APLIKASI METODE MOLINA DAN RAO PADA
PENDUGAAN UKURAN KEMISKINAN MONETER
DI KABUPATEN DAN KOTA MALANG
NURUL HIDAYATI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2013
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
©
Dengan ini saya menyatakan bahwa tesis berjudul Aplikasi Metode Molina dan Rao pada Pendugaan Ukuran Kemiskinan Moneter di Kabupaten dan Kota Malang adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2013 Nurul Hidayati NIM G152100191
RINGKASAN
NURUL HIDAYATI. Aplikasi Metode Molina dan Rao pada Pendugaan Ukuran Kemiskinan Moneter di Kabupaten dan Kota Malang. Dibimbing oleh ASEP SAEFUDDIN dan ANANG KURNIA.
Strategi penanggulangan kemiskinan membutuhkan ketersediaan data kemiskinan yang akurat dan tepat. Salah satu sisi penting dari data kemiskinan adalah metode pengukuran kemiskinan. Pengukuran kemiskinan yang dipercaya dapat menjadi instrumen tangguh bagi pengambil kebijakan dalam memfokuskan upaya pengentasan kemiskinan.
Konsep kemiskinan yang digunakan oleh Badan Pusat Statistik (BPS) adalah pendekatan moneter dengan mengukur kemiskinan berdasarkan pengeluaran per kapita per bulan rumah tangga. Indikator-indikator yang digunakan BPS menggunakan indikator yang dikembangkan Foster et. al (1984), yaitu (1) persentase penduduk miskin (Head Count Index, P0), (2) indeks
kedalaman kemiskinan (Poverty Gap Index, ), dan (3) indeks keparahan kemiskinan (Distributionally Sensitive Index, ).
Pendugaan ukuran kemiskinan moneter dilakukan BPS secara langsung berdasarkan data Survei Sosial Ekonomi Nasional (Susenas). Metode pendugaan langsung ini tidak mampu memberikan ketelitian yang baik jika ukuran contoh kecil, sehingga statistik yang diperoleh akan memiliki ragam yang besar dan akurasi yang rendah. Hal ini dapat diatasi dengan menggunakan metode pendugaan area kecil.
Penelitian ini bertujuan mengkaji pengaruh ukuran contoh pada pendugaan ukuran kemiskinan moneter yang digunakan oleh BPS dan mencari solusi alternatif pendugaan ukuran kemiskinan moneter pada saat ukuran contoh kecil.
Simulasi dilakukan dengan cara membangkitkan data pengamatan (observasi) berukuran 10.000 untuk 9 (sembilan) skenario berdasarkan pola sebaran data lognormal, , yang parameternya dikombinasikan untuk menghasilkan suatu nilai harapan yang sama. Evaluasi dilakukan berdasarkan ukuran contoh yang bervariasi dan diulang sebanyak 500 kali, sedangkan contoh aplikasi menggunakan data Survei Sosial Ekonomi Nasional (Susenas) dan Potensi Desa (PODES) tahun 2008 Propinsi Jawa Timur. Pengeluaran per kapita per bulan rumah tangga sebagai peubah respon ( ) dan data jumlah desa yang memiliki status kelurahan sebagai peubah penjelas untuk rumah tangga anggota contoh ( diambil dari dari data Susenas tahun 2008. Adapun data pendukung adalah proporsi desa dari setiap kecamatan yang berstatus kelurahan ( ) diambil dari data Podes tahun 2008.
Kajian simulasi menunjukkan bahwa jika ukuran contoh kecil, nilai dugaan yang dihasilkan pendugaan langsung tidak berbias, namun memiliki ragam yang besar. Hal ini diperjelas melalui perbandingan simulasi berbagai ukuran contoh dan perilaku Relative Bias (RB), Absolute Relative Bias (ARB), dan Relative Mean Square Error (RMSE) untuk semua skenario penelitian.
Analisis terhadap data kemiskinan di Provinsi Jawa Timur memperlihatkan bahwa evaluasi pendugaan ukuran kemiskinan moneter level kabupaten/kota relatif tidak ada masalah karena ukuran contoh besar, kecuali Kota Mojokerto dan
Kota Blitar yang masing-masing nilai dugaannya sebesar 0% kemiskinan, sesuatu yang tidak mungkin terjadi bahwa nilai dugaan kemiskinan disuatu daerah benilai nol, tapi itu bisa terjadi ketika pengaruh ukuran contoh yang tidak mencukupi. Hal serupa terjadi pada saat dilakukakan analisis untuk level kecamatan.
Pendugaan area kecil memperbaiki prosedur pendugaan langsung dengan menyusun model yang baik yang menggambarkan populasi. Model ini menghasilkan penduga tak langsung dan memungkinkan mengurangi galat pendugaan, seperti yang ditunjukkan oleh metode Bayes empirik (Molina dan Rao, 2010) pada kasus pendugaan kemiskinan di Kabupaten/Kota Malang.
Kata kunci: ukuran kemiskinan moneter, pendugaan langsung, pendugaan Molina dan Rao
SUMMARY
NURUL HIDAYATI. Moneter Poverty Estimate With Molina dan Rao Method Application in County and City Malang. Supervised by ASEP SAEFUDDIN and ANANG KURNIA.
The strategy of poverty solution needs the availability of accurate data regarding the poverty itself. One of the most important things on the poverty data is the poverty measurement. The poverty measurement is assumed to become a powerful instrument for the policy makers to focus their attention toward the living condition of poor people. The concept of poverty which is used by Badan Pusat Statistik (The Statistic Center) is the monetary approach by measuring the poverty based on the expenses per capita of the house holders. The indicators used by the BPS in measuring the poverty are the monetary approach developed by Foster, et. al. they are (1) the percentage of poor people [Head Count Index (HCI), P0], (2) Poverty Gap Index [(PGI), P1], and (3) the Distributional Sensitive Index [(DSI), P2].
The estimation calculation of the monetary poverty measurement is done directly by BPS which is based on the data of Survei Sosial Ekonomi Nasional (Susenas)/The National Survey of Socio Economy. This direct estimation method was not be able to give the good accurateness if it is conducted on the small scale sample, therefore the statistical result gained through this method will show the big various score as well as the lack of accuracy. Nevertheless, this situation can be solved by a method called the small area estimation method.
This study aims to analyze the sample size on the monetary poverty estimation which is used by BPS and to find the alternative solution on the monetary poverty measurement estimation in the case small sample area.
The approach of the study is divided into two groups – the simulation and the application. The simulation was conducted through nine scenarios based on the pattern of which has the combined parameter to make the same expectation score E( ). It was also conducted through resampling data by using various size of sample, for 500 repetition. The application in this study is from two data sources, they are the data from the Survei Sosial Ekonomi Nasional (Susenas) in 2008 and the data from the Potensi Desa (PODES)/the village potency in 2008 in East Java. From Susenas data, there are two variables – the data of householders’ expenses per capita as the treatment variable ( ), and the data of village amount which has kelurahan status as the control variable for the householder member sample ( The PODES is used as the source for supporting i.e the proportion of kelurahan status in each kecamatan. This data is used as the control variable for non-sample householder.
The result on the simulation approach shows that if the sample size is small, so the estimation value resulted on the direct estimation method is unbiased with big variance. This situation is proved by the simulation comparison of all samples’ size and also by looking into the index bias behavior of bias Relative Bias (RB), Absolute Relative Bias (ARB), and Relative Mean Square Error (RMSE). Whereas, the result from the Bayes empiric found non-zero result. Therefore, the
direct estimation can be corrected by the Bayes empiric estimation in term of small scale sample.
Key words: monetary poverty measurement, direct estimation, Bayes empiric estimation.
© Hak Cipta Milik IPB, Tahun 2013
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah, dan pengutipan tersebut tidak merugikan kepentingan IPB.
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis ini dalam bentuk apa pun tanpa izin IPB.
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika Terapan
APLIKASI METODE MOLINA DAN RAO
PADA PENDUGAAN UKURAN KEMISKINAN MONETER DI KABUPATEN DAN KOTA MALANG
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2013
Judul Tesis : Aplikasi Metode Molina dan Rao pada Pendugaan Ukuran Kemiskinan Moneter di Kabupaten dan Kota Malang Nama : Nurul Hidayati
NIM : 0 152100191
Disetujui oleh
Komisi Pembimbing
Prof. Dr. Ir. Asep Saefuddin. MSc Dr. An Kurnia
Ketua Anggota
Diketabui oleh
Ketua Program Studi Statistika Terapan
Dr. Ir. Anik Djuraidah, MS
Tanggal Ujian: 08 Mei 2013 Tanggal Lulus:
Judul Tesis : Aplikasi Metode Molina dan Rao pada Pendugaan Ukuran Kemiskinan Moneter di Kabupaten dan Kota Malang Nama : Nurul Hidayati
NIM : G152100191
Disetujui oleh Komisi Pembimbing
Prof. Dr. Ir. Asep Saefuddin, M. Sc Ketua
Dr. Anang Kurnia Anggota
Diketahui oleh
Ketua Program Studi Statistika Terapan
Dr. Ir. Anik Djuraidah, M. S
Dekan Sekolah Pascasarjana
Dr. Ir. Dahrul Syah, M. Sc. Agr
PRAKATA
Puji dan syukur kehadirat Allah SWT yang telah memberikan rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan tesis yang berjudul Aplikasi
Metode Molina dan Rao pada Pendugaan Ukuran Kemiskinan Moneter di Kabupaten dan Kota Malang. Penelitian ini bertujuan untuk melihat karakteristik
nilai dugaan dengan berbagai ukuran contoh dengan metode pendugaan langsung dan mencari solusi alternatif pendugaan ukuran kemiskinan moneter pada ukuran contoh kecil. Keberhasilan penulisan tesis ini tidak lepas dari bantuan, bimbingan, dan arahan dari berbagai pihak.
Terimakasih penulis sampaikan kepada Bapak Prof. Dr. Ir. Asep Saefuddin, M. Sc selaku pembimbing I dan Bapak Dr. Anang Kurnia selaku pembimbing II, yang telah meluangkan waktu untuk memberikan bimbingan, arahan, dan saran kepada penulis dalam menyelesaikan tesis ini. Terimakasih untuk Bapak Dr. Farit Muhammad Affendi, M. Si selaku penguji tesis dan Ibu Dr. Ir. Anik Djuraidah, M. S selaku Ketua Program Studi Statistika Terapan S2. Disamping itu, penulis juga mengucapkan terimakasih kepada seluruh staf administrasi Rektorat dan staf Program Studi Statistika yang telah turut membantu kelancaran administrasi dalam penyelesaian tesis ini.
Ungkapkan terimakasih terkhusus penulis sampaikan kepada ayahanda (Prof. Dr. Syukri Hamzah, M. Si), Ibunda (Pancawati, S. E), kakak (Dian Fitriansyah, S. T) dan adik-adikku (Ikhsanulhakim, S. E dan Rizky Aulia), Bucik (Meliyani) dan lentera hati, serta seluruh keluarga atas do’a yang tulus, pengorbanan yang tak ternilai, dukungan dan kasih sayangnya. Terimakasih juga untuk teman-teman Statistika (S1, S2, dan S3) dan Statistika Terapan (S2), Sekolah Tinggi Ilmu Statistik (STIS) Jakarta, dan Staf Badan Pusat Statistik (BPS) Jakarta atas bantuan, saran, dan ilmu yang positif.
Penulis menyadari sepenuhnya bahwa tesis ini masih banyak kekurangan dan jauh dari kesempurnaan. Oleh karena itu, penulis mengharapkan kritik dan saran yang bersifat membangun guna menyempurnakan tesis ini dan karya ilmiah secara utuh. Semoga tesis ini dapat menambah wawasan dan bermanfaat.
Bogor, Juli 2013 Nurul Hidayati
DAFTAR ISI
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vii
1 PENDAHULUAN ... 1
Latar Belakang... 1
Tujuan Penelitian ... 2
2 TINJAUAN PUSTAKA ... 3
Ukuran Kemiskinan Moneter ... 3
Pendugaan Ukuran Kemiskinan FGT Menggunakan Metode Bayes Empirik ... 4
3 METODE ... 7
Kajian Simulasi ... 7
Kajian Aplikasi ... 10
4 HASIL DAN PEMBAHASAN ... 12
Kajian Simulasi ... 12 Kajian Aplikasi ... 16 5 KESIMPULAN ... 24 DAFTAR PUSTAKA ... 25 LAMPIRAN ... 27 RIWAYAT HIDUP ... 41
DAFTAR TABEL
1 Kombinasi Nilai Tengah , Simpangan Baku ( ), dan
... 8 2 Deskriptif Statistik Pengeluaran per Kapita per Bulan
Rumah Tangga (dalam rupiah) ... 16 3 Jumlah Rumah Tangga dan Nilai Penduga Langsung
Ukuran Kemiskinan Moneter Tingkat Kabupaten/Kota di
Provinsi Jawa Timur (dalam persen) ... 18 4 Hasil Penduga Langsung Ukuran Kemiskinan dan
Pendugaan Bayes Empirik Tingkat Kecamatan di
Kabupaten/Kota Malang (dalam persen) ... 19
DAFTAR GAMBAR
1 Diagram Alir Kajian Simulasi ... 9 2 Diagram Alir Kajian Aplikasi ... 11 3 Diagram Alir Metode Adopsi Molina dan Rao (2010) ... 11 4 Plot ukuran evaluasi Relative Bias (RB) metode penduga
langsung ukuran kemiskinan moneter hasil simulasi vs
ukuran contoh yang digunakan: (a) , (b) , (c) ... 12 5 Plot ukuran evaluasi ARB metode penduga langsung
ukuran kemiskinan moneter hasil simulasi vs ukuran
contoh yang digunakan: (a) , (b) , (c) ... 13 6 Plot ukuran evaluasi RMSE metode penduga langsung
ukuran kemiskinan moneter hasil simulasi vs ukuran contoh
yang digunakan: (a) , (b) , (c) ... 15 7 Histogram Pengeluaran per Kapita per Bulan Rumah Tangga ... 16 8 Nilai Pendugaan Langsung Ukuran Kemiskinan dan
Pendugaan Bayes Emprik Tingkat Kecamatan di
Kabupaten/Kota Malang(a) , (b) , (c) ... 20 9 Peta Kabupaten Malang Berdasarkan Persentase Penduduk
Miskin: (a) Penduga Langsung, (b) Bayes Empirik ... 22 10 Peta Kota Malang Berdasarkan Persentase Penduduk Miskin:
DAFTAR LAMPIRAN
1 Algoritma Metode Penduga Langsung Kajian Simulasi ... 27
2 Syntax Program R Kajian Simulasi Penduga Langsung... 28
3 Garis Kemiskinan Kabupaten dan Kota di Propinsi Jawa Timur Tahun2008 ... 29
4 Relative Bias (RB) Kajian Simulasi ... 30
5 Relative Bias (RB) Kajian Simulasi ... 31
6 Relative Bias (RB) Kajian Simulasi ... 32
7 Absolute Relatif Bias (ARB), Relatif Mean Square Error (RMSE), dan Simpangan Baku (σ) Rij Kajian Simulasi P0 ... 33
8 Absolute Relatif Bias (ARB), Relatif Mean Square Error (RMSE), dan Simpangan Baku (σ) Rij Kajian Simulasi P1 ... 34
9 Absolute Relatif Bias (ARB), Relatif Mean Square Error (RMSE), dan Simpangan Baku (σ) Rij Kajian Simulasi P2 ... 35
10 Algoritma Metode Molina dan Rao ... 36
11 Syntax Program R Metode Molina dan Rao (2010) ... 38
1 PENDAHULUAN
Latar Belakang
Kemiskinan merupakan sebagian dari masalah pembangunan yang berkaitan dengan berbagai dimensi yang meliputi sosial, ekonomi, budaya, politik, regional dan waktu. Kemiskinan didefinisikan sebagai keadaan masyarakat yang berada pada suatu kondisi yang serba terbatas, baik keterbatasan dalam aksebilitas pada faktor produksi, peluang atau kesempatan berusaha, pendidikan, maupun fasilitas hidup lainnya, sehingga dalam setiap aktivitas maupun usaha menjadi sangat terbatas pula (Mafruhah, 2009).
Di sisi lain, strategi penanggulangan kemiskinan membutuhkan ketersediaan data kemiskinan yang akurat dan tepat. Salah satu sisi penting dari data kemiskinan adalah pengukuran kemiskinan. Pengukuran kemiskinan dapat menjadi instrumen bagi pengambil kebijakan dalam memfokuskan perhatian pada kondisi hidup orang miskin. Data kemiskinan yang baik dapat digunakan untuk mengevaluasi kebijakan pemerintah terhadap kemiskinan, membandingkan kemiskinan antar waktu dan daerah, serta menentukan target penduduk miskin dengan tujuan untuk mengentaskan kemiskinan.
Pendekatan-pendekatan untuk mengukur kemiskinan, yaitu pendekatan nonmoneter dan pendekatan moneter. Pada pendekatan nonmoneter, konsep kesejahteraan dilihat dalam bentuk pencapaian atas keberhasilan dari individu dan rumah tangga. Dengan demikian indikator yang digunakan dalam pendekatan nonmoneter adalah indikator yang melekat pada individu dan rumah tangga (Abdillah, 2011). Pada pendekatan moneter, kesejahteraan diukur dari total konsumsi (kalori) yang dinikmati individu. Menurut Rozuli (2012) indikator yang digunakan dalam pendekatan moneter adalah pendapatan dan pengeluaran konsumsi per kapita rumah tangga.
Konsep kemiskinan yang digunakan oleh Badan Pusat Statistik (BPS) adalah pendekatan moneter. BPS mendefinisikan kemiskinan sebagai ketidakmampuan untuk memenuhi standar tertentu dari kebutuhan dasar, baik makanan maupun bukan makanan (BPS, 2008). Kebutuhan dasar ini diukur berdasarkan pengeluaran, dalam bentuk pengeluaran per kapita per bulan rumah tangga. Penduduk yang memiliki rata-rata pengeluaran per kapita per bulan di bawah garis kemiskinan dikategorikan sebagai penduduk miskin (BPS, 2008).
Foster et.al (1984) mengembangkan ukuran kemiskinan yang dikenal dengan rumus Foster, Greer, dan Thorbecke (FGT) yaitu (1) persentase penduduk miskin (Head Count Index, P0) adalah persentase penduduk yang berada di bawah garis kemiskinan, (2) indeks kedalaman kemiskinan (Poverty Gap Index, ) adalah rata-rata kesenjangan pengeluaran masing-masing penduduk miskin terhadap garis kemiskinan, semakin tinggi indeks maka semakin jauh rata-rata pengeluaran penduduk dari garis kemiskinan dan (3) indeks keparahan kemiskinan (Distributionally Sensitive Index, adalah gambaran penyebaran pengeluaran diantara penduduk miskin, semakin tinggi nilai indeks maka semakin tinggi ketimpangan pengeluaran diantara penduduk miskin.
2
Perhitungan pendugaan ukuran kemiskinan moneter dilakukan BPS secara langsung berdasarkan data Survei Sosial Ekonomi Nasional (Susenas). Pendugaan langsung ini tidak mampu memberikan ketelitian yang baik jika ukuran contoh kecil, sehingga statistik yang diperoleh akan memiliki ragam yang besar dan akurasi yang rendah. Kondisi tersebut dapat diatasi dengan menggunakan suatu metode pendugaan area kecil untuk meningkatkan efektifitas ukuran contoh dengan cara menambahkan informasi pada area tersebut dari area lain atau sumber informasi lain melalui pembentukan model yang tepat.
Pendugaan parameter kemiskinan moneter saat ini dirasakan sangat penting seiring dengan berkembangnya otonomi daerah untuk mendapatkan informasi-informasi pada level kabupaten/kota, kecamatan, bahkan kelurahan atau desa. Informasi-informasi tersebut dapat digunakan untuk pedoman dalam menyusun sistem perencanaan, pemantauan, dan kebijakan daerah lainnya tanpa harus mengeluarkan biaya yang besar untuk mengumpulkan data sendiri. Namun demikian, ada suatu permasalahan yang ditemui dalam pendugaan parameter kemiskinan moneter untuk area administrasi di bawah kabupaten/kota, yaitu pengamatan survei (dalam hal ini Susenas) memiliki ukuran contoh yang kecil.
Elbers, Lanjouw dan Lanjouw (2003) mengusulkan suatu metode yang kemudian diterapkan oleh Bank Dunia dalam pemetaan kemiskinan yang mengasumsikan satuan model level dari kombinasi data sensus dan survei. Haslett et. al (2010) membandingkan teknik-teknik regresi untuk menentukan model yang cocok pada pendugaan kemiskinan area kecil dalam metode ELL. Proyek EURAREA yang dilakukan di Eropa mengembangkan metode pendugaan karakteristik pendapatan area kecil yang terbatas pada parameter linier. Metode tersebut berdasarkan pada aplikasi model campuran yang menggunakan informasi tambahan untuk mendefinisikan penduga-penduga dalam area kecil (Saei dan Chambers, 2003).
Tesis ini membahas karakteristik nilai dugaan ukuran kemiskinan moneter dengan menggunakan metode pendugaan langsung dan pemecahan masalah pendugaannya dengan mengadopsi metode yang diajukan oleh Molina dan Rao (2010). Lebih rinci tulisan ini akan membahas tentang pengaruh ukuran contoh pada pendugaan ukuran kemiskinan moneter yang digunakan oleh BPS dan solusi alternatif pendugaan ukuran kemiskinan moneter pada saat ukuran contoh kecil.
Tesis ini memaparkan hasil simulasi metode pendugaan langsung yang dievaluasi menggunakan relative bias, absolute relative bias, dan relative mean square error serta metode yang disarankan diaplikasikan pada data Susenas untuk area administrasi di bawah kabupaten/kota dengan ukuran contoh kecil.
Tujuan Penelitian
Tujuan dari penelitian ini adalah mengkaji pengaruh ukuran contoh terhadap pendugaan parameter kemiskinan moneter dan menentukan alternatif pendugaan ukuran kemiskinan moneter pada saat ukuran contoh kecil.
3
2 TINJAUAN PUSTAKA
Ukuran Kemiskinan Moneter
Berkenaan dengan kemiskinan, Foster et. al (1984) merumuskan tiga ukuran kemiskinan, yaitu indeks kemiskinan (P0), indeks kedalaman kemiskinan ( ) dan
indeks keparahan kemiskinan ( ). Tiga ukuran kemiskinan ini juga dikenal sebagai ukuran kemiskinan FGT (Foster, Greer, dan Thorbecke). Ukuran kemiskinan FGT ini kemudian dikembangkan oleh Molina dan Rao, dengan persamaan sebagai berikut :
(1)
dan
(2)
dengan :
= Garis kemiskinan
= Rata-rata pengeluaran per kapita per bulan rumah tangga pada area = Jumlah penduduk pada area
= Persentase penduduk miskin pada area = Indeks kedalaman kemiskinan pada area = Indeks keparahan kemiskinan pada area
serta jika (rumah tangga yang dikategorikan miskin) dan jika (rumah tangga yang dikategorikan tidak miskin). Penduga langsung dari ukuran kemiskinan FGT untuk area adalah
(3)
Jika adalah pembobot survei untuk setiap contoh (tergantung metode penarikan contoh yang digunakan), maka penduga langsung untuk adalah
4
dengan adalah penduga tak bias bagi dan adalah bobot satuan contoh ke- dari area ke- . Jika ukuran contoh yang dipilih dari area ke- sangat kecil atau kejadiannya nol, maka penduga langsung (3) atau (4) tidak tepat digunakan.
Pendugaan Ukuran Kemiskinan FGT Menggunakan Metode Bayes Empirik
Pendugaan Bayes empirik bagi ukuran kemiskinan , yaitu (Molina dan Rao, 2010):
(5)
untuk memperoleh nilai penduga dari Bayes empirik ( ) digunakan model regresi linier tersarang. Model ini berhubungan secara linier untuk semua area, peubah populasi ditransformasi ke vektor yang mengandung nilai dari peubah penjelas dan termasuk sebuah pengaruh khusus area acak dan memiliki galat (Molina dan Rao, 2010):
(6)
dengan pengaruh area dan galat saling bebas. Misalkan didefinisikan vektor dan matriks yang diperoleh dengan stacking element untuk area :
Kemudian vektor saling bebas dengan dengan:
(7) dengan dinotasikan sebuah vektor kolom dari sesuatu yang berukuran dan adalah matriks identitas .
Misalkan penguraian dari adalah anggota contoh dan bukan anggota contoh, dengan dan penguraian yang bersesuaian dari
dan . Sehingga sebaran dari bersyarat adalah:
(8) dengan :
5 (10)
untuk dan
-. Jika diasumsikan bahwa partisi ) dari ke dan diketahui serta peubah penjelas diketahui berhubungan dengan , maka dan akan mempunyai sebaran yang sama.
Selanjutnya, Molina dan Rao (2010) menyatakan bahwa pendekatan Monte Carlo dilakukan dengan mensimulasi buah vektor yang berukuran - , dengan sebaran . Simulasi ini diulang sebanyak kali. Namun, simulasi ini tidak dapat dikerjakan dengan mudah jika besar. Adapun prosedur yang dapat digunakan untuk mengatasi persoalan ini adalah membangkitkan dengan menggunakan model berikut:
(11) dengan matriks (10) bersesuaian dari matrik koragam . Pengaruh peubah acak yang baru dan galat yang saling bebas dan memenuhi:
Persamaan (11) digunakan untuk membangun vektor normal ganda , untuk . Seperti yang dijelaskan sebelumnya parameter model
yang diduga dari dan peubah dibangun dari pendugaan sebaran normal yang bersesuaian.
Setelah melakukan simulasi untuk memperoleh nilai dengan menggunakan persamaan (11), selanjutnya menghitung nilai dengan menggunakan persamaan (1). Langkah berikutnya adalah menghitung nilai penduga Bayes empirik bagi ukuran kemiskinan dengan menggunakan persamaan (5).
Secara ringkas langkah-langkah metode EBP untuk menduga ukuran kemiskinan, yaitu:
a. Menduga parameter yang tidak diketahui dari sebaran vektor y yang ditransformasi menggunakan data contoh .
b. Mengambil vektor yang merupakan vektor luar contoh, dengan l=1,...,L. Dari (8) atau (11), tetapi dengan mengganti parameter yang tidak diketahui dengan penduga yang diperoleh pada bagian (a).
c. Menggabungkan masing-masing dari bangkitan vektor dengan data sampel untuk membentuk vektor populasi , menghitung parameter area kecil . Pendekatan Monte Carlo pada EBP dari yang diperoleh dengan merata-ratakan parameter area kecil untuk simulasi L populasi :
6
Metode ini hanya memerlukan sebaran dari transformasi dari peubah pengeluaran per kapita rumah tangga yang diketahui dan sebaran bersyarat dari dapat diperoleh.
7
3 METODE
Kajian Simulasi
Data kajian simulasi yang digunakan dalam penelitian ini adalah data pengeluaran per kapita per bulan rumah tangga di Propinsi Jawa Timur tahun 2008 yang diasumsikan menyebar lognormal dengan nilai tengah dan simpangan baku atau . Hal ini dikarenakan sebaran log normal mengakomodir bentuk dari karakteristik pengeluaran per kapita per bulan rumah tangga di Propinsi Jawa Timur tahun 2008. Oleh karena itu, data ini perlu ditransformasi log sedemikian sehingga
Berdasarkan hasil dari transformasi data aplikasi diperoleh nilai tengah dan simpangan baku , sehingga nilai harapan dapat ditentukan.
Nilai tengah , simpangan baku dan yang diperoleh akan digunakan untuk membangkitkan data sebanyak pengamatan ( ) yang mengikuti sebaran . Pembangkitan data dilakukan sebanyak sembilan gugus data, yang selanjutnya disebut skenario. Skenario pertama dibangkitkan dengan menggunakan nilai tengah dan simpangan baku yang diperoleh dari data pengeluaran per kapita per bulan rumah tangga yaitu nilai tengah dan simpangan baku , sedangkan nilai tengah dan simpangan baku untuk skenario-skenario yang lain diperoleh dengan cara membuat kombinasi nilai tengah dan simpangan baku sedemikian sehingga nilai . Persamaan yang digunakan untuk membuat kombinasi nilai tengah dan simpangan baku , yaitu :
Hasil kombinasi nilai tengah dan simpangan baku disajikan pada Tabel 1. Kombinasi nilai tengah dan ragam dengan nilai sama untuk masing-maisng skenario digunakan untuk mengevaluasi efisiensi dugaan pada berbagai kondisi keragaman data.
Kajian simulasi dalam penelitian ini bertujuan untuk mengevaluasi pengaruh ukuran contoh terhadap perhitungan pendugaan langsung ukuran kemiskinan. Adapun tahapan-tahapan dalam kajian simulasi adalah sebagai berikut:
Tahap I : Pembangkitan data simulasi
Data dibangkitkan mengikuti sebaran lognormal
dengan dan ( bernilai tetap untuk setiap skenario) yang merupakan nilai rata-rata garis kemiskinan dari 38 kabupaten/kota di Propinsi Jawa Timur dan parameter hasil kombinasi yang tertera pada Tabel 1. Gugus data
8
bangkitan ini selanjutnya disebut skenario. Berikut tabel kombinasi nilai tengah dan , simpangan baku ( ) :
Tabel 1 Kombinasi Nilai Tengah , Simpangan Baku ( ), untuk
Tahap II : Perhitungan nilai dari data pada setiap skenario dengan
persamaan :
Tahap III : Melakukan penarikan contoh
Melakukan penarikan contoh dengan menggunakan ukuran contoh (n)
yang bervariasi, yaitu 250, dan 300
sebanyak 500 kali ulangan.
Tahap IV : Perhitungan nilai dari setiap penarikan contoh dengan
persamaan:
Tahap V : Evaluasi nilai penduga
Dari data yang telah dibangkitkan pada tahap I-IV, selanjutnya dilakukan analisis untuk mengevaluasi nilai duga dari penduga langsung. Evaluasi nilai penduga dilakukan dengan tiga metode yaitu: relative bias (RB), absolute relative bias (ARB), dan relative means square error (RMSE). Persamaan yang digunakan adalah sebagai berikut :
Skenario 1 12,6 0,6 2 11,8 1,4 3 11,5 1,6 4 9,9 2,4 5 9,4 2,6 6 7,0 3,4 7 6,3 3,6 8 3,1 4,4 9 2,2 4,6
9
RB =
ARB =
RMSE =
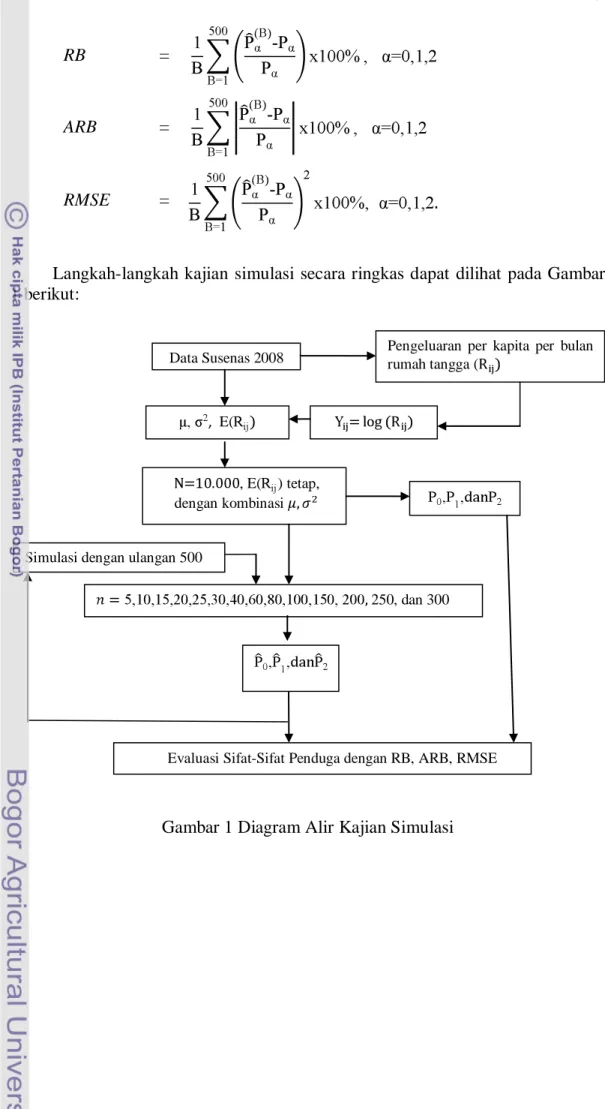
Langkah-langkah kajian simulasi secara ringkas dapat dilihat pada Gambar 1 berikut:
Gambar 1 Diagram Alir Kajian Simulasi
, E( ) tetap,
dengan kombinasi
250, dan 300 Simulasi dengan ulangan 500
Data Susenas 2008
, E(
Evaluasi Sifat-Sifat Penduga dengan RB, ARB, RMSE
Pengeluaran per kapita per bulan rumah tangga (
10
Kajian Aplikasi
Kajian aplikasi menggunakan dua sumber data, yaitu data Survei Sosial Ekonomi Nasional (Susenas) 2008 dan data Potensi Desa (PODES) 2008 Propinsi Jawa Timur. Pada data Susenas 2008 diambil dua peubah, yaitu data pengeluaran per kapita per bulan rumah tangga sebagai peubah respon ( ) dan data jumlah desa yang memiliki status kelurahan sebagai peubah penjelas untuk rumah tangga anggota contoh ( . Data Potensi Desa (PODES) 2008 yang digunakan sebagai sumber data pendukung adalah data proporsi desa yang berstatus kelurahan dari setiap kecamatan. Data ini digunakan sebagai peubah penjelas untuk rumah tangga yang bukan anggota contoh ).
Kajian aplikasi dilakukan untuk mengevaluasi pendugaan langsung pada data aplikasi yaitu ukuran kemiskinan moneter tingkat kabupaten/kota dan kecamatan di Kabupaten dan Kota Malang, Propinsi Jawa Timur. Salah satu metode alternatif yang digunakan untuk mengevaluasi pendugaan langsung adalah metode Bayes empirik.
Langkah-langkah yang dilakukan pada kajian aplikasi adalah sebagai berikut:
1. Eksplorasi data dan menentukan bentuk sebaran dari peubah (pengeluaran per kapita per bulan rumah tangga).
2. Perhitungan nilai duga ukuran kemiskinan untuk tingkat Kabupaten/Kota menggunakan persamaan (1).
3. Perhitungan nilai duga ukuran kemiskinan untuk tingkat kecamatan di Kabupaten Kota Malang di Provinsi Jawa Timur menggunakan persamaan (1).
4. Pengulangan langkah 3 dengan mengadopsi metode yang diajukan oleh Molina dan Rao (2010) dengan data aplikasinya adalah data PODES 2008, sebagai peubah penyerta. Penjelasan langkah-langkah metode Molina dan Rao yang lebih rinci terdapat di lampiran 7.
