Perancangan dan Implementasi Modul Klasifikasi
Jenis Kejadian pada Kronologi dalam Proses
Klaim Asuransi Kendaraan Menggunakan Metode
Word Embedding
Artikel Ilmiah
Diajukan kepada
Fakultas Teknologi Informasi
untuk memperoleh Gelar Sarjana
Komputer
Peneliti :
Robin Febrianto Darmo Husodo - 672015073
Program Studi Teknik Informatika
Fakultas Teknologi Informasi
Universitas Kristen Satya Wacana
Salatiga
Januari 2020
I. PENDAHULUAN
Kendaraan merupakan alat yang digunakan manusia untuk berpindah dari satu tempat ke tempat lain. Kendaraan sudah menjadi kebutuhan sehari-hari baik untuk pergi kesekolah, bekerja, maupun liburan. Dalam sehari-hari terdapat resiko yang tidak dapat diprediksi secara pasti seperti bencana alam, kecelakaan, hingga kematian. Resiko-resiko tersebut dapat diartikan sebagai ketidakpastian atas sesuatu yang dapat menimbulkan kerugian di masa depan, dimana kejadiannya seringkali tidak dapat diprediksi baik atas frekuensinya maupun besar atau kecilnya kerugian yang ditimbulkan. Hal tersebut membuat banyaknya perusahaan asuransi yang berdiri untuk menjadi sebuah perlindungan dan dapat meminimalisasi kerugian secara tepat dan benar. Perusahaan asuransi juga termasuk salah satu tehnik dalam menajemen resiko yang menerima pengalihan risiko dari tertanggung, sehingga aktifitas keseharian perusahaan adalah mengelola risiko pihak lain. Banyaknya manfaat yang dapat dipetik oleh individu atau perusahaan dari kegiatan perasuransian, seperti perasaan aman yang diperoleh tertanggung atas risiko-risiko yang mungkin timbul dimasa yang akan datang. [1]
Jika kendaraan rusak maka mengakibatkan terhambatnya keperluan sehari-hari. Hal tersebut akan bertambah lama jika proses klaim asuransi kendaraan juga tidak cepat. Didalam proses klaim asuransi kendaraan terdapat proses pengecekan kronologi. Tujuan dari pengecekan kronologi adalah mengkategorikan kronologi ke jenis kejadian yang dicover. Jika jenis kejadian tersebut dicover maka klaim akan diterima, sedangkan jika jenis kejadian tidak dicover maka klaim ditolak. Proses ini menjadi sangat penting karena menentukan klaim diterima atau ditolak. Proses ini dapat dilakukan secara otomatis melihat perkembangan teknologi yang cukup pesat, terutama dalam bidang pemrosesan bahasa manusia.
Salah satu bidang yang cocok untuk menyelesaikan masalah ini adalah kecerdasan buatan. Kecerdasan Buatan atau Artifical Intelligence merupakan bagian dari ilmu komputer yang membuat agar mesin (komputer) dapat melakukan pekerjaan seperti dan sebaik yang dilakukan manusia. Sistem cerdas (intelligent system) adalah sistem yang dibangun dengan menggunakan teknik-teknik Artificial Intelligence. [2] Sejak komputer ditemukan, para peneliti telah berpikir adakah kemungkinan agar komputer dapat belajar. Jika kita mengerti bagaimana cara memprogram komputer agar mereka dapat belajar, dan berkembang dari pengalaman secara otomatis, hasilnya akan luar biasa dramatis. Bayangkan komputer belajar dari data-data medical untuk menemukan cara baru menangani suatu penyakit, belajar dari pengalaman untuk mengoptimumkan energi yang dibutuhkan untuk melakukan pekerjaan rumah tangga, dan lain-lain. [3]
Penelitian ini mengambil latar belakang dari evaluasi klaim, fokus dari penelitian ini adalah bagaimana melakukan klasifikasi kronologi terhadap jenis kejadian menggunakan metode word embedding. Sebelumnya penelitian mengenai implementasi word embedding sudah dilakukan seperti pada penelitian berjudul “klasifikasi Opini pada Fitur Produk Berbasis Graph Opinion Classification for Product Feature Based on Graph” yang menggunakan word embedding sebagai klasifikasi opini, dan “Penerapan Algoritma Cosine Similarity dan Pembobotan TF-IDF pada Sistem Klasifikasi Dokumen Skripsi” yang menggunakan word embedding untuk klasifikasi dokumen skripsi. Tetapi untuk tema klasifikasi jenis kejadian untuk mempercepat proses klaim asuransi belum pernah diakukan. Tujuan akhir dari penelitan ini adalah adalah dengan automasi klasifikasi jenis kejadian ini dapat mengurangi waktu evaluasi klaim dengan tingkat akurasi jawaban yang tinggi. Dalam proses klasifikasi jenis kejadian terdapat kata yang berbeda tetapi memiliki makna yang sama. Hal tersebut menjadi masalah jika sistem hanya dapat mencocokan berdasarkan kata yang sama. Pada penelitian ini peneliti akan melakukan perancangan dan implementasi modul klasifikasi jenis kejadian pada kronologi menggunakan metode
word embedding. Metode word embedding ini diharapkan dapat melakukan pencocokan kata yang berbeda dalam
II. TINJAUAN PUSTAKA
Berikut adalah beberapa riset terbaru yang berkaitan dengan penelitian ini. Dalam artikel berjudul “Klasifikasi Opini pada Fitur Produk Berbasis Graph Opinion Classification for Product Feature Based on Graph” permasala-hannya berawal dari banyaknya opini-opini dari sebuah produk yang belum terkategori apakah opini tersebut merupakan opini positif atau opini negatif. Solusi yang diberikan penelitian tersebut diperlukan sebuah sistem yang dapat mengkategorikan opini dari konsumen. Metode yang digunakan dalam penelitian tersebut adalah Word2Vec dan WordNet. Word2Vec merupakan representasi kata dalam bentuk vektor yang digunakan untuk menghasilkan word embeddings. Sedangkan WordNet merupakan sebuah database kamus bahasa Inggris yang memiliki hirarki keterhubungan antar kata melalui jalur yang dimiikinya. Penelitian ini memiliki tujuan yang sa-ma yaitu mengkategorikan sebuah kalisa-mat. Perbedaannya adalah kalisa-mat dalam penelitian ini dikategorikan ber-dasarkan jenis kejadiannya.
Riset selanjutnya yang berkaitan dengan penelitian ini adalah “Penerapan Algoritma Cosine Similarity dan Pembobotan TF-IDF pada Sistem Klasifikasi Dokumen Skripsi”. Banyaknya arsip dokumen skripsi yang terkumpul dalam bentuk soft file yang tidak terklasifikasi dengan baik mengakibatkan proses pencarian kembali menjadi sulit. Untuk mengakses informasi yang dibutuhkan menjadi kurang cepat dan tepat apabila keseluruhan dokumen disimpan dalam satu folder database. Maka dari itu diperlukan suatu sistem yang dapat mengklasifi-kasikan dokumen secara otomatis ke dalam folder berbeda pada database agar lebih mudah dalam mengelola dokumen yang ada. Metode TF-IDF merupakan suatu cara untuk memberikan bobot hubungan suatu kata (term) terhadap dokumen. Metode cosine similarity merupakan metode untuk menghitung kesamaan antara dua buah objek yang dinyatakan dalam dua buah vector dengan menggunakan keywords (kata kunci) dari sebuah dokumen sebagai ukuran. [5] Penelitian ini mengambil konsep penilaian sebuah kemiripan kata menggunakan konsep
co-sine similarity. Metode tersebut dinilai sangat baik dalam mencari kemiripan dari sebuah dokumen, hasil dari
riset tersebut menunjukkan bahwa cosine similarity mendukung nilai akurasi dari sistem hingga sistem memiliki akurasi sebesar 98%.
Riset berjudul “Perancangan Chatbot Pusat Informasi Mahasiswa Menggunakan AIML sebagai Virtual Assistant Berbasis Web” Mengambil tema dari keinginan program studi teknik informatika untuk mengembangkan layanan terhadap mahasiswa, informasi yang diperoleh melalui sistem informasi dan chatting yang dilakukan antara pengguna dengan pihak Virtual Assistant. Penelitian ini bertujuan untuk membangun chatbot yang mempunyai tujuan sebagai Virtual Assistant yang memberikan informasi kepada mahasiswa melalui data yang tersimpan pa-da sistem yang berisi informasi mengenai program studi teknik informatika pa-dan penambahan pengetahuan baru apabila data yang tersimpan tidak ditemukan. Pada perancangan dan implementasi perangkat lunak ini menghasilkan sebuah prototipe chatbot yang dibangun dengan menggunakan mesin ALICE (Artificial Linguistik Internet Computer Entity) sebagai penerjemah AIML (Artificial Intelligence Markup Language). AIML ini me-nyebabkan chatbot dapat mengintegrasikan input yang diterima berupa input text. Sehingga akan dihasilkan percakapan antara pengguna dan program. Dengan pemanfaatan chatbot yang telah dilengkapi dengan informasi berupa audio, membuat pengguna dapat lebih mudah mendaatkan informasi yang berasal dari basis data yang diinformasikan kepada pengguna. Dari hasil pengujian verifikasi, pengujian validitas dan pengujian prototipe yang dilakukan sistem berjalan dengan baik sesuai dengan perencanaan. Dengan pemanfaatan chatbot yang telah dilengkapi dengan kecerdasan buatan, membuat pengguna dapat lebih mudah mendapatkan informasi yang be-rasal dari basis data yang diinformasikan kepada pengguna secara cepat dengan ketepatan jawaban sekitar 80%.[6] Dari riset tersebut diambil beberapa konsep pemrosesan teks menjadi sebuah vektor yang nantinya dapat diproses oleh sistem.
III. METODOLOGI PENELITIAN
Tahap penelitian yang akan digunakan dalam perancangan dan implementasi modul klasifikasi jenis kejadian pada kronologi dalam proses klaim asuransi kendaraan menggunakan metode word embedding secara umum dapat dijabarkan sebagai berikut,
Gambar. 1. Tahap Penelitian
Berdasarkan gambar 1, penelitian dimulai dari menidentifikasi masalah yang akan dikaji dalam penelitian. Pada tahap ini yang menjadi fokus dari masalah yang akan diidentifikasi adalah bagaimana proses pencocokan kronologi dengan cangkupan asuransi yang dimiliki oleh tertanggung. Cangkupan asuransi terbagi menjadi 2 yaitu cangkupan yang dijamin dan cangkupan yang tidak dijamin. Jika kronologi yang diberikan tertanggung termasuk dalam cangkupan yang dijamin maka klaim asuransinya akan cair, sedangkan jika kronologi yang diberikan tertanggung termasuk dalam cangkupan yang tidak dijamin maka klaim asuransinya tidak cair.
Tahap selanjutnya adalah perancangan modul, pada tahap ini sudah diketahui dua variabel yang akan digunakan dalam pembuatan modul ini yaitu kronologi dan cangkupan asuransi lalu data kronologi yang digunakan berupa 72894 kronologi. Pertama-tama yang dilakukan adalah melakukan anotasi manual terhadap riwayat kronologi yang pernah masuk. Anotasi manual dilakukan dengan tujuan mendapatkan kata kunci yang mewakili untuk cangkupan asuransi. Hasil dari anotasi manual tersebut akan membentuk kata kunci dengan contoh sebagai berikut :
Cangkupan Asuransi Kata Kunci
Tabrakan Tabrakan
Benturan Benturan
Benturan Menyenggol
Tergelincir Tergelincir
Terbalik Terbalik
Tabel 1. Pembentukan Kata Kunci
Dari kata kunci tersebut akan dibentuk modul pencarian alias menggunakan metode word embedding. Word
embedding adalah sebuah pendekatan yang digunakan untuk merepresentasikan vector kata. Word embedding
merupakan pengembangan komputasi permodelan kata-kata yang sederhana seperti perhitungan menggunakan jumlah dan frekuensi kemunculan kata dalam sebuah dokumen. Hasil dari word embedding ini dapat digunakan untuk menggambarkan kedekatan sebuah kata atau sebuah dokumen namun harus dipahami kedekatan tersebut adalah kedekatan kontekstual sesuai dengan data latih yang digunakan dalam pembentukannya, sehingga seringkali kedekatan tersebut bukan merupakan makna sebuah kata. [13] Berikut adalah tahap proses word
embedding yang digunakan dalam penelitian ini:
1) Pra-pemrosesan data
Data yang digunakan adalah data riwayat kronologi. Dari data tersebut lalu dilakukan sebuah pra-pemrosesan data yaitu tokenizing. Proses tokenizing adalah . Dalam proses tokenizing pemecahan katanya berjumlah satu dan dua gram. Dalam pra-pemrosesan data tidak dilakukan proses filtering stopword dan stemming. Hal tersebut bertujuan untuk menjaga orisinalitas dari sebuah kalimat, karena nantinya kata dalam kalimat tersebut dicari karakteristiknya. Hasil dari proses tokenizing adalah sebagai berikut :
Kalimat Hasil Tokenizing (1 Gram) Hasil Tokenizing (2 Gram)
Saat bayar parkir me-nyerempet bagian depan karena gelap
[“saat”,”bayar”,”parkir”,”menyeremp et”,”bagian”,”depan”,”karena”,”gela p”]
[“saat bayar”,”bayar parkir”,”parkir me-nyerempet”,”menyerempet bagi-an”,”bagian depan”,”depan kare-na”,”karena gelap”]
Pada saat mundur bagian kanan menyerempet pa-pan reklame
[“pa-da”,”saat”,”mundur”,”bagian”,”kana n”,”menyerempet”,”papan”,”reklame ”]
[“pada saat”,”saat mundur”,”mundur ba-gian”,”bagian kanan”,”kanan menyerem-pet”,”menyerempet papan”,”papan reklame”]
Saat belok terlalu mepet kanan sehingga body me-nyerempet pohon
[“saat”,”belok”,”terlalu”,”mepet”,”ka nan”,”sehingga”,”body”,”menyeremp et”,”pohon”]
[“saat belok”,”belok terlalu”,”terlalu me-nyerempet”,”menyerempet kanan”,”kanan sehingga”,”sehingga body”,”body me-nyerempet”,”menyerempet pohon”] Diserempet motor vario
tekno di jalan
[“diserem-pet”,”motor”,”vario”,”tekno”,”di”,”ja lan”]
[“diserempet motor”,”motor vario”,”vario tekno”,”tekno di”,”di jalan”]
Pada saat mundur bagian belakang mobil terkena besi bangunan yang men-onjol
[“pa-da”,”saat”,”mundur”,”bagian”,”belak ang”,”mobil”,”terkena”,”besi”,”bang unan”,”yang”,”menonjol”]
[“pada saat”,”saat mundur”,”mundur ba-gian”,”bagian belakang”,”belakang mo-bil”,”mobil terkena”,”terkena besi”,”besi bangunan”,”bangunan yang”,”yang men-onjol”]
Tabel 2. Hasil Tokenizing Kalimat 2) Skip gram
Gambar 1. Ilustrasi Model Skip Gram
Skip gram terdiri atas sebuah lapisan tersembunyi Neural Network. Pembentukan model skip gram dipengaruhi oleh be-berapa parameter, diantaranya jumlah dimensi dari neuron (yang disebut variabel d) dan jumlah window kata (yang disebut dengan variabel t) yang digunakan. [8]
Model skip gram yang digunakan dalam riset ini memiliki jumlah window dua kata didepan dan dua kata dibelakang. Berikut merupakan implementasi model skip gram dalam riset ini :
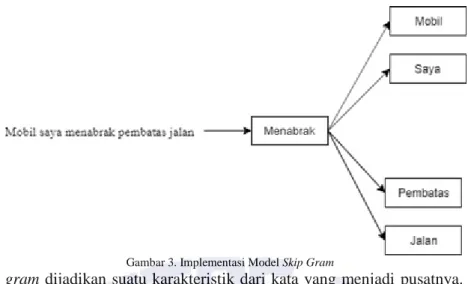
Gambar 3. Implementasi Model Skip Gram
Hasil dari model skip gram dijadikan suatu karakteristik dari kata yang menjadi pusatnya. Melihat dari gambar diatas maka karakteristik dari kata “menabrak” adalah [“mobil”, ”saya”, ”pembatas”, ”jalan”]. Karakteristik kata “menabrak” dapat bertambah contohnya adalah jika terdapat kalimat “Depan mobil saya ngerem mendadak se-hingga mobil saya menabrak mobil tersebut”. Karakteristik kata “menabrak” bertambah menjadi :
“Menabrak“ = [“mobil”,”saya”,”pembatas”,”jalan”] + [“mobil”,”saya”,”mobil”,”tersebut”] “Menabrak“ = [“mobil”,”saya”,”pembatas”,”jalan”,”tersebut”]
3) Continuous Bag of Words
Algoritma Continuous Bag of Word (CBOW) digunakan untuk melihat panjang tertentu dari sebuah kata pada dokumen masukan. [5] Kelemahan penggunaan CBOW sebagai fitur klasifikasi teks adalah ukuran/dimensi yang besar. Jumlah fitur yang besar dapat menurunkan kinerja dari algoritma klasifikasi yang digunakan, karena tidak semua fitur tersebut relevan [9]. Tetapi hal tersebut sudah dioptimalkan dengan metode skip gram. Metode skip gram membatasi penggunaan kata yang akan diambil yaitu 2 kata depan dan 2 kata belakang, sehingga untuk kata-kata lain yang tidak relevan tidak terambil menjadi data pembelajaran sistem. Berikut adalah contoh implementasi CBOW dalam riset ini :
Kata Karakteristik
“Menabrak” [“mobil”,”saya”,”pembatas”,”jalan”,”tersebut”] “Tergelincir” [“mobil”,”kendaraan”,”masuk”,”jurang”,”dalam”]
“Mobil” [“tabrak”,”saya”,”tidak”,”sengaja”,”kendali”] Tabel 3. Karaktersitik Kata
Karakteristik dari kata lalu diubah kedalam bentuk CBOW. Hasilnya akan berbentuk vektor seperti pada tabel dibawah ini :
Kata
Continuous Bag of Words (Karakteristik)
mobil saya kendaraan pembatas jalan ...
Menabrak 1 1 0 0 1 ...
Tergelincir 1 0 1 0 0 ...
Mobil 0 1 0 0 0 ...
Tabel 4. Hasil Pemrosesan CBOW
Vektor dalam CBOW lalu dijadikan sebagai karakteristik sebuah kata. Akan menghasilkan seperti pada tabel dibawah ini :
Kata Karakteristik (Vektor)
“Menabrak” [1,1,0,0,1,..]
“Tergelincir” [1,0,1,0,0,..]
“Mobil” [0,1,0,0,0,..]
4) Principal Component Analysis
Principal Component Analysis merupakan teknik yang biasa digunakan untuk menyederhanakan suatu data,
dengan cara mentransformasi data secara linier sehingga terbentuk sistem koordinat baru dengan varians maksi-mum. Analisis PCA dapat digunakan untuk mereduksi suatu data tanpa mengurangi karakteristik data tersebut secara signifikan. [10] Hasil pembentukan karakteristik dari sebuah kata, lalu direduksi dimensinya menjadi dua sehingga terbentuk koordinat x dan koordinat y. Mereduksi dimensi dengan cara membuang vektor-vektor eigen dengan nilai eigen yang sangat kecil tidak akan membuat kita kehilangan data yang penting. Vektor-vektor eigen dengan nilai eigen yang terbesar disebut sebagai principal component dari sebuah matriks. Cara untuk mendapat-kan principal component dari sebuah matriks dilakumendapat-kan dalam beberapa langkah. Langkah pertama yang dil-akukan adalah mengurangi setiap nilai dari matriks dengan rata-rata nilai dari setiap masing-masing dimensi. Caranya adalah menggunakan rumus standar deviasi :
𝑆 = √∈𝑖=1 𝑛 (𝑋
𝑖− 𝑋′)2 𝑛 − 1
Dimana S merupakan standar deviasi, X adalah sebuah himpunan data dan X’ adalah ratarata dari X. Dengan menggunakan rumus (1), maka himpunan data [0 6 15 40] akan memiliki nilai standar deviasi 17.6139 se-dangkan himpunan data [4 6 8 9] akan memiliki nilai standar deviasi 2.2173. Nilai standar deviasi yang besar menunjukkan bahwa nilai data-data yang ada di dalam sebuah himpunan tersebar jauh dari rata-rata nilai him-punan tersebut, sedangkan nilai standar deviasi yang kecil menunjukkan bahwa nilai data-data yang ada di dalam sebuah himpunan berkumpul di sekitar rata-rata nilai himpunan tersebut [14].
Langkah berikutnya adalah menghitung matriks kovariannya dan dilanjutkan dengan mencari vektor eigen dan nilai eigen dari matriks kovarian tersebut. Standar deviasi dan varian hanya beroperasi pada data dengan satu di-mensi. Padahal banyak himpunan data lebih dari satu dimensi, dan tujuan dari analisis statistik adalah untuk melihat apakah ada hubungan antar dimensi. Kovarian dapat melakukan perhitungan tersebut. Kovarian adalah ukuran untuk mengetahui seberapa kuat hubungan antar dimensi satu sama lain pada himpunan data. Kovarian selalu diukur antar dua dimensi. Jika kita memiliki himpunan data yang berdimensi tiga (x, y, z), maka kita dapat menghitung kovarian antara dimensi x dan y, antara dimensi x dan z, dan antara dimensi y dan z. Melakukan perhitungan kovarian antara x dan x, y dan y,dan z dan z masing-masing akan memberikan nilai varian dari x, y, dan z. Jika nilai kovarian positif, maka hal ini menunjukkan bahwa kedua dimensi berbanding lurus. Sedangkan jika nilai kovarian negatif, maka hal ini menunjukkan bahwa kedua dimensi berbanding terbalik. Dan jika nilai kovarian nol, maka hal ini menunjukkan bahwa kedua dimensi tidak berhubungan sama sekali. Jika X dan Y ada-lah dua dimensi yang tidak independen, a dan b adaada-lah suatu konstanta, maka kovarian di antara dua dimensi ini memiliki beberapa properti sebagai berikut [15]:
1. Cov(X,X) = Var(X) 2. Cov(X,Y) = Cov(Y,X) 3. Cov(aX, bY) = abCov(X,Y) 4. Cov(X+a, Y+b) = Cov(X,Y)
Kovarian selalu mengukur antara dua dimensi, jika kita memiliki himpunan data yang lebih dari dua dimensi, maka akan lebih dari satu nilai koarian yang dapat dihitung. Sebagai contoh, dari himpunan data dengan tiga di-mensi (didi-mensi x, y, dan z) kita dapat menghitung cov(x,y), cov(x,z), dan cov(y,z). Dan untuk himpunan data dengan n dimensi, maka akan ada 𝑛! (𝑛−2)!2 nilai kovarian yang berbeda Cara yang paling mudah untuk mendapatkan semua nilai kovarian yang mungkin dari suatu himpunan data adalah dengan menghitung semua nilai kovarian yang mungkin dan meletakkannya pada sebuah matriks, yang sering disebut dengan matriks kovar-ian. Jika kita memiliki himpunan data dengan tiga dimensi, yang terdiri dari dimensi x,y, dan z, maka matriks kovarian akan memiliki tiga baris dan tiga kolom. Matriks kovarian merupakan matriks yang simetrik pada diag-onal utama. Hal ini sesuai dengan properti yang dimiliki oleh kovarian [16].
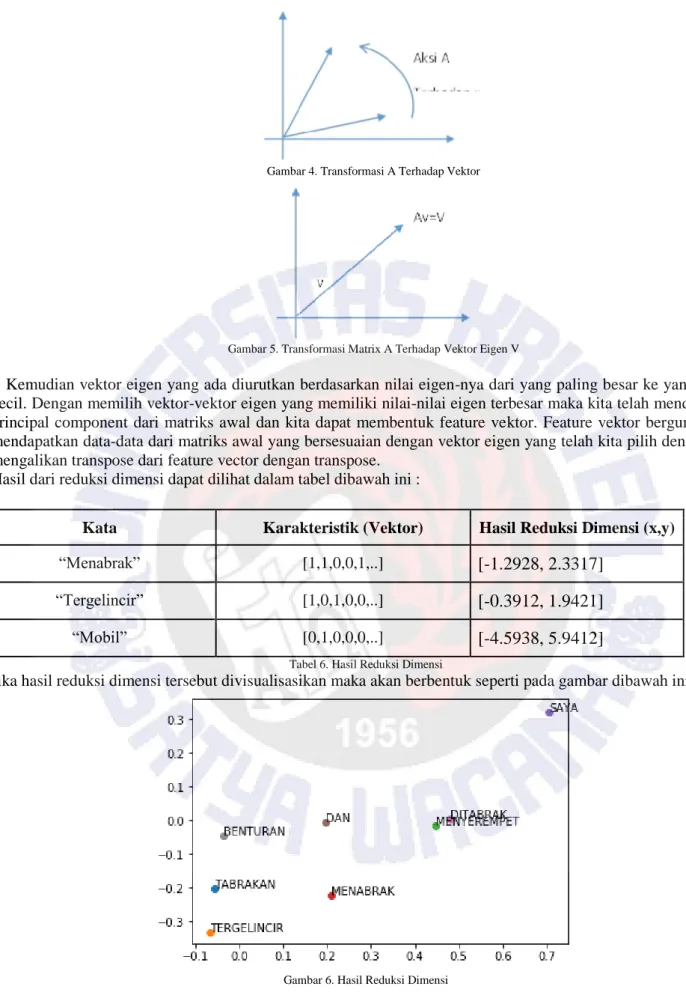
Kemudian vektor eigen yang ada diurutkan berdasarkan nilai eigen-nya dari yang paling besar ke yang paling kecil. Cara menghitung nilai eigen dan vektor eigen adalah sebagai berikut, jika A adalah suatu matriks persegi berdimensi n x n dalam ruang Cn, serta x dan b adalah suatu vektor berdimensi n x 1, dan terdapat persamaan linear Ax = b ………. (4) Maka maksudnya adalah transformasi dilakukan oleh matriks A terhadap vektor x ke suatu vektor baru[17]. Ilustrasi dari transformasi yang dilakukan oleh matriks A terhadap vektor x dapat dilihat pada gambar 4 dan gambar 5.
Gambar 4. Transformasi A Terhadap Vektor
Gambar 5. Transformasi Matrix A Terhadap Vektor Eigen V
Kemudian vektor eigen yang ada diurutkan berdasarkan nilai eigen-nya dari yang paling besar ke yang paling kecil. Dengan memilih vektor-vektor eigen yang memiliki nilai-nilai eigen terbesar maka kita telah mendapatkan principal component dari matriks awal dan kita dapat membentuk feature vektor. Feature vektor berguna untuk mendapatkan data-data dari matriks awal yang bersesuaian dengan vektor eigen yang telah kita pilih dengan cara mengalikan transpose dari feature vector dengan transpose.
Hasil dari reduksi dimensi dapat dilihat dalam tabel dibawah ini :
Kata Karakteristik (Vektor) Hasil Reduksi Dimensi (x,y)
“Menabrak” [1,1,0,0,1,..]
[-1.2928, 2.3317]
“Tergelincir” [1,0,1,0,0,..]
[-0.3912, 1.9421]
“Mobil” [0,1,0,0,0,..]
[-4.5938, 5.9412]
Tabel 6. Hasil Reduksi Dimensi
Jika hasil reduksi dimensi tersebut divisualisasikan maka akan berbentuk seperti pada gambar dibawah ini :
Gambar 6. Hasil Reduksi Dimensi 5) Cosine Similarity
Cosine Similarity yaitu sebuah metode untuk menghitung kesamaan antara dua vektor (atau dokumen pada ruang
vektor). Perhitungan dilakukan dengan menghitung kosinus sudut diantara keduanya. Dalam penelitian ini cosine
similarity digunakan untuk melihat seberapa mirip kata dengan kata pembandingnya. Contohnya cosine similarity
dan dihitung menggunakan cosine similarity dengan persamaan untuk menghitung cosing similarity antara dua vektor yaitu seperti pada persamaan 2 berikut [12]:
𝐶𝑜𝑠 𝑎 = 𝐴 • 𝐵 |𝐴||𝐵|=
∑𝑖=1𝑛 𝐴𝑖 𝑥 𝐵𝑖 √∑𝑖=1𝑛 (𝐴𝑖)2 𝑥 √∑𝑖=1𝑛 (𝐵𝑖)2 Keterangan :
A = Vektor A, yang akan dibandingkan kemiripannya B = Vektor B, yang akan dibandingkan kemiripannya A • B = Dot product antara vektor A dan vektor B |A| = Panjang vektor A
|B| = Panjang vektor B
|A||B| = Cross product antara |A| dan |B|
Tahap paling akhir adalah tahap pengujian, dalam tahap ini kata yang digunakan berupa kata “tabrak” dan kata “menubruk”. Kata “tabrak” memiliki nilai vektor [3.044, 1.222] sedangkan kata “menubruk” memiliki nilai vektor [5.22, 9.43]. Nilai tersebut merupakan nilai vektor yang sudah melalui proses Principal Component
Analy-sis sehingga sudah dikonversi menjadi dua dimensi. Berikut adalah implementasi perhitungan cosine similarity :
(3,044 . 5,22) + (1,222 . 9,43)
√(5,22)2+ (9,43)2 = 0.7753811290456954
Maka hasil kemiripan kata menurut cosine similarity dari kata “tabrak” dan “menubruk” adalah 77.53%. Nilai yang didapat cukup baik melihat kata tersebut merupakan kata tersebut memiliki makna yang sama. Nilai tersebut dapat meningkat seiring ditambahnya kronologi kedalam data training.
IV. HASILDANDISKUSI
Untuk mengetahui hasil dari sistem perlu dilakukan pengujian dari awal memasukkan kronologi hingga mendapatkan hasil akhir dari sistem. Pengujian dilakukan menggunakan salah satu sampel kronologi. Berikut spesifikasi data yang digunakan. Kronologinya adalah “mobil saya menyerempet tiang saat parkir”. Cangkupan asuransi yang dimiliki tertanggung adalah tabrakan, benturan, tergelincir dan terbalik.
Gambar. 7. Contoh Pengujian Sistem
Kronologi tersebut dimasukkan kedalam sistem, lalu mendapatkan hasil jenis kejadian berupa tabrakan dan benturan. Hal tersebut dikarenakan jenis kejadian tabrakan memiliki kata kunci tabrakan, dimana menurut metode word embedding kata tersebut memiliki kesamaan 88.89% dengan kata menyerempet. Lalu jenis kejadian benturan memiliki kata kunci menyenggol dimana kata tersebut memiliki kesamaan 90.81% dengan kata menyerempet dan 73.09% dengan kata saya menyerempet. Berikut adalah hasil eksperimen menggunakan 10 sampel data :
Case ke- Kata I Kata II Nilai Kemiripan
1 Tabrak Menubruk 77.53%
2 Menyenggol Menyerempet 90.81% 3 Menyenggol Saya menyerempet 73.09%
4 Tabrakan Menyerempet 80.89%
5 Terperosok Masuk jurang 82.35% 6 Oleng Kehilangan kendali 74.06%
7 Kecelakaan Menabrak 91.05%
8 Mengemudi Berkendara 84.71%
9 Kendaraan Mobil 84.12%
10 Mobil Motor 71.44%
Tabel. 7. Hasil Eksperimen
Dari tabel diatas dapat dilihat kemiripan kata I dengan kata II memiliki nilai kemiripan yang cukup baik. Akurasi dari model tersebut didapat dari banyaknya jumlah riwayat kronologi yang dimiliki. Riwayat kronologi diambil dari database tahun 2012 – 2019 dengan jumlah 72894 kronologi. Selanjutnya adalah melakukan pengujian menggunakan metode Black Box dengan nilai batas ambang untuk kemiripan minimal 70%. Hasilnya adalah sebagai berikut :
No Skenario Pengujian
Hasil yang
Di-harapkan Input Output Kesimpulan
1 Memasukkan kronologi yang terk-lasifikasi kedalam sis-tem
Sistem memberikan jawaban jenis ke-jadian
Kronologi : "Mobil saya menyerempet tiang saat parkir"
Jenis Kejadian :
["Tabrakan","Benturan"]
Valid
2 Memasukkan kronologi yang tidak terklasifikasi kedalam sistem
Sistem memberikan jawaban list jenis kejadian kosong
Kronologi : "Tidak melihat ada sepeda menyebrang"
Jenis Kejadian : [] Valid
Tabel 8. Hasil Pengujian Black Box
Dari hasil pengujian Black Box, dapat dilihat bahwa sistem dapat menjawab kronologi yang memiliki jenis kejadian maupun kronologi yang tidak memiliki jenis kejadian. Dari percobaan nomor 1 dapat dilihat bahwa kata “menyerempet” memiliki relasi dengan jenis kejadian “tabrakan” dan “benturan”. Lalu selanjutnya untuk percobaan nomor 2 dapat dilihat sistem tidak memberikan jenis kejadian karena kronologinya tidak berisi akibat dari hal tersebut.
V. KESIMPULANDANSARAN
Berdasarkan penelitian modul klasifikasi jenis kejadian pada kronologi dalam proses klaim asuransi kendaraan menggunakan word embedding diperoleh bahwa penggunaan metode ini sangat cocok untuk memperoleh kata yang memiliki makna yang sama. Penggunaan metode ini dapat mengurangi anotasi manual pada pembentukan kata kunci. Metode ini juga dapat selalu belajar terhadap kronologi baru sehingga pencarian kata alias akan semakin baik seiring bertambahnya kronologi. Kata yang dapat dicari maknanya tidak hanya satu kata saja, melainkan dua dan tiga kata dapat dicari aliasnya. Nilai akurasi yang didapat juga dinilai cukup baik melihat dari nilai kesamaan dari kata “menyenggol” dengan kata “menyerempet” bernilai 90.81%, kata “kendaraan” dengan kata “mobil” bernilai 84.12%, kata “kecelakaan” dengan kata “menabrak” bernilai 91.05%, dan hasil yang lainnya dapat dilihat di tabel 3.
Saran untuk penelitian selanjutnya adalah meneliti penggunaan word embbeding disertai dengan tahap pembentukan kata dasar, sehingga dapat meningkatkan akurasi dari metode ini. Lalu direkomendasikan pula untuk mengkombinasikan dengan metode natural language processing seperti naïve bayes pada chatbot untuk mengurangi pembentukan anotasi manual sehingga pemilihan kata kunci dapat diautomasikan dengan metode tersebut.
DAFTAR PUSTAKA
[1] A, Salim. 2000. Manajemen Transportasi. Cetakan Pertama. Edisi Kedua. Ghalia Indonesia. Jakarta.
[2] S. Kusumadewi., Artificial Intelligence (Teknik dan Aplikasinya). Yogyakarta : Peneribit Graha Ilmu, 2003. [3] Andoko., Perancangan Program Studi Deteksi Wajah dengan Support Vector Machines. Skripsi Teknik
In-formtika dan Matematika Universitas Bina Nusantara, 2007.
[4] A.W. Kencana dan W., Maharani. Klasifikasi Opini pada Fitur Produk Berbasis Graph. E-Proceeding of En-gineering : Vol. 4, No. 2, 2017.
[5] S. Joan, dkk., Self-Training Naïve Bayes Berbasis Word2Vec untuk Kategorisasi Berita Bahasa Indonesia. JNTETI, Vol. 7, No. 2, 2018.
[6] Maskur., Perancangan Chatbot Pusat Informasi Mahasiswa Menggunakan AIML Sebagai Virtual Assistant Berbasis Web. Skripsi Teknik Informatik Universitas Muhammadiyah Malang, 2016.
[7] A.D. Akbari, A. Novyanty, dan C. Setianingsih., Analisis Sentimen Menggunakan Metode Learning Vector Quantization. Skripsi Sistem Komputer Universitas Telkom, 2017.
[8] R. Faisal, S.E.I. Deasy, dan A.R. Obby., Evaluasi Fitur Word2Vec pada Sistem Ujian Esai Online. JIPI, Vol. 4, No. 1, 2019.
[9] O. Somantri dan M. Khambali, Feature Selection Klasifikasi Kategori Cerita Pendek Menggunakan Naive Bayes dan Algoritma Genetika. Jurnal Internasional Teknik Elektro dan Teknologi Informasi, Vol. 6, No. 3, hal. 301-306, 2017.
[10] P. Diyah, K.S. Dyan, dan S. Boko., Dampak Reduksi Sampel Menggunakan Principal Component Analysis (PCA) pada Pelatihan Jaringan Syaraf Tiruan Terawasi (Studi Kasus : Pengenalan Angka Tulisan Tangan). Jurnal Pseudocode : Vol. 2, No. 1, 2014 .
[11] N.W. Nabila, B. Arif, L.S. Indra., Analisis Word2vec untuk Perhitungan Kesamaan Sematik antar Kata. e-Proceeding of Engineering, Vol. 5, No. 3, 2018.
[12] T. W. Rizki, P. Dhidik, dan S. Eko., Penerapan Algoritma Cosine Similarity dan Pembobotan TF-IDF pada Sistem Klasifikasi Dokumen Skripsi. Jurnal Teknik Elektro, Vol. 9, No. 1, 2017.
[13] D. P. Yulius, L. M. Tedi, dan S. Meylisa. 2019. Pembentukan Vector Space Model Bahasa Indonesia Menggunakan Metode Word to Vector. Skripsi. Jakarta : Kalbis Institute.
[14] Cahyadi, D., 2007. Ektraksi dan Kemiripan Mata pada Sistem Identifikasi Buron. http://lontar.ui.ac.id/file?file=digital/123280-SK-691, diakses tanggal 10 Mei 2014.
[15] Weisstein, E. W., 2007, Distance, http://mathwordl.wolfram.com/distance.html, diakses tanggal 19 Desem-ber 2019
[16] Manning, C. D., Raghavan, P., Schütze, H., 2009, Introduction to Information Retrieval, Cambridge, Cam-bridge University Press.