RELEVANCE FEEDBACK PADA TEMU KEMBALI TEKS
BERBAHASA INDONESIA DENGAN METODE IDE-DEC-HI
DAN IDE-REGULAR
Oleh:
Andika Wahyu Agusetyawan
G64101007
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
RELEVANCE FEEDBACK PADA TEMU-KEMBALI TEKS
BERBAHASA INDONESIA DENGAN METODE IDE-DEC-HI
DAN IDE-REGULAR
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh:
Andika Wahyu Agusetyawan
G64101007
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
ANDIKA WAHYU AGUSETYAWAN. Relevance Feedback pada Temu Kembali Teks Berbahasa Indonesia dengan Metode Ide-Dec-Hi dan Ide-Regular. Dibimbing oleh JULIO ADISANTOSO dan AHMAD RIDHA.
Tujuan penelitian ini adalah mengimplementasikan dan menganalisis kinerja perluasan kueri dengan relevance feedback pada sistem temu kembali informasi untuk dokumen berbahasa Indonesia. Metode relevance feedback yang digunakan adalah Ide-Dec-Hi dan Ide-Regular. Untuk kepentingan pengujian, penelitian ini juga melengkapi corpus yang digunakan dengan 30 kueri disertai gugus jawabannya. Evaluasi kinerja relevance feedback dilakukan menggunakan test and control group. Masing-masing group terdiri atas 500 dokumen yang berupa artikel-artikel pertanian berbahasa Indonesia dari berbagai situs media massa. Sistem dasar yang digunakan adalah sistem temu kembali berbasis vector space model hasil penelitian Ridha (2002). Sistem ini melakukan rule-based stemming sekaligus memakai stoplist untuk bahasa Indonesia. Variasi jumlah dokumen yang diperiksa yakni lima dan sepuluh.
Hasil penelitian menunjukkan bahwa relevance feedback secara keseluruhan meningkatkan kinerja sistem temu kembali. Siklus relevance feedback dalam penelitian ini telah menunjukkan hasil memuaskan pada iterasi pertama. Peningkatan kinerja terbesar diperoleh ketika menggunakan formula Ide-Dec-Hi. Hasil ini sesuai dengan hasil penelitian Ruthven & Lalmas (2003). Kinerja sistem tanpa relevance feedback adalah 0.447 sedangkan dengan Ide-Dec-Hi mencapai 0.516, meningkat 15.44%. Sementara menggunakan Ide-Regular peningkatan yang diperoleh adalah 14.54%, menjadi 0.512. Dari perbandingan query-by-query dapat disimpulkan bahwa penggunaan relevance feeback tidak terlalu membantu pada kueri yang kinerja awalnya memang sudah tinggi. Sebaliknya, untuk kueri-kueri yang memberikan hasil buruk pada pencarian awal, relevance feedback sangat cocok untuk digunakan dan menjanjikan peningkatan kinerja yang cukup tinggi.
Kata Kunci: Temu Kembali Informasi, Relevance Feedback, formula Rocchio, Ide-Dec-Hi dan Ide-Regular.
Judul :
Relevance Feedback pada Temu Kembali Teks Berbahasa
Indonesia dengan Metode Ide-Dec-Hi dan Ide-Regular
Nama
: Andika Wahyu Agusetyawan
NRP
: G64101007
Menyetujui:
Pembimbing I,
Ir. Julio Adisantoso, M.Kom
NIP 131578807
Pembimbing II,
Ahmad Ridha, S.Kom
NIP 132311931
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. Ir. Yonny Koesmaryono, MS
NIP 131473999
RIWAYAT HIDUP
Penulis dilahirkan di Kendal pada tanggal 14 Agustus 1983 dari ayah Sugeng dan ibu Sri Wahyuni. Penulis merupakan putra kedua dari dua bersaudara. Tahun 2001 penulis lulus dari SMU Negeri 1 Kendal dan pada tahun yang sama diterima di IPB melalui jalur Undangan Seleksi Masuk IPB (USMI). Penulis memilih Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Pada tahun 2005 penulis menjalankan praktek lapangan di Rumah Sakit Azra Bogor, Divisi Sistem Informasi Rumah Sakit selama kurang lebih dua bulan. Di tahun yang sama penulis berkesempatan menjadi pengembang Sistem Informasi Akademik Universitas Winaya Mukti di Jatinangor, Sumedang. Pada bulan Agustus tahun 2005 penulis beserta dua rekan seangkatan mendirikan CV INTEGRA SOLUSI AKSESINDO, sebuah perusahaan konsultan teknologi informasi yang berlokasi di Bogor.
PRAKATA
Alhamdulillah wa syukrulillah penulis panjatkan ke hadirat Allah Subhanahu wa ta’ala atas segala rahmat, kasih sayang, hidayah dan cinta-Nya sehingga skripsi ini berhasil diselesaikan. Shalawat serta salam selalu untuk Nabi Muhammad Shallalahu ‘alaihi wasallam beserta seluruh sahabat dan umatnya hingga akhir zaman. Tema yang dipilih pada penelitian ini adalah temu kembali informasi, dengan judul Relevance Feedback pada Temu Kembali Teks Berbahasa Indonesia Dengan Metode Ide-Dec-Hi dan Ide-Regular.
Penulis sampaikan terima kasih kepada semua pihak yang telah membantu dan memberikan pengalaman yang menyenangkan selama melakukan penelitian ini. Khususnya kepada Bapak Ir. Julio Adisantoso, M.Kom dan Bapak Ahmad Ridha, S.Kom serta Ibu Yeni Herdiyeni, S.Si, M.Kom yang telah memberikan begitu banyak masukan, bimbingan dan pelajaran berharga selama menjadi pembimbing dan penguji. Selanjutnya penulis juga ingin mengucapkan terima kasih kepada:
1. Keluarga tercinta, khususnya kedua orang tua penulis atas rasa cinta, kasih sayang, kesabaran, dukungan dan doa yang tak pernah berhenti, yang selalu meringankan langkah penulis bahkan di saat-saat terberat sekalipun. Terima kasih juga kepada Mas A’an yang selalu memberi inspirasi, semangat dan ide-ide baru.
2. Ratna Purnama Sari, yang dengan kesabarannya dan keceriaannya semakin memantapkan langkah penulis di setiap harinya.
3. Sahabat-sahabat Ilkom angkatan 38, terimakasih atas persahabatan kita yang penuh gelak tawa selama ini.
4. Sahabat-sahabat ‘serumah’ di Pakuan.
5. Departemen Ilmu Komputer, staf dan dosen yang telah begitu banyak membantu baik selama pelaksanaan skripsi ini maupun sebelumnya.
Kepada semua pihak lainnya yang telah memberikan kontribusi yang besar selama pengerjaan penelitian ini yang tidak dapat disebutkan satu-persatu, terima kasih.
Semoga penelitian ini dapat memberikan manfaat.
Bogor, Januari 2006
DAFTAR ISI
Halaman
DAFTAR TABEL ... viii
DAFTAR GAMBAR ... ix DAFTAR LAMPIRAN ... x PENDAHULUAN ... Latar Belakang ... 1 Tujuan ... 1 Ruang Lingkup ... 1 TINJAUAN PUSTAKA Information Retrieval System (Sistem Temu Kembali Informasi) ... 1
Query (Kueri) ... 2
Daftar Kata Buang... 2
Stemming ... 2
Vector Space Model (VSM) ... 2
Pembobotan Istilah... 2
Query Expansion (Perluasan Kueri) dan Relevance Feedback... 3
Pembobotan dan Pemilihan Istilah ... 3
Corpus ... 4
Recall –Precision ... 4
Average Precision (AVP)... 4
Algoritma RF... 4
METODOLOGI Algoritma RF ... 5
Sistem Temu Kembali dan Evaluasinya ... 5
Evaluasi RF... 5
Corpus... 6
Asumsi-asumsi... 6
Lingkungan Pengembangan... 7
HASIL DAN PEMBAHASAN Gugus Kueri dan Gugus Jawaban ... 6
Evaluasi RF... 6
KESIMPULAN DAN SARAN Kesimpulan ... 9
Saran ... 10
DAFTAR TABEL
Halaman
1. Deskripsi koleksi pengujian ... 7
2. Contoh hasil pooling beberapa kueri... 7
3. Perbandingan nilai average precision sebelum dan setelah menggunakan RF ... 8
DAFTAR GAMBAR
Halaman
1. Kurva recall-precision RG5 dan DH5 pada iterasi ke-1 ... 9
2. Kurva recall-precision RG10 dan DH10 pada iterasi ke-1 ... 9
3. Kurva recall-precision RG5 dan DH5 pada iterasi ke-2 ... 9
DAFTAR LAMPIRAN
Halaman
1. Proses penemukembalian informasi (Baeza-Yates & Ribeiro-Neto 1999) ... 13
2. Antarmuka implementasi ... 14
3. Contoh dokumen dalam koleksi... 15
4. Contoh kueri dan deskripsinya... 16
5. Gugus kueri dan gugus jawaban ... 17
1
PENDAHULUAN
Latar Belakang
Sejalan dengan semakin populernya penggunaan Internet dan Perpustakaan Digital, informasi dalam jumlah yang luar biasa besar kini bisa diakses secara luas oleh masyarakat, suatu hal yang tidak tersedia di masa lalu. Akan tetapi bersamaan dengan itu, muncul masalah baru. Pengguna kini harus menyaring seluruh kumpulan informasi tersebut untuk menemukan kebutuhan informasinya. Bahkan setelah melalui bantuan search engine pun, yang rata-rata kini telah mengindeks milyaran halaman Web dari beragam kategori, setelah disaring melalui penggunaan kata kunci, pengguna seringkali belum bisa menemukan dokumen yang relevan dengan informasi yang dicarinya.
Dalam temu kembali informasi, jumlah dokumen relevan yang ditemukembalikan akan dipengaruhi oleh jumlah kata kunci yang digunakan untuk pencarian. Dalam Web, pencarian pada umumnya dilakukan menggunakan kueri pendek, hanya kurang dari tiga kata (Spink et al. 2000). Hal ini cukup menyulitkan karena kueri pendek hanya menyediakan sedikit informasi bagi sistem temu kembali mengenai kebutuhan pencarian pengguna. Sebagai hasilnya adalah meskipun jumlah dokumen yang ditemukembalikan banyak akan tetapi hanya sedikit yang dianggap relevan oleh pengguna.
Masalah lain yang sering terjadi dalam Web dan Perpustakaan Digital adalah pilihan kata yang digunakan pengguna dalam kueri seringkali berbeda dengan pilihan kata yang yang digunakan penulis dalam dokumen. Bahkan ketika beberapa pengguna memiliki kebutuhan informasi yang sama, jarang mereka menggunakan pilihan kata yang sama untuk menggambarkannya dalam kueri (Xu & Croft 2005). Beberapa pendekatan dalam temu kembali informasi telah dilakukan untuk menangani perbedaan ini.
Salah satu pendekatannya adalah penggunaan relevance feedback. Dalam pendekatan ini sistem menemukembalikan dokumen-dokumen yang mungkin relevan bagi kueri pengguna, selanjutnya pengguna memeriksa beberapa dokumen tersebut dan menandai dokumen yang dianggap relevan. Informasi ini digunakan oleh sistem untuk memodifikasi atau menambahkan kata dalam kueri dan diharapkan meningkatkan hasil pencarian. Siklus ini bisa terus diulang sampai
pengguna merasa kebutuhan informasinya telah terpenuhi.
Tujuan
Penelitian ini bertujuan mengimplementasikan dan menganalisis kinerja perluasan kueri dengan relevance feedback pada sistem temu kembali informasi untuk dokumen berbahasa Indonesia.
Ruang Lingkup
Penelitian ini dibatasi pada analisis kinerja relevance feedback pada sistem temu kembali informasi berbahasa Indonesia menggunakan formula Ide-Dec-Hi dan Ide-Regular. Model sistem temu kembali yang digunakan adalah vector space model.
TINJAUAN PUSTAKA
Information Retrieval System (Sistem Temu
Kembali Informasi)
Tujuan utama sebuah information retrieval system (IRS) adalah menemukembalikan informasi yang mungkin berguna atau relevan bagi pengguna sesuai dengan kueri yang telah dimasukkannya. Penekanannya adalah pada penemukembalian informasi, bukan data (Baeza-Yates & Ribeiro-Neto 1999). Kerangka proses penemukembalian informasi dapat dilihat pada Lampiran 1.
IRS memberikan pengguna kemampuan untuk bisa mengakses informasi elektronik dalam jumlah yang sangat besar dalam waktu yang relatif singkat. Informasi tersebut bisa berupa dokumen teks, halaman web, gambar, audio atau video.
Sejumlah fitur membedakan IRS dengan sistem pencarian informasi yang lain, antara lain IRS tidak menyaring dan tidak pula memproses informasi yang terkandung dari objek informasi yang diaksesnya. Data yang diakses IRS juga biasanya tidak berstruktur, begitu pula informasi yang diterimanya (Ruthven & Lalmas 2003). Berbeda dengan sistem basisdata yang kuerinya terikat dalam aturan tertentu, IRS bisa menangani kueri seperti “Bagaimana keadaan perekonomian Irak setelah jatuhnya rezim Saddam Husein?” atau “Apa saja penelitian di bidang temu kembali informasi yang telah dilakukan mahasiswa Indonesia?”. IRS pada dasarnya memang ditujukan untuk menangani permintaan informasi yang jawabannya tidak harus unik atau objektif.
2
Query (Kueri)
Menurut Baeza-Yates & Ribeiro-Neto (1999), kueri adalah pernyataan kebutuhan informasi pengguna dalam bentuk masukan berupa bahasa yang dikenali oleh sistem informasi. Jenis bahasa masukan sederhana yang paling banyak digunakan adalah kata kunci dan beberapa penghubung berupa ekspresi Boolean.
Daftar Kata Buang
Salah satu langkah dalam pengindeksan adalah menghilangkan istilah-istilah yang sangat sering muncul dalam koleksi dan yang tidak membantu penemukembalian dokumen relevan. Daftar istilah-istilah yang dihilangkan ini disebut daftar kata buang (stoplist). Daftar kata buang dapat berupa daftar yang dibuat secara umum yang bisa digunakan pada kebanyakan jenis koleksi atau daftar yang khusus dibuat untuk satu koleksi tertentu. (Ruthven & Lalmas 2003). Daftar kata buang biasanya kebanyakan terdiri dari kata sandang dan kata penghubung (Selberg 1997). Semisal “sang”, ”si”, ”namun”, dan “tetapi”.
Stemming
Istilah bisa muncul dalam berbagai variasi linguistik dari kata yang sama. Sebagai contoh, kata “petani” dan “bertani” sebenarnya berasal dari satu bentuk dasar yaitu “tani”. Dalam sistem temu kembali hal ini akan cukup menyulitkan pengguna karena ketika pengguna memasukkan kueri ”bertani”, sistem akan menemukembalikan semua dokumen yang mengadung kata “bertani” tapi tidak yang mengandung kata “petani”.
Untuk menghindari kesulitan tersebut sehingga pengguna tidak perlu mencoba semua kemungkinan variasi untuk setiap kata dalam kueri, banyak sistem temu kembali yang mengubah istilah-istilahnya ke bentuk dasarnya. Proses ini disebut stemming (Ruthven & Lalmas 2003).
Vector Space Model (VSM)
Vector space model merupakan model temu kembali yang paling populer sekaligus sederhana (Baeza-Yates & Ribeiro-Neto 1999). Berikut adalah beberapa definisi matematika yang digunakan dalam VSM (Selberg 1997):
1. D={d0, d1, ..., dN} adalah himpunan N
dokumen dalam koleksi. d mengacu pada sembarang dokumen di
∈
D.2. T={t0, t1, ..., tm } adalah himpunan m
istilah yang terindeks dalam D. t mengacu pada sembarang istilah ti
∈
T.3. wi adalah bobot dari istilah ti. Bobot bisa
diartikan sebagai suatu nilai numerik yang menyatakan tingkat kepentingan sebuah istilah.
4. di adalah sebuah dokumen tunggal,
direpresentasikan sebagai vektor berdimensi m, di=[wi1, wi2, ..., wim] dengan
wij adalah bobot istilah tj dalam dokumen
di. Dalam kasus paling sederhana, wij
bernilai 1 jika istilah tj muncul dalam
dokumen di, dan wij bernilai 0 jika
sebaliknya.
5. Q adalah kueri yang direpresentasikan sebagai sebuah vektor berdimensi m, mirip dengan dokumen, Q=[w1, w2, ...,wm]
dengan wi adalah bobot istilah ti dalam Q.
Hasil penemukembalian ditampilkan berupa daftar dokumen yang telah teranking berdasar tingkat kesamaan dokumen dengan kueri. Ukuran kesamaan sim(dj,q) antara
dokumen di dan kueri Q dihitung
menggunakan kosinus sudut antara di dan Q
sebagai berikut (Baeza-Yates & Ribeiro-Neto 1999):
(
)
||
||
||
||
,
Q
d
Q
d
Q
d
sim
i i i×
•
=
. Pembobotan IstilahPembobotan dilakukan terhadap istilah-istilah yang berada dalam dokumen koleksi. Sistem temu kembali yang paling sederhana memboboti dengan bobot biner, 1 jika istilah itu muncul di dokumen dan 0 jika sebaliknya. Semakin canggih suatu sistem temu kembali, semakin kompleks skema pembobotannya. Berbagai macam penelitian dalam temu kembali informasi selama bertahun-tahun telah menunjukkan bahwa pembobotan yang optimal didapatkan melalui penggunaan fungsi tf*idf (Liddy 2001). Pada fungsi tf*idf bobot istilah ke-i pada dokumen ke-j dihitung dari perkalian term frequency dan inverse document frequency yang dinyatakan sebagai berikut (Baeza-Yates & Ribeiro-Neto 1999):
idf
tf
w
i,j=
*
, selanjutnya(
l,j)
l j ifreq
max
freq
tf
=
, ,3
dengan freqi,j merupakan frekuensi
kemunculan istilah ke-i dalam dokumen ke-j, maxl(freql,j) sebagai frekuensi maksimum
istilah-istilah yang berada dalam dokumen ke-jdan i
n
N
log
idf
=
,dengan N adalah jumlah total dokumen dalam koleksi serta ni merupakan jumlah dokumen
yang mengandung istilah ke-i.
Query Expansion (Perluasan Kueri) dan Relevance Feedback
Menurut Selberg (1997), perluasan kueri adalah sekumpulan teknik untuk memodifikasi kueri dengan tujuan untuk memenuhi sebuah kebutuhan informasi. Seringnya modifikasi dilakukan dengan penambahan istilah ke dalam kueri, meskipun sebenarnya perluasan kueri juga meliputi penyesuaian bobot dan penghapusan istilah kueri.
Perluasan kueri bisa dilakukan dengan salah satu dari dari tiga metode berikut: 1. Manual Query Expansion (MQE)
Menggunakan metode ini pengguna memodifikasi kueri secara manual. Sistem tidak memberikan bantuan sama sekali kepada pengguna.
2. Automatic Query Expansion (AQE)
Dalam metode ini sistem akan memodifikasi kueri secara otomatis tanpa perlu bantuan kendali dari pengguna. Beberapa teknik yang biasa digunakan antara lain:
a. Global Analysis (GA)
GA beroperasi dengan cara memeriksa seluruh dokumen yang ada dalam koleksi untuk membangun suatu struktur yang mirip dengan tesaurus. Menggunakan tesaurus ini, kueri akan diperluas dengan istilah-istilah yang dianggap berhubungan erat dengan istilah kueri dalam ruang lingkup koleksi (Baeza-Yates & Ribeiro-Neto 1999).
b. Local Analysis (LA)
Dalam LA, sistem menemu-kembalikan dokumen dengan sebuah kueri awal, memilih dan memeriksa sejumlah dokumen dengan ranking teratas, mengasumsikan bahwa dokumen-dokumen teratas tersebut relevan, untuk kemudian
membangkitkan sebuah kueri baru (Baeza-Yates & Ribeiro-Neto 1999). c. Local Context Analysis (LCA)
LCA merupakan sebuah teknik baru yang mengkombinasikan GA dan LA. Berdasar penelitian Xu dan Croft (1996), LCA mampu mengalahkan efektifitas dan konsistensi dari GA dan LA.
3. Interactive Query Expansion (IQE) IQE mencakup metode-metode yang di dalamnya pengguna melakukan interaksi dengan sistem dalam proses perluasan kueri. Teknik yang tercakup di dalamnya adalah relevance feedback dan teknik inilah yang menjadi topik dalam penelitian ini.
Relevance feedback (RF) adalah metode yang sudah diterima secara luas untuk meningkatkan keefektifan penemu-kembalian secara interaktif. Sebuah pencarian awal dilakukan oleh sistem menggunakan kueri yang diberikan oleh pengguna dan sebagai hasilnya menemu-kembalikan sejumlah dokumen. Pengguna memeriksa dokumen-dokumen tersebut dan menandai dokumen yang dianggap relevan. Sistem kemudian secara otomatis memodifikasi kueri berdasar penilaian relevansi pengguna tadi. Kueri baru dijalankan untuk menemukembalikan kumpulan dokumen yang lebih relevan. Proses ini dapat berulang hingga pengguna merasa kebutuhan informasinya terpenuhi (Buckley et al. 1994 ).
Penelitian yang dilakukan Ruthven dan Lalmas (2003) melalui simulasi yang dilakukan pada pengguna berpengalaman, menyimpulkan bahwa IQE memberikan peningkatan kinerja yang lebih stabil daripada AQE. Sementara Belkin et al. (1997) menunjukkan bahwa kinerja RF tidak lebih buruk dibandingkan LCA.
Pembobotan dan Pemilihan Istilah
Teknik RF biasanya berfokus pada salah satu dari dua pendekatan berikut:
1. Pembobotan Istilah, adalah sebuah proses yang di dalamnya istilah-istilah kueri diboboti atau disesuaikan bobotnya. Bobot masing-masing istilah akan berbeda, bergantung pada tingkat kepentingan istilah tersebut untuk menemukembalikan tambahan dokumen relevan.
2. Pemilihan Istilah, adalah sebuah proses penambahan, atau dalam beberapa kasus, penghapusan istilah-istilah kueri. Biasanya
4
pemilihan istilah diimplementasikan dengan menggunakan sebuah formula perankingan untuk mengurutkan seluruh istilah yang menjadi kandidat, dan kemudian memilih x kandidat teratas (Selberg 1997).
Corpus
Istilah corpus terutama dikenal dalam bidang linguistik yang pada prinsipnya bermakna koleksi yang memiliki lebih dari satu teks. Suatu corpus modern memiliki beberapa karakteristik yakni (McEnery & Wilson 2001):
1. Sampling & representativeness 2. Finite size
3. Machine-readable form 4. A standard reference
Menurut Hiemstra & Leeuwen (2001), suatu corpus pengujian sistem temu kembali informasi terdiri dari koleksi dokumen, topik-topik, yang dapat digunakan sebagai kueri, dan penilaian relevansi sebagai daftar dokumen yang relevan dengan topik-topik yang tersedia.
Corpus dapat menyediakan pendekatan yang seragam dalam evaluasi kinerja sistem temu kembali informasi. Teknik evaluasi ini juga digunakan dalam Text Retrieval Conference (TREC).
Dalam TREC, daftar dokumen relevan untuk setiap topik/kueri didapat melalui sebuah kumpulan dokumen yang dimungkinkan relevan yang disebut pool. Pool ini dibentuk dari K dokumen teratas (biasanya K=100) dari hasil perankingan oleh beberapa sistem temu kembali informasi yang telah teruji kinerjanya. Dokumen-dokumen dalam pool kemudian diperlihatkan pada penguji untuk memberikan penilaian relevansi untuk tiap dokumen.
Teknik mendapatkan daftar dokumen relevan ini disebut metode pooling dan berdasar pada dua asumsi. Pertama, nyaris seluruh dokumen relevan berhasil dikumpulkan ke dalam pool. Kedua, dokumen-dokumen yang tidak termasuk dalam pool dianggap tidak relevan. Kedua asumsi ini telah terbukti akurat dalam pengujian yang dilakukan pada konferensi TREC (Baeza-Yates & Ribeiro-Neto 1999).
Recall –Precision
Recall dan precision dapat dinyatakan sebagai berikut (Baeza-Yates & Ribeiro-Neto 1999):
||
||
||
||
R
Ra
call
Re
=
,||
||
||
||
A
Ra
n
Precisio
=
,dengan Ra adalah jumlah dokumen relevan yang ditemukembalikan, R adalah jumlah dokumen relevan dalam koleksi dan A adalah jumlah dokumen yang ditemukembalikan.
Average Precision (AVP)
Average Precision adalah suatu ukuran evaluasi IRS yang diperoleh dengan menghitung rata-rata tingkat precision pada berbagai tingkat recall, yang. biasanya digunakan adalah sebelas tingkat recall standar yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0.
Adakalanya tingkat recall yang bisa didapat untuk tiap kueri kurang dari sebelas tingkat recall standar yang ada. Untuk kasus seperti ini digunakan prosedur interpolasi. Misalkan rj, j
∈{0, 1, 2,. . . ,10} adalah tingkat recall
standar ke-j maka
( )
rmax
r r rP
( )rP
j j
j
=
≤≤ +1 ,sehingga precision terinterpolasi pada tingkat recall standar ke-j adalah precison tertinggi pada setiap tingkat recall antara j hingga (j+1) (Baeza-Yates & Ribeiro-Neto 1999).
Algoritme RF
Teknik RF ditemukan pertama kali oleh Rocchio dan diterapkan dalam vector space model. Rocchio memandang temu kembali sebagai permasalahan mencari sebuah kueri optimal, yaitu kueri yang memaksimalkan selisih antara vektor rataan dokumen relevan dengan vektor rataan dokumen tak-relevan.
RF berguna untuk mendekatkan vektor kueri ke vektor rataan dokumen relevan dan menjauhkan dari vektor rataan dokumen tak-relevan. Ini bisa dilakukan melalui penambahan istilah kueri dan penyesuaian bobot istilah kueri sehingga sesuai dengan kegunaan istilah tersebut dalam fungsinya membedakan dokumen relevan dan tak-relevan (Ruthven & Lalmas 2003).
Formula awal Rocchio adalah sebagai berikut:
∑
∑
= =−
+
=
1 2 1 2 1 1 0 11
1
n i i n i iS
n
R
n
Q
Q
,5
dengan Q0=vektor kueri awal, Q1=vektor
kueri baru, n1=jumlah dokumen relevan,
n2=jumlah dokumen tak-relevan, Ri=vektor
dokumen relevan ke-i, Si=vektor dokumen
tak-relevan ke-i. Kueri yang telah termodifikasi akan memiliki istilah-istilah baru (dari dokumen-dokumen relevan). Selain itu penyesuaian bobot diterapkan terhadap istilah-istilah kueri. Jika bobot istilah kueri turun hingga nol atau di bawah nol, istilah tersebut dihilangkan dari kueri.
Ide (1971), diacu dalam Ruthven & Lalmas (2003), kemudian melakukan modifikasi terhadap formula Rocchio, dinamakan Ide-Dec-Hi, dengan menggunakan hanya dokumen tak-relevan pertama yang ditemukembalikan. Formula tersebut adalah sebagai berikut: i n i i
s
r
Q
Q
r−
+
=
0∑
1 ,dengan nr=jumlah dokumen relevan ,
ri=vektor dokumen relevan ke-i, si=vektor
dokumen tak-relevan pertama.
Modifikasi lain yang lazim dilakukan adalah dengan memboboti kontribusi relatif kueri awal, dokumen relevan dan dokumen tak-relevan terhadap proses RF. Dalam persamaan di bawah ini, nilai α, β dan γ merupakan derajat pengaruh tiap komponen dalam RF.
∑
∑
= =−
+
=
1 2 1 2 1 1 0 1.
n i i n i iS
n
R
n
Q
Q
α
β
γ
,Versi yang lebih baru lagi dari skema Ide adalah Ide-regular, yang menggunakan semua dokumen non-relevan yang ditemu-kembalikan. Ide-regular juga berdasar formula Rocchio namun tidak melakukan normalisasi terhadap vektor-vektor dokumen. Berikut adalah formula Ide-regular:
∑
∑
= =−
+
=
2 1 1 0 1 1 n i i n i iS
R
Q
Q
.METODOLOGI
Algoritme RFPenelitian ini akan menginvestigasi kinerja relatif dua algoritme RF yaitu Ide-Dec-Hi dan Ide-Regular. Keduanya dipilih karena meskipun formula Dec-Hi dan Ide-Regular tidak memberikan peningkatan kinerja yang signifikan namun lebih konsisten
dibanding formula Rocchio (Ruthven & Lalmas 2003).
Sistem Temu Kembali dan Evaluasinya
Sistem dasar yang digunakan untuk pengujian RF adalah sistem temu kembali hasil penelitian Ridha (2002). Sistem yang dihasilkan menggunakan vector space model dengan pembobotan tf*idf. Dalam penelitian ini diterapkan rule-based stemming dan penggunaan daftar kata buang dalam Bahasa Indonesia.
Cara yang paling umum untuk mengevaluasi sistem temu kembali adalah dengan menentukan kinerjanya dalam recall dan precision. Hal ini dilakukan dengan menggunakan koleksi pengujian yang terdiri dari kumpulan dokumen yang disertai gugus kueri dan penilaian relevansinya (gugus jawaban).
Dari hasil penemukembalian yang dilakukan sistem, dihitung precision pada berbagai tingkat recall. Tingkat recall yang digunakan adalah sebelas tingkat recall standar terinterpolasi. Hasilnya kemudian dirata-rata untuk mendapatkan average precision (AVP).
Evaluasi RF
Chang et al. (1971), diacu dalam Ruthven & Lalmas (2003) menunjukkan bahwa evaluasi algoritme RF memiliki beberapa masalah berkaitan dengan recall dan precision. RF bertujuan untuk meningkatkan recall dan precision berdasar informasi dari dokumen-dokumen relevan yang diidentifikasi pengguna, hal ini biasanya akan membuat dokumen-dokumen relevan yang telah diidentifikasi (yaitu dokumen relevan yang digunakan oleh RF) terdorong menempati ranking teratas. Ranking effect ini seolah-olah membuat kurva recall-precision meningkat tajam karena sistem meranking ulang dokumen relevan yang telah diidentifikasi. Seberapa banyak RF meningkatkan penemukembalian dokumen relevan yang belum teridentifikasi, feedback effect-nya, justru tidak terdeteksi.
Untuk mengatasi masalah pengukuran feedback effect, digunakan teknik test and control groups. Dalam teknik ini, koleksi dokumen dibagi menjadi dua bagian, test group dan control group. Modifikasi kueri dilakukan oleh RF pada test group dan kueri baru dijalankan pada control group. Penilaian recall dan precision hanya dilakukan pada
6
control group sehingga tidak terjadi ranking effect. Test and control pada dasarnya mengukur kinerja relatif kueri baru pada tiap iterasi (Ruthven & Lalmas 2003).
Dalam penelitian ini pembagian koleksi untuk test dan control group dilakukan dengan cara sebagai berikut:
1. Dokumen-dokumen dikelompokkan ber-dasar sumbernya
2. Pada masing-masing kelompok, dokumen diurutkan berdasar ID dokumen
3. Untuk setiap kelompok, separuh dokumen teratas dimasukkan ke dalam test group dan sisanya masuk ke control group Untuk melihat pengaruh penggunaan RF terhadap kinerja sistem dilakukan pengukuran average precision pada lima jenis penemukembalian, yakni:
1. NoRF: penemukembalian awal pada control group
2. DH5: menggunakan Ide-Dec-Hi dengan memeriksa 5 dokumen teratas
3. DH10: menggunakan Ide-Dec-Hi dengan memeriksa 10 dokumen teratas
4. RG5: menggunakan Ide-Regular dengan memeriksa 5 dokumen teratas
5. RG10: menggunakan Ide-Regular dengan memeriksa 10 dokumen teratas
Perbandingan query-by-query juga dilakukan untuk melihat secara lebih detail pengaruh RF pada tiap kueri. Selanjutnya dilakukan pengujian statistik uji Wilcoxon Signed Rank Test dengan selang kepercayaan 95% terhadap:
1. DH5 - NORF dan DH10 - NORF: untuk pengaruh formula Ide-Dec-Hi
2. RG5 - NORF dan RG10 - NORF: untuk pengaruh formula Ide-Regular
3. RG10 - RG5 dan DH10 - DH5: untuk pengaruh jumlah dokumen yang diperiksa. 4. DH10 - RG5, DH5 - RG10, DH5 - RG5
dan DH10 - RG10: untuk perbedaan kinerja Ide-Dec-Hi dan Ide-Regular. Pengujian dilakukan oleh dua mahasiswa Fakultas Pertanian dengan skenario sebagai berikut:
1. Penguji mengeksekusi kueri yang telah disediakan pada gugus kueri pada test group.
2. Dari hasil penemukembalian diperiksa dokumen-dokumen teratas. Dokumen yang dianggap relevan ditandai dan seluruh dokumen yang tidak ditandai akan dianggap tidak relevan.
3. RF kemudian dilakukan untuk memodifikasi kueri.
4. Kueri yang telah dimodifikasi lalu dijalankan pada control group.
Antarmuka implementasi diberikan pada Lampiran 2.
Pengujian RF dilakukan pada kedua formula, Ide-Dec-Hi dan Ide-Regular. Untuk masing-masing formula dilakukan dua kali iterasi dan untuk setiap kali iterasi variasi jumlah dokumen yang diperiksa adalah lima dan sepuluh.
Corpus
Penelitian ini menggunakan corpus yang merupakan hasil penelitian Adisantoso & Ridha (2004). Koleksi dokumen yang dimiliki corpus ini terdiri dari 1000 artikel berbahasa Indonesia yang seluruhnya mempunyai domain yang sama, yaitu pertanian. Artikel-artikel ini dikumpulkan dari berbagai situs web Indonesia, yang sebagian besar merupakan situs-situs media massa. Sumber-sumber tersebut antara lain:
1. Gatra 2. Indosiar 3. Kompas 4. Media Indonesia 5. Republika 6. Situs Hijau 7. Suara Karya 8. Suara Merdeka
Sebagian besar dokumen yang terkumpul bersifat artikel media umum sedangkan hanya 22 dokumen yang merupakan tulisan ilmiah. Seluruh sumber artikel menggunakan Bahasa Indonesia semi-formal/formal (Adisantoso & Ridha 2004). Contoh dokumen dapat dilihat pada Lampiran 3.
Untuk kepentingan evaluasi RF koleksi dokumen dibagi dua secara acak menjadi test dan control group. Langkah berikutnya adalah pembentukan gugus kueri untuk pengujian beserta gugus jawabannya karena keduanya belum tersedia dalam corpus. Pembentukan gugus kueri dan gugus jawaban dilakukan oleh dua mahasiswa Fakultas Pertanian yang dianggap kompeten untuk menentukan penilaian relevansi dokumen-dokumen dengan domain pertanian.
Asumsi-asumsi
Asumsi-asumsi yang digunakan dalam penelitian ini adalah sebagai berikut:
1. Jumlah dokumen yang diperiksa untuk feedback dalam setiap iterasi adalah tetap. 2. Jumlah dokumen relevan untuk tiap kueri
7
3. Penilaian relevansi yang dilakukan akurat.
Lingkungan Pengembangan
Lingkungan pengembangan yang digunakan adalah sebagai berikut:
1. Perangkat lunak: Windows XP Professional, Visual Basic 6.0, Microsoft Access 2004.
2. Perangkat keras: Duron 1.2 GHz, 256 MB RAM.
HASIL DAN PEMBAHASAN
Gugus Kueri dan Gugus Jawaban
Kueri yang dibuat untuk pengujian penelitian ini berjumlah 30. Sebagian besar berupa frasa, seperti “gagal panen” atau “tanaman obat” , yang panjangnya kurang dari lima kata. Hal ini dilakukan untuk mensimulasikan keadaan di dunia nyata yang pada umumnya pengguna jarang menggunakan kueri panjang. Contoh kueri pengujian dan deskripsinya dapat dilihat pada Lampiran 4.
Setelah kueri tersedia, hal selanjutnya yang harus dilakukan adalah pembentukan gugus jawaban pada test dan control group. Pembentukan gugus jawaban merupakan proses yang penting dan sangat mempengaruhi hasil evaluasi RF sekaligus sistem temu kembali pada umumnya. Jika gugus jawaban yang dibentuk tidak akurat maka kinerja sistem akan tampak buruk karena ada dokumen-dokumen yang ditemukembalikan sistem, yang sebenarnya relevan, akan dianggap tidak relevan sebab tidak ada dalam gugus jawaban dan berakibat mengurangi nilai recall dan precision.
Pembentukan gugus jawaban menggunakan metode pooling dan dilakukan sebanyak dua kali. Pada kali pertama, sistem-temu kembali yang digunakan untuk mendapatkan pool adalah Google Desktop Search 20050325 dan Copernic Desktop Search versi 1.63. Keduanya merupakan perangkat lunak freeware yang dikenal luas sebagai mesin pencari dengan kinerja yang cukup baik. Hasil pool yang didapat ternyata tidak terlalu akurat karena setelah diperiksa masih cukup banyak dokumen-dokumen yang sebenarnya relevan namun tidak termasuk dalam pool. Alasannya adalah karena memang kedua sistem temu kembali tersebut tidak dikhususkan untuk mencari dokumen-dokumen berbahasa Indonesia. Keduanya
tidak menggunakan stemming terhadap kueri maupun dokumen-dokumen berbahasa Indonesia yang terindeks.
Pada kali kedua, sistem temu kembali hasil penelitian Ridha (2002) diikutsertakan untuk mendapatkan calon dokumen relevan tambahan. Karena sistem ini memang dikhususkan untuk Bahasa Indonesia, hasil yang didapat cukup memuaskan dengan didapatkannya tambahan dokumen relevan hampir untuk setiap kueri yang diujikan. Pada Lampiran 5 tertera daftar lengkap kueri beserta gugus jawabannya. Tabel 1 menunjukkan deskripsi corpus yang digunakan sedangkan di Tabel 2 dapat dilihat contoh hasil pooling beberapa kueri menggunakan ketiga sistem yakni Google Desktop Search (GDS), Copernic Desktop Search (CDS) dan sistem temu kembali hasil penelitian Ridha (2002) (R2002).
Tabel 1 Deskripsi koleksi pengujian
Koleksi Test Control
Jumlah kueri 30 30 Ukuran (KB) 16.048 23.972 Jumlah dokumen 500 500 Rataan kata tiap kueri 2,6 2,6 Rataan kata tiap dokumen 166 177 Rataan dokumen
relevan tiap kueri
13 18,8
Tabel 2 Contoh hasil pooling beberapa kueri
Tingkat Recall * ID GDS CDS R2002 1 28/48 (8) 21/48 (4) 25/48 (8) 5 21/39 (6) 17/39 (2) 26/39 (9) 11 34/57 (7) 30/57 (5) 41/57 (9) *Angka di dalam tanda kurung menunjukkan jumlah dokumen unik yang hanya ditemukan pada sistem tersebut dan tidak ditemukan di kedua sistem lainnya.
Evaluasi RF
Hasil pengujian RF dengan perhitungan average precision dapat dilihat pada Tabel 3 sedangkan hasil Wilcoxon Signed Rank Test dirinci pada Tabel 4.
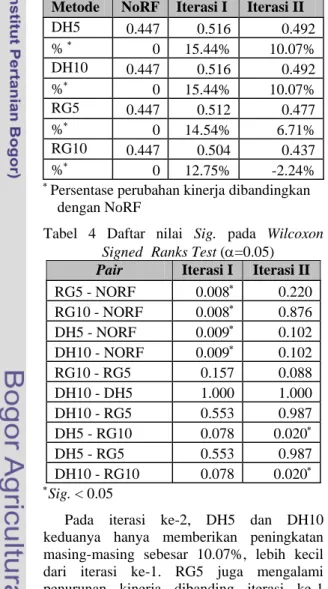
Dari Tabel 3 terlihat bahwa hampir secara keseluruhan RF memberikan peningkatan kinerja pada sistem. Pada DH5 dan DH10 iterasi ke-1, terlihat bahwa dengan RF kinerja sistem meningkat 15.44% dibanding tanpa RF. Peningkatan kinerja ini secara statistik
8
signifikan (Sig. < 0.05). Pada Ide-Regular, peningkatan juga signifikan, RG5 mencapai 14.54%, akan tetapi kemudian turun pada RG10 tinggal 12.75%. Ini menunjukkan bahwa meskipun secara statistik tidak ada perbedaan signifikan antara Ide-Dec-Hi dan Ide-Regular (Sig. > 0.05), Ide-Dec-Hi mampu memberikan hasil yang lebih konsisten daripada Ide-Regular. Hal ini sesuai dengan hasil penelitian Ruthven dan Lalmas (2003). Kekonsistenan ini karena Ide-Dec-Hi hanya menggunakan satu dokumen tak-relevan teratas. Sehingga meskipun terjadi ketidakakuratan penilaian relevansi saat pengguna memberikan feedback, yaitu dokumen relevan tidak ditandai oleh pengguna dan dihitung sebagai dokumen tak-relevan, hal itu tidak akan terlalu memperburuk kueri yang baru.
Tabel 3 Perbandingan nilai average precision sebelum dan setelah menggunakan RF
Metode NoRF Iterasi I Iterasi II
DH5 0.447 0.516 0.492 % ∗ 0 15.44% 10.07% DH10 0.447 0.516 0.492 %∗ 0 15.44% 10.07% RG5 0.447 0.512 0.477 %∗ 0 14.54% 6.71% RG10 0.447 0.504 0.437 %∗ 0 12.75% -2.24%
∗ Persentase perubahan kinerja dibandingkan
dengan NoRF
Tabel 4 Daftar nilai Sig. pada Wilcoxon Signed Ranks Test (α=0.05)
Pair Iterasi I Iterasi II
RG5 - NORF 0.008∗ 0.220 RG10 - NORF 0.008∗ 0.876 DH5 - NORF 0.009∗ 0.102 DH10 - NORF 0.009∗ 0.102 RG10 - RG5 0.157 0.088 DH10 - DH5 1.000 1.000 DH10 - RG5 0.553 0.987 DH5 - RG10 0.078 0.020∗ DH5 - RG5 0.553 0.987 DH10 - RG10 0.078 0.020∗ ∗ Sig. < 0.05
Pada iterasi ke-2, DH5 dan DH10 keduanya hanya memberikan peningkatan masing-masing sebesar 10.07%, lebih kecil dari iterasi ke-1. RG5 juga mengalami penurunan kinerja dibanding iterasi ke-1 menjadi 6.71%. RG10 bahkan menurun hingga -2.24%. Pada iterasi kali ini, DH5 dan
DH10 secara signifikan lebih baik bila dibandingkan RG10 namun tidak jika dibandingkan RG5. Melalui pemeriksaan lebih lanjut, alasan penurunan kinerja ini adalah karena pada iterasi ke-1 RF sudah bekerja dengan sangat baik sehingga pada hampir semua kueri, seluruh dokumen relevan untuk kueri tersebut telah ditemukan oleh sistem. Lebih jauh lagi untuk kueri-kueri yang belum seluruh dokumen relevannya ditemukan tingkat recall-nya sudah mencapai di atas 90%. Hal lain yang berkaitan erat dengan penurunan ini adalah kinerja sistem dasar yang ternyata sudah cukup tinggi.
Melalui hasil perbandingan query-by-query, ditemukan pula bahwa kueri yang tidak berhasil ditingkatkan kinerjanya adalah kueri-kueri yang seluruh atau setidaknya nyaris seluruh dokumen relevannya telah muncul di penemukembalian awal. Hal ini mengindikasikan bahwa pada keadaan-keadaan seperti ini RF sudah tidak cocok lagi digunakan untuk membantu menemukan tambahan dokumen relevan. Perbandingan query-by-query secara lengkap tertera pada Lampiran 6.
Pada lampiran tersebut terlihat bahwa kueri ke-27 yakni “upaya peningkatan pendapatan petani” menunjukkan nilai AVP nol pada NoRF. Ini terjadi karena memang tidak ada satu pun dokumen relevan yang ditemukan. Ketiga stem istilah dalam kueri, yaitu “upaya”, “peningkatan” dan “pendapatan” hanya muncul di tiga dokumen di control group, semuanya tidak relevan. Di lain pihak, stem istilah “petani” muncul di semua dokumen sehingga nilai idf-nya nol, akibatnya bobotnya juga nol. Setelah menggunakan RF nilai AVP kueri ini bisa ditingkatkan mencapai di atas 0.3. Penambahan istilah-istilah dari test group terlihat sangat membantu kinerja kueri ini.
Keseluruhan hasil yang ada pada penelitian ini menunjukkan bahwa RF memberikan peningkatan kinerja terbesar ketika menggunakan Ide-Dec-Hi. Penambahan jumlah dokumen yang diperiksa dari lima menjadi sepuluh ternyata tidak berpengaruh terhadap hasil yang diperoleh. Ini menunjukkan bahwa pemeriksaan lima dokumen sudah optimal untuk koleksi pengujian ini. Iterasi ke-2 tampaknya tidak diperlukan karena kinerja RF telah maksimal pada iterasi ke-1 dengan menemukembalikan nyaris seluruh dokumen relevan untuk semua kueri, sekali lagi ini hanya berlaku untuk
9
koleksi pengujian dalam penelitian ini. Hal ini sangat dipengaruhi oleh ukuran koleksi dan gugus jawaban yang relatif kecil.
Selain menunjukkan kinerja yang sangat baik, secara komputasional Ide-Dec-Hi juga lebih efektif daripada Ide-Regular karena hanya menggunakan satu dokumen tak-relevan teratas untuk perhitungan, berbeda dengan Ide-Regular yang menggunakan seluruh dokumen tak-relevan.
0.0 0.2 0.4 0.6 0.8 1.0 0 0.2 0.4 0.6 0.8 1 Recall Pr e s ic io n
Ide-Dec-Hi Ide-Regular NoRF
Gambar 1 Kurva recall-precision RG5 dan DH5 pada iterasi ke-1.
0.0 0.2 0.4 0.6 0.8 1.0 0 0.2 0.4 0.6 0.8 1 Recall P re s ic io n
Ide-Dec-Hi Ide-Regular NoRF
Gambar 2 Kurva recall-precision RG10 dan DH10 pada iterasi ke-1.
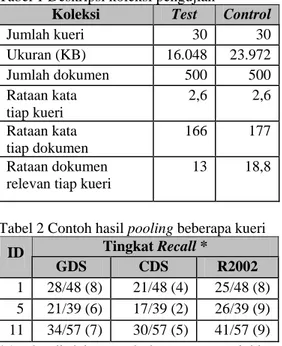
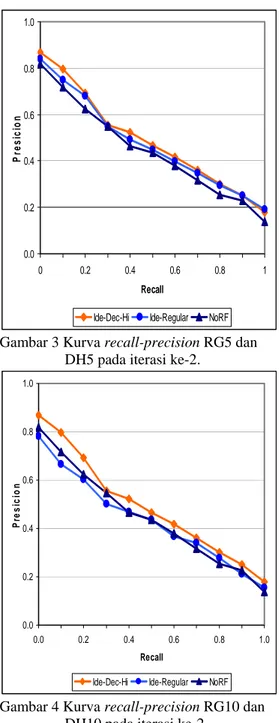
RF umumnya dipandang sebagai suatu mekanisme untuk meningkatkan recall. Akan tetapi melalui penelitian ini, terlihat dari kurva recall-precision pada Gambar 1-4, precision
setelah menggunakan RF ternyata lebih tinggi pada hampir semua tingkat recall dibanding sebelum menggunakan RF. Ini mengindikasikan bahwa RF juga bisa menjadi mekanisme untuk memperbaiki precision.
0.0 0.2 0.4 0.6 0.8 1.0 0 0.2 0.4 0.6 0.8 1 Recall P resi ci o n
Ide-Dec-Hi Ide-Regular NoRF
Gambar 3 Kurva recall-precision RG5 dan DH5 pada iterasi ke-2.
0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 Recall P re s ic io n
Ide-Dec-Hi Ide-Regular NoRF
Gambar 4 Kurva recall-precision RG10 dan DH10 pada iterasi ke-2.
KESIMPULAN DAN SARAN
Kesimpulan
Melalui penelitian ini dapat ditarik kesimpulan sebagai berikut:
1. Menggunakan penilaian relevansi yang diberikan oleh pengguna, RF teruji mampu
10
meningkatkan kinerja sistem temu kembali informasi. Pengguna juga cukup dimudahkan karena hanya perlu mengenali dokumen yang dianggapnya relevan, tanpa perlu mendeskripsikannya.
2. Pada kasus kali ini, peningkatan kinerja yang optimal dicapai melalui penggunaan formula Ide-Dec-Hi dan cukup melalui pemeriksaan lima dokumen teratas. Iterasi ke-2 juga tidak perlu dilakukan karena pada iterasi ke-1, RF telah memberikan hasil yang sangat baik dengan tingkat recall mendekati 100%.
3. Penggunaan relevance feeback tidak terlalu membantu pada kueri yang kinerja awalnya memang sudah tinggi. Sebaliknya, untuk kueri-kueri yang memberikan hasil buruk pada pencarian awal, RF sangat cocok untuk digunakan dan menjanjikan peningkatan kinerja yang cukup tinggi.
Saran
Untuk pengembangan penelitian disarankan hal-hal sebagai berikut:
1. Penggunaan koleksi pengujian dan gugus jawaban dengan ukuran maupun jumlah lebih besar sehingga bisa memberikan gambaran yang lebih akurat mengenai kinerja RF pada umumnya.
2. Penggabungan formula Ide-Dec-Hi dengan teknik pemilihan istilah diperkirakan akan memberikan peningkatan kinerja yang cukup signifikan (Selberg EW 1997). 3. Penggunaan teknik Automatic Query
Expansion, seperti Local Analysis dan Local Context Analysis. Hasilnya kemudian bisa diperbandingkan dengan RF yang merupakan teknik Interactive Query Expansion.
DAFTAR PUSTAKA
Adisantoso J, Ridha A. 2004. Corpus
Dokumen Teks Bahasa Indonesia untuk Pengujian Efektivitas Temu Kembali Informasi. Laporan Akhir Hibah Penelitian SP4. Departemen Ilmu Komputer FMIPA IPB, Bogor.
Baeza-Yates R, Ribeiro-Neto B. 1999.
Modern Information System. Addison-Wesley.
Belkin NJ et al. 2000. Relevance Feedback
versus Local Context Analysis as Term Suggestion Devices. Rutgers' TREC-8 Interactive Track Experience.
Buckley C, Salton G, Allan J. 1994. The
Effect of Adding Relevance Information in a Relevance Feedback Environment Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval.
Chang YK, Cicirillo C, Razon J. 1971.
Evaluation of Feedback Retrieval using Modified Freezing, Residual Collection &Test and Control Groups. The SMART Retreival System - Experiments In Automatic Document Processing 17: 355-370.
Hiemstra D, Leeuwen D.van. 2001. Creating
a Dutch Information Retrieval Test Corpus.
Ide E. 1971. New Experiments in Relevance
Feedback. The SMART Retrieval System - Experiments In Automatic Document Processing 16:337-354.
Liddy E. 2001. How a Search Engine Works.
Searcher 9(5). Information Today, Inc.
McEnery T, Wilson A. 2001. Corpus
Linguistic 2nd Edition. Edinburgh University Press.
Ridha A. 2002. Pengindeksan Otomatis
dengan Istilah Tunggal untuk Dokumen Berbahasa Indonesia. Skripsi. Departemen Ilmu Komputer FMIPA IPB, Bogor.
Ruthven I, Lalmas M. 2003. A Survey on the
Use of Relevance Feedback for Information Access Systems. Knowledge Engineering Review 18(2): 95-145.
Selberg EW. 1997. Information Retrieval
Advances Using Relevance Feedback. Department of Computer Science and Engineering University of Washington, Seattle.
Spink A, Jansen BJ, Ozmultu HC. 2000.
Use of Query Reformulation and Relevance Feedback by Excite Users. Internet Research:Electronic Networking Applications and Policy 10(4):317-328.
Xu J, Croft WB. 1996. Query Expansion
Using Local and Global Document Analysis. Proceedings of the 19th Annual International ACM SIGIR Conference on
11
Research and Development in Information Retrieval.
Xu J, Croft WB. 2000. Improving the
Effectiveness of Information Retrieval with Local Context Analysis. ACM Transactions on Information Systems 18(1):79-112.
13
Lampiran 1 Proses penemukembalian informasi (Baeza-Yates & Ribeiro-Neto 1999)
User Interface Operasi Teks DB Module Manager Pengindeksan Operasi Kueri Pencarian Perankingan Indeks Basisdata Teks teks t eks kebut uhan pengguna logical view logical view inverted file kueri dokumen yang dit emukan dokumen teranking feedback pengguna
14
15
Lampiran 3 Contoh dokumen dalam koleksi <DOC>
<DOCNO>situshijau051103-001</DOCNO>
<TITLE>Nilai Tukar Petani pada Agustus Naik Setelah Enam Bulan Anjlok</TITLE> <AUTHOR>(MAR/boy/eta)</AUTHOR>
<DATE>05/11/2003</DATE> <TEXT>
Nilai tukar petani (NTP) pada bulan Agustus mengalami kenaikan 1,35 persen dibanding dengan bulan Juli 2003. Kenaikan ini memperbaiki nilai tukar petani yang sejak enam bulan sebelumnya terus anjlok. Deputi Bidang Statistik Ekonomi Badan Pusat Statistik (BPS) Slamet Mukeno dalam jumpa pers di Jakarta, Senin (3/11), mengatakan, kenaikan NTP disebabkan oleh kemampuan petani tanaman pangan dan tanaman perkebunan rakyat mampu menjual hasil produksinya sebesar 1,96 persen lebih tinggi dibanding dengan bulan Juli. Sementara itu, harga rata-rata barang dan jasa konsumsi rumah tangga pedesaan untuk keperluan produksi pertanian hanya naik 0,60 persen.
Kenaikan itu merupakan kenaikan pertama kalinya sejak bulan Februari tahun ini. Dari laporan BPS sebelumnya, sejak bulan Februari hingga Juli NTP selalu mengalami penurunan. NTP tertinggi terjadi pada bulan Februari. Namun, setelah itu terus turun.
NTP diperoleh dari perbandingan indeks harga yang diterima petani terhadap indeks harga yang dibayar petani. NTP merupakan indikator relatif tingkat kesejahteraan petani. Semakin tinggi NTP, berarti semakin tinggi pula kesejahteraan petani. Pengukuran NTP berdasarkan hasil pemantauan harga-harga di 16 provinsi di Indonesia.
Dari provinsi yang diamati itu, kenaikan NTP bulan Agustus yang tertinggi terjadi di Jawa Tengah, yaitu sebesar 3,39 persen. Hal ini diakibatkan harga cabai merah di Jawa Tengah naik 23,59 persen. Adapun penurunan NTP terendah terjadi di Jawa Timur sebesar 5,44 persen akibat harga tembakau rajangan turun 32,32 persen.
Meskipun demikian, dibanding dengan NTP Agustus 2002, NTP Agustus tahun ini naik 5,66 persen. </TEXT>
16
Lampiran 4 Contoh kueri dan deskripsinya
ID : 25
Kata kunci : Institut Pertanian Bogor
Deskripsi : Dokumen dianggap relevan jika memuat informasi hasil penelitian atau laporan kegiatan Institut Pertanian Bogor. Dokumen yang hanya memuat informasi tentang orang atau jabatan tertentu di Institut Pertanian Bogor tanpa menyinggungnya sebagai suatu institusi tidak dianggap relevan.
Contoh dokumen relevan : <DOC>
<DOCNO>republika100704-002</DOCNO> <TITLE>IPB Benahi Program Penelitian</TITLE> <AUTHOR>ant</AUTHOR>
<DATE>10 juli 2004</DATE> <TEXT>
BOGOR – Institut Pertanian Bogor (IPB) terus melakukan pembenahan guna menuju research based university. Sebagai perguruan tinggi pertanian di Asia Tenggara, IPB terus memperkuat kegiatan riset."Sudah cukup lama IPB mencita-citakan payung penelitian ini, namun hingga kini hal tersebut masih belum dapat terealisasi karena keinginan dan pola pikir yang terlalu melebar," kata Kepala Lembaga Penelitian dan Pemberdayaan Masyarakat (LPPM) IPB, Prof Dr Rizal Syarief, DESS di Bogor, Jumat pagi. Lebih lanjut ia menjelaskan bahwa untuk bisa membuat payung penelitian perlu semacam portofolio dan roadmap penelitian. Hal itu diperlukan untuk menganalisis kekuatan, kelemahan, peluang, dan ancaman atau lebih dikenal dengan "Analisis SWOT". "Saat ini IPB mencoba terus menelusuri judul-judul penelitian apa saja yang kita miliki, baik yang dilakukan lembaga pusat, fakultas maupun departemen," katanya. Ia mengemukakan, tercetusnya payung penelitian ini bermula dari banyaknya penelitian di IPB yang arahnya tersebar. "Kadang-kadang penelitian hanya sebagai karya penelitian dan belum membantu di dalam pemecahan masalah, juga belum memberikan kontribusi dalam konsep, dan barangkali juga belum memberikan kontribusi dalam pengembangan Iptek itu sendiri," katanya.
Oleh karena itu, menurut dia, perlu payung penelitian yang skenario pertamanya adalah bahwa payung itu tidak hanya satu melainkan bisa lebih dari satu, tetapi tidak terlalu banyak. "Dan bentuk payung itu betul-betul mengerucut, bukan terbalik yang tidak menghasilkan apa-apa," katanya.
Dengan adanya payung penelitian ini, diharapkan penelitian IPB benar-benar jelas sasaran dan target yang diinginkan serta hasilnya. Adapun target yang ingin dihasilkan adalah dalam rangka memperkuat pendidikan, perkuliahan, dan pengajaran di IPB, sehingga dari berbagai penelitian di IPB akan keluar paket-paket teknologi yang bisa diterapkan dalam rangka pemberdayaan masyarakat.
Dengan melakukan analisis SWOT, IPB akan mengevaluasi diri untuk melihat kekuatan dan kelemahannya. Hal tersebut nantinya baru akan dibahas pada forum pimpinan IPB sesuai skala prioritas. Dalam upaya memperkuat penelitian itu, maka IPB perlu mencari sumber dana.
Salah satu yang tengah dipikirkan adalah mencoba mengembangkan kembali apa yang disebut livy grant: dana riset dicari dan dialokasikan berdasarkan komoditas. "Tetapi hal ini perlu dipikirkan kembali seperti apa sistemnya," kata Dr Rizal Syarief.
</TEXT> </DOC>
17
Lampiran 5 Gugus kueri dan gugus jawaban
No. Kueri Gugus Jawaban
1 gagal panen gatra070203, gatra190802, gatra190902-02, gatra301002, indosiar010504, indosiar031203,
indosiar040903, indosiar050704-002, indosiar070504, indosiar130504, indosiar140204, indosiar160304, indosiar170603, indosiar180304, indosiar240703, indosiar260803-001, indosiar260803-003, kompas030704, kompas031003, kompas170504, mediaindonesia030603, mediaindonesia050604-001, mediaindonesia110703, mediaindonesia140203, mediaindonesia160603, mediaindonesia240503, mediaindonesia310503, republika030903-002, republika060804-001, republika080703, republika090804-01, republika120804-04, republika130704-001, republika130804-02, republika200603, republika230704-005, republika260604-003, situshijau091203-002, situshijau100603-003, situshijau110303-002, situshijau280404-002, suarakarya000000-002-02, suarakarya000000-011, suaramerdeka120104, suaramerdeka130602, suarapembaruan120104, suarapembaruan260703-001, suarapembaruan260703-002
2 petani tebu indosiar190504-002, indosiar290604, kompas031003, kompas250901, kompas310702,
republika010704-003, republika020804, republika100902, republika140704-004, republika150604-002, republika200704-001, republika220604-002, republika280704-002, republika310704-001, situshijau280203, suarakarya000000-007, suarakarya000000-028, suaramerdeka130902, suarapembaruan100903, suarapembaruan220403
3 industri gula gatra200103, kompas031003, kompas250901, mediaindonesia120604-002,
pikiranrakyat300704-002, republika010704-003, republika020804, republika090902, republika100902, republika220604-002, republika280704-002, republika301002, situshijau210103-001, suarakarya000000-001-01, suarakarya000000-007, suarakarya000000-028, suaramerdeka130902, suarapembaruan100903, suarapembaruan220403
4 perdagangan hasil
pertanian
gatra011102, indosiar070204, indosiar201103, jurnal000000-002, jurnal000000-027, kompas031003, kompas041102, kompas101002, kompas140802, kompas160304, kompas270401, kompas270502-001, kompas271103, kompas311203, mediaindonesia030104, mediaindonesia101003, mediaindonesia150903, mediaindonesia170303, republika020604-001, republika041102, republika281202, situshijau130303-001, situshijau191103, situshijau240203-002, suarakarya000000-013, suaramerdeka120104, suaramerdeka270601, suarapembaruan080903-001, suarapembaruan080903-002, wartapenelitian000000-006
5 penerapan teknologi pertanian
republika201102, situshijau080103, situshijau270703-005, jurnal000000-001, jurnal000000-011, jurnal000000-013, jurnal000000-017, jurnal000000-024, kompas121099, kompas290402, republika131203-001, republika140604-001, republika180504-001, republika220604-003, republika230704-08, suarapembaruan020603-No, suarapembaruan160702, situshijau181103-002, mediaindonesia170403, situshijau281003-003, kompas251003, suarapembaruan060602, wartapenelitian000000-009, situshijau100603-003, situshijau270503-002, indosiar250204-001, situshijau290503-003, wartapenelitian000000-003, republika050903, republika260803, situshijau030603-001, situshijau140103-002, situshijau140903-001, situshijau140903-003, situshijau180603-003, situshijau180803-002, situshijau270303-004, suarakarya000000-034, wartapenelitian000000-007
6 pupuk organik
balaipenelitian000000-001, kompas270502-002, kompas280502, kompas300502-001, republika050804-007, republika190104, republika201102, republika270604, situshijau091203-004, situshijau140103-001, suarakarya000000-001-02, suarakarya000000-037, suaramerdeka031101, suaramerdeka170602-002, suarapembaruan090202, suarapembaruan130103, suarapembaruan160702, suarapembaruan220802,
wartapenelitian000000-002, wartapenelitian000000-008
7 penyakit hewan ternak
gatra270104-002, gatra270104-003, gatra300104, mediaindonesia090204, republika150103, republika160704-003, republika260704-004, republika300604-002, suarakarya000000-004, suarakarya000000-008, suarakarya000000-014, suarakarya000000-017, suaramerdeka260302-01
8 penerapan bioteknologi di indonesia
kompas121099, situshijau070103-001, situshijau130503-002, situshijau150403-001, situshijau270703-005, situshijau300403, suarapembaruan020603, situshijau030603-001, suarapembaruan020603-No, situshijau150403-002, situshijau140103-003, situshijau140503-001-01, suarakarya000000-014, republika290704-002, situshijau310303-No, wartapenelitian000000-009, situshijau070103-003, situshijau070103-002, republika220604-003, situshijau050703-001, suarapembaruan151102, situshijau270503-002, situshijau160103, situshijau210503-001, situshijau310303, situshijau200103-001, situshijau100603-002, puslitbang000000-001, jurnal000000-018, suarakarya000000-001-02, situshijau130503-001, situshijau210103-003, situshijau180803-003, situshijau040603, situshijau100603-003, situshijau000000-002, situshijau110303-002, situshijau130103-001, situshijau140103-002, situshijau140903-001, situshijau180603-003, situshijau270303-004
18
Lanjutan
No. Kueri Gugus Jawaban
9 laboratorium pertanian
balaipenelitian000000-010, gatra100203, indobic130504-002, indosiar010704, jurnal000000-027, kompas220801, kompas241203, kompas300502-002, mediaindonesia290903-002, republika050804-007, republika120704-005, republika230704-004, republika300604-002, situshijau040603, situshijau051103-02, situshijau100603-001, situshijau140503-001-01, situshijau150403-002, situshijau180603-003, suarakarya000000-003, suaramerdeka031101
10 riset pertanian
situshijau130503-002, situshijau080503-001, gatra270104-002, indobic130504-001, jurnal000000-026, kompas010499, kompas170104, kompas221003, kompas230603, mediaindonesia131003, republika070604-002, republika140104, republika210704-001, wartapenelitian000000-009, republika210704-003, situshijau040603, situshijau091203-003, situshijau140903-001, situshijau150403-002, situshijau300403, situshijau250203, suarakarya000000-019, suarakarya000000-034, suaramerdeka270601, suarapembaruan020603, suarapembaruan241003, republika100704-002, 018, puslitbang000000-001, 008, jurnal000000-015, republika220604-003, situshijau130103-001, republika190604-001, suarakarya000000-027, situshijau290503-001, situshijau180803-002, suarapembaruan290802-001, situshijau270303-004, suarapembaruan160702, suarakarya000000-001-02, suarapembaruan060602, republika260803, republika190604-002, situshijau140903-003, wartapenelitian000000-007, situshijau140103-002, situshijau201003-002, situshijau210503-001, suarapembaruan110702-01, suarapembaruan110702, suarakarya000000-037, suarapembaruan000000-002, situshijau070503, situshijau181103-002, situshijau210103-003, suarakarya000000-010, republika300604-003, situshijau200103-001, suarapembaruan151102, situshijau200103-001-No, republika280703, republika170604-001, situshijau310303, republika030903-002, republika241203, balaipenelitian000000-012, jurnal000000-019, situshijau101103-004
11 harga komoditas pertanian
kompas270401, indosiar071103, kompas311203, kompas030502-001, suaramerdeka290802, republika140704-004, indosiar180603, pikiranrakyat300604, mediaindonesia060803, indosiar300304, poskota000000-002, kompas180504, poskota000000-003, indosiar240604, jurnal000000-027, kompas030502-002, kompas100399, kompas101004, kompas111099, kompas140802, kompas160304, kompas170104, kompas171002, kompas230603, kompas250901, kompas270502-001, republika090902, wartapenelitian000000-002, situshijau070503, republika060804-001, situshijau280404-003, republika060804-003, mediaindonesia310503, situshijau280404-002, indosiar221003, kompas180502, suarapembaruan220403, kompas 170402, suarapembaruan100903, trubus000004, situshijau280404-001, jurnal000000-022, kompas080702 , kompas270203-001, kompas280602, pikiranrakyat240404, republika030804-002, republika060503 , republika061102, situshijau050703-002, situshijau130203-002, situshijau240203-002, situshijau280203 , suarakarya000000-002-02 , suarakarya000000-021 , suaramerdeka170602-001 , suaramerdeka311003
12 tanaman pangan
bitraindonesia000000-001, indosiar021203-001, indosiar030304, indosiar050704-002, indosiar130504, indosiar160304, indosiar180304, indosiar310504, kompas020603, kompas120102, kompas120702, kompas171002, kompas180701, kompas240302, kompas260203, kompas311203, republika220604-003, indosiar130104 , mediaindonesia030104, mediaindonesia160603, mediaindonesia170303, mediaindonesia220303, republika030304, republika050903, republika080604-004, republika150903, republika200603 , republika230704-006, republika241203, republika260604-001, republika271003, situshijau070103-003, situshijau140903-001, situshijau181103-001, situshijau290403-002, suarakarya000000-001-02, suarakarya000000-011, suarakarya000000-013, suarakarya000000-031, suaramerdeka160703, suaramerdeka250302, suarapembaruan151102, suarapembaruan260703-002
13 kelompok masyarakat tani
bitraindonesia000000-001, indosiar021203-002, jurnal000000-017, kompas211103, kompas250901, kompas260304, kompas270502-002, kompas300502-001, replubika110804, republika110604-004, republika131203-001, republika140703, kompas180502, kompas260902, kompas270203-002, republika030304, republika151202, republika180303, republika270704-001, republika280703, republika300704-001, situshijau070503, situshijau120303-003, situshijau130303-001, situshijau190303-002, situshijau200103-002, situshijau281003-004, suarakarya000000-001-02, suarakarya000000-037, suaramerdeka260902, suarapembaruan090202, suarapembaruan130103
14 musim panen
gatra240203, indosiar021203-002, indosiar300304, indosiar060204, indosiar010504, gatra190902-02, gatra230103-001, indosiar071103, indosiar110304, indosiar240604, kompas030502-001, kompas041103, kompas220901-001, kompas240103, kompas300502-001, mediaindonesia131203-001, mediaindonesia230604, pikiranrakyat300604, poskota261202, republika240604-005, republika300704-002, situshijau280404-002, suaramerdeka120104, suarakarya000000-007, pikiranrakyat240404, republika060804-001, republika060804-003, republika100704-003, republika151202, republika171102, republika290604-007, situshijau000000-001, situshijau040603, situshijau080503-004, situshijau250403-004, situshijau270503-002, suarakarya000000-023, suarakarya000000-028, suaramerdeka290901, suarapembaruan031002
19
Lanjutan
No. Kueri Gugus Jawaban
15 tanaman obat
indosiar010704, situshijau070103-004, balaipenelitian000000-008, balaipenelitian000000-009, indobic120504, indosiar260803-002, republika020604-003, republika270604, republika290604-001, situshijau030203-republika290604-001, situshijau041203, situshijau060503, situshijau101103-003, republika030804-002, situshijau070103-005, situshijau100603-002, situshijau120303-004, situshijau130103-002, situshijau130503-001, situshijau140103-003, situshijau140903-004, situshijau180203-002, situshijau201003-002, situshijau270303-003, situshijau270503-002, situshijau270703-002, situshijau290503-001, situshijau180203-001, situshijau270303-001
16 gabah kering
giling
indosiar180603, indosiar240703, indosiar300304, kompas 170402, kompas030502-001, kompas160704, kompas170903, mediaindonesia250304, pikiranrakyat300604, republika040303, republika210704-001, republika060804-003, republika100704-003, republika100804, republika120804-01, republika180504-002, republika230704-001, republika231202-001, republika231202-002, republika290604-003, republika290604-007, situshijau281003-004, suarakarya000000-007, suaramerdeka090104
17 impor beras
Indonesia
gAtra220802, indosiar200304, republika240604-001, gatra180103, kompas101002, kompas310702, indosiar180603, kompas 170402, kompas050602, kompas101004, kompas160704, kompas180504, kompas270401, kompas270502-002, mediaindonesia050104, mediaindonesia060803, mediaindonesia100203, mediaindonesia131003, mediaindonesia250304, republika090902, republika210704-001, suaramerdeka130104, republika100704-003, indosiar180703, indosiar300703-002, suarapembaruan100903, republika060804-001, suaramerdeka270601, kompas 170402, republika231202-002, republika231202-001, mediaindonesia160603, republika020604-001, republika100703, republika180504-002, republika230704-001, republika300704-002, situshijau281003-004, suarakarya000000-007, suarakarya000000-023, suaramerdeka120104, suaramerdeka170602-001, suarapembaruan110903
18 pertanian organik
republika150303, indosiar250204-002, situshijau091203-001, jurnal000000-017, kompas010499, kompas030502-002, kompas050802, kompas081203, kompas181099, kompas221001, kompas241203, kompas260304, kompas270502-002, kompas300502-001, republika131203-001, situshijau091203-004, republika180303, situshijau070503, situshijau290503-003, suarakarya000000-001-02, suarapembaruan000000-002, suarapembaruan090202, suarapembaruan110702-01, suarapembaruan160702
19 swasembada pangan
indosiar021203-002, kompas170104, kompas230603, kompas060503, kompas100901, kompas110201, kompas150304-002, kompas230899, kompas270401, kompas270502-002, republika220604-003, republika220604-003, republika060503, mediaindonesia160603, kompas270203-001, suarakarya000000-021, suarakarya000000-002-02, suarapembaruan110903, republika030304, republika061003, republika080703, republika100704-005, republika230902-001, republika230902-002, republika231202-republika230902-001, republika231202-002, suarakarya000000-001-02, suarakarya000000-016, suaramerdeka170602-001, suarapembaruan221102
20 penyuluhan pertanian
bitraindonesia000000-001, gatra190902-02, indosiar310504, 005, jurnal000000-014, kompas050802, kompas130699, kompas170104, kompas200503-002, republika200203, republika180303, republika220604-003, situshijau201003-002, republika171003, situshijau270703-001, wartapenelitian000000-007, mediaindonesia160603, poskota110703, republika030903-002, republika050804-001, republika061003, republika210504-001, republika260604-003, republika300604-003, situshijau230103-001, suaramerdeka271102, wartapenelitian000000-002
21 tadah hujan gatra210704, gatra301002, indosiar260803-001, indosiar310504, jurnal000000-001,
kompas270502-002, mediaindonesia160603, mediaindonesia310503, republika090804-01, republika210704-004, republika230704-005, republika240604-005, republika290604-007, suarakarya000000-001-02, suarakarya000000-030, suaramerdeka130602, suarapembaruan260703-002, wartapenelitian000000-004
22 bencana kekeringan
gatra210704, mediaindonesia270803, republika270503, republika070604-001, pikiranrakyat020704, gatra301002, republika250604, gatra070203, gatra161002, indosiar010903, indosiar170603, indosiar260803-003, indosiar310504, kompas210504, kompas250803, mediaindonesia050604-001, mediaindonesia110703, suarapembaruan260703-002, republika200603, republika210704-004, republika130804-02, suaramerdeka130602, republika090804-01, mediaindonesia240503, suaramerdeka190903, republika120804-01, republika120804-04, indosiar220503, mediaindonesia310503, mediaindonesia160603, mediaindonesia260803, republika030903-001, republika030903-002, republika270704-002, situshijau181103-001, suarakarya000000-002-01, suarakarya000000-021, suarapembaruan150903, suarapembaruan180303