PERLUASAN METODE
FEATURE POINT
EXTRACTION
UNTUK PENGENALAN
HURUF JEPANG
HIRAGANA
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Sains
Program Studi Ilmu Komputer
Oleh:
Antonius Willy Setiawan
NIM: 043124003
PROGRAM STUDI ILMU KOMPUTER JURUSAN MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
METHOD FOR JAPANESE
HIRAGANA
LETTER
RECOGNITION
A THESIS
Presented as Partial Fulfillment of the Requirements to Obtain the Sarjana Sains Degree
in Computer Science Study Program
By:
Antonius Willy Setiawan
ID: 043124003
COMPUTER SCIENCE STUDY PROGRAM DEPARTMENT OF MATHEMATIC FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
vi Kupersembahkan skripsi ini untuk:
• Tuhan Yesus Kristus, Bunda Maria, dan Santo Yusuf, serta Santo
Antonius dan Santo Aloysius di Surga atas segala rahmat, kasih,
perlindungan, dan bimbingan-Nya.
• Papa, Mama, dan Ko Ai atas kasih, dukungan, dan doa.
• Almamaterku Universitas Sanata Dharma, khususnya Ilmu Komputer
vii
HALAMAN MOTTO
శ㒶⍫
ߎ߁ࠎ߿
ߩᅤ
ߏߣ
ߒޕ
(Time is running like an arrow.)
⑳
ࠊߚߒ
ߪ
ߥࠎ
ߩߚߦ↢
߈ߡࠆߩ㧫
(What am I still living for?)
↢
߈ߡࠆ㒢
߆߉
ࠅޔ⧰
ߊࠆ
ߒߎߣ߇ࠆޕ
(People will always face problem as long as they live.)
ੱ
߭ߣ
ߩᝄ
߰
ࠅ
ߺ
ߡᚒ
ࠊࠇ
߇ᝄ
߰
ࠅ⋥
ߥ߅
ߖޕ
(The wise one always fixes his/her own mistake.)
ੱ
߭ߣ
ߪㆊ
߆ߎ
ߦ↢
߈ࠆ߽ߩߦࠄߕޔ
߹
ߢ߈ࠆߎߣࠍ
߿ࠇ߫ߩߢߔޕ
ix
ABSTRAK
PERLUASAN METODE FEATURE POINT EXTRACTION
UNTUK PENGENALAN HURUF JEPANG HIRAGANA
Bagi para penggemar kebudayaan Jepang, huruf Hiragana merupakan huruf dasar di Jepang yang digunakan untuk menuliskan kata-kata Jepang asli, dimana salah satu kesulitan yang dialami para peminat bahasa Jepang ialah mengenali tulisan huruf Jepang. Manusia mengenali objek berdasarkan ciri-ciri dan pengetahuan yang pernah diamatinya dari objek tersebut. Tujuan dari pengenalan pola adalah mengklarifikasi dan mendeskripsikan objek. Salah satu metode pengenalan pola yang relatif awal ialah Feature Point Extraction.
Dalam Feature Point Extraction, digunakan tabel hubungan ketetanggaan antarpiksel. Matriks dari karakter input dicocokkan dengan tabel untuk mendapatkan nilai tertentu, dan dicari selisihnya dengan tiap template. Karakter input digolongkan ke dalam template yang memiliki total selisih minimum.
x
THE EXTENSION OF FEATURE POINT EXTRACTION METHOD FOR JAPANESE HIRAGANA LETTER RECOGNITION
For those who are interested about Japanese cultural, Hiragana is a basic letter used to write Japanese words, which unfortunately, one of many difficulties in learning Japanese cultural is recognizing these Japanese letters. Human recognize object based on characteristics and knowledge which they have observed from that object. The purpose of pattern recognition is to clarify and to describe an object. Feature Point Extraction is one of many methods of pattern recognition, which is used earlier.
Feature Point Extraction method uses table of enumeration of possible pixel neighborhood. Matrix from the character input is matched with those in the table to gain a value, and then this value is used to count the subtraction between the input and the template. The character input is concluded as a template which has a minimum total of subtraction.
xi
KATA PENGANTAR
Puji dan syukur penulis haturkan ke hadapan Tuhan Yesus Kristus karena
atas berkat dan kasih-Nya yang tiada henti, penulis dapat menyelesaikan skripsi
yang berjudul “PERLUASAN METODE FEATURE POINT EXTRACTION UNTUK PENGENALAN HURUF JEPANG HIRAGANA” pada waktunya. Terima kasih karena Engkau selalu memberikan yang terbaik untukku.
Adapun skripsi ini ditulis untuk memenuhi salah satu syarat memperoleh
gelar Sarjana Sains pada Program Studi Ilmu Komputer, Jurusan Matematika,
Fakultas Sains dan Teknologi, Universitas Sanata Dharma Yogyakarta.
Penulis tentu tidak sendirian selama masa studi; bantuan demi bantuan
penulis terima dari berbagai pihak dalam berbagai bentuk. Oleh karena itu, pada
kesempatan ini, dengan rendah hati, penulis ingin mengucapkan rasa syukur dan
terima kasih sebesar-besarnya kepada:
1. Romo Greg selaku dekan FST, Bu Rosa selaku Kaprodi Ikom, Pak Eko
Hari selaku dosen pembimbing akademik, dan Pak Joko selaku dosen
pembimbing TA, serta Mas Tukijo dan Mbak Linda atas pelayanannya di
Sekretariat. Terima kasih atas kesempatan, perhatian, dukungan,
bimbingan, dan bantuannya kepada saya selama masa perkuliahan,
khususnya masa-masa skripsi.
2. Papa, Mama, Ko Ai, dan Cie Kristin yang tak henti-hentinya memberikan
doa, dukungan moral dan materi, serta Lessie dan anjing-anjingku lainnya
3. Para kerabat: Ku Khing sekeluarga, Ik Liang, Ik Gwat sekeluarga, dan Ku Nga sekeluarga, yang selalu memberi bantuan dan perhatian selama studi.
4. Opa Harjoko beserta kerabat-kerabat lainnya di Surga atas jasa-jasanya.
5. Mbah Dasro sekeluarga yang bersedia memberikan tempat kos yang
murah dan nyaman, serta makanan yang enak-enak.
6. Sahabat-sahabat terbaikku di Yogya: Agung “Acenk”, Budi “Ndut”, Beny
“Bendot”, Maman “Coeman”, Henry “Ondie”, Hendra “Ganyong”, Dicky,
Jimy “Jigo”, Frans “Njoohe”, Andy “Cimeng”, Prast, Adi “Gemblung”,
Mas Agung “Sawitri”, Toak, Raymond “Emon”, Vandi, Hermez, Bayu
“Celeng”, Fery, dan teman-teman lainnya, khususnya teman-teman Tasura
52. Aku tidak akan pernah melupakan kegilaan, kebrutalan, kebersamaan,
persahabatan, petualangan, dan pengalaman yang sangat mengesankan
selama bersama kalian. Kalian telah memberikan semangat dan motivasi
sehingga aku dapat terus berkarya. Go on top yuu’…pengen ngulti neh…! 7. Terima kasih juga untuk sahabat-sahabat cewek: Nanda “Nandut”, Cie
Lian, Intan “Singo”, Mbak Ina, Kadek “Krik2”, Ayu, Bella, Wiwit, Fany,
Ratna Asien, Vera “Kero”, dan lain-lain, atas pengalaman dan
persahabatan yang mengesankan.
8. Teman-temanku di Jember, khususnya teman-teman SMUK Santo Paulus:
David “Ping-ping”, Kiki “Mashimaro”, Vena “Bokong”, Teddy “Tweety”, Eliana “Ayam”, Pak Gora “Goraemon”, dan teman-temanku lainnya
terlebih III IPA3 tahun 2003/2004; teman-teman spiritualku: Romo Agung
xiii
cucu-cucuku Ayu, Astrid, Lia, Yuke, dkk; serta EPSILON CLUB: Vico, Brahma, Petrus (sekarang sudah Frater), Santoso, Teddy “GPC”, Bayu
“Bayek”, Adi “Timbul”, Fauzan “Uyan”, Hambar, Teguh, Yones, dan
Aditya “Mbah”, atas kenangan dan persahabatannya hingga sekarang.
9. Teman-temanku dari USD: Campus Ministry: Mas Darto, Mbak Nita,
Gaudeamus Choir, dan teman-teman lainnya atas pengalaman yang tidak terlupakan; teman-teman KKN angkatan XXXV kelompok 24: Mono,
Silvi “Bundo”, Mayora “Beng-beng”, Linda, Ita, Alfa “Galon”, Naomi
“Mami”, beserta Pak DPL-nya: Pak Hery Santoso, atas kegilaan dan
pengalaman yang mengesankan; teman-teman Ikom, khususnya angkatan
2004: Henry, Kornel, Damian, Beni, Ipung, Hali, Beli, Amel, Deby, Desy,
Eka, dan semuanya atas kebersamaan dan perjuangannya selama kuliah.
10. Beserta pihak-pihak lain yang tidak mungkin dapat disebutkan satu per
satu yang telah banyak berjasa.
Penulis sadar bahwa skripsi ini masih belum sempurna. Oleh karena itu,
penulis memohon maaf atas ketidaksempurnaan ini dan bersedia menerima
masukan demi kebaikan bersama. Akhir kata, penulis berharap semoga karya ini
berguna bagi para pembaca sekalian. Terima kasih.
