Lingkungan Pengembangan Sistem
Sistem dikembangkan menggunakan kompiler Matlab R2008b dan sistem operasi Windows 7. Spesifikasi hardware komputer yang digunakan adalah Processor Intel (R) Atom (TM) CPU N280 @1,66 Ghz, Memory 1 GB, dan Harddisk 80 GB.
HASIL DAN PEMBAHASAN Percobaan pertama yang dilakukan pada penelitian ini adalah mencari parameter JST propagasi balik yang optimal untuk digunakan pada proses pengenalan karakter berdasarkan huruf a dan t kecil.
Menentukan Parameter JST yang Optimal Pada penelitian ini dilakukan percobaan untuk mengetahui dampak pengubahan parameter-parameter JST terhadap generalisasi atau tingkat akurasi. Percobaan ini bertujuan untuk menemukan kombinasi yang optimal antara hidden neuron, epoch, toleransi galat, dan learning rate.
Pengaruh Jumlah Hidden Neuron terhadap Generalisasi
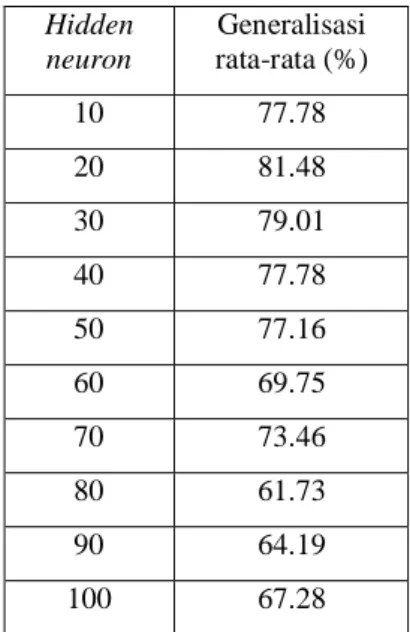
Pada percobaan ini jumlah hidden neuron diubah-ubah untuk mendapatkan jumlah hidden neuron yang optimal sehingga menghasilkan generalisasi yang baik. Grafik hubungan antara jumlah hidden neuron dengan generalisasi rata-rata dapat dilihat pada Gambar 4.
Gambar 4 Pengaruh hidden neuron terhadap generalisasi
Jumlah hidden neuron yang digunakan pada percobaan ini, sebesar 10, 20, 30, 40, 50, 60, 70, 80, 90, dan 100 neuron. Pada percobaan pengaruh hidden neuron digunakan galat sebesar 10-4, epoch 1000, learning rate
0.01 dan masing-masing diulang sebanyak tiga kali.
Generalisasi rata-rata maksimum hasil percobaan pengaruh hidden neuron adalah 81.48%. Generalisasi tersebut dicapai pada saat jumlah hidden neuron sebanyak 20.
Generalisasi rata-rata untuk setiap jumlah hidden neuron dapat dilihat pada Tabel 6.
Data selengkapnya pada percobaan ini dapat dilihat pada Lampiran 4.
Tabel 6 Jumlah hidden neuron dengan generalisasi rata-ratanya
Hidden neuron
Generalisasi rata-rata (%)
10 77.78
20 81.48
30 79.01
40 77.78
50 77.16
60 69.75
70 73.46
80 61.73
90 64.19
100 67.28
Pada Tabel 6, generalisasi rata-rata semakin meningkat mulai dari jumlah hidden neuron 10 sampai 20 hidden neuron. Pada saat hidden neuron berjumlah 30, generalisasi mulai menurun dan tidak stabil. Jumlah hidden neuron yang besar membuat jaringan lebih fleksibel dan dapat menghasilkan generalisasi yang lebih baik tetapi jika jumlah hidden neuron terlalu besar generalisasi cenderung akan menurun dan tidak stabil, selain itu waktu yang dibutuhkan untuk pelatihan jaringan lebih lama. Oleh karena itu, untuk percobaan pengaruh epoch terhadap generalisasi digunakan jumlah hidden neuron sebesar 10 dan 20, karena pada saat hidden neuron 10 dan 20 generalisasi mengalami peningkatan dan waktu yang dibutuhkan untuk pelatihan jaringan lebih cepat.
