ANALISIS HASIL UJIAN NASIONAL TAHUN 2016-2019 TINGKAT SEKOLAH MENENGAH PERTAMA
DENGAN PENDEKATAN SAINS DATA
TESIS
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Magister Pendidikan
Program Studi Pendidikan Matematika Program Magister
MARGARETHA NOBILIO PASIA JANU NIM : 181442009
PROGRAM STUDI PENDIDIKAN MATEMATIKA PROGRAM MAGISTER JURUSAN PENDIDIKAN MATEMATIKA DAN ILMU PENGETAHUAN ALAM
FAKULTAS KEGURUAN DAN ILMU PENDIDIKAN UNIVERSITAS SANATA DHARMA
YOGYAKARTA 2020
i
ANALISIS HASIL UJIAN NASIONAL TAHUN 2016-2019 TINGKAT SEKOLAH MENENGAH PERTAMA
DENGAN PENDEKATAN SAINS DATA
TESIS
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Magister Pendidikan
Program Studi Pendidikan Matematika Program Magister
MARGARETHA NOBILIO PASIA JANU NIM : 181442009
PROGRAM STUDI PENDIDIKAN MATEMATIKA PROGRAM MAGISTER JURUSAN PENDIDIKAN MATEMATIKA DAN ILMU PENGETAHUAN ALAM
FAKULTAS KEGURUAN DAN ILMU PENDIDIKAN UNIVERSITAS SANATA DHARMA
YOGYAKARTA 2020
iv
MOTTO DAN HALAMAN PERSEMBAHAN
“...Dan bukan hanya itu saja, kita malah bermegah juga dalam kesengsaraan kita. Karena kita tahu, bahwa kesengsaraan itu menimbulkan ketekunan, dan ketekunan menimbulkan tahan uji, dan tahan uji menimbulkan pengharapan”
(Roma 5:3:4)
Karya ini kupersembahkan untuk Tuhan Yesus yang penuh dengan kesetiaan juga untuk Papa Nober, Mama Bibiana, dan para sahabat (Grace,Atok, Lolik, Jimi).
vii ABSTRAK
Janu, Margaretha Nobilio Pasia.(2020).Analisis Hasil Ujian Nasional Tahun 2016-2019 Tingkat Sekolah Menengah Pertama dengan Pendekatan Sains Data.
Penelitian ini bertujuan untuk: (1) mengetahui hasil analisis hasil Ujian Nasional semua provinsi di Indonesia yang diperoleh melalui visualisasi data, (2) mengetahui nilai mana yang paling berpengaruh terhadap capaian nilai ujian nasional, dan (3) mengetahui hasil analisis klaster pada data Ujian Nasional.
Jenis penelitan yang dipakai adalah deskriptif-kuantitatif dengan analisis.
Objek penelitian dalam tulisan ini adalah data UN 2016-2019 tingkat Sekolah Menengah Pertama. Langkah analisis data dimulai dengan (1) mengumpulkan dan membaca berbagai literatur Sains Data, (2) mengumpulkan data hasil Ujian Nasional dari laman puspendik.kemdikbud.go.id/hasilun/, (3) membuat visualisasi, (4) menganalisis hasil visualisasi, (5) melakukan Analisis Komponen Utama dengan bantuan perangkat lunak R, dan (6) melakukan analisis hasil klasterisasi wilayah.
Dengan menggunakan uji Friedmann yang bertujuan untuk melihat ada tidaknya perbedaan rata-rata yang signifikan terhadap capaian UN, diketahui bahwa secara nasional terdapat perbedaan rata-rata antara tahun 2016 dengan tahun 2017,2018, dan 2019 untuk semua mata pelajaran. Pemberlakuan soal HOTS, pelakasanaan UNBK dan pelaksanaan USBN diprediksi turut berpengaruh terhadap turunnya rata-rata Ujian Nasional. Pembagian wilayah berdasarkan zona waktu menunjukkan terdapat perbedaan rata-rata di zona WIT, WITA, dan WIB setiap tahunnya, sementara berdasarkan tahun pelaksanaannya disimpulkan tidak ada perbedaan rata-rata yang signifikan antar ketiga zona waktu. Terdapat tujuh provinsi yang menunjukkan hasil capaian nilai rata-rata berada di bawah capaian nilai rata-rata secara nasional yaitu provinsi Aceh,Jambi,Sumatera Selatan,Kalimantan Barat,Lampung,NTB, dan Banten.
Hasil Analisis Komponen Utama menunjukkan tahun 2016 dan 2019 mata pelajaran yang menyumbang nilai cukup besarterhadap tinggiatau rendahnyacapaian nilai rata-rata UN secara nasional adalah Bahasa Inggris dan IPA.Sementara pada tahun 2017 dan 2018 adalah Matematika dan IPA. Hasil analisis klaster pada tingkat nasional dengan K-Means Clustering menunjukkan dari empat klaster yang terbentuk ada enam provinsi lain yang masuk dalam klaster yang sama dengan ketujuh provinsi yang mencapai nilai rata-rata terendah selama empat tahun terakhir untuk semua mata pelajaran. Proses klasterisasi pada provinsi Nusa Tenggara Timur menghasilkan tiga klaster. Klaster dengan capaian rata-rata rendah adalah klaster 3. Kabupaten-kabupaten di pulau Flores masuk dalam kelompok klaster dengan capaian nilai yang cukup baik.Proses klasterisasi di Kabupaten Manggarai menghasilkan empat klaster. Daerah di desa lebih banyak berada pada klaster terbaik.
Kata Kunci : Sains Data, Unsupervised Learning, Analisis Komponen Utama, Klaster
viii ABSTRACT
Janu, Margaretha Nobilio Pasia. (2020). Analysis of the 2016-2019 National Exam Results for Junior High Schools Using Data Science Approach.
This study aims to: (1) find out an analysis result of National Examination result of all provinces in Indonesia obtained through of all provinces in Indonesia, which are obtained through data visualization, (2) find out which scores influence the national exam result the most, and (3) acknowledge the results of cluster analysis on the National exam data.
This is a descriptive-quantitative with analysis research. The object of this research is junior high school’s 2016-2019 national examination result. The data was analysedby (1) collecting and reading various Data Science literature, (2) collecting the National Examination results as a data from puspendik.kemdikbud.go.id/hasilun/, (3) creating visualizations, (4) analyzing the results of the visualization, (5) analyzing the Principle Component using R software, and (6) performing an analysis of the regional clustering results.
By using the Friedmann test which aims to see whether there is a significant difference in the average on National Examination results. It is acknowledged that there is a national average difference within 2016 to 2017 and 2018 to 2019 for all subjects. The implementation of HOTS questions, the implementation of UNBK and the implementation of USBN are predicted to have an effect on the decline in the National Exam average. The division of regions based on time zones shows that there are average differences in the WIT, WITA, and WIB zones each year.
However there is no significant difference in the average between the three time zones based on the year of the implementation. There are seven provinces which results are below the national average, namely the provinces of Aceh, Jambi, South Sumatra, West Kalimantan, Lampung, NTB, and Banten. The results of the main component analysis show that in 2016 and 2019 the subjects that contributed significantly to the fluctuation in the national examination average were English and Science, while in 2017 and 2018 were Mathematics and Science. The results of the cluster analysis at the national level with K-Means Clustering show that out of the four clusters formed, there are six other provinces that are included in the same cluster with those which achieved the lowest average score over the last four years for all subjects. The clustering process in the province of East Nusa Tenggara resulted in three clusters. The cluster with low average performance is the third cluster. The districts on the island of Flores are included in the cluster group with fairly good scores. The clustering process in Manggarai Regency produces four clusters. Most of the areas in the village are in the best cluster.
Keywords: Sains Data, Unsupervised Learning, Analisis Komponen Utama, Klaster
xi DAFTAR ISI
HALAMAN JUDUL i
HALAMAN PERSETUJUAN PEMBIMBING ii
HALAMAN PENGESAHAN iii
HALAMAN MOTTO DAN PERSEMBAHAN iv
HALAMAN PERNYATAAN KEASLIAN KARYA v
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
vi
ABSTRAK vii
ABSTRACT viii
KATA PENGANTAR ix
DAFTAR ISI xi
DAFTAR GAMBAR xiv
DAFTAR TABEL xvii
BAB I PENDAHULUAN 1
A. Latar Belakang 1
B. Rumusan Masalah 7
C. Tujuan Penelitian 7
D. Tinjauan Pustaka 8
E. Kebaruan Penelitian 8
F. Batasan Masalah 8
G. Metode Penelitian 8
xii
H. Sistematika Penulisan 9
BAB II LANDASAN TEORI 11
A. Pengertian Data 11
B. Sains Data 12
C. Visualisasi Data 17
D. Ukuran Pemusatan dan Penyebaran Data 20
E. Uji Statistik-Uji Friedmann 22
F. Analisis Komponen Utama 26
G. Analisis Klaster Berbasis K-Means 33
BAB III METODOLOGI PENELITIAN 36
A. Jenis Penelitian 36
B. Objek Penelitian 36
C. Jenis Data 36
D. Teknik Pengumpulan dan Analisis Data 36
BAB IV HASIL DAN PEMBAHASAN 37
A. Capaian Nilai Rata-Rata Nasional Tahun 2016-2019 37 B. Capaian Nilai Rata-Rata Provinsi Tahun 2016-2019 44 C. Capaian Nilai Rata-Rata Provinsi untuk Setiap Mata Pelajaran 51 D. Capaian Nilai Rata-Rata Berdasarkan Zona Waktu 71 E. Perbandingan Capaian Nilai Rata-Rata Antar Zona Waktu 79 F. Provinsi-Provinsi dengan Capaian Rata-Rata di bawah Rata-Rata
Nasional
83
G. Analisis Komponen Utama pada Ujian Nasional 93
xiii
H. Hasil Klasterisasi Provinsi di Indonesia 99
I. Hasil Klasterisasi Kabupaten di Nusa Tenggara Timur 104 J. Hasil Klasterisasi Sekolah di Kabupaten Manggarai 107
BAB V KESIMPULAN, SARAN, DAN REFLEKSI 112
A. Kesimpulan 112
B. Saran 115
C. Refleksi 116
DAFTAR PUSTAKA 119
LAMPIRAN A 123
LAMPIRAN B 124
LAMPIRAN C 125
LAMPIRAN D 128
LAMPIRAN E 129
LAMPIRAN F 130
LAMPIRAN G 137
LAMPIRAN H 138
xiv
Daftar Gambar
Gambar 2.1. Diagram venn sains data 13
Gambar 2.2. Supervised Learning 14
Gambar 2.3. Regresi dalam supervised learning 15 Gambar 2.4. Klasifikasi dalam supervised learning 15
Gambar 2.5. Unsupervised Learning 16
Gambar 2.6. Klasterisasi dalam unsupervised learning 16
Gambar 2.7. Bentuk-bentuk visualisasi 17
Gambar 2.8. Boxplot tanpa outlier 18
Gambar 2.9. Boxplot dengan outlier 19
Gambar 2.10. Macam-macam histogram 20
Gambar 2.11. Scree plot 29
Gambar 2.12. Visualisasi elbow method 35
Gambar 4.1. Capaian nilai rata-rata nasional tahun 2016-2019 38 Gambar 4.2. Boxplot capaian nilai rata-rata nasional tahun 2016 -2019 39 Gambar 4.3. Capaian nilai rata-rata nasional Bahasa Indonesia 41 Gambar 4.4. Capaian nilai rata-rata nasional Bahasa Inggris 41 Gambar 4.5. Capaian nilai rata-rata nasional Matematika 41 Gambar 4.6. Capaian nilai rata-rata nasional IPA 41
Gambar 4.7. Boxplot mapel secara nasional 42
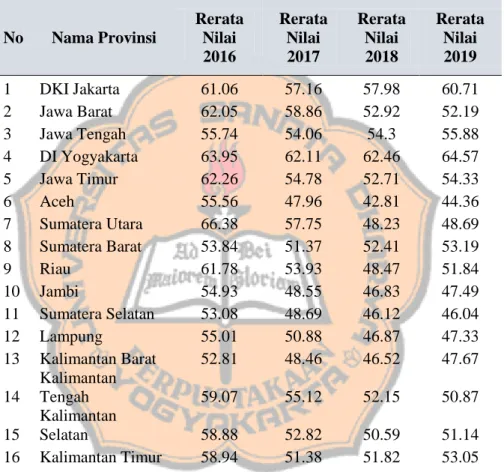
Gambar 4.8. Boxplot capaian nilai rata-rata provinsi 45
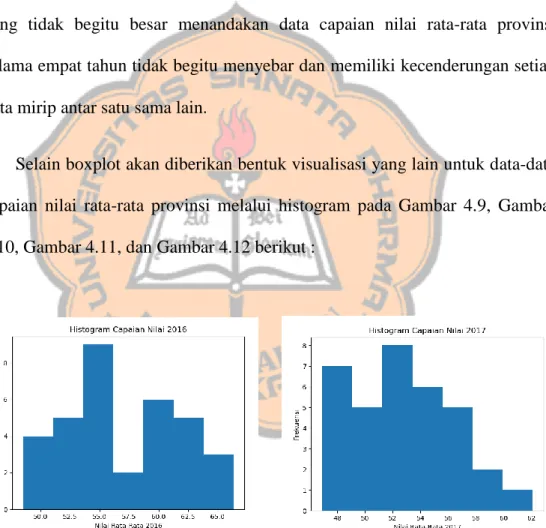
Gambar 4.9. Histogram 2016 47
xv
Gambar 4.10. Histogram 2017 47
Gambar 4.11. Histogram 2018 48
Gambar 4.12. Histogram 2019 48
Gambar 4.13. Boxplot capaian nilai rata-rata provinsi mapel Bahasa Indonesia
52
Gambar 4.14. Histogram Bahasa Indonesia 2016 54 Gambar 4.15. Histogram Bahasa Indonesia 2017 54 Gambar 4.16. Histogram Bahasa Indonesia 2018 54 Gambar 4.17. Histogram Bahasa Indonesia 2019 54 Gambar 4.18. Boxplot capaian nilai rata-rata provinsi mapel Bahasa
Inggris
57
Gambar 4.19. Histogram Bahasa Inggris 2016 59
Gambar 4.20. Histogram Bahasa Inggris 2017 59
Gambar 4.21. Histogram Bahasa Inggris 2018 59
Gambar 4.22. Histogram Bahasa Inggris 2019 59
Gambar 4.23. Boxplot capaian nilai rata-rata provinsi mapel Matematika 62
Gambar 4.24. Histogram Matematika 2016 64
Gambar 4.25. Histogram Matematika 2017 64
Gambar 4.26. Histogram Matematika 2018 64
Gambar 4.27. Histogram Matematika 2019 64
Gambar 4.28. Boxplot capaian nilai rata-rata provinsi mapel IPA 67
Gambar 4.29. Histogram IPA 2016 69
Gambar 4.30. Histogram IPA 2017 69
xvi
Gambar 4.31. Histogram IPA 2018 69
Gambar 4.32. Histogram IPA 2019 69
Gambar 4.33. Boxplot capaian nilai rata-rata WIT 73 Gambar 4.34. Boxplot capaian nilai rata-rata WITA 75 Gambar 4.35. Boxplot capaian nilai rata-rata WIB 77
Gambar 4.36. Boxplot Zona Waktu 2016 79
Gambar 4.37. Boxplot Zona Waktu 2017 79
Gambar 4.38. Boxplot Zona Waktu 2018 80
Gambar 4.39. Boxplot Zona Waktu 2019 80
Gambar 4.40. Capaian selisih provinsi Aceh 86
Gambar 4.41. Capaian selisih provinsi Jambi 87
Gambar 4.42. Capaian selisih provinsi Sumsel 88 Gambar 4.43. Capaian selisih provinsi Lampung 90 Gambar 4.44. Capaian selisih provinsi Kalbar 91
Gambar 4.45. Capaian selisih provinsi NTB 92
Gambar 4.46. Capaian selisih provinsi Banten 93
Gambar 4.47. Scree plot provinsi 100
Gambar 4.48. Scree plot kabupaten 104
Gambar 4.49. Scree plot sekolah 107
xvii
Daftar Tabel
Tabel 2.1. Rancangan uji Friedmann 22
Tabel 2.2. Kemampuan logam menahan korosi 24
Tabel 2.3. Nilai eigen contoh 2.2 30
Tabel 2.4. Vektor eigen contoh 2.2 31
Tabel 2.5. Komponen utama contoh 2.2 31
Tabel 4.1. Capaian nilai rata-rata nasional tahun 2016-2019 37 Tabel 4.2. Deskripsi boxplot capaian nilai rata-rata tahun 2016-2019 39 Tabel 4.3. Capaian nilai rata-rata mata pelajaran secara nasional 40 Tabel 4.4. Deskripsi boxplot capaian nilai rata-rata mata pelajaran
secara nasional
42
Tabel 4.5. Capaian nilai rata-rata provinsi 44 Tabel 4.6. Informasi boxplot capaian nilai rata-rata provinsi 45 Tabel 4.7. Capaian nilai rata-rata provinsi mapel Bahasa Indonesia 51 Tabel 4.8. Informasi boxplot capaian nilai rata-rata Bahasa Indonesia 53 Tabel 4.9. Capaian nilai rata-rata provinsi mapel Bahasa Inggris 56 Tabel 4.10. Informasi boxplot capaian nilai rata-rata Bahasa Inggris 58 Tabel 4.11. Capaian nilai rata-rata provinsi mapel Matematika 61 Tabel 4.12. Informasi boxplot capaian nilai rata-rata Matematika 63 Tabel 4.13. Capaian nilai rata-rata mapel IPA 66 Tabel 4.14. Informasi boxplot capaian nilai rata-rata IPA 68 Tabel 4.15. Data nama provinsi di setiap zona waktu 71
xviii
Tabel 4.16. Jumlah siswa di setiap zona waktu 71 Tabel 4.17. Jumlah siswa di setiap zona waktu 71 Tabel 4.18. Informasi boxplot capaian nilai rata-rata WIT 73 Tabel 4.19. Informasi boxplot capaian nilai WITA 75 Tabel 4.20. Informasi boxplot capaian nilai rata-rata WIB 77 Tabel 4.21. Informasi boxplot capaian nilai rata-rata antar zona waktu
2016
80 Tabel 4.22. Informasi boxplot capaian nilai rata-rata antar zona waktu
2017
80 Tabel 4.23. Informasi boxplot capaian nilai rata-rata antar zona waktu
2018
81 Tabel 4.24. Informasi boxplot capaian nilai rata-rata antar zona waktu
2019
81 Tabel 4.25. Hasil uji Kruskal Wallis dengan Python 83 Tabel 4.26. Provinsi dengan capaian kurang dari rata-rata nasional 84
Tabel 4.27. Nilai eigen tahun 2016 94
Tabel 4.28. Vektor eigen tahun 2016 94
Tabel 4.29. Komponen utama 2016 95
Tabel 4.30. Nilai eigen tahun 2017 96
Tabel 4.31. Vektor eigen tahun 2017 96
Tabel 4.32. Komponen utama 2017 96
Tabel 4.33. Nilai eigen tahun 2018 97
Tabel 4.34. Vektor eigen tahun 2018 97
Tabel 4.35. Komponen utama 2018 97
Tabel 4.36. Nilai eigen tahun 2019 98
Tabel 4.37. Vektor eigen tahun 2019 99
xix
Tabel 4.38. Komponen utama 2019 99
Tabel 4.39. Pusat data provinsi setelah proses normalisasi 101
Tabel 4.40. Pusat data provinsi 101
Tabel 4.41. Klaster provinsi 101
Tabel 4.42. Pusat data kabupaten setelah proses normalisasi 105
Tabel 4.43. Pusat data kabupaten 105
Tabel 4.44. Klaster kabupaten di NTT 106
Tabel 4.45. Pusat data sekolah setelah proses normalisasi 108
Tabel 4.46. Pusat data sekolah 108
Tabel 4.47. Klaster sekolah di Manggarai 109
1 BAB I
PENDAHULUAN
A. Latar Belakang
Dewasa ini, keberadaan data dalam berbagai bidang kehidupan sangatlah penting. Disadari atau tidak, manusia senantiasa menghasilkan dan berhubungan dengan data. Data bisa ditemukan dengan mudah dalam kehidupan sehari-hari dengan bentuk beragam yang dapat berupa angka, gambar, rekaman, atau tulisan.
Menurut Kamus Besar Bahasa Indonesia (KBBI), data adalah keterangan atau bahan nyata yang dapat dijadikan dasar kajian baik sebagai bahan analisis atau untuk menarik kesimpulan. Data dapat dipandang pula sebagai sekumpulan keterangan yang diperoleh dari suatu pengamatan yang dapat berupa angka, lambang, maupun sifat (Kuswandi, 2004). Sementara itu, menurut Webster’s New World Dictionary, data berarati sesuatu yang dapat memberikan gambaran tentang suatu keadaan atau persoalan. Data dapat juga dipandang sebagai semua fakta dan angka- angka yang dapat dijadikan sebagai bahan untuk menyusun sebuah informasi (Suharsimi Arikunto, 2002:96).
Bertolak dari beberapa pengertian tentang data di atas, penulis dapat menyimpulkan bahwa data adalah sekumpulan fakta, keterangan atau informasi mentah yang tidak terorganisir, berupa angka, simbol, kata-
kata, atau sifat yang diperoleh melalui proses pengamatan atau pencarian ke sumber-sumber tertentu.
Perkembangan teknologi yang pesat memungkinkan data diambil, disimpan, didistribusikan, dan diproses secara cepat dan murah.
Berdasarkan pengamatan penulis, beberapa tahun terakhir, data semakin heterogen dan kompleks. Volumenya pun meningkat cepat secara eksponensial. “Data never sleeps”, demikian bunyi salah satu istilah yang dipakai untuk menggambarkan bagaimana pada akhirnya seluruh aspek kehidupan diubah ke dalam data. Hal inipun dipaparkan secara gamblang oleh Jhon Gantz dan David Reinsel dalam Suryanto (2019). Pada tahun 2011 volume data mencapai dan meningkat lebih dari 50%
menjadi pada tahun 2012. Volume data sudah menjadi di tahun 2013 dan diperkirakan volume data akan terus meningkat hingga mencapai di tahun 2020.
Meskipun diketahui jumlahnya begitu besar dan peningkatannya terjadi amat cepat, banyak pihak yang tidak menyadari arti penting data.
Umumnya data dalam jumlah banyak tersebut dibiarkan begitu saja.
Padahal, data perlu diolah agar dapat diperoleh manfaat darinya. Sejalan dengan perkembangan ilmu pengetahuan dan teknologi, data menjadi bahan penting untuk melakukan analisis terhadap suatu gejala tertentu.
Ketika diproses, data akan menghasilkan informasi yang selanjutnya bisa bermanfaat untuk memproduksi pengetahuan baru.
Dewasa ini, analisis data berkenaan dengan proses pengolahan dan penyajian data. Analisis data menjadi penting sebab pola data perlu dikenali, sehingga dapat kita temukan kecenderungan tertentu dari data tersebut. Lewat data dapat dibuat keputusan atau kesimpulan yang tepat dari gejala yang ada. Selain itu melalui proses analisis data dapat dibuat prediksi atas apa yang akan terjadi di masa depan. Dengan demikian proses analisis data menjadi penting karena data menjadi berguna setelah diproses, ditafsirkan, diorganisir, disusun ataupun disajikan, sehingga dapat dimengerti oleh pihak-pihak yang menerimanya.
Dalam kurun waktu satu dekade terakhir, Sains Data berkembang menjadi suatu disiplin ilmu baru dalam pembahasan tentang data dan proses analisisnya. Sains Data adalah bagian dari Artificial Intellegence (AI) yakni bidang yang berusaha mengajari suatu mesin menirukan cara manusia belajar. Tentu saja komponen dasar yang dipakai adalah data.
Sains Data dapat dipandang juga sebagai sebuah bidang interdisipliner yang menggunakan metode saintifik, algoritma, dan proses untuk mendapatkan pengetahuan dan pemahaman mendalam tentang data.
Dalam pembahasan selanjutnya, Sains Data dapat dipandang sebagai interseksi matematika dan statistik, computer science, dan domain/bussiness knowladge.
Sains Data berkembang dalam berbagai ranah kehidupan. Di bidang kesehatan dan bioinformatika misalnya, Sains Data memiliki potensi besar untuk memperbaiki sistem kesehatan. Data dapat dianalisis
guna mengidentifikasi praktik terbaik untuk meningkatkan perawatan dan mengurangi biaya. Di bidang bioinformatika, Sains Data dapat dipakai untuk proses penemuan gen, inferensi fungsi protein, diagnosis penyakit, dan lain-lain.
Di bidang analisis pasar, Sains Data dapat dihubungkan dengan teknik pemodelan yang didasari teori bahwa jika seorang membeli kelompok item tertentu, maka orang tersebut akan cenderung membeli kelompok item lainnya. Teknik ini memungkinkan pengecer memahami perilaku pembelian pembeli. Untuk menyelidiki kejahatan, Sains Data dapat dipakai mendeteksi penipuan (Fraud Detection). Beberapa contoh tersebut menunjukkan data sebagai bahan mentah dapat diolah lebih lanjut dan memiliki kebermanfaatan.