Yogyakarta, Agustus 2008
xiv
halaman
Halaman Judul ……… i
Title ……… ii
Halaman Persetujuan ……… iii
Halaman Pengesahan ……… iv
Halaman Pernyataan Keaslian Karya ……… v
Halaman Persembahan ……… vi
Halaman Motto ……… vii
Halaman Persetujuan Publikasi ……… viii
Abstrak ……… ix
Abstract ……… x
Kata Pengantar ……… xi
Daftar Isi ……… xiv
Daftar Gambar ……… xviii
Daftar Tabel ……… xxi
BAB I PENDAHULUAN ……… 1
1.1 Latar Belakang Masalah ……… 1
1.2 Rumusan Masalah ……… 3
1.3 Batasan Masalah ……… 3
xv
1.5 Manfaat Penelitian ……… 4
1.6 Metode Penelitian ……… 4
1.7 Sistematika Penulisan ……… 6
BAB II LANDASAN TEORI ……… 7
2.1 Pengolahan Citra ……… 7
2.1.1 Definisi ……… 7
2.1.2 Preprocessing ……… 8
2.1.2.1Thresholding ……… 8
2.2 Pengenalan Pola (Pattern Recognition) ……… 12
2.3 Feature Point Extraction ……… 16
2.4 Huruf Hiragana ……… 22
BAB III DESAIN ……… 26
3.1 Gambaran Sistem Secara Umum ……… 26
3.2 Desain Proses ……… 32
3.2.1 Proses binerisasi ……… 32
3.2.2 Proses menghilangkan pinggiran putih ………… 36
3.2.3 Proses segmentasi 9 bagian ……… 38
3.2.4 Proses pencocokan dengan tabel ……… 39
3.2.5 Proses mencari selisih minimum dengan template … 40 3.3 Navigasi Menu ……… 43
3.4.1 Home ……… 44
3.4.2 Daftar Hiragana ……… 45
3.4.3 Bantuan ……… 45
3.4.4 Tentang Program ……… 46
3.4.5 Input Gambar ……… 46
3.4.6 Kesimpulan ……… 47
3.4.7 Kesimpulan untuk input salah ……… 48
3.5 Spesifikasi Hardware dan Software ……… 48
3.5.1 Hardware ……… 48
3.5.2 Software ……… 49
BAB IV HASIL DAN PEMBAHASAN ……… 50
4.1 Hasil Tampilan User Interface ……… 50
4.1.1 Tampilan Home ……… 50
4.1.2 Tampilan Daftar Hiragana ……… 51
4.1.3 Tampilan Bantuan ……… 52
4.1.4 Tampilan Tentang Program ……… 53
4.1.5 Tampilan Input Gambar ……… 53
4.1.6 Tampilan Kesimpulan ……… 54
4.1.7 Tampilan Kesimpulan untuk Input yang Salah …… 55
4.2 Hasil Pengujian Karakter ……… 55
xvii
4.4 Implementasi dengan 512 Hubungan Ketetanggaan
Antarpiksel ……… 64
4.5 Analisis Unjuk Kerja ……… 67
4.6 Kelemahan Aplikasi ……… 72
BAB V PENUTUP ……… 74
5.1 Kesimpulan ……… 74
5.2 Saran ……… 75
DAFTAR PUSTAKA ……… 76
LAMPIRAN ……… 77
Cuplikan Listing Program ……… 78
xviii
halaman
Gambar 2.1 Jenis distribusi intensitas citra ……… 9
Gambar 2.2 Citra dengan distribusi intensitas yang jelas ……… 9
Gambar 2.3 Hasil threshold yang baik ……… 10
Gambar 2.4 Citra dengan distribusi intensitas yang hampir sama ……… 10
Gambar 2.5 Hasil threshold yang kurang baik ……… 11
Gambar 2.6 Thresholding setelah operasi deteksi tepi ……… 11
Gambar 2.7 Skema umum proses pengenalan pola……… 14
Gambar 2.8 Template matching ……… 15
Gambar 2.9 Pemecahan matriks 9x9 menjadi 9 bagian ……… 19
Gambar 2.10 Karakter input dan karakter template ……… 19
Gambar 2.11 Karakter-karakter yang dipecah menjadi 9 bagian ……… 20
Gambar 2.12 Contoh segmentasi karakter “A” ……… 21
Gambar 2.13 Perbandingan penulisan Hiragana dan Katakana ………… 22
Gambar 2.14 Contoh aturan penulisan huruf Hiragana ……… 22
Gambar 2.15 Karakter dasar Hiragana ……… 23
Gambar 2.16 Karakter-karakter tambahan Hiragana ……… 24
Gambar 2.17 Contoh penulisan Furigana ……… 25
Gambar 3.1 Diagram gambaran sistem secara umum ……… 27
Gambar 3.2 Diagram pemrosesan citra input ……… 27
xix
Gambar 3.4 Diagram proses binerisasi secara keseluruhan ………… 32
Gambar 3.5 Diagram proses thresholding ……… 33
Gambar 3.6 Diagram proses binerisasi ……… 34
Gambar 3.7 Diagram proses penukaran piksel hitam dan piksel putih jika objek berwarna putih ……… 35
Gambar 3.8 Diagram proses menghilangkan pinggiran putih ………… 37
Gambar 3.9 Diagram proses segmentasi 9 bagian ……… 38
Gambar 3.10 Diagram proses pencocokan dengan tabel ……… 39
Gambar 3.11 Diagram proses mencari selisih minimum dengan template ……… 40
Gambar 3.12 Diagram proses menghitung prosentase kemiripan ……… 42
Gambar 3.13 Navigasi menu ……… 43
Gambar 3.14 Desain interface Home ……… 44
Gambar 3.15 Desain interface Daftar Hiragana ……… 45
Gambar 3.16 Desain interface Bantuan ……… 45
Gambar 3.17 Desain interface Tentang Program ……… 46
Gambar 3.18 Desain interface Input Gambar ……… 46
Gambar 3.19 Desain interface Kesimpulan ……… 47
Gambar 3.20 Desain interface Kesimpulan untuk input yang salah …… 48
Gambar 4.1 Tampilan interface Home ……… 50
Gambar 4.2 Tampilan interface Daftar Hiragana ……… 51
Gambar 4.3 Tampilan interface Bantuan ……… 52
Gambar 4.5 Tampilan interface Input Gambar sebelum memilih
Huruf ……… 53
Gambar 4.6 Tampilan Interface Input Gambar setelah memilih
Huruf ……… 54
Gambar 4.7 Tampilan Interface Kesimpulan ……… 54 Gambar 4.8 Tampilan Interface Kesimpulan untuk Input yang Salah … 55 Gambar 4.9 Karakter input beserta hasil-hasil pemrosesan citranya … 62 Gambar 4.10 Hasil segmentasi karakter input ……… 62 Gambar 4.11 Bagian segmentasi karakter input yang memenuhi
kriteria ……… 67
xxi
DAFTAR TABEL
halaman
Tabel 2.1 Tabel hubungan ketetanggaan antarpiksel,
piksel pada posisi (2,2) bernilai 0 ……… 17
Tabel 2.2 Tabel perbandingan I ……… 21
Tabel 2.3 Tabel perbandingan II ……… 21
Tabel 2.4 Tabel komposisi nilai karakter “A” ……… 22
Tabel 3.1 Tabel hubungan ketetanggaan antarpiksel, piksel pada posisi (2,2) bernilai 1 ……… 30
Tabel 4.1 Tabel hasil pengujian karakter ……… 55
Tabel 4.2 Tabel komposisi nilai karakter input berdasarkan tabel 256 hubungan ketetanggaan antarpiksel ……… 63
Tabel 4.3 Tabel komposisi nilai karakter input berdasarkan tabel 512 hubungan ketetanggaan antarpiksel ……… 64
1
PENDAHULUAN
1.1 Latar Belakang Masalah
Kemampuan manusia yang banyak bermanfaat dalam aktivitas sehari-harinya ialah kemampuan mengindera, baik dengan mata, telinga,
maupun indera lainnya. Dengan mata, manusia dapat melihat serta
memutuskan objek apa yang dilihatnya. Walaupun beberapa objek yang
dilihat tidak sama persis, tetapi manusia mampu melihat kesamaannya
sebagai satu golongan yang sejenis. Misalnya, manusia melihat berbagai
macam jenis gelas. Walaupun bentuknya berbeda-beda, tetapi manusia tetap
tahu bahwa itu semua adalah gelas. Kemampuan manusia ini disebabkan
karena dalam ingatan manusia telah terdapat begitu banyak ciri yang
membedakan antara satu objek dengan objek yang lain. Contohnya, dalam ingatan, manusia telah menyimpan begitu banyak objek gelas, yang tentu
saja memiliki ciri-ciri khusus yang dapat membedakannya dengan objek lain.
Sehingga di hadapan berbagai jenis gelas yang berbeda bentuk dan
penampakannya, dengan begitu mudahnya, manusia masih tetap dapat
berkata bahwa itu adalah gelas. Bagaimana manusia melakukan generalisasi
terhadap sekian banyak ciri-ciri objek (padahal tidak semua objek pernah
dilihat manusia) masih sulit untuk dijelaskan.
Komputer, yang kecerdasannya mendekati manusia, mulai banyak
2
sebagai mesin penghitung (masalah sederhana), sekarang dapat
menyelesaikan masalah-masalah manusia yang lebih kompleks, misalnya
mengidentifikasi tanda tangan, mengidentifikasi wajah, mengidentifikasi
tulisan/huruf, dsb. Metode-metode yang dipakai dalam mengenali suatu pola
ada bermacam-macam, misalnya Jaringan Syaraf Tiruan, seperti ADALINE dan Back Propagation, Feature Point Extraction, Logika Kabur, dan sebagainya.
Kebudayaan Jepang sekarang banyak peminatnya, termasuk penulis
sendiri, baik musik, film, anime, hingga seni penulisan huruf Jepang. Huruf
Hiragana merupakan huruf dasar yang digunakan untuk menuliskan kata-kata Jepang asli, dimana penulisannya mirip seperti huruf Jawa, yaitu per
suku kata. Selain huruf Hiragana ada juga huruf Katakana (untuk menuliskan kata-kata serapan/asing dan bunyi-bunyian) serta huruf Kanji (gabungan dari huruf Hiragana yang tiap hurufnya sudah memiliki arti kata tersendiri dan lebih rumit cara penulisannya). Salah satu kesulitan yang dialami para peminat bahasa Jepang adalah dalam mengenali huruf Jepang
karena bentuk hurufnya lebih rumit dibandingkan dengan huruf alfabet biasa.
Berdasarkan masalah seperti telah diungkapkan di atas, penulis ingin
membuat suatu aplikasi yang dapat mengenali huruf Jepang, yaitu huruf
Hiragana dengan menggunakan metode Feature Point Extraction. Metode ini merupakan metode yang relatif awal berkaitan dengan pengenalan
ialah susunan piksel dalam matriks dari tiap karakter. Metode ini juga
memiliki syarat, yaitu hanya matriks yang memiliki ketentuan tertentu saja
yang akan dipakai, sedangkan yang tidak memenuhi ketentuan tersebut akan
diabaikan.
1.2 Rumusan Masalah
Bagaimana membangun sebuah aplikasi untuk dapat mengenali huruf
Jepang Hiragana dengan metode Feature Point Extraction?
1.3 Batasan Masalah
1. Input berupa file gambar berekstensi *.jpg, *.jpeg, *.bmp, atau *.gif. 2. Aplikasi yang dirancang hanya dapat mengenali satu karakter untuk tiap
pengenalannya dari total 46 huruf Hiragana dasar.
3. Tingkat pengenalan terbatas pada jumlah template sebanyak 5 buah untuk tiap karakter, dan tidak dapat dilakukan penambahan template. 4. Semakin besar dimensi file gambar, tingkat pengenalan juga semakin
berkurang (penulis menggunakan resolusi 100x100 piksel).
5. Software yang digunakan adalah MatLab.
1.4 Tujuan Penelitian
4
1.5 Manfaat Penelitian
1. Sebagai bahan studi bagi peneliti lainnya untuk mengembangkan
aplikasi serupa yang lebih baik.
2. Sebagai bantuan bagi penggemar kebudayaan Jepang mengenali huruf
Hiragana.
1.6 Metode Penelitian
Metode yang digunakan dalam penelitian ini adalah sebagai berikut:
1. Analisis Kebutuhan
Yang dilakukan dalam analisis kebutuhan ialah mengumpulkan
sampel tulisan Hiragana dalam berbagai jenis tulisan. Caranya ialah dengan membagi-bagikan contoh tulisan Hiragana kepada banyak orang untuk ditulis ulang. Sampel yang diperoleh ini akan digunakan sebagai
template untuk pengenalan huruf Hiragana.
Selain itu, peneliti juga mengumpulkan serta meninjau berbagai bahan/referensi mengenai algoritma yang digunakan dalam pengenalan
pola, yaitu Feature Point Extraction, baik secara teoritis maupun secara praktis. Hasilnya ialah berbagai macam sampel tulisan Hiragana serta bahan-bahan/referensi mengenai algoritma Feature Point Extraction. 2. Desain
Dalam desain, peneliti mulai menyusun tampilan antarmuka serta
Hasilnya ialah sebuah aplikasi yang telah mempunyai tampilan
antarmuka lengkap beserta fasilitas input-outputnya tetapi belum
berfungsi.
3. Implementasi/Coding
Dalam tahap ini, peneliti mulai mengimplementasikan algoritma
Feature Point Extraction ke dalam bahasa komputer sesuai dengan desain yang telah disusun. Hasilnya ialah sebuah aplikasi yang dapat
membaca tulisan Hiragana dan memberikan output-nya. 4. Evaluasi
Setelah aplikasi dibangun, perlu dilakukan pengujian atas
kemungkinan terjadinya kesalahan. Proses perbaikan dilakukan
terus-menerus hingga aplikasi yang dibuat relatif tidak memuat kesalahan
(kesalahan yang mungkin muncul adalah kesalahan yang memang
merupakan kelemahan dari algoritma Feature Point Extraction). Hasilnya ialah sebuah aplikasi pengenalan huruf Hiragana yang lebih akurat.
5. Penyusunan Laporan
Dalam tahap ini, peneliti menyusun laporan ilmiah tertulis
tentang penelitian yang dilakukan, mulai dari tahap awal hingga akhir.
Proses penyusunan laporan ini dapat dimulai bersamaan dengan
dimulainya penelitian serta mengalami revisi sejalan dengan perubahan
6
1.7 Sistematika Penulisan
Berikut adalah garis besar dari isi karya ilmiah yang akan disusun:
BAB I PENDAHULUAN
Bab I tersusun atas latar belakang masalah, rumusan masalah,
batasan masalah, tujuan penelitian, manfaat penelitian, metode
penelitian, serta sistematika penulisan.
BAB II LANDASAN TEORI
Bab II berisi tentang teori-teori yang dipakai dalam implementasi,
contohnya adalah teori tentang pengolahan citra dan Feature
Point Extraction.
BAB III DESAIN
Pada bagian desain, berisi mengenai bagaimana rancangan dari
aplikasi yang akan dibangun, misalnya ialah gambaran sistem
secara umum, desain proses, serta desain interface.
BAB IV HASIL DAN PEMBAHASAN
Bab IV berisi mengenai hasil implementasi dari program yang
dibuat serta pembahasannya.
BAB V PENUTUP
7
LANDASAN TEORI
2.1 Pengolahan Citra 2.1.1 Definisi
Berikut ini adalah definisi mengenai pengolahan citra.
Citra adalah gambar dua dimensi yang dihasilkan dari gambar analog dua dimensi yang kontinu menjadi gambar diskrit melalui proses
sampling. Gambar analog dibagi menjadi N baris dan M kolom sehingga menjadi gambar diskrit. Persilangan antara baris dan kolom tertentu disebut
dengan piksel. Contohnya adalah gambar/titik diskrit pada baris n dan kolom m disebut dengan piksel [n,m].
Sampling adalah proses untuk menentukan warna pada piksel tertentu pada citra dari sebuah gambar yang kontinu. Pada proses sampling biasanya dicari warna rata-rata dari gambar analog yang kemudian
dibulatkan. Proses sampling sering juga disebut proses digitasi.
Derau (noise) adalah gambar atau piksel yang mengganggu kualitas citra. Derau dapat disebabkan oleh gangguan fisis (optik) pada alat
akuisisi maupun secara disengaja akibat proses pengolahan yang tidak
sesuai. Contohnya adalah bintik hitam atau putih yang muncul secara acak
yang tidak diinginkan di dalam citra. Bintik acak ini disebut dengan derau
8
2.1.2 Preprocessing
Preprocessing merupakan suatu langkah dalam pengolahan citra yang perlu dilakukan untuk menghilangkan objek-objek yang tidak
diperlukan, bahkan dapat mengganggu suatu citra, sehingga proses
pengenalan pola dapat menjadi lebih akurat (Pearson, 2001: 96).
2.1.2.1 Thresholding
Dalam berbagai pemrosesan citra, sangat membantu jika dapat
dipisahkan antara daerah/citra sebagai objek (yang dikehendaki) dari citra
yang merupakan latar belakang (background) dari keseluruhan citra.
Thresholding memberikan kemudahan dalam melakukan segmentasi ini berdasarkan perbedaan intensitas warna dari kedua citra tersebut.
Input dari thresholding dapat berupa citra grayscale ataupun berwarna. Dalam implementasi yang paling sederhana, outputnya
merupakan citra biner yang merepresentasikan segmentasi. Piksel hitam
menggambarkan background sedangkan piksel putih menggambarkan
foreground (atau bisa juga sebaliknya). Segmentasi dilakukan berdasarkan sebuah parameter yang disebut sebagai intensitas threshold. Tiap piksel dari suatu citra dibandingkan dengan parameter ini. Jika piksel citra
nilainya lebih tinggi dari threshold, piksel tersebut diset menjadi putih atau bernilai 1 sebagai outputnya. Jika tidak, diset menjadi hitam atau
bernilai 0 (atau sebaliknya).
ditentukan dengan melihat histogram intensitas dari citra. Jika
memungkinkan untuk memisahkan foreground dari citra berdasarkan intensitas piksel maka intensitas piksel pada objek foreground harus benar-benar berbeda dari intensitas piksel background. Dalam hal ini, dapat dilihat dari perbedaan puncak dalam histogram.
Gambar 2.1 Jenis distribusi intensitas citra
Gambar 2.1 A) menunjukkan distribusi intensitas bi-modal. Citra ini dapat disegmentasi menggunakan threshold tunggal T1. Gambar 2.1 B)
terlihat lebih kompleks. Dianggap bahwa puncak di tengah merupakan
objek yang diinginkan maka segmentasi memerulukan dua threshold: T1 dan T2. Pada gambar 2.1 C), kedua puncak dari distribusi bi-modal terlihat hampir sama maka hampir tidak mungkin untuk dapat melakukan
segmentasi dengan baik menggunakan threshold tunggal.
10
Gambar 2.2 di atas menunjukkan distribusi bi-modal yang baik; pada histogram, puncak yang lebih rendah merepresentasikan objek,
sedangkan yang lebih tinggi merepresentasikan background.
Citra pada gambar 2.2 dapat disegmentasi menggunakan threshold tunggal dengan nilai intensitas piksel 120. Hasilnya adalah seperti pada
gambar 2.3 sebagai berikut:
Gambar 2.3 Hasil threshold yang baik
Tetapi dengan adanya gradasi pencahayaan yang cukup jelas,
seperti gambar 2.4 di bawah ini, puncak yang merepresentasikan
foreground dan background dapat tampak memiliki kesamaan, maka threshold yang sederhana tidak dapat memberikan hasil yang baik.
Gambar 2.4 Citra dengan distribusi intensitas yang hampir sama
Gambar 2.5 Hasil threshold yang kurang baik
Thresholding juga dapat dipakai untuk memfilter output maupun input untuk operator lain. Sebagai contoh, deteksi tepi, seperti operasi
Sobel, akan menandai daerah dari citra yang memiliki gradien tinggi. Jika yang diinginkan hanya gradien di atas nilai tertentu (misalnya tepi yang tajam), maka thresholding dapat digunakan hanya untuk menyeleksi garis-garis yang tajam saja dan mengeset piksel lainnya menjadi hitam.
(a) (b) (c)
Gambar 2.6 Thresholding setelah operasi deteksi tepi
Pada gambar 2.6, gambar (a) merupakan gambar mula-mula,
kemudian dikenai operasi Sobel dan menghasilkan gambar (b). Hasil akhirnya, yaitu gambar (c), diperoleh setelah gambar (b) dikenai
12
Berikut ini adalah langkah-langkah dalam melakukan iterative
thresholding:
1. Dipilih sembarang nilai untuk inisalisasi awal threshold (T) 2. Citra disegmentasi menjadi objek dan background, yang
menghasilkan dua bagian:
a. G1 = {f(m,n):f(m,n)>=T} (piksel objek) b. G2 = {f(m,n):f(m,n)<T} (piksel background)
Sebagai catatan, f(m,n) adalah nilai dari piksel yang terletak pada kolom ke-m dan baris ke-n.
3. Rata-rata dari tiap bagian dihitung.
a. m1 = nilai rata-rata G1 b. m2 = nilai rata-rata G2
4. Nilai threshold baru diperoleh dari rata-rata m1 dan m2
T’ = (m1+m2)/2
5. Kembali ke langkah kedua, tetapi dengan menggunakan nilai
threshold yang baru didapat dari langkah (4). Terus diulang sampai nilai threshold yang diperoleh sama dengan nilai
threshold sebelumnya.
2.2 Pengenalan Pola (Pattern Recognition)
Membaca merupakan kegiatan yang berperan penting dalam hidup
memang sedang belajar membaca maupun yang sedang mengajari membaca.
Langkah pertama dalam belajar membaca adalah pembelajaran huruf alfabet.
Kemampuan untuk mengenali huruf dan karakter sangat penting dalam
mengartikan suatu bahasa; tetapi, untuk komputer, sebuah karakter dalam
suatu halaman lebih sebagai gambar atau objek yang mesti dikenali. Hanya
untuk mengenali huruf a saja, pemrograman komputer memerlukan berbagai teknik untuk dapat melakukannya.
Tidak diketahui bagaimana manusia mengenali objek visual dengan
begitu mudahnya, yang jelas tidak serumit komputer. Kemampuan otak
manusia dan komputer memiliki detail yang berbeda. Permasalahan dalam
Optical Character Recognition (OCR) ini harus diselesaikan dengan pendekatan dari sudut pandang komputer.
Dalam mengenali sebuah pola, sistem OCR harus melakukan beberapa hal dengan tingkat kemiripan yang tinggi. Misalkan inputnya
berupa gambar tulisan. Hal pertama yang perlu dilakukan adalah mengecek orientasi gambar pada halaman tersebut. Gambar juga perlu disegmentasi
menjadi biner (hitam dan putih). Jika karaker yang diuji merupakan karakter
dimana sistem pernah dilatih untuk mengenalinya, ada kemungkinan
pengenalan dilakukan dengan tepat.
Karena komputer merupakan mesin penghitung yang sangat cepat,
sangat mungkin untuk mengecek karakter input di antara sekian banyak
14
harus dilatih untuk mengenali semua kemungkinan karakter (Parker, 1997:
275-277).
Pattern recognition muncul dikarenakan kemampuan manusia yang mampu mengenali objek-objek yang ada. Manusia mengenali objek
berdasarkan ciri-ciri dan pengetahuan yang pernah diamatinya dari objek
tersebut. Tujuan dari pengenalan pola adalah mengklarifikasi dan mendeskripsi pola atau objek kompleks melalui pengukuran sifat-sifat atau
ciri objek tertentu.
Ada tiga macam pendekatan pada Pattern Recognition yang dikenalkan yang meliputi: pendekatan sintaktis, pendekatan statistika, dan
pendekatan jaringan saraf tiruan (JST). Pendekatan sintaktis adalah
pengenalan pola dimana data yang disimpan dan dibandingkan adalah
aturan-aturan pola yang diberikan saja. Pendekatan statistika adalah pengenalan pola
dimana data yang disimpan adalah pola/ciri-ciri objek tersebut. Sedangkan
pendekatan jaringan saraf tiruan (JST) adalah gabungan dari metode sintaktis dan metode statistika (Scratchz, 2007).
Gambar 2.7 Skema umum proses pengenalan pola
dokumen scanning preprocessing
ekstraksi ciri pengambilan
keputusan pengenalan
karakter
karakter digital
masukan digitalisasi matriks
karakter
pencocokan identifikasi
karakter
Database dapat dipakai sebagai sarana dalam template matching. Dalam hal ini, dilakukan perbandingan tiap piksel antara karakter yang
disimpan (template) dengan karakter yang diinputkan.
(a) (b) (c)
Gambar 2.8Template matching
Pada gambar 2.8, bagian (a) merupakan karakter yang diinputkan.
Karekter ini yang nantinya hendak dikenali. Dalam database telah disimpan masing-masing huruf “A” dan angka “8”, seperti pada bagian (b) dan (c) atas.
Pada saat proses pencocokan, nilai piksel dari karakter inputan yang sesuai
dengan nilai piksel dari karakter dalam database tampak berwarna hitam,
sedangkan yang tidak sesuai tampak berwarna abu-abu. Dalam kasus ini,
16
2.3 Feature Point Extraction
Yang dimaksudkan dengan feature point ialah suatu titik dari citra yang diperhatikan oleh manusia. Titik dapat merupakan perpotongan antara
dua garis, atau merupakan sebuah pojok, atau juga hanya titik begitu saja.
Titik-titik ini dapat membantu dalam mendefinisikan suatu keterhubungan
dalam dua garis yang berbeda. Dua garis dapat saja bersilangan penuh satu dengan yang lain, berpotongan seperti dalam huruf “Y” atau “T”, membentuk
sebuah pojok, atau tidak berpotongan sama sekali. Orang-orang cenderung
sensitif dengan keterhubungan semacam ini; susunan titik-titik sedemikian
rupa yang membentuk sebuah huruf “Z” lebih diperhatikan daripada jumlah
titiknya. Jenis keterhubungan inilah yang digunakan dalam pengenalan
karakter.
Algoritma-algoritma yang banyak digunakan dalam OCR mampu memberikan tingkat keakuratan yang tinggi dan cepat, tetapi tetap saja
hampir semuanya melakukan kesalahan yang tidak masuk akal dari sudut pandang manusia. Jika kesalahannya dalam membedakan karakter “5”
dengan “S”, masih termasuk wajar karena kemiripan kedua karakter tersebut.
Tetapi kesalahan dalam membedakan “5” dari “M” sangat di luar dugaan.
Kesalahan semacam ini disebabkan karena algoritma-algoritma tersebut
umumnya lebih memperhatikan sekumpulan ciri-ciri yang berbeda dari sudut
Kesalahan dalam mengenali karakter juga disebabkan oleh karena
terbatasnya jumlah ciri yang dikumpulkan. Apabila ciri-ciri dari karakter
diperbanyak maka keakurasian akan meningkat.
