8
LANDASAN TEORI
2.1 Database
Menurut Inmon (2005 : 493), data merupakan rekaman dari fakta, konsep, atau instruksi pada suatu media penyimpanan untuk komunikasi, pengambilan, dan pengolahan dengan cara otomatis dan dapat dipresentasikan sebagai informasi yang dapat dipahami oleh manusia. Data merupakan elemen terkecil dan terpenting pada sebuah sistem informasi. Tanpa adanya data, sebuah sistem informasi tidak dapat memberikan nilai ataupun manfaat kepada penggunanya. Dari pengertian di atas, dapat diambil kesimpulan bahwa data merupakan kumpulan dari fakta-fakta yang belum dikelola dan diorganisir yang kemudian dapat diubah menjadi informasi yang telah terstruktur sehingga dapat dimanfaatkan dan memberikan nilai kepada orang yang menggunakannya. Sebagai contoh dari data adalah fakta-fakta dari orang seperti nama, jenis kelamin, dan umur orang tersebut.
Database (Satzinger, Jackson, dan Burd, 2004 : 398) merupakan sebuah kumpulan dari data yang disimpan dan terintegrasi yang dikelola dan dikontrol secara terpusat. Sedangkan menurut Inmon (2005 : 493), database adalah kumpulan data yang saling terkait yang disimpan sesuai dengan skema. Dari pengertian di atas dapat disimpulkan database merupakan kumpulan dari data terstruktur yang saling berhubungan yang disimpan, dikelola, dan dikontrol secara terpusat dan dapat digunakan untuk memenuhi kebutuhan akan informasi. Hal ini juga dinyatakan oleh Connolly dan Begg (2010 : 65) bahwa database merupakan sebuah kumpulan dari data yang berhubungan secara logikal dan deskripsinya, yang dirancang untuk memenuhi kebutuhan dari informasi dari perusahaan. Sebagai contoh dari database
adalah kumpulan dari data nama, jenis kelamin, dan umur dari mahasiswa yang terdapat di Binus University.
Menurut Connolly dan Begg (2010 : 150), model database relasional merupakan konsep yang didasarkan pada konsep matematikal dari suatu relasi yang secara fisik digambarkan dalam bentuk tabel. Untuk lebih memahami tentang pemodelan pada database relasional perlu diketahui jenis-jenis dari key relasional yang secara unik mengidentifikasi setiap tuple data yang ada di dalam tabel. Key-key relasional tersebut yaitu :
• Superkey
Superkey merupakan suatu atribut atau kumpulan dari dari atribut yang secara unik mengidentifikasi sebuah tuple di dalam relasi.
• Candidate key
Candidate key merupakan atribut-atribut dari relasi yang memiliki keunikan dan tidak boleh terdapat di relasi lain. Sebagai contohnya yaitu nomor induk pegawai dan nomor kartu tanda penduduk yang sama-sama memiliki keunikan.
• Composite key
Composite key merupakan candidate key yang terdiri dari atribut yang lebih dari satu.
• Primary key
Primary key merupakan candidate key yang dipilih untuk mengidentifikasi sebuah tuple yang terdapat di dalam relasi secara unik. Sebagai contohnya yaitu kode barang yang dipilih karena paling unik bila dibandingkan dengan nama barang.
• Foreign key
Foreign key merupakan suatu atribut atau kumpulan atribut yang terdapat di dalam satu relasi yang sesuai dengan candidate key dari beberapa relasi. Sebagai contohnya yaitu kode barang yang terdapat di relasi yang lain.
2.2 Data Warehouse
Data warehouse merupakan sebuah tempat penyimpanan data saat ini dan data historis yang berorientasi pada subjek, terintegrasi, time variant, dan nonvolatile yang dihasilkan untuk mendukung proses pembuatan keputusan oleh manajemen. Sedangkan menurut Connolly dan Begg (2010 : 1197), data warehouse merupakan sebuah kumpulan dari data yang berorientasi pada subjek, terintegrasi, bervarian pada waktu, dan nonvolatile dalam mendukung proses pembuatan keputusan manajemen.
Data warehouse memiliki beberapa karakteristik yaitu sebagai berikut : • Subject Oriented
Subject oriented merupakan data yang diatur oleh subjek yang detail, seperti sales, product, atau customer, yang mengandung informasi yang hanya berhubungan untuk mendukung pengambilan suatu keputusan. Orientasi pada subjek memungkinkan pengguna untuk tidak hanya menentukan bagaimana proses bisnis tersebut dilaksanakan tetapi juga mengapa proses bisnisnya dilaksanakan. Orientasi subjek menyediakan pandangan yang lebih komprehensif dari sebuah organisasi.
• Integrated
Integrasi berhubungan dengan orientasi subjek. Data warehouse harus menempatkan data dari berbagai sumber yang berbeda ke dalam sebuah bentuk
yang konsisten. Sebuah data warehouse harus secara penuh terintegrasi untuk dapat dikatakan sebagai data warehouse.
• Time variant (time series)
Sebuah data warehouse mempertahankan data historis. Data tidak diperlukan untuk menyediakan status saat ini (kecuali dalam sistem real time) namun data tersebut dapat digunakan untuk mendeteksi tren, deviasi, hubungan jangka panjang untuk peramalan dan perbandingan yang dapat digunakan untuk proses pembuatan keputusan. Terdapat kualitas temporal untuk setiap data warehouse. Waktu merupakan sebuah dimensi yang penting yang harus didukung oleh semua data warehouse. Data yang digunakan untuk proses analisis yang berasal dari beragam sumber mengandung berbagai titik waktu seperti tampilan per hari, per minggu, maupun per bulan.
• Nonvolatile
Nonvolatile merupakan karakteristik dari data warehouse dimana setelah data dimasukkan ke dalam data warehouse, pengguna tidak dapat mengubah atau melakukan update terhadap data tersebut. Data yang tidak terpakai akan dibuang dan adanya perubahan akan disimpan sebagai sebuah data baru. Ini memungkinkan data warehouse untuk diperbaiki hampir secara ekslusif untuk akses data.
Dalam membangun suatu data warehouse, dibutuhkan suatu model arsitektur yang dapat mendukung proses tersebut. Menurut Connolly dan Begg (2010 : 1203), model arsitektur yang umumnya digunakan terdiri dari komponen-komponen utama yaitu sebagai berikut :
• Operational Data
Dalam membangun suatu data warehouse, dibutuhkan data-data yang kemudian akan diproses untuk dimasukkan ke dalam data warehouse. Sumber-sumber data untuk suatu data warehouse dapat berasal dari :
Data operasional yang terletak di database jaringan dan hirarki generasi pertama. Hal ini dikarenakan mayoritas data operasional perusahaan terletak di dalam sistem tersebut.
Data departemental yang terletak di sistem file seperti VSAM, RMS, dan Relasional DBMS
Data pribadi yang terletak di workstation dan private server
Sistem eksternal seperti internet, database yang tersedia secara komersial, atau database yang berhubungan dengan supplier atau customer dari suatu organisasi
• Operational Data Store (ODS)
Operational data store merupakan tempat penyimpanan dari data operasional sekarang dan terintegrasi yang digunakan untuk proses analisis.
• Load Manager
Load manager atau yang juga disebut sebagai komponen frontend merupakan sebuah bagian yang melakukan seluruh operasi yang berhubungan dengan proses ekstraksi data dari sumber data atau operational data store, transformasi sederhana pada data dan kemudian memasukkan hasil proses tersebut ke dalam warehouse.
• Warehouse Manager
Warehouse manager melakukan seluruh operasi yang berhubungan dengan manajemen dari data tersebut di dalam warehouse seperti analisis data untuk
memastikan konsistensi dari data, back-up data, transformasi dan penggabungan data sumber dari tempat penyimpanan sementara ke dalam tabel-tabel data warehouse, dan membuat index dan view pada tabel dasar.
• Query Manager
Query manager juga disebut sebagai komponen backend. Query manager melakukan seluruh operasi yang berhubungan dengan manajemen dari query user seperti mengarahkan query ke tabel yang tepat dan menjadwalkan waktu eksekusi dari query.
• Detailed Data
Detailed data merupakan bagian pada warehouse yang menyimpan seluruh data detil dalam skema database.
• Lightly and Higly Summarized Data
Lightly and highly summarized data merupakan bagian pada warehouse yang menyimpan seluruh data ringkat dan sangat ringkas yang dihasilkan oleh warehouse manager. Tujuan dari informasi yang diringkas adalah untuk mempercepat kinerja dari query.
• Archive/Backup Data
Archive/backup data merupakan bagian dalam warehouse yang menyimpan data detil dan ringkas dengan tujuan pengarsipan atau backup. Data dikirim ke tempat penyimpanan untuk arsip seperti magnetic tape atau optical disk.
• Metadata
Bagian dalam warehouse ini menyimpan seluruh metadata yang dapat digunakan untuk berbagai tujuan seperti proses ekstraksi dan loading, proses manajemen warehouse, dan sebagai bagian dari proses manajemen query.
• End-User Access Tool
End-user acces tool merupakan bagian dimana user dapat berinteraksi dengan warehouse yang dapat menyediakan informasi ke pengguna bisnis untuk dapat membantu pembuatan keputusan yang strategis. Beberapa contoh end-user access tool antara lain reporting dan query tool, Sistem informasi eksekutif tool, OLAP tool, dan data mining tool.
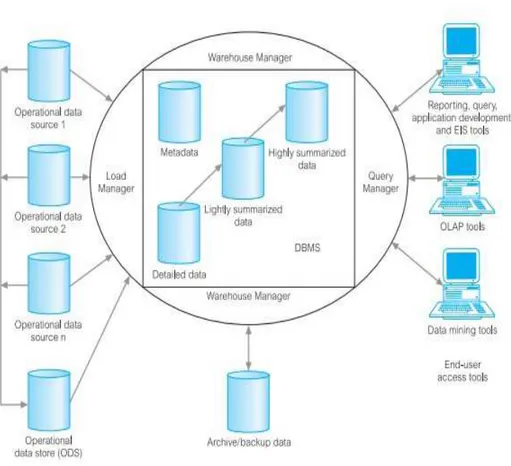
Gambar 2.1 Arsitektur dari data warehouse (Connolly dan Begg, 2010 : 1204)
Berdasarkan model arsitektur pada gambar 2.1 yang dikemukakan oleh Connolly dan Begg (2010 : 1204), data-data operasional yang akan digunakan diekstrak dari sumber-sumber seperti private network, workstation, dan operational data source. Data tersebut kemudian dimasukkan ke dalam load manager untuk ditransformasi sesuai dengan kebutuhan yang diinginkan dan kemudian dimasukkan
kedalam warehouse manager. Di dalam warehouse manager, data tersebut kemudian dikelola seperti diringkas ke dalam data yang ringkas dan sangat ringkas untuk mempercepat kinerja dari query. Selain itu, data juga diback-up dengan tujuan pengarsipan ke dalam secondary storage seperti magnetic tape atau optical disk. Di dalam warehouse manager juga terdapat metadata yang berfungsi untuk menyimpan seluruh metadata yang berguna untuk proses ekstraksi dan loading, proses manajemen warehouse, dan bagian dari manajemen query. Data-data yang terdapat di dalam data warehouse kemudian akan diatur oleh query manager yang berfungsi untuk mengatur seluruh operasi yang berhubungan dengan manajemen dari query user sehingga data dapat diakses oleh end-user access tool seperti EIS tool, OLAP tool, dan data mining tool.
Namun disamping arsitektur di atas, berdasarkan Ariyachandra dan Watson (2006 : 4-6) terdapat arsitektur alternatif yang dapat digunakan dalam membangun sebuah data warehouse yang tipe desain arsitektural dasarnya tidak murni enterprise data warehouse maupun data mart. Arsitektur tersebut yaitu :
• Independent data mart architecture
Di dalam arsitektur ini, data mart dikembangkan untuk beroperasi secara independen antara satu sama lain.
• Data mart bus architecture with linked dimensional data marts
• Hub-and-spoke architecture
Di dalam arsitektur ini, perhatian difokuskan pada membangun sebuah
infrastruktur yang dapat dijaga dan di ukur. Arsitektur ini dikembangkan dengan cara iteratif, area subjek dengan area subjek, dan data mart dependen
• Centralized data warehouse architecture
Arsitektur ini serupa dengan hub-and-spoke architecture namun perbedaan terletak pada tidak adanya data mart dependen. Pada arsitektur ini disarankan untuk menggunakan data warehouse tanpa adanya data mart sehingga dapat menyediakan akses ke seluruh data di dalam data warehouse kepada user daripada membatasinya ke dalam data mart.
• Federated architecture
Pada arsitektur ini, menggunakan seluruh cara yang memungkinkan untuk mengintegrasikan sumber daya analitikal dari berbagai sumber untuk memenuhi perubahan kebutuhan atau kondisi bisnis.
Gambar 2.2 Alternatif arsitektur data warehouse (Ariyachandra dan Watson, 2006 : 5)
Dalam membangun sebuah data warehouse, selain dibutuhkan arsitektur yang mendukung juga dibutuhkan perencanaan yang baik. Seperti halnya sistem informasi lain, tahap awal dan penting dalam membangun sebuah data warehouse adalah melakukan analisis kebutuhan. Hal ini juga dinyatakan oleh Poolet (2009) yang menyatakan bahwa tahapan discover atau analisis dan definisi kebutuhan merupakan tahapan penting karena hasil akhir dari kebutuhan data warehouse harus dapat mendukung tujuan akhir dari organisasi.
2.2.1 Dimensionality Modeling
Dimensionality modeling (Connolly dan Begg, 2010 : 1227) merupakan teknik desain logikal yang bertujuan untuk menampilkan data di dalam standar, bentuk yang intuitif yang memungkinkan akses dengan performa yang tinggi. Setiap dimensional modeling terdiri dari satu primary key komposit yang disebut tabel fakta dan sebuah kumpulan dari tabel yang lebih kecil yang disebut dengan tabel dimensional. Setiap tabel dimensional memiliki primary key yang tidak komposit yang sesuai dengan salah satu dari komponen key komposit di dalam tabel fakta.
Di dalam proses dimensional modeling, dikenal beberapa jenis dari key yaitu sebagai berikut :
• Natural key/business key
Natural key atau business key merupakan sebuah indeks yang secara unik dapat berfungsi untuk mengidentifikasi baris pada kolom-kolom yang terdapat di dalam tabel yang sesuai dengan proses bisnis. Sebagai contohnya yaitu primary key pada database OLTP.
• Surrogate key
Surrogate key merupakan key alternatif yang dipakai untuk menggantikan natural key yang digunakan untuk menghubungkan tabel fakta dan tabel dimensi
secara efisien. Dengan adanya surrogate key memungkinkan data di dalam tempat penyimpanan untuk memiliki kebebasan dari data yang digunakan dan dihasilkan dari sistem OLTP. Menurut Kimball, Ross, Decker, Mundy, & Thornthwaite (2008 : 285), surrogate key bukan sekedar key alternatif melainkan generalisasi yang diperlukan dari produksi key natural dan salah satu elemen dasar di dalam desain data warehouse.
Dimensional modeling digunakan karena dapat memberikan beberapa keuntungan yang penting di dalam suatu lingkungan data warehouse. Keuntungan-keuntungan tersebut yaitu :
• Efisiensi
• Kemampuan untuk menangani perubahan kebutuhan • Ekstensibilitas
• Kemampuan untuk memodelkan situasi bisnis yang umum • Pemrosesan query yang dapat diprediksi
Menurut Connolly dan Begg (2010 : 1227-1229), terdapat tiga jenis dari model data untuk dimensional modeling yaitu :
• Star Schema
Star schema merupakan sebuah model data dimensional dimana memiliki sebuah tabel fakta di tengah dan dikelilingi oleh tabel dimensi yang telah didenormalisasi. Sebagai contoh dari model star schema dapat dilihat pada gambar 2.3 di bawah.
Gambar 2.3 Contoh star schema
• Snowflake Schema
Snowflake schema merupakan sebuah model data dimensional yang memiliki tabel fakta di tengah dan dikelilingi oleh tabel dimensi yang telah dinormalisasi. Snowflake schema merupakan variasi dari star schema yang memungkinkan tabel dimensi untuk memiliki tabel-tabel dimensi. Sebagai contohnya dapat dilihat pada gambar 2.4 di bawah.
Gambar 2.4 Contoh Snowflake schema
• Starflake Schema
Starflake schema merupakan sebuah model data dimensional yang memiliki tabel fakta di tengah dan dikelilingi oleh tabel dimensi yang telah dinormalisasi dan tabel dimensi yang telah didenormalisasi. Model ini merupakan kombinasi
dari model star schema dan snowflake schema. Sebagai contohnya dapat dilihat pada gambar 2.5 di bawah.
