PENGENALAN HURUF JEPANG
HIRAGANA
MENGGUNAKAN PERLUASAN METODE
FEATURE POINT EXTRACTION
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Yohanes Vandi Kurniawan
NIM: 055314050
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
JAPANESE
HIRAGANA
LETTER RECOGNITION
USING THE EXTENSION OF
FEATURE POINT EXTRACTION
METHOD
A THESIS
Presented as Partial Fulfillment of the Requirements
to Obtain the Sarjana Komputer Degree in Informatics Engineering Study Program
By:
Yohanes Vandi Kurniawan
ID: 055314050
INFORMATICS ENGINEERING STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
vi
HALAMAN PERSEMBAHAN
Kupersembahkan skripsi ini untuk:
• Sang Tunggal Trinitas Yang Suci, Allah Bapa, Allah Putra, dan Allah
Roh Kudus, atas segala rahmat, kasih, perlindungan, dan
bimbingan-Nya.
• Papa, Mama, Cece, dan Titi, atas dukungan dan doa mereka.
• Segenap keluarga besarku yang tidak bisa kusebutkan satu persatu,
atas segala bantuan moral dan material, semangat dan kegigihan, yang
telah diberikan kepadaku.
• Almamaterku Universitas Sanata Dharma, khususnya program studi
vii
Ada harga yang harus dibayar untuk bisa tumbuh dan berkembang,
Bayarannya adalah komitmen.
ix ABSTRAK
PENGENALAN HURUF JEPANG HIRAGANA
MENGGUNAKAN PERLUASAN METODE
FEATURE POINT EXTRACTION
Huruf Hiragana merupakan salah satu huruf tradisional sederhana yang dipakai oleh bangsa Jepang untuk menuliskan kata-kata yang memiliki makna asli
dalam bahasa Jepang, yang seringkali digunakan bersama huruf Kanji yang lebih
rumit penulisannya. Walaupun termasuk huruf yang lebih sederhana dibandingkan
huruf Kanji, tetapi huruf Hiragana memiliki tingkat kerumitan diatas huruf latin,
sehingga lebih sulit untuk dipelajari dan dikenali.
Dalam mengenali suatu obyek dibutuhkan proses pembelajaran, yang
didapatkan berdasarkan ciri-ciri dan pengalaman yang didapatnya dari
pengalaman mengamati obyek yang serupa. Dalam implementasi di bidang
komputasi, hal ini disebut pengenalan pola, dan salah satu metode untuk
mendapatkan ciri-ciri suatu obyek adalah dengan perluasan metode Feature Point Extraction.
Dalam Feature Point Extraction, digunakan tabel hubungan ketetanggaan antarpiksel. Matriks yang didapat dari karakter input dicocokkan dengan tabel untuk mendapatkan nilai tertentu, kemudian dihitung selisihnya dengan tiap
template. Dalam menghitung selisih antara input dan template digunakan metode selisih jarak Euclidean yang memakai ciri tiap obyek. Karakter input yang memiliki selisih jarak paling kecil lkemudian digolongkan sebagai huruf yang
x ABSTRACT
JAPANESE HIRAGANA LETTER RECOGNITION USING THE EXTENSION OF
FEATURE POINT EXTRACTION METHOD
Hiragana letter were a traditional letter which Japanese use to write down words that have a real meaning in Japanese words, which also often met together
with Kanji letter in daily use, which is more complicated ones. Even though it is simpler compared to Kanji, Hiragana has more complex grade compared to those
latin letters, which result in difficulties for learnt and recognized.
In recognizing an object, it is necessary to get a learning progress, which
comes from the result of observing the same kind of object and get features from
it. In computational implementation, those named “pattern recognition”, and one
of the methods for getting those feature were Feature Point Extraction.
In Feature Point Extraction method, a numeration of possible pixel neighborhood were used, The matrix which got from the input character were
compared to the table, thus result in some value. Those value then being used by
subtracting the input value with all templates value. When calculating a
subtraction of those two, we used Euclidean distance method which uses each
value of both input and templates object. The input and a template which has more
xi
KATA PENGANTAR
Puji dan syukur kepada Allah Bapa Yang Maha Kuasa karena atas
penyertaan-Nya penulis dapat menyelesaikan tugas akhir yang berjudul
“PENGENALAN HURUF JEPANG HIRAGANA MENGGUNAKAN PERLUASAN METODE FEATURE POINT EXTRACTION“.
Adapun tugas akhir ini ditulis untuk memenuhi salah satu syarat
memperoleh gelar Sarjana Komputer pada Program Studi Teknik Informatika,
Fakultas Sains dan Teknologi, Universitas Sanata Dharma Yogyakarta.
Penulis mendapat banyak sekali bantuan selama awal perkuliahan sampai
dengan selesainya masa studi di Universitas Sanata Dharma ini. Oleh karena itu,
pada kesempatan ini, penulis ingin mengucapkan rasa syukur dan terima kasih
sebesar-besarnya kepada:
1. Bu Rosa selaku dekan Fakultas Sains dan teknologi, Bu Rido selaku
Kaprodi Teknik Informatika, Pak Wawan selaku dosen pembimbing
akademik, dan Pak Eko Hari selaku dosen pembimbing TA, serta pihak
sekretariat atas pelayanan administrasinya selama ini. Terima kasih atas
bimbingan dan bantuannya kepada penulis selama masa perkuliahan,
khususnya masa-masa skripsi.
2. Papa, Mama, Cece, dan Titi yang tak henti-hentinya memberikan doa,
xii
3. Para kerabat dari keluarga besar Njoo Khay Liem yang selama ini telah
banyak memberikan banyak dorongan motivasi, dan bantuan doa serta
materi yang melimpah sehingga studi ini dapat diselesaikan: Ik Po Lik, Wa
I De, Wa I Eng, Wa I Lie, Ik Lik, dan keluarga lainnya yang selalu
memberi bantuan dan perhatian melimpah selama studi.
4. Para kerabat dari keluarga besar Tjioe Swie Lien yang selama ini telah
banyak memberikan banyak dorongan motivasi, dan bantuan doa serta
materi yang melimpah: Ama A Tjan, Cek Gie, Kho Beng, Kho Eng, dan
kerabat lainnya yang memberi dukungan dan perhatian selama studi.
5. Semua kerabatku yang sudah dipanggil Tuhan atas pertolongan dan
perhatian mereka padaku selama hidup dan juga sampai saat ini: Ang
Kong Swie Lin, Gua Kong Khay Liem, Gua Ma Lian Hwa, Po Ngah, Ik
Liang, Thio A Hwie, dan semuanya yang tidak dapat kusebutkan
satu-persatu.
6. Semua teman-teman yang telah banyak membantu dan mendukung,
menyemangati dan mendorong, sehingga penulis dapat menyelesaikan
studi ini. “Hanyou” wimon atas bantuannya yang teramat banyak,
teman-teman TI seperjuangan Sesar, Yunianto, Ricky, Alex, Kartono, Fendy,
Charles, dan semua teman yang tentunya sangat membantu tetapi belum
xiii
7. Bapak T.C. Hardiono dari kost Tasura, serta Mbak Santhi dan Mas Agung
dari kost Sawahan yang telah memberikan lebih dari sekedar tumpangan
tempat tinggal.
Penulis memohon maaf atas segala kesalahan yang ada dan bersedia
menerima masukan demi kemajuan yang lebih baik. Akhir kata, penulis berharap
semoga karya ini berguna bagi para pembaca sekalian. Terima kasih.
Yogyakarta, Juli 2012
xiv
DAFTAR ISI
halaman
Halaman Judul ……… i
Title ……… ii
Halaman Persetujuan ……… iii
Halaman Pengesahan ……… iv
Halaman Pernyataan Keaslian Karya …..……… v
Halaman Persembahan ……… vi
Halaman Motto ……… vii
Halaman Persetujuan Publikasi ……… viii
Abstrak ……… ix
Abstract ……… x
Kata Pengantar ……… xi
Daftar Isi ……… xiv
Daftar Gambar ……… xviii
Daftar Tabel ……… xxi
BAB I PENDAHULUAN ……… 1
1.1 Latar Belakang Masalah ……… 1
1.2 Rumusan Masalah ……… 3
xv
1.4 Tujuan Penelitian ……..……… 3
1.5 Manfaat Penelitian ……… 4
1.6 Metodologi Penelitian ……… 4
1.7 Sistematika Penulisan ……… 6
BAB II LANDASAN TEORI ………. 8
2.1 Pengolahan Citra ……… 8
2.3.1 Definisi ... 8
2.3.2 Preprocessing ... 9
2.3.3 Thesholding ... 9
2.2 Feature Point Extraction ... 14
2.3 Template Matching ... 21
2.4 Jarak Minimum Euclidean ... 24
2.5 Huruf Hiragana ……… 26
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 29
3.1 Gambaran Sistem ...……… 29
3.2 Desain Proses ………... 33
3.3 Analisis Kebutuhan ………...….. 38
3.4 Logical Design ……….………. 39
3.5 Navigasi Menu ……… 42
3.6 Desain UserInterface……… 44
xvi
3.8 Spesifikasi Perangkatuntuk Menjalankan Sistem ………….. 52
BAB IV IMPLEMENTASI SISTEM ……… 53
4.1 Implementasi Proses ……… 53
4.1.1 Proses Binerisasi ……….……… 53
4.1.2 Proses Segmentasi Citra ………. 53
4.1.3 Proses Ekstraksi Ciri ………..………… 54
4.1.4 Proses Penghitungan Jarak Euclidean …...…….…... 55
4.1.5 Proses Penghitungan Persentase Kemiripan …….…. 58
4.2 Implementasi Interface ……… 59
4.2.1 Cover Menu Utama ………….……….. 59
4.2.2 Menu Bantuan Aplikasi ………...………….……….. 60
4.2.3 Menu Daftar Tabel Hiragana ………….……….. 61
4.2.4 Menu tentang Program …..……...………….……….. 62
4.2.5 Menu Pemilihan Gambar ………….……….…….….. 63
4.2.6 Menu Pemberitahuan Kesalahan ……….….………… 64
4.2.7 Menu Hasil Pengolahan Citra …..…….…….………… 65
BAB V ANALISIS HASIL DAN KESIMPULAN ………....….. 66
5.1 Hasil Pengujian Karakter ………. 66
BAB VI PENUTUP ……… 68
xvii
6.2 Saran ….. ……… 68
DAFTAR PUSTAKA ………. 69
LAMPIRAN ………...………. 70
Citra Template …………….. 71
xviii
DAFTAR GAMBAR
halaman
Gambar 2.1 Jenis distribusi intensitas citra ……… 10
Gambar 2.2 Citra dengan distribusi intensitas yang jelas ……… 11
Gambar 2.3 Hasil threshold yang baik ……… 11
Gambar 2.4 Citra dengan distribusi intensitas yang hampir sama ……… 12
Gambar 2.5 Hasil threshold yang kurang baik ……… 12
Gambar 2.6 Thresholding setelah operasi deteksi tepi ……… 13
Gambar 2.7 Pemecahan matriks 9x9 menjadi 9 bagian ....……… 17
Gambar 2.8 Karakter huruf input S dan E ……… 18
Gambar 2.9 Karakter-karakter yang dipecah menjadi 9 bagian ..……… 18
Gambar 2.10 Skema templatematching secara umum …………....……… 22
Gambar 2.11 Contoh template dari obyek huruf dan obyek wajah .……… 22
Gambar 2.12 Digram jarak antara dua titik ……… 24
Gambar 2.13 Rumus Jarak Euclidean ……………… 25
Gambar 2.14 Perbandingan penulisan Hiragana dan Katakana ………… 26
Gambar 2.15 Karakter dasar Hiragana dan Katakana ……… 27
Gambar 2.16 Karakter-karakter tambahan Hiragana ……… 28
xix
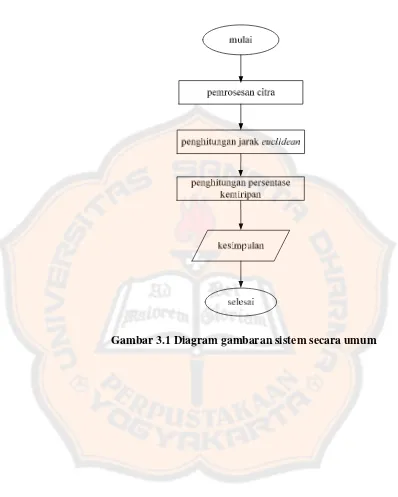
Gambar 3.1 Diagram gambaran sistem secara umum ……… 31
Gambar 3.2 Diagram pemrosesan citra ……….……… 32
Gambar 3.3 Diagram pembagian segmentasi ……… 33
Gambar 3.4 Diagram proses segmentasi menjadi 9 bagian ……… 33
Gambar 3.5 Diagram prosespencocokan dengan tabel ……… 34
Gambar 3.6 Diagram proses penghitungan jarak Euclidean ……… 35
Gambar 3.7 Diagram proses penghitungan persentase kemiripan ……… 36
Gambar 3.8 Diagram Use Case ……… 37
Gambar 3.9 Context Diagram ……… 38
Gambar 3.10 Data Flow Diagram level 1 ……… 38
Gambar 3.11 Data Flow Diagram level 2 proses pengolahan data gambar 39 Gambar 3.12 Entity Relationship Diagram ……… 40
Gambar 3.13 Navigasi menu ……… 41
Gambar 3.14 Desain interface Home ……… 43
Gambar 3.15 Desain interface Input Gambar ……… 44
Gambar 3.16 Desain interface Kesimpulan pengenalan pola ……… 45
Gambar 3.17 Desain interface Pemberitahuan Kesalahan ……… 46
Gambar 3.18 Desain interface Daftar Hiragana ……… 47
Gambar 3.19 Desain interface Tentang Program ……… 48
Gambar 3.20 Desain interface Bantuan ……..……… 49
Gambar 4.1 Tampilan Menu Utama Aplikasi ……… 59
Gambar 4.2 Tampilan Menu Bantuan Aplikasi ……… 60
xx
Gambar 4.4 Tampilan Menu Tentang Program ………. 62
Gambar 4.5 Tampilan Menu Pemilihan Gambar ……… 63
Gambar 4.6 Tampilan Menu Pemberitahuan Kesalahan ……….……… 64
xxi
DAFTAR TABEL
Halaman
Tabel 2.1 Tabel hubungan ketetanggaan antarpiksel,
piksel pada posisi (2,2) bernilai 0 ……… 16
Tabel 2.2 Tabel hubungan ketetanggaan antarpiksel,
piksel pada posisi (2,2) bernilai 1 ……… 19
Tabel 2.3 Tabel hasil nilai tiap segmen ……...……… 20
1
BAB I
PENDAHULUAN
1.1. Latar Belakang Masalah
Penginderaan adalah salah satu kemampuan alami manusia yang
memungkinkan manusia untuk membedakan suatu hal dengan hal lainnya.
Dalam perkembangan selanjutnya, pembedaan yang dilakukan manusia
menyebabkan terjadinya suatu klasifikasi. Suatu obyek yang memiliki
tingkat kemiripan yang tinggi berdasarkan kategori yang ditentukan oleh
manusia itu sendiri, akan dikelompokkan menjadi suatu kumpulan obyek
yang sejenis. Suatu contoh dari kemampuan pengindraan itu sendiri adalah
kemampuan manusia untuk membedakan dan mengklasifikasikan sebuah
obyek bernama kursi. Fungsi, karakteristik, dan ciri-ciri dari obyek kursi
yang selama ini telah dilihat manusia tersebut disimpan di dalam ingatan
manusia tersebut, dan mengalami proses generalisasi. Sehingga, meskipun
dia tidak melihat semua jenis kursi yang ada, namun ia akan tetap dapat
mengidentifikasi setiap obyek kursi yang ia lihat.
Kemampuan penginderaan manusia tersebut juga telah
mengembangkan tingkat pola pikir manusia, dan salah satu hasil dari
perkembangan pikiran manusia adalah komputer. Sejalan dengan
perkembangan pola pikir manusia, komputer juga terus berkembang. Dari
komputer yang hanya berfungsi sebagai alat bantu hitung, semakin
berkembang menjadi perangkat yang memiliki kecerdasan buatan seperti
manusia, yang dapat membantu melakukan pekerjaan-pekerjaan yang
kompleks seperti mengidentifikasi tanda tangan, mengidentifikasi wajah,
mengidentifikasi tulisan/huruf, dsb. Metode-metode yang dipakai dalam
Jaringan Syaraf Tiruan, Logika Kabur, Pendekatan menggunakan statistik,
dan sebagainya.
Selain perkembangan pola pikir, adanya kemampuan penginderaan
telah menimbulkan peningkatan pola pikir manusia dan munculnya suatu
unsur seni, dan akibat dari hal tersebut adalah muncul dan berkembangnya
kebudayaan. Salah satu kebudayaan yang muncul akibat adanya perubahan
dalam pola pikir dan unsur seni manusia adalah kebudayaan jepang.
Kebudayaan Jepang klasik mulai berkembang pada abad ke-3, ketika
penduduk Jepang mulai berinteraksi dengan kekaisaran di China. Dari
proses interaksi tersebut tercipta suatu sistem penulisan baru di Jepang,
antara lain Hiragana, Katakana, dan Kanji. Huruf hiragana, adalah suatu huruf yang dikembangkan dari karakter huruf China. Huruf dasar dari
Hiragana berjumlah 46, dan dikembangkan dari tulisan kaligrafi China yang mengalami penyederhanaan. Karena bentuk dan cara penulisannya
yang berbeda dari aksara latin, maka pada umumnya peminat bahasa
Jepang harus melakukan suatu penyesuaian tersendiri akibat tingkat
kerumitan huruf Hiragana yang lebih tinggi dari tulisan latin.
Berdasarkan permasalahan yang telah diungkapkan sebelumnya,
maka penulis ingin membuat suatu aplikasi yang dapat mengenali huruf
Hiragana dengan menggunakan menggunakan rumus pengukuran jarak
Euclidean. Metode ini adalah suatu metode yang menentukan tingkat kemiripan suatu data dengan cara mengukur jarak berdasarkan rumus
tertentu. Tolak ukur dalam mengelompokkan data tersebut diambil dari
“ciri” yang didapat dari data tersebut. Sebagai jalan untuk mendapatkan
1.2. Rumusan Masalah
Rumusan masalah yang muncul dalam pembuatan aplikasi ini
adalah sebagai berikut:
Bagaimana cara mengenali karakter huruf Jepang Hiragana dengan menggunakan Feature Point Extraction dan metode pengukuran jarak
Euclidean?
1.3. Batasan Masalah
Beberapa batasan masalah dalam aplikasi pengenalan huruf Jepang
Hiragana ini adalah sebagai berikut:
1. Metode yang digunakan untuk mengenali huruf Jepang Hiragana
adalah metode perbandingan dengan mengukur jarak Euclidean.
2. Proses pengambilan ciri menggunakan perluasan metode Feature Point Extraction
3. Pengenalan huruf Jepang Hiragana ini dibuat dengan menggunakan aplikasi pemrograman MatLab.
4. Data huruf Jepang Hiragana yang akan diklasifikasikan berupa file gambar yang berekstensi *.jpg, *.jpeg, atau *.bmp
5. Aplikasi yang dibangun untuk mengenali huruf Jepang Hiragana
hanya dapat menginputkan satu karakter untuk setiap pemasukan
hurufnya.
6. Huruf Jepang Hiragana yang akan dikenali adalah 5 karakter dari huruf Hiragana dasar yaitu ”ma”, ”mi”, ”mu”, ”me”, dan ”mo”.
1.4. Tujuan Penelitian
Tujuan yang akan dicapai dalam penelitian ini adalah:
Membangun sebuah aplikasi untuk mengenali lima jenis huruf Jepang
1.5. Manfaat Penelitian
1. Membantu pengguna aplikasi dalam mengenali huruf Jepang
Hiragana.
2. Membantu pengguna dalam mengetahui derajat kebenaran huruf
Jepang Hiragana.
1.6. Metodologi Penelitian
Metodologi penelitian yang digunakan dalam penelitian ini adalah:
1. Studi Pustaka
Dalam menyusun penelitian ini, penyusun mempelajari buku dan
literatur-literatur dari internet mengenai Feature Point Extraction, pemrograman MatLab, jarak Euclidean, dan aksara Jepang Hiragana, yang selanjutnya akan dimanfaatkan sebagai dasar dalam membangun
perangkat lunak yang diuji coba dalam laboratorium komputer.
2. Metode Perancangan Perangkat Lunak Waterfall
1. Analisis Kebutuhan
Yang dilakukan dalam tahapan ini adalah mengumpulkan
sampel huruf Jepang Hiragana dalam berbagai jenis gaya penulisan. Pengumpulan sampel data berupa huruf Jepang akan dilakukan
dengan membagi-bagikan contoh karakter huruf Hiragana kepada banyak orang untuk ditulis ulang. Sampel yang diperoleh ini akan
digunakan sebagai template untuk pengenalan huruf Hiragana. Selain hal tersebut, peneliti mengumpulkan dan meninjau
pengenalan huruf Hiragana, yaitu, baik secara teoritis maupun secara praktis. Hasilnya ialah berbagai macam sampel huruf
Hiragana serta referensi mengenai ekstraksi ciri menggunakan
Feature Point Extraction.
2. Desain Sistem
Dalam perancangan sistem, peneliti mulai melakukan proses
perancangan sistem dengan membuat diagram alur data/ Data Flow
Diagram (DFD), ER Diagram, serta penyusunan tampilan antarmuka
dan berbagai tombol/fungsi yang akan digunakan untuk membangun
sebuah aplikasi yang dapat mengenali huruf Hiragana, baik untuk input maupun output. Hasil akhir yang menjadi tujuan dalam tahap
ini adalah terciptanya suatu desain sistem dan rancangan tampilan
antarmuka lengkap dengan sarana untuk input dan output yang
ditujukan bagi pemakai sistem, walaupun fasilitas input dan output
tersebut masih belum berfungsi sepenuhnya.
3. Implementasi/Coding
Dalam tahap ini, metode ekstraksi ciri menggunakan Feature Point Extraction dan pengukuran jarak Euclidean mulai diimplementasikan ke dalam sistem sesuai dengan rancangan dan
desain sistem yang telah disusun dalam tahap sebelumnya. Hasil
mengenali huruf Hiragana dan memberikan output kepada pemakai sistem.
4. Integrasi dan Testing Sistem
Dalam tahap integrasi dan testing sistem ini, dilakukan
pengujian terhadap aplikasi yang telah dibangun dengan tujuan untuk
dapat menemukan kemungkinan terjadinya kesalahan dalam sistem.
Proses evaluasi akan dilakukan secara berkesinambungan sehingga
sistem yang dibangun relatif lebih akurat daripada sebelumnya. Hasil
yang ingin dicapai dalam tahap ini adalah terciptanya sebuah aplikasi
yang dapat mengenali huruf Hiragana secara lebih akurat.
5. Pemeliharaan Sistem
Dalam tahap pemeliharaan sistem ini, kesalahan dan
kekurangan sistem yang telah ditemukan akan berusaha diatasi,
sehingga program yang telah dihasilkan akan menjadi lebih
sempurna.
1.7. Sistematika Penulisan
Berikut adalah garis besar dari isi karya ilmiah yang akan disusun:
BAB I PENDAHULUAN
Bab I membahas tentang latar belakang masalah, rumusan
masalah, batasan masalah, tujuan penelitian, manfaat penelitian,
BAB II LANDASAN TEORI
Bab II membahas tentang teori-teori yang melandasi penelitian,
seperti teori tentang pengolahan citra dan metode pengukuran
jarak Euclidean.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab III membahas tentang analisa dan perancangan sistem, yang
berisi bagaimana rancangan aplikasi yang akan dibangun,
meliputi gambaran sistem secara umum, desain proses, analisis
kebutuhan, Data Flow Diagram, ER Diagram, desain interface, serta kebutuhan Hardware dan Software.
BAB IV IMPLEMENTASI SISTEM
Bab IV berisi hasil implementasi dari program yang dibuat serta
pembahasannya.
BAB V ANALISIS HASIL DAN PEMBAHASAN
Bagian analisis hasil implementasi ini berisikan analisa dari
implementasi yang telah dibuat.
BAB VI PENUTUP
Penutup berisi tentang kesimpulan dan saran dari hasil dari
8
BAB II
LANDASAN TEORI
Penyusunan tugas akhir ini membutuhkan beberapa landasan teori yang
digunakan sebagai acuan dalam memahami dan mengimplementasikan metode
pengukuran jarak Euclidean untuk mengenali citra berupa huruf Jepang Hiragana, antara lain: Pengolahan citra, Feature Point Extraction, Template Matching, Jarak Euclidean, dan Huruf Hiragana.
2.1 Pengolahan Citra
2.1.1 Definisi
Berikut ini adalah definisi mengenai pengolahan citra.
Citra adalah istilah lain untuk gambar, yang merupakan salah satu
komponen multimedia yang memegang peranan sangat penting sebagai
bentuk informasi visual. Secara harafiah, citra adalah gambar pada bidang
dwimatra (dua dimensi), sedangkan ditinjau dari sudut pandang matematis,
citra merupakan fungsi menerus (continue) dari intensitas cahaya pada bidang dwimatra (Munir, 2004).
Digitalisasi Citra adalah proses untuk merepresentasikan suatu citra
secara numerik dengan nilai-nilai diskrit. Representasi citra dari fungsi
kontinu menjadi nilai-nilai diskrit yang dinamakan digitalisasi inilah yang
Derau (noise) adalah gambar atau piksel yang mengganggu
kualitas citra. Derau dapat disebabkan oleh gangguan fisis (optik) pada alat
akuisisi maupun secara disengaja akibat proses pengolahan yang tidak
sesuai. Contohnya adalah bintik hitam atau putih yang muncul secara acak
yang tidak diinginkan di dalam citra. Bintik acak ini disebut dengan derau
salt & pepper. Noise tidak dapat ditebak secara tepat karena sifatnya yang acak namun dapat dikarakterisasikan dengan efeknya pada sebuah citra.
(Parker, 1997).
2.3.2 Preprocessing
Preprocessing merupakan suatu proses awal yang dilakukan untuk memperbaiki kualitas citra (edge enhancement) dengan menggunakan teknik-teknik pengolahan citra (Munir, 2004). Beberapa proses yang
termasuk dalam preprocessing ini adalah pengubahan histogram citra,
penapisan derau (noise filtering), dan pengubahan geometrik.
2.3.3 Thresholding
Dalam berbagai pemrosesan citra, sangat membantu jika dapat
dipisahkan antara daerah/citra sebagai objek (yang dikehendaki) dari citra
yang merupakan latar belakang (background) dari keseluruhan citra.
Thresholding memberikan kemudahan dalam melakukan segmentasi ini berdasarkan perbedaan intensitas warna dari kedua citra tersebut (Fisher,
Input dari berwarna. Dalam
merupakan citra bi
menggambarkan b foreground (atau bi sebuah parameter y
dari suatu citra di
nilainya lebih tingg
atau bernilai 1 seb
bernilai 0 (atau seba
Tidak semu
yang sederhana. Bis
ditentukan dengan
memungkinkan un
intensitas piksel m
benar-benar berbed
Dalam hal ini, dapa
Gambar 2.
ari thresholding dapat berupa citra grayscale
m implementasi yang paling sederhana, ou
biner yang merepresentasikan segmentasi. Piks
background sedangkan piksel putih menggam bisa juga sebaliknya). Segmentasi dilakukan berd
er yang disebut sebagai intensitas threshold. Tia
dibandingkan dengan parameter ini. Jika piks
nggi dari threshold, piksel tersebut diset menja sebagai outputnya. Jika tidak, diset menjadi hit
ebaliknya).
ua citra dapat disegmentasi menggunakan thresho
Bisa atau tidaknya sebuah citra disegmentasi deng
gan melihat histogram intensitas dari citra
untuk memisahkan foreground dari citra berd maka intensitas piksel pada objek foreground
beda dari intensitas piksel background (Fisher pat dilihat dari perbedaan puncak dalam histogram
ar 2.1 Jenis distribusi intensitas citra
Gambar 2.1 a) menunjukkan distribusi intensitas bi-modal. Citra ini dapat disegmentasi menggunakan threshold tunggal T1. Gambar 2.1 b) terlihat lebih kompleks. Dianggap bahwa puncak di tengah merupakan
objek yang diinginkan maka segmentasi memerulukan dua threshold: T1
dan T2. Pada gambar 2.1 c), kedua puncak dari distribusi bi-modal terlihat hampir sama maka hampir tidak mungkin untuk dapat melakukan
segmentasi dengan baik menggunakan threshold tunggal.
Gambar 2.2 Citra dengan distribusi intensitas yang jelas
Gambar 2.2 di atas menunjukkan distribusi bi-modal yang baik; pada histogram, puncak yang lebih rendah merepresentasikan objek,
sedangkan yang lebih tinggi merepresentasikan background.
Citra pada gambar 2.2 dapat disegmentasi menggunakan threshold
tunggal dengan nilai intensitas piksel 120. Hasilnya adalah seperti pada
gambar 2.3 sebagai berikut:
Tetapi dengan adanya gradasi pencahayaan yang cukup jelas,
seperti gambar 2.4 di bawah ini, puncak yang merepresentasikan
foreground dan background dapat tampak memiliki kesamaan, maka threshold yang sederhana tidak dapat memberikan hasil yang baik.
Gambar 2.4 Citra dengan distribusi intensitas yang hampir sama
Citra pada gambar 2.5 menunjukkan hasil segmentasi yang kurang
baik untuk threshold tunggal dari citra pada gambar 2.2 dengan nilai 80 dan 120 berturut-turut:
Gambar 2.5 Hasil threshold yang kurang baik
Thresholding juga dapat dipakai untuk memfilter output maupun input untuk operator lain. Sebagai contoh, deteksi tepi, seperti operasi
Jika yang dii
kemudian dikenai
akhirnya, yaitu g
thresholding dengan n Berikut ini
diinginkan hanya gradien di atas nilai tertentu (mi
), maka thresholding dapat digunakan hany garis yang tajam saja dan mengeset piksel
(b) (c)
bar 2.6 Thresholding setelah operasi deteksi te
bar 2.6, gambar (a) merupakan gambar mu
ai operasi Sobel dan menghasilkan gambar (b gambar (c), diperoleh setelah gambar (b)
gan nilai 60 (Fisher, 2003).
ni adalah langkah-langkah dalam melakukan
ilih sembarang nilai untuk inisalisasi awal threshold
disegmentasi menjadi objek dan background
hasilkan dua bagian:
3. Rata-rata dari tiap bagian dihitung.
a. m1 = nilai rata-rata G1
b. m2 = nilai rata-rata G2
4. Nilai threshold baru diperoleh dari rata-rata m1 dan m2
T’ = (m1+m2)/2
5. Kembali ke langkah kedua, tetapi dengan menggunakan nilai
threshold yang baru didapat dari langkah (4). Terus diulang sampai nilai threshold yang diperoleh sama dengan nilai
threshold sebelumnya.
2.2 Feature Point Extraction
Yang dimaksudkan dengan feature point ialah suatu titik dari citra yang diperhatikan oleh manusia. Titik dapat merupakan perpotongan antara
dua garis, atau merupakan sebuah pojok, atau juga hanya titik begitu saja.
Titik-titik ini dapat membantu dalam mendefinisikan suatu keterhubungan
dalam dua garis yang berbeda. Dua garis dapat saja bersilangan penuh satu
dengan yang lain, berpotongan seperti dalam huruf “Y” atau “T”, membentuk
sebuah pojok, atau tidak berpotongan sama sekali. Orang-orang cenderung
sensitif dengan keterhubungan semacam ini; susunan titik-titik sedemikian
rupa yang membentuk sebuah huruf “Z” lebih diperhatikan daripada jumlah
titiknya. Jenis keterhubungan inilah yang digunakan dalam pengenalan
Algoritma-algoritma yang banyak digunakan dalam OCR (Optical Character Recognition) mampu memberikan tingkat keakuratan yang tinggi
dan cepat, tetapi tetap saja hampir semuanya melakukan kesalahan yang tidak
masuk akal dari sudut pandang manusia. Jika kesalahannya dalam
membedakan karakter “5” dengan “S”, masih termasuk wajar karena
kemiripan kedua karakter tersebut. Tetapi kesalahan dalam membedakan “5”
dari “M” sangat di luar dugaan. Kesalahan semacam ini disebabkan karena
algoritma-algoritma tersebut umumnya lebih memperhatikan sekumpulan
ciri-ciri yang berbeda dari sudut pandang manusia untuk keperluan komputasi
(Brown, 1992).
Kesalahan dalam mengenali karakter juga disebabkan oleh karena
terbatasnya jumlah ciri yang dikumpulkan. Apabila ciri-ciri dari karakter
diperbanyak maka keakurasian akan meningkat (Brown, 1992).
Algoritma ini pada dasarnya membandingkan susunan piksel dalam
tiap matriks biner 3x3 dengan tabel yang memuat nilai-nilai untuk tiap
kemungkinan susunan piksel tersebut. Yang dibandingkan ialah matriks yang
memiliki piksel di posisi (2,2) bernilai 0 atau berwarna hitam saja.
Karena piksel tersebut memiliki 8 tetangga dan tiap tetangga memiliki
kemungkinan bernilai 0 atau 1 maka seluruhnya memiliki 256 (28)
kemungkinan susunan piksel. Nilai yang ada dalam tabel bernilai 0 sampai
9 25 41 57 73 89 105 121 137 153 169 185 201 217 233 249
Contoh Penerapan Feature Point Extraction
Contoh yang digunakan berikut ini menggunakan matriks awal
berukuran 9x9. Apabila dipecah-pecah menjadi submatriks berukuran 3x3
maka akan menjadi seperti terlihat pada gambar berikut ini:
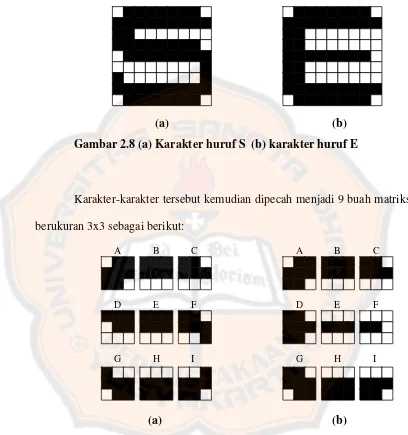
Sebagai contoh, gambar 2.8 (a) dan (b) di bawah ini adalah dua buah
karakter huruf input.
(a) (b)
Gambar 2.8 (a) Karakter huruf S (b) karakter huruf E
Karakter-karakter tersebut kemudian dipecah menjadi 9 buah matriks
berukuran 3x3 sebagai berikut:
(a) (b)
Gambar 2.9 Karakter huruf yang telah dipecah menjadi 9 bagian
Tiap potongan matriks yang berukuran 3x3 pada gambar 2.12
tersebut kemudian akan dicocokkan dengan tabel ketetanggaan antar pixel
untuk diketahui nilai feature atau cirinya. Feature inilah yang akan digunakan sebagai acuan untuk penerapan metode pengukuran jarak Euclidean.
A B C
D E F
G H I
A B C
D E F
Karena matriks yang berada pada posisi tengah tidak selalu berwarna
hitam (bernilai biner 0), maka tabel perbandingan harus diberi kemungkinan
untuk matriks yang bernilai 1 (berwarna putih), sehingga tabel hubungan
ketetanggaan antar piksel yang sebelumnya berjumlah 28 (256), harus
ditambahkan satu kemungkinan lagi, sehingga tabel hubungan ketetanggaan
antar piksel akan berjumlah 29 (512).
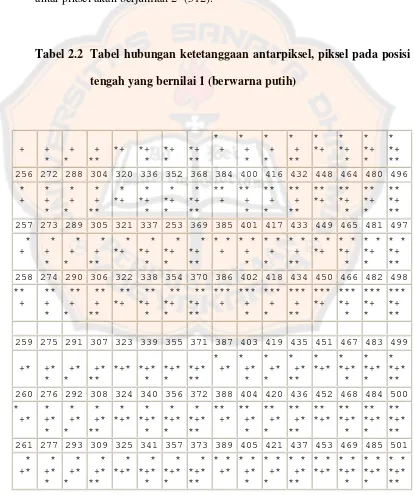
Tabel 2.2 Tabel hubungan ketetanggaan antarpiksel, piksel pada posisi
tengah yang bernilai 1 (berwarna putih)
Berdasarkan 512 kemungkinan nilai fitur yang didapatkan dari tabel
ketetanggaan antar piksel tersebut, maka dari gambar 2.9 akan diperoleh nilai
fitur untuk tiap karakternya, seperti yang akan ditunjukkan pada tabel 2.3:
Tabel 2.3 Tabel hasil nilai tiap segmen
A B C D E F G H I
a) 119 199 197 135 199 205 220 124 118
b) 119 199 197 245 68 64 221 124 116
Nilai-nilai fitur yang terdapat pada tiap huruf dari setiap segmen
inilah yang kemudian akan digunakan sebagai tolak ukur dalam penghitungan
kemiripan berdasarkan jarak Euclidean.
2.3 Template Matching
Template Matching adalah sebuah teknik membandingkan beberapa variabel berdasarkan sudut pandang (view point) tertentu dari sebuah obyek yang diamati (Brunelli, 2009).
Template Matching mungkin adalah sebuah teknik pengenalan pola yang paling sederhana Pola diidentifikasi dengan cara membandingkan pola
input dengan deretan data yang mewakili pola-pola, dan deretan data itulah
Gambar 2.10 Skema Template Matching secara umum (Pearson, 2001)
Sebuah pola input yang ditunjukkan seperti pada gambar 2.10
diproses ke sebuah komparator atau pembanding yang bertugas untuk
mengukur kemiripan antara pola input tersebut dengan pola-pola template
yang sebelumnya sudah ada. Pembandingan tersebut akan menghasilkan hasil
pencocokan terbaik yang akan dianggap sebagai pola yang dikenali jika
pasangan yang cocok tersebut memiliki nilai kemiripan yang melampaui nilai
threshold atau kriteria yang sebelumnya ditentukan (Pearson, 2001).
Gambar 2.11 Contoh template dari obyek huruf dan obyek wajah
Dalam template matching, menemukan cara alternatif dalam
menghitung dan merepresentasikan citra dengan waktu yang lebih singkat
dibatasi adanya citra template yang secara konten cukup serupa. Namun ada
beberapa efek samping yang perlu diperhatikan ketika menggambarkan data
(atribut dan template) secara hemat atau sedikit (Brunelli, 2009):
1. Kriteria penggolongan yang dikenakan pada data seringkali
memiliki parameter yang lebih sedikit untuk dihitung.
2. Sampel data yang lebih sedikit dibutuhkan untuk mewakili
pendekatan distribusi kemungkinan yang lebih baik.
3. Pengenalan pola dapat dilakukan dengan kecepatan yang lebih
tinggi apabila data yang dikerjakan lebih sedikit (atribut,
template, resolusi, dan sebagainya).
Hal-hal tersebut terkait dengan fakta bahwa volume sebuah data
meningkat sebanding dengan banyaknya dimensi data. Jika resolusi yang ada
diperbaiki dengan tujuan untuk lebih menjelaskan adanya distribusi data,
maka jumlah sampel juga akan meningkat secara eksponensial (Brunelli,
2009).
Jika hal tersebut dihubungkan dengan sebuah citra seperti citra wajah,
maka meskipun dibutuhkan ribuan piksel untuk merepresentasikan data, maka
hal tersebut tidak akan memenuhi semua kemungkinan dimensi citra yang
nantinya akan berisikan semua kemungkinan citra (Brunelli, 2009).
unik pola yang hanya s
sebelumnya. Perlu dii
variasi posisi, tidak d
karena adanya perbeda
bentuknya benar-benar
2.4 JarakMinimum Eucli
Dalam konteks
titik yang bisa diukur
Rumus jarak Euclidean
1996).
Gambar
Pada diagram
horizontal antara dua titi
jarak vertikalnya sebes
a sedikit berbeda dari template-template yang sud
diingat bahwa variasi pola seperti rotasi, ukur
dapat diatasi dengan mudah oleh template m
edaan orientasi antara input dengan template, w
ar identik (Pearson, 2001).
Euclidean
eks matematika, jarak Euclidean adalah jarak an ukur menggunakan suatu alat, seperti misalnya pe
ean bersumber dari theorema Phytagoras (Bog
ar 2.12 Diagram jarak antara dua titik
m seperti pada gambar 2.10 dapat terlihat bahw
a titik data yaitu (-2, 2) dan (-2, -1) adalah sebes
besar 3. Dengan menggunakan rumus Pythagora
sudah ada
ukuran, dan
matching
, walaupun
antara dua
penggaris.
ogomolny,
ahwa jarak
esar 4 dan
didapatkan bahwa jarak hypotenuse dari dua titik tersebut adalah =3 +4 sehingga didapatkan bahwa jarak hypotenuse adalah sebesar 5.
Berdasarkan rumus pengukuran jarak tersebut maka dapat dibuat
rumus jarak dengan metode yang sama, yang disebut jarak Euclidean.
Gambar 2.13 Rumus Jarak Euclidean
Penerapan rumus jarak ini dapat diuji dengan menggunakan data pada
gambar 2.10
Jarak ( (2,-1) , (2,2) ) = ( 2 −(−2) ) + ( (−1)−2)
= ( 2 + 2) + (−1−2)
= ( 4) + (−3)
= √16 + 9
= √25
= 5
Jika rumus jarak pada dua titik berbentuk segitiga diukur dengan
menggunakan rumus Phytagoras, maka untuk penerapan penghitungan jarak
dalam jarak dan kasus yang nyata, digunakan rumus jarak Euclidean. Penerapan ini digunakan karena ada banyak atribut yang menentukan ’jarak
yang nyata’ seperti kecepatan, bentuk permukaan bumi, dan lain sebagainya,
2.5 Huruf Hiragana
Sejarah berbagai huruf di jepang salah satunya diketahui berawal dari
jaman Kaisar Ojin sekitar 370 M yang memanggil dua sarjana Korea ke istana
untuk mengajar huruf dan literatur Tiongkok pada putra mahkota (Fischer,
2004). Huruf ini kemudian pada abad ke-8 berubah menjadi dua golongan
sistem penulisan yaitu kanbun dan wabun yang kelak akan mempengaruhi penulisan huruf jepang modern.
Kanbun menggunakan huruf tiongkok dan pengucapannya berusaha disesuaikan dengan lidah setempat. Sedangkan wabun menggunakan huruf tiongkok yang bunyi pengucapannya benar-benar independen dan berbeda dari
pengucapan huruf tiongkok tersebut. Huruf wabun kemudian berubah bentuk menjadi huruf hiragana dan katakana.
Huruf hiragana dan katakana merupakan huruf yang identik secara pengucapan (syllabaries), hanya berbeda pada tampilan luar dan penggunaannya, karena memiliki sistem yang sama, tapi tulisan yang berbeda
(Fischer, 2004).
Dilihat dari segi penggunaan tulisan, huruf Hiragana hanya digunakan untuk menulis kata-kata asli Jepang saja, sedangkan huruf Katakana
digunakan untuk menulis suatu kata serapan asing dan bunyi-bunyian.
Dilihat dari segi cara penulisan, perbedaan terlihat jelas pada tingkat
kursif / lengkungan huruf. Huruf Hiragana umumnya lebih bersifat kursif atau melengkung dibandingkan dengan huruf Katakana yang lebih bersifat anguler atau bergaris lurus (Fischer, 2004).
Pada akhir 1800 M, huruf hiragana dan katakana yang ada direduksi sehingga menjadi 96 buah huruf saja. Kemudian pada tahun 1900 M direduksi
lagi berdasarkan pengucapan, sehingga meninggalkan 92 huruf saja: 46 untuk
hiragana dan 46 untuk katakana (Fischer, 2004).
Masing-masing huruf Hiragana dan Katakana terdiri dari 46 lambang penulisan yang mewakili 46 huruf dasar, seperti dapat dilihat pada gambar
2.14. Selain suku kata ”n”, masing-masing huruf ini merupakan kombinasi
dari 5 bunyi hidup (a i u e o) dan konsonan.
Gambar 2.15 Karakter dasar huruf Hiragana dan Katakana
Huruf Hiragana dan Katakana dapat diperhalus maupun dipertajam bunyinya dengan menambahkan tanda di pojok kanan atas huruf. Dengan
ditambahnya tanda yang menyerupai tanda petik ganda atau lingkaran di pojok
kanan atas suatu huruf maka akan dapat diciptakan karakter Hiragana dan
Gambar 2.16 Karakter-karakter tambahan Hiragana
Selain menambahkan suatu tanda baca di pojok kanan atas dari suatu
huruf untuk menciptakan suatu huruf dan suku kata baru, penggabungan dua
buah karakter huruf Hiragana juga dapat menciptakan suatu bentuk pelafalan baru, seperti dapat dilihat pada gambar berikut:
Gambar 2.17 Karakter-karakter penggabungan 2 buah huruf Hiragana
Secara teoritis, huruf hiragana dapat digunakan untuk menulis seluruh tulisan Jepang, namun dalam prakteknya, huruf ini hanya digunakan untuk
akhiran kata, kata benda, dan kata sifat, partikel, dan beberapa kata-kata
Jepang asli yang tidak dituliskan dalam Kanji. Hal ini berbeda dengan huruf
29
BAB III
ANALISIS DAN PERANCANGAN SISTEM
Dalam membangun sebuah aplikasi untuk mengenali lima buah huruf Jepang
hiragana yang menjadi tujuan dari tugas akhir ini, dibutuhkan beberapa tahap
terstruktur yang akan membantu proses terbentuknya sebuah aplikasi sesuai yang
diinginkan.Tahap-tahap tersebut bertujuan agar aplikasi yang akan dibangun nantinya
akan sesuai dengan tujuan dan hasil akan yang dicapai sejak semula.
3.1 Gambaran Sistem
Sistem yang akan dibangun akan dipakai dalam mengenali huruf
Hiragana dan akan menggunakan metode pengukuran jarak minimum
Euclidean sebagai tolak ukur pengenalan polanya, sedangkan untuk
pengambilan ciri digunakan perluasan metode Feature Point Extraction.
Karakter huruf yang akan dikenali dalam sistem ini adalah 5 karakter huruf
dasar Hiragana, yaituhuruf ”ma”, ”mi”, ”mu”, ”me”, dan ”mo”.
Input data pada sistem berupa file gambar yang memiliki ekstensi *.jpg,
*.jpeg, *.bmp, atau *.png. Data berupa gambar yang telah diinputkan tersebut
kemudian akan dibinerisasi. Setelah dilakukan proses binerisasi, maka akan
dilakukan proses penghilangan pinggiran putih, perubahan ukuran menjadi
matriks 9x9, dan kemudian dilakukan segmentasi menjadi 9 buah matriks yang
masing-masing berukuran 3x3.
Karakter input yang sudah dimasukkan kemudian dapat dicocokkan
dengan tabel, setelah itu data dapat menjalani proses penghitungan jarak.
Setelah proses penghitungan jarak minimum tersebut selesai, maka aplikasi
akan menunjukkan data yang sudah diinputkan, hasil analisa citra, segmentasi,
Setelah proses penghitungan jarak minimum Euclidean selesai maka tiap posisi
piksel dalam citra input dan template akan ditinjau untuk mendapatkan
prosentase kemiripan.
Proses ini dilakukan dengan 3 tahap utama:
Tahap 1: Menganalisa data citra input dan citra template.
Tahap 2: Menghitung jarak data input dengan tiap-tiap template.
Tahap 3: Menentukan hasil analisa citra input dengan jarak Euclidean.
Tahap 4: Menghitung prosentase kemiripan berdasarkan nilai piksel.
Tahap awal dalam proses ini adalah pengolahan citra input yang terdiri
dari proses grayscaling, dan kemudian citra grayscale tersebut akan dikenai
thresholding yaitu binerisasi. Kemudian citra akan mengalami proses resizing
citra sehingga menjadi berukuran 9x9, dan kemudian citra akan dibagi atau
disegmentasi menjadi 9 bagian.
Data citra yang sudah dipisah menjadi 9 segmen tersebut kemudian akan
dicocokkan dengan tabel yang ada untuk pengambilan ciri, dan kemudian akan
dihitung dan dibandingkan dengan semua template yang ada berdasarkan jarak
Euclidean. Setelah template yang paling identik dengan input didapatkan maka
akan dihitung jumlah piksel dengan nilai yang sama dalam kedua citra tersebut.
3.2 Desain Proses
3.2.1 Proses segmentasi citra menjadi 9 bagian
Proses ini bertujuan untuk membagi citra gambar menjadi 9
bagian/segmen yang sebelumnya telah mengalami proses binerisasi. Citra
berukuran 9x9 yang telah didapatkan akan dipisahkan menjadi 9 bagian ,
yang masing-masing segmennya berukuran 3x3.
S_BL (1:3 , 1:3)
S_U (1:3 , 4:6)
S_TL (1:3 , 7:9)
S_B (4:6 , 1:3)
S_C (4:6 , 4:6)
S_T (4:6 , 7:9)
S_BD (7:9 , 1:3)
S_S (7:9 , 4:6)
S_TG (7:9 , 7:9)
Gambar 3.3 Diagram pembagian segmentasi
citra 9x9 Mulai
pembagian citra menjadi 9 segmen
Segmen S_BL, S_U,..., S_TG
Selesai
3.2.2 Proses pencocokan dengan tabel
Tiap segmen citra berukuran 3x3 yang terbentuk dari proses 3.2.1
akan dicocokkan dengan tiap nilai matrik dari tabel kemungkinan
ketetanggaan antar piksel yang berjumlah 512 (256 kemungkinan untuk
piksel tengah berwarna hitam, dan 256 kemungkinan untuk piksel tengah
berwarna putih).
Dari pencocokan tersebut akan diperoleh suatu nilai indeks yang
sesuai dengan tabel, dimana nilai indeks tersebut nantinya akan digunakan
sebagai fitur untuk tiap segmen.
3.2.3 Proses penghitungan jarak Euclidean dari data gambar
Proses ini bertujuan untuk menentukan tingkat kemiripan antara
huruf dari citra gambar yang dimasukkan dengan data dari
template-template yang telah ada. Gambar yang telah dihitung jarak Euclidean nya
tersebut kemudian akan memiliki nilai jarak yang beragam. Berdasarkan
nilai jarak Euclidean yang bervariasi tersebut kemudian akan diambil
jarak atau nilai yang paling minimum sehingga gambar citra input dapat
diidentifikasi.
Nilai fitur citra input (a2,b2,c2,…,i2)
Mulai
data dan nilai fitur dengan jarak paling minimum
Selesai Nilai fitur citra
template (A,B,C,…, I)
Perhitungan jarak Euclidean dengan tiap
template loop sebanyak jumlah
template (j= 1:jumlah template)
Membandingkan jarak paling minimum j ≤ jumlah template
j >jumlah template
Setelah proses penghitungan jarak Euclidean selesai dilakukan,
maka akan dicari template bersangkutan yang memiliki jarak paling
minimal, dan program akan mengidentifikasi huruf tersebut sebagai
golongan huruf yang sama dengan template tersebut.
3.2.4 Proses penghitungan persentase kemiripan
Untuk mencari persentase kemiripan antara citra input dan citra
template dengan jarak Euclidean paling minimum, akan diperiksa setiap
posisi piksel yang ada, apakah nilai citra input dan citra template pada
posisi tertentu memiliki nilai yang sama. Jumlah posisi piksel yang
bernilai sama akan disimpan dalam suatu variabel dan dibagi dengan
jumlah piksel yang ada.
Perhitungan matematis yang dipakai untuk mendapatkan dalam
proses ini adalah : Persentase kemiripan = × 100%
Dimana rate adalah jumlah piksel yang posisi dan nilainya sama,
dan jumlah piksel adalah jumlah keseluruhan piksel dari citra yang sudah
diresizing, yaitu sejumlah 81.
Berikut adalah diagram proses perhitungan persentase kemiripan
yang nantinya akan diterapkan dalam proses implementasi:
3.3 Analisis Kebutuhan
3.3.1 Use Case Diagram
Berikut adalah use case diagram dari sistem ini :
3.4 Logical Design
3.4.1 Context Diagram
Context diagram dari sistem ini dapat dilihat pada gambar 3.9 :
Gambar 3.9 Context Diagram
3.4.2 Data Flow Diagram Level 1
Data Flow Diagram dari sistem ini dapat dilihat pada gambar 3.10
berikut:
Sistem aplikasi pengenalan Huruf Jepang Hiragana memiliki dua
proses utama, yaitu proses pengolahan data gambar dan proses
penghitungan jarak Euclidean.
Proses pengolahan data gambar befungsi mengolah data gambar mulai
dari proses pengolahan citra binerisasi hingga proses thresholding, data
yang telah diolah tersebut kemudian dapat diukur jaraknya dengan
template yang telah ada sebelumnya, sehingga proses pengenalan dapat
dilakukan. Proses penghitungan jarak Euclidean befungsi untuk
menghitung jarak citra input yang dimasukkan oleh user, dengan tiap
template yang ada dalam library.
3.4.3 Data Flow Diagram Level 2 Proses Pengolahan Data Gambar
Detail proses Proses Pengolahan Data Gambar dari sistem ini dapat
dilihat pada gambar 3.16 berikut:
Dalam proses Pengolahan Data Gambar ini, gambar yang telah
dimasukkan oleh user akan mengalami proses thresholding yang meliputi
grayscaling dan binerisasi. Setelah proses binerisasi selesai, maka akan
dilakukan proses segmentasi menjadi 9 bagian, nilai data gambar yang
bersifat biner dari hasil segmentasi ini kemudian menjadi berukuran 3x3
untuk tiap segmennya. Tiap matriks dari segmen yang berukuran 3x3
tersebut kemudian akan dicocokkan dengan tabel yang berjumlah 512 dan
akan menghasilkan nilai tertentu. Nilai tiap segmen tersebut kemudian
akan dihitung dengan metode penghitungan jarak Euclidean untuk
mengetahui jarak terminimum antara citra input dengan citra template.
Sebagai akhir dari proses pengolahan gambar, hasil informasi yang
akan muncul berupa berupa gambar input, gambar grayscale, gambar
biner, dan gambar biner 9x9 yang telah disegmentasi menjadi 9 bagian
(masing-masing berukuran 3x3), akan ditampilkan pada user sebagai
output proses.
3.4.4 Entity Relationship Diagram
Context diagram dari sistem ini dapat dilihat pada gambar 3.17 :
3.5 Navigasi Menu
Berikut ini adalah alur navigasi dari semua menu yang dapat diakses
oleh user:
Gambar 3.18 Navigasi menu
Dalam aplikasi yang akan dibangun untuk mengenali tulisan tangan
Hiragana ini, terdapat 5 buah menu, yaitu Menu Home, Proses, Daftar Hiragana,
Bantuan, dan Tentang Program. Berikut ini adalah menu-menu tersebut dan
kegunaannya:
Home : Menuju ke halaman awal progam
Proses : Melakukan proses penghitungan untuk
mengenali pola berdasarkan template yang
Daftar Hiragana : Menampilkan daftar huruf Hiragana yang
ada, yaitu 46 huruf Hiragana dasar.
Bantuan : Menampilkan informasi mengenai petunjuk
penggunaan program
Tentang Program : Menampilkan informasi program dan kebutuhan
minimum untuk spesifikasi Hardware
Selain menu-menu tersebut, terdapat menu untuk keluar dari program
yang dapat dijalankan dengan cara menekan tanda ”x” di pojok kanan
atas tampilan program, dan menu minimize yang dapat diakses dengan
3.6 Desain User Interface
Berikut ini adalah rancangan desain user interface dari aplikasi yang
akan dibangun untuk mengenali karakter huruf Jepang Hiragana.
3.6.1 Halaman Utama (Home)
Gambar 3.19 Desain interface Home
Halaman utama / Home ini merupakan tampilan aplikasi yang
pertama kali akan ditemui oleh user. Pada halaman ini user dapat mulai
melihat daftar huruf Hiragana dasar, melihat tentang program, ataupun
melihat menu bantuan, dengan cara memilih menu yang ada di atas
tampilan aplikasi. Untuk keluar dari program user dapat menekan tanda ”x”
3.6.2 Input Gambar
Gambar 3.20 Desain interface Input Gambar
Pada halaman ini, user dapat memulai proses pengenalan pola
dengan memilih gambar yang akan dianalisa. Pemilihan input huruf
Hiragana dapat dilakukan dengan memilih salah satu gambar yang bertipe
*.jpg, *.jpeg, *.bmp, ataupun *.png.
Proses pemilihan gambar dapat dilakukan dengan menekan
tombol ”cari”, kemudian user dapat memilih gambar lewat menu explorer.
Alamat dari gambar yang dituju kemudian akan muncul pada field ”Lokasi
file”. Setelah proses pemilihan gambar selesai, user dapat melihat gambar
dengan menekan tombol ”lihat”. Kemudian user dapat menganalisa
3.6.3 Kesimpulan Pengenalan Pola
Gambar 3.21 Desain interface Kesimpulan
Halaman Kesimpulan ini akan muncul setelah tombol “Proses” pada
halaman “Input Data Huruf” sebelumnya ditekan. Dalam halaman ini akan
ditampilkan hasil dari proses pengolahan citra gambar yang telah
dilakukan dan juga hasil analisa kesimpulan dari pengenalan pola
menggunakan metode Feature Point Extraction dan Jarak Euclidean.
Untuk memasukkan gambar lainnya user dapat menekan tombol ”Ulangi”
3.6.4 Pemberitahuan Kesalahan
Gambar 3.22 Desain interface Bantuan
Halaman ”Pemberitahuan Kesalahan” ini akan ditampilkan pada
user bila terdapat suatu kesalahan pada proses yang dijalani. Yang
termasuk dalam kesalahan yang dimaksud adalah:
- File gambar yang diinputkan pada proses ”Input Data Huruf”
semuanya berwarna putih (gambar kosong)
- Pada saat proses ”Input Data Huruf”, tidak ada data citra yang
3.6.5 Daftar Hiragana
Gambar 3.23 Desain interface Daftar Hiragana
Halaman ”Daftar Hiragana” ini dapat ditampilkan pada user dengan
menekan menu file ” Daftar Hiragana” dan kemudian akan muncul
halaman ” Daftar Hiragana”. Pada halaman ini user dapat mengetahui
3.6.6 Tentang Program
Gambar 3.24 Desain interface Tentang Program
Halaman ”Tentang Program” ini dapat ditampilkan pada user
dengan menekan menu file ” Tentang Program” dan kemudian akan
muncul halaman ” Tentang Program”. Pada halaman ini user dapat
melihat informasi umum tentang program ini dan kebutuhan minimum
3.6.9 Bantuan
Gambar 3.25 Desain interface Bantuan
Halaman ”Bantuan” ini dapat ditampilkan pada user dengan
menekan menu file ” Bantuan” dan kemudian akan muncul
halaman ”bantuan”. Pada halaman ini user dapat mendapatkan informasi
tentang petunjuk penggunaan program, sehingga user dapat mengerti cara
dan langkah penggunaan program. User dapat menekan
tombol ”Selanjutnya” atau ”Kembali” untuk memilih topik bantuan yang
3.7 Spesifikasi Hardware dan Software Untuk Membangun Sistem
Berikut ini adalah spesifikasi hardware dan software yang digunakan
dalam membangun aplikasi yang bertujuan untuk mengenali huruf Jepang
Hiragana:
3.7.1 Hardware
3.7.1.1 AMD Athlon 64 Processor 1.81 GHz
3.7.1.2 DDR 512MB Visipro
3.7.1.3 Radeon 9250 GECUBE
3.7.1.4 HDD Seagate 80GB SATA
3.7.2 Software
3.7.2.1 Microsoft Windows XP Professional Service Pack 2
3.7.2.2 Matlab 7
3.7.2.3 Adobe Photoshop 7
3.8 Spesifikasi Hardware dan Software Untuk Menjalankan Sistem
Berikut ini adalah spesifikasi hardware dan software yang dapat
digunakan untuk menjalankan aplikasi pengklasifikasikan huruf Jepang
Hiragana:
3.8.1 Hardware
3.8.1.1 AMD Sempron
3.8.1.2 DDR 512MB Visipro
3.8.1.3 Radeon 9250 GECUBE
3.8.1.4 HDD Seagate 40GB SATA
3.8.2 Software
3.8.2.1 Microsoft Windows XP Professional Service Pack 2
53
BAB IV
IMPLEMENTASI SISTEM
4.1 Implementasi Proses
4.1.1 Proses Binerisasi
Proses Binerisasi berfungsi untuk mengkonversi citra gambar
masukan user yang sudah diubah sebelumnya menjadi citra grayscale (8
bit), menjadi citra yang hanya berwarna hitam dan putih saja (1 bit).
Proses binerisasi ini dilakukan dengan level threshold 0.75, dengan kata
lain bagian citra yang derajat keabuannya diatas 0.75 akan dianggap
sebagai warna putih (bernilai 1) dan yang dibawah atau sama dengan
0.75 akan dianggap sebagai warna hitam (0).
function BW=binerisasi(citra_gs)
BW = im2bw(citra_gs,0.75);
4.1.2 Proses Segmentasi Citra
Proses segmentasi citra dilakukan untuk mendapatkan
bagian-bagian citra yang sudah dipecah-pecah menjadi 9 bagian-bagian, sehingga proses
ekstraksi ciri dapat dilakukan.
function [A,B,C,D,E,F,G,H,I]=feature_ex(pola_15)
% segmentasi pola menjadi 9 bagian A-I
S_BL = pola_15(1:3,1:3); %ambil matrik baris 1-3 kolom 1-3
S_C = pola_15(4:6,4:6); S_T = pola_15(4:6,7:9); S_BD = pola_15(7:9,1:3); S_S = pola_15(7:9,4:6); S_TG = pola_15(7:9,7:9);
4.1.3 Proses Pencocokan dengan Tabel dan Ekstraksi Ciri
Proses ekstraksi ciri dilakukan dengan mencocokkan bagian-bagian
citra yang sudah dipecah sebelumnya dengan tabel. Tabel tersebut berisi
semua kemungkinan keanggotaan antar piksel. Masing-masing
kemungkinan memiliki nilai yang selanjutnya dapat digunakan untuk
proses pengenalan pola dengan metode perluasan feature point extraction
dan jarak euclidean.
% hitung nilai tiap segmen berdasarkan tabel
A=tabel(S_BL); B=tabel(S_U); C=tabel(S_TL); D=tabel(S_B); E=tabel(S_C); F=tabel(S_T); G=tabel(S_BD); H=tabel(S_S); I=tabel(S_TG);
function derajat=proses_tabel(input)
% matrik 3x3 untuk pixel tengah hitam
( semua kemungkinan sampai dengan)
m{509} = [0 1 1; 0 1 0; 0 0 0]; m{510} = [0 0 1; 0 1 0; 0 0 0]; m{511} = [0 1 0; 0 1 0; 0 0 0]; m{512} = [0 0 0; 0 1 0; 0 0 0];
% loop to match every matrix value
% if image input = matrix value
for i=1:512
if (input == m{i}) nilai=i-1; break; end
end
4.1.4 Proses Penghitungan Jarak Euclidean
Proses ini dilakukan untuk mencocokkan data input berupa citra
huruf hiragana dengan setiap template yang ada dalam program. Proses
ini kemudian dilanjutkan dengan penghitungan jarak dengan metode
Jarak Euclidean dan mencari jarak paling minimum dari semua template
yang ada.
% pola input
[a2,b2,c2,d2,e2,f2,g2,h2,i2]=feature_extract(pola);
% pola template
template_in=data_templates;
%[A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y]=templa te_extract(template_in);
[A,B,C,D,E,F,G,H,I,template_15]=template_extract(template_i n);
% menghitung jarak euclidean input dengan tiap template
for j=1:length(template_in) % uji untuk setiap template yg ada dr jrk min sebelumnya
jarak_min=jar{j};
indeks_template=j; % dapatkan indeks template dgn jarak terminimum dgn inputan
end
% menemukan indeks template ma=1,mi=2,mu=3,me=4,mo=5
indeks_template_yang_sesuai = mod(indeks_template,5); jawab=0;
if indeks_template_yang_sesuai==1 hiragana=imread('pics/ma.gif');
axes('position',[0.53 0.4 0.18 0.18]);
else if indeks_template_yang_sesuai==2 hiragana=imread('pics/mi.gif');
axes('position',[0.53 0.4 0.18 0.18]); imshow(hiragana);
uicontrol(...
'Units','normalized',... else if indeks_template_yang_sesuai==3
'FontName','Arial',...
'FontSize',10,...
'FontWeight','Bold',...
'ForegroundColor',[0 0 0],...
'BackgroundColor',[1 1 1],...
'HorizontalAlignment','left',...
'String','Dikenali sebagai huruf "MO" ');
end
end
end
end end
4.1.5 Proses Penghitungan Persentase Kemiripan
Peroses ini dilakukan dengan cara menghitung persentase kemiripan
antara tiap piksel citra input dengan tiap piksel citra template. Citra
template yang digunakan dalam proses ini adalah citra template hasil
proses penghitungan jarak Euclidean (proses 4.1.4), yang mana jarak
Euclideannya poaling minimum bila dibandingkan dengan template yang
lain. Persentase kemiripan dihitung dengan mencari jumlah piksel yang
cocok dalam kedua citra tersebut dibagi dengan jumlah piksel yang ada :
% menentukan persentase kemiripan berdasarkan posisi tiap piksel
rate=0;
for i=1:9 for j=1:9
if( pola(i,j) == template_15{indeks_template}(i,j) ) rate=rate+1;
end
end end
persentase=round((rate/81)*100);
4.2.1 Menu Utama Aplikasi
Implementasi interface yang muncul sebagai splash screen adalah
sebagai berikut:
Gambar 4.1 Menu Utama Aplikasi
4.2.2 Menu Bantuan Aplikasi
Implementasi interface yang muncul sebagai menu bantuan adalah
4.2.3 Menu Daftar Tabel Hiragana
Tampilan berikut akan muncul jika user memilih menu Hiragana, yang
berisikan dafta 46 huruf hiragana yang ada. Dalam interface ini juga
ditampilkan 5 buah huruf hiragana yang akan dikenali dalam aplikasi ini,
yang ditandai dengan lingkaran berwarna merah:
4.2.4 Menu Tentang Program
Tampilan berikut akan muncul jika user memilih menu ”About” yang
berisikan tentang penyusun tugas akhir:
4.2.5 Menu Pemilihan Gambar
Implementasi interface yang akan muncul sebagai form pemilihan
gambar adalah sebagai berikut:
4.2.6 Menu Pemberitahuan Kesalahan
Tampilan berikut akan muncul jika user melakukan keslaahan pada
saat proses pemasukan gambar, misalnya ketika user tidak memasukkan
gambar citra dan langsung menekan tombol ”Proses”: