TUGAS AKHIR – SS141501
KLASIFIKASI GEN YANG TERKAIT SINDROM
ALZHEIMER
MENGGUNAKAN METODE
NAÏVE
BAYES CLASSIFIER, BINARY LOGISTIC
REGRESSION
DAN
LOGISTIC REGRESSION
ENSEMBLE
REYNALDI WISNU WERDHANA NRP 1313 100 097
Dosen Pembimbing Dr.rer.pol. Heri Kuswanto
PROGRAM STUDI SARJANA DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT TEKNOLOGI SEPULUH NOPEMBER
HALAMAN JUDUL
TUGAS AKHIR – SS141501
KLASIFIKASI GEN YANG TERKAIT SINDROM
ALZHEIMER MENGGUNAKAN METODE
NAÏVE BAYES
CLASSIFIER, BINARY LOGISTIC REGRESSION
DAN
LOGISTIC REGRESSION ENSEMBLE
REYNALDI WISNU WERDHANA NRP 1313 100 097
Dosen Pembimbing
Dr.rer.pol. Heri Kuswanto
PROGRAM STUDI SARJANA DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT TEKNOLOGI SEPULUH NOPEMBER
FINAL PROJECT– SS141501
CLASSIFICATION OF ALZHEIMER’S DISEASE
RELATED GENES USING NAÏVE BAYES CLASSIFIER,
BINARY LOGISTIC REGRESSION AND LOGISTIC
REGRESSION ENSEMBLE
REYNALDI WISNU WERDHANA NRP 1313 100 097
Supervisors
Dr.rer.pol. Heri Kuswanto
UNDERGRADUATE PROGRAM DEPARTMENT OF STATISTICS
FACULTY OF MATHEMATICS AND NATURAL SCIENCES INSTITUT TEKNOLOGI SEPULUH NOPEMBER
vii
LOGISTIC REGRESSION ENSEMBLE
Nama : Reynaldi Wisnu Werdhana NRP : 1313 100 097
Departemen : Statistika
Pembimbing : Dr.rer.pol. Heri Kuswanto, M.Si.
Abstrak
Alzheimer merupakan penyakit degeneratif dan penyebab paling umum dari kasus dimensia. Salah satu kunci menangani penyakit ini adalah deteksi dini. Deteksi tersebut dapat diketahui melalui ekspresi dari gen yang terkandung dalam DNA, dengan memanfaatkan teknologi Microarray DNA. Masalah paling mendasar dalam memprediksi ekspresi adalah mendapatkan metode terbaik. Dalam penelitian ini, metode Logistic Regression Ensemble (LORENS) akan dibandingkan dengan metode Naive Bayes
Classifier serta Binary Logistic Regression dengan
mempertimbangkan 20 variabel yang diduga berpengaruh dalam proses klasifikasi. Variabel dalam penelitian ini berjumlah 178, yang terdiri dari 2 kelas yaitu gen Alzheimer sebanyak 98 pengamatan dan gen normal sebanyak 80 pengamatan. Hasil analisis menggunakan prosedur evaluasi full training set menghasilkan metode terbaik adalah metode LORENS 4 partisi dan threshold 0,5 memberikan hasil paling baik. Akurasi yang dihasilkan model ini adalah 76,4% dan nilai AUC 0,774. Dengan menggunakan prosedur evaluasi Cross Validation, metode LORENS adalah metode terbaik. Metode LORENS dengan 10 folds memberikan hasil partisi optimal yang digunakan adalah 5 partisi dengan threshold 0,5. Akurasi yang dihasilkan sebesar 75,28% dan nilai AUC sebesar 0,759. Metode terbaik untuk menangani masalah klasifikasi gen menggunakan data microarray dalam penelitian ini adalah metode LORENS Cross Validation 5 partisi dengan threshold 0,5.
ix
GENES USING NAÏVE BAYES CLASSIFIER, BINARY LOGISTIC REGRESSION AND LOGISTIC REGRESSION ENSEMBLE
Student’s Name : Reynaldi Wisnu Werdhana
NRP : 1313 100 097 Departement : Statistics
Supervisor : Dr.rer.pol. Heri Kuswanto, M.Si.
Abstrak
Alzheimer is a degenerative disease and most common case of dementia. One of the keys to treat Alzheimer is early detection. The detection can be carned out by analyzing the expression of the genes contained in DNA, using DNA microarray technology. The most basic problem in classification is to find a best method. In this research, Logistic Regression Ensemble (LORENS) is applied and compared with Naïve Bayes Classifier and Binary Logistic Regression. Research examines to 178 observation, consisting of 2 classes, where 98 observations as a Alzheimer’s genes and 80 observations as a normal genes. The result of the analysis using full training set found that LORENS with 4 partitions and threshold of 0,5 is the best setting. This method has accuracy of is the best method. Meanwhile, LORENS has been proven to outier from the others by Cross Validation evalution, where the optional result is obtained by 5 partition and threshold of 0,5. The accuracy is 75,28% with AUC of 0,759.
xi
Assalamu’alaikum Warahmatullah Wabarokatuh.
Puji syukur alhamdulillah senantiasa penulis panjatkan kehadirat Allah SWT yang telah melimpahkan rahmat, hidayah dan karunia-Nya sehingga penulis dapat menyelesaikan Tugas Akhir dengan judul
“KLASIFIKASI GEN YANG TERKAIT SINDROM
ALZHEIMER MENGGUNAKAN METODE NAÏVE BAYES
CLASSIFIER, BINARY LOGISTIC REGRESSSION DAN
LOGISTIC REGRESSION ENSEMBLE”
Sholawat dan salam tak lupa penulis sampaikan pada junjungan besar Nabi Muhammad SAW. Dalam menyelesaikan laporan Tugas Akhir ini penulis telah banyak menerima bantuan dan dukungan dari berbagai pihak. Oleh karena itu penulis mengucapkan terima kasih kepada :
1. Dr. rer. pol. Heri Kuswanto selaku dosen pembimbing, yang telah membimbing saya, memberikan segala masukan, waktu serta pengetahuan demi terselesaikannya Tugas Akhir ini.
2. Dr. Suhartono selaku Ketua Departemen Statistika ITS yang telah memberikan fasilitas dan sarana dalam penyusunan Tugas Akhir ini.
3. Dr. Suhartono dan Ibu Santi Wulan Purnami, Ph.d. selaku dosen penguji, yang telah memberikan banyak saran, kritik dan masukan demi kesempurnaan Tugas Akhir saya. 4. Dr. Sutikno, M.Si selaku Ketua Program Studi S1 Statistika
dan segenap dosen maupun tenaga pendidik Departemen Statistika ITS.
5. Kedua orang tua tercinta dan keluarga besar yang telah melimpahkan kasih sayang dan segala doa.
xii
7. Teman-teman S1 Statistika angkatan 2013 yang berjuang bersama dalam penyelesaian Tugas Akhir, terima kasih atas dukungan dan segala bantuan dalam penyelesaian Tugas Akhir.
8. Semua pihak yang memberikan semangat serta motivasi kepada penulis untuk terus menggapai cita-cita.
Penulis menyadari bahwa Tugas Akhir ini masih jauh dari sempurna, oleh karena itu kritik dan saran yang bersifat membangun sangat diharapkan.
Wassalamu’alaikum Warahmatullah Wabarokatuh.
Surabaya, Juli 2017
xiii
DAFTAR ISI
Halaman
HALAMAN JUDUL ... i
PAGE OF TITLE ... iii
HALAMAN PENGESAHAN ... v
ABSTRAK ... vii
ABSTRACT ... ix
KATA PENGANTAR ... xi
DAFTAR ISI ... xiii
DAFTAR GAMBAR ... xv
DAFTAR TABEL ... xvii
DAFTAR LAMPIRAN ... xix
BAB I. PENDAHULUAN 1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 6
1.3 Tujuan Penelitian ... 6
1.4 Batasan Masalah ... 7
BAB II. TINJAUAN PUSTAKA 2.1 Naïve Bayes Classifier... 9
2.2 BinaryLogistic Regression ... 11
2.2 Logistic Regression Classification by Ensembles From Random Partition (LR CERP) ... 14
2.3 Logistic Regression Ensemble ... 16
2.4 Cross Validation ... 20
2.5 AUC (Area Under Curve) ... 22
2.6 DNA Microarray ... 23
BAB III. METODOLOGI PENELITIAN 3.1 Sumber Data ... 25
3.2 Variabel Penelitian ... 25
3.3 Langkah Analisis ... 26
xiv
4.2 Pengujian Proporsi Variabel Respon ... 34
4.3 Analsis Naïve Bayes ClassifierFull Training Set ... 34
4.4 Analsis Naïve Bayes ClassifierCross Validation ... 39
4.5 Analsis Binary Logistic RegressionFull Training Set ... 40
4.6 Analsis Binary Logistic Regression Cross Validation ... 43
4.7 Analsis LORENS Full Training Set ... 47
4.8 Analsis LORENS Cross Validation ... 53
4.9 Pemilihan Metode Terbaik ... 57
BAB V. KESIMPULAN DAN SARAN 5.1 Kesimpulan... 61
5.2 Saran ... 63
DAFTAR PUSTAKA ... 65
xv
Halaman
Gambar 2.1 Bagan Konsep LR CERP ... 15
Gambar 2.2 Bagan Konsep LORENS ... 19
Gambar 3.1 Diagram Alur Penelitian ... 29
Gambar 4.1 Perbandingan Jumlah Gen Antara Gen Normal
dan Alzheimer ... 31
Gambar 4.2 Perbandingan Rata-Rata Nilai Scanning
Microarray Gen Normal dan Alzheimer ... 32
xvi
xvii
DAFTAR TABEL
Halaman
Tabel 3.1 Struktur Data Penelitian ... 25
Tabel 3.2 Variabel Penelitian ... 26
Tabel 4.1 Perbandingan p-value dengan alpha ... 31
Tabel 4.2 Rata-Rata dan Standar Deviasi Setiap Prediktor
dan Kelas ... 36
Tabel 4.3 Peluang Tiap Kategori pada Data Testing
Pertama ... 37
Tabel 4.4 Perhitungan Posterior Probability pada Data
Testing Pertama ... 38
Tabel 4.5 Tabulasi Silang pada Analisis Naïve Bayes
Classifier ... 39
Tabel 4.6 Tabulasi Silang Kelas Aktual dan Prediksi Naïve
Bayes Classifier Cross Validation ... 40
Tabel 4.7 Ukuran Kebaikan Klasifikasi Naïve Bayes
Classifier Cross Validation ... 40
Tabel 4.8 Koefisien Parameter Awal Model Binary Logistic
Regression Full Training Set ... 41
Tabel 4.9 Koefisien Parameter Terbaik Model Binary
Logistic Regression ... 42
Tabel 4.10 Tabulasi Silang pada Analisis Binary Logistic
Regression ... 43
Tabel 4.11 Ukuran Kebaikan Model Binary Logistic
Regression ... 43
Tabel 4.12 Koefisien Parameter Awal Model Fold ke-1 CV
Binary Logistic Regression Full Training Set.... 44
Tabel 4.13 Koefisien Parameter Terbaik Model Fold ke-1
CV Binary Logistic Regression ... 45
Tabel 4.14 Model Binary Logistic Regression Pada Seluruh
Fold ... 46
Tabel 4.15 Tabulasi Silang pada Model Binary Logistic
xviii
Tabel 4.16 Ukuran Kebaian Model Binary Logistic
Regression CV ... 47
Tabel 4.17 Random Sampling Variabel Prediktor pada 4 Ruang Partisi Threshold 0,5 ... 48
Tabel 4.18 Koefisien Model Regresi Logistik 4 Partisi Threshold 0,5 ... 49
Tabel 4.19 Rata-Rata Nilai Probabilitas Pada 4 Partisi Threshold 0,5 ... 51
Tabel 4.20 Tabulasi Silang pada LORENS 4 Ruang Partisi Threshold 0,5 ... 52
Tabel 4.21 Ukuran Kebaikan Model LORENS Full Training Set ... 52
Tabel 4.22 Threshold Optimal untuk 2 Partisi ... 54
Tabel 4.23 Threshold Optimal untuk 3 Partisi ... 54
Tabel 4.24 Threshold Optimal untuk 4 Partisi ... 55
Tabel 4.25 Threshold Optimal untuk 5 Partisi ... 55
Tabel 4.26 Tabulasi Silang Hasil Klasifikasi LORENS dengan Cross Validation ... 56
Tabel 4.27 Ukuran Kebaikan Klasifikasi LORENS dengan Cross Validation ... 56
Tabel 4.28 Perbandingan Ketepatan Klasifikasi Pada Prosedur Evaluasi Full Traininig Set ... 58
xix
Lampiran 1. Data Microarray Ekspresi Gen ... 67
Lampiran 2. Rata-Rata Variabel Prediktor Tiap Kelas . 68
Lampiran 3. Peluang Posterior Naïve Bayes Full
Training Set ... 69
Lampiran 4. Peluang Posterior Naïve Bayes Cross
Validation ... 70
Lampiran 5. Output Learning Decision LORENS
Full Training Set ... 71
Lampiran 6. Alokasi Variabel Prediktor Pada
LORENS 2 Partisi Threshold 0,5 ... 72
Lampiran 7. Alokasi Variabel Prediktor Pada
LORENS 2 Partisi Threshold Optimal ... 73
Lampiran 8. Alokasi Variabel Prediktor Pada
LORENS 3 Partisi Threshold 0,5 ... 74
Lampiran 9. Alokasi Variabel Prediktor Pada
LORENS 3 Partisi Threshold Optimal ... 75
Lampiran 10. Alokasi Variabel Prediktor Pada
LORENS 4 Partisi Threshold 0,5 ... 76
Lampiran 11. Alokasi Variabel Prediktor Pada
LORENS 4 Partisi Threshold Optimal ... 77
Lampiran 12. Alokasi Variabel Prediktor Pada
LORENS 5 Partisi Threshold Optimal ... 78
Lampiran 13. Koefisien Model Regresi Logistik
LORENS 2 Partisi Threshold 0,5 ... 79
Lampiran 14. Koefisien Model Regresi Logistik
LORENS 2 Partisi Threshold Optimal ... 80
Lampiran 15. Koefisien Model Regresi Logistik
LORENS 3 Partisi Threshold 0,5 ... 81
Lampiran 16. Koefisien Model Regresi Logistik
LORENS 3 Partisi Threshold Optimal ... 82
Lampiran 17. Koefisien Model Regresi Logistik
xx
Lampiran 19. Koefisien Model Regresi Logistik
LORENS 5 Partisi Threshold Optimal ... 85
Lampiran 20. Syntax R untuk split data... 86
Lampiran 21. Syntax R untuk Logistic Regression
1
1.1 LatarBelakang
Otak merupakan pusat sistem saraf yang mengatur seluruh kegiatan didalam tubuh makhluk hidup. Gangguan atau penyakit sekecil apapun pada otak dapat mempengaruhi kegiatan yang terjadi didalam tubuh makhluk hidup. Salah satu penyakit yang menyerang otak manusia adalah penyakit Alzheimer. Alzheimer pertama kali diidentifikasi lebih dari 100 tahun yang lalu. Penyakit ini merupakan penyakit degeneratif dan penyebab paling umum dari kasus dimensia. Hal ini ditandai dengan penurunan memori/ingatan manusia, penurunan kemampuan memecahakan masalah dan ketrampilan kognitif yang lainnya. Akibatnya kemampuan seseorang untuk melakukan aktivitas sehari-hari akan terganggu atau bahkan tidak bisa melakukan aktivitas sama sekali dalam kondisi dimensia yang parah. Penurunan kemampuan ini terjadi karena sel-sel syaraf (neuron) di bagian otak yang terlibat dalam fungsi kognitif telah rusak dan biasanya tidak berfungsi lagi (Anonim, 2016). Meskipun banyak penelitian yang meneliti tentang penyaki ini, masih banyak hal yang belum terungkap mengenai penyakit ini. Terutama tentang perubahan biologis yang menyebabkan terjadinya Alzheimer, mengapa penyakit ini dapat berlangsung lebih cepat pada beberapa orang dan bagaimana penyakit ini bisa dicegah atau bahkan dihentikan. Para peneliti percaya bahwa salah satu kunci menangani penyakit ini adalah deteksi dini. Deteksi tersebut dapat diketahui dengan melihat ekspresi dari gen yang terkandung dalam DNA.
Masalah yang paling mendasar dalam memprediksi ekspresi gen dengan menggunakan data microarray adalah mendapatkan metode dan model terbaik yang dapat menganalisis dengan tepat. Data microarray yang pada umumnya merupakan high dimensional data mengharuskan metode klasifikasi statistika sebaiknya dilakukan dengan pendekatan komputasi. Tantangan para analis sekarang ini adalah big data dan high dimensional data. Pendekatan statistik yang mengharuskan untuk memenuhi asumsi-asumsi tertentu akan menjadi lemah ketika dihadapkan dengan big data ataupun high dimentional data. Pendekatan parametrik yang menggunakan pengujian signifikansi juga akan menjadi lemah ketika dihadapkan dengan big data ataupun high dimentional data. Hal itu dikarenakan p-value sensitif terhadap banyaknya observasi yang dilakukan (Lin, Lucas, & Shmueli, 2013). Permasalahan yang terjadi pada tahap pengujian hipotesis dengan pendekatan statistika inferensial adalah pembuktian hipotesa null dapat ditolak. Pengujian dengan menggunakan data yang besar cenderung menghasilkan keputusan bahwa parameter yang diuji berpengaruh signifikan karena p-value cenderung bernilai 0. Pendekatan parametrik untuk menganalisa data dengan jumlah yang besar akan menjadi tidak berguna, bahkan menghasilkan kesimpulan yang salah. Pendekatan komputasional dikembangkan untuk menangani kelemahan pendekatan inferensial, karena pendekatan komputasional tidak mengenal pengujian asumsi dan pengujian parameter. Pendekatan komputasional sangat dapat dipercaya, karena pendekatan ini mengadaptasi pendekatan inferensial dan menyempurnakannya dengan algoritma yang agregatif.
20 gen dengan rangking teratas. Penelitian ini memberikan hasil yang tepat dalam mengidentifikasi gen yang terkait penyakit Alzheimer. Penelitian dengan menggunakan data microarray juga pernah dilakukan untuk klasifikasi gen yang terkait penyakit kanker. Matsumoto, Aoki & Ohwada (2015) menggunakan metode Random Forest dan SVM untuk memprediksi proteksi radiasi dan toksisitas. Dalam prediksi fungsi proteksi radiasi, metode SVM menghasilkan akurasi yang lebih baik dibandingkan metode Random Forest. Sebaliknya, metode Random Forest memberikan akurasi yang lebih baik dibandingkan metode SVM saat memprediksi toksisitas.
Sebuah metode klasifikasi baru telah dikembagkan oleh Lim pada tahun 2007 dengan menggunakan algoritma Classification
by Ensembles from Random Partition (CERP) pada metode
klasifikasi regresi logistik biner. Metode baru tersebut memperbolehkan data kategori menjadi variabel prediktornya. Algoritma CERP mempartisi variabel prediktor menjadi beberapa subruang. Model-model berbasis Logistic Regression dari masing-masing partisi yang didapat kemudian akan digabung kembali menjadi satu fungsi. Metode tersebut dikenal dengan nama Logistic Regression Ensembles (LORENS). Metode LORENS memiliki keunggulan, karena menggunakan algoritma CERP yang menyebabkan variabel prediktor menjadi saling mutually exclusive dan dibangun dari sifat Logistic Regression yang informatif dan juga representatif (Lee, Ahn, Moon, Kodell, & Chen, 2013). LORENS diciptakan untuk mengatasi kasus dengan banyak variabel prediktor mempunyai jumlah yang jauh lebih besar daripada pengamatan yang dilakukan. Dalam metode klasifikasi, pada umumnya threshold yang digunakan adalah 0,5. Hal tersebut menjadi sebuah masalah, karena tidak adil jika probabilitas masing-masing kelas dinyatakan bernilai 0,5. LORENS mampu mengatasi masalah tersebut dengan menyediakan threshold yang optimal untuk masing-masing kelas.
Leukimia). Dalam penelitian tersebut, didapatkan kesimpulan bahwa metode LORENS terbukti meningkatkan akurasi, sensitivity dan specificity disbanding metode klasifikasi lainnya. Penelitian serupa juga pernah dilakukan oleh Kuswanto, Asfihani, Sarumaha, & Ohwada (2015), dimana LORENS digunakan dalam mengklasifikasikan kasus pembelotan konsumen dengan ukuran sample yang sangat besar. Kemampuan LORENS dalam menangani big data, ketidak-seimbangan variabel respon, dan ketimpangan variabel prediktor yang cukup baik, LORENS disimpulkan lebih terpercaya walaupun tidak bisa menjelaskan hubungan antar variabel karena tidak dapat menghasilkan model yang intepretatif. Metode LORENS juga pernah digunakan oleh Zakharov & Dupont (2011) untuk menanggani data microarray. Hasil dari penelitian tersebut menyebutkan bahwa LORENS menghasilkan hasil klasifikasi yang lebih stabil dan jauh lebik akurat daripada menggunakan regresi logistik. LORENS mampu menanggani kasus data dengan jumlah observasi yang jauh lebih sedikit daripada jumlah variabelnya.
lebih sederhana, serta metode binary logistic regression yang merupakan base classifier dari metode LORENS. Perbandingan ketiga metode tersebut diharapkan mampu memberikan hasil yang baik.
1.2 Rumusan Masalah
Metode klasifikasi untuk prediksi gen normal dan tidak normal dari data DNA microarray telah menjadi perhatian bagi pakar dibidang biologi molekular. Setelah diteliti oleh Ohwada (2015) menggunakan metode Random Forest, kasus ini akan diteliti dengan metode Naive Bayes Classifier, Binary Logistic Regrssion dan Logistic Regression Ensembles (LORENS). Dalam penelitian ini akan diteliti mengenai metode dan model klasifikasi yang terbaik dalam mengklasifikasikan gen normal dan gen yang terpengaruh penyakit Alzheimer. Pendekatan untuk prediksi klasifikasi pada kasus ini tidak menggunakan pendekatan inferensial. Pendekatan inferensial kurang terpercaya untuk menangani kasus dengan data yang besar, karena cenderung menghasilkan kesimpulan menolak hipotesa null pada tahap pengujian parameter. Oleh karena itu, pada kasus ini digunakan metode Naive Bayes Classifier dan Logistic Regression
Ensembles (LORENS) yang tidak memerlukan pengujian
parameter. Namun kelemahan kedua metode ini adalah tidak dapat memberikan model intepretatif yang dapat mengintepretasikan hubungan antara variabel prediktor dengan variabel respon. Perbandingan kedua metode diperlukan untuk memilih metode terbaik berdasarkan ketepatan klasifikasi yang diperoleh.
1.3 Tujuan Penelitian
Berdasarkan rumusan masalah yang dijelaskan diatas, berikut ini adalah tujuan penelitian dai penelitin ini.
2. Menghitung dan menganalisis hasil klasifikasi dan ketepatan klasifikasi gen yang terkait sindrom Alzheimer menggunakan metode Binary Logisic Regression.
3. Menghitung hasil klasifikasi dan ketepatan klasifikasi gen yang terkait penyakit Alzheimer menggunakan metode Logistic Regression Ensembles (LORENS).
4. Memilih metode klasifikasi terbaik dari hasil analisis mengunakan metode Naive Bayes Classifier, Binary Logistic Regression dan Logistic Regression Ensembles (LORENS).
1.5 Batasan Masalah
9
2.1 Naïve Bayes Classifier
Naïve Bayes Classifier merupakan sebuah metode
pengklasifikasi probabilitas sederhana yang menerapkan Teorema Bayes dengan asumsi ketidaktergantungan yang tinggi. Konsep dasar dari metode ini adalah teorema Bayes, dimana didalam statisik teorema ini banyak digunakan untuk menghitung peluang. Bila diketahui A A1, 2,...,An adalah sebuah kejadian yang
merupakan sebuah kejadian random dan kejadian
( | )i
P A B merupakan posterior probability karena nilai
( | )i
P A B bergantung pada nilai B. P A( )i disebut prior probability karena nilainya tidak bergantung pada nilai B, sedangkan P B A( | )i adalah fungsi likelihood dan
P B
( )
merupakan keterangan.
Metode Naïve Bayes Classifier menggunakan konsep dari teorema Bayes. Bila diberikan { ,A A1 2,..., }An adalah atribut yang
digunakan untuk menentukan kelas C, dengan menggunakan teorema Bayes maka perhitungan posterior probability untuk setiap kelas C adalah sebagai berikut (Gorunescu, 2011).
1 2
Apabila kelas tersebut memaksimalkan nilai
1 2 ( j | , ,..., n)
P C A A A atau memaksimalkan nilai P A A( ,1 2,...,A Cn| j),
maka kelas tersebut yang dipilih. Berdasarkan persamaan diatas, diperlukan perhitungan P A A( ,1 2,...,A Cn| j). Setiap atribut
diasumsikan independen untuk setiap kelas C. Apabila terdapat atribut yang memiliki sifat kuantitatif atau kontinyu, maka
( i| j)
P A C dihitung dengan pendekatan distribusi normal. 2 dan kelas Cj, sehingga data baru dapat diklasifikasikan kedalam
kelas Ck jika peluang yang didapat merupakan yang terbesar
2.2 Binary Logistic Regression
Salah satu metode klasifikasi dasar adalah Logistic Regression. Logistic Regression dengan kasus menggunakan dua kelas respon bernama Binary Logistic Regression. Binary Logistic Regression merupakan suatu metode analisis data yang berguna untuk mencari sebuah hubungan variabel respon y yang bersifat biner dengan variabel prediktor x yang bersifat polikotomus (Hosmer dan Lemeshow, 2000). Variabel respon (y) dari regresi logistik biner terdiri dari 2 kategori yaitu “sukses” dan “gagal”, dimana notasi dariy1 untuk kategori “sukses” dan y0 untuk kategori “gagal”. Sehingga variabel respon y mengikuti distribusi Bernoulli untuk setiap observasi tunggalnya. Fungsi probabilitas untuk setiap observasinya adalah sebagai berikut:
1
dimana p adalah banyak variabel prediktor. Nilai f z( ) terletak antara 0 dan 1 untuk setiap nilai z yang diberkan, karena nilai z sendiri terletak antara dan . Model regresi logistik tersebut sebenarnya menggambarkan sebuah probabilitas dari suatu objek. Model regresi logistiknya adalah sebagai berikut.
0 1 1
Pendugaan parameter regresi dapat diuraikan dengan menggunakan transformasi logit dari persamaan
0 1 1
Pada regresi logistik, variabel respon dapat dituliskan sebagai y( )x dimana memiliki nilai 1 ( )x dengan peluang ( )x jika y = 1 atau ( )x dengan peluang 1( )x
jika y = 0. Kedua kemungkinan tersebut mengikuti distribusi binomial dengan rata-rata nol dan varians ( ( ))(1 x ( ))x .