Di Indonesia sendiri, terdapat ribuan jenis data dari berbagai bidang kehidupan yang belum dimanfaatkan secara optimal. Sebagai calon pendidik, penulis melihat bahwa salah satu data penting di Indonesia adalah data-data dari bidang pendidikan. Data-data pendidikan yang tersedia sebenarnya akan sangat berguna untuk meningkatkan kualitas pendidikan di Indonesia.
Upaya pemerintah untuk meningkatkan mutu pendidikan di Indonesia antara lain melakukan perbaikan baik dalam hal kurikulum, profesionalitas dan kualitas guru, serta infrastruktur. Salah satu sektor penting dalam bidang pendidikan selain yang telah disebutkan sebelumnya adalah sistem evaluasi. Menurut Ralph Tyler (1950) dalam Arikunto
(2018), evaluasi adalah sebuah proses pengumpulan data untuk menentukan sejauh mana, dalam hal apa, dan bagaimana tujuan pendidikan sudah tercapai. Lebih lanjut Cronbach dan Stufflebeam menambahkan bahwa evaluasi bukan sekedar mengukur sejauh mana tujuan tercapai, tetapi digunakan untuk membuat keputusan.
Salah satu hal yang dibuat dalam proses evaluasi di Indonesia adalah penilaian pendidikan yang terdiri atas penilaian hasil belajar oleh pendidik, satuan pendidikan, dan pemerintah (PP no.19/2005 pasal 63).
Bentuk evaluasi yang dilakukan pemerintah ialah dengan dilaksanakannya penilaian yang termaktub dalam penyelenggaraan Ujian Nasional (UN).
Ujian Nasional bertujuan untuk menilai pencapaian kompetensi lulusan secara nasional pada mata pelajaran tertentu .
Selanjutnya, seperti yang dikutip dari laman puspendik.kemdikbud.go.id/hasilun/, Ujian Nasional (UN) diselenggarakan untuk mengukur pencapaian kompetensi lulusan peserta didik pada jenjang satuan pendidikan dasar dan pendidikan menengah sebagai hasil dari proses pembelajaran sesuai dengan Standar Kompetensi Lulusan (SKL). Tujuan penyelenggaraan UN seperti yang telah dijelaskan sebelumnya merupakan tujuan umum yang ditetapkan pemerintah pusat.
Dengan kata lain, capaian nilai Ujian Nasional hanya dipakai untuk pencapaian tujuan-tujuan tersebut.
Volume data Ujian Nasional yang cukup besar membuat hal-hal lain yang penting dan menarik tidak segera terlihat. Padahal dalam
praktiknya data Ujian Nasional dapat dianalisis lebih lanjut untuk melihat pola lain yang ingin disampaikan data-data tersebut tentang pendidikan itu sendiri, sehingga diperoleh suatu pengetahuan baru untuk membuat keputusan dan alat prediksi di masa mendatang.
Sains Data pada akhirnya dapat digunakan oleh sebuah institusi untuk mengambil keputusan yang akurat dan juga untuk memprediksi hasil siswa. Data yang tersedia divisualisasikan terlebih dahulu untuk dianalisis lebih lanjut. Melalui hasil yang diperoleh, sebuah institusi bisa fokus pada apa yang harus diajarkan dan bagaimana cara mengajarnya, sehingga dapat digunakan untuk perbaikan mutu.
Beberapa penelitian di bidang pendidikan telah menggunakan data ujian nasional sebagai bahan pengolahan datanya. Hampir semua penelitian yang dilakukan terbatas pada suatu daerah tertentu, misalnya pada penelitian milik Aris Dwiatmoko, dkk dengan judul “Analisis Statistik Data Nilai Ujian Nasional dan Nilai Sekolah Menengah Atas Di Daerah Istimewa Yogyakarta” yang dilaksanakan pada tahun 2015, atau pada penelitian milik Pakpahan dan Juni Miniarti (2013) dengan judul
“Pengelompokan Sekolah Menengah Pertama Berdasarkan Rata-Rata Nilai Ujian Akhir Nasional Di Kota Binjai dengan Analisis Hierrarkhi Clustering”, juga pada penelitian yang dilakukan Prihatiningtyas (2011)
“Analisis Hasil Ujian Nasional Tingkat SMA di Kabupaten Banyumas Menggunakan Analisis Cluster dan Biplot”.
Oleh karena itu, penulis tertarik menggunakan pendekatan Sains Data untuk menganalisis capaian hasil Ujian Nasional seluruh daerah di Indonesia pada jenjang Sekolah Menengah Pertama, sehingga dapat diperoleh suatu pengetahuan yang baru untuk pengambilan keputusan atau kebijakan yang lebih tepat di masa yang akan datang.
B. Rumusan Masalah
Berdasarkan latar belakang yang telah dipaparkan penulis, rumusan masalah penulisan tesis ini adalah sebagai berikut :
1. Bagaimana hasil analisis nilai rata-rata Ujian Nasional semua provinsi di Indonesia yang diperoleh melalui visualisasi data yang diperoleh?
2. Nilai mata pelajaran manakah yang berpengaruh besar terhadap capaian hasil Ujian Nasional?
3. Bagaimana hasil analisis klaster pada data Ujian Nasional?
C. Tujuan Penelitian
Berdasarkan rumusan masalah yang telah dipaparkan penulis, tujuan penulisan tesis ini adalah sebagai berikut :
1. Mengetahui hasil analisis nilai rata-rata Ujian Nasional semua provinsi di Indonesia yang diperoleh melalui visualisasi data.
2. Mengetahui nilai pada mata pelajaran manakah yang paling berpengaruh terhadap capaian nilai Ujian Nasional.
3. Mengetahui hasil analisis klaster pada data Ujian Nasional
D. Tinjauan Pustaka
Pada bagian ini, penulis membahas apa itu Data, Sains Data, Visualisasi Data, Ukuran Pemusatan dan Penyebaran Data, Uji Statistik- Uji Friedmann, Analisis Komponen Utama, dan Proses Clustering.
E. Kebaruan Penelitian
Jika pada penelitian yang telah dilakukan sebelumnya, analisis data dilakukan dalam lingkup yang lebih sederhana dan cakupan wilayah penelitian yang lebih sempit, maka pada penulisan tesis ini data yang dianalisis mencakup data ujian nasional selama kurun waktu 2016-2019 untuk seluruh wilayah di Indonesia dengan pendekatan Sains Data dan divisualisasikan dengan bantuan program Python.
F. Batasan Masalah
Penelitian ini terbatas pada penggunaan data hasil UN jenjang SMP di seluruh Indonesia tahun 2016-2019.
G. Metode Penelitian
Metode penelitian yang digunakan penulis adalah studi pustaka dan analisis data menggunakan pendekatan Sains Data dengan langkah- langkah sebagai berikut :
1. Mengumpulkan dan membaca berbagai literatur yang berhubungan dengan Sains Data.
2. Mengumpulkan data hasil Ujian Nasional tahun 2016-2019 pada jenjang SMP dimana data diperoleh dari laman puspendik.kemdikbud.go.id/hasilun/.
3. Membuat visualisasi data dengan bantuan perangkat lunak Python.
4. Menganalisis hasil visualisasi data Ujian Nasional tahun 2016-2019.
5. Melakukan Analisis Komponen Utama dengan bantuan perangkat lunak R.
6. Melakukan analisis hasil klasterisasi wilayah berdasarkan capaian Ujian Nasional.
H. Sistematika Penulisan
Secara umum, sistematika penulisan tesis ini terdiri dari enam pokok bahasan sebagai berikut :
1. Bab I : Pendahuluan
Pada bab ini, penulis menjelaskan latar belakang masalah, rumusan masalah, tujuan penulisan, tinjauan pustaka, kebaruan penelitian, batasan masalah, metode penelitian, dan sistematika penulisan.
2. Bab II : Landasan Teori
Pada bab ini, penulis menjelaskan beberapa teori yang mendukung penulisan tesis ini antara lain Data, Sains Data, Visualisasi Data, Ukuran Pemusatan dan Penyebaran Data , Uji Statistik-Uji Friedmann,
Analisis Komponen Utama, dan Analisis Klaster Berbasis K-Means Clustering.
3. Bab III : Metode Penelitian
Bagian ini berisi jenis penelitian, objek penelitian, jenis data, teknik pengumpulan dan analisis data.
