i
BERAT BADAN BAYI SAAT LAHIR DI KOTA SURAKARTA MENGGUNAKAN METODE POHON REGRESI
oleh
NINA HARYATI M0107040
SKRIPSI
ditulis dan diajukan untuk memenuhi sebagian persyaratan memperoleh gelar Sarjana Sains Matematika
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SEBELAS MARET
SURAKARTA 2012
perpustakaan.uns.ac.id digilib.uns.ac.id
iii
Nina Haryati, 2012. ANALISIS FAKTOR-FAKTOR YANG MEMPENGARUHI
BERAT BADAN BAYI SAAT LAHIR DI KOTA SURAKARTA
MENGGUNAKAN METODE POHON REGRESI. Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Sebelas Maret.
Di Surakarta, kita masih sering menjumpai bayi lahir dengan Berat Badan Lahir Rendah (BBLR). Beberapa faktor yang mempengaruhi berat badan bayi saat lahir adalah usia ibu hamil, jarak kehamilan, jumlah anak yang dilahirkan, kenaikan berat badan ibu, penyakit saat kehamilan, kadar hemoglobin, frekuensi pemeriksaan kehamilan, status pekerjaan ibu dan pendidikan ibu. Dalam penelitian ini, kami membahas tentang pola hubungan antara variabel prediktor dan variabel respon menggunakan metode pohon regresi. Metode ini dipilih karena berat badan bayi saat lahir sebagai variabel respon bertipe kontinu sedangkan faktor-faktor yang berpengaruh terhadap berat badan bayi saat lahir sebagai variabel prediktor bertipe kategorik maupun kontinu.
Data secara random dibagi menjadi 2 bagian yaitu data pelatihan dan data uji dengan proporsi data pelatihan sebesar 90% dan data uji sebesar 10%. Proses ini diulang sebanyak 10 kali sehingga diperoleh 10 kelompok data percobaan. Masing-masing kelompok data digunakan untuk membentuk pohon regresi. Langkah pertama adalah penumbuhan pohon menggunakan data pelatihan. Langkah kedua adalah proses pemberhentian pembentukan pohon. Langkah ketiga adalah proses pemangkasan pohon. Langkah keempat adalah proses pemilihan pohon regresi optimal menggunakan data uji. Langkah terakhir adalah pemilihan pohon regresi optimal dari 10 kelompok data percobaan.
Berdasarkan pohon regresi optimal, terbentuk pola hubungan antara tiga variabel prediktor terhadap berat badan bayi saat lahir. Adapun tiga variabel yang membentuk pola hubungan adalah variabel usia ibu hamil, kenaikan berat badan ibu, dan status pekerjaan ibu.
Kata kunci: pohon regresi, BBLR, kontinu, kategorik
perpustakaan.uns.ac.id digilib.uns.ac.id
iv ABSTRACT
Nina Haryati, 2012. ANALYSIS OF FACTORS AFFECTING BIRTH WEIGHT BABIES IN THE CITY OF SURAKARTA USING REGRESSION TREE METHOD. Faculty of Mathematics and Natural Sciences, Sebelas Maret University.
In Surakarta, we still often see babies born with Low Birth Weight (LBW). Several factors that affect the newborn weight are maternal age, pregnancy spacing, number of children born, maternal weight gain, illness during pregnancy, hemoglobin level, frequency of prenatal care, maternal employment status and maternal education. In this research, we discussed about patterns of relationships between predictor and response variables using regression tree method. This method was chosen because the newborn weight as response variable is continuous and the factors that affect newborn weight as predictor variables are categorical or continuous.
Data were randomly divided into two parts, namely training data and test data with the proportion of 90% training data and test data by 10%. This process was repeated 10 times to get 10 data sets. Each data sets is used to perform regression tree. The first step is tree growing process using training data. The second step is stopping the tree building process. The third step is pruning the tree. The fourth step is selection of optimal regression tree using the test data. The final step is the selection of optimal regression tree of 10 data sets.
Based on optimal regression tree we can find the relationship pattern between three predictor variables and newborn weight. The three variables are maternal age, maternal weight gain, and employment status mother.
Key words: regression tree, LBW, continuous, categorical
perpustakaan.uns.ac.id digilib.uns.ac.id
v
“Dan segala sesuatu telah Kami terangkan dengan jelas” (Q.S. Al-Israa’: 12)
“Dan katakanlah: Ya Tuhanku, tambahkanlah kepadaku ilmu pengetahuan”
(Q.S. Thaahaa: 114)
perpustakaan.uns.ac.id digilib.uns.ac.id
vi
PERSEMBAHAN
Karya ini kupersembahkan kepada:
“Bapak, Ibu, Kakak dan Adik yang telah memberikan amanah, harapan dan kepercayaan untuk mewujudkan cita-citaku.
Senyum dan kebahagiaan kalian adalah semangat hidupku”
perpustakaan.uns.ac.id digilib.uns.ac.id
vii
Segala puji bagi Allah atas limpahan rahmat, hidayah serta nikmat kesehatan jasmani dan rohani sehingga penulis dapat menyelesaikan skripsi ini. Keberhasilan penulisan skripsi ini tidak lepas dari bimbingan, kerjasama, serta bantuan dari berbagai pihak sehingga dalam kesempatan ini penulis mengucapkan terima kasih kepada
1. Ibu Winita Sulandari, M.Si sebagai dosen Pembimbing I yang telah memberikan bimbingan, nasehat, kritik dan saran kepada penulis selama menyelesaikan skripsi ini.
2. Bapak Drs. Muslich, M.Si sebagai dosen Pembimbing II yang telah memberikan bimbingan, perbaikan dan saran dalam penulisan skripsi ini. 3. Ibu-ibu kader posyandu dan ibu-ibu yang memiliki balita yang telah
membantu penulis dalam mengumpulkan data.
4. Teman-teman di Jurusan Matematika FMIPA UNS angkatan 2007, teman-teman di Wisma Linaya dan Novita Anggraeni yang telah membantu dan memberi semangat kepada penulis selama menyelesaikan skripsi ini.
5. Mbak Putri dan Sony Arjanggi di ITS yang telah membantu penulis dalam mencari referensi.
Semoga skripsi ini bermanfaat bagi pihak yang berkepentingan.
Surakarta, Juli 2012
Penulis
perpustakaan.uns.ac.id digilib.uns.ac.id
viii
2.1.1 Variabel yang berpengaruh terhadap Berat Badan Bayi Saat Lahir ... 5
2.1.2 Classification And Regression Trees (CART) ... 8
2.1.3 Struktur CART ... 9
2.1.4 Pemilahan Rekursif Biner ... 10
2.1.5 Metode Pohon Regresi ... 11
2.1.6 Langkah Kerja Pembentukan Pohon Regresi ... 13
a. Aturan Pemilahan dalam Pohon Regresi ... 13
b. Aturan Penumbuhan Pohon dan Kriteria Pemilah Terbaik ... 14
perpustakaan.uns.ac.id digilib.uns.ac.id
ix
c. Pemberhentian Pemilahan Pohon ... 15
d. Pemangkasan Pohon Regresi ... 15
e. Penentuan Ukuran Pohon Regresi Optimal ... 18
f. Penduga Kesalahan Standar... 18
2.2 Kerangka Pemikiran ... 23
BAB III METODE PENELITIAN ... 24
3.1 Sumber Data ... 24
3.2 Analisis Data ... 25
BAB IV HASIL DAN PEMBAHASAN ... 27
4.1 Statistik Deskriptif ... 27
4.2 Analisis Pohon Regresi ... 31
4.2.1 Pembentukan Pohon Regresi Maksimal... 31
4.2.2 Pemangkasan Pohon Regresi Maksimal ... 37
4.2.3 Pohon Regresi Optimal ... 40
4.2.4 Pemilihan Pohon Regresi dari Kelompok Data Percobaan ... 48
BAB V PENUTUP ... 49
5.1 Kesimpulan ... 49
5.2 Saran ... 50
DAFTAR PUSTAKA ... 51
LAMPIRAN ... 53
perpustakaan.uns.ac.id digilib.uns.ac.id
x
DAFTAR TABEL
Tabel 3.1 Variabel Prediktor dari Berat Badan Bayi Saat Lahir ... 21
Tabel 4.1 Statistik Deskriptif Berat Badan Bayi Saat Lahir, Umur Ibu Hamil dan Kenaikan Berat Badan Ibu…. ... 24
Tabel 4.2 Selisih Jumlah Kuadrat Deviasi dari Semua Kemungkinan Pemilahan ... 30
Tabel 4.3 Data Berat Badan Bayi pada Simpul Terminal ... 34
Tabel 4.4 Selisih Jumlah Kuadrat Deviasi pada Proses Pemangkasan Pertama ... 36
Tabel 4.5 Data Uji ... 37
Tabel 4.6 Nilai Kesalahan Relatif Penduga Sampel Uji ... 38
Tabel 4.7 Perhitungan ... 39
Tabel 4.8 Perhitungan ... 40
Tabel 4.9 Pohon Regresi dari Kelompok Data Percobaan ... 43
perpustakaan.uns.ac.id digilib.uns.ac.id
xi
Gambar 2.1 Bentuk CART ... 9
Gambar 2.2 Proses Partisi ... 11
Gambar 2.3 Pohon Regresi T... 16
Gambar 2.4 Cabang ... 16
Gambar 2.5 Pohon Regresi ... 16
Gambar 4.1.(a) Diagram Batang Pendidikan Ibu ... 25
Gambar 4.1.(b) Diagram Batang Jumlah Anak yang Dilahirkan ... 25
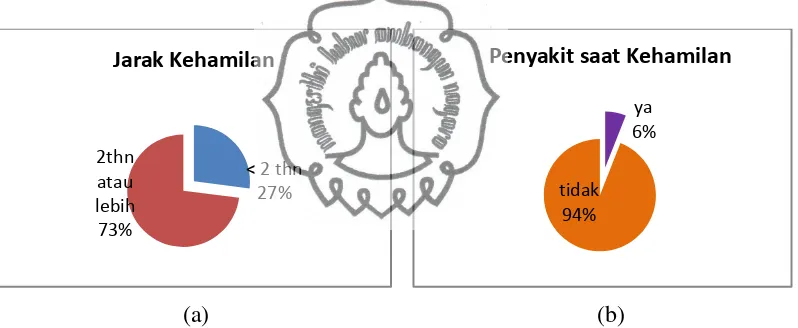
Gambar 4.2.(a) Diagram Lingkaran Jarak Kehamilan ... 26
Gambar 4.2.(b) Diagram Lingkaran Penyakit Saat Kehamilan ... 26
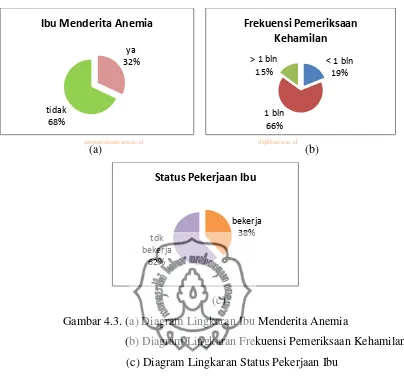
Gambar 4.3.(a) Diagram Lingkaran Ibu Menderita Anemia... 27
Gambar 4.3.(b) Diagram Lingkaran Frekuensi Pemeriksaan Kehamilan ... 27
Gambar 4.3.(c) Diagram Status Pekerjaan Ibu... 27
Gambar 4.4 Pemilah Pertama ... 32
Gambar 4.5 Model Pohon Regresi Maksimal ... 33
Gambar 4.6 Pohon Regresi Optimal ... 41
perpustakaan.uns.ac.id digilib.uns.ac.id
xii
DAFTAR NOTASI
: variabel prediktor : variabel respon
: ruang pengukuran variabel prediktor : ruang pengukuran variabel respon : simpul : harapan kuadrat kesalahan relatif
: variansi dari dan harapan kuadrat kesalahan menggunakan nilai
: kesalahan penduga sampel uji
: kesalahan relatif penduga sampel uji : pohon (biner)
: cabang dari dengan simpul akar : pohon maksimal
: jumlah kuadrat deviasi dan penduga pengganti pada simpul : jumlah kuadrat pohon regresi dan penduga pengganti dari : pemilah
: kumpulan pemilah biner : selisih jumlah kuadrat deviasi
: pendugaan respon dari pengamatan ke pada pohon ke- : kesalahan penduga sampel uji dari penduga respon
: kesalahan relatif penduga sampel uji dari penduga respon : penduga kesalahan standar dari
perpustakaan.uns.ac.id digilib.uns.ac.id
1 BAB I PENDAHULUAN
1.1Latar Belakang Masalah
Gambaran tentang status gizi bayi baru lahir dapat dilihat dari angka berat badan saat lahir. Berdasarkan laporan Dinas Kesehatan Kota Surakarta (2010) pada tahun 2009, Angka Kematian Bayi (AKB) di kota Surakarta sebesar 5,67 per seribu kelahiran hidup. Angka tersebut mengalami peningkatan jika dibandingkan dengan AKB tahun 2008 sebesar 3,63 per seribu kelahiran hidup. Seperti dikutip dalam http://bataviase.co.id salah satu penyebabnya adalah bayi dengan Berat Badan Lahir Rendah (BBLR). Menurut Dinas Kesehatan Kota Surakarta (2010) terjadi peningkatan angka BBLR pada tahun 2008 sebesar 1,30% menjadi 1,60% pada tahun 2009. Menurut Jaya (2009) dan Siza (2008) terdapat beberapa faktor yang mempengaruhi berat badan bayi saat lahir yaitu faktor internal yang terdiri dari usia ibu hamil, jarak kehamilan, paritas (jumlah anak yang dilahirkan), status gizi ibu hamil (kenaikan berat badan ibu sejak hamil sampai melahirkan), penyakit saat kehamilan, kadar hemoglobin (ibu menderita anemia atau tidak), frekuensi pemeriksaan kehamilan, serta faktor eksternal yang terdiri dari status pekerjaan ibu dan pendidikan ibu. Yuliana (2007) melakukan penelitian tentang pengaruh antara Lingkar Lengan Atas (LLA) dan kadar hemoglobin terhadap berat bayi saat lahir menggunakan regresi linear sederhana. Hasil penelitian menunjukkan bahwa ada pengaruh positif antara kadar hemoglobin terhadap berat bayi saat lahir.
Pengetahuan antara berat badan bayi saat lahir dengan faktor-faktor yang mempengaruhinya menjadi hal penting untuk menanggulangi masalah BBLR. Hubungan tersebut bukan hanya berasal dari satu faktor saja, tetapi dapat berasal dari faktor lain yang mempengaruhinya. Apabila pola hubungan itu dapat diketahui, langkah-langkah yang diambil dapat lebih terarah. Metode Classification and Regression Trees (CART) dapat digunakan untuk mengetahui pola hubungan tersebut. Metode CART merupakan pendekatan untuk regresi nonparametrik yang dikembangkan oleh Breiman et al. (1993). Metode CART mempunyai beberapa
perpustakaan.uns.ac.id digilib.uns.ac.id
2
kelebihan dibandingkan dengan metode regresi biasa yaitu variabel-variabel dalam CART tidak bergantung pada asumsi-asumsi seperti pada regresi biasa sehingga CART termasuk dalam metode statistik nonparametrik, variabel-variabel prediktor dalam CART dapat bertipe kategorik (nominal dan ordinal) maupun bertipe kontinu, interpretasi dari pohon yang dihasilkan oleh CART sangat mudah dipahami karena hasilnya berupa diagram pohon (Lewis and Roger, 2000). Metode CART terdiri dari 2 analisis yaitu pohon klasifikasi dan pohon regresi. Menurut Komalasari (2007) dan Soni (2010) CART menghasilkan pohon klasifikasi jika variabel respon yang dimiliki bertipe kategorik sedangkan jika variabel respon yang dimiliki bertipe kontinu maka CART akan menghasilkan pohon regresi. Damayanti (2011) melakukan penelitian tentang aplikasi algoritma CART yaitu metode pohon klasifikasi pada Asuransi Bumiputera untuk mengklasifikasikan data nasabah. Berdasarkan uraian tersebut, karena berat badan bayi saat lahir sebagai variabel respon yang bertipe kontinu sedangkan faktor-faktor yang mempengaruhi berat badan bayi saat lahir sebagai variabel prediktor mempunyai tipe variabel yang berbeda-beda sehingga peneliti akan membentuk pohon regresi dari berat badan bayi saat lahir dengan menggunakan metode pohon regresi untuk mengetahui pola hubungan antara variabel-variabel yang berpengaruh terhadap berat badan bayi saat lahir di kota Surakarta.
1.2Perumusan Masalah
Berdasarkan uraian dalam latar belakang masalah, dapat dirumuskan permasalahan bagaimana pola hubungan antara variabel-variabel yang berpengaruh terhadap berat badan bayi saat lahir di kota Surakarta menggunakan metode pohon regresi.
1.3Tujuan Penelitian
Berdasarkan perumusan masalah maka tujuan dari penelitian ini adalah untuk mengetahui pola hubungan antara variabel-variabel yang berpengaruh terhadap berat badan bayi saat lahir di kota Surakarta.
perpustakaan.uns.ac.id digilib.uns.ac.id
1.4 Manfaat Penelitian
Manfaat yang dapat diperoleh dari penelitian ini adalah memberikan informasi kepada pemerintah khususnya pemerintah kota Surakarta dalam mengurangi terjadinya BBLR sebagai salah satu penyebab kematian bayi.
perpustakaan.uns.ac.id digilib.uns.ac.id
4 BAB II
LANDASAN TEORI
2.1Tinjauan Pustaka
Metode CART dikembangkan oleh Breiman et al. sekitar tahun 1980. Seiring perkembangan ilmu pengetahuan, metode CART diterapkan dalam berbagai bidang penelitian. Pada tahun 2007 Komalasari melakukan penelitian di bidang pertanian untuk eksploratori penciri tingkat pendapatan usaha tani di Jawa Timur pada tahun 2004 menggunakan metode pohon regresi dengan bantuan software SPSS Answer Tree Versi 2.a. Banerjee et al. (2008) melakukan penelitian di bidang biologi menggunakan analisis CART untuk memperoleh variabel penting dari parameter yang berpengaruh terhadap fleksibilitas rata-rata protein keluarga kinase CaMK. Pada tahun 2011, Damayanti melakukan penelitian tentang aplikasi algoritma CART yaitu metode pohon klasifikasi pada Asuransi Jiwa Bersama Bumiputera untuk mengklasifikasikan data nasabah. Pada penelitian ini akan diterapkan metode pohon regresi dalam bidang kesehatan untuk mengetahui pola hubungan faktor-faktor yang berpengaruh terhadap berat badan bayi saat lahir di kota Surakarta. Penelitian sebelumnya tahun 2007 dalam bidang kesehatan Yuliana meneliti tentang pengaruh antara LLA dan kadar hemoglobin terhadap berat bayi lahir menggunakan regresi linear sederhana. Hasil penelitian menunjukkan bahwa ada pengaruh antara kadar Hb terhadap berat bayi lahir. Berat badan bayi saat lahir bukan hanya dipengaruhi oleh satu faktor saja tetapi dapat dipengaruhi oleh banyak faktor. Penggunaan analisis regresi linear sederhana dalam menganalisis faktor-faktor yang berpengaruh terhadap berat badan bayi saat lahir akan bergantung pada banyak asumsi, sehingga untuk memenuhi semua asumsi menjadi sangat sulit. Oleh karena itu, dilakukan penelitian untuk menganalisis faktor-faktor yang mempengaruhi berat badan bayi saat lahir di kota Surakarta dengan menerapkan metode pohon regresi.
perpustakaan.uns.ac.id digilib.uns.ac.id
2.1.1 Variabel yang berpengaruh terhadap Berat Badan Bayi Saat Lahir Berat badan bayi saat lahir merupakan hasil interaksi dari berbagai faktor melalui suatu proses yang berlangsung selama berada dalam kandungan. Menurut Pudjiadi (Yuliana, 2007) pada umumnya bayi dilahirkan setelah dikandung kurang lebih 40 minggu dalam rahim ibu. Secara umum berat badan bayi lahir yang normal adalah antara 3000 sampai 4000 gram, dan bila di bawah atau kurang dari 2500 gram dikatakan BBLR. Menurut Jaya (2009) dan Siza (2008) terdapat faktor-faktor yang mempengaruhi berat badan bayi saat lahir, yaitu
1. Faktor internal: a. Usia ibu hamil
Usia ibu erat kaitannya dengan berat bayi lahir. Kehamilan dibawah umur 20 tahun merupakan kehamilan beresiko tinggi 2-4 kali lebih tinggi dibandingkan dengan kehamilan pada wanita yang cukup umur. Meskipun kehamilan di bawah umur sangat beresiko tetapi kehamilan di atas usia 35 tahun juga tidak dianjurkan karena dalam proses persalinan, kehamilan di usia lebih akan menghadapi kesulitan akibat lemahnya kontraksi rahim serta sering timbul kelainan pada tulang panggul tengah. Faktor usia memegang peranan penting terhadap derajat kesehatan dan kesejahteraan ibu hamil serta bayi, maka perencanaan kehamilan yang baik dilakukan pada usia antara 20-30 tahun. b. Jarak kehamilan
Menurut anjuran yang dikeluarkan oleh Badan Koordinasi Keluarga Berencana Nasional (BKKBN), jarak kehamilan yang ideal adalah 2 tahun atau lebih, karena jarak kelahiran yang pendek akan menyebabkan seorang ibu belum cukup untuk memulihkan kondisi tubuhnya setelah melahirkan sebelumnya.
c. Paritas
Paritas secara luas mencakup jumlah kehamilan, jumlah kelahiran, dan jumlah keguguran sedangkan dalam arti sebenarnya yaitu jumlah atau banyaknya anak yang dilahirkan. Paritas dikatakan tinggi apabila seorang ibu melahirkan anak empat atau lebih. Seorang wanita yang sudah mempunyai tiga anak dan
perpustakaan.uns.ac.id digilib.uns.ac.id
6
terjadi kehamilan lagi keadaan kesehatannya mulai menurun dan sering mengalami kurang darah, terjadi pendarahan lewat jalan lahir, dan letak bayi yang sungsang ataupun melintang.
d. Status gizi ibu hamil
Menurut Almaiser (Yuliana, 2007) status gizi ibu hamil berarti keadaan tubuh sebagai akibat konsumsi makanan dan penggunaan zat-zat gizi sewaktu hamil. Status gizi ibu pada waktu pembuahan dan selama hamil sangat mempengaruhi pertumbuhan janin dalam kandungan ibu hamil, apabila gizi ibu buruk sebelum dan selama kehamilan maka akan menyebabkan BBLR. Status gizi ibu hamil dapat diketahui melalui kenaikan berat badan ibu sejak awal kehamilan sampai melahirkan. Bertambahnya umur kehamilan biasanya disertai dengan pertambahan berat badan yang sesuai. Pertambahan berat badan ibu yang tidak normal dapat menyebabkan terjadinya keguguran, prematur, BBLR, gangguan pada rahim dan perdarahan setelah melahirkan. e. Penyakit saat kehamilan
Penyakit pada saat kehamilan yang dapat mempengaruhi berat bayi lahir diantaranya adalah Diabetes Mellitus, cacar air, dan penyakit infeksi TORCH (Toxsoplasma, Rubella, Cytomegalovirus dan Herpes). Pada ibu hamil yang menderita Diabetes Mellitus biasanya akan melahirkan bayi dengan ukuran yang lebih besar dan lebih berat daripada bayi normal. Seorang ibu hamil yang menderita penyakit cacar air berarti ibu tersebut telah terserang virus Varicella Zooster. Jika tidak ditangani secara cepat dan tepat, penyakit ini mendatangkan masalah. Jika ibu hamil terjangkit cacar air akan menambah risiko pada janin yaitu kematian janin atau sindroma Varicella Kongenital berupa kelainan bentuk dan saraf yang parah sehingga bayi mengalami retardasi mental, bayi lahir prematur. Ibu dengan cacar air dapat mengalami komplikasi berupa radang otak atau radang paru bahkan dapat menyebabkan kematian. Penyakit TORCH adalah suatu istilah jenis penyakit infeksi yaitu Toxsoplasma, Rubella, Cytomegalovirus dan Herpes. Keempat jenis penyakit ini sama bahayanya bagi ibu hamil yaitu dapat mengganggu janin yang
perpustakaan.uns.ac.id digilib.uns.ac.id
dikandungnya, seperti terkena katarak mata, tuli, gangguan pertumbuhan organ tubuh, serta mengakibatkan berat bayi tidak normal.
f. Kadar hemoglobin
Hemoglobin adalah parameter yang digunakan secara luas untuk menetapkan anemia. Anemia kehamilan disebabkan karena berkurangnya cadangan besi untuk kebutuhan janin. Kadar hemoglobin sangat berpengaruh terhadap berat bayi yang dilahirkan. Ibu hamil yang terserang anemia karena hemoglobin yang rendah dapat membahayakan ibu hamil dan juga mengganggu pertumbuhan dan perkembangan serta dapat membahayakan jiwa janin. g. Frekuensi pemeriksaan kehamilan
Pemeriksaan kehamilan harus dilakukan secara berkala. Pemeriksaan kehamilan bertujuan untuk mengetahui dan mengidentifikasi masalah yang timbul selama kehamilan, sehingga kesehatan selama kehamilan dapat dipelihara dan yang terpenting ibu dan bayi dalam kandungan akan baik dan sehat sampai saat persalinan. Masalah gizi dan kesehatan pada ibu hamil dapat ditanggulangi dengan pemeriksaan kehamilan yang rutin setiap satu bulan sekali sehingga gangguan/kelainan pada ibu hamil dan bayi yang dikandung dapat segera ditangani oleh tenaga kesehatan.
2. Faktor eksternal:
a. Status pekerjaan ibu
Pekerjaan fisik banyak dihubungkan dengan peranan seorang ibu yang mempunyai pekerjaan tambahan diluar pekerjaan rumah tangga dalam upaya meningkatkan pendapatan keluarga. Beratnya pekerjaan ibu selama kehamilan dapat menimbulkan terjadinya prematuritas karena ibu tidak dapat beristirahat dan hal tersebut dapat mempengaruhi janin yang sedang dikandung. Ibu yang bekerja cenderung memiliki sedikit waktu istirahat sehingga berisiko terjadinya komplikasi kehamilan, seperti terlepasnya plasenta yang secara langsung berhubungan dengan BBLR (Sistiarani, 2008).
perpustakaan.uns.ac.id digilib.uns.ac.id
8
b. Pendidikan ibu
Pendidikan mempengaruhi kehamilan khususnya terhadap kejadian bayi dengan berat badan lahir rendah. Hal ini dikaitkan dengan pengetahuan ibu dalam memelihara kondisi kehamilan serta upaya mendapatkan pelayanan dan pemeriksaan kesehatan selama kehamilan (Sistiarani, 2008). Seorang ibu hamil dengan tingkat pendidikan yang lebih tinggi akan lebih mudah meyerap informasi dan menerapkannya dalam sikap dan perilaku sehari-hari, khususnya dalam hal kesehatan dan gizi.
Pengetahuan antara berat badan bayi saat lahir dengan faktor-faktor yang mempengaruhinya menjadi hal penting untuk menanggulangi masalah BBLR. Metode CART yaitu metode pohon regresi dapat digunakan untuk mengetahui pola hubungan tersebut.
2.1.2 Classification and Regression Trees (CART)
CART adalah salah satu metode dari salah satu teknik eksplorasi data yaitu teknik pohon keputusan. Menurut Breiman et al. (1993) CART merupakan metode statistik nonparametrik yang dikembangkan untuk topik analisis klasifikasi, baik untuk variabel respon kategorik maupun kontinu. Metode CART terdiri dari dua analisis yaitu pohon klasifikasi dan pohon regresi. Menurut Komalasari (2007) dan Soni (2010), CART menghasilkan pohon klasifikasi jika variabel respon yang dimiliki bertipe kategorik sedangkan jika variabel respon yang dimiliki bertipe kontinu maka CART akan menghasilkan pohon regresi.
Menurut Lewis (2000) beberapa keunggulan CART dibandingkan dengan metode statistik yang lain (khususnya parametrik) adalah
1. variabel-variabel dalam CART tidak bergantung pada asumsi-asumsi seperti pada regresi biasa, sehingga CART termasuk dalam metode statistik nonparametrik, 2. variabel-variabel prediktor dalam CART dapat bertipe kategorik (nominal dan
ordinal) maupun bertipe kontinu,
3. interpretasi dari pohon yang dihasilkan oleh CART sangat mudah dipahami karena hasilnya berupa diagram pohon.
perpustakaan.uns.ac.id digilib.uns.ac.id
2.1.3 Struktur CART
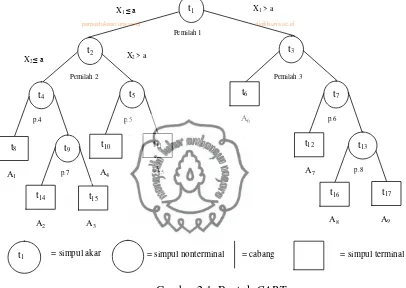
Metode CART termasuk dalam anggota analisis klasifikasi yang disebut pohon keputusan karena proses analisis dari CART digambarkan dalam bentuk atau struktur yang menyerupai sebuah pohon, lebih tepatnya pohon klasifikasi yang berbentuk biner. Adapun bentuk CART digambarkan pada Gambar 2.1 berikut
Gambar 2.1. Bentuk CART
Keterangan Gambar 2.1:
1. Simpul akar digambarkan dengan lingkaran. Merupakan simpul internal paling awal (paling atas) dan tempat inisialisasi data pelatihan yang dimiliki.
2. Cabang digambarkan dengan 2 garis lurus yang merupakan cabang dari simpul akar. Cabang merupakan tempat kriteria pemilahan dari masing-masing simpul internal. Sebagai contoh: kriteria pemilahan pertama pada cabang kiri adalah
dan cabang kanan adalah .
10
pemilahan tertentu. Sebagai contoh: objek-objek yang berada dalam simpul internal merupakan himpunan bagian dari objek-objek yang berada dalam simpul internal yang memenuhi kriteria pemilahan .
4. Simpul akhir atau simpul terminal, digambarkan dengan persegi. Merupakan simpul tempat diprediksikannya sebuah objek pada kelas tertentu. Sebagai contoh, jika ada beberapa objek yang masuk dalam simpul akhir , maka objek-objek tersebut akan dimasukkan ke dalam kelas .
5. Simpul dan merupakan simpul anak dari simpul sedangkan simpul merupakan simpul anak dari simpul akar . Begitu juga sebaliknya simpul akar
merupakan simpul induk untuk simpul dan simpul , simpul merupakan simpul induk untuk simpul dan , sedangkan simpul merupakan simpul induk untuk simpul dan , dan seterusnya.
2.1.4 Pemilahan Rekursif Biner
Teknik atau proses kerja dari CART dalam membuat sebuah pohon klasifikasi dikenal dengan istilah pemilahan rekursif biner (Binary Recursive Patitioning). Proses disebut biner karena setiap simpul induk akan selalu mengalami pemilahan ke dalam tepat dua simpul anak. Sedangkan rekursif berarti bahwa proses pemilahan tersebut akan diulang kembali pada setiap simpul anak hasil pemilahan terdahulu, sehingga simpul anak tersebut sekarang menjadi simpul induk. Proses pemilahan akan terus dilakukan sampai tidak ada kesempatan lagi untuk melakukan pemilahan berikutnya. Dan istilah pemilahan berarti bahwa data pelatihan yang dimiliki dipecah ke dalam bagian-bagian atau partisi-partisi yang lebih kecil.
Kriteria pemecahan didasarkan pada nilai-nilai dari variabel prediktor yang dimiliki. Misal dimiliki variabel yang bertipe kontinu dan variabel-variabel prediktor . Proses pemilahan rekursif biner dapat diilustrasikan sebagai proses pembagian dari ruang berdimensi dari variabel-variabel prediktor ke dalam partisi-partisi yang berbentuk persegi panjang dan tidak saling bertumpang tindih yaitu dengan membagi ruang berdimensi dari variabel-variabel prediktor ke dalam beberapa partisi dimana masing-masing partisi berisi objek-objek yang
perpustakaan.uns.ac.id digilib.uns.ac.id
homogen. Maksud homogen adalah objek-objek tersebut merupakan anggota satu kelas yang sama walaupun pada kenyataannya secara teori tidak mudah diperoleh. Proses pemilahan akan berlanjut sampai didapat pohon yang paling besar atau maksimal (proses pemilahan tidak bisa dilakukan lagi).
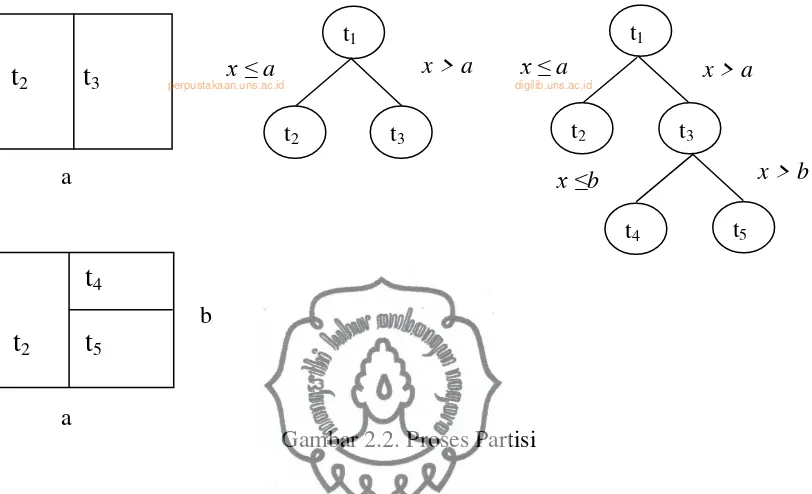
Gambar 2.2. Proses Partisi
Untuk memperjelas proses partisi, akan diberikan contoh pemilahan yaitu pada Gambar 2.2 terlihat proses partisi simpul dipilah dengan kriteria pemilahan dan . Pemilahan yang dihasilkan adalah simpul akibat dari kriteria
sedangkan simpul terbentuk akibat kriteria pemilahan . Kemudian proses partisi berlanjut pada simpul , dengan kriteria pemilahan dan . Simpul terbentuk karena memenuhi kriteria dan simpul terbentuk karena kriteria
.
2.1.5 Metode Pohon Regresi
Dalam regresi, suatu objek terdiri dari data dimana merupakan nilai yang berada dalam ruang pengukuran dan adalah angka bernilai riil yang berada dalam ruang pengukuran . Variabel biasa disebut sebagai variabel respon sedangkan variabel disebut sebagai variabel prediktor. Aturan prediksi atau
12
pendugaan respon adalah fungsi yang ditentukan pada dan menghasilkan nilai riil. Jadi, adalah fungsi dari yang bernilai riil
Metode pohon regresi dalam CART merupakan istilah umum dalam pembentukan penduga respon yang berasal dari data pelatihan . Pembentukan penduga respon memiliki dua tujuan, yaitu (1) untuk memprediksi variabel respon secara tepat dan teliti yang berhubungan dengan data yang akan datang (2) untuk mengetahui hubungan struktural antara variabel respon dan variabel prediktor.
Jika terdapat data pelatihan yang terdiri dari objek
digunakan untuk membentuk penduga respon dan terdapat sebanyak data uji maka ketepatan dapat diukur dengan rata-rata kuadrat kesalahan (mean squared error), yaitu
dengan sebagai penduga respon dari .
Definisi 2.1. (Breiman et al., 1993) Rata-rata kuadrat kesalahan dari penduga respon didefinisikan sebagai
artinya adalah harapan kuadrat kesalahan menggunakan sebagai penduga respon .
Definisi 2.2. (Breiman et.al., 1993) Rata-rata kuadrat kesalahan relatif pada sebagai penduga respon adalah
dimana adalah penduga respon untuk jika nilai tidak diketahui dan adalah variansi dari serta merupakan rata-rata kuadrat kesalahan menggunakan nilai .
Jika rata-rata dan variansi dari data uji masing-masing adalah
dan maka penduga pengganti untuk adalah
dimana adalah penduga pengganti rata-rata kuadrat kesalahan
perpustakaan.uns.ac.id digilib.uns.ac.id
relatif, adalah penduga pengganti untuk , dan adalah rata-rata kuadrat kesalahan dari data uji. Rumus kesalahan relatif penduga sampel uji untuk
adalah
dengan rumus kesalahan penduga sampel uji untuk adalah
(Breiman et. al., 1993).
2.1.6 Langkah Kerja Pembentukan Pohon Regresi
Menurut Lewis (2000) pada dasarnya dalam membuat sebuah pohon regresi, CART bekerja dalam empat langkah utama. Langkah pertama adalah pembentukan pohon regresi melalui proses pemilahan simpul yaitu proses pemilahan simpul induk menjadi dua buah simpul anak melalui aturan pemilahan tertentu dan dilakukan secara berulang-ulang. Langkah kedua adalah proses pemberhentian pembentukan pohon regresi. Pada tahap ini pohon maksimal (Tmax) telah terbentuk. Langkah ketiga adalah proses pemangkasan pohon menjadi pohon yang lebih kecil . Selanjutnya langkah terakhir adalah proses pemilihan pohon regresi optimal. Berikut ini dijelaskan langkah kerja pembentukan pohon regresi.
a. Aturan Pemilahan dalam Pohon Regresi
Tahapan pemilahan seperti dijelaskan oleh Komalasari (2007) sebagai berikut: 1. Semua kemungkinan pemilahan ditentukan dari setiap variabel prediktor. Tiap
pemilahan tergantung pada nilai yang berasal dari satu variabel prediktor. Misal terdapat variabel prediktor sebanyak . Untuk variabel kontinu dengan adalah jenis variabel prediktor, pemilahan yang diperbolehkan adalah dan dimana adalah nilai tengah antara dua nilai amatan variabel secara berurutan. Jika mempunyai sebanyak nilai yang berbeda maka akan terdapat pemilahan.
perpustakaan.uns.ac.id digilib.uns.ac.id
14
2. Pada variabel kategorik pemilahan yang terjadi berasal dari semua kemungkinan pemilahan berdasarkan terbentuknya dua anak gugus yang saling lepas (disjoint). Jika adalah variabel kategorik nominal dengan kategori, maka akan ada pemilahan, sedangkan jika adalah variabel kategorik ordinal maka akan terdapat pemilahan.
b. Aturan Penumbuhan Pohon dan Kriteria Pemilah Terbaik Proses pemilahan dilakukan pada tiap simpul dengan cara sebagai berikut. 1. semua kemungkinan pemilahan dicari pada setiap variabel prediktor (Timofeev,
2004),
2. pemilah terbaik dipilih dari masing-masing pemilahan terbaik yang ada. Pemilah terbaik dihitung berdasarkan selisih jumlah kuadrat deviasi dari masing-masing simpul dengan simpul pemilahnya. Selisih terbesar akan dijadikan sebagai pemilah terbaik.
Jumlah kuadrat deviasi digunakan sebagai kriteria kehomogenan pada tiap-tiap simpul . Jumlah kuadrat deviasi di dalam simpul adalah
dengan dimana dalam suatu simpul , nilai adalah nilai individu variabel respon dalam simpul , nilai adalah nilai individu variabel prediktor yang berada dalam simpul , nilai adalah nilai rata-rata untuk semua data dalam simpul , dan adalah jumlah data yang berada dalam simpul (Breiman et al., 1993).
Definisi 2.3. (Breiman et al., 1993) Pemilah terbaik dari simpul adalah pemilah
pada yang memaksimumkan jumlah kuadrat pohon regresi .
Setiap pemilah dari menjadi dan maka
Pemilihan pemilah terbaik menjadi sebuah pemilah menyebabkan
perpustakaan.uns.ac.id digilib.uns.ac.id
yaitu selisih jumlah kuadrat deviasi terbesar yang dijadikan pemilah terbaik dimana adalah kumpulan pemilah biner, dan masing-masing adalah simpul anak kiri dan simpul anak kanan.
c. Pemberhentian Pemilahan Pohon
Proses pembentukan pohon regresi berhenti apabila sudah tidak dimungkinkan lagi dilakukan proses pemilahan. Awalnya dibentuk pohon yang besar kemudian dilakukan proses pemilahan untuk meminimumkan . Pemilahan berhenti apabila tidak terdapat lagi penurunan keheterogenan atau semua nilai yang ada pada sebuah simpul adalah sama (homogen), ukuran simpul induk minimum 10 (Steinberg and Colla, 1998) yaitu ukuran minimum dimana simpul tidak akan dipilah, hanya terdapat satu pengamatan pada tiap simpul anak atau adanya batasan minimum serta adanya batasan jumlah level atau tingkat kedalaman pohon maksimal (Breiman et al., 1993). Pemilahan yang akan menghasilkan simpul anak yang lebih kecil tidak dipertimbangkan. Penambahan simpul induk yang diperbolehkan dan ukuran simpul anak digunakan untuk mengatur atau membatasi pertumbuhan pohon (Steinberg and Colla, 1998). Simpul-simpul yang tidak mengalami pemilahan lagi akan menjadi simpul terminal atau simpul akhir. Pohon regresi yang terbentuk sebagai hasil dari proses ini dinamakan pohon maksimal .
d. Pemangkasan Pohon Regresi
Pohon yang dibentuk dengan aturan pemilahan dan aturan pembentukan berukuran sangat besar. Hal ini karena aturan pemberhentian yang digunakan hanya berdasarkan banyaknya data pada simpul akhir atau besarnya peningkatan kehomogenan. Oleh karena itu, pemangkasan pohon dilakukan untuk mendapatkan pohon akhir yang lebih sederhana. Pemangkasan pohon dilakukan dengan memangkas menjadi beberapa pohon regresi yang ukurannya lebih kecil (sub pohon).
Sebuah simpul disebut descendan (anak) dari simpul dan simpul disebut ancestor dari simpul jika kedua simpul ini bisa dihubungkan oleh jalur-jalur yang
perpustakaan.uns.ac.id digilib.uns.ac.id
16
Definisi 2.4. (Breiman et al., 1993) Suatu cabang dari dengan simpul akar terdiri dari simpul itu sendiri dengan semua descendant dari dalam .
Sebagai contoh pada Gambar 2.4 cabang terdiri dari simpul dan descendant
dari yaitu dan .
Definisi 2.5. (Breiman et al., 1993) Pemangkasan sebuah cabang dari pohon akan menghasilkan semua descendant dari kecuali simpul akarnya ( itu sendiri). Sebagai contoh pada Gambar 2.5 pohon regresi adalah hasil pemangkasan dari simpul . Jika pemangkasan terjadi pada simpul maka descendant dari yaitu dan dipangkas kecuali simpul akarnya yaitu simpul itu sendiri.
Definisi 2.6. (Breiman et al., 1993) Jika diperoleh dari sebagai hasil dari pemangkasan suatu cabang, maka disebut pruned subtree dari dan dinotasikan
dengan . Sebagai catatan dan memiliki simpul akar yang sama.
Sebagai contoh gambar pohon regresi menunjukkan pruned subtree.
Proses pemangkasan pohon dimulai dengan mengambil yang merupakan simpul anak kanan dan yang merupakan simpul anak kiri dari yang dihasilkan dari simpul induk . Jika diperoleh dua simpul anak dan simpul induk pada persamaan (2.3) berjumlah 0 atau maka simpul anak dan tersebut dipangkas. Hasilnya seperti pada persamaan (2.4) yaitu pohon yang memenuhi kriteria . Inti dari pemangkasan adalah pemotongan hubungan terlemah (weakest-link cutting) pada pohon regresi (Breiman et al., 1993). Jika pada pohon regresi tidak terpenuhi maka pemangkasan dimulai dari pohon yang memenuhi . Proses pemangkasan diulang sampai tidak ada lagi pemangkasan yang mungkin dan diperoleh urutan sebagai berikut
dimana dengan .
perpustakaan.uns.ac.id digilib.uns.ac.id
18
e. Penentuan Ukuran Pohon Regresi Optimal
Pohon regresi yang terbentuk dapat berukuran besar dan kompleks dalam menggambarkan struktur data. Sehingga perlu dilakukan suatu pemangkasan pohon untuk mendapatkan pohon akhir yang lebih sederhana. Pemangkasan dilakukan dengan memangkas bagian pohon yang kurang penting sehingga didapat pohon optimal. Pemangkasan yang digunakan adalah dengan membagi data menjadi data pelatihan dan data uji. Proporsi pembagian pohon data pelatihan dan data uji ditentukan sendiri oleh peneliti karena tidak ada aturan dalam membagi data. Proses pemangkasan pohon yang terjadi adalah dengan membangun pohon menggunakan data pelatihan kemudian menggunakan pohon yang terbentuk untuk sampel data uji.
Menurut Breiman et al. (1993) cara yang digunakan untuk menduga tingkat kesalahan prediksi dari suatu model pohon regresi adalah dengan menggunakan nilai kesalahan penduga sampel uji, data pengamatan dibagi dua secara acak menjadi data pelatihan dan data uji . Data pelatihan digunakan untuk membentuk urutan
dari pemangkasan pohon. Rumus kesalahan penduga sampel uji adalah
dimana adalah jumlah data uji, adalah nilai individu variabel prediktor yang berada dalam data uji, adalah nilai individu variabel respon yang berada dalam data uji, dan adalah dugaan respon dari pengamatan ke pada pohon ke .
f. Penduga Kesalahan Standar
Penduga kesalahan standar adalah ukuran dari ketidakpastian di sekitar tingkat kesalahan sebenarnya (sampel uji) dari pohon regresi saat berhadapan dengan data baru. Jadi, nilai penduga kesalahan standar memberikan gambaran ketidakpastian dari penduga tingkat kesalahan.
Berdasarkan Definisi (2.2) (Breiman et al., 1993) yaitu sebagai dasar penduga respon untuk jika nilai tidak diketahui dan yaitu variansi dari yang merupakan rata-rata kuadrat kesalahan menggunakan nilai
perpustakaan.uns.ac.id digilib.uns.ac.id
yang tetap sebagai penduga respon . Jika ditentukan dan atau maka kesalahan relatif penduga sampel uji pada pohon ke- seperti pada persamaan (2.1) dapat dituliskan menggunakan persamaan (2.2) menjadi
persamaan (2.5) merupakan penduga rata-rata kuadrat kesalahan dari
Pada penduga kesalahan standar, nilai dapat diganti dengan dalam menentukan kesalahan standar dari . Untuk menentukan kesalahan standar dari
, dianggap adalah tetap dan persamaan (2.6) dapat ditulis dalam bentuk
dengan dan adalah penduga yang tetap untuk dan dan adalah penduga yang tetap untuk . Variansi dari sama seperti variansi dari
yaitu
perpustakaan.uns.ac.id digilib.uns.ac.id
20
dimana , dan untuk .
Misal data pelatihan sebanyak dipilih secara independen dari suatu distribusi probabilitas tertentu dan anggap bahwa data pelatihan digunakan untuk membentuk penduga respon . Data uji sebanyak dipilih secara independen dari distribusi
yang sama dinotasikan dengan . Setiap pasangan
memiliki distribusi yang sama, sehingga variansi dari setiap pasangan sama dengan variansi dari pasangan pertama.
menggunakan estimasi momen sampel
sehingga
perpustakaan.uns.ac.id digilib.uns.ac.id
diketahui bahwa
dengan demikian dapat diestimasi dengan
Diketahui bahwa
menggunakan estimasi momen sampel
sehingga
perpustakaan.uns.ac.id digilib.uns.ac.id
22
diperoleh
dengan demikian dapat diestimasi dengan
Diketahui bahwa
diperoleh
perpustakaan.uns.ac.id digilib.uns.ac.id
dengan demikian dapat diestimasi dengan
Rumus kesalahan standar dari diperoleh menggunakan persamaan (2.7), (2.8) dan (2.9) sebagai berikut
2.2.Kerangka Pemikiran
Berdasarkan tinjauan pustaka, dapat dibuat kerangka pemikiran yaitu metode CART merupakan salah satu metode eksplorasi nonparametrik yang digunakan untuk melihat hubungan antara variabel respon dengan variabel-variabel prediktor dengan tipe variabel yang berbeda-beda. Metode CART terdiri dari dua analisis yaitu pohon klasifikasi dan pohon regresi. Jika variabel respon yang dimiliki bertipe kategorik maka CART menghasilkan pohon klasifikasi. Jika variabel respon yang dimiliki bertipe kontinu maka CART menghasilkan pohon regresi. Berat badan bayi merupakan variabel respon yang bertipe kontinu dan faktor-faktor yang mempengaruhi berat badan bayi merupakan variabel prediktor yang memiliki tipe variabel berbeda-beda sehingga penelitian tentang pola hubungan antara berat badan bayi yang lahir di Kota Surakarta dengan faktor-faktor yang mempengaruhinya dapat dianalisis dengan metode pohon regresi.
perpustakaan.uns.ac.id digilib.uns.ac.id
24 BAB III
METODE PENELITIAN
Metode penelitian yang digunakan pada penelitian ini adalah studi kasus, yaitu membentuk pohon regresi dari berat badan bayi saat lahir di kota Surakarta dengan faktor-faktor yang mempengaruhinya menggunakan metode pohon regresi.
3.1 Sumber Data
Data yang digunakan dalam penelitian ini berupa data primer yang diperoleh dengan menyebarkan kuesioner kepada ibu-ibu yang memiliki balita di kota Surakarta. Sampel yang digunakan sebanyak 100 responden dari 5 kecamatan yang berada di kota Surakarta, yaitu Kecamatan Banjarsari, Kecamatan Jebres, Kecamatan Pasar Kliwon, Kecamatan Serengan dan Kecamatan Laweyan.
Langkah-langkah yang dilakukan dalam mengumpulkan data meliputi: 1. Pengambilan sampel
a. Pemilihan variabel-variabel yang akan diteliti.
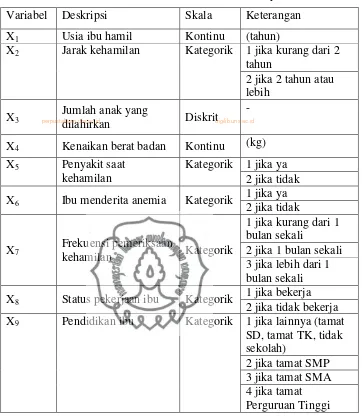
Variabel yang digunakan meliputi variabel respon (Y) berskala kontinu yaitu berat badan bayi saat lahir (kilogram) di Kota Surakarta dan variabel prediktor (X) seperti pada Tabel 1.
b. Pemilihan teknik sampling, ukuran sampling dan unit-unit sampling.
Teknik yang digunakan adalah sampling kluster dengan semua kecamatan di kota Surakarta sebagai klusternya. Setiap kecamatan dipilih dua kelurahan secara random sederhana. Masing-masing kelurahan diambil 10 sampel. Jumlah sampelnya adalah 100. Unit sampel adalah ibu-ibu yang memiliki balita.
c. Perancangan kuesioner.
Kuesioner yang digunakan dalam penelitian ini dapat dilihat pada Lampiran 1. d. Pengumpulan data primer di kota Surakarta dengan menyebar kuesioner
sebanyak 100 kepada ibu-ibu yang memiliki balita.
perpustakaan.uns.ac.id digilib.uns.ac.id
Tabel 1. Variabel Prediktor dari Berat Badan Bayi Saat Lahir
Variabel Deskripsi Skala Keterangan
X1 Usia ibu hamil Kontinu (tahun)
X2 Jarak kehamilan Kategorik 1 jika kurang dari 2
tahun X6 Ibu menderita anemia Kategorik
1 jika ya X8 Status pekerjaan ibu Kategorik
1 jika bekerja 2 jika tidak bekerja X9 Pendidikan ibu Kategorik 1 jika lainnya (tamat
SD, tamat TK, tidak
Langkah-langkah dalam menyelesaikan analisis data sebagai berikut: 1. Pembentukan statistik deskriptif dari masing-masing variabel.
2. Pembagaian data menjadi 2 bagian yaitu data pelatihan dan data uji. Proporsi pembagian data pelatihan dan data uji ditentukan sendiri oleh peneliti karena tidak ada aturan dalam membagi data. Peneliti menggunakan data dengan proporsi data pelatihan 90% dipilih secara random sebagai metode pemangkasan karena ukuran sampel yang besar, sehingga diperoleh pembagian data pelatihan
perpustakaan.uns.ac.id digilib.uns.ac.id
26
sebanyak 90 data dan data uji sebanyak 10 data. Pemilihan data secara random dilakukan sebanyak 10 kali sehingga diperoleh 10 kelompok data percobaan (dataset).
3. Pembentukan pohon regresi dengan algoritma CART pada 10 kelompok data percobaan menggunakan Software Salford Predictive Miner CART versi 4.0. dengan tahapan sebagai berikut:
a. Pembentukan pohon regresi dengan aturan pemilahan secara biner menggunakan data pelatihan dimana selisih jumlah kuadrat deviasi terbesar digunakan untuk memilah sebuah simpul.
b. Proses pemberhentian pembuatan atau pembentukan pohon regresi. Proses pemilahan berhenti jika tidak terdapat lagi penurunan keheterogenan yang berarti atau semua nilai yang ada pada sebuah simpul adalah sama (homogen), ukuran simpul induk minimum 10 yaitu ukuran minimum dimana simpul tidak akan dipilah (Steinberg, 1998), atau hanya terdapat satu pengamatan pada tiap simpul anak (Breiman, 1993).
c. Pemangkasan pohon regresi. Pemangkasan dilakukan jika dua simpul anak dan simpul induk pada persamaan (2.3) berjumlah 0. Jika tidak dipenuhi maka pemangkasan dimulai dari pohon yang memenuhi
dan berhenti sampai tidak dimungkinkan lagi proses pemangkasan.
d. Pemilihan pohon regresi optimal dengan menggunakan data uji yaitu dipilih sub pohon yang mempunyai nilai kesalahan penduga sampel uji terkecil. 4. Pemilihan pohon regresi optimal dari pohon regresi yang dibentuk oleh 10
kelompok data percobaan.
perpustakaan.uns.ac.id digilib.uns.ac.id
27 BAB IV
HASIL DAN PEMBAHASAN
Pada bagian ini dibahas tentang deskripsi variabel penelitian dan pembentukan pohon regresi dari berat badan bayi saat lahir di kota Surakarta.
4.1 Statistik Deskriptif
Statistik deskriptif digunakan untuk melihat homogen atau tidaknya data yang digunakan sebagai pemilah dalam pembentukan pohon regresi. Data yang digunakan dalam pembentukan pohon regresi adalah data berat badan bayi saat lahir di kota Surakarta dan faktor-faktor yang mempengaruhinya. Jumlah data yang digunakan sebanyak 100 data yang diperoleh dengan menyebarkan kuesioner. Data terdiri dari 9 variabel prediktor dan 1 variabel respon yang terdapat dalam Lampiran 2.
Informasi mengenai gambaran secara umum terhadap berat badan bayi saat lahir, umur ibu hamil dan kenaikan berat badan ibu dapat dilihat melalui statistik deskriptif berikut.
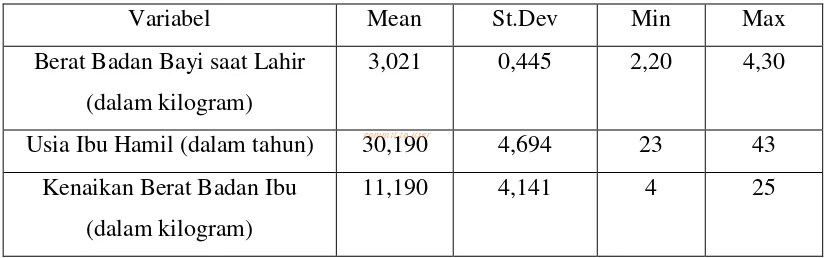
Tabel 4.1. Statistik Deskriptif Berat Badan Bayi Saat Lahir, Umur Ibu Hamil, dan Kenaikan Berat Badan Ibu
Variabel Mean St.Dev Min Max
Berat Badan Bayi saat Lahir (dalam kilogram) 3,021 kilogram, standar deviasi sebesar 0,445 dengan berat badan bayi paling rendah adalah 2,20 kilogram dan berat badan bayi paling tinggi adalah 4,30 kilogram. Rata-rata usia ibu saat hamil adalah 30,190 tahun dengan standar deviasi sebesar 4,694 dan
perpustakaan.uns.ac.id digilib.uns.ac.id
28
usia ibu saat hamil paling rendah adalah 23 tahun serta paling tinggi adalah 43 tahun. Rata-rata kenaikan berat badan ibu adalah 11,190 kilogram dengan standar deviasi sebesar 4,141 dan kenaikan berat badan ibu paling rendah adalah 4 kilogram serta paling tinggi adalah 25 kilogram.
Variabel pendidikan ibu dibedakan menjadi 4 kategori yaitu tamat SMP, tamat SMA, tamat Perguruan Tinggi dan pendidikan ibu yang tidak termasuk ke dalam 3 kategori sebelumnya, masuk ke dalam kategori lainnya. Variabel jumlah anak dibedakan menjadi 4 kategori yaitu jumlah anak 2, 3, 4 dan 5. Deskripsi pendidikan ibu dan jumlah anak disajikan dengan diagram batang sebagai berikut.
(a) (b)
Gambar 4.1. (a) Diagram Batang Pendidikan Ibu
(b) Diagram Batang Jumlah Anak yang Dilahirkan
Pada Gambar 4.1.(a) terlihat bahwa tingkat pendidikan ibu paling banyak adalah tamat SMA, yaitu ada sebanyak 56 orang. Pendidikan ibu paling sedikit adalah tamat Perguruan Tinggi dan lainnya, yaitu masing-masing sebesar 13 orang. Pada Gambar 4.1.(b) terlihat bahwa sebanyak 67 orang mempunyai anak yang dilahirkan berjumlah 2 anak, sebanyak 23 orang mempunyai anak yang dilahirkan berjumlah 3 anak, sebanyak 8 orang mempunyai anak yang dilahirkan berjumlah 4 anak, dan sebanyak 2 orang mempunyai anak yang dilahirkan berjumlah 5 anak.
dibedakan menjadi 2 kategori yaitu pernah menderita dan tidak pernah menderita. Deskripsi variabel jarak kehamilan dan penyakit ibu saat hamil disajikan dengan diagram lingkaran seperti pada Gambar 4.2.
Pada Gambar 4.2.(a) terlihat bahwa ada sebanyak 73 orang yang memiliki jarak kehamilan 2 tahun atau lebih dengan persentase sebesar 73% dan sebanyak 27 orang memiliki jarak kehamilan kurang dari 2 tahun dengan persentase sebesar 27%. Hal ini berarti sebagian besar ibu memiliki jarak kehamilan yang baik sesuai anjuran BKKBN. Pada Gambar 4.2.(b) terlihat bahwa sebanyak 94 orang tidak memiliki penyakit saat kehamilan dengan persentase sebesar 94% dan sebanyak 6 orang memiliki penyakit saat kehamilan dengan persentase sebesar 6%. Hal ini berarti sebagian besar ibu tidak memiliki penyakit saat hamil.
(a) (b)
Gambar 4.2. (a) Diagram Lingkaran Jarak Kehamilan
(b) Diagram Lingkaran Penyakit Saat Kehamilan
Variabel ibu menderita anemia dibedakan menjadi 2 kategori yaitu pernah anemia dan tidak pernah anemia. Variabel frekuensi pemeriksaan kehamilan dibedakan menjadi 3 kategori yaitu kurang dari satu bulan sekali, satu bulan sekali, dan lebih dari satu bulan sekali. Variabel status pekerjaan ibu dibedakan menjadi 2 kategori yaitu bekerja dan tidak bekerja. Deskripsi variabel ibu menderita anemia, frekuensi pemeriksaan kehamilan dan status pekerjaan ibu disajikan dengan diagram lingkaran seperti pada Gambar 4.3.
30
(a) (b)
(c)
Gambar 4.3. (a) Diagram Lingkaran Ibu Menderita Anemia
(b) Diagram Lingkaran Frekuensi Pemeriksaan Kehamilan (c) Diagram Lingkaran Status Pekerjaan Ibu
saat hamil dengan persentase sebesar 38%. Hal ini berarti sebagian besar ibu tidak bekerja saat hamil.
Berdasarkan deskripsi statistik terlihat bahwa semua data tidak homogen (heterogen). Dengan demikian, data tersebut dapat digunakan untuk analisis selanjutnya yaitu pembentukan pohon regresi.
4.2 Analisis Pohon Regresi
Langkah pertama dari analisis pohon regresi adalah pembentukan pohon regresi. Langkah selanjutnya adalah pemangkasan pohon regresi, pemilihan pohon regresi optimal, dan pemilihan pohon regresi dari kelompok data percobaan. Data penelitian dibagi menjadi 2 yaitu data pelatihan dan data uji. Pembagian sampel data dilakukan secara acak sebanyak 10 kali sehingga diperoleh 10 kelompok data percobaan (dataset) dengan pembagian data pelatihan sebesar 90% yaitu sebanyak 90 data dan data uji sebesar 10% yaitu sebanyak 10 data. Data pelatihan digunakan untuk proses pembentukan pohon regresi, sedangkan data uji digunakan untuk melakukan validasi model. Selanjutnya dibentuk pohon regresi dari berat badan bayi saat lahir di kota Surakarta yang melibatkan 9 variabel prediktor, yaitu usia ibu hamil, jarak kehamilan, jumlah anak yang dilahirkan, kenaikan berat badan, penyakit saat kehamilan, ibu menderita anemia, frekuensi pemeriksaan kehamilan, status pekerjaan ibu, dan pendidikan ibu. Berikut ini dijelaskan proses pembentukan pohon regresi dari salah satu kelompok data percobaan. Pembentukan pohon regresi dari 9 kelompok data percobaan lainnya dilakukan dengan cara yang sama.
4.2.1Pembentukan Pohon Regresi Maksimal
Pembentukan pohon regresi maksimal dilakukan menurut aturan pemilahan yaitu dimulai dari pemilahan data berat badan bayi saat lahir dari 90 data pelatihan oleh variabel pemilah terbaik dari masing-masing variabel prediktor. Banyaknya kemungkinan pemilahan diperoleh dengan cara sebagai berikut
perpustakaan.uns.ac.id digilib.uns.ac.id
32
1. jika pada variabel prediktor kontinu terdapat sebanyak nilai pengamatan yang berbeda, maka terdapat sebanyak pemilahan yang mungkin dilakukan. Dalam hal ini, variabel yang bertipe kontinu adalah
a. variabel usia ibu hamil memiliki 19 – 1 = 18 kemungkinan pemilahan b. variabel kenaikan berat badan ibu ( ) memiliki 16 – 1 = 15 kemungkinan
pemilahan
2. jika pada variabel prediktor kategorik ordinal terdapat kategori, maka terdapat sebanyak pemilahan yang mungkin dilakukan. Dalam hal ini, variabel yang bertipe kategorik ordinal adalah
a. variabel jarak hamil ( ) memiliki 2 – 1 = 1 kemungkinan pemilahan b. variabel jumlah anak ( ) memiliki 4 – 1 = 3 kemungkinan pemilahan
c. variabel frekuensi pemeriksaan kehamilan ( ) memiliki 3 – 1 = 2 kemungkinan pemilahan
d. variabel pendidikan ibu ( ) memiliki 4 – 1 = 3 kemungkinan pemilahan 3. jika pada variabel prediktor kategorik nominal terdapat kategori, maka terdapat
sebanyak pemilahan yang mungkin dilakukan. Dalam hal ini, variabel yang bertipe kategorik nominal adalah
a. variabel penyakit saat kehamilan ( ) memiliki kemungkinan
Pembentukan pohon regresi maksimal dimulai dengan mencoba 45 kemungkinan pemilahan pada data berat badan bayi saat lahir dari 90 data yang terkumpul dalam suatu himpunan yang disebut simpul akar dan diberi nama simpul 1. Masing-masing kemungkinan pemilahan menghasilkan 2 kelompok data yang dinamakan simpul anak kiri dan simpul anak kanan, kedua simpul anak diberi nama simpul 2 dan simpul 3. Pemilah terbaik dihitung berdasarkan selisih jumlah kuadrat deviasi dari masing-masing simpul dengan simpul pemilahnya. Selisih terbesar akan
perpustakaan.uns.ac.id digilib.uns.ac.id
dijadikan pemilah terbaik. Selisih jumlah kuadrat deviasi dapat dilihat pada perhitungan berikut
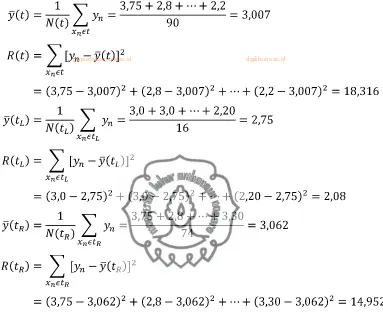
Pemilah terbaik pertama, variabel kenaikan berat badan ibu kilogram
Perhitungan selisih jumlah kuadrat deviasi dari kemungkinan pemilahan lainnya dilakukan dengan cara yang sama dan diperoleh hasil seperti pada Tabel 4.2. Pemilah terbaik diperoleh dengan kriteria kenaikan berat badan ibu kilogram. Variabel kenaikan berat badan ibu terpilih karena memiliki selisih jumlah kuadrat deviasi terbesar daripada variabel yang lainnya.
perpustakaan.uns.ac.id digilib.uns.ac.id
34
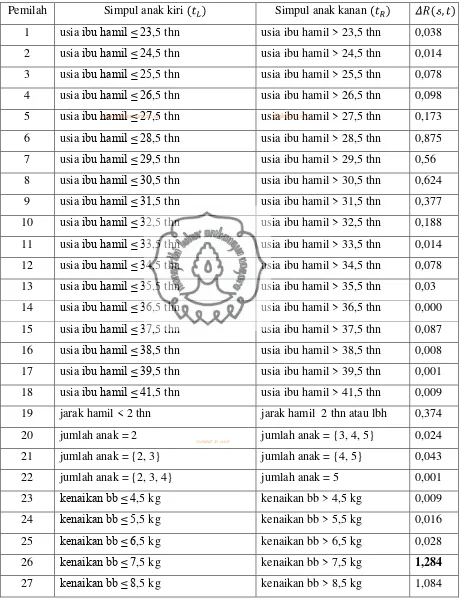
Tabel 4.2. Selisih Jumlah Kuadrat Deviasi dari Semua Kemungkinan Pemilahan
Pemilah Simpul anak kiri Simpul anak kanan
28 kenaikan bb ≤ 9,5 kg kenaikan bb > 9,5 kg 0,642
42 status pekerjaan ibu = bekerja
status pekerjaan ibu = tidak
bekerja 0,313
43 pendidikan ibu = (lainnya)
pendidikan ibu = (SMP,
SMA, P.T) 0,150
44 pendidikan ibu = (lainnya, SMP) pendidikan ibu = (SMA, P.T) 0,464 45 pendidikan ibu = (lainnya, SMP, SMA) pendidikan ibu = (P.T) 0,028
Setelah terbentuk dan diperoleh pemilah terbaik, maka simpul pertama yang berisi data dipilah menjadi buah simpul akhir. Simpul akhir terbentuk akibat kriteria variabel kenaikan berat badan ibu kilogram. Simpul akhir terbentuk akibat kriteria variabel kenaikan berat badan ibu kilogram. Pemilahan pertama dapat dilihat pada Gambar 4.4. Sebanyak data berat badan bayi dipilah berdasarkan kriteria kenaikan berat badan ibu, yaitu data dengan kenaikan berat badan ibu kilogram masuk ke dalam simpul akhir dan data dengan kenaikan berat badan ibu kilogram masuk ke dalam simpul akhir 2.
perpustakaan.uns.ac.id digilib.uns.ac.id
36
Proses pemilahan terus dilakukan pada simpul berikutnya dan berhenti apabila tidak terdapat lagi penurunan keheterogenan atau semua nilai y yang ada pada sebuah simpul adalah sama (homogen), ukuran simpul induk minimum 10 yaitu ukuran minimum dimana simpul tidak akan dipilah (Steinberg and Colla, 1998), atau hanya terdapat satu pengamatan pada tiap simpul anak. Pemilahan yang akan menghasilkan simpul anak yang lebih kecil tidak dipertimbangkan. Pohon regresi yang terbentuk sebagai hasil dari proses ini dinamakan pohon regresi maksimal (Tmax) secara umum ditunjukkan pada Gambar 4.5.
Gambar 4.5. Model Pohon Regresi Maksimal
Simpul yang berwarna hijau pada Gambar 4.5 merupakan simpul dalam sedangkan simpul yang berwarna merah merupakan simpul akhir. Pohon regresi
maksimal tersebut memiliki 15 simpul dalam dan 16 simpul akhir, dengan kedalaman pohon regresi sebesar 8 tingkatan. Kedalaman pohon menunjukan jumlah level atau tingkatan dari pohon regresi yang dihitung dari simpul utama sampai pada simpul akhir yang terbawah. Pohon regresi maksimal secara detail dapat dilihat pada Lampiran 3.
Pada pohon regresi yang terbentuk, CART menghitung ringkasan statistik di setiap simpul-simpul akhir yaitu nilai rata-rata dan standar deviasi dari variabel respon. Nilai rata-rata dari simpul akhir merupakan nilai prediksi dari variabel respon pada kasus simpul terakhir tersebut. Data berat badan bayi dari setiap simpul akhir pada pohon regresi maksimal dapat dilihat pada Tabel 4.3. Nilai yang terdapat pada baris terakhir masing-masing kolom merupakan nilai rata-rata dari setiap simpul akhir. Contoh perhitungan nilai rata-rata dan standar deviasi pada simpul akhir 1 dalam Tabel 4.3 adalah sebagai berikut.
Simpul akhir 1: Rata-rata Variansi
Standar deviasi
4.2.2Pemangkasan Pohon Regresi Maksimal
Pemangkasan pohon regresi maksimal menghasilkan 11 sub pohon. Proses pemangkasan pohon dapat dilihat pada Lampiran 4. Pemangkasan pohon dimulai dengan mengambil yang merupakan simpul anak kiri dan yang merupakan simpul anak kanan dari pohon maksimal. Jika diperoleh dua simpul anak dan simpul induk pada persamaan (2.3) berjumlah 0 atau maka simpul anak dan
perpustakaan.uns.ac.id digilib.uns.ac.id
38
tersebut dipangkas. Jika pada pohon regresi tidak terpenuhi maka
pemangkasan dimulai dari pohon yang memenuhi .
Tabel 4.3. Data Berat Badan Bayi pada Simpul Akhir term.
Simpul maksimal memiliki 15 simpul dalam dengan perhitungan selisih jumlah kuadrat deviasi sebagai berikut.
Simpul 9 (memiliki simpul anak yaitu simpul terminal 5 dan simpul terminal 6 seperti pada Tabel 4.3)
perpustakaan.uns.ac.id digilib.uns.ac.id
Perhitungan selisih jumlah kuadrat deviasi pada 14 simpul dalam lainnya dilakukan dengan cara yang sama dan diperoleh hasil seperti pada Tabel 4.4. Pada Tabel 4.4 terlihat bahwa semua simpul dalam pohon regresi maksimal tidak memenuhi sehingga pemangkasan dimulai dari pohon yang memiliki
perpustakaan.uns.ac.id digilib.uns.ac.id
40
. Pemangkasan pertama terjadi pada simpul 9 karena simpul 9 memiliki nilai selisih jumlah kuadrat deviasi terkecil. Simpul anak dari simpul 9 yaitu simpul akhir 5 dan simpul akhir 6 dipangkas sehingga simpul 9 menjadi simpul akhir. Pemangkasan pertama menghasilkan 14 simpul dalam dan 15 simpul akhir. Pada proses pemangkasan kedua, simpul 13 mengalami pemangkasan karena memiliki selisih jumlah kuadrat deviasi terkecil diantara 13 simpul dalam lainnya. Simpul anak dari simpul 13 yaitu simpul 14, simpul 15, simpul akhir 12, 13, 14, dan 15 dipangkas sehingga simpul 13 menjadi simpul akhir. Pemangkasan kedua menghasilkan 11 simpul dalam dan 12 simpul akhir. Proses pemangkasan berlanjut sampai tidak ada lagi pemangkasan yang mungkin yaitu hanya terdapat 1 simpul dalam dan 2 simpul anak.
Tabel 4.4. Selisih Jumlah Kuadrat Deviasi pada Proses Pemangkasan Pertama
4.2.3Pohon Regresi Optimal
Setelah dilakukan pemangkasan pohon, langkah selanjutnya adalah pemilihan pohon regresi optimal. Dari 11 sub pohon yang terbentuk akan dipilih 1 pohon regresi dengan nilai kesalahan penduga pengganti terkecil. Data uji yang digunakan dapat dilihat pada Tabel 4.5. Rumus kesalahan penduga sampel uji yaitu
dan rumus kesalahan relatif penduga sampel uji
digunakan untuk pemilihan pohon regresi optimal. Nilai kesalahan relatif penduga sampel uji dari masing-masing sub pohon terlihat pada Tabel 4.6. Nilai rata-rata dari setiap simpul akhir merupakan nilai prediksi dari variabel respon pada kasus simpul terakhir tersebut. Nilai dapat dilihat pada Gambar 4.6.
Tabel 4.5. Data Uji
No. Y X1 X2 X3 X4 X5 X6 X7 X8 X9
1 3,50 35 2 3 12 2 2 1 2 3
2 2,60 26 1 2 15 2 2 3 2 2
3 3,20 35 2 2 10 2 2 1 2 3
4 2,65 25 2 2 14 2 2 2 2 2
5 3,60 35 2 3 10 2 1 1 2 3
6 3,10 25 1 2 8 2 2 2 1 3
7 3,10 40 2 2 15 2 2 2 1 3
8 3,00 29 2 2 12 2 1 1 1 2
9 3,10 31 2 3 12 2 2 2 2 3
10 3,60 24 1 2 10 2 2 2 2 3
Perhitungan kesalahan relatif pada pohon optimal menggunakan penduga sampel uji sebagai berikut.
Kesalahan penduga sampel uji:
perpustakaan.uns.ac.id digilib.uns.ac.id
42
Rata-rata kesalahan data uji:
Kesalahan relatif penduga sampel uji :
Nilai ± pada Tabel 4.6 merupakan nilai penduga kesalahan standar yaitu ukuran dari ketidakpastian di sekitar tingkat kesalahan sebenarnya (sampel uji) dari pohon tersebut saat berhadapan dengan data baru. Nilai penduga kesalahan standar memberikan gambaran ketidakpastian dari penduga tingkat kesalahan. Penduga kesalahan standar diperoleh menggunakan persamaan (2.10) yaitu
perpustakaan.uns.ac.id digilib.uns.ac.id
Tabel 4.6. Nilai Kesalahan Relatif Penduga Sampel Uji Sub
Pohon
Jumlah Simpul Akhir
Kesalahan Relatif Penduga Sampel Uji
1 16 0,945 ± 0,251
2 15 1,011 ± 0,275
3 12 0,955 ± 0,242
4 11 0,924 ± 0,230
5 8 0,895 ± 0,223
6 7 0,895 ± 0,223
7** 5 0,778 ± 0,189
8 4 1,043 ± 0,054
9 3 1,043 ± 0,054
10 2 1,061 ± 0,161
11 1 1,171 ± 0,275
**Optimal
Perhitungan penduga kesalahan standar sebagai berikut.
Berdasarkan data pada Tabel 4.7 diperoleh nilai sebagai berikut
Berdasarkan data pada Tabel 4.3 diperoleh nilai dan sebagai berikut
perpustakaan.uns.ac.id digilib.uns.ac.id
44
Tabel 4.7. Perhitungan
3,1 2,912 0,035 0,001
3,1 2,912 0,035 0,001
3 2,912 0,008 0,000
2,6 3,095 0,245 0,060
2,65 3,095 0,198 0,039
3,1 3,095 0,000 0,000
3,6 3,095 0,255 0,065
3,5 3,456 0,002 0,000
3,2 3,456 0,066 0,004
3,6 3,456 0,021 0,000
jumlah 0,865 0,172
Berdasarkan data pada Tabel 4.8 diperoleh nilai sebagai berikut
perpustakaan.uns.ac.id digilib.uns.ac.id
Tabel 4.8. Perhitungan
Jadi, nilai penduga kesalahan standar atau ukuran dari ketidakpastian di sekitar tingkat kesalahan sebenarnya (sampel uji) dari pohon tersebut saat berhadapan dengan data baru sebesar . Pada Tabel 4.6 dapat ditunjukkan bahwa pohon regresi optimal yang terpilih adalah pohon regresi yang memiliki kesalahan relatif penduga sampel uji terkecil sebesar yang berarti nilai kesalahan prediksi besarnya berat badan bayi saat lahir dari pohon regresi optimal terhadap data yang dihitung berdasarkan penduga sampel uji berkisar antara sampai .
perpustakaan.uns.ac.id digilib.uns.ac.id
46 status pekerjaan ibu .
Gambar 4.6. Pohon Regresi Optimal
Pada simpul 2, sebanyak 16 data berat badan bayi dipilah lagi berdasarkan variabel usia ibu hamil menjadi 2 kelompok yaitu sebanyak 6 data berat badan bayi dengan usia ibu hamil tahun masuk ke dalam simpul kiri yaitu simpul akhir 1 (sudah homogen) dan 10 data lainnya dengan usia ibu hamil tahun, masuk ke dalam simpul kanan yaitu simpul akhir 2 (sudah homogen). Rata-rata berat badan bayi saat lahir adalah 2,750 kilogram dengan standar deviasi sebesar 0,361.
Pada simpul 3, variabel status pekerjaan ibu memberi nilai penurunan keheterogenan yang tinggi sebagai pemilah. Sebanyak 74 data berat badan bayi dipilah menjadi 2 kelompok yaitu sebanyak 29 data berat badan bayi dengan status pekerjaan ibu adalah bekerja masuk ke dalam simpul kiri yaitu simpul akhir 3 (sudah homogen) dan 45 data lainnya dengan status pekerjaan ibu tidak bekerja, masuk ke dalam simpul kanan yaitu simpul 4. Rata-rata berat badan bayi saat lahir adalah 3,062 kilogram dengan standar deviasi sebesar 0,450.
Pada simpul 4, variabel usia ibu hamil memberi nilai penurunan keheterogenan yang tinggi sebagai pemilah. Sebanyak 45 data berat badan bayi dipilah menjadi 2 kelompok yaitu sebanyak 37 data berat badan bayi dengan usia ibu hamil tahun masuk ke dalam simpul kiri yaitu simpul akhir 4 (sudah homogen) dan 8 data lainnya dengan usia ibu hamil tahun, masuk ke dalam simpul kanan yaitu simpul akhir 5 (sudah homogen). Rata-rata berat badan bayi saat lahir adalah 3,159 kilogram dengan standar deviasi sebesar 0,449.
Pada setiap simpul akhir diketahui bahwa sebanyak 6 data berat badan bayi masuk ke dalam simpul akhir 1 dengan rata-rata berat badan bayi saat lahir adalah 2,450 dan standar deviasi sebesar 0,126. Sebanyak 10 data berat badan bayi masuk ke dalam simpul akhir 2 dengan rata-rata berat badan bayi saat lahir adalah 2,930 dan standar deviasi sebesar 0,335. Sebanyak 29 data berat badan bayi masuk ke dalam simpul akhir 3 dengan rata-rata berat badan bayi saat lahir adalah 2,912 dan standar deviasi sebesar 0,407. Sebanyak 37 data berat badan bayi masuk ke dalam simpul akhir 4 dengan rata-rata berat badan bayi saat lahir adalah 3,095 dan standar deviasi sebesar 0,399. Sebanyak 8 data berat badan bayi masuk ke dalam simpul akhir 5
perpustakaan.uns.ac.id digilib.uns.ac.id
48
dengan rata-rata berat badan bayi saat lahir adalah 3,456 dan standar deviasi sebesar 0,539.
4.2.4Pemilihan Pohon Regresi dari Kelompok Data Percobaan
Berdasarkan percobaan yang dilakukan pada 10 kelompok data yang dipilih secara random ternyata tidak semua kelompok data menghasilkan pohon regresi. Dari 10 kelompok data percobaan, terbentuk 5 pohon regresi yang memiliki nilai kesalahan relatif penduga sampel uji. Perhitungan nilai kesalahan relatif penduga sampel uji dilakukan dengan cara sama seperti perhitungan pada Tabel 4.6 dan dengan menggunakan software diperoleh hasil seperti terlihat pada Tabel 4.9.
Tabel 4.9. Pohon Regresi dari Kelompok Data Percobaan Kelompok relatif penduga sampel uji terkecil yaitu 0,778 0,189. Dengan demikian, kelompok data ke-2 terpilih sebagai pohon regresi yang digunakan untuk membentuk pola hubungan antara variabel-variabel yang berpengaruh terhadap berat badan bayi saat lahir di kota Surakarta. Pohon regresi optimal yang terpilih dapat dilihat pada Gambar 4.6.
perpustakaan.uns.ac.id digilib.uns.ac.id