1
Agar lebih mudah, fungsi likelihood tersebut dimaksimumkan dalam bentuk log l( ) dan dinyatakan dengan hasilnya adalah sama dengan nol.
0
0
Dengan statistik uji sebagai berikut.
ˆ
2.3 Logistic Regression Classification By Ensembles From
Random Partition (LR CERP)
LR CERP (Logistic Regression Classification By Ensembles
From Random Partition) adalah pasangan dari C-T CERP
(Classification Tree Classification By Ensembles From Random Partition) yang menggunakan regresi logistik sebagai basis pengkasifikasi. Algoritma ini mempartisi ruang prediktor secara random menjadi sub-sub ruang yang saling mutually exclusive dengan ukuran yang sama. Misalnya adalah sebuah ruang prediktor yang dipartisi menjadi K sub ruang ( , ,..., )
1 2
k yangsaling mutually exclusive dengan ukuran yang sama sehingga dapat diasumsikan tdak terdapat bias dalam pengambilan prediktor pada masing-masing sub ruang.
Berdasarkan base classifier regresi logistik diatas, performa CERP sangat tergantung oleh banyaknya variabel prediktor yang digunakan dalam satu partisi. Partisi yang optimal dapat diperoleh dari persamaan berikut ini.
6 p partisi yang optimal dapat didapatkan dengan membagi data sebanyak
i
menjadi pi , dimana
kurang dari n. K p i
yang menghasilkan akurasi tertinggi
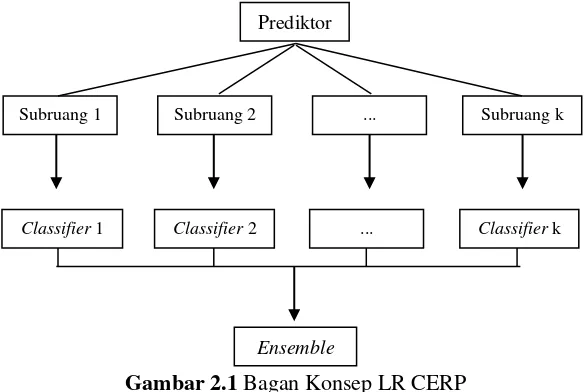
merupakan jumlah partisi yang optimal. Berikut ini adalah bagan yang menggambarkan konsep Logistic Regression Classification by Ensembles from Random Partition.
Gambar 2.1 Bagan Konsep LR CERP
Model klasifikasi akan dibentuk pada tiap-tiap subruang dengan model regresi logistik, dimana model regresi logistik memiliki kelemahan pada pemilihan variabel. LR CERP berguna meningkatkan akurasi dengan cara mengombinasikan hasil klasifikasi pada masing-masing sub ruang yang terbentuk. Hal tersebut disebabkan jumlah prediktor dalam satu subruang lebih daripada banyaknya pengamatan. Kombinasi beberapa model regresi logistik yang dilakukan LR CERP berguna untuk meningkatkan akurasi dengan mengambil rata-rata nilai prediksi yang dihasilkan dalam satu ensemble. Nilai prediksi yang dihasilkan dari semua base classifiers dirata-rata dan dikategorikan menjadi 0 atau 1 berdasarkan threshold (Lim, 2007).
Prediktor
Subruang 1 Subruang 2 ... Subruang k
Classifier 1 Classifier 2 ... Classifier k
2.3 LogisticRegression Ensemble
LORENS dikembangkan oleh Lim, Ahn, Moon dan Chen pada tahun 2010 dengan menggunakan regresi logistik sebagai base classifier dan berdasarkan algoritma LR CERP. Dalam rangka meningkatkan akurasi prediksi, LORENS mengombinasikan hasil model regresi logistik untu mendapatkan satu classifier yang kuat dibanding metode agregasi kompleks lainnya. LORENS menggunakan prosedur yang sama dengan LR CERP, namun disini LORENS mengulangi prosedur LR CERP beberapa kali sampa terbentuk beberapa ensemble. LORENS mempartisi ruang prediktor yang dipartisi menjadi K subruang
1 2
( , ,..., )
k yang sama. Subruang dipilih secara acakberdasarkan distribusi yang sama, diasumsikan tidak terdapat bias pada saat pengambilan prediktor pada masing-masing subruang. Model regresi yang terbentuk pada masing-masing ruang dilakukan tanpa melalui seleksi variabel. Dengan melakukan pengacakan ini, diharapkan probabilitas yang sama pada pada masing-masing classifier pada satu ensemble dan juga error klasifikasi yang hampir sama.
Peningkatan akurasi dalam satu ensemble yang dihasilkan LORENS didapatkan dengan mengombinasikan nilai prediksi dari model-model regresi logistik pada masing masing partisi yang didapat. Dengan mengulangi prosedur LR CERP, LORENS mendapatkan kombinasi rata-rata ataupun nilai terbanyak yang menghasilkan akurasi yang hampir sama. Rata-rata menghasilkan nilai sedikit lebih unggul daripada nilai terbanyak, sehingga LORENS lebih baik menggunakan nilai rata-rata. Dengan menggunakan prosedur LR CERP, LORENS menghasilkan beberapa ensemble dengan patisi acak yang berbeda-beda pula. Dari beberapa ensemble yang terbentuk, diambil nilai terbanyak diantaranya. Berdasarkan nilai tersebut didapatkan satu akurasi umum. Nilai akurasi tersebut telah ditingkatka dengan sumbangsih dari beberapa ensemble yang dibangun.
klasifikasi dengan respon biner adalah 0,5. Apabila proporsi kelas 0 dan 1 tidak seimbang, akurasi klasifikasi tidak akan baik.
Threshold yang optimal dibutuhkan untuk menyeimbangkan
sensitifity dan spesificity. Berikut merupakan rumus untuk menghitung threshold optimal dari LORENS.
0, 5
2
p
Threshold (2.17)
p adalah probabilitas pengamatan yang berada di kelas positif. Berikut merupakan tahapan dalam proses klasifikasi.
1. Membentuk model logit dari data training.
2. Memasuka data testing ke dalam model logit, sehingga diperoleh nilai probabilitas.
3. Mengklasifikasikan pengamatan data testing. Jika nilai probabilitasnya lebih besar daripada nilai threshold maka pengamatan masuk ke dalam kelas positif, sebaliknya jika nilai probabilitasnya lebih kecil daripada nilai threshold maka pengamatan masuk ke dalam kelas negatif.
4. Membandingkan kelas aktual dengan prediksi klasifikasi. 5. Mengelompokkan hasil perbandingan ke dalam kelompok
TP, TN, FP, dan FN.
TP (True Positive) adalah total ekspresi gen positif yang tepat terprediksi ke dalam kelas positif. TN (True Negative) adalah total ekspresi gen negatif yang tepat terprediksi ke dalam kelas negatif. FP (False Positive) adalah total ekspresi gen negatif yang terprediksi ke dalam kelas positif. FN (False Negative) adalah total ekspresi gen positif yang terprediksi ke dalam kelas negatif. Berikut merupakan tabel yang menunjukan prediksi klasifikasi dan kelas aktual.
Tabel 2.1 Tabel Tabulasi Silang Klasifikasi Aktual dan Klasifikasi Prediksi
Kelas Aktual
p (+) n (-)
Kelas Prediksi p (+) True Positive False Positive
Untuk menghitung ketepatan prediksi klasifikasi, dapat dihitung dengan cara membagi jumlah prediksi yang tepat dengan total jumlah prediksi. Rumus untuk menghitung ukuran ketepatan klasifikasi adalah sebagai berikut (Catal, 2010).
( )
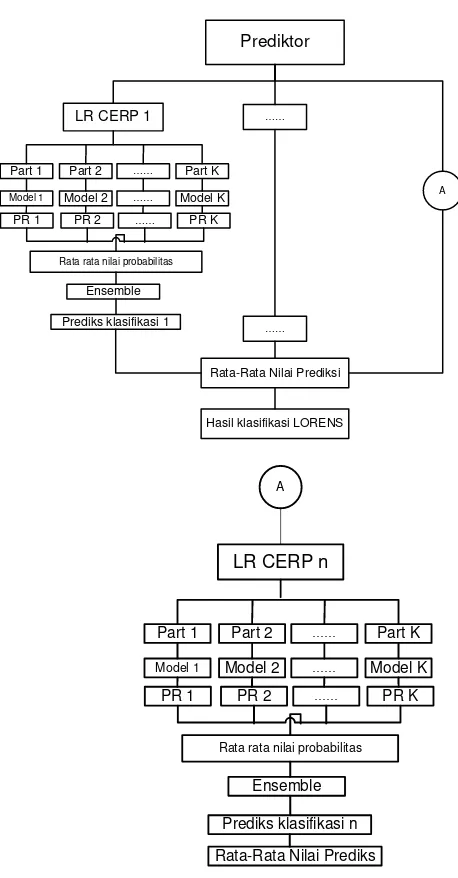
Prediktor
LR CERP 1
PR 1 PR 2 …… PR K Part 1 Part 2 …… Part K
Model 1 Model 2 …… Model K
Rata rata nilai probabilitas
Ensemble
Prediks klasifikasi 1
Rata-Rata Nilai Prediksi
Hasil klasifikasi LORENS
…… ……
A
A
PR 1 PR 2 …… PR K Part 1 Part 2 …… Part K
Model 1 Model 2 …… Model K
Rata rata nilai probabilitas
Ensemble
Prediks klasifikasi n
LR CERP n
Rata-Rata Nilai Prediks
LORENS mempunyai kelebihan bebas dari asumsi dimensi data, karena LORENS melakukan partisi secara acak terhadap prediktornya. Dalam hal komputasi, LORENS lebih unggul daripada LR CERP yang masih menggunakan tree algorithm (algoritma pohon). Keakuratan metode dapat menjadi lebih baik dengan dua keunggulan LORENS tersebut diatas (Lee dkk., 2013).
2.4 Cross Validation
Terdapat beberapa metode untuk mengevaluasi performa sebuah model dalam melakukan prediksi melalui data testing dan data training, diantaranya adalah Holdout dan Cross Validation (Witten, Frank, & Hall, 2001). Metode Holdout menggunakan dua-pertiga dari data untuk digunakan menjadi data training dan menggunakan sisanya sebagai data testing. Ada kemungkinan sampel yang diambil tidak representatif, karena ada peluang setiap kelas dalam data tidak terwakili. Untuk memeriksa apakah sampel yang diambil representatif atau tidak, yaitu dengan cara menyeimbangkan proporsi masing-masing kelas untuk data testing dan data training. Apabila ada satu kelas yang tidak terwakili dalam data training, classifier tidak dapat terbentuk dengan baik untuk melakukan klasifikasi dalam data testing. Pengambilan sampel secara random harusnya memperhatikan dan menjamin bahwa sampel yang diambil sudah cukup mewakili masing-masing kelas yang ada. Salah satu cara agar setiap kelas dapat terwakili dalam data trainig dan data testing adalah dengan melakukan stratifikasi. Berikut merupakan langkah sederhana untuk melakukan stratifikasi.
1. Memisahkan data berdasarkan kelasnya.
2. Mengambil sampel dari masing-masing kelas dengan proporsi yang tepat.
3. Menggabungkan sampel dari masing-masing kelas yang terpilih.
saat gilirannya. Jelasnya, metode cross validation menggunakan satu partisi data sebagai data testing dan k1 sisanya sebagai data training. Prosedur ini terus berulang sampai semua partisi data telah menjadi data testing. Metode atau prosedur ini dikenal dengan nama k fold cross validation. Namun apabila prosedur stratifikasi juga dilakukan, metode ini disebut stratified k fold cross validation. Misalnya digunakan 10 folds untuk metode cross validation. Pertama, data dibagi secara acak menjadi 10 bagian dengan proporsi sama. Selanjutnya metode cross validation ini dijalankan sebanyak 10 kali dengan data training yang berbeda. Dimana setiap set data memiliki jumlah yang sama dengan set data yang lainnya. Pengujian telah dilakukan dengan menggunakan data yang berbeda dan teknik belajar yang berbeda pula, kesimpulanya 10 folds merupakan folds terbaik untuk mendapatkan kesalahan yang terbaik. Metode 10 folds cross validation telah menjadi metode standar dalam machine learning dan data mining. Metode evaluasi ini juga menunjukan dengan penggunaan stratifikasi dapat meningkatkan akurasi prediksi. Berikut merupakan langkah dalam melakukan metode Cross Validation.
1. Memisahkan variabel respon berdasarkan kelasnya. 2. Membagi keseluruhan pengamatan menjadi 10 partisi
pada masing-masing kelas.
3. Menggabungkan kedua kelas pada bagian yang sama. 4. Mengunakan salah satu partisi sebagai data testing dan
menggunakan bagian kedua sampai ke sepuluh menjadi data training pada folds yang pertama. Terus berlanjut sampai folds ke sepuluh menjadi data testing.
Prosedur ini menggunakan sebanyak 100 kali algoritma pada dataset, dengan tujuan mendapatkan performa yang baik. Pembagian data menjadi 9
10 data training dan 1
2.5 AUC (Area Under Curve)
Salah satu ukuran dasar yang digunakan mengukur dan mengevaluasi performa klasifikasi adalah sensitivitas dan spesifitas. Satu model klasifikasi biner memiliki sepasang sensitivitas dan spesifitas. Apabila dalam suatu kasus klasifikasi digunakan beberapa model klasifikasi, akan timbul masalah dalam hal pemilihan model dan metode terbaik. Hal tersebut dikarenakan terdapat beberapa pasang sensitifitas dan spesifitas dari model klasifikasi yang digunakan. Masalah tersebut dapat diatasi dengan menggunakan kurva ROC (Receiving Operating
Characteristic). Kurva ROC merupakan representasi dari
hubungan antara sensitifitas dan spesifitas secara grafis (Erke & Pattynama, 1998).
Kurva ROC sering digunakan untuk mengevaluasi metode klasifikasi karena mempunyai kemampuan menyeluruh dan cukup baik (Chou dkk., 2010). Pada kurva ROC, sensitivitas (true positive rate) diplot dalam fungsi 1-spesifitas (false positive rate) untuk poin cut off yang berbeda-beda. Setiap titik pada kurva ROC merupakan pasangan dari sensitivitas dan spesifitas yang sesuai dengan batasan keputusan tertentu. Sebuah tes dengan diskriminasi sempurna memiliki plot yang melewati sudut kiri atas dari kurva ROC (sensitivitas 100% dan spesifitas 100%. Semakin dekat plot ROC ke sudut kiri atas, maka semakintinggi pula akurasi dari keseluruhan tes (Zweig & Campbell, 1993).
Metode yang umum digunakan untuk menghitung performasi klasifikasi adalah dengan menghitung luas daerah dibawah kurva ROC. Area dibawah kurva ROC biasa disebut
Area Under The ROC Curve (AUC). Nilai AUC berada diantara 0
dan 1. Apabila nilai AUC semakin mendekati 1, maka model klasifikasi yang terbentuk semakin akurat. Kurva ROC yang baik berada disebelah atas dari garis diagonal (0,0) dan (1,1), sehingga tidak ada nilai AUC yang lebih kecil dari 0,5.
interpolasi kinier antara masing-masing titik pada kurva ROC. Khusus untuk kasus biner, nilai AUC dapat didekati dengan nilai Balanced Accuracy (Bekkar, Djemaa, & Alitouch, 2013).
1
Tabel 2.2 Kategori Pengklasifikasian Model Berdasarkan Nilai AUC
Nilai AUC Model Diklasifikasikan Sebagai
0,91-1,00 Excelent (Sempurna) 0,81-0,90 Very Good (Sangat baik) 0,71-0,80 Good (Baik)
0,61-0,70 Fair (Cukup) 0,51-0,60 Poor (Lemah)
Sumber : Bekkar dkk. (2013)
2.6 DNA Microarray Alzheimer
Perubahan atau mutasi gen dalam DNA tertentu dapat menjadi indikator untuk terjadinya penyakit tertentu. Namun sangat sulit untuk mengembangkan tes untuk mendeteksi mutasi ini. Pada kasus kanker payudara herideter dan kanker ovarium misalnya, mutasi pada gen BRCA1 dan BRCA2 menyebabkan menyebabkan 60% dari jumlah kasus tersebut. Peneliti menyimpulkan bahwa tidak hanya satu mutasi saja yang meyebabkan kasus tersebut, namun ditemukan lebih dari 800 mutasi yang berbeda pada gen BRCA1 saja. Microarray DNA merupakan alat yang digunakan untuk menentukan apakah DNA dari suatu makhluk hidup tertentu mengandung mutasi gen seperti pada gen BRCA1 dan BRCA2. Microarray DNA berupa chip yang terdiri dari lempengan kaca kecil yang terbungkus plastik. Setiap chip berisi ratusan bahkan ribuan fragmen DNA (Anonim, 2015).
25
3.1 Sumber Data
Data yang digunakan dalam penelitian ini adalah data sekunder yag berasal dari penelitian yang dilakukan oleh Nishiwaki dkk (2015). Dalam penelitian tersebut telah dilakukan seleksi variabel menggunakan metode Random Forest. Dari hasil penelitian tersebut didapatkan 20 variabel dari 11.555 variabel dengan importance scores tertinggi. Sehingga dalam penelitian ini hanya menggunakan 20 variabel terbaik yang didapatkan dari penelitian sebelumnya. Terdapat dua jenis ekspresi gen dalam data penelitian ini, yaitu gen normal dan gen abnormal (Alzheimer).
3.2 Variabel Penelitian
Variabel yang digunakan dalam penelitian ini terdiri dari 1 variabel respon biner (Y) yaitu Gen Normal dan Gen AD (Alzheimer Disease) dan 20 variabel prediktor. Berikut merupakan struktur data yang akan digunakan dalam penelitian ini.
