Perbandingan Metode Support Vector Machine (SVM) dan Artificial Neural Network (ANN) pada Klasifikasi Gizi Balita
Studi Kasus pada Puskesmas Salissingan
(Comparison of Support Vector Machine (SVM) and Artificial Neural Network (ANN) Methods in Toddler Nutrition Classification (Case Study at Salissingan Health Center))
Harifa Hananti 1*, Kartika Sari 1,2
1 Program Studi Magister Statistika Terapan, FMIPA, Universitas Padjadjaran, Indonesia
2 Badan Pusat Statistik Kabupaten Serang, Provinsi Banten Kubu Cotu Jorong V, Taruang-Taruang, Rao, Pasaman, Sumatera Barat E-mail : 1[email protected], 2[email protected].
ABSTRAK
Kasus kekurangan gizi atau gizi buruk pada balita menyebar hampir di seluruh provinsi yang ada di Indonesia. Provinsi Sulawesi Barat merupakan salah satu provinsi yang memiliki nilai persentase kekurangan gizi pada balita, sehingga dari faktor-faktor yang mempengaruhi gizi balita sangat penting untuk dilakukan dalam pengklasifikasian. Data yang digunakan adalah data dari Puskesmas Salissingan pada Tahun 2018. Penelitian ini bertujuan untuk melakukan pengklasifikasian dan mendapatkan metode terbaik pada gizi balita (gizi baik & gizi kurang) di Puskesmas Salissingan Sulawesi Barat dengan metode support vector machine (SVM) dan artificial neural network (ANN). Metode klasifikasi yang terbaik dalam melihat ukuran ketepatan klasifikasi adalah metode SVM dan ANN. Dari hasil analisis diperoleh ukuran ketepatan klasifikasi pada metode ANN (accuracy=94,82%, precision=51.00%, recall=51.09%, dan AUC=0.910), sedangkan pada metode SVM (accuracy=94,46%, precision=46.08%, recall=50.59%, dan AUC=0.900) dan dari hasil ukuran tersebut diperoleh bahwa metode yang terbaik dalam pengklasifikasian gizi balita di Puskesmas Salissingan Sulawesi Barat adalah ANN.
Kata kunci: support vector machine, SVM, artificial neural network, ANN, Gizi Balita
ABSTRACT
Cases of malnutrition or in children under five spread in almost all provinces in Indonesia. West Sulawesi Province is one of the provinces that has a percentage value of malnutrition in children under five, so that the factors that affect the nutrition of children under five are very important to do in classification. The data used is data from the Salissingan Health Center in 2018. This study aims to classify and obtain the best method of under-five nutrition (good nutrition &
poor nutrition) at the Salissingan Health Center, West Sulawesi with the support vector machine (SVM) method and artificial neural network ( ANN). The best classification method in seeing the size of classification accuracy is the SVM and ANN methods. From the analysis results obtained a measure of classification accuracy in the ANN method (accuracy
= 94.82%, precision = 51.00%, recall = 51.09%, and AUC = 0.910), while the SVM method (accuracy = 94.46%, precision = 46.08% , recall = 50.59%, and AUC = 0.900) and from the results of these measurements it was found that the best method for classifying under-five nutrition at the Salissingan Health Center, West Sulawesi, was ANN.
Keywords: support vector machine, SVM, artificial neural network, ANN, malnutrition
PENDAHULUAN
Indonesia sampai saat ini masih mengalami masalah kekurangan gizi balita. Berdasarkan data BPS pada tahun 2018 kekurangan gizi balita (0-23 bulan) meningkat sebesar 0,4 persen dari tahun 2017. Kekurangan gizi disebabkan oleh banyak faktor, seperti krisis ekonomi, budaya kesehatan, tingkat pendidikan, konsumsi makanan, pola asuh gizi, lingkungan, maupun penduduk yang saling berhubungan. Secara umum gangguan gizi dipengaruhi oleh faktor sekunder dan primer (Fitri, R.K, dkk, 2017).
Masa balita merupakan masa tumbuh kembang fisik dan mental yang pesat, pada masa balita ini otak telah siap menghadapi berbagai stimulus seperti belajar berjalan dan mengungkapkan kata lebih lancar.
