II-1 2.1. Distribusi Frekuensi
Distribusi frekuensi adalah pengelompokan data kedalam beberapa kategori yang menunjukkan banyak data dalam setiap kategori dan setiap data tidak dapat dimasukkan dua atau lebih kategori (Supranto, 1977). Bagian-bagian dalam distribusi frekuensi adalah sebagai berikut:
1. Kelas
Kelompok nilai data atau variabel dari hasil pengukuran dan perhitungan yang dibatasi dengan nilai terendah dan nilai tertinggi, kualitatif ataupun kuantitatif mengenai karakteristik tertentu dari semua anggota kumpulan yang lengkap.
2. Batas Kelas
Nilai-nilai yang membatasi kelas yang satu dengan kelas yang lainnya, sehingga kelas tersebut dipisahkan oleh batasnya masing-masing yang tertera dalam distribusi frekuensi. Batas kelas terdiri atas dua bagian, antara lain:
a. Batas kelas bawah yaitu terdapat di deretan sebelah kiri setiap kelas atau nilai yang berada di posisi awal kelas.
b. Batas kelas atas yaitu terdapat di deretan sebelah kanan setiap kelas atau nilai yang berada di posisi akhir kelas.
3. Tepi Kelas
Batas kelas yang tidak memiliki lubang untuk angka tertentu antara kelas yang satu dengan kelas yang lain, sehingga kelas tersebut akan memiliki batas yang saling berhubungan. Tepi kelas terdiri dari dua bagian, antara lain:
a. Tepi kelas bawah yaitu batas kelas bawah yang sebenarnya yang berada di posisi awal kelas.
b. Tepi kelas atas yaitu batas kelas atas yang sebenarnya yang berada di posisi akhir kelas.
Tepi kelas bergantung pada keakuratan pencatatan data, sehingga rumus tepi kelas adalah sebagai berikut:
Tepi Bawah Kelas = Batas bawah kelas – 0,5 Tepi Atas Kelas = Batas atas kelas – 0,5 4. Titik Tengah Kelas
Angka atau nilai data yang tepat terletak ditengah suatu kelas yang tertera dalam distribusi frekuensi. Titik tengah kelas bergantung pada keakuratan penelitian data, sehingga rumus titik tengah adalah sebagai berikut:
Titik Tengah Kelas = 2 1
(batas atas + batas bawah) kelas 5. Interval Kelas
Selang yang memisahkan kelas yang satu dengan kelas yang lain dengan kelas adalah intervalnya.
6. Panjang Interval Kelas
Merupakan jarak dari sebuah kelas yang terletak antara tepi atas kelas dan tepi bawah kelas.
7. Frekuensi Kelas
Banyaknya data yang termasuk kedalam kelas tertentu.
2.1.1 Penyusunan Distribusi Frekuensi
Data kuantitatif yang dikumpulkan dari lapangan (data mentah), nilainya tidak selalu sama atau seragam tetapi bervariasi dari satu pengamatan ke pengamatan yang lain, misalnya data hasil produksi, data hasil penjualan, data tingkat konsumsi, dan lain-lain. Data hasil pengamatan di lapangan mempunyai jumlah yang besar maka data mentah tersebut perlu diolah dengan cara meringkas data tersebut dan didistribusikan ke dalam kelas atau kategori (Supranto, 1977).
Tabel yang berisi susunan data yang terbagi ke dalam beberapa frekuensi kelas disebut distribusi frekuensi atau tabel frekuensi. Penyajian data dalam bentuk distribusi frekuensi maka akan memudahkan bagi pihak yang berkepentingan terhadap data tersebut untuk melakukan analisis data, dibandingkan jika data yang disajikan masih berupa data mentah dan dalam jumlah yang banyak. Penyusunan suatu tabel adalah sebagai berikut:
1. Mengurutkan Data dari yang Terkecil Sampai yang Terbesar
Data yang diteliti dalam sebuah penelitian biasanya data mentah dan data yang diberikan masih tidak teratur. Data yang tidak teratur tersebut sangat menyulitkan untuk membuat sebuah distribusi frekuensinya, sehingga agar memudahkan pembuatan data tersebut digunakan cara mengurutkan data dari yang terkecil sampai dengan yang terbesar.
2. Menentukan Jangkauan dari Data (R)
Data yang ada memiliki nilai yang bermacam-macam data tersebut setelah diurutkan dari yang terkecil sampai yang terbesar maka memiliki nilai tersendiri. Nilai tersebut dari data yang telah tersusun hanya menggunakan dua nilai yaitu data yang terkecil dan data yang terbesar, sehingga rumus jangkauan adalah sebagai berikut:
Jangkauan = Data terbesar – data terkecil
3. Menentukan Banyaknya Kelas (k)
Banyaknya kelas sebaiknya paling banyak adalah 5 sampai dengan 20 kelas. Semakin besar jumlah data yang tersedia, semakin banyak kelas yang harus digunakan. Jumlah kelas terlalu sedikit, maka mungkin akan menyembunyikan ciri-ciri yang paling penting dari data karena adanya pengelompokkan. Memiliki terlalu banyak kelas, maka akan timbul kelas yang kosong dan distribusi itu tidak akan ada artinya. Jumlah kelas harus ditetapkan dari banyaknya data yang tersedia dan keseragaman data. Sampel yang terkecil memerlukan lebih sedikit kelas, sehingga mencari banyaknya kelas digunakan rumus sebagai berikut:
3 , 3 1 k + log n Keterangan: k : Banyaknya kelas. n : Banyaknya data.
4. Menentukan Panjang Interval Kelas (i)
Interval kelas memiliki aturan umum untuk menetapkan panjang kelas atau lebar kelas, bagilah selisih-selisih antara pengukuran terbesar dan pengukuran terkecil dengan jumlah kelas yang diinginkan dan tambahkan secukupnya pada hasil bagi sehingga mencapai angka yang cocok untuk panjang kelas. Semua kelas, mungkin dengan pengecualian untuk kelas yang terkecil dan yang terbesar, harus mempunyai lebar yang sama. Memungkinkan untuk mengadakan perbandingan yang seragam terhadap frekuensi kelas. Mencari panjang interval kelas digunakan rumus adalah sebagai berikut:
k R i Keterangan:
i : Panjang Interval Kelas. R : Jangkauan.
k : Banyaknya kelas.
Menentukan interval kelas memiliki beberapa aturan. Beberapa hal yang perlu diperhatikan dalam interval, antara lain:
a. Banyaknya kelas sebaiknya antara 7 dan 15, paling banyak 20 (tidak ada aturan umum yang menentukan jumlah kelas). Seorang bernama H.A. Strugess pada tahum 1926 memiliki artikel dengan judul “the choice of a class interval” dalam journal of the american statistical asosiation mengemukanan suatu rumus untuk menentukan banyaknya kelas adalah sebagai berikut:
k = 1 + 3,322 log n Keterangan:
n : Banyaknya nilai observasi. b. Kelas Interval tidak Perlu Sama
Pembuatan kelas interval sangat tergantung kepada tujuan. Misalnya kalau hanya tertarik kepada rincian perusahaan yang mempunyai modal antara 50–70 dan dibawah 50 serta 70 atau lebih, maka bentuk tabel frekuensinya adalah sebagai berikut:
Tabel 2.1. Kurang dari atau Lebih Besar dari
Batas Kelas Modal F
< 50 5
50 – 59 11
60 – 69 20
≥ 70 64
(Sumber : Statistik teori dan aplikasi, 1977) Keterangan:
< : Kurang dari atau lebih kecil dari. ≥ : Sama atau lebih besar dari.
c. Datanya diskrit (= hasil pengumpulan data dari variabel diskrit), maka pembuatan kelas intervalnya seperti terlihat dalam tabel berikut:
Tabel 2.2. Karyawan Suatu Perusahaan menurut Tingkat Upah Mingguan
Upah Mingguan (Rp) Banyaknya karyawan (F) < 1.000 2.918 1.000 – 1.999 5.327 2.000 – 2.999 6.272 3.000 – 3.999 7.275 4.000 – 4.999 7.117 5.000 – 5.999 6.363
Tabel 2.2. Karyawan Suatu Perusahaan menurut Tingkat Upah Mingguan (lanjutan)
Upah Mingguan (Rp) Banyaknya karyawan (F)
6.000 – 7.499 6.940
7.500 – 9.999 5.186
10.000 – 14.999 3.107
≥ 15.000
(Sumber : Statistik teori dan aplikasi, 1977) 5. Menentukan Batas Kelas
Mulailah dengan kelas yang terendah sehingga pengukuran terendah tercukup. Menambahkan kelas-kelas yang masih tinggal batas-batas kelas harus dipilih sehingga suatu pengukuran tidak mungkin jatuh pada suatu batas.
2.1.2 Frekuensi Relatif, Kumulatif, dan Grafik
Sering kali untuk keperluan analisis, selain dibuat tabel frekuensi juga dibuat tabel frekuensi relatif dan kumulatif (untuk analisis tabel), kemudian dibuat grafiknya (untuk analisis grafik). Grafik yang berupa gambar pada umumnya lebih mudah diambil kesimpulannya secara cepat dari pada tabel. Sebuah data dalam bentuk grafik itulah yang menyebabnya maka sering kali data disajikan dalam bentuk grafik (Supranto, 1977). Dasarnya, bentuk tabel frekuensi relatif dan kumulatif adalah sebagai berikut:
Tabel 2.3. Frekuensi Relatif dan Kumulatif X f fr fk fk 1 x f1 n f1 1 f f1 f2 ... fi ... fk 2 x f2 n f2 2 1 f f f2 ... fi ... fk . . . . . . . . . . i x fi n fi i f f f1 2 ... fi ... fk . . . . . . . . . . k x fk n fk k i f f f f1 2 ... ... fk Jml
k i i n f 1 1
n fi(Sumber : Statistik teori dan aplikasi, 1977)
Jumlah pengukuran yang masuk dalam suatu kelas tertentu, dengan kelas i, disebut frekuensi kelas dan ditentukan oleh simbol fi. Frekuensi
kelas diberikan dalam kolom kelima dari tabel 2.3. Kolom terakhir dari tabel menyajikan dari jumlah keseluruhan pengukuran yang masuk dalam setiap kelas. Data ini disebut frekuensi relatif kelas. Data di atas n menunjukkan jumlah seluruh pengukuran, misalnya dengan n=25 maka frekuensi relatif untuk kelas ke-i adalah fi dibagi dengan n, dengan rumus sebagai berikut:
Frekuensi Relatif = n fi
Penyusunan tabel yang disajikan dapat dinyatakan secara grafik dalam bentuk suatu histogram frekuensi, seperti dalam gambar 2.1. Grafik dalam suatu histogram frekuensi, persegi panjang didirikan diatas setiap interval kelas, tingginya sebanding dengan pengukuran (frekuensi kelas) yang masuk dalam setiap interval kelas pada histogram frekuensi.
Histogram frekuensi adalah himpunan batang persegi panjang yang alasnya disumbu datar, lebarnya sama dengan panjang selang kelas, dan luasnya sebanding dengan frekuensi kelas (Sumartojo, 1993).
0 2 4 6 8 10 12 14 68,5 79,5 90,5 101,5 112,5 123,5 Lingkar Pinggang F re k u e n s i
Gambar 2.1 Grafik Histogram (Sumber: Statistik Teori dan Aplikasi, 1977)
Seiring lebih mudah untuk untuk mengubah histogram frekuensi dengan menggambarkan frekuensi relatif kelas daripada frekuensi kelas. Sebuah histogram frekuensi relatif disajukan dalam gambar 2.2. Para ahli
statistik jarang membuat pembedaan antara histogram frekuensi dan histogram frekuensi relatif dan mengacu kedua-duanya sebagai suatu histogram frekuensi atau hanya sebagai histogram. Nilai-nilai frekuensi dan frekuensi relatif bersangkutan ditandai sepanjang sumbu-sumbu vertikal dari grafik, maka histogram frekuensi dan frekuensi relatif adalah sama (bandingkan gambar 2.1 dan gambar 2.2).
0,25 2,25 4,25 6,25 8,25 10,25 12,25 14,25 68,5 79,5 90,5 102 113 124 Lingkar Pinggang F re k u e n s i
Gambar 2.2 Grafik Histogram Frekuensi Relatif (Sumber: Statistik Teori dan Aplikasi, 1977)
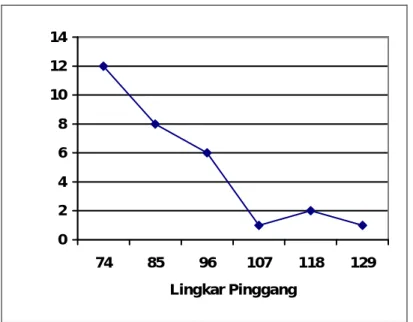
Grafik poligon atau poligon frekuensi adalah himpunan ruas garis yang menghubungkan titik tengah ujung batang histogram dan dihubungkan dengan ruas garis dari titik tengah dan berujung ke sumbu datar (Sumartojo, 1993).
0 2 4 6 8 10 12 14 74 85 96 107 118 129 Lingkar Pinggang
Gambar 2.3 Grafik Poligon
(Sumber: Statistik Teori dan Aplikasi, 1977)
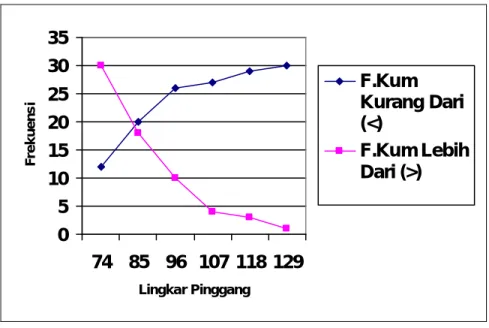
Grafik dapat dibuat analisis, khususnya dalam masalah pemerataan pendapat, dikenakan suatu kurva yang disebut kurva lorenz (lorenz curve). Kurva lorenz ini pada dasarnya juga merupakan kurva dari frekuensi kumulatif. Data yang kemudian apabila sumbu tegak (vertical axis) menunjukkan angka-angka kumulatif mengenai frekuensi, maka sumbu mendatar (horizontal axis) menunjukkan kumulatif lingkar pinggang.
0 5 10 15 20 25 30 35 74 85 96 107 118 129 Lingkar Pinggang F re k u e n s i F.Kum Kurang Dari (<) F.Kum Lebih Dari (>)
Gambar 2.4 Grafik Ogif
(Sumber: Statistik Teori dan Aplikasi, 1977)
2.2. Ukuran Pemusatan
Definisi ukuran pemusatan adalah nilai tunggal yang mewakili suatu kumpulan data dan menunjukan karakteristik dari data. Ukuran pemusatan menunjukan pusat dari nilai data sembarang ukuran yang menunjukkan pusat segugus data yang telah diurutkan dari yang terkecil sampai terbesar atau sebaliknya dari terbesar sampai terkecil, serta data yang belum diurutkan disebut ukuran lokasi pusat atau ukuran pemusatan (Yohana, 2007).
Memperoleh gambaran yang lebih jelas tentang sekumpulan data, baik sampel maupun populasi, diperlukan ukuran-ukuran yang merupakan wakil dari kumpulan data tersebut. Terdapat 3 macam ukuran yang biasa digunakan orang dalam perhitungan. Pertama adalah ukuran pemusatan (gejala pusat), kedua adalah ukuran letak dan yang ketiga adalah ukuran
simpangan (dispersi). Pembahasan ukuran pemusatan dapat dikelompokan dalam dua bagian, yaitu:
1. Rata–rata (hitung, ukur, dan harmonik), median, modus data yang belum berkelompok dan data yang sudah berkelompok.
2. Ukuran peletakan harus memiliki kuartil, desil, dan persentil untuk data yang belum berkelompok dan sudah berkelompok.
1.2.1 Rata-rata Hitung
Rata–rata hitung adalah nilai yang di peroleh dengan menjumlahkan semua nilai data dan membaginya dengan jumlah data, dengan demikian rata–rata hitung menunjukan pusat nilai data dan merupakan nilai yang dapat mewakili dari keterputusan data (Supranto, 1977). Memudahkan pembahasan mengenai rata–rata hitung ini dibagi dalam tiga bagian, yaitu: 1. Rata–Rata Hitung Data yang Belum Berkelompok
Rata–rata hitung data yang belum berkelompok adalah nilai rata–rata dari sekumpulan data yang di peroleh dengan cara menjumlahkan semua nilai data dan membaginya dengan jumlah data (Walpole, 1995). Rumus rata–rata hitung data belum berkelompok adalah sebagai berikut:
n
X
X
Keterangan:
X : Nilai rata–rata hitung dari seluruh nilai pengamatan. ∑ X : jumlah nilai setiap data pengamatan.
2. Rata–Rata Hitung Data Berkelompok
Rata–rata hitung data berkelompok adalah nilai rata–rata dari data yang berkelompok. Pengertian berkelompok disini adalah data dikelompokan dalam bentuk distribusi frekuensi (Yohana, 2007).
Pengelompokan data dalam distribusi frekuensi akan mempermudah pemahaman karena data yang berbeda dalam suatu kelas akan memiliki karakteristik yang sama yang dicerminkan oleh nilai tengah kelasnya. Data di dapat dengan cara menjumlahkan dahulu nilai dari titik tengah kelas dan dikalikan dengan frekuensi kelas lalu dibagi dengan jumlah frekuensi data. Rumus rata–rata hitung dengan data berkelompok adalah sebagai berikut:
n
X
f
X
.
i Keterangan:X : Nilai rata-rata dari data kelompok. F : Frekuensi dari tiap kelas.
Xi : Nilai tengah dari tiap kelas.
∑ FXi : Jumlah dari seluruh hasil perkalian antara frekuensi dan nilai tengah dari tiap kelas.
n : Jumlah data pengamatan dalam sampel atau populasi.
Metode Pengkodean didapat dengan cara mengambil titik tengah kelas yang bernilai nol ditambah dengan interval kelas lalu dikalikan dengan jumlah kode titik tengah kelas dikali dengan frekuensi kelas lalu dibagi dengan jumlah frekuensi data. Metode tersebut apabila dituliskan kedalam bentuk rumus adalah sebagai berikut:
i n F X X a
. Keterangan: X : Rata-rata sampel. aX : Frekuensi yang paling besar. F : Frekuensi.
µ : Kode frekuensi pada kelas besar.
n : Jumlah frekuensi data sample atau populasi. i : Panjang interval kelas.
3. Rata–Rata Hitung Tertimbang
Rata–rata hitung yang telah dijelaskan di atas, data yang dianggap memiliki bobot yang sama, pada kenyataan cukup banyak data yang memiliki bobot yang berbeda walaupun nilainya sama. Rumus rata–rata hitung bertimbang adalah sebagai berikut:
w
X.w)
(
Xw
keterangan:X w : Rata rata hitung tertimbang. X : Nilai data pengamatan.
W : Nilai bobot atau timbangan dari suatu data.
2.2.2 Rata-Rata Ukur (Geometrik Mean)
Rata-rata ukur digunakan untuk menggambarkan keseluruhan data, khususnya bila data tersebut mempunyai ciri tertentu, yaitu banyak nilai data yang satu sama lain saling berkelipatan sehingga perbandingan tiap dua
data yang berurutan tetap atau hampir tetap. Kegunaan rata-rata ukur antara lain menghitung rata-rata terhadap persentase atau rasio perubahan suatu gejala pada data tertentu (Walpole, 1995).
Rata-rata ukur mempunyai beberapa cara untuk melakukan perhitungan sehingga akan memperoleh hasil yang baik. Perhitungan rata-rata ukur dibagi menjadi 3, yaitu:
1. Rata-rata ukur untuk data tidak berdistribusi, digunakan untuk menentukan tiap gejala yang terjadi dalam bentuk persentase dan banyaknya data atau dengan kata lain masih dalam data yang mentah dan baru akan diolah. Rumus untuk rata-rata untuk data tidak terdistribusi adalah sebagai berikut:
100 .... . 2 1 n n X X X RU Keterangan:
X : Titik tengah tiap kelas.
2. Rata-rata ukur untuk data berdistribusi, diperoleh dengan cara menentukan rata-rata dengan titik tengah dan frekuensinya telah diketahui, sehingga mempermudah untuk proses pengolahan data. Rata-rata ukur distribusi apabila dituliskan dalam bentuk rumus adalah sebagai berikut:
n x F LogRU .log Keterangan: F : Frekuensi data.X : Titik tengah tiap kelas. n : Jumlah frekuensi data.
3. Rata-rata ukur sebagai pengukuran tingkat pertumbuhan, digunakan untuk menghitung tingkat pertumbuhan manusia mulai dari kelahiran hingga kematian, dapat menggunakan penghitungan rata-rata ukur. Data yang diukur dalam pengukuran tersebut digunakan untuk menentukan pertumbuhan dan kematian yang terjadi sehingga dapat diteliti sensus penduduknya.
2.2.3 Rata-Rata Harmonik (Harmonik Mean)
Cara lain yang dipakai untuk menentukan ukuran pemusatan data adalah dengan rata-rata harmonik, khususnya bila suatu kelompok data mempunyai ciri-ciri tertentu yang merupakan bilangan pecahan atau bilangan dalam harmonik. Rata-rata harmonik ialah proses mencari nilai rata-rata dengan cara menjumlahkan data dibagi dengan jumlah satu persetiap data (Walpole, 1995). Rata-rata harmonik data tunggal ialah proses perhitungan untuk mencari rata-rata dengan cara banyaknya data dibagi dengan 1 per nilai tiap data atau harga tiap data. Perhitungan rata-rata harmonik dengan data tunggal adalah sebagai berikut:
n X n X X 1 1 1 2 1 Keterangan:
X : Harga atau nilai tiap data. n : Banyaknya data.
2.2.4 Median
Median termasuk dengan nilai median adalah nilai yang berada ditengah–tengah data setelah data di urutkan. Kegunaan median adalah
untuk menutupi kelemahan rata–rata hitung dimana rata–rata hitung sering memiliki data-data yang berbeda secara ekstrem. Pengertian median secara lengkap adalah median adalah titik tengah dari semua nilai yang telah diurutkan dari nilai terkecil sampai yang terbesar atau sebaliknya dari yang besar sampai yang terkecil (Supranto, 1977). Median ini dibagi menjadi dua data, yaitu:
1. Data Belum Berkelompok
Median dengan data belum berkelompok dapat di bagi menjadi dua yaitu jumlah datanya (n) ganjil dan jumlah datanya genap. Langkah untuk mencari median adalah sebagai berikut:
a. Tentukan letak median dengan cara jumlah n di tambah 1 lalu di bagi 2 dengan cara ( n + 1 ) / 2.
b. Urutkan data dari yang terkecil sampai terbesar atau sebaliknya. c. Tentukan nilai median, untuk data n yang ganjil nilai median adalah
data yang terletak ditengah sedangkan untuk jumlah data yang genap nilai median adalah dua data yang terletak di tengah di jumlahkan lalu di bagi 2.
2. Data Sudah Berkelompok
Pengertian median dengan data sudah berkelompok adalah sama dengan median data belum berkelompok yaitu nilai yang letaknya ada di tengah data sehingga data berada setengahnya diatas dan setengahnya di bawah.
Membedakan median dengan data berkelompok median data tidak berkelompok adalah karakteristik masing-masing data tidak dapat di identifikasi lagi yang dapat di ketahui hanya karakter dari kelas atau intervalnya. Langkah untuk menentukan median dengan data berkelompok adalah sebagai berikut:
a. Tentukan letak kelas dimana nilai, median berada letakan median adalah n /2 dimana n adalah jumlah frekuensi.
b. Lakukan interpolasi di kelas median berada untuk mendapatkan nilai median rumus interpolasi adalah sebagai berikut:
i . f FK -n 2 1 L Md Keterangan: Md : Nilai median.
L : Batas bawah atau tepi kelas dimana median berada. FK : Frekuensi komulatif sebelum kelas median berada. f : Frekuensi dimana kelas median berada.
i : Besarnya interval kelas (jarak antara batas atas kelas dengan batas bawah kelas).
2.2.5 Modus
Modus dari suatu kelompok nilai adalah nilai dari kelompok tersebut yang mempunyai frekuensi tertinggi. Nilai yang paling banyak terjadi di dalam suatu kelompok nilai untuk lebih mudah disingkat dengan mod (Supranto, 1977).
Suatu distribusi tidak mempunyai mod, mungkin mempunyai dua mod atau lebih. Distribusi disebut unimodal, kalau mempunyai satu mod, sedangkan bimodal mempunyai dua mod atau multimodal apabila mempunyai lebih dari dua mod.
Terdapat dua cara mencari dan menghitung modus baik untuk data yang belum berkelompok maupun untuk data yang sudah berkelompok, yaitu:
1. Data yang belum berkelompok maka modus adalah nilai yang paling sering muncul atau frekuensi yang paling banyak .
2. Data yang sudah berkelompok maka modus di cari dan di tentukan dengan rumus sebagai berikut:
i . d d d L Mo 2 1 1 Keterangan: Mo : Nilai Modus.
L : Batas bawah atau kelas dimana modus berada.
1
d : Selisih frekuensi kelas modus dengan kelas sebelumnya
2
d : Selisih frekuensi kelas modus dengan kelas sesudahnya. i : Besarnya interval kelas.
2.2.6 Kuartil
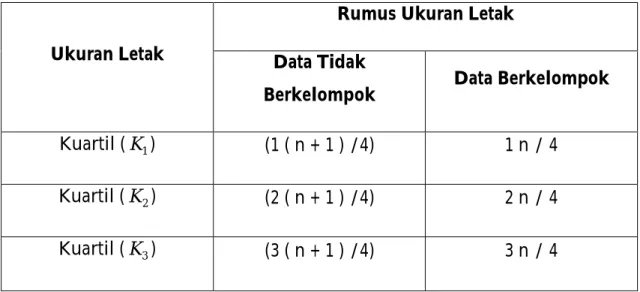
Kuartil adalah ukuran letak yang membagi data yang telah di urutkan atau data yang berkelompok menjadi 4 bagian yang sama besar masing masing 25% (Supranto, 1977). Kuartil dibagi menjadi 3 buah kuartil yaitu kuartil 1, kuartil 2, dan kuartik 3. Kuartil 1 membagi data atas dua bagian dengan 25% dibawahnya. Kuartil 2 menbagi data atas dua bagian dengan 50% dibawahnya. Kuartil 3 membagi data atas dua bagian dengan 75% dibawahnya. Letak bagian pertama dari kuartil pada suatu data disebut kuartil 1 atau K1 bagian kedua di sebut:
Tabel 2.4. Kuartil Ukuran Letak
Ukuran Letak
Rumus Ukuran Letak
Data Tidak
Berkelompok Data Berkelompok
Kuartil (K1) (1 ( n + 1 ) /4) 1 n / 4
Kuartil (K2) (2 ( n + 1 ) /4) 2 n / 4
Kuartil (K3) (3 ( n + 1 ) /4) 3 n / 4
(Sumber: Statistik teori dan aplikasi, 1977)
Menghitung Kuartil untuk data berkelompok pada dasarnya sama dengan menghitung data tidak berkelompok, Perbedaanya hanya pada mencari nilai Kuartil yang menggunakan Rumus interpolasi. Langkah mencari kuartil untuk data berkelompok adalah sebagai berikut:
a. Tentukan letak data kuartil dengan rumus yang telah dijelaskan di atas. b. Hitung nilai kuartil dengan menggunakan rumus interpolasi sebagai
berikut.
Kuartil untuk data berkelompok adalah sebagai berikut:
Ci F FK n i L NK . ) 4 ( Keterangan:
NK : Nilai kuartil ke–i dimana i = 1,2,3. L : Tepi kelas dimana kuartil berada. n : Jumlah data atau frekuensi total.
i n
FK : Frekuensi komulatif sebelum kelas kuartil. F : Frekuensi pada kelas kuartil.
Ci : Interval kelas kuartil.
2.2.7 Desil
Kelompok data dimana n ≥ 10 tentukan 9 nilai yang membagi kelompok data tersebut menjadi 10 bagian yang sama misalnya D1, D2, ...
9
D , artinya setiap bagian mempunyai jumlah observasi yang sama, sedemikian rupa sehingga 10% observasi nilainya sama atau lebih kecil dari
1
D , 20% nilainya sama dengan atau lebih kecil dari D2 dan seterusnya. Nilai
tersebut dinamakan desil pertama, desil ke dua dan seterusnya sampai desil ke sembilan. Kelompok data tersebut nilainya sudah diurutkan nilai dari yang terkecil (= X1) sampai yang terbesar (= Xn).
Rumus–rumus yang di pakai dalam desil pada dasarnya juga sama dengan rumus dalam mencari kuartil yang berbeda hanya pembagiannya yaitu desil dibagi 10. Rumus–rumus untuk desil adalah sebagai berikut:
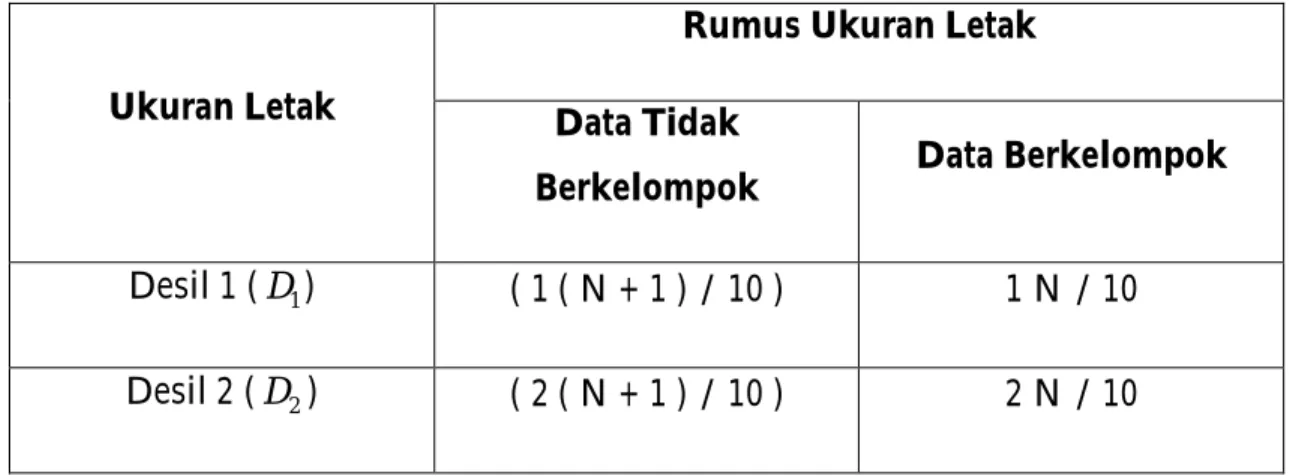
Tabel 2.5. Desil Ukuran Letak
Ukuran Letak
Rumus Ukuran Letak
Data Tidak
Berkelompok Data Berkelompok
Desil 1 (D1) ( 1 ( N + 1 ) / 10 ) 1 N / 10
Tabel 2.5. Desil Ukuran Letak (Lanjutan)
Ukuran Letak
Rumus Ukuran Letak
Data Tidak
Berkelompok Data Berkelompok
Desil 3 (D3) ( 3 ( N + 1 ) / 10 ) 3 N / 10
. . .
Desil 9 (D9) ( 9 ( N + 1 ) / 10 ) 9 N / 10
(Sumber: Statistik teori dan aplikasi, 1977)
Desil untuk data berkelompok adalah sebagai berikut: Ci F FK n i L ND (. /10) . Keterangan:
ND : Nilai desil ke–i dimana i = 1, 2, 3, ..., 9. L : Tepi kelas dimana letak desil berada. n : Jumlah data atau frekuensi total. (i.n / 10 ) : Rumus mencari data desil.
FK : Frekuensi komulatif sebelum kelas desil. F : Frekuensi pada kelas desil.
Ci : Interval kelas desil.
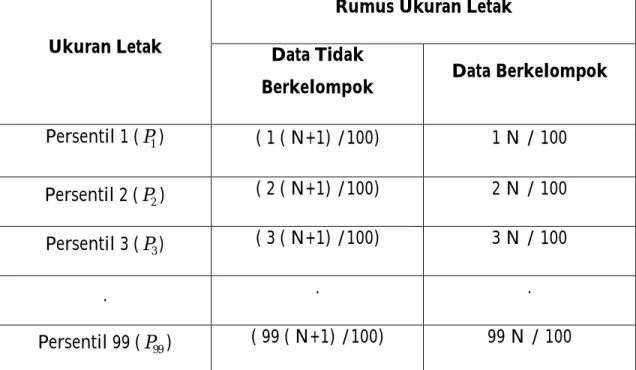
2.2.8 Persentil
Persentil adalah kelompok data dimana n ≥ 100, tentukan 99 nilai, P1, 2
P , ...., P99 yang disebut persentil pertama, kedua dan ke-99, yang membagi
jumlah observasi yang sama, sedemikian rupa, sehingga 1% dari observasi mempunyai nilai yang sama atau lebih kecil dari P1 2% observasi
mempunyai nilai yang sama atau lebih kecil dari P2 dan seterusnya.
Rumus-rumus untuk persentil adalah sebagai berikut:
Tabel 2.6. Persentil Ukuran Letak
Ukuran Letak
Rumus Ukuran Letak
Data Tidak
Berkelompok Data Berkelompok
Persentil 1 (P1) ( 1 ( N+1) /100) 1 N / 100
Persentil 2 (P2) ( 2 ( N+1) /100) 2 N / 100
Persentil 3 (P3) ( 3 ( N+1) /100) 3 N / 100
. . .
Persentil 99 (P99) ( 99 ( N+1) /100) 99 N / 100
(Sumber: Statistik teori dan aplikasi, 1977)
persentil data yang tidak berkelompok:
NP = NPB + { (LP – LPB) / ( LPA- LPB) x (NPA - NPB) } Keterangan:
NP : Nilai persentil.
NPB : Nilai persentil yang berada dibawah letak persentil. LP : Letak persentil.
LPB : Letak data persentil yang berada dibawah letak persentil. LPA : Letak data persentil yang berada diatas letak persentil. NPA : Nilai persentil yang berada diatas letak persentil.
Persentil untuk data berkelompok: Ci F FK n i L NP (. /100) . Keterangan:
NP : Nilai persentil ke–i dimana i = 1,2,3...9. L : Tepi kelas dimana letak persentil berada. n : Jumlah data atau frekuensi total.
(i.n / 10 ) : Rumus mencari data persentil.
FK : Frekuensi komulatif sebelum kelas persentil. F : Frekuensi pada kelas persentil.
Ci : Interval kelas persentil.
2.3. Ukuran Penyebaran
Ukuran penyebaran digunakan untuk memberikan kejelasan informasi karena terjadinya nilai dari rata-rata mempunyai perbedaan nilai rata-rata yang ekstrim antara nilai tertinggi dengan nilai terendah (Yohana, 2007).
Ukuran penyebaran digunakan untuk menunjukan seberapa besar persebaran data yang terjadi pada data dengan melihat selisih dari data terbesar dan data terkecil.
Ukuran penyebaran terdapat kuartil, simpangan rata-rata, varians dan ukuran-ukuran yang lain. Ukuran penyebaran terdiri dari ukuran penempatan. Ukuran penempatan merupakan ukuran letak sebagai pengembangan dari beberapa penyajian data yang berbentuk tabel, grafis, dan diagram. Analisa dalam memutuskan ukuran apa yang tepat digunakan untuk sekelompok data tertentu, dimana sebuah ukuran saja tidak mampu menjelaskan sekelompok data maupun distribusi frekuensinya. Salah satu
contoh dari ukuran penyebaran adalah pemakaian ukuran penyebaran pada kegiatan di bidang ekonomi.
Ukuran Penyebaran Untuk Data Tunggal
Pencarian ukuran penyebaran pada data tunggal maka dilakukan dengan mencari nilai range, deviasi, rata–rata dan varians serta deviasi standar (Yohana, 2007).
1. Range (Jarak)
Ukuran paling sederhana dari ukuran penyebaran adalah nilai range atau jarak yang dirumuskan dengan selisih atau perbedaan dari nilai terbesar dan nilai terkecil dari suatu kelompok data, baik populasi maupun sampelnya. Rumus dari range atau jarak adalah sebagai berikut:
Terkecil Nilai -Terbesar Nilai ) Jarak ( Range Catatan:
Semakin kecil nilai range maka semakin baik karena data mendekati pada nilai pusatnya (nilai rata–ratanya), demikian sebaliknya.
2. Deviasi Rata–Rata
Ukuran pada range atau jarak, kesimpulan ditarik dari nilai tertinggi terendah saja, dengan kata lain data lainnya baik populasi maupun sampel terabaikan. Deviasi agar dapat melihat pengaruh data lainnya maka diperlukan deviasi rata-rata yang mengukur besarnya variasi atau selisih dari setiap nilai pada populasi atau sampel dari rata rata–rata hitungnya. Deviasi rata-rata dapat didefinisikan rata–rata hitung dari nilai mutlak deviasi antara data pengamatan dengan rata-rata hitungnya. Rumus deviasi rata-rata data tunggal adalah sebagai berikut:
n X -X MD
Keterangan: MD : Deviasi rata-rata.X : Nilai setiap data pengamatan.
X : Nilai rata-rata hitung dari seluruh nilai pengamatan. N : Jumlah data dalam sampel atau populasi.
: Lambang nilai mutlak. Catatan:
Nilai atau angka mutlak dipakai karena jumlah dari selisih nilai data dengan nilai hitung rata-rata adalah sama dengan nol, oleh karenanya digunakan angka mutlak.
3. Varians dan Standar Deviasi Populasi
Varians dan standar deviasi merupakan dua buah ukuran yang paling sering digunakan untuk mengetahui ukuran penyebaran seperangkat data. Varians adalah kuadrat dari standar deviasi sebaliknya standar deviasi adalah akar (pangkat dua) dari varians. Varians dapat dibedakan menjadi varians sampel dan varians populasi. Rumus varians populasi data tunggal adalah sebagai berikut:
n x dimana n -x 2
Rumus standar deviasi populasi data tunggal adalah sebagai berikut:
2
Keterangan :
2
: Varians populasi (dibaca tho).
µ : Nilai rata-rata hitung dalam populasi. n : Jumlah total data dalam populasi.
2
: Standar deviasi populasi. 4. Varians dan Standar Deviasi Sampel
Sampel adalah bagian dari populasi yang digunakan jika perangkat datanya besar. Jumlah data atau populasi kecil ( ≤ 30) maka usahakan semua data masuk dalam perhitungan dengan kata lain digunakan varians dan standar deviasi populasi dan jika datanya besar ( ≥ 30) maka digunakan varians dan standar deviasi sampel. Rumus varians sampel data tunggal adalah sebagai berikut:
1 -n ) X -(X 2
SRumus standar deviasi sampel data tunggal adalah sebagai berikut:
2 S S Keterangan : 2 S : Variasi sampel.
X : Nilai setiap data atau pengamatan dalam populasi. µ : Nilai rata-rata hitung dalam populasi.
n : Jumlah total data dalam populasi.
2
S : Standar deviasi sampel.
2.3.2 Ukuran Penyebaran untuk Data Berkelompok
Pencarian ukuran penyebaran pada data berkelompok maka dilakukan dengan mencari nilai range, deviasi, rata–rata dan varians serta deviasi standar.
1. Range (Jarak)
Ukuran paling sederhana dari ukuran penyebaran adalah nilai range atau jarak yang dirumuskan dengan selisih atau perbedaan dari nilai terbesar dan nilai terkecil dari suatu kelompok data, baik populasi maupun sampelnya. Rumus dari range atau jarak untuk data berkelompok adalah sebagai berikut:
terbawah kelas bawah Batas tertinggi kelas atas Batas ) Jarak ( Range 2. Deviasi Rata–Rata
Ukuran pada range atau jarak, kesimpulan ditarik dari nilai tertinggi atau terendah saja, dengan kata lain data lainnya baik populasi maupun sampel terabaikan. Data agar dapat melihat pengaruh data lainnya maka diperlukan deviasi rata–rata yang mengukur besarnya variasi atau selisih dari setiap nilai pada populasi atau sampel dari rata rata–rata hitungnya. Deviasi rata-rata dapat didefinisikan rata-rata–rata-rata hitung dari nilai mutlak deviasi antara data pengamatan dengan rata-rata hitungnya. Rumus deviasi rata–rata data berkelompok adalah sebagai berikut:
n X f X dimana n X -X f MD
Keterangan: MD : Deviasi rata-rata.f : Jumlah frekuensi setiap kelas. X : Nilai setiap data pengamatan.
X : Nilai rata-rata hitung dari seluruh nilai pengamatan. N : Jumlah data dalam sampel atau populasi.
Catatan:
Nilai atau angka mutlak dipakai karena jumlah dari selisih nilai data dengan nilai hitung rata-rata adalah sama dengan nol, oleh karenanya digunakan angka mutlak.
3. Varians dan Standar Deviasi Data Berkelompok
Varians dan deviasi standar untuk data berkelompok pada dasarnya sama dengan varians dan deviasi pada data tunggal, perbedaan hanya pada perkalian yang dilakukan dengan frekuensi kelas. Rumus varians sampel data berkelompok adalah sebagai berikut:
1 -n ) X -(X f 2 2
SRumus standar deviasi sampel data berkelompok adalah sebagai berikut:
2 S S Keterangan: 2 S : Variasi sampel.
X : Nilai setiap data atau pengamatan dalam populasi. µ : Nilai rata-rata hitung dalam populasi.
n : Jumlah total data dalam populasi.
2
S : Standar deviasi sampel.
2.3.3 Ukuran Penyebaran Lainnya
Ukuran untuk pencarian ukuran penyebaran lainnya maka dilakukan dengan mencari nilai range inter kuartil dan deviasi kuartil (Supranto, 1977).
1. Range Inter Kuartil
Kuartil dinyatakan sebagai ukuran letak yang membagi data yang telah diurutkan atau data berkelompok menjadi 4 bagian sama rata dengan masing-masing 25%.
Kuartil 1 (K1) membatasi daerah data dibawahnya sebesar 25% dan
daerah diatasnya sebesar 75% sedangkan kuartil 3 (K3) sebaliknya membatasi
data diatasnya 25% dan membatasi data dibawahnya 75%. Ukuran range inter kuartilnya ialah K3 dikurangi K1 adalah sebagai berikut:
1 3 K K il Interkuart Range 2. Deviasi Kuartil
Deviasi kuartil dirumuskan sebagai setengah dari selisih range inter kuartil sehingga rumus deviasi kuartil adalah sebagai berikut :
2 K K (DK) kuartil Deviasi 3 1
2.3.4 Ukuran Kemencengan, Keruncingan, dan Angka Baku
Ukuran untuk melihat seberapa nilai kemencengan dan keruncingan dari data perhitungan ukuran penyebaran maka digunakan ukuran kemencengan dan ukuran keruncingan (Yohana,2007).
1. Ukuran Kecondongan (Skewness)
Ukuran kecondongan atau skewness untuk melihat seberapa kecondongan data jika dibuat dalam bentuk kurva. Kecondongan terjadi jika
Mo. Md
X Jenis kecondongan ada dua, pertama condong positif dimana kurva condong ke kiri dengan nilai XMdMo. Kecondongan yang kedua adalah condong negatif dimana kurva condong kekanan dengan nilai
Mo Md
-Mo Sk
Keterangan:
Sk : Koefisien kecondongan. : Nilai rata–rata hitung. Md : Nilai median.
Mo : Nilai modus. : Standar deviasi.
2. Ukuran Keruncingan (Kurtosis)
Ukuran keruncingan atau kurtosis untuk melihat berapa runcingnya data jika dibuat dalam kurva. Kurtosis adalah derajat keruncingan suatu distribusi (biasanya diukur relatif terhadap distribusi normal). Kurva yang lebih runcing dari distribusi normal dinamakan leptokurtik, yang lebih datar platikurtik dan distribusi normal disebut mesokurtik. Kurtosis dihitung dari momen keempat terhadap mean. Distribusi normal memiliki kurtosis = 3, sementara distribusi yang leptokurtik biasanya kurtosisnya > 3 dan platikurtik <>. Rumus keruncingan adalah sebagai berikut:
x i x N K 1 4 4 ( ) 1 ) ( Keterangan:K : Keruncingan atau kurtosis. N : Jumlah data.
σ : Standar deviasi. x : Nilai data.
3. Angka Baku (Z-Score)
Angka baku adalah ukuran penyimpangan data dari rata-rata populasi. z dapat bernilai nol (0), positif (+), atau negatif (-). Angka baku memiliki beberapa nilai, yaitu:
a. z nol (0) adalah data bernilai sama dengan rata-rata populasi. b. z positif (+) adalah data bernilai di atas rata-rata populasi. c. z negative(-) adalah data bernilai di bawah rata-rata populasi. Rumus angka baku adalah sebagai berikut:
S
x
z
Keterangan: z : Angka baku. x : Nilai data. : Rata-rata populasi.S : Simpangan baku populasi.
2.4. Probabillitas
Dalam teori peluang mempelajari gejala acak yang sebagian awal dari gejala tertentu atau deterministic dengan cara memperhatikan hasil suatu percobaan. Hasil percobaan ini tidak selalu memberikan hasil yang sama, dengan mengumpulkan semua hasil yang mungkin dari percobaan itu. Hasil tersebut berfungsi sebagai himpunan semesta (S). Himpunan bagian dari S akan menyatakan hasil yang mungkin muncul dan dapat ingin tahu kemungkinan dan peluang kejadian.
Probabilitas, peluang atau kebolehjadian adalah cara untuk mengungkapkan pengetahuan atau kepercayaan bahwa suatu kejadian akan
berlaku atau telah terjadi. Konsep ini telah dirumuskan dengan lebih ketat dalam matematika, dan kemudian digunakan secara lebih luas dalam tidak hanya dalam matematika atau statistika, tapi juga keuangan, sains dan filsafat.
Probabilitas suatu kejadian adalah angka yang menunjukkan kemungkinan terjadinya suatu kejadian, nilainya di antara 0 dan 1. Kejadian yang mempunyai nilai probabilitas 1 adalah kejadian yang pasti terjadi, dan tentu tidak akan mengejutkan sama sekali. Misalnya matahari yang masih terbit di timur sampai sekarang, sedangkan suatu kejadian yang mempunyai nilai probabilitas 0 adalah kejadian yang mustahil atau tidak mungkin terjadi. Misalnya seekor kambing melahirkan seekor sapi.