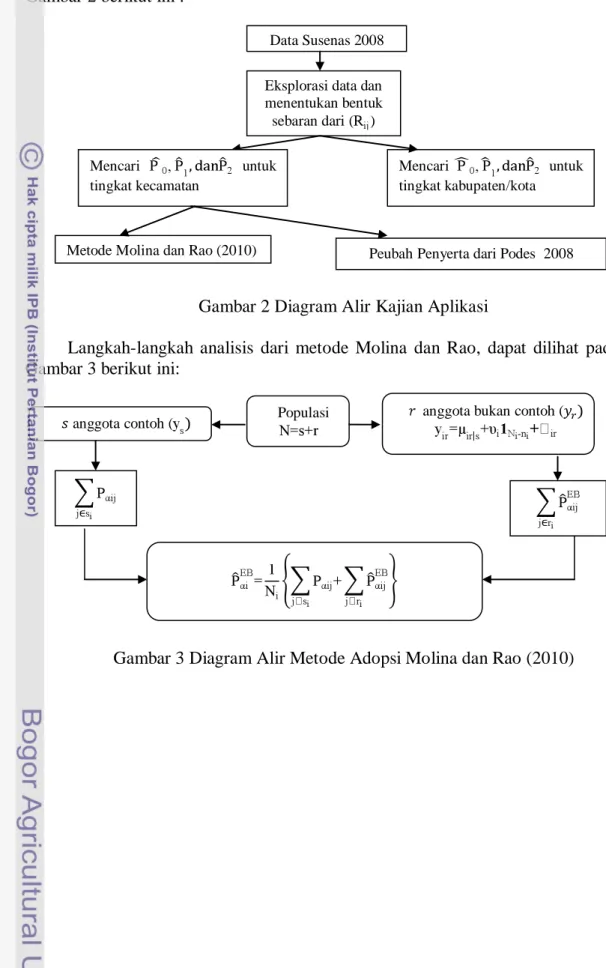
11 Langkah-langkah analisis data aplikasi secara ringkas dapat dilihat pada Gambar 2 berikut ini :
Gambar 2 Diagram Alir Kajian Aplikasi
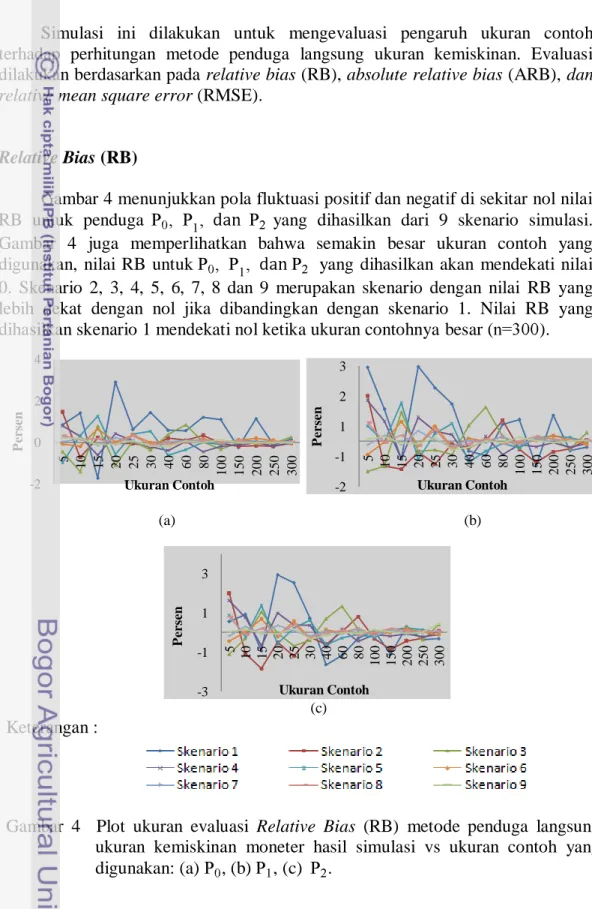
Langkah-langkah analisis dari metode Molina dan Rao, dapat dilihat pada Gambar 3 berikut ini:
Gambar 3 Diagram Alir Metode Adopsi Molina dan Rao (2010)
Eksplorasi data dan menentukan bentuk sebaran dari ( ) Mencari untuk tingkat kabupaten/kota Mencari untuk tingkat kecamatan
Metode Molina dan Rao (2010)
Data Susenas 2008
Peubah Penyerta dari Podes 2008
Populasi anggota bukan contoh (
12
4 HASIL DAN PEMBAHASAN
Kajian Simulasi
Simulasi ini dilakukan untuk mengevaluasi pengaruh ukuran contoh terhadap perhitungan metode penduga langsung ukuran kemiskinan. Evaluasi dilakukan berdasarkan pada relative bias (RB), absolute relative bias (ARB), dan relative mean square error (RMSE).
Relative Bias (RB)
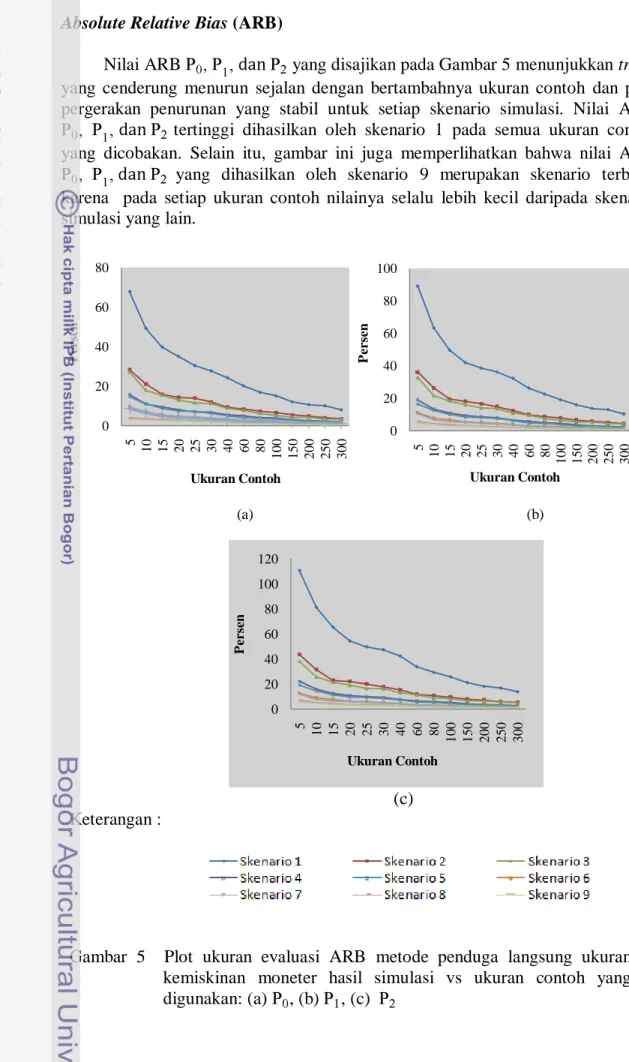
Gambar 4 menunjukkan pola fluktuasi positif dan negatif di sekitar nol nilai RB untuk penduga yang dihasilkan dari 9 skenario simulasi. Gambar 4 juga memperlihatkan bahwa semakin besar ukuran contoh yang digunakan, nilai RB untuk yang dihasilkan akan mendekati nilai 0. Skenario 2, 3, 4, 5, 6, 7, 8 dan 9 merupakan skenario dengan nilai RB yang lebih dekat dengan nol jika dibandingkan dengan skenario 1. Nilai RB yang dihasilkan skenario 1 mendekati nol ketika ukuran contohnya besar ( ).
p (a) (b) (c) Keterangan :
Gambar 4 Plot ukuran evaluasi Relative Bias (RB) metode penduga langsung ukuran kemiskinan moneter hasil simulasi vs ukuran contoh yang digunakan: (a) , (b) , (c) . -2 0 2 4 5 10 15 20 25 30 40 60 80 100 150 200 250 300 P er se n Ukuran Contoh -2 -1 1 2 3 5 10 15 20 25 30 40 60 80 100 150 200 250 300 P er se n Ukuran Contoh -3 -1 1 3 5 10 15 20 25 30 40 60 80 100 150 200 250 300 P er se n Ukuran Contoh
13 Absolute Relative Bias (ARB)
Nilai ARB yang disajikan pada Gambar 5 menunjukkan trend yang cenderung menurun sejalan dengan bertambahnya ukuran contoh dan pola pergerakan penurunan yang stabil untuk setiap skenario simulasi. Nilai ARB tertinggi dihasilkan oleh skenario 1 pada semua ukuran contoh yang dicobakan. Selain itu, gambar ini juga memperlihatkan bahwa nilai ARB yang dihasilkan oleh skenario 9 merupakan skenario terbaik, karena pada setiap ukuran contoh nilainya selalu lebih kecil daripada skenario simulasi yang lain.
(a) (b)
(c) Keterangan :
Gambar 5 Plot ukuran evaluasi ARB metode penduga langsung ukuran kemiskinan moneter hasil simulasi vs ukuran contoh yang digunakan: (a) , (b) , (c) 0 20 40 60 80 5 10 15 20 25 30 40 60 80 100 150 200 250 300 P er se n Ukuran Contoh 0 20 40 60 80 100 5 10 15 20 25 30 40 60 80 100 150 200 250 300 P er se n Ukuran Contoh 0 20 40 60 80 100 120 5 10 15 20 25 30 40 60 80 100 150 200 250 300 P er se n Ukuran Contoh
14
Salah satu sifat dari penduga parameter adalah konsisten. Suatu penduga dikatakan konsisten apabila nilai dugaan cenderung mendekati nilai parameter untuk yang semakin besar atau mendekati tak hingga. Jadi, ukuran contoh yang besar cenderung memberikan penduga yang lebih baik dibandingkan ukuran contoh kecil. Bila ukuran contoh pada subpopulasi kecil bahkan nol maka statistik dari penduga langsung akan memiliki ragam galat yang besar bahkan pendugaan tidak dapat dilakukan (Rao, 2003).
Hal ini sejalan dengan hasil simulasi yang telah dilakukan, yaitu semakin besar ukuran contoh maka bias yang dihasilkan akan semakin kecil. Sebaliknya, semakin kecil ukuran contoh yang digunakan, maka bias yang dihasilkan akan semakin besar.
Relative Mean Square Error (RMSE)
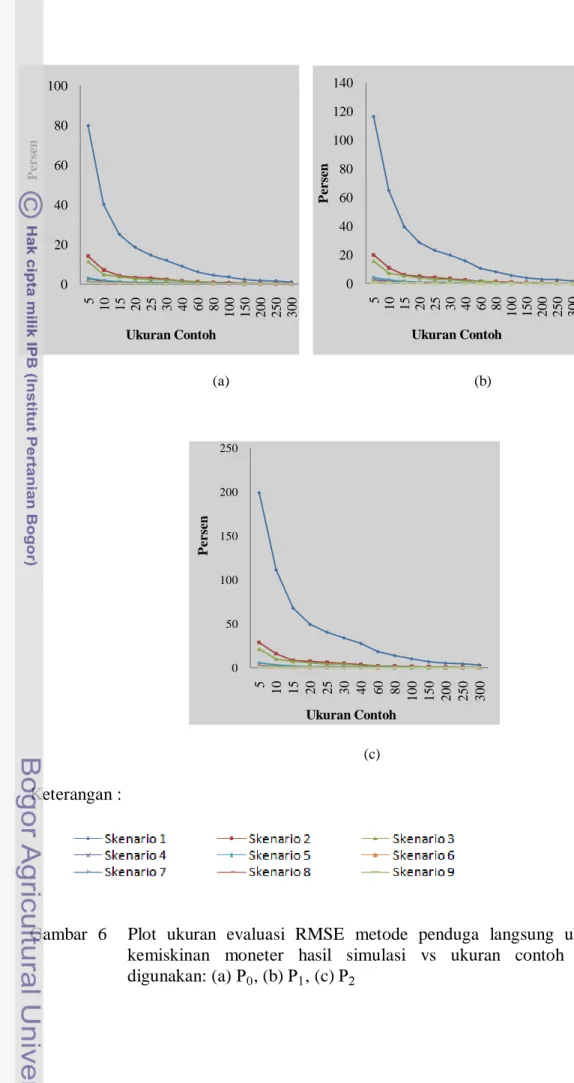
Gambar 6 menyajikan hasil nilai RMSE untuk dari 9 skenario. Gambar 6 memperlihatkan adanya pergerakan penurunan nilai RMSE
yang stabil seiring bertambahnya jumlah ukuran contoh yang digunakan. Nilai RMSE yang dihasilkan berbanding terbalik dengan ukuran contoh yang digunakan. Semakin besar ukuran contoh yang digunakan, maka semakin kecil nilai RMSE yang dihasilkan atau nilainya mendekati nol. Hal ini terlihat dari nilai RMSE yang dihasilkan untuk setiap skenario. Nilai RMSE yang tertinggi terdapat di skenario 1 dengan dan yang terendah terdapat di skenario 9 dengan . Artinya bahwa ketika jarak data penelitian besar untuk ukuran contoh yang kecil, nilai RMSE yang dihasilkan akan besar. Begitupun sebaliknya, jika menggunakan ukuran contoh yang besar pada jarak data yang besar, nilai RMSE yang dihasilkan kecil.
Suatu penduga yang baik memiliki sifat mean square error (MSE) dengan ragam dan bias yang kecil. Untuk menemukan pendugaan dengan sifat MSE yang baik, perlu dicari penduga yang mengontrol ragam dan bias. Pada beberapa kasus tertentu, ada perpotongan antara ragam dengan biasnya yaitu kenaikan kecil dari bias akan menyebabkan penurunan nilai ragam, sehingga akan menghasilkan kenaikan nilai MSE (Casella dan Berger, 2002).
15 (a) (b) (c) Keterangan :
Gambar 6 Plot ukuran evaluasi RMSE metode penduga langsung ukuran kemiskinan moneter hasil simulasi vs ukuran contoh yang digunakan: (a) , (b) , (c) 0 20 40 60 80 100 5 10 15 20 25 30 40 60 80 100 150 200 250 300 P er se n Ukuran Contoh 0 20 40 60 80 100 120 140 5 10 15 20 25 30 40 60 80 100 150 200 250 300 P er se n Ukuran Contoh 0 50 100 150 200 250 5 10 15 20 25 30 40 60 80 100 150 200 250 300 P er se n Ukuran Contoh
16
Kajian Aplikasi
Eksplorasi Data
Eksplorasi data dilakukan terhadap data pengeluaran per kapita dari tiap kabupaten di Propinsi Jawa Timur. Pengeluaran per kapita per bulan rumah tangga di Provinsi Jawa Timur sangat beragam yang ditunjukkan oleh simpangan baku sebesar Rp. 291.371. Kabupaten Trenggalek memilki pengeluaran per kapita per bulan rumah tangga paling kecil (Rp. 41.350) dan Kota Surabaya memiliki pengeluaran per kapita per bulan rumah tangga sebesar Rp. 5.442.241. Deskriptif statistik pengeluaran per kapita per bulan rumah tangga Provinsi Jawa Timur dapat dilihat pada Tabel 2.
Tabel 2 Deskriptif Statistik Pengeluaran per Kapita per Bulan Rumah Tangga (dalam rupiah)
Statistik Pengeluaran per Kapita per Bulan Rumah Tangga
Rata-Rata 337.106
Simpangan Baku 291.371
Minimum 41.350
Maksimum 5.442.241
Pola sebaran log normal mengakomodir bentuk dari karakteristik pengeluaran per kapita di Provinsi Jawa Timur yaitu bernilai positif, memiliki ekor yang cenderung menjulur ke kanan dan pengeluaran yang mengumpul di sisi kiri. Selain itu, pola datanya bersifat cenderung mengelompok di suatu nilai dan terlihat ada beberapa rumah tangga memiliki pengeluaran per kapita yang jauh melebihi rata-rata pengeluaran per kapita rumah tangga. Histogram sebaran data pengeluaran per kapita per bulan rumah tangga dapat dilihat pada Gambar 7.
17
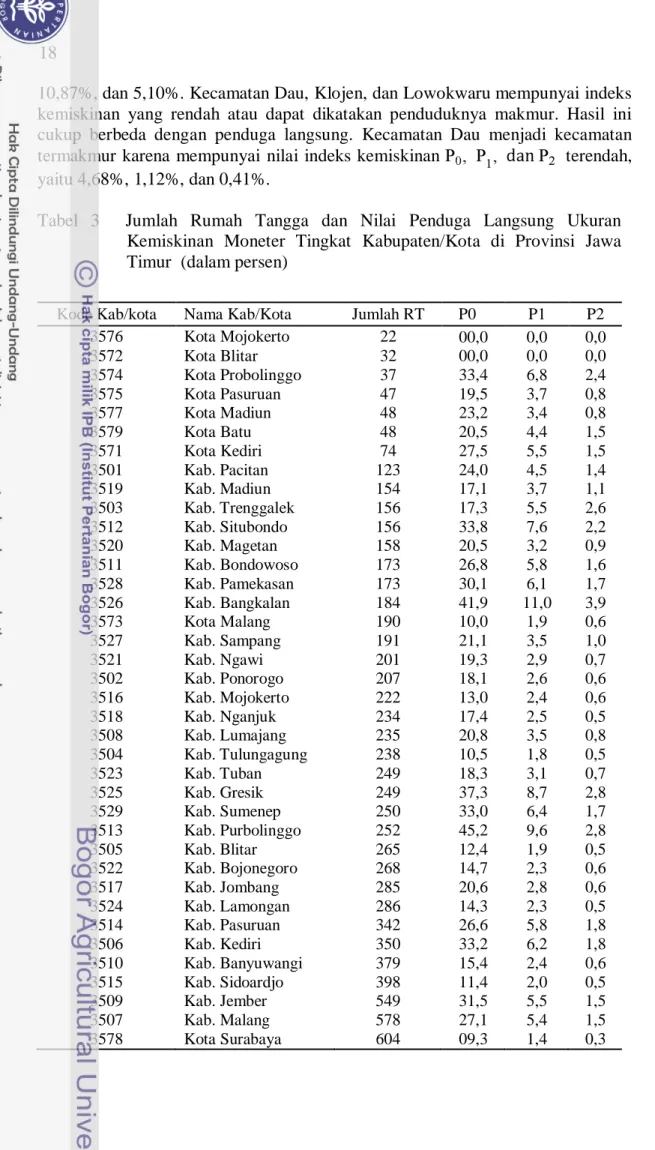
Evaluasi Penduga Langsung Tingkat Kabupaten/Kota di Provinsi Jawa Timur
Hasil penduga langsung ukuran kemiskinan moneter untuk tingkat kabupaten/kota di Propinsi Jawa Timur disajikan pada Tabel 3. Kabupaten Probolinggo memiliki nilai yang tertinggi sebesar 45% dan juga nilai yang tertinggi, 11%. Adapun nilai tertinggi yaitu sebesar 3,9% terdapat pada kabupaten Bangkalan. Lebih lanjut, untuk nilai dan yang terendah terdapat pada Kota Surabaya, dengan masing-masing pendugaan nilai ukuran kemiskinannya yaitu sebesar 9,3%, 1,4%, dan 0,3%.
Metode pendugaan yang digunakan oleh BPS untuk data Susenas adalah metode penduga langsung yaitu metode pendugaan yang didasarkan pada data yang diperoleh dari suatu proses penarikan contoh di suatu area tertentu. Metode pendugaannya semata-mata didasarkan pada metode penarikan contoh yang digunakan.
Hasil penduga langsung yang disajikan pada Tabel 3, menunjukkan bahwa untuk ukuran contoh rumah tangga yang kecil tidak diperoleh hasil nilai dugaan ukuran kemiskinan moneter (nilai pendugaannya nol). Hal ini karena penduga langsung pada subpopulasi relatif tidak memiliki presisi yang memadai karena kecilnya jumlah contoh yang digunakan untuk memperoleh dugaan survei sensus. Hasil yang diperoleh dari penduga langsung memberikan gambaran bahwa pada area dengan ukuran contoh kecil dapat menghasilkan pendugaan yang kurang akurat. Suatu area sangat tidak mungkin nilai persentase penduduk miskinnya bernilai nol.
Evaluasi Penduga Langsung Tingkat Kecamatan di Kabupaten dan Kota Malang
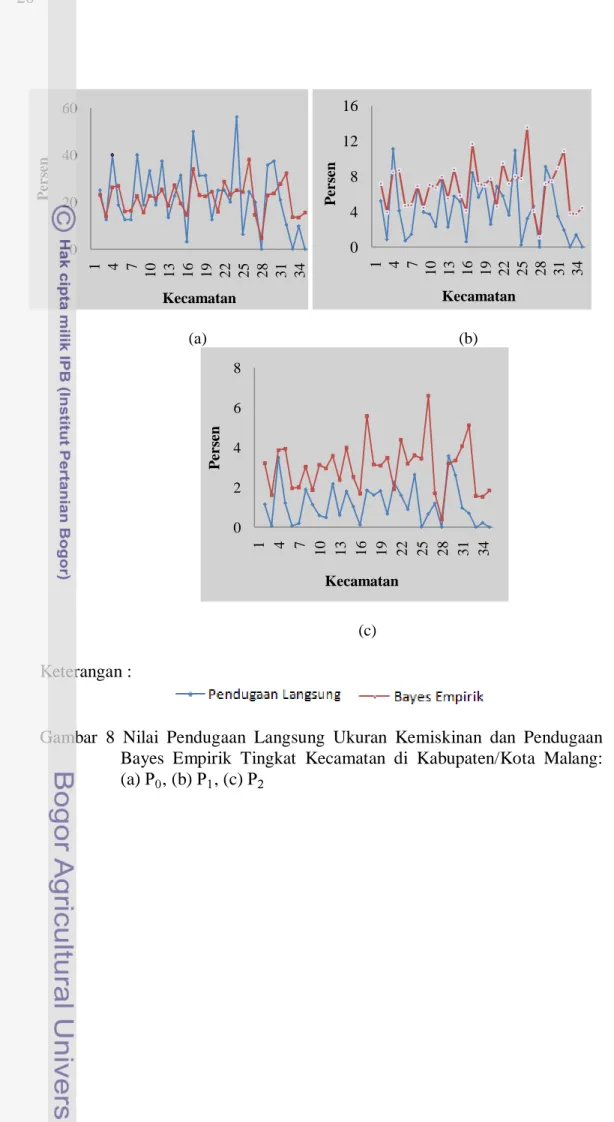
Penduga langsung ukuran kemiskinan dan pendugaan Bayes empirik untuk setiap kecamatan di Kabupaten dan Kota Malang disajikan pada Gambar 8 dan Tabel 4. Dapat dilihat bahwa Kecamatan Pakis, Pagak, dan Purjon merupakan tiga kecamatan yang mempunyai indeks kemiskinan tertinggi di Kabupaten Malang. Hal ini dapat dilihat dari nilai . Kecamatan Pakis mempunyai nilai tertinggi yaitu sebesar 56,25%, Kecamatan Pagak mempunyai nilai tertinggi yaitu sebesar 11,09%, dan Kecamatan Purjon mempunyai nilai tertinggi yaitu sebesar 3,58%. Kecamatan Dau, Klojen, dan Lowokwaru mempunyai indeks kemiskinan yang rendah. Hal ini dapat dilihat dari nilai yang mencapai nilai 0%. Pendugaan langsung ini mempunyai berbagai kelemahan, salah satunya yaitu ukuran contoh. Jika ukuran contoh kecil maka akan cenderung mempunyai tingkat akurasi dugaan yang rendah, artinya meskipun sifat dari pendugaan ini tidak bias tetapi mempunyai ragam yang besar. Hal ini didukung oleh hasil simulasi seperti pembahasan di atas. Solusi untuk mengatasi permasalahan ini yaitu dengan pendugaan Bayes.
Pada Tabel 4, dengan metode penduga Bayes dapat dilihat bahwa Kecamatan Singosari merupakan kecamatan termiskin di Kabupaten Malang. Hal ini dapat dilihat dari nilai berturut-turut yaitu 38,11%, 13,54%, dan 6,58%. Kecamatan Sukun merupakan kecamatan termiskin di Kota Malang. Hal ini dapat dilihat dari nilai berturut-turut yaitu 32,21%,
18
10,87%, dan 5,10%. Kecamatan Dau, Klojen, dan Lowokwaru mempunyai indeks kemiskinan yang rendah atau dapat dikatakan penduduknya makmur. Hasil ini cukup berbeda dengan penduga langsung. Kecamatan Dau menjadi kecamatan termakmur karena mempunyai nilai indeks kemiskinan terendah, yaitu 4,68%, 1,12%, dan 0,41%.
