isprs archives XLII 2 W7 149 2017
Teks penuh
Gambar
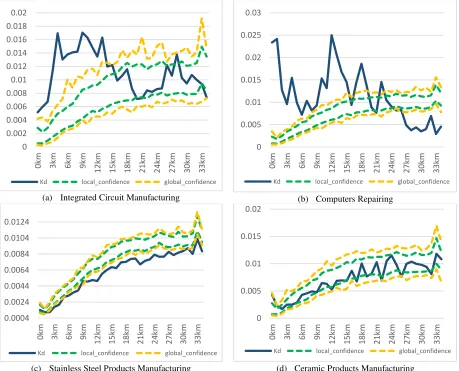
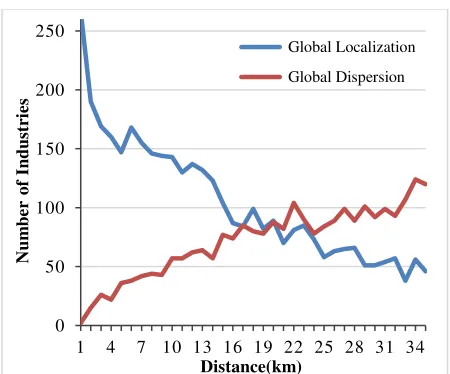
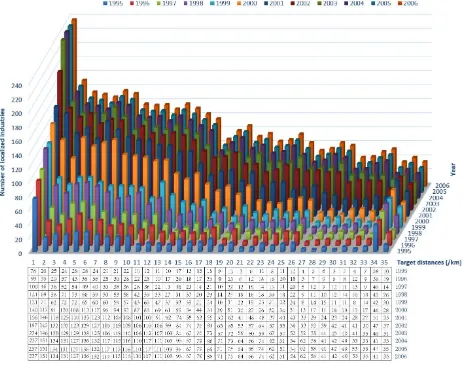
Dokumen terkait
2. Pelayanan sekunder : pendidikan, fasilitas umum dan sosial, perdagangan dan jasa, perumahan serta ruang terbuka hijau. Sub pusat pelayanan kota yang berada di Kawasan Pasar
Data yang dibutuhkan pada penelitian ini adalah single line diagram Gardu Induk Bandung Selatan 150kV, data GI yang terhubung dengan GI Bandung Selatan, data transmisi,
Evaluasi Koordinasi Setting Rele Proteksi OCR pada Jaringan Distribusi Daya Pemakaian Sendiri di PT Indonesia Power Unit Pembangkitan. Semarang Tambak Lorok Bok I
Atas pelayanan terhadap pemberian Izin Gangguan dikenakan retribusi yang ditetapkan dengan Peraturan Daerah tersendiri... memotret seseorang yang berkaitan dengan
4.3.2 Perbandingan hasil pengukuran dan nilai standar dari konverter chopper DC ke motor.. Muhammad Rasyid
Pada proses perancangan dan penenlitian yang dilakukan terdiri dari proses simulasi dan rancang bangun prototipe rangkaian inverter sebagai driver motor induksi tiga
Apabila kita melakukan perbuatan haram atau dosa, maka membuat hati kita jadi hitam, sehingga hati kita jadi keras, mati, sehingga cahaya dari Allah tidak bisa masuk ke dalam
Hasil uji Spearman menunjukkan bahwa tidak ada hubungan yang signifikan antara lama otore dengan ambang hantaran tulang penderita OMSK keseluruhan dan OMSK tipe maligna