Gambar 2.5 Contoh Starflake schema
Setelah mengetahui fundamental dan model-model dari dimensional modeling, hal lain yang perlu diketahui adalah langkah-langkah dalam merancang suatu database dimensional. Menurut Kimball dan Ross (2002 : 30), terdapat empat langkah utama dalam merancang database dimensional. Langkah-langkah tersebut adalah sebagai berikut :
• Memilih proses bisnis untuk model
Tahap awal dalam merancang database dimensional adalah memilih proses bisnis yang akan dimodelkan. Proses bisnis adalah aktivitas alami dari bisnis yang dilakukan di dalam suatu organisasi yang secara khusus didukung oleh sistem kumpulan sumber data. Salah satu hal yang paling efektif dalam menentukan proses adalah dengan mendengarkan kebutuhan dari user. Contoh dari proses bisnis adalah pembelian bahan baku, pengiriman, penyimpanan, dan penjualan.
• Deklarasi grain dari proses bisnis
Mendeklarasi grain dapat berarti menspesifikasikan secara tepat apa yang akan direpresentasikan oleh suatu baris tabel fakta individual. Sebuah grain
menyampaikan tingkat kedetailan yang berhubungan dengan pengukuran tabel fakta. Pemilihan grain di dalam tabel fakta juga menentukan grain dari setiap tabel dimensi. Untuk itu pemilihan grain merupakan langkah yang sangat penting yang juga dapat mempengaruhi implementasi dari data warehouse nantinya, Contoh dari grain pada tabel fakta propertysale yaitu sebuah individual property sale yang kemudian grain pada tabel dimensional clientnya adalah detail dari client yang membeli property tertentu.
• Memilih dimensi-dimensi yang dapat diterapkan ke setiap baris tabel fakta Dimensi dapat ditentukan dengan menata tabel fakta dengan sekumpulan dimensi yang menyatakan seluruh deskripsi yang memungkinkan yang mengambil nilai tunggal di dalam konteks dari setiap pengukuran. Dimensi ini berasal dari bagaimana orang bisnis menjelaskan data-data yang dihasilkan dari proses bisnis. Sebagai contoh dari dimensi yang umum digunakan yaitu dimensi waktu, produk, pelanggan, dan lain sebagainya.
• Identifikasi fakta-fakta numerik yang akan mengisi setiap baris tabel fakta Dalam menentukan fakta-fakta yang akan mengisi setiap baris tabel fakta dapat dilakukan dengan mengacu pada pertanyaan apakah yang akan diukur. Setiap kandidat dari fakta di dalam desain harus sesuai dengan grain yang didefinisikan di langkah kedua. Fakta yang secara jelas merupakan milik dari grain lain harus berada di dalam tabel fakta yang berbeda. Grain dari tabel fakta menentukan fakta mana yang dapat digunakan untuk proses bisnis yang ada.
Selain tahapan di atas, menurut Kimball, Reeves, Ross, dan Thornthwaite, 1998 : 266), dalam membangun dimensional model dapat menggunakan tahapan desain logikal dari data warehouse dengan pendekatan perencanaan top-down yang
disebut data warehouse bus architecture matrix. Terdapat beberapa tahapan dalam data warehouse bus architecture matrix yaitu :
• Melakukan analisis terhadap kebutuhan bisnis dari organisasi dan sumber datanya. Tahapan ini merupakan tahapan yang wajib dilakukan sebelum melanjutkan ke tahap selanjutnya. Dalam membangun data warehouse, tidak hanya dilakukan dengan membayangkan data apa saja yang akan dimasukkan ke dalam data warehouse melainkan juga dibutuhkan informasi yang di dapatkan dari proses interview dengan user seperti pekerjaan dari user, tujuan yang diinginkan dan hambatan yang dihadapi oleh user serta bagaimana strategi diambil untuk keputusan sekarang atau di masa yang akan datang.
• Tahapan selanjutnya yang harus dilakukan adalah mendaftar data marts mana saja yang termasuk single-source data marts. Single-source data mart merupakan data mart yang berasal dari sumber data tunggal. Data mart yang dimaksud disini merupakan kumpulan dari fakta-fakta numerik. Untuk memudahkan penentuan data mart, data mart dipilih dari proses bisnis tunggal. Langkah selanjutnya yaitu menentukan multiple–source data mart yang menggabungkan desain single-source ke dalam bentuk tampilan yang luas dari bisnis.
• Setelah menentukan seluruh data mart yang memungkinkan, selanjutnya menentukan seluruh dimensi yang terdapat di dalam data mart.
2.2.2 Data Mart
Data Mart (Connolly dan Begg, 2010 : 1214) merupakan sebuah database yang berisi sebagian dari data perusahaan untuk mendukung kebutuhan analitikal dari sebuah unit bisnis tertentu atau untuk mendukung user yang mempunyai kebutuhan yang sama untuk menganalisis sebuah proses bisnis tertentu.
Menurut Turban, Sharda, dan Delen (2010 : 330), data mart terbagi menjadi dua jenis antara lain independent data mart dan dependent data mart. Dependent data mart merupakan bagian data mart yang langsung dibuat dari data warehouse untuk itu data diambil dari dalam data warehouse langsung. Dependent data mart mendukung konsep data model besar perusahaan, namun data warehouse harus dibangun terlebih dahulu. Sebagai contohnya dapat dilihat pada gambar 2.6 dimana data mart pada bagian finance, bagian manufaktur, dan bagian lain yang dibuat berdasarkan data yang diambil dari data warehouse perusahaan. Sedangkan Independent data mart adalah sebuah warehouse atau tempat penyimpanan kecil yang dirancang untuk sebuah bisnis unit strategis atau departemen yang sumbernya bukan dari enterprise data warehouse (EDW). Sebagai contohnya dapat dilihat pada gambar 2.7 dimana data mart tersendiri yang dimiliki oleh bagian finance, bagian manufaktur, dan bagian lainnya yang sumber datanya bukan dari enterprise data warehouse melainkan dari sistem transaksi pada suatu departemen.
Gambar 2.6 Contoh dependent data mart
Data source
Gambar 2.7 Contoh independent data mart
Menurut Connolly dan Begg (2010 : 1215), terdapat beberapa alasan penggunaan data mart yaitu sebagai berikut :
• Untuk memberikan akses kepada pengguna ke data yang sering dibutuhkan untuk analisis
• Untuk menyediakan data dalam bentuk yang sesuai dengan tampilan kolektif dari data oleh sekumpulan pengguna dalam sebuah departmen atau sekumpulan pengguna yang tertarik dengan suatu proses bisnis tertentu
• Untuk meningkatkan waktu respon pengguna akhir dengan adanya pengurangan jumlah data untuk diakses
• Untuk menyediakan data terstruktur yang layak sebagaimana sesuai dengan kebutuhan dari alat akses pengguna akhir seperti alat OLAP dan data mining, yang mungkin membutuhkan struktur internal database tersendiri
• Data mart menggunakan lebih sedikit data, sehingga proses ETL data lebih tidak kompleks dan pengimplementasian serta pengaturan data mart lebih sederhana dibandingkan dengan membangun enterprise data warehouse
• Biaya yang dibutuhkan untuk pengimplementasian data mart (dalam hal uang, waktu, dan sumber daya) biasanya lebih sedikit daripada yang dibutuhkan untuk membangun sebuah enterprise data warehouse.
• Pengguna dari data mart lebih jelas terdefinisi dan dapat lebih mudah untuk ditargetkan untuk mendapatkan dukungan untuk sebuah proyek data mart daripada proyek enterprise data warehouse.
2.2.3 Metadata
Metadata adalah data yang menerangkan data. Menurut Turban,Sharda, dan Delen (2010 : 332), metadata menjelaskan struktur dan beberapa arti dari data, sehingga dapat berkontribusi untuk penggunaan yang efektif atau tidak efektif. Sedangkan menurut Kimball, Reeves, Ross, dan Thornthwaite (1998 : 435), metadata di dalam data warehouse dapat dibagi menjadi dua yaitu front room metadata dan back room metadata. Front room metadata merupakan metadata yang lebih deskriptif dan dapat membantu query tool dan report writers berfungsi secara lancar. Front room metadata sebagian besar digunakan untuk kepentingan end user. Front room metadata mencakup seluruh area bisnis metadata dan BI teknikal metadata. Sebagai contohnya yaitu data model, laporan standar, metadata komponen front-end sistem BI, dan dokumen pengguna seperti manual, glossary, dan dokumen informasi bisnis. Sedangkan back room metadata berfungsi untuk membantu database administrator untuk membawa data ke dalam warehouse. Back room metadata berhubungan dengan proses dan menuntun proses ekstrasi, cleaning, dan loading data ke dalam data warehouse. Back room metadata mencakup seluruh area sumber data dan BI teknikal metadata. Sebagai contohnya yaitu ETL metadata, data model yang merupakan struktur data utama, dan audit trail untuk melakukan pengecekan pemakaian dan aksi yang dilakukan pada data.
Connolly dan Begg (2010 : 1206) menjabarkan bahwa metadata di dalam suatu warehouse dapat digunakan untuk berbagai macam tujuan, antara lain :
• Proses ekstrasi dan loading
Pada proses ini, metadata dapat digunakan untuk memetakan sumber data ke dalam tampilan umum dari data yang terdapat di dalam data warehouse. Metadata harus mendeskripsikan sumber data dan perubahan apapun yang
dilakukan terhadap data. Hal ini dapat dilakukan dengan memberikan identifikasi unik, nama field yang original, tipe sumber data, dan lokasi asal beserta nama sistem dan objek dengan tipe data destinasi dan nama tabel destinasinya ke dalam setiap field dari sumber.
• Proses manajemen warehouse
Pada proses ini, metadata digunakan untuk menghasilkan tabel summary secara otomatis dan menjelaskan data pada saat disimpan di dalam warehouse. Setiap objek yang ada dan data dalam setiap tabel, indeks, view, dan konstrain lain yang terkait harus dideskripsikan.
• Sebagai bagian dari proses manajemen query
Pada proses ini, metadata digunakan untuk mengarahkan query ke sumber data yang paling layak.
Dari pengertian di atas dapat diambil kesimpulan bahwa metadata merupakan data yang memiliki arti dan struktur yang menerangkan tentang suatu data yang memiliki peranan penting khususnya dalam membangun suatu data warehouse. Hal ini mengingat dari berbagai fungsi dari metadata yang dapat mendukung proses pembangunan dari data warehouse dan menjadikan data warehouse terintegrasi secara menyeluruh. Tujuan utama dari metadata dalam data warehouse adalah untuk dapat menunjukkan dari mana data berasal sehingga seorang administrator warehouse dapat mengetahui histori dari item dalam data warehouse. Contoh dari metadata dapat dilihat pada gambar 2.8.
SOURCE TARGET DATA SOURCE
LOAD STATUS
COLOUMN TYPE/LENGTH DESCRIPTION TABLE FIELD
NAME TYPE/LENGTH
KD_outlet Int SURROGATE
KEY CREATE
outlet_ID char(5) BUSINESS
KEY Msoutlet outlet_ID char(5) TRANSFORM BC_NAME varchar(50) Msoutlet outlet_NAME varchar(80) TRANSFORM
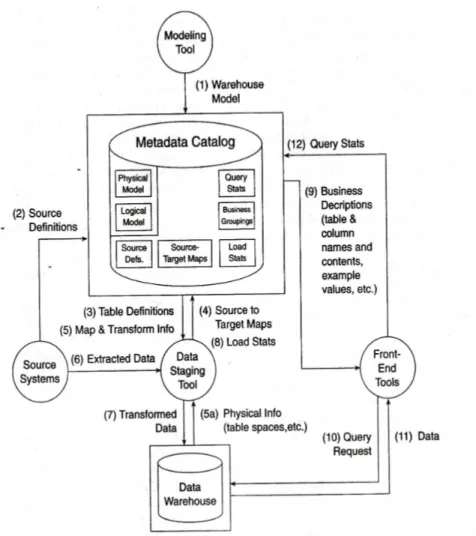
Menurut Kimball, Reeves, Ross, dan Thornthwaite (1998 : 439), metadata seperti sebuah sistem dokumentasi sederhana yang pengunaannya dapat terbatas bila di alihkan ke proyek lain. Untuk itu dibutuhkan metadata aktif yang merupakan metadata yang lebih menjalankan proses daripada dokumentasi. Active metadata dapat dihasilkan dengan menggunakan flow chart metadata sederhana seperti yang ditunjukkan pada gambar 2.9 di bawah.
Gambar 2.9 Metadata flow diagram
Dari diagram metadata flow diatas, terdiri dari tahapan-tahapan sebagai berikut : 1. Pengambilan model data warehouse
Pada awal dari tahap ini, diperlukan model data dari data warehouse. Secara teknis, proses ini dapat dilakukan dengan menggunakan salah satu dari tool modeling yang ada. Tool ini dapat digunakan untuk mengekstrak metadata dari database yang telah ada. Selain itu juga perlu dibuat model logikal dan fisikal yang terdiri dari nama kolom bisnis atau logikal, nama kolom fisikal, istilah dan deskripsi yang berhubungan dengan bisnis, nilai dari contoh, dan tips query. Setelah model dibuat dapat disimpan ke dalam model penyimpanan terbuka dalam database relasional dari tool tersebut.
2. Pengambilan definisi dari sumber data
Pada tahap ini dilakukan pengambilan definisi dari sumber data yang dapat berasal dari sistem sumber seperti flat files dan database mainframe. Hal ini dikarenakan tool dari staging data harus mengetahui tentang sumber selain target dari proses staging yang didapat dari langkah sebelumnya.
3. Pengambilan definisi dari tabel
Setelah dilakukan pengambilan definisi dari sumber data, langkah selanjutnya yaitu mengambil definisi tabel dari staging tool dan mendefinisikan hubungan mapping antara sumber dan targetnya. Pada tahap ini juga dilakukan pengambilan informasi tentang perubahan yang mungkin terjadi selama proses staging. Staging tool yang baik dapat mempengaruhi hasil metadata yang telah dibuat tentang tabel target pada tahap awal.
4. Menyimpan keseluruhan ke dalam model penyimpanan terbuka berbasis relasional dari data staging tool
Pada tahap ini, dapat diciptakan mapping sebanyak yang kita inginkan dengan mendefinisikan hubungan antara dua entri metadata yang telah ada dan menyimpannya di dalam metadata catalog.
5. Staging tool melakukan query terhadap metadata
Setelah itu, data staging tool melakukan query pada metadata untuk menemukan semua hal yang perlu diketahui tentang tipe dan lokasi dari sumber data, tipe dan lokasi data target, dan mapping diantaranya. Selain itu, juga dapat melakukan query terhadap database target untuk informasi saat ini dari kondisi fisik sistem. 6. Ekstraksi sumber data yang mentah
7. Memasukkan data transformasi ke dalam warehouse
8. Pengambilan beberapa informasi statistik dan audit tentang load dan menyimpan kembali di ke dalam metadata catalog
9. Membuat business metadata
Dengan adanya metadata yang telah dimasukkan, user dapat mengetahui dimana harus menemukan informasi yang diinginkan. Hal ini terdapat di dalam data model seperti nama tabel dan kolom, deskripsi dan contoh dari isi, dan sebagainya. Namun hal itu tidak lah cukup mengingat orang lebih cenderung berpikir pengelompokkan berdasarkan bisnis bukan berdasarkan daftar alfabetikal. Untuk mengatasi hal tersebut perlu dibuat business metadata. Pengelompokkan ini dapat berupa tabel fakta yang terdapat dalam dimensional modeling. Business metadata biasanya dapat dibuat dengan front-end tool atau application server. Setelah business metadata dihasilkan, akan sangat membantu untuk menyediakan front-end sederhana berbasis web untuk metadata. Hal ini dikarenakan user dapat melakukan pengelompokan berdasarkan bisnis, drill
down untuk melihat tabel di dalam pengelompokan, dan drill further untuk melihat kolom-kolom yang terletak di dalam tabel.
10. Formulasi query dan submit ke dalam database
Setelah ditemukan data yang tepat dari front-end tool, user dapat memformulasi query dan submit query ke dalam database.
11. Hasil data diberikan ke user
Setelah dilakukan formulasi query dan submit ke dalam database, hasil dari proses query yang berupa data/informasi diberikan kepada user melalui front-end tool dari data warehouse.
12. Penulisan beberapa pemakaian informasi
Setelah hasil data diberikan ke user, sebuah query tool yang baik harus menuliskan beberapa informasi pemakaian ke dalam metadata catalog.
2.2.4 ETL
ETL adalah singkatan dari Extraction , Transformation, dan Loading. ETL (Connolly dan Begg, 2010 : 1208) merupakan sebuah proses yang terdiri dari ekstraksi data dari satu atau lebih sumber data, perubahan data ke dalam bentuk yang konsisten dan mudah untuk dianalisis, dan kemudian dimasukkan ke dalam enterprise data warehouse (EDW).
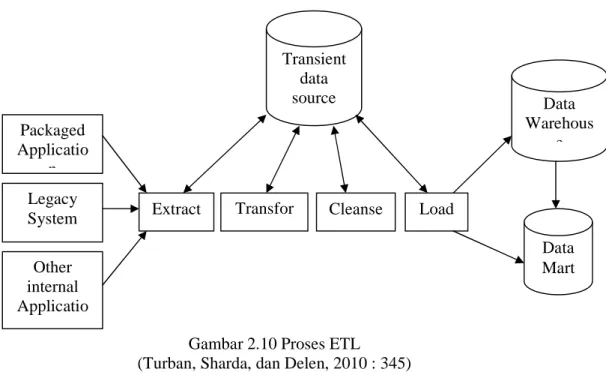
ETL merupakan hal yang sangat penting dalam integrasi data dan data warehouse. Tujuan dari proses ETL adalah untuk memberikan data yang terintegrasi dan bersih kepada warehouse. Agar lebih memahami proses dari ETL, proses tersebut dapat dilihat pada gambar 2.10 dibawah ini.
Gambar 2.10 Proses ETL (Turban, Sharda, dan Delen, 2010 : 345)
Proses ETL diawali dengan data yang nantinya akan digunakan di dalam data warehouse diambil dari sumber-sumber data seperti sistem sebelumnya, aplikasi internal lainnya dan packaged application. Data yang telah diekstrak tersebut kemudian disalin ke tempat penyimpanan sementara seperti staging area untuk kemudian dilakukan proses transformasi ke dalam bentuk yang sesuai dengan kebutuhan dan proses pembersihan data dari data-data yang tidak digunakan. Setelah proses transformasi selesai dilakukan, data kemudian baru dapat dimasukkan ke dalam data warehouse dan dapat digunakan lebih lanjut pada dependent data mart.
• Extraction
Extraction merupakan tahap awal dalam proses ETL dimana dilakukan proses ekstraksi atau pengambilan data-data dari sumber data yang berhubungan. Tahap extraction biasanya dilakukan dengan menyalin data yang telah diekstrak ke tempat penyimpanan sementara yang disebut Operational Data Store (ODS) atau Staging Area (SA). Sumber data untuk proses ETL dapat berasal dari file
Packaged Applicatio n Legacy System Other internal Applicatio ns Transient data source Extract Transfor m Cleanse Load Data Warehous e Data Mart
yang diambil dari database OLTP (Online Transaction Processing), spreadsheets, personal databases (i.e Microsoft Access), atau file eksternal.
• Transform
Transform merupakan tahap dimana data yang telah diekstrak dari sumber data kemudian diubah dari bentuk awal ke bentuk yang diinginkan sehingga dapat diletakkan di data warehouse atau database lain. Pada tahap ini dilakukan serangkaian aturan dan fungsi pada data yang telah diekstrak yang menentukan bagaimana data tersebut akan digunakan untuk analisis dan dapat dilibatkan dalam proses transformasi seperti penjumlahan data, penggabungan data, pemisahan data, dan encoding data. Hasil dari tahap transform adalah data yang bersih dan konsisten, data telah terletak di warehouse, serta data telah dalam bentuk yang dapat dianalisis oleh pengguna dari warehouse.
• Load
Load merupakan tahap akhir dari proses ETL dimana data diletakkan di dalam warehouse dan dapat terjadi setelah semua proses transformasi dilakukan ataupun sebagai bagian dari proses transformasi. Pada tahap ini, tambahan kendala yang didefinisikan dalam skema database seperti mandatory fields dan referential integrity akan diterapkan. Data di dalam warehouse dapat dilakukan penjumlahan lebih lanjut atau dikirimkan ke database lain yang berhubungan seperti data mart.
2.3 Business Intelligence
Business intelligence (Connolly dan Begg, 2010 : 1195) merupakan sebuah istilah yang mengacu pada proses pengumpulan dan analisis data, teknologi-teknologi yang digunakan di dalam proses ini, dan informasi yang didapatkan dari proses-proses ini yang digunakan untuk mendukung pengambilan keputusan di
dalam perusahaan. Dengan business intelligence, data dapat diubah ke dalam knowledge yang membantu organisasi dalam mengambil suatu keputusan untuk meningkatkan keuntungan kompetitifnya.
Menurut Negash, (2004 : 180) terdapat beberapa pekerjaan yang dapat dilakukan oleh business intelligence yaitu :
• Menciptakan peramalan yang didasarkan pada data historis, kinerja masa lampau dan masa kini, dan perkiraan tentang masa depan.
• Analisis ‘what-if’ dari dampak perubahan dan skenario alternatif
• Access ad-hoc ke data untuk menjawab pertanyaan yang spesifik dan non-routine
• Strategic insight
Menurut Chee, Chan, Chuah, Tan, Wong, dan Yeoh (2009 : 100), sistem business intelligence bukan merupakan suatu sistem baru melainkan produk dari berbagai tool dan teknik komputasi yang terintegrasi dan berevolusi. Secara teknikal, business intelligence yang mengintegrasikan berbagai tool tersebut memiliki komponen-kompenen penting yang harus terdapat di dalamnya.
2.3.1 Komponen Business Intelligence
Menurut Olszak dan Ziemba (2007 : 138-139), komponen penting tersebut terdiri dari ETL tools, data warehouse, analitical tools, data mining tools, reporting tools, dan presentation layer. Berikut ini merupakan penjabaran dari masing-masing komponen penting tersebut yaitu :
• Tool untuk proses extract-transform-load yang berfungsi untuk membawa data ke dalam data warehouse.
• Data warehouse yang menyediakan tempat penyimpanan untuk data agregat dan data yang siap untuk dianalisis.
• Analitical tool yang berupa OLAP yang dapat dilihat pada subbab 2.3.2 hal.35 yang berperan untuk memungkinkan pengguna untuk melakukan akses, analisis, dan memodelkan masalah bisnis dan berbagi informasi yang disimpan di dalam data warehouse.
• Tool data mining yang memungkinkan user untuk menemukan berbagai pola , generalisasi, dan aturan pada data.
• Tool untuk laporan dan ad-hoc yang memungkinkan untuk menciptakan dan memanfaatkan laporan sintetik yang berbeda.
• Presentation layer dimana aplikasi yang terdiri dari tampilan grafis dan multimedia dimana memiliki tugas untuk menyediakan informasi dalam bentuk yang mudah diakses dan nyaman kepada pengguna.
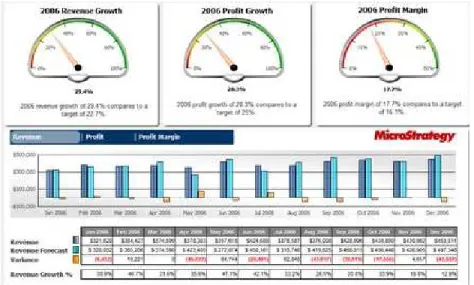
Terdapat berbagai jenis dari presentation layer yang dapat digunakan di dalam konsep business intelligence, namun presentation layer yang paling sering digunakan adalah performance dashboard. Performance dashboard (Turban, Sharda, dan Delen, 2010 : 408) merupakan suatu tool yang dapat menyediakan tampilan visual dari informasi penting yang digabungkan dan diatur pada suatu layar tunggal sehingga informasi dapat dicerna dengan cepat dan dieksplorasi dengan mudah. Performance dashboard lebih digunakan pada level operasional dan taktikal. Untuk lebih memahami bentuk dari performance dashboard, dapat dilihat pada gambar 2.11.
Gambar 2.11 Contoh performance dashboard
(http://www.dashboardzone.com/regional-performance-management-dashboard-microstrategy)
Menurut Eckerson (2006 : 13), terdapat tiga fitur aplikasi pada performance dashboard yaitu :
• Monitoring
Dengan adanya fitur aplikasi monitoring, dapat memberitahukan status dari kinerja dan tren yang sedang terjadi dengan cepat kepada pengguna. Fitur ini dapat diberikan dengan adanya gaugemeter seperti pada gambar 2.12 yang terdapat di dalam performance dashboard. Dengan adanya gaugemeter, user dapat melakukan pengamatan dengan cepat akan jumlah perbandingan dari profit margin aktual dengan profit margin yang ditargetkan.
• Analysis
Dengan fitur analisis, performance dashboard dapat membantu pengguna dalam memberitahukan adanya kondisi exception. Hal ini dapat dilakukan dengan adanya penanda berupa warna merah pada gaugemeter seperti pada gambar 2.12 yang dapat memberikan peringatan tentang adanya kondisi bahwa profit margin aktual telah melewati batas dari profit margin yang ditargetkan. Selain penanda berupa warna dapat juga ditandai dengan penanda berupa pop-up alert yang akan muncul pada kondisi tertentu seperti kondisi warning. Setelah mengetahui adanya kondisi yang ada, user kemudian dapat menganalisis faktor-faktor apa saja yang menjadi penyebab kondisi tersebut dan dapat mendukung untuk analisis strategi yang akan diambil.
• Management
Dengan adanya fitur aplikasi manajemen, dapat mendukung berbagai jenis proses bisnis baik formal dan informal yang dapat mengarahkan bagaimana user berbagi informasi dari kinerja yang ada saat ini. Sebagai contohnya yaitu adanya informasi berupa laporan dalam bentuk grafik tentang jumlah pendapatan setiap bulan selama tahun 2006 seperti pada gambar 2.11 di atas.
Selain tiga fitur aplikasi di atas, menurut Eckerson (2006 : 14) terdapat juga tiga tampilan atau layer dari informasi yang terdapat di dalam performance dashboard yaitu :
• Summarized graphical view
Merupakan bagian layer paling atas yang menyediakan tampilan yang ringkas dari status dari kondisi exception dan key performance metric yang biasanya berupa tampilan grafis seperti gaugemeter. Kondisi exception dapat
ditunjukkan dengan adanya peringatan yang muncul pada layar dan juga adanya perubahan warna pada bentuk ,simbol, ataupun grafik yang berhubungan dengan metrik. Sebagai contohnya dapat dilihat pada gambar 2.12 dimana gaugemeter dapat memberikan tampilan yang ringkas tentang jumlah pencapaian profit margin aktual dengan profit margin yang ditargetkan secara langsung kepada user.
• Multidimensional view
Multidimensional view merupakan layer yang terletak di tengah dimana berperan dalam menyediakan data pada metrik grafis dan alert. Salah satu teknologi yang dapat mendukung tampilan multidimensional adalah OLAP dimana user dapat melihat data berdasarkan dimensi ataupun hierarki yang diinginkan. Sebagai contohnya dapat dilihat pada gambar 2.13 dimana user dapat mengatur tampilan informasi sesuai dengan variabel yang diinginkan. User dapat melihat informasi penjualan berdasarkan tahun penjualan dan produknya ataupun berdasarkan nama customer dan produknya.
Gambar 2.13 Contoh multidimensional view pada performance dashboard (http://demos.devexpress.com/ASPxPivotGridDemos/Features/Drilldown.asp
x) • Detailed reporting view
Merupakan layer paling bawah yang dapat memberikan tampilan laporan yang detail dan juga catatan dari transaksi-transaksi kepada user. Sebagai contoh dari layer ini yaitu dapat dilihat pada gambar 2.14 dimana dapat ditampilkan data detail dari pemesanan alfreds futterkiste untuk aniseed syrup seperti jumlah pemesanan dan tanggal pemesanannya dengan mengklik fieldnya.
Gambar 2.14 Contoh detailed reporting view pada performance dashboard (http://demos.devexpress.com/ASPxPivotGridDemos/Features/Drilldown.asp
2.3.2 OLAP
OLAP adalah singkatan dari Online Analytical Processing. Menurut Connolly dan Begg (2010 : 1250), OLAP merupakan sebuah istilah yang menjelaskan teknologi yang menggunakan tampilan mutidimensional dari data agregat untuk menyediakan akses yang cepat ke informasi dengan tujuan analisis yang advanced. OLAP memungkinkan pengguna untuk mendapatkan pemahaman dan pengetahuan yang mendalam tentang berbagai aspek dari data perusahaan melalui akses yang cepat, konsisten, dan interaktif ke berbagai jenis tampilan yang memungkinkan dari data.
Salah satu kebutuhan penting dari aplikasi OLAP yaitu kemampuan untuk menyediakan informasi kepada pengguna yang mampu digunakan untuk membuat keputusan efektif tentang arah dari organisasi. Menurut OLAP Council White, terdapat beberapa fitur penting yang harus dimiliki oleh semua aplikasi OLAP, antara lain :
• Tampilan data yang multidimensional
Tampilan data yang multidimensional dari sebuah data korporat merupakan kebutuhan inti dari membangun sebuah model bisnis. Hal ini dikarenakan dengan adanya tampilan yang multidimensional, user dapat melihat data dalam sebuah laporan dari berbagai sudut pandang. Dengan adanya tampilan yang multidimensional, menyediakan dasar untuk pemrosesan analitikal melalui akses yang fleksibel ke data korporat. Data multidimensional dapat ditampilkan dengan menggunakan beberapa format yaitu tabel relasional, matrix, dan data cube.
Sebuah software OLAP harus menyediakan berbagai metode komputasi yang kuat yang menggunakan algoritma tren seperti moving average dan presentase dari pertumbuhan yang salah satu contohnya dapat digunakan untuk peramalan penjualan di masa yang akan datang.
• Time Intelligence
Time intelligence merupakan fitur kunci di dalam hampir semua aplikasi analitikal dimana kinerja selalu diukur berdasarkan waktu. Sebagai contohnya, aplikasi OLAP harus dapat membandingkan data bulan ini dengan bulan lalu atau bulan ini dengan bulan yang sama di tahun lalu.
Menurut Connolly dan Begg (2010 : 1257), dengan adanya tampilan yang multidimensional sebagai salah satu fitur yang penting dari teknologi OLAP terdapat beberapa operasi yang dapat dilakukan pada data multidimensional yaitu sebagai berikut :
• Roll-up
Roll-up merupakan suatu operasi dimana dapat melakukan proses agregasi pada data dengan bergerak ke atas hierarki dimensional atau dengan dimensional reduction seperti melihat data dengan empat dimensi sebagai data dengan tiga dimensi. Sebagai contoh dari operasi roll-up adalah user dapat melihat data berdasarkan kode area kemudian berdasarkan wilayah dan berdasarkan kota.
• Drill-down
Drill-down merupakan operasi dimana prosesnya merupakan kebalikan dari proses roll up dan berhubungan dengan menampilkan data yang detail yang membentuk data agregat. Drill-down dapat dilakukan dengan bergerak ke bawah hierarki dimensional. Sebagai contoh dari operasi drill-down adalah user dapat
melihat tampilan data berdasarkan region ke kota dan ke wilayah. Untuk lebih jelasnya operasi drill-down dapat dilihat pada gambar 2.15 di bawah ini.
Gambar 2.15 Contoh operasi drill-down (Inmon, 2005 : 243) • Slice and dice
Slice and dice merupakan operasi dimana memiliki kemampuan untuk melihat data dari sudut pandang yang berbeda-beda. Operasi slice memungkinkan untuk seleksi satu dimensi dari data sedangkan operasi dice memungkinkan untuk seleksi dari dua atau lebih dimensi. Sebagai contoh operasi slice adalah data yang dihasilkan dari data sales dimana tipe customer =’binusian’ sedangkan contoh dari operasi dice adalah data yang dihasilkan dari data sales dimana dilakukan pemilihan dari dua atau lebih dimensi seperti tipe customer =’binusian’ dan tipe pembayaran=’debit’.
• Pivot
Pivot merupakan operasi dimana memiliki kemampuan untuk memutar data untuk menyediakan tampilan alternatif atau berbeda dari data yang sama. Sebagai contoh dari operasi pivot adalah data sales yang dapat ditampilkan dengan produk di axis x dan waktu axis y ataupun dengan tampilan sebaliknya yaitu produk di axis y dan waktu di axis x.
2.3.3 Executive Information System
Salah satu konsep dari sistem informasi yang dapat menerapkan konsep dan tool dari business intelligence adalah sistem informasi eksekutif. Sistem informasi eksekutif (Watson, Houdeshel, dan Rainer, 1997 : 3) merupakan sistem komputerisasi yang menyediakan akses yang mudah ke informasi internal maupun eksternal yang berhubungan dengan critical success factor kepada para eksekutif. Sedangkan menurut McLeod dan Schell (2007 : 191), sistem informasi eksekutif merupakan sebuah sistem yang menyediakan informasi kepada manajer tingkat atas tentang keseluruhan kinerja dari perusahaan. Dengan SIE, informasi dapat diambil secara mudah dan pada berbagai level kedetailan. Jadi, dari pengertian di atas dapat disimpulkan bahwa sistem informasi eksekutif merupakan sistem yang dapat menyediakan informasi dengan mudah kepada para eksekutif yang dapat digunakan untuk penentuan strategi yang berhubungan dengan critical success factor bagi perusahaan.
Dengan menerapkan sistem informasi eksekutif , sebuah perusahaan dapat memperoleh keuntungan kompetitif dalam bersaing dengan perusahaan kompetitornya. Hal ini juga diakui oleh Papageorgiou dan Bruyn (2010 : 66) yang menyatakan bahwa dengan mempergunakan EIS, seluruh pengguna dalam bisnis akan mendapatkan keuntungan kompetitif dibandingkan kompetitornya dan diposisikan secara strategis dalam lingkungan bisnis yang terus berubah. Menurut McLeod dan Schell (2001 : 331), terdapat tiga konsep fundamental dari manajemen yang dapat digunakan dalam EIS yaitu :
• Critical success factors
EIS memungkinkan eksekutif untuk melakukan pengawasan tentang seberapa berhasilnya perusahaan dalam hal tujuan dan juga critical success factornya.
• Management by exception
Dengan EIS, eksekutif dapat melakukan management by exception dengan melakukan perbandingan antara kinerja yang dibudget dan kinerja sebenarnya. EIS software dapat secara otomatis mengidentifikasi pengecualian yang ada dan membuat pengecualian tersebut menarik perhatian eksekutif.
• Mental Models
Peran utama dari EIS adalah untuk menggabungkan atau melakukan penyaringan pada data dan informasi yang berjumlah besar untuk meningkatkan utilitasnya. Proses tersebut biasa disebut kompresi informasi dan menghasilkan tampilan atau model mental dari kegiatan perusahaan.
Untuk dapat disebut sebagai sistem informasi eksekutif (SIE), sebuah sistem harus memiliki karakteristik yaitu :
• Disesuaikan dengan individu dari pengguna eksekutif • Ekstrak, filter, kompres, dan pelacakan data kritikal
• Menyediakan akses status on-line, analisis tren, exception reporting, dan drilldown (yang memungkinkan user untuk mengakses detail yang mendukung atau data yang mendasari data yang diringkas)
• Akses dan integrasi berbagai data internal dan eksternal
• User friendly dan membutuhkan sedikit training atau tidak adanya training sama sekali untuk menggunakannya
• Digunakan langsung oleh eksekutif tanpa adanya perantara
• Mempresentasikan informasi berupa grafis, tabular, atau informasi tekstual Menurut Inmon (2005 : 240), terdapat beberapa manfaat tipikal dari SIE yaitu sebagai berikut :
• Pemantauan dan pengukuran indikator key ratio • Analisis drill-down
• Pemantauan masalah • Analisis kompetitif
• Pemantauan key performance indicator (KPI)
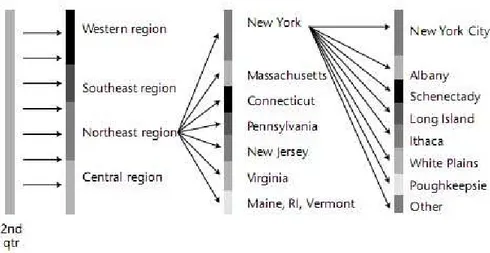
Agar dapat lebih memahami sistem informasi eksekutif , berikut dapat dilihat contoh dari tampilan SIE pada gambar 2.16 di bawah ini.
Dari contoh di atas dapat dilihat dengan adanya SIE, seorang eksekutif dapat melihat tampilan total dari policies yang ada, melihat tampilan dari total new casualty policies, dan kemudian mengidentifikasi tren dari new casualty policies yang ada yaitu adanya penurunan dari sales casualty di setiap kuarter. Dan kemudian dari tren yang ada tersebut, seorang eksekutif dapat mencari tahu penyebab terjadinya penurunan tersebut.
Sistem informasi eksekutif memiliki hubungan yang sangat erat dengan data warehouse karena data warehouse dapat beroperasi dengan kondisi yang paling efektif bila berada di dalam lingkungan sistem informasi eksekutif . Hal ini dikarenakan data warehouse menyediakan infrastruktur atau basis data yang dibutuhkan oleh seorang SIE analis untuk mendukung pemrosesan SIE secara efektif. Selain itu, data warehouse beroperasi pada level granularity yang rendah. Hal ini sangat dibutuhkan oleh sistem informasi eksekutif dimana kebutuhan informasi dari suatu perusahaan tidak diketahui dengan pasti. Menurut Inmon (2005 : 247), dengan adanya data warehouse dapat mempermudah pekerjaan dari seorang SIE analis. Hal-hal yang dapat diberikan oleh data warehouse kepada seorang SIE analis yaitu : • Mengakses informasi secara cepat
• Melihat data yang terintegrasi
• Menganalisa data melalui spektrum waktu • Operasi drill-down
Dalam membangun sebuah aplikasi sistem informasi eksekutif , diperlukan sebuah model arsitektur yang dapat digunakan untuk membantu proses perancangannya. Berdasarkan Cheung dan Babin (2006 : 1590), arsitektur tradisional dari SIE terdiri dari dua komponen utama yaitu database terpusat yang menyimpan data yang diekstrak dari berbagai sumber dan engine yang digunakan untuk analisis
data dan presentasi dari hasilnya. Namun arsitektur tradisional ini memiliki kekurangan pada kompleksnya proses ekstraksi dan update data dari sumber data lokal yang berbeda ke dalam database terpusat sehingga dikembangkanlah arsitektur baru yaitu arsitektur kontemporer SIE yang digabungkan dengan teknologi data warehouse dan OLAP yang dapat dilihat pada gambar 2.17.
Gambar 2.17 Arsitektur kontemporer SIE (Cheung dan Babin, 2006 : 1591) Berdasarkan model arsitektur kontemporer SIE di atas, data yang berasal dari sumber data lokal yang berbeda diekstrak, dibersihkan dan ditransformasi oleh bagian yang dinamakan integrator yang didasarkan pada skema data yang terintegrasi dan setelah itu ditempatkan di dalam data warehouse. Data yang terdapat di dalam data warehouse kemudian dapat dilakukan proses analisis data multidimensional dengan teknik OLAP sehingga memungkinkan user untuk melihat tampilan data dari berbagai dimensi yang diinginkan. Dari penjelasan tersebut, dapat dilihat bahwa OLAP juga dapat digunakan untuk mendukung SIE.
2.4 Unified Process
Unified process (Satzinger, Jackson, dan Burd, 2004 : 50) merupakan sebuah metodologi pengembangan sistem yang berorientasi pada objek. Di dalam unified process terdapat empat fase siklus yaitu :
• Inception
Inception merupakan fase dimana manajer dari proyek mengembangkan dan mendefinisikan visi untuk sistem baru untuk menunjukkan bagaimana sistem dapat meningkatkan operasi dan menyelesaikan masalah yang ada. Selain itu pada fase ini juga dibuat kasus bisnis, pendefinisian ruang lingkup, dan perkiraan kasar dari biaya dan jadwal pelaksanaan. Pada fase ini, biasanya hanya dilakukan dalam satu iterasi.
• Elaboration
Pada fase ini biasanya dilakukan beberapa iterasi. Tujuan dari fase ini yaitu untuk mengkaji kembali visi, mengidentifikasi dan menjelaskan seluruh kebutuhan , finalisasi ruang lingkup, desain dan implementasi arsitektur inti dan fungsinya, dan menghasilkan estimasi yang realistis dari biaya dan penjadwalan.
• Construction
Pada fase construction melibatkan beberapa kali iterasi yang melanjutkan proses desain dan implementasi dari sistem. Tujuan dari fase ini untuk mengimplementasi sisa dari elemen yang memiliki resiko yang lebih rendah, dapat diprediksi, dan lebih mudah dan menyiapkan untuk proses deployment.
• Transition
Dalam fase transition, iterasi final melibatkan proses user-acceptance dan beta test. Proses user-acceptance bertujuan agar sistem yang dibangun dapat menghasilkan manfaat bagi penggunanya.
Di dalam setiap fase pada unified process life cycle, dilakukan proses iterasi berdasarkan disiplin-disiplin yang ada. Siklus hidup dari unified process ini dapat dilihat pada gambar 2.18. Menurut Satzinger, Jackson, dan Burd (2004 : 52), disiplin merupakan suatu kumpulan aktivitas yang terhubung secara fungsional yang bersama-sama berkontribusi ke satu aspek dari proyek pengembangan unified process. Terdapat enam disiplin utama dari proses pengembangan dengan model unified process yaitu :
• Business modeling
Tujuan utama dalam business modeling adalah untuk memahami dan mengkomunikasikan keadaan dari lingkungan bisnis dimana sistem baru akan digunakan. Di dalam disiplin ini, terdapat akivitas utama yang harus dilakukan yaitu memahami lingkungan bisnis, menciptakan visi dari sistem, dan menciptakan model dari bisnis. Pada disiplin ini dilakukan proses business modeling dengan menggunakan rich picture dan data flow diagram. Untuk lebih jelasnya, rich picture dapat dilihat di sub bab 2.5.1 hal. 50 dan data flow diagram dapat dilihat di sub bab 2.5.2 hal 52.
• Requirement
Tujuan utama dari requirement adalah untuk memahami dan mendokumentasikan kebutuhan bisnis dan pemrosesan kebutuhan untuk sistem baru. Aktivitas di dalam disiplin ini adalah mengumpulkan informasi yang detail, mendefinisikan kebutuhan fungsional dan nonfungsional, memprioritaskan kebutuhan, mengembangkan dialog dari user interface, dan mengevaluasi kebutuhan dengan user.
• Design
Tujuan dari desain adalah untuk mendesain sistem solusi yang didasarkan pada kebutuhan yang sebelumnya telah didefinisikan. Terdapat enam aktivitas utama di dalam disiplin ini yaitu mendesain arsitektur yang mendukung servis dan lingkungan deployment, arsitektur software, realisasi use case, database, sistem dan user interface, serta tingkat keamanan dan kontrol dari sistem. Pada disiplin ini dilakukan desain dengan menggunakan UML seperti use case yang dapat dilihat di sub bab 2.6.1 hal. 56, class diagram sub pada bab 2.6.2 hal. 59, sequence diagram pada sub bab 2.6.3 hal. 64, navigation diagram pada sub bab 2.6.4 hal. 67, dan deployment diagram pada sub bab 2.6.5 hal. 67.
• Implementation
Di dalam implementation, terdapat beberapa aktivitas seperti membangun, mendapatkan, dan mengintegrasikan komponen perangkat lunak.
• Testing
Di dalam testing terdapat beberapa aktivitas seperti mendefinisikan dan melakukan unit testing, integration testing, usability testing, dan user acceptance testing. Usability testing biasanya berfokus pada melakukan pengecekan pada manfaat dan mudahnya penggunaan dari desain user interface.
• Deployment
Aktivitas deployment dapat terjadi pada setiap iterasi namun lebih sering terjadi pada proses persiapan untuk fase transition. Aktivitas yang terdapat pada deployment adalah mendapatkan hardware dan software sistem, penginstalan komponen, training user, dan konversi serta inisialisasi data.
Gambar 2.18 Siklus hidup dari unified process dengan fase, iterasi, dan disiplin
(http://www.devarticles.com/c/a/Development-Cycles/Organizing-RUP-SE-Projects/1/) 2.5 Proses Modeling
Proses bisnis (Whitten, Bentley, dan Dittman, 2004 : 27) merupakan pekerjaan, prosedur, dan aturan yang diperlukan untuk menyelesaikan tugas bisnis, tanpa adanya teknologi informasi yang digunakan untuk mendukung hal tersebut. Proses bisnis wajib untuk dipahami sebelum dapat melakukan proses analisis akan kebutuhan sistem informasi dari sebuah perusahaan. Untuk itu, dalam menggambarkan suatu proses bisnis di dalam perusahaan dibutuhkan sebuah pemodelan akan proses bisnis yang bertujuan untuk membantu memberikan gambaran secara keseluruhan akan proses bisnis yang terjadi di dalam sebuah perusahaan kepada seorang user. Beberapa tool yang dapat digunakan dalam melakukan proses modeling yaitu rich picture dan data flow diagram.
2.5.1 Rich Picture
Menurut Mathiassen, Munk-Madsen, Nielsen, dan Stage (2000 : 26), Rich picture merupakan gambaran informal yang mempresentasikan pemahaman dari ilustrator akan situasi yang ada. Sebuah rich picture harus dapat memberikan pemahaman yang luas meskipun tujuan dari rich picture bukan untuk menciptakan deskripsi yang detail melainkan memberikan sebuah gambaran dari situasi secara
cepat. Dalam membuat sebuah rich picture tidak didasarkan pada notasi spesial. Bentuk notasi hanya ditentukan berdasarkan kesepakatan bersama di dalam proyek tentang bagaimana aspek-aspek yang ada dideskripsikan. Terdapat beberapa komponen dalam membangun sebuah rich picture yaitu :
• Entitas
Dalam membuat rich picture sebaiknya diawali dengan mengambar entitas yang penting seperti orang, objek fisik, tempat, organisasi, peran, dan tugas.
• Proses
Setelah mendeskripsikan entitas-entitas yang relevan, kemudian dilanjutkan dengan mendeskripsikan relasi diantara entitas tersebut yang dilakukan dengan menghubungkan elemen yang ada di dalam rich picture. Proses menjelaskan aspek dari situasi yang dapat berubah, tidak stabil, dan dibawah pengembangan. • Struktur
Struktur juga menjelaskan adanya hubungan dari elemen-elemen di dalam rich picture. Namun struktur lebih menjelaskan aspek dari situasi yang stabil dan tidak mudah berubah.
• Masalah
Masalah merupakan suatu keadaan yang menggambarkan adanya konflik dan perbedaan dalam relasi di dalam proses dan struktur. Sebagai contoh dari masalah yaitu adanya perbedaan antara keinginan pasien dan karyawan yang telah puas dengan kondisi ruang yang terpisah dan keinginan dari manajemen yang ingin lebih memanfaatkan sumber daya yang ada.
Menurut Mathiassen, Munk-Madsen, Nielsen, dan Stage (2000 : 31), rich picture dianggap bermanfaat dalam sebuah pendefinisian sistem bila rich picture mengandung banyak informasi dan terbuka untuk diinterpretasikan, menjelaskan
struktur dan proses, menunjukkan paling tidak satu area masalah, beberapa sistem terkomputerisasi yang berhubungan, dan menghindari menampilkan data dan pemrosesan data. Berikut contoh dari rich picture pada gambar 2.19.
Gambar 2.19 Contoh rich picture 2.5.2 Data Flow Diagram
Data flow diagram (Whitten, Bentley, dan Dittman, 2004 : 344) merupakan model proses yang digunakan untuk menunjukkan aliran dari data di dalam sistem dan kerja atau pemrosesan yang dilakukan oleh sistem. Data flow diagram juga dikenal dengan bubble chart, transformation graph, dan process model. Terdapat beberapa komponen dalam membuat data flow diagram yaitu :
• Proses
Proses merupakan pekerjaan yang dapat ditangani oleh sistem dalam responnya terhadap adanya aliran data atau kondisi yang masuk ke dalam sistem. Dalam memahami konsep proses di dalam data flow diagram, terdapat dua istilah
penting yang harus diketahui yaitu function dan event. Function merupakan sekumpulan dari aktivitas bisnis yang berhubungan dan sedang berlangsung sedangkan sebuah event merupakan bagian logikal dari kerja yang harus diselesaikan secara keseluruhan. Function terdiri dari proses-proses yang merespon kepada event yang ada. Setiap event memiliki pemicu dan respon yang akan dihasilkan. Sebagai contohnya di dalam function manajemen bahan baku dapat merespon event-event seperti pengecekan kualitas bahan baku, melakukan stok bahan baku baru, dan pembuangan bahan baku yang rusak. Proses biasanya digambarkan dalam bentuk oval atau bubble. Sebuah proses event dapat diubah lebih lanjut ke dalam bentuk proses elementary yang menggambarkan ke dalam bentuk yang detail bagaimana sistem harus merespon terhadap adanya event. Proses elementary juga disebut dengan proses primitif. Menurut Whitten, Bentley, dan Dittman (2004 : 351), dalam membuat proses terdapat beberapa kesalahan yang umum terjadi yaitu adanya input namun tidak ada output, adanya output tetapi tidak ada input, dan adanya input yang tidak mencukupi untuk menghasilkan output.
• Agen eksternal
Agen eksternal merupakan orang luar, bagian organisasi, sistem, atau organisasi yang berinteraksi langsung dengan sistem. Agen eksternal dapat digambarkan dengan bentuk persegi dengan sudut siku-siku.
• Data stores
Data stores merupakan istilah yang digunakan dalam data flow diagram untuk menjelaskan tempat penyimpanan dari data yang nantinya dapat digunakan. Dalam penamaan suatu data store harus menghindari pemakaian istilah fisik seperti file, database, file folder, dan hal lainnya yang serupa.
• Data flows
Data flows merupakan representasi bentuk dari adanya input data ke dalam proses dan output dari data dari proses. Selain itu data flows juga digunakan untuk menggambarkan pembuatan, membaca, menghapus, dan mengupdate data di dalam file atau database atau disebut juga data store di dalam data flow diagram. Data flows digambarkan dalam bentuk tanda panah.
Jadi, dari pengertian di atas dapat disimpulkan bahwa data flow diagram merupakan suatu bentuk model diagram yang menggambarkan adanya aliran data dari agen eksternal yang berhubungan langsung dengan sistem, proses-proses yang ada, dan data storenya. Berikut contoh dari data flow diagram pada gambar 2.20.
trRegistration
trPayment
Gambar 2.20 Contoh data flow diagram
Selain data flow diagram, terdapat beberapa jenis lain dari data flow diagram yang harus dipahami di dalam pemodelan proses yaitu context data flow diagram dan primitive data flow diagram. Menurut Whitten, Bentley, dan Dittman (2004 : 372), context data flow diagram merupakan sebuah model proses yang digunakan untuk mendokumentasikan ruang lingkup pada sistem. Sebuah context data flow diagram mengandung hanya satu proses, eksternal agen yang digambarkan
Customer 2.0 melakukan pembayara n 1.0 melakukan pendaftaran