Tabel 3.1 Struktur Data Penelitian
No
Ekspresi Gen Gene Symbol
Normal/AD WWOX TAGLN3 MT1H
1 Normal
X
1,1X
2,1X
20,12 AD X1,2 X2,2 X20,2
3 Normal
X
1,3X
2,3X
20,3178 AD
X
1,178 X2,178X
20,178penyakit Alzheimer. Tabel dibawah ini merupakan kode-kode protein gen beserta nama ilmiahnya.
Tabel 3.2 Variabel Penelitian
Variabel Gene title Symbol
X1 WW domain containing oxidoreductase WWOX
X2 transgelin 3 TAGLN3
X3 collagen, type V, alpha 2 COL5A2
X4 metallothionein 1F MT1F
X5 Ets2 repressor factor ERF
X6 apelin receptor APLNR
X7 WNT inhibitory factor 1 WIF1
X8 glial fibrillary acidic protein GFAP
X9 inositol-trisphosphate 3-kinase B ITPKB
X10 collectin sub-family member 12 COLEC12
X11 lactate dehydrogenase A LDHA
X12 solute carrier family 16, member 5 SLC16A5
X13 neuritin 1 NRN1
X14 synaptotagmin V SYT5
X15 versican VCAN
X16 neuronal pentraxin II NPTX2
X17 hippocalcin HPCA
X18 RAB6A, member RAS oncogene family RAB6A
X19 WW domain containing transcription WWTR1
X20 metallothionein 1H MT1H
3.3 Langkah Analisis
1. Membuat analisa deskriptif terhadap data.
2. Melakukan analisis klasifikasi menggunakan metode Naïve Bayes Classifier dengan prosedur evaluasi full training set. 3. Melakukan analisis klasifikasi menggunakan metode Naïve
Bayes Classifier dengan prosedur evaluasi Cross Validation. a. Melakukan stratifikasi pada data.
b. Membagi data menjadi 10 bagian yang sama.
c. Mengambil sampel satu bagian data sebagai data testing dan menggunakan 9 bagian data lainnya sebagai data training.
d. Menghitung rata-rata dan standar deviasi dari setiap prediktor pada masing-masing kelas pada data training. e. Menghitung peluang tiap masing-masing variabel
prediktor pada masing-masing kategori.
f. Menghitung posterior probability pada data testing. g. Menentukan kelas prediksi pada data testing.
4. Melakukan analisis klasifikasi menggunakan metode Binary Logistic Regression dengan prosedur evaluasi full training set.
5. Melakukan analisis klasifikasi menggunakan metode Binary
Logistic Regression dengan prosedur evaluasi Cross
Validation..
6. Melakukan analisis klasifikasi menggunakan metode LORENSdengan prosedur evaluasi full training set.
7. Melakukan analisis klasifikasi menggunakan metode Logistic Regression dengan prosedur evaluasi Stratified 10-folds Cross Validation.
a. Melakukan stratifikasi pada data.
b. Membagi data menjadi 10 bagian yang sama.
c. Mengambil sampel satu bagian data sebagai data testing dan menggunakan 9 bagian data lainnya sebagai data training.
e. Mempartisi variabel prediktor menjadi (
k
) subruang partisi dari data training.f. Menyusun model LR masing-masing subruang partisi dari data training.
g. Mendapatkan nilai akurasi prediksi dari masing-masing model untuk semua pengamatan dari data testing.
h. Menghitung nilai rata-rata dari semua nilai prediksi untuk masing-masing pengamatan.
i. Mengulangi langkah a hingga e sampaiterbentuk n ensemble.
j. Mencari nilai prediksi terbanyak masing-masing pengamatan diantara semua ensemble.
k. Menghitung nilai threshold optimal.
l. Membandingkan hasil dari langkah g dengan nilai threshold 0,5 dan threshold optimal.
m.Mengulangi semua langkah hingga semua data telah diperlakukan sebagai data training dan data testing. 8. Menghitung nilai accuracy, sensitivity, specificity dan AUC
dari semua model yang terbentuk.
9. Memilih metode terbaik dari hasil analisis pada langkah 2, 3, 4, 5 dan 6 berdasarkan ketepatan klasifikasi terbaik.
10. Membuat kesimpulan dari hasil analisis yang telah dilakukan.
Gambar 3.1 Diagram Alir Penelitian Mulai
Data Microarray DNA
Analisis Karakteristik Data
Analisis NBC Analisis Binary Logistic Regression
Analisis LORENS
Evaluasi full training set
dan CV
Evaluasi full training set dan
CV Evaluasi hold out
(70% training dan 30% testing)
Perhitungan ukuran kebaikan model
Pemilihan metode terbaik
31
4.1 Analisis Karakteristik Data
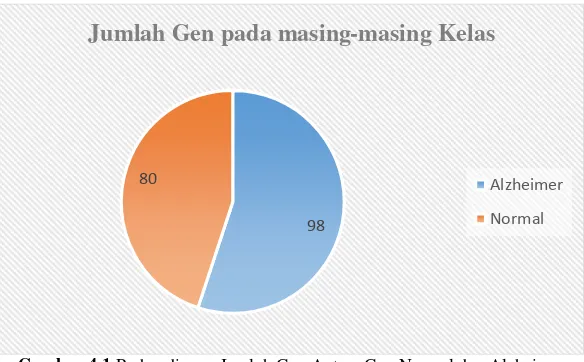
Penelitian mengenai klasifikasi gen ini ditujukan untuk mengetahui deteksi dini penyakit Alzheimer dengan memanfaatkan data yang diperoleh dari microarray DNA. Penelitian ini menggunakan variabel respon yang bersifat biner, yaitu gen yang bersifat normal dan gen yang terindikasi penyakit Alzheimer. Sedangkan variabel prediktor yang digunakan adalah 20 gen yang diduga sebagai identifier penyakit Alzheimer. Sebanyak 178 sampel ekspresi gen dari hasil scanning microarray DNA digunakan untuk memprediksi klasifikasi gen normal dan Alzheimer. Gambar 4.1 berikut menunjukan proporsi kelas respon yang digunakan dalam penelitian ini.
Gambar 4.1Perbandingan Jumlah Gen Antara Gen Normal dan Alzheimer
Gambar 4.1 menunjukan bahwa sebanyak 98 gen Alzheimer atau sebanyak 55% gen Alzheimer digunakan sebagai sampel dalam penelitian ini, sedangkan gen normal yang digunakan dalam penelitian ini adalah 80 atau 45% dari total sampel gen yang digunakan. Hal tersebut menunjukan bahwa kelas respon
98 80
Jumlah Gen pada masing-masing Kelas
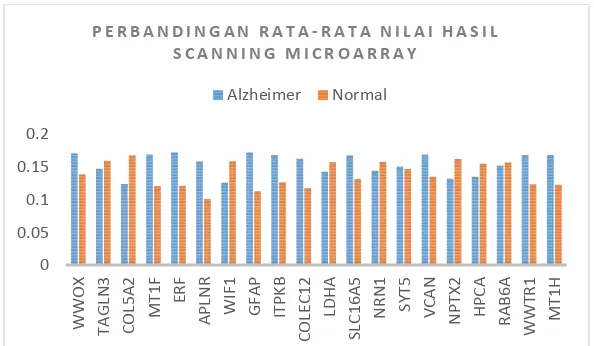
yang digunakan dalam penelitian ini tidak balance, sehingga diperlukan perhitungan threshold optimal dalam proses klasifikasi yang akan dilakukan. Klasifikasi dilakukan dengan menggunakan 20 variabel prediktor yang telah diseleksi dari 11.555 variabel. Variabel prediktor yang digunakan merupakan komponen penyusun DNA. Nilai variabel prediktor yang digunakan dalam penelitian ini adalah nilai hasil scanning microarray. Gambar dibawah ini merupakan grafik perbandingan nilai rata-rata nilai hasil scanning microarray ke-20 variabel prediktor antara gen normal dan gen yang terkait dengan sindrom Alzheimer.
Gambar 4.2Perbandingan Rata-Rata Nilai Scanning Microarray Gen Normal dan Alzheimer
4.2 Pengujian Proporsi Variabel Respon
Pengujian proporsi antar kelas dalam variabel respon diperlukan untuk mengetahui apakah proporsi antara gen Alzheimer dan gen normal seimbang atau tidak. Pengujian proporsi ini mengunakan uji Z statistik, dengan hipotesis sebagai berikut.
H0 : Proporsi Kelas Alzheimer sama dengan 0,5
H1 : Proporsi Kelas Alzheimer tidak sama dengan 0,5
Pengambilan keputusan dilakukan dengan mengunakan p-value. Berikut ini merupakan tabel perbandingan p-value dengan alpha 0,05.
Tabel 4.1. Perbandingan P-value dan alpha
Z P-value Alpha
1,349 0,202 0,05
Karena p-value lebih besar daripada alpha 0,05, maka keputusannya adalah gagal menolak H0. Artinya proporsi antara
kelas gen Alzhiemer dan Normal dikatakan sama secara statistik. Hal tersebut mengakibatkan nilai accuracy dan AUC yang digunakan akan memiliki nilai yang hampir sama. Namun proporsi antara kelas Alzheimer dan normal belum tentu sama pada tiap fold Cross Validation, sehingga AUC tetap digunakan dalam penelitian ini.
4.3 Analisis Naive Bayes Classifier Full Training Set
terbesar. Apabila nilai peluang kelas respon 1 lebih besar daripada kelas respon 0, maka data tersebut masuk kedalam kelas 1, begitu juga sebaliknya. Dengan menggunakan 20 prediktor, gambar struktur Naïve Bayes memprediksi gen dapat diilustrasikan kedalam gambar berikut.
Gambar 4.3 Struktur Naïve Bayes Klasifikasi Gen
Selanjutnya adalah melakukan perhitungan nilai probabilitas pada masing-masing pasangan data. nilai probabilitas yang terbesar memiliki kecendrungan lebih besar terhadap prediksi klasifikasi variabel respon. Naïve Bayes mengharuskan variabel prediktornya diskrit, apabila ada beberapa atau semua variabel prediktor yang bersifat kontinyu maka (P A Ci| j) harus dihitung dengan pendekatan distribusi normal. Sebelum menghitung nilai
( i| j)
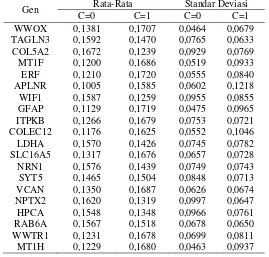
dibawah ini merupakan perhitungan rata-rata dan standar deviasi pada semua variabel prediktor dan kelas respon.
Tabel 4.2 Rata-Rata dan Standar Deviasi Setiap Prediktor dan Kelas
Gen Rata-Rata Standar Deviasi
C=0 C=1 C=0 C=1
WWOX 0,1381 0,1707 0,0464 0,0679
TAGLN3 0,1592 0,1470 0,0765 0,0633
COL5A2 0,1672 0,1239 0,0929 0,0769
MT1F 0,1200 0,1686 0,0519 0,0933
ERF 0,1210 0,1720 0,0555 0,0840
APLNR 0,1005 0,1585 0,0602 0,1218
WIF1 0,1587 0,1259 0,0955 0,0855
GFAP 0,1129 0,1719 0,0475 0,0965
ITPKB 0,1266 0,1679 0,0753 0,0721
COLEC12 0,1176 0,1625 0,0552 0,1046
LDHA 0,1570 0,1426 0,0745 0,0782
SLC16A5 0,1317 0,1676 0,0657 0,0728
NRN1 0,1576 0,1439 0,0749 0,0743
SYT5 0,1465 0,1504 0,0848 0,0713
VCAN 0,1350 0,1687 0,0626 0,0674
NPTX2 0,1620 0,1319 0,0997 0,0647
HPCA 0,1548 0,1348 0,0966 0,0761
RAB6A 0,1567 0,1518 0,0678 0,0650
WWTR1 0,1231 0,1678 0,0699 0,0811
MT1H 0,1229 0,1680 0,0463 0,0937
Tabel 4.3 Peluang Tiap Kategori Pada Data Testing Pertama
Variabel Prediktor P X( 1| C0) P X( 1| C 1)
WWOX 0,3698 0,1638
TAGLN3 0,9975 0,9281
COL5A2 0,0878 0,0050
MT1F 0,4011 0,1759
ERF 0,0004 5,6.10-5
APLNR 2,5.10-8 3,1.10-6
WIF1 0,4107 0,1456
GFAP 0,0001 0,0018
ITPKB 0,0010 8,3.10-8
COLEC12 0,9226 0,8656
LDHA 0,4089 0,3177
SLC16A5 0,0004 3,6.10-6
NRN1 0,1841 0,1159
SYT5 0,0089 0,0016
VCAN 0,0657 0,0038
NPTX2 0,9428 0,4809
HPCA 0,5952 0,2605
RAB6A 0,1847 0,1323
WWTR1 0,0202 0,0005
MT1H 0,6539 0,3689
Tabel 4.3 diatas menunjukan nilai peluang untuk masing-masing variabel prediktor pada data testing pertama. Untuk peluang parsial pada masing-masing prediktor pada tabel diatas dapat diketahui bahwa nilai peluang variabel prediktor X1 yaitu
1 2 20 0 1,1 0 1, 2 0 1, 20 0
Berdasarkan ilustrasi perhitungan posterior probability pada data testing pertama, didapatkan hasil bahwa data testing pertama diklasifikasikan kedalam kelas 0, yaitu gen normal. Hal tersebut dilakukan karena nilai peluang dari kelas gen normal lebih tinggi daripada kelas gen Alzheimer. Perhitungan yang sama dilakukan sampai dengan data testing terakhir.
Tabel 4.4 Perhitungan Posterior Probability pada Data Testing
No Kelas 0
(Gen Normal)
Kelas 1
(Gen Alzheimer) Kelas Prediksi
Berdasarkan Tabel 4.4, didapatkan nilai posterior probability untuk keseluruhan data testing. Dari nilai tersebut selanjutnya dapat dilakukan prediksi klasifikasi. Kelas prediksi didapatkan dari nilai peluang terbesar pada masing-masing kelas. Apabila kelas 0 ata gen normal memiliki nilai peluang yang lebi tinggi maka data testing tersebut masuk kedalam kelas 0 atau gen normal, begitu juga sebaliknya. Setelah semua data testing berhasil diprediksi, selanjutnya dilakukan pengelompokan True Positive, True Negative, False Positif dan False Negative. Hasil pengelompokan tersebut dapat dilihat pada tabel dibawah ini.
Tabel 4.5 Tabulasi Silang pada Analisis Naïve Bayes Classifier
Kelas Aktual
+ -
Kelas Prediksi + 59 39
- 12 68
Bedasarkan Tabel 4.15, dapat diketahui bahwa analisis menggunakan Naïve Bayes Classifier dan menggunakan 20 variabel memberikan hasil 59 ekspresi gen Alzheimer yang tepat diprediksi sebagai gen Alzheimer dan 68 ekspresi gen normal yang diprediksi sebagai gen normal. Sedangkan terdapat 39 ekspresi gen Alzheimer yang diprediksi sebagai gen normal dan 12 ekpresi gen normal yang diprediksi sebagai gen Alzheimer. Ukuran accuracy dari hasil prediksi diatas adalah 0,71348 dengan sensitivity sebesar 0,83098 dan specificity 0,6355. Analisis menggunakan Naïve Bayes Classifier telah mampu memprediksi ekpresi gen dengan ketepatan sebesar 71,35%. Metode ini cukup baik mengkasifikasikan gen Alzheimer tepat kedalam kelasnya sebesar 83,1%, sedangkan untuk memprediksi gen normal tepat terklasifikasi kedalam gen normal sebesar 63,55%.
4.4 Analisis Naive Bayes Classifier Cross Validation
testing. Analisis ini dilakukan dengan membagi data menjadi 10-folds yang seimbang. Salah satu fold akan dijadikan data testing dan Sembilan sisanya akan menjadi data training. Hal tersebut berulang sampai semua fold pernah menjadi data testing. Berikut ini merupakan tabulasi silang dari analisis Naïve Bayes Classifier.
Tabel 4.6 Tabulasi Silang Kelas Aktual dan Prediksi Naïve Bayes
Classifier Cross Validation
Kelas Aktual
+ -
Kelas Prediksi + 40 65 - 15 58
Berdasarkan Tabel 4.6, dapat diketahui bahwa terdapat 40 gen Alzheimer yang terprediksi tepat kedalam kelas Alzheimer. 58 gen normal yang tepat terprediksi kedala gen normal, sedangkan kesalahan dari prediksi sangat besar. Kesalahan dalam memprediksi gen Alzheimer namun masuk kedalam kelas normal terdapat 65 gen dan kesalahan dalam memprediksi gen normal namun masuk kedalam kelas Alzheimer terdapat 15 gen. berikut ini merupakan perhitungan ketepatan klasifikasi.
Tabel 4.7. Ukuran Kebaikan Klasifikasi Naïve Bayes Classifier
Crosss Validation
Accuracy Sensitivity Specifity AUC
0.55056 0.72727 0.47154 0.59941
Ukuran accuracy dari analisis diatas termasuk rendah bila dibandingkan dengan akurasi dari metode lainnya, hanya sekitar 55,06% dengan sensitivity sebesar 72,73% dan specifity sebesar 47,15%. Analisis ini memiliki nilai AUC sebesar 0,5994, yang mengindikasikan bahwa analisis ini lemah dalam menangani kasus klasifikasi gen.
4.5 Analisis Binary Logistic Regression Full Training Set
Evaluasi dalam analisis ini mmenggunakan prosedur Full Training Set. Dimana keseluruhan data akan digunakan sebagai data training, dan keseluruhan data pula yang digunakan sebagai data testing untuk menguji seberapa baik model yang terbentuk.
Koefisien parameter model regresi diestimasi menggunakan
Maximum Likelihood Estimation dari data training yang
digunakan untuk membangun model. Berikut ini adalah hasil estimasi parameter model Binary Logistic pada data training.
Tabel 4.8 Koefisien Parameter Awal Model Binary Logistic Regression
Full Training Set
Parameter Koefisien Wald P-Value
variabel yang tidak signifikan sampai didapatkan koefisien model regresi logistik yang seluruhnya signifikan. Berikut ini merupakan tabel koefisien regresi logistik biner yang telah melalui eliminasi backward.
Tabel 4.9 Koefisien Parameter Terbaik Model Binary Logistic
Regression
Parameter Koefisien Wald P-Value
Intercept -4,26 16,1 0,000 variabel prediktor yang dieliminasi dari total 20 variabel prediktor. Seluruh koefisien parameter mempunyai p-value diatas batas kesalahan yang ditetapkan untuk mengeliminasi, yaitu 5%. Setelah koefisien parameter didapatkan, selanjutnya dapat dilanjutkan dengan menuliskan model yang terbentuk. Model regresi logistik biner yang terbentuk adalah sebagai berikut.
4 5 6 19
Tabel 4.10 Tabulasi Silang pada Binary Logistic Regression
Kelas Aktual
+ -
Kelas Prediksi + 68 6
- 30 74
Berdasarkan Tabel 4.10, dapat diketahui bahwa dari 54 data testing yang digunakan, 26 gen Alzheimer tepat terprediksi kedalam kelas Alzheimer, 7 gen normal tepat terprediksi kedalam kelas gen normal dan sisanya tidak terklasifikasi dengan tepat. Dari tabulasi diatas, selanjutnya dapat dhitung nilai keteatan klasifikasi. Berikut ini merupakan perhitungan ketepatan klasifikasi.
Tabel 4.11 Ukuran Kebaikan Model Binary Logistic Regression
Model Accuracy Sensitivity Specificity AUC
Regresi Logistik 0,798 0,694 0,925 0,809
Model Binary Logistic Regression mampu memperoleh akurasi sebesar 79,8%. Dengan nilai sensitivity dan specificity sebesar 69,4% dan 92,5%. AUC yang dihasilkan oleh analisis ini adalah 80,9%. Model yang terbentuk dapat mengklasifikasikan variabel respon dengan baik.
4.6 Analisis Binary Logistic Regression Cross Validation
Salah satu prosedur evaluasi dalam klasifikasi adalah Cross
Validation. Prosedur ini dapat mengevaluasi model yang
terbentuk dengan baik, karena semua data diperlakukan sebagai data training dan data testing. Pada penelitian ini, Cross Validation dilakukan dengan menggunakan 10 folds. Pada masing-masing fold akan terbentuk satu model regresi logistik biner, sehingga dalam analisis ini akan terbentuk 10 model regresi logistik biner yang berbeda.
signifikansi parameter sampai dengan didapatkan model terbaik dari masing-masing fold. Berikut ini adalah estimasi koefisien parameter model Binary Logistic pada fold pertama.
Tabel 4.12 Koefisien Parameter Awal Model fold ke-1 CV Binary
Logistic Regression
Parameter Koefisien Wald P-Value
parameter dari model regresi logistik yang telah seluruhnya signifikan.
Tabel 4.13 Koefisien Parameter Terbaik Model Fold ke-1 CV Binary
Logistic Regression
Parameter Koefisien Wald P-Value
Intercept -5,06 15,01 0,000
X3 -12,42 9,90 0,002
X8 25,84 9,47 0,002
X10 16,64 5,80 0,016
X12 -9,33 6,17 0,013
X15 -15,67 4,05 0,044
X16 -19,77 7,04 0,008
X18 20,02 6,73 0,009
X20 18,45 6,02 0,013
Tabel 4.14 Model Binary Logistic Regression Pada Seluruh Fold
Fold Model Binary Logistic Regression
1 3 8 10 12 15 16 18 20
3 8 10 12 15 16 18 20
5,06 12,42 25,84 16,64 9,33 15,67 19,77 20,02 18,45 5,06 12,42 25,84 16,64 9,33 15,67 19,77 20,02 18,45
1
4,39 9,32 13,92 9,49 10,88 21,06 16,44 17,42 12,3 4,39 9,32 13,92 9,49 10,88 21,06 16,44 17,42 12,3
1
1,81 16,19 12,68 16,92 11,97 14,94 28,89 20,7 1,81 16,19 12,68 16,92 11,97 14,94 28,89 20,7
1
3,33 24,66 26,28 23,72 38,44 3,33 24,66 26,28 23,72 38,44
1
Dari model yang terbentuk pada masing-masing fold, selanjunya dapat dihitung True Positive, True Negative, False Positive dan False Negative dari seluruh fold. Dari perhitungan tersebut, dapat dilanjutkan dengan menghitung ukuran ketepatan klasifikasi model Binary Logistic Regression dengan prosedur evaluasi Cross Validation. Tabel dibawah ini merupakan tabel yang menunjukan ukuran ketepatan klasifikasi pada analisis Binary Logistic Regression dengan prosedur evaluasi Cross Validation.
Tabel 4.15 Tabulasi Silang pada Binary Logistic Regression
klasifikasi pada analisis ini cukup besar. Perhitungan ukuran kebaikan model diperlukan untuk mengevaluasi model yang terbentuk. Berikut ini merupakan tabel yang menunjukan ukuran kebaikan model Binary Logistic Regression dengan evaluasi Cross Validation.
Tabel 4.16 Ukuran Kebaikan Model Binary Logistic Regression CV
Model Acc Sens Spec AUC
10 Fold CV Binary Logistic 0,652 0,562 0,781 0,671
Analisis Binary Logistic Regression dengan prosedur evaluasi Cross Validation mampu menghasilkan accuracy sebesar 65,2% dengan sensitifity 56,2% dan specificity sebesar 78,1%. Nilai AUC yang dihasilkan pada analisis ini sebesar 0,671, artinya model yang terbentuk belum cukup baik untuk menangani kasus klasifikasi gen yang terkait sindrom Alzheimer.
4.7 Analisis LORENS Full Training Set
Analisis Logistic Regression Ensembles (LORENS) merupakan pendekatan komputasional untuk menyelesaikan masalah klasifikasi. LORENS tidak memiliki asumsi apapun untuk dipenuhi. Demi mendapatkan hasil klasifikasi terbaik, analisis LORENS dilakukan beberapa kali dengan jumlah partisi yang berbeda pula. Dalam kasus ini, partisi yang dibentuk adalah sebanyak 2, 3, 4 dan 5 partisi. Kelebihan LORENS yang lain adalah dapat menemukan nilai threshold optimal, namun pada penelitian ini analisis LORENS dengan threshold 0,5 tetap akan digunakan sebagai perbandingan. Nilai ensemble yang akan digunakan dalam penelitian ini adalah sebesar 10, karena dari hasil penelitian sebelumnya dapat menghasilkan akurasi klasifikasi yang baik. Dengan ukuran ensemble 10, model yang didapatkan untuk 2 partisi adalah 20 model, 3 partisi adalah 30 model, 4 partisi adalah 40 model dan untuk 5 partisi adalah 50 model.
terus sampai dengan jumlah ensemble yang ditentukan. Dalam penelitian ini, 20 variabel prediktor yang digunakan akan dialokasikan ke dalam ruang-ruang partisi yang terbentuk. Berikut ini adalah analisis LORENS untuk masing-masing ruang partisi. Pada analisis LORENS full training set, didapatkan hasil paling baik menggunakan 5 partisi dengan threshold 0,5.
Analisis LORENS menggunakan 4 partisi dengan threshold 0,5 dan proses tersebut berulang sebanyak ensemble yang ditentukan, yaitu 10 kali membentuk 40 model regresi logistik. Tahap pertama dalam analisis LORENS adalah membagi variabel kedalam beberapa ruang partisi, partisi yang menghasilkan hasil terbaik pada penelitian ini adalah sebesar 4 partisi. Berikut adalah tabel pengalokasian variabel prediktor kedalam ruang partisi.
Tabel 4.17 Random Sampling Variabel Prediktor pada 4 Ruang Partisi
Tabel 4.17 menunjukan pengalokasian variabel prediktor
ruang partisi keempat. Cara pengalokasian variabel prediktor yang sama juga dilakukan untuk ensemble ke-2 hingga ke-10. Tiap ensemble akan terbentuk 4 model regresi logistik yang berbeda dengan variabel prediktor yang berbeda pula.
Tabel 4.18 Koefisien Model Regresi Logistik 4 Partisi Threshold 0,5
Intercept ens1 ens2 ens3 ens4 ens5 ens6 ens7 ens8 ens9 ens10
Partisi ke-1 dilambangkan warna Partisi ke-2 dilambangkan warna Partisi ke-3 dilambangkan warna Partisi ke-4 dilambangkan warna
masing-masing ensemble. Pada masing-masing ensemble terbentuk 4 model dengan koefisien yang ada pada tabel 4.2 diatas. Koefisien variabel prediktor tiap model regresi logistik sesuai dengan pengalokasian variabel prediktor pada tabel 4.1. Berikut ini merupakan ilustrasi beberapa model regresi logistik yang terbentuk pada ensemble pertama.