i
Program Studi Teknik Informatika
Oleh :
PETRA VALENTIN WAHYUNINGTIAS
NIM : 085314025
HALAMAN JUDUL BAHASA INDONESIA
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
USING HIDDEN MARKOV MODELS
A THESIS
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Komputer Degree
In Departement of Informatics Engineering
By :
PETRA VALENTIN WAHYUNINGTIAS
STUDENT ID : 085314025
HALAMAN JUDUL BAHASA INGGRIS
INFORMATICS ENGINEERING STUDY PROGRAM
INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
v
LOVE WHAT YOU DO..”
This thesis
belongs to…
Jesus Christ, my Saviour, my Life, my Eternal Love and my Power..
Thank You for stay with me and for gave me wonderful world..
My parent, my spring, my joy, my life..
Thank you for give me a chance to feel the world..
My friends and Audrey..
viii
Suara manusia dapat dijadikan salah satu cara untuk mengidentifikasi apa
yang diucapkan manusia dan siapa yang mengucapkannya. Pada tugas akhir ini
dikembangkan sebuah sistem yang dapat mengidentifikasi secara otomatis suara
manusia dengan menggunakan pendekatan Hidden Markov Models (HMM) dan
ekstraksi ciri Mel-frequency Cepstral Coefficients (MFCC). Secara umum HMM
digunakan untuk signal processing dan speech processing sedangkan MFCC
merupakan salah satu metode ektraksi ciri yang digunakan untuk pengenalan
suara manusia.
Penelitian ini menggunakan suara manusia yang terdiri dari 4 (empat)
speaker(pembicara) yang terdiri dari 2 laki-laki dan 2 perempuan. Pembagian data
untuk proses training dan testing menggunakan metode 5-fold cross validation.
Hasil pengujian yang didapatkan dari proses identifikasi dengan berbagai
kombinasi feature, windows state dan jumlah state diperoleh tingkat akurasi
ix
processing and speech processing and MFCC is use for feature extraction for
human voice.
This research employed four human as the object for the study. Data
including voices of two man and two woman. Data for testing and training were
separeted unsing 5-fold cross validation.
The highest result of identification using any combination of feature,
windows size and number of states are 95% for speech recognition and 93% for
x
Puji dan syukur kepada Tuhan Yesus Kristus yang telah senantiasa
memberikan berkat dan rahmat yang tak berkesudahan serta kesempatan yang
sangat berharga sehingga penulis dapat menyelesaikan skripsi dengan judul
“
Identifikasi Suara Manusia Sebagai Kata Sandi atau Password
Menggunakan Metode Hidden Markov Models
“.
Dalam kesempatan ini, penulis juga ingin mengucapkan terima kasih
sebesar-besarnya terhadap semua pihak yang telah memberi dukungan dan
semangat sehingga skripsi ini dapat selesai :
1.
Romo Dr. C. Kuntoro Adi, S.J., M.A., M.Sc. selaku dosen pembimbing
dan dosen pembimbing akademik Teknik Informatika kelas A angkatan
2008. Terima kasih atas semua bantuan , bimbingan, pengorbanan waktu,
kesabaran, ilmu serta semangat yang telah diberikan.
2.
Ibu Paulina Heruningsih Prima Rosa, S.si., M.Sc. selaku Dekan Fakultas
Sains dan Teknologi. Terima kasih atas semua bantuan dan bimbingan
serta kesabarannya dalam menghadapi mahasiswa.
3.
Bapak Eko Hari Parmadi , S.si., M.Kom. dan bapak Alb. Agung
Hadhiatma, S.T., M.T. selaku dosen penguji. Terima kasih atas saran dan
kritik yang telah diberikan.
4.
Seluruh Dosen Teknik Informatika yang selama masa kuliah telah
membagikan ilmu dan pengetahuannya yang sangat berguna bagi penulis.
5.
Laboran Laboratorium Komputer, Tinus dan Fidi. Terima kasih atas
8.
Kedua adikku, Bernadeta Listiani dan Felicia Ratriana Putri. Terima kasih
telah ada di dunia ini.
9.
Tim Ceriwis. Pucha dan Itha. Teman suka dan duka. Terima kasih atas
segala dukungan dan semangat serta kesabaran yang telah diberikan
sehinggan skripsi kita selesai.
10.
Untuk Angga, Endra, Surya, Devi, Ocha, Siska, Bebeth, Esy, Agnes dan
seluruh teman-teman Teknik Informatika angkatan 2008. Terima kasih
atas dukungannya.
11.
Untuk Maleo, mbak Vero, mbak Lia dan Mbak Debby. Terima kasih atas
bantuannya untuk ‘
break’
ke negri sebrang sehingga skripsi ini dapat
selesai dengan bahagia.
12.
Semua pihak yang telah membantu penulis dalam menyelesaikan skripsi.
Penulis menyadari masih banyak kekurangan yang terdapat dalam laporan
tugas akhir ini. Saran dan kritik sangat diharapkan untuk hasil yang lebih baik di
masa depan.
Yogyakarta, 22 Mei 2013
xii
HALAMAN JUDUL BAHASA INDONESIA ... I
HALAMAN JUDUL BAHASA INGGRIS ... II
HALAMAN PERSETUJUAN PEMBIMBING ... III
HALAMAN PENGESAHAN ... IV
HALAMAN PERSEMBAHAN ... V
PERNYATAAN KEASLIAN KARY ... VI
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK
KEPENTINGAN AKADEMIS ... VII
ABSTRAK ... VIII
ABSTRACT ... IX
KATA PENGANTAR ... X
DAFTAR ISI ... XII
DAFTAR GAMBAR ... XVI
DAFTAR TABEL ... XVIII
BAB I PENDAHULUAN ... 1
1.1 L
ATARB
ELAKANGM
ASALAH... 1
1.2 R
UMUSANM
ASALAH... 3
1.3 T
UJUAN... 3
2.3 S
PEAKERR
ECOGNITION... 13
2.3.1 Struktur Dasar dari Sistem Speaker Recognition ... 14
2.4 F
EATUREE
XTRACTION... 16
2.5 M
EL-F
REQUENCYC
EPSTRALC
OEFFICIENTS(MFCC) ... 18
2.5.1 Frame Blocking ... 20
2.5.2 Windowing ... 21
2.5.3 Fast Fourier Transform (FFT) ... 23
2.5.4 Mel-Frequency Wrapping ... 24
2.5.5 Cepstrum ... 26
2.6 M
ETODEH
IDDENM
ARKOVM
ODELS(
HMM
) ... 27
2.7 A
LGORITMAP
EMODELANH
IDDENM
ARKOVM
ODELS... 30
2.7.1 Algoritma Training dengan Baum-Welch ... 31
2.7.2 Algoritma Testing dengan Viterbi ... 34
2.8 M
ETODEE
VALUASI5-F
OLDC
ROSSV
ALIDATION... 34
BAB III ANALISA DAN PERANCANGAN SISTEM ... 37
3.1 P
ERANCANGANS
ISTEMS
ECARAU
MUM... 37
3.2 G
AMBARANS
ISTEM... 38
3.5 P
ERANCANGANA
NTARM
UKAS
ISTEM... 41
3.5.1 Halaman Depan ... 42
3.5.2 Halaman Pengujian ... 43
3.5.3 Halaman Bantuan ... 46
3.6 S
PESIFIKASIH
ARDWARE DANS
OFTWARE... 48
3.6.1 Hardware ... 48
3.6.2 Software ... 48
BAB IV ... 49
ANALISA HASIL DAN IMPLEMENTASI SISTEM... 49
4.1 A
NALISAH
ASILI
DENTIFIKASIS
UARA... 49
4.2
I
MPLEMENTASIA
NTARMUKAS
ISTEM... 60
4.2.1 Halaman Depan ... 60
4.2.2 Halaman Pilihan Menu Pengujian ... 61
4.2.3 Halaman Pengujian Hidden Markov Models untuk Speech Recognition ... 62
4.2.4 Halaman Pengujian Hidden Markov Models untuk Speaker Verification ... 64
4.2.5 Halaman Pengambilan Suara ... 65
4.2.6 Halaman Pengujian Sistem untuk Speech Recognition ... 67
4.2.7 Halaman Pengujian Sistem untuk Speaker Verification ... 68
4.2.8 Halaman Bantuan ... 74
4.2.9 Halaman Tentang Programmer ... 75
BAB V ... 76
SCRIPT DAN FILE PENDUKUNG ... 84
LAMPIRAN III ... 161
xvi
Gambar
Keterangan
Halaman
2.1
Cakupan speech processing (Joseph P. Campbell, 1997)
10
2.2
Skema Speech Recognition (Melissa, 2008)
12
2.3
Struktur dari Speaker Identification (Furui, 1996)
15
2.4
Struktur dari Speaker Verification (Furui, 1996)
15
2.5
Diagram blok proses MFCC
19
2.6
Proses frame blocking
20
2.7
Sinyal dengan proses windowing
22
2.8
Sinyal tanpa proses windowing
22
2.9
Grafik hubungan skala mel dan frekuensi (IPB)
25
2.10
Contoh mel-spaced Filter-bank (IPB)
25
2.11
Contoh tiga tipe rantai HMM
31
2.12
Ilustrasi dari operasi Baum-Welch
33
3.1
Skema sistem pengenalan suara manusia
38
3.2
Gambaran sistem secara umum
38
3.3
Tahap training dan testing
39
3.4
Proses tahap testing
40
3.5
Proses tahap testing
41
3.6
Rancangan halaman depan
42
3.7
Rancangan halaman Pengujian sistem tahap pertama
43
3.8
Rancangan jendela peringatan apabila password salah
44
3.9
Rancangan jendela peringatan apabila password benar
44
3.10
Rancangan halaman pengujian HMM tahap pertama
45
3.11
Rancangan halaman pengujian HMM tahap kedua
46
3.12
Rancangan halaman bantuan untuk cara kerja program
47
3.13
Rancangan halaman bantuan tentang program
47
4.1
Grafik Tingkat Akurasi Identifikasi Suara Manusia dengan
Feature MFCC_D untuk Speech Recognition
54
4.2
Grafik Tingkat Akurasi Identifikasi Suara Manusia dengan
Feature MFCC_D untuk Speaker Verification
55
4.3
Halaman Depan
60
4.4
Halaman pilihan pengujian
61
4.5
Halaman Pengujian Hidden Markov Model untuk Speech
Recognition
63
4.6
Halaman Pengujian Hidden Markov Model untuk Speaker
Verification
65
4.7
Halaman Pengambilan Suara
66
4.8
Halaman Peringatan
66
xviii
Tabel
Keterangan
Halaman
2.1
Tingkat akurasi berbagai metode feature extraction
(Universite Pierre&MarrieCurrie, LA Science A Paris,
2004)
17
2.2
Pembagian kelompok data menjadi 5 bagian
35
2.3
Gambaran metode 5-fold cross validation
35
2.4
Contoh confusion matrix
36
4.1
Hasil Akurasi Identifikasi Suara untuk Speech Recognition
50
4.2
Hasil Akurasi Identifikasi Suara untuk Speaker Verification
52
4.3
Hasil identifikasi suara berdasarkan tipe feature pada proses
Speech Recognition
56
4.4
Confusion Matrix MFCC_D untuk Speech Recognition
57
4.5
Hasil identifikasi suara berdasarkan tipe feature pada proses
Speaker Recognition
58
1
Meskipun teknologi sudah berkembang pesat tetapi keamanan
pengguna teknologi masih perlu diperhatikan lagi. Gangguan keamanan
yang diakibatkan perkembangan teknologi dapat menyebabkan privasi
seseorang terganggu. Hal ini dapat dilihat dari berbagai contoh seperti
password yang dicuri kemudian disalahgunakan, pembicaraan telepon
yang disadap dan lain sebagainnya. Maka dari itu, keamanan menjadi hal
yang patut diperhatikan seiring dengan perkembangan teknologi.
Saat ini teknologi juga menawarkan berbagai fasilitas untuk
meningkatkan keamanan masyarakat. Salah satunya adalah dengan kata
sandi atau password yang diaplikasikan dalam berbagai perangkat. Tentu
saja kata sandi yang ditawarkan bukan sandi konvensional seperti
memasukkan angka atau huruf melainkan dengan menggunakan suara,
deteksi retina, sidik jari serta pengenalan tulisan tangan. Dari sekian
banyak contoh tersebut pengenalan suara merupakan salah satu cara yang
dapat digunakan sebagai kata sandi yang memiliki variasi yang cukup unik
(Hidayanto dan Sumardi, 2006).
Suara adalah salah satu hal yang membedakan antara manusia satu
aksen yang berbeda bahkan yang kembar identik sekalipun. Keunikan
suara inilah yang dapat dijadikan sebagai kata sandi untuk meningkatkan
keamanan pengguna dalam menggunakan suatu sistem (Setyabudi,
Purwanto dan Warsono, 2007).
Sudah banyak penelitian tentang pengenalan pola suara dengan
menggunakan berbagi metode serta implementasi yang berbeda-beda.
Salah satu metode yang cukup baik dan memiliki akurasi yang tinggi
dalam menangani variasi data dan keberagaman suara adalah Hidden
Markov Models (HMM) dan dengan menggunakan ekstraksi ciri
Mel-frequency Cepstral Coefficients (MFCC). Pada penelitian Pengenalan
Ucapan Kata Terisolasi dengan Metode Hidden Markov Models (HMM)
melalui Ekstraksi Ciri Linear Predictive Coding ( LPC ) (Hidayanto dan
Sumardi, 2006) dihasilkan akurasi yang berkisar pada angka 99,82% untuk
pengenalan ucapan kata yang berkorelasi tinggi pada pengujian dengan
data rekaman. Sedangkan pada pengujian online memberikan akurasi
berkisar pada angkan 87,58%. LPC sendiri adalah salah satu metode yang
digunakan untuk proses ekstrasi ciri.
Pada penelitian Identifikasi Pembicara Menggunakan Algoritme
VF15
dengan
MFCC
sebagai
Pengekstraksi
Ciri
(Zilvan
&
Muttaqien,2011) menghasilkan akurasi identifikasi suara tertinggi
mencapai 97%. VF15 merupakan salah satu algoritma yang digunakan
Pendekatan Hidden Markov Model
“.
Perbedaan tugas akhir ini dengan
penelitian sebelumnya adalah selain untuk mengetahui apa yang akan
diucapkan sebagai kata sandi, sistem juga akan mengidentifikasi pemilik
suara.
1.2
Rumusan Masalah
Dari latar belakang masalah diatas, rumusan masalah yang diambil
adalah Seberapa besar akurasi metode Hidden Markov Model mampu
mengenali suara manusia dan bagaimana mengimplementasinya ke dalam
sistem.
1.3
Tujuan
Merancang, menganalisa, mengimplementasi dan mengetahui
kelebihan serta kekurangan metode Hidden Markov Models dalam
1.4
Batasan Masalah
1.
Pola suara yang diteliti adalah pola suara manusia yang mencakup
suara laki-laki dan perempuan dengan mengucapkan kata tertentu.
Kata yang diucapkan adalah kata ‘satu’, ‘dua’, ‘tiga’, ‘empat’, ‘lima’,
‘enam’, ‘tujuh’, ‘delapan’, ‘sembilan’, dan ‘nol’. Setiap kata yang
diucapkan akan diulang sebanyak lima kali dengan menggunakan
aksen atau cara pengucapan yang berbeda.
2.
Ekstraksi ciri atau feature extraction menggunakan Mel-frequency
Cepstral Coefficients (MFCC)
3.
Suara manusia yang diproses adalah suara berekstensi .wav dan
diambil dengan menggunakan microphone yang terhubung ke
komputer menggunakan program Sound Recorder yang merupakan
program bawaan dari Sistem Operasi Windows . Suara direkam dengan
menggunakan frekuensi sampling 44100Hz dengan karakteristik sound
yang digunakan adalah stereo sound dengan bit data sebesar 16 bit.
4.
Pemodelan suara manusia menggunakan algoritma Baum-Welch.
5.
Identifikasi suara manusia menggunakan algoritma Viterbi.
6.
Terdapat 200 data yang akan digunakan untuk penelitian ini dengan
rincian 100 data dari suara perempuan dan 100 data dari suara
1.5
Metologi Penelitian
Metode yang akan digunakan dalam penelitian meliputi :
1.
Studi Pustaka
Tahap ini dilakukan dengan mempelajari buku-buku referensi dan
sumber-sumber dari internet yang berkaitan dengan Hidden Markov
Models, Speech Processing, feature extraction, algoritma
Baum-Welch, algoritma Viterbi dan tutorial pemrograman Matlab.
2.
Tahap Pengambilan Data
Tahap ini dilakukan dengan cara mengambil data berupa ucapan dari 4
orang yang terdiri dari 2 laki-laki dan 2 perempuan. Tahap ini
dilakukan dengan menggunakan microphone yang terhubung ke
komputer.
3.
Tahap Pembuatan Model
Model sendiri merupakan gambaran statistik dari ucapan yang telah
dimasukkan. Dalam tahap ini model akan dibangun dengan
menggunakan metode Hidden Markov Model.
4.
Tahap Pembuatan Sistem Pengenal Ucapan
Pembuatan sistem akan dilakukan berdasarkan data yang telah
Pada tahap ini juga akan dilakukan evaluasi terhadap sistem yang
dibangun. Apabila data yang dimasukkan adalah data yang belum
dimodelkan maka proses pengujian juga akan dibandingkan dengan
data yang telah dimodelkan terlebih dahulu tetapi dalam program akan
muncul pesan bahwa password atau kata sandi salah.
1.6
Sistematika Penulisan
BAB I
PENDAHULUAN
Berisi latar belakang masalah, rumusan masalah, tujuan,
batasan masalah, metologi penelitian, dan sistematika
penulisan.
BAB II
LANDASAN TEORI
Berisi landasan teori mengenai Speech Processing, Speech
Recognition, Speaker Recognition, teori Hidden Markov
Model,
Mel-frequency
cepstral
coefficients (MFCC),
algoritma Baum-Welch dan algoritma Viterbi yang
BAB III
ANALISA DAN PERANCANGAN SISTEM
Bab ini berisi analisa dan gambaran atau rancangan dari
sistem yang akan dibangun yaitu sebuah sistem yang dapat
mengenali suara manusia sebagai kata sandi atau password
serta menjelaskan alur dari proses training dan testing.
BAB IV
IMPLEMENTASI SISTEM
Bab ini berisi implementasi sistem dengan menggunakan
pendekatan Hidden Markov Model
BAB V
ANALISA HASIL DAN PEMBAHASAN
Bab ini berisi tentang hasil dari implementasi sistem yang
kemudian dianalisa dan diuji.
BAB VI
KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan dan saran yang didapatkan dari
proses pembuatan tugas akhir ini, serta saran agar
9
landasan untuk mengembangkan penelitian beserta perangkatnya.
Teori-teori yang akan dibahas antara lain Speech Processing, Speech
Recognition, Speaker Recognition, Metode Hidden Markov Models ,
Feature Extraction, Mel-frequency Cepstral Coefficients (MFCC),
algoritma Baum-Welch dan algoritma Viterbi.
2.1
Speech Processing
Ucapan merupakan sinyal yang sangat kaya akan informasi yang di
dalamnya terkandung frekuensi, amplitudo dan waktu. Contohnya adalah
gerakan resonansi, harmonisasi, intonasi, dan lain sebagainya. Hal tersebut
digunakan untuk menyampaikan informasi tentang kata-kata dari identitas
pembicara yang dipengaruhi oleh aksen, ekspresi, serta kondisi kesehatan
dari si pembicara.
Sinyal ucapan yang digunakan oleh manusia sehari-hari dapat
dipelajari pada Speech Processing. Speech processing merupakan sebuah
studi yang mempelajari tentang sinyal dari sebuah ucapan dan juga metode
Speech Processing terbagi dalam beberapa cabang ilmu sesuai
dengan tujuan dari pengolahan suaranya. Hal tersebut dapat dilihat pada
Gambar 2.1
Gambar 2.1 Cakupan speech processing (Joseph P. Campbell, 1997)
Apabila dilihat dari Gambar 2.1 terdapat beberapa ilmu yang sudah
sering digunakan dalam aplikasi yang berkaitan dengan ucapan. Speech
recognition dan speaker recognition merupakan cabang ilmu dari specch
processing yang paling sering diaplikasikan untuk pengenalan suara.
Speech recognition sendiri merupakan proses identifikasi suara
yang akan dikonversikan dalam bentuk teks. Sedangkan speaker
recognition dan speaker recognition dalam proses identifikasi suara.
2.2
Speech Recognition
Speech Recognition adalah suatu pengembangan dalam sebuah
sistem yang memungkinkan sebuah komputer untuk mengolah masukan
atau perintah yang berupa suara. Speech Recognition memungkinkan
sebuah sistem untuk dapat mengenali dan memahami perintah suara.
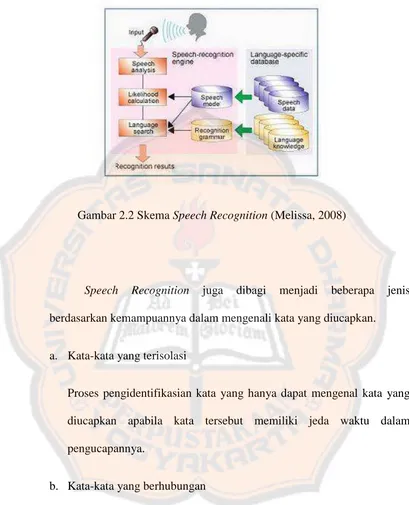
Terdapat 4 tahap dalam Speech Recognition (Mellisa, 2008) yaitu :
a.
Penerimaan data input
b.
Ekstraksi, yaitu penyimpanan data masukan sekaligus pembuatan
database untuk template
c.
Pembandingan / pencocokan, yaitu tahap pencocokan data baru dengan
data suara pada template.
Gambar 2.2 Skema Speech Recognition (Melissa, 2008)
Speech Recognition juga dibagi menjadi beberapa jenis
berdasarkan kemampuannya dalam mengenali kata yang diucapkan.
a.
Kata-kata yang terisolasi
Proses pengidentifikasian kata yang hanya dapat mengenal kata yang
diucapkan apabila kata tersebut memiliki jeda waktu dalam
pengucapannya.
b.
Kata-kata yang berhubungan
Proses pengidentifikasian kata yang mirip dengan kata-kata terisolasi,
metode khusus untuk membedakan kata-kata yang diucapkan dalam
jeda waktu yang sangat sebentar.
d.
Kata-kata spontan
Proses pengidentifikasian kata yang dapat mengenal kata-kata yang
diucapkan secara spontan tanpa jeda waktu antar kata.
e.
Verifikasi atau identifikasi suara
Proses pengidentifikasian kata yang tidak hanya mampu mengenali
kata tapi juga mampu mengidentifikasi siapa yang berbicara.
2.3
Speaker Recognition
Speaker recognition merupakan salah satu metode yang dapat
digunakan secara otomatis untuk mengenali suara seseorang yang
mengucapkan sesuatu (Joseph P. Campbell, 1997). Speaker recognition
juga merupakan bagian dari Speech Proccesing yang mana terdiri dari
Apabila dilihat dari gambar 2.1 sebelumnya, Speaker Recognition
mencakup Speaker Identification dan Speaker Verification. Speaker
Verification merujuk kepada bagaimana sebuah suara dapat menguji
seseorang apakah seseorang tersebut merupakan speaker atau bukan.
Sedangkan Speaker Identification hanya menitikberatkan terhadap
penentuan 1 (satu) speaker dari sekumpulan speaker yang ada.
Metode dari Speaker Recognition juga dapat dibedakan menjadi
text-dependent dan metode text-independent. Metode text-dependent
membutuhkan speaker untuk mengucapkan kata untuk pemodelan dan
pengujian sedangkan metode text-independent tidak bergantung terhadap
kata yang diucapkan speaker untuk pemodelan. Pada pembuatan tugas
akhir ini akan menggunakan metode Speaker Recognition yang bertipe
text-dependent.
2.3.1
Struktur Dasar dari Sistem Speaker Recognition
Speaker Identification dan Speaker Verification memiliki struktur
yang berbeda. Berikut adalah struktur dari Speaker Verification dan
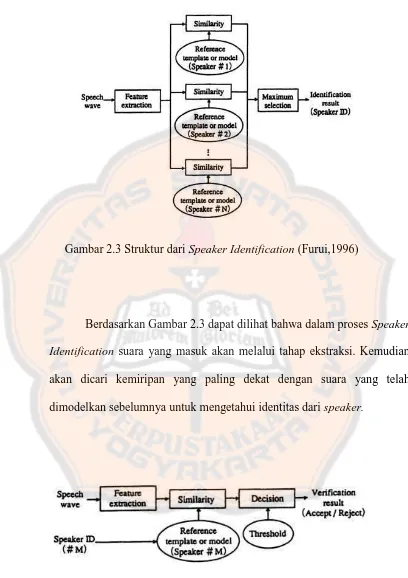
Gambar 2.3 Struktur dari Speaker Identification (Furui,1996)
Berdasarkan Gambar 2.3 dapat dilihat bahwa dalam proses Speaker
Identification suara yang masuk akan melalui tahap ekstraksi. Kemudian
akan dicari kemiripan yang paling dekat dengan suara yang telah
dimodelkan sebelumnya untuk mengetahui identitas dari speaker.
Pada Speaker Verification suara yang masuk akan di ekstraksi
kemudian akan dibandingkan dan dicari kemiripan dengan suara dari
speaker yang telah dimodelkan sebelumnya dan dari speaker id.
Perbandingan tersebut akan digunakan untuk menolak atau menerima
suara yang masuk.
2.4
Feature Extraction
Feature extraction merupakan metode untuk mengubah sinyal
menjadi beberapa parameter. Data yang akan digunakan merupakan data
dari suara manusia sehingga berupa data sinyal. Tetapi tidak semua data
sinyal tersebut dapat digunakan. Hal ini disebabkan karena berbagai faktor
seperti suara-suara yang berada di sekitar speaker pada saat pengambilan
data suara. Dengan tahap feature extraction diharapkan menghasilkan
feature yang memiliki kemampuan untuk membedakan kemiripan
pengucapan setiap model sehingga tidak memerlukan data training yang
banyak. Pada umumnya feature extraction memiliki tiga tahap (Reynold,
2002), yaitu:
1.
Penggunaan program deteksi suara untuk menghilangkan noise dari
sinyal suara yang menjadi obyek.
2.
Feature diekstrak untuk memperoleh informasi
dilihat pada Tabel 2.1 (Chetouani, 2004)
Tabel 2.1 Tingkat akurasi berbagai metode feature extraction
(Sumber : Universite Pierre&MarrieCurrie, LA Science A Paris,
2004)
Dari Tabel 2.1 di atas dapat dilihat bahwa metode NPC memiliki
tingkat identifikasi yang paling tinggi dan sempurna kemudian diikuti oleh
metode MFCC. NPC merupakan salah satu algoritma ekstraksi ciri yang
merupakan perluasan dari LPC. Dalam kasus ini metode MFCC dirasa
paling tepat karena cara kerja metode MFCC sama dengan telinga manusia
sehingga untuk mengidentifikasi suara manusia lebih baik menggunakan
2.5
Mel-Frequency Cepstral Coefficients (MFCC)
Mel-Frequency Cepstral Coefficients (MFCC) merupakan metode
pengolahan suara yang memiliki tujuan untuk mengidentifikasi asal dari
sumber suara. MFCC berdasarkan pada variasi bandwidth kritis terhadap
frekuensi pada telinga manusia sehingga cara kerja yang diterapkan pada
metode ini meniru karakteristik telinga manusia (Zilvan dan Muttaqien,
2011). Pada telinga manusia terdapat filter-filter yang berguna untuk
membedakan suara yang memililki frekuensi rendah dan suara yang
memiliki frekuensi tinggi. Pada metode MFCC, filter pada telinga manusia
digambarkan dalam skala mel-frekuensi yang berfungsi untuk menangkap
karakter penting pada suatu ucapan.
Beberapa keunggulan dari metode MFCC adalah ( Manunggal, 2005):
1.
Mampu menangkap karakteristik suara yang sangat penting bagi
pengenalan suara atau dengan kata lain dapat menangkap
informasi-informasi penting yang terkandung dalam signal suara.
2.
Menghasilkan data seminimal mungkin tanpa menghilangkan
informasi-informasi penting yang terkandung di dalamnya.
3.
Mereplikasi organ pendengaran manusia dalam melakukan persepsi
terhadap signal suara.
Filter-filter yang terdapat dalam telinga manusia juga memiliki
Gelombang suara yang dihasilkan oleh speaker dapat memiliki
berbagai variasi tergantung dari kondisi fisik speaker tersebut. MFCC
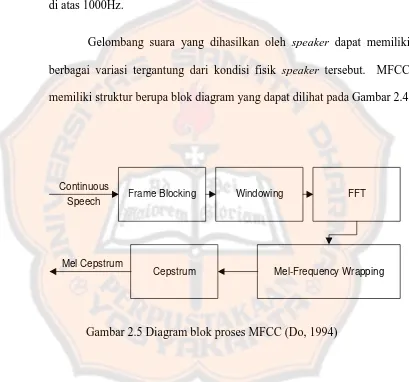
memiliki struktur berupa blok diagram yang dapat dilihat pada Gambar 2.4
Frame Blocking Continuous
Speech Windowing FFT
Mel-Frequency Wrapping Cepstrum
[image:37.595.100.509.226.608.2]Mel Cepstrum
Gambar 2.5 Diagram blok proses MFCC (Do, 1994)
Apabila dilihat dari Gambar 2.5, terdapat beberapa proses feature
2.5.1
Frame Blocking
Sinyal suara terus mengalami perubahan karena adanya pergeseran
artikulasi dari organ produksi vokal. Oleh karena itu, sinyal harus diproses
secara short segments ( short frame). Panjang frame yang biasanya
digunakan untuk pemrosesan sinyal adalah antara 10-30 ms. Panjang
frame yang digunakan sangat mempengaruhi keberhasilan dalam analisa
spektral. Di satu sisi, ukuran dari frame harus sepanjang mungkin untuk
dapat menunjukkan resolusi frekuensi yang baik. Tetapi, di sisi lain frame
juga harus cukur pendek untuk dapat menunjukkan waktu yang baik.
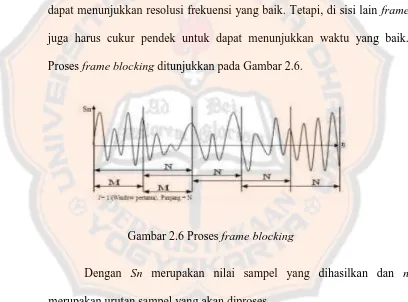
[image:38.595.101.509.306.608.2]Proses frame blocking ditunjukkan pada Gambar 2.6.
Gambar 2.6 Proses frame blocking
Dengan Sn merupakan nilai sampel yang dihasilkan dan n
merupakan urutan sampel yang akan diproses
Sinyal ucapan yang terdiri dari S sampel (X(S)) dibagi menjadi
beberapa frame yang berisi N sampel, yang masing-masing sampel
dipisahkan oleh M (M<N). Frame pertama berisi sampel N pertama.
Proses frame ini dilakukan terus sampai seluruh sinyal dapat
diproses. Selain itu, proses ini umumnya dilakukan secara overlap yang
umum digunakan adalah kurang lebih 30% sampai 50% dari panjang
frame. Overlapping dilakukan untuk menghindari hilangnya ciri atau
karakteristik suara pada perbatasan perpotongan setiap frame.