Algoritma ini pada dasarnya membandingkan susunan piksel dalam
tiap matriks biner 3x3 dengan tabel yang memuat nilai-nilai untuk tiap
kemungkinan susunan piksel tersebut. Yang dibandingkan ialah matriks yang memiliki piksel di posisi (2,2) bernilai 0 atau berwarna hitam saja. Karena piksel tersebut memiliki 8 tetangga dan tiap tetangga memiliki
kemungkinan bernilai 0 atau 1 maka seluruhnya memiliki 256 (28)
kemungkinan susunan piksel. Nilai yang ada dalam tabel bernilai 0 sampai
dengan 255 (Brown, 1992).
Tabel 2.1 Tabel hubungan ketetanggaan antarpiksel, piksel pada posisi (2,2) bernilai 0
Contoh Penerapan Feature Point Extraction
Contoh yang digunakan berikut ini menggunakan matriks awal
berukuran 9x9. Apabila dipecah-pecah menjadi submatriks berukuran 3x3
maka akan menjadi seperti terlihat pada gambar berikut ini:
Gambar 2.9 Pemecahan matriks 9x9 menjadi 9 bagian
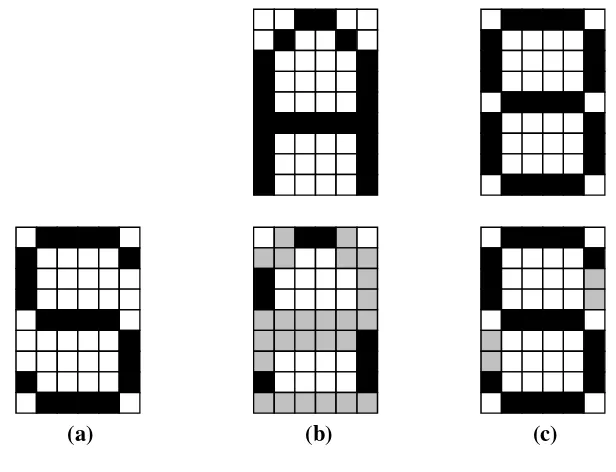
Sebagai contoh, gambar 2.10 (a) di bawah ini adalah karakter input, sedangkan gambar 2.10 (b) dan (c) adalah karakter template.
(a) (b) (c)
Gambar 2.10 (a) Karakter input, (b) dan (c) karakter template
Karakter-karakter tersebut kemudian dipecah menjadi 9 buah matriks
20
(a) (b) (c)
Gambar 2.11 Karakter-karakter yang dipecah menjadi 9 bagian
Tiap potongan matriks 3x3 pada gambar 2.11 di atas dicocokkan
dengan tabel untuk kemudian dicari nilainya. Pencocokan dimulai dari bagian
A sampai dengan bagian I.
Tanda + pada tabel menunjukkan posisi (2,2), sedangkan tanda * menunjukkan piksel-piksel di sekeliling tanda + yang bernilai 0. Jadi, misalnya dalam matriks, hanya piksel di posisi (2,2) yang bernilai 0 maka
nilai matriks 3x3 ini adalah 0, tetapi seandainya semua piksel bernilai 0 maka nilainya 255, dan seterusnya. Metode ini digunakan untuk kesembilan
matriks 3x3.
Dalam pengambilan keputusan untuk menentukan pengenalan
karakter yang diujikan, untuk setiap matriks yang bersesuaian dari karakter
input dan tiap karakter template, dihitung selisihnya (sehingga akan menghasilkan 9 buah nilai selisih). Nilai-nilai selisih ini kemudian
dijumlahkan. Karakter input akan digolongkan ke dalam kelompok karakter yang memiliki total nilai selisih paling sedikit.
A B C
D E F
G H I
A B C
D E F
G H I
A B C
D E F
Hasilnya dapat dilihat pada Tabel 2.2 dan Tabel 2.3:
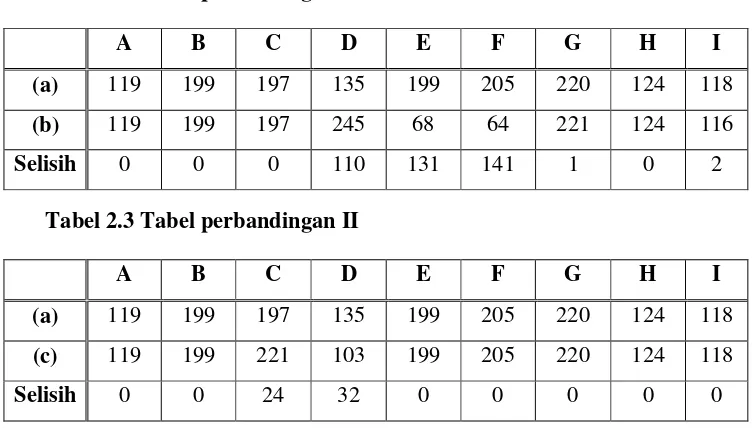
Tabel 2.2 Tabel perbandingan I
A B C D E F G H I
(a) 119 199 197 135 199 205 220 124 118
(b) 119 199 197 245 68 64 221 124 116
Selisih 0 0 0 110 131 141 1 0 2
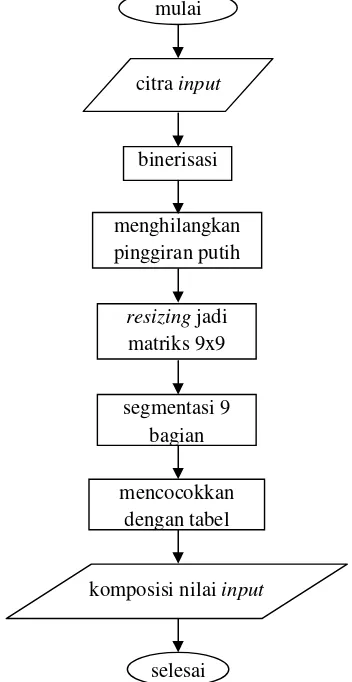
Tabel 2.3 Tabel perbandingan II
A B C D E F G H I
(a) 119 199 197 135 199 205 220 124 118
(c) 119 199 221 103 199 205 220 124 118
Selisih 0 0 24 32 0 0 0 0 0
Dari kedua tabel di atas tampak bahwa perbandingan I menghasilkan jumlah selisih 385, sedangkan pada perbandingan II menghasilkan jumlah
selisih 56. Sehingga karena nilai selisih pada tabel perbandingan II lebih kecil dari nilai selisih pada tabel perbandingan I maka karakter (a) digolongkan
sebagai karakter (c).
Berikut ini adalah contoh lain pemrosesan karakter beserta komposisi
nilai yang didapat dari hasil pencocokan dengan tabel.
Gambar 2.12 Contoh segmentasi karakter “A”
A B C
D E F
22
Tabel 2.4 Tabel komposisi nilai karakter “A”
A B C D E F G H I
52 199 88 253 124 127 241 ? 31
Tanda “?” menunjukkan matriks yang memiliki piksel di posisi (2,2)
bernilai 1 atau berwarna putih. Tanda “?” ini tidak diperhitungkan
(diabaikan). Oleh karena itu, karakter yang memuat tanda “?” tidak dapat ikut dibandingkan.
2.4 Huruf Hiragana
Sekitar abad ke-9, Jepang mengembangkan sistem penulisan sendiri
berdasarkan suku kata: Hiragana dan Katakana (dikenal sebagai Kana). Dari kedua sistem Kana ini, huruf Hiragana lebih banyak lengkungannya (kursif), sedangkan huruf Katakana lebih banyak sudutnya (anguler), seperti pada gambar 2.13. Dalam penulisan huruf-huruf Jepang, harus diperhatikan urutan
dan arah garis dalam tiap karakter, seperti pada gambar 2.14.
Gambar 2.13 Perbandingan penulisan (a) Hiragana dan (b) Katakana
Gambar 2.14 Contoh aturan penulisan huruf Hiragana
߁
߁
߁
Hiragana dan Katakana masing-masing terdiri dari 46 lambang, yang dapat dilihat pada gambar 2.15. Karakter-karakter ini sebenarnya merupakan
huruf Kanji yang sekarang telah jauh disederhanakan selama berabad-abad. Saat melihat teks dalam huruf Jepang, pembaca dapat dengan mudah
membedakan antara huruf Kanji yang rumit dan Kana yang lebih sederhana. Suku kata-suku kata tersebut di antaranya ialah 5 bunyi hidup (a i u e o). Sisanya adalah suku kata yang merupakan kombinasi dari bunyi hidup dan
konsonan (ka ki ku ke ko ra ri ru re ro …). Satu pengecualian ialah n.
24
Sebagai tambahan, beberapa suku kata dapat diperhalus atau
dipertajam dengan menambahkan semacam tanda petik ganda atau bulatan
kecil di pojok kanan atas dari karakter yang bersangkutan, sebagai berikut.
Gambar 2.16 Karakter-karakter tambahan Hiragana
Walaupun secara teoritis diperbolehkan menulis seluruh tulisan
Jepang dengan huruf Hiragana, tetapi huruf ini biasanya digunakan hanya untuk akhiran kata, kata benda, dan kata sifat, partikel, dan beberapa
kata-kata Jepang asli (tidak seperti kata-kata serapan yang ditulis dengan Katakana) yang tidak ditulis dalam Kanji. Hiragana adalah huruf yang pertama kali diajarkan kepada anak-anak di Jepang. Buku-buku untuk anak-anak pun
Hiragana kadang-kadang juga ditulis di atas atau di sebelah huruf Kanji untuk membantu pelafalan. Hiragana yang digunakan seperti ini disebut furigana atau ruby. Dalam teks horisontal, furigana diletakkan di atas huruf Kanji, sedangkan dalam teks vertikal, furigana terletak di sebelah kanan huruf Kanji.
26
BAB III
DESAIN
3.1 Gambaran Sistem Secara Umum
Sistem yang dibangun akan dipakai untuk mengenali huruf Hiragana menggunakan metode Feature Point Extraction. Karakter yang dapat dikenali ialah huruf-huruf dasar Hiragana, yaitu sebanyak 46 karakter, dimana pengenalannya dilakukan per karakter.
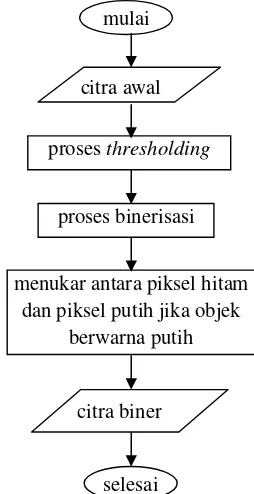
Input berupa file gambar dengan ekstensi *.jpg, *.jpeg, *.bmp, atau *.gif. Gambar yang di-input-kan kemudian dikenai ekstraksi ciri yang meliputi binerisasi, penghilangan pinggiran putih, perubahan ukuran menjadi
matriks 9x9, dan segmentasi menjadi 9 buah matriks berukuran 3x3. Lalu
masing-masing matriks 3x3 tersebut dicocokkan dengan tabel untuk
mendapatkan nilainya. Diagram proses citra input ada pada gambar 3.2. Langkah selanjutnya ialah melakukan ekstraksi ciri untuk template
-template yang telah ada, yaitu sebanyak 230 karakter (5 model untuk tiap karakter). Sama seperti karakter input, setelah disegmentasi menjadi 9 buah matriks berukuran 3x3, dilakukan pencocokan dengan tabel untuk memperoleh nilainya. Diagram proses citra template ada pada gambar 3.3.
Gambar 3.1 Diagram gambaran sistem secara umum
Gambar 3.2 Diagram pemrosesan citra input
mulai
mencari selisih minimum
input dengan template
kesimpulan
selesai pemrosesan citra input
pemrosesan citra template
mulai
citra input
binerisasi
menghilangkan pinggiran putih
segmentasi 9 bagian
mencocokkan dengan tabel
resizing jadi matriks 9x9
28
Gambar 3.3 Diagram pemrosesan citra template
Pada prinsipnya, matriks yang hendak dikenai algoritma Feature
Point Extraction merupakan matriks berukuran 3x3, dimana piksel di posisi (2,2) harus bernilai 0 atau berwarna hitam. Jika tidak maka matriks ini
diabaikan, atau dalam perhitungan nilainya berisi “?”. Dengan adanya
ketentuan ini maka hanya ada 8 piksel yang nilainya dapat berubah-ubah.
Selain itu, karena perubahan ini hanya antara 0 atau 1 maka total
kemungkinan perubahan posisi piksel ialah 28 atau sama dengan 256, dengan
jangkauan nilai dari 0 sampai dengan 255 seperti pada tabel. mulai
citra template
binerisasi
menghilangkan pinggiran putih
segmentasi 9 bagian
mencocokkan dengan tabel
resizing jadi matriks 9x9
selesai
Karakter yang hendak dikenali akan disegmentasi terlebih dahulu menjadi beberapa submatriks 3x3 sehingga matriks-matriks yang terbentuk
dapat dicocokkan dengan tabel untuk memperoleh nilai tertentu. Dengan
demikian, dengan diabaikannya matriks yang bernilai 1 di posisi (2,2), berarti
ada informasi yang terbuang, mengingat tidak semua matriks 3x3 yang
terbentuk pasti bernilai 0 di posisi (2,2), tetapi bisa saja bernilai 1. Tidak
menutup kemungkinan bahwa matriks yang diabaikan ini justru berpengaruh
besar dalam pengenalan karakter. Tetapi karena diabaikan maka matriks ini
tidak dapat diproses lebih lanjut karena tidak memiliki nilai untuk
dibandingkan.
Berdasarkan pertimbangan tersebut, penulis mencoba mencari jalan
keluar untuk mengatasi kelemahan di atas, yaitu memperhitungkan perubahan
piksel di posisi (2,2). Seluruh piksel pada matriks 3x3 pun bisa berubah
nilainya antara 0 atau 1. Sehingga, total kemungkinan perubahan piksel
berjumlah 29 atau 512. Dengan demikian, tidak ada matriks (informasi) yang
terbuang karena setiap matriks yang terbentuk pasti memiliki nilai sehingga
dapat dibandingkan.
Penulis menambahkan 256 hubungan ketetanggaan antarpiksel yang
30
Tabel 3.1 Tabel hubungan ketetanggaan antarpiksel, piksel pada posisi (2,2) bernilai 1
** + * ** + ** ** + * * ** + *** ** *+ * ** *+ ** ** *+ * * ** *+ *** *** + * *** + ** *** + * * *** + *** *** *+ * *** *+ ** *** *+ * * *** *+ *** 267 283 299 315 331 347 363 379 395 411 427 443 459 475 491 507 +* * +* ** +* * * +* *** *+* * *+* ** *+* * * *+* *** * +* * * +* ** * +* * * * +* *** * *+* * * *+* ** * *+* * * * *+* *** 268 284 300 316 332 348 364 380 396 412 428 444 460 476 492 508 * +* * * +* ** * +* * * * +* *** * *+* * * *+* ** * *+* * * * *+* *** ** +* * ** +* ** ** +* * * ** +* *** ** *+* * ** *+* ** ** *+* * * ** *+* *** 269 285 301 317 333 349 365 381 397 413 429 445 461 477 493 509 * +* * * +* ** * +* * * * +* *** * *+* * * *+* ** * *+* * * * *+* *** * * +* * * * +* ** * * +* * * * * +* *** * * *+* * * * *+* ** * * *+* * * * * *+* *** 270 286 302 318 334 350 366 382 398 414 430 446 462 478 494 510 ** +* * ** +* ** ** +* * * ** +* *** ** *+* * ** *+* ** ** *+* * * ** *+* *** *** +* * *** +* ** *** +* * * *** +* *** *** *+* * *** *+* ** *** *+* * * *** *+* *** 271 287 303 319 335 351 367 383 399 415 431 447 463 479 495 511
Perbedaannya dengan Tabel 2.1 hanya terletak pada nilai dan definisi
tanda “+”; jika pada Tabel 2.1 tanda + berarti piksel di posisi (2,2) yang
bernilai 0 maka pada Tabel 3.1, tanda + berarti piksel di posisi (2,2) yang
bernilai 1. Tanda * artinya tetap sama, yaitu piksel-piksel yang bernilai 0 atau
32
3.2 Desain Proses
3.2.1 Proses binerisasi
Input dari proses ini adalah citra awal, output-nya berupa citra biner. Proses ini terdiri dari 3 tahap, yaitu proses thresholding, proses binerisasi, dan proses menukar antara piksel hitam dan piksel putih
jika objek berwarna putih. Berikut ini adalah diagram-diagramnya.
Gambar 3.4 Diagram proses binerisasi secara keseluruhan
mulai
proses thresholding
proses binerisasi
menukar antara piksel hitam dan piksel putih jika objek
berwarna putih
selesai citra awal
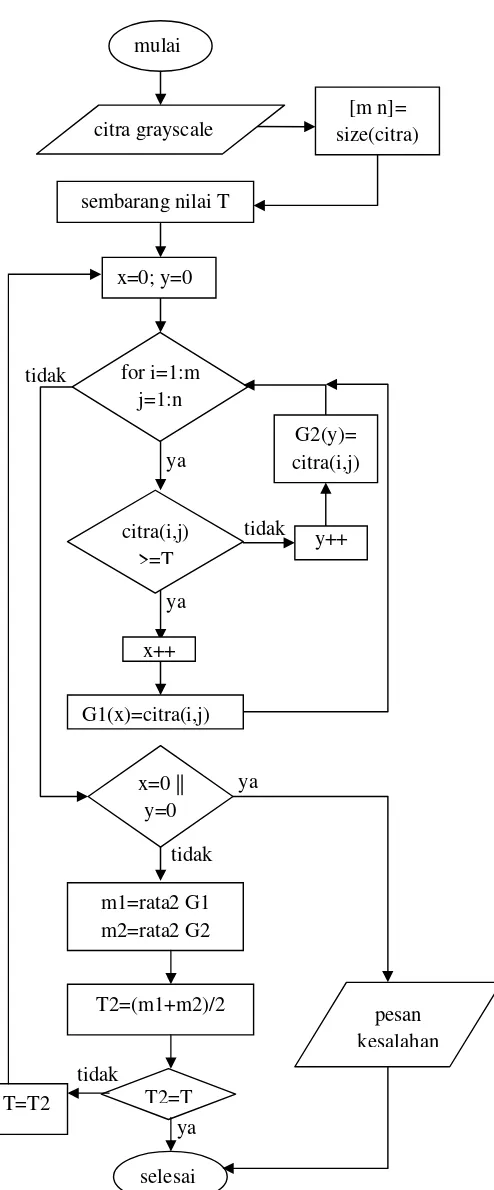
Gambar 3.5 Diagram proses thresholding
mulai
citra grayscale
sembarang nilai T
for i=1:m j=1:n x=0; y=0
citra(i,j)
>=T y++
x++
m1=rata2 G1 m2=rata2 G2
T2=(m1+m2)/2
T2=T T=T2
ya tidak
tidak
ya
ya tidak
[m n]= size(citra)
selesai x=0 ||
y=0
G2(y)= citra(i,j)
ya
tidak
34
Pesan kesalahan pada gambar 3.5 di atas muncul karena gambar yang dipilih untuk diuji tidak memiliki objek. Penjelasan selengkapnya
akan dibahas pada bab berikutnya.
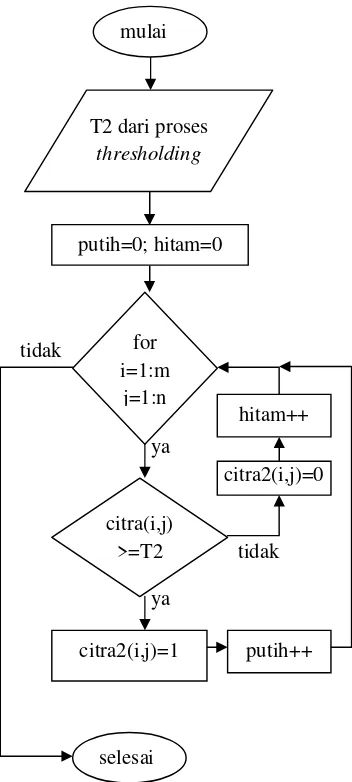
Gambar 3.6 Diagram proses binerisasi
for i=1:m
j=1:n
citra(i,j) >=T2
ya
tidak
ya
citra2(i,j)=1 tidak
citra2(i,j)=0 putih=0; hitam=0
putih++ hitam++ mulai
selesai T2 dari proses
Gambar 3.7 Diagram proses penukaran piksel hitam dan piksel putih jika objek berwarna putih
Proses binerisasi diawali dengan thresholding secara iteratif seperti gambar 3.5. Input berupa citra grayscale. Pertama, ditentukan
citra2
selesai hitam>
putih
for i=1:m
j=1:n ya
citra2(i,j) =0
citra2(i,j)=1 citra2(i,j)=0 ya
tidak ya
tidak tidak mulai
variabel hitam
dan putih dari proses binerisasi citra2 dari proses
36
sembarang nilai ambang (T) untuk memisahkan citra menurut objek dan background-nya. Lalu dicari rata-rata untuk objek dan background (m1 dan m2), didapat nilai ambang baru (T2) yaitu rata-rata m1 dan m2. Iterasi terus diulang hingga T2 sama dengan T. Perulangan dilakukan dengan nilai T yang dimodifikasi sama dengan T2. Binerisasi (gambar 3.6) dilakukan memakai nilai T2 yang terakhir diperoleh (optimum).
Pada gambar 3.7, jika objek berwarna putih (diketahui dari
jumlah piksel hitam yang lebih banyak daripada putih), dilakukan
reverse antara piksel hitam dan piksel putih. Langkah ini dilakukan atas pertimbangan proses selanjutnya, yaitu proses menghilangkan pinggiran putih. Jika background berwarna hitam maka pinggiran yang seharusnya tidak digunakan ialah yang berwarna hitam. Oleh karena
itu, background dijadikan putih dahulu apabila berwarna hitam.
3.2.2 Proses menghilangkan pinggiran putih
Tujuan proses ini adalah untuk mengurangi kemungkinan
pergeseran objek sehingga mengganggu keakuratan. Caranya adalah
dengan mencari piksel bernilai 0 (berwarna hitam) teratas, terkanan,
terbawah, dan terkiri. Keempat posisi piksel tersebut disimpan untuk digunakan sebagai batas citra yang hendak digunakan. Sehingga piksel
berwarna putih di luar batas-batas itu diabaikan dan citra yang diproses
hanya citra dengan batas-batas tersebut. Input berupa citra biner, dan
Gambar 3.8 Diagram proses menghilangkan pinggiran putih
mulai
citra (i,j)=0
tidak
ya
ya tidak
batas atas=i citra
[m n]= size(citra)
for i=1:m
j=1:n
A citra (i,j)=0
tidak
ya
ya tidak
batas kanan=j for j=n:1 i=1:m
A
selesai citra (i,j)=0
tidak
ya
ya tidak
batas bawah=i for i=m:1
j=1:n
citra (i,j)=0
tidak
ya
ya tidak
batas kiri=j for j=1:n i=1:m
38
3.2.3 Proses segmentasi 9 bagian
Gambar 3.9 Diagram proses segmentasi 9 bagian
mulai
citra 9x9
atas_kiri = citra(1:m/3 , 1:n/3) [m n]=
size(citra)
atas_tengah = citra(1:m/3 , n/3+1:2*n/3)
atas_kanan = citra(1:m/3 , 2*n/3+1:n)
tengah_kiri = citra(m/3+1:2*m/3 , 1:n/3)
tengah_tengah = citra(m/3+1:2*m/3 , n/3+1:2*n/3)
tengah_kanan = citra(m/3+1:2*m/3 , 2*n/3+1:n)
bawah_kiri = citra(2*m/3+1:m , 1:n/3)
bawah_tengah = citra(2*m/3+1:m , n/3+1:2*n/3)
bawah_kanan = citra(2*m/3+1:m , 2*n/3+1:n)
Citra yang digunakan dalam proses ini ialah citra berukuran 9x9, yaitu hasil resizing dari citra tanpa pinggiran putih. Citra berukuran 9x9 ini kemudian dipecah-pecah menjadi berukuran 3x3, sehingga
terbentuk 9 buah matriks dengan ukuran 3x3.
3.2.4 Proses pencocokan dengan tabel
Gambar 3.10 Diagram proses pencocokan dengan tabel
Tiap matriks 3x3 yang terbentuk kemudian dicocokkan dengan tabel, yaitu sebanyak 512, sehingga diperoleh suatu nilai tertentu
sesuai pada tabel. Karena nilainya dimulai dari 0 hingga 511
sedangkan indeks array dimulai dari 1 maka nilai yang didapat (berdasarkan indeks array yang bersangkutan) harus dikurangi 1.
mulai
selesai citra 3x3
for i=1:512
citra= tabel(i)
nilai=i-1 ya
tidak
ya
40
3.2.5 Proses mencari selisih minimum dengan template
mulai
nilai input= a2,b2,…,i2
nilai template= A,B,…,I
for i=1:230
hasil_a{i}=(a2-A{i})2
hasil_i{i}=(i2-I{i})2 ……
hasil_selisih{i}= sqrt(hasil_a{i}+hasil_b{i}+…+hasil_i{i}) ya
tidak hasil=1534
hasil_selisih{i}< hasil
cacah=1
indeks_hasil_selisih{cacah}=i
hasil= hasil_selisih{i} ya
indeks_hasil_selisih{cacah}=i cacah++
hasil_selisih{i}= hasil tidak
ya
tidak hasil_b{i}=(b2-B{i})2
Gambar 3.11 Diagram proses mencari selisih minimum dengan template cacah>1
hasil= -1
for i=1:cacah
hasil=kotak_sama{indeks_hasil_selisih{i}} kotak_sama
{indeks_hasil_selisih{i}}>hasil
indeks_kotak_sama=indeks_hasil_selisih{i} indeks=
indeks_hasil_selisih{1}
tidak
ya
ya
tidak
indeks=indeks_kotak_sama ya
tidak ya
tidak
selesai
kotak_sama {indeks_hasil_selisih{i}}++ a2= A{indeks_hasil_selisih{i}}
b2= B{indeks_hasil_selisih{i}} kotak_sama{indeks_hasil_selisih{i}}=0
tidak
tidak
ya i2= I{indeks_hasil_selisih{i}}
ya
…
kotak_sama {indeks_hasil_selisih{i}}++
kotak_sama {indeks_hasil_selisih{i}}++
42
Selanjutnya, seperti gambar 3.11 di atas, ialah mencari selisih miminum dengan tiap template, dengan menggunakan rumus jarak.
Misal, titik A(x1,y1), B(x2,y2) maka jaraknya
(
x2−x1) (
2+ y2−y1)
2 .Penggunaan rumus jarak dimaksudkan agar nilai yang diperoleh lebih
teliti. Variabel hasil, dipakai untuk pembanding awal, diinisialisasi
dengan nilai terbesar yang mungkin terjadi, yaitu 5112×9+1=1534.
Jika hanya ada satu selisih minimum, indeks template yang sesuai disimpan. Banyak template yang memiliki nilai minimum disimpan di variabel cacah. Jika ditemukan lebih dari satu, dicari yang memiliki nilai sama dengan input (dari A hingga I) terbanyak. Jika ada, indeksnya disimpan kemudian dicocokkan dengan daftar template. Karakter uji digolongkan ke dalam template dengan indeks tersebut.
Terakhir ialah mencari prosentase kemiripan, yaitu dari matriks
9x9, jumlah piksel input yang sama dengan piksel template dibagi jumlah piksel seluruhnya. Berikut ini adalah diagramnya.
Gambar 3.12 Diagram proses menghitung prosentase kemiripan
mulai
sama=0
for i=1:9 j=1:9
sama++
input(i,j)=
template(i,j)
persen=(sama/81)*100
ya
tidak
ya tidak
3.3 Navigasi Menu
Berikut ini adalah jalur navigasi dari menu-menu yang dapat diakses.
Gambar 3.13 Navigasi Menu
Home
Bantuan
Tentang Program
Keluar Home
Pilih gambar
input
Bantuan
Tentang Program
Keluar
Kesimpulan
kembali ke menu sebelumnya
Bantuan
Tentang Program
Keluar
Pilih gambar
input
kembali ke menu sebelumnya
kembali ke menu sebelumnya
Home
Home Daftar
Hiragana
Daftar
Hiragana
Daftar
44
Dalam aplikasi tersedia 2 pilihan menu, yaitu Menu dan Informasi. Berikut ini submenu-submenu yang dapat diakses:
Menu
Home : Menuju ke tampilan awal program
Daftar Hiragana : Menampilkan daftar huruf Hiragana yang dapat dikenali oleh program
Keluar : Keluar dari program Informasi
Bantuan : Menampilkan informasi mengenai cara menggunakan program
Tentang Program : Menampilkan informasi mengenai program yang sedang dijalankan
3.4 Desain Interface
Berikut ini adalah rancangan user interface dari aplikasi yang akan dibangun.
3.4.1 Home
Gambar 3.14 Desain interface Home Menu
JUDUL
Oleh: …
Logo USD
Lanjut
3.4.2 Daftar Hiragana
Gambar 3.15 Desain interface Daftar Hiragana
3.4.3 Bantuan
Gambar 3.16 Desain interface Bantuan
JUDUL
Logo USD
Huruf-huruf Hiragana
OK
JUDUL
Logo USD
Isi
46
3.4.4 Tentang Program
Gambar 3.17 Desain interface Tentang Program
3.4.5 Input Gambar
Gambar 3.18 Desain interface Input Gambar
JUDUL
Logo USD
Isi
OK
Menu
JUDUL
Logo USD
Gambar huruf Hiragana yang dipilih
lihat
lokasi file cari
Untuk memasukkan file gambar, klik tombol cari. Setelah didapat, jika ingin melihatnya, user dapat mengklik tombol lihat. Untuk melanjutkan, klik tombol lanjut.
3.4.6 Kesimpulan
Gambar 3.19 Desain interface Kesimpulan
Pada halaman kesimpulan, selain mengetahui hasil akhir pengenalan
karakter, user juga dapat melihat citra yang dipilih untuk diuji beserta
hasil-hasil pemrosesannya, meliputi gambar biner, gambar biner 9x9,
serta hasil segmentasi menjadi 9 buah matriks 3x3. Selain itu user juga
dapat melihat hasil perhitungan optimum dari algoritma Feature Point
Extraction. Tombol ulangi digunakan untuk kembali ke halaman Input
Gambar untuk memilih karakter lainnya.
Menu
JUDUL
Kesimpulan
Pola dikenali sebagai huruf … Prosentase kemiripan …%
Hasil Perhitungan
Logo USD
keluar home
gambar input
gambar biner
gambar biner
9x9
segmen tasi 9 bagian
gambar asli
48
3.4.7 Kesimpulan untuk input salah
Gambar 3.20 Desain interface Kesimpulan untuk input yang salah
Halaman ini muncul jika user memasukkan gambar yang tidak ada
objeknya, atau dengan kata lain, hanya gambar kosong/polos. Proses
akan terhenti pada saat binerisasi. Penjelasan selengkapnya akan
dibahas pada bab berikutnya.
3.5 Spesifikasi Hardware dan Software
Berikut adalah spesifikasi hardware dan software yang digunakan untuk membangun aplikasi pengenalan karakter:
3.5.1 Hardware
3.5.1.1 Intel Pentium D 2.66GHz
3.5.1.2 DDR 512MB Visipro
Menu
JUDUL
Pemberitahuan kesalahan
Logo USD
keluar home
gambar input
3.5.1.3 NVidia GeForce FX 5200 128MB 3.5.1.4 HDD 40GB Maxtor
3.5.2 Software
3.5.2.1 Microsoft Windows XP Professional Service Pack 2
3.5.2.2 Matlab 7
3.5.2.3 Adobe Photoshop 7
50
BAB IV
HASIL DAN PEMBAHASAN
4.1 Hasil Tampilan User Interface
4.1.1 Tampilan Home
4.1.2 Tampilan Daftar Hiragana
52
4.1.3 Tampilan Bantuan
4.1.4 Tampilan Tentang Program
Gambar 4.4 Tampilan Interface Tentang Program
4.1.5 Tampilan Input Gambar
54
Gambar 4.6 Tampilan Interface Input Gambar setelah Memilih Huruf
4.1.6 Tampilan Kesimpulan
4.1.7 Tampilan Kesimpulan untuk Input yang Salah
Gambar 4.8 Tampilan Interface Kesimpulan untuk Input yang Salah
4.2 Hasil Pengujian Karakter
Berikut ini adalah hasil dari pengujian karakter-karakter input dengan perluasan metode feature point extraction.
Tabel 4.1 Tabel hasil pengujian karakter
Input Hasil Pengenalan
Karakter Bunyi Bunyi Selisih Durasi Proses (detik)
56
Input Hasil Pengenalan
Karakter Bunyi Bunyi Selisih Durasi Proses (detik)
i i 94.5093 34.7031
fu fu 135.834 34.9531
mi mi 87.4528 34.7813
yu yu 181.488 34.7813
ha ha 21.9089 34.8906
yo yo 70.4273 34.3281
Input Hasil Pengenalan
Karakter Bunyi Bunyi Selisih Durasi Proses (detik)
ke ke 20.6155 34.7969
ro ro 248.753 34.5938
te te 258.706 34.7500
ku ku 264.992 34.7813
a a 79.1012 34.5938
ma ma 226.1 34.4688
58
Input Hasil Pengenalan
Karakter Bunyi Bunyi Selisih Durasi Proses (detik)
mo mo 172.722 34.8906
ru ru 148.354 34.2813
he he 137.717 34.1563
ko ko 144.941 34.1094
to to 34.5254 34.3281
me nu 284.255 34.3594
Input Hasil Pengenalan
Karakter Bunyi Bunyi Selisih Durasi Proses (detik)
no no 212.012 34.8750
ta ta 20.0998 34.3906
su su 168.392 34.6719
ra ra 64.8151 34.6250
hi hi 259.779 34.7031
mu mu 237.137 34.6719
60
Input Hasil Pengenalan
Karakter Bunyi Bunyi Selisih Durasi Proses (detik)
wa wa 189.808 34.8594
wo wo 300.683 34.7969
ya ya 140.855 34.8125
n n 176.187 34.7656
ho ho 154.738 34.9375
u u 151.37 34.9219
Input Hasil Pengenalan
Karakter Bunyi Bunyi Selisih Durasi Proses (detik)
o o 278.683 34.9688
re re 264.394 34.6406
ki ki 70.2638 34.7188
chi chi 73.1027 35.0469
tsu tsu 64.5058 34.7813
he he 62.8172 34.3438
62
4.3 Implementasi dengan 256 Hubungan Ketetanggaan Antarpiksel
Di bawah ini adalah salah satu contoh hasil implementasi dari
pengenalan suatu karakter input menggunakan metode feature point
extraction dengan 256 hubungan ketetanggaan antarpiksel.
(a) (b)
(c) (d)
Gambar 4.9 Karakter input beserta hasil-hasil pemrosesan citranya
Gambar 4.9 (a) merupakan gambar awal yang diinputkan. Gambar 4.9 (b) adalah hasil dari proses binerisasi, sehingga gambar menjadi hitam-putih. Gambar 4.9 (c) adalah hasil dari proses penghilangan pinggiran putih. Proses ini dilakukan untuk tetap menjaga konsistensi dari gambar sebelum
dan sesudah mengalami pemrosesan (preprocessing). Maksudnya, apabila gambar yang hendak dikenali tidak dihilangkan dulu pinggiran putihnya, ada
kemungkinan terjadi pergeseran posisi objek sehingga menyebabkan
ketidakakuratan dalam proses pengenalan. Dengan kata lain, hanya objeknya
saja yang nantinya akan diproses untuk dikenali polanya. Gambar 4.9 (d)
merupakan gambar hasil resizing menjadi berukuran 9x9. Pengubahan menjadi ukuran 9x9 adalah karena matriks yang dibutuhkan adalah matriks
ukuran 3x3 (kelipatan 3) untuk dicocokkan dengan tabel. Selain itu,
pengubahan ukuran ini juga dimaksudkan untuk mengurangi lama waktu
pengenalan. Maksudnya, semakin besar ukuran gambar, semakin lama pula
proses akan berlangsung. Oleh karena itu, penulis memilih 9 buah matriks
berukuran 3x3 untuk diproses. Gambar 4.10 adalah gambar hasil segmentasi menjadi 9 buah matriks berukuran 3x3, seperti yang baru saja dibahas.
Setelah dicocokkan dengan tabel, didapatkan 9 buah nilai untuk
tiap-tiap bagian dari A sampai dengan I sebagai berik