Pengaruh Jumlah Epoch Terhadap Generalisasi
Pada percobaan ini jumlah epoch diubah untuk mendapatkan besarnya epoch yang optimal sehingga menghasilkan generalisasi yang baik. Jumlah epoch yang digunakan pada percobaan ini sebesar 1000, 1500, 2000, 2500, 0
20 40 60 80 100
10 20 30 40 50 60 70 80 90 100
Generalisasi rata-rata
Hidden Neuron
dan 3000, 3500, dan 4000 epoch. Pada percobaan ini digunakan jumlah hidden neuron sebanyak 10 dan 20 neuron. Jumlah hidden neuron ini dipakai karena pada percobaan sebelumnya memberikan hasil generalisasi yang cukup baik. Selain itu, pada percobaan ini digunakan galat sebesar 10-4, learning rate sebesar 0.01 dan masing-masing percobaan diulang sebanyak tiga kali. Grafik hubungan antara jumlah epoch dengan generalisasi rata-rata menggunakan 10 dan 20 hidden neuron dapat dilihat pada Gambar 5.
Gambar 5 Generalisasi rata-rata terhadap jumlah epoch menggunakan 10 dan 20 hidden
neuron
Generalisasi rata-rata maksimum hasil percobaan pengaruh epoch dengan 10 hidden neuron adalah 87.04% dicapai pada saat jumlah epoch sebesar 3000, sedangkan generalisasi rata-rata maksimum dengan 20 hidden neuron dicapai pada epoch 3500 yaitu sebesar 87.65%. Generalisasi rata-rata menggunakan 10 dan 20 hidden neuron dapat dilihat pada Tabel 7. Data selengkapnya pada percobaan ini dapat dilihat pada Lampiran 5 dan Lampiran 6.
Tabel 7 Generalisasi rata-rata menggunakan 10 dan 20 hidden neuron
Epoch Generalisasi Rata-rata (%) 10 hidden
neuron
20 hidden neuron
1000 77.78 81.48
1500 84.57 85.80
2000 84.57 86.42
2500 86.42 84.57
3000 87.04 85.19
3500 82.10 87.65
4000 81.48 85.81
Pada percobaan dengan 20 hidden neuron, walaupun generalisasi lebih besar dibandingkan generalisasi pada 10 hidden neuron, tetapi epoch yang diperlukan untuk mencapai generalisasi maksimum tersebut lebih besar dibandingkan dengan 10 hidden neuron. Epoch yang lebih besar akan mengakibatkan waktu pelatihan menjadi lebih lama. Oleh karena itu, karena selisih generalisasi maksimum antara 10 dan 20 hidden neuron tidak berbeda jauh yaitu 0.61
% maka untuk percobaan pengaruh galat akan digunakan 10 hidden neuron dengan epoch maksimum 3000 epoch.
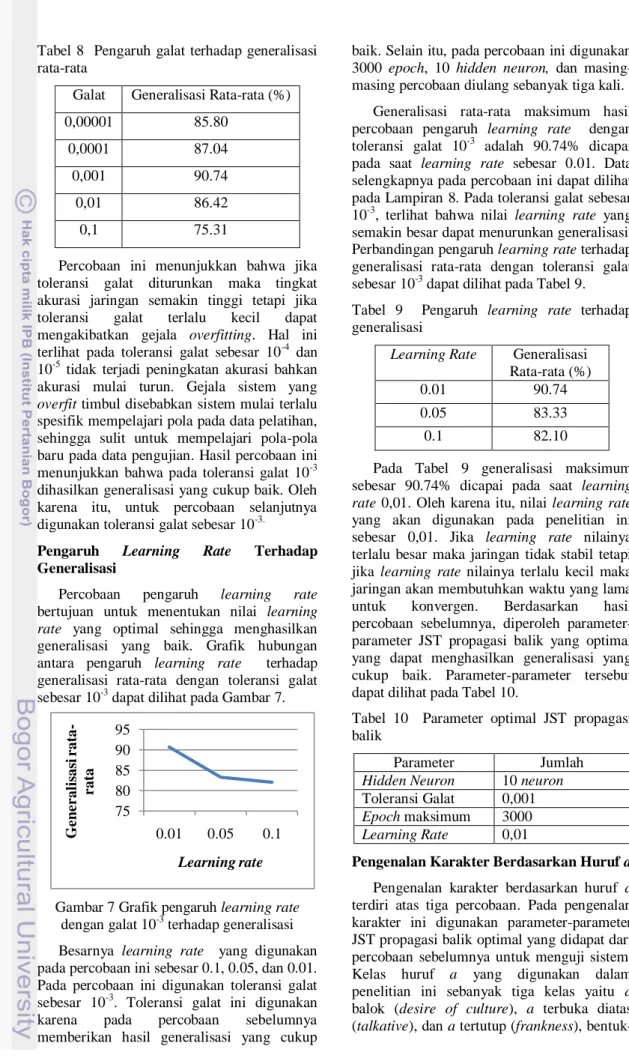
Pengaruh Galat Terhadap Generalisasi Percobaan ini bertujuan untuk menentukan toleransi galat yang optimal sehingga menghasilkan generalisasi yang baik.
Besarnya toleransi galat yang digunakan pada percobaan ini sebesar 10-1, 10-2, 10-3, 10-4, dan 10-5. Pada percobaan ini digunakan jumlah hidden neuron sebanyak 10, epoch maksimum sebesar 3000 epoch, learning rate sebesar 0.01 dan masing-masing percobaan diulang sebanyak tiga kali. Grafik hubungan antara pengaruh galat terhadap generalisasi rata-rata dilihat pada Gambar 6.
Gambar 6 Pengaruh galat terhadap generalisasi rata-rata
Generalisasi rata-rata maksimum hasil percobaan pengaruh galat adalah 90.74%
dicapai pada saat galat sebesar 10-3. Generalisasi rata-rata untuk setiap besarnya galat dapat dilihat pada Tabel 8. Data selengkapnya pada percobaan ini dapat dilihat pada Lampiran 7.
70 75 80 85 90
Generalisasi rata-rata
Epoch
10 neuron 20 neuron
0 10 20 30 40 50 60 70 80 90 100
Generalisasi rata-rata
Galat
Tabel 8 Pengaruh galat terhadap generalisasi rata-rata
Galat Generalisasi Rata-rata (%)
0,00001 85.80
0,0001 87.04
0,001 90.74
0,01 86.42
0,1 75.31
Percobaan ini menunjukkan bahwa jika toleransi galat diturunkan maka tingkat akurasi jaringan semakin tinggi tetapi jika toleransi galat terlalu kecil dapat mengakibatkan gejala overfitting. Hal ini terlihat pada toleransi galat sebesar 10-4 dan 10-5 tidak terjadi peningkatan akurasi bahkan akurasi mulai turun. Gejala sistem yang overfit timbul disebabkan sistem mulai terlalu spesifik mempelajari pola pada data pelatihan, sehingga sulit untuk mempelajari pola-pola baru pada data pengujian. Hasil percobaan ini menunjukkan bahwa pada toleransi galat 10-3 dihasilkan generalisasi yang cukup baik. Oleh karena itu, untuk percobaan selanjutnya digunakan toleransi galat sebesar 10-3.
Pengaruh Learning Rate Terhadap Generalisasi
Percobaan pengaruh learning rate bertujuan untuk menentukan nilai learning rate yang optimal sehingga menghasilkan generalisasi yang baik. Grafik hubungan antara pengaruh learning rate terhadap generalisasi rata-rata dengan toleransi galat sebesar 10-3 dapat dilihat pada Gambar 7.
Gambar 7 Grafik pengaruh learning rate dengan galat 10-3 terhadap generalisasi Besarnya learning rate yang digunakan pada percobaan ini sebesar 0.1, 0.05, dan 0.01.
Pada percobaan ini digunakan toleransi galat sebesar 10-3. Toleransi galat ini digunakan karena pada percobaan sebelumnya memberikan hasil generalisasi yang cukup
baik. Selain itu, pada percobaan ini digunakan 3000 epoch, 10 hidden neuron, dan masing- masing percobaan diulang sebanyak tiga kali.
Generalisasi rata-rata maksimum hasil percobaan pengaruh learning rate dengan toleransi galat 10-3 adalah 90.74% dicapai pada saat learning rate sebesar 0.01. Data selengkapnya pada percobaan ini dapat dilihat pada Lampiran 8. Pada toleransi galat sebesar 10-3, terlihat bahwa nilai learning rate yang semakin besar dapat menurunkan generalisasi.
Perbandingan pengaruh learning rate terhadap generalisasi rata-rata dengan toleransi galat sebesar 10-3 dapat dilihat pada Tabel 9.
Tabel 9 Pengaruh learning rate terhadap generalisasi
Learning Rate Generalisasi Rata-rata (%)
0.01 90.74
0.05 83.33
0.1 82.10
Pada Tabel 9 generalisasi maksimum sebesar 90.74% dicapai pada saat learning rate 0,01. Oleh karena itu, nilai learning rate yang akan digunakan pada penelitian ini sebesar 0,01. Jika learning rate nilainya terlalu besar maka jaringan tidak stabil tetapi jika learning rate nilainya terlalu kecil maka jaringan akan membutuhkan waktu yang lama untuk konvergen. Berdasarkan hasil percobaan sebelumnya, diperoleh parameter- parameter JST propagasi balik yang optimal yang dapat menghasilkan generalisasi yang cukup baik. Parameter-parameter tersebut dapat dilihat pada Tabel 10.
Tabel 10 Parameter optimal JST propagasi balik
Parameter Jumlah
Hidden Neuron 10 neuron Toleransi Galat 0,001 Epoch maksimum 3000 Learning Rate 0,01
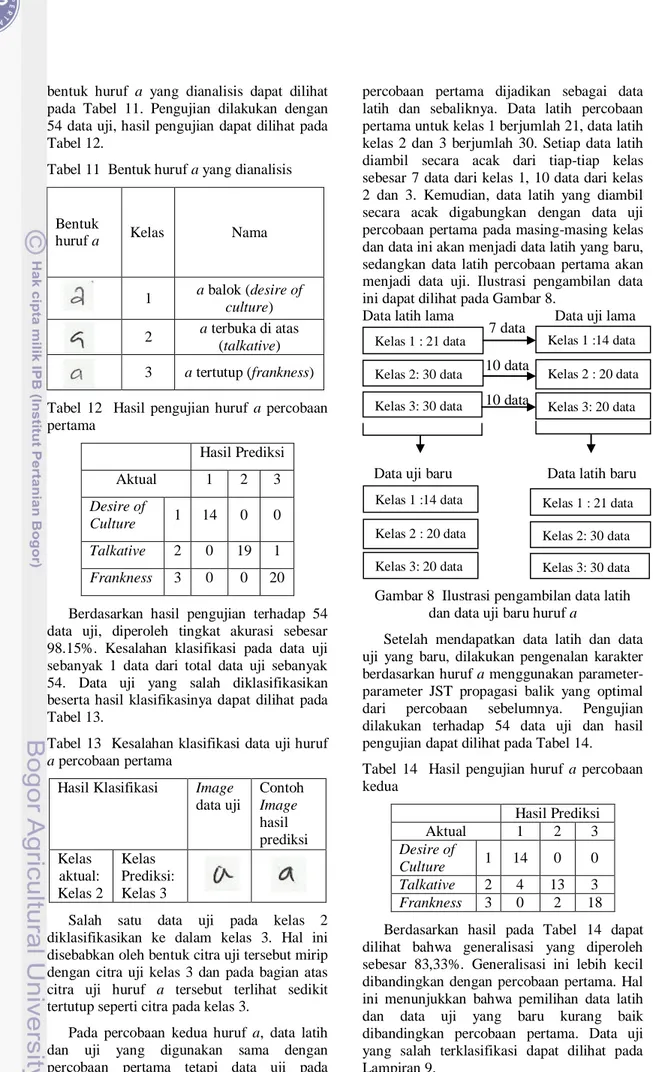
Pengenalan Karakter Berdasarkan Huruf a Pengenalan karakter berdasarkan huruf a terdiri atas tiga percobaan. Pada pengenalan karakter ini digunakan parameter-parameter JST propagasi balik optimal yang didapat dari percobaan sebelumnya untuk menguji sistem.
Kelas huruf a yang digunakan dalam penelitian ini sebanyak tiga kelas yaitu a balok (desire of culture), a terbuka diatas (talkative), dan a tertutup (frankness), bentuk- 75
80 85 90 95
0.01 0.05 0.1 Generalisasi rata- rata
Learning rate
bentuk huruf a yang dianalisis dapat dilihat pada Tabel 11. Pengujian dilakukan dengan 54 data uji, hasil pengujian dapat dilihat pada Tabel 12.
Tabel 11 Bentuk huruf a yang dianalisis
Bentuk
huruf a Kelas Nama
1 a balok (desire of culture) 2 a terbuka di atas
(talkative) 3 a tertutup (frankness) Tabel 12 Hasil pengujian huruf a percobaan pertama
Hasil Prediksi
Aktual 1 2 3
Desire of
Culture 1 14 0 0 Talkative 2 0 19 1 Frankness 3 0 0 20 Berdasarkan hasil pengujian terhadap 54 data uji, diperoleh tingkat akurasi sebesar 98.15%. Kesalahan klasifikasi pada data uji sebanyak 1 data dari total data uji sebanyak 54. Data uji yang salah diklasifikasikan beserta hasil klasifikasinya dapat dilihat pada Tabel 13.