Tabel 3 Jumlah Rumah Tangga dan Nilai Penduga Langsung Ukuran Kemiskinan Moneter Tingkat Kabupaten/Kota di Provinsi Jawa Timur (dalam persen)
Kode Kab/kota Nama Kab/Kota Jumlah RT P0 P1 P2
3576 Kota Mojokerto 22 00,0 0,0 0,0 3572 Kota Blitar 32 00,0 0,0 0,0 3574 Kota Probolinggo 37 33,4 6,8 2,4 3575 Kota Pasuruan 47 19,5 3,7 0,8 3577 Kota Madiun 48 23,2 3,4 0,8 3579 Kota Batu 48 20,5 4,4 1,5 3571 Kota Kediri 74 27,5 5,5 1,5 3501 Kab. Pacitan 123 24,0 4,5 1,4 3519 Kab. Madiun 154 17,1 3,7 1,1 3503 Kab. Trenggalek 156 17,3 5,5 2,6 3512 Kab. Situbondo 156 33,8 7,6 2,2 3520 Kab. Magetan 158 20,5 3,2 0,9 3511 Kab. Bondowoso 173 26,8 5,8 1,6 3528 Kab. Pamekasan 173 30,1 6,1 1,7 3526 Kab. Bangkalan 184 41,9 11,0 3,9 3573 Kota Malang 190 10,0 1,9 0,6 3527 Kab. Sampang 191 21,1 3,5 1,0 3521 Kab. Ngawi 201 19,3 2,9 0,7 3502 Kab. Ponorogo 207 18,1 2,6 0,6 3516 Kab. Mojokerto 222 13,0 2,4 0,6 3518 Kab. Nganjuk 234 17,4 2,5 0,5 3508 Kab. Lumajang 235 20,8 3,5 0,8 3504 Kab. Tulungagung 238 10,5 1,8 0,5 3523 Kab. Tuban 249 18,3 3,1 0,7 3525 Kab. Gresik 249 37,3 8,7 2,8 3529 Kab. Sumenep 250 33,0 6,4 1,7 3513 Kab. Purbolinggo 252 45,2 9,6 2,8 3505 Kab. Blitar 265 12,4 1,9 0,5 3522 Kab. Bojonegoro 268 14,7 2,3 0,6 3517 Kab. Jombang 285 20,6 2,8 0,6 3524 Kab. Lamongan 286 14,3 2,3 0,5 3514 Kab. Pasuruan 342 26,6 5,8 1,8 3506 Kab. Kediri 350 33,2 6,2 1,8 3510 Kab. Banyuwangi 379 15,4 2,4 0,6 3515 Kab. Sidoardjo 398 11,4 2,0 0,5 3509 Kab. Jember 549 31,5 5,5 1,5 3507 Kab. Malang 578 27,1 5,4 1,5 3578 Kota Surabaya 604 09,3 1,4 0,3
19 Tabel 4 Hasil Penduga Langsung Ukuran Kemiskinan dan Pendugaan Bayes Empirik Tingkat Kecamatan di Kabupaten/Kota Malang (dalam persen)
Nama Kecamatan Jumlah RT
Pendugaan Langsung Bayes Empirik
P0 P1 P2 P0 P1 P2 Kab.Malang Donomulyo 16 25,00 5,21 1,15 23,04 7.20 3.20 Kalipare 16 12,50 0,84 0,06 13,92 3.92 1.62 Pagak 15 40,00 11,09 3,50 26,28 8.48 3.86 Bantur 32 18,75 4,10 1,21 26,93 8.67 3.94 Gedangan 16 12,50 0,71 0,06 16,06 4.64 1.96 Sumbermanjing 16 12,50 1,43 0,19 16,34 4.74 2.00 Dampit 30 40,00 6,67 1,90 22,39 6.89 3.03 Tirtoyudo 16 18,75 3,93 1,13 15,50 4.44 1.86 Ampelgading 15 33,33 3,71 0,58 22,65 7.04 3.12 Poncokusumo 16 18,75 2,31 0,48 21,71 6.68 2.95 Wajak 32 37,50 7,44 2,18 25,15 7.96 3.57 Turen 15 13,33 2,26 0,60 18,49 5.50 2.37 Bululawang 31 22,58 5,74 1,80 27,16 8.76 3.98 Gandanglegi 16 31,25 5,14 1,03 19,40 5.82 2.52 Kepanjen 32 3,13 0,59 0,11 14,52 4.09 1.69 Sumberpucung 16 50,00 8,38 1,85 33,84 11.67 5.56 Ngajum 16 31,25 5,61 1,61 22,84 7.09 3.14 Wonosari 16 31.25 7,12 1,82 22,45 6.96 3.08 Wagir 16 12,50 2,55 0,67 24,43 7.73 3.48 Pakisaji 32 25,00 6,85 2,25 15,93 4.57 1.91 Tajinan 16 25,00 5,76 1,61 28,76 9.48 4.38 Tiumpang 15 20,00 3,59 0,89 23,00 7.16 3.18 Pakis 16 56,25 10,92 2,64 25,11 7.99 3.60 Lawang 16 6,25 0,23 0,01 24,27 7.66 3.44 Singosari 45 24,44 3,21 0,66 38,11 13.54 6.58 Karangploso 15 20,00 4,61 1,19 14.44 4.09 1.70 Dau 15 0,00 0,00 0,00 4.68 1.12 0.41 Purjon 14 35,71 9,06 3,58 22.96 7.18 3.20 Ngantang 16 37,50 7,31 2,62 23.73 7.46 3.34 Kota Malang Kedungkandang 48 20,83 3,47 0,96 27.60 8.92 4.06 Sukun 48 10,42 1,92 0,70 32.21 10.87 5.10 Klojen 16 0,00 0,00 0,00 13.58 3.81 1.57 Blimbing 31 9,68 1,38 0,22 13.46 3.74 1.53 Lowokwaru 47 0,00 0,00 0,00 15.54 4.43 1.84
20 (a) (b) (c) Keterangan :
Gambar 8 Nilai Pendugaan Langsung Ukuran Kemiskinan dan Pendugaan Bayes Empirik Tingkat Kecamatan di Kabupaten/Kota Malang: (a) , (b) , (c) 0 20 40 60 1 4 7 10 13 16 19 22 25 28 31 34 P e rs en Kecamatan 0 4 8 12 16 1 4 7 10 13 16 19 22 25 28 31 34 P e r se n Kecamatan 0 2 4 6 8 1 4 7 10 13 16 19 22 25 28 31 34 P e r se n Kecamatan
21 Indikator kemiskinan ini mempunyai hubungan yang kuat. Hal ini dibuktikan dengan hasil dari nilai korelasi antara pada Kabupaten dan Kota Malang yang mendekati satu dan bernilai positif.
Berdasarkan data persentase penduduk miskin yang diperoleh dari metode penduga langsung dan Bayes emprik, maka masing-masing daerah kecamatan di Kabupaten dan Kota Malang dapat dibagi menjadi tiga kriteria. Kriteria tersebut didasarkan atas tiga interval yaitu 1) persentase penduduk miskin lebih dari 18,5% tergolong tinggi, 2) persentase penduduk miskin 15,4% sampai dengan 18,5% tergolong sedang, dan 3) persentase penduduk miskin kurang dari 15,4% tergolong rendah. Skala interval diperoleh berdasarkan persentase penduduk miskin tingkat propinsi Jawa Timur (18,5%) dan nasional (15,4%).
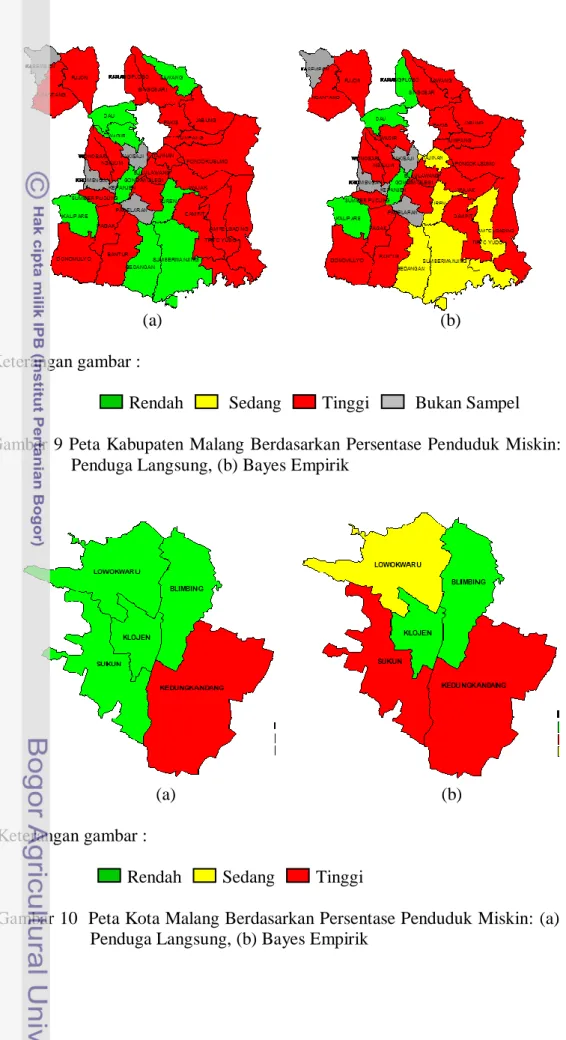
Gambar 9 menyajikan persentase penduduk miskin untuk setiap kecamatan di Kabupaten Malang dengan menggunakan metode penduga langsung dan Bayes empirik. Gambar 9 (a) memperlihatkan bahwa daerah yang mempunyai persentase penduduk miskin yang tergolong tinggi ada dua puluh satu daerah kecamatan, yaitu: Donomulyo, Pagak, Bantur, Dampit, Tirtoyodo, Ampelgading, Poncokusumo, Wajak, Bululawang, Gandanglegi, Sumberpucung, Ngajum, Wonosari, Pakisaji, Tajman, Tiumpang, Pakis, Singosari, Karangploso, Purjon, dan Ngantang. Sedangkan daerah yang persentase penduduk miskinnya tergolong rendah ada delapan kecamatan, yaitu: Kalipare, Gedangan, Sumbermanjing, Turen, Kepanjen, Wagir, Lawang, dan Dau.
Persentase penduduk miskin untuk setiap kecamatan di Kabupaten Malang dengan metode Bayes Empirik yang disajikan pada Gambar 9b menunjukkan bahwa persentase penduduk miskin yang tergolong tinggi ada dua puluh daerah kecamatan, yaitu: Donomulyo, Pagak, Bantur, Dampit, Ampelgading, Poncokusumo, Wajak, Bululawang, Gandanglegi, Sumberpucung, Ngajum, Wonosari, Wagir, Tajinan, Tiumpang, Pakis, Lawang, Singosari, Purjon, dan Ngantang. Daerah yang tergolong sedang berdasarkan persentase penduduk miskinnya ada lima kecamatan, yaitu Gedangan, Sumbermanjing, Tirtoyudo, Turen, dan Pakisaji. Sedangkan daerah yang persentase penduduk miskinnya rendah ada empat kecamatan, yaitu Kalipare, Kepanjen, Karangploso, dan Dau.
Pada Gambar 10a dapat dilihat bahwa persentase penduduk miskin yang tergolong tinggi di Kota Malang ada empat daerah kecamatan, yaitu Kecamatan Sukun, Klojen, Blimbing, dan Lowokwaru. Daerah yang tergolong rendah persentase penduduk miskinnya, yaitu Kecamatan Kedungkandang.
Berdasarkan Gambar 10b, persentase penduduk miskin yang tergolong tinggi di Kota Malang ada dua daerah kecamatan, yaitu Kecamatan Klojen dan Bimbing. Daerah yang persentase penduduk miskinnya tergolong sedang yaitu Kecamatan Lowokwaru. Sedangkan daerah yang persentase penduduk miskinnya tergolong rendah adalah kecamatan Kedungkandang dan Sukun.
22
(a) (b) Keterangan gambar :
Rendah Sedang Tinggi
Gambar 10 Peta Kota Malang Berdasarkan Persentase Penduduk Miskin: (a) Penduga Langsung, (b) Bayes Empirik
(a) (b) Keterangan gambar :
Rendah Sedang Tinggi Bukan Sampel
Gambar 9 Peta Kabupaten Malang Berdasarkan Persentase Penduduk Miskin: (a) Penduga Langsung, (b) Bayes Empirik
23 Berdasarkan Gambar 9 dan 10, perbedaan hasil diperoleh dari metode penduga langsung dan Bayes empirik. Kabupaten Malang pada penduga langsung dan Bayes empirik ada tiga kecamatan yang mengalami penurunan peringkat tingkat kemiskinan, sedangkan untuk sembilan kecamatan yang lain mengalami kenaikan peringkat tingkat kemiskinan. Kecamatan di Kota Malang juga mengalami perubahan peringkat tingkat kemiskinan. Ada tiga kecamatan yang mengalami kenaikan peringkat tingkat kemiskinan, sedangkan kecamatan yang lain mengalami penurunan peringkat tingkat kemiskinan. Perubahan peringkat tingkat kemiskinan yang ditunjukkan pada gambar 9 dan 10 menunjukkan bahwa metode penduga langsung dapat dikoreksi dengan metode Bayes empirik, karena memberikan hasil pendugaan yang cukup akurat, ditunjukkan dengan ragam yang kecil dan dapat menduga titik yang bukan anggota contoh dengan memanfaatkan kekuatan area sekitarnya.
24
5 KESIMPULAN
Permasalahan yang dihadapi dalam pendugaan area kecil adalah besarnya keragaman dari penduga langsung, sehingga statistik yang dihasilkan tidak efisien dan presisi dugaan yang rendah. Nilai ARB dan RMSE hasil penduga langsung untuk suatu nilai garis kemiskinan (titik potong) tertentu semakin kecil dengan meningkatnya kemiringan data (simpangan baku yang semakin besar). Dalam penelitian ini pendugaan ukuran kemiskinan moneter dengan Metode Bayes empirik yang diajukan oleh Molina dan Rao (2010) cukup mampu memperbaiki keragaman dari penduga langsungnya.
25
DAFTAR PUSTAKA
Abdillah R. 2011. Pengelompokkan Kabupaten/Kota Berdasarkan Ukuran Kemiskinan Moneter dan Nonmoneter di Jawa Tengah Tahun 2008 [skripsi]. Jakarata : Sekolah Tinggi Ilmu Statistik.
[BPS] Badan Pusat Statistik. 2008. Analisis dan Penghitungan Tingkat Kemiskinan 2008. Jakarta : Badan Pusat Statistik
Casella G, Berger RL. 2002. Statistical Inference. California: Duxbury.
Elbers C, Lanjouw JO, Lanjouw P. 2003. Micro-level Estimation of Poverty and Inequality. Econometrica, 71, hlm. 355–364.
Foster J, Greer J, Thorbecke E. 1984. A Class of Decomposable Poverty Measures. Econometrica, Vol. 52 No.3, hlm. 761-766.
Haslett S, Jones G, Isidro M. 2010. Potential for Small Area Estimation of Malnutrition at District and Commune level in Cambodia. Massey University : Feasibility Report Phases 1 and 2.
Mafruhah I. 2009. Multidimensi Kemiskinan. Surakarta: LPP dan UNS Press. Molina I, Rao JNK. 2010. Small Area Estimation of Poverty Indicators. The
Canadian Journal Statistics, 2010, Vol.38, No.3, p:369-385.
Rao JNK. 2003. Small Area Estimation. New York : John Willey &Sons..
Rozuli AI. 2012. Menakar Program-Program Penanggulangan Kemiskinan dan Upaya Pembangunan Berkelanjutan. [diacu 2012 Mei 8]. Tersedia dari: http://www.infid.org/wp-content/uploads/2012/05/Poverty-Reduction-Imron-Rozuli-FISIB-UB-Malang.pdf.
Saei A, Chambers R. 2003. Small Area Estimation: A Review of Methods Based on The Application of Mixed Model. University of Southampton: S3RI Methodology Working Paper M30/16.
27 Lampiran 1 Algoritma Metode Penduga Langsung Kajian Simulasi
ALGORITMA :
1. Pembangkitan data dengan jumlah populasi sebanyak 10.000 (untuk skenario ke-1)
2. Perhitungan nilai dari data populasi yang telah dibangkitkan. Persamaan yang digunakan :
3. Penarikan contoh dengan ukuran contoh
dengan pengulangan sebanyak 500 kali untuk masing-masing ukuran contoh.
4. Perhitungan nilai dari masing-masing ukuran contoh pada setiap ulangan dengan menggunakan persamaan pada algoritma 2.
28
Lampiran 2 Syntax Program R Kajian Simulasi Penduga Langsung
############################# Populasi ############################# z<-185000
n<-10000
meanlog<-12.6 ##### Diganti sesuai nilai yang tertera di Tabel 1 ##### sdlog<-0.6 ##### Diganti sesuai nilai yang tertera di Tabel 1 ##### pengeluaran<-rlnorm(n, meanlog, sdlog)
miskin<-ifelse(pengeluaran<z,1,0) df<-dataframe(pengeluaran,miskin) y<-subset(df, miskin==1)$pengeluaran P0<-(1/n)*sum(((z-y)/z)^0) P1<-(1/n)*sum(((z-y)/z)^1) P2<-(1/n)*sum(((z-y)/z)^2) writetable(pengeluaran,file="d:kapita1csv",sep=",")
################ fungsi untuk menentukan nilai p0,p1,p2################ p<-function(x) { n<-length(x) y<-subset(x,x<z) P0<-(1/n)*sum(((z-y)/z)^0) P1<-(1/n)*sum(((z-y)/z)^1) P2<-(1/n)*sum(((z-y)/z)^2) out<-c(P0, P1, P2)} ######################### Penarikan Contoh #########################
nsamp300 <-list() #nsamp ( 250,
300) #
for(i in 1:500){nsamp300[[paste("samp",i,sep="")]]<-sample(pengeluaran,300,replace="T")}
######### menentukan nilai p untuk penarikan contoh 300 (500 kali) ######### p300<- list() ####memesan tempat####
for(i in 1:500){p300[[i]]<-p(nsamp300[[paste("samp",i,sep="")]])}
#################### Untuk Menyimpan di Excel #################### pc<-c()
for (i in 1:500) {pc[i]<-p300[[i]][1]}
writeClipboard(ascharacter(for (i in 1:500) {p300[[i]][1]})) writeClipboard(ascharacter(pc))
29 Lampiran 3 Garis Kemiskinan Kabupaten dan Kota di Propinsi Jawa Timur
Tahun2008 NO KECAMATAN Gk (Rp/Kap/Bulan) 1 Kab. Pacitan 150.734 2 Kab. Ponorogo 150.572 3 Kab.Trenggalek 138.454 4 Kab.Tulungagung 174.251 5 Kab. Blitar 162.667 6 Kab. Kediri 164.818 7 Kab.Malang 17.08 8 Kab.Lumajang 147,758 9 Kab.Jember 158.377 10 Kab. Banyuwangi 169.52 11 Kab.Bondowoso 160.958 12 Kab.Situbondo 173.795 13 Kab.Purbolinggo 178.717 14 Kab.Pasuruan 175.195 15 Kab.Sidoardjo 222.101 16 Kab.Mojokerto 187.127 17 Kab.Jombang 184.252 18 Kab.Nganjuk 176.322 19 Kab.Madiun 163.321 20 Kab.Magetan 152.841 21 Kab.Ngawi 147.918 22 Kab.Bojonegoro 149.846 23 Kab.Tuban 151.582 24 Kab.Lamongan 177.003 25 Kab.Gresik 225.554 26 Kab.Bangkalan 193.525 27 Kab.Sampang 147.399 28 Kab.Pamekasan 150.523 29 Kab.Sumenep 161.732 30 Kota Kediri 234.709 31 Kota Blitar 213.578 32 Kota Malang 249.32 33 Kota Probolinggo 262.053 34 Kota Pasuruan 212.149 35 Kota Mojokerto 222.41 36 Kota Madiun 216.127 37 Kota Surabaya 250.015 38 Kota Batu 229,474
30
Lampiran 4 Relative Bias (RB) Kajian Simulasi
n Relative Bias Skenario 1 2 3 4 5 6 7 8 9 5 0,85 1,46 -0,45 0,80 -0,99 -0,09 0,04 0,33 0,21 10 1,41 -0,72 -1,41 0,29 0,33 -0,19 0,15 0,14 0,19 15 -1,72 0,21 0,79 -0,62 1,26 0,66 -0,14 0,18 -0,10 20 2,91 -0,05 -1,10 0,42 -0,58 0,01 0,22 -0,06 -0,09 25 0,62 -0,06 0,06 0,07 0,39 0,35 0,04 0,32 0,08 30 1,44 -0,23 -0,36 -0,21 0,53 0,00 -0,19 -0,11 -0,17 40 0,59 0,20 0,38 -0,40 -0,62 0,03 0,04 -0,08 -0,21 60 0,56 0,10 0,85 0,05 -0,35 0,01 0,09 0,03 0,06 80 1,21 0,33 0,01 -0,46 0,01 0,17 0,10 0,07 -0,02 100 1,10 -0,04 -0,33 -0,19 -0,10 -0,05 -0,02 0,00 0,14 150 -0,25 -0,19 -0,02 -0,12 0,12 0,11 0,05 0,10 -0,01 200 1,15 -0,16 -0,04 -0,02 0,04 0,20 -0,01 0,00 -0,03 250 -0,12 -0,19 -0,05 -0,17 0,06 0,09 0,03 0,03 -0,02 300 0,15 -0,04 0,26 -0,02 -0,05 -0,06 -0,05 0,03 0,00
31 Lampiran 5 Relative Bias (RB) Kajian Simulasi
n Relative Bias Skenario 1 2 3 4 5 6 7 8 9 5 2,45 1,51 -1,00 1,35 0,51 -0,44 -0,12 0,63 0,07 10 1,06 -0,83 -0,83 0,66 -0,02 -0,03 0,19 -0,04 0,15 15 -0,59 -0,92 0,97 -0,59 1,28 0,65 -0,11 0,20 -0,08 20 2,48 -0,36 -0,34 0,79 -0,60 -0,14 0,35 -0,13 -0,08 25 1,78 -0,75 -0,28 0,33 0,26 0,50 0,03 0,38 0,12 30 1,24 -0,09 -0,45 0,22 0,59 -0,19 -0,15 -0,23 -0,28 40 -0,32 -0,21 0,53 -0,60 -0,70 0,09 0,04 -0,07 -0,20 60 -0,48 0,02 1,13 0,15 -0,33 0,00 -0,05 0,08 0,01 80 0,56 0,70 0,15 -0,45 -0,07 0,16 0,17 -0,08 -0,04 100 0,72 -0,27 -0,22 -0,10 -0,21 -0,07 -0,13 0,00 0,13 150 -0,81 -0,70 0,12 -0,18 0,12 0,03 0,11 0,16 0,02 200 0,87 -0,35 0,09 -0,04 0,18 0,19 -0,03 0,06 -0,05 250 -0,32 -0,25 -0,26 -0,20 0,12 0,04 0,02 0,04 0,01 300 -0,19 0,05 0,29 -0,07 -0,01 -0,11 0,04 0,03 0,02
32
Lampiran 6 Relative Bias (RB) Kajian Simulasi
n Relative Bias P2 Skenario 1 2 3 4 5 6 7 8 9 5 0,55 1,98 -1,11 1,61 0,87 -0,45 -0,18 0,79 0,03 10 0,92 -1,09 -0,31 0,75 -0,23 0,01 0,30 -0,12 0,16 15 -0,95 -1,84 1,04 -0,69 1,38 0,67 -0,08 0,20 -0,04 20 2,94 -0,50 -0,04 0,98 -0,57 -0,21 0,35 -0,14 -0,07 25 2,53 -1,21 -0,69 0,38 0,21 0,57 0,06 0,38 0,17 30 0,73 -0,23 -0,40 0,36 0,62 -0,27 -0,19 -0,25 -0,33 40 -1,64 -0,60 0,69 -0,76 -0,64 0,12 0,07 -0,05 -0,17 60 -1,18 0,04 1,32 0,17 -0,28 0,00 -0,08 0,10 -0,03 80 -0,29 0,79 0,16 -0,46 -0,11 0,19 0,19 -0,14 -0,05 100 0,07 -0,32 -0,22 -0,12 -0,24 -0,11 -0,19 0,01 0,13 150 -1,11 -0,86 0,16 -0,19 0,11 -0,01 0,11 0,19 0,03 200 0,28 -0,44 0,18 -0,07 0,24 0,18 -0,04 0,07 -0,06 250 -0,37 -0,29 -0,37 -0,22 0,13 0,02 0,00 0,05 0,02 300 -0,32 0,09 0,40 -0,11 -0,01 -0,13 0,08 0,03 0,43
33
Lampiran 7 Absolute Relatif Bias (ARB), Relatif Mean Square Error (RMSE), dan Simpangan Baku (σ) Rij Kajian Simulasi P0
n
Skenario
1 2 3 4 5 6 7 8 9
= 0,6 = 1,4 = 1,6 = 2,4 = 2,6 = 3,4 = 3,6 = 4,4 = 4,6
ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE
5 67,94 79,79 28,37 14,02 27,37 11,32 15,82 2,77 14,69 2,89 9,72 1,28 8,81 1,23 4,10 0,49 3,37 0,39 10 49,33 40,09 21,18 7,13 18,10 4,83 11,09 1,31 11,04 1,76 7,10 0,69 6,68 0,62 3,52 0,21 3,05 0,19 15 39,93 24,99 15,88 4,12 15,59 3,69 9,56 0,95 8,82 1,21 5,64 0,57 4,90 0,38 3,21 0,15 2,64 0,11 20 35,19 18,54 14,31 3,24 13,09 2,68 8,09 0,66 7,32 0,84 4,71 0,33 4,34 0,31 2,78 0,10 2,49 0,09 25 30,50 14,57 14,00 3,05 11,74 2,18 7,05 0,54 7,34 0,82 4,34 0,29 4,06 0,25 2,64 0,10 2,28 0,07 30 27,90 11,97 12,10 2,30 11,43 2,02 6,82 0,51 6,34 0,62 3,84 0,24 3,47 0,18 2,30 0,07 2,02 0,05 40 24,43 8,98 9,47 1,50 9,06 1,29 5,60 0,34 5,05 0,41 3,25 0,16 3,03 0,15 1,89 0,05 1,75 0,04 60 20,25 6,21 8,47 1,12 7,91 0,97 5,04 0,26 4,02 0,26 2,67 0,11 2,41 0,09 1,55 0,04 1,31 0,03 80 17,00 4,50 7,31 0,80 6,50 0,66 4,15 0,18 3,70 0,21 2,34 0,09 2,32 0,08 1,35 0,03 1,20 0,02 100 15,20 3,68 6,66 0,68 5,28 0,46 3,93 0,17 3,41 0,18 2,16 0,07 2,01 0,06 1,09 0,02 1,11 0,02 150 12,23 2,33 5,49 0,45 4,51 0,32 3,06 0,10 2,56 0,10 1,77 0,05 1,59 0,04 0,97 0,01 0,85 0,01 200 10,74 1,76 4,88 0,38 4,46 0,31 2,62 0,07 2,33 0,08 1,58 0,04 1,34 0,03 0,80 0,01 0,77 0,01 250 10,23 1,65 4,03 0,26 3,61 0,20 2,35 0,06 2,18 0,08 1,34 0,03 1,22 0,02 0,68 0,01 0,65 0,01 300 8,16 1,06 3,56 0,20 3,53 0,19 2,11 0,05 1,91 0,06 1,15 0,02 1,08 0,02 0,69 0,01 0,60 0,01
38
Lampiran 8 Absolute Relatif Bias (ARB), Relatif Mean Square Error (RMSE), dan Simpangan Baku (σ) Rij Kajian Simulasi P1
n
Skenario
1 2 3 4 5 6 7 8 9
= 0,6 = 1,4 = 1,6 = 2,4 = 2,6 = 3,4 = 3,6 = 4,4 = 4,6
ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE
5 89,13 116,30 36,18 19,95 32,85 15,69 18,98 2,69 16,48 4,25 11,11 1,75 10,48 1,56 5,90 0,67 4,65 0,50 10 63,43 64,82 26,49 11,03 21,73 7,28 13,51 1,40 12,56 2,42 7,74 0,95 6,74 0,76 4,41 0,28 3,84 0,23 15 49,67 39,56 19,55 5,99 18,41 5,38 10,89 0,91 10,02 1,56 6,74 0,72 5,56 0,49 3,89 0,20 3,11 0,14 20 42,00 28,65 18,15 5,11 16,10 4,01 9,40 0,65 8,44 1,09 5,44 0,45 5,16 0,42 3,17 0,14 2,95 0,13 25 38,59 23,15 16,69 4,37 14,03 3,09 8,56 0,54 8,16 1,05 5,03 0,40 4,45 0,31 2,80 0,13 2,52 0,09 30 36,22 19,90 14,79 3,41 13,70 2,87 8,19 0,51 7,58 0,88 4,49 0,32 4,03 0,26 2,57 0,09 2,22 0,07 40 32,29 15,81 12,49 2,45 10,88 1,85 6,52 0,32 6,29 0,59 3,78 0,23 3,62 0,21 2,21 0,07 1,94 0,06 60 26,30 10,63 9,90 1,57 9,69 1,45 5,81 0,25 4,68 0,35 3,01 0,14 2,76 0,12 1,85 0,05 1,62 0,04 80 22,63 8,26 8,86 1,28 7,49 0,93 5,01 0,18 4,52 0,31 2,82 0,13 2,65 0,11 1,52 0,03 1,41 0,03 100 19,09 5,65 7,98 0,99 6,59 0,71 4,57 0,16 3,80 0,24 2,50 0,10 2,20 0,08 1,33 0,03 1,21 0,02 150 16,08 3,90 6,62 0,68 5,52 0,48 3,68 0,10 2,97 0,14 1,98 0,07 1,82 0,05 1,16 0,02 1,00 0,02 200 13,73 2,87 5,96 0,56 5,37 0,44 3,00 0,07 2,73 0,11 1,78 0,05 1,55 0,04 0,99 0,01 0,88 0,01 250 13,08 2,63 5,14 0,41 4,51 0,33 2,84 0,06 2,47 0,10 1,56 0,04 1,40 0,03 0,85 0,01 0,75 0,01 300 10,38 1,73 4,44 0,32 4,16 0,27 2,36 0,04 2,25 0,08 1,39 0,03 1,26 0,02 0,76 0,01 0,66 0,01
Lampiran 9 Absolute Relatif Bias (ARB), Relatif Mean Square Error (RMSE), dan Simpangan Baku (σ) Rij Kajian Simulasi P2 n Skenario 1 2 3 4 5 6 7 8 9 = 0,6 = 1,4 = 1,6 = 2,4 = 2,6 = 3,4 = 3,6 = 4,4 = 4,6
ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE ARB RMSE
5 110,50 199,10 43,57 28,63 38,09 21,37 22,06 2,88 19,12 5,59 12,44 2,27 11,85 1,95 7,118 0,832 5,47 0,60 10 81,12 111,19 31,52 15,96 25,62 10,05 15,67 1,49 14,35 3,11 8,99 1,23 7,47 0,93 4,980 0,337 4,47 0,29 15 65,31 67,76 22,88 8,34 21,40 7,27 12,53 0,95 11,28 1,97 7,49 0,90 6,25 0,61 4,408 0,256 3,54 0,18 20 54,35 49,27 22,11 7,52 18,91 5,55 10,67 0,69 9,43 1,38 6,21 0,60 5,87 0,53 3,430 0,169 3,26 0,16 25 49,62 40,44 19,94 6,17 16,27 4,27 9,77 0,56 9,12 1,32 5,75 0,52 4,93 0,38 3,135 0,151 2,71 0,12 30 47,31 34,00 17,65 4,98 16,14 3,98 9,24 0,53 8,45 1,11 5,11 0,41 4,55 0,33 2,929 0,113 2,44 0,09 40 42,38 27,63 15,30 3,58 12,98 2,61 7,53 0,34 7,18 0,78 4,40 0,30 4,04 0,26 2,483 0,087 2,18 0,07 60 33,81 18,29 11,80 2,19 11,19 1,96 6,51 0,25 5,36 0,45 3,41 0,18 3,12 0,16 2,098 0,060 1,78 0,05 80 29,30 13,84 10,72 1,88 8,82 1,28 5,76 0,20 5,16 0,41 3,22 0,16 2,96 0,14 1,701 0,040 1,60 0,04 100 25,62 9,99 9,53 1,41 7,98 1,03 5,15 0,16 4,27 0,30 2,87 0,13 2,42 0,09 1,498 0,031 1,34 0,03 150 21,09 6,83 7,87 0,97 6,48 0,66 4,17 0,11 3,46 0,19 2,25 0,08 2,02 0,07 1,308 0,025 1,13 0,02 200 18,01 5,04 7,18 0,81 6,23 0,59 3,45 0,07 3,10 0,14 2,01 0,06 1,73 0,05 1,136 0,018 0,98 0,01 250 16,72 4,28 5,92 0,56 5,45 0,48 3,29 0,06 2,81 0,13 1,75 0,05 1,58 0,04 0,979 0,013 0,83 0,01 300 13,82 3,10 5,37 0,48 4,86 0,37 2,73 0,04 2,51 0,10 1,58 0,04 1,43 0,03 0,852 0,011 1,13 0,41
36
Lampiran 10 Algoritma Metode Molina dan Rao
ALGORITMA :
1. Membangun model awal dengan persamaan modelnya:
2. Mencari nilai duga . . dan dengan metode pendugaan langsung. Model yang digunakan pada Metode pendugaan langsung. yaitu :
didefinisikan :
3. Mentransformasi nilai menjadi atau .
dengan adalah pengeluaran per kapita rumah tangga yang tersampel dalam setiap kecamatan di kabupaten dan kota Malang.
4. Membangkitkan data pengeluaran per kapita rumah tangga. sebanyak jumlah RT yang tak tersampel dengan 1000 kali ulangan. dengan mengikuti sebaran normal dan menggunakan nilai dugaan , , dan yang diperoleh dari
model pada tahap 1.
dengan
untuk data pengeluaran perkapita yang tak tersampel
dan
-(packages R yang digunakan adalah nlme)
5. Mentransformasi nilai menjadi
6. Mencari nilai , , dan dari data pengeluaran rumah tangga bukan anggota contoh yang sudah dibangkitkan.
7. Menghitung Bayes empirik bagi untuk setiap ulangan di masing-masing kecamatan dengan menggunakan persamaan :
8. Menghitung nilai rata-rata nilai , , dan Bayes empirik yang diperoleh pada tahap 7 dari n kali ulangan untuk masing-masing rumah tangga.
38
Lampiran 11 Syntax Program R Metode Molina dan Rao (2010)
###################### Metode Pendugaan Langsung ################### rm()
data <- as.matrix(read.table("data.txt". header=T)) data <- as.data.frame(data)
attach(data)
logkapita <- log(kapita)
model <- lme(logkapita~xis. data=data. random=(~1|kode_kec)) summary(model) var.u <- diag(getVarCov(model)) var.e <- model$sigma std.u <- sqrt(var.u) std.e <- sqrt(var.e) kkec <- unique(kode_kec) kk <- length (kkec) direct <- cbind(kkec. 1. 2. 3) for (i in 1:kk) {
olah <- subset(data. kode_kec==kkec[i]) nz <- as.numeric(olah[1.6]) rw <- nrow(olah) pov <- rep(1.rw) for (j in 1:rw) { T <- as.numeric(olah[j.3]) if(T < nz) {pov[j] <- (nz-T)/nz} else {pov[j] <- 0} }
direct [i.2] <- sum(pov!=0)/rw direct [i.3] <- sum(pov^1)/rw direct [i.4] <- sum(pov^2)/rw }
####################### Metode Bayes Empirik ####################### beta <- as.matrix(fixef(model))
eb <- cbind(kkec.1.2.3)
data_k <- as.matrix(read.table("data_kec.txt". header=T)) data_k <- as.data.frame(data_k)
attach(data) for (i in 1:kk) {
kapita_1 <- subset(data[.3]. kode_kec==kkec[i]) olah <- subset(data. kode_kec==kkec[i])
Ni <- olah2[1.2] ni <- olah2[1.3] mi <- Ni - ni im <- as.matrix(rep(1.mi)) iin <- as.matrix(rep(1.ni)) dn <- diag(1.ni) Yis <- log(olah[.3]) Xis <- cbind(1.olah[.5]) Xir <- cbind(1.rep((olah[1.4]).mi)) vis <- var.u*(iin%*%t(iin))+var.e*dn mu.irs <- (Xir%*%beta)+(var.u)*(((im%*%t(iin)%*%solve(vis)))%*%(Yis-(Xis%*%beta))) gama <- var.u*(var.u+(var.e/ni))^-1 rv <- sqrt(var.u*(1-gama)) tempr <- cbind(1:10. 2. 3) for (j in 1:10) { #vi <- as.matrix(rnorm(mi. 0. rv)) v <- as.matrix(rnorm(1. 0. rv)) vi <- matrix(v.mi.1)
e.ir <- as.matrix(rnorm(mi. 0. std.e)) mu <- as.matrix(mu.irs)
yir <- mu + vi + e.ir Yir <- as.vector(yir)
ysim <- exp(Yir+(rv^2+std.e^2)/2) ysim <- c(ysim. kapita_1)
zt <- as.numeric(olah[1.6]) pov <- rep(1. length(ysim)) for(k in 1:length(ysim)) { T <- as.numeric(ysim[k]) if(T<zt) {pov[k] <- (zt-T)/zt} else {pov[k] <- 0} } tempr [j.1] <- sum(pov!=0)/Ni tempr [j.2] <- sum(pov^1)/Ni tempr [j.3] <- sum(pov^2)/Ni } cmeans <- colMeans(tempr) eb[i. 2] <- cmeans[1] eb[i. 3] <- cmeans[2] eb[i. 4] <- cmeans[3] } write.xlsx(direct. "direct1.xlsx") write.xlsx(eb. "eb1.xlsx")