Selanjutnya pada masa balita ini, tumbuh kembang sangat perlu diperhatikan, hal ini didasarkan pada fakta bahwa kurang gizi yang terjadi pada masa ini bersifat irreversible (tidak dapat pulih). Anak yang berusia berumur 5 tahun (balita) merupakan anak-anak yang menunjukkan pertumbuhan fisik ataupun badan yang
24.80%, dan 24.70%. Selanjutnya berdasarkan data BPS , jika dibandingkan dengan empat provinsi terdekat (Sulawesi Utara, Sulawei Tengah, Sulawesi Selatan, dan Sulawesi Tenggara), maka Provinsi Sulawesi Barat merupakan Provinsi dengan Balita Kekurangan Gizi (BPS, 2018).
Beberapa algoritma klasifikasi yang dapat digunakan untuk model dengan faktor yang yang ada, sehingga dapat mengklasifikasikan gizi balita dengan akurasi yang tinggi adalah metode support vector machine (SVM) dan artificial neural network (ANN) (Sihombing, P.R, dkk, 2017). Berdasarkan masalah yang telah dijelaskan maka penelitian ini bertujuan untuk melakukan pengklasifikasian gizi balita (gizi baik dan gizi kurang) dengan metode support vector machine (SVM) & artificial neural network (ANN) di salah satu puskesmas Provinsi Sulawesi Barat dan untuk mendapatkan metode yang terbaik pada pengklasifikasian gizi buruk dari kedua metode (SVM & ANN) yang dilakukan. Hasil penelitian ini diharapkan dapat dimanfaatkan oleh Puskesmas Salissingan maupun pemerintah Provinsi Sulawesi Barat dalam bidang kesehatan,, khususnya gizi balita.
METODE
Kekurangan Gizi
Gizi merupakan satu dari beberapa banyak faktor penting yang mempengaruhi seseorang maupun sekelompok, sehingga hal tersebut menjadi dasar dalam kesehatan masyarakat (Emerson, E, 2005). Gizi buruk merupakan suatu kondisi kekurangan konsumsi zat gizi yang dapat disebabkan oleh minimnya konsumsi energi protein dalam makanan sehari-hari, yang ditandai dengan berat dan tinggi badan di bawah rata-rata (tidak sesuai umur) dan harus ditetapkan oleh tenaga medis (BPS 2018). Kejadian gizi kurang dan buruk dapat disebabkan juga oleh faktor lainnya seperti keadaan ekonomi, pendidikan, pola asuh, sanitasi lingkungan, morbiditas (penyakit ifeksi), dan akses ke pelayanan kesehatan (Tjukami, T, dkk, 2011).
Data Mining
Data mining merupakan komponen dari beberapa disiplin ilmu yang menggabungkan metode ataupun teknik dari pembelajaran mesin, pengenalan pola, statistik, database, dan visualisasi untuk penanganan kasus pengambilan informasi dari database yang besar (Mardi, Yuli , 2014).
Algoritma Klasifikasi
Klasifikasi merupakan operasi untuk memisahkan beragam entitas kedalam beberapa kelas (Nisbet, dkk, 2009). Pengklasifikasian merupakan pelatihan pada fungsi f (target/label) yang memasangkan setiap atribut x ke satu dari jumlah label kelas y yang tersedia. Jika target kelas sudah diketahui maka proses klasifikasi termasuk dalam supervised. Akan tetapi, apabila dataset belum memiliki target kelas maka termasuk unsupervised, contohnya proses klaster. Penelitian ini menggunakan teknik klasifikasi supervised, yaitu membandingkan dua metode, yaitu Support Vector Machine (SVM) dan Artificial Neural Network (ANN).
SVM dan ANN adalah algorithma klasifikasi yang digunakan untuk menilai objek data dan memasukkan data kedalam kelas tertentu (Sihombing, P.R, dkk, 2017). Pembangunan model dilakukan pada proses klasifikasi dan pemodelan dimanfaatkan untuk melakukan klasifikasi/prediksi pada suatu obyek supaya diketahui di bagian mana objek data tersebut pada pemodelan yang telah dilakukan.
Cross Validation (CV)
Cross-validation (CV) adalah teknik validasi yang digunakan untuk melakukan evaluasi kerja model atau algoritma, dimana data dibagi menjadi dua subset yaitu yang pertama data proses pembelajaran dan yang kedua data validasi / evaluasi. Penelitian ini menggunakan 10 fold CV, dikarenakan hal ini sering kali menghasilkan pendugaan akurasi yang kurang bias dibandingkan dengan CV biasa, leave-one-out CV dan bootstrap.
Support Vector Machines (SVM)
Support Vector Machines (SVM) merupakan salah satu algoritma yang sangat kuat digunakan dalam klasifikasi dan regresi (Burges, C. (1998). SVM juga digunkan dalam prediksi numerik (Han, dkk, 2012).
Konsep klasifikasi dengan SVM ini dilakukan dengan mencari hyperplane terbaik yang digunakan sebagai
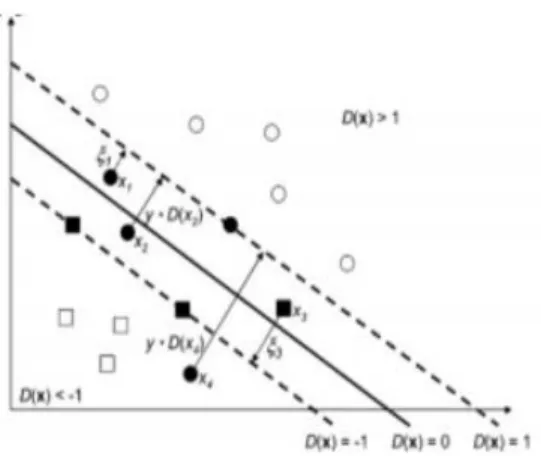
Gambar 1. Decision Boundary dengan Marginal Maksimum
Gambar 1 menunjukkan pembagian antara dua bagian kelas, yaitu kelas +1 dan -1. Data pada kelas -1 dilambangkan dengan tanda segiempat sedangkan data pada kelas +1 dilambangkan dengan tanda bulat. Untuk mendaptakan hyperplane (batas keputusan) yang baik antara bagian dua kelas, maka dilakukan dengan cara mengukur margin dan mendapatkan titik optimumnya. Margin (garis putus-putus) merupakan jarak antara hyperplane dengan data terdekat (support vector) dari masing-masing kelas. Pada gambar 1 terdapat sebuah garis lurus yang merupakan hyperplane yang terbaik, yaitu garis yang berada ditengah-tengah yang membagi kedua kelas.
Artificial Neural Network (ANN)
Artificial Neural Network (ANN) merupakan sebuah jaringan saraf yang memiliki sekumpulan neuron buatan yang saling terikat untuk melakukan proses informasi guna menyatukan untuk proses perhitungan (Laksana, T.G. 2013). Artificial Neural Network (ANN) dikenal dengan Jaringan Saraf Tiruan (JST) yaitu sebuah sistem analisis data yang terinspirasi dari konfigurasi otak manusia. Hal tersebut digunakan untuk mengidintifikasi, memproses, dan saling bergantung untuk menyelesaikan sebuah permasalahan tertentu (Khademi, F, dkk, 2016).
