Fakultas Ilmu Komputer
Universitas Brawijaya
209
Peramalan Harga Saham Menggunakan Support Vector Regression Dengan
Algoritme Genetika
Nanda Agung Putra1, Budi Darma Setiawan2, Putra Pandu Adikara3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Saham merupakan bukti investasi ke perusahaan yang mana pemegang saham berhak untuk mengklaim aset dan keuntungan perusahaan. Pemegang saham dapat memperoleh keuntungan seperti pembagian dividen dan menjual saham dengan nilai yang lebih tinggi (capital gain). Pemegang saham perlu berhati-hati dalam mengolah sahamnya karena harga saham yang terus berubah. Pemegang saham biasanya memantau pergerakan harga saham dan menganalisanya dengan cara melakukan peramalan. Support Vector Regression (SVR) merupakan metode peramalan yang handal dalam meramalkan data yang linier dan non linier. SVR juga handal dalam membuat model yang pas yaitu tidak overfit dan underfit. SVR juga memiliki kelemahan yaitu kinerja SVR sangat bergantung terhadap parameter di dalamnya. Menentukan nilai parameter yang tepat merupakan hal yang sangat penting. Salah satu algoritme optimasi yang handal adalah algoritme genetika. Algoritme genetika digunakan untuk menentukan parameter SVR yang tepat sehingga mampu menghasilkan peramalan yang baik. SVR yang dioptimasi dengan algoritme genetika mampu menghasilkan peramalan yang bagus. Hasil pengujian menunjukkan nilai kesalahan/MAPE yang diperoleh adalah 0,165% dibandingkan hanya dengan menggunakan SVR saja yaitu 1,612% dengan parameter terbaik antara lain ukuran populasi 50, banyaknya generasi 200, tingkat crossover 0,4, tingkat mutasi 0,6 , rentang nilai sigma 0,5-1 , rentang nilai epsilon 10-7-10-3, rentang nilai C 0,01-5, dan rentang nilai gamma 10-5 -10-3.
Kata kunci: Saham, SVR, Algoritme Genetika, MAPE
Abstract
Stock is a proof of investing in a corporation and stock holders have the right to claim part of corporation’s earning and assets. Stock holders can gain a lot ot of benefit such receiving dividens and selling their stocks with higher value (capital gain). Stock holders need to be careful to manage their assets because stock prices keep changing over time. Stock holders usually monitor stock prices change and analyze them by forecasting. Support Vector Regression (SVR) is one of forecasting methods that performs well in both linear and non linear data. SVR can obtained a fitted model that is neither overfit nor underfit. However SVR has one drawback. The performance of SVR is greatly affected by its parameter. So finding the right parameter value on SVR is needed to gain a good forecasting result. One of optimization algorithms is Genetic Algorithm. Genetic Algorithm is used in order to get the right value of SVR parameter. SVR that is optimized by Genetic Algorithm is capable of getting a good result in forecasting. The test shows error rate/MAPE of forecasting is 0.165% which is smaller than using SVR which is 1.612% with best parameters such as population size 50,
generation 200, crossover rate 0.4, mutation rate 0.6, range of sigma 0.5-1, range of epsilon 10-7-10-3,
range of C 0.001-5, and range of gamma 10-5-10-3.
Keywords: Stock, SVR, Genetic Algorithm, MAPE
1. PENDAHULUAN
Saham adalah tanda bukti kepemilikan suatu perusahaan. Saham juga merupakan bukti investasi atas modal/pendanaan terhadap suatu
perusahaan yang nantinya digunakan oleh perusahaan dalam menjalankan bisnis dan kegiatan operasionalnya (Dalton, 2001). Dengan memiliki saham, pemegang saham memiliki hak untuk mengklaim atas laba dan
aset perusahaan. Beberapa keuntungan yang didapat dengan memiliki saham adalah pembagian keuntungan (dividen) dari perusahaan dan menjual kembali saham dengan nilai yang lebih besar (capital gain) (Darmadji dan Fakhruddin, 2001).
Investasi saham tidak lepas dari risiko. Terdapat 2 jenis risiko yang perlu diperhatikan yaitu risiko sistematik dan risiko tidak sistematik. Risiko sistematik adalah risiko yang terjadi dalam pasar. Risiko tidak sistematik adalah risiko khusus yang terjadi dalam perusahaan. Dampak kedua risiko tersebut adalah fluktuasi harga saham dan perusahaan dapat mengalami kebangkrutan sehingga pemegang saham tidak mendapatkan keuntungan (Samsul, 2006).
Fluktuasi harga saham yang tidak mudah ditebak mengharuskan investor untuk berhati-hati dalam mengolah saham. Investor biasanya memantau pergerakan harga saham dan menganalisisnya. Salah satu strategi investasi adalah strategi berdasarkan pertumbuhan. Strategi ini diaplikasikan dengan meramalkan harga saham pada masa depan berdasarkan data pada masa lampau. Apabila peramalan tepat maka investor mendapatkan keuntungan melalui capital gain. Apabila peramalan tidak tepat akan mengakibatkan terjebaknya investor dalam anomaly momentum atau pergerakan harga saham yang selalu naik/turun (Sina, 2016).
Untuk meminimalisir kesalahan dalam melakukan peramalan dibutuhkan sebuah metode yang menghasilkan hasil peramalan yang mendekati hasil aktual. Penelitian mengenai peramalan harga saham pernah dilakukan sebelumnya oleh Ariyo, dkk (2014) menggunakan metode Auto Regressive
Integrated Moving Average (ARIMA). Harga
saham yang diprediksi adalah harga saham Nokia dan Zenith Bank. Hasil dari penelitian menunjukkan metode ARIMA bekerja dengan baik dalam peramalan jangka pendek. Kelemahan dari metode ARIMA adalah buruk dalam memprediksi data yang memiliki titik balik dan proses identifikasi model yang benar sulit dipahami dan biasanya mahal dalam komputasi serta sangat bergantung terhadap kemampuan dan pengalaman peramal.
Support Vector Regression (SVR) adalah
salah satu metode dalam meramalkan data secara non linier. Dasar dari metode ini adalah mengubah data ke dalam dimensi yang lebih tinggi berdasarkan fungsi tertentu (Christianini
dan Taylor, 2000). Salah satu penelitian yang menggunakan metode Support Vector
Regression adalah penelitian yang dilakukan
oleh Sari (2009). Penelitian yang dilakukan bertujuan untuk memprediksi bonus tahunan karyawan berdasarkan kinerja. Kriteria yang digunakan dalam menilai kinerja karyawan adalah produktifitas, inisiatif, interpersonal
skill, kualitas, job knowledge, kemandirian dan
kerjasama. Metode SVR mampu memberikan hasil yang baik. Hal ini dibuktikan dengan nilai kesalahan Mean Squared Error (MSE) dan
Mean Absolute Deviation (MAD) yang
didapatkan yaitu sebesar 8,091x10-4 dan 0,0248. Kinerja SVR sangat bergantung terhadap beberapa parameter di dalamnya. Menentukan parameter yang optimal dalam SVR merupakan hal yang sangat penting. Untuk itu diperlukan sebuah metode pengoptimalan yang handal agar mampu memperoleh parameter yang optimal dalam SVR sehingga hasil ramalan yang diperoleh menjadi lebih baik. Salah satu metode pengoptimalan yang handal adalah Algoritma Genetika. Hal ini dibuktikan dalam penelitian yang dilakukan oleh Ghorbani, dkk (2016). Penelitian bertujuan untuk memprediksi pengendapan asphaltin menggunakan SVR dengan algoritma genetika. Hasil penelitian menunjukkan bahwa SVR dengan algoritma genetika mempu memberikan performa dan hasil ramalan yang baik yaitu dengan nilai kesalahan Root Mean Square Error (RMSE) sebesar 0,1 – 0,22. Penelitian yang dilakukan Yuan (2012) mencoba untuk membandingkan metode Support Vector Regression – Algoritme genetika dengan metode lain. Hasil yang diperoleh dalam penelitian menunjukkan bahwa SVR-GA mampu memberikan hasil yang lebih baik daripada metode Least Mean Square, Backpropagation dan SVR.
Berdasarkan permasalahan yang telah dijelaskan, dilakukan penelitian untuk meramalkan harga saham menggunakan SVR yang dioptimasi dengan algoritme genetika.
2. Tinjauan Pustaka
2.1. Saham
Saham adalah sebuah bukti bahwa seorang investor menginvestasikan dana kepada suatu perusahaan. Dana yang berasal dari penerbitan saham akan digunakan oleh perusahaan untuk kegiatan operasionalnya. Kinerja perusahaan dapat dinilai dengan banyaknya saham yang dimiliki para investor. Kinerja perusahaan
tinggi apabila investor memiiki banyak saham, dan sebaliknya (Azis, Mintarti dan Nadir, 2015).
Karakteristik yang dimiliki saham antara lain: (1) limited risk, tanggung jawab pemegang saham hanya sebatas jumlah saham yang dimiliki, (2) ultimate control, fokus dan sasaran perusahaan secara kolektif ditentukan oleh para pemegang saham, (3) residual claim, menjadi pihak terakhir dalam pembagian keuntungan apabila perusahaan dibubarkan (likuidasi) (Dwimulyani, 2008). Selain itu karakteristik lain dari saham adalah mendapatkan dividen selama perusahaan mengalami keuntungan dan mampu memindahkan kepemilikan atas sahamnya (Fakhruddin dan Andianto, 2001).
2.2. Support Vector Regression
Support Vector Machine (SVM) pada
awalnya dikembangkan untuk mengatasi masalah klasifikasi namun dalam perkermbangannya SVM juga mampu mengatasi masalah regresi. SVM yang mampu mengatasi masalah regresi disebut Support
Vector Regression (SVR). SVR
mempertahankan fitur utama dalam SVM yang merupakan ciri dari algoritme batas maksimal (Chen, Lu, Yang dan Li, 2004). SVR bertujuan untuk membuat garis pemisah yang dekat dengan sebanyak-banyaknya data dan memperkecil jarak antara garis pemisah dan data.
SVR tidak hanya mampu mengatasi masalah dengan data linier namun mampu mengatasi data nyata yang bersifat non linier. Pada data non linier, SVR mengubah vektor
input ke dimensi yang lebih tinggi dengan
menggunakan fungsi kernel. SVR non linear dapat diformulasikan pada Persamaan 1.
𝑓(𝑥) = ∑ (𝛼𝑖∗− 𝛼
𝑖) (𝐾(𝑥𝑖, x) + 𝜆2) 𝑙
𝑖=1 (1)
𝛼𝑖∗ dan 𝛼𝑖 merupakan variabel Lagrange, K(xi,x) merupakan fungsi kernel dan λ merupakan variabel skalar
.
Fungsi kernel bertujuan untuk memetakan data yang awalnya non linier ke dalam ruang fitur. Dengan menggunakan fungsi kernel mampu mendeteksi hubungan linear dalam ruang fitur tersebut. Fungsi kernel yang sering digunakan dan dipakai dalam penelitian ini adalah Radial Basis Function (RBF) yang dapat diformulasikan pada Persamaan 2.
𝐾(𝑥𝑖, 𝑥𝑗) = 𝑒𝑥𝑝 (
−‖𝑥𝑖−𝑥𝑗‖2
2𝜎2 ) (2)
||xi-xj|| merupakan jarak euclidean dan σ merupakan parameter bebas.
Sequential learning diajukan untuk
menemukan nilai 𝛼𝑖∗ dan 𝛼𝑖 dengan lebih cepat. Langkah-langkah sequential learning adalah sebagai berikut:
a. Inisialisasi variabel 𝛼𝑖∗ dan 𝛼𝑖 sebanyak data.
b. Hitung matriks Hessian (R) dengan Persamaan 3.
[𝑅]𝑖𝑗 = 𝐾(𝑥𝑖, x) + 𝜆2 (3) Keterangan:
Rij = matriks Hessian
c. Untuk setiap data latih, i= 1,2,...,n lakukan Persamaan 4-8. 𝐸𝑖= 𝑦𝑖− ∑ (𝛼𝑖∗− 𝛼 𝑖)𝑅𝑖𝑗 𝑛 𝑖=1 (4) δαi*= min{max[γ(E i-ε),-αi*] ,C-αi*} (5) δαi=min{ max[γ(-Ei-ε),-αi] ,C-αi} (6) 𝛼𝑖∗= 𝛼 𝑖∗+ 𝛿𝛼𝑖∗
(7) 𝛼𝑖= 𝛼𝑖+ 𝛿𝛼𝑖
(8) Keterangan: Ei = nilai error ke-i yi = nilai aktualdata ke-i
δαi* , δαi = perubahan nilai αi* dan αi ε = epsilon
C = kompleksitas γ= laju pembelajaran
d. Proses dapat dihentikan apabila sudah mencapai iterasi maksimum atau 𝑚𝑎𝑥 |𝛿𝛼𝑖∗| < 𝜀 dan 𝑚𝑎𝑥 |𝛿𝛼𝑖| < 𝜀. Apabila salah satu syarat belum terpenuhi maka ulangi langkah c. Untuk mengetahui seberapa baik kinerja SVR maka diperlukan cara untuk mengevaluasi hasil peramalan. Salah satu cara evaluasi kinerja SVR adalah menggunakan Mean
Absolute Percentage Error (MAPE). MAPE
dapat dibangkitkan dengan Persamaan 9. 𝑀𝐴𝑃𝐸 = 100𝑛 ∑ |𝑆𝑖−𝑅𝑖
𝐴𝑖 |
𝑛
𝑖=1 (9)
S adalah hasil aktual, R adalah hasil peramalan dan n adalah banyaknya data.
2.3. Algoritme Genetika
Algoritme Genetika merupakan algoritme yang terinspirasi dari kinerja gen dan proses seleksi alam. Algoritme genetika biasanya digunakan untuk menghasilkan solusi yang terbaik dari masalah pencarian dan optimisasi.
Algoritme genetika adalah algoritme iteratif yang biasanya beroperasi dalam populasi yang konstan dan dieksekusi berdasarkan urutan tertentu. Algoritme genetika diawali dengan proses pembentukan populasi yang diinisialisasi secara acak. Kromosom terdiri dari 4 gen berupa bilangan riil yang merupakan parameter SVR yang akan dioptimasi. Parameter tersebut antara lain sigma (σ) yang mempengaruhi Gaussian kernel yang terbentuk, epsilon (ε) yang mempengaruhi batas dimana kesalahan klasifikasi dapat diabaikan, C yang mempengaruhi nilai penalti yang diberikan ketika terjadi kesalahan klasifikasi dan gamma (ɣ) yang mempengaruhi laju pembelajaran. Proses selanjutnya yaitu proses pembentukan individu baru yang didapatkan dengan melakukan crossover dan mutasi. Contoh representasi kromosom dapat dilihat pada Tabel 1.
Tabel 1 Contoh Representasi Kromosom
Individu σ ε C ɣ
I1 0,4544 14,530 1,091x10-05 0,062
I2 0,6938 68,024 8,657x10-05 0,003
Crossover merupakan operator genetika
utama. Proses ini mengombinasikan kedua gen induk untuk mengasilkan sebuah keturunan. Pada penelitian digunakan metode extended
intermediate crossover untuk menghasilkan
keturunan. Metode crossover tersebut dipilih karena mampu menghasilkan individu baru yang hampir sama dengan individu induk atau sedikit berbeda dengan individu induk.
Crossover ini dapat dibangkitkan dengan
Persamaan 10 dan 11.
𝐴1= 𝐼1+ 𝛼(𝐼2− 𝐼1) (10)
𝐴2= 𝐼2+ 𝛼(𝐼1− 𝐼2) (11) A merupakan individu anak, I adalah individu induk dan α merupakan faktor skalar dengan rentang [-d,1+d]. Contoh hasil crossover dengan alpha sebesar 0,5 dapat dilihat pada Tabel 2.
Tabel 2 Contoh Proses Crossover
Individu σ ε C ɣ
A1 0,5741 41,277 4,87x10-05 0,0325
Proses menghasilkan keturunan juga mampu diperoleh dengan mutasi. Berbeda dengan crossover,mutasi hanya memerlukan 1 buah induk untuk menghasilkan keturunan. Mutasi bekerja dengan mengubah beberapa/semua gen dalam induk untuk menghasilkan keturunan. Metode mutasi yang
digunakan dalam penelitian adalah random
mutation. Kelebihan mutasi tersebut adalah
mudah dalam implementasi namun mampu menjaga keberagaman individu dalam satu generasi. Mutasi ini dapat dibangkitkan dengan Persamaan 12.
𝐴𝑖 = 𝐼𝑖+ 𝑟(𝑚𝑎𝑥𝑖− 𝑚𝑖𝑛𝑖) (12) A merupakan individu anak, I merupakan individu induk dan r adalah bilangan acak. Contoh hasil mutasi dengan nilai r sebesar -0,0248 dapat dilihat pada Tabel 3.
Tabel 3 Contoh Hasil Mutasi
Individu σ ε C ɣ
A2 0,6714 65,537 8,41x10-05 0,001
Proses selanjutnya yaitu evaluasi. Evaluasi bertujuan untuk mengetahui seberapa baik kualitas dari solusi yang ditemukan. Proses evaluasi menggunakan fungsi fitness yang dapat dibangkitkan dengan Persamaan 13.
𝑓𝑖𝑡𝑛𝑒𝑠𝑠 = 1
1+𝑀𝐴𝑃𝐸 (13)
Proses selanjutnya yaitu proses seleksi. Seleksi bertujuan untuk menyeleksi individu-individu yang akan masuk ke generasi selanjutnya. Metode seleksi yang digunakan dalam penelitian adalah elitsm. Metode ini bekerja dengan mengurutkan semua individu berdasarkan fitness-nya dari yang terbesar hingga terkecil kemudian meloloskan individu-individu dengan fitness tertinggi sejumlah populasi ke generasi berikutnya. Kelebihan dari metode seleksi ini tetap menjaga agar individu terbaik akan selalu lolos.
Proses algoritme genetika dapat dihentikan apabila mencapai generasi maksimum, telah menghasilkan solusi yang bisa dihandalkan atau kondisi berhenti yang lebih canggih yang mampu mengindikasikan adanya konvergensi secara prematur (Affenzeler, Wagner, Winkler dan Beham, 2009).
3. MODEL EKSPERIMEN
3.1. Model Algoritme Genetika-SVR
Proses SVR yang dioptimasi dengan Algoritme Genetika diawali dengan Algoritme Genetika. Algoritme Genetika digunakan untuk memperoleh parameter SVR yang optimal. Setelah proses Algoritme Genetika selesai dan mendapatkan parameter SVR yang optimal akan dilanjutkan ke proses SVR. SVR diawali dengan proses normalisasi data dan dilanjutkan ke proses pembelajaran dengan data latih.
Proses pembelajaran akan menghasilkan model regresi yang akan digunakan dalam melakukan peramalan. Model regresi yang telah didapat akan dicoba pada data uji untuk mengetahui seberapa bagus model tersebut. Diagram alur proses Algoritme Genetika-SVR dapat dilihat pada Gambar 1.
Gambar 1 Diagram Alur Algoritme Genetika-SVR
3.2. Data Penelitian
Data yang digunakan dalam penelitian adalah data harga saham Bank BRI pada periode waktu 2015-2016 yang diambil dari Google Finance. Data terdiri dari 4 fitur yaitu
open, close, highest dan lowest namun fitur
yang dipakai dalam penelitian adalah rata-rata dari 4 fitur tersebut.
Data latih yang digunakan dalam penelitian adalah harga saham pada periode waktu 2015
sedangkan data uji yang digunakan adalah harga saham pada periode waktu 2016.
4. PENGUJIAN DAN ANALISIS
Terdapat 8 pengujian yang dilakukan dalam penelitian. Pengujian yang dilakukan antara lain jumlah populasi, banyaknya generasi, kombinasi rentang crossover dan rentang mutasi, rentang nilai SVR yang dioptimasi dan jumlah iterasi dalam SVR.
4.1. Pengujian dan Analisis Ukuran Populasi
Berdasarkan Gambar 2 dapat diketahui bahwa nilai MAPE cenderung menurun ketika ukuran populasi semakin banyak. Ukuran populasi mempengaruhi seberapa banyak solusi yang ditemukan. Populasi yang kecil akan menemukan sejumlah kecil solusi namun populasi yang besar akan menemukan lebih banyak solusi. Ukuran populasi yang terlampau besar tidak akan meningkatkan akurasi solusi namun hanya menambah waktu komputasi. Dalam masalah ini ukuran populasi yang dipilih adalah 50.
Gambar 2 Hasil Pengujian Ukuran Populasi
4.2. Pengujian dan Analisis Banyaknya Generasi
Berdasarkan Gambar 3 dapat diketahui bahwa nilai MAPE cenderung menurun ketika banyaknya generasi membesar. Generasi mempengaruhi seberapa lama proses Algoritme Genetika. Semakin besar nilai generasi semakin lama banyaknya solusi yang ditemukan. Nilai generasi yang terlampau besar hanya akan menambah waktu komputasi tanpa meningkatkan akurasi solusi yang ditemukan. Banyaknya generasi yang dipilih dalam masalah ini adalah 200 karena proses algoritme genetika sudah mengalami konvergensi.
2,772 2,779 0,788 0,785 0,572 0,572 0,572 0,572 0,572 0,572 0 1 2 3 10 20 30 40 50 60 70 80 90 100 MAP E Ukuran Populasi Mulai Cr, mr,ukuran populasi, generasi, rentang parameter
SVR
Inisialisasi
Crossover For i=1 to generasi
i Mutasi Evaluasi Seleksi Parameter SVR optimal Normalisasi Data Sequential Learning
Uji Model Regresi Hasil Ramalan, MAPE
Gambar 3 Hasil Pengujian Banyaknya Generasi
4.3. Pengujian dan Analisis Kombinasi Tingkat Crossover dan Mutasi
Gambar 4 Hasil Pengujian Kombinasi Tingkat Crossover dan Mutasi
Berdasarkan Gambar 4 dapat diketahui bahwa tingkat crossover dan mutasi cenderung stabil. Tingkat crossover mengontrol kemampuan Algoritme Genetika dalam hal eksploitasi atau proses mencari solusi terbaik menggunakan individu yang sudah diketahui agar mencapai solusi lokal yang optimal. Tingkat mutasi mengontrol kecepatan Algoritme Genetika dalam hal eksplorasi area yang baru. Nilai tingkat crossover dan mutasi yang dipilih dalam masalah ini adalah 0,4 dan 0,6.
4.4. Pengujian dan Analisis Rentang Nilai Sigma
Berdasarkan Gambar 5 dapat diketahui bahwa rentang nilai sigma yang kecil menghasilkan nilai MAPE yang bagus. Sigma mempengaruhi bagaimana pemetaan data terbentuk. Nilai sigma yang kecil akan memetakan data secara tajam. Nilai sigma yang besar akan memetakan data secara data. Nilai rentang sigma yang dipilih dalam masalah ini adalah 0.5-1.
Gambar 5 Hasil Pengujian Rentang Nilai Sigma
4.5. Pengujian dan Analisis Rentang Nilai Epsilon
Gambar 6 Hasil Pengujian Rentang Nilai Epsilon
Berdasarkan Gambar 6 dapat diketahui bahwa nilai epsilon yang kecil akan menghasilkan nilai MAPE yang bagus. Epsilon mempengaruhi batas kesalahan dapat diabaikan. Nilai epsilon yang kecil menunjukkan batas kesalahan yang ditoleransi kecil sehingga proses pembelajaran menjadi lebih lama untuk menemukan model yang cocok. Nilai rentang epsilon yang dipilih dalam masalah ini adalah 10-7-0.001
4.6. Pengujian dan Analisis Rentang Nilai C
Gambar 7 Hasil Pengujian Rentang Nilai C
Berdasarkan Gambar 7 dapat diketahui bahwa semakin besar nilai C maka semakin bagus nilai MAPE yang dihasilkan. Nilai C berpengaruh terhadap penalti yang diberikan ketika terjadi kesalahan dalam klasifikasi. Nilai rentang C yang dipilih dalam masalah ini 0,918 0,619 0,633 0,581 0,579 0,577 0,577 0,575 0,575 0,575 0,575 0,575 0 0,2 0,4 0,6 0,8 1 25 50 75 100 125 150 175 200 225 250 500 1 0 00 MAP E Banyaknya Generasi 0,5740,574 0,5710,5730,570,5710,5710,5720,5720,572 0,596 0,55 0,56 0,57 0,58 0,59 0,6 mr 1 0.90.80.70.60.50.40.30.20.1 0 cr 0 0.10.20.30.40.50.60.70.80.9 1 MAP E
Kombinasi tingkar crossover dan mutasi
8,9538,9538,9538,9539,3099,309 4,5444,544 1,6271,628 0,57 0,573 0 2 4 6 8 10 0. 00 1-0. 01 0 .0 0 1 -0 .1 0 .0 0 5 -0 .0 1 0 .0 0 5 -0 .1 0 .0 1 -0 .1 0 .0 1 -1 0 .0 5 -0 .1 0 .0 5 -1 0 .1 -1 0 .1 -5 0 .5 -1 0. 5-5 MAP E
Rentang Nilai Sigma
0,572 0,569 0,57 0,572 0,57 0,571 1,6971,915 1,329 0 0,51 1,52 2,5 M AP E
Rentang Nilai Epsilon
1,52 0,5710,5710,5690,570,5710,5710,57 0 0,5 1 1,5 2 MAP E Rentang Nilai C
adalah 0.01-5
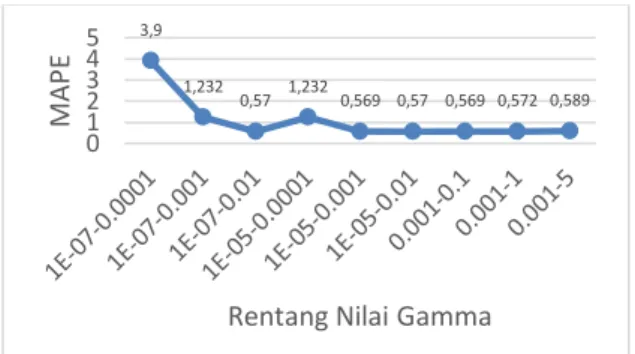
4.7. Pengujian dan Analisis Rentang Nilai Gamma
Berdasarkan Gambar 8 dapat diketahui bahwa nilai rentang gamma dengan rentang 0.00001-0.001 menghasilkan nilai MAPE terendah. Nilai gamma berpengaruh terhadap laju pembelajaran. Nilai gamma yang kecil mengakibatkan laju pembelajaran berjalan pelan dan konvergensi lama dicapai. Nilai gamma yang besar mengakibatkan laju pembelajaran berjalan dengan cepat dan memungkinkan nilai minimum tidak mampu didapatkan.
Gambar 8 Hasil Pengujian Rentang Nilai Gamma
4.8. Pengujian dan Analisis Jumlah Iterasi SVR
Berdasarkan Gambar 9 dapat diketahui bahwa nilai MAPE semakin turun dengan meningkatnya iterasi. Iterasi mempengaruhi lama proses pembelajaran dilakukan. Semakin besar iterasi maka proses pembelajaran berlangsung lama sehingga mampu menghasilkan model yang lebih tepat. Nilai iterasi yang dipilih dalam masalah ini adalah 2000.
Gambar 9 Hasil Pengujian Jumlah Iterasi SVR
5. KESIMPULAN
Berdasarkan hasil yang diperoleh dalam penelitian peramalan harga saham dengan menggunakan SVR dan algoritme genetika
mampu meramalkan harga saham secara tepat dengan nilai kesalahan/MAPE yang kecil yaitu 0,165% dibandingkan dengan hasil peramalan menggunakan SVR saja yaitu 1,612%.
6. DAFTAR PUSTAKA
Affenzeler, M., Wagner, S., Winkler, S. dan Beham, A., 2009. Genetic Algorithm and Genetic Programming: Modern Concepts
and Practical Applications. United States
of America: CRC Press.
Ariyo, A.A., Adewumi, A.O. dan Ayo, C.K., 2014. Stock Price Prediction Using the ARIMA Model. 2014 UKSim-AMSS 16th International Conference on Computer
Modelling and Simulation, [daring]
hal.106–112. Tersedia pada:
<http://ieeexplore.ieee.org/document/70460 47/>.
Azis, M., Mintarti, S. dan Nadir, M., 2015. manajemen Investasi Fundamental, Teknikal, Perilaku Investor dan Return
Saham. Deepublish.
Chen, N., Lu, W., Yang, J. dan Li, G., 2004.
Support Vector Machine in Chemistry.
Singapore: World Scientific.
Christianini, N. dan Taylor, J.S., 2000. An Introduction to Support Vector Machines
and Other Kernel-based Learning Method.
Cambridge: Cambridge University Press. Dalton, J.M., 2001. How The Stock Market
WOrks. 3 ed. United States of America:
New York Institute of Finance. Darmadji, T. dan Fakhruddin, H.M., 2001.
Pasar Modal di Indonesia. Salemba Empat.
Dwimulyani, S., 2008. Analisis Pemecahan Saham (Stock Split): Dampaknya Terhadap Likuidiyas Perdagangan Saham dan Pendapatan Perusahaan Publik Indonesia. Jurnal Informasi , Perpajakan, Akuntansi
dan Keuangan Publik, 3(1).
Fakhruddin, M. dan Andianto, S., 2001. Perangkat dan Model Analisis Investasi di
Pasar Modal. Jakarta: PT. Elex Media
Komputindo.
Ghorbani, M., Zargar, G. dan Jazayeri-rad, H., 2016. Prediction of asphaltene precipitation using support vector regression tuned with genetic algorithms. Petroleum 2, [daring] 2(3), hal.301–306. Tersedia pada:
<http://dx.doi.org/10.1016/j.petlm.2016.05. 006>. 3,9 1,232 0,57 1,232 0,569 0,57 0,569 0,572 0,589 0 1 2 3 4 5 MAP E
Rentang Nilai Gamma
0,431 0,323 0,276 0,247 0,2260,210 0,1960,1840,174 0,165 0,000 0,100 0,200 0,300 0,400 0,500 200 400 600 800 1000 1200 0041 1600 1800 2000 MAP E Iterasi
Samsul, M., 2006. Pasa Modal & Manajemen
Portofolio. Indonesia.
Sari, D.P., 2009. Analisis Performansi Support Vector Regression Dalam Memprediksi Bonus Tahunan Karyawan. J@TI Undip, IV(1), hal.17–26.
Sina, P.G., 2016. Financial Contemplation Part 2. Guepedia.
Yuan, F.-C., 2012. Parameters Optimization Using Genetic Algorithms in Support Vector Regression for Sales Volume Forecasting. Applied Mathematics, 3(October), hal.1480–1486.