Tabel 13 Kesalahan klasifikasi data uji huruf a percobaan pertama
Hasil Klasifikasi Image data uji
Contoh Image hasil prediksi Kelas
aktual:
Kelas 2
Kelas Prediksi:
Kelas 3
Salah satu data uji pada kelas 2 diklasifikasikan ke dalam kelas 3. Hal ini disebabkan oleh bentuk citra uji tersebut mirip dengan citra uji kelas 3 dan pada bagian atas citra uji huruf a tersebut terlihat sedikit tertutup seperti citra pada kelas 3.
Pada percobaan kedua huruf a, data latih dan uji yang digunakan sama dengan percobaan pertama tetapi data uji pada
percobaan pertama dijadikan sebagai data latih dan sebaliknya. Data latih percobaan pertama untuk kelas 1 berjumlah 21, data latih kelas 2 dan 3 berjumlah 30. Setiap data latih diambil secara acak dari tiap-tiap kelas sebesar 7 data dari kelas 1, 10 data dari kelas 2 dan 3. Kemudian, data latih yang diambil secara acak digabungkan dengan data uji percobaan pertama pada masing-masing kelas dan data ini akan menjadi data latih yang baru, sedangkan data latih percobaan pertama akan menjadi data uji. Ilustrasi pengambilan data ini dapat dilihat pada Gambar 8.
Data latih lama Data uji lama
Data uji baru Data latih baru
Gambar 8 Ilustrasi pengambilan data latih dan data uji baru huruf a
Setelah mendapatkan data latih dan data uji yang baru, dilakukan pengenalan karakter berdasarkan huruf a menggunakan parameter- parameter JST propagasi balik yang optimal dari percobaan sebelumnya. Pengujian dilakukan terhadap 54 data uji dan hasil pengujian dapat dilihat pada Tabel 14.
Tabel 14 Hasil pengujian huruf a percobaan kedua
Hasil Prediksi
Aktual 1 2 3
Desire of
Culture 1 14 0 0 Talkative 2 4 13 3 Frankness 3 0 2 18 Berdasarkan hasil pada Tabel 14 dapat dilihat bahwa generalisasi yang diperoleh sebesar 83,33%. Generalisasi ini lebih kecil dibandingkan dengan percobaan pertama. Hal ini menunjukkan bahwa pemilihan data latih dan data uji yang baru kurang baik dibandingkan percobaan pertama. Data uji yang salah terklasifikasi dapat dilihat pada Lampiran 9.
7 data
10 data 10 data Kelas 1 : 21 data
Kelas 3: 30 data Kelas 2: 30 data
Kelas 1 :14 data Kelas 2 : 20 data Kelas 3: 20 data
Kelas 1 :14 data Kelas 2 : 20 data Kelas 3: 20 data
Kelas 1 : 21 data
Kelas 3: 30 data Kelas 2: 30 data
Pada percobaan ketiga huruf a, jumlah data kelas 2 dan 3 dikurangi masing-masing sebanyak 9 citra sehingga total data latih kelas 2 dan 3 masing-masing menjadi 21 citra sama seperti jumlah data pada kelas 1. Begitu juga dengan data uji kelas 2 dan 3 dikurangi masing-masing sebanyak 6 citra sehingga total data uji kelas 2 dan 3 masing-masing menjadi 14 citra. Jadi, pada percobaan ketiga ini jumlah seluruh data latih sebesar 63 citra dan jumlah data uji sebanyak 42 citra. Hal ini bertujuan untuk melihat hasil generalisasi yang diperoleh jika jumlah data masing- masing kelas sama. Pengujian dilakukan terhadap 42 data uji dan hasil pengujian dapat dilihat pada Tabel 15.
Tabel 15 Hasil Pengujian huruf a percobaan ketiga
Hasil Prediksi
Aktual 1 2 3
Desire of
Culture 1 14 0 0
Talkative 2 0 12 2 Frankness 3 0 3 11 Hasil klasifikasi data uji pada percobaan ketiga huruf a diperoleh generalisasi sebesar 88,09 %. Data uji yang salah terklasifikasi dapat dilihat pada Lampiran 10. Hasil ini lebih besar dibandingkan pada percobaan kedua karena data latih dan data uji yang digunakan adalah data latih dan data uji pada percobaan pertama hanya jumlah data kelas 2 dan 3 dikurangi. Pemilihan data percobaan pertama lebih baik dibandingkan data pada percobaan kedua sehingga generalisasi pada percobaan ketiga masih lebih besar dibandingkan percobaan kedua.
Jika percobaan ketiga dibandingkan dengan percobaan pertama, maka generalisasi dari percobaan ketiga lebih kecil karena jumlah data yang digunakan lebih sedikit sehingga pola yang dikenali jaringan kurang bervariatif. Oleh karena itu, penambahan data pada pelatihan dapat membuat jaringan lebih bervariatif dalam mengenali pola, sehingga generalisasi yang diperoleh pun lebih besar.
Data citra sebaiknya ditambah untuk melihat kinerja sistem.
Berdasarkan percobaan pertama, kedua, dan ketiga huruf a, hasil klasifikasi untuk kelas 1 (a balok) selalu dikenali dengan benar seluruhnya karena bentuk dari huruf a kelas 1 (a balok) ini memang sangat berbeda dengan bentuk huruf a kelas 2 (a terbuka di atas) dan kelas 3 (a tertutup). Kesalahan dalam
klasifikasi umumnya terjadi pada kelas 2 yang diklasifikasikan ke dalam kelas 3 dan sebaliknya, hal ini disebabkan oleh bentuk huruf a kelas 2 dan 3 mirip dan perbedaanya pun hanya ditentukan pada bagian atas huruf a yaitu terbuka atau tertutup sehingga kemungkinan salah klasifikasi cukup besar.
Generalisasi yang paling besar diperoleh pada percobaan pertama yaitu sebesar 98,15%.
Oleh karena itu, data latih dan data uji dari percobaan pertama yang akan digunakan dalam penelitian ini.
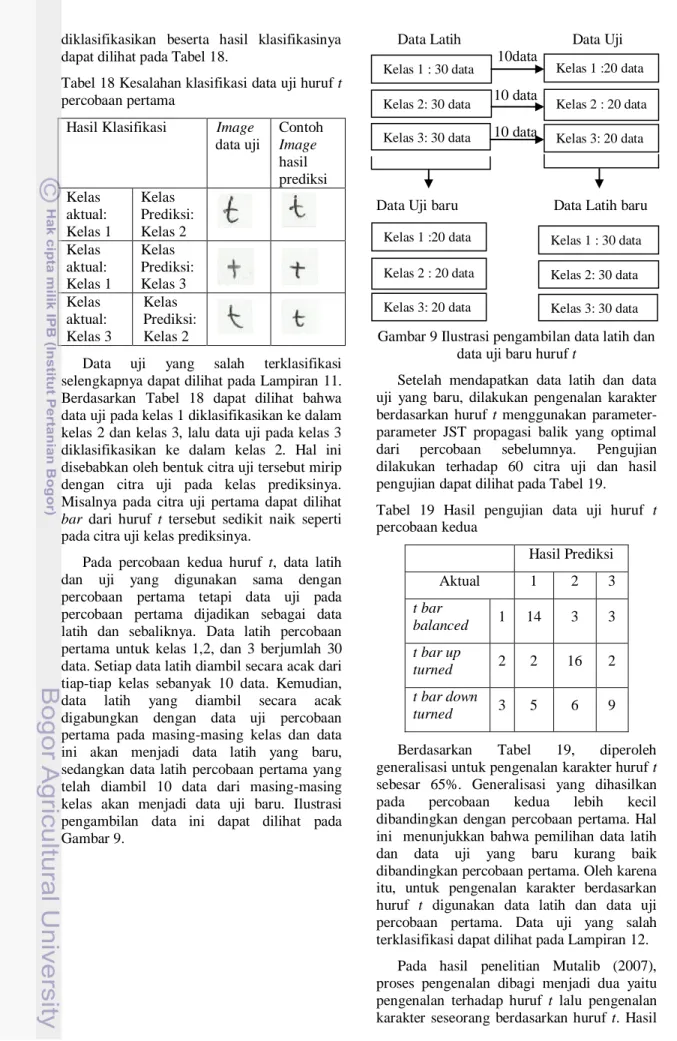
Pengenalan Karakter Berdasarkan Huruf t Pengenalan karakter berdasarkan huruf t terdiri atas dua percobaan. Perobaan pertama yaitu data latih yang digunakan sebanyak 90 citra dan data uji sebanyak 60 citra.
Parameter-parameter JST propagasi balik yang digunakan berasal dari percobaan sebelumnya. Kelas huruf t yang digunakan dalam penelitian ini sebanyak tiga kelas yaitu t bar balanced, t bar up turned, dan t bar down turned, bentuk-bentuk huruf t yang dianalisis dapat dilihat pada Tabel 16.
Pengujian dilakukan dengan 60 data uji dan hasil pengujian dapat dilihat pada Tabel 17.
Tabel 16 Bentuk huruf t yang dianalisis Bentuk
huruf t Kelas Nama 1 t bar balanced 2 t bar up turned 3
t t bar down turned Tabel 17 Hasil pengujian data uji huruf t percobaan pertama
Hasil Prediksi
Aktual 1 2 3
t bar
balanced 1 14 4 2 t bar up
turned 2 3 15 2
t bar down
turned 3 2 3 15
Berdasarkan Tabel 17, diperoleh generalisasi untuk pengenalan karakter huruf t sebesar 73.33%. Kesalahan klasifikasi pada data uji sebanyak 16 data dari total data uji sebanyak 60. Beberapa data uji yang salah
diklasifikasikan beserta hasil klasifikasinya dapat dilihat pada Tabel 18.
Tabel 18 Kesalahan klasifikasi data uji huruf t percobaan pertama
Hasil Klasifikasi Image data uji
Contoh Image hasil prediksi Kelas
aktual:
Kelas 1
Kelas Prediksi:
Kelas 2 Kelas
aktual:
Kelas 1
Kelas Prediksi:
Kelas 3 Kelas
aktual:
Kelas 3
Kelas Prediksi:
Kelas 2
Data uji yang salah terklasifikasi selengkapnya dapat dilihat pada Lampiran 11.
Berdasarkan Tabel 18 dapat dilihat bahwa data uji pada kelas 1 diklasifikasikan ke dalam kelas 2 dan kelas 3, lalu data uji pada kelas 3 diklasifikasikan ke dalam kelas 2. Hal ini disebabkan oleh bentuk citra uji tersebut mirip dengan citra uji pada kelas prediksinya.
Misalnya pada citra uji pertama dapat dilihat bar dari huruf t tersebut sedikit naik seperti pada citra uji kelas prediksinya.
Pada percobaan kedua huruf t, data latih dan uji yang digunakan sama dengan percobaan pertama tetapi data uji pada percobaan pertama dijadikan sebagai data latih dan sebaliknya. Data latih percobaan pertama untuk kelas 1,2, dan 3 berjumlah 30 data. Setiap data latih diambil secara acak dari tiap-tiap kelas sebanyak 10 data. Kemudian, data latih yang diambil secara acak digabungkan dengan data uji percobaan pertama pada masing-masing kelas dan data ini akan menjadi data latih yang baru, sedangkan data latih percobaan pertama yang telah diambil 10 data dari masing-masing kelas akan menjadi data uji baru. Ilustrasi pengambilan data ini dapat dilihat pada Gambar 9.
Data Latih Data Uji
Data Uji baru Data Latih baru
Gambar 9 Ilustrasi pengambilan data latih dan data uji baru huruf t
Setelah mendapatkan data latih dan data uji yang baru, dilakukan pengenalan karakter berdasarkan huruf t menggunakan parameter- parameter JST propagasi balik yang optimal dari percobaan sebelumnya. Pengujian dilakukan terhadap 60 citra uji dan hasil pengujian dapat dilihat pada Tabel 19.
Tabel 19 Hasil pengujian data uji huruf t percobaan kedua
Hasil Prediksi
Aktual 1 2 3
t bar
balanced 1 14 3 3 t bar up
turned 2 2 16 2
t bar down
turned 3 5 6 9
Berdasarkan Tabel 19, diperoleh generalisasi untuk pengenalan karakter huruf t sebesar 65%. Generalisasi yang dihasilkan pada percobaan kedua lebih kecil dibandingkan dengan percobaan pertama. Hal ini menunjukkan bahwa pemilihan data latih dan data uji yang baru kurang baik dibandingkan percobaan pertama. Oleh karena itu, untuk pengenalan karakter berdasarkan huruf t digunakan data latih dan data uji percobaan pertama. Data uji yang salah terklasifikasi dapat dilihat pada Lampiran 12.
Pada hasil penelitian Mutalib (2007), proses pengenalan dibagi menjadi dua yaitu pengenalan terhadap huruf t lalu pengenalan karakter seseorang berdasarkan huruf t. Hasil
10data
10 data 10 data Kelas 1 : 30 data
Kelas 3: 30 data Kelas 2: 30 data
Kelas 1 :20 data Kelas 2 : 20 data Kelas 3: 20 data
Kelas 1 :20 data Kelas 2 : 20 data Kelas 3: 20 data
Kelas 1 : 30 data
Kelas 3: 30 data Kelas 2: 30 data
akurasi pada pengenalan huruf t cukup tinggi yaitu sebesar 90,27%, tetapi akurasi dari pengenalan karakter berdasarkan huruf t kurang baik yaitu sebesar 60%. Hal ini dapat disebabkan oleh analisis karakter melalui huruf t hanya dilihat berdasarkan kemiringan garis bar pada huruf t, sehingga perbedaannya tidak terlalu signifikan. Selain itu, akurasi pengenalan huruf t yang tidak 100% yang dapat memengaruhi akurasi dalam pengenalan karakter berdasarkan huruf t. Jadi, kesalahan sistem dalam mengklasifikasikannya cukup besar. Jaringan syaraf tiruan propagasi balik yang digunakan dalam penelitian Mutalib yaitu JST propagasi balik dengan momentum.
Berbeda dengan penelitian Mutalib (2007), pada penelitian ini tidak dilakukan pengenalan terhadap huruf t tetapi hanya pengenalan karakter seseorang berdasarkan huruf t.
Generalisasi yang diperoleh lebih besar dibandingkan hasil penelitian Mutalib (2007) yaitu sebesar 73,33%. Hal ini karena pada penelitian ini tidak dilakukan pengenalan huruf t tetapi langsung pada pengenalan karakter seseorang berdasarkan huruf t, sehingga dapat mengurangi kesalahan dalam klasifikasi. Selain itu, huruf t dalam penelitian ini dipotong (cropping) secara manual.
Generalisasi yang didapat dari analisis huruf t jauh lebih kecil dibandingkan dengan generalisasi yang dihasilkan pada pengenalan karakter berdasarkan huruf a. Hal ini dapat disebabkan oleh analisis karakter melalui huruf t hanya dilihat berdasarkan kemiringan garis bar pada huruf t, sehingga perbedaan antar kelas huruf t tidak terlalu signifikan.
Selain itu, tidak ada proses rotasi dalam tahap praproses yang menyebabkan posisi huruf t tidak seragam sehingga memengaruhi kemiringan bar huruf t yang dapat menyebabkan kesalahan klasifikasi.
Kesalahan klasifikasi baik untuk huruf t dan a dapat disebabkan oleh bentuk dan ukuran huruf-huruf yang mirip antar kelas sehingga memungkinkan sistem salah dalam mengklasifikasikannya ke dalam kelas karakter yang benar. Selain itu, kemiringan huruf pada data latih setiap kelas pun tidak seragam sehingga memengaruhi hasil klasifikasi.
KESIMPULAN DAN SARAN Kesimpulan
Jaringan syaraf tiruan propagasi balik standar dapat melakukan pembelajaran
dengan baik dan melakukan pengenalan terhadap suatu pola dengan tingkat generalisasi yang cukup tinggi. Implementasi analisis grafologi menggunakan jaringan syaraf tiruan propagasi balik dapat menjadi alat bantu grafologist untuk analisis tulisan tangan.
Parameter-parameter JST propagasi balik yang optimal hasil percobaan ini yaitu 10 hidden neuron, learning rate sebesar 0.01, toleransi galat sebesar 10-3, dan epoch maksimum sebesar 3000 epoch. Sistem ini mampu melakukan pengenalan dengan tingkat generalisasi yang cukup tinggi sebesar 98.15
% untuk huruf a dan 73.33% untuk huruf t.
Saran
Penelitian ini masih dapat dikembangkan untuk membuat sistem yang lebih baik lagi.
Saran-saran bagi penelitian lebih lanjut di antaranya:
1 Parameter untuk analisis grafologi sebaiknya ditambah, tidak hanya huruf a dan t kecil saja.
2 Proses pengenalan huruf a dan t diautomatisasi sehingga tidak dipotong (cropping) secara manual.
3 Dalam tahap praproses sebaiknya ditambahkan proses rotasi.
DAFTAR PUSTAKA
Amend KK, Ruiz MS. 1980. Handwriting Analysis, The Complete Basic Book. USA:
Book Mart Press.
Baggett BA. 1993. The Secret To Making Love Happen. USA: Empresse Publishing.
Champa HN, Kumar AKR. 2010. Artificial Neural Network for Human Behavior Prediction through Handwriting Analysis.
International Journal of Computer Applications (0975-8887). Vol.2, No.2, Mei 2010. India: SJB Institute of Technology.
Fauset L. 1994. Fundamentals of Neural Networks. New Jersey: Prentice-Hall.
Gonzales RC, Woods RE. 2002. Digital Image Processing. Massachussets:
Addison Wasley.
Mutalib S, Rahman SA, Yusoff M, Mohamed A. 2007. Personality Analysis Based on Letter t Using Back Propagation Neural Network. Proceedings of the International