Probabilitas suatu kejadian A terjadi dilambangkan dengan notasi P(A), p(A), atau Pr(A). Probabilitas sebaliknya, probabilitas [bukan A] atau komplemen A, atau probabilitas suatu kejadian A tidak akan terjadi, adalah 1-P(A).
2.4.1 Definisi Istilah
Probabilitas adalah suatu ukuran kuantitatif dari suatu ketidak pastian, merupakan suatu angka yang membawa kekuatan keyakinan atas suatu kejadian dari suatu peristiwa yang tidak pasti. Dibawah ini beberapa istilah dalam probabilitas, yaitu:
a. Himpunan (set) adalah suatu kumpulan elemen.
b. Himpunan semesta (universal set) adalah suatu himpunan yang berisi apa saja dalam suatu konteks tertentu.
c. Himpunan kosong (empty set) adalah suatu himpunan yang tidak memiliki elemen.
d. Komplemen A ( A ) adalah suatu himpunan yang berisi semua elemen di dalam himpunan semesta yang bukan anggota himpunan A.
e. Irisan (intersection) A dan B, (A∩B) adalah suatu himpunan yang berisi semua elemen yang menjadi anggota himpunan A dan B.
f. Gabungan (union) A dan B, (A U B) adalah suatu himpunan yang berisi semua elemen yang menjadi anggota A atau B.
g. Eksperimen (experiment) adalah suatu proses yang menyebabkan satu dari beberapa kemugkinan berhasil.
h. Outcome adalah hasil dari sebuah eksperimen.
i. Ruang sampel (sample space) adalah seluruh kemungkinan outcome dari suatu eksperimen.
j. Peristiwa (event) adalah bagian atau kumpulan outcome dari sebuah eksperimen.
Kemungkinan peristiwa A adalah ukuran relatif A dihubungkan dengan ukuran ruang ssampel, S. Kemungkinan peristiwa A adalah sebagai berikut: | | | | ) ( S A A P
Ruang sampel yang jumlahnya terbatas atau finite adalah sebagai berikut: ) ( ) ( ) ( s n A n A P 2.4.2 Peran Probabilitas
Ketidakpastian (uncertainty) meliputi seluruh aspek-aspek kegiatan manusia. Probabilitas adalah salah satu alat yang sangat penting karena
probabilitas banyak digunakan untuk menaksir derajat ketidakpastian dan oleh karenanya mengurangi risiko (Yohana, 2007).
Orang yang belum pernah mendapatkan pengajaran secara formal tentang topik ini tentu sudah mengenal probabilitas ini karena konsep ini meliputi hampir semua aspek kehidupan. Tanpa disadari baik secara langsung ataupun tidak langsung selalu berhadapan dengan probabilitas. Banyak keputusan yang dihasilkan untuk mengetahui sebuah peluang dalam pekerjaan berdasarkan perhitungan probabilitas. Misalnya, Ketika ingin menghadapi ujian. Mengetahui topik yang akan keluar dalam sebuah ujian yang ingin dikerjakan, sehingga dapat lebih mudah memfokuskan sistem belajar dan kemudian dapat lebih mengonsentrasikan belajar pada topik-topik tersebut.
Dunia usaha, probabilitas berperan penting dalam pengambilan keputusan, sebagai contoh, pemilik toko sepatu tentu akan memesan sepatu dengan ukuran tertentu yang ia yakini akan dapat terjual dengan cepat. Pemimpin usaha penerbit buku pun akan menentukan judul-judul dan hasil karya pengarang tertentu yang dia yakin akan disukai oleh konsumen.
2.4.3 Konsep Dasar Probabilitas
Probabilitas atau dalam bahasa Indonesia sering diartikan kemungkinan adalah konsep dasar yang biasanya dipelajari pada awal-awal perkualiahan statistik, dalam postingan kali ini, penulis akan menggunakan kata probabilitas.
Probabilitas adalah peluang terjadinya sebuah peristiwa. Biasanya probabilitas dinyatakan dalam pecahan seperti ½, ¾, ¼ ataupun dalam bentuk decimal seperti 0,50, 0,75, ataupun 0,25. Rentangan probabilitas antara
0 sampai dengan 1. Mengatakan probabilitas sebuah peristiwa adalah 0, maka peristiwa tersebut tidak mungkin terjadi. Mengatakan bahwa probabilitas sebuah peristiwa adalah 1 maka peristiwa tersebut pasti terjadi.
Dua hal yang harus dipahami dalam konsep probabilitas adalah mutually exclusive dan collectively exhaustive. Mutually exclusive adalah peristiwa yang terjadi terpisah satu sama lain. Ketika melempar uang logam, maka hanya ada satu sisi yang memiliki kemungkinan untuk muncul. Kemungkinan munculnya sisi belakang atau sisi depan disebut mutually exclusive. Perbedaan tersebut akan tetapi jika ada lebih dari satu kemungkinan untuk munculnya sebuah peristiwa maka hal itu disebut collectively exhaustic (Supranto, 1977).
Probabilitas setidaknya sering kali menggunakan sampel daripada menggunakan populasi biaya mahal kalau harus seluruh populasi, tidak mungkin mengamati semua populasi, menguji semua populasi cenderung mempebesar kesalahan dan pengujian atau eksperimen kadangkala destruktif. Dalam probabilitas terdapat pula penyimpangan antara lain:
1. Kekeliruan atau Gross Error atau Blunder
Terjadi karena kebingungan atau kekurang telitian pengamat. Kesalahan jenis ini tidak bisa dimasukkan dalam hitung perataan dan harus dibuang. 2. Kesalahan Sistematis
Kesalahan akibat perbedaan standar peralatan. Disebabkan mengikuti hukum hukum fisika, kesalahan semacam ini dapat dimodelkan, diprediksi, atau dieliminir dengan metoda pengukuran tertentu.
3. Kesalahan Acak (Random Errors)
Kesalahan yang masih tersisa setelah kesalahan sistematik dihilangkan. Biasanya muncul karena ketidaksempurnaan alat sempurna atau indera manusia.
2.4.4 Aturan-Aturan Pokok Probabilitas
Probabilitas atau peluang dasarnya sebuah cara untuk mengungkapkan pengetahuan atau kepercayaan bahwa suatu kejadian akan berlaku atau telah terjadi. Aturan-aturan dalam probabilitas, yaitu:
Aturan satu 1:
Untuk setiap peristiwa,probabilitas P(A) adalah 0 ≤ P (A) ≤ 1
Nilai 0 dan 1, semakin besar probabilitas, semakin besar keyakinan akan terjadinya suatu peristiwa yang dipertanyakan. Probabilitas 0,95 menyatakan keyakinan yang sangat tinggi karena peristiwa itu akan terjadi. Probabilitas 0,80 menyatakan keyakinan yang tinggi bahwa peristiwa itu akan terjadi. Probabilitas 0,50 menyatakan kemungkinan itu akan terjadi sama dengan kemungkinan peristiwa itu terjadi. Suatu probabilitas apabila angka itu 0,20 menunjukan itu peristiwa sangat mungkin terjadi, sedangkan jika itu menetapkan probabilitas 0,05 maka peristiwa itu akan terjadi, dan seterusnya.
Aturan 2:
Contoh 1:
Probabilitas mengambil kartu As dari sebuah bungkus kartu bridge adalah 4/52, maka probabilitas kartu yang terambil bukan kartu As adalah 48/52.
Contoh 2:
Anggaplah pak Suto seorang petani buah semangka (S) dan melon (M) sedangkan memperkirakan bahwa hasil panen semangka tahun ini akan berhasil dengan baik adalah 0,65. Tentu saja pak Suto menyadari bahwa hasil panen yang jelek tahun ini adalah 0,35 (1 – 0,65).
Contoh 1:
Menghitung probabilitas pristiwa bahwa kartu yang ditarik As atau Spade A G. Menghitung bahwa probabilitas peristiwa terambilnya sebuah kartu As adalah 4/52, probabilitas terambilnya sebuah kartu Spade adalah 13/52 dan Spade adalah 1/52, maka probabilitas terambilnya sebuah kartu adala As atau Spade sesuai dengan aturan 2.5 adalah:
P(As B Spade) = P(As)+P(Spade)-P(As Spade) = 4/52 + 13/52 – 1/52 = 16/52
Probabilitas memiliki beberapa kriteria yang menunjukkan suatu peristiwa sebuah data. Probabilitas juga dapat dibuat data dengan sampel atau populasi, sehingga di bawah ini langkah-langkah agar probabilitas dapat sukses, yaitu:
Aturan 3:
1. Rata–Rata Hitung Probabilitas
Rata–rata hitung, merupakan nilai yang dianggap mewakili nilai-nilai dalam probabilitas dan juga merupakan juga nilai harapan (expected value) yang dilambangkan dengan notasi E (x). Nilai rata–rata hitung dalm probabilitas juaga nerupakan nilai rata-rata tertimbang karena seluruh kemungkinan diberi bobot berupa probabilitasnya masing–masing. Rumus dari rata–rata hitung adalah sebagai berikut:
µ= E (x) = ∑ (x) . P (x) Keterangan:
µ : Nilai rata–rata hitung distribusi probabilitas. E(X) : Nilai harapan (expected value).
X : Aktifitas atau kejadian.
P(x) : Probabilitas suatu aktifitas atau kejadian. 2. Varians dan Standar Deviasi Probabilitas
Rumus untuk varians dan standar deviasi dalam probabilitas adalah sebagai berikut: Varians : σ² = ∑( X – µ) ². P ( x) Standar deviasi : σ = 2 Keterangan: σ² : Varians. σ : Standar deviasi.
x : Nilai aktifitas kejadian.
µ : Nilai rata rata hitung distribusi probabilitas. P (x) : Probabilitas aktifitas atau kejadian x.
3. Distribusi Probabilitas Binomial
Distribusi probabilitas adalah salah satu jenis distribusi probabilitas diskret yang sederhana dan cukup banyak digunakan. Distribusi binomial adalah distribusi untuk proses bernoulli (penemu binomial). Proses bernoulli sendiri adalah suatu proses atau kegiatan yang mempunyai ciri-ciri sebagai berikut:
a. Aktifitas atau percobaan berlangsung n kali, tiap aktivitas atau eksperimen berlangsung dalam cara dan kondisi yang sama.
b. Aktivitas atau eksperimen hanya ada dua peristiwa yang mungkin terjadi. Dua peristiwa tersebut adalah saling lepas dan independen satu sama lain, misalnya dalam percobaan melempar mata uang maka hasilnya akan adalah jika tidak keluar gambar (G) maka akan keluar Angka (A). Kedua peristiwa tersebut biasa disebut sebagai peristiwa sukses dan peristiwa gagal. Probabilitas peristiwa sukses dinotasikan dengan P dan probabilitas peristiwa gagal dinotasikan dengan q.
c. Probabilitas sukses dan probabilitas gagal dari suatu percobaan atau aktivitas ke percobaan lain adalah konstan sehingga P + q = n!. Rumus untuk ditribusi binomial adalah sebagai berikut:
)! ( ! ) ( r n n r P Keterangan:
P(r): Nilai probabilitas binomial.
r : Banyaknya sukses untuk keseluruhan percobaan. n : Jumlah total aktifitas atau percobaan.
q : Probabilitas gagal yang diperoleh dengan q = 1-p. ! : Notasi faktorial.
Data di atas dapat disebut juga sebagai permutasi. Kombinasi adalah pengaturan sejumlah berhingga objek yang dipilih tanpa memperhatikan urutannya. Rumus kombinasi adalah sebagai berikut: )! ( ! ! r n r n Cr n Keterangan: C : Kombinasi
n : Jumlah total aktifitas atau pecobaan.
r : Banyaknya sukses untuk keseluruhan percobaan.
2.5. Distribusi Hipergeometrik
Distribusi Hipergeometrik adalah salah satu jenis distribusi variabel random diskrit yang digunakan untuk mencari probabilitas sukses pada situasi-situasi adalah sebagai berikut (Yohana, 2007):
1. Terdapat n penyempelan dari N populasi.
2. Hanya tedapat dua peristiwa yaitu peristiwa sukses atau peristiwa gagal. 3. Jumlah sukses total adalah S.
4. Sampel yang telah diambil tidak dikembalikan (dengan kata lain penyampelan satu dengan yang lain adalah dependen atau saling bergantung).
Distribusi Hipergeometrik timbul bila contoh-contoh dari suatu populasi berhingga (yang terdiri atas dua jenis elemen, misalnya, baik dan
buruk) sedang diperiksa. Distribusi ini merupakan distribusi yang mendasari banyak cara pengambilan sample yang digunakan sehubungan dengan diterimanya sampling dan pengendalian mutu (Alfredo, 1987).
Misalkan dalam sebuah populasi berukuran N terdapat D buah termasuk kategori A. Sebuah sampel acak berukuran n diambil dari populasi itu. Berapa peluang terdapat x buah termasuk kategori A dari sampel tersebut?
Pernyataan diatas dijawab dengan distribusi hypergeometrik, dan rumus dari distribusi hipergeometrik adalah sebagai berikut:
N n D N x n D xx
P
)
(
Keterangan: x : 1, 2, …, nDefinisi dari distribusi hipergeometrik adalah bila dalam populasi N benda, k benda diantaranya diberi label berhasil dan N-k benda lainnya diberi label gagal. Nilai sebaran peluang bagi peubah acak hipergeometrik X, yang menyatakan banyaknya keberhasilan dalam contoh acak berukuran n, adalah sebagai berikut:
N n k N x n k xk
n
N
x
h
)
,
,
;
(
Keterangan:
x : Peubah acak dimana, x : 0, 1, 2, ..., k N : Populasi.
n : Sampel.
k : Nilai keberhasilan.
Bila ada populasi berukuran N, diambil sampel sebanyak n, dalam populasi tersebut ada sejumlah a komponen yang rusak. Mula–mula diambil satu sampel, maka kemungkinan mendapat komponen yang rusak adalah
n
a . Komponen itu tidak dikembalikan ke populasi, maka kemungkinan untuk mendapat komponen yang rusak adalah sebagai berikut:
1
1
N
a
jika komponen yang terambil pertama rusak.
1
1
N
a
jika komponen yang terambil pertama tidak rusak.
Terlihat bahwa pengambilan ke-2 bergantung pada hasil pengamatan ke-1. Komponen oleh karenanya dikatakan bahwa pengambilan sampel tidak independent atau dependent. Keadaan ini tidak memenuhi asumsi distribusi binomial yang mengharuskan pengambilan sampel yang independent, keadaan diatas tidak dapat diperhitungkan sebagai distribusi binomial, maka digunakan distribusi hipergeometrik. Percobaan hipergeometrik bercirikan tiga sifat adalah sebagai berikut:
1. Suatu contoh acak berukuran n diambil dari populasi yang berukuran N. 2. K dari N benda diklasifikasikan sebagai berhasil dan N-k benda
diklasifikasikan sebagai gagal.
Banyaknya keberhasilan x dalam suatu percobaan hipergeometrik disebut peubah acak hipergeometrik. Distribusi peluang bagi peubah acak hipergeometrik disebut distribusi hipergeometrik.
2.5.1 Nilai Tengah dan Ragam Distribusi Hipergeometrik
Menentukan nilai tengah (µ) dan ragam (σ²) bagi distribusi hipergeometrik, dituliskan: N k n. N k N k n N n N 1 . . . 1 2
Nilai n relatif lebih kecil dibandingkan N, maka peluang pada setiap pengambilan akan berubah kecil sekali. Nilai n sehingga praktis dapat dikatakan bahwa dihadapkan dengan percobaan binomial, maka dapat menghampiri distribusi hipergeometrik dengan menggunakan distribusi binomial dengan P kN. Nilai tengah dan ragamnya dapat dihampiri dengan melalui rumus nilai tengah dan ragam diatas (Supranto, 1977).
2.5.2 Perbedaan Distribusi Hipergeometrik dengan Distribusi Binomial Distribusi hipergeometrik dan distribusi binomial merupakan distribusi peluang diskret yang digunakan untuk mencari peluang suatu kejadian yang jumlah datanya diketahui. Perbedaan antara keduanya antara lain:
1. Perbedaan Pertama dengan Sebuah Pengambilan, yaitu:
a. Perbedaan pada distribusi binomial misalkan pada percobaan pengambilan kartu dilakukan pemulihan.
b. Perbedaan pada distribusi hipergeometrik misalkan pada percobaan pengambilan kartu dilakukan tanpa pemulihan.
2. Perbedaan Kedua dengan Ulangan dan Pengulangan, yaitu:
a. Perbedaan pada distribusi binomial ulangan-ulangannya bersifat bebas antara satu sama lain.
b. Perbedaan pada distribusi hipergeometrik setiap ulangan bergantung dari hasil ulangan sebelumnya (bersifat peluang bersyarat).
3. Perbedaan Ketiga dengan Menggunakan Rumus, yaitu:
a. Perbedaan untuk distribusi binomial rumus yang digunakan: b (x ; n , p) =
nx .p x
.qnx x : 0,1,2,…,n.
b. Perbedaan untuk distribusi hipergeometrik rumus yang digunakan:
N n k N x n k xk
n
N
x
h
)
,
,
;
(
x : 0,1,2,…,k4. Perbedaan Keempat dengan Nilai Tengah dan Variasinya, yaitu:
a. Perbedaan untuk distribusi binomial nilai tengah dan variansnya adalah:
µ = n p s σ² = n p q
b. Perbedaan untuk distribusi hipergeometrik nilai tengah dan variansnya adalah:
N k n. N k N k n N n N 1 . . . 1 2 2.6. Distribusi Normal
Distribusi normal disebut pula distribusi Gauss, adalah distribusi probabilitas yang paling banyak digunakan dalam berbagai analisis statistika. Distribusi normal baku adalah distribusi normal yang memiliki rata-rata nol dan simpangan baku satu. Distribusi ini juga dijuluki kurva lonceng (bell curve) karena grafik fungsi kepekatan probabilitasnya mirip dengan bentuk lonceng.
Distribusi normal memodelkan fenomena kuantitatif pada ilmu alam maupun ilmu sosial. Beragam skor pengujian psikologi dan fenomena fisika seperti jumlah foton dapat dihitung melalui pendekatan dengan mengikuti distribusi normal. Distribusi normal banyak digunakan dalam berbagai bidang statistika, misalnya distribusi sampling rata-rata akan mendekati normal, meski distribusi populasi yang diambil tidak berdistribusi normal. Distribusi normal juga banyak digunakan dalam berbagai distribusi dalam statistika, dan kebanyakan pengujian hipotesis mengasumsikan normalitas suatu data.
Distribusi normal pertama kali diperkenalkan oleh Abraham de Moivre dalam artikelnya pada tahun 1733 sebagai pendekatan distribusi binomial untuk n besar. Karya tersebut dikembangkan lebih lanjut oleh Pierre Simon de Laplace, dan dikenal sebagai teorema Moivre-Laplace. Laplace menggunakan distribusi normal untuk analisis galat suatu eksperimen. Metode kuadrat terkecil diperkenalkan oleh Legendre pada tahun 1805.
Gauss mengklaim telah menggunakan metode tersebut sejak tahun 1794 dengan mengasumsikan galatnya memiliki distribusi normal.
Istilah kurva lonceng diperkenalkan oleh Jouffret pada tahun 1872 untuk distribusi normal bivariat. Sementara itu istilah distribusi normal secara terpisah diperkenalkan oleh Charles S. Peirce, Francis Galton, dan Wilhelm Lexis sepenulisr tahun 1875. Terminologi ini secara tidak sengaja memiki nama yang sama (http://id.wikipedia.org/wiki/Distribusi_normal).
Tahun tersebut juga 1733, De Moivre menemukan persamaan matematika untuk kurva normal yang menjadi dasar dalam banyak teori statistika induktif. Yaitu, sebuah perubah acak X dengan rata–rata µ dan varians 2 mempunyai fungsi densitas sebagai berikut:
Rumus tersebut sehingga, dengan demikian µ dan 2
yang di ketahui, maka seluruh kurva normal dapat di ketahui sebagai berikut:
Gambar 2.5 Kurva Normal (Sumber: Statistika Industri 1, 1997)
Kurva normal mempunyai bentuk seperti lonceng dan simetris terhadap rata–rata (µ). Untuk keperluan probabilitas, luas kurva normal disamakan dengan satu satuan (100%). Mencari luas daerah pada suatu kurva normal dengan menggunakan tabel:
P (0 ≤ z ≤a) : nilai tabel a
Gambar 2.6 Kurva Normal Nilai A P (z ≥ a) : 0.5 – nilai tabel a
P (z ≥ -a) : 0.5 + nilai tabel –a
Gambar 2.8 Kurva Normal Nilai Di atas A P (z ≤ a) : nilai tabel a + 0.5
Gambar 2.9 Kurva Normal Di atas A P (a1 ≤ z ≤ a2) : nilai tabel a2 – nilai tabel a1
P (a1 ≤ z ≤ a2) : nilai tabel a2 + nilai tabel a1 )
Gambar 2.11 Kurva Normal Antara A2 dan A1
(Sumber: www.snapdrive.net/files/622773/Modul%20Dist.%20Normal.pdf)
Terdapat pula beberapa bentuk kurva normal, dibandingkan dalam 2 kurva yang berbeda. Bentuk kurva yang berbeda adalah sebagai berikut: 1. Dua kurva berbeda dalam rata–rata dan simpangan baku.
2. Dua kurva dengan simpangan baku berbeda tapi rata–rata sama. 3. Dua kurva normal baik rata–rata maupun simpangan baku berbeda.
Kurva Normal dengan µ1 ≤ µ2 dan 1 ≤ 2
Kurva Normal dengan µ1 ≤ µ2 dan 1 ≤ 2
Gambar 2.13 Kurva Normal Nilai yang Berdempetan (Sumber: Statistika Industri 1, 1997)
Pengolahan data agar mempermudah pencarian suatu distribusi normal dibunakan rumus untuk dua kurva. Rumus dua kurva dibagi menjadi 3, yaitu:
1. Rumus untuk data lebih dari menggunakan rumus, yaitu:
)) ( ( 1 ) ( ) ( Zx Z P x a P X Zx x a P i
2. Rumus untuk data kurang dari menggunakan rumus, yaitu:
) ( ( ) ( ) ( Zx Z P x a P X Zx x a P i
3. Rumus untuk data antara menggunakan rumus, yaitu: P (Za < x < Zb) = P (Za < - < Zb)
2.6.1 Ciri-Ciri Distribusi Normal
Abad ke-18 Karl Gauss mengemukakan bahwa variabel-variabel dalam ilmu sosial maupun ilmu pengetahuan alam banyak yang memiliki distribusi dengan ciri-ciri adalah sebagai berikut:
1. Kurvanya mempunyai puncak tunggal. 2. Kurvanya berbentuk seperti lonceng.
3. Rata-rata terletak ditengah distribusi dan distribusinya simetris di sepenulisr garis tegak lurus yang ditarik melalui rata-rata.
4. Kedua ekor kurva memanjang tak terbatas dan tak pernah memotong sumbu horizontal.
Distribusi normal karena begitu banyaknya variabel yang memiliki distribusi dengan ciri-ciri seperti di atas maka distribusi yang demikian itu dinamakan distribusi normal (Sri Mulyono, 1990). Berkaitan dengan sifat yang berlaku untuk sebuah fungsi densitas, dalam Distribusi Normal berlaku pula rumus sebagai berikut:
2.6.2 Luas Dibawah Kurva Normal
Sebuah kurva normal, sangat penting artinya dalam menghitung peluang, sebab luas daerah yang ada dalam kurva tersebut menunjukkan besarnya peluang.
Misalnya, suatu peubah acak X, mempunyai harga masing – masing X = a, dan X = b, ingin di cari P (a < X < b). Rumus luas dibawah kurva normal adalah sebagai berikut:
Dinyatakan oleh luas daerah yang diarsir: P(a < X < b) : luas daerah yang diarsir
Gambar 2.14 Kurva Perubahan Acak (Sumber: Statistika Industri 1, 1997)
Kepentingan praktis, rumus di atas sudah disusun dalam sebuah daftar, sehingga memudahkan para praktisi. Daftar yang di maksud adalah daftar distribusi normal standar (baku). Distribusi normal standar adalah
distribusi normal dengan rata–rata µ dan simpangan baku , ini diperoleh dari transformasi adalah sebagai berikut:
Keterangan:
Z : Standar Normal. µ : Rata–rata Populasi. X : Rata–rata Sampel. : Standar Deviasi.
Sehingga fungsi densitasnya berbentuk:
Catatan:
Untuk z dalam daerah - < z < .
Setelah diperoleh distribusi normal baku maka di cari luas daerah dibawah kurva normal baku tersebut. Caranya adalah Hitung z hingga 2 desimal adalah sebagai berikut:
1. Gambarkan kurvanya, sebuah kurva harus mengikuti data yang telah didapat dan hasil perhitungannya.
2. Letakkan harga z pada gambar datar, lalu tarik garis vertikal hingga memotong kurva.
3. Luas daerah yang tertera dalam daftar, adalah luas daerah antara garis ini dengan garis tegak di titik nol.
4 Daftar distribusi normal baku, cari harga z pada kolom paling kiri hanya 1 desimal, dan desimal keduanya di cari pada baris paling atas.
a. Daftar dari z di kolom kiri, maju kekanan dan dari z baris atas turun ke bawah, maka di dapat bilangan yang merupakan luas daerah yang di cari. Bilangan yang di dapat, di tulis dalam bentuk 0,.... (4 angka di belakang 0).
b. Daftar dari z ke kolom kanan, maju kekiri dan dari z baris atas turun ke bawah, maka di dapat bilangan yang merupakan luas daerah yang di cari. Bilangan yang di dapat, di tulis dalam bentuk -0,.... (4 angka di belakang 0).
Luas seluruh kurva adalah 1, dan kurva simetris di m = 0, maka luas garis tegak pada titik nol ke kiri ataupun kekanan adalah 0.5.
Luas untuk mencari kembali z, jika luasnya di ketahui, maka dilakukan langkah sebaliknya. Misalnya, jika luas = 0.4931, maka dalam badan daftar di cari 4931, lalu menuju ke pinggir sampai pada kolom z, di dapat 2.4 dan menuju ke atas samapai batas z, dan di dapat 6. Jadi harga z = 2.46 (Mutaqim, 1997).
2.6.3 Pendekatan Distibusi Binomial ke Distribusi Normal
Antara distribusi binomial dan distribusi normal terdapat hubungan tertentu. Jika untuk fenomena yang terdistribusi binomial berlaku kondisi sebagai berikut:
1. Ukuran N cukup besar.
2. Jumlah suatu distribusi mempunyai n ≥ 30 dan n,p ≥ 5 atau n ( 1 – p ) ≥ 5 maka penyelesaian probabilitas dapat menggunakan pendekatan
distribusi binomial ke distribusi normal dengan terlebih dahulu mencari nilai µ dan , yaitu:
Keterangan:
p : Probabilitas sukses. q : Probabilitas gagal.
Jika x merupakan variabel diskrit sekaligus variabel kontinyu maka perlu di adakan koreksi dengan menambah atau menguarangi dengan 0.5. Pendekatan normal terhadap binomial sangat memudahkan dalam perhitungan (Mutaqim, 1997).
2.6.4 Uji Distribusi Normal
Keperluan analisis selanjutnya, dalam statistika, ternyata model distribusi harus di ketahui bentuknya terlebih dahulu. Teori menaksir dan uji hipotesis misalnya, perhitungan dilakukan berdasarkan asumsi bahwa populasi berdistribusi normal. Asumsi ini tidak dipenuhi, artinya ternyata populasi berdistribusi normal, maka kesimpulan berdasarkan teori itu tidak berlaku. Karenanya, sebelum teori itu berlanjut lebih jauh di gunakan dan kesimpulan di ambil, terlebih dahulu di selidiki apakah asumsi normal itu di penuhi atau tidak (Mutaqim, 1997). Distribusi normal ada beberapa cara pengujiannya adalah sebagai berikut: