BAB I
RUANG LINGKUP EKONOMETRIKA
Tujuan Pengajaran:
Setelah mempelajari bab ini, anda diharapkan dapat: Mengerti definisi ekonometrika
Mengerti keilmuan yang terkait dengan ekonometrika Membedakan jenis-jenis ekonometrika
Memahami kegunaan ekonometrika
BAB I
RUANG LINGKUP EKONOMETRIKA Pengertian Ekonometrika
Kalau dilihat dari segi namanya, ekonometrika berasal dari dari dua kata, yaitu “ekonomi” dan “metrika”. Kata “Ekonomi” di sini dapat dipersamakan dengan kegiatan ekonomi, yaitu kegiatan manusia untuk mencukupi kebutuhannya melalui usaha pengorbanan sumber daya yang seefisien dan seefektif mungkin untuk mendapatkan tujuan yang seoptimal mungkin. Kata “Metrika” mempunyai arti sebagai suatu kegiatan pengukuran. Karena dua kata ini bergabung menjadi satu, maka gabungan kedua kata tersebut menunjukkan arti bahwa yang dimaksud dengan ekonometrika adalah suatu pengukuran kegiatan-kegiatan ekonomi.
Kegiatan ekonomi manusia tidak berjalan sesaat, tetapi berkelanjutan dari waktu ke waktu, dari peristiwa ke peristiwa, dari berbagai suasana, dari berbagai lintas sektor, lintas faktor. Untuk mengukur suatu kegiatan dalam keberagaman kondisi seperti itu, maka data merupakan sesuatu yang mutlak diperlukan. Melalui data, informasi itu dapat dianalisis, diinterpretasi, untuk mengungkap kejadian-kejadian di masa lampau, serta dapat digunakan untuk prediksi masa mendatang.
Pengungkapan data atau analisis data dalam kegiatan ekonomi, dapat dilakukan dengan berbagai cara atau model, di antaranya melalui penggunaan grafik yang biasa disebut dengan metode grafis, atau melalui penghitungan secara matematis yang biasa disebut dengan metode matematis. Penggunaan metode ini tentu harus sesuai
dengan teori, khususnya teori ekonomi, karena ekonometrika bertujuan untuk mengukur kegiatan ekonomi. Kedua metode tersebut mempunyai kelebihan dan keunggulan masing-masing.
Metode grafis sendiri dapat digolongkan ke dalam bentuk grafik berupa kurva, atau grafik dalam bentuk diagram. Metode grafis mempunyai keunggulan dalam kecepatan interpretasi informasi, karena grafik terrepresentasi dalam bentuk gambar yang mudah untuk dimaknai. Kelemahan metode grafis terletak pada kekurangakuratan interpretasi karena data umumnya ditampilkan dalam bentuk skala, yang bersifat garis besar, tentu kurang dapat menjelaskan secara rinci dan detil.
Metode matematis mempunyai keunggulan dalam keakuratan interpretasi, karena melalui hitungan-hitungan secara rinci, sedang kelemahannya terletak pada tingkat kesulitan untuk menghitungnya, terlebih lagi jika variabel-variabel yang dihitung berjumlah sangat banyak. Guna mempermudah penghitungannya, maka dibuatlah berbagai rumus-rumus hitungan yang diambil dari berbagi data. Perbedaan di antara kedua metode tersebut, metode grafis dan matematis, terletak pada seberapa besar variabel dapat diungkap secara rinci.
Perbedaan Metode Grafis dan Matematis
Perihal Grafis Matematis
Interpretasi Relatif Lebih mudah diinterpretasi
Relatif lebih sulit diinterpretasi
Output Berupa grafik, seperti kurva atau diagram
Hitungan matematis berupa rumus
Keakuratan Cenderung kurang akurat, karena berdasar data yang bersifat skala
Dapat lebih akurat, karena dihitung secara rinci sesuai dengan keadaannya
Uraian di atas menjelaskan kepada kita bahwa dalam ekonometrika diperlukan tiga hal pokok yang mutlak ada, yaitu: teori ekonomi, data, dan model. Teori ekonomi meliputi teori ekonomi mikro, makro, manajemen, pemasaran, operasional, akuntansi, keuangan, dan lain-lain. Guna memahami data, memerlukan disiplin ilmu tentang data, yaitu statistika. Model sendiri memerlukan disiplin ilmu matematika. Oleh karena itu, ekonometrika merupakan gabungan dari ilmu ekonomi, statistika, dan matematika, yang digunakan secara simultan untuk mengungkap dan mengukur kejadian-kejadian atau kegiatan-kegiatan ekonomi.
Beberapa pakar mendefinisikan ekonometrika sebagai berikut:
Ekonometrika dapat didefinisikan sebagai ilmu sosial yang menggunakan alat berupa teori ekonomi, matematika, dan statistika inferensi yang digunakan untuk menganalisis kejadian-kejadian ekonomi (Arthur S. Goldberger, 1964.p.1).1
Ekonometrik adalah gabungan penggunaan matematik dan statistik untuk memecahkan persoalan ekonomi (J. Supranto, 1983. p.6).2
Ekonometri adalah suatu ilmu yang mengkombinasikan teori ekonomi dengan statistik ekonomi, dengan tujuan menyelidiki dukungan empiris dari hukum skematik yang dibangun oleh teori ekonomi. Dengan memanfaatkan ilmu ekonomi, matematik, dan statistik, ekonometri membuat
1
Diterjemahkan dari buku KARYA Damodar Gujarati, Essential of
Econometrics, second edition, Irwin McGraw Hill, 1999.
2
hukum-hukum ekonomi teoritis tertentu menjadi nyata (Sugiyanto, Catur, 1994, p.3).3
Pentingnya Ekonometri
Suatu perusahaan ataupun unit-unit pengambil keputusan, terutama dalam kegiatan ekonomi, tentu memerlukan suatu tindakan evaluatif untuk memastikan keefektifan tindakannya atau bahkan mempunyai keinginan untuk melakukan prediksi guna menentukan langkah terbaik yang perlu diambil. Keinginan evaluasi ataupun prediksi seperti itu akan mudah diperoleh jika tindakan-tindakan sebelumnya itu diukur melalui teknik-teknik pengukuran yang terstruktur dengan baik, baik melalui teori yang melandasi, metodologi yang digunakan, ataupun data pendukungnya. Suatu bentuk keilmuan yang mengakomodasi bentuk pengukuran kegiatan ekonomi itulah yang disebut sebagai ekonometri.
Data dalam ekonometrika merupakan suatu kemutlakan, begitu pula penentuan jenis data, teknik analisanya, ataupun penyesuaian dengan tujuannya. Data yang diperlakukan sebagai pengungkap sejarah (historical
data) akan menghasilkan evaluasi, dan untuk data yang
diperlakukan pengungkap kecenderungan (trend data) akan menghasilkan prediksi. Hasil evaluasi ataupun prediksi yang mempunyai tingkat keakuratan tinggi saja yang akan mempunyai sumbangan terbesar bagi pengambilan keputusan. Di sinilah letak pentingnya ekonometrika.
Sebagai contoh dalam mengungkap pentingnya ekonometrika, mari kita mencermati apa yang terjadi pada hukum permintaan dan penawaran. Hukum permintaan menjelaskan bahwa bila harga suatu barang cenderung 3
mengalami penurunan, maka jumlah permintaan terhadap barang tersebut akan mengalami peningkatan. Begitu pula dalam hukum penawaran, semakin sedikit barang yang ditawarkan, maka harga barang akan cenderung tinggi, tetapi ketika jumlah barang yang ditawarkan semakin banyak, maka harga barang akan semakin turun. Pernyataan-pernyataan seperti itu merupakan bentuk penyederhanaan yang hanya membahas keterkaitan antara dua variabel, yaitu variabel harga (P) dan variabel jumlah barang (Q) saja. Hukum permintaan menunjukkan bahwa hubungan antara variabel P dan Q berlawanan. Di sebut berlawanan karena jika P turun, maka Q yang diminta (D) akan bertambah, begitu pula sebaliknya. Oleh karena itu permintaan ditunjukkan oleh kurva atau garis yang cenderung menurun dari kiri atas ke kanan bawah (downward sloping). Lihat gambar 1.
P P1 P2 D Q Q1 Q2 Gambar 1
Kondisi seperti ini berbeda bila di hadapkan dengan hukum penawaran. Pada hukum penawaran hubungan antara variabel P dan Q adalah searah, artinya jika P meningkat, maka Q juga meningkat. Atau sebaliknya, jika P menurun, maka Q juga mengalami penurunan. Oleh karena itu penawaran ditunjukkan oleh garis atau kurva yang cenderung meningkat dari kiri bawah ke kanan atas (upward sloping). Lihat gambar 2.
P S P2 P1 Q1 Q2 Q Gambar 2
Tidak hanya terhenti pada dua teori di atas saja, banyak teori-teori ekonomi lain yang hipotesisnya hanya bersifat kualitatif seperti hukum permintaan dan penawaran di atas. Pengungkapan yang sangat kualitatif seperti contoh tersebut, tidak dapat diketahui seberapa besar pengaruh antara variabel P terhadap Q, atau Q terhadap P. Karena tidak dapat menjelaskan secara angka-angka tentu saja bentuk kurva atau garis yang ditunjukkan juga tidak dapat menggambarkan kondisi dengan sangat
tepat. Kurva hanya dapat menggambarkan kecenderungan. Untuk menjawab persoalan itu, ekonometrika dengan menggunakan pendekatan kuantitatif dalam bentuk model pendekatan matematis yang berupa hitungan-hitungan metematika akan mampu untuk menunjukkan seberapa besar pengaruh suatu variabel tertenu terhadap variabel yang lain.
