan manusia mempunyainya.
2.5 Human Brain
Otak manusia terdiri dari berjuta-juta sel syaraf yang bertugas untuk memproses informasi. Tiap-tiap sel bekerja seperti suatu proses yang sederhana, namun masing-masing sel tersebut saling berinteraksi dalam jaringan yang amat besar sehingga mendukung kemampuan kerja otak manusia dalam proses pembelajaran maupun dalam proses pemecahan masalah. Adapun sistem kerja otak manusia digambarkan secara sederhana seperti pada Gambar 2.2 berikut ini (Arbib, 1987):
Bila dibandingkan dengan komputer modern, kecepatan dari neuron pada otak manusia jauh lebih lambat, namun karena jumlah neuron yang amat banyak
Stimul us Recept ors Neural net Effect ors Response
pada otak manusia –diperkirakan sekitar sepuluh miliar neuron– menyebabkan otak manusia dapat melakukan pekerjaan yang amat cepat serta menggunakan energi yang amat efisien. Pengenalan objek seperti wajah seseorang dapat dilakukan hanya dalam waktu sepersepuluh detik sementara dengan database yang sama komputer modern sekarang membutuhkan waktu yang jauh lebih lama setidaknya beberapa menit (Faggin, 1991).
2.5.1 Jaringan S yaraf Tiruan
Jaringan Syaraf Tiruan, sesuai dengan namanya, merupakan sistem arsitektur informasi yang mengambil analogi seperti pada halnya neuron biologis yang terdapat pada jaringan otak makhluk hidup. Hal ini muncul karena usaha pengembangan dalam bidang IS untuk meningkatkan kemampuan komputer dalam bentuk analisa pembelajaran pola maupun proses penyelesaian masalah seperti yang dapat dilakukan oleh otak manusia, misalnya ketika manusia belajar membaca, berbicara dan berhitung.
M enurut Kulkarni (2001), jaringan saraf tiruan adalah suatu sistem pemrosesan informasi yang memetakan vektor data input kedalam vektor data output. M enurut Forsyth (2003), jaringan saraf tiruan menghubungkan fungsi vektor f dengan beberapa input x dengan menggunakan serangkaian layer. Definisi lain dari jaringan saraf tiruan menurut Azcarraga (1999) adalah sekumpulan data set yang besar dari interkoneksi unit sederhana yang dieksekusi secara paralel untuk melakukan tugasnya.
Beberapa kelebihan yang dimiliki oleh JST (Jaringan Syaraf Tiruan) adalah sebagai berikut (Haykin, 1999, p2 - p6):
1. Nonlinearity, yaitu :
a. Pemodelan dari fungsi dan proses yang tidak linear. b. Sifat non-linear didistribusikan lewat jaringan.
c. Setiap neuron umumnya memilki output yang non-linear. 2. Mapping Input-Output, yaitu :
a. M apping input-output dipelajari dari training data set.
b. Bobot synapsis (termasuk parameter konstan bebas maupun bias) dapat dimodifikasi untuk mengoptimasi JST (Jaringan Syaraf Tiruan). Dalam hal ini proses pembelajaran dapat berjalan sangat lambat.
3. Adaptivity, yaitu :
a. Bobot dapat dilatih ulang dengan data yang baru.
b. Jaringan dapat beradaptasi dengan input-input yang tidak lengkap. Dalam hal ini perubahan harus bergerak secara perlahan, bila pergerakan terjadi secara signifikan maka kemampuan JST untuk melakukan perhitungan juga akan meleset jauh (menyebabkan turunnya tingkat akurasi dan kepercayaan).
4. Evidential Response, yaitu :
a. JST (Jaringan Syaraf Tiruan) dapat menyediakan informasi tentang tingkat kepercayaan atas pengambilan keputusan.
b. JST (Jaringan Syaraf Tiruan) dapat melakukan penolakan terhadap pengenalan pola, hasil bahwa pola tidak dikenali.
5. Contextual Information, yaitu: a. M eningkat secara alami.
6. Fault Tolerance, yaitu :
a. Berhubungan dengan hardware, bila satu neuron mengalami kerusakan (mis. akibat data loss pada memori), unjuk kerja akan menurun tetapi hanya berpengaruh kecil khususnya dalam J ST yang berskala besar.
b. Apabila terjadi perubahan pada sebuah bobot yang diakibatkan oleh kesalahan pembaca data atau faktor lainnya, maka unjuk kerja akan menurun namun tidak signifikan.
7. VLSI (Very Large Scale Integrated) Implementability
a. JST (Jaringan Syaraf Tiruan) berfungsi dengan amat baik untuk teknologi berskala sangat besar.
b. Neurocomputer sudah mulai dibuat dan dikembangkan untuk menciptakan komputer dengan kemampuan menyerupai otak manusia (tidak hanya menyelesaikan masalah dalam satu bidang saja).
8. Uniformity of Analysis and Design
a. Neuron merupakan bagian dasar dalam semua JST (Jaringan Syaraf Tiruan)
b. M odul-modul dapat dipakai dalam J ST lainnya dan dapat di-integrasikan dalam JST dengan skala yang lebih besar.
9. Neurobiological Analogy
a. Otak manusia cepat, powerful, fault tolerant, dan menggunakan perhitungan paralel yang amat besar, misalnya adalah otak manusia dapat digunakan untuk melakukan pengenalan wajah dari begitu
banyak bentuk wajah yang diketahuinya hanya dalam waktu 100-200 milidetik dan jauh lebih cepat dibanding komputer konvensional. b. Neurobiologist dapat menjelaskan cara kerja otak manusia melalui
JST.
c. Engineer menggunakan prinsip-prinsip perhitungan jaringan syaraf dalam menyelesaikan masalah yang kompleks.
2.5.2 Neuron
Neuron adalah unit pemrosesan informasi (information-processing unit) yang terkecil dalam sebuah jaringan biologis, merupakan bagian paling terpenting dalam jaringan syaraf.
Neuron memiliki tiga elemen dasar dalam melakukan proses informasi, ketiga elemen ini harus dimiliki oleh sebuah neuron supaya neuron ini dapat diaktifkan, elemen-elemen ini adalah (Haykin, 1999, p10):
1. Synapses
Satu neuron pada umumnya memiliki beberapa synapsis, masing-masing memiliki weight-nya sendiri. Di sini weight / bobot pada neuron biologis memiliki nilai penguatan yang bervariasi, nilai weight ini adalah nilai yang positif, bisa bernilai kecil dan bisa pula bernilai besar. Tidak seperti pada neuron biologis, weight pada neuron tiruan dapat bernilai negatif maupun positif sesuai dengan pelatihan yang dilakukan.
2. Summing adder
Sesuai dengan namanya, elemen ini berfungsi untuk menambahkan sinyal-sinyal input yang telah dibobotkan sesuai dengan weight dari sinapsis yang dilewati oleh sinyal-sinyal tersebut.
3. Activation Function
Fungsi aktivasi ini membatasi amplitude dari output sebuah neuron, fungsi ini yang menentukan range dari sinyal output yang nantinya akan dikirimkan kepada lapisan di atasnya.
Selain dari ketiga elemen dasar, neuron juga dapat memiliki bias. Seperti weight, bias ini berfungsi untuk menguatkan atau melemahkan sinyal input, namun bias ini sendiri tidak mengirimkan sinyal.
2.5.3 Pemrosesan Informasi
Setiap neuron mengirim sinyal-sinyal dari neuron lain melalui suatu jalur sambungan / jembatan yang disebut synapsis. Sebagian sinyal input cenderung menyebabkan neuron tereksitasi (excited), sementara sebagian yang lainnya menyebabkan neuron terhambat / terlemahkan (inhibited).
Ketika efek kumulatif dari sinyal tersebut melebihi suatu batas threshold, neuron yang bersangkutan akan menembakkan sinyal ke neuronnya. Sebuah neuron tunggal dalam konsep JST digambarkan dalam bentuk node yang menerima sinyal-sinyal input dan menghasilkan output dengan proses tersebut diatas dan karenanya sering pula disebut Summing Divice.
M odel komputasinya dapat dituliskan sebagai berikut :
∑
= = n i i iW X Y 1 (2.5)dengan net output = f(y).
f disebut sebagai fungsi aktivasi, sedangkan net output merupakan level aktivasi, Wi adalah weight / bobot yang menunjukkan kekuatan synapsis.
2.5.4 Karakteristik Jaringan S yaraf Tiruan
JST atau Jaringan Syaraf Tiruan merupakan sebuah sistem informasi yang memiliki karakteristik serupa dengan jaringan neural biologis. Karakteristik yang didapati antara lain adalah :
1. Jumlah yang besar dari pemrosesan elemen / neuron, 2. Neuron-neuron bekerja secara paralel, dan
3. M emiliki sifat fault tolerance.
Fungsi dan kinerja sebuah JST (Jaringan Syaraf Tiruan) sebagai sebuah sistem sangat tergantung pada 3 hal berikut :
1. Neuron Characteristic, terkait dengan fungsi aktivasi yang digunakan, 2. Network Topologyy, terkait dengan bagaimana sejumlah neuron dalam
sistem / model JST (Jaringan Syaraf Tiruan) dihubungkan, dan
3. Learning Process, terkait dengan aturan-aturan pembelajaran yang digunakan.
Dalam fungsi aktivasi, terdapat beberapa fungsi yang dapat digunakan sesuai dengan karakteristik neuron, antara lain :
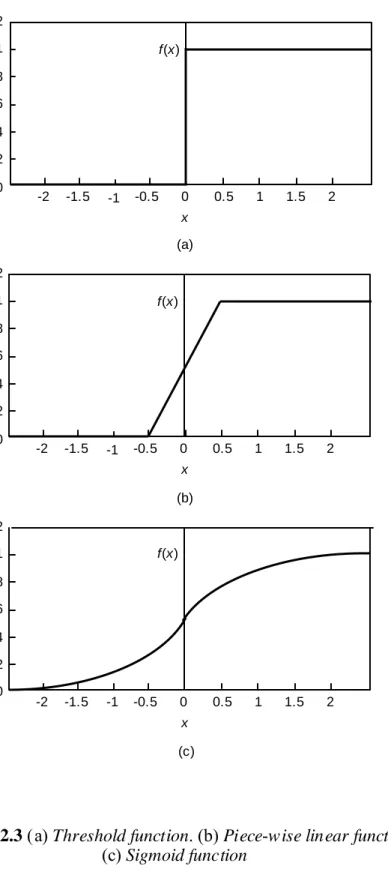
1. Threshold Function
Fungsi ini dirumuskan dengan persamaan umum:
( )
⎩ ⎨ ⎧ = 0 1 x f (2.1) if x ≥ 0 if x < 0Fungsi ini digambarkan dalam Gambar 2.3a, fungsi ini bisa memiliki range tidak hanya antara nol sampai satu (fungsi threshold biner) tetapi dapat juga memiliki range antara minus satu sampai satu (fungsi threshold bipolar).
2. Piecewise-Linear Function
Fungsi ini dirumuskan dengan persamaan umum:
( )
⎪⎩ ⎪ ⎨ ⎧ = , 0 , , 1 x x f (2.2)Fungsi ini digambarkan dalam Gambar 2.3b, bentuk dari fungsi aktivasi ini merupakan fungsi pendekatan terhadap amplifikasi non-linear dan pengembangan dari fungsi threshold.
3. Sigmoid Function
Fungsi yang digambarkan dengan grafik kurva-s ini merupakan fungsi yang paling sering dipakai dalam arsitektur jaringan syaraf tiruan. Salah satu contoh persamaan yang biasa dipakai untuk range nilai nol sampai satu (fungsi sigmoid biner, Gambar 2.3c) adalah fungsi logistik, persamaannya adalah sebagai berikut:
( )
) exp( 1 1 ax x f − + = (2.3)Fungsi ini merupakan fungsi yang memiliki keseimbangan yang baik nilai pasangan x dan f(x). Dalam fungsi ini tidak terdapat persamaan
x ≥ +0.5
+0.5 > x > -0.5
umum sebab terdapat persamaan yang berbeda yang dapat menghasilkan grafik kurva-s. 1.2 1 0.8 0.6 0.4 0.2 0 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 f(x) x (a) 1.2 1 0.8 0.6 0.4 0.2 0 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 f(x) x (b) (c) x 1.2 1 0.8 0.6 0.4 0.2 0 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 f(x)
Gambar 2.3 (a) Threshold function. (b) Piece-wise linear function. (c) Sigmoid function
Sementara salah satu fungsi persamaan yang biasa dipakai untuk range nilai minus satu sampai satu adalah:
( )
) exp( 1 ) exp( 1 ax ax x f − + − − = (2.4)dimana a adalah parameter fungsi logistik, parameter ini mempengaruhi gradien kurva-s.
Dalam bentuk topologi JST, terdapat banyak model arsitektur yang dapat digunakan sesuai kegunaan J ST tersebut, beberapa diantaranya :
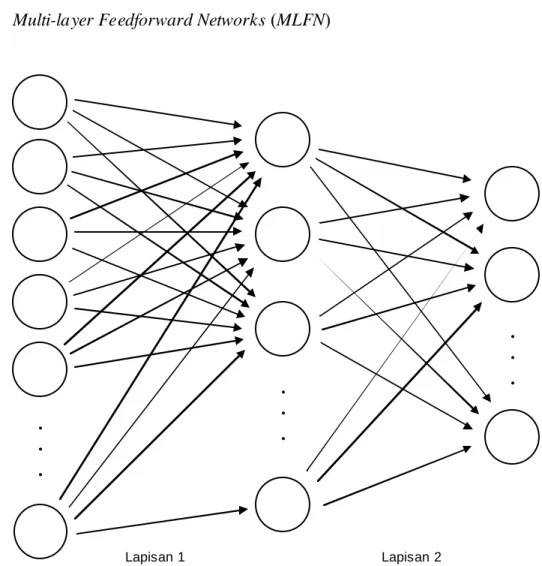
1. Multi-layer Feedforward Networks (MLFN)
Input Layer Hidden Lay er Output Layer Lapisan 1 Lapisan 2 . . . . . . . . .
M LFN merupakan perkembangan yang lebih lanjut dari single-layer
feedforward networks, perbedaannya adalah topologi ini memiliki hidden
layer untuk meningkatkan unjuk kerja. Topologi ini menggunakan umpan maju berupa parameter-parameter input dan fungsi aktivasi serta pemakaian hidden layer (bisa lebih besar dari satu) dalam permrosesan informasinya; dan untuk proses training, topologi ini menggunakan
learning rule (learning rule yang biasa digunakan dengan M LFN adalah error-correction learning rule). Bentuk umum dari M LFN adalah seperti
pada Gambar 2.4.
2. Bidirectional Associative Memory (BAM)
Topologi ini hanya menggunakan sebuah input layer dan sebuah output layer tanpa adanya hidden layer, topologi ini menggunakan feedback, sementara fungsi aktivasi yang biasa digunakan adalah fungsi threshold biner dan bipolar. Feedback dalam topologi ini berfungsi untuk memperbaiki nilai weight, mirip dengan proses backward dalam M LFN. BAM merupakan topologi jaringan syaraf yang bekerja dengan baik dan sangat mudah implementasinya, namun yang menjadi kekurangannya adalah kemampuan memori yang amat sedikit dan bila digunakan untuk mengenali pola-pola yang terlalu banyak maka BAM menjadi tidak efektif. Beberapa cara dapat dilakukan untuk dapat memaksimalkan penggunaan memori BAM seperti konvergensi pasangan input-output. Learning rule yang digunakan adalah Hebbian learning rule yang sederhana.
Bentuk umum topologi BAM adalah seperti pada Gambar 2.5 :
3. Self Organizing Map (SOM)
SOM adalah sebuah topologi yang dapat dikatakan spesial dalam jaringan syaraf tiruan, hal ini dikarenakan SOM merupakan sistem yang dapat berjalan sendiri (unsupervised learning, pembelajaran tanpa adanya
teacher).
Gambar 2.5 Topologi Bidirectional Associative Memory . . . . . . Distribution
Untuk learning process, topologi ini menggunakan competitive learning, hanya ada satu neuron output, neuron-neuron output akan saling bersaing dan yang memenangkan kompetisi menjadi neuron output yang aktif dan mengirimkan sinyal bagi lapisan berikutnya dan bersaing dengan neuron-neuron output lainnya sampai lapisan terakhir.
Adapun bentuk umum dari topologi adalah seperti pada Gambar 2.6.
Dalam jenis-jenis learning process yang dipakai untuk proses training, terdapat beberapa rule / aturan, yaitu:
1. Error-correction learning
Proses pembelajaran disini meminimisasi nilai error (hasil pengurangan nilai perhitungan sistem dari nilai target sebenarnya), learning rule ini biasa disebut sebagai delta rule atau Widrow-Hoff rule (Widrow and
Input
Hoff, 1960). Proses dilakukan sampai nilai error hasil sistem lebih kecil dari nilai error yang ditentukan atau sampai nilai bobot dari synapsis mencapai nilai yang stabil.
2. Memory-based learning
Dalam proses pembelajaran memory-based, semua (atau sebagian besar) dari pengetahuan / pengalaman yang sudah ada disimpan secara eksplisit di dalam memori besar dari J ST. Pembagian dilakukan dalam kelas-kelas; bila ada titik / nilai yang mau diketahui kelasnya, maka akan dihitung jarak Euclidean-nya. Memory-based learning lebih dikenal dengan nama
nearest neighbor rule.
3. Hebbian learning
Learning process ini merupakan learning rule yang pertama dan yang paling terkenal dari seluruh learning rule yang ada. Prinsip dari Hebbian learning adalah bila dua neuron pada kedua sisi dari synapsis diaktifkan secara bersamaan maka kekuatan / bobot dari synapsis menguat, dan sebaliknya kekuatan dari synapsis akan melemah jika kedua neuron aktif dengan tidak bersamaan (Hebb, 1949, p62). Pada proses pembelajaran ini beberapa neuron dapat aktif secara bersamaan.
4. Competitive learning
Sesuai dengan namanya, neuron-neuron output saling berkompetisi pada jaringan syaraf untuk menjadi aktif (fired). Tidak seperti pada Hebbian
learning, pada competitive learning hanya ada satu neuron yang aktif dalam satu waktu. Hal ini sangat cocok digunakan untuk menemukan fitur utama yang bisa dipakai untuk mengklasifikasikan pasangan-pasangan dari model / pola input secara tepat.
5. Boltzmann learning
Boltzmann learning adalah algoritma pembelajaran stokastik yang diturunkan dari ilmu mekanik statistical. Jaringan syaraf yang didesain dengan menggunakan proses pembelajaran Botzmann ini disebut dengan mesin Boltzmann. Dalam mesin Boltzmann, neuron bekerja dalam angka biner, satu untuk menyatakan ”on” dan minus satu untuk menyatakan ”off”; neuron juga terbagi menjadi dua jenis sesuai dengan fungsinya yaitu visible neuron dan hidden neuron.
2.5.5 Metode Pembelajaran
Disamping arsitektur jaringan, metode untuk menentukan weight juga merupakan karakteristik yang penting yang membedakan jaringan saraf tiruan. Jaringan saraf tiruan dapat dikelompokkan ke dalam dua jenis berdasarkan metode pembelajarannya (Haykin, 1999, p63 – p66), yaitu:
1. Supervised Learning
Pada metode supervised learning, sejumlah data pelatihan tersedia untuk setiap kelas dan digunakan pada proses pelatihan. Proses pembelajaran dilakukan dengan penyesuaian nilai weight terhadapa vektor input yang diasosiasikan dengan vektor output. Contoh dari kategori ini antara lain :
perceptron, back-propagation network, Hamming network, dan Hopfield nets.
2. Unsupervised learning
Pada metode unsupervised learning, data pelatihan tidak tersedia, sehingga metode ini berhubungan dengan proses pembelajaran sendiri (self learning). Pada metode ini terdapat serangkaian vektor input, tetapi tidak ada target vektor yang diasosiasikan. Jaringan memodifikasi nilai
weight sehingga nilai vektor input yang serupa diasosiasikan dengan unit
output yang sama. Contoh dari kategori ini antara lain : adaptive
resonance theory (ART), competitive learning , dan Kohonen’s self organizing maps.
2.6 Metode Moving Average
M oving average (M A) ini adalah salah satu metode analisa statistik yang dahulu dipakai untuk melakukan peramalan dalam bidang ekonomi (saham dan pasar uang), selain metode ini masih ada metode-metode lainnya yang bisa dipakai untuk meramal (M uis, 2006). Ada beberapa jenis metode dari metode MA ini, masing-masing dapat dipakai untuk JST ini, namun pada skripsi ini penulis menggunakan hanya gabungan dua dari empat metode yang tersedia.
2.6.1 Metode S imple Moving Average (S MA)
Teknik ini merupakan teknik rata-rata berjalan yang paling mudah, sangat sederhana dan mudah dipergunakan sebagai alat bantu meramal pergerakan
harga kurs. Rata-rata kurs yang dimaksud dihitung berdasarkan periode tertentu, sehingga nilai rata-rata terhitung berjalan mengikuti pergeseran data harian.
m x SMA n m n i i
∑
+ − = = 1 (3.6)Nilai rata-rata dengan periode m (m = 1, 2, ...) memiliki sifat penghalusan berbeda-beda tergantung pada besaran m dan pemberian bobot kepada variabel x. Semakin besar nilai m maka penghalusan akan semakin baik, akan tetapi besarnya m juga memberikan arti lambatnya respon / kurang sensitive terhadap perubahan nilai xn (nilai x terakhir).
2.6.2 Metode Weighted Moving Average (WMA)
M etode ini memperbaiki kelemahan dari metode SM A dengan cara memberikan bobot yang berbeda pada tiap x, x yang lebih baru mendapat bobot yang lebih besar dari x yang lama. Pemakaian bobot yang berbeda ini dikarenakan tingkat pengaruh yang diberikan tiap-tiap data juga berbeda, dimana data yang terakhir / terbaru seharusnya lebih relevan dengan kondisi sekarang dan masa depan apabila dibandingkan dengan data-data sebelumnya.
WMA =
[
[
]
]
1 ... ) 2 ( ) 1 ( / . 1 ... ). 1 ( . 1 1 + + − + − + + + − + − − + m m m x x m x m n n n m (3.7)dimana m = periode yang dipakai dan x adalah variabel yang dipakai untuk perhitungan WM A.
2.6.3 Metode Exponential Moving Average (EMA)
M etode ini mirip dengan metode WM A, hanya saja jika pemberian bobot pada WM A diberikan secara linear, pada EM A pemberian bobot tidak dilakukan secara linear. E = A . ( C – P ) + P (3.8) Keterangan: E = EMA (tn) A = konstanta penghalusan = 2/(m+1) C = harga sekarang, xn P = EM A periode sebelumnya (tn-1) m = Periode EM A
Untuk EM A pertama sama dengan rata-rata data (xn). Penggunaan EM A dan WM A berbeda sesuai dengan kondisi fluktuasi harga yang terjadi, bila fluktuasi tinggi (data naik dan turun dalam periode singkat) maka metode EM A ini lebih baik daripada WM A, sementara pada transaksi sesungguhnya, harga kurs bersifat sangat fluktuatif, sehingga EM A lebih baik untuk meramal.
2.6.4 Metode Moving Average Convergence Divergence (MACD)
M etode ini memanfaatkan teknik rata-rata berjalan eksponensial (EM A) dengan dua periode yang berbeda yaitu periode n1 dan n2 sementara untuk garis
pemicu ditetapkan periode 9 (M uis, 2006). Perumusan M ACD dinyatakan dalam:
MACD = EMA(n1)-EM A(n2)
MACDtrig = EM A(n3), EM A(n3) disini menggunakan n3 data M ACD,
Disini penulis tidak menjelaskan secara terperinci mengenai empat metode MA yang ada, hal ini dikarenakan penulis membatasi ruang lingkup pembahasan agar tidak terlalu melebar dan justru menyulitkan pembaca (bagi pembaca yang tertarik untuk mempelajari lebih lanjut dapat melihat buku acuan M uis, 2006).
2.7 Metode Konversi Variabel
M etode ini merupakan metode yang dipakai untuk mengkonversikan data yang tadinya tidak bernilai dalam range tertentu menjadi data yang bernilai dalam range tertentu (mis. antara -1 sampai 1). Tujuan metode ini adalah untuk menyesuaikan data untuk dapat dipakai oleh sistem jaringan syaraf yang bersangkutan khususnya sesuai dengan fungsi aktivasi yang dipakai, namun perubahan yang dilakukan tidak memberi gangguan yang signifikan terhadap fluktuasi data yang terjadi, sehingga diperlukan pemilihan metode sesuai yang diperlukan.
2.7.1 Transformasi variabel (penyekalaan / scaling dan pergeseran)
Disini data ditransformasi menjadi lebih kecil, misalnya dengan scaling maka data dibagi dengan variabel konstan tertentu atau dikalikan dengan variabel konstan tertentu (metode ini tidak merubah tingkat fluktuasi data sama sekali), sementara dengan pergeseran maka data ditambah atau dikurangi dengan variabel tertentu (bila menggunakan pergeseran maka perlu diperhitungkan tingkat fluktuasi data, bisa menyebabkan fluktuasi data meningkat tajam atau menurun tajam).
Contoh: Bila data-data bernilai 2,3,5,6,8,10,12,20. Range data bernilai positif dari 2 sampai 20, maka untuk mengubah data menjadi range 0 sampai 1, dapat membagi dengan nilai 20 (bila nilai maksimum data adalah 20), atau dengan membagi dengan nilai yang lebih besar dari 20 (bila nilai maksimum bisa lebih besar dari 20, hal ini dilakukan untuk mencegah munculnya data dengan nilai lebih besar dari 20 di kemudian hari).
2.7.2 S tatistik (rata-rata variabel)
Pada metode ini, beberapa data yang memiliki koefisien korelasi tinggi akan digabungkan. Bila data-data bernilai sama (data A, B dan C sama-sama bernilai antara range yang sama) maka cukup merata-ratakan data-data tersebut dan kemudian menggunakan transformasi, dapat pula sebaliknya (transformasi terlebih dahulu baru merata-ratakan). Tetapi bila data-data memiliki range berbeda maka masing-masing data harus di-transformasi dahulu baru di rata-rata kan.
2.7.3 Normalisasi variabel
Dalam metode ini diperhitungkan kemungkinan bahwa masing-masing variabel memiliki tingkat pengaruh yang berbeda, yang satu lebih kuat sementara yang lain lebih lemah, karena itu diberikan bobot untuk menormalisasikan data yang dipakai.
Contoh: Bila data A, B dan C memiliki pengaruh yang berbeda maka masing-masing data diberikan variabel bobot yang berbeda dengan total semua
variabel bobot adalah satu. Data A diberi bobot 0,2 sementara data B dan C masing-masing diberikan bobot 0,3 dan 0,5.
M asih ada banyak cara-cara di atas yang dapat dipakai, namun ketiga metode diatas merupakan metode dasar yang dapat digabung satu sama lain untuk memenuhi kebutuhan sistem yang berjalan, dengan variasi penggunaan metode, maka hampir semua data dapat dikonversi menjadi nilai dengan range tertentu tanpa perubahan yang signifikan dari data mula-mula (data yang dikonversi dapat dipakai tanpa merubah pola yang terkandung pada data secara signifikan).
2.8 Backpropagation
Backpropagation merupakan algoritma pembelajaran yang terawasi dan
biasanya digunakan oleh perceptron dengan banyak lapisan untuk mengubah bobot-bobot yang terhubung dengan neuron-neuron yang ada pada lapisan tersembunyinya. Algoritma backpropagation menggunakan error output untuk mengubah nilai bobot-bobotnya dalam arah mundur (backward). Untuk mendapatkan error ini, tahap perambatan maju (feedforward) harus dikerjakan terlebih dahulu.
Back-propagation merupakan suatu teknik untuk meminimalisasi
gradient pada dimensi weight dalam jaringan saraf tiruan lapis banyak (Haykin, 1999, p202), proses pelatihan akan dilakukan berulang-ulang sampai nilai error lebih kecil dari yang ditentukan.
Dalam proses pelatihan jaringan propagasi balik ini, digunakan fungsi nilai ambang batas binary sigmoid. Sebelum melakukan proses pelatihan, terdapat beberapa parameter jaringan yang harus ditentukan dahulu (Fausett, 1994, p292), yaitu:
a. Tingkat pelatihan (learning rate) yang dilambangkan dengan D. Parameter ini harus diberikan dan mempunyai nilai positif kurang dari 1. semakin tinggi nilainya, maka semakin cepat kemampuan jaringan untuk belajar, tetapi hal ini kurang baik, karena error yang dihasilkan tidak merata.
b. Toleransi kesalahan (error tolerance), semakin kecil maka jaringan akan memiliki nilai bobot yang lebih akurat, tetapi akan memperpanjang waktu pelatihan.
c. Jumlah maksimal proses pelatihan yang dilakukan (maximum epoch,) biasanya bernilai besar dan diberikan untuk mencegah terjadi perulangan tanpa akhir.
d. Nilai ambang batas atau bias (threshold value), dilambangkan dengan θ. Parameter ini tidak harus diberikan (optional). Apabila tidak diberikan, maka nilainya sama dengan 0.
Berikut adalah algoritma pelatihan jaringan propagasi balik (Fausett, 1994, p294) untuk satu hidden layer:
1. Inisialisasi bobot dengan memberikan nilai acak. 2. Selama kondisi berhenti false, lakukan langkah 3-9.
3. Untuk setiap pasangan data pelatihan (x_setb,tb) dimana b=1,…l, lakukan
langkah 4-8.
4. M emulai proses forward, setiap unit input (Xi , i = 1,…,n) menerima
sinyal input xi dan melanjutkannya ke hidden layer, setiap unit
tersembunyi (Zj , j = 1,…p) menjumlahkan sinyal-sinyal input terbobot,
∑
= + = n i ij i j j v xv in z 1 0 _gunakan fungsi aktivasi untuk menghitung sinyal outputnya,
(
j)
j f z in
z = _
dan lanjutkan sinyal ke semua unit di lapisan atasnya (output layer). 5. Setiap unit output (Yk , k = 1,…,m) menjumlahkan sinyal-sinyal input
terbobot,
∑
= + = p j jk j k k w z w in y 1 0 _gunakan fungsi aktivasi untuk menghitung sinyal outputnya,
(
k)
k f y in
y = _
dan lanjutkan ke proses backward.
6. Tiap-tiap unit output (Yk , k = 1,…,m ) menerima pola target yang
berhubungan dengan pola input pembelajaran, hitung informasi error Gk,
(
k k) (
k)
k = t −y f' y_in δ
hitung koreksi bobot 'wjk,
j k jk z
w =αδ
hitung koreksi bias 'w0k,
k k
w =αδ
Δ 0
dan kirimkan nilai informasi error ke lapisan bawahnya.
7. Tiap-tiap hidden unit menjumlahkan hasil kali informasi error dengan weight,
∑
= = m k jk k j w in 1 _ δ δ hitung informasi error Gj,(
j)
j j δ_in f' z_in δ = koreksi bobot 'vij, i j ij x v =αδ Δ dan koreksi bias 'v0j,j j
v =αδ
Δ 0
lanjutkan ke tahap peng-update-an weight.
8. Setiap unit output (Yk , k = 1,…,m) memperbaiki bobot dan biasnya (j = 0,…,p),
jk jk
jk baru w lama w
w ( )= ( )+Δ
setiap unit tersembunyi (Zj , j = 1,…,p) memperbaiki bobot dan biasnya
(i = 0,…,n),
ij ij
ij baru v lama v
v ( ) = ( )+Δ
lanjutkan ke tes kondisi.
Keterangan: X = input neuron Z = hidden neuron Y = output neuron f(x) = fungsi aktivasi x_setb = (x1,x2,…,xn)
n = jumlah neuron pada input layer l = banyaknya pasangan data pel atihan p = jumlah neuron pada hidden layer k = jumlah neuron pada output layer v = weight lapisan pertama
w = weight lapisan kedua
z_in = sinyal input untuk hidden neuron y_in = sinyal input untuk output neuron x = sinyal input
z = sinyal output / level aktivasi dari hidden neuron y = sinyal output / level aktivasi dari output neuron