Gambar 2. Ilustrasi Skema Neuron
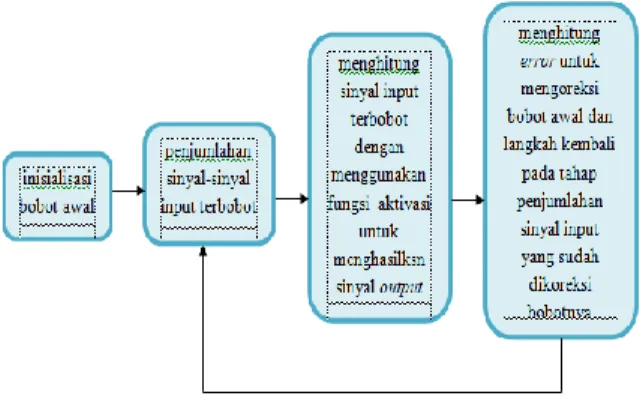
ANN bekerja dengan cara kerja seperti manusia, misalnya belajar dengan sebuah contoh. Terdapat tiga proses pada ANN, yaitu yang pertama proses input (input layer), kedua tersembunyi (hidden layer), dan ketiga output (ouput layer). Ada beberapa penghubung antara hidden layer dengan layer lainnya yaitu dengan bobot, bias dan fungsi transfer. Selanjutnya untuk menentukan fungsi error dengan menggunakan output jaringan dan target. Sedangkan untuk mengecilkan error dengan menggunakan teknik optimasi dengan cara menyesuaikan bobot dan bias. Semua proses training dilakukan secara berulang-ulang dengan beberapa epoch, hingga mencapai keakuratan dalam proses hasil yang diinginkan. Selanjutnya setelah melakukan training bobot dan bias juga digunakan dalam proses memvalidasi data pada jaringan. Adapun secara umum, alur kerja pada algoritma ANN dapat dilihat pada Gambar 3 berikut ini :
Gambar 3. Alur Perhitungan Output pada ANN Langkah-langkah Analisis
Analisis yang dilakukan dalam penelitian ini menggunakan software Rapid Miner Studio, Tahapan awal dalam penelitian ini adalah melakukan PreProcessing Data, dalam proses PreProcessing Data ini menggunakan variabel tambahan yaitu “ID” dengan d1-d72, variabel status Gizi sebagai “label”, dan variabel lainnya sebagai atribut. Tahapan selanjutnya adalah “Implementasi dan Evaluasi data”, pada tahap ini hasil dari preprocessing data kemudian di implemetasikan kedalam kedua algoritma. Pada Neural Network, parameter yang digunakan adalah learning rate dan momentum dengan terdapat 1 hidden layer. Sedangkan pada SVM parameter yang digunakan adalah kernel linear. Kedua model menggunakan 10-fold cross validation, sehingga akan diperoleh tingkat akurasi dari metode algoritma untuk memperoleh model yang akurat dan optimal dalam melakukan pengklasifikasian terhadap gizi balita.
Data dan Sumber Data
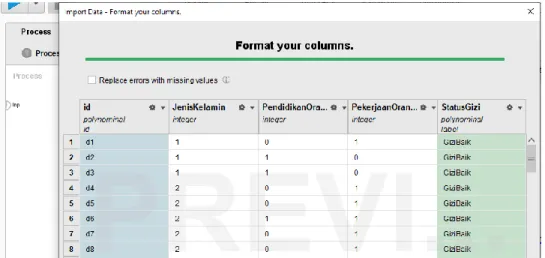
Data yang digunakan pada penelitian ini adalah data sekunder, yang berasal dari Puskesmas Salissingan Provinsi Sulawesi Barat pada tahun 2018. Data yang digunakan ada sebanyak 72 dan atribut variabel yang digunakan ada sebanyak empat, yaitu: jenis kelamin, pendidikan orang tua, pekerjaan orang tua, dan status gizi, seperti yang terdapat pada Tabel.1.
Tabel.1. Atribut Variabel
Atribut Variabel Kategori
Jenis Kelamin Pria 1
Wanita 2
Pendidikan Orang Tua SD 0
SLTP 1
Pekerjaan Orang Tua Wiraswasta 0
Nelayan 1
Status Gizi Gizi Baik 1
Gizi Kurang 2
HASIL DAN PEMBAHASAN
Penelitian ini dilakukan pada 72 balita. Pada tabel 2 terlihat bahwa masih terdapat 4 balita yang berstatus gizi buruk (gizi kurang) pada Puskesmas Silissingan Provinsi Sulawesi Barat, sedangkan gizi baik sebanyak 68 balita.
Tabel.2. Deskripsi Data
Atribut Variabel Kategori Frekuensi
Jenis Kelamin Pria 35
Wanita 37
Pendidikan Orang Tua SD 33
SLTP 39
Artificial Neural Network (ANN)
Tahap awal dalam pemodelan ANN pada pengkasifikasian gizi balita di Puskesmas Salissingan adalah melakukan PreProcessing Data, yang diawali dengan import data excel ke dalam Rapid Miner menggunakan operator Read Excel.
Gambar 4. PreProcessing Data ANN
Setelah melakukan PreProcessing Data Tahapan selanjutnya dalam pengklasifikasian gizi balita di Puskesmas Salissingan adalah “Implementasi dan Evaluasi data”, pada tahap ini hasil dari preprocessing data kemudian di implemetasikan kedalam algoritma ANN.
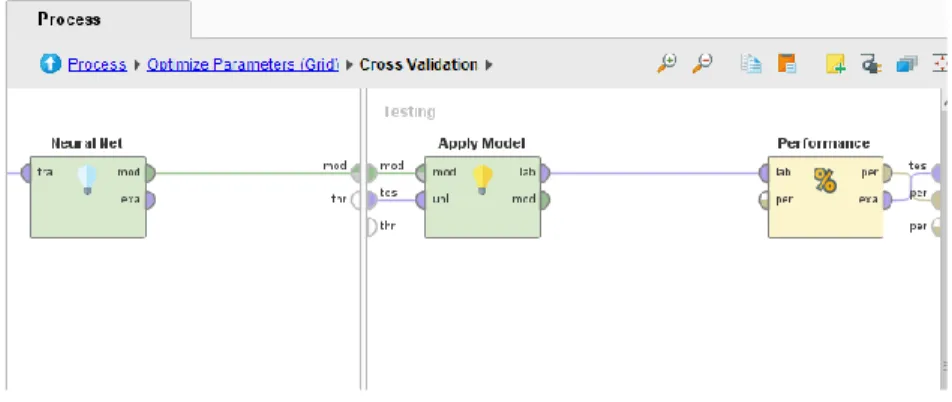
Gambar 5. Model Algoritma ANN
Pada metode ini parameter yang digunakan adalah learning rate dengan nilai terendah yang digunakan adalah 0. 01, tertinggi 0.9, dan steps 5 dengan scale linier. Selanjutnya metode ANN ini juga menggunakan parameter momentum, dengan nilai terendah 0.1, tertinggi 0.9, dan steps 5 dengan scale linier. Proses parameter tersebut diakukan pada langkah Optimized Parameter, setelah melakukan import data, pemilihan variabel dan atribut, validation, dan Optimized Paramaters (Grid). Sehingga secara ringkas hasil pengukuran ketepatan klasifikasi ANN output Rapid Miner Studio dapat dilihat pada Tabel.3.
Tabel.3 Ketepatan Klasifikasi ANN
Ukuran Ketepatan Klasifikasi ANN
Accuracy 94.82%
Precision 51.00%
Recall 55.09%
AUC 0.910
Berdasarkan Tabel 3, menunjukkan bahwa tingkat akurasi untuk metode ANN sangat baik yaitu sebesar 94.82%. Untuk nilai precision dan recall memiliki nilai yang cukup, yaitu secara berurutan sebesar 51.00%
dan 55.09%. Ini artinya ketepatan klasifikasi pada status gizi balita di Puskesmas Salissingan akan tepat namun masih dapat terjadi kesalahan klasifikasi. Selanjutnya, nilai AUC sebesar 0.910 yang menunjukkan bahwa klasifikasi sangat baik. Oleh karena itu, berdasarkan keterangan di atas dapat disimpulkan bahwa metode ANN dapat memberikan tingkat performansi yang sangat baik pada pengklasifikasian status gizi balita di Puskesmas Salissingan, ini artinya pengklasifikasian dapat memprediksi kelas status gizi baik dan status gizi kurang di
Support Vector Machine (SVM)
Langkah awal dalam pemodelan SVM pada pengklasifikasian gizi balita di Puskesmas Salissingan Sulawesi Barat adalah sama dengan metode ANN yaitu melakukan PreProcessing Data, yang diawali dengan import data excel ke dalam Rapid Miner menggunakan operator Read Excel.