4. Bab IV : Hasil dan Pembahasan
Pada bab ini, penulis menganalisis hasil visualisasi data nilai rata-rata Ujian Nasional, menganalisis komponen utama untuk mengetahui nilai pada mata pelajaran mana yang paling berpengaruh terhadap capaian nilai ujian nasional, juga menganalisis hasil klasterisasi data UN.
5. Bab V : Penutup
Pada bab ini, penulis menuliskan kesimpulan yang diperoleh dari bab IV serta menuliskan saran yang sekiranya bermanfaat untuk kepentingan penelitian berikutnya.
6. Bab IV : Refleksi Penulisan Tesis
Pada bab ini terdapat refleksi penulis tentang penulisan tesis.
11 BAB II
LANDASAN TEORI
A. Pengertian Data
Data memiliki kegunaan yang beragam. Untuk memperoleh gambaran tentang keadaan ekonomi suatu negara, pemerintah harus mengumpulkan data tentang kegiatan-kegiatan ekonomi masyarakat seperti kegiatan produksi, konsumsi, besar pendapatan, harga barang, dan lain sebagainya. Untuk mengetahui jumlah penduduk, Badan Pusat Statistik memerlukan data jumlah anggota keluarga, berapa besar angka kelahiran dan kematian, dan lain sebagainya. Beberapa contoh tersebut memberikan gambaran tentang kegunaan data yakni sebagai sarana membuat keputusan. Selain itu beberapa kegunaan lain dari data adalah sebagai dasar perencanaan, alat pengendalian, atau sebagai dasar evaluasi.
Menurut Kamus Besar Bahasa Indonesia (KBBI), data adalah keterangan atau bahan nyata yang dapat dijadikan dasar kajian baik sebagai bahan analisis atau untuk menarik kesimpulan. Data dapat dipandang sebagai sekumpulan keterangan yang diperoleh dari suatu pengamatan yang dapat berupa angka, lambang, maupun sifat (Kuswandi, 2004). Sementara itu, menurut Webster’s New World Dictionary, data berarti sesuatu yang dapat memberikan gambaran tentang suatu keadaan atau persoalan. Data dapat juga dipandang sebagai semua fakta dan angka- angka yang dapat dijadikan sebagai bahan untuk menyusun sebuah informasi (Suharsimi Arikunto, 2002:96).
Bertolak dari beberapa pengertian tentang data di atas, penulis dapat menyimpulkan bahwa data adalah sekumpulan fakta, keterangan atau informasi mentah yang tidak terorganisir, berupa angka, simbol, kata- kata, atau sifat yang diperoleh melalui proses pengamatan atau pencarian ke sumber-sumber tertentu.
B. Sains Data
Dalam kurun waktu satu dekade terakhir, Sains Data berkembang menjadi suatu disiplin ilmu baru dalam pembahasan tentang data. Menurut Chikio Hayashi dari Institut Statistika Matematika Sakuragaoka sains data adalah ilmu pengetahuan yang interdisipliner tentang metode komputasi untuk mendapatkan wawasan berharga yang dapat ditindaklanjuti dari kumpulan data yang mencakup tiga fase yaitu desain data, mengumpulkan data, dan analisis data.
Sains data adalah bagian dari Artificial Intellegence (AI) yakni bidang yang berusaha mengajari suatu mesin menirukan cara manusia belajar. Tentu saja komponen dasar yang dipakai adalah data. Sains Data dapat dipandang juga sebagai sebuah bidang interdisipliner yang menggunakan metode saintifik, algoritma, dan proses untuk mendapatkan pengetahuan dan pemahaman mendalam tentang data. Dalam pembahasan selanjutnya, Sains Data dapat dipandang sebagai interseksi matematika dan statitik, computer science, dan domain/bussiness knowladge. Hal tersebut dapat kita lihat pada gambar 2.1 berikut :
Gambar 2.1. Diagram venn sains data
Matematika yang dipakai biasanya berkaitan dengan optimisasi, computer science berkaitan dengan proses pengolahan data yang besar dan memanipulasi data agar data dapat digunakan. Sementara domain/bussines knowladge artinya dimana sains data akan dipakai. Data scientis tidak akan menginterpretasikan data dengan baik jika tidak memiliki pengetahuan yang cukup tentang bidang yang ingin diselidiki tersebut. Ciri dari sains data adalah segala prosesnya dimulai dari data baik itu untuk diekstrak, diinterpretasikan, dan untuk memperoleh pengetahuan baru baik dari data terstruktur maupaun data yang tidak terstruktur.
Ada dua aliran pada Sains Data yakni Supervised Learning dan Unsupervised Learning.
1. Supervised Learning
Supervised Learning adalah sebuah pendekatan dimana sudah terdapat data yang dilatih, dan terdapat variabel yang ditargetkan sehingga
tujuan dari pendekatan ini adalah mengelompokan suatu data ke data yang sudah ada.
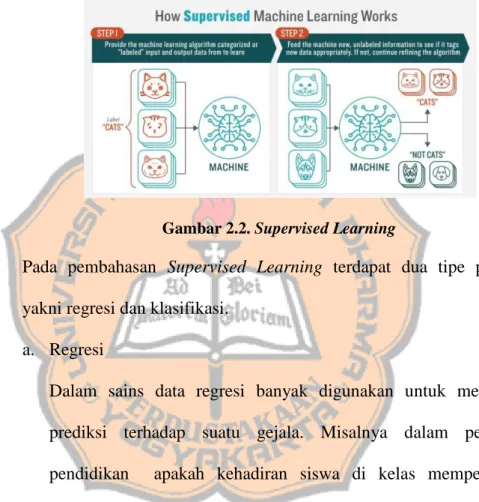
Representasi dari Supervised Learning dapat dilihat pada Gambar 2.2 berikut :
Gambar 2.2. Supervised Learning
Pada pembahasan Supervised Learning terdapat dua tipe problem yakni regresi dan klasifikasi.
a. Regresi
Dalam sains data regresi banyak digunakan untuk melakukan prediksi terhadap suatu gejala. Misalnya dalam penelitian pendidikan apakah kehadiran siswa di kelas mempengaruhi prestasi belajar siswa. Data kehadiran siswa dapat dimasukan ke dalam sistem, sehingga dapat dibuat prediksi tentang prestasi belajar siswa. Bentuk regresi dapat kita lihat pada Gambar 2.3
Gambar 2.3. Regresi dalam Supervised Learning b. Klasifikasi
Pada Gambar 2.4 berikut akan ditampilkan contoh klasifikasi dalam Supervised Learning. Klasifikasi dalam sains data dipakai untuk membuat algoritma pengklasifikasian kelas secara otomatis.
Misalnya pengklasifikasian sentimen analisis dalam bidang politik.
Gambar 2.4. Klasifikasi dalam Supervised Learning
2. Unsupervised Learning
Lain halnya dengan Supervised Learning, Unsupervised Learning tidak memiliki data yang dilatih, sehingga dari data yang ada, kita
mengelompokan data tersebut menjadi 2 bagian atau 3 bagian dan seterusnya. Bentuknya dapat kita lihat pada Gambar 2.5 berikut ini :
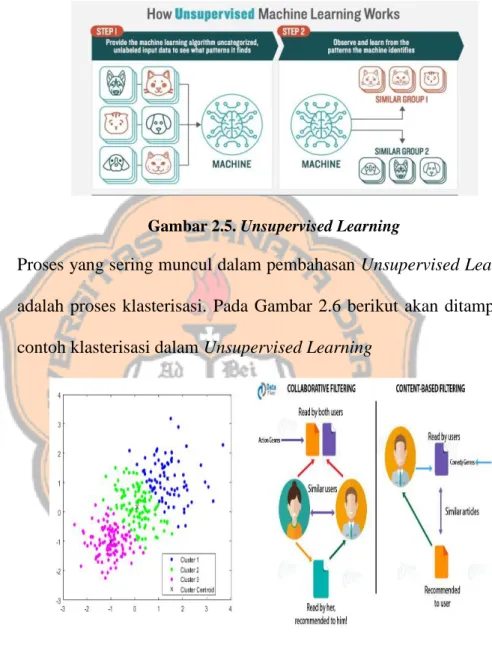
Gambar 2.5. Unsupervised Learning
Proses yang sering muncul dalam pembahasan Unsupervised Learning adalah proses klasterisasi. Pada Gambar 2.6 berikut akan ditampilkan contoh klasterisasi dalam Unsupervised Learning
Gambar 2.6. Klasterisasi dalam Unsupervised Learning
Pembahasan tentang sains data pun tidak lepas dari Machine Learning.
Secara ringkas Machine Learning merupakan cabang dari Artificial Intelligence dengan kemampuan mesin untuk mengakses data yang ada dengan perintah mereka sendiri. Machine Learning juga mampu mempelajari data yang ada dan melakukan tugas-tugas tertentu. Machine
Learning mampu melakukan ini dengan metode mempelajari algoritma dan model statistik yang ada. Hal ini dapat kita bandingkan pula dengan gambar sebelumnya dimana Machine Learning dapat dipandang sebagai irisan dari computer science dengan ilmu matematika dan statistika.
C. Visualisasi Data
Dalam sains data, visualisasi sangat diperlukan. Visualisasi data memiliki dua kegunaan yaitu memudahkan analisis bagi perancang dan memudahkan proses membaca sebuah informasi oleh pengguna. Beberapa teknik visualisasi data yang dapat digunakan diantaranya visualisasi berorientasi pixel, berorientasi geometris, dan berbasis ikon (J han et all, 2012).
Beberapa bentuk visualisasi yang kita kenal ditunjukkan pada Gambar 2.7 berikut :
Gambar 2.7.Bentuk-bentuk visualisasi
Dalam tulisan ini dibahas beberapa bentuk visualisasi yang dipakai diantaranya boxplot dan histogram, yang masing –masing akan dijelaskan sebagai berikut :
1. Boxplot
Boxplot (juga dikenal sebagai diagram box-and-whisker) merupakan suatu box (kotak berbentuk bujur sangkar). Boxplot adalah salah satu cara dalam statistik deskriptif untuk menggambarkan secara grafis data numeris melalui lima nilai yakni nilai minimum, nilai Q1, Q2, dan Q3, juga nilai maksimum. Dalam boxplot juga ditunjukkan nilai outlier dari observasi (jika ada). Boxplot dapat digunakan untuk menunjukkan perbedaan antara populasi tanpa menggunakan asumsi distribusi statistik yang mendasarinya. Jarak antara bagian-bagian dari box menunjukkan derajat dispersi (penyebaran) dan skewness (kecondongan) dalam data. Dalam penggambarannya, boxplot dapat digambarkan secara horisontal maupun vertikal. Pada Gambar 2.8 dan Gambar 2.9 berikut akan ditampilkan boxplot vertikal dan horisontal tanpa outlier dan dengan outlier.
Gambar 2.8.Boxplot tanpa outlier
Gambar 2.9. Boxplot dengan outlier
Adanya outlier disebabkan oleh adanya data yang nilainya terlampau besar atau terlampau kecil dalam suatu set data. Secara matematis dapat ditulis :
2. Histogram
Bentuk visualisasi data berikutnya adalah histogram. Histogram adalah adalah tampilan grafis dari tabulasi frekuensi. Tiap tampilan batang menunjukkan proporsi frekuensi pada masing-masing deret kategori yang berdampingan dengan interval yang tidak tumpang tindih.
Gambar 2.10. Macam-macam histogram
D. Ukuran Pemusatan dan Penyebaran Data
Dalam tulisan ini akan dibahas beberapa ukuran pemusatan dan penyebaran data tunggal yang mendukung analisis data penelitian.
1. Rata-Rata (Mean)
Mean data tunggal dinotasikan dengan ̅, dan dirumuskan sebagai : ̅ ∑
2. Median
Median didefinisikan sebagai data tengah setelah data diurutkan.
Median untuk data ganjil adalah :
Sementara untuk data genap, median dapat ditentukan dengan cara : (
*
3. Modus
Modus adalah data yang paling sering muncul, atau data dengan nilai terbanyak.
4. Quartil
Quartil ialah suatu nilai yang membagi data yang telah diurutkan ke dalam empat bagian yang nilainya sama besar. Quartil pada suatu data dapat didapatkan dengan cara membagi data tersebut secara terurut ke dalam empat bagian yang memiliki nilai sama besar. Quartil itu sendiri terdiri atas tiga macam diantaranya Quartil bawah (Q1), Quartil tengah / median (Q2), dan Quartil atas (Q3).
5. Rentang (range)
Range (R) adalah selisih antara nilai maksimum dan nilai minimum.
6. Inter Quatile Range (IQR)
IQR didefinisikan sebagai selisih antara quartil ketiga (Q3) dengan quartil pertama (Q1), Dapat ditulis :
7. Standar Deviasi
Standar deviasi untuk sampel disimbolkan dengan , sedangkan Standar deviasi untuk sampel disimbolkan dengan . Kuadrat dari standar deviasi adalah varians, sehingga varians untuk sampel disimbolkan dengan dan varians untuk populasi disimbolkan dengan .
√∑ ∑ Dan
√∑ ∑
E. Uji Statistik-Uji Friedmann
Uji Friedmann merupakan metode nonparametrik yang digunakan untuk rancangan acak kelompok lengkap. Tujuannya adalah untuk melihat ada tidaknya pengaruh antar perlakuan. Ketika perlakuan memiliki pengaruh yang berbeda, respon dan subjek yang diberi suatu perlakuan akan memiliki median yang sama dengan respon dari subjek yang diberi perlakuan lainnya, setelah pengaruh pengelompokkan peubah dihilangkan.
Rancangan data untuk uji Friedmann ditampilkan pada Tabel 2.1. berikut : Tabel 2.1. Rancangan uji Friedmann
Kelompok Perlakuan
Dimana :
Data di setiap perlakuan
Ranking untuk setiap kelompok perlakuan Asumsi :
a) Data terdiri dari kelompok yang saling bebas dengan ukuran perlakuan.
b) Peubah yang diamati bersifat kontinu.
c) Tidak ada interaksi antar kelompok perlakuan.
d) Pengamatan dalam setiap kelompok dapat diperingkat berdasarkan besarnya.
Hipotesis :
atau perlakuan memiliki median yang sama
= Ada minimal satu , dimana , dan
Statistik Uji Friedmann ditentukan dengan prosedur berikut : a) Data pengamatan diurutkan dalam kelompok terpisah
b) Jika terdapat ties (nilai yang sama) dalam kelompok, maka ranking yang dipakai adalah nilai tengahnya
c) Statistik Uji Friedmann diperoleh melalui rumus :
∑
Dimana
Apabila terdapat ties maka,
∑ (∑ ∑ ) Catatan :
= banyaknya kelompok = banyaknya perlakuan
= jumlah peringkat perlakuan ke-i
= banyaknya pengamatan yang bernilai sama (ties) Contoh 2.1 :
Di bawah ini adalah data jumlah korosi berbagai jenis logam pada tiga jenis segel. Dengan uji Friedmann selediki apakah ketiga jenis segel memiliki kemampuan menahan korosi yang berbeda (gunakan taraf nyata
Tabel 2.2. Kemampuan logam menahan korosi
Logam Segel
A B C
1 21 2 23 3 15 1
2 29 2 30 3 21 1
3 16 1 19 3 18 2
4 20 3 19 2 18 1
5 13 2 10 1 14 3
6 5 1 12 3 6 2
7 8 1 18 3 12 2
8 26 2 32 3 21 1
9 17 2 20 3 9 1
10 4 2 10 3 2 1
18 27 15
Dengan menggunakan rumus uji Friedmann diperoleh :
Selanjutnya dengan nilai dan diperoleh nilai . Dari tabel khi-kuadrat, diperoleh
.
Karena , maka ditolak artinya ada minimal satu pasang nilai media yang berbeda.
Selanjutnya untuk melihat nilai median manakah yang berbeda digunakan prosedur perbandingan berganda untuk uji Friedmann. Untuk membandingkan semua kemungkinan pasangan perlakuan pada taraf nyata , dan banyak kelompok adalah besar, maka :
| |
√
Untuk dari tabel normal diperoleh ,sehingga diperoleh :
√
Jumlah peringkat adalah
| | | | | | .
Dapat disimpulkan bahwa segel jenis B dan C mempunyai kemmapuan menahan korosi yang berbeda karena nilai | |
F. Analisis Komponen Utama
Data multivariat melibatkan banyak variabel sehingga cukup sulit dianalisis. Principle Component Analysis (PCA) atau Analisis Komponen Utama hadir dengan tujuan mereduksi dimensionalitas himpunan data multivariat dengan mentransformasi suatu himpunan variabel ke himpunan variabel baru yang disebut komponen utama.
Komponen utama dapat dipandang sebagai kombinasi linear dari variabel asal yang tidak berkorelasi dan diurutkan sedemikian, sehingga sejumlah variabel urutan pertama menjelaskan sebagian besar variansi dari variabel-variabel asal. Hasil dari analisis komponen utama adalah terbentuknya sejumlah kecil variabel baru (komponen utama), sehingga tersedia bentuk yang lebih sederhana untuk keperluan analisis grafis data multivariat lebih lanjut. Analisis Komponen Utama dapat dibuat secara geometris dan aljabar. Dalam tulisan ini akan dibahas Analisis Komponen Utama secara aljabar.
Pada intrepretasi geometris , penerapan Analisis Komponen Utama untuk data dengan jumlah variabel yang banyak cukup sulit dilakukan, sehingga perlu interpretasi secara aljabar. Pada pendekatan aljabar, komponen utama adalah kombinasi linear dari peubah acak , dan variabel adalah sebuah vektor dengan pengamatan pada data multivariat, sehingga komponen utama dapat didefenisikan sebagai berikut :
Di mana :
(
) , adalah Komponen Utama
( )
(
) , adalah transpose dari vektor
eigen
( ) , adalah variabel ke , di mana
Komponen utama pertama adalah komponen utama dari seluruh variabel yang memiliki nilai varians terbesar. Defenisi dari komponen utama pertama adalah sebagai berikut :
Komponen utama kedua adalah komponen utama dari seluruh variabel yang memiliki nilai varians terbesar kedua. Definisi dari komponen utama kedua adalah sebagai berikut :
Komponen Utama ke , diperoleh dari kombinasi linear peubah acak yang didefinisiskan sebagai berikut :
Dengan demikian, bentuk analisis komponen utama yang diasumsikan menjadi variabel , sebagai berikut :
Dalam pendekatan aljabar, komponen utama dapat dianalisis dengan langkah-langkah sebagai berikut :
1. Menentukan matriks kovarian.
2. Menentukan nilai eigen.
3. Menentukan vektor eigen.
4. Menentukan banyak komponen utama.
Ada tiga cara dalam menentukan banyak komponen utama .
1. Menggunakan scree plot
Pada Gambar 2.11 berikut akan ditampilkan scree plot untuk menentukan banyak komponen utama. Banyanya komponen utama dipilih dengan melihat titik sebelum kurva menurun tajam atau mulai melandai.
Gambar 2.11 Scree plot
2. Menggunakan proporsi kumulatif varians terhadap total
Jika menggunakan cara ini, maka rumus yang dapat dipakai adalah ∑
∑ Untuk
3. Menggunakan nilai eigen yang bernilai lebih besar dari satu .
Pada bagian ini dipilih dan dibahas tentang cara menentukan banyak komponen utama menggunakan nilai eigen yang diperkuat dengan menggunakan proporsi kumulatif pada cara kedua.
Contoh 2.2 (Contoh ini diambil dari skripsi Devita Nurin Sari, 2020) :
Terdapat 3 kelompok rugby dengan anggota masing-masing 30 orang di setiap kelompoknya. Diketahui ada enam variabel yang mempengaruhi design helm para pemain. Adapun variabel-variabel tersebut antara lain :
: Ukuran lebar kepala terbesar : Ukuran lingkar kepala
: Ukuran jarak dari mata ke kepala bagian belakang : Ukuran jarak dari mata ke kepala bagaian atas : Ukuran jarak dari telinga ke kepala bagaian atas : Ukuran panjang rahang
Dengan menggunakan langkah-langkah Analisis Komponen Utama diperoleh :
1. Matriks kovarian
(
) 2. Nilai eigen :
Setelah memperoleh matriks kovarian, diperoleh data nilai eigen pada Tabel 2.3 berikut :
Tabel 2.3. Nilai eigen contoh 2.2 Nilai Eigen
3. Vektor eigen
Pada Tabel 2.4 berikut akan ditampilkan nilai vektor eigen dari contoh di atas.
Tabel 2.4. Vektor eigen contoh 2.2
4. Menentukan banyak komponen utama
Selanjutnya pada Tabel 2.5 berikut akan ditampilkan enam komponen utama yang diperoleh melalui perangkat lunak R.
Tabel 2.5. Komponen utama contoh 2.2
Dari Tabel 2.3 diketahui terdapat dua nilai eigen yang lebih dari satu, sehingga dapat disimpulkan bahwa untuk menganalisis faktor yang mempengaruhi desain helm cukup dengan menggunakan dua komponen utama saja dan sudah cukup baik untuk menggambarkan keseluruhan data. Dengan menggunakan proporsi kumulatif diperoleh :
Artinya dua komponen utama dapat menjelaskan data secara keseluruhan.
Dari sana diperoleh :
Komponen utama 1 didominasi oleh variabel (ukuran lingkar kepala), (ukuran dari mata ke kepala bagian belakang), dan (ukuran rahang). Sementara komponen utama 2 didominasi oleh variabel (ukuran lebar kepala terbesar), (ukuran dari mata ke kepala bagian atas), dan (ukuran dari telinga ke kepala bagian atas).
G. Analisis Klaster Berbasis K-Means Clustering
Proses mengklaster adalah salah satu ciri dari Unsupervised Learning.
Klastering merupakan pekerjaan memisahkan data/vektor ke dalam sejumlah kelompok menurut karateristiknya. Data dengan kemiripan karateristik akan berkumpul dalam satu klaster yang sama, dan data-data dengan karateriktik berbeda akan terpisah dalam klaster berbeda. Tidak diperlukan label kelas untuk setiap data yang diproses karena nantinya label baru akan diberikan ketika klaster sudah terbentuk.
K-Means adalah salah satu cara yang dapat digunakan untuk proses pengklasteran. Algoritma K-Means merupakan algoritma pengelompokan iteratif yang melakukan partisi set data ke dalam sejumlah klaster.
K-Means dapat diterapkan pada data dimensi ruang tempat. K-Means mengelompokkan set data r-dimensi, { | }, di mana , yang menyatakan data ke sebagai titik data. Algoritma K- Means mengelompokkan semua titik data dalam , sehingga setiap titik hanya jatuh dalam satu dari partisi.
Untuk set data dalam dikelompokkan berdasarkan konsep kedekatan atau kemiripan, tetapi kuantitas yang digunakan untuk mengukurnya adalah ketidakmiripan. Artinya, data-data dengan ketidakmiripan yang kecil atau dekat dapat bergabung membentuk sebuah klaster. Data dengan ketidakmiripan yang kecil dari pusat data dapat diketahui melalui konsep jarak Euclidean berikut :
‖ ‖ √∑
dan adalah fitur ke dari dan , sedangkan adalah jumlah fitur dalam vektor.
Berikut ini adalah algoritma K-Means Clustering : 1. Pilih buah titik centroid secara acak.
2. Kelompokkan data sehingga terbentuk buah klaster dengan titik centroid dari setiap cluster merupakan titik centroid yang telah dipilih sebelumnya.
3. Perbaharui nilai titik centroid.
4. Ulangi langkah 2 dan 3 sampai nilai dari titik centroid tidak lagi berubah.
Perbedaan jarak atau besaran angka yang cukup jauh dalam data, dapat menyulitkan proses pengelompokan. Salah satu solusi yang digunakan untuk memperkecil besaran angka antar variabel adalah melakukan normalisasi dengan menggunakan rumus :
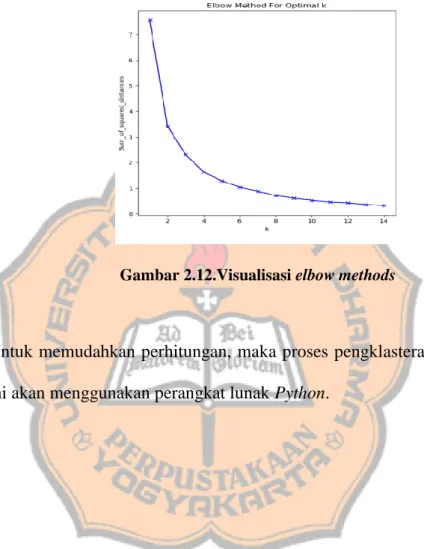
Selain itu untuk menentukan berapa banyak klaster yang paling optimal digunakan dapat digunakan elbow method. Penentuan banyaknya klaster sama seperti cara melihat scree plot pada pembahasan sebelumnya. Pada
Gambar 2.12 berikut akan ditampilkan visualisasi elbow method untuk menentukan banyak klaster optimal.
Gambar 2.12.Visualisasi elbow methods
Untuk memudahkan perhitungan, maka proses pengklasteran pada tulisan ini akan menggunakan perangkat lunak Python.
36 BAB III
METODOLOGI PENELITIAN
A. Jenis Penelitian
Penelitian yang dipakai adalah deskriptif-kuantitatif dengan analisis, dimana data-data diuraikan dan dijabarkan melalui hasil analisis.
B. Objek Penelitian
Objek penelitian dalam tulisan ini adalah data UN 2016-2019 tingkat Sekolah Menengah Pertama.
C. Jenis Data
Jenis data yang dipakai adalah data sekunder berupa data capaian nilai ujian nasional tahun 2016-2019.
D. Teknik Pengumpulan dan Analisis Data
1. Mengumpulkan dan membaca berbagai literatur yang berhubungan dengan Sains Data.
2. Mengumpulkan data hasil Ujian Nasional tahun 2016-2019 pada jenjang SMP dari laman puspendik.kemdikbud.go.id/hasilun/.
3. Membuat visualisasi dengan bantuan perangkat lunak Python.
4. Menganalisis hasil visualisasi data ujian nasional tahun 2016-2019.
5. Melakukan Analisis Komponen Utama dengan bantuan perangkat lunak R.
6. Melakukan analisis hasil klasterisasi wilayah berdasarkan capaian Ujian Nasional.
37 BAB IV
HASIL DAN PEMBAHASAN
Pada bagian ini akan disajikan beberapa bentuk pembahasan. Pada pembahasan pertama penulis akan berfokus pada hasil capaian nilai rata-rata secara nasional, pada pembahasan berikutnya akan dibahas capaian nilai rata-rata provinsi juga capaian nilai berdasarkan zona waktu. Selanjutnya akan dibahas pula analisis komponen utama (PCA) dan proses pengklasteran dengan algoritma K-Means Clustering pada tingkat provinsi, kabupaten, dan sekolah. Sebelum memulai pembahasan yang lebih jauh tentang hasil capaian Ujian Nasional, dikumpulkan berbagai jenis data berupa capaian nilai rata-rata hasil UN pada laman
https://puspendik.kemdikbud.go.id/hasilun/.
A. Capaian Nilai Rata-Rata Nasional Tahun 2016-2019
Dari laman https://puspendik.kemdikbud.go.id/hasilun/, diperoleh data capaian nilai Ujian Nasional baik capaian secara nasional maupun capaian per provinsi.
Capaian nilai rata-rata secara nasional dapat dilihat pada Tabel 4.1 berikut : Tabel 4.1. Capaian nilai rata-rata nasional tahun 2016-2019
No Pelaksanaan UN
Jumlah Satuan Pendidikan
Jumlah Peserta UN
CapaianNilai Rata-Rata
1 Tahun 2016
2 Tahun 2017
3 Tahun 2018
4 Tahun 2019
Selanjutnya dibuat visualisasi sederhana dari data tersebut. Hasil visualisasi dapat dilihat pada Gambar 4.1 dan Gambar 4.2 berikut :
Gambar.4.1. Capaian nilai rata-rata nasional tahun 2016-2019
Dari Gambar 4.1 di atas diketahui secara nasional nilai rata-rata berkisar pada nilai dan , artinya secara nasional terdapat cukup banyak wilayah yang memperoleh kisaran nilai di atas
Dari segi capaian nilai rata-rata secara nasional terjadi penurunan secara berturut-turut sekitar dari tahun 2016 sampai tahun 2018, dan kenaikan sekitar dari tahun 2018 ke tahun 2019. Selanjutnya pada Gambar 4.2 berikut diberikan sebuah boxplot yang dapat memberikan informasi penting lain terkait capaian nilai rata-rata nasional selama empat tahun terakhir.
58,61
54,25
51,1 51,76
Tahun 2016 Tahun 2017 Tahun 2018 Tahun 2019 Grafik Capaian Nilai Rata-Rata Nasional
Series1
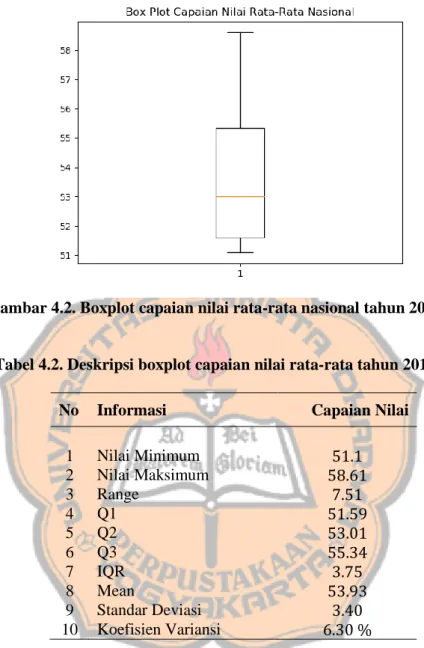
Gambar 4.2. Boxplot capaian nilai rata-rata nasional tahun 2016-2019
Tabel 4.2. Deskripsi boxplot capaian nilai rata-rata tahun 2016-2019
No Informasi Capaian Nilai
1 Nilai Minimum
2 Nilai Maksimum
3 Range
4 Q1
5 Q2
6 Q3
7 IQR
8 Mean
9 Standar Deviasi
10 Koefisien Variansi
Nilai maksimum dicapai pada tahun 2016 dan nilai minimum dicapai pada tahun 2018. Dari boxpolot di atas diketahui pula bahwa 25 % data berada di bawah nilai 51.59, 50 % berada di bawah nilai 53.01 dan 75 % lainnya berada di bawah nilai 55.34. Panjang whisker atas menunjukan bahwa jarak antara nilai maksimum dengan Q3 cukup jauh. Jarak antar kuartil pun tidak begitu
besar. Jarak antar kuartil ini memberikan gambaran kepada kita tentang bagaimana data tersebut menyebar di sekitar 50 % set data yang dimiliki.
Hal lain lain yang akan diamati adalah bagaimana capaian nilai mata pelajaran secara nasional tahun 2016-2019. Pada Tabel 4.3 berikut ini akan ditampilkan capaian nilai rata-rata nasional untuk setiap mata pelajaran.
Tabel.4.3.Capaian nilai rata-rata mata pelajaran secara nasional
Mata Pelajaran
Tahun Pelaksanaan
UN
Capaian Nilai Rata-Rata
Bahasa Indonesia
Tahun 2016 Tahun 2017 Tahun 2018 Tahun 2019
Bahasa Inggris
Tahun 2016 Tahun 2017 Tahun 2018 Tahun 2019
Matematika
Tahun 2016 Tahun 2017 Tahun 2018 Tahun 2019 IPA
Tahun 2016 Tahun 2017 Tahun 2018 Tahun 2019
Informasi yang dapat kita ketahui dari tabel di atas adalah bahwa secara umum nilai rata-rata UN paling tinggi untuk semua mata pelajaran dicapai pada tahun 2016, kecuali pada mata pelajaran Matematika. Sejauh amatan penulis ada beberapa faktor yang diprediksi menjadi penyebab turunnya nilai rata-rata ujian nasional setelah tahun 2016 antara lain mulai diperkenalkannya soal HOTS, pelakasanaan UN berbasis komputer, dan pelakasanaan USBN yang menjadikan UN bukan lagi alat utama penentu kelulusan.
Hasil visualisasi dari data pada tabel di atas dapat dilihat pada Gambar 4.3, Gambar 4.4, Gambar 4.5, dan Gambar 4.6 berikut :
Dari gambar di atas dapat kita ketahui, nilai Bahasa Indonesia dan IPA memiliki trend yang sama dengan capaian rata-rata secara nasional untuk keeempat mata pelajaran. Sementara itu trend yang ditampilkan mata pelajaran Bahasa Inggris, sama untuk tahun 2016-2018 dan cukup berbeda pada tahun 2019. Lain halnya pula dengan mata pelajaran Matematika. Trend yang ditampilkan berbeda dengan capaian rata-rata nasional untuk keempat mata pelajaran.
Hal lain yang dapat kita amati pada gambar di atas adalah penurunan nilai yang cukup ekstrem terjadi pada mata pelajaran Bahasa Indonesia dan Bahasa Inggris pada tahun 2016 ke tahun 2017, dan pada mata pelajaran Matematika
Gambar.4.3. Capaian nilai rata-rata nasional Bahasa Indonesia
Gambar.4.4. Capaian nilai rata-rata nasional Bahasa Inggris
Gambar.4.5.Capaian nilai rata-rata nasional Matematika
Gambar.4.6.Capaian nilai rata-rata nasional IPA