2.5.2
Windowing
Proses framing dapat menyebabkan kebocoran spektral atau
aliasing. Aliasing merupakan sinyal baru yang memiliki frekuensi yang
berbeda dengan sinyal aslinya. Hal ini dapat terjadi karena rendahnya
jumlah sampling rate atau proses frame blocking yang menyebabkan
sinyal menjadi discontinue. Maka dari itu, tahap windowing diperlukan
agar menghidari kebocoran spektral.
Pada tahap windowing, sinyal suara yang telah mengalami frame
blocking telah dibagi menjadi beberapa frame. Setiap frame yang diperoleh
akan dijadikan window untuk memperkecil kemungkinan gangguan sinyal
yang terputus pada awal dan akhir setiap frame. Window dapat
didefinisikan sebagai berikut :
N merupakan jumlah sample pada setiap frame. Hasil yang
didapatkan dari proses windowing adalah sinyal (y(n)) yang dapat
didefinisikan sebagai berikut :
y(n) = x(n) w(n) ,
dimana 0 ≤ n ≤ (
N-1 )
(2-2)
Terdapat banyak fungsi window, namun yang paling sering
digunakan untuk proses speaker recognition adalah hamming window.
Fungsi window ini menghasilkan sidelobe level yang tidak terlalu tinggi
(kurang lebih -43dB) selain itu noise yang dihasilkan juga tidak terlalu
besar. Fungsi hamming window adalah sebagai berikut :
w(n) = 0.54
–
0.46 cos [
2 π n /
(N
–
1)],
dimana 0 ≤ n ≤ (
N-1 )
(2-3)
Gambar berikut menunjukkan perbedaan antara sinyal yang
melalui proses windowing dan sinyal yang tanpa melalui proses
windowing.
Gambar 2.7 Sinyal dengan proses windowing
[image:40.595.99.516.198.603.2]lain untuk menghitung DFT dengan cepat dengan menggunakan algoritma
FFT dimana FFT menghilangkan proses perhitungan yang kembar dari
DFT.
Jumlah sinyal yang akan dimasukkan dalam algoritma ini harus
merupakan kelipatan dua (2
M). Algoritma FFT dimulai dengan membagi
sinyal menjadi dua bagian. Bagian pertama merupakan sinyal yang
memiliki nilai suara pada indeks waktu genap sedangkan bagian kedua
merupakan sinyal yang memiliki nilai suara pada indeks waktu ganjil.
Fast Fourier Transform adalah himpunan dari N sample [X
n] yang
didefinisikan sebagai berikut :
�
=
�
�−2�
−1
=0
, dimana n =
0,1,2,3,…..
N-1
(2-4)
FFT seringkali digunakan untuk mendapatkan besarnya reaksi
frekuensi dari setiap frame. Ketika FFT dijalankan pada sebuah frame,
dapat diasumsikan bahwa sinyal dalam sebuah frame adalah periodik dan
Apabila dilihat dari rumusan diatas, dapat dilihat bahwa X
nmerupakan angka yang kompleks. Hasil dari X
ndapat dijabarkan sebagai
berikut:
1.
Ketika n = 0 merupakan keadaaan frekuensi saat kosong.
2.
Ketika 1 ≤
n
≤ (
N/2
–
1) merupakan keadaan saat frekuensi bernilai
positif (0 < f < F
s/2).
3.
Ketika N/
2+1 ≤
n
≤
N-1 merupakan keadaaan saat frekuensi bernilai
negatif (F
s/2 < f < 0).
F
ssendiri merupakan frekuensi sample. Hasil yang diperoleh
berupa spektrum sinyal atau periodogram.
2.5.4
Mel-Frequency Wrapping
Sinyal suara terdiri dari nada-nada yang memiliki frekuensi yang
berbeda. Setiap nada dengan frekuensi yang sebenarnya, f, diukur dalam
Hz. Nada yang subyektif diukur dengan menggunakan skala Mel. Sebagai
acuan, nada dengan frekuensi 1kHz, 40dB diatas dari threshold
pendengaran, didefinisikan sebagai 1000 mels. Rumus yang digunakan
untuk menghitung mels dengan frekuensi dalam Hz adalah sebagai
berikut:
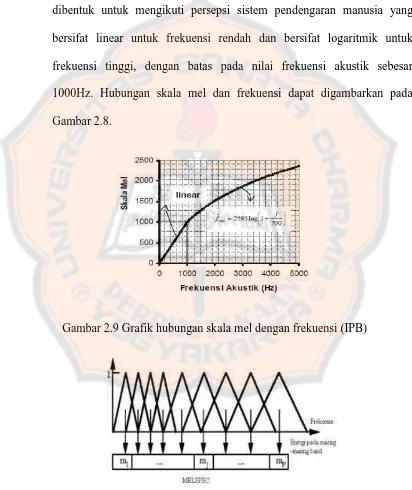
bersifat linear untuk frekuensi rendah dan bersifat logaritmik untuk
frekuensi tinggi, dengan batas pada nilai frekuensi akustik sebesar
[image:43.595.97.509.220.710.2]1000Hz. Hubungan skala mel dan frekuensi dapat digambarkan pada
Gambar 2.8.
Gambar 2.9 Grafik hubungan skala mel dengan frekuensi (IPB)
Dari M filter yang telah terbentuk, maka dilakukan wrapping
terhadap sinyal domain frekuensi dan menghasilkan satu komponen untuk
setiap filter dengan menggunakan rumus ( Buono, 2009) :
�
= log
10=0−1
� �
(2-6)
Dengan i
= 1,2,3….
M dan H
i(k) adalah nilai filter segitiga ke-i
untuk frekuensi akustik sebesar k. Hasil dalam spektrum mel ini kemudian
akan dipilih cepstrum coefficients, nilai koefisien diperoleh dengan
menggunakan transformasi cosinus. Rumus yang digunakan adalah :
=
=1�
cos
−
1
/2
�(2-7)
Dengan j
= 1,2,3…
K yang merupakan jumlah cepstrum coefficients
dan M merupakan jumlah filter.
2.5.5
Cepstrum
Pada langkah terakhir, logaritma dari spektrum mel harus
dikonversikan kembali ke domain waktu. Hasil yang didapatkan bernama
mel-frequency cepstrum coefficients (MFCCs) (Hasan, Jamil, Rabbani dan
Rahman, 2004). Karena koefisien dari mel merupakan bilangan nyata,
dapat juga dikonversikan ke dalam domain berbasis waktu menggunakan
Discrete Cosine Transform (DCT).
speaker yang spesifik. Dengan menerapkan prosedur yang telah
dijelaskan, untuk setiap frame sekitar 30 ms dengan overlap,
koefisien-koefisien dari mel cepstrum dapat dihitung.
2.6
Metode Hidden Markov Models ( HMM )
Hidden Markov Models merupakan sebuah pemodelan statistik dari
sebuah sistem yang diasumsikan sebagai ‘Rantai Markov‘ dengan
parameter yang tidak diketahui, dan tantangannya adalah menemukan
parameter yang tersembunyi (hidden) dari parameter yang diketahui
(observer) (Przytycka, 2000). Parameter yang telah digunakan kemudian
dapat digunakan untuk analisa yang lebih jauh, misalnya untuk Speaker
Recognition. HMM disebut statistik karena mencari means, varians, dan
probabilitas dari model yang digunakan.
Dalam jurnal yang berjudul “
Hidden Markov Models For Speech
Recognition
“ yang ditulis oleh B. H. Juang dan L. R. Rabiner disebutkan
bahwa metode HMM sangat populer dikarenakan memiliki kerangka
matematika. Hal ini karena kemudahan dan ketersediaan dari algoritma
training yang dimiliki HMM untuk memperkirakan parameter dari sebuah
model dengan data yang terbatas.
Dari Hidden Markov Models, suara dianggap sebagai sinyal yang
kemudian dimodelkan. Kemudian suara yang datang akan dibandingkan
dengan seluruh model yang ada dan akan melihat tingkat kecocokan yang
paling mendekati.
Hidden Markov Models didefinisikan sebagai kumpulan 5
parameter yaitu
N, M, A, B, π.
Dengan menganggap
λ = { A, B, π }
maka
Hidden Markov Models mempunyai parameter tertentu yaitu N dam M.
Maka dari itu, ciri-ciri dari HMM adalah :
1.
Observasi diketahui tetapi urutan keadaan ( state ) tidak diketahui
sehingga disebut hidden.
2.
Observasi adalah fungsi probabilitas keadaan
3.
Perpindahan keadaan adalah bentuk probabilitas
Hidden Markov sendiri memiliki parameter distribusi sebagai berikut:
1.
Probabilitas Transisi
A = { a
ij}
, a
ij= P (q
t+1= S
j| q
t= S
i) , 1 ≤
i , j
≤
N
Dengan syarat a
ij≥ 0 dan
π = { π
i}
, π
i= P (q
i= S
j)
Sedangkan terdapat dua parameter tertentu pada Hidden Markov
Models yaitu N dan M.
1.
N merupakan jumlah keadaan model. Dinotasikan sebagai himpunan
terbatas untuk keadaan yang mungkin adalah S = { S
1, S
2……S
N}
2.
M adalah jumlah dari simbol observasi atau keadaan. Simbol observasi
berhubungan dengan keluaran fisik dari sistem yang dimodelkan.
Dinotasikan sebagai himpunan terbatas untuk observasi yang mungkin
adalah V = { V
1, V
2……V
M}
Apabila diberi nilai yang tepat untuk variabel-variabel diatas maka
Hidden Markov Models dapat digunakan untuk memberikan sekuens
observasi.
Dimana untuk setiap observasi O
tadalah satu dari simbol yang ada
pada V, dan T
adalah banyaknya observasi yang ada pada sekuens
tersebut.
Metode Hidden Markov Models memiliki beberapa algoritma
pemodelan yang akan dijelaskan dalam subbab selanjutnya.
2.7
Algoritma Pemodelan Hidden Markov Models
Algoritma dalam Hidden Markov Models digunakan untuk
pembuatan model yang mencakup proses training dan testing. Pemodelan
dapat berbentuk kontinu untuk data yang berlanjut sesuai dengan waktu
seperti data suara yang akan diterapkan pada penelitian ini dan pemodelan
diskret yang digunakan pada data citra.
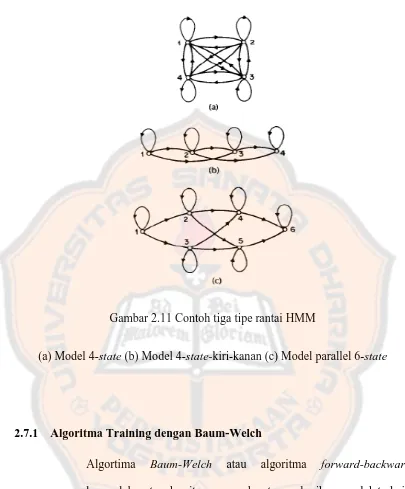
Bentuk dari model Hidden Markov Models adalah berupa
state-state yang saling berhubungan, yang mana setiap state-state terhubung dari state-state
Gambar 2.11 Contoh tiga tipe rantai HMM
(a) Model 4-state (b) Model 4-state-kiri-kanan (c) Model parallel 6-state
2.7.1
Algoritma Training dengan Baum-Welch
Algortima
Baum-Welch
atau
algoritma
forward-backward
merupakan salah satu algoritma yang dapat memberikan model terbaik
berupa means dan varians karena dapat mengoptimalkan probabilitas
observasi sekuens O parameter-parameter model
λ = { A, B, π }
.
Perhitungan pada algoritma ini digunakan untuk mencari nilai maximum
likehood atau angka kemiripan maksimum yang merupakan sebuah model
Variabel forward didefinisikan sebagai observasi parsial dari
probabilitas state sekuen yang dilambangkan dengan
O1, O2, …. Ot
(
hingga waktu t ) dan state Si pada waktu t , dengan model
λ
, dan
α
sebagai
t(i) . Untuk variabel backward didefinisikan sebagai observasi parsial dari
probabilitas state sekuen dari t+1 ke state sebelumnya yang mana terdapat
state Si pada waktu t, dengan model
λ
dan
α
sebagai t(i). Observasi dari
probabilitas state sekuen ini dihitung dengan rumus:
�
=
=1 ��
=
=1 �( )
(2.10)
Probabilitas pada saat berada pada state Si pada waktu t , dan
diberikan sekuens observasi O , dan model
λ
adalah :
�
=
∝� ( |��( ))(2.11)
(b) variabel backward
Gambar 2.12 Ilustrasi dari operasi Baum-Welch
Pada saat menghitung model yang akan akan digunakan maka akan
membutuhkan banyak sampel data yang akan dimodelkan. Karakteristik
dari setiap contoh akan diekstrak dan disimpan dalam sebuah parameter
vektor sekuens xt. Parameter ini yang akan dipetakan sebagai ekuivalensi
dari Ot.
Metode Baum-Welch memiliki cara kerja sebagai berikut :
1.
Estimasikan sebuah model HMM sebagai
λ = { A, B, π }
2.
Dengan nilai
λ
dari sekuens observasi O, hitung sebuah model baru
�
=
,
,
�
Seperti
3.
Jika
� − ��
> threshold, maka hentikan langkah ini. Jika tidak,
maka letakkan nilai
�
untuk menggantikan
λ
dan ulangi langkah 1.
2.7.2
Algoritma Testing dengan Viterbi
Algoritma Viterbi digunakan untuk menghitung sekuens state Q
yang paling dekat dengan kemungkinan atau probabilitasnya dari sekuens
Observasi O. Algoritma Viterbi dapat didefinisikan sebagai:
δ
t(i) = max
q1,q2…q3P[q
1,q
2,…q
t= i, O
1O
2….O
t| λ ]
(2.12)
δ
t(i) merupakan nilai probabilitas terbaik pada waktu t, yang
dihitung pada observasi t pertama yang diakhiri pada state S
i.2.8
Metode Evaluasi 5-Fold Cross Validation
Metode 5-Fold Cross-Validation digunakan pada saat evaluasi
untuk mengukur tingkat akurasi sebuah sistem. Metode 5-Fold Cross
Validation membagi tiap kelompok data suara menjadi data yang
kemudian akan menjadi data untuk proses training dan testing
Dalam penelitian ini, terdapat 4 (lima) kelompok data yang mana
masing-masing kelompok mewakili setiap orang yang akan diambil
suaranya. Setiap kelompok memiliki data sebanyak 50 yang kemudian
Suara 1 Suara 2 Suara 3 Suara 4 Suara 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
Pada metode evaluasi 5-fold cross validation, iterasi yang
dilakukan akan melibatkan data yang berbeda setiap proses training
maupun testing.
Tabel 2.3 Gambaran metode 5-fold cross validation
Testing
Pengujian ke 1 Pengujian ke 2 Pengujian ke 3 Pengujian ke 4 Pengujian ke 5
Pengukuran tingkat akurasi dilakukan dengan menggunakan
confusion matrix seperti pada tabel berikut.
Tabel 2.4 Contoh confusion matrix
Suara 1
Suara 2
Suara 3
Suara 4
Suara 1
Suara 2
Suara 3
Suara 4
Suara 5
Suara 5
Evaluasi dari ketepatan confusion matrix dilakukan dengan cara
membandingkan output hasil dari identifikasi oleh sistem dengan label uji
yang tersedia untuk data tersebut. Perhitungan untuk mengukur tingkat
akurasinya adalah dengan rumus berikut:
Akurasi = S/T x 100%
(2.13)
Keterangan :
S = jumlah sample yang dikenal secara benar oleh sistem ( jumlah
diagonal dari confusion matrix )
37
yang akan dibangun. Sistem ini berfungsi untuk menganalisa tingkat
akurasi metode Hidden Markov Models dalam mengenali suara manusia.
3.1
Perancangan Sistem Secara Umum
Sistem ini digunakan untuk mengenali suara manusia yang
ditampilkan dalam bentuk password untuk disimulasikan sebagai kata
kunci untuk masuk ke dalam suatu sistem dengan menggunakan metode
Hidden Markov Models. Data suara terdiri dari 4 orang yang mana
merupakan 2 laki-laki dan 2 perempuan. Suara akan diambil dengan
menggunakan microphone dan akan diekstraksi terlebih dahulu sebelum
dimasukkan ke dalam sistem. Sistem akan melakukan proses training dan
testing dan akhirnya sistem akan menampilkan hasil apakah suara yang
Data suara berektensi
.wav
Feature Extraction
Training
Testing
Estimasi mode Model
Proses perhitungan probabilitas
Nilai
maksimum Evaluasi hasil
Gambar 3.1 Skema sistem pengenalan suara manusia
Gambar 3.1 menjelaskan tahapan dari proses pengenalan suara.
Dimulai dari data masuk yang berupa file berekstensi .wav kemudian akan
memasuki proses feature extraction yang menggunakan MFCC. Hasil dari
feature extraction sendiri merupakan file berekstensi .mfc. Data suara
yang telah diproses kemudian menjadi input untuk proses training dan
testing dengan menggunakan pendekatan HMM. Setelah itu akan
dihasilkan suara yang dikenali sebagai hasil klasifikasi.
3.2
Gambaran Sistem
user Pola Suara Sebagai Sistem Pengenalan Password
User memasukkan data suara dengan microphone
Sistem menampilkan hasil apakah masukan diterima atau tidak
3.3
Proses Training
Proses training akan menghasilkan model dari data yang telah
diambil sebelumnya. Proses training ini akan menggunakan algoritma
Baum-Welch yang telah dibahas dalam bab sebelumnya. Gambar 3.3
menunjukkan proses training data dan pembuatan model. Dalam proses
training terdapat proses feature extraction yang akan menggunakan
metode Mel-Frequency Cepstral Coefficients (MFCC). Untuk estimasi
model akan menggunakan pendekatan Hidden Markov Models (HMM).
Sesuai dengan metode 5 Fold Cross-Validation yang telah dibahas pada
bab sebelumnya maka pada proses training dalam membentuk sebuah
Input suara
Feature extraction
Estimasi model
M1 M2 Mn
....
....
Gambar 3.4 Proses tahap training
3.4
Proses Testing
Pada tahap testing akan menggunakan algoritma Viterbi. Proses ini
menggunakan data yang baru. Untuk mengenali data baru yang masuk,
sistem akan menghitung probabilitas dari data baru dengan model yang
ada dilihat dari kemiripan atau kedekatannya. Data yang memiliki
probabilitas tertinggi akan menunjukkan bahwa data suara baru yang
masuk dapat diidentifikasi dan diterima oleh sistem. Gambar 3.4
Untuk implementasi HMM dan identifikasi suara manusia maka
pada pembuatan tugas akhir ini penulis menggunakan HMM Toolkit (HTK).
HTK menyediakan tools termasuk algoritma Baum-Welch yang digunakan
pada proses training dan algoritma Viterbi untuk proses testing.
3.5
Perancangan Antar Muka Sistem
Pada perancangan antar muka untuk sistem pengenalan suara
manusia ini terdiri dari beberapa halaman yang mewakili proses
perhitungan dari Hidden Markov Models serta cara kerja dari sistem, yaitu:
1.
Halaman depan
2.
Halaman pengujian sistem
3.
Halaman pengujian HMM dan cara kerja sistem
3.5.1
Halaman Depan
Halaman ini merupakan halaman pembuka yang berisi dua menu
utama yaitu MENU dan BANTUAN serta penjelasan mengenai tentang
nama sistem, logo Universitas Sanata Dharma, identitas pembuat program
dan nama Dosen pembimbing. Rancangan dari halaman depan sistem ini
dapat dilihat pada Gambar 3.6
suara. Sedangkan pada halaman pengujian HMM akan berisi tentang cara
kerja dari HMM dan cara kerja sistem. Rancangan halaman pengujian
dapat dilihat pada beberapa gambar berikut ini.
Gambar 3.7 Rancangan Halaman Pengujian sistem tahap pertama
Apabila dalam memasukkan password salah maka akan muncul
Gambar 3.8 Rancangan Jendela peringatan apabila password salah
Apabila password benar maka akan muncul peringatan seperti pada
Gambar 3.9
Gambar 3.9 Rancangan Jendela peringatan apabila password benar.
Selanjutnya, untuk rancangan halaman pengujian HMM terdapat
menu untuk mengambil contoh data suara dari direktori yang ada untuk
diuji dengan HMM. Untuk mendengarkan suara yang diambil dapat
menekan tombol DENGAR. Data suara yang telah diambil dapat
divisualisasikan menjadi spectogram dan signal. Kemudian untuk
memproses suara terdapat tombol PROSES yang akan melakukan proses
pengenalan suara yang hasilnya dapat dilihat pada label HASIL.
Gambar 3.10 Rancangan halaman pengujian HMM tahap pertama
Rancangan halaman berikutnya berisi tentang keterangan data yang
terdapat dalam sistem. Pengguna dapat memilih parameter yang
digunakan, windows size dan jumlah state yang digunakan. Dengan
menekan tombol PROSES maka data akan diproses dengan menggunakan
HMM. Apabila proses telah selesai maka akan muncul confusion matrix
Gambar 3.11 Rancangan halaman pengujian HMM tahap kedua
3.5.3
Halaman Bantuan
Halaman bantuan berisi tentang bagaimana cara menggunakan
program serta sedikit keterangan mengenai program yang terdiri dari tujuan
serta manfaat dari program. Rancangan dari halaman bantuan dapat dilihat
Gambar 3.12 Rancangan halaman Bantuan untuk cara kerja program
3.6
Spesifikasi Hardware dan Software
Berikut adalah spesifikasi hardware dan software yang digunakan
pada pembuatan sistem ini.
3.6.1
Hardware
Processor
: AMD E-450 APU with Radeon(tm) HD Graphics
1.65GHz
Memory (RAM) : 2.00 GB
System-type
: 32-bit operating system
3.6.2
Software
Windows 7 Ultimate
49
sistem beserta penjelasan tentang penggunaan tombol dan keterangan dari
sistem. Hal yang utama dalam pembahasan bab ini adalah analisa hasil
dari identifikasi suara manusia dari berbagai pengujian yang telah
dilakukan yang meilbatkan jumlah feature, besarnya windows size serta
jenis parameter yang dipilih.
4.1
Analisa Hasil Identifikasi Suara
Dalam proses identifikasi suara manusia ini dilakukan dengan
menggunakan windows size, tipe feature dan dengan jumlah state yang
berbeda dan diharapkan menghasilkan akurasi yang tinggi. Ukuran
windows size yang digunakan pada sistem ini adalah 4ms sampai dengan
6ms, sedangkan tipe feature yang digunakan adalah MFCC, MFCC_D,
dan MFCC_D_A. Sedangkan jumlah state yang dapat digunakan yaitu 10,
15, 20 dan 25.
Pada setiap pengujian akan dihasilkan confusion matrix serta
akurasi data yang berupa persentase. Pada bagian ini akan ditampilkan
pengujian. Tabel 4.1 dan Tabel 4.2 di bawah ini menunjukkan hasil setiap
pengujian dengan berbagai macam variasi feature, windows size dan
jumlah state. Tabel 4.1 merupakan hasil pengujian untuk Speech
[image:68.595.100.527.218.753.2]Recognition dan Tabel 4.2 merupakan hasil pengujian untuk Speaker
Recognition
Tabel 4.1 Hasil Akurasi Identifikasi Suara untuk Speech
Recognititon
No
Windows Size
Feature
Jumlah State Akurasi (%)
1
4 MFCC
10
81
2
4 MFCC
15
88
3
4 MFCC
20
89
4
4 MFCC
25
91
5
5 MFCC
10
82
6
5 MFCC
15
88
7
5 MFCC
20
88
8
5 MFCC
25
90
9
6 MFCC
10
83
10
6 MFCC
15
89
11
6 MFCC
20
90
12
6 MFCC
25
93
13
4 MFCC_D
10
80
14
4 MFCC_D
15
89
15
4 MFCC_D
20
88
16
4 MFCC_D
25
92
23
6 MFCC_D
20
92
24
6 MFCC_D
25
95
25
4 MFCC_D_A
10
79
26
4 MFCC_D_A
15
85
27
4 MFCC_D_A
20
85
28
4 MFCC_D_A
25
87
29
5 MFCC_D_A
10
82
30
5 MFCC_D_A
15
88
31
5 MFCC_D_A
20
89
32
5 MFCC_D_A
25
93
33
6 MFCC_D_A
10
75
34
6 MFCC_D_A
15
87
35
6 MFCC_D_A
20
88
Tabel 4.2 Hasil Akurasi Identifikasi Suara untuk Speaker
Recognition
No
Windows Size
Feature
Jumlah State
Akurasi (%)
1
4 MFCC
10
85
2
4 MFCC
15
91
3
4 MFCC
20
88
4
4 MFCC
25
90
5
5 MFCC
10
87
6
5 MFCC
15
91
7
5 MFCC
20
91
8
5 MFCC
25
92
9
6 MFCC
10
85
10
6 MFCC
15
90
11
6 MFCC
20
89
12
6 MFCC
25
91
13
4 MFCC_D
10
86
14
4 MFCC_D
15
85
15
4 MFCC_D
20
87
16
4 MFCC_D
25
90
17
5 MFCC_D
10
86
18
5 MFCC_D
15
87
19
5 MFCC_D
20
91
20
5 MFCC_D
25
88
21
6 MFCC_D
10
80
28
4 MFCC_D_A
25
72
29
5 MFCC_D_A
10
82
30
5 MFCC_D_A
15
81
31
5 MFCC_D_A
20
88
32
5 MFCC_D_A
25
87
33
6 MFCC_D_A
10
78
34
6 MFCC_D_A
15
83
35
6 MFCC_D_A
20
88
Pada Gambar 4.1 berikut merupakan grafik yang menunjukkan
tingkat akurasi identifikasi suara manusia dengan menggunakan feature
MFFC_D dan dengan kombinasi windows size dan jumlah state yang
berbeda. Grafik di bawah ini merupakan pengujian pada Speech
[image:72.595.99.547.198.602.2]Recognition.
Gambar 4.1 Tingkat Akurasi Identifikasi Suara Manusia dengan Feature
MFCC_D untuk Speech Recognition
7075 80 85 90 95 100
4 5 6
A
ku
rasi
Window Size
Hasil Pengujian
10
15
20
Gambar 4.2 Tingkat Akurasi Identifikasi Suara Manusia dengan Feature
MFCC_D untuk Speaker Recognition
70 75 80 85 90 95
4 5 6
A
ku
rasi
Windows Size
Hasil Pengujian
10
15
20
25
Pada Tabel 4.3 dan Tabel 4.5 berikut ini menunjukkan tingkat akurasi dari
berbagai jenis tipe feature yang berbeda. Pada Tabel 4.3 jumlah state yang
digunakan adalah 25 dengan ukuran windows size adalah 6ms. Sedangkan
pada Tabel 4.5 jumlah state yang digunakan adalah 20 dengan ukuran
windows size adalah 6ms.
Tabel 4.3 Hasil identifikasi suara berdasarkan tipe feature pada proses
Speech Recognition
Feature
Akurasi (%)
MFCC
93
MFCC_D
95
MFCC_D_A
92
Hasil dari pengujian tersebut menunjukkan bahwa tingkat akurasi
yang dihasilkan bervariasi mulai dari 92% sampai dengan 95%. Pengujian
Hidden Markov Models yang menggunakan tipe feature MFCC_D dengan
jumlah state 25 dan besar windows size 6ms memiliki akurasi yang paling
tinggi.
Tabel berikut ini merupakan confusion matrix untuk pengujian
yang memiliki tingkat akurasi yang paling tinggi. Confusion matrix di
satu
0
20
0
0
0
0
0
0
0
0
dua
0
0
19
0
0
0
0
0
1
0
tiga
0
0
0
19
0
1
0
0
0
0
empat
0
0
0
0
19
0
0
0
1
0
lima
0
0
0
0
0
18
0
0
1
1
enam
0
0
0
0
0
0
18
0
0
2
tujuh
0
0
0
0
0
0
1
17
0
2
delapan
0
0
0
0
0
0
0
0
20
0
sembila
n
0
0
0
0
0
0
0
0
0
20
Pada confusion matrix di atas dapat dilihat bahwa sistem dapat
mengidentifikasi suara dengan baik. Pada pengucapan kata ‘satu’,
‘delapan’, dan ‘sembilan’ mampu dikena
li dengan tepat dengan
menunjukkan hasil maksimal yaitu 20. Nilai terendah dari confusion matrix
tersebut adalah 17 yaitu pada penguca
pan kata ‘tujuh’.
Dalam proses identifikasi speech recognition, suara yang masuk
tetapi bukan berasal dari speaker yang telah dimodelkan sebelumnya dapat
diproses dan terkadang hasil pengujian tepat. Hal ini dikarenakan pola kata
[image:75.595.99.519.166.565.2]tidak berasal dari speaker yang telah dimodelkan masih dapat dikenali
dengan mencari kedekatan yang maksimum.
Tabel 4.5 Hasil identifikasi suara berdasarkan tipe feature pada proses
Speaker Recognition
Feature
Akurasi (%)
MFCC
89
MFCC_D
93
MFCC_D_A
88
Hasil dari pengujian tersebut menunjukkan bahwa tingkat akurasi
yang dihasilkan bervariasi mulai dari 88% sampai dengan 93%. Pengujian
Hidden Markov Models yang menggunakan tipe feature MFCC_D dengan
jumlah state 20 dan besar windows size 6ms memiliki akurasi yang paling
[image:76.595.97.514.222.560.2]tinggi.
Tabel berikut ini merupakan confusion matrix untuk pengujian yang
memiliki tingkat akurasi yang paling tinggi. Confusion matrix di bawah ini
Yudhi
1
0
0
49
Pada confusion matrix diatas hasil paling tinggi adalah 49 yaitu
pada speaker yang bernama Yudhi. Sedangkan jumlah paling kecil yaitu
44 yang merupakan speaker yang bernama Deta.
Pada proses speaker verification terdapat beberapa faktor yang
mempengaruhi tingkat akurasi proses identifikasi. Salah satu faktor
tersebut adalah speaker yang memiliki hubungan darah dapat membuat
sistem sedikit sulit untuk membedakan speaker tersebut. Dalam kasus ini
Petra dan Deta adalah speaker yang memiliki hubungan darah sehingga
[image:77.595.95.507.147.655.2]4.2
Implementasi Antarmuka Sistem
4.2.1
Halaman Depan
Halaman Depan merupakan halaman yang pertama kali dilihat oleh
user ketika menjalankan sistem ini. Halaman depan berisi judul dari sistem
beserta nama dari mahasiswa beserta nama dari dosen pembimbing. Pada
halaman depan terdapat dua menu utama yang terdapat di kiri atas. Setiap
menu utama memiliki sub-menu yang lain. Tampilan dari Halaman Depan
[image:78.595.104.547.271.661.2]dapat dilihat pada Gambar 4.1 berikut.
Gambar 4.4 Halaman Pilihan Pengujian
4.2.3
Halaman Pengujian Hidden Markov Models untuk Speech
Recognition
Halaman Pengujian Hidden Markov Models Speech Recognition
untuk adalah halaman yang berfungsi untuk menguji metode Hidden
Markov Models dengan jenis feature, windows size dan jumlah state yang
berbeda-beda. Pengujian ini dilakukan untuk mengetahui tingkat akurasi
dari hasil identifikasi suara. Dalam pengujian ini akan dihasilkan
confusion matrix, tingkat akurasi, lama jalannya program serta banyaknya
data yang cocok dan tidak cocok. Tampilan dari halaman ini dapat dilihat
pada Gambar 4.3.
Pada halaman ini terdapat beberapa kolom yang berisi tentang
berbagai keterangan. Pada kolom Keterangan Data berisi tentang
keterangan mengenai jumlah data yang akan