Gambar 6. PreProcessing Data SVM
Sama halnya dengan metode ANN, maka selanjutnya pada pengklasifikasian gizi balita di Puskesmas Salissingan Sulawesi Barat adalah melakukan PreProcessing Data, yaitu “Implementasi dan Evaluasi data”, pada tahap ini hasil dari preprocessing data kemudian di implemetasikan kedalam algoritma SVM.
Gambar 7. Model Algoritma SVM
Metode SVM ini hanya menggunakan kernel_ linier, Optimize Parameter C, dengan rentang nilai 0.2- 100, untuk steps=10, dan scale legacy. Tahap tersebut dilakukan pada saat optimized setelah melakukan import data, Optimized Parameters (Grid), Validation, dan classification. Sehingga secara ringkas hasil pengukuran ketepatan klasifikasi SVM output Rapid Miner Studio dapat dilihat pada Tabel.4.
Tabel.4 Ketepatan Klasifikasi SVM
Ukuran Ketepatan Klasifikasi SVM
Accuracy 94.46%
Precision 46.08%
Recall 50.59%
AUC 0.900
Berdasarkan Tabel 4, menunjukkan bahwa tingkat akurasi untuk metode SVM sangat baik yaitu sebesar 94.46%. Untuk nilai precision dan recall memiliki nilai cukup, yaitu secara berurutan sebesar 46.08% dan 50.59%. Ini artinya ketepatan klasifikasi status gizi balita di Puskesmas Salissingan Provinsi Sulawesi Barat akan tepat namun masih dapat terjadi kesalahan klasifikasi. Selanjutnya, nilai AUC sebesar 0.900 yang
Berikut secara keseluruhan pada Tabel. 5 ditampilkan hasil accuracy, precision, recall, dan AUC yang telah diperoleh dari kedua metode, yaitu ANN dan SVM pada pengklasifikasian gizi balita di Puskesmas Salissingan Sulawesi Barat.
Tabel.5 Pengklasifikasian Gizi Balita
Metode Accuracy Precision Recall AUC
Artificial Neural Network (ANN) 94,82% 51.00% 55.09% 0.910
Support Vector Machine (SVM) 94,46% 46.08% 50.59% 0.900
Dari Tabel.5 diketahui bahwa nilai akurasi yang berarti ketepatan dalam pengklasifikasian status gizi balita di salah satu puskesmas (Salissingan) Provinsi Sulawesi Barat memiliki nilai yang sangat baik untuk kedua metode. Sehingga kedua metode dapat menggambarkan pengklasifikasikan status gizi di Provinsi Sulawesi Barat. Dimana tingkat akurasi pada metode ANN lebih tinggi yaitu sebesar 94,82% jika dibandingankan dengan metode SVM sebesar 94,46%. Untuk nilai Precision metode ANN memiliki nilai yang lebih tinggi, yaitu sebesar 51.00% dibandingkan dengan metode SVM, yang hanya sebesar 46.08%.
Sedangkan Recall metode ANN juga memiliki nilai yang lebih tinggi, yaitu sebesar 55,59% dibandingkan metode SVM nilai Recall nya sebesar 55.09%.
Selain itu, untuk untuk menunjukkan apakah klasifikasi salah, buruk, cukup, baik, dan sangat baik dapat dilihat pada nilai AUC. Kedua metode juga memiliki nilai AUC yang sangat baik, yaitu ANN sebesar 0. 910 dan SVM sebesar 0.900. Sehingga dapat disimpulkan bahwa metode ANN adalah metode yang terbaik pada pengklasifikasian gizi balita (gizi baik dan gizi kurang) di Puskesmas Salissingan Provinsi Sulawesi Barat, hal ini dapat dilihat dari masing-masing nilai (accuracy, precision, recall, dan AUC ) pada pengklasifikasian menggunakan metode ANN lebih tinggi dibandingkan SVM. yang telah diperolah. Ini artinya pengklasifikasian gizi balita menggunakan metode ANN pada Puskesmas Salissingan merupakan metode terbaik dalam memprediksi kelas status gizi baik dan status gizi kurang di Puskesmas Salissingan Sulawesi Barat.
KESIMPULAN
Berdasarkan analisis yang telah dilakukan, dapat disimpulkan bahwa metode metode support vector machine (SVM) dan artificial neural network (ANN) dapat menggambarkan pengklasifikasian gizi balita di Puskesmas Salissingan Provinsi Sulawesi Barat berdasarkan status gizi baik & gizi kurang. Untuk ukuran ketepatan klasifikasi pada metode ANN, yaitu accuracy sebesar 94,82%, precision sebesar 51.00%, recall sebesar 51.09%, dan AUC sebesar 0.910, sedangkan pada metode SVM, yaitu accuracy sebesar 94,46%, precision sebesar 46.08%, recall sebesar 50.59%, dan AUC sebesar 0.900. Dari hasil ukuran ketepatan klasifikasi tersebut, maka dapat disimpulkan bahwa metode ANN merupakan metode yang terbaik pada pengklasifikasian gizi balita di Puskesmas Salissingan Provinsi Sulawesi Barat. Hal ini dapat dilihat dari masing-masing ukuran ketepatan pada metode ANN lebih besar dibandingkan dengan metode SVM.
DAFTAR PUSTAKA
Burges, C. (1998). A tutorial on support vector machines for pattern recognition. Data Mining and Knowledge Discovery, 2, 2.
Badan Pusat Statistik. (2018). Prevelensi Balita Kekurangan Gizi Menurut Provinsi di Indonesia (PSG) 2016- 2018. BPS
Emerson, E. (2005). Underweight, obesity and exercise among adults with intellectual disabilities in supported accommodation in Northern England. Journal of Intellectual Disability Research, 49(2): 134–143.
Fitri, R.K., Fatimah, S., dan Rahfiludin, M.Z. (2017). Analisis Faktor-Faktor yang Mempengaruhi Status Gizi Balita Suku Anak Dalam (SAD). Jurnal Kesehatan Masyarakat Vol. 5 No. 4, ISSN: 2356-3346.
http://ejournal3.undip.ac.id/index.php/jkm.
Gorunescu, F. (2011). Data Mining; Concept, Models, and Techniques. Verlag Berlin Heidelberg: Springer.
Han, Jiawei, Micheline Kamber dan Jian Pei. (2012). Data Mining: Concepts and Techniques 3rd Edition.
Massachusetts: Elsevier Inc.
Khademi, F., Jamal, S. M., Deshpande, N., & Londhe,S. (2016). Predicting strength of recycled aggregate concrete using Artificial Neural Network, Adaptive Neuro-Fuzzy Inference System and Multiple Linear
Laksana, T.G. (2013). Perbandingan Algoritma Neural Nerwork (NN) dan Support Vector Machines (SVM) dalam Peramalan Penduduk Miskin di Indonesia. Jurnal Online ICT STMIK IKMI – Vol. 10-No. 1.
Mardi, Yuli (2014) Analisa Data Rekam Medis untuk Menentukan Penyakit Terbanyak Berdasarkan International Classification Of Disease (ICD) Menggunakan Decision Tree C4.5 (Studi Kasus : RSU.
CBMC Padang). UPI YPTK Padang.
Nisbet, Robert, John Elder, dan Gary Miner. (2009). Handbook of Statistical Analysis and Data Mining Applications. California: Elsevier Inc.
Rapid Miner. (2014). Rapidminer Studio Manual. Manual-Rapidminer Documentation.
https://docs.rapidminer.com
Sihombing, P.R. dan Hendarsin, O.P. (2017). Perbandingan Metode Artificial Neural Network (ANN) dan Support Vector Machine (SVM) untuk Klasifikasi Kinerja Perusahaan Daerah Air Minum (PDAM) di Indonesia. Jurnal Ilmu Komputer VOL. XIII No. 1 : p-ISSN: 1979-5661 e-ISSN: 2622-321X.
Tjukami, T., Prihatini, S., dan Hermina. (2011). Faktor Pembeda Prevalensi Gizi Kurang dan Buruk pada Balita di Daerah Tidak Miskin. Bul. Penelit. Kesehat, Vol. 39, No.2, 2011: 52 – 61.