Untuk menjawab tuntutan seperti itu, maka teori ekonomi yang sudah ada perlu dilengkapi dengan berbagai data yang diperlukan. Dalam hal ini perannya ditunjukkan oleh statistika. Fungsi dari statistika tidak hanya sekedar pengumpulan data saja, tetapi meluas hingga interpretasi terhadap pentingnya data tersebut, cara perolehan, jenis data, hingga sifat data. Peran statistik akan semakin berarti jika dianalisis dengan model matematis yang sesuai dengan teori-teori ekonomi yang dianalisis.
Jenis Ekonometrika
Ekonometrika dapat dibagi menjadi 2 (dua) macam, yaitu ekonometrika teoritis (theoretical econometrics) dan ekonometrika terapan (applied econometrics). Ekonometrik teoritis berkenaan dengan pengembangan metode yang tepat/cocok untuk mengukur hubungan ekonomi dengan menggunakan model ekonometrik. Ekonometrika terapan menggambarkan nilai praktis dari penelitian ekonomi, sehingga lingkupnya mencakup aplikasi teknik-teknik ekonometri yang telah lebih dulu dikembangkan dalam ekonometri teoritis pada berbagai bidang teori ekonomi, untuk digunakan sebagai alat pengujian ataupun pengujian teori maupun peramalan.
Meskipun ekonometrika dapat didikotomikan ke dalam ekonometrika teoritis maupun terapan, namun tujuan-tujuan ekonometrika dapat dipersatukan sebagai
alat verifikasi, penaksiran, ataupun peramalan. Fungsi verifikasi ini bertujuan untuk mengetahui dengan pasti kekuatan suatu teori melalui pengujian secara empiris, karena teori yang mapan adalah teori yang dapat diuji dengan empiris. Ekonometrika berkaitan dengan analisa kuantitatif yang menghasilkan taksiran-taksiran numerik yang dapat digunakan untuk melakukan taksiran-taksiran dari hasil suatu kegiatan ekonomi. Fungsi seperti itu disebut sebagai fungsi penaksiran. Taksiran-taksiran numerik seperti dijelaskan di atas dapat pula digunakan untuk mengindera kejadian masa yang akan datang dengan pengukuran derajat probabilitas tertentu. Fungsi seperti ini lebih dikenal dengan forecasting (peramalan). Penggunaan ekonometrika
Dalil-dalil ekonomi umumnya dijelaskan secara kualitatif dan dibatasi oleh asumsi-asumsi. Penggunaan asumsi dalam ilmu ekonomi merupakan refleksi dari kesadaran bahwa tidak mungkin untuk dapat mengungkap dengan pasti faktor-faktor apa saja yang saling terkait atau saling mempengaruhi faktor tertentu. Wajar saja, karena ilmu ekonomi merupakan rumpun ilmu sosial, dimana dalam kegiatan sosial antara variabel satu dan yang lainnya saling berinteraksi, berkaitan, dan saling mempengaruhi. Oleh karena itu penggunaan asumsi adalah untuk membantu penyederhanaan model. Asumsi yang paling sering digunakan adalah asumsi ceteris
paribus (hal-hal yang tidak diungkapkan dianggap tetap).
Asumsi ini digunakan mengingat sangat banyaknya variabel-variabel dalam ilmu sosial yang saling mempengaruhi, yang sangat sulit untuk dianalisis secara bersamaan.
Pembatasan penggunaan variabel untuk menganalisis kegiatan ekonomi melalui penetapan ceteris paribus
tersebut, senyatanya adalah untuk mempermudah penafsiran-penafsiran serta pengukuran kegiatan ekonomi. Oleh karena itu dibuatlah pernyataan-pernyataan yang mewakili variabel yang diukur saja, dan mengasumsikan variabel lainnya bersifat tetap. Sebagai contoh, kalau kita hendak mencari jawaban tentang pertanyaan kenapa seseorang mengonsumsi suatu barang, maka kita dapat mengidentifikasi berbagai faktor yang mempengaruhi seperti: tingkat penghasilan, harga barang itu sendiri, harga barang lain, selera, kebutuhan, ekspektasi masa mendatang, tingkat pengeluaran, iklan, promosi, faktor barang pengganti, ketersediaan barang, kondisi politik, trend, gengsi, dan lain-lain, yang tentu itu tidak dapat dijelaskan secara pasti. Banyaknya faktor yang mempengaruhi tingkat konsumsi seseorang tersebut tentu tidak dapat diidentifikasi secara pasti, maka dalam ekonometrika disiasati dengan membentuk model, yang mengabstraksikan realita, dengan cara mengidentifikasi faktor-faktor besar saja (misalnya 1-5 faktor terpenting saja), selebihnya diwakili dengan asumsi ceteris paribus tersebut.
Model matematis merupakan salah satu model untuk menggambarkan teori yang diterjemahkan dalam bentuk matematis. Umumnya model dikembangkan dalam bentuk persamaan, dimana sebelah kiri tanda persamaan mewakili variabel yang dipengaruhi, sedang variabel yang berada di sebelah kanan tanda persamaan mewakili variabel yang mempengaruhi. Variabel yang dipengaruhi disebut pula sebagai variabel terikat, variabel dependen (dependent variables). Variabel yang mempengaruhi disebut pula sebagai variabel bebas, variabel independen (independent variable), variabel penduga, juga variabel prediktor. Untuk memudahkan tahapan proses analisis, dan mendapatkan jawaban yang valid maka perlu menggunakan metodologi ekonometri yang memadai.
Metodologi Ekonometri
Metodologi ekonometri merupakan serangkaian tahapan-tahapan yang harus dilalui dalam kaitan untuk melakukan analisis terhadap kejadian-kejadian ekonomi. Secara garis besar, tahapan metodologi ekonometri dapat diurutkan sebagai berikut:
1. merumuskan masalah 2. merumuskan hipotesa 3. menyusun model 4. mendapatkan data 5. menguji model 6. menganalisis hasil 7. mengimplementasikan hasil Merumuskan Masalah
Merumuskan masalah adalah hal yang sangat penting, karena merupakan “pintu pembuka” untuk menentukan tahapan-tahapan selanjutnya. Merumuskan suatu masalah berarti mengungkap hal-hal apa yang ada di balik gejala atau informasi yang ada, dan sekaligus mengidentifikasi penyebab-penyebab utamanya. Oleh karena itu, di dalam merumuskan masalah tidak dapat dilepaskan dari pemahaman teori-teori yang melandasi atau kontekstual dengan penelitian, mengungkap mengapa penelitian itu dilakukan, dan sekaligus mampu membuat rencana untuk menentukan langkah untuk mendapatkan jawaban dari permasalahan yang ada.
Rumusan masalah merupakan pedoman untuk membuat struktur isi penelitian. Wajar saja bila sebagian besar orang berpendapat bahwa perumusan masalah adalah tahapan yang paling sulit dan menentukan.
Perumusan masalah yang baik tentu disertai dengan latar belakang masalah, karena itu merupakan sumber informasi yang digunakan untuk memahami keterkaitan permasalahan yang dirumuskan. Umumnya perumusan masalah dalam suatu penelitian diungkapkan dalam bentuk kalimat pertanyaan yang membutuhkan jawaban. Karena membutuhkan jawaban, maka akan semakin baik jika apa yang mendasari permasalahan itu adalah hal-hal yang menarik minat peneliti.
Sebagai ilustrasi dari perumusan masalah, beberapa contoh dikemukakan sebagai berikut:
1. Seperti dijelaskan di atas, bahwa evaluasi pegawai dalam rangka penempatan kerja di lingkungan Dinas Pendidikan Nasional Kabupaten Sukoharjo belum dilakukan secara memadai. Dengan tidak dilakukannya evaluasi yang memadai, maka tidak dapat diketahui informasi yang terkait dengan apa yang diharapkan pegawai, seberapa besar tingkat stres pegawai, maupun berapa besar potensi prestasi kerja yang tersimpan maupun yang telah dapat diwujudkan. Untuk itu dalam penelitian ini permasalahan-permasalahan seperti itu akan dirumuskan dalam bentuk pertanyaan sebagai berikut: apakah dalam penempatan kerja pegawai Depdiknas Kabupaten Sukoharjo selama ini telah sesuai dengan karakteristik individu masing-masing pegawai, atau karena terpaksa harus bertahan karena tuntutan yang lain? berapa besar tingkat stress yang dialami pegawai dilingkungan Depdiknas Kabupaten Sukoharjo, dan apa faktor yang yang paling signifikan mempengaruhinya? seberapa besar
tingkat prestasi kerja pegawai Depdiknas Kabupaten Sukoharjo selama ini? adakah stress kerja yang dialami pegawai mempengaruhi prestasi kerja, seberapa besar pengaruhnya?
2. Setelah Juni 1997 diketahui bahwa terdapat kesamaan arah antara inflasi, kurs, dan suku bunga. Ketika inflasi meningkat kurs USD terhadap IDR juga mengalami peningkatan, begitu pula suku bunga juga mengalami peningkatan. Tetapi ketika inflasi mengalami penurunan ternyata baik kurs dan suku bunga juga mengalami hal serupa. Berdasar pada hal tersebut, maka timbul pertanyaan “apakah kurs IDR terhadap USD dan suku bunga simpanan berjangka rupiah mempengaruhi tingkat inflasi di Indonesia ?”
Merumuskan Hipotesa
Hipotesa merupakan jawaban sementara terhadap masalah penelitian, sehingga perlu diuji lebih lanjut melalui pembuktian berdasarkan data-data yang berkenaan dengan hubungan antara dua atau lebih variabel. Rumusan hipotesa yang baik seharusnya dapat menunjukkan adanya struktur yang sederhana tetapi jelas, sehingga memudahkan untuk mengetahui jenis variabel, sifat hubungan antar variabel, dan jenis data.
Perumusan hipotesa biasanya berupa kalimat pernyataan yang merupakan jawaban sementara dari masalah yang akan diteliti. Berdasarkan contoh pada sub
merumuskan masalah di atas, maka dapat dicontohkan penarikan hipotesis seperti ini:4
1. Pegawai di lingkungan Dinas Pendidikan Kabupaten Sukoharjo banyak yang mengalami stres kerja yang dapat berakibat pada menurunnya motivasi kerjanya.
2. Inflasi di Indonesia setelah tahun 1997 dipengaruhi oleh kurs nilai tukar IDR-USD dan bunga deposito. Hubungannya bersifat searah.
Menyusun Model
Pada dasarnya setiap ilmu pengetahuan bertujuan untuk menganalisis kenyataan yang wujud di alam semesta dan di dalam kehidupan manusia. Namun, karena fakta-fakta mengenai kenyataan yang wujud dalam ilmu sosial ( dimana ilmu ekonomi termasuk salah satu cabangnya) berjumlah sangat banyak dan saling terkait satu sama lainnya, maka menggambarkan kenyataan yang sebenarnya berlaku dalam perekonomian adalah merupakan hal yang tidak mudah. Agar dapat menjelaskan realitas yang kompleks seperti itu, maka perlu dilakukan abstraksi melalui penyusunan suatu model. Oleh karena itu model merupakan abstraksi dari realitas.
Dalam ilmu ekonomi, model ekonomi didefinisikan sebagai konstruksi teoritis atau kerangka analisis ekonomi yang menggabungkan konsep, definisi, anggapan, persamaan, kesamaan (identitas) dan ketidaksamaan dari
4
Penulisan hipotesis ini bersifat garis besar. Penulisan hipotesis dalam penelitian biasanya dituliskan sekaligus dua hipotesis yang berlawanan, yaitu hipotesis nol dan hipotesis alternative.
mana kesimpulan akan diturunkan.5 Sebagaimana namanya, dalam ilmu ekonomi tentu yang digunakan adalah variabel-variabel ekonomi saja. Untuk variabel non ekonomi tidak perlu dipilih, atau dimasukkan saja ke dalam asumsi ceteris paribus. Variabel ekonomi dibedakan menjadi:6
1. Variabel Endogin, yaitu variabel yang menjadi pusat perhatian si pembuat model, atau variabel yang ditentukan di dalam model dan ingin diamati variansinya.
2. Variabel Eksogin, yaitu variabel yang dianggap ditentukan di luar sistem (model) dan diharapkan mampu menjelaskan variasi variabel endogin.
3. variabel kelambanan, yaitu variabel dengan unsur lag, yang umumnya digunakan untuk data runtut waktu.
Fungsi model dalam ekonometrika adalah sebagai tuntunan untuk mempermudah menguji ketepatan model penduga. Salah satu bentuk model adalah berupa persamaan fungsi secara matematis. Karena pada hakikatnya sebuah fungsi adalah sebuah persamaan matematis yang menggambarkan hubungan sebab akibat antara sebuah variabel dengan satu atau lebih variabel lain. Ketepatan model itu sendiri mempunyai dua tujuan yaitu: Pertama, untuk mengetahui apakah model penduga tersebut merupakan model yang tepat sebagai estimator.
Kedua, untuk mengetahui daya ramal atau goodness of fit
dari model penduga. Model persamaan ini disebut pula
5
Insukindro, Pembentukan Model dalam Penelitian Ekonomi, Jurnal Ekonomi dan Bisnis Indonesia, 7(1), 1-18.
6
Kuncoro, Mudrajad, Metode Kuantitatif, Teori dan Aplikasi Untuk Bisnis dan Ekonomi, UPP AMP YKPN, 2001, p.5.
sebagai metode regresi yang diharapkan dapat menjawab hipotesis yang telah ditentukan.
Model ekonometrika setidaknya terdiri dari dua golongan variabel, yaitu variabel terikat (dependen) yang berada pada sebelah kiri tanda persamaan, dan variabel bebas (independen) yang berada di sebelah kanan tanda persamaan. Jumlah variabel bebas tidak harus satu, tetapi dapat berjumlah lebih dari satu variabel. Untuk model dengan satu variabel bebas disebut dengan regresi tunggal (single regression), sedang untuk model yang mempunyai lebih dari satu variabel bebas disebut regresi berganda (multiple regression).
Mendapatkan Data
Mendapatkan data merupakan suatu langkah yang harus dilakukan oleh peneliti, agar dapat menjamin bahwa data yang dianalisis adalah benar-benar menggunakan data yang tepat. Hal ini penting untuk mendapatkan hasil analisis yang tidak bias atau menyesatkan. Para peneliti terdahulu telah mengingatkan agar jangan sampai dalam penelitian terdapat GIGO, garbage In garbage out. Tahapan yang dapat ditempuh untuk mendapatkan data pra analisis meliputi: penyuntingan data, pengembangan variabel, pengkodean data, cek kesalahan, pembentukan struktur data, tabulasi.
Penyuntingan data, adalah upaya proses data untuk mendapatkan data yang memberikan kejelasan, dapat dibaca, konsisten, dan komplit.
Pengembangan variabel, yaitu memperluas variansi data, misalnya mentransformasi menjadi data dalam
angka logaritma, melakukan indeksasi data, komposit, dan lain-lain.
Pengkodean data, melakukan koding terhadap data yang akan digunakan dengan cara yang sesuai, seperti koding terhadap variabel dummy, data ordinal, data interval, dan lain-lain.
Cek kesalahan, merupakan finalisasi pengujian data agar betul-betul mendapatkan data akhir yang valid.
Strukturisasi data, membuat kesedian data agar dapat digunakan dengan baik di kemudian hari.
Tabulasi data, biasanya tidak dimasukkan sebagai prosedur analitik dalam penelitian ilmiah karena tidak mengungkapkan hubungan dalam data. Kendati demikian, banyak riset bisnis yang ditujukan untuk penjelasan masalah dan atau menemukan hubungan. Tabulasi menyajikan hitungan hitungan frekuensi dari satu hal (analisis frekuensi) atau perkiraan numerik tentang distribusi sesuatu (analisis deskriptif). Tabulasi merupakan alat analisis bisnis. Tabulasi juga bermanfaat bagi peneliti sebagai alat menyusun kategori ketika mengubah variabel interval menjadi klasifikasi nominal. Dengan kata lain, tabulasi mendeskripsikan jumlah individu yang menjawab pertanyaan tertentu. Tabulasi dapat juga digunakan untuk menciptakan statistik deskriptif mengenai variabel-variabel yang digunakan atau tabulasi silang.7
Menguji Model
Untuk mengetahui sejauh mana tingkat kesahihan model terbaik yang dihasilkan, maka perlu dilakukan uji ketepatan fungsi regresi dalam menaksir nilai actual dapat 7
diukur dari goodness of fit-nya. Untuk melakukan uji
goodness of fit pengukurannya dilakukan dengan menguji
nilai statistik t, nilai statistik F, dan koefisien determinasinya (R2) pada hasil regresi yang telah memenuhi uji asumsi klasik.
Uji nilai statistik t untuk mengetahui pengaruh secara individual variabel independen terhadap variabel dependen. Uji F untuk mengetahui secara bersama-sama semua variabel independen dalam mempengaruhi variabel dependen. Sedangkan koefisien determinasi untuk menentukan seberapa besar sumbangan variabel independen terhadap variabel dependen.
Uji asumsi klasik juga perlu dilakukan terhadap model agar memperteguh validitas model, yang dapat dilakukan melalui pengujian normalitas, autokorelasi, multikolinearitas, juga heteroskedastisitas.
Menganalisis Hasil
Analisis ekonometrika dimulai dari interpretasi terhadap data dan keterkaitan antar variabel yang dijelaskan di dalam model. Tidak hanya analisis regresi, analisis korelasi juga perlu dilakukan untuk mendapatkan hasil pengukuran hingga benar-benar valid. Analisis regresi akan mendapatkan hasil pengaruh antara variabel independen terhadap variabel dependen. Sedang untuk analisis korelasi berguna untuk mengetahui hubungan antar variabel tanpa membedakan apakah itu variabel dependen ataukah independen.
Tanda positif atau negatif pada masing-masing koefisien perlu untuk dicermati, karena mempunyai keterkaitan langsung terhadap kesesuaian dengan teori yang dirumuskan dalam model. Pengabaian terhadap kedua tanda tersebut, dapat menjadikan hasil regresi tidak sesuai dengan teori yang melatar belakangi.
Hal lain yang tidak kalah pentingnya adalah pengimplemantasian dari hasil pengukuran. Karena sebagus dan sebenar apapun hasil penelitian, apabila tidak ditindaklanjuti dalam bentuk implementasi, tidak akan berarti apa-apa.
-000-Tugas:
1. Buatlah rangkuman dari pembahasan di atas
2. Cobalah untuk menyimpulkan maksud dari uraian bab ini
3. Jawablah pertanyaan-pertanyaan di bawah ini: a. Apa yang dimaksud dengan ekonometrika b. Bidang keilmuan apa saja yang terkait secara
langsung dengan ekonometrika c. Jelaskan pentingnya ekonometrika d. Uraikan tahapan-tahapan ekonometrika
BAB II
MODEL REGRESI
Tujuan Pengajaran:
Setelah mempelajari bab ini, anda diharapkan dapat: Mengerti definisi model
Mengerti definisi regresi Menyebutkan model-model regresi Menjelaskan kegunaan model regresi
Menuliskan alternatif notasi model Memahami perbedaan-perbedaan model Menggunakan model untuk menjabarkan teori
BAB II
MODEL REGRESI
Keilmuan sosial mempunyai karakteristik berupa banyaknya variabel-variabel atau faktor-faktor yang saling mempengaruhi satu sama lain. Kondisi yang demikian ini menyebabkan kesulitan dalam menentukan secara pasti faktor apa saja yang menyebabkan faktor tertentu. Sebagai contoh, apabila kita ingin mengetahui faktor apa saja yang mempengaruhi permintaan suatu barang tertentu (sebut saja barang X), maka dengan mengidentifikasi kemungkinan faktor-faktor yang mempengaruhinya, kita akan mendapatkan banyak sekali faktor-faktor itu seperti: harga barang tersebut, harga barang lain, mutu barang, pendapatan, anggaran pengeluaran, prediksi harga masa yang akan datang, selera, trend yang berkembang, persepsi atas barang tersebut, kebutuhan, gengsi, return usaha yang mungkin diperoleh, tingkat bunga bank, stabilisasi keamanan, tempat penjualan barang tersebut, barang pengganti, dan tentu masih banyak lagi faktor-faktor lainnya yang sangat sulit untuk ditentukan secara mutlak, bahwa harga barang X tersebut hanya ditentukan oleh faktor-faktor yang telah dijelaskan.
Dari beragam faktor-faktor yang disebutkan di atas, tentu mempunyai tingkat signifikansi yang berbeda. Beberapa faktor mungkin mempunyai tingkat signifikansi yang tinggi, sementara yang lain mungkin tingkat signifikansinya rendah, atau biasa disebut tidak signifikan. Dalam kepentingan untuk mengidentifikasi beberapa variabel saja, maka dibenarkan untuk mengabaikan variabel-variabel yang lain. Cara yang
dilakukan adalah membuat model, yang menjelaskan variabel-variabel yang hendak diteliti saja. Sedang untuk variabel-variabel lain yang terkait tetapi tidak hendak diteliti, dapat diabaikan. Hal ini dibenarkan dalam keilmuan sosial (ekonomi), karena terlalu banyak faktor-faktor yang saling terkait dan sangat sulit untuk diidentifikasi secara menyeluruh, sehingga perlu asumsi yang menganggap tidak adanya perubahan dari variabel-variabel yang disebut dengan ceteris paribus.
Model dalam keilmuan ekonomi berfungsi sebagai panduan analisis melalui penyederhanaan dari realitas yang ada. Sehingga model sering diartikan refleksi dari realita atau simplikasi dari kenyataan. Hal ini akan semakin jelas kalau kita runut dari bentuk suatu model yang memang berbentuk sangat sederhana. Penulisan model dalam ekonometrika adalah merupakan pengembangan dari persamaan fungsi secara matematis, karena pada hakikatnya sebuah fungsi adalah sebuah persamaan yang menggambarkan hubungan sebab akibat antara sebuah variabel dengan satu atau lebih variabel lain. Penulisan model dalam bentuk persamaan fungsi tersebut dicontohkan dalam persamaan berikut ini:
Persamaan Matematis
Æ Y = a + b X ……….. (pers.1) Persamaan Ekonometrika
Æ Y = b0 + b1X + e ……….. (pers.2)
Munculnya e (error term) pada persamaan ekonometrika (pers.2) merupakan suatu penegasan bahwa sebenarnya banyak sekali variabel-variabel bebas yang mempengaruhi variabel terikat (Y). Karena dalam model tersebut hanya ingin melihat pengaruh satu variabel X saja, maka variabel-variabel yang lain dianggap bersifat tetap atau ceteris paribus, yang dilambangkan dengan e.
Bentuk Model
Model persamaan fungsi seperti dicontohkan pada pers.2 bertujuan untuk mengetahui pengaruh variabel bebas terhadap variabel terikat. Oleh karena itu, persamaan tersebut disebut juga sebagai persamaan regresi. Model Regresi mempunyai bermacam-macam bentuk model yang dapat dibedakan berdasarkan sebaran data yang terlihat dalam scatterplott-nya.8 Setidaknya terdapat tiga jenis model yaitu: Model Regresi Linier, Model Regresi Kuadratik, Model Regresi Kubik
Model Regresi Linier
Kata “linier” dalam model ini menunjukkan linearitas dalam variabel maupun lineraitas dalam data. Kata linier menggambarkan arti bahwa sebaran data dalam scatter
plot menunjukkan sebaran data yang mendekati bentuk
garis lurus. Data semacam ini dapat wujud apabila perubahan pada variabel Y sebanding dengan perubahan variabel X. Jika sebaran datanya berkecenderungan melengkung, maka cocoknya menggunakan dengan regresi kuadratik. Jika sebaran datanya kecenderungannya seperti bentuk U atau spiral regresinya menggunakan regresi kubik.
Model linier sendiri dapat dibedakan sebagai single linier maupun multiple linier. Disebut single linier apabila variabel bebas hanya berjumlah satu dengan batasan pangkat satu. Sedang multiple linier apabila variabel bebas lebih dari satu variabel dengan batasan pangkat satu. Untuk lebih jelasnya akan dicontohkan bentuk 8
persamaan single linier (pers.3) dan persamaan multiple linier (pers.4) sebagai berikut:
Y = b0 + b1X + e ……….. (pers.3) Y = b0 + b1X1 + b2X2 + …… + bnXn + e ……….. (pers.4)
Misalkan dari pers.3 dianggap bahwa Y = Inflasi, dan X = bunga deposito (Budep) pada periode tertentu, dan jika datanya telah diketahui, maka data akan tergambar dalam bentuk titik-titik yang merupakan sebaran data dalam scatter plot. Dengan menggunakan data penelitian hubungan antara inflasi dan bunga deposito antara Januari 2001 hingga Oktober 2002, maka sebaran datanya tergambar sebagai berikut:
Hubungan Suku Bunga terhadap Inflasi 16 15 14 13 12 11 10 9 8 INFLAS I 13 .0 13 .5 14 .0 14 .5 15 .0 15 .5 16 .0 16 .5 BUDEP Gambar 3
Sebaran data tersebut di atas (gambar 3) menunjukkan hubungan yang positif, yaitu jika bunga deposito meningkat, maka inflasi juga meningkat. Begitu pula jika bunga deposito menurun, inflasi juga turun. Sedangkan contoh sebaran data yang digambarkan dalam
scatter plot di bawah ini (gambar 4), menunjukkan bahwa
hubungan antara variable Afenegat (Afeksi negative) dan Latribut (Atribut) mempunyai hubungan yang negative. Jika atributnya berkurang, maka afeksi negatifnya meningkat. Begitu pula sebaliknya.
Dari scatter plot kedua gambar tersebut (baik gambar di atas maupun di bawah ini) menunjukkan bahwa sebaran datanya menyebar memanjang lurus, sehingga dapat diwakili dengan garis lurus. Oleh karena itu, kedua scater plot tersebut akan tepat digunakan regresi linier.
40 30 20 10 0 LATRIBUT 1.9 1.8 1.7 1.6 AFENEGAT Gambar 4
Model Kuadratik
Salah satu ciri model kuadratik dapat diketahui dari adanya pangkat dua pada salah satu variabel bebasnya. Ciri yang lain dapat dilihat dari pengamatan terhadap
scatter plott yang menunjukkan kecenderungan sebaran
data membentuk lengkung, tidak seperti model linier yang cenderung lurus.
Model kuadratik dituliskan dalam persamaan fungsi sebagai berikut:
Y = b0 + b1X1 + b2X1 2
+ e ……….. (pers.5)
Model Kubik
Salah satu ciri model kubik dapat diketahui dari adanya pangkat tiga pada salah satu variabel bebasnya. Oleh karena itu sering disebut juga dengan fungsi berderajat tiga. Ciri yang lain dapat dilihat dari pengamatan terhadap scatter plott yang menunjukkan kecenderungan sebaran data yang berbentuk lengkung dengan arah yang berbeda. Setiap fungsi kubik setidak-tidaknya mempunyai sebuah titik belok (inflexion point), yaitu titik peralihan bentuk kurva dari cekung menjadi cembung atau dari cembung menjadi cekung.9
Model kuadratik dituliskan dalam persamaan fungsi sebagai berikut: Y = b0 + b1X1 + b1X1 2 + b1X1 3 + e ……….. (pers.6) 9
Dumairy, Matematika Terapan Untuk Bisnis dan Ekonomi, BPFE, Yogjakarta, p.140
Notasi Model
Huruf Y memerankan fungsi sebagai variabel dependen atau variabel terikat. Y sering juga disebut sebagai variabel gayut, variabel yang dipengaruhi, atau variabel endogin. Dengan alasan keseragaman, penulisan huruf Y diletakkan disebelah kiri tanda persamaan. Sedang variabel independen yang secara umum disimbolkan dengan huruf X diletakkan disebelah kanan tanda persamaan.
Huruf X menggambarkan variabel bebas atau variabel yang mempengaruhi. Oleh karena itu variabel ini mempunyai nama lain seperti variabel independen, variabel penduga, variabel estimator, atau juga variabel eksogen. Peletakannya di sebelah kanan tanda persamaan menunjukkan perannya sebagai variabel yang mempengaruhi.
Huruf b0 sering juga dituliskan dengan huruf a, α, atau juga β0. Secara substansi penulisan itu mempunyai arti yang sama, yaitu menunjukkan konstanta atau
intercept yang merupakan sifat bawaan dari variabel Y.
Konstanta ini mempunyai angka yang bersifat tetap yang sekaligus menunjukkan titik potong garis regresi pada sumbu Y. Jika konstanta itu bertanda positif maka titik potongnya di sebelah atas titik origin (0), sedang bila bertanda negatif titik potongnya di sebelah bawah titik origin. Nilai konstanta ini merupakan nilai dari variabel Y ketika variabel X bernilai nol. Atau dengan bahasa yang mudah, nilai konstanta merupakan sifat bawaan dari Y.
Huruf b1, b2, bn merupakan parameter yang menunjukkan slope atau kemiringan garis regresi. Parameter ini sering juga dituliskan dengan bentuk b, atau β1, β2, βn. Meskipun dituliskan dengan tanda yang
berbeda, secara substansi parameter ini menunjukkan beta atau koefisien korelasi yang sekaligus menunjukkan tingkat elastisitas dari variabel X tersebut. Nilai beta ini memungkinkan untuk bernilai positif maupun negatif. Tanda positif menunjukkan hubungan yang searah antara variabel X dengan variabel Y. Artinya jika X mengalami peningkatan maka Y juga mengalami peningkatan. Sebaliknya jika X mengalami penurunan maka Y pun akan menurun. Arah hubungan seperti itu tidak terjadi pada beta yang berangka negatif. Karena jika tandanya negatif arah hubungan X terhadap Y saling berlawanan. Jika X meningkat maka Y menurun, sebaliknya jika X menurun maka nilai statistik t meningkat.
Demikian pula, karena nilai koefisien korelasi ini juga menunjukkan tingkat elastisitas, maka dari besarnya nilai koefisien korelasi (b) tersebut dapat ditentukan jenis elastisitasnya. Jika nilai b besarnya lebih dari satu (b>1) maka disebut elastis. Artinya, jika variabel X mengalami perubahan, maka variabel Y akan mengalami perubahan yang lebih besar dari perubahan yang ada pada variabel X tersebut. Jika nilai b besarnya sama dengan angka satu (b=1) disebut uniter elastis. Artinya, jika variabel X mengalami perubahan, maka variabel Y akan mengalami perubahan yang sama besar dengan perubahan yang ada pada variabel X tersebut. Jika nilai b besarnya lebih kecil dari angka satu (b<1) disebut inelastis. Artinya, jika variabel X mengalami perubahan, maka variabel Y akan mengalami perubahan yang lebih kecil dari perubahan yang ada pada variabel X tersebut.
Huruf e merupakan kependekan dari error term atau kesalahan penggganggu. Simbol error ini tidak jarang dituliskan dalam huruf ε atau μ. Simbol ini merupakan karakteristik dari ekonometrika yang tidak dapat dilepaskan dari unsur-unsur stokhastik atau hal-hal yang mengandung probabilita, karena hasil yang
ditunjukkan oleh model ekonometrika hanya bersifat perkiraan, dalam arti tidak menunjukkan kebenaran yang mutlak. Oleh karena itu nama lain dari simbol ini tidak terlepas dari sifat dasar itu seperti: disturbance error atau
stochastic disturbance.
Kesalahan pengganggu ini sendiri mempunyai banyak sebab yang dapat menimbulkannya seperti:
1. tidak seluruh variabel bebas yang mempunyai potensi dalam mempengaruhi variabel terikat dapat disebutkan dalam model.
2. kesalahan asumsi dalam menentukan teori yang diwujudkan sebagai model.
3. ketidaklengkapan data yang dianalisis.
4. ketidaktepatan model yang digunakan. Misalnya, seharusnya digunakan model kuadratik tetapi justru yang digunakan adalah model linier, atau sebaliknya.
Spesifikasi Model dan Data
Secara spesifik model dalam ekonometrika dapat dibedakan menjadi: model ekonomi (economic model) dan model statistic (statistical model).
Model Ekonomi
biasanya dituliskan dalam bentuk persamaan sebagai berikut:
Y = b0 + b1X1 + b2 X2
Tanda b = parameter, menunjukkan ketergantungan variabel Y terhadap variabel X
b0 = intercept, menjelaskan nilai variabel terikat ketika masing-masing variabel bebasnya bernilai 0 (nol).
Model ini menggambarkan rata-rata hubungan sistemik antara variabel Y, X1, X2. Dalam model ini nilai e tidak tertera, karena nilai e diasumsikan non random. Dalam realita, model ini tidak mampu menjelaskan variabel-variabel ekonomi secara pas (clear), oleh karena itu membutuhkan regresi.
Model Statistik
Model ekonomi seperti yang dijelaskan di atas, mencerminkan nilai harapan, maka dapat pula ditulis:
E (Y) = b0 + b1X1 + b2 X2
Karena nilai harapan, maka tentu tidak akan secara pasti sesuai dengan realita. Oleh karena itu akan muncul nilai
random error term (e). Nilai e sendiri merupakan selisih
antara nilai kenyataan dan nilai harapan. Secara matematis dapat dituliskan sebagai berikut:
e = Y – E(Y) atau e = Y –Yˆ
jadi, Y = Yˆ+ e
karena, Yˆ= E (Y) = b0 + b1X1 + b2 X2 maka Y = b0 + b1X1 + b2 X2 + e
tanda e pada persamaan di atas mencerminkan distribusi probabilitas. Atau dapat pula dianggap sebagai pengganti variabel-variabel berpengaruh lain selain variabel yang dijelaskan dalam model. Dalam teori ekonomi, e merupakan representasi dari asumsi ceteris paribus. Pengakuan adanya variabel lain yang berpengaruh, meskipun tidak disebutkan variabel apa, cukup ditulis dengan tanda e, maka model menjadi lebih realistik. Agar
terdapat gambaran yang jelas, maka nilai e harus diasumsikan. Asumsi-asumsinya adalah:
1. Nilai harapan e sama dengan 0 (nol).
E(e) = 0, masing-masing random error mempunyai distribusi probabilitas = 0. Meskipun e bisa bernilai positif atau negatif, tetapi rata-rata e harus = 0. 2. Variance residual sama dengan standar deviasi
Var (e) = σ 2
, artinya: masing-masing random error mempunyai distribusi probabilitas variance yang sama dengan standar deviasi (σ 2
). Asumsi ini menjelaskan bahwa residual bersifat homoskedastik.
3. Kovarian ei dan ej mempunyai nilai nol.
Cov (ei, ej) = 0. Nilai nol dalam asumsi ini menjelaskan bahwa antara ei dan ej tidak ada korelasi serial atau tida berkorelasi (autocorrelation).
4. Nilai random error mempunyai distribusi probabilitas yang normal.
Karena masing, masing observasi Y tergantung pada e, maka masing-masing Y juga memiliki varian yang random. Dengan demikian, statistik Y menjadi sebagai beriku:
1. Nilai harapan Y tergantung pada nilai masing-masing variabel penjelas dan parameter-parameternya. Dengan menggunakan asumsi E(e) = 0, maka rata-rata perubahan nilai Y untuk setiap observasi ditentukan oleh fungsi regresi.
E (Y) = b0 + b1X1 + b2 X2
2. Variance distribusi probabilitas Y tidak dapat berubah setiap observasi.
Var (Y) = Var (e) = σ 2
3. Tidak ada kaitan langsung antara observasi satu dengan observasi lainnya.
Cov (Yi, Yj) = Cov (ei, ej) = 0
4. Nilai Y secara normal terdistribusi di sekitar rata-rata.
Asumsi-asumsi di atas difokuskan pada pembahasan variabel terikat. Perlu adanya asumsi tambahan terhadap variabel penjelas, yaitu:
1. Variabel independen tidak bersifat random, karena dengan jelas dapat diketahui dari data.
2. Variabel independen tidak merupakan fungsi linear dari yang lain. Asumsi ini penting agar tidak terjadi
redundancy, yang menyebabkan multikolinearitas.
Kesimpulan:
Dalam suatu model regresi terdapat dua jenis variabel, yaitu variabel terikat dan variabel bebas, yang dipisahkan oleh tanda persamaan. Variabel terikat sering disimbolkan dengan Y, biasa pula disebut sebagai variabel dependen, variabel tak bebas, variabel yang dijelaskan, variabel yang diestimasi, variabel yang dipengaruhi. Cirinya, berada pada sebelah kiri tanda persamaan (=). Variabel bebas sering disimbolkan dengan X, biasa pula disebut sebagai variabel independen, variabel yang mempengaruhi, variabel penjelas, variabel estimator, variabel penduga, variabel yang mempengaruhi, variabel prediktor. Cirinya terletak pada sebelah kanan tanda persamaan (=).
Dalam suatu model juga terdapat parameter-parameter yang disebut konstanta, juga koefisien korelasi. Konstanta sering disimbolkan dengan a, atau b0, atau β0. Koefisien korelasi disebut pula sebagai beta, B, b, menunjukkan slope, kemiringan, elastisitas.
-000-Tugas:
1. Buatlah rangkuman dari pembahasan di atas!
2. Cobalah untuk menyimpulkan maksud dari uraian bab ini!
3. Jawablah pertanyaan-pertanyaan di bawah ini: a. Jelaskan apa yang dimaksud dengan model!
b. Sebutkan apa saja jenis-jenis model ekonometrika!
c. Jelaskan perbedaan antara jenis-jenis model ekonometrika!
d. Coba uraikan asumsi-asumsi yang harus dipenuhi dalam regresi linier!
BAB III
MODEL REGRESI DENGAN DUA VARIABEL
Tujuan Pengajaran:
Setelah mempelajari bab ini, anda diharapkan dapat: Mengetahui kegunaan dan spesifikasi model
Menjelaskan hubungan antar variabel Mengaitkan data yang relevan dengan teori
Mengembangkan data Menghitung nilai parameter Mengetahui arti dan fungsi parameter Menentukan signifikan tidaknya variabel bebas
Membaca hasil regresi Menyebutkan asumsi-asumsi.
BAB III
MODEL REGRESI DENGAN DUA VARIABEL
Bentuk model
Model regresi dengan dua variabel10 umumnya dituliskan dengan simbol berbeda berdasarkan sumber data yang digunakan, meskipun tetap dituliskan dalam persamaan fungsi regresi. Fungsi regresi yang menggunakan data populasi (FRP) umumnya menuliskan simbol konstanta dan koefisien regresi dalam huruf besar, sebagai berikut:
Y = A + BX + ε ……….. (pers.3.1)
Fungsi regresi yang menggunakan data sampel (FRS) umumnya menuliskan simbol konstanta dan koefien regresi dengan huruf kecil, seperti contoh sebagai berikut:
Y = a + bX + e ……….. (pers.3.2) Dimana:
A atau a; merupakan konstanta atau intercept
B atau b; merupakan koefisien regresi, yang juga menggambarkan tingkat elastisitas variabel independen
Y; merupakan variabel dependen X; merupakan variabel independen
10
Notasi a dan b merupakan perkiraan dari A dan B. Huruf a, b, disebut sebagai estimator atau statistik, sedangkan nilainya disebut sebagai estimate atau nilai perkiraan.11 Meskipun penulisan simbol konstanta dan koefisien regresinya agak berbeda, namun penghitungannya menggunakan metode yang sama, yaitu dapat dilakukan dengan metode kuadrat terkecil biasa (ordinary least
square)12, atau dengan metode Maximum Likelihood.
Metode Kuadrat Terkecil Biasa (Ordinary Least
Square) (OLS)
Penghitungan konstanta (a) dan koefisien regresi (b) dalam suatu fungsi regresi linier sederhana dengan metode OLS dapat dilakukan dengan rumus-rumus sebagai berikut:
Rumus Pertama (I)
Mencari nilai b: n
(
∑
XY)
−(
∑
X)(
∑
Y)
2 b = n(
∑
X)
−(
∑
X)
2 mencari nilai a:∑
Y − b.∑
X a = nRumus kedua (II)
11
Supranto, J., Ekonometrik, Buku satu, LPFEUI, Jakarta, 1983 12
Ordinary Least Square (OLS) ditemukan oleh Carl Friedrich Gauss, seorang
Mencari nilai b:
∑
xy b = 2∑
x mencari nilai a: a =Y −b XMisalnya saja kita ingin meneliti pengaruh bunga deposito jangka waktu 1 bulan (sebagai variabel X = Budep) terhadap terjadinya inflasi di Indonesia (sebagai variabel Y=Inflasi) pada kurun waktu Januari 2001 hingga Oktober 2002, yang datanya tertera sebagai berikut:
Observasi Y X1 Jan 01 8.28 13.06 Peb 01 9.14 13.81 Mar 01 10.62 13.97 Apr 01 10.51 13.79 Mei 01 10.82 14.03 Jun 01 12.11 14.14 Jul 01 13.04 14.39 Agu 01 12.23 14.97 Sep 01 13.01 15.67 Okt 01 12.47 15.91 Nop 01 12.91 16.02 Des 01 12.55 16.21 Jan 02 14.42 16.19 Peb 02 15.13 15.88 Mar 02 14.08 15.76 Apr 02 13.3 15.55 Mei 02 12.93 15.16 Jun 02 11.48 14.85 Jul 02 10.05 14.22 Agu 02 10.6 13.93 Sep 02 10.48 13.58 Okt 02 10.33 13.13 Jumlah 260.49 324.22
Bantuan dengan SPSS
Cara memasukkan data tersebut di atas ke dalam SPSS, dapat dilakukan dengan tahapan sebagai berikut:
1. Pastikan bahwa lembar worksheet SPSS sudah siap digunakan. Caranya: tampilkan program SPSS di layar monitor.
2. Masukkan data ke masing-masing kolom. Pastikan bahwa yang aktif adalah Data View (lihat pojok kiri bawah), bukan variabel View!
3. Beri nama kolom tersebut sesuai nama variabelnya. Caranya: klik Variabel View (pojok kiri bawah), maka akan muncul kolom: Name, Type, Width, Decimals, label, values, missing, columns, align, measure. Masukkan nama variabel ke dalam kolom Name. Misal kita mau memberi nama variabel dengan Y, maka ketik Y. Jika hendak memberi nama tersebut dengan Inflasi, maka ketik inflasi. (Meskipun yang dimasukkan adalah huruf besar, tetapi dalam kolom akan muncul huruf kecil).
4. Data awal yang dimasukkan tadi dapat dikembangkan menjadi seperti hitungan dalam tabel di bawah (misal menjadi X12). Caranya: klik Transform, kemudian pilih Compute, maka layar SPSS akan berubah menjadi seperti dalam gambar sebagai berikut:
Pada kotak Target Variable (kanan atas) isilah dengan nama variabel baru (variabel pengembangan). Sesuai contoh, ketik X12, dimana X12 ini merupakan X1 yang dikuadratkan. Karena akan menghitung kuadrat, maka caranya: variabel yang ada di kolom Type&Label diblok (klik)
pindahkan ke dalam kolom Numeric Expression menggunakan langkah klik pada tanda segitiga penunjuk arah. Setelah itu pilih ** (pada tuts kalkulator) dan ketik angka 2 (karena hendak mengkuadratkan), dan kemudian ketik OK. Jika tahapan tersebut telah dilalui, worksheet data akan menampakkan variabel baru dengan data yang dihitung tadi.
5. Untuk membuat data perkalian, lakukan dengan
cara memindahkan salah satu nama variabel yang hendak dikalikan (misalnya, Y) dari kotak Type&Label ke Numeric Expression, pilih tanda pengali (*) dan ikuti dengan memindahkan lagi variabel lainnya yang hendak dikalikan (misal X),
setelah itu klik OK.
Berdasarkan data yang tertera di atas, maka nilai a dan b dapat dicari melalui penggunakan kedua rumus tersebut, baik itu rumus pertama ataupun kedua. Seandainya kita ingin menggunakan rumus pertama, maka langkah awal yang dapat dilakukan adalah mengadakan penghitungan-penghitungan atau pengembangan data untuk disesuaikan dengan komponen rumus, sehingga nantinya dapat secara langsung diaplikasikan ke dalam rumus. Pengembangan data yang dimaksudkan adalah menentukan nilai X12, nilai
Y2, serta nilai XY. Hasil pengembangan data dapat dilihat pada tabel berikut:
Observasi Y X1 X1 2 Y2 XY Jan 01 8.28 13.06 170.5636 68.5584 108.1368 Peb 01 9.14 13.81 190.7161 83.5396 126.2234 Mar 01 10.62 13.97 195.1609 112.7844 148.3614 Apr 01 10.51 13.79 190.1641 110.4601 144.9329 Mei 01 10.82 14.03 196.8409 117.0724 151.8046 Jun 01 12.11 14.14 199.9396 146.6521 171.2354 Jul 01 13.04 14.39 207.0721 170.0416 187.6456 Agu 01 12.23 14.97 224.1009 149.5729 183.0831 Sep 01 13.01 15.67 245.5489 169.2601 203.8667 Okt 01 12.47 15.91 253.1281 155.5009 198.3977 Nop 01 12.91 16.02 256.6404 166.6681 206.8182 Des 01 12.55 16.21 262.7641 157.5025 203.4355 Jan 02 14.42 16.19 262.1161 207.9364 233.4598 Peb 02 15.13 15.88 252.1744 228.9169 240.2644 Mar 02 14.08 15.76 248.3776 198.2464 221.9008 Apr 02 13.3 15.55 241.8025 176.89 206.815 Mei 02 12.93 15.16 229.8256 167.1849 196.0188 Jun 02 11.48 14.85 220.5225 131.7904 170.478 Jul 02 10.05 14.22 202.2084 101.0025 142.911 Agu 02 10.6 13.93 194.0449 112.36 147.658 Sep 02 10.48 13.58 184.4164 109.8304 142.3184 Okt 02 10.33 13.13 172.3969 106.7089 135.6329 Jumlah 260.49 324.22 4800.525 3148.48 3871.398
Setelah mendapatkan hitungan-hitungan hasil pengembangan data, maka angka-angka tersebut dapat secara langsung dimasukkan ke dalam rumus I, sebagai berikut: Mencari nilai b: n
(
∑
XY)
−(
∑
X)(
∑
Y)
2 b = n(
∑
X)
−(
∑
X)
222
(
3.871,398)
−(
324,22)(
260,49)
b = 22(
4.800,525) (
− 324,22)
2 85.170,76 −84.456,0678 = 105.611,60 −105.118,6084 714,6922 = 492,9916 b = 1,4497dengan diketahuinya nilai b, maka nilai a juga dapat ditentukan, karena rumus pencarian a terkait dengan nilai b. Mencari nilai a: −b. X a =
∑
Y∑
n 260,49 −1,4497 (324,22) = 22 260,49 − 470,022 = 22 a = -9.5241Seperti telah dijelaskan di atas, bahwa nilai a dan b dapat pula dicari dengan menggunakan rumus kedua. Demikian pula, agar dapat secara langsung menggunakan rumus II ini, perlu menghitung dulu komponen-komponen rumus.Langkah yang dapat dilakukan dicontohkan sebagai berikut:
Mencari nilai b, menggunakan rumus kedua:
∑
xyb = 2
∑
xDari rumus di atas, kita perlu menemukan dulu nilai dari
∑
xy atau∑
x2 yang dapat dilakukan dengan rumus-rumus sebagai berikut:2 2
∑
x =∑
X −(
∑
X)
2 / n 2 2∑
y =∑
Y −(
∑
Y)
2/ n∑
xy =∑
XY − (∑
X∑
Y ) / n maka: 2 324.22 2∑
x = 4800.53 -22 = 4800.53 – 4778.12 = 22.41 260.492 y2 = 3148.48-∑
22 = 3148.48 – 3084.32 = 64.16(324.22 − 260.49)
∑
xy = 3871,40-22
= 3871.40 – 3838.91 = 32.49
Dengan diketahuinya, nilai-nilai tersebut, maka nilai b dapat ditentukan, yaitu:
32.49
b = = 1.4498
22.41
Dengan diketahuinya nilai b, maka nilai a juga dapat dicari dengan rumus sebagai berikut:
a =Y −b X
= 11.8405 – (1.4498 x 14.7373) = 11.8405 – 21.3661
a= -9.5256
Hasil pencarian nilai a dan b dengan menggunakan rumus I dan II didapati angka yang cenderung sama. Pada penghitungan rumus I nilai a = –9,5241 dan b = 1,4497. Sedangkan hasil penghitungan dengan rumus II, nilai a = -9,5256 dan b = 1,4498. Tampak bahwa hingga dua angka di belakang koma tidak terdapat perbedaan, sedangkan tiga angka di belakang koma mulai ada perbedaan. Perbedaan ini sifatnya tidak tidak substansial, karena munculnya perbedaan itu sendiri akibat dari
pembulatan. Dengan demikian dapat disimpulkan bahwa, mencari a dan b dengan rumus I ataupun rumus II akan menghasilkan nilai yang sama.
Bantuan dengan SPSS
Nilai a dan b dapat dilakukan dengan melalui bantuan SPSS. Caranya: Klik Analize, pilih regression, pilih linear, masukkan variabel Y ke dalam kotak Dependent Variable (caranya pilih variabel Y dan pindahkan dengan klik pada segitiga hitam), pindahkan variabel X ke kotak Independent Variable, kemudian klik OK. SPSS akan menunjukkan hasilnya. Nilai a dan b akan tertera dalam output berjudul Coefficient.
Output
Model Summary .857a .734 .721 .9236 Model 1 R R Square Adjusted R Square Std. Error of the Estimate Predictors: (Constant), X1 a.b
ANOVA
Model
Sum of
Squares df Mean Square F Sig. Regression Residual Total 1 47.101 17.059 64.160 1 20 21 47.101 .853 55.220 .000a a. Predictors: (Constant), X1 b. Dependent Variable: Y Coefficientsa Model Unstandardized Coefficients Standardi zed Coefficien ts t Sig. B Std. Error Beta 1 (Constant) X1 -9.527 1.450 2.882 .195 .857 -3.305 7.431 .004 .000 a. Dependent Variable: Y Catatan:
Hasil penghitungan manual dan SPSS tampaknya ada perbedaan dalam desimal. Itu disebabkan adanya penghitungan pembulatan.
Meskipun nilai a dan b dapat dicari dengan menggunakan rumus tersebut, namun nilai a dan b baru dapat dikatakan valid (tidak bias)13 apabila telah memenuhi beberapa asumsi, yang terkenal dengan
13
Tidak bias artinya nilai a atau nilai b yang sebenarnya. Dikatakan demikian sebab, jika asumsi tidak terpenuhi, nilai a dan b besar kemungkinannya tidak merupakan nilai yang sebenarnya.
sebutan asumsi klasik.14 Asumsi-asumsi yang harus dipenuhi dalam OLS ada 3 asumsi, yaitu:
1). Asumsi nilai harapan bersyarat (conditional expected
value) dari ei, dengan syarat X sebesar Xi, mempunyai
nilai nol.
2). Kovarian ei dan ej mempunyai nilai nol. Nilai nol dalam asumsi ini menjelaskan bahwa antara ei dan ej tidak ada korelasi serial atau tida berkorelasi (autocorrelation).
3). Varian ei dan ej sama dengan simpangan baku (standar deviasi).
Asumsi 1,2,3, di atas diringkas sebagai berikut:
Asumsi Dinyatakan dalam E
Dinyatakan dalam Y Digunakan
untuk membahas
1 E (ei/Xi) = 0 E (Yi/Xi) = A + Bxi
Multikolinea-ritas
2 Kov (ei , ej) = 0,
i ≠ j
Kov (Yi , Yj) = 0, i ≠ j Autokorelasi
3 Var (ei/Xi) = σ 2 Var (Yi/Xi) = σ 2 Heteroskedas
-tisitas
Penjelasan asumsi-asumsi ini secara rinci akan dibahas pada bab tersendiri tentang Multikolinearitas, Autokorelasi, dan Heteroskedastisitas.
Prinsip-prinsip Metode OLS
14
Disebut klasik karena penemuannya pada jaman klasic (classic era), modelnya sering juga disebut sebagai model regresi klasik, baku, umum (classic, standard,
Perlu diketahui bahwa dalam metode OLS terdapat prinsip-prinsip antara lain:
1. Analisis dilakukan dengan regresi, yaitu analisis untuk menentukan hubungan pengaruh antara variabel bebas terhadap variabel terikat. Regresi sendiri akan menghitung nilai a, b, dan e (error), oleh karena itu dilakukan dengan cara matematis. 2. Hasil regresi akan menghasilkan garis regresi. Garis
regresi ini merupakan representasi dari bentuk arah data yang diteliti. Garis regresi disimbolkan dengan
Yˆ (baca: Y topi, atau Y cap), yang berfungsi sebagai Y perkiraan. Sedangkan data disimbolkan dengan Y saja.
Perlu diingat, bahwa dalam setiap data tentu mempunyai lokus sebaran yang berbeda dengan yang lainnya, ada data yang tepat berada pada garis regresi, tetapi ada pula yang tidak berada pada garis regresi. Data yang tidak berada tepat pada garis regresi akan memunculkan nilai residual yang biasa disimbulkan dengan ei, atau sering pula disebut dengan istilah kesalahan pengganggu. Untuk data yang tepat berada pada garis maka nilai Y sama dengan Yˆ .
Nilai a dalam garis regresi digunakan untuk menentukan letak titik potong garis pada sumbu Y. Jika nilai a > 0 maka letak titik potong garis regresi pada sumbu Y akan berada di atas origin (0), apabila nilai a < 0 maka titik potongnya akan berada di bawah origin (0). Nilai b atau disebut koefisien regresi berfungsi untuk menentukan tingkat kemiringan garis regresi. Semakin rendah
nilai b, maka derajat kemiringan garis regresi terhadap sumbu X semakin rendah pula. Sebaliknya, semakin tinggi nilai b, maka derajat kemiringan garis regresi terhadap sumbu X semakin tinggi. Gambaran uraian di atas dapat dilihat pada gambar berikut:
Y i i a bX Y ˆ = + Y1 . . . . . e . . e . . . a b o . 0 X1 X
Munculnya garis Yˆi = a + bX i seperti dalam gambar
di atas, didapatkan dari memasukkan angka Xi ke dalam persamaan Yi = a + bXi +e. Dengan menggunakan hasil hitungan pada data di atas, maka garis Yˆi = a + bX i besarnya adalah:
ˆ
Yi = −9,525 +1,449Xi
Karena nilai a dalam garis regresi bertanda negatif (-) dengan angka 9,525, maka garis regresi akan memotong sumbu Y dibawah origin (0) pada angka – 9,525. Nilai parameter b variabel X yang besarnya 1,449 menunjukkan arti bahwa variabel X tersebut tergolong elastis, karena nilai b > 1. Artinya, setiap
perubahan nilai X akan diikuti perubahan yang lebih besar pada nilai Y. Tanda positif pada parameter b tersebut menunjukkan bahwa jika variabel X meningkat maka Y juga akan meningkat. Sebaliknya, jika X mengalami perubahan yang menurun, maka Y juga akan menurun, dengan perbandingan perubahan 1:1,449.
Ingat Elastisitas
Jenis Koefisien Sifat Elastisitas Elastisitas Elastisitas
Elastik E > 1 Perubahan yang terjadi pada variabel bebas diikuti dengan perubahan yang lebih besar pada variabel terikat Elastik E = 1 Perubahan yang terjadi pada variabel Unitary bebas diikuti dengan perubahan yang
sama besar pada variabel terikat Inelastik E < 1 Perubahan yang terjadi pada variabel
bebas diikuti dengan perubahan yang lebih kecil pada variabel terikat Tanda (+) pada koefisien regresi menunjukkan hubungan yang searah. Artinya, jika variabel bebas meningkat, maka variabel terikat juga meningkat. Demikian pula sebaliknya. Tanda (-) pada koefisien regresi menunjukkan hubungan yang berlawanan. Artinya, jika variabel bebas meningkat, maka variabel terikat akan menurun. Demikian pula sebaliknya.
Menguji Signifikansi Parameter Penduga
Seperti dijelaskan di muka, dalam persamaan fungsi regresi OLS variabelnya terbagi menjadi dua, yaitu: variabel yang disimbolkan dengan Y (yang terletak di sebelah kiri tanda persamaan) disebut dengan variabel terikat (dependent variable). Variabel yang disimbolkan dengan X (disebelah kanan tanda persamaan) disebut dengan variabel bebas (independent variable). Utamanya metode OLS ditujukan tidak hanya menghitung berapa besarnya a atau b saja, tetapi juga digunakan pula untuk menguji tingkat signifikansi dari variabel X dalam mempengaruhi Y.
Pengujian signifikansi variabel X dalam mempengaruhi Y dapat dibedakan menjadi dua, yaitu: 1) pengaruh secara individual, dan 2) pengaruh secara bersama-sama. Pengujian signifikansi secara individual pertama kali dikembangkan oleh R.A. Fisher, dengan alat ujinya menggunakan pembandingan nilai statistik t dengan nilai t tabel. Apabila nilai statistik t lebih besar dibandingkan dengan nilai t tabel, maka variabel X dinyatakan signifikan mempengaruhi Y. Sebaliknya, jika nilai statistik t lebih kecil dibanding dengan nilai t tabel, maka variabel X dinyatakan tidak signifikan mempengaruhi Y. Metode dengan membandingkan antara nilai statistik (nilai hitung) dengan nilai tabel seperti itu digunakan pula pada pengujian signifikansi secara serentak atau secara bersama-sama. Hanya saja untuk pengujian secara bersama-sama menggunakan alat uji pembandingan nilai F. Hal Pengujian ini dikembangkan oleh Neyman dan Pearson.
Hal mendasar yang membedakan antara penggunaan uji t dan uji F terletak pada jumlah variabel bebas yang diuji signifikansinya dalam mempengaruhi Y. Jika hanya menguji signifikansi satu variabel bebas saja,
maka yang digunakan adalah uji t. Oleh karena itu disebut sebagai uji signifikansi secara individual. Sedangkan pengujian signifikansi yang menggunakan lebih dari satu variabel bebas yang diuji secara bersama-sama dalam mempengaruhi Y, maka alat ujinya adalah menggunakan uji F. Sebagai perbandingan antara penggunaan uji t dan uji F dapat dilihat pada tabel berikut:
Tabel. 2. Pembandingan antara uji t dan uji F
Hal yang dibandingkan Uji t Uji F
Penemu R.A. Fisher Neyman, Pearson
Signifikan t hitung > t tabel F hitung > F tabel Tidak signifikan t hitung < t tabel F hitung < F tabel
Pengujian Individual Serentak
Banyaknya variabel Satu Lebih dari satu
Uji t
Untuk menguji hipotesis bahwa b secara statistik signifikan, perlu terlebih dulu menghitung standar error atau standar deviasi dari b. Berbagai software komputer telah banyak yang melakukan penghitungan secara otomatis, tergantung permintaan dari user. Namun perlu bagi kita untuk mengetahui formula dari standar error dari b, yang ternyata telah dirumuskan sebagai berikut:
2
∑
(
Yt − Yˆ t)
Sb = 2
(
n − k)
∑(
Xt − X)
∑
et 2Sb = 2
(
n − k)
∑(
Xt − X)
Dimana:
Yt dan Xt adalah data variabel dependen dan independen pada periode t
Yˆt adalah nilai variabel dependen pada periode t yang didapat dari perkiraan garis regresi
X merupakan nilai tengah (mean) dari variabel independen
e atau Yt − Yˆ t merupakan error term n adalah jumlah data observasi
k adalah jumlah perkiraan koefisien regresi yang meliputi a dan b
(n-k) disebut juga dengan degrees of freedom (df).
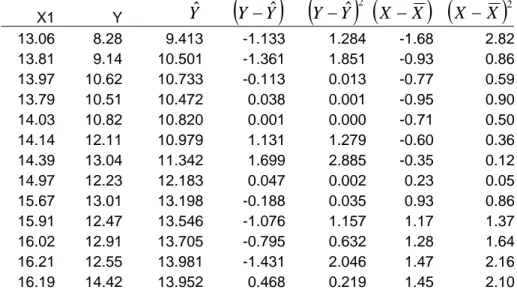
Guna menghitung standar deviasi dari data yang tersedia berdasar rumus di atas, maka diperlukan menghitung nilai Yˆt terlebih dulu, untuk mempermudah penghitungan e atau Yt − Yˆ t . Caranya adalah memasukkan nilai X ke dalam hasil regresi yang di hasilkan di atas. Dengan demikian tabel data akan menghasilkan kolom Yˆt sebagaimana tertera pada
Bantuan dengan SPSS
• Uji t dapat dilihat dalam output hasil regresi dengan SPSS pada tabel Coefficient.
• Uji F dapat dilihat dalam output hasil regresi dengan SPSS pada tabel ANOVA.
• Kolom Sig. baik pada tabel Coefficient maupun ANOVA menunjukkan tingkat signifikansi pada derajat kesalahan (α) tertentu. Misal, kolom Sig. menunjukkan angka 0,04 itu berarti bahwa tingkat kesalahannya mencapai 4%. Angka sebesar itu dapat dikatakan signifikan jika derajat kesalahan (α) telah ditentukan sebesar 0,05. Tetapi jika α ditentukan 0,01 maka angka tersebut tidak signifikan.
Tabel pengembangan data untuk menghitung Standar Deviasi
Yˆ
(
Y − Yˆ) (
Y − Yˆ)
2(
X − X) (
X − X)
2X1 Y 13.06 8.28 9.413 -1.133 1.284 -1.68 2.82 13.81 9.14 10.501 -1.361 1.851 -0.93 0.86 13.97 10.62 10.733 -0.113 0.013 -0.77 0.59 13.79 10.51 10.472 0.038 0.001 -0.95 0.90 14.03 10.82 10.820 0.001 0.000 -0.71 0.50 14.14 12.11 10.979 1.131 1.279 -0.60 0.36 14.39 13.04 11.342 1.699 2.885 -0.35 0.12 14.97 12.23 12.183 0.047 0.002 0.23 0.05 15.67 13.01 13.198 -0.188 0.035 0.93 0.86 15.91 12.47 13.546 -1.076 1.157 1.17 1.37 16.02 12.91 13.705 -0.795 0.632 1.28 1.64 16.21 12.55 13.981 -1.431 2.046 1.47 2.16 16.19 14.42 13.952 0.468 0.219 1.45 2.10
15.88 15.13 13.502 1.628 2.650 1.14 1.30 15.76 14.08 13.328 0.752 0.566 1.02 1.04 15.55 13.3 13.024 0.277 0.076 0.81 0.66 15.16 12.93 12.458 0.472 0.223 0.42 0.18 14.85 11.48 12.009 -0.528 0.279 0.11 0.01 14.22 10.05 11.095 -1.045 1.092 -0.52 0.27 13.93 10.6 10.675 -0.075 0.006 -0.81 0.66 13.58 10.48 10.167 0.313 0.098 -1.16 1.35 13.13 10.33 9.515 0.816 0.665 -1.61 2.59 324.22 260.49 260.591 -0.101 17.060 -0.06 22.41
Dengan adanya pengembangan data menjadi seperti tertera pada tabel di atas, maka Sb dapat segera dicari, dimana hasilnya ditemukan sebesar:
17.06 Sb = 20(22.41) 17.06 = 448.2 = 0.195
Selain dicari dengan rumus seperti di atas, Sb dapat pula dicari melalui jalan lain dengan rumus yang dapat dituliskan sebagai berikut:
2
se
Sb =
∑
xi 2Bila kita hendak menggunakan rumus ini, maka perlu terlebih dulu mencari nilai Se 2 yang dapat dicari dengan membagi nilai total ei2 dengan n-2. Jadi Se 2 dapat dicari dengan rumus sebagai berikut:
∑
ei 22
s e= n − 2
Agar rumus ini dapat langsung digunakan, tentu terlebih dulu harus mencari nilai total ei2 yang dapat dicari melalui rumus berikut ini:
Rumus mencari nilai total ei 2:
2 2 2 2
∑
ei =∑
yi − b∑
xiDengan memasukkan nilai komponen rumus yang telah didapatkan melalui hitungan-hitungan terdahulu, maka nilai ei2 dapat diketahui, yaitu:
ei
2
= 64.16 – 2.1019 (22.41) = 64.16 – 47.1040
= 17.056
Hitungan di atas telah memastikan bahwa nilai ei 2
adalah sebesar 17,056. Dengan diketemukannya nilai
ei
2
ini maka nilai se
2
pun dapat diketahui melalui hitungan sebagai berikut: 2 2
∑
ei s e= n − 2 17.056 = 22 − 2 17.056 = 20 = 0.8528Karena nilai se 2 merupakan salah satu komponen untuk mencari nilai Sb, maka dengan ditemukannya nilai
se 2 sebesar 0,8528 tentu saja nilai Sb pun dapat diketahui, yaitu: se 2 Sb =
∑
xi 2 0.8528 = 22.41 = 0.195Hitungan dengan rumus ini ternyata menghasilkan nilai Sb yang sama besar dengan hitungan menggunakan rumus yang pertama, yaitu nilai Sb sebesar 0,195. Dengan diketahuinya nilai Sb, maka nilai statistik t (baca: t hitung)
dapat ditentukan, karena rumus mencari t hitung adalah:
b
t =
sb
Jadi, nilai t hitung variabel X adalah sebesar:
1.4498
t =
0.195
= 7.4348
Penghitungan nilai t dengan cara yang dilakukan di atas, menunjukkan bahwa nilai statistik t sebesar
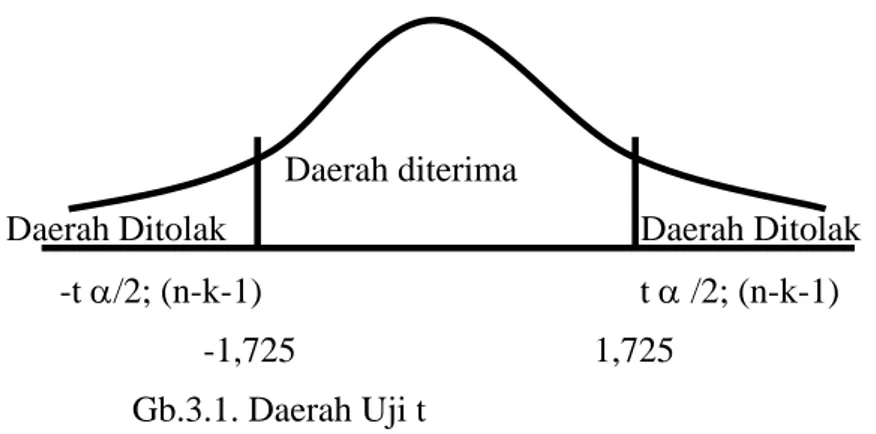
7,4348. Angka tersebut umumnya disebut pula sebagai nilai t hitung. Besarnya angka t hitung ini yang menentukan signifikan tidaknya variabel X dalam mempengaruhi variabel Y. Cara menentukan signifikan tidaknya nilai t tersebut adalah melalui pembandingan antara nilai t hitung dengan nilai t tabel. Nilai t tabel sebenarnya telah ditentukan pada tabel t student yang telah ditetapkan oleh para penemunya. Karena untuk menentukan signifikan tidaknya nilai t hitung adalah melalui upaya membandingkan dengan nilai t tabel, maka dapat diketahui bahwa, jika nilai t hitung > t tabel, maka signifikan. Jika nilai t hitung < t tabel, maka tidak signifikan.
Dengan menggunakan contoh data di atas, seandainya kita menggunakan derajat kesalahan yang ditolerir adalah 5 % (baca: α = 0,05), dan karena jumlah observasi adalah sebanyak 22 (baca: n=22), maka degree of freedom (df) sama dengan sebesar n-k = 20, n-karena jumlah n-k adalah 2, yaitu 1 parameter a dan 1 parameter b, maka nilai t tabelnya adalah sebesar 1,725. (Lihat data t tabel di halaman lampiran).
Nilai t tabel yang besarnya 2,086, sudah tentu angka tersebut lebih kecil dibanding dengan nilai t hitung yang besarnya 7,4348. Atas dasar itu dapat dipastikan bahwa variabel X (budep) signifikan mempengaruhi Y (inflasi).
Gambaran pengujian nilai t dapat disimak melalui